
ABSTRACT
Automatic speech recognition (ASR) is an emerging technology that has been used in recognizing non-typical speech of people with speech impairment and enhancing the language sample transcription process in communication sciences and disorders. However, the feasibility of using ASR for recognizing speech samples from high-tech Augmentative and Alternative Communication (AAC) systems has not been investigated. This proof-of-concept paper aims to investigate the feasibility of using AAC-ASR to transcribe language samples generated by high-tech AAC systems and compares the recognition accuracy of two published ASR models: CMU Sphinx and Google Speech-to-text. An AAC-ASR model was developed that transcribes simulated AAC speaker language samples. The AAC-ASR model’s word error rate (WER) was compared with those of CMU Sphinx and Google Speech-to-text. The WER of the AAC-ASR model outperformed (28.6%) compared with CMU Sphinx and Google when tested on the testing files (70.7% and 86.2% retrospectively). Our results demonstrate the feasibility of using the ASR model to automatically transcribe high-technology AAC-simulated language samples to support language sample analysis. Future steps will focus on developing the model with diverse AAC speech training datasets and understanding the speech patterns of individual AAC users to refine the AAC-ASR model.
Introduction
Augmentative and Alternative Communication (AAC) could provide opportunities for self-advocacy, education, and communication for millions of people with complex communication needs (Beukelman & Light, Citation2020). Speech-language pathologists (SLPs) use the language sample analysis (LSA) results to guide future treatment sessions (Hill & Romich, Citation2001; Savaldi-Harussi & Soto, Citation2016; Soto & Hartmann, Citation2006). Before conducting LSA, SLPs need to record verbal language samples from clients, including AAC speakers. Since AAC speakers usually have limited verbal language, SLPs could record AAC users’ speech output (e.g., synthesized text-to-speech) from their AAC systems as their language samples (Dada & Alant, Citation2009; Soto, Citation2022). SLPs would then manually transcribe language samples from video or audio recordings to text scripts, which has been the most time-consuming step in the process (Fox et al., Citation2021; Kemp & Klee, Citation1997; Pavelko et al., Citation2016). This issue has discouraged SLPs from using LSA as the gold standard to monitor language performance (Klatte et al., Citation2022; Pavelko et al., Citation2016), further impeding the evidence-based practice in the AAC field (Hill, Citation2004; Kovacs & Hill, Citation2015; Van Tatenhove, Citation2014). Therefore, it is crucial to develop a new approach that enhances the manual transcription step of the LSA process for AAC data. This improvement is essential for clinicians, as it allows frequent collection of AAC language data, enabling them to monitor the language and communication performance of AAC speakers, to support AAC evidence-based practice.
Collecting the data entries (data logs) in AAC systems could be a direct way to access language data (Cross & Segalman, Citation2016; Hill & Romich, Citation2001; Lesher et al., Citation2000). However, currently, the majority of AAC apps do not allow 3rd party to access their data logs, and the data formats of limited existing logs vary (Chen et al., Citation2019). Recognizing these limitations, automatic speech recognition (ASR) could be a solution to accelerate the transcription procedure regardless of AAC apps by automatically detecting an audio recording and transcribing it into text for LSA, thereby promoting inclusivity in the AAC language data collection and analysis.
Several studies have provided evidence of the effectiveness of ASR in transcribing language samples and reducing the labor-intensive transcription process before analyzing the samples (Fox et al., Citation2021; Jongman et al., Citation2021). Fox et al. (Citation2021) also demonstrated a high correlation between ASR transcription and real-time human transcription. These studies support the idea of using ASR to enhance the transcription step and ultimately improve the efficiency of the LSA process for people with communication disorders. However, for ASR to be an effective solution, it is critical to ensure the accuracy of the ASR, especially when recognizing non-typical speech.
Accurate word-by-word transcription enables clinicians to calculate precise linguistic metrics such as the total number of words, the total number of different words, and more. This level of accuracy is crucial for effectively monitoring language development and recovery progress (Fox et al., Citation2021). A standardized way to measure ASR systems’ performance is using the word-error rate (WER). WER is a metric used to evaluate the accuracy of ASR systems and compare the performance of different ASR systems or variations of the same system. It measures the disagreement between the recognized words generated by an ASR system and the ground-truth transcript of the spoken utterance from manual transcriptions (De Russis & Corno, Citation2019; Mustafa et al., Citation2015). When WER is low, this means that the accuracy of an ASR system is high.
Despite the higher accuracy achieved by commercial ASR products like Apple Siri, Google Assistant, Amazon Alexa, and others for speakers with typical speech, it is important to note that they still exhibit a higher WER when recognizing non-typical speech compared to typical speech (De Russis & Corno, Citation2019; Rohlfing et al., Citation2021). For example, De Russis and Corno (Citation2019) reported that when recognizing speech from people with dysarthria, three commercially available ASR systems (IBM Watson, Google Cloud, and Microsoft Azure Bing) exhibited WER ranging from 60% to 67%. Compared to other groups, the WER for a control group without dysarthria ranged from 4% to 7%. This substantial difference highlights the significant challenge faced by these ASR systems in accurately transcribing non-typical speech, which can be attributed to the lack of non-typical speech data during the training of ASR models.
To address the variability of different types of non-typical speech, researchers have developed specialized ASR models tailored to the unique characteristics and challenges of different non-typical speech types, including dysarthria (Joshy & Rajan, Citation2022; Kim et al., Citation2018; Vyas et al., Citation2017), stuttering (Alharbi et al., Citation2017; Shonibare et al., Citation2022), and aphasia (Le & Provost, Citation2016). Google’s Project Euphonia also has made significant effort in this field by including over 500 speakers with diverse etiologies and speech patterns to aim to improve ASR for non-typical speech (MacDonald et al., Citation2021). However, the project primarily focused on natural non-typical speech and did not extensively consider synthesized speech samples, such as those produced by AAC speakers. Thus, further research that tailors ASR models to address the specific needs and nuances of AAC speakers’ synthesized speech remains necessary.
Speech patterns of AAC speakers are varied because they are highly heterogeneous depending on their diagnoses and their AAC systems (Beukelman & Light, Citation2020). Even AAC speakers with the same diagnosis can have different severities, leading to different speech patterns depending on individual cognition, language, and motor skills. AAC speakers can have long pauses between words during AAC display navigation, repeated letters, words, or short phrases based on individual AAC system settings. Some AAC systems are programmed to have speech output after every click, so repetitions for words or letters are more common (Savaldi-Harussi & Soto, Citation2016). For example, when an AAC speaker wants to say, “I like apples,” the AAC speaker needs to navigate through the AAC system and select each word individually. After the speaker selects each word of the sentence, the speaker can then use the “speak” function to speak the complete sentence. The speech output can sound like: “I,” “like,” “toys, “I like toys.” During this process, the pauses between word selections are longer than in natural speech, and the overall speech pattern differs from that of individuals without AAC systems. Consequently, using commercial ASR systems or ASR for dysarthric or dysphonic speech can lead to poor accuracy when attempting to recognize AAC language samples.
Thus, this paper aims to develop a preliminary AAC-ASR model using the AAC language samples from a simulated condition with compare its WER to two common ASR systems: Google Speech-to-text and CMU Sphinx. There are many other products currently on the market that could produce different results, however, Google STT is one of the popular commercial ASR systems on the market (Bohouta & Këpuska, Citation2017; Del Rio et al., Citation2021). CMU Sphinx has larger vocabulary databases, which previous research studies in healthcare have used (Bohouta & Këpuska, Citation2017; Dhankar, Citation2017; Dharmale et al., Citation2019; Huh et al., Citation2023; Shonibare et al., Citation2022). We hypothesize that the AAC-ASR model would have a lower WER than Google STT and CMU Sphinx. Comparing the performances of the AAC-ASR model with two ASR models provides a benchmark for evaluating ASR’s potential to support the automatic transcription step when transcribing the AAC language sample before conducting LSA.
Methods
We used the following ASR training procedures to train the AAC-ASR model and evaluate its accuracy, thus testing if AAC-ASR had a lower WER than the other two models. depicts the process of the AAC-ASR model training along with the following explanations.
Figure 1. AAC-ASR model training process.
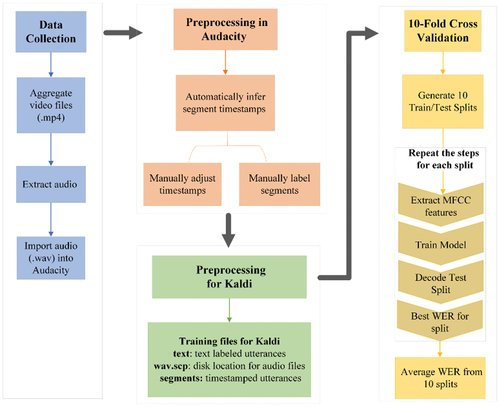
Data collection
The data set consists of 28 videos of simulated AAC language samples. These videos were recorded in a natural setting on an iPhone in four common AAC mobile apps or software that are seen in clinical settings. CoughDrop (CoughDrop INC, Citation2019), Proloquo2Go (AssistiveWare, Citation2019), Speak for Yourself (Speak for yourself LLC, Citation2019) and Words for Life (PRC Co, Citation2020), which use the default text-to-speech output and account for the major AAC features, to emulate the most practical condition in clinical settings, that is, clinicians or caregivers use their smartphones to record some language samples instead of using a professional recording setup. The simulated AAC language samples consisted of one- to three-word utterances, to represent the length of utterances that includes 2–3 symbols, as produced by pediatric AAC users (Binger et al., Citation2020; Kovacs & Hill, Citation2017). The vocabulary includes common words such as I, like, toy, bubble, etc. that are commonly used in clinical settings with pediatric AAC users. summarized the numbers of videos from each software. The audio used to train the AAC-ASR model was extracted from this video dataset. The full dataset consists of 871 words, 395 unique utterances, and 107 unique words. Utterances are one or more words associated with a single time range in an audio file. For example, the word “HE” and the sentence “HE HAD FOOD” are both valid utterances. For automatic utterance segmentation, the boundaries for utterances begin when the audio volume is above the set silence threshold (−26 dB) and are terminated when the audio volume is below the same threshold for longer than 0.3 second. The automatic segmentation also pads the start and end times of the label by 0.1 second. These parameters were used to accurately predict the largest number of segments in the given dataset.
Table 1. Summary of AAC software.
Data pre-processing in Audacity®
After audio extraction, an open-source software, Audacity® (Audacity Team, Citation2021), was used to detect roughly where utterances occur initially. Audacity is open-source software that provides a simple user interface to edit audio files. In addition to editing audio, Audacity has features to mark areas where audio is detected. This feature was useful during preprocessing to create an automated audio-labeling workflow to speed up the data-labeling process. Given a certain audio threshold, Audacity’s sound finder generated approximate timestamped labels from the extracted audio. This automated step prevented the transcriber from having to manually generate timestamps for potentially tens or hundreds of labels per file.
Refine the audacity segmentation
This step is essential for supervised machine learning approaches. Model training can only take place once there is enough labeled data available. Data labeling includes data cleaning, deliberate errors and noisy data are introduced to help the model adjust its parameters and enhance system robustness by accommodating more variations. A trained transcriber validated the approximate timestamp from Audacity’s sound finder for each utterance and manually aligned the timestamp with the visual endpoints of the utterance waveform (see ), to receive the best quality of files for training. After exporting the labels as text files from Audacity, the transcriber used a text editor to add various metadata flags to each label. These flags assess the quality of the recordings before and after manual segmentation. Specifically, these flags include whether the utterance required a manual adjustment for the timestamp and if the intelligibility of the utterance improved after the adjustment. If no adjustment is needed, no metadata is added (e.g., , Line 1). If the transcriber adjusted an utterance waveform. The two metadata flags would be added. For example, in , Line 2, the first symbol “+” means that that transcriber could recognize the utterance before manual adjustment. The second symbol “/” means that the quality of utterance remains the same after adjustment. Another example, in , Line 3, the first symbol “-” means the transcriber could not recognize the whole utterance before manual adjustment. The second symbol “+” means that the transcriber could recognize the whole utterance after adjustment. The metadata flags were used to calculate the improvement of intelligibility of utterances. The intelligibility of the utterances improved from 75% to 96%.
Figure 2. Examples of automatic and manual segmentation using Audacity.
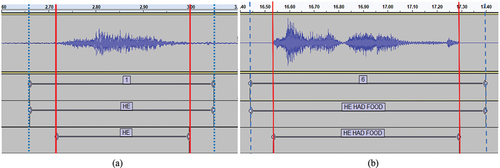
Figure 3. Examples of using metadata.

Data pre-processing for Kaldi (training preparation)
Once the labels were generated, Audacity’s text-formatted label files were then parsed to generate training files used by the Kaldi speech recognition toolkit (Povey et al., Citationn.d..). Kaldi is a research-oriented, open-source toolkit that has been widely utilized in numerous studies for developing speech recognition models (Manfredi, Citation2021) and comparing them to commercial ASR models (Del Rio et al., Citation2021). Its robust functionality and flexibility make it a popular choice for building advanced ASR models. Kaldi’s training files are text, segments, and wav.scp. The text file is the utterance-by-utterance transcript. The segment file includes the start and end times for each utterance in an audio file. The wav.scp file includes the directory location for each audio file. These training files are used to map each utterance ID (UID) to the data for that utterance, including labeled text, timestamps, and source file, respectively. Using the first line in as an example, UID is C2–0. The utterance is “HE.” This utterance started from 2.12 seconds to 2.35 seconds in the wav file. The wav.scp indicated the location of the C2 audio file.
Figure 4. Examples of formatting for each of the training files used by Kaldi.
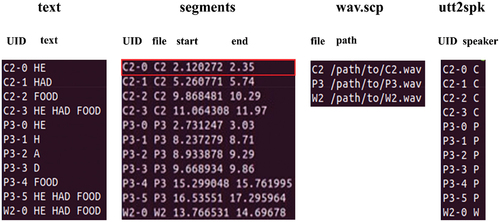
In addition to generating the training files for Kaldi, the CMU Pronouncing Dictionary (The CMU Pronouncing Dictionary, Citationn.d.) was used to build the phonetic lexicon used in training. The phonetic lexicon is necessary for training to provide a mapping between words and their corresponding sequence of phones. For example, the word “car’s phonetic lexicon is/k a r/. A script was used to filter the CMU Pronouncing Dictionary from roughly 35,000 words to match only words present in our corpus (The CMU Pronouncing Dictionary, Citationn.d.). The final pre-processing step included generating the file spk2utt. The utt2spk file includes the utt_id and speaker_id (AAC software) and maps each speaker_id and the utterances generated by the AAC software. For example, in , Line 1’s utt2spk file shows that C2–0 was generated by speaker C, which means CoughDrop.
AAC-ASR model training
A classic ASR training procedure was used first to prove our concept of the feasibility of training an AAC-ASR model. The Hidden Markov Model and Gaussian Mixture Model were used to perform speech recognition (Wang et al., Citation2019). In the context of ASR, the acoustic characteristics can be broken down into frames. The individual phones (a.k.a. phonemes) for a word are modeled by the Hidden Markov Model. For a given frame, the probability density of a state transition to a given phone is represented by the Gaussian Mixture Model. Because these probability density functions are Gaussians, their parameters can be expressed by mean and covariance.
The Kaldi toolkit was used to perform the following training steps. The first step was to extract Mel-frequency Cepstrum Coefficient (MFCC) features from the raw audio. The MFCC features are the signals that humans perceive as music and speech. Cepstral mean and variance normalization was also applied to these MFCC features to reduce acoustic noise in the training files. After the features were extracted and normalized, the model was trained using the Expectation Maximization algorithm. Using the algorithm, the model iteratively optimizes the mean and covariance to best “fit” the training data (Gales & Young, Citation2007).
10-Fold cross-validation
We used 10-fold cross-validation to train and evaluate the performance of the AAC-ASR model. This method is commonly used in small sample-size data (Refaeilzadeh et al., Citation2016). The entire data set was divided into 90% and 10% in training and testing 10 times (fold), where each file was represented at least once in training and once in testing. We then repeated the training of the AAC-ASR model based on the 10 different splits and summarized the performance of the overall AAC-ASR model based on the 10 training splits.
Automatic speech recognition
We evaluated the recognition accuracies of two typical ASR systems that were trained and optimized for typical speech and on our AAC-ASR model to the speech of our four AAC software. The first typical ASR model was accessed through the CMU Sphinx (CMUSphinx, Citationn.d.). CMU Sphinx is an open-source ASR tool developed by Carnegie Mellon University for low-resource platforms. The second typical ASR model was accessed via Google’s Speech-to-Text Application Programming Interface (API) (Google Speech-to-Text, Citationn.d.). Google’s Speech-to-Text is available and integrated into third-party products.
All three models recognized the same test files for each different fold. The WER was recorded for each fold and then averaged by 10 folds to generate the average WERs for each of the three ASR models. WER is a standard metric to evaluate ASR models and calculates the number of insertions (I), deletions (D), and substitutions (S) for each hypothesized utterance in the output transcript (Errattahi et al., Citation2018). We computed the WER between the transcriber-labeled text and the transcribed texts provided by each model. WER is defined as WER = (S + I + D)/N, while N is the number of words labeled by the transcriber. It is possible to have over 100% WER because extra insertions between correctly hypothesized words can still penalize the model. When ASR models cannot recognize a word, they will then recognize the word as one of the errors.
Results
The overall performance of the model was measured on 10-fold cross-validation. shows that the CMU Sphinx and Google models recorded an average WER of 70.7% and 86.2%, respectively. In contrast, the mean WER of the AAC-ASR model was substantially lower, with a mean WER of 28.6%.
Figure 5. WER comparison of three models.
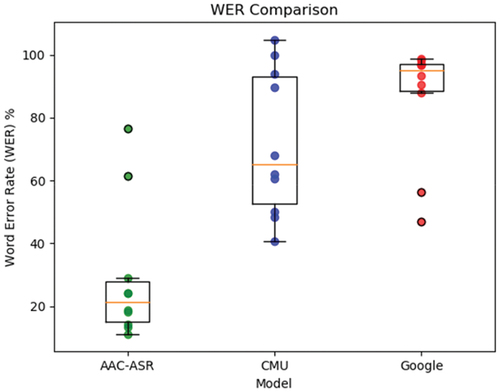
From the box plots in , we can see that the size of the box for the CMU Sphinx model is the longest, which means that its result is diverse. Meanwhile, the CMU model has much longer lower and upper whiskers (outliers) compared to our AAC-ASR and Google. Although the CMU model’s WER is lower than Google’s, it could be much worse (WER close to 100%), for some scenarios, and indicates that the overall speech recognition performance of the CMU model is not stable and reliable. Compared to CMU Sphinx, the performance of Google’s model is stable, as it has a narrow boxplot with much shorter whiskers. However, its overall error rate is the highest. Overall, the boxplot of our AAC-ASR model is narrow with relatively short whiskers; it has stable performance with the lowest error rate. It outperforms CMU Sphinx and Google Speech-to-text when tested on our AAC speech dataset.
Error analysis
To reveal the insides of the model performance, we further analyzed the transcribed error types of the transcribed errors in the three models. shows how many percentages for each type of error. From the analysis, most of the AAC-ASR errors, The CMU-Sphinx, and Google ASR are retrospective substitution, insertion, and deletion. The CMU model has the lowest deletion errors while its substitution rate (51.2%) is the highest. This means that the overall WER of the CMU model is mainly due to incorrect recognition. The overall WER of the Google model is mainly due to its highest deletion error rate (83.3%). It means the Google model could not handle the non-typical speech well and simply removes the unrecognizable phrases. All three individual error types of our AAC-ASR are in the lower bound in and achieve the best overall performance.
Table 2. Occurrences for error types.
Discussion
Our results demonstrate the feasibility of the AAC-ASR model for recognizing AAC speech samples from four different AAC software by a simulated data set. The accuracy of the AAC-ASR model outperformed (that is, mean WER of 28.6%) compared to CMU Sphinx (that is, mean WER of 70.7%) and Google STT (mean WER of 86.2%). The result answered our hypothesis that the AAC-ASR model has lower WER than the other two ASR models. The result also echoes the inadequacy of using commercially available ASR systems to recognize non-typical speech (De Russis & Corno, Citation2019; Green et al., Citation2021). Although our findings are encouraging, more research is needed to evaluate the performance of the AAC-ASR model during more complicated speaking conditions, such as during longer utterances or spontaneous conversations of AAC users.
Despite the overall positive result of the AAC-ASR model WER, which was close to other non-typical speech ASR models (Mendelev et al., Citation2021; Xiong et al., Citation2019), the WER of the AAC-ASR model was 28.6%, which is higher than the ideal target (10%) that researchers have been trying to achieve (Green et al., Citation2021). The performance of recognition accuracy could be due to factors such as a smaller training set and a not-sufficient signal-to-noise ratio, and non-typical speech features of AAC speech (Errattahi et al., Citation2018; Green et al., Citation2021). Additionally, it’s worth noting that this impact extends to other ASR systems, too, which would also face challenges in handling non-typical speech under varying levels of signal-to-noise ratios. These findings highlight the need for further research to determine what noise sources cause low signal-to-noise ratio, such as environmental noise and the components of AAC speech, like long pauses, unintended repetitions, and miss-hits, etc. in AAC speech (Savaldi-Harussi & Soto, Citation2016), and thus improving the signal-to-noise ratio and consequently improving the accuracy of the AAC-ASR model. Furthermore, it is important to note that the AAC-ASR model is aimed at reducing the burden of manual transcription as the prior step of LSA (Fox et al., Citation2021). After an accurate transcript is generated by the AAC-ASR model, clinicians can then proceed with more in-depth LSA, such as lexical analysis can be produced.
The AAC-ASR model demonstrates the merits of speech recognition for AAC users, even though it is elementary compared to the state-of-the-art ASR models. The state-of-the-art ASR models, such as CMU Sphinx and Google ASR, assume the speeches are in standard patterns and structured languages and can leverage an abstracted language model on top of acoustic models. Therefore, during the stage of model learning, their training dataset does not include enough non-typical speech patterns. As a result, both the CMU sphinx and Google STT models have a higher WER on our AAC speech data set. From the further error analysis, the CMU and Google models have the highest substitution error and deletion error rates, respectively. It means that when a regular model is not confident of predicting non-typical speaking utterances, it chooses either making wrong guesses (CMU Sphinx) or treating them as noise and ignoring them (Google STT).
Our study focuses on using WER to assess and compare ASR performance among three models: the AAC-ASR model and the other two ASR models. A low WER is indicative of precise word-by-word transcription, which in turn paves the way for deriving objective linguistic metrics like total word count and communication rates for monitoring the trajectories of language development and recovery. However, it is important to acknowledge that word-by-word transcription generated from ASR might affect the understandability of the messages due to ASR errors (Kafle & Huenerfauth, Citation2019; Mishra et al., Citation2011). Hence, when understandability of the messages and words is the outcome measure, it becomes critical to incorporate other measures that evaluate the meaning of words and messages generated from the ASR transcription.
Future work
The results of this proof-of-concept study demonstrate the potential of using the AAC-ASR model to improve the efficiency of the language sample analysis process by providing automatic transcription. The accuracy of the AAC-ASR model was better than that of the two typical-speech ASR models when recognizing simulated AAC speech. However, a limitation should be addressed. Our study focused on a specific set of ASR systems and simulated speech samples under a control condition, which may not fully represent the diversity of AAC users and their communication patterns. Future research aims to include AAC language data from a broader range of AAC users, encompassing different AAC systems with various text-to-speech, speech characteristics, and communication contexts. This will help us to understand individual AAC users’ speech patterns and refine the models using advanced ASR training methods. Additionally, more research is needed to improve the AAC-ASR model when speech is produced under more complicated real-world conditions, such as everyday conversation or intervention sessions with other communication partners, and when speech is characterized by high variability from different AAC speakers.
Furthermore, as we continue to refine and improve the AAC-ASR model, it is important to conduct future studies that explore its practical application in supporting complete reliable functional language sample analysis that incorporates these pre-processing steps into the AAC-ASR model, therefore the final application will only require SLPs use the original audio files as this would make the entire process less time consuming and not require SLPs to perform data pre-preprocessing steps manually. These studies should not only focus on evaluating the accuracy and performance of the ASR model but also seek feedback from SLPs regarding the automatic transcription process. Understanding the perspectives and experiences of SLPs will provide valuable insights for further development and enhancement of the AAC-ASR technology, ensuring its effectiveness and usefulness in clinical practice.
Acknowledgements
The first author created the simulated data set at the State University of New York at Fredonia. We thank Vaneiqua Wilson for transcribing the simulated data for developing the AAC-ASR model, and Zoe Nelson and Jenna O’Donnell for assisting the manuscript preparation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author, SKC, upon reasonable request.
References
- Alharbi, S., Hasan, M., Simons, A. J. H., Brumfitt, S., & Green, P. (2017). Detecting stuttering events in transcripts of children’s speech. In N. Camelin, Y. Estève, & C. Martín-Vide (Eds.), Statistical language and speech processing (Vol. 10583, pp. 217–228). Springer International Publishing. https://doi.org/10.1007/978-3-319-68456-7_18
- AssistiveWare. (2019). Proloquo2go [Mobile App]. http://www.assistiveware.com/product/proloquo2go
- Audacity Team. (2021). Audacity(r): Free audio editor and recorder [Computer application]. Version 3.0.0. Retrieved March 17, 2021, from https://audacityteam.org/
- Beukelman, D. R., & Light, J. C. (2020). Augmentative & alternative communication: Supporting children and adults with complex communication needs (5th ed.). Paul H. Brookes Publishing Co., Inc.
- Binger, C., Kent-Walsh, J., Harrington, N., & Hollerbach, Q. C. (2020). Tracking early sentence-building progress in graphic symbol communication. Language, Speech, and Hearing Services in Schools, 51(2), 317–328. https://doi.org/10.1044/2019_LSHSS-19-00065
- Bohouta, G., & Këpuska, V. (2017). Comparing speech recognition systems (Microsoft API, Google API and CMU Sphinx). International Journal of Engineering Research and Applications, 2248–9622(03), 20–24. https://doi.org/10.9790/9622-0703022024
- Chen, S.-H. K., Wadhwa, S., & Nyberg, E. (2019). Design and analysis of interoperable data logs for augmentative communication practice. The 21st International ACM SIGACCESS Conference on Computers and Accessibility, 533–535. https://doi.org/10.1145/3308561.3354614
- The CMU Pronouncing Dictionary. (n.d.). In Carnegie Mellon speech group. https://github.com/cmusphinx/cmudict
- CMUSphinx [ Computer software]. (n.d.). https://cmusphinx.github.io/
- CoughDrop. INC. (2019). CoughDrop [Mobile App]. www.mycoughdrop.com
- Cross, R. T., & Segalman, B. (2016). The realize language system: An online SGD data log analysis tool. Assistive Technology Outcomes & Benefits (ATOB), 10(1), 75–93.
- Dada, S., & Alant, E. (2009). The effect of aided language stimulation on vocabulary acquisition in children with little or no functional speech. American Journal of Speech-Language Pathology, 18(1), 50–64. https://doi.org/10.1044/1058-0360(2008/07-0018)
- Del Rio, M., Delworth, N., Westerman, R., Huang, M., Bhandari, N., Palakapilly, J., McNamara, Q., Dong, J., Zelasko, P., & Jette, M. (2021). Earnings-21: A practical benchmark for ASR in the wild. Interspeech, 2021, 3465–3469. https://doi.org/10.21437/Interspeech.2021-1915
- De Russis, L., & Corno, F. (2019). On the impact of dysarthric speech on contemporary ASR cloud platforms. Journal of Reliable Intelligent Environments, 5(3), 163–172. https://doi.org/10.1007/s40860-019-00085-y
- Dhankar, A. (2017). Study of deep learning and CMU sphinx in automatic speech recognition. 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), 2296–2301. https://doi.org/10.1109/ICACCI.2017.8126189
- Dharmale, G., Thakare, V. M., & Patil, D. (2019). Implementation of efficient speech recognition system on mobile device for Hindi and English language. International Journal of Advanced Computer Science & Applications, 10(2), 83–87. https://doi.org/10.14569/IJACSA.2019.0100212
- Errattahi, R., El Hannani, A., & Ouahmane, H. (2018). Automatic speech recognition errors detection and correction: A review. Procedia Computer Science, 128, 32–37. https://doi.org/10.1016/j.procs.2018.03.005
- Fox, C. B., Israelsen-Augenstein, M., Jones, S., & Gillam, S. L. (2021). An evaluation of expedited transcription methods for school-age children’s narrative language: Automatic speech recognition and real-time transcription. Journal of Speech, Language, & Hearing Research, 64(9), 3533–3548. https://doi.org/10.1044/2021_JSLHR-21-00096
- Gales, M., & Young, S. (2007). The application of hidden Markov models in speech recognition. Foundations and trends® in Signal Processing, 1(3), 195–304. https://doi.org/10.1561/2000000004
- Google Speech-to-Text. (n.d.). Google. https://cloud.google.com/speech-to-text/
- Green, J. R., MacDonald, R. L., Jiang, P., Cattiau, J., Heywood, R., Cave, R., Seaver, K., Ladewig, M. A., Tobin, J., Brenner, M. P., Nelson, P. C., & Tomanek, K. (2021). Automatic speech recognition of disordered speech: Personalized models outperforming human listeners on short phrases. Interspeech, 2021, 4778–4782. https://doi.org/10.21437/Interspeech.2021-1384
- Hill, K. (2004). Augmentative and alternative communication and language: Evidence‐based practice and language activity monitoring. Topics in Language Disorders, 24(1), 18–30. https://doi.org/10.1097/00011363-200401000-00004
- Hill, K. J., & Romich, B. A. (2001). A language activity monitor for supporting AAC evidence-based clinical practice. Assistive Technology: The Official Journal of RESNA, 13(1), 12–22. https://doi.org/10.1080/10400435.2001.10132030
- Huh, J., Park, S., Lee, J. E., & Ye, J. C. (2023). Improving medical speech-to-text accuracy with vision-language pre-training model ( arXiv:2303.00091). arXiv. http://arxiv.org/abs/2303.00091
- Jongman, S. R., Khoe, Y. H., & Hintz, F. (2021). Vocabulary size influences spontaneous speech in native language users: Validating the use of automatic speech recognition in individual differences research. Language and Speech, 64(1), 35–51. https://doi.org/10.1177/0023830920911079
- Joshy, A. A., & Rajan, R. (2022). Automated dysarthria severity classification: A study on acoustic features and deep learning techniques. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 30, 1147–1157. https://doi.org/10.1109/TNSRE.2022.3169814
- Kafle, S., & Huenerfauth, M. (2019). Predicting the understandability of imperfect English captions for people who are deaf or hard of hearing. ACM Transactions on Accessible Computing, 12(2), 1–32. https://doi.org/10.1145/3325862
- Kemp, K., & Klee, T. (1997). Clinical language sampling practices: Results of a survey of speech-language pathologists in the United States. Child Language Teaching and Therapy, 13(2), 161–176. https://doi.org/10.1177/026565909701300204
- Kim, M., Cao, B., An, K., & Wang, J. (2018). Dysarthric speech recognition using convolutional lstm neural network. Interspeech, 2018, 2948–2952. https://doi.org/10.21437/Interspeech.2018-2250
- Klatte, I. S., Van Heugten, V., Zwitserlood, R., & Gerrits, E. (2022). Language sample analysis in clinical practice: Speech-language pathologists’ barriers, facilitators, and needs. Language, Speech & Hearing Services in Schools, 53(1), 1–16. https://doi.org/10.1044/2021_LSHSS-21-00026
- Kovacs, T., & Hill, K. (2015). A tutorial on reliability testing in AAC language sample transcription and analysis. Augmentative and Alternative Communication, 31(2), 159–169. https://doi.org/10.3109/07434618.2015.1036118
- Kovacs, T., & Hill, K. (2017). Language samples from children who use speech-generating devices: Making sense of small samples and utterance length. American Journal of Speech-Language Pathology, 26(3), 939–950. https://doi.org/10.1044/2017_AJSLP-16-0114
- Le, D., & Provost, E. M. (2016). Improving automatic recognition of aphasic speech with aphasiabank. Interspeech, 2016, 2681–2685. https://doi.org/10.21437/Interspeech.2016-213
- Lesher, G. W., Rinkus, G. J., Moulton, B. J., & Higginbotham, D. J. (2000). Logging and analysis of augmentative communication. Proceedings of the RESNA 2000 Annual Conference, 82–85. Orlando, FL.
- MacDonald, R. L., Jiang, P.-P., Cattiau, J., Heywood, R., Cave, R., Seaver, K., Ladewig, M. A., Tobin, J., Brenner, M. P., Nelson, P. C., Green, J. R., & Tomanek, K. (2021). Disordered speech data collection: Lessons learned at 1 million utterances from project euphonia. Interspeech, 2021, 4833–4837. https://doi.org/10.21437/Interspeech.2021-697
- Manfredi, E. by C. (2021). Models and analysis of vocal emissions for biomedical applications (Florence) [Text]. https://books.fupress.com/catalogue/models-and-analysis-of-vocal-emissions-for-biomedical-applications/7364
- Mendelev, V., Raissi, T., Camporese, G., & Giollo, M. (2021). Improved robustness to disfluencies in rnn-transducer based speech recognition. ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6878–6882. https://doi.org/10.1109/ICASSP39728.2021.9413618
- Mishra, T., Ljolje, A., & Gilbert, M. (2011). Predicting human perceived accuracy of ASR systems. Proceedings of Interspeech -2011, 1945–1948. https://doi.org/10.21437/Interspeech.2011-364
- Mustafa, M. B., Rosdi, F., Salim, S. S., & Mughal, M. U. (2015). Exploring the influence of general and specific factors on the recognition accuracy of an ASR system for dysarthric speaker. Expert Systems with Applications, 42(8), 3924–3932. https://doi.org/10.1016/j.eswa.2015.01.033
- Pavelko, S. L., Owens, R. E., Ireland, M., & Hahs-Vaughn, D. L. (2016). Use of language sample analysis by school-based SLPs: Results of a nationwide survey. Language Speech and Hearing Services in Schools, 47(3), 246–246. https://doi.org/10.1044/2016_LSHSS-15-0044
- Povey, D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Goel, N., Hannemann, M., Motlıcˇek, P., Qian, Y., Schwarz, P., Silovsky, J., Stemmer, G., & Vesely, K. (n.d.). The Kaldi speech recognition toolkit. 4.
- PRC Co. (2020). LAMP words for life [Mobile App]. https://www.prentrom.com/prc_advantage/lamp-words-for-life-language-system
- Refaeilzadeh, P., Tang, L., & Liu, H. (2016). Cross-Validation. In L. Liu & M. T. Özsu (Eds.), Encyclopedia of database systems (pp. 1–7). Springer New York. https://doi.org/10.1007/978-1-4899-7993-3_565-2
- Rohlfing, M. L., Buckley, D. P., Piraquive, J., Stepp, C. E., & Tracy, L. F. (2021). Hey siri: How effective are common voice recognition systems at recognizing dysphonic voices? The Laryngoscope, 131(7), 1599–1607. https://doi.org/10.1002/lary.29082
- Savaldi-Harussi, G., & Soto, G. (2016). Using SALT: Considerations for the analysis of language transcripts of children who use SGDs. Perspectives of the ASHA Special Interest Groups, 1(12), 110–124. https://doi.org/10.1044/persp1.sig12.110
- Shonibare, O., Tong, X., & Ravichandran, V. (2022). Enhancing ASR for stuttered speech with limited data using detect and pass. Cureus, 14(9). https://doi.org/10.48550/ARXIV.2202.05396
- Soto, G. (2022). The protocol for the analysis of aided language samples in Spanish: A tutorial. Perspectives of the ASHA Special Interest Groups, 7(2), 523–532. https://doi.org/10.1044/2021_PERSP-21-00236
- Soto, G., & Hartmann, E. (2006). Analysis of narratives produced by four children who use augmentative and alternative communication. Journal of Communication Disorders, 39(6), 456–480. https://doi.org/10.1016/j.jcomdis.2006.04.005
- Speak for yourself LLC. (2019). Speak for yourself [Mobile App]. https://www.speakforyourself.org/
- Van Tatenhove, G. (2014). Issues in language sample collection and analysis with children using AAC. Perspectives on Augmentative and Alternative Communication, 23(2), 65–65. https://doi.org/10.1044/aac23.2.65
- Vyas, G., Dutta, M. K., & Prinosil, J. (2017). Improving the computational complexity and word recognition rate for dysarthria speech using robust frame selection algorithm. International Journal of Signal & Imaging Systems Engineering, 10(3), 136. https://doi.org/10.1504/IJSISE.2017.086037
- Wang, D., Wang, X., & Lv, S. (2019). An overview of end-to-end automatic speech recognition. Symmetry, 11(8), 1018. https://doi.org/10.3390/sym11081018
- Xiong, F., Barker, J., & Christensen, H. (2019). Phonetic analysis of dysarthric speech tempo and applications to robust personalised dysarthric speech recognition. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5836–5840. https://doi.org/10.1109/ICASSP.2019.8683091