Abstract
This research analyses the use of language-based strategies in human-chatbot interactions, namely the use of self-disclosure, question asking, expressions of similarity, empathy, humour, and the communication competence of the chatbot. This study aims to discover whether humans and a social chatbot communicate differently. Furthermore, we analyzed to what extent the chatbot’s expressions affect the human users’ expressions. A content analysis was conducted based on previously collected data from a longitudinal study, in which participants interacted seven times with chatbot Mitsuku over the course of three weeks. A randomly selected sample of 60 interactions was coded and results revealed that the participants self-disclosed more (intimately) and used more reciprocal self-disclosures, while the chatbot asked more questions, more reciprocal questions and more follow-up questions, expressed more similarity and humour. Moreover, the more questions the chatbot asked, the more the participants reciprocated these questions, and the more they self-disclosed. Our findings show that chatbots are programmed to gather information, by asking questions, to keep the conversation going, which elicits self-disclosure in human users. However, the self-disclosure was not reciprocated, which may hinder human-chatbot relationship formation.
1. Introduction
The number of chatbots, text-based conversational agents who engage in natural, conversational exchanges with human users (Kowatsch et al., Citation2018), has grown exponentially over the past years. By mid-2018, there were over 300,000 chatbots available on Facebook Messenger alone (Johnson, Citation2018), with thousands more integrated into websites or other familiar instant messaging applications (Skjuve & Brandtzaeg, Citation2018).
This multiplicity of chatbots have been used in many ways. One major application has been for broad customer service or marketing purposes. These commercial chatbots typically operate within restricted domains with well-defined schemas (Shum et al., Citation2018), e.g., addressing targeted questions about highly specific topics. In contrast, social chatbots are not designed with the goal of answering questions or of solving particular problems within a narrow, specific domain. Instead, these chatbots are created to fulfil people’s need for affection and communication and to emotionally connect with their users (Shum et al., Citation2018). In other words, they are meant to be a user’s virtual companion. To be effective, social chatbots are trained to communicate in a human-like way, emulating interpersonal communication (Chang et al., Citation2008). They do so via dialog systems that process textual input (i.e., natural language processing; Jurafsky & Martin, Citation2019) and aim to generate satisfactory textual reactions (i.e., natural language generation; Gatt & Krahmer, Citation2018).
The real challenge for chatbots, whether social or commercial, is the sheer complexity of communication. This can range from non-direct or contextual work word usage (Hill et al., Citation2015), to expressions of emotions, jokes, or even implicit references that both parties (usually) understand. A good chatbot needs to be able to somehow take in this information and provide some meaningful responses in return (Chaves & Gerosa, Citation2021).
As one might expect, frequently reported problems with chatbots involve miscommunications, misunderstandings, the provision of incorrect answers, lack of variation, and lack of conversational flow (Beran, Citation2018; Chang et al., Citation2008; Skjuve & Brandtzaeg, Citation2018).
To effectively communicate with (and thereby serve as virtual companions to) human users, a social chatbot needs to be able to develop a number of language based-strategies that minimize miscommunications and misunderstandings (Demeure et al., Citation2011; Shum et al., Citation2018). One place to learn such strategies is from humans. When humans get to know each other, there are a number of strategies they can use that enhance friendship formation. For example, to decrease uncertainty about how an individual will respond, people use interactive strategies (Eaton & Rose, Citation2011; Walther, Citation2019), which include asking questions and disclosing personal information about themselves (Berger & Calabrese, Citation1975). These interactive strategies are especially useful in text-based communication, such as online chat, as features of these interactions induce more uncertainty, due to a reduced number of cues, compared to face-to-face communication (e.g., Antheunis et al., Citation2012). Additionally, empathy, the process of understanding and responding to another person’s emotional expressions, is important in interpersonal social interactions, as it is a prerequisite for providing emotional support and enables individuals to alleviate one another’s negative emotional states (Bickmore & Picard, Citation2005; Shum et al., Citation2018). Expressions of humour, meanwhile, are shown to appeal to positive emotions and making interactions more enjoyable (Callejas et al., Citation2011). Finally, research shows that humans enjoy communicating with individuals who are similar to themselves (Wagner et al., Citation2019), especially in initial, getting-acquainted interactions.
Humans clearly use these various language-based strategies when initially communicating. If social chatbots are to succeed in their function, then they should too. What remains unclear, however, is (i) if current social chatbots also employ these language-based strategies in initial human-chatbot interactions, and (ii) if and how their usage differs from the ways in which their human interaction partners employ these strategies.
By comparing a social chatbot’s expressions to human expressions, the present study aims to discover to what extent human language use differs from that of social chatbots in initial, human-chatbot interactions. Furthermore, this study aims to examine whether there is an impact of the chatbot’s expressions on the language use of its users. To achieve these aims, the present study utilizes a longitudinal research design to analyse human-chatbot interactions and the language-based strategies they employ when getting acquainted. Specifically, this study focuses on the use of question asking and self-disclosure (both amount and intimacy), as well as expressions of empathy, similarity, humour, profanity, and the chatbot’s appropriate responses. The insights about the current use of language-based strategies for social interactions will help to improve the conversational skills of the chatbot, aiming to develop a chatbot that can interact in varied, informative and adequate manner over a longer period of time across multiple interactions.
2. Theoretical framework
2.1. The rise of social chatbots
A distinction can be made between commercial and social chatbots. Commercial chatbots are typically designed for customer or marketing services, developed to assist customers with very specific questions within a specific domain (Shum et al., Citation2018). In contrast, social chatbots do not necessarily answer a user’s questions, but are designed to become a virtual companion to their users (Shum et al., Citation2018). The most well-known social chatbots currently are Cleverbot, ALICE, Replika, and Kuki, the five-time winner of the Loebner prize (in 2013 and from 2016 to 2019), which is awarded annually to the most human-like computer application. Social chatbots are designed to engage in unstructured small talk to fulfil people’s need for social interaction (Brandtzaeg & Følstad, Citation2017). In doing so, these chatbots need to be able to initiate conversations, proactively generate new conversational topics, formulate questions and follow-up questions, and respond in a human-like, empathic way (Chaves & Gerosa, Citation2021).
Although social chatbots are becoming increasingly better communicators, even the best social chatbots still have important limitations. One is that a chatbot does not have a Theory of Mind – a reflection of the interactions partner’s perceived knowledge and intentions derived from the previous interaction (Heyselaar & Bosse, Citation2020; Milligan et al., Citation2007). Social chatbots are usually unable to refer back to prior conversations with individual users, which means there is no element of shared history between user and chatbot (Hill et al., Citation2015). Another limitation of a chatbot is that they cannot generate a broad variety of responses. As they typically follow pre-defined scripts, chatbots oftentimes respond with repetitive and non-personalized texts. Research shows that when humans communicate with a chatbot, they perceive the chatbot’s responses as less natural compared to human communication (Mou & Xu, Citation2017). This may be because a chatbot’s responses are not personalized; they provide the same answers to all users, which can lead to frustration among its users (Chaves & Gerosa, Citation2021). Furthermore, human language is often motivated by emotions; something a computer cannot have (Beran, Citation2018). Human-chatbot communication often results in misunderstandings, due to nonsensical or inappropriate responses, reference errors, and repetitive, predictable, and irrelevant dialogue (Callejas et al., Citation2011; Chang et al., Citation2008; Creed et al., Citation2015).
Thus, research shows that chatbot communication is still less natural compared to human communication and that human users react differently to chatbots, compared to human interlocutors. What remains unexplored is to what extent specific social processes associated with social and relational communication are expressed in repeated interactions between humans and a chatbot, and whether these expressions differ between humans and a chatbot. From computer-mediated communication (CMC) research we know that when humans communicate in a digital, text-based environment they apply different language-based strategies compared to face-to-face interactions (e.g., Antheunis et al., Citation2012; Walther et al., Citation2005). This is because the visual anonymity of CMC, the ability to think about and edit textual messages, and the absence of non-verbal cues means people feel safer to express themselves (Joinson, Citation2001). Although chatbot communication resembles a CMC environment, this is still an inherently different experience (Hill et al., Citation2015; Huang et al., Citation2021; Mou & Xu, Citation2017), as people are interacting with a chatbot instead of another human. Thus, the present study explores whether the strategies often found in initial, CMC interactions between two humans are also found in human-chatbot interactions and whether human users apply the same strategies as a social chatbot. Specifically, in this study we examine the expression of question asking, self-disclosure, similarity, empathy, humour, profanity, and appropriate responses in human-chatbot interactions.
2.2. Uncertainty reduction in human-chatbot interactions: Self-disclosure and question asking
When two people get to know each other, there is interpersonal uncertainty, which is defined as a lack of interpersonal knowledge about how the other person will react in an interaction (Eaton & Rose, Citation2011; Walther, Citation2019). This uncertainty motivates individuals to engage in reciprocal communication to gather information about the other person, which ultimately leads to impression formation (Walther, Citation2019). Research investigating the process of uncertainty reduction often builds on the Uncertainty Reduction Theory (URT), which claims that the process of information seeking in initial interactions reduces uncertainty and aids relationship formation (Berger & Calabrese, Citation1975). Specifically, interpersonal uncertainty is reduced through reciprocal communication between two people; by gathering information about one another by using conversational strategies (Walther, Citation2019).
Based on URT, three types of strategies that people use when getting to know someone can be distinguished: passive, active and interactive URSs (Berger et al., Citation1976). The present study focuses on interactive strategies, which involve direct communication between two people. Examples of interactive strategies are question asking and self-disclosure, defined as the act of revealing personal information to another person (Archer & Burleson, Citation1980). These strategies can vary in breadth, or amount, and depth, or intimacy (Tidwell & Walther, Citation2002). Specifically, breadth refers to sharing superficial facts in an interaction, like details related to the type of work one has or what hobbies one enjoys (Altman & Taylor, Citation1973). Depth, in contrast, refers to sharing more intimate details about one’s life, which involves thoughts, feelings and details regarding one’s relationships with other people. Thus, people typically get to know someone by asking (intimate) questions and disclosing (intimate) information to one another and reciprocation is important in the process of overcoming interpersonal uncertainty (Ligthart et al., Citation2019).
Research shows that when humans communicate to a chatbot, they are more likely to self-disclose when the chatbot shows high reciprocity (Mou & Xu, Citation2017). Furthermore, studies show that people prefer to talk to chatbots who exhibit reciprocal self-disclosure (Zamora, Citation2017). In fact, it has been found that self-disclosure and reciprocity in human-chatbot interactions improve trust and overall interaction satisfaction and enjoyment (Lee et al., Citation2017). Extending this, it is natural to say that reciprocal self-disclosure likely improves a chatbot’s overall performance, which is an essential factor in improving trust (Rheu et al., Citation2021). Generally, studies show that proactive communication in human-chatbot interactions, as shown by initiating a conversation, suggesting new topics, disclosing new information or formulating follow-up questions, keeps users engaged (Chaves & Gerosa, Citation2021; Citation2021). Moreover, a study by Ligthart et al. (Citation2019) revealed that when a robot asked closed-ended questions to a child, this elicited self-disclosure, but this self-disclosure was limited in terms of amount and intimacy. In line with this, Yang et al. (Citation2017) found that a lack of relevant questions in human-chatbot interactions inhibited the user’s desire to continue interacting with the chatbot. Thus, although chatbots are capable of eliciting self-disclosure by asking questions, these questions can be limited and, as a result, the self-disclosures can lack intimacy. It still remains unclear whether a chatbot is capable of responding appropriately to the disclosures of human users. This leads to our first two research questions:
RQ1: To what extent do humans and a social chatbot differ in the expression of self-disclosure (RQ1a), intimacy of self-disclosure (RQ1b), and reciprocal self-disclosure (RQ1c) in initial human-chatbot interactions?
RQ2: To what extent do humans and a social chatbot differ in the expression of question asking (RQ2a), intimacy of question asking (RQ2b), reciprocal question asking (RQ2c), and the use of follow-up questions (RQ2d) in initial human-chatbot interactions?
2.3. Similarity, empathy, and humour in human-chatbot interactions
Burgoon and Hale (Citation1984) define similarity as the communication of attitude likeness, which suggests an interest in a deeper relationship. Expressions of similarity signal relational familiarity and depth, which correlates with interpersonal attraction (Mehrabian & Williams, Citation1969). In contrast, expressions of dissimilarity signal decreased involvement in an interaction, which causes negative arousal (Burgoon et al., Citation1999). Further, the degree to which communicators express similarities in initial interactions indicates an interest in a deeper relationship (Walther & Burgoon, Citation1992). If two strangers find one another similar, they are likely to want to continue interacting with one another, as people gravitate towards those who display similar characteristics (Houser et al., Citation2008).
According to the ‘similarity attraction principle,’ humans prefer talking to people who are similar to themselves, and this also applies to chatbots (Bickmore & Picard, Citation2005). Humans prefer talking to a chatbot that matches with them in terms of personality; this makes them like the chatbot more (Callejas et al., Citation2011). Furthermore, human users prefer chatbots that become more like them over time, which results in more cooperation between user and chatbot (Bickmore & Picard, Citation2005). Although we know from previous research that expressions of similarity aid relationship development and result in positive interaction outcomes, while dissimilarity hinders relationship development, we do not yet know whether humans and a social chatbot express (dis)similarity to one another in human-chatbot interactions and whether this differs between humans and a chatbot. This motivates our third research question:
RQ3: To what extent do humans and a social chatbot differ in the expression of similarity (RQ3a) and dissimilarity (RQ3b) in initial human-chatbot interactions?
Empathy, the process of understanding and responding to another’s emotional expressions, is one of the fundamental processes in relationship formation and a prerequisite for providing emotional support (Bickmore & Picard, Citation2005). According to Shum et al. (Citation2018), a social chatbot needs to be able to develop empathy, which is the ability to identify the user’s emotions and emotional needs from conversation. What is especially needed is other-oriented empathy (i.e., caring for others) which has been shown to be effective in positively influencing people’s perceptions about a chatbot’s capabilities (Chin & Yi, Citation2021). However, it is not clear if chatbots are capable of demonstrating empathy, as they do not possess true feelings (Bickmore & Picard, Citation2005). Studies show that computers can appear to be empathic as long as they are accurate in the feedback they give (Klein et al., Citation2002). Thus, the appropriate use of empathy by a chatbot can alleviate frustration and make its users feel understood (Bickmore & Picard, Citation2005).
Currently, social chatbots do seem capable of recognizing and controlling users’ feelings by showing (apparent) empathy and understanding, which can aid relationship formation (Chaves & Gerosa, Citation2021). That said, when chatbots express sympathy and empathy, it can come across as “uncanny” (Beale & Creed, Citation2009; Mori, Citation1970). Overly humanized chatbots can heighten users’ expectations of these bots, which can lead to frustration if the bot fails to meet these expectations (Chaves & Gerosa, Citation2021). Expressions of empathy by a chatbot can be perceived as uncanny, as empathy is believed to be a uniquely human quality (Liu & Sundar, Citation2018). Nevertheless, although a chatbot lacks emotions, it should be able to display empathy and/or supportive communication for humans to be able to communicate with it in a natural way. Previous research is conflicted on whether or not chatbots are capable of communicating in an empathic way. This suggests our fourth research question:
RQ4: To what extent do humans and a social chatbot differ in the expression of empathy in initial human-chatbot interactions?
Similarly, the use of humour is believed to be an important strategy in relationship formation and maintenance, and can increase liking in human-chatbot interactions (Bickmore & Picard, Citation2005). A social chatbot who has a sense of humour is likely to be perceived as more natural and humanlike in the way it communicates (Chaves & Gerosa, Citation2021; Shum et al., Citation2018), and interactions with humour-using chatbots are taken to be more enjoyable (Callejas et al., Citation2011); text-based chatbots who display humour are rated more positively, compared to chatbots who lack a sense of humour (Morkes et al., Citation1998). Furthermore, chatbots adopting informal language through, for example, small talk, emoticons, and animated images (GIFs) are found to enhance social presence and, in turn, perceived enjoyment and trust towards the chatbot (De Cicco et al., Citation2020). However, we do not yet know how well social chatbots are able to express humour and whether this differs from the ways in which human users use humour in human-chatbot interactions. Thus, our fifth research question:
RQ5: To what extent do humans and a social chatbot differ in the expression of humour in initial human-chatbot interactions?
2.4. Social chatbots and communication competence
Finally, the present study aims to examine how communicatively competent social chatbots are in initial human-chatbot interactions by measuring (in)appropriate responses. Although some studies show that chatbots can be perceived as competent in their communication, which can make them more believable (e.g., Demeure et al., Citation2011; Edwards et al., Citation2014), many chatbots still respond in an inappropriate way. This can result in frustration (Callejas et al., Citation2011), especially when social chatbots user demands become complex, as chatbots frequently fail to meet these demands. Additionally, when building a believable social chatbot needs to be able to respond appropriately and coordinate between internal and external responses (Ortony, Citation2003). When a chatbot does not correctly interpret the meanings of a user’s utterances, the chatbot comes across as less credible. So, the use of inappropriate responses can hinder an interaction with a chatbot and makes the bot come across as less credible, believable, and competent. In the present study, we thereby also test the following research question:
RQ6: To what extent does a social chatbot lack communication competence in initial human-chatbot interactions, as shown by inappropriate responses?
2.5. The adaptation hypothesis
According to the adaptation hypothesis, interaction partners are likely to adapt to one another (Hill et al., Citation2015). Adapting one’s language to one’s conversation partner is a common behaviour for humans (Chaves & Gerosa, Citation2021). Depending on whom we are talking to, we tend to adapt our expectations, behaviours, and reactions to different interaction partners and contexts (De Angeli et al., Citation2001). A common criticism of contemporary conversational agents is that they are unable to personalize or adapt the dialogue interaction to individual users or contexts (Mairesse & Walker, Citation2009). Although it is a natural process for humans to adapt to one another’s language style, personality, and context, chatbots struggle to do so.
Since present-day chatbots are able to communicate in such a way that it resembles human interaction, human users are likely to adapt their language style to the chatbot (Skjuve et al., Citation2019). Specifically, the way human users communicate with a chatbot may be impacted by how the chatbot communicates. For example, if a chatbot is capable of communicating in a human-like way, but is unable to self-disclose, this can affect how human users perceive the interaction and how they, subsequently, adapt their language to the chatbot (Skjuve et al., Citation2019). Additionally, if a chatbot fails to ask relevant questions, human users may lack the desire to continue the interaction with the chatbot, leaving it unable to successfully elicit self-disclosure. Similarly, if a chatbot fails to appropriately reciprocate a human user’s self-disclosure, this may result in frustration and dissatisfaction, potentially hindering the self-disclosure process (Chaves & Gerosa, Citation2021).
Thus, while it is natural for humans to adapt to each other in conversation, this adaptation is far from a given in interactions between humans and chatbots. In this study, we will explore if human also adapt to the language of a chatbot interaction partner. Therefore, our final research question is:
RQ7: To what extent do the chatbot’s expressions have an effect on the expressions of human users in initial human-chatbot interactions?
3. Method
3.1. Procedure and participants
This study is a content analysis based on previously collected data from a longitudinal study, in which 118 participants interacted with social chatbot Kuki, previously called Mitsuku, an 18-year old female chatbot from Leeds, England (https://chat.kuki.ai/). Kuki was developed in 2005 by Steve Worswick and is available on existing chat applications like Facebook Messenger and Telegram. In the longitudinal study, the interactions were held every three days over a three-week period; so participants had a total of seven interactions. The interactions lasted at least five minutes. Between each interaction, there was a two-day interval where no interaction took place. On the day of the interaction, participants received a reminder that they had to interact with Kuki. These interactions took place wherever the participants chose. The interactions were logged and anonymized. Furthermore, we randomly selected 60 participants (15 male, 45 female; Mage = 24.13; SDage = 8.42) from the total sample and coded the interactions of these participants (N = 420 interactions). We chose a sample of 60 participants, leading to 420 interactions, which is a more than sufficient sample to get accurate and representative results. The majority (83.3%) of the participants had the Dutch nationality; the other 16.7% came from various cultural backgrounds. Participants had an above-average experience with chatbots (M = 3.67; SD = 0.84) with the main purpose for communicating with chatbots being customer service (53.3%), followed by fun/entertainment (20%), online shopping (18.3%), the news and/or weather (5%), online dating (5%) and other (3%). None of the participants indicated that they had communicated with chatbot Kuki prior to the study.
3.2. Content analysis
The content analysis procedure consisted of two phases. In the first phase, three judges coded the chatbot’s expressions. In the second phase, four judges coded the participants’ expressions. In both phases, all judges individually coded the same twelve, randomly selected transcripts (20%). The first step in both phases of the coding process is to divide the transcripts into utterances, defined as the expression of an idea unit or a proposition (Antheunis et al., Citation2012). The coding of utterances is done by placing utterance breaks in the transcripts to show the end of one utterance and the beginning of the next (Tidwell & Walther, Citation2002). For example, “I am Kuki,” “I am a robot girl,” and “I live in Leeds” are three separate utterances. The intercoder reliability was calculated using the percent agreement, by dividing the number of agreements in utterance breaks by the total number of utterance breaks coded in a conversation. In phase 1, the percent agreement was 85%, and in phase 2, the percent agreement was 99.6%, signifying good agreement. This allowed the judges in both phases to continue the coding process by splitting the remaining 48 transcripts evenly among them (16 transcripts per judge in phase 1; 12 transcripts per judge in phase 2).
The second step of the coding process consisted of coding the utterances for self-disclosure (amount, intimacy, and reciprocity), question asking (amount, intimacy, reciprocity, and follow-up questions), (dis-)similarity, empathy, profanity, and humour. In addition, in the first phase, the variable “inappropriate responses” was also coded for the chatbot’s utterances, which was not coded in phase 2 for the utterances of the participant. In this step of the coding process the 60 transcripts, coded into utterances, were divided evenly among all judges who received extensive training with a codebook. This codebook included the variables, a definition and some examples to clarify the coding process. After receiving instructions, the judges individually coded the same 12 transcripts (20%). The remaining 48 transcripts were divided evenly among all coders after intercoder reliability was established and deemed sufficient.
In both phases we used two measures to determine intercoder reliability, namely Krippendorff’s Alpha (Kalpha) in phase 1, which can handle more than two raters, and Kappa in phase 2, combined with percent agreement. This was done because many of the coded variables in this study are binary variables (0–1) and Krippendorff’s Alpha and Kappa can be unjustifiably low for binary, skewed data, for example when one of the categories is coded very rarely (De Swert, Citation2012; see ). While in phase 1 three judges coded all variables, in phase 2, four judges were divided into two teams of 2 judges to code the variables. Two judges coded self-disclosure (intimacy and reciprocity) and question asking (intimacy and reciprocity), while the two other judges coded similarity, empathy, profanity, and humour. In addition, since the intercoder reliability for intimacy of self-disclosure and question asking for the chatbot’s utterances was rather low in phase 1 (Kalpha = 0.58, percent agreement = 0.66) this variable was coded again for the chatbot in phase 2 to establish better reliability ().
Table 1. Intercoder reliability for all variables in phase 1.
Table 2. Intercoder reliability for all variables in phase 2.
3.2.1. Self-disclosure and question asking
Amount of self-disclosure and question asking are both part of the variable “uncertainty reduction strategy.” In this study, self-disclosure was operationalized as an utterance related to personal information about the chatbot which tells something about the chatbot, describes the chatbot in some way or refers to her experiences, thoughts or feelings (Tidwell & Walther, Citation2002; e.g., “I like to make new friends”). A question was operationalized as a phrase or interrogative sentence that invites a reply (Tidwell & Walther, Citation2002), for example “Where do you live?” Utterances that did not fall under the categories “self-disclosure” (1) or “question” (2) were coded as “other” (3).
3.2.2. Intimacy of self-disclosure and question asking
Next to amount of self-disclosure and question asking, the intimacy, or depth, of these variables was also coded based on Altman and Taylor’s (Citation1973) classification scheme. To do so, each disclosure and question was rated in terms of intimacy by assigning a value of (1) for low intimacy, (2) for medium intimacy and (3) for high intimacy. The classification scheme consists of three layers of intimacy: peripheral, intermediate, and core. The peripheral layer concerns disclosures of questions related to biographical information, such as age, gender, height and other basic information. An example is “I am a girl from Leeds.” The intermediate layer is concerned with attitudes, opinions and values, for example, “I like robots, computers, and chatting online.” The core layer is related to personal beliefs, needs, fears, emotions and things people are ashamed of (Antheunis et al., Citation2012; Tidwell & Walther, Citation2002). An example is, “When is the last time you cried?”
3.2.3. Reciprocity of self-disclosure, question asking and follow-up questions
Both self-disclosure and question asking were coded for reciprocity (Jourard, Citation1971), so whether or not the disclosure was a response to a question (e.g., X: “What is your name?,” Y: “My name is Kuki”), or a reaction to someone else’s disclosure (e.g., X: “I love animals,” Y: “Me too”). Reciprocity of self-disclosure was coded as (0) none, (1) a response to a question, or (3) a reciprocal self-disclosure. Additionally, reciprocal question asking can be a reaction to an earlier question in the conversation (e.g., “I am doing fine, and you?”), while a follow-up question suggests a question related to an earlier question, or a reaction to a disclosure of the other person (e.g., X: “Do you believe cloning humans is wrong?,” Y: “Yes, I believe it is wrong” X: “Why, what’s wrong with it?”). Reciprocity of question asking was coded as (0) none, (1) a follow-up question, or (3) reciprocal question.
3.2.4. Similarity and dissimilarity
To code similarity, judges assigned a value of (0) when the utterance did not contain an expression of similarity or dissimilarity, (1) if it contained an expression of dissimilarity and (2) if it concerned an expression of similarity. An example of an expression of similarity is “I love animals too,” while an expression of dissimilarity is X: “Kebabs taste lovely, but they are not very healthy,” Y: “I don’t really like it.”
3.2.5. Empathy
Empathy is defined as an utterance, which indicates that the chatbot feels bad or sorry for the user, acknowledges the user’s feelings or shows understanding for how the user is feeling (Liu & Sundar, Citation2018). An example of an empathic utterance is the following response: X: “My mother died five years ago,” Y: “That is sad, were you close to her?.” Empathy was coded with (1) for an empathic utterance and (0) if the utterance was not empathic.
3.2.6. Humour
Humour is defined as an utterance by the chatbot that the user recognizes as an attempt to amuse, be sarcastic or tell a joke. In this study, we define humour as innocent humour, which is not intended or perceived as sexual, aggressive, or derisive (Morkes et al., Citation1998). If the chatbot attempted to amuse the user in an utterance this was assigned the value (1) as an expression of humour, while the value (0) suggested no expression of humour. An example of a humorous utterance is in the following exchange: X: “I’m going for a break,” Y: “Have you tried looking in a bone? There should be some breaks there.”
3.2.7. Inappropriate responses
This variable was only coded for the chatbot’s utterances. Inappropriate responses refer to statements where the chatbot speaks or responds in an inappropriate way. For example, the chatbot may speak or answer in a way that does not fit within the context of the conversation. An example is the following exchange: X: “Quite honestly, I wouldn’t worry myself about that,” “Y: Wouldn’t worry about what?,” X: “No would worry about what would not,” Y: “You make no sense.” In this exchange, the third utterance leads to confusion and was coded as an inappropriate response (1). Appropriate utterances were awarded the value (0).
For all variables, except for intimacy of self-disclosure and question asking, proportions were calculated, by dividing the frequency of a variable by the total number of utterances in each individual conversation. The reason to conduct the analyses with proportions is that the conversations varied in the number of utterances. For both disclosure and question intimacy a composite score was calculated as an index for the mean amount of intimacy. This score was calculated by summing the number of disclosures and questions weighted by their intimacy score (1, 2, or 3) and by dividing that score by the total number of utterances.
4. Results
To test RQ1-RQ5, we performed independent t-tests to see whether expressions of (intimacy of) self-disclosure, (intimacy of) question asking, reciprocity of self-disclosure and question asking, the use of follow-up questions, similarity, dissimilarity, empathy, and humour would differ between the participants and chatbot Kuki. The means and standard deviations are presented in .
Table 3. Means and standard deviations for all variables for the participants’ and Mitsuku’s utterances
4.1. Self-disclosure
First, we tested to what extent there is a difference in the amount (RQ1a), intimacy (RQ1b) and reciprocity (RQ1c) of self-disclosure between participants and Kuki. On average, participants self-disclosed significantly more frequently (M = 0.25, SD = 0.13) compared to chatbot Kuki (M = 0.23, SD = 0.13), Mdif = 0.03, t(833.97) = 2.84, p = 0.005.
The use of intimate self-disclosures was also found to significantly differ between participants and Kuki, Mdif = 0.43, t(602.70) = 11.92, p < 0.001. Specifically, participants expressed more intimate self-disclosures (M = 1.63, SD = 0.32) compared to chatbot Kuki (M = 1.20, SD = 0.67).
The use of reciprocal self-disclosure also differed between the participants and chatbot Kuki, Mdif = 0.07, t(816.73) = 9.39, p < 0.001. The results showed that participants expressed more reciprocal self-disclosure (M = 0.16, SD = 0.11) compared to Kuki (M = 0.09, SD = 0.09). These results show that participants expressed significantly more self-disclosures, more intimate self-disclosures, and more reciprocal self-disclosures than the chatbot did.
4.2. Question asking
Second, we tested to what extent there is a difference in the amount (RQ2a), intimacy (RQ2b) and reciprocity (RQ2c) of question asking and the use of follow-up questions (RQ2d) between participants and Kuki. On average, the use of question asking by Kuki (M = 0.28, SD = 0.11) was significantly higher than the use of question asking by the participants (M = 0.21, SD = 0.11), Mdif = −0.07, t(838) = −9.63, p < 0.001.
The intimacy of question asking did not differ between the participants and chatbot Kuki, Mdif = 0.49, t(838) = 1.18, p = 0.237. The results showed that the level of intimacy of the questions asked by Kuki and the participants did not significantly differ.
The use of reciprocal questions did significantly differ between participants and Kuki, Mdif = −0.01, t(838) = −5.04, p < 0.001. Specifically, Kuki asked more reciprocal questions (M = 0.03, SD = 0.03) compared to the participants (M = 0.02, SD = 0.03).
The use of follow-up questions also differed between the participants and chatbot Kuki, Mdif = −0.04, t(833.07) = −7.99, p < 0.001. The results showed that Kuki asked more follow-up questions (M = 0.08, SD = 0.07) compared to the participants (M = 0.04, SD = 0.06). In fact, Kuki asked significantly more questions, more reciprocal questions, and more follow-up questions compared to the participants in this study. The use of intimate questions did not differ between the participants and the chatbot.
4.3. Similarity
Third, we tested to what extent there is a difference in expressions of similarity (RQ3a) and dissimilarity (RQ3b) between participants and Kuki. On average, Kuki expressed more similarity (M = 0.02, SD = 0.03) compared to the participants (M = 0.01, SD = 0.03), Mdif = −0.01, t(838) = −3.26, p = 0.001. Expressions of dissimilarity did not significantly differ between participants and Kuki, Mdif = 0.00, t(774.49) = 1.02, p = 0.310.
4.4. Empathy
To test the fourth research question to see to what extent there is a difference in expressions of empathy between participants and Kuki an independent t-test was performed. The results showed that expressions of empathy did not differ between the participants and Kuki, Mdif = 0.00, t(838) = 0.93, p = 0.355.
4.5. Humour
Fifth, we tested to what extent expressions of humour differ in interactions between the participants and Kuki. The results revealed that Kuki uttered significantly more humorous expressions (M = 0.03, SD = 0.04) compared to the participants (M = 0.01, SD = 0.02); Mdif = −0.03, t(551.30) = −12.52, p < 0.001.
4.6. Inappropriate responses
RQ6 asked to what extent social chatbot lacks communication competence in initial human-chatbot interactions, as shown by inappropriate responses. Over the course of the seven interactions, the chatbot often responded inappropriately, as seen in .
Table 4. Means and standard deviations for the Chatbot’s inappropriate responses.
4.7. Repeated measures analyses for chatbot Kuki
Additional repeated measures ANOVAs were conducted to see if there were differences concerning the expression of the aforementioned variables between Kuki and the participants over the course of the seven conversations. For all analyses, we ran simple contrasts where we compared all time points to the last time point (7), the reference group. Below we first discuss the results for the chatbot, followed by the results for the participants. All analyses were conducted with time (7 time points) as a within-subject factor and (intimacy of) self-disclosure, (intimacy of) question asking, reciprocity of self-disclosure and question asking, the use of follow-up questions, similarity, dissimilarity, empathy, and humour as the dependent variables.
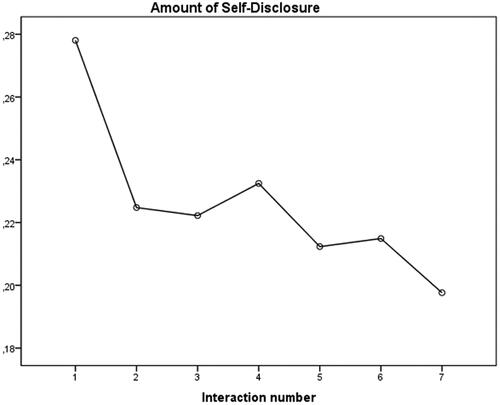
For the analysis of amount of self-disclosure, Mauchly’s test indicated that the assumption of sphericity had been violated, χ2(20) = 62.29, p < 0.001, therefore, a Greenhouse-Geisser correction was used. (ε = .75). The analysis revealed that there was a significant effect of time on amount of self-disclosure, F(4.48, 264.18) = 4.50, p = 0.001. Simple contrasts revealed that there was a significant difference between time point 1 (M = 0.28; SD = 0.16), time point 2 (M = 0.22; SD = 0.11), and time point 3 (M = 0.22; SD = 0.11), compared to time point 7 (M = 0.20; SD = 0.10) with regards to the use of self-disclosure. These results show that there was a significant decrease in the use of self-disclosure over time point 1 (F(1, 59) = 17.75, p < 0.001), time point 2 (F(1, 59) = 4.10, p = 0.047) and time point 3 (F(1, 59) = 3.91, p = 0.053) compared to the seventh time point. The results are visualized in .
Figure 1. The decrease of amount of self-disclosure for chatbot Mitsuku over the seven interactions.
The analysis revealed that intimacy and reciprocity of self-disclosure did not differ significantly between time points (all F’s < 1.76; all p’s > .107).
Concerning question asking, the results showed that amount of question asking, intimacy of question asking, reciprocity of question asking, and the use of follow-up questions did not differ significantly between time points (all F’s < 1.35; all p’s > .233).
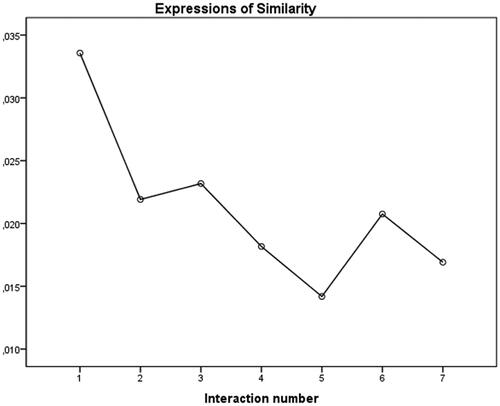
For similarity, Mauchly’s test indicated that the assumption of sphericity had been violated, χ2(20) = 57.05, p < 0.001, therefore, a Greenhouse-Geisser correction was used. (ε = .77). The analysis showed that the effect of time on expressions of similarity was significant, F(4.64, 274.02) = 3.26, p = 0.009. Simple contrasts revealed that there was a significant difference between time point 1 (M = 0.03; SD = 0.04) and time point 7 (M = 0.02 SD = 0.02) concerning expressions of similarity. These results show that there was a significant decrease in expressions of similarity when comparing time point 1 (F(1, 59) = 9.97, p = 0.003) to the seventh time point. The results are visualized in .
Figure 2. The decrease of expressions of similarity for chatbot Mitsuku over the seven interactions.
With regards to dissimilarity, empathy, humour, and inappropriate responses, the analyses revealed that the effect of time on these variables was not significant (all F’s < 1.99; all p’s > .120).
In sum, the results of the repeated measures analyses showed that expressions of self-disclosure and expressions of similarity by chatbot Kuki decreased over the course of the seven interactions. The expression of all other variables did not differ across interactions.
4.8. Repeated measures analyses for the participants
For the participants we also conducted repeated measures ANOVA’s with time (7 time points) as a within-subject factor and self-disclosure, question asking, similarity, empathy, and humour as the dependent variables. The analyses revealed that the effect of time on these variables was not significant (all F’s < 2.01; all p’s > 0.063).
4.9. The adaptation hypothesis
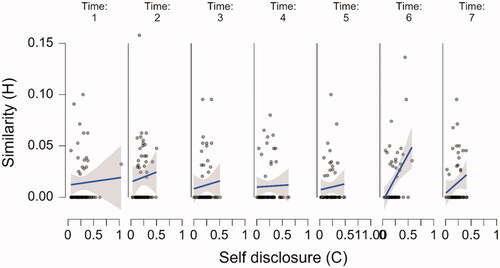
To test RQ7, we investigated several relationships between chatbot and human variables with a special interest in development over time using linear mixed effects modelling. For each relationship, we fitted a linear mixed effects model using JASP 0.14 (JASP Team, Citation2021). In all the models, participants were entered as random effects (grouping factors). Time (representing the seven interactions between the participant and the chatbot) was entered as a fixed (ordinal) factor and the chatbot variable of interest was entered as a fixed (predictor) variable. All models were fitted using REML and model terms were tested with the Satterthwaite method. Following Barr et al. (Citation2013), all models started out as maximal, and higher order terms were removed until convergence was achieved. In all models, this meant that that random slopes for time as well as those for the interaction with time and the predictor needed to be removed due to convergence issues. This never resulted in substantially different estimates. Below, the analyses of interest for RQ7 are presented. All in all, eight models and 24 effects are estimated, so correcting for multiple comparisons is in order (with a corrected alpha of 0.05/24 = 0.002). Nevertheless, given that most significant effects pass this test (and the nonsignificant ones obviously do not), we choose to report the effects as is, also reflecting the exploratory nature of this study.
displays all eight relationships of interest for each of the seven interactions. As can be seen from this figure, there are many strong relationships between the utterances of the chatbot and those of the participant. Below, the relationships between chatbot and participant expressions, the effect of time, and the effect of the interaction between chatbot expressions and time on participant expressions are presented. In the interest of readability, further details of the final mixed models can be found in Appendix A.
Figure 3. The relationship between the chatbot’s utterances and the participants’ utterances over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands. Note. “P stands for “participant,” C stands for “chatbot.”
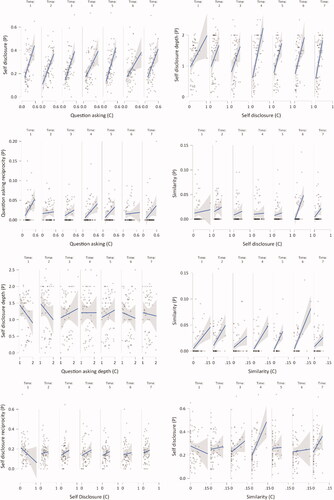
Starting with the upper left panel of , the relationship between chatbot question asking and participant self-disclosure was significant (β = 0.495, SE = 0.07; t(47.48) = 7.19, p < 0.001), as was the relationship between chatbot questing asking and participant question asking reciprocity (second left panel from above; β = 0.039, SE = 0.016; t(60.78) = 2.37, p = 0.021) and the relationship between chatbot question asking depth and participant self-disclosure depth (third left panel from above; β = 0.29, SE = 0.058; t(55.521) = 5.35, p = 0.001). However, the relationship between chatbot self-disclosure and participant self-disclosure reciprocity (bottom left panel) was not significant (β = −0.06, SE = 0.052; t(279.551) = 1.33, p = 0.185) Looking at the top panel on the right of , there appears to be a consistent relationship between chatbot self-disclosure and human self-disclosure depth. However, this relationship is not significant (β = 0.42, SE = 0.24; t(55.323) = 1.737, p = 0.088), likely due to the substantial amount of variation. The second right panel of shows the significant relation between chatbot self-disclosure and participant expressions of similarity (β = 0.03, SE = 0.012; t(138.36) = 2.448, p = 0.016) while the third panel on the right shows the significant relationship between chatbot expressions of similarity and participant expressions of similarity (β = 0.335, SE = 0.061; t(48.00) = 5.517, p < 0.001). Finally, the bottom right panel shows the relationship between chatbot expressions of similarity and participant self-disclosure, while apparently a large effect, this relationship was not significant β = 0.503, SE = 0.259; t(154.19) = 1.946, p = 0.053.
With respect to the effect of time on the expressions of the participant, none of the analyses showed a significant effect of time (all Fs < 1.68, all p’s > .13) and crucially, the interaction effect between time and the predictor variable (i.e., the chatbot’s expressions on the participant’s expressions never reached significance (all Fs < 1.661, all p’s > .130).
In sum, we find evidence of relationships between chatbot question asking and self-disclosure, chatbot question asking depth and self-disclosure depth, and mutual expressions of similarity. The evidence for the relationship between chatbot question asking and question asking reciprocity is much weaker and the same is true for the relationship between chatbot self-disclosure and expressions of similarity. No evidence of a relationship between chatbot self-disclosure and self-disclosure reciprocity or depth was found, and the same holds for the relationship between chatbot expressions of similarity and self-disclosure. Crucially, none of these relationships were affected by time. If there was an effect of chatbot behavior on the behavior of the human participant, it was present from the start and did not increase, if there was no effect of chatbot expressions in the beginning of the interaction, it did not emerge during the interaction either.
5. Discussion
The present study aimed to examine whether the use of self-disclosure, question asking, similarity, empathy, and humour differs between humans and a social chatbot in human-chatbot interactions. Furthermore, we examined whether chatbots lack communication competence, as shown by the expression of inappropriate responses. Finally, we examined whether the chatbot’s expressions had an effect on the humans’ expressions. Below we discuss our findings in detail.
First, our findings show that human users expressed more self-disclosures, more intimate self-disclosures, and more reciprocal self-disclosures compared to the social chatbot, whose use of self-disclosure declined over the course of the seven interactions. In contrast, the chatbot asked more questions and more follow-up questions compared to the human users. In initial human-human interactions, there is interpersonal uncertainty, which individuals attempt to reduce by asking questions and disclosing personal information (e.g., Antheunis et al., Citation2012). Previous research has shown that a proactive chatbot comes across as more natural, by proactively suggesting new topics and by formulating (follow-up) questions (Chaves & Gerosa, Citation2021). Furthermore, chatbots learn from their interactions and consequently need information to remember the user’s preferences and make useful recommendations (Chaves & Gerosa, Citation2021). This explains why the social chatbot in this study asked more questions than the human user, as this is a means to gather information to keep the conversation going. Moreover, as asking questions elicits self-disclosure, this explains why the human users disclosed more information compared to the chatbot.
Furthermore, our results reveal that the chatbot expressed more similarity than the human users, but these expressions of similarity decreased over the course of the seven interactions. This is relevant because humans prefer chatbots that are more like them and match their personality (Callejas et al., Citation2011; Wagner et al., Citation2019). The social chatbot in the present study did attempt to express similarity in the interactions with the human users, but lack of reciprocity may explain why these expressions decreased over time. Our findings show that while the chatbot attempted to establish common ground with its human users by expressing similarity (Corti & Gillespie, Citation2016), the study participants did not perceive the chatbot as similar to them, as they expressed similarity less than the chatbot. This can be explained by the fact that Kuki was not perceived as similar, holding different opinions than the participants.
The expression of empathy was not found to differ between humans and the chatbot, suggesting that the chatbot and the human express the same amount of empathic language. This finding shows that humans and a chatbot are equally empathic in human-chatbot conversations. According to Shum et al. (Citation2018) social chatbots need to be able to express empathy and our findings show that they do – and to the same extent as humans do. Our findings are in line with previous studies that state that although chatbots do not have feelings, they can appear to be empathic as long as they provide accurate, appropriate feedback (Klein et al., Citation2002).
Surprisingly, the chatbot in the present study showed more expressions of humour, compared to the human participants. Humour is viewed as a humanlike, positive quality which social chatbots should possess (Shum et al., Citation2018). In the present study, we defined humour as innocent humour, which is not intended as sexual, aggressive, or derisive (Morkes et al., Citation1998). Specifically, humour was operationalized as an attempt to amuse, be sarcastic, or tell a joke. Our findings show that a social chatbot is capable of expressing humour, and Kuki expresses even more humour than humans do. It seems that, in the interactions with Kuki, humour is apparently not reciprocated by expressions of humour by the participants. Chaves and Gerosa (Citation2021) state that it is a challenge for chatbot builders to personalize a chatbot’s sense of humour to an individual’s culture and personal interests; one can read our results as indicating that this challenge is still partially unanswered.
Our findings also show that the chatbot’s responses were, at times, inappropriate, which can hinder the naturalness of the conversation and make the chatbot come across as less communicatively competent. Many of today’s chatbots still respond in an inappropriate way, which can result in frustration on the part of the user (Callejas et al., Citation2011). Although we did not measure the effect of these inappropriate responses, our results show that they arise in human-chatbot interactions, which may cause the conversation to fail and can hinder relationship building.
Finally, we found that the chatbot’s expressions indeed impacted the human users’ expressions. The more questions the chatbot asked, the more participants reciprocated these questions, and the more they self-disclosed. Furthermore, the more intimate questions the chatbot asked, the more intimate self-disclosures participants offered. This is in line with earlier studies on interactions between humans, which found that direct questioning results in higher levels of self-disclosure, especially in CMC (Schouten et al., Citation2009). In interactions between strangers, individuals tend to use question asking as a strategy to elicit self-disclosure and reduce uncertainty about their interaction partners (Berger & Calabrese, Citation1975). The chatbot in our study is programmed to ask questions to gather information, which results in more self-disclosure from the human interactants. Participants also match the intimacy of the questions asked in terms of what they disclose.
We also found that more self-disclosure by the chatbot resulted in more expressions of similarity by the participants, and that the more expressions of similarity the chatbot uttered, the more similarity participants expressed. Previous research shows that people prefer the company of others who express views and attitudes similar to their own (Byrne, Citation1971). There are several reasons for this, but most importantly, when people communicate with someone who shares their beliefs, they feel less alone. Perceived similarity also reduces uncertainty and enhances the predictability of future interactions, it also increases attractiveness (e.g., McGarva and Warner, Citation2003). Thus, this element of reciprocity has been shown to be an important factor in getting-acquainted interactions and relationship development in human-human interaction (Lehr & Geher, Citation2006; Sprecher, Citation1998). Our results show that human-chatbot interactions are similar, in that individuals’ reactions are triggered by the chatbot’s expressions.
However, none of these relationships were affected by time – the expressions stayed constant throughout the interactions. We offer several possible explanations for this. First, according to the Social Penetration Theory, relationships may develop in a non-linear manner (Altman et al., Citation1981; Skjuve et al., Citation2021). They can slow down and even reverse. The speed at which relationships develop is dependent upon the costs and rewards people perceive in a relationship. This suggests that self-disclosure does not always increase and become more intimate over time – it may even reduce as relationships progress. This is dependent on a number of factors, including trust, which is facilitated by mutual self-disclosure (Skjuve et al., Citation2021). Trust is important in relationship building and self-disclosure, especially with chatbots, where privacy may be an issue (McKnight et al., Citation2011). When people feel secure, they are comfortable to share at a deeper level. This sense of security is facilitated by people’s perceptions of the chatbot as non-judgmental and caring (Skjuve et al., Citation2021). Possibly, trust development was hindered in our study due to a lack of mutual self-disclosure, and/or the chatbot’s inability to make the user feel cared for. Furthermore, the fact that people were participating in an experiment made them perhaps very self-aware, which can withhold them from sharing more personal information with the chatbot.
5.1. Theoretical and practical implications
Our findings have implications for theory and research on human-chatbot communication. First, our findings give important insights into the social strategies that were used by the chatbot in order to have a social interaction. Our study involves one of the best social chatbots at the moment, Kuki, and our findings show that this chatbot mainly employs easy to script language-based strategies for social communication, such as expressions of similarity and question asking, which elicit self-disclosure from human users. However, this self-disclosure is not reciprocated by the chatbot. This matters, because reciprocal self-disclosure has been shown to result in more positive evaluations of a chatbot (Bickmore & Picard, Citation2005; Chaves & Gerosa, Citation2021). Failing to reciprocate the human users’ self-disclosure, but also failing to enact other more difficult to script strategies like expressing empathy and providing appropriate responses, may hinder interaction enjoyment and negatively impact relationship building.
The results of this study further stress the importance of focusing on the development of a theory of mind for chatbots. Our results show that the chatbot has a lack of understanding of the ongoing interaction with the human interaction partner. This is because the current chatbots have no ability to attribute mental states to others and hence have no ability to understand that the human conversation partner can have different beliefs, desires, and perspectives. The lack of theory of mind of the chatbot is an important barrier in the successful use of chatbots in more social domains where multiple, longer chatbot interactions are required, such as mental and social support. Future research should therefore focus on how to improve these social language-based strategies in order to develop a more engaging chatbot.
Finally, our findings have practical implications for chatbot developers, as this study shows that the social chatbot employed in this study does not engage in (reciprocal) self-disclosure, a process important for interaction intimacy and relationship development (Ligthart et al., Citation2019). The goal of social chatbots is to be a virtual companion to its users (Shum et al., Citation2018), which suggests that the chatbot should be able to self-disclose as well. Although the chatbot in the current study asks questions to elicit self-disclosure, self-disclosure can also be elicited by self-disclosing first. Initiating self-disclosure is easier to pre-script compared to reciprocating a human’s self-disclosure.
5.2. Limitations and suggestions for future research
Although our study sheds light on the language-based strategies humans and a social chatbot use over the course of multiple social interactions, it is not without limitations. First, this study is a preliminary study, which gives insight into the ways in which humans and a chatbot communicate with one another, and how expressions of various strategies and social skills differ. Although this study sheds new light on whether participants adapt their communication style to a social chatbot, this was analysed at the conversation level, as opposed to at an utterance level. Conducting an in-depth analysis for every conversation at the utterance level could have given a more detailed overview of whether the participants and the chatbot adapted the way they spoke to one another. Specifically, a turn-by-turn analysis may give more insight into how an interaction initiates, unfolds, and progresses (Gan, Citation2010). Since this study focused on the use of language-based strategies, as opposed to smaller linguistic cues (e.g., intonation, inter-turn silence; Roberts et al., Citation2006; Schaffer, Citation1983), using the conversation as the unit of analysis seems warranted and is common practice in the literature (e.g., Antheunis et al., Citation2012; Tidwell & Walther, Citation2002). Furthermore, the present research does not analyse the possible impact of these strategies on variables like interaction enjoyment, satisfaction, or feelings of liking towards the chatbot. Thus, although we give insight into how a chatbot communicates, compared to humans, we do not know the impact of this communication on how the interactions were perceived. Future studies could attempt to examine specific patterns of language in these interactions, to see, for instance, the ways in which humorous and/or empathic chatbot expressions are perceived and whether they come across as intended.
Second, a limitation of this study lies in the overall research design. Specifically, the findings of this study are based on interactions with a single chatbot (i.e., Kuki) at a given point in time (albeit over the course of several interactions). As a result, the findings reported here may be limited to the characteristics of this one chatbot as implemented at the time of the study and not all social chatbots in general. This is a limitation of the current study and may have consequences for the generalizability of our findings. The chatbot we selected in this study is currently one of the best social chatbots around, which means that other chatbots may not perform as well. Thus, the findings of this study do not provide general knowledge on differences in interaction patterns between humans and all social chatbots.
Third, it could be interesting for future studies to directly compare human-human text-based interactions to human-chatbot interactions, to determine whether there is a difference in the expressions of the variables examined in the present study between these two conditions. In this study, we did not compare human-human and human-chatbot interactions, because we wanted to explore how humans communicate with a chatbot and whether this differs from the way in which a chatbot communicates. In so doing, we have outlined the most important processes and social skills that social chatbots must possess in order for a conversation to be humanlike and natural. Future research could extend our findings by comparing human-chatbot to human-human conversations, to see whether the overall expression of the variables analysed in the present research differ between those two conditions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Emmelyn A. J. Croes
Emmelyn Croes is an Assistant Professor at the department of Communication and Cognition at Tilburg University in the Netherlands. Her research interests include computer-mediated communication, human-chatbot communication and influencer marketing. Her work has been published in the Journal of Social and Personal Relationships, Computers in Human Behavior, and other journals.
Marjolijn L. Antheunis
Marjolijn Antheunis is full professor of communication and technology in the department of Communication and Cognition at Tilburg University. Her research focuses on the impact of technology on interpersonal communication and well-being in social and healthcare settings.
Martijn B. Goudbeek
Martijn Goudbeek studied auditory category formation (MPI Nijmegen, PhD) and vocal expression of emotion (CISA Geneva, postdoc). He is currently an associate professor at Tilburg University and recently finished an NSF project on the relation between emotion and language production. His other interests include methodology, statistics, and culture.
Nathan W. Wildman
Nathan Wildman is assistant professor of philosophy at Tilburg University, and member of Tilburg Center for Moral Philosophy, Epistemology, and Philosophy of Science. His research focuses on metaphysics, philosophy of language, logic, and aesthetics. His interests are foundations of modality, logic of fictional truth, and nature/aesthetics of interactive fictions.
References
- Altman, I., & Taylor, D. A. (1973). Social penetration: The development of interpersonal relationships. Holt, Rinehart & Winston.
- Altman, I., Vinsel, A., & Brown, B. B. (1981). Dialectic conceptions in social psychology: An application to social penetration and privacy regulation. In Advances in experimental social psychology (Vol. 14, pp. 107–160). Academic Press.
- Antheunis, M. L., Schouten, A. P., Valkenburg, P. M., & Peter, J. (2012). Interactive uncertainty reduction strategies and verbal affection in computer-mediated communication. Communication Research, 39(6), 757–780. https://doi.org/10.1177/0093650211410420
- Archer, R. L., & Burleson, J. A. (1980). The effects of timing of self-disclosure on attraction and reciprocity. Journal of Personality and Social Psychology, 38(1), 120–130. https://doi.org/10.1037/0022-3514.38.1.120
- Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68(3), 255–278. https://doi.org/10.1016/j.jml.2012.11.00
- Beale, R., & Creed, C. (2009). Affective interaction: How emotional agents affect users. International Journal of Human-Computer Studies, 67(9), 755–776. https://doi.org/10.1016/j.ijhcs.2009.05.001
- Beran, O. (2018). An attitude towards an artificial soul? Responses to the “Nazi Chatbot”. Philosophical Investigations, 41(1), 42–69. https://doi.org/10.1111/phin.12173
- Berger, C. R., & Calabrese, R. J. (1975). Some explorations in initial interaction and beyond: Toward a developmental theory of interpersonal communication. Human Communication Research, 1(2), 99–112. https://doi.org/10.1111/j.1468-2958.1975.tb00258.x
- Berger, C. R., Gardner, R. R., Parks, M. R., Schulman, L., & Miller, G. R. (1976). Interpersonal epistemology and interpersonal communication. In G. R. Miller (Ed.), Explorations in interpersonal communication (pp. 149–171). Sage. https://doi.org/10.1016/B978-0-08-018757-0.50003-2
- Bickmore, T. W., & Picard, R. W. (2005). Establishing and maintaining long-term human computer relationships. ACM Transactions on Computer-Human Interaction, 12(2), 293–327. https://doi.org/10.1145/1067860.1067867
- Brandtzaeg, P. B., & Følstad, A. (2017, November). Why people use chatbots. In International conference on internet science (pp. 377–392). Springer. https://doi.org/10.1007/978-3-319-70284-1
- Burgoon, J. K., & Hale, J. L. (1984). The fundamental topoi of relational communication. Communication Monographs, 51(3), 193–214. https://doi.org/10.1080/03637758409390195
- Burgoon, J. K., Buller, D. B., White, C. H., Afifi, W., & Buslig, A. L. (1999). The role of conversational involvement in deceptive interpersonal interactions. Personality and Social Psychology Bulletin, 25(6), 669–686. https://doi.org/10.1177/0146167299025006003
- Byrne, D. E. (1971). The attraction paradigm. Academic Press.
- Callejas, Z., López-Cózar, D., Ábalos, N., & Griol, D. (2011). Affective conversational agents: The role of personality and emotion in spoken interactions. In D. Pérez-Marín & I. Pascual-Nieto (Eds.), Conversational agents and natural language interaction: Techniques and effective practices (pp. 203–222). IGI Global. https://doi.org/10.4018/978-1-60960-617-6.ch009.
- Chang, Y. K., Morales-Arroyo, M. A., Chavez, M., & Jimenez-Guzman, J. (2008). Social interaction with a conversational agent: An exploratory study. Journal of Information Technology Research, 1(3), 14–26. https://doi.org/10.4018/978-1-60566-966-3
- Chaves, A. P., & Gerosa, M. A. (2021). How should my chatbot interact? A survey on social characteristics in human–chatbot interaction design. International Journal of Human–Computer Interaction, 37(8), 729–758. https://doi.org/10.1080/10447318.2020.1841438
- Chin, H., & Yi, M. Y. (2021). Voices that care differently: Understanding the effectiveness of a conversational agent with an alternative empathy orientation and emotional expressivity in mitigating verbal abuse. International Journal of Human–Computer Interaction, 1–15. https://doi.org/10.1080/10447318.2021.1987680
- Corti, K., & Gillespie, A. (2016). Co-constructing intersubjectivity with artificial conversational agents: People are more likely to initiate repairs of misunderstandings with agents represented as human. Computers in Human Behavior, 58(2016), 431–442. https://doi.org/10.1016/j.chb.2015.12.039
- Creed, C., Beale, R., & Cowan, B. (2015). The impact of an embodied agent's emotional expressions over multiple interactions. Interacting with Computers, 27(2), 172–188. https://doi.org/10.1093/iwc/iwt064
- De Angeli, A., Johnson, G. I., & Coventry, L. (2001). The unfriendly user: exploring social reactions to chatterbots. In Proceedings of the international conference on affective human factors design, london (pp. 467–474).
- De Cicco, R., da Costa e Silva, S. C. L., & Palumbo, R. (2020). Should a chatbot disclose itself? Implications for an online conversational retailer. In International workshop on chatbot research and design (pp. 3–15). Springer, Cham.
- De Swert, K. (2012). Calculating inter-coder reliability in media content analysis using Krippendorff’s Alpha. https://www.polcomm.org/wp-content/uploads/ICR01022012.pdf
- Demeure, V., Niewiadomski, R., & Pelachaud, C. (2011). How is believability of a virtual agent related to warmth, competence, personification, and embodiment? Presence: Teleoperators and Virtual Environments, 20(5), 431–448. https://doi.org/10.1162/PRES_a_00065
- Eaton, A. A., & Rose, S. (2011). Has dating become more egalitarian? A 35 year review using Sex Roles. Sex Roles, 64(11–12), 843–862. https://doi.org/10.1007/s11199-011-9957-9
- Edwards, C., Edwards, A., Spence, P. R., & Shelton, A. K. (2014). Is that a bot running the social media feed? Testing the differences in perceptions of communication quality for a human agent and a bot agent on Twitter. Computers in Human Behavior, 33(2014), 372–376. https://doi.org/10.1016/j.chb.2013.08.013
- Gan, Z. (2010). Interaction in group oral assessment: A case study of higher-and lower-scoring students. Language Testing, 27(4), 585–602. https://doi.org/10.1177/0265532210364049
- Gatt, A., & Krahmer, E. (2018). Survey of the state of the art in natural language generation: Coretasks, applications and evaluation. Journal of Artificial Intelligence Research, 61(2018), 65–170. https://doi.org/10.1613/jair.5477
- Heyselaar, E., & Bosse, T. (2020). Using theory of mind to assess users’ sense of agency in social chatbots. In International workshop on chatbot research and design (pp. 158–169). Springer.
- Hill, J., Ford, W. R., & Farreras, I. G. (2015). Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations. Computers in Human Behavior, 49(2015), 245–250. https://doi.org/10.1016/j.chb.2015.02.026
- Houser, M. L., Horan, S. M., & Furler, L. A. (2008). Dating in the fast lane: How communication predicts speed-dating success. Journal of Social and Personal Relationships, 25(5), 749–768. https://doi.org/10.1177/0265407508093787
- Huang, Y., Sundar, S. S., Ye, Z., & Johnson, A. C. (2021). Do women and extroverts perceive interactivity differently than men and introverts? Role of individual differences in responses to HCI vs. CMC interactivity. Computers in Human Behavior, 123(2021), 106881. https://doi.org/10.1016/j.chb.2021.106881
- JASP Team. (2021). JASP (Version 0.15) [Computer software].
- Johnson, K. (2018). Facebook Messenger passes 300,000 bots. https://venturebeat.com/2018/05/01/facebook-messenger-passes-300000-bots/
- Joinson, A. N. (2001). Self‐disclosure in computer‐mediated communication: The role of self awareness and visual anonymity. European Journal of Social Psychology, 31(2), 177–192. https://doi.org/10.1002/ejsp.36
- Jourard, S. M. (1971). Self-disclosure: An experimental analysis of the transparent self. Wiley-Interscience.
- Jurafsky, D., & Martin, J. (2019). Speech and language processing: An introduction on natural language processing, computational linguistics, and speech recognition (3rd ed.). Prentice Hall.
- Klein, J., Moon, Y., & Picard, R. W. (2002). This computer responds to user frustration: Theory, design, and results. Interacting with Computers, 14(2), 119–140. https://doi.org/10.1016/S0953-5438(01)00053-4
- Kowatsch, T., Nißen, M., Rüegger, D., Stieger, M., Flückiger, C., Allemand, M., & von Wangenheim, F. (2018). The impact of interpersonal closeness cues in text-based healthcare chatbots on attachment bond and the desire to continue interacting: An experimental design [Paper presentation]. Paper presented at the 26th European Conference on Information Systems (ECIS), Portsmouth, UK.
- Lee, D., Oh, K. J., Choi, H. J. (2017). The chatbot feels you-a counseling service using emotional response generation. In 2017 IEEE international conference on big data and smart computing (BigComp) (pp. 437–440). IEEE.
- Lehr, A. T., & Geher, G. (2006). Differential effects of reciprocity and attitude similarity across long-versus short-term mating contexts. The Journal of Social Psychology, 146(4), 423–439. https://doi.org/10.3200/SOCP.146.4.423-439
- Ligthart, M., Fernhout, T., Neerincx, M. A., van Bindsbergen, K. L., Grootenhuis, M. A., Hindriks, K. V. (2019). A child and a robot getting acquainted-interaction design for eliciting self-disclosure. In Proceedings of the 18th international conference on autonomous agents and multiagent systems (pp. 61–70). International Foundation for Autonomous Agents and Multiagent Systems.
- Liu, B., & Sundar, S. S. (2018). Should machines express sympathy and empathy? Experiments with a health advice chatbot. Cyberpsychology, Behavior and Social Networking, 21(10), 625–636. https://doi.org/10.1089/cyber.2018.0110
- Mairesse, F., & Walker, M. A. (2009). Can conversational agents express big five personality traits through language?: Evaluating a psychologically-informed language generator. Cambridge University Engineering.
- McGarva, A. R., & Warner, R. M. (2003). Attraction and social coordination: Mutual entrainment of vocal activity rhythms. Journal of Psycholinguistic Research, 32(3), 335–354. https://doi.org/10.1023/A:1023547703110
- McKnight, D. H., Carter, M., Thatcher, J. B., & Clay, P. F. (2011). Trust in a specific technology: An investigation of its components and measures. ACM Transactions on Management Information Systems, 2(2), 1–25. https://doi.org/10.1145/1985347.1985353
- Mehrabian, A., & Williams, M. (1969). Nonverval concomitants of perceived and intended persuasiveness. Journal of Personality and Social Psychology, 13(1), 37–58. https://doi.org/10.1037/h0027993
- Milligan, K., Astington, J. W., & Dack, L. A. (2007). Language and theory of mind: meta-analysis of the relation between language ability and false-belief understanding. Child Development, 78(2), 622–646. https://doi.org/10.1111/j.1467-8624.2007.01018.x
- Mori, M. (1970). Bukimi no tani [the uncanny valley]. Energy, 7, 33–35. https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=6213238
- Morkes, J., Kernal, H. K., & Nass, C. (1998, April). Humor in task-oriented computer-mediated communication and human-computer interaction [Paper presentation]. CHI 98 Conference Summary on Human Factors in Computing Systems (pp. 215–216). ACM. https://doi.org/10.1145/286498.286704
- Mou, Y., & Xu, K. (2017). The media inequality: Comparing the initial human-human and human-AI social interactions. Computers in Human Behavior, 72(2017), 432–440. https://doi.org/10.1016/j.chb.2017.02.067
- Ortony, A. (2003). On making believable emotional agents believable. In R. Trappl, P. Petta, & S. Payr (Eds.), Emotions in humans and artifacts (pp. 189–212). The MIT Press.
- Rheu, M., Shin, J. Y., Peng, W., & Huh-Yoo, J. (2021). Systematic review: Trust-building factors and implications for conversational agent design. International Journal of Human–Computer Interaction, 37(1), 81–96. https://doi.org/10.1080/10447318.2020.1807710
- Roberts, F., Francis, A. L., & Morgan, M. (2006). The interaction of inter-turn silence with prosodic cues in listener perceptions of “trouble” in conversation. Speech Communication, 48(9), 1079–1093. https://doi.org/10.1016/j.specom.2006.02.001
- Schaffer, D. (1983). The role of intonation as a cue to turn taking in conversation. Journal of Phonetics, 11(3), 243–257. https://doi.org/10.1016/S0095-4470(19)30825-3
- Schouten, A. P., Valkenburg, P. M., & Peter, J. (2009). An experimental test of processes underlying self-disclosure in computer-mediated communication. Cyberpsychology: Journal of Psychosocial Research on Cyberspace, 3(2), Article 3. https://cyberpsychology.eu/article/view/4227/3270.
- Shum, H. Y., He, X. D., & Li, D. (2018). From Eliza to XiaoIce: Challenges and opportunities with social chatbots. Frontiers of Information Technology & Electronic Engineering, 19(1), 10–26. https://doi.org/10.1631/FITEE.1700826
- Skjuve, M., Følstad, A., Fostervold, K. I., & Brandtzaeg, P. B. (2021). My chatbot companion-A study of human-chatbot relationships. International Journal of Human-Computer Studies, 149(2021), 102601. https://doi.org/10.1016/j.ijhcs.2021.102601
- Skjuve, M. B., & Brandtzaeg, P. B. (2018). Chatbots as a new user interface for providing health information to young people. In Yvonne Andersson, Ulf Dahlquist, & Jonas Ohlsson (Eds.), Youth and news in a digital media environment – Nordic-Baltic perspectives. Nordicom.
- Skjuve, M., Haugstveit, I. M., Følstad, A., & Brandtzaeg, P. B. (2019). Help! Is my chatbot falling into the uncanny valley? An empirical study of user experience in human-chatbot interaction. Human Technology, 15(1), 30–54. https://doi.org/10.17011/ht/urn.201902201607
- Sprecher, S. (1998). Social exchange theories and sexuality. Journal of Sex Research, 35(1), 32–43. https://doi.org/10.1080/00224499809551915
- Tidwell, L. C., & Walther, J. B. (2002). Computer‐mediated communication effects on disclosure, impressions, and interpersonal evaluations: Getting to know one another a bit at a time. Human Communication Research, 28(3), 317–348. https://doi.org/10.1111/j.1468-2958.2002.tb00811.x
- Wagner, K., Nimmermann, F., & Schramm-Klein, H. (2019). Is it human? The role of anthropomorphism as a driver for the successful acceptance of digital voice assistants [Paper presentation]. Proceedings of the 52nd Hawaii International Conference on System Sciences (pp. 1386–1395). https://doi.org/10.24251/HICSS.2019.169
- Walther, J. B. (2019). Interpersonal versus personal uncertainty and communication in traditional and mediated encounters: A theoretical reformulation. In S. R. Wilson & S. W. Smith (Eds.), Reflections on interpersonal communication research (pp. 375–393). Cognella Academic Publishing.
- Walther, J. B., & Burgoon, J. K. (1992). Relational communication in computer‐mediated interaction. Human Communication Research, 19(1), 50–88. https://doi.org/10.1111/j.1468-2958.1992.tb00295.x
- Walther, J. B., Loh, T., & Granka, L. (2005). Let me count the ways the interchange of verbal and nonverbal cues in computer-mediated and face-to-face affinity. Journal of Language and Social Psychology, 24(1), 36–65. https://doi.org/10.1177/0261927X04273036
- Yang, Y., Ma, X., & Fung, P. (2017). Perceived emotional intelligence in virtual agents [Paper presentation]. Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems (CHI’17) (pp. 2255–2262). ACM. https://doi.org/10.1145/3027063.3053163
- Zamora, J. (2017, March). Rise of the chatbots: Finding a place for artificial intelligence in India and US. In Proceedings of the 22nd international conference on intelligent user interfaces companion (pp. 109–112). ACM. https://doi.org/10.1145/3030024.3040201
Appendix A
The relationship between chatbot question asking and human self-disclosure
shows that there is a strong relationship between question asking by the chatbot and the resulting self-disclosure by the participants that seems unaffected by the number of interactions (“time”). Confirming these observations, the ANOVA summary of the model (BIC = −439.14) showed a strong effect of question asking on self-disclosure (F(1, 47.48) = 51.64, p < 0.001), but no effect of time (F(6, 350.23) = 0.53, p = 0.79) and no interaction between time and question asking (F(6, 354.89) = 1.16, p = 0.33). So, while the amount of question asking certainly has a strong positive effect on the amount of self disclosure (β = 0.495, SE = 0.07; t(47.48) = 7.19, p < 0.001), this is unaffected by the unfolding conversation.
The relationship between chatbot question asking and human question asking reciprocity
shows that the relation between chatbot question asking and the reciprocity of question asking by the participant over time is sometimes strong and positive (time 1, 4, 5, and 6), but sometimes almost absent (time 2 and 6). This is borne out by the modeling, which shows a weaker model fit than in the previous analysis (BIC = −1604.69), which might also be attenuated by the many zeroes in the data. The effect of chatbot question asking on question asking reciprocity is small but significant (F(1, 30.78) = 5.59, p = 0.021; β = 0.039, SE = 0.016; t(60.78) = 2.37, p = 0.021). As before, no effect of time (F(6, 364.63) = 0.53, p = 0.78) and no interaction between time and question asking was found (F(6, 362.84) = 0.87, p = 0.52).
The relationship between chatbot question asking depth and human self-disclosure depth
As with the previous relationship, shows that the relationship between chatbot question asking depth and self-disclosure depth is not consistent over time. Somewhat unexpectedly, the model (BIC = 535.19) shows a sizeable relationship between question asking depth and self-disclosure depth (F(1, 50.37) = 11.98, p = 0.001; β = 0.29, SE = 0.058; t(55.521) = 5.35, p = 0.001). As before, neither the effect of time (F(6, 341.92) = 1.42, p = 0.21) nor the interaction between time and question asking depth (F(6, 341.74) = 1.19, p = 0.31) were significant.
The relationship between chatbot self-disclosure and human self-disclosure reciprocity
While suggests, there first is a negative relationship between chatbot self-disclosure and self-disclosure reciprocity (likely due to an outlier) that turns into a positive relationship from the second interaction onwards, none of the effects are significant (chatbot self-disclosure; F(1, 279.55) = 1.77, p = 0.19, Time; F(6, 347.36) = 1.68, p = 0.13, Time*Self disclosure; F(6, 346.23) = 1.06, p = 0.39).
The model fit (BIC = −538.74) itself was problematic with too large gradients for the maximum likelihood estimate. The model fit (BIC = −538.74) itself was problematic with too large gradients for the maximum likelihood estimate. However, removal (nor addition) of random slopes for time and/or the interaction between time and self-disclosure did alter the effects in any meaningful way. Based on this, there is no convincing evidence of a relation between human self-disclosure reciprocity and chatbot self-disclosure, nor of the relationship or interaction with time.
The relationship between chatbot self-disclosure and human self-disclosure depth
shows a consistent relationship between chatbot self-disclosure and human self-disclosure depth that is largely unaffected by time. While consistent, there is a substantial amount of variation, resulting in a poor model fit (BIC = 531.894) and a sizeable, but nonsignificant effect of chatbot self-disclosure on human self-disclosure depth F(1, 54.32) = 3.02, p = 0.088; β = 0.42, SE = 0.24; t(55.323) = 1.737, p = 0.088). As in the previous analyses, there is no effect of time (F(6, 332.90) = 1.13, p = 0.347) nor is there a significant interaction F(6, 333.10) = 1.56, p = 0.16).
The relationship between chatbot self-disclosure and human expressions of similarity
The model (BIC = −1723.77) revealed a small but significant effect of chatbot self-disclosure on human expressions of similarity (F(1, 138.36) = 5.99, p = 0.016; β = 0.03, SE = 0.012; t(138.36) = 2.448, p = 0.016). This effect could potentially be attenuated by the many zeroes in the dataset, where neither the human nor the chatbot expresses self-disclosure or similarity. As before, there was no effect of time (F(6, 337.45) = 1.01, p = 0.418) and no interaction between time and chatbot self-disclosure (F(6, 315.01) = 1.661, p = 0.130). displays the relationship between chatbot self-disclosure and similarity over time.
The relationship between chatbot expressions of similarity and human expressions of similarity
As can be seen in , there is a clear positive relationship between chatbot expressions of similarity and human expressions of similarity, a relationship that is largely unaffected by time. The model (BIC = −1818.864) indeed shows a sizeable effect of chatbot expressions of similarity on human expressions of similarity (F(1, 48.00) = 30.439, p < 0.001; β = 0.335, SE = 0.061; t(48.00) = 5.517, p < 0.001), especially considering the high number of zeroes in the data. As before, there was no effect of time on human expressions of similarity (F(6, 330.05) = 0.484, p = 0.820), nor was there a significant interaction; F(6, 358.58) = 0.778, p = 0.588.
The relationship between chatbot expressions of similarity and human self-disclosure
Finally, shows that the relationship between chatbot expressions of similarity and self-disclosure varies considerably across time. Indeed, the model (BIC = −404.099) shows a large but non-significant effect of expressions of similarity; F(1, 154.19) = 3.787, p = 0.053; β = 0.503, SE = 0.259; t(154.19) = 1.946, p = 0.053). Similarly, the interaction of chatbot expressions of similarity and time is not significant (F(6, 314.21) = 1.870, p = 0.085), nor is there an effect of time on human self-disclosure (F(6,351.44) = 1.496, p = 0.179).
Figure A1. The relationship between chatbot question asking and human self disclosure over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
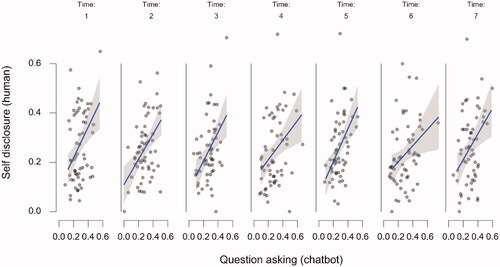
Figure A2. The relationship between chatbot question asking and human question asking reciprocity over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands. Note. “H stands for “human,” C stands for “chatbot.”
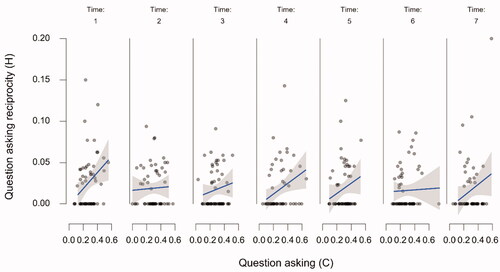
Figure A3. The relationship between chatbot question asking depth and human self-disclosure depth over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
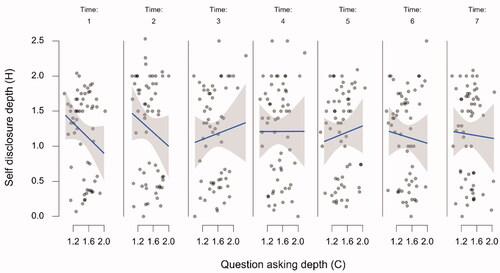
Figure A4. The relationship between chatbot self-disclosure and human self-disclosure reciprocity over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
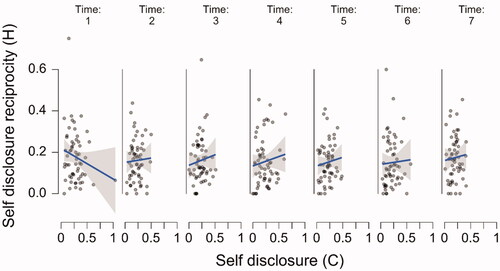
Figure A5. The relationship between chatbot self-disclosure and human self-disclosure depth over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
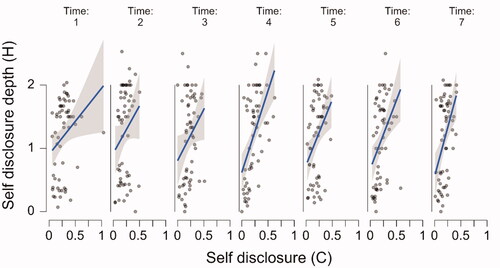
Figure A6. The relationship between chatbot self-disclosure and human expression of similarity over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
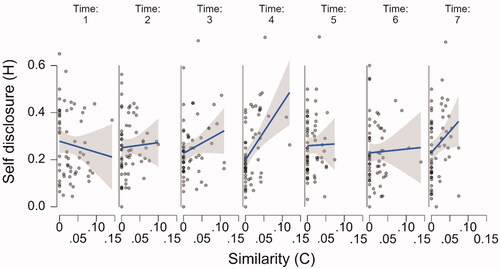
Figure A7. The relationship between chatbot expression of similarity and human expression of similarity over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.
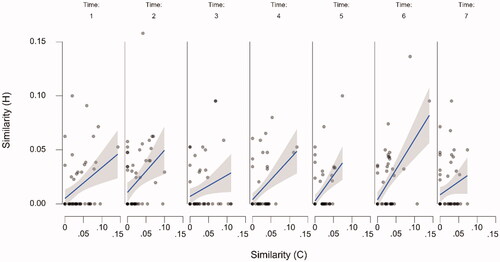
Figure A8. The relationship between chatbot human expression of similarity and human self disclosure over time. The raw data points are accompanied by a regression line and corresponding 95% confidence bands.