
Abstract
Virtual reality (VR) collaborative manipulation requires a proper understanding of the user’s self, other collaborators, and shared objects in the virtual environment. Users must be aware of the movements of themselves and others to coordinate their actions when they hand over an object or move it together. The awareness of collaboration plays an essential role in virtual environments. However, previous studies have focused on providing awareness only for cooperative manipulation. This study proposes a novel framework for dual awareness that comprehensively manages the state of interactions between multiple users and shared virtual objects and provides distinct sensory cues to distinguish themselves from collaborators. The experimental results showed that participants could easily and quickly collaborate on manipulation using our feedback, and they also answered positively in the subjective evaluation.
1. Introduction
Nowadays, virtual reality (VR) is not restricted to research laboratories and is used in various fields, such as education (Desai et al., Citation2017; Doumanis et al., Citation2019), industry (Oyekan et al., Citation2019), or design (Sharma et al., Citation2019). Since the onset of the COVID-19 pandemic, VR has received significant attention, particularly as a collaborative platform. In collaborative virtual environments (CVEs), multiple users can share virtual workspaces and have collaborative experiences at a distance (Churchill & Snowdon, Citation1998). This has resulted in people needing to perform team projects productively in VR. However, virtual collaboration does not always guarantee high efficiency or seamless communication experiences. The difficulties of working in these environments multiply, particularly when users interact directly with virtual objects in CVEs.
Manipulation refers to the interaction that people perform as they select and transform objects (Bowman & Hodges, Citation1999). Collaborative manipulation involves several people manipulating the same object simultaneously; however, this meaning has been used only for cooperative manipulation, which is a narrow definition (Pinho et al., Citation2008). In fact, collaborative manipulation includes both cooperative manipulation and the manipulation of objects by each user in the virtual environment, as shown in . In other words, collaborative manipulation includes holding and moving an object together as a group as well as grasping an object held by others or handing the object over to others. In the real world, people coordinate their actions to perform such activities after identifying what movements the other person is doing (Shah, Citation2013). Although coordination activities are essential for groups to collaborate successfully, this is only possible if they are aware of others’ behavior during collaborative work. Awareness in this context refers to the knowledge that a person has regarding the activities of their collaborator (Dourish & Bellotti, Citation1992).
Figure 1. Collaborative manipulation in virtual environments.
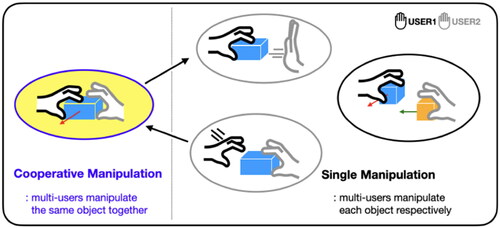
According to research on computer-supported cooperative work (CSCW), which addresses and studies the issues of users’ awareness, each individual must understand what is happening in the shared workspace and understand the activities of their collaborators to integrate their actions and achieve common goals (Schmidt, Citation2002). Several technologies have been developed to provide this awareness. Some studies have been conducted to provide awareness when jointly manipulating a virtual object (García et al., Citation2009; Ullah, Citation2011); however, they were limited to cooperative manipulations involving moving only a virtual object held by two people. When considering collaborative work in real life, one must be aware of not only their own movements but also those of the collaborators. When two people attempt to move an object together toward a target point, both of them must be holding the object correctly. If one side does not hold the object well and the other moves, the object may fall. When passing an object hand to hand, the giver must wait for the receiver to grasp the object, and the receiver must remain still until the giver releases the object. However, in VR, it is difficult for users to understand their own manipulation and that of other users simultaneously. Therefore, these perceptions must be provided in a virtual space, as in reality where people can intuitively and naturally identify such indicators through the physical interaction of a shared object.
This study aims to provide awareness for VR users to separately identify the inter action status of themselves and their collaborators which we termed dual awareness. We designed a new framework that modeled collaborative manipulation to manage the interaction states of objects and users systematically. It generates feedback with distinct sensory cues in parallel, which indicate interactions of user oneself and other collaborators separately. The remainder of this article is organized as follows. Section 2 presents the related work. Section 3 explains the proposed dual awareness framework. Section 4 describes user experiments to verify whether this feedback affects users’ performance on collaborative manipulation. Section 5 shows the results and discussion obtained. Finally, the conclusion is presented.
2. Related work
In a virtual environment, types of collaboration can be classified according to the user’s physical location (co-located/remote), collaboration time (synchronous/asynchronous), and user’s role (symmetric/asymmetric). Regardless of the type of collaboration users perform, the user’s awareness of the collaborator’s interactions in a virtual space plays an essential role in collaborative activities. This section describes previous studies on VR collaborative manipulation in two aspects: awareness and feedback.
2.1. Awareness of collaborative manipulation in VR
VR collaboration does not begin when collaborators simply work in a shared space. To genuinely collaborate with others, users should establish a common understanding of who is around, what others do, and what the states of artifacts are in a workspace (Nguyen & Duval, Citation2014). This is referred to as awareness, corresponding to a comprehensive knowledge of the environment in which the users work and of their collaborators’ activities. This awareness knowledge enables users to adjust their actions according to the environment (Harrison & Dourish, Citation1996).
There has been considerable research on awareness techniques to improve VR collaboration. Several studies focused on improving the awareness of other collaborators. Allmendinger (Citation2010) revealed that avatars that can represent non-verbal behaviors significantly impact social interaction in VR. Steptoe et al. (Citation2008) found that displaying users’ gazes in a virtual space enhances collaboration performances. Moreover, a few studies have found that the specifications of the system (Duval & Zammar, Citation2006; Olson & Olson, Citation2000) and awareness of physical space (Duval et al., Citation2014) also affect the collaboration work. However, these studies did not explore manipulation in CVEs. Le Chénéchal et al. (Citation2014) argued that explicit feedback is needed for users to be aware of others, as information on collaborators is limited when they do not co-locate.
As shown in , collaborative manipulation includes cooperative manipulations, and users can have different interaction states during manipulation. There are two categories of collaborative manipulation depending on the role of users (Ruddle et al., Citation2002). One is symmetric collaboration, and the other is asymmetric collaboration. In symmetric collaboration, users perform identical interaction techniques and jobs and complete tasks by performing the task at the same level [e.g., moved to the average point of two users’ cursors (Pinho et al., Citation2008)]. In contrast, users can perform different functions to do the same tasks, referred to as asymmetric collaboration [e.g., separate the degrees of freedom (DOF) for the movement (Pinho et al., Citation2002)]. Sometimes, two users perform asymmetric collaboration even though they have identical interaction manipulation techniques. SkeweR (Duval et al., Citation2006), the most typical method, allows users to hold two crushing points and move the object to rotate the object, similar to the real world. When handing over an object, two users have different roles (giver or receiver) due to the different timings of the release behavior. These collaborative manipulation methods presuppose the user’s overall perception of others and themselves. Thus, collaborative manipulation is possible only when users have a common knowledge of the overall interaction state of the shared object.
The role of awareness for collaborative manipulation is becoming crucial given the development of sophisticated collaborative manipulation technologies. With recent advances in VR hardware, there has been no limit on the number of users participating in cooperative work. For example, Grandi et al. (Citation2017) leveraged handheld devices to allow multi-user manipulation so that an unlimited number of users could contact the same object. These techniques help users perform various VR tasks; however, many interaction state changes in the collaborative process make it difficult for users to perform their tasks. This means that collaborators must be made aware of the overall state of the collaborative manipulation.
2.2. Feedback for collaborative manipulation
To perform proper collaborative manipulation, several feedback studies have suggested methods to provide the awareness of others and the awareness of coordinating actions. Notification is the most common method to provide awareness of collaboration (Lopez & Guerrero, Citation2017). This method delivers information as clearly as possible without unnecessary interruptions and distractions (Ardissono & Bosio, Citation2012). However, this method was designed for cooperative manipulation rather than overall collaborative manipulation. They were designed to be limited to instances in which a particular object could be held by two users simultaneously and moved at the same speed and direction. Some studies have supported cooperative manipulation by notifying users that they need to coordinate their behavior. De Oliveira and Pinho (Citation2017) provided feedback when two users held a virtual object together to encourage users to drop the object less frequently. This study demonstrated that vibration feedback was more effective than visual feedback in using the SkeweR (Duval et al., Citation2006). However, it was implemented to provide a warning alarm before releasing an object, and therefore, this feedback can only be leveraged for SkeweR techniques.
To the best of our knowledge, few researchers have focused on informing the inter action of others and the user’s own actions. Some of them used multimodal feedback for users to identify their collaboration well. García et al. (Citation2008, Citation2009) supported cooperative manipulation using visual icons and arrows to indicate the direction and states of users’ manipulation. Multi-sensory signals, such as sound or vibration only provided alarms to prevent users from dropping objects and did not contribute to awareness of the overall collaborative manipulation. This study was similar to ours in that it considered awareness of collaborative manipulation. However, previous works had focused on providing awareness for cooperative manipulation. In addition, VR multi-sensory feedback has been focused on supplementing a visual channel and increasing immersion (Ariza et al., Citation2018; Yin et al., Citation2019). Although some studies have shown that these multimodal cues can be utilized to increase the awareness of rich informational content and improve users’ task performance (Cooper et al., Citation2018), it has been not applied to interactions, such as collaborative manipulation. In summary, collaborative manipulation should be designed considering the user’s awareness. Some previous studies have demonstrated that multimodal feedback improves users’ ability to manipulate; however, these were limited to cooperation during manipulation and were not designed for collaborative works. As a result, there is a need for new feedback that allows users to be aware of the overall collaborative manipulation in VR.
3. Dual awareness framework
We propose a dual awareness framework to provide awareness to users in collaborative manipulation using multimodal cues. It allows users to understand and distinguish not only their interaction state but also the interaction state of collaborators manipulating the same object during collaborative manipulation.
3.1. Overview
The framework for providing awareness with explicit feedback in collaborative manipulation consists of three parts: manipulation detection, collaborative manipulation manager, and feedback generator (see ). Manipulation detection detects the type of interaction when a user manipulates an object. As all interactions are per formed independently by each user, the interaction states of the users and their hands must be handled comprehensively. The collaborative manipulation manager (CMM) manages the states of the users’ hands and objects in the virtual space from the perspective of collaborative manipulation. The feedback generator generates feedback according to the state of the hand and the object of the CMM. The feedback consists of dominant feedback, which provides awareness of the user’s interaction state, and subsidiary feedback, which provides awareness of the interaction states of others sharing the object. Through the proposed framework, it is possible to manage the state of collaborative manipulation and generate feedback without limiting the number of users or virtual objects.
Figure 2. Block diagram of the dual awareness framework.
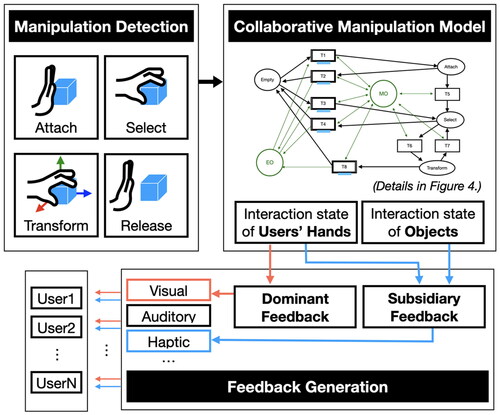
3.2. Collaborative manipulation
In various interaction techniques, a user manipulates a virtual object. As object manipulation technology significantly impacts the user experience of most VR applications, it is essential for a user to feel seamless interactions to avoid causing fatigue during prolonged use (de Belen et al., Citation2019). Direct manipulation using one’s bare hands was chosen as the most intuitive method among the various proposed techniques as it simulates interactions with real objects (LaViola et al., Citation2017). We considered manipulation in which users use their bare hands directly in collaborative manipulation.
Collaborative manipulation occurs through each user’s manipulation interaction, which changes the state of the virtual object and that of the user’s hand. This section describes the states of the user’s hand and the virtual object according to the manipulation.
3.2.1. Interaction state of hand
A user can select an object by grasping it in direct manipulation and then modify its position by moving a hand. Nevertheless, this method has challenges in terms of indicating whether an interaction occurred immediately. Many users struggled to grab a virtual object correctly and often floundered around it. Therefore, we decided to distinguish between the manipulating state from the “just touching” state to help users better understand their interactions before and after they occur. Touching an object is specified when a user attaches a hand to the object, yet the object cannot be repositioned to the desired place. We divide the manipulation states based on Bowman’s interaction taxonomy (Bowman & Hodges, Citation1999). The select refers to the user indicating an object to be manipulated, whereas the transform refers to when the user moves an object in three dimensions after selection. While users select, transform, or attach an object, they can end the interaction with an object by releasing it. When a user performs the manipulation interaction with a hand, the interaction through the state of the user’s hand is composed as follows (see ).
Figure 3. Interaction states of collaborative manipulation (a) hand’s states, (b) object’s states.
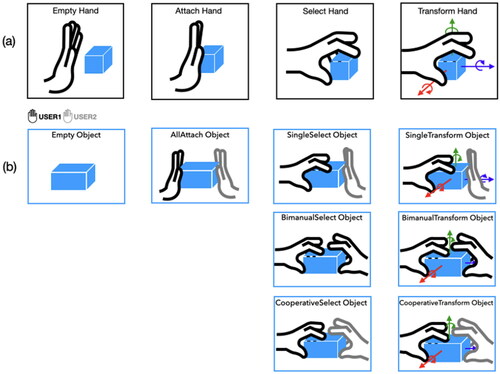
Empty: State of the hand not interacting with an object (when the hand releases an object).
Attach: State of the hand touching an object.
Select: State of the hand grasping an object.
Transform: State of the hand moving an object.
3.2.2. Interaction state of object
When a user interacts with a virtual object, the user’s hand and the object have an interaction state according to the manipulation described in Section 3.2.1. Suppose one hand interacts with a virtual object and the states of the user’s hand and the virtual object change in a one-to-one correspondence according to the manipulation. For example, when the user grasps an object with one hand, both the hand’s interaction state and the object’s interaction state are “Select.” However, if two or more hands interact with the same object, the interaction state of each hand is the same, whereas the interaction state of the object must be expanded. In an interaction where one hand holds an object and the other hand touches an object, the state of the hand is the same as that of the interaction, namely “Select” and “Attach,” respectively. In contrast, the state of interaction with an object being manipulated, the state of collaborative manipulation, should be changed. However, there is no state of the object representing the manipulation interaction. In this study, the interaction states for collaborative manipulation are classified and expressed based on the object. The one-handed manipulation interaction is extended to multi-handed interaction for multiple users in collaborative manipulation. During collaborative manipulation, the interaction state of an object is as follows (see ).
Empty: State of an object in which no hand is interacting.
AllAttach: State of an object when all hands are touching it.
SingleSelect: State of an object when only one hand grasps it while the rest just touches it.
SingleTransform: State of an object when only one hand moves it while the rest just touch or select it.
BimanualSelect: State of an object when a single user grasps it with both hands while the rest just touch it.
BimanualTransform: State of an object when a single user moves it with both hands while the rest just touch or select it.
CooperativeSelect: State of an object when two or more users’ hands grasp it together.
CooperativeTransform: State of an object when two or more users’ hands move it together.
3.3. Collaborative manipulation modeling
3.3.1. Collaborative manipulation model using colored Petri-net
In the virtual environment, the collaboration of multiple users is performed through each user’s independent interaction. However, users must be aware of the collaborator’s interaction to perform collaborative manipulation correctly. Therefore, it is necessary to represent and manage the interactions performed by each user from the overall point of view in the virtual environment. We modeled the collaborative manipulation based on object state using colored Petri-net (CPN) (Jensen, Citation1997), which is helpful for modeling and simulating distributed systems. As shown in , the collaborative manipulation model expressed by the colored Petri-net was simplified using a hierarchical structure.
Figure 4. Collaborative manipulation model.
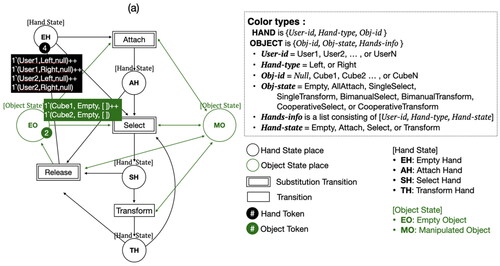
The interactions performed independently by each user, namely attach, select, transform, and release, are expressed as transitions. According to the interaction, the states of the hand and the target object are also changed. The states of the hand and the object are each expressed as a place. That is, the state of the hand was modeled as a place representing an empty hand (EH), an attaching hand (AH), a selecting hand (SH), and a transforming hand (TH). The object was modeled as an empty object (EO), which is a non-manipulated state, and a manipulated object (MO) place, which is a manipulated state. To model collaborative manipulation without limiting the number of users and objects, users’ hands and objects in the virtual space are expressed as tokens. Tokens representing the user’s hand include a user identifier (User-id), left or right hand (Hand-type), and object identifier with interaction (Obj-id). The virtual object token has Obj-id, with the state of an object (Obj-state) representing its interaction state, and information on all hands interacting with the object (Hands-info). When the user interacts with an object by hand, the object token stores the Obj-id, Hand-type, and Hand-state in Hands-info and creates the interaction state of the object from Hands-info.
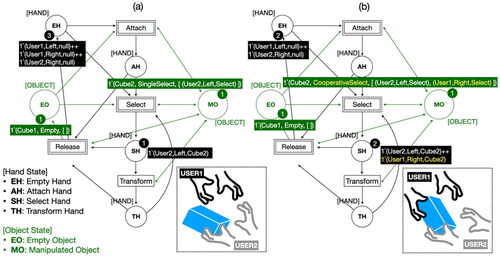
According to the interaction performed by the hand, the states of the user’s hand and the virtual object change together. The states of the hand are described in Section 3.2.1 as empty hand, attached hand, selected hand, and transformed hand, whereas the states of the object change by reflecting all interactions that have occurred with the object. When an interaction occurs with an object, the states of hands interacting with the object are checked, and the interaction state of the object defined in Section 3.2.2 is obtained. In addition, transitions for the same type of interaction are grouped and represented in substitution transitions. For example, Attach is grouped into Attach1 where a hand touches an empty object (no one is touching), and Attach2 where a hand touches an object that is already being touched by someone else’s hand. The detailed description of the substitution transitions in is shown in . is an example of a CPN model for collaborative manipulation when two users (User1 and User2) collaboratively interact with two virtual objects (Cube1 and Cube2) in a virtual environment. shows the CPN when User2 selects Cube2 with his left hand, and when User1 selects the same object Cube2 with his right hand in succession, the CPN becomes as shown in . Cube2 adds User1’s hand information to Hands-info and shows that Cube2’s state is “CooperativeSelect” because there are two different hands that selected Cube2.
Figure 5. Substitution transitions in collaborative manipulation model (a) attach, (b) select, and (c) release.
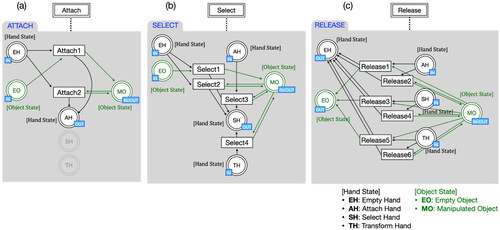
Figure 6. Example of CPN (a) when User2 selects Cube2 with the left hand, (b) when User1 and User2 select Cube2 together.
3.3.2. Validation of model
When we specify collaborative manipulation, users’ hands can interact independently with objects and interact with them again even after they release the objects. Therefore, the CPN model can fire transitions without limitations and return to home marking during the process. To validate the accurate modeling of our collaborative manipulation, we created a statistical report using CPN tools for state-space. All states that a model can reach are calculated from their initial states. Then, some properties can be proven based on them. Statistically, strongly connected component (SCC) graphs with 1 node and 0 arcs prove that this model can transition indefinitely and has no termination. The statistical report also showed that the model was always reversible and that there were no dead elements (marking and transition).
Additionally, we analyzed the boundedness of the model. Owing to the initial number of objects and hands being determined, all places were bound. This also confirmed that the interaction transitions of the model were included in the infinite firing sequences. If only one hand was interacting, the Release transition could only occur after the user touched or grasped an object, so all transitions have fair properties.
3.4. Dual awareness
As described in the previous section, we designed a CMM that can change the inter action states of the user’s hand and the object when each user interacts. Through the CMM, all user interactions are expressed in an integrated manner based on an object, and consequently, information for users to be aware of the collaborator’s manipulation is generated. When a user interacts with an object, dual awareness is provided by giving dominant feedback on one’s hand manipulation and subsidiary feedback on the hand manipulation of other users interacting with the object. For example, if the object’s state is “SingleSelect” when the user touches it, it is interpreted as a situation where another collaborator is holding the object (see ). This allows the user to integrate and recognize the interaction state of the collaborator, even if more collaborators manipulate the objects together. Providing dual awareness allows users to identify the entire process of collaborative manipulation.
Figure 7. Example of dominant and subsidiary feedback for two collaborators.
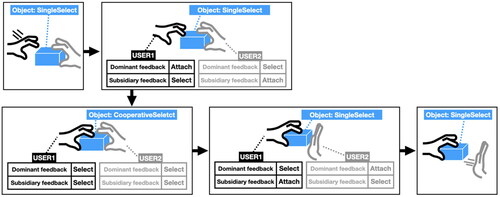
According to Wickens’ multiple resource theory (Wickens et al., Citation1984), humans can perceive large amounts of information simultaneously when provided with separate sensory signals. Considering this, we implemented a feedback generator that provides different sensory cues so that users can differentiate their interactions and collaborators’ interactions. The feedback generator can use multiple senses, such as audio, visual, and tactile signals, and the feedback rendering is modularized to enable a variety of multimodal interfaces. By providing two distinct sensory signals for the dominant and subsidiary feedback, users can recognize aware ness information, which is the interaction information between themselves and their collaborators, in parallel. Thus, the dominant and subsidiary feedback can be delivered with various arbitrary sensory signals, depending on the target application and system settings. Multimodal feedback can also have different combinations of visual touch, visual-auditory, and so on. For example, suppose the dominant feedback is visual, and vibration and sound are selected as subsidiary feedback. In that case, the user can perceive their manipulations by sight and touch, while they can perceive others’ manipulation through the ears.
4. User study
A user study was conducted to verify whether the proposed method, which provides dual awareness using multimodal cues, helps users perform collaborative manipulation effectively.
4.1. Experimental setup
4.1.1. Subjects
Participants were recruited from the Korea Institute of Science and Technology through email flyer [32 people (20 females, 12 males) aged 21–39 years (average age 26.9 years)]. Participants were given a gift certificate worth about $10 as a re ward for their participation. Nine of the participants had no experience with virtual reality, and seven had five or more experience, mainly through games, exhibitions and experiments. Most participants had experience interacting with virtual objects using a controller, and three had experience interacting with their hands through hand tracking system, such as Leap Motion, Kinect, or 3GearSystems.
4.1.2. Apparatus
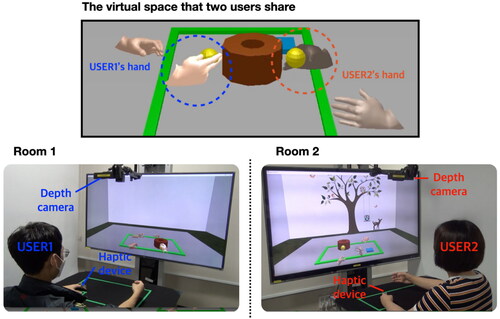
As shown in , participants sat in front of an immersive three-dimensional display and controlled a virtual hand by moving a real hand on a table. A 3GearSystems camera was used to track the movement of the participant’s hands. We utilized the physics-based manipulation method of virtual objects proposed by Kim and Park (Citation2016). The method allows a realistic hand to grasp a virtual object by hand in the same way as manipulating a real object. During the experiment, participants wore a vibration haptic ring on the index finger of their left hand and placed their left hand on a table. The experiments were conducted on two identical computers using the same Intel Core i7-3770 3.5 GHz with 16 GB memory. The experimental systems were implemented in Open frameworks from OpenGL to C++ and in Bullet Physics 2.82 for the physical simulation. One of these systems acts as a server, and the physics engine and the proposed framework were run on the server. The experimental system was networked, and the systems graphically demonstrated the same virtual space from their respective views.
Figure 8. Experimental system setup. The display used was a 40″ three-dimensional monitor. We used the 3GearSystems camera as a depth camera to recognize the pose of the participant’s hands and to track the movement of the participant’s hands. To receive feedback on the collaborator’s interaction, participants wear a vibrating haptic device on their left index finger. Participants’ experimental systems in separate locations are networked with each other and collaborate by sharing the same virtual space (top).
4.2. Experimental tasks
Two collaborative manipulation tasks were performed, as shown in : (1) two users move a virtual object together, and (2) one user passes a virtual object to another user. Moving together (Task 1) is a cooperative manipulation, a typical collaborative manipulation, designed to investigate the effect of the proposed feedback when two users continuously collaborate. Handover (Task 2) is performed to investigate the effect of the proposed method on collaborative manipulation, as shown in . In this task, participants give and receive an object at a specific point. In both the tasks, the virtual object manipulated by the participant was a brown block (see ). The block had yellow handles on its either side for an easy grip. Participants held the yellow handle to move or place the block. The green line at the bottom (see ) indicated the commencement of the task. This line grayed out when a collaborative manipulation ended successfully and turned red when it was unsuccessful. Participants practiced the grasp method prior to experiments and the task failure did not occur because of the grasp failure.
Figure 9. Experimental tasks (a) Task 1: Move together (1. Two users grasp together, 2–3. Two users move together, 4. Two users stop together), (b) Task 2: Handover (1. The giver grasps, 2. The receiver grasps, 3. The giver releases, 4. The receiver moves).
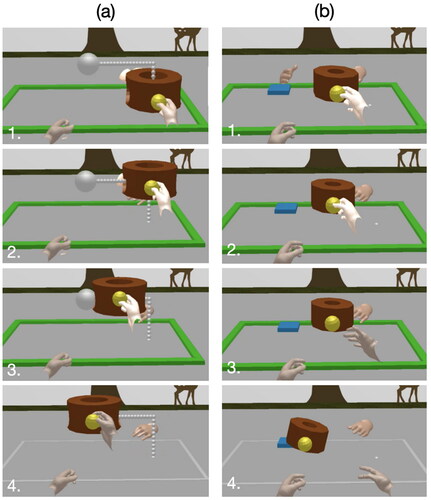
For Task 1, we instructed each pair of participants to move the block along a guide line together as quickly as possible (see ). The guideline is indicated by the grey dotted line in . If one of the participants dropped the yellow handle, the other had to wait for the participant who dropped to pick it up again; otherwise, the task would fail. This task was performed eight times under each feedback case. We measured the time and distance from the start of the task until the block reached the target point, as well as the ratio of cooperative manipulation and single manipulation for each measured value.
The goal of Task 2 was to hand over a block; one participant in front of the block had to give it to the other participant, and the receiver had to place the brown block on top of a blue square box (see ). The manipulation was repeated until three successful attempts; further, the roles of the giver and receiver were exchanged. If the block was not properly delivered, the task failed. In addition to the completion time, we measured the handover time, defined as the time taken for the giver to release the object after the receiver grabs it. Furthermore, we counted the number of failed trials in each task, indicating the number of times the participants attempted to hand over the object but failed.
4.3. Experimental cases
In this study, we presented a method for providing dual awareness of collaborative manipulation interactions through the use of distinct sensory cues. The proposed method was compared and tested with three other feedback methods. In the first case, Baseline only informed one’s manipulation. In the second case, unimodal awareness (Uni-A), apart from receiving their own manipulation, each participant receives the collaborator’s manipulation with a single sense of sight without considering collaboration. The third case, unimodal feedback using dual awareness (Uni-DA), informed collaborative manipulation through the same sensory cue. Finally, in the proposed method, multimodal feedback using dual awareness (Multi-DA), differentiated oneself from other people and informed them with different senses about collaborative manipulation.
All participants were able to see two pairs of 3D-rendered hands, one their own and the other a collaborator’s hand, in all experimental cases. We developed and used visual cues by highlighting the participants’ hands at different levels to indicate different interaction states, including attach, select, and transform for three comparison cases (Baseline, Uni-A, Uni-DA). That is, a hand appears darkest when not holding an object, slightly brightens when it touches an object (attach), becomes brighter when grasping (select), or becomes brightest when moving while grasping an object (transform). To focus on the effect of using multiple sensory modalities, we excluded auditory feedback and selected visual and tactile cues to test multimodal feedback in a simple manner. The Multi-DA case used the highlighting cue for primary awareness (dominant feedback), and secondary awareness (subsidiary feedback) was provided as vibrations from a tactile device worn on the participant’s finger.
The Baseline case only provides feedback on the user’s interactions but does not provide information about collaborators. The visual highlighting of their own hands indicates attach and select states. Therefore, each participant is only aware of their interaction state. Meanwhile, Uni-A provides visual feedback on all user interactions, so it does not use the proposed framework. The visual highlighting in this case also indicated attach and select states. Furthermore, Uni-DA provides dual awareness with a single-mode cue. Although it appears similar to Uni-A, participants can only obtain the awareness of others (secondary awareness) when they interact by sharing an object. It distinguished all three interaction states (attach, select, and transform) by using different levels of intensity. The proposed case, Multi-DA, provides dual awareness with multimodal cues that differentiates sensory cues for a user’s and a collaborator’s interaction.
4.4. Procedure
In the user study, the two tasks (Task1 and Task2) described above were tested with four cases. Before the experiments, the participants practiced orientation using the experiment guide (∼7 min) and manipulating a virtual object with their bare hands (∼3 min). Furthermore, they received sufficient instructions and observed the feedback cases before each experiment. The order of cases was counterbalanced among the participants using a 4 × 4 Latin square design. Each pair of participants performed two tasks with the feedback case and completed the experiments across the four cases. After the experiments, the participants filled out a questionnaire and took a break. The experiments took an average of 75 min, including orientation and question answering ().
Table 1. Statements in the questionnaire (five-point Likert items).
5. Results
We performed a one-way repeated-measures analysis of variance (RM-ANOVA) with Greenhouse-Geisser correction for sphericity violations, if required, and post-hoc pair wise comparisons with Bonferroni correction for each task. The Friedman test and post-hoc analysis based on the Wilcoxon signed-rank test were used for subjective ratings.
5.1. Task1: Moving together
We analyzed the extent to which participants cooperated in four feedback cases for Task1. The ratio of collaborative manipulation of the completion time to the moving distance was divided into cooperative time/distance (the time and distance of cooperative manipulation) and single time/distance (the time and distance of single manipulation). When participants failed to move the object together, the rate of cooperative manipulation was low. Particularly, if the participant moved without knowing that the collaboration is not holding the object, the amount of object manipulation by one user alone increased. The proposed feedback allowed users to cooperatively move the object longer and farther, as shown in .
Figure 10. Moving together task: Ratio of collaborative manipulation to (a) cooperative distance, (b) cooperative time, (c) single distance, and (d) single time (x: mean, y: ratio from 0 to 1, *, ***: pairwise significant difference).
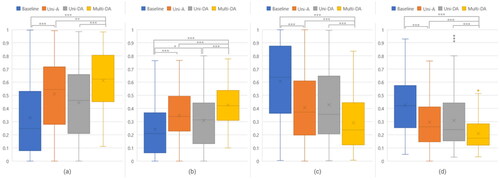
Descriptive statistics indicated that participants operatively traveled approximately 85% more distances using Multi-DA than using the Baseline case, where no collaborator information was provided. Providing Uni-A and Uni-DA to participants facilitated 55% and 35% more collaboration than providing Baseline. (Baseline: M = 33.0%, SD = 0.28; Uni-A: M = 51.0%, SD = 0.27; Uni-DA: M = 44.5%, SD = 0.28; Multi-DA: M = 61.2%, SD = 0.23). A similar trend was observed in the time domain. Multi-DA increased the cooperative time by 76% compared to Baseline.
Uni-A is 43% better than the baseline, and Uni-DA is 28% better (Baseline: M = 24.2%, SD = 0.20; Uni-A: M = 34.7%, SD = 0.18; Uni-DA: M = 31.0%, SD = 0.20; Multi-DA: M = 42.6%, SD = 0.15). Using RM-ANOVA, it was found that there was a statistically significant difference in the degree of cooperation in time and distance according to the feedback cases [cooperative time: F(3, 381) = 26.219, p < .001; cooperative distance: F(3, 381) = 27.911, p < .001; single time: F(2.735, 347.360) = 36.961, p < .001; and single distance: F(3, 381) = 34.209, p < .001].
Post-hoc analysis using Bonferroni correction, cooperative time, and cooperative distance showed a significantly higher proportion of cooperative manipulation of time and distance in Multi-DA than other feedbacks. Participants manipulated the object alone for much longer with Baseline feedback than with the other feedback.
5.2. Task2: Handover
shows the results of Task2: the completion time, the handover time, and the number of failures. When using Multi-DA, the participants performed the best in all dependent variables. Interestingly, using Baseline was better than using Uni-A or Uni-DA. Multi-DA was the fastest to complete a task, whereas Uni-DA was the slowest (Baseline: M = 23.82s, SD = 15.2; Uni-A: M = 25.30s, SD = 12.5; Uni-DA: M = 25.82s, SD = 14.5; Multi-DA: M = 20.21s, SD = 8.94). However, the RM-ANOVA showed a slight difference (p = 0.006), which appeared to be due to an inconsistent time from the moment the participant received an object to the time the participant put down the object to finish the task. As a result of analyzing the handover time, which specifically measured the time difference from one hand to another, there was a significant difference between the feedback cases [F(3, 285) = 9.374, p < .001]. The results of the handover time showed a similar trend (Baseline: M = 3.250s, SD = 2.50; Uni-A: M = 2.822s, SD = 1.68; Uni-DA: M = 3.509s, SD = 2.81; Multi-DA: M = 2.079s, SD = 1.28). The pairwise comparison with the Bonferroni correction indicated that Multi-DA was significantly faster than the other cases for handover time.
Figure 11. Handover task: (a) completion time (x: mean, y: second), (b) handover time (x: mean, y: second), and (c) failure count (x: mean, y: count) (*, ***: pairwise significant difference).
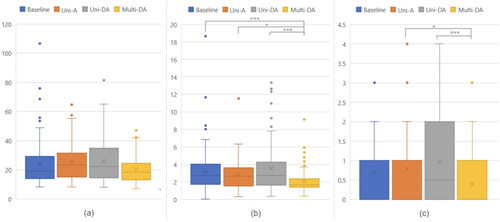
Similarly, participants had fewer failures per task when using Multi-DA than other feedbacks, and Uni-A feedback and Uni-DA had more failed attempts than Baseline (Baseline: M = 0.688count, SD = 0.94; Uni-A: M = 0.781count, SD = 1.02; Uni-DA: M = 0.958count, SD = 1.20; Multi-DA: M = 0.396count, SD = 0.62). RM-ANOVA with a Greenhouse-Geisser revealed a statistical significance [F(2.670, 253.613) = 5.856, p = 0.001]. The post-hoc analysis showed that Multi-DA failed significantly less than Uni-A and Uni-DA.
5.3. Subjective data
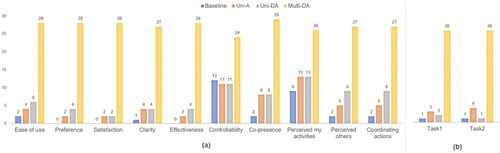
For each feedback case, positive and negative questions were answered on 10 items. Normalized ratings ranging from 0 to 10 were obtained to represent a high rating as a positive rating. As shown in , Multi-DA received the highest score across all items. Baseline, however, did not score the lowest overall. It was the second highest in clarity and scored almost the same as Uni-A and Uni-DA in controllability. This result suggested that several visual feedbacks made the interactions being perceived unclearly, and participants felt that, in these visual feedbacks, they could not manipulate properly.
Figure 12. Average questionnaire scores (x: mean, y: normalized score from 0 to 10) (***: significant difference).
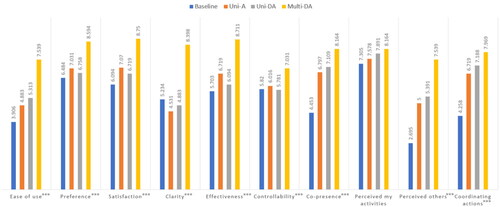
The Friedman test indicated statistically significant differences between feedback cases except for one item [Ease of use: X2(3) = 37.247, p < .001; Preference: X2(3) = 22.559, p < .001; Satisfaction: X2(3) = 20.995, p < .001; Clarity: X2(3) = 37.603, p < .001; Effectiveness: X2(3) = 35.231, p < .001; Controllability: X2(3) = 11.332, p < .001; Co-presence: X2(3) = 28.283, p < .001; Perceived others’ activities: X2(3) = 44.814, p < .001; Coordinating actions: X2(3) = 31.569, p < .001]. Only “Perceived activities (self)” could not find any significant difference. The difference in the ratings between the lowest and highest scores did not exceed 1 point [X2(3) = 3.991, p = 0.262]. This is because each user’s virtual hand was highlighted in all cases to identify their interaction state. In a post-hoc analysis using the Wilcoxon rank test, Multi-DA scored significantly higher than all cases in terms of ease of use, preference, satisfaction, clarity, effectiveness, and perceived action of others.
The feedback with the most selection in all items as a suitable feedback case was the proposed Multi-DA. In “Controllability” and “Perceived activities (self),” other feedback cases received relatively more votes than others for the above reasons (the results are shown in ). To select the most appropriate feedback to perform both tasks, Multi-DA received the most votes (see ). Those who selected Uni-A or Uni-DA answered, “It was more intuitive because I could see other people’s actions with my eyes.”
Figure 13. Number of votes of the most proper feedback (a) 10 items (multiple selections possible), (b) 2 tasks.
6. Discussion
6.1. Task1: Moving together
In Task1, we found that participants could move the object together longer using the proposed feedback. Uni-A and Uni-DA promoted collaboration next, followed by Baseline.
It was difficult for the participants to perform this task on Baseline because they could not see their partner’s hands. Most of them answered that it was challenging to work because they did not know whether the partner was holding the handle. Some pointed out that they could not inform the partner that they had not yet grabbed the handle. One participant said, “I didn’t know if the other dropped the object in the process, so I needed time to wait. In the end, the completion time was delayed.” In summary, compared to others, Baseline prevented participants from moving together because it did not represent the interaction state of collaborators.
In contrast, visually displaying the interaction of partners was beneficial to the participants. However, additional problems occurred. Participants said Uni-A was “the most intuitive and helpful because it informed me of my opponent’s interactions when I could see their hands.” Uni-DA, which changed the highlight of the hand at three levels (attach/select/transform), received positive comments: “It was easy to control the speed of object manipulation,” and “It helped me adjust the timing of movements.” However, in both cases, there were many comments stating it was not helpful when the partner’s hand was occluded, such as “the partner’s hand is not very different from Baseline because it is hidden by the object, especially when moving the object.” Because occlusion is a common problem in virtual environments, it is difficult to overlook the drawback of visual feedback. One of the interesting responses was the difference in the highlight of one’s own hands and the partner’s hands. The participants argued that the hand highlight made it easy to perceive manipulation interaction if it was one’s own hand; however, the collaborator’s hand was hard to view and indistinguishable from the color change. These visual representations ultimately distracted and confused the participants.
Using Multi-DA, participants were able to get out of occlusion issues. They evaluated the vibration cues to be the best means to inform the collaborator’s interaction state “because I could immediately know the other person’s manipulations.” Some said, “It was easy to wait for the other person until I felt the vibration.” and added, “It allowed me to control my actions.” However, it was also confirmed that maintaining vibration for a long time could cause discomfort to some. Some participants said, “The continuous vibration interfered,” and commented, “I needed high concentration to detect this vibration.” Nevertheless, there was a strong opinion that Multi-DA was consistent with the simulated physical interaction. Specifically, one participant said, “I thought it was possible to communicate through the object,” and the other answered, “I thought Multi-DA was better because physical properties, such as weight seemed to be expressed by vibration.”
6.2. Task2: Handover
The results of Task2 demonstrated the benefits of using the proposed feedback and the limitations of visual feedback. This task required the participants to notice changes in the other’s manipulation immediately. This is because the giver had to release the object after the receiver had grasped it, and the receiver must not have transformed the object until the giver released it. The proposed feedback could inform the user of the partner’s state change, but visual feedback was inappropriate.
The participants commented that the vibration cue of Multi-DA was “very clear” and “helpful in that it tells me the exact time to act.” Meanwhile, in the cases of Uni-A and Uni-DA, participants reported, “It was difficult to know when to manipulate the object because partner’s hand was invisible.” Owing to object occlusion, using visual feedback to represent the collaborator’s interaction was impractical. Some replied, “I focused too much on changing the color of my hand,” adding, “This appears to make me miss the object.” Regarding Baseline feedback, the participants said, “My partner and I had to wait for a certain amount of time because we had to estimate how long my partner would grasp.” In other words, performing actions when they deliberately waited rather than detecting changes in the partner’s hand highlighting was more efficient. One comment stated, “Baseline was easier than other visual feedback (Uni-A or Uni-DA) because I could focus only on my actions and hand highlights.” This explains that in Uni-A and Uni-DA, participants took longer to finish Task2 and dropped the object more frequently than in Baseline.
Finally, we asked participants to compare the two tasks regarding the differences in feedback. The most mentioned was that with Uni-A and Uni-DA, they were more uncomfortable doing Task2 than Task1. This indicated that the user should be aware of the collaborator’s manipulation at the exact time when the user hands over the object; however, the partner’s hand was slightly visible, making the task more difficult. One participant stated that the absence of collaborator’s interaction feedback had a more negative effect on Task1 than on Task2, adding, “This is because we have to perceive other’s interaction for a longer time.” Several clarified the difference between Uni-A and Uni-DA. One comment said, “There seemed to be no distinction between them when performing Task1, but when performing Task2, Uni-DA was very useful as it separated when a partner was approaching and when stopped.” However, the results were the opposite. Others had rated Uni-A better than Uni-DA when performing Task1, stating, “The color change was seen too quickly because of frequent hand-stop or moving movements, which was a hindrance.” In that respect, visual feedback should be designed to distinguish between providing continuous signals and alarms based on a specific situation. The problem is that these additional adjustments are intuitively difficult to accept for humans and sometimes take a long time to learn. Conversely, most participants answered that Multi-DA was much more helpful when performing both tasks. This proves that using multi-sensory cues to inform the partner’s manipulation is much more effective in supporting VR collaborative manipulation.
7. Conclusion
This study proposes a novel dual awareness framework that supports multiple users in collaborating virtual objects effectively. This study extended the interaction between users, which was earlier limited to the cooperative manipulation of virtual objects, to collaborative manipulation and systematically modeled the interaction process. Thus, providing feedback on manipulations consistently is possible, not only for single manipulation but also for all interactions, including cooperative and collaborative manipulation, and multiple users can effectively collaborate with multiple virtual objects. The proposed framework supports the user in providing multimodal cues to distinguish the interaction state of a participant and the collaborator. This enables multiple users to manipulate virtual objects together as shown by the results of a user study.
However, the experimental virtual environment had limitations in terms of depth perception due to the lack of stereoscopic vision as well as the absence of visual cues, such as shadows. These cues are important for users to understand the spatial location of objects within the environment, and the absence of these cues made it more difficult for participants to position their hands accurately to grasp the handles of the virtual objects, which can slow down actions. In the future, it would be beneficial to address these limitations by incorporating additional perceptual cues into the virtual environment to improve the accuracy and efficiency of collaborative manipulation.
Nevertheless, the proposed feedback is a robust method that can be used even when the object obscures a collaborator’s hand. Participants can efficiently match their inter action timing by explicitly representing their manipulation status. Without providing the awareness regarding collaborators, VR participants could not accurately perform collaborative manipulation. When the user’s and partner’s interactions were presented with the same sensory cue, the participant found it more difficult to manipulate. This demonstrates that using different sensory cues is more appropriate for users performing collaborative manipulations. In the future, we plan to study combinations of sensory cues to provide further feedback to collaborators.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Hyunju Kim
Hyunju Kim is a Ph.D. student at Cornell University focusing on Extended Reality, HCI, and CSCW. She earned her undergraduate degree in Electrical Engineering from Ewha Womans University and a master’s degree in Culture Technology from KAIST. Prior to Cornell, she worked as a research assistant at KIST.
Jung-Min Park
Jung-Min Park is a Principal Research Scientist at Korea Institute of Science and Technology (KIST). She received a Ph.D. degree in computer science and engineering from Ewha Womans University in 2008. Her research interests include virtual reality/extended reality, human-computer interaction, and user interface.
References
- Allmendinger, K. (2010). Social presence in synchronous virtual learning situations: The role of nonverbal signals displayed by avatars. Educational Psychology Review, 22(1), 41–56. https://doi.org/10.1007/s10648-010-9117-8
- Ardissono, L., & Bosio, G. (2012). Context-dependent awareness support in open collaboration environments. User Modeling and User-Adapted Interaction, 22(3), 223–254. https://doi.org/10.1007/s11257-011-9100-1
- Ariza, O., Bruder, G., Katzakis, N., & Steinicke, F. (2018). Analysis of proximity-based multi modal feedback for 3D selection in immersive virtual environments. In 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR) (pp. 327–334). https://doi.org/10.1109/VR.2018.8446317
- Bowman, D. A., & Hodges, L. F. (1999). Formalizing the design, evaluation, and application of interaction techniques for immersive virtual environments. Journal of Visual Languages & Computing, 10(1), 37–53. https://doi.org/10.1006/jvlc.1998.0111
- Churchill, E. F., & Snowdon, D. (1998). Collaborative virtual environments: An introductory review of issues and systems. Virtual Reality, 3(1), 3–15. https://doi.org/10.1007/BF01409793
- Cooper, N., Milella, F., Pinto, C., Cant, I., White, M., & Meyer, G. (2018). The effects of substitute multisensory feedback on task performance and the sense of presence in a virtual reality environment. PLOS One, 13(2), e0191846. https://doi.org/10.1371/journal.pone.0191846
- de Belen, R. A. J., Nguyen, H., Filonik, D., Del Favero, D., & Bednarz, T. (2019). A systematic review of the current state of collaborative mixed reality technologies: 2013–2018. AIMS Electronics and Electrical Engineering, 3(2), 181–223. https://doi.org/10.3934/ElectrEng.2019.2.181
- De Oliveira, T. V., & Pinho, M. S. (2017). Usage of tactile feedback to assist cooperative object manipulations in virtual environments. In 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (pp. 2367–2372).
- Desai, K., Belmonte, U. H. H., Jin, R., Prabhakaran, B., Diehl, P., Ramirez, V. A., & Gans, M. (2017). Experiences with multi-modal collaborative virtual laboratory (MMCVL). In 2017 IEEE Third International Conference on Multimedia Big Data (BIGMM) (pp. 376–383). https://doi.org/10.1109/BigMM.2017.62
- Doumanis, I., Economou, D., Sim, G. R., & Porter, S. (2019). The impact of multimodal collaborative virtual environments on learning: A gamified online debate. Computers & Education, 130, 121–138. https://doi.org/10.1016/j.compedu.2018.09.017
- Dourish, P., & Bellotti, V. (1992). Awareness and coordination in shared workspaces. In Proceedings of the 1992 ACM Conference on Computer-Supported Cooperative Work (pp. 107–114). https://doi.org/10.1145/143457.143468
- Duval, T., Lécuyer, A., & Thomas, S. (2006). Skewer: A 3D interaction technique for 2- user collaborative manipulation of objects in virtual environments. In 3D User Interfaces (3DUI’06) (pp. 69–72).
- Duval, T., Nguyen, T. T. H., Fleury, C., Chauffaut, A., Dumont, G., & Gouranton, V. (2014). Improving awareness for 3D virtual collaboration by embedding the features of users’ physical environments and by augmenting interaction tools with cognitive feedback cues. Journal on Multimodal User Interfaces, 8(2), 187–197. https://doi.org/10.1007/s12193-013-0134-z
- Duval, T., & Zammar, C. (2006). Managing network troubles while interacting within collaborative virtual environments. In CSAC (pp. 85–94).
- García, A. S., Molina, J. P., González, P., Martínez, D., & Martínez, J. (2009). An experimental study of collaborative interaction tasks supported by awareness and multimodal feedback. In Proceedings of the 8th International Conference on Virtual Reality Continuum and Its Applications in Industry (pp. 77–82). https://doi.org/10.1145/1670252.1670270
- García, A. S., Molina, J. P., Martínez, D., & González, P. (2008). Enhancing collaborative manipulation through the use of feedback and awareness in CVEs. In Proceedings of the 7th ACM SIGGRAPH International Conference on Virtual-Reality Continuum and Its Applications in Industry (pp. 1–5). https://doi.org/10.1145/1477862.1477904
- Grandi, J. G., Debarba, H. G., Nedel, L., & Maciel, A. (2017). Design and evaluation of a handheld-based 3D user interface for collaborative object manipulation. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (pp. 5881–5891). https://doi.org/10.1145/3025453.3025935
- Harrison, S., & Dourish, P. (1996). Re-place-ing space: The roles of place and space in collaborative systems. In Proceedings of the 1996 ACM Conference on Computer Supported Cooperative Work (pp. 67–76). https://doi.org/10.1145/240080.240193
- Jensen, K. (1997). A brief introduction to coloured Petri nets. In International Workshop on Tools and Algorithms for the Construction and Analysis of Systems (pp. 203–208).
- Kim, J.-S., & Park, J.-M. (2016). Direct and realistic handover of a virtual object. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 994–999). https://doi.org/10.1109/IROS.2016.7759170
- LaViola, J. J. Jr., Kruijff, E., McMahan, R. P., Bowman, D., & Poupyrev, I. P. (2017). 3D user interfaces: Theory and practice. Addison-Wesley Professional.
- Le Chénéchal, M., Arnaldi, B., Duval, T., Gouranton, V., & Royan, J. (2014). From 3D bimanual toward distant collaborative interaction techniques: An awareness issue. In 2014 International Workshop on Collaborative Virtual Environments (3DCVE) (pp. 1–8). https://doi.org/10.1109/3DCVE.2014.7160929
- Lopez, G., & Guerrero, L. A. (2017). Awareness supporting technologies used in collaborative systems: A systematic literature review. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (pp. 808–820).
- Nguyen, T. T. H., & Duval, T. (2014). A survey of communication and awareness in collaborative virtual environments. In 2014 International Workshop on Collaborative Virtual Environments (3DCVE) (pp. 1–8). https://doi.org/10.1109/3DCVE.2014.7160928
- Olson, G. M., & Olson, J. S. (2000). Distance matters. Human–Computer Interaction, 15(2–3), 139–178. https://doi.org/10.1207/S15327051HCI1523_4
- Oyekan, J. O., Hutabarat, W., Tiwari, A., Grech, R., Aung, M. H., Mariani, M. P., López-Dávalos, L., Ricaud, T., Singh, S., & Dupuis, C. (2019). The effectiveness of virtual environments in developing collaborative strategies between industrial robots and humans. Robotics and Computer-Integrated Manufacturing, 55, 41–54. https://doi.org/10.1016/j.rcim.2018.07.006
- Pinho, M. S., Bowman, D. A., & Freitas, C. M. (2002). Cooperative object manipulation in immersive virtual environments: Framework and techniques. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology (pp. 171–178).
- Pinho, M. S., Bowman, D. A., & Freitas, C. M. (2008). Cooperative object manipulation in collaborative virtual environments. Journal of the Brazilian Computer Society, 14(2), 53–67. https://doi.org/10.1007/BF03192559
- Ruddle, R. A., Savage, J. C., & Jones, D. M. (2002). Symmetric and asymmetric action integration during cooperative object manipulation in virtual environments. ACM Transactions on Computer–Human Interaction, 9(4), 285–308. https://doi.org/10.1145/586081.586084
- Schmidt, K. (2002). The problem with ‘Awareness’: Introductory remarks on ‘Awareness in CSCW’. Computer Supported Cooperative Work, 11(3–4), 285–298. https://doi.org/10.1023/A:1021272909573
- Shah, C. (2013). Effects of awareness on coordination in collaborative information seeking. Journal of the American Society for Information Science and Technology, 64(6), 1122–1143. https://doi.org/10.1002/asi.22819
- Sharma, S., Bodempudi, S.-T., Arrolla, M., & Upadhyay, A. (2019). Collaborative virtual assembly environment for product design. In 2019 International Conference on Computational Science and Computational Intelligence (CSCI) (pp. 606–611). https://doi.org/10.1109/CSCI49370.2019.00114
- Steptoe, W., Wolff, R., Murgia, A., Guimaraes, E., Rae, J., Sharkey, P., & Steed, A. (2008). Eye-tracking for avatar eye-gaze and interactional analysis in immersive collaborative virtual environments. In Proceedings of the 2008 ACM Conference on Computer Supported Cooperative Work (pp. 197–200). https://doi.org/10.1145/1460563.1460593
- Ullah, S. (2011). Multi-modal assistance for collaborative 3D interaction: Study and analysis of performance in collaborative work. Human–Computer Interaction.
- Wickens, C., Boles, D., Tsang, P., & Carswell, M. (1984). The limits of multiple resource theory in display formatting: Effects of task integration (Tech. Rep.). Illinois University at Urbana-Champaign.
- Yin, G., Otis, M. J.-D., Fortin, P. E., & Cooperstock, J. R. (2019). Evaluating multimodal feedback for assembly tasks in a virtual environment. Proceedings of the ACM on Human–Computer Interaction, 3(EICS), 1–11. https://doi.org/10.1145/3331163