
Abstract
Algorithms have become part of our daily lives and have taken over many decision-making processes. It has often been argued and shown that algorithmic judgment can be as accurate or even more accurate than human judgement. However, humans are reluctant to follow algorithmic advice, especially when they do not trust the algorithm to be better than they are themselves: self-confidence has been found as one factor that influences the willingness to follow algorithmic advice. However, it is unknown whether this is an individual or a contextual characteristic. The current study analyses whether individual or contextual factors determine whether humans are willing to request algorithmic advice, to follow algorithmic advice, and whether their performance improves given algorithmic advice. We consider the use of algorithmic advice in fake news detection. Using data from 110 participants and 1610 news stories of which almost half were fake, we find that humans without algorithmic advice correctly assess the news stories 64% of the time. This only marginally increases to 66% after they have received feedback from an algorithm that itself is 67% correct. The willingness to accept advice indeed decreases with participants’ self-confidence in the initial assessment, but this effect is contextual rather than individual. That is, participants who are on average more confident accept advice just as often as those who are on average less confident. What does hold, however, is that a participant is less likely to accept algorithmic advice for the news stories about which that participant is more confident We outline the implications of these findings for the design of experimental tests of algorithmic advice and give general guidelines for human-algorithm interaction that follow from our results.
1. Introduction
Algorithms have become part of our daily lives and have taken over many decision-making processes (Prahl & Van Swol, Citation2017). Rapid developments in technology and data accessibility have also led to an improved efficiency and accuracy of these algorithms (Logg et al., Citation2019). The literature has often reported that algorithmic judgment has a higher accuracy compared to human judgment (cf. Dawes et al., Citation1989), and that people following the advice of these forecasting algorithms make more accurate judgments than people following their own judgments (Önkal et al., Citation2009). Even with experts, this difference in accuracy between model-based advice and human judgment does not decrease (Highhouse, Citation2008).
Even though there might be good reasons for humans to trust algorithmic advice or decisions at least in some cases, there is a tendency for humans not to take algorithmic advice into account (Prahl & Van Swol, Citation2017) and also a tendency that humans, when they do change their judgment in the direction of an algorithm's advice, show advice discounting: they underweigh the advice from the model (cf. Liberman et al., Citation2012; Minson et al., Citation2011; Soll & Larrick, Citation2009). An over-reliance on algorithmic advice has been reported as well. This “automation bias” is more pronounced with people with less expertise (Bond et al., Citation2018; Goddard et al., Citation2014). Factors influencing automation bias include task difficulty and trust in the system (Goddard et al, Citation2014).
When the goal is to increase humans' task performance, it makes sense to focus on trust calibration (de Visser et al., Citation2020, p. 461; Zhang, et al., Citation2020): “the process of updating the trust stance by aligning the perception of trustworthiness with the actual trustworthiness so that the prediction error is minimized.” By mitigating aversion and automation biases, a correct mental model can be created, which might yield better decision-making performance. Incorrect calibration of trust in algorithms might lead to more errors, inefficiency, and possibly rejection of automated systems (Fallon et al., Citation2010). The reasons for the poor calibration of trust in several cases are not completely clear. Some researchers have reported a general sense of algorithm aversion (Önkal et al., Citation2009) and a preference for advice from human experts over advice from algorithms (Dietvorst et al., Citation2015) while others refute this (Saragih & Morrison, Citation2022). Several other factors have been reported to potentially affect the trust in model-based advice: accuracy (Yin et al., Citation2019), algorithmically appropriateness of domain (Logg et al., Citation2019), accountability (Harvey & Fischer, Citation1997; Shin & Park, Citation2019), users’ expertise (Bond et al., Citation2018; Goddard et al., Citation2014; Logg et al., Citation2019), model transparency (Kizilcec, Citation2016; Zhang et al., Citation2020; Zhang & Curley, Citation2018), high performance goals (Dietvorst, Citation2016), self-confidence (Desender et al., Citation2018), model response time (Efendić et al., Citation2020), and amount of interaction (Gutzwiller & Reeder, Citation2021).
Especially when algorithmic suggestions are used, in principle, as an aid to the human, as in using algorithms to drive a car (Hegner et al., Citation2019) or to offer medical advice, it is necessary to better understand which factors drive the (appropriate amount of) trust of humans in algorithmic advice. We consider one such case in which algorithmic advice might be a useful tool: algorithmic help in detecting fake news.
Social media enable people to share any article effortlessly, with no one checking the article’s truthfulness. Because of this, social media enable the spread of “fake news” or intentionally deceptive news (Rubin, et al., Citation2015). The problem manifests itself even more, as it is known to be difficult for people to identify what is fake and what is not (e.g., Bond & DePaulo, Citation2006).
To help people distinguish fake from real content, several approaches have been proposed. One option is to prevent people from ever seeing fake news articles. This could be done by hiding articles on the news feed that have been identified as fake news, or by banning websites that are known to spread fake news altogether. However, the feasibility of this solution depends on being able to detect fake news with (close to) 100% accuracy, and restricts people’s freedom tremendously, making it less appropriate even when this would be feasible. Another method would be to adapt and improve people’s fake news detection skills. Pennycook and Rand (Citation2019) hypothesized that, currently, most people do not apply the appropriate reasoning when dealing with potentially fake news. Pennycook and Rand (Citation2019) considered two competing explanations for people’s belief in fake news: one based on motivated reasoning, and one based on classical reasoning. The motivated reasoning argument suggests that people’s prejudices drive the acceptance of fake news. The classical reasoning argument states that analytic thinking guides correct judgment. Their findings suggest that the acceptance of fake news is primarily explained by mistakes that people make during classical reasoning, which can be interpreted loosely as the human’s mistakes being mainly driven by “lazy thinking” (Pennycook & Rand, Citation2019, p. 39). A third solution is the provision of tools that help people detect fake news. An example of one of these tools can be found on Facebook or Twitter, where “flags” are used to identify (potential) fake news. By having third-party fact-checkers manually flagging posts and ads as “false,” “satire,” “false headline,” and “mixture” (Hern, Citation2019), these flags assist people in recognising fake news. An approach with human fact-checkers involved, however, is labour intensive and therefore not likely to scale well and hence does not provide a sustainable solution. This has led researchers to create systems that automatically nudge people into analytical thinking. Such advice-giving systems might help people to reason more analytically, or at least warn people to think twice about whether they should trust the content of an article. These systems can be relatively straightforward, such as “FeedReflect,” a browser extension for Twitter that nudges users to reflect more on the credibility of news-related tweets through emphasis and reflective questions (Bhuiyan et al., Citation2018). Or, they can be more advanced and based on complex algorithms. Buster.ai (Citationn.d.) is an example of a tool that uses algorithms for fact-checking claims provided by users. For transparency, the tool outputs a list of sources supporting their recommendation. At this point in time, as far as we know there are no flawless algorithms for fake news detection, so these systems should be seen as a potential aid, but not as definitive judgment (yet). Although algorithms do not reach 100% accuracy, Zhou and Buyya (Citation2018) showed that there are algorithms that have obtained a higher accuracy in detecting fake news than (a large part of the) humans. Hence, at least in principle, humans can benefit from the help of such an algorithm that provides hints as to the believability of news content (note that humans could in fact even benefit from algorithms that are not necessarily better on average, but are performing well on those cases where humans perform poorly).
For algorithms to affect people’s judgment the algorithm’s decisions must be trusted when appropriate, that is, when the algorithm correctly delivers an assessment that is contrary to what the user thinks (Khasawneh et al., Citation2003). Unfortunately, getting people to trust algorithms when they should, turns out to be complicated to achieve. Many other factors can influence a person’s trust in algorithms. Three broad categories can be defined: (1) algorithm characteristics, such as their transparency or their objective accuracy (2) user characteristics, such as a user’s general willingness to take advice, gender, experience with other algorithms, or knowledge level about the topic, and (3) contextual factors, such as the topic at hand, how the algorithm is visually presented, or whether the decision is considered an important one. Here, we focus on one aspect of trust in model-based advice, namely the certainty or confidence that a user has in their initial assessment of a potential fake news message.
2. Confidence as an individual or contextual characteristic
Confidence is a crucial factor in fake news detection. For instance, Wise (Citation2000) showed that confident people are better at detecting fake news compared to less confident people. Furthermore, people who underestimate their judgmental skills, or people who are not confident about their ability and may have less experience or knowledge, rely more on advice from others (Yaniv, Citation2004). Consequently, the ability to use advice to improve judgments is inhibited by users overestimating their own judgmental ability (Harvey & Fischer, Citation1997).
Factors that contribute to (over)confidence are gender and the level of initial knowledge, for instance. Men are more confident (Santos et al., Citation2010), which might explain why females have been shown to rely significantly more on an algorithm’s advice than males (Wise, Citation2000). In addition, confidence depends on the topic and higher levels of initial knowledge may lead to an increase in confidence (Kramer, Citation2016). In this sense, human expertise can also be seen as a factor in the willingness to accept model-based advice. Experts tend to trust algorithmic advice less (probably because they think they do not need it; cf. Logg et al., Citation2019).
It is important to note that concepts such as “certainty” or “confidence” (and “overconfidence”) in judgment or advice are being defined and assessed in many ways across different research lines. For instance, certainty can be understood as the width of the subjectively estimated confidence interval surrounding a prediction, as the (subjectively estimated) comparison with general others, the expected number of correct answers, or -an approach that we will favour here- as a subjectively assessed position on the scale from “totally unsure” to “absolutely certain” (cf., Blavatskyy, Citation2009). These measurements differ in subtle but important ways and experimental results might depend crucially on whether one measures one or the other. In our contribution, we focus on one aspect of confidence (we stick to “confidence” instead of certainty from now on) that is typically neglected: whether one considers confidence an individual characteristic (person A is, on average, more confident than person B) or as a contextual characteristic (person A is more confident about assessment X than about assessment Y). The difference between these two might appear subtle at first glance but has potentially important implications. First, although it is hard to produce a general statement about this issue, we assess that most of the literature treats confidence as an individual characteristic. Individuals who are more confident about their judgments will be less likely to take advice. In other words, we have confident persons and less confident persons, and they behave differently. Instead, the effect of confidence could depend on what is being evaluated rather than on the individual. This can occur for instance when, even though individuals might differ in how confident they are on average, they agree about which object they are most confident (or least unconfident). shows a stylized example.
Figure 1. Stylized example of individual vs contextual effects. Dark dots represent cases from participant 1, clear dots from participant 2. Although participant 1 is less confident than 2, there is no effect of (average) individual confidence on the willingness to accept advice. There is, however, an effect of the contextual confidence: participants are less likely to accept advice for cases about which they are more confident (even though the case about which participant 1 is most confident, is a lower confidence level than even the lowest of participant 2).
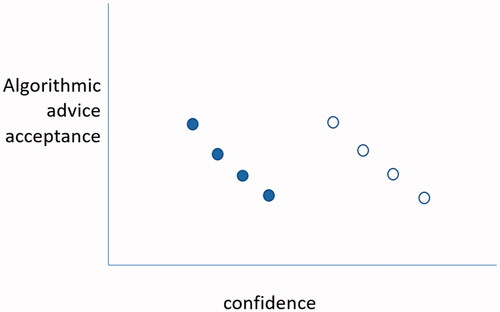
Scholars do not often refer to this difference between individual or contextual effects explicitly, which complicates the interpretation of results. Or, scholars might not be able to differentiate between the two given their design, for instance when they measure only one assessment per person, in which case it is impossible to distinguish individual versus contextual effects. This is problematic, as the conclusion about the underlying processes at work are different. This is the first research question we consider:
What is the effect of users’ confidence in fake news judgments on the likelihood to accept model-based advice and do these effects reflect individual or contextual differences?
A second issue we consider is whether the confidence of users about their initial assessment helps or hinders them in arriving at a final judgment. The literature suggests that there are reasons to be careful about whether humans can benefit from cooperating with model-based advice, even when the model is on average better than they are. First, in cognitive psychological research it is a well-established finding that often the confidence of the assessor does not correlate with how good the performance is. A general conclusion is even that people have the tendency to be more certain than they should be, which increases with their expertise (see, e.g., Fischhoff & MacGregor, Citation1982). Moreover, Harvey and Fischer (Citation1997) have found that, in the case of human advisors, advisors who are more experienced are trusted more compared to novice advisors. But even when people know that the advisor is more experienced than they are themselves, their initial judgment is still weighted higher than the advisor’s judgments. For algorithms, similar behaviour has been observed, even when there is unambiguous evidence that the advice presented by an algorithm was (on average) more accurate than their human judgement (Dietvorst et al., Citation2015). This phenomenon of algorithm aversion (or “advice discounting”) seems to be related to the level of confidence someone possesses and seems to be more evident for difficult tasks than for easy tasks (Larrick et al., Citation2007). There is also evidence that points in the opposite direction. Tazelaar and Snijders (Citation2013) for instance showed that the initial confidence of risk assessments by purchasing managers was predictive of how well the managers performed. This brings us to our second research question:
What is the effect of the confidence of a user's fake news judgments on the overall performance in the assessment task and do these effects reflect individual or contextual differences?
3. Method
3.1. Design
To answer the research questions, a within-subject design was employed, where participants determined for 15 randomized news articles whether the article was fake news, after which they could request advice from the fake news detection algorithm and adapt their initial judgement. For each article, the participants indicated their confidence, which resulted in a confidence score per participant (which thus varies between persons) and contextual confidence (which varies within and between participants) as independent variables. The dependent variables are the acceptance of the model-based advice and the overall performance. The study further included a 2 (type of advice: text-based versus “humanized” advice) by 2 (type of reward: fixed fee of 6 euros versus 5 euros and lottery tickets for a prize of 50 euros, depending on the number of correctly identified fake news articles) between-subjects design. These two factors are beyond the scope of the current article. The full experiment has been approved by the Ethical Review Board of the school of Innovation Sciences.
3.2. Participants
Participants were randomly selected from the JSF participant database at Eindhoven University of Technology (November 2019). For the necessary sample size, we based ourselves on wanting to be able to detect a 10-percentage point difference between conditions. In a design without repeated measurements, this would require about 1100 cases (using power = 0.9, alpha = 0.05). Given previous research in our lab with a similar “trust in algorithm” setup (unpublished), we assessed that the percentage of variance at the individual level was rather low (about 15%) and hence about 100 participants (leading to 100 × 15 = 1500 cases but with some within participant variance) was anticipated to be a reasonable amount. 1848 panel members were contacted, of which 111 completed the experiment. In total, 60 males (55%) and 50 females (45%) participated. One person did not want to disclose gender. The mean age of all participants was 27.6 years old. The youngest participant was 18 years, the oldest was 82 years old; more than half (63%) were between 20 and 23 years old. The majority, 85 participants, (77%), are currently enrolled in a university-level programme. The remaining participants are studying Pre-University Education (2%), General Secondary Education (3%), Secondary Vocational Education (5%) and Higher Professional Education (5%). Ten people (9%) indicated “Non-student.” One participant rushed through the experiment and was excluded from the observations. Eight participants classified 10 news articles instead of 15 because of a coding error in the randomization, but these cases were included in the analyses (and we checked whether it would make a difference if they were excluded, which it did not). Accordingly, the final dataset consisted of 1610 news articles, judged by 110 participants.
3.3. Procedure
Participants were invited (by email) to complete an experiment about “Fake news detection” in the HTI-lab at the Eindhoven University of Technology campus (November 2019). After providing informed consent, the participants were asked to individually complete two consecutive stages of questions in a cubicle. The study was conducted in English through the online survey tool LimeSurvey.
The first stage of the experiment consisted of several demographic questions (gender, age, and current level of education) and several questionnaires, including participants’ general interest in the news and experience with computer algorithms.
In the second stage, participants were asked to judge 15 news articles. First, an instruction text explained that participants could receive help from an algorithm in deciding whether a news article was real or fake. The text used for conveying this message to the participants is presented in . The instruction text was meant as an explanation of the algorithmic advice, to increase the transparency of the model. Multiple studies found that transparency of a model is important for participants’ trust (e.g., Nilashi et al., Citation2016) and we wanted to convey that the algorithm was a sincere effort to produce the appropriate assessment.
Figure 2. The instruction text explaining the algorithmic advice.

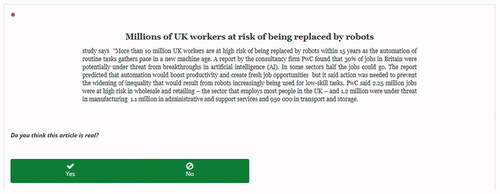
Thereafter, the participants were presented with 15 news articles, one by one. The news articles were chosen from a dataset of news articles that was designed for the detection of fake news by Pérez-Rosas et al. (Citation2017). Their dataset was constructed by a crowdsourcing collection in six domains (Business, Entertainment, Politics, Technology, Education and Sports) and the news items were obtained by a variety of US news websites such as New York Times and CNN. Pérez-Rosas et al. (Citation2017) manually fact-checked every article and eventually used a total of 240 news articles, 40 in every domain. Afterwards, they generated fake versions for each of these 240 news articles using crowdsourcing. Based on their dataset, we first considered whether the article topic was likely to be known by Dutch students. Because of this, the Sports domain was completely excluded, as it was mainly based on sports in the United States. Eventually this led to a total of 75 articles (40 real, 35 fake, 15 per domain) that were used in our experiment. In our set of 75, there was only one set of two articles where the fake version was an adaptation of the real one, but we ensured not to include both for a single participant. Each participant was shown three random news articles from each of the five domains. The order in which the domains were presented was fixed while the order of the articles within the domain was random. shows one of the articles that was used in the experiment.
Figure 3. Example of a (real) article as used in the experiment.
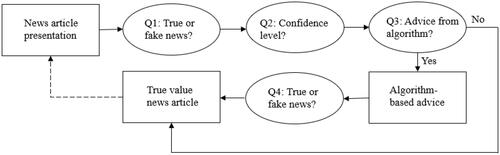
For each article, the participant first was asked to decide (without any help) whether the article was real or fake, and how confident they were about this assessment. Then the participant was given the choice to obtain advice from the algorithm. The advice from the algorithm was set to an accuracy rate of 70% across all cases. This ensured that the algorithm was not perfect (as there were no flawless fake news detection algorithms yet) but had an accuracy that we expected to be higher than the participants’ accuracy (based on some test runs we assessed human accuracy at about 60%). Participants were not told the accuracy of the algorithm, but were informed that the algorithm was not flawless. If the participant did not want to receive advice, the participant was immediately shown the feedback on whether the article was real or fake (“This article is FAKE/REAL”). If the participant did want to receive the advice, the algorithm gave its advice (“The algorithm thinks this article is FAKE/REAL”), and the participant could reconsider the initial assessment (“After having seen the advice of this algorithm, do you think this article is real?”). Thereafter, the participant also received feedback on the true value of the news article (“This article is FAKE/REAL”). visualizes the procedure that was followed per scenario. On average participants took 17 min and 51 s to complete the experiment (SD = 5 min and 24 s).
Figure 4. Visualisation of the procedure per news article.
3.4. Measurements
3.4.1. Trust in advice
The first dependent variable in our analysis is trust in advice, which is calculated in two ways. First, we determined whether the participant followed the advice. This is not always evident from the interaction with the algorithm. To measure whether the participant followed the advice, five potential scenarios were identified:
0. No advice requested (n = 302)
1. Advice was opposite and followed (n = 265)
2. Advice was opposite and not followed (n = 353)
3. Advice equals initial answer, but answer changed (n = 25)
4. Advice equals initial and second answer (n = 665)
Scenario 0 gives no useful data with respect to following advice, since there is no involvement with the algorithm. We likewise excluded scenario 4 since no undisputed conclusion could be drawn from these cases. Scenario 1 was considered as trustful behaviour by the participant and labelled “1,” scenarios 2 and 3 were considered not trustful and labelled “0.” A total of 643 (=265 + 353 + 25) cases were left for defining whether the participant changed the assessment in the direction of the algorithmic advice. In 41% of these cases (265 out of 643), participants changed their assessment and hence trusted the algorithm enough to revise their assessment.
Second, we measured whether the participants requested the advice to begin with. That is, we consider whether the participant trusts the algorithmic advice enough to be willing to at least see the model’s assessment. In 81% of the cases (1308 out of 1610) the participants requested to receive the advice.
3.4.2. Task performance
The second dependent variable is task performance. Task performance indicated whether the final assessment of the participant, with or without the use of algorithmic advice, was correct. In 66% of the cases (1063 out of 1610) the final assessment was correct.
3.4.3. Confidence
Confidence is the most important independent variable in this study This was measured after each initial answer for fifteen distinct news articles. Participants indicated their confidence on a five-points scale, ranging from one: “it’s a guess” to five: “I’m almost completely certain.” Additionally, two measures of confidence were created. The average individual confidence (which varies between participants) and contextual confidence (which varies within and between participants), defined as the deviation from the average individual confidence score. That is, contextual confidence = confidence – mean (confidence per person).
The average confidence of a participant (individual confidence) in the 643 cases that we consider has a mean of 3.30 (SD = 0.63) and the deviation of participants from their average confidence across cases (contextual confidence) has a mean of −0.2 (SD = 0.95). The average confidence of a participant (individual confidence) in all 1610 cases has a mean of 3.31 (SD = 0.63) and the deviation of participants from their average confidence across cases (contextual confidence) has a mean of zero (by definition, with a SD = 0.94).
3.4.4. Feedback
After each (final) assessment, participants received feedback whether their definitive answer was the correct one. In the analyses we include the percentage of negative feedback thus far received for a given assessment round (equal to 0 in round 1). Another variable that was used in the analysis is the number of questions for which the algorithm had already given incorrect advice to the participant.
3.4.5. Assessment (number)
Every participant was asked to analyse fifteen articles divided over five different news domains (business, entertainment, technology, politics, and education). Because of this setup, we included two categorical variables, the question number and the news domain, as independent variables. However, since the order in which participants were shown the different domains was always the same, the article domain and question number are related, forcing us to only use one of the two in the analysis. We use assessment number in our analyses and disregard the domain differences. Any effect of question number could therefore, in principle, also be an effect of the domain type. Since this is not our main concern, we just control for question number.
3.4.6. Software experience
An item scale based on the work of Anonymized (Citation2019) was used to get insight into how participants experience computer algorithms. The scale for software experience measured experience, interest, and knowledge of the participant regarding computer algorithms (see Appendix A) and had a Cronbach’s alpha value of .76.
3.4.7. News involvement
News involvement was measured in two ways, based on the motivation for news consumption, measured via an item scale, and news media use, which was indicated by two questions about the time spent on consuming news. Both these methods are proposed by Maksl et al. (Citation2015). For motivation for news consumption, they adapted a scale from O’Connor and Vallerand (Citation1990), who reported a Cronbach’s alpha that ranged from 0.89 to 0.92. In our study, we measured a Cronbach’s alpha of only 0.50. Due to this low value, we decided to not use the item scale.
New media use was measured by Maksl et al. (Citation2015) using separate time estimates for consumption from every media channel, such as reading a newspaper or watching news programs. We merged these questions on news media use into two questions. Firstly, asking whether a participant reads news at all, if yes, we asked them for a time estimate in hours spent on average on the consumption of all the types of news media combined. Due to low variance in the latter question, only the (binary) variable indicating whether a participant reads the news or not was included in the analyses.
3.4.8. Control variables
Although the conditions (type of advice: humanized versus text-based, and type of reward: lottery versus fixed fee) were out of scope for the current article, these were included as two control variables. In addition, several demographical variables were included, related to age, gender, and educational level. The “participants” section gives a summary of these variables.
4. Results
Out of the 1610 rated news articles, 64% of the initial human assessments were correct. This performance is better than random, but slightly lower than the algorithm’s accuracy (67%). After participants received algorithmic advice, their accuracy only slightly increased to 66%, which is a statistically insignificant (and in any case small) increase (p = 0.16). When participants chose not to receive the advice, their assessments were correct in 71% of the cases. This shows that participants’ assessments are slightly better when they choose to forego the algorithm's advice. In these cases, their accuracy is higher than that of the algorithm. When comparing the effect of the algorithmic advice across the news topics, we see that the effect of the advice was negligible when facing articles about politics (accuracy improved from 61% to 62% correct), business (70–68%), or education (67–66%). When the article is about entertainment or technology, the positive effect of the help of the algorithm was more noticeable (59–67% and 65–70% correct, respectively). When we compare the different scenarios outlined under “Trust in Advice” we find:
0. No advice requested (71% correct final answer)
1. Advice was opposite and followed (57% correct final answer)
2. Advice was opposite and not followed (47% correct final answer)
3. Advice equals initial answer, but answer changed (48% correct final answer)
4. Advice equals initial and second answer (79% correct final answer)
Performance is best for those cases where either the advice equalled the initial and second answer, or no advice was requested (71 and 79% correct). We also see that it is beneficial to follow the advice. When we compare scenarios 1 and 2, we see that following the advice leads to an increase from 47% to 57% (p = 0.014). When we compare scenarios 3 and 4, we see that following the advice leads to an increase from 48% to 79% correct (p < 0.001). If we compare scenario 0 with all others, effectively comparing whether performance was better if advice was asked, we find a negative but non-significant effect of asking the advice (71 versus 66%; p = 0.09). Obviously, participants will be more likely not to ask for advice when they feel they are certain (enough) about the assessment, so it is hard to attribute a clear meaning to this (non-significant) difference.
4.1. Effect on trust in the algorithm (RQ1)
To analyse trust in the algorithm, we analysed whether the participant followed the advice (in the 643 cases in which the algorithm’s assessment differed from the participant’s initial assessment) and whether the participant requested to see the advice (in all 1610 cases). In 41% of these cases (265 out of 643), participants followed the algorithm's advice and in 81% of the cases (1308 out of 1610) the participants wanted to receive the advice.
shows stylized estimated effects of individual and contextual confidence on trust, measured by both following the advice and requesting the advice, without controlling for any other kinds of potentially intervening variables. The results suggest that individual confidence has no or a small effect and contextual confidence has a negative effect on trust. The more certain a participant is about a given case, the less likely it is that the participant trusts the algorithm.
Figure 5. Visualizations of the estimated effects of individual and contextual confidence on trust (left: following advice; right: asking for advice).
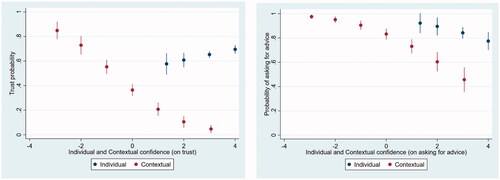
We now consider these effects in more statistical detail, in a series of multilevel (logistic) regression analyses. First, we consider three models with participant's willingness to follow the algorithm's advice, see , models 1–3. When we run an empty model, we find that 9.6% of the model’s variance lies at the participant level. Hence, a relatively modest part of the variance in trust is due to individual differences. The first model (M1) only includes confidence as a predictor variable. The effect of confidence on the willingness to follow the algorithmic advice is negative and statistically significant (−0.672, p < 0.001). When splitting this confidence into individual confidence and contextual confidence (M2), it is shown that the contextual confidence shows a significant effect (−0.843, p < 0.001), while individual confidence does not (−0.099, p = 0.57), a result that was already suggested in . Note that this rejects the argument that participants who are more certain about their assessments are less likely to trust algorithmic help. Instead, participants are more likely to trust algorithmic advice when the particular case they are considering is one that they themselves are less certain about than they are about other cases they assessed. Model 3, introducing several other predictor variables, does not change this. In addition, this model shows that if the previous advice was more often incorrect, the willingness to follow the advice decreases, while the trust slightly increases as the rounds progress.
Table 1. Multi-level logistic regression models for trust in advice and task performance.
In models 4–6, we use whether the participant asked to see the advice as a measure of trust in algorithmic advice. In model 4, with only confidence as a predictor, confidence is again statistically significant (−1.099, p < 0.001). Participants are less willing (or less in need) to see the advice when they are more certain. When we split the effect into individual and contextual confidence (M5), we see that there is evidence for both effects, as already indicated in . Individual (−0.830, p = 0.07) and especially contextual confidence (−1.108, p < 0.001) have a negative effect on the willingness to see the algorithmic advice. This indicates that participants who are more confident about their assessment in general, and participants who are more confident in this particular case, compared to other cases, are less likely to request the academic advice. In the full model (M6), these effects still hold. Moreover, it is found that people with more software experience more often ask for advice. Finally, if the previous advice was more often incorrect, people were less willing to see the advice (similarly to following the advice).
4.2. Effects on task performance (RQ2)
As a measure of task performance, we use whether the final assessment of the participant, with or without the use of algorithmic advice, was correct (so analyses are based on all 1610 cases). shows stylized (estimated) effects of individual and contextual confidence on task performance, without controlling for any other kinds of potentially intervening variables. The results suggest that individual confidence and contextual confidence have no or a small effect on task performance.
Figure 6. Visualization of the estimated effects of individual and contextual confidence on task performance.
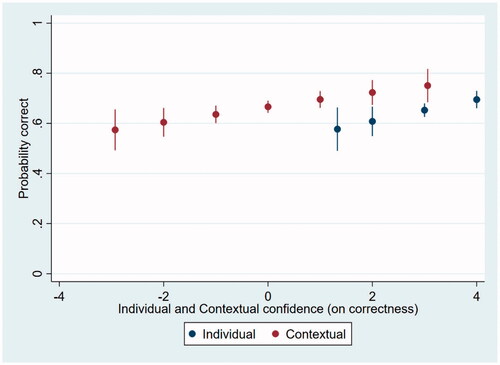
Once again these effects are analysed in more statistical detail, in a series of multilevel (logistic) regression analyses, see models 7–9 in . In model 7 with just the confidence variable as a predictor, we see that higher confidence goes with better task performance (0.153, p < 0.001). As expected from , we see that there is evidence for both an effect of individual confidence and of contextual confidence (M8). That is, participants who are more certain (on average), get higher scores (0.195, p = 0.029). Also, within participants, the cases that participants are more certain of, are more often correctly assessed (0.136, p = 0.016). This effect is larger for the individual confidence (between participant) effect, compared to the contextual confidence. Interestingly, when adding additional predictors (M9), the contextual confidence is even no longer significant. Within this model, the advice-following scenarios played an important part. The best performance occurs when the advice equals the initial answer and participants stick to it (0.501, p = 0.004). Second best are the cases where no advice was asked (the control condition in model 9). Worse, though only significant at the p = 0.06 level, are those cases where the advice was opposite and followed (−0.373, p = 0.063). Finally, worst are the cases where either the advice was opposite and not followed (−0.878, p < 0.001), or the advice equalled the initial assessment but was nevertheless changed (this happened only in 25 cases, −0.799, p = 0.07).
5. Discussion
In this study, we aimed to determine which factors influence user's trust in algorithmic advice for fake news detection. Our emphasis was on the effects of judgmental confidence on human's trust in algorithmic advice (RQ1), based on both the willingness to request algorithmic advice and the willingness to follow algorithmic advice. In addition, we analysed the effects of confidence on overall task performance of our participants (RQ2). For both research questions, we determined whether these effects reflected individual or contextual differences.
We found that confidence has a negative effect on the willingness to accept and request algorithmic advice. This corroborates the literature on accepting advice from others, which also showed that people with less knowledge or lower confidence rely more on advice (Yaniv, Citation2004). It is unclear, however, whether these effects as found in the literature are showing individual or contextual differences. Distinguishing between these two, we found that only contextual confidence has a significant effect on someone’s willingness to follow the advice. This implies that a participant is more likely to trust the model for cases where he or she is less confident about the assessment (compared to the cases where this participant is more confident). In contrast, participants who are on average less confident were not more likely to follow algorithmic advice than participants who are on average more confident. For the willingness to request algorithmic advice, both individual and contextual confidence were found to affect how often people asked for algorithmic advice. These results suggest that, especially for the willingness to follow algorithmic advice, it is important to (be able to) distinguish between individual and contextual confidence, as not distinguishing them might lead to incorrect conclusions about the source of the confidence effect. Our results show that those who are generally confident do not differ much from those who are generally less confident when it comes to following algorithmic advice. That there exists a difference between individual versus contextual confidence, has a clear practical implication for empirical or experimental research on trust in algorithms: measuring assessment confidence for just one case per participant is not enough, as it does not allow disentangling the two. Similarly, the theoretical implication is that any kind of argumentation about effects of confidence should make clear whether it considers individual or contextual effects, as they are not the same theoretically and (at least in our case) also not empirically.
Second, while the literature showed conflicting views on the relation between self-confidence and task performance, this study found a clear positive effect of confidence on performance, consistent with the results in Tazelaar and Snijders (Citation2013). Participants who are in general more certain are more likely to perform better compared to participants who are generally less certain. Both contextual and individual confidence were found to have a significant positive influence on the overall performance. For task performance, the effect was larger for individual confidence, meaning that the effect is greater for differences in confidence between persons than within a person. The effect within a person (contextual confidence), even became insignificant the moment the different advice-following scenarios were included as possible predictor variables. This could be explained by the possibility that contextual confidence has an indirect effect on performance since it has a direct effect on trust. Again, these results stress the importance of being able to distinguish between individual and contextual confidence. Once again this implies that it is important to have multiple confidence measurements per person, otherwise distinguishing between these two effects is impossible.
We found several other algorithmic, user, and contextual characteristics that influenced trust in the algorithm and the task performance. On average, participants were slightly more likely to follow advice over the period of the experiment. However, the number of times the previously given advice was incorrect was the only predictor that had a significant effect on all outcome metrics. Poor algorithmic advice (i.e. a higher number of incorrect suggestions) goes with participants being less likely to request and to follow advice, while their overall task performance increased. These findings are in line with previous research that concluded that trust is reduced when the system makes an error (Dietvorst et al., Citation2018; Dzindolet et al., Citation2003). Interestingly, having received an incorrect suggestion in the previous round did not affect trust and task performance, which is consistent with the idea that the participant did not directly penalize the algorithm when it made an error: the participants showed some trust resilience. In addition, software experience was found to positively influence requesting algorithmic advice. Task performance decreased when people asked for advice, which appears strange at first sight. However, when advice is asked for, following the advice did improve the performance. Participants (correctly) ask for advice for the cases where they would have performed worse based on their initial judgments, and may follow this advice some of the time, but the combination of a case about which they are not confident with the benefit of algorithmic advice is still worse in terms of task performance than cases where advice was not asked for.
Taken together, our results suggest that the integration of algorithmic advice in detecting fake news is not likely to benefit users much, especially when the algorithm’s accuracy is not close to 100%. Several potential solutions might help give algorithm advice on fake news a better chance though. Given that we do not have 100% accurate algorithms, one could try to train algorithms that are really accurate mainly for those cases where humans perform poorly and want advice. In this way, the algorithm itself need not be perfect for all cases, if only it performs well in that part of the data. An alternative that has been tried in some other papers with mixed success, would be to have the algorithm include confidence estimates (or other explanations), so that humans become more likely to follow the advice.
The current study has several limitations in the experimental setup. First, the study sample was Dutch, with a large majority of students, while all news articles were American. Although a selection of articles was made that only included articles that are familiar to Dutch students, one could argue that the participants are less familiar with American news articles. In addition, 23% of the participants did not read the news on a typical weekday. On the one hand it can be argued that this is a good thing, as the benefits of algorithmic advice are potentially larger in such a case, but on the other the lower familiarity with American news articles and the lack of interest may suggest a lack of validity for this group of participants. For future work, it is important to consider whether these effects still hold when people are more familiar with the type of news and certain topics.
Second, the specific way of framing the experiment could have resulted in the participants being more willing to change their initial judgement. After participants asked for algorithmic advice, they were given the opportunity to change their initial assessment. This could be seen as a 'nudge' towards changing their opinion. This 'nudge' was not present when no advice was asked for (as it was considered odd to ask for a judgement twice in a row). Hence, it might be that participants were slightly more likely to change their advice, just because they were allowed to do so (and not necessarily because of the algorithmic advice). However, this would not affect the first research question, as here only cases where included were algorithmic advice was requested. In addition, we feel that the effects on the second research question would be negligible, as we consider it unlikely that many responses would have been different.
Finally, irrespective of the unfamiliarity of the participants, the percentage of fake news judgements that were initially correct was already as high as 64%. This is remarkable given that Bond and DePaulo (Citation2006) found that humans are only slightly better than chance in detecting deception. Even though the differences in performance were small overall, significant improvement was realized when an algorithm’s advice was followed (in the order of magnitude of 10 percentage points or higher). Hence, for future work it would be interesting to study whether the algorithmic advice leads to a larger improvement in performance when the difference in performance between person and algorithm performance is larger (e.g., by using more difficult articles or an algorithm with a higher accuracy rate).
The results show some important implications for the design of experimental tests of algorithmic advice and human-algorithm interaction in general. The fact that asking for advice only resulted in improved task performance in the cases where the advice was followed, might prove interesting for future research to find out where these advantages of algorithm advice reside, precisely when an algorithm is not 100% correct. The aim is to ascertain that the algorithm is useful at the moments when humans are uncertain about themselves, or when the algorithm shows higher performance compared to humans. For example, an algorithm might show lower accuracy on average compared to human judgement, but might be better at the identification of articles that are typically difficult for humans. In such cases, explanations of the advice could aid the human in identifying the right moments in time where the algorithm might outperform them (Nilashi et al., Citation2016). Future work should determine what types of explanations result in some form of calibrated trust, where the human does not overly rely on the system or on themselves, but strikes the right balance between the two (see e.g., Bussone et al., Citation2015).
Perhaps most importantly, our study showed that the kind of confidence, individual or contextual, makes a substantial difference on trust and performance and that these have different effects on both trust and performance. The fact that confidence seems to cover two distinctive characteristics might explain the reason for the conflicting results found in literature. The importance of being able to distinguish within and between participant effects within experimental studies, making it necessary to measure multiple tasks per participant.
Disclosure statement
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Additional information
Notes on contributors
Chris Snijders
Chris Snijders is a professor of the Sociology of Technology and Innovation at the Human-Technology Interaction group of Eindhoven University of Technology. His research interests include human and model-based decision making, learning analytics, and explainable AI.
Rianne Conijn
Rianne Conijn is an assistant professor at the Human-Technology Interaction group of Eindhoven University of Technology. Her research interests include learning analytics and explainable AI.
Evie de Fouw
Evie de Fouw is a master student in Data Science in Engineering at Eindhoven University of Technology. Her research interests include Human-Computer interaction, explainable AI and Data Visualization.
Kilian van Berlo
Kilian van Berlo is a master student in Embedded Systems at Delft University of Technology. His research interests include Human-Technology interaction, Computer Vision and Tactile Internet.
References
- Anonymized. (2019). The influence of expertise on trust in model-based advice [Bachelor thesis]. Eindhoven University of Technology.
- Bhuiyan, M. M., Zhang, K., Vick, K., Horning, M. A., & Mitra, T. (2018). FeedReflect: A tool for nudging users to assess news credibility on Twitter. In Companion of the 2018 ACM Conference on Computer Supported Cooperative Work and Social Computing (pp. 205–208). ACM. https://doi.org/10.1145/3272973.3274056
- Blavatskyy, P. R. (2009). Betting on own knowledge: Experimental test of overconfidence. Journal of Risk and Uncertainty, 38(1), 39–49. https://doi.org/10.1007/s11166-008-9048-7
- Bond, C. F., & DePaulo, B. M. (2006). Accuracy of deception judgments characterizations of deception. Personality and Social Psychology Review, 10(3), 214–234. https://doi.org/10.1207/s15327957pspr1003_2
- Bond, R. R., Novotny, T., Andrsova, I., Koc, L., Sisakova, M., Finlay, D., Guldenring, D., McLaughlin, J., Peace, A., McGilligan, V., Leslie, S. J., Wang, H., & Malik, M. (2018). Automation bias in medicine: The influence of automated diagnoses on interpreter accuracy and uncertainty when reading electrocardiograms. Journal of Electrocardiology, 51(6), S6–S11. https://doi.org/10.1016/j.jelectrocard.2018.08.007
- Bussone, A., Stumpf, S., & O’Sullivan, D. (2015). The role of explanations on trust and reliance in clinical decision support systems. In International Conference on Healthcare Informatics (pp. 160–169). IEEE. https://doi.org/10.1109/ICHI.2015.26
- Buster.ai – Verify any piece of information in less than 1 minute. (n.d.). Retrieved March 31, 2022, from https://buster.ai/en/
- Dawes, R. M., Faust, D., & Meehl, P. E. (1989). Clinical versus actuarial judgment. Science, 243(4899), 1668–1674. https://doi.org/10.1126/science.2648573
- de Visser, E. J., Peeters, M. M. M., Jung, M. F., Kohn, S., Shaw, T. H., Pak, R., & Neerincx, M. A. (2020). Towards a theory of longitudinal trust calibration in human–robot teams. International Journal of Social Robotics, 12(2), 459–478. https://doi.org/10.1007/s12369-019-00596-x
- Desender, K., Boldt, A., & Yeung, N. (2018). Subjective confidence predicts information seeking. Psychological Science, 29(5), 761–778. https://doi.org/10.1177/0956797617744771
- Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology. General, 144(1), 114–126. https://doi.org/10.1037/xge0000033
- Dietvorst, B. J., Simmons, J. P., & Massey, C. (2018). Overcoming algorithm aversion: People will use imperfect algorithms if they can (even slightly) modify them. Management Science, 64(3), 1155–1170. https://doi.org/10.1287/mnsc.2016.2643
- Dietvorst, B. J. (2016). Algorithm aversion (pp. 1–93). Publicly Accessible Penn Dissertations.
- Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G., & Beck, H. P. (2003). The role of trust in automation reliance. International Journal of Human-Computer Studies, 58(6), 697–718. https://doi.org/10.1016/S1071-5819(03)00038-7
- Efendić, E., Van de Calseyde, P. P. F. M., & Evans, A. M. (2020). Slow response times undermine trust in algorithmic (but not human) predictions. Organizational Behavior and Human Decision Processes, 157(January), 103–114. https://doi.org/10.1016/j.obhdp.2020.01.008
- Fallon, C. K., Murphy, A. K. G., Zimmerman, L., & Mueller, S. T. (2010). The calibration of trust in an automated system: A sensemaking process. In 2010 International Symposium on Collaborative Technologies and Systems, CTS 2010 (pp. 390–395). IEEE. https://doi.org/10.1109/CTS.2010.5478488
- Fischhoff, B., & MacGregor, D. (1982). Subjective confidence in forecasts. Journal of Forecasting, 1(2), 155–172. https://doi.org/10.1002/for.3980010203
- Goddard, K., Roudsari, A., & Wyatt, J. C. (2014). Automation bias: Empirical results assessing influencing factors. International Journal of Medical Informatics, 83(5), 368–375. https://doi.org/10.1016/j.ijmedinf.2014.01.001
- Gutzwiller, R. S., & Reeder, J. (2021). Dancing with algorithms: Interaction creates greater preference and trust in machine-learned behavior. Human Factors, 63(5), 854–867. https://doi.org/10.1177/0018720820903893
- Harvey, N., & Fischer, I. (1997). Taking advice: Accepting help, improving judgment, and sharing responsibility. Organizational Behavior and Human Decision Processes, 70(2), 117–133. https://doi.org/10.1006/obhd.1997.2697
- Hegner, S., Beldad, A., & Brunswick, G. (2019). In automatic we trust: Investigating the impact of trust, control, personality characteristics, and extrinsic and intrinsic motivations on the acceptance of autonomous vehicles. International Journal of Human–Computer Interaction, 35(19), 1769–1780. https://doi.org/10.1080/10447318.2019.1572353
- Hern, A. (2019). Facebook fact checkers did not know they could vet adverts. The Guardian. https://www.theguardian.com/technology/2019/oct/26/facebook-fact-checkers-paid-adverts-misinformation-mark-zuckerberg-congress
- Highhouse, S. (2008). Stubborn reliance on intuition and subjectivity in employee selection. Industrial and Organizational Psychology, 1(3), 333–342. https://doi.org/10.1111/j.1754-9434.2008.00058.x
- Khasawneh, M. T., Bowling, S. R., Jiang, X., Gramopadhye, A. K., Melloy, B. J. (2003). A model for predicting human trust in automated systems. In 8th International Conference on Industrial Engineering - Theory, Applications and Practice (pp. 216–222). SIE.
- Kizilcec, R. F. (2016). How much information? Effects of transparency on trust in an algorithmic interface. In Conference on Human Factors in Computing Systems - Proceedings (pp. 2390–2395). ACM. https://doi.org/10.1145/2858036.2858402
- Kramer, M. M. (2016). Financial literacy, confidence and financial advice seeking. Journal of Economic Behavior and Organization,, 131, 198–217. https://doi.org/10.1016/j.jebo.2016.08.016
- Larrick, R. P., Burson, K. A., & Soll, J. B. (2007). Social comparison and confidence: When thinking you’re better than average predicts overconfidence (and when it does not). Organizational Behavior and Human Decision Processes, 102(1), 76–94. https://doi.org/10.1016/j.obhdp.2006.10.002
- Liberman, V., Minson, J. A., Bryan, C. J., & Ross, L. (2012). Naïve realism and capturing the “wisdom of dyads”. Journal of Experimental Social Psychology, 48(2), 507–512. https://doi.org/10.1016/j.jesp.2011.10.016
- Logg, J. M., Minson, J. A., & Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes, 151, 90–103. https://doi.org/10.1016/j.obhdp.2018.12.005
- Maksl, A., Ashley, S., & Craft, S. (2015). Measuring news media literacy. Journal of Media Literacy Education, 6(3), 29–45. https://doi.org/10.23860/jmle-6-3-3
- Minson, J. A., Liberman, V., & Ross, L. (2011). Two to tango: Effects of collaboration and disagreement on dyadic judgment. Personality & Social Psychology Bulletin, 37(10), 1325–1338. https://doi.org/10.1177/0146167211410436
- Nilashi, M., Jannach, D., Ibrahim, O. b., Esfahani, M. D., & Ahmadi, H. (2016). Recommendation quality, transparency, and website quality for trust-building in recommendation agents. Electronic Commerce Research and Applications, 19, 70–84. https://doi.org/10.1016/j.elerap.2016.09.003
- O’Connor, B. P., & Vallerand, R. J. (1990). Religious motivation in the elderly: A French-Canadian replication and an extension. The Journal of Social Psychology, 130(1), 53–59. https://doi.org/10.1080/00224545.1990.9922933
- Önkal, D., Goodwin, P., Thomson, M., Gönül, S., & Pollock, A. (2009). The relative influence of advice from human experts and statistical methods on forecast adjustments. Journal of Behavioral Decision Making, 22(4), 390–409. https://doi.org/10.1002/bdm.637
- Pennycook, G., & Rand, D. G. (2019). Lazy, not biased: Susceptibility to partisan fake news is better explained by lack of reasoning than by motivated reasoning. Cognition, 188(June), 39–50. https://doi.org/10.1016/j.cognition.2018.06.011
- Pérez-Rosas, V., Kleinberg, B., Lefevre, A., Mihalcea, R. (2017). Automatic detection of fake news. https://doi.org/10.48550/arXiv.1708.07104
- Prahl, A., & Van Swol, L. V. (2017). Understanding algorithm aversion: When is advice from automation discounted? Journal of Forecasting, 36(6), 691–702. https://doi.org/10.1002/for.2464
- Rubin, V. L., Chen, Y., & Conroy, N. J. (2015). Deception detection for news: Three types of fakes. Proceedings of the Association for Information Science and Technology, 52(1), 1–4. https://doi.org/10.1002/pra2.2015.145052010083
- Santos, W., Tabak, B. M., Fernandes, J. L. B., Matsumoto, A. S., & Chagas, P. C. (2010). The determinants of overconfidence: An experimental approach. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.1680962
- Saragih, M., & Morrison, B. (2022). The effect of past algorithmic performance and decision significance on algorithmic advice acceptance. International Journal of Human–Computer Interaction, 38(13), 1228–1237. https://doi.org/10.1080/10447318.2021.1990518
- Shin, D., & Park, Y. J. (2019). Role of fairness, accountability, and transparency in algorithmic affordance. Computers in Human Behavior, 98, 277–284. https://doi.org/10.1016/j.chb.2019.04.019
- Soll, J. B., & Larrick, R. P. (2009). Strategies for revising judgment: How (and how well) people use others’ opinions. Journal of Experimental Psychology. Learning, Memory, and Cognition, 35(3), 780–805. https://doi.org/10.1037/a0015145
- Tazelaar, F., & Snijders, C. (2013). Operational risk assessments by supply chain professionals: Process and performance. Journal of Operations Management, 31(1–2), 37–51. https://doi.org/10.1016/j.jom.2012.11.004
- Wise, M. A. (2000). Individual operator compliance with a decision-support system. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 44(2), 350–353. https://doi.org/10.1177/154193120004400215
- Yaniv, I. (2004). Receiving other people’s advice: Influence and benefit. Organizational Behavior and Human Decision Processes, 93(1), 1–13. https://doi.org/10.1016/j.obhdp.2003.08.002
- Yin, M., Vaughan, J. W., & Wallach, H. (2019). Understanding the effect of accuracy on trust in machine learning models. In Conference on Human Factors in Computing Systems - Proceedings (pp. 1–12). ACM. https://doi.org/10.1145/3290605.3300509
- Zhang, J., & Curley, S. (2018). Exploring explanation effects on consumers’ trust in online recommender agents. International Journal of Human–Computer Interaction, 34(5), 421–432. https://doi.org/10.1080/10447318.2017.1357904
- Zhang, Y., Liao, Q. V., & Bellamy, R. K. E. (2020). Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. In Conference on Fairness, Accountability, and Transparency (p. 11). ACM. https://doi.org/10.1145/3351095.3372852
- Zhou, B., & Buyya, R. (2018). A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Computing Surveys, 51(1), 1–40. https://doi.org/10.1145/3395046
Appendix A
Software experience scale (adapted from Anonymized, Citation2019).
(strongly disagree – disagree – disagree somewhat – neither agree nor disagree – somewhat agree – agree – strongly agree)
I often watch series and/or movies about artificial intelligence
During my study, I have gained knowledge of computer algorithms
I have a lot of knowledge about ICT
I have experience with computer algorithms
People in my social circle work in the ICT sector
I often use a Google Home, Alexa, or similar technology
I encounter computer algorithms/artificial intelligence on a daily basis
I follow the news about the most recent developments of new technologies