
ABSTRACT
This article examines the ideologies reproduced in AI-generated images, focusing in particular on representations of dementia. Utilising Stable Diffusion version 1.4, a text-to-image AI model, we conduct a multimodal critical discourse analysis of 171 images generated from the text prompt “dementia.” Our analysis aims to identify and contextualise the visual discourses within the generated images by comparing these with existing multimodal representations of dementia. As well as observing a general lack of visual diversity (with an over-representation of older, light-skinned individuals), we find that these images tend to depict dementia by recycling existing, prominent visual discourses surrounding the syndrome, including a biomedical focus on the disease, narratives of loss, and dementia as a “living death.” These visual discourses combine with particular semiotic choices that promote emotional distance between viewers and people with dementia. Overall, this study highlights the potential for AI-generated images to reinforce and amplify harmful stereotypes and biases. As well as demonstrating the ideological import of such imagery, and thus the need for these to be critically interrogated by (multimodal) critical discourse analysts, this study underscores the need for ethical consideration in AI design and usage, including developing more diverse and inclusive training datasets.
1. Introduction
Dementia is a syndrome characterised by diseases and injuries that affect the brain and progressively impair memory, reasoning, perception and communication (World Health Organization [WHO] Citation2023). While individuals are more likely to develop dementia as they age, this is not inevitable and young onset dementia (whereby symptoms occur before the age of 65) accounts for up to 9% of diagnoses worldwide (ibid.). People experiencing different dementia types, the most common of which is Alzheimer’s disease, will present with different symptoms. Even if diagnosed with the same dementia variant, the experiences of each individual will be unique and a person’s cognitive abilities can fluctuate across time and contexts (Sabat Citation2018). Dementia is “conceptually slippery” (Zeilig Citation2014, 260). Its ambiguity partly results from the variability mentioned above, but it also reflects uncertainty in scientific and clinical communities regarding the blurred boundaries between diagnostic categories (e.g. between ageing and dementia), as well as the extent to which the symptoms of dementia can be connected to bio-physiological changes to the brain (e.g. older people can exhibit the pathological signs of Alzheimer’s disease but not its symptoms) (Lock Citation2013). Acknowledging these ambiguities, an “entanglement” approach encourages a more holistic understanding of dementia as resulting from an intertwinement of molecular, social, political and environmental factors (ibid.).
The present study is particularly concerned with social aspects of dementia, since the way in which dementia is discursively constructed informs how people with dementia experience life with the syndrome, including their relationships, social treatment, sense of identity, and expectations for the future (Kitwood Citation1997; Sabat Citation2018). By “discourse”, we refer to a “set of meanings, metaphors, representations, images, stories, statements and so on that in some way together produce a particular version of events’ (Burr Citation2015, 32). Importantly, discourse not only reflects but shapes social realities (Foucault Citation1972). It is therefore significant that dementia is widely conflated with fears of ageing, loss of self, and death (Zeilig Citation2014, 260). As Castaño (Citation2022, 2) argues, such anxieties stem from long-standing cultural and philosophical ideologies such as the Cartesian body–mind dichotomy, in which the self is attributed to the mind and not the body (Gordijn Citation1999); hypercognitivism, which elevates rational thought, memory and (economic) productivity to the detriment of other abilities (Post Citation2000); and notions of “successful” ageing, which emphasise continuing independence, control, productivity and being physically and cognitively active (Latimer Citation2018). Against such a focus, dementia is often discursively constructed as the antithesis of social values: a condition of frailty, dependence, deterioration and (social and physical) death, rendering those diagnosed with it as “revolting subjects” (Latimer Citation2018, 843). A key consequence of such fear-inducing and reductive discourses, then, is that alongside living with a presently incurable condition, people diagnosed with dementia must also navigate stigma. Goffman (Citation1963) defined stigma broadly as a “spoiled identity”, wherein the stigmatised aspects of a person’s identity are used to define and discredit them. Amongst other things, dementia stigma contributes to deep shame, social isolation, poorer healthcare outcomes and human rights violations for people diagnosed with dementia (e.g. Benbow and Jolley Citation2012; Cahill Citation2018; Swaffer Citation2016).
Considering these harmful repercussions, improving understanding of dementia and reducing the stigma surrounding it has become a global priority (Alzheimer’s Disease International Citation2019; Cahill Citation2018). Stigmatising dementia ideologies can be reproduced and reinforced in, but also challenged by, social texts such as speeches, literature, news media, stock images and picture books (discussed in the next section). Given the growing popularity of Artificial Intelligence (AI) text-to-image generation, these visual outputs constitute important, but currently understudied, social texts to attend to in relation to complex social phenomena. The objective of this paper is thus to provide a critical account of the ideologies that are (re)produced in AI-generated imagery, in this case focusing on visual representations of dementia.
In this paper, we adopt the position of users of an AI text-to-image generation model (specifically, Stable Diffusion version 1.4). The perspective we assume (at least in terms of generating the images) is of the average user who does not necessarily possess in-depth technical expertise regarding how, exactly, the model functions. Our understanding is that AI text-to-image generation uses AI algorithms to create imagery based upon textual prompts given by a human user. The algorithm is trained on a large database of images (often sampled from the internet), each of which is captioned with a short text description. By repeatedly noising and denoising this data, the model learns how to translate noise into an image for whatever prompt it is given (Farid Citation2022). As such, AI models and the content they generate do not provide “neutral” or “objective” representations of society, nor indeed entirely “new” ones, but rather representations that are shaped by the biases and perspectives of those who develop and use the technology, alongside the patterning and biases evident in the images on which the models are trained. In this way, AI-generated images exist in a “dialectal” (Fairclough Citation2015) relationship with society, as they not only reflect existing societal discourses, but once those images enter society, they have the potential to reinforce and shape those discourses and the ideologies they carry. It is important, then, to critically interrogate such images in order to better understand the discourses they propagate.
This article presents, to our knowledge, the first discourse-based study of AI-generated images. Specifically, we subject a series of AI-generated images for the text prompt “dementia” to a multimodal critical discourse analysis, with the objective of identifying the visual discourses that these images (re)produce. To support our interpretation of the data, we compare the visual discourses we identify against those that have been reported in existing multimodal discourse studies of dementia representation. Through this step, we broadly seek to contextualise the observed visual discourses within the wider network of representations that constitute dementia within society, thereby allowing us to consider how these visual discourses have come about (i.e. what existing visual discourses are they likely to be based upon?), as well as what their social implications could be for people living with and/or trying to understand dementia. To contextualise this study, we therefore begin by outlining the existing literature on contemporary representations of dementia, before considering the implications of AI text-to-image generation for this and other social phenomena.
2. Dementia discourses
There are many different facets of dementia that could be discursively foregrounded. In dementia research, for instance, dementia can be approached through a biomedical lens (focusing largely on pathology, diagnosis and molecular research), a psychosocial one (concerned with how personhood and/or selfhood can be undermined or maintained; e.g. Kitwood Citation1997), a rights-based lens (focusing on improving human/citizen rights; e.g. Bartlett and O’Connor Citation2010), an embodied and relational one (focusing on the relational nature of humans and the creativity, intentionality and communicative attributes of the body; e.g. Kontos, Miller, and Kontos Citation2017) or a more holistic one that combines the above approaches (e.g. Shakespeare, Zeilig, and Mittler Citation2019). In public discourse, however, a dichotomy prevails between two key discourses: the long-standing and still-dominant “tragedy” discourse, which emphasises loss and decline; and the newer, less established “living well” discourse, which instead focuses on supporting the strengths of an individual and recognising their enduring personhood (McParland, Kelly, and Innes Citation2017, 259). For instance, there are some examples of representations that emphasise the perspectives, abilities and rights of people with dementia (Leone, Winterton, and Blackberry Citation2023), and that attempt to reframe the syndrome as transformative, rather than simply decline and loss (Venkatesan and Kasthuri Citation2018), but these remain in the minority at present.
The more pervasive “tragedy” discourse has many facets. For example, research indicates that people with dementia are consistently homogenised and marginalised in media to the point that they are “essentially voiceless” (Clarke Citation2006, 272). Diagnosed individuals are regularly pathologised as (often passive) patients (Sabat Citation2018), including through narratives that either focus on the threat of dementia (Johnstone Citation2013), or focus on biomedical research and the brain, at the expense of individuals’ life experiences (Bailey, Dening, and Harvey Citation2021). Dementia is presented as a loss of not only abilities but of the core of an individual, and thus as an “unbecoming of self” (Fontana and Smith Citation1989), or even as a “living death” (Aquilina and Hughes Citation2006). The mistreatment of and discrimination against people with dementia can then be normalised in the news and healthcare contexts if “the person is gone” (Clarke Citation2006, 272). In line with the notion of “successful ageing,” focus has increasingly shifted onto individual actions to prevent dementia, which, while attributing agency to (generally pre-dementia) individuals to “stave off” the syndrome, simultaneously risks blaming people with dementia for past actions, likely exacerbating stigma (Lawless, Augoustinos, and LeCouteur Citation2018).
Despite a general emphasis on language over image, researchers and dementia non-profit and advocacy groups are increasingly recognising that “images can be powerful, but they can also be damaging if they create or reinforce a generalisation of what someone living with dementia looks or behaves like” (Bould Citation2018, 31). It is therefore notable that existing multimodal analyses of different social texts (namely stock images, newspapers, picture books and campaign posters) show that individuals living with dementia are often visualised in ways that foreground suffering, loss, vacantness, lifelessness and passivity, and that distance these individuals from other represented participants or viewers, whether through a lack of eye contact or a close-up shot of disembodied body parts, such as wrinkled hands (Ang, Yeo, and Koran Citation2023; Brookes et al. Citation2018; Brookes, Putland, and Harvey Citation2021; Caldwell, Falcus, and Sako Citation2021; Harvey and Brookes Citation2019; Putland Citation2022a). Brain imaging outputs are a popular visual metonym for people with dementia, reflecting the widespread influence of biomedical perspectives (Brookes et al. Citation2018; Harvey and Brookes Citation2019). Visual metaphors are also a popular means of symbolising dementia, and these too tend to orient around loss and deficit, whether through a missing jigsaw piece or leaves of a tree, a brain in flames, or the erosion of a face made of sand (Ang, Yeo, and Koran Citation2023; Brookes et al. Citation2018; Harvey and Brookes Citation2019; Putland Citation2022b).
Far less frequently, people with dementia are shown as interacting, smiling and active (Ang, Yeo, and Koran Citation2023; Harvey and Brookes Citation2019), sparking calls for more images of people with dementia enjoying life, interacting with others, and being active citizens (Alzheimer Europe and European Working Group of People with Dementia Citation2022). There are similar calls to diversify who is represented as having dementia, including by challenging the overrepresentation of white, older people – who are seemingly more often portrayed as women and as economically well off (ibid.).
A central issue, then, is the (harmful) imbalance of representations of dementia. However, it is worth noting that while an important counter-discourse to the dominant “tragedy” discourse, a “living well” discourse can be criticised for ignoring the suffering that dementia entails and for marginalising people who do not fit with the “successful ageing” narrative, such as those with late stage dementia (McParland, Kelly, and Innes Citation2017). Rather than aiming to replace the more disabling and dementia-first visual tropes with only person-first and empowering ones, the focus should be on presenting a more multifaceted and thus accurate picture of what dementia and life with the syndrome can mean overall, which can account for both empowerment and suffering (e.g. Putland Citation2022a). Of interest, then, are both the types of visual tropes and the level of diversity amongst AI-generated images. The existing research described above provides a useful point of comparison and something of an evidence base for us to be able to contextualise and interpret the AI-generated visual discourses we identify in the ensuing analysis.
3. AI text-to-image generation
AI text-to-image generation has a range of applications, including being integrated into image banks. Image banks sell vast assortments of images and videos, which can then be used in the production of a wide range of texts (Machin Citation2004). As such, they are a leading force in producing and disseminating visual representations, which includes shifting the world’s visual language from one that emphasises photography as a witness of reality (i.e. taking photos of real life), to one that emphasises photography as a symbolic system (i.e. using photos to signify generic and/or abstract concepts rather than naturalistic standards of reality) (Machin and Van Leeuwen Citation2007, 151). AI-generated images are currently fulfilling a similar function to traditional stock images, but provide users with greater choice and control regarding the images they use.
While AI-related ethics is currently underdeveloped overall, numerous ethical dilemmas are emerging in relation to text-to-image generation specifically. Such concerns relate to the negative impact that the technology could have on human creativity (Somepalli et al. Citation2022), and the potential for its wide – and normalised – use to contribute to an “AI industrial revolution” that threatens the security of jobs in various industries (Elliott Citation2023). Debates are also ongoing concerning the ownership and copyright status of images generated using text-to-image AI (Appel, Neelbauer, and Schweidel Citation2023). Concerns have also been expressed regarding how the technology could be used for malicious purposes, such as creating “deep fake” images, or content that is otherwise misleading and might constitute a form of visual misinformation .
Here, we are primarily concerned with the discursive ideologies (and biases inherent therein) that AI-generated images can reproduce, and which risk contributing to the perpetuation of harmful stereotypes or even discrimination against certain groups. Such bias can occur at the level of the images and corresponding text labels used to train AI models (Crawford and Paglen Citation2021), as well as in the AI-generated outputs themselves. Notably, Bianchi et al. (Citation2023) found persistent stereotypes across occupations (e.g. a chef/cook), and were often unable to mitigate racist, sexist and ableist biases through altering textual prompts in Stable Diffusion. While AI-generated imagery has been considered through a content analysis lens (e.g. Bianchi et al. Citation2023), as far as we are aware, the present study represents the first discourse-based study of AI-generated images.
4. Methodology
4.1. Software selection
With many different text-to-image models (and versions) to choose from, it is important to outline the software selection process. This study uses Stable Diffusion, version 1.4 (model hash: fe4efff1e1). Stable Diffusion is a deep learning, latent diffusion model that can generate images in a range of styles from the user’s textual prompts (Barazida Citation2022). The programme was released in 2022 as open-source code and is free to use or adapt (Stability AI Citation2022). Stable Diffusion’s popularity and transparency (including regarding training datasets) makes it well-suited as a software for research purposes such as ours, and our hope is that this (relative) transparency can facilitate a replicable analysis in the spirit of open research.
The creators of Stable Diffusion openly acknowledge that, since their “models were trained on image-text pairs from a broad internet scrape, the model may reproduce some societal biases” (Stability AI Citation2022). It is therefore useful to be able to consider what datasets these models were trained on, namely pairs of images and captions taken from LAION-5B, a publicly available dataset scraped from the web. LAION-5B contains 5.85 billion image-text pairs, of which 2.32 billion contain English language, and Stable Diffusion is trained on subsets of this dataset that have a higher resolution and aesthetic rating (Schuhmann et al. Citation2022). It is possible to search the training database (or a sample of it) for the same textual prompt (here, “dementia”) to explore the images that Stable Diffusion’s AI model likely draws on when generating new images. Initial search results for “dementia” included image genres such as photographs, clipart and artwork.
To aid both processing speed and replicability, we use the Web User Interface version of Stable Diffusion, since this enables users to run the software on their own computer system, rather than online. This is important for replicability, since we found in the study pilot that the same image seed (a distinct number that corresponds to an image, which should theoretically result in the same image if the same diffusion sampler is used) remained stable in the Web User Interface but not when using the online software. We also added a Variational autoencoder separately, as this enhances detail (e.g. regarding facial expressions) without changing the images generated, enabling close analysis.
4.2. Generating images
Since bias can occur not only in the data but at different stages of the research process itself, it is equally important to be transparent about our research processes and approach. Here, we discuss the choices that were made when generating our dataset of images, before outlining our analytical approach in the following section.
We generated all images in of “dementia” in our data in batches of three on 12th March 2023. In order to maximise the chance of a diverse and randomly generated sample, we chose the “random seed” function for image generation. shows a screen capture of our settings, one of which is the positive textual prompt, “dementia.” We did not use multiple or negative text prompts in our study since we did not want to restrict the results obtained in response to the broad concept of “dementia,” including its associations with other concepts according to the algorithmic training.
Figure 1. A screen capture of our interface for Stable Diffusion, version 1.4.
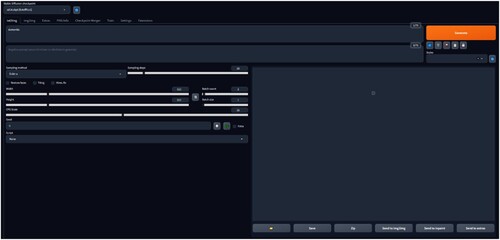
Throughout, we tried to balance image quality with processing demands, as the two tend to correlate. As such, we did not select the option for high resolution. Another important factor to consider is the number of sampling steps, which is the number of steps in the de-noising process that the model includes during image generation (see for an illustration of the outputs associated with different numbers of steps). Here, we selected 20 sampling steps (from a possible range of 0–150), as that is a common choice and balances sufficiently high-quality results with an achievable processing demand for the computer we used. However, it is worth noting that changing the number of sampling steps can influence the composition of the image produced, as exemplified by the changed angle of the frog produced following 12 and 15 steps in .
Figure 2. The results for the textual prompt “frog,” according to the number of sampling steps used*. * Sampler: Euler A, CFG scale: 15, Seed: 4193228899, Size: 512 × 512.

Our sample size was determined by balancing size variations and diffusion sampler methods with generating an appropriate number of images for qualitative analysis. Image size was determined by balancing image quality with the correlating processing demand. To account for the different types of images that can be generated for different widths and heights, we used the following popular visual formats: landscape (512 × 704), portrait (512 × 704) and square (512 × 512). We selected to generate 171 images (all of which are shown in Supplementary Table A), since this could include three of each format for every one of the 19 available diffusion samplers. As shows, some diffusion samplers appear to produce more similar outputs for the same image seed than others, but each output is unique, which motivated our decision to incorporate every sampler method within our dataset.
Figure 3. The first generated result for each diffusion sampler, using the same image seed*. *Seed: 3463148386, Steps: 20, CFG scale: 15, Size: 512 × 704. Diffusion samplers displayed left-right in order of appearance in the option menu.

The classifier free guidance (CFG) scale should also be carefully considered. This is a scale from 1-30, whereby 1 entails absolute creative freedom for the model (meaning that, often, the image looks nothing like the prompt), while 30 necessitates that everything in the prompt must be included, with the output tending to be incoherent as a result. Since it is the middle value, we chose 15 for the CFG scale. When piloting this setting, we found that the CFG scale appeared to be less applicable to “dementia,” likely since this is a single word prompt. In our case, changing the CFG value created distinctly different images despite using the same seed (for instance, a film poster of a person changed to an abstract brain).
Finally, to facilitate transparency and replicability, planning how metadata about the generated images will be stored is essential. provides an illustration of what this metadata may look like. Here, we selected the options to save text information about generation parameters (e.g. the image seed, textual prompt) both as a corresponding text file and to the images themselves. To achieve the latter, all images were saved in the Portable Network Graphics (PNG) format because this is effective at storing metadata with the image, which can then be read for free using a range of online programmes.
Figure 4. An example of the type of metadata saved for each generated image.

4.3. Analytical approach: multimodal critical discourse analysis
After generating the images, we subjected them to a qualitative Multimodal Critical Discourse Analysis, with the aim of identifying visual discourses of dementia that were (re)produced within them. Critical Discourse Analysis (CDA) is an approach to discourse analysis which synthesises close analysis of text(s) with theoretically informed accounts of context in order to elucidate how discourse produces and reproduces social practices and legitimises particular ways of acting and being. The perspective on discourse we take in this study is informed by Fairclough’s (Citation2015) dialectical–relational view, according to which discourse can be understood as being constitutive of and constituted by social practices. From this perspective, it is through discourse that social phenomena, including health conditions like dementia, are constituted and contested, and through which social change relating to those phenomena is accomplished. More specifically, we take a multimodal approach to identifying discourses. Multimodal Critical Discourse Analysis (MCDA; Machin Citation2013) involves examining how discourses are entextualised not only through linguistic choices, but through a culmination of semiotic modes which include but also go beyond language (e.g. image, font, layout, colour, sound, texture, and so on; Kress and Van Leeuwen Citation2020). All approaches to CDA, including MCDA, are united by a focus on the discursive dimensions of power and social justice, and as such share an explicitly problem-oriented, emancipatory agenda. Thus, the aim of CDA is to not only describe and critique discourses but to also explain the social and ideological conditions which both give rise to those discourses and are enabled by them.
Following Harvey and Brookes’s (Citation2019) study of dementia representation in stock imagery, we take a two-tiered approach which broadly corresponds to the Barthian notions of denotation (what is depicted?) and connotation (what is meant or implied?) (Barthes Citation1977), described below. First, we document the composition of the generated images. We take an affordance-based approach to this (Machin Citation2016), focusing only on visual forms of semiosis and paying particular attention to following:
Participants: who is depicted?
Settings: where are the participants?
Gaze: where is the participant(s)’ eye gaze directed? Do they engage the viewer or other represented participants, or look elsewhere?
Angle of interaction: from what angle or perspective do we view the participant(s)?
Colour: what choices are made regarding brightness, saturation, purity, differentiation, and hue?
Second, we interpret recurring elements within the images in terms of the discourses – that is, the dementia-related and age-related attitudes, ideas, and values – that they constitute. As part of this second step, and in order to interpret how these visual discourses are likely to have come about (i.e. what kinds of wider, existing public discourses they (re)produce), we draw comparisons with the visual discourses identified in previous studies of contemporary visual representations of dementia (Ang, Yeo, and Koran Citation2023; Brookes et al. Citation2018; Brookes, Putland, and Harvey Citation2021; Harvey and Brookes Citation2019; Putland Citation2022a, Citation2022b). Through this comparison, we are also able to better appreciate the ideological significance of these (re)produced discourses, and hypothesise the impacts they might have for people living with and trying to understand dementia (should generated images like these, (re)producing similar discourses, be used by public communicators in the real world).
5. Findings
Of the 171 images in the data, we identified 130 as showing people, of which the majority (107) featured an individual, rather than multiple people. Considering the textual prompt, “dementia,” we assumed every image showing people to include at least one individual representing someone living with dementia. The remaining 41 images that did not explicitly show a person included metaphorical images, images of texts (e.g. variants of the word “dementia,” presentation slides, infographics and reports), images of brain microstructures (e.g. neurones) or were otherwise too ambiguous to confidently categorise.
In this section, we focus on recurring visual tropes, with a particular emphasis on how the solitary individual with dementia is depicted, as a face or a brain (or both), since this type of depiction constitutes the majority of our dataset. Relating to this, we then consider visualisations of brain microstructures and the most prevalent visual metaphor: the brain as a tree. Finally, we turn to less prevalent images, notably images with multiple social actors, and some visual anomalies. Throughout, we demonstrate how particular semiotic choices can be interpreted in relation to dominant and often interrelated dementia discourses, particularly the biomedical discourse and its emphasis on disease above the person, the discourse of dementia as loss (of memories, of self, etc.) and the discourse of dementia as a metaphorical and literal “living death,” all of which can facilitate the distancing and disenfranchisement of people with dementia (e.g. Aquilina and Hughes Citation2006; Cahill Citation2018; Sabat Citation2018). Through analysing some of the anomalous images, we also consider how counter-discourses, such as that of “living well” with dementia, might be visually enacted.
5.1. The individual with dementia
Immediately striking across the generated images in our data is the emphasis on the individual with dementia, who tends to be presented alone and through a close-up head and shoulders shot (e.g. ). Despite the intimate personal distance usually suggested by such a close shot (Kress and Van Leeuwen Citation2020), we argue that a sense of emotional distance from both the image subject’s lifeworld and from viewers is regularly established in these AI-generated images through particular semiotic choices observed elsewhere in human-made images of dementia (Brookes et al. Citation2018; Brookes, Putland, and Harvey Citation2021; Harvey and Brookes Citation2019).
Figure 5. The individual living with dementia.

Firstly, as demonstrate, the image subjects are regularly set against decontextualised backgrounds which provide no information about the individual’s setting but rather position them – much as stock images do – as “a generalised example, rather than a specific person” (Orton Citation2022, 7). Represented participants also tend to gaze away from the central point of the image at which imaginary eye contact with viewers could be made, either by looking elsewhere (e.g. (a) and (b)) or by having their eyes closed (e.g. 5f and 5j). Whereas directly gazing at viewers would, as in real life, “demand” some form of connection and relationship, this lack of eye contact instead “offers” these individuals to viewers to look at more impersonally, as objects that can provide information and evoke thought, much like “specimens in a display case” (Kress and Van Leeuwen Citation2020, 118). Such features thus encourage dispassionate observation, rather than encouraging or allowing for the possibility of a human connection with the image subjects.
As generic exemplars of people with dementia, the distinct lack of visual diversity exemplified by is significant. Our image subjects are always lightly skinned (with the only possible exceptions being silhouettes of a generic human face, e.g. (a)) and appear to be in their seventies/eighties or older. This older age is clearly conveyed through detailed markers of ageing that the close-up shots facilitate, such as white hair, wrinkles and age spots – signs that are culturally infused with notions of degeneration and fragility (Brookes et al. Citation2018). This age imbalance reiterates the discursive conflation of dementia with older age, and, combined with the overrepresentation of white people, reproduces existing visual biases that fail to reflect the reality of dementia, which affects people of all ethnic backgrounds and, in up to 9% of cases, people aged below 65 (Alzheimer Europe and European Working Group of People with Dementia Citation2022; Ang, Yeo, and Koran Citation2023; Bould Citation2018; WHO Citation2023).
Equally, these image subjects are never displayed engaging in physical activities and consistently lack markers of individual personality. The person is depicted in a passive, immobile pose, and oftentimes they gaze elsewhere with a vacant expression, which, similarly to closing one’s eyes, has been associated in a dementia context with being disconnected from one’s surroundings, in a zombie-like state (Harvey and Brookes Citation2019; Latimer Citation2018). Colour can be used to exacerbate this “living death” connotation since, with some notable exceptions, the palettes in and tend to be either muted blues (and sometimes browns) or black and white. This restricted and often dull colour palette presents a lower visual modality (in terms of both saturation and range) than the naturalistic standards by which viewers tend to judge reality (Kress and Van Leeuwen Citation2020), which here drains the individuals of vitality and separates them from everyday reality. These colour tones are commonly associated with depression, lethargy and ghostliness, exemplified by the negative colour connotations in phrases such as “grey sky,” “white as a ghost” and “feeling blue” (Brookes, Putland, and Harvey Citation2021, 257). Indeed, on the more general red-blue hue continuum, colours towards the blue end tend to be associated with “cold, calm, distance, and backgrounding” (Kress and Van Leeuwen Citation2002, 357). Combined, then, these passive poses, vacant facial expressions and colder, restricted colour palettes subtly infuse these subjects with a sense of lifelessness and disconnect from the rest of the world, reflecting and reiterating the popular discourse that having dementia is a “living death” (e.g. Aquilina and Hughes Citation2006).
One exception to this overall trend of passive vacantness is that of the “head clutcher” or “head in hands” image (Bennett Citation2023; Bould Citation2018), exemplified by . While the individual remains disengaged from the world (note the closed or near-closed eyes), the represented participants are engaged in an act of sorts: the act of (visible) suffering. Each of these individuals places their hands or fingers on the upper region of their head, with a pained facial expression indicative of perplexity, suffering and/or despair. The consistent placement of the subject’s fingers on their forehead or on the sides of the head locates their source of suffering – here, dementia – in the brain. This image type represents the person living with dementia through neurological or psychological symptoms. It is a form of abstraction which impersonalises the individuals featured (Ang, Yeo, and Koran Citation2023). Such representations reflect a popular visual trope that has met criticism, regarding both dementia and mental health more broadly, for foregrounding a particular experience (suffering) above all others, for risking reducing the person to this particular “symptom” of dementia, and for simplifying this multifaceted symptom to a “visual cipher” (Bennett Citation2023, 47). This emphasis is perhaps most apparent in (c), in which the man’s fingers direct the viewer’s gaze to his forehead, obscuring some of his face in the process, and so encouraging viewers to “see the disease (or an aspect of its manifestation) before and perhaps instead of the person” (Brookes et al. Citation2018, 384).
Figure 6. Variants of the “head clutcher” image for individuals living with dementia.

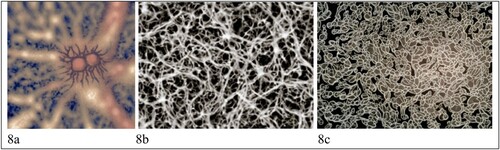
Other images in the data make the underlying biomedical discourse and its emphasis on the brain of someone with dementia far more explicit. shows some examples of such images, which draw on medical imaging and diagrams to “make visible what is normally invisible” to the human eye (Kress and Van Leeuwen Citation2020, 152), which here is “the space inside the skull” (Beaulieu Citation2000). In each image, a person’s face and head (or outline thereof) is present, but is backgrounded in favour of the brain, which is represented either as a fleshy organ or a neural network (and in (c), through neural electric impulses). We categorised 23 images as showing an individual in this way, while an additional three images do so for multiple people (e.g. (a)), and nine do so metaphorically (e.g. ). A further 14 images appear to depict micro-structures of the brain; namely cells, networks or tangles (see ), and three others are rather abstract but likely draw from medical images of the brain.
Figure 7. The brain of people with dementia.
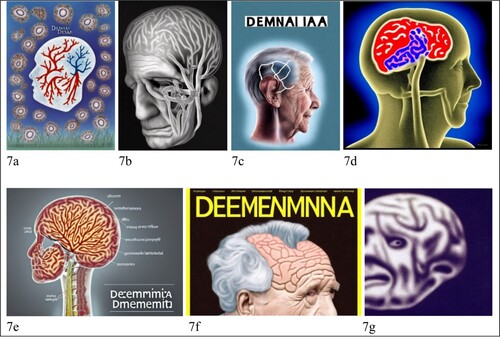
Figure 8. Cellular level visualisations of the brain of someone living with dementia.
The popularity of such brain-oriented images reflects another visual trope in dementia representation: the brain scan (Brookes et al. Citation2018; Harvey and Brookes Citation2019). Similar to photographs, while neuroimaging outputs – such as brain scans – should be interpreted as a form of “mediated communication,” they are instead commonly regarded as visualising an “objective truth” (Newton Citation1998, 8); namely that dementia can be identified and understood in terms of tangible neurological damage, despite counter evidence that such cellular changes do not necessarily correlate with dementia symptoms (Lock Citation2013). There is evidence that such neuroimaging outputs can be incredibly persuasive for audiences (Pickersgill Citation2013), since they are frequently regarded as “expert images” that offer a straightforward and objective insight into the person, as well as into specific mental health conditions. Moreover, such images are imbued with significant symbolic capital, which they derive from being for experts to interpret and understand (Dumit Citation2004). In this data, while some images, such as 7e, contain (nonsense) text that mimics the labels of medical diagrams, images that mimic brain scans (e.g. (d)) provide no explanation of how to interpret the different colours. This lack of guidance leaves viewers to draw on broader social discourses to interpret the image’s denotive and connotative meanings. One potentially influential discourse with remarkable repercussions for people with dementia is the discursive conflation of the person with their brain (Van Gorp and Vercruysse Citation2012).
The prevalence of images of brains in our data arguably reflects the current “saturation of public discourse with biological and neurological ways of thinking” (Thornton Citation2011, 112). A consequence of this, it has been argued, is that we (as viewers) are increasingly encouraged to understand ourselves in relation to what Vidal (Citation2009, 6) terms “brainhood”; that is, “the property or quality of being, rather than simply having, a brain.” Sometimes this person-brain conflation is visually explicit, as in (f) and (g) which literally combine a person’s face with the brain itself. Such neuro-focused images risk “reducing the person with dementia to their (seemingly aberrant) neurobiology” (Harvey and Brookes Citation2019, 996), as if “everything a person with dementia does and feels is the outcome of brain damage and is abnormal in one way or another” (Sabat Citation2014, 108). These “diseased brains” – and by extension, diseased people – are implicitly contrasted against “healthy” or “normal” brains, reinforcing the dichotomy which segregates a normal “us” of people without dementia from the abnormal “them” of people living with the syndrome (Harvey and Brookes Citation2019, 996). Equally, as illustrates, some images remove the person entirely by focusing instead on the cellular level of the brain. As Ang, Yeo, and Koran (Citation2023) argue, this form of somatisation further objectifies social actors by representing them entirely through their (impaired) body part: here, their “diseased” brain.
As well as drawing from the visual traditions of medicine and neurology, the AI-generated images use metaphor to visualise the (processes of the) brain with dementia. Metaphors enable us to communicate and understand complex and abstract concepts, such as dementia (Brookes Citation2023), by comparing them to more tangible and familiar concepts (Semino Citation2008). In this way, metaphors are powerful framing devices, as they foreground certain aspects of a scenario while backgrounding others, thereby promoting “a particular problem definition, causal interpretation, moral evaluation and/or treatment recommendation for the item described” (Entman Citation1993, 52). It is therefore significant that existing research indicates that visual representations of dementia use metaphors to communicate brain degeneration (see, for example, Harvey and Brookes Citation2019). As shows, in the AI-generated images, one metaphor dominates: that of the brain as a tree.
Figure 9. Metaphorical visualisations of the brain of someone living with dementia.
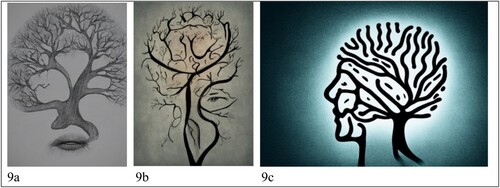
The tree, a “symbol of life and image of seasonal change,” is popularly associated with the brain (Zimmermann Citation2017, 80). Correspondingly, the brain of someone living with dementia is often metaphorically envisioned as a tree losing leaves, in which the leaves may represent brain cells, memories or personal qualities (Ang, Yeo, and Koran Citation2023; Putland Citation2022b; Zimmermann Citation2017). Reflecting this visual trope, the images in depict a bare tree, without leaves, which is clearly associated with the person themselves through the shaping of the tree’s branches such that they resemble the silhouette of a human head. Branches can also be shaped so that they resemble certain facial features, such as lips, an eye or nose, to visually merge the tree with the face of someone living with dementia. The bare branches situate these individuals as being in winter, which, when applied to the lifecycle, is widely associated with bleakness and death (Lakoff and Turner Citation2009), something further reinforced by the cold and dull colour palette of these images (Kress and Van Leeuwen Citation2002). This reiterates the metaphorical positioning of dementia as a “death sentence” (Castaño Citation2020), which ignores the new experiences and growth that people with dementia can experience (O’Connor et al. Citation2022).
If leaves do indeed represent brain health, memories or personal qualities, then having lost leaves also risks implying that people with dementia are not only “diseased brains” but incomplete and (both literally and metaphorically) lesser persons. Such a connotation reiterates the discursive positioning of people with dementia as dehumanised “empty shells” (Van Gorp and Vercruysse Citation2012, 1277) and as a subhuman group of the “living dead” (Aquilina and Hughes Citation2006). Throughout the data, then, whether presented as a face or brain, the individual living with dementia is repeatedly distanced from viewers and their social worlds. They are depicted as a generic example of either someone with dementia or of dementia as a syndrome, which is repeatedly contextualised in terms of suffering, neurology and loss.
5.2. Dementia in the social world
We now turn to the less frequent visual tropes, beginning with depictions of people with dementia alongside others. Twenty-three images in our data show multiple people, of which eighteen were interpreted as showing some kind of interaction. This is contrasted against images that displayed multiple faces/people alongside each other without a clear sense of engagement, often showing similarly vacant or pained expressions to the images discussed above (e.g. (e–h)). In two interactional instances, the images display two faces looking at one another, with either their brains or neural networks foregrounded in a similar way to the images in (e.g. (a)), again encouraging viewers to look at the brain ahead of the person. Other interactional images use pencil sketches, comics and film poster styles, tending to show either a couple touching (e.g. (d)) or people talking and/or being gathered as a group around a central focal point ((b) and (c); also see (b)).
Figure 10. Images with multiple people in different visual styles.
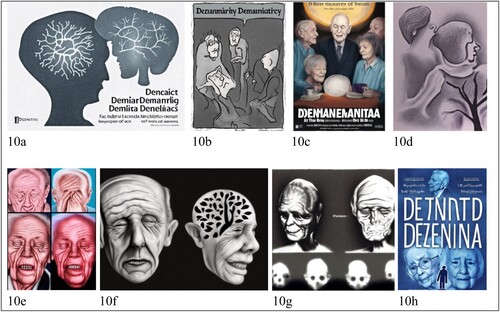
Most commonly, though, interactional images use stock image conventions (see ). These images use generic models, settings and decontextualised backgrounds (note that most of these backgrounds are either blurry or one colour) to denote more generic concepts, people and places, rather than “specific, unrepeatable moments” – all key features of stock images (Machin and Van Leeuwen Citation2007, 152). The level and type of interaction varies across these images. Firstly, (f–h) share many similarities with the “head clutcher” trope previously discussed in relation to the individual living with dementia (see ). Here, the distinction is that another person’s hand touches the forehead and/or eyes of the person with dementia, whose facial expression conveys distress, confusion or suffering. Since only the hand of the other person tends to be shown in detail, this severely restricts interpretations of their interaction, although it certainly provides the potential for viewers to interpret the images as showing another person causing distress, sharing in it, or comforting the person with dementia. Other than this additional interactional meaning potential, the images maintain the focus on the psychological or neurological symptoms of dementia discussed earlier and so do not differ greatly from the individual “head clutcher” images.
Figure 11. Interactions between people with (and without) dementia.

In contrast, the other five images show two or more people in the frame. Often, the background situates these interactions as happening outside, which interestingly counters the more usual domestic or institutional (i.e. hospital or care home) settings previously observed in dementia-related images (Harvey and Brookes Citation2019). Equally, (b–d) show three sets of couples engaging in social interaction, either by looking at one another, talking, or walking together and holding hands. (c) is notable for representing someone with dementia engaging with another person and actively moving their body, interrupting the trends both of disconnect and passive, sedentary poses found here and elsewhere (Brookes et al. Citation2018; Caldwell, Falcus, and Sako Citation2021; Harvey and Brookes Citation2019). It is worth noting, though, that these happier, more connected examples seem to be reserved for couples coded as being heterosexual, which is reflective of a broader view of “successful ageing,” in which “heterosexual romantic coupledom functions as a sign of a happy future” (Sandberg Citation2015, 38).
Interactionally, (a) bears much greater resemblance to photos of people with dementia and caregiver(s) that have been critiqued elsewhere (Brookes et al. Citation2018; Harvey and Brookes Citation2019). Here, the middle figure appears to be coded as the person living with dementia; while the other two subjects look at this central individual and place a hand on her hand or shoulder – a gesture that commonly signals care and support – the individual herself simply sits, appearing not to even acknowledge the others’ presence. This lack of interaction from the central figure, including their downwards gaze and immobile pose, creates a sense of distance both from the other represented participants and from viewers, positioning the person living with dementia as withdrawn and isolated, even when in the company of others.
Finally, (e) is noteworthy for its distinctly odd appearance relative to human generated stock images. Here, six figures walk past one another, no one making eye contact, as if each person is in their own world. Notably, the four figures whose backs are turned to the viewers all have the same short white hair and white jumpsuits, which appear almost like a uniform of sorts. While this could perhaps be associated with the standardisation associated with institutionalisation (are these people care providers or recipients?) the precise meaning is ambiguous. Nonetheless, the visual similarity amongst these four figures speaks well to a consistent issue amongst these images (and indeed, most of the images in the data): a distinct lack of diversity. In this case, the eight images in consistently use the same restricted colour palettes (note, for instance, the repeated blue, beige or white clothes) and only appear to show pale skinned (heterosexual) older people with white hair as being someone living with or otherwise affected by dementia.
5.3. Considering anomalies
Having considered the dominant visual trends in our data, at this point we consider images that are anomalous in the sense that they present alternative means of discursively representing both dementia and people with it. presents three images, each of which provides an interesting contrast to the tropes discussed above. The first (12a) is notable for depicting a man as both smiling and gazing directly ahead, imitating eye contact. This visual form of direct address “demands that the viewer enter into some kind of imaginary relation with him,” while his facial expression – a smile – suggests that this is one of “social affinity,” a marked contrast from the social distance encouraged by most of the images in our data (Kress and Van Leeuwen Citation2020, 117). Drawing on Ang, Yeo, and Koran’s (Citation2023) Visual Discourses of Disability framework, such an image can be interpreted as advocating for people with dementia in the sense that, while it foregrounds dementia through the sign that the individual holds (given the context, it is reasonable to interpret the incorrectly spelled sign as saying “dementia”), this is done in a personising manner through the close up, frontal and eye-level angle taken to depict the individual, who directly gazes at viewers, thus demanding a social connection, as equals. As well as challenging the social distance so often established through images of people with dementia, the act of smiling also interrupts the association of living with dementia with confusion, vacantness and suffering (Brookes, Putland, and Harvey Citation2021), to show that people with dementia can enjoy life and experience happiness, a key tenet of the “living well” counter-discourse. Indeed, similar visual strategies have been used in anti-stigma initiatives in relation to dementia and other conditions (Bennett Citation2023).
Figure 12. Three visual anomalies in the data.

Of course, (a) should be used in conjunction with a variety of others, otherwise it risks becoming a reductive visual trope and, in this case, ignoring the suffering that living with dementia can entail (McParland, Kelly, and Innes Citation2017). Considering the two other images in , it is notable that neither have the represented participants look directly at the viewer (thus, they are presented as objects of the viewer’s gaze), and neither explicitly link the represented participants to dementia. The middle image is formatted like a comic or graphic novel and is distinct for its inclusion of multiple stages of a conversation between people who are smartly dressed and socially engaged (note the eye contact between the characters throughout), and who demonstrate a range of facial expressions, including both seriousness and smiles. This image notably enables plurality (at least in an emotional sense) in its depiction of people living with or otherwise affected by dementia. Indeed, people both with and without lived experience have been found to largely prefer – and indeed often call for – a greater use of such multidimensional representations, both in relation to dementia and in a broader mental health context (Bennett Citation2023; Putland Citation2022a).
The third image is marked by its rainbow-like use of a spectrum of vibrant colours, which swirl around the face of a man who is visually coded as younger through full, dark facial hair and a lack of wrinkles. Although his downward gaze (and possibly closed eyes) is comparable to many of the images in , here the effect is different. This is a particularly ambiguous image with multiple meaning potentials; the man may be interpreted as smiling, overwhelmed, serene, in his own world – the list continues. The colours may metaphorically represent thoughts, feelings, memories, in-the-moment perceptions – or none of these. For us, regardless of these more specific possible interpretations, the swirling colours connote a dynamism and fluidity that is rarely seen in dementia imagery. Its overall ambiguity and fluidity may be seen by some to better “resonate with experiences that are inchoate, mutable and multidimensional” than a more precise approach to metaphor (Bennett Citation2023, 57), such as the brain/person with dementia being a tree losing its leaves (see ). In the context of the data overall, then, these anomalous images exemplify potential avenues for a more varied range of images that rely less on fixed metaphors and tropes, and which include more colour, social connection, routes for advocacy, contradictory emotions, and a focus on more diverse peoples and their experiences.
6. Discussion and concluding remarks
In this study, we have produced and subsequently analysed a dataset of AI-generated images related to dementia. Our analysis indicates that these images employ specific visual tropes, such as emphasising the solitary individual with dementia, which (re)produce existing biases associated with the syndrome. Notably, images depicting individuals with dementia also exhibited a distinct lack of visual diversity. The represented participants were predominantly older individuals with light skin, reinforcing the conflation of dementia with old age and reproducing visual biases that fail to reflect the diversity of people living with the syndrome. Such findings support broader observations of biases and discriminatory practices in AI outputs, both visual and otherwise (Bianchi et al. Citation2023; Crawford and Paglen Citation2021).
We have identified multiple prominent and interrelated (visual) discourses, namely a biomedical emphasis on the disease (or “diseased” brain) above the person, a discourse of loss, and a discourse of dementia as a “living death.” The latter discourse manifested in images of generally solitary individuals with dementia, who tended to be overwhelmingly depicted in passive and immobile poses, often with vacant expressions, while muted colour palettes (predominantly blues, browns, or black and white) contributed further to a sense of lifelessness and disconnection from everyday reality. A part-for-whole visual metonymy, where the person with dementia is reduced to their (diseased) brain/head, was also a distinct visual trope, both literally (i.e. with brain scans) and metaphorically, with bare tree heads. The bare tree heads, in particular, connote loss (of neurones, and perhaps self) alongside a personal winter (and thus, proximity to death).
This focus on the brain and head, above all other aspects of the subject’s corporeality and indeed personhood, reiterates a discourse of “brainhood” (Vidal Citation2009). This discourse is arguably (re)produced in other images too, such as those which offer “head clutcher” or “head in hands” portrayals of individuals as engaged in an act of suffering. Such brain-oriented images display, on the denotative level, the brain of a person with dementia. However, on the connotative level they serve to render visible dementia itself. The visual emphasis placed on the brain reflects a broader biomedical discourse wherein the person with dementia is reduced to their neurobiology – a discourse which also risks further perpetuating a (perhaps harmful) dichotomy between “normal” and “abnormal” brains (and with that, “normal” and “abnormal” people) (Sabat Citation2014, Citation2018).
In combination with the above discourses, it is significant that semiotic choices (e.g. gaze and setting) consistently create a sense of emotional distance between the viewers’ and the represented participants’ respective lifeworlds. Such features include decontextualising the individual through blank backgrounds, which position them as generalised examples of how (someone with) dementia may look, rather than as specific individuals, and avoiding making direct eye contact with viewers, which encourages a dispassionate observation of the individuals as objects rather than fostering human connection. Overwhelmingly, the representations and attendant discourses that we have highlighted here have, in the literature we have cited as part of our comparison with previous findings, been linked to negative portrayals of dementia and to the stigmatisation of people living with the syndrome (e.g. Van Gorp and Vercruysse Citation2012). Notably, when the affective and normative distancing observed in these images is applied more broadly, it risks justifying and normalising human rights violations of people with dementia by (Cahill Citation2018; Johnstone Citation2013).
It is important to reiterate that although these specific images have been generated by AI, they seem to strongly reflect existing visual discourses of dementia (although of course, AI is not an exact mirror to social discourses: Ciston Citation2019). In this sense, the process by which the images come about can be viewed as a form of recontextualization, where recurring visual elements are retained and emphasised (sometimes to an unrealistic extent). Meanwhile, the infrequent, even anomalous, (visual) discourses that likely reflect minority groups, experiences and perspectives (at least in a Western context), are largely lost. The result, then, is an exaggerated (visual) manifestation of already-dominant discourses, with limited scope for alternative perspectives.
On this basis, there is perhaps warrant for concern that the widespread availability of text-to-image AI could perpetuate and amplify existing (harmful) stereotypes on a large scale. Of course, the images we have studied here were generated in experimental conditions and for research purposes, and so are not technically naturally occurring. However, in producing these images we have, as far as possible, aimed to emulate the kind of approach that could be taken (or perhaps is already being taken) by someone creating a dementia-related text intended for public consumption (e.g. in news, advertising or awareness-raising). In this way, it is quite possible – indeed, likely – that those seeking to use text-to-image technology for such purposes will arrive at the same sorts of images that we have, carrying similar discourses. Of course, when used in this way, such images will again be recontextualised. At this point, the selection of the images, along with their possible editing, placement within texts, and accompanying images and language, will all contribute to the meaning(s) they co-construct in context.
There is considerable scope for human agency, then, not only in how AI tools are designed but also in how they are used. For instance, Struppek, Hintersdorf, and Kersting (Citation2022) observe how replacing single characters in textual descriptions with visually similar non-Latin characters can be used to strategically offset the (American) Western bias of AI text-to-image models. Equally, building on Bianchi et al.’s (Citation2023) bias mitigation work, it is important to explore using different textual prompts to diversify dementia representations; for instance, what would typing “living well with dementia” or “people with dementia being active” or using negative prompts (textual prompts the AI avoids) produce? We also propose using a cluster of synonymous (but syntactically and lexically different) multi-word prompts to more comprehensively test biases in the AI model. Such approaches could better explore the possibilities for counter-discourses and plural perspectives, as well as considering how results for “dementia” relate to intersectional issues, such as older age and ageism, gender and sexuality, racism, and disability. Outside of academia, disseminating image generation models based upon more ethical image databases could present a valuable means of providing more diverse and multifaceted representations of complex topics, here, dementia. If done rigorously and in collaboration with people affected by dementia, the resulting image generation could perform a similar function to the Centre for Ageing Better’s (Citation2021) free Age-Positive Image Library, which aims to depict older people in non-stereotypical ways to help counter mainstream visual tropes.
We conclude by adding our voices to those, such as Bianchi et al. (Citation2023), who highlight the need for ethically and socially responsible design and use of text-to-image generation technology. This will require greater transparency and accountability in the creation and use of machine learning training sets, and explicit acknowledgement by both developers and users of the limitations of such tools, as well as necessitating training datasets that are more diverse in terms of the people and perspectives they represent (Ciston Citation2019). Such efforts will require critical and reflexive approaches to the use of AI-generated images – approaches which place at the forefront an ethical concern for the social implications of their use. In developing more ethical practice, developers and users alike should critically appraise the tools and training sets they use, and what these (and their outputs) represent. As our analysis has shown, the discourses that characterise such images often manifest in subtle visual trends, some of which only really become apparent when viewed as part of a large collection of similar texts, at which point their incremental effects become more obvious. It is therefore important to approach the design and use of such tools with due critical literacy, and for us, this is where the intervention and contribution of critical discourse research is vital in appraising and interpreting the affordances and uses of emerging communicative technologies. In this endeavour, AI-generated images – and other forms of semiosis – offer rich data which can be studied as representations of existing social biases and dominant discourses. Such research is necessary to better understand the processes by which dominant and potentially harmful discourses are reproduced in AI-generated content, and ultimately to work towards more ethical – and critical – engagement with emerging technologies.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alzheimer Europe and European Working Group of People with Dementia. 2022. “Guidelines for the Ethical and Inclusive Communication about Portrayal of Dementia and People with Dementia. Accessed July 13, 2023. https://www.alzheimer-europe.org/sites/default/files/2023-01/Alzheimer%20Europe%20and%20European%20Working%20Group%20of%20People%20with%20Dementia%20Guidelines%20for%20the%20ethical%20and%20inclusive%20communication%20about%20portrayal%20of%20dementia%20and%20people%20with%20dementia.pdf.
- Alzheimer’s Disease International. 2019. World Alzheimer Report 2019: Attitudes to Dementia. London: ADI.
- Ang, Pei Soo, Siang Lee Yeo, and Leela Koran. 2023. “Advocating for a Dementia-Inclusive Visual Communication.” Dementia 22 (3): 628–645. https://doi.org/10.1177/14713012231155979.
- Appel, Gil, Juliana Neelbauer, and David A. Schweidel. 2023. “Generative AI Has an Intellectual Property Problem.” Harvard Business Review. https://hbr.org/2023/04/generative-ai-has-an-intellectual-property-problem.
- Aquilina, Carmelo, and Julian C. Hughes. 2006. “The Return of the Living Dead: Agency Lost and Found?” In Dementia: Mind, Meaning, and the Person, edited by Julian C. Hughes, Stephen Louw, and Steven R. Sabat, 143–161. Oxford: Oxford University Press.
- Bailey, Annika, Tom Dening, and Kevin Harvey. 2021. “Battles and Breakthroughs: Representations of Dementia in the British Press.” Ageing and Society 41 (2): 362–376. https://doi.org/10.1017/S0144686X19001120.
- Barazida, Nir. 2022. “Stable Diffusion: Best Open Source Version of DALL·E 2.” Medium. Towards Data Science (blog). August 30, 2022. https://towardsdatascience.com/stable-diffusion-best-open-source-version-of-dall-e-2-ebcdf1cb64bc.
- Barthes, Roland. 1977. Image-Music-Text. New York, NY: Farrar, Straus and Giroux.
- Bartlett, Ruth, and Deborah O’Connor. 2010. Broadening the Dementia Debate: Towards Social Citizenship. Bristol: Policy Press.
- Beaulieu, Anne. 2000. The Space Inside the Skull : Digital Representations, Brain Mapping and Cognitive Neuroscience in the Decade of the Brain. Amsterdam: Department of Science and Technology, Dynamincs, University of Amsterdam. https://pure.uva.nl/ws/files/1079859/47879_UBA002000265_08.pdf.
- Benbow, Susan M., and David Jolley. 2012. “Dementia: Stigma and its Effects.” Neurodegenerative Disease Management 2 (2): 165–172. https://doi.org/10.2217/nmt.12.7.
- Bennett, Jill. 2023. “Visual Communication and Mental Health.” Visual Communication 22 (1): 46–70. https://doi.org/10.1177/14703572221130451.
- Bianchi, Federico, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. “Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale.” In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT ‘23), 1493–1504. New York, NY: Association for Computing Machinery. https://dl.acm.org/doi/10.1145/3593013.3594095.
- Bould, Emma. 2018. Dementia-Friendly Media and Broadcast Guide: A Guide to Representing Dementia in the Arts, Culture and Popular Discourse. London: Alzheimer’s Society. https://www.alzheimers.org.uk/sites/default/files/2018-09/Dementia%20Friendly%20Media%20and%20Broadcast%20Guide.pdf.
- Brookes, Gavin. 2023. “Killer, Thief or Companion? A Corpus-Based Study of Dementia Metaphors in UK Tabloids.” Metaphor and Symbol 38 (3): 213–230. https://doi.org/10.1080/10926488.2022.2142472.
- Brookes, Gavin, Kevin Harvey, Neil Chadborn, and Tom Dening. 2018. “‘Our Biggest Killer’: Multimodal Discourse Representations of Dementia in the British Press.” Social Semiotics 28 (3): 371–395. https://doi.org/10.1080/10350330.2017.1345111.
- Brookes, Gavin, Emma Putland, and Kevin Harvey. 2021. “Multimodality: Examining Visual Representations of Dementia in Public Health Discourse.” In Analysing Health Communication: Discourse Approaches, edited by Gavin Brookes, and Daniel Hunt, 241–269. London: Palgrave Macmillan.
- Burr, Vivien. 2015. Social Constructionism. London: Taylor & Francis Group.
- Cahill, Suzanne. 2018. Dementia and Human Rights. Bristol: Policy Press.
- Caldwell, Elizabeth F., Sarah Falcus, and Katsura Sako. 2021. “Depicting Dementia: Representations of Cognitive Health and Illness in Ten Picturebooks for Children.” Children's Literature in Education 52 (1): 106–131. https://doi.org/10.1007/s10583-020-09405-w.
- Castaño, Emilia. 2020. “Discourse Analysis as a Tool for Uncovering the Lived Experience of Dementia: Metaphor Framing and Well-Being in Early-Onset Dementia Narratives.” Discourse & Communication 14 (2): 115–132. https://doi.org/10.1177/1750481319890385.
- Castaño, Emilia. 2022. “Blogging through Dementia: Reworking Mainstream Discourse through Metaphor in Online Early-Onset Dementia Narratives.” Dementia 22 (1): 105–124. https://doi.org/10.1177/14713012221136659.
- Centre for Ageing Better. 2021. “Age-Positive Image Library Launched to Tackle Negative Stereotypes of Later Life.” Accessed July 18, 2023. https://www.ageing-better.org.uk/news/age-positive-image-library-launched.
- Ciston, Sarah. 2019. “Intersectional AI is Essential: Polyvocal, Multimodal, Experimental Methods to Save Artificial Intelligence.” Journal of Science and Technology of the Arts 11 (2): 3–8. https://doi.org/10.7559/citarj.v11i2.665.
- Clarke, Juanne. 2006. “The Case of the Missing Person: Alzheimer’s Disease in Mass Print Magazines 1991-2001.” Health Communication 19 (3): 269–276. https://doi.org/10.1207/s15327027hc1903_9.
- Crawford, Kate, and Trevor Paglen. 2021. “Excavating AI: The Politics of Images in Machine Learning Training Sets.” AI & SOCIETY 36 (4): 1105–1116. https://doi.org/10.1007/s00146-021-01162-8.
- Dumit, Joseph. 2004. Picturing Personhood: Brain Scans and Biomedical Identity. Oxford: Princeton University Press.
- Elliott, Larry. 2023. “The AI Industrial Revolution Puts Middle-Class Workers under Threat this Time.” The Guardian. https://www.theguardian.com/technology/2023/feb/18/the-ai-industrial-revolution-puts-middle-classworkers-under-threat-this-time.
- Entman, Robert M. 1993. “Framing: Toward Clarification of a Fractured Paradigm.” Journal of Communication 43 (4): 51–58. https://doi.org/10.1111/j.1460-2466.1993.tb01304.x.
- Fairclough, Norman. 2015. Language and Power. 3rd ed. London: Routledge.
- Farid, Hany. 2022. “Text-to-Image AI: Powerful, Easy-to-Use Technology for Making Art – and Fakes.” The Conversation, 2022. http://theconversation.com/text-to-image-ai-powerful-easy-to-use-technology-for-making-art-and-fakes-195517.
- Fontana, Andrea, and Ronald Smith. 1989. “Alzheimer’s Disease Victims: The ‘Unbecoming’ of Self and the Normalization of Competence.” Sociological Perspectives 32 (1): 35–46. https://doi.org/10.2307/1389006.
- Foucault, Michel. 1972. Archaeology of Knowledge. Translated by A. M. Sheridan Smith. London: Routledge.
- Goffman, Erving. 1963. Stigma: Notes on the Management of Spoiled Identity. Hoboken, NJ: Prentice-Hall.
- Gordijn, B. 1999. “The Troublesome Concept of the Person.” Theoretical Medicine and Bioethics 20 (4): 347–359. https://doi.org/10.1023/A:1009990632439.
- Harvey, Kevin, and Gavin Brookes. 2019. “Looking through Dementia: What Do Commercial Stock Images Tell us about Aging and Cognitive Decline?” Qualitative Health Research 29 (7): 987–1003. https://doi.org/10.1177/1049732318814542.
- Johnstone, Megan-Jane. 2013. “Metaphors, Stigma and the ‘Alzheimerization’ of the Euthanasia Debate.” Dementia 12 (4): 377–393. https://doi.org/10.1177/1471301211429168.
- Kitwood, Tom M. 1997. Dementia Reconsidered: The Person Comes First. Buckingham: Open University Press.
- Kontos, Pia, Karen-Lee Miller, and Alexis Kontos. 2017. “Relational Citizenship: Supporting Embodied Selfhood and Relationality in Dementia Care.” Sociology of Health & Illness 39 (2): 182–198. https://doi.org/10.1111/1467-9566.12453.
- Kress, Gunther, and Theo Van Leeuwen. 2002. “Colour as a Semiotic Mode: Notes for a Grammar of Colour.” Visual Communication 1 (3): 343–368. https://doi.org/10.1177/147035720200100306.
- Kress, Gunther, and Theo Van Leeuwen. 2020. Reading Images: The Grammar of Visual Design. 3rd ed. London: Routledge.
- Lakoff, George, and Mark Turner. 2009. More than Cool Reason: A Field Guide to Poetic Metaphor. Chicago, IL: University of Chicago Press.
- Latimer, Joanna. 2018. “Repelling Neoliberal World-Making? How the Ageing–Dementia Relation Is Reassembling the Social.” The Sociological Review 66 (4): 832–856. https://doi.org/10.1177/0038026118777422.
- Lawless, Michael, Martha Augoustinos, and Amanda LeCouteur. 2018. “‘Your Brain Matters’: Issues of Risk and Responsibility in Online Dementia Prevention Information.” Qualitative Health Research 28 (10): 1539–1551. https://doi.org/10.1177/1049732317732962.
- Leone, Carmela, Rachel Winterton, and Irene Blackberry. 2023. “Media Discourses on the Socio-Spatial Rights of Older People Living with Dementia and Their Carers.” Dementia 22 (1): 161–179. https://doi.org/10.1177/14713012221137961.
- Lock, Margaret. 2013. The Alzheimer Conundrum: Entanglements of Dementia and Aging. Princeton, NJ: Princeton University Press.
- Machin, David. 2004. “Building the World’s Visual Language: The Increasing Global Importance of Image Banks in Corporate Media.” Visual Communication 3 (3): 316–336. https://doi.org/10.1177/1470357204045785.
- Machin, David. 2013. “What is Multimodal?” Critical Discourse Studies 10 (4): 347–355. https://doi.org/10.1080/17405904.2013.813770.
- Machin, David. 2016. “The Need for a Social and Affordance-Driven Multimodal Critical Discourse Studies.” Discourse & Society 27 (3): 322–334. https://doi.org/10.1177/0957926516630903.
- Machin, David, and Theo Van Leeuwen. 2007. Global Media Discourse: A Critical Introduction. Florence: Taylor & Francis Group.
- McParland, Patricia, Fiona Kelly, and Anthea Innes. 2017. “Dichotomising Dementia: Is there Another Way?” Sociology of Health & Illness 39 (2): 258–269. https://doi.org/10.1111/1467-9566.12438.
- Newton, Julianne H. 1998. “The Burden of Visual Truth: The Role of Photojournalism in Mediating Reality.” Visual Communication Quarterly 5 (4): 4–9. https://doi.org/10.1080/15551399809363390.
- O’Connor, Deborah, Mariko Sakamoto, Kishore Seetharaman, Habib Chaudhury, and Alison Phinney. 2022. “Conceptualizing Citizenship in Dementia: A Scoping Review of the Literature.” Dementia 21 (7): 2310–2350. https://doi.org/10.1177/14713012221111014.
- Orton, Laura. 2022. “Are Stereotypes, Such as the ‘Headclutcher’, in Stock Images for Mental Illness Stigmatizing?.” https://doi.org/10.21606/drs.2022.354.
- Pickersgill, Martyn. 2013. “The Social Life of the Brain: Neuroscience in Society.” Current Sociology 61 (3): 322–340. https://doi.org/10.1177/0011392113476464.
- Post, Stephen. 2000. “The Concept of Alzheimer Disease in a Hypercognitive Society.” In Concepts of Alzheimer Disease: Biological, Clinical, and Cultural Perspectives, edited by Peter Whitehouse, Konrad Maurer, and Jesse Ballenger, 245–255. Baltimore: Johns Hopkins University Press.
- Putland, Emma. 2022a. Representing Dementia: A Qualitative Analysis of How People Affected by Dementia Situate Themselves in Relation to Different Dementia Discourses. Nottingham: University of Nottingham.
- Putland, Emma. 2022b. “The (in)Accuracies of Floating Leaves: How People with Varying Experiences of Dementia Differently Position the Same Visual Metaphor.” Dementia 21 (5): 1471–1487. https://doi.org/10.1177/14713012211072507.
- Sabat, Steven. 2014. “A Bio-Psycho-Social Approach to Dementia.” In Excellence in Dementia Care: Research into Practice, edited by Murna Downs, and Barbara Bowers, 107–121. New York, NY: Open University Press.
- Sabat, Steven. 2018. Alzheimer’s Disease and Dementia: What Everyone Needs to Know. New York, NY: Oxford University Press.
- Sandberg, Linn. 2015. “Towards a Happy Ending? Positive Ageing, Heteronormativity and Un/happy Intimacies.” lambda nordica 20 (4): 19–44.
- Schuhmann, Christoph, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, and Theo Coombes. 2022. “LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models.” In Track on Datasets and Benchmarks, 1–50. New York, NY: Cornell University.
- Semino, Elena. 2008. Metaphor in Discourse. Cambridge: University Press.
- Shakespeare, Tom, Hannah Zeilig, and Peter Mittler. 2019. “Rights in Mind: Thinking Differently About Dementia and Disability.” Dementia 18 (3): 1075–1088. https://doi.org/10.1177/1471301217701506.
- Somepalli, Gowthami, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2022. Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models. New York, NY: Computer Science: Machine Learning. Cornell University. http://arxiv.org/abs/2212.03860.
- Stability AI. 2022. “Stable Diffusion Public Release.” Stability AI, 2022. https://stability.ai/blog/stable-diffusion-public-release.
- Struppek, Lukas, Dominik Hintersdorf, and Kristian Kersting. 2022. The Biased Artist: Exploiting Cultural Biases via Homoglyphs in Text-Guided Image Generation Models. New York, NY: Computer Science: Machine Learning. Cornell University. http://arxiv.org/abs/2209.08891.
- Swaffer, Kate. 2016. What the Hell Happened to my Brain? Living Beyond Dementia. London: Jessica Kingsley.
- Thornton, David. 2011. Brain Culture: Neuroscience and Popular Media. Piscataway, New Jersey: Rutgers University Press.
- Van Gorp, Baldwin, and Tom Vercruysse. 2012. “Frames and Counter-Frames Giving Meaning to Dementia: A Framing Analysis of Media content.” Social Science & Medicine 74 (8): 1274–1281. https://doi.org/10.1016/j.socscimed.2011.12.045.
- Venkatesan, Sathyaraj, and Raghavi Kasthuri. 2018. “‘Magic and Laughter’: Graphic Medicine, Recasting Alzheimer Narratives and Dana Walrath’s Aliceheimer’s: Alzheimer’s Through the Looking Glass.” Concentric: Literary and Cultural Studies 44 (1): 61–84. https://doi.org/10.6240/concentric.lit.201803.44(1).0004.
- Vidal, Fernando. 2009. “Brainhood, Anthropological Figure of Modernity.” History of the Human Sciences 22 (1): 5–36. https://doi.org/10.1177/0952695108099133.
- World Health Organization. 2023. “Dementia, Fact Sheets.” Accessed October 7, 2023. https://www.who.int/news-room/fact-sheets/detail/dementia.
- Zeilig, Hannah. 2014. “Dementia as a Cultural Metaphor.” The Gerontologist 54 (2): 258–267. https://doi.org/10.1093/geront/gns203.
- Zimmermann, Martina. 2017. “Alzheimer’s Disease Metaphors as Mirror and Lens to the Stigma of Dementia.” Literature and Medicine 35 (1): 71–97. https://doi.org/10.1353/lm.2017.0003.