Abstract
As more and more people regularly interact with chatbots in their everyday lives, it is crucial to understand how users perceive and evaluate them. This study examined whether free text (vs. button) interaction with and social (vs. neutral) error responses of chatbots effectively improve user responses. Using an online experiment (N = 416) in which participants interacted with a customer service chatbot, we investigated how interaction mechanism and error response influence perceived warmth and competence, satisfaction, usage intention, and emotional connection with the company. Contrary to our hypotheses, we found no evidence that free text interaction increases acceptance. Interacting via buttons was preferred, potentially because participants perceived the free text chatbot as less warm and competent. Interestingly, social error responses only increased satisfaction. We discuss the results considering recent advances in Large Language Models and highlight how the findings can guide further research and help practitioners develop efficient, user-friendly chatbots.
Even before ChatGPT (OpenAI, Citation2023) and Large Language Models (LLM) started to dominate the headlines around the globe in 2023, improvements in artificial intelligence (AI) and automation drove the proliferation of chatbots in various sectors and will continue to do so in the future. Implementing chatbot technology enables companies to save staff and training costs by automating customer service processes like recommending products, managing complaints, and answering questions (Desai, Citation2023; Rivas & Zhao, Citation2023). According to a recent study by Gartner, chatbots will become the primary customer service channel for about a quarter of companies by 2027 (Costello & LoDolce, Citation2022). Accordingly, more and more people will regularly interact with chatbots in their everyday lives, which renders it crucial to systematically study how people perceive and evaluate them. For companies, implementing chatbots can lead to cost savings, but requires first investments in skilled personnel and technology (Vial et al., Citation2023). Our study can provide guidance to companies and practitioners on how to design efficient, accurate, and accessible chatbots that can improve the customer’s service experience while being economically beneficial to the company.
Chatbots are automated text-based dialogue systems with which humans can interact via natural language (Shawar & Atwell, Citation2007). One can communicate with chatbots and not only through them, which makes them communicative subjects (Guzman, Citation2018). Many customer service chatbots rely on AI-based technologies such as natural language recognition and processing. Although labeled the gold standard in human-chatbot interaction, free text interactions with chatbots often result in frustration and abandoned conversations because the chatbot does not understand user queries, phrases, or context (Klopfenstein et al., Citation2017). In addition, free text interactions require users to input text through typing on their keyboards, which can be a cumbersome and unattractive task, particularly for users who are not experienced at typing. Structuring elements, such as buttons that display pre-defined answer options for users to click on, are already employed in state-of-the-art chatbots as well as LLM-powered chatbots, e.g., Microsoft’s Bing chatbot (Bing, Citation2023). Buttons make the conversation flow more transparent but can also negatively affect perceived humanness, social presence, and user-chatbot bonding (Diederich et al., Citation2019; Mai et al., Citation2022). In this study, we thus want to investigate how the interaction mechanism (buttons vs. free text) affects the perception of the chatbot.
Most people use chatbots for productivity reasons, i.e., because they are easy to use and respond to requests quickly (Brandtzaeg & Følstad, Citation2017). However, chatbots that do not meet these requirements might negatively impact customers’ trust and word-of-mouth (Seeger & Heinzl, Citation2021). Since non-understandings are common in user-chatbot conversations, it is crucial to prevent users from losing motivation and abandoning the conversation (Ashktorab et al., Citation2019; Følstad & Taylor, Citation2020). How the error response is presented, i.e., whether the chatbot apologizes and reveals its weaknesses, is a potential factor in improving user perception but has been neglected in research on chatbots so far (Benner et al., Citation2021). We, therefore, want to study how a social response to errors affects users’ perceptions of the chatbot, satisfaction, use intention, and emotional connection with the company.
The aim of our paper is to answer the following research question: How do free text interaction and social error responses influence perceived warmth and competence, satisfaction, intention to use, and emotional connection with the company? We use the Media Are Social Actors (MASA) paradigm (Lombard & Xu, Citation2021), which extends the Computers Are Social Actors (CASA) paradigm (Nass et al., Citation1994), social response theory (Lombard & Xu, Citation2021; Nass & Moon, Citation2000) and the concept of anthropomorphism (Epley et al., Citation2007) to derive our hypotheses. We test our hypotheses using an online experiment where participants interact with a state-of-the-art chatbot in a typical online retail customer service scenario.
Previous studies have investigated either the effects of a chatbot’s interaction mechanism (Diederich et al., Citation2019; Haugeland et al., Citation2022) or the effects of a chatbot’s verbal cues (Chattaraman et al., Citation2019; Lee et al., Citation2020) without considering possible interaction effects between the two. We complement existing research on the impact of combinations of different types of social cues on user responses (Lombard & Xu, Citation2021) by examining whether interaction mechanism and a chatbot’s reaction to errors interact in their effects on the outcomes of interest. In addition to the theoretical implications, studying this interaction may also have important practical implications for the design and implementation of human-like and efficient customer service chatbots by practitioners and companies. By analyzing whether two dimensions central to the evaluation of new agents, i.e., warmth and competence, mediate the effects of interaction mechanism and error responses on the outcome variables, we expand existing research by shedding light on the mechanisms underlying the relationship between social cues and user responses.
This study extends previous research on the impact of a chatbot’s interaction mechanism (Diederich et al., Citation2019; Haugeland et al., Citation2022) and error handling (Ashktorab et al., Citation2019; Lee et al., Citation2010) by investigating their influence on five user-related outcomes. The five outcomes represent central variables for assessing user perceptions, user experiences, and the company perspective (Cheng & Jiang, Citation2020; Fiske et al., Citation2007; Verma et al., Citation2016). First, we look at the warmth and competence of the chatbot as perceived by users. Warmth and competence are the basic dimensions along which people evaluate new actors (Fiske et al., Citation2007). Based on prior research on AI-based agents (Blut et al., Citation2021; Cameron et al., Citation2021), we argue that more human-like interactions with a chatbot might be positively correlated with users’ evaluations thereof. We do not include perceptions of agents that have been studied extensively, such as social presence or trust (Zierau et al., Citation2020). Negative emotions like anger (Crolic et al., Citation2022) are not considered either because the interaction in this study is unlikely to elicit much anger due to the experimental design, i.e., all participants have to solve the same fictitious tasks with the help of the chatbot. Second, we examine two central variables related to users’ experiences with the system: satisfaction, i.e., the extent to which the chatbot experience meets their needs and expectations (ISO, Citation2018), and intention to use the system, i.e., the desire to use it in the future (Gopinath & Kasilingam, Citation2023). Satisfaction with a system is considered one of the main objectives of system design and evaluation in human-machine interaction (ISO, Citation2018). Both variables are commonly used to investigate user responses to machine agents in human-computer interaction research (Cheng & Jiang, Citation2020; De Andrés-Sánchez & Gené-Albesa, Citation2023). Third, we consider a company-related outcome, namely users’ emotional attachment to it, i.e., the affinity between consumers and the company. Previous research has shown that anthropomorphic chatbot cues positively impact the relationship-building of companies with their customers (Araujo, Citation2018), which in turn has been shown to increase word-of-mouth, customer loyalty, and continuity expectation (Verma et al., Citation2016).
1. Theoretical framework
1.1. Social responses to chatbots
An established framework for researching human-machine communication is the Computers Are Social Actors (CASA) paradigm. The CASA paradigm was derived from the media equation, which states that humans treat computers and other media as real people (Reeves & Nass, Citation1996). According to the CASA paradigm, humans apply similar rules in their interactions with machines as in their interactions with other humans (Nass et al., Citation1994; Nass & Moon, Citation2000). The idea of humans treating machines as social actors is closely linked to the concept of anthropomorphism, the tendency of humans to ascribe human characteristics, motivations, intentions, and emotions to non-human entities (Epley et al., Citation2007). Nass & Moon (Citation2000) propose three main characteristics incorporated in machines leading people to act socially towards them. These properties are especially evident in text-based chatbots. The first characteristic refers to chatbots outputting written or spoken words. Second, chatbots are based on dialogue and turn-taking and are thus highly interactive. Third, chatbots fill roles traditionally occupied by humans, e.g., customer service agents, learning tutors, or mental health advisors (Følstad et al., Citation2019). These characteristics make chatbots media agents, defined as “technological artifacts that demonstrate sufficient social cues to indicate the potential to be a source of social interaction” (Gambino et al., Citation2020, p. 73).
The Media Are Social Actors (MASA) paradigm structurally extends the CASA paradigm by emphasizing the impact of social cues on users’ responses to various kinds of media agents like social robots and voice- or text-based conversational agents (Lombard & Xu, Citation2021). Media agents provide verbal and non-verbal social cues that send out social signals, which in turn elicit social user responses (Feine et al., Citation2019; Go & Sundar, Citation2019; Lombard & Xu, Citation2021). Social cues are defined as “features salient to observers because of their potential as channels of useful information” (Fiore et al., Citation2013, p. 2). In contrast, social signals refer to how the perceiving person interprets the social cues of the sender media agent (Fiore et al., Citation2013). Examples of social cues include eye gaze, gesture, body movement, and language use, which can send out social signals like responsiveness, interactivity, and even personality and social identity (Feine et al., Citation2019; Lombard & Xu, Citation2021).
Social cues in media agents have previously been categorized in different ways. For example, Seeger et al. (Citation2021) distinguish between human identity, verbal, and non-verbal cues, whereas Feine et al. (Citation2019)’s taxonomy comprises verbal, visual, auditory, and invisible cues. This study investigates the effect of a chatbot’s verbal cues in the form of its responses to errors on user responses. Verbal cues are expressed in written or spoken words, which can signal responsiveness, attentiveness, understanding, support, and human-likeness (Feine et al., Citation2019; Lombard & Xu, Citation2021). Previous research has shown that we are more easily persuaded when we perceive a conversational partner to be similar vs. not similar in how we communicate verbally (Fogg, Citation2003). Even slight verbal variations, e.g., regarding the conversational style of the chatbot or short text messages, e.g., “I am sorry,” can convey human-likeness and, thus, influence our perceptions and evaluations of media agents (Van Pinxteren et al., Citation2023; J. Chen et al., Citation2023; Chattaraman et al., Citation2019). However, as our study not only examines verbal error responses but also different mechanisms of interaction between user and chatbot, we also make use of Fogg (Citation2003)’s category of social dynamics cues. Social dynamics cues are “unwritten rules of how people interact with each other” (Fogg, Citation2003, p. 105) and entail turn-taking, cooperation, and reciprocity (Lombard & Xu, Citation2021). Cues representing social dynamics follow from the mechanism through which the interaction with a media agent takes place, e.g., through free text input or by clicking on buttons with pre-defined answer options (Jain et al., Citation2018). Social dynamics cues can thus influence the perceived engagement and interactivity of a media agent, which in turn can affect user responses (Haugeland et al., Citation2022). In the following two sections, we lay out the current state of the research and present our hypotheses on the impact of interaction mechanisms and error responses on user responses.
1.2. Interaction mechanism and user responses to chatbots
A factor that might strongly influence user acceptance is the interaction mechanism (Haugeland et al., Citation2022), also referred to as message form (Klopfenstein et al., Citation2017), interaction paradigm (Valério et al., Citation2020), interaction method (Mai et al., Citation2022) or turn-taking mechanism (Zierau et al., Citation2020). The interaction mechanism of a system refers to the kind of input it receives from the user during the interaction (Jaimes & Sebe, Citation2007). Different types of inputs are made in different ways: In this article, we distinguish between free text interaction, i.e., interaction with a chatbot by entering text via the keyboard, and button interaction, i.e., interaction with a chatbot by clicking on buttons with pre-defined answer options using the mouse.
Previous research on the effects of chatbots’ interaction mechanisms on user responses has yielded mixed results. On the one hand, there is empirical evidence that using buttons reduces a chatbot’s perceived humanness, potentially leading to lower user acceptance. In Diederich et al. (Citation2019)’s experiment, for example, participants interacted with one of two chatbots where one was based on free text while the other was based on a combination of free text and preset answer buttons. The authors found that buttons reduced the perceived humanness and social presence of the conversational agent in the interaction. Along these lines, the experimental study by Mai et al. (Citation2022) showed that free-text interaction improves the working alliance by enhancing the feeling of mutual respect, perceived sympathy, and appreciation by a coaching chatbot. A mixed-methods case study by Valério et al. (Citation2020) showed that people with scientific backgrounds do not prefer free text over button chatbots. In turn, data from daily chatbot users analyzed by Jain et al. (Citation2018) revealed that users preferred chatbots “that provided either a “human-like” natural language conversation ability or an engaging experience that exploited the benefits of the familiar turn-based messaging interface” (p. 895).
On the other hand, structured chatbot designs utilizing buttons might enhance user experience (Narducci et al., Citation2020). In an experiment on voting advice applications, Kamoen et al. (Citation2022) found that buttons appeared more playful to all participants and easier to use to lower-educated participants than text fields. A randomized within-subjects experiment by Haugeland et al. (Citation2022) found that button interaction leads to a higher pragmatic and hedonic user experience than free text interaction.
Based on the MASA paradigm and social response theory, we argue that users perceive interactions via free text as more human-like, i.e., more like their communication with other humans, and, accordingly, to have more similar social dynamics than interactions via buttons. Thus, users perceive chatbots based on free text input as warmer. Based on higher similarity to human-to-human interactions, we also propose that chatbots based primarily on free text input are perceived as more competent as they seem able to understand the requests written by the user. In addition, free text interaction mimics natural human communication more adequately than button interaction, leading to users expending less cognitive effort (Gambino et al., Citation2020) and, in turn, to increased satisfaction, intention to use it, and emotional connection with the company.
H1. When users interact with a chatbot primarily via free text (as opposed to buttons), (a) perceived warmth and (b) competence of, (c) satisfaction with, (d) intention to use the chatbot, and (e) emotional connection with the company will be higher.
1.3. Responses to errors and user acceptance
As conversational breakdowns in user-chatbot conversations occur frequently, users should be prevented from losing motivation and abandoning the conversation (Ashktorab et al., Citation2019; Følstad & Taylor, Citation2020). Investigating the error repair strategies of chatbots is thus crucial. Repair strategies refer to strategies “that a chatbot […] could adopt to tackle the above problems—providing evidence for the breakdown and supporting repair towards a desirable direction for the system model” (Ashktorab et al., Citation2019, p. 2).
Ashktorab et al. (Citation2019) found proactive repair strategies, like providing options and explanations, were favored among several chatbot repair strategies. Sheehan et al. (Citation2020) similarly found that a chatbot that tries to clarify its mistake increases people’s adoption intent compared to a chatbot that ignores its mistake. Positive effects of social error-handling strategies, such as offering an apology after an error to mitigate its negative impact, have also been demonstrated in social robots (Cameron et al., Citation2021; M. K. Lee et al., Citation2010). Besides apologizing for mistakes, social error-handling strategies include justifying or explaining the reasons for the error, promising to do better in the future (Robinette et al., Citation2015), as well as self-blame (Groom et al., Citation2010).
In particular, combinations of different error management strategies can lead users to continue the conversation (Benner et al., Citation2021). The combination of apologizing to the user for the error and admitting weaknesses has great potential to prevent conversation dropouts but has not been systematically studied for chatbots. We define an error response that contains verbal human-like cues like apologizing and admitting weaknesses as a social error response. A neutral response to errors does not contain verbal social cues. We argue that a social error response is more efficient in increasing our outcomes of interest than a neutral error response because people perceive it to be more human-like. We propose the following hypothesis:
H2. When a chatbot’s responses to errors are social (as opposed to neutral), (a) perceived warmth and (b) competence of, (c) satisfaction with, (d) intention to use the chatbot, and (e) emotional connection with the company will be higher.
1.4. The interplay of interaction mechanism and error response
In line with the MASA paradigm and social response theory, social error responses in combination with free text (vs. button) input might make the chatbot appear more human-like as more social cues lead to more positive user responses (Lombard & Xu, Citation2021). Chatbots based on pre-defined buttons are perceived as more rule-based and less error-prone due to their structured design (Jain et al., Citation2018; Valério et al., Citation2020). However, suppose a button-based chatbot does not understand a request. In that case, users might expect a neutral and formal response rather than a social one, which might be more likely perceived as inconsistent, resulting in feelings of irritation and confusion among users. User responses might thus be less positive, as research on combining text-based chatbots with a human-like avatar (Ciechanowski et al., Citation2019) has shown. We do not expect substantial differences in user responses between free text and buttons when the error response is neutral since neutral error responses do not contribute as much to a human-like perception of the chatbot as social ones. Therefore, we hypothesize the following:
H3. The type of interaction mechanism moderates the effect of the error response on the outcomes, such that the effect of social (as opposed to neutral) error responses is stronger when the interaction mechanism is free text (as opposed to buttons).
1.5. Underlying processes
When people are confronted with a new actor, they evaluate them on two basic dimensions: perceived warmth and competence (Fiske, Citation2018). According to the MASA paradigm and Social Response Theory, people treat technological entities, including chatbots, as social actors (Nass & Moon, Citation2000). We, therefore, argue that people evaluate a chatbot they encounter for the first time similarly to another person. An actor’s first impression, e.g., regarding their likability or perceived intelligence, is often the most influential factor for their further assessment—and if positive, can lead to more positive evaluations (Bartneck et al., Citation2009). Previous research has shown that the more human-like, and therefore, similar to oneself, a machine is perceived, the more people tend to like and be socially attracted to it, and the more intelligent people perceive it (Beattie et al., Citation2020; Ciechanowski et al., Citation2019; Toader et al., Citation2019). Consequently, when people perceive a machine to be likable and intelligent, user responses like the intention to use the machine turn out to be more positive (Blut et al., Citation2021; Cameron et al., Citation2021). Perceived intelligence refers to the extent to which people believe a machine is capable of independent thought, learning, and problem-solving; likability refers to qualities that elicit a favorable (first) impression (Bartneck et al., Citation2009). Free text interaction and social error responses are social cues that make the conversation with the chatbot more human-like. As H1 and H2 suggest positive effects of free text interaction and social error responses on satisfaction with, intention to use the chatbot, and emotional connection with the company, we assume these effects are mediated by perceived warmth and competence.
H4.1. Perceived warmth mediates the positive effects of free text interaction on (a) satisfaction with, (b) intention to use the chatbot, and (c) emotional connection with the company.
H4.2. Perceived competence mediates the positive effects of free text interaction on (a) satisfaction with, (b) intention to use the chatbot, and (c) emotional connection with the company.
H5.1. Perceived warmth mediates the positive effects of social responses to errors on (a) satisfaction with, (b) intention to use the chatbot, and (c) emotional connection with the company.
H5.2. Perceived competence mediates the positive effects of social responses to errors on (a) satisfaction with, (b) intention to use the chatbot, and (c) emotional connection with the company.
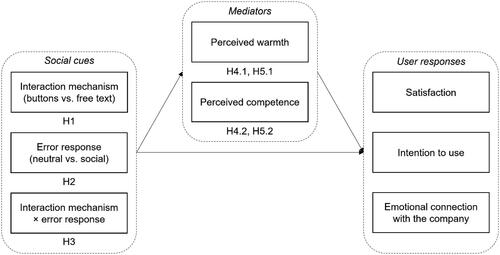
The research framework of this study is shown in .
Figure 1. Research framework.
2. Method
2.1. Overview
We conducted a 2 (interaction mechanism: buttons vs. free text) x 2 (error response: neutral vs. social) between-subjects online experiment. After providing informed consent, participants were randomly assigned to one of four conditions where they interacted with a real customer service chatbot that we adapted to this specific research setting in collaboration with a company specializing in Conversational AI to make the setting as realistic as possible. We chose this context as chatbots are already frequently employed in customer service and continue to hold great potential in this area (Costello & LoDolce, Citation2022). Each condition comprised between 93 and 110 participants. The study was approved by the ethics committee of the Leibniz-Institut für Wissensmedien Tübingen (LEK 2022/046) and preregistered at https://osf.io/shb6z.
2.2. Participants
An a-priori power analysis to determine the minimum sample size to detect an effect of f = 0.14, with α = .05 and a power (1 − β) of 80% yielded 403 participants (Faul et al., Citation2007). To account for potential exclusions, we recruited 450 German participants via the online sampling platform Prolific in October 2022. Respondents received £2.85 for participating in the experiment, which took around 20 minutes.
Following our preregistration, we excluded participants who had not followed the experimental instructions (n = 30) or experienced technical difficulties and could not interact with the chatbot (n = 4). The final sample comprised 416 cases. Participants’ average age was 29.90 years (SD = 9.16, range = 18, 71), and 50.00% identified as females. 61.78% indicated having used a chatbot at least once in the last three months.
2.3. Procedure
After starting the questionnaire, participants were asked to put themselves in a typical customer service scenario. They should imagine that they have placed an order and now have some questions to be answered and tasks to be completed by the chatbot. All participants received the same set of tasks, i.e., they were to find out (1) the balance of the gift card used to pay, (2) what happens if the recipient is not at home when the package is delivered, (3) the current location of the package, (4) the cost of return shipping, and they were (5) to subscribe to the newsletter (optional). To ensure anonymous data collection, all participants were given the same fake customer credentials, such as an email address, order number, parcel tracking id, and pin code, to share with the chatbot while working through the list of questions and tasks. We gave participants some general instructions for chatbot interaction: type their requests as free text in the text box if no options were offered, try to rephrase their request if the chatbot did not understand it, and type “I want to start over” if they wanted to start a new conversation. After reading the instructions, participants were prompted to click a button, opening a chat window embedded in the online survey. To make it easier for participants to answer the questions, they could see the list of tasks and the credentials while interacting with the chatbot. Participants received instructions to interact with the chatbot for a maximum of five minutes. To make the conversation more realistic and to be able to manipulate the experimental factor error response later, participants experienced at least one situation where the chatbot did not understand the user’s request during the interaction. We chose this type of error because failure to understand user requests is one of the most common mistakes users encounter when interacting with a chatbot (De Sá Siqueira et al., Citation2023). After the interaction, participants answered a questionnaire on their perceptions of the chatbot and the interaction. Participants could then comment on the study and were redirected to Prolific.
2.4. Stimuli and manipulation of independent variables
To give our research practical relevance and increase external validity, we created the chatbots in collaboration with a company specialized in conversational AI. The partner provided access to their low-code Conversational AI platform, which allowed us to create four chatbot versions for experimental purposes. The chatbots were based on a set of technologies that power automated human-like interactions, e.g., natural language processing (NLP), which enables the chatbots to understand human language text, and the deep learning architecture BERTFootnote1 which represents the key functionality of the matching process between the intent predicted from a user’s chat message and the chatbot’s response. The conversations with the chatbots were largely automated, except for the error situations, which we pre-defined (Appendix A). Specifically, when participants tried to solve tasks 2 (what happens if the recipient is not at home when the package is delivered) and 4 (the cost of return shipping), they were automatically redirected to separate conversational flows. No matter what they entered here, the chatbot did not understand their request and asked them to rephrase their question. After participants had rephrased, the chatbot provided the correct answer. As the interaction with the chatbot took place freely and unsupervised, some participants might have encountered more than two errors.
Anthropomorphic cues improve user responses to text-based chatbots, e.g., emotional connection with the company (Araujo, Citation2018) and user compliance (Adam et al., Citation2021). We thus equipped our chatbots with anthropomorphic cues, i.e., a gender-neutral name (“Mika”) and profile picture. The chatbots resembled currently employed customer service chatbots in design and functionality (Clustaar, Citation2019). The chatbots greeted the participants in all conditions, saying, “Hello! I am Mika, the chatbot of myclothes.deu”. Prior research has shown that dynamically delayed response times increase user satisfaction (Gnewuch et al., Citation2018). Thus, the chatbot typically responded after two seconds and after three seconds if its response was longer than two sentences or if the chatbot had a task to complete, such as registering the user for the newsletter.
2.4.1. Interaction mechanism
Interaction mechanism was manipulated by creating two chatbot versions: One chatbot required participants to enter their requests via their keyboard into the text field. The other chatbot was based on pre-defined buttons, i.e., participants had to click the respective button to make their requests. No free text input was possible when participants could select a button. The chatbots were based either mainly on free text or mainly on buttons. Since there is no pure type in the real world, the free text chatbot also had a button menu at the beginning, and the button chatbot also had two free text input situations where participants had to enter the fake credentials we provided, such as their gift card pin code or newsletter signup email address.
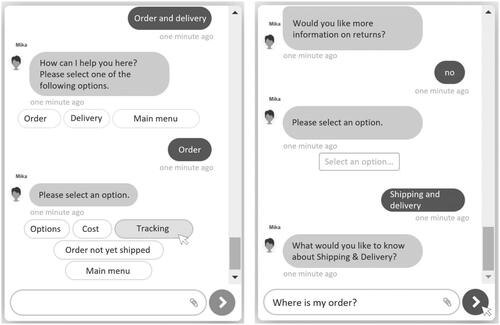
To test the chatbots’ functionality, we conducted a two-group (button vs. free text chatbot) pre-study with 50 subjects recruited via Prolific (nFemale = 24, MAge = 29.6, SDAge = 10.20). In addition to common usability scales, such as the User Experience Questionnaire (UEQ; Schrepp et al., Citation2017), the System Usability Scale (SUS; Bangor et al., Citation2008), and the Chatbot Usability Questionnaire (CUQ; Holmes et al., Citation2019), participants were asked open-ended feedback questions about positive and negative aspects of the chatbot as well as selected demographic information. The pretest showed that both chatbots worked reliably. Usability scores were in the acceptable range. UEQ was measured on a scale from −3 to +3 where values between −0.8 and 0.8 represent a neutral evaluation of the corresponding scale, values above 0.8 a positive, and values below −0.8 a negative evaluation (Schrepp et al., Citation2017): MButton = 1.06, SDButton = 0.86, MFree text = 0.67, SDFree text = 0.85. A two-sample t-test yielded no significant differences between the two conditions (t(46.95) = 1.59, p = .118). We assessed SUS and CUQ on scales from 1 = fully disagree to 5 = fully agree and converted the results to an overall score (0–100). According to the interpretation scheme (Bangor et al., Citation2008), both chatbots yielded acceptable SUS scores (MButton = 83.20, SDButton = 11.10, MFree text = 75.25, SDFree text = 12.00) with the button chatbot being slightly more acceptable, as shown in a two-sample t-test (t(46.32) = 3.40, p = .020). CUQ scores were similar in magnitude and direction (MButton = 76.75, SDButton = 11.90, MFree text = 69.16, SDFree text = 10.1, t(46.32) = 2.41, p = .020). Based on the participants’ comments, we made minor improvements to both chatbots, e.g., regarding knowledge base and category naming. shows exemplary screenshots of the button and free text chatbots used in the experiment.
Figure 2. Translated exemplary screenshots of button (left) and free text chatbots.
2.4.2. Error response
After ensuring that the button and free text chatbots functioned reliably and that each conversational flow included two situations where the chatbot did not understand the user’s request, we focused on manipulating the chatbots’ error response, our second experimental factor. In the social error response conditions, the chatbot responded to a mistake it made socially, i.e., its response comprised an apology and a disclosure statement that it is still learning: “I am sorry, unfortunately, I did not understand that. I am still learning. Please rephrase your request”. In the neutral error response conditions, the chatbot responded to errors neutrally, i.e., it simply said: “I did not understand that. Please rephrase your request”. We provide translated exemplary conversations for each condition in Appendix A. Videos of conversations in the original language are available in our OSF repository: https://osf.io/j8hde/.
2.5. Measures
2.5.1. Perceived warmth and competence
Perceived warmth refers to a person’s perceived friendliness, likability, and sociability; perceived competence refers to a person’s perceived intelligence, capability, and agency (Fiske, Citation2018). To assess users’ perceptions of the chatbot’s warmth and competence, we used the likability and perceived intelligence scales from the German version of the Godspeed Questionnaire (Bartneck et al., Citation2009; Cameron et al., Citation2021), comprising five items each. There are alternative scales that emphasize other facets of perceived warmth and competence, e.g., Lee et al. (Citation2023) operationalized perceived warmth and competence using scales initially developed to measure subscales of trusting beliefs (McKnight et al., Citation2002) and Zheng et al. (Citation2023) used a perceived warmth scale that also captures the perceived sociability during the interaction. However, warmth and likability as well as competence and intelligence, respectively, are conceptually very similar cognitive responses to new actors (Cameron et al., Citation2021; Fiske et al., Citation2007; Wojciszke et al., Citation2009). In addition, the items of the Godspeed questionnaire scales were explicitly developed to assess key concepts of human-robot interaction and are commonly used in HCI research (Weiss & Bartneck, Citation2015). Therefore, participants were asked to rate their impressions of the chatbot on seven-point semantic differential scales. Likability items included “unlikable–likable,” “unfriendly–friendly,” “impolite–polite,” “agreeable–disagreeable,” and “awful–nice”. Perceived intelligence items included “incompetent–competent,” “ignorant–educated,” “irresponsible–responsible,” “unintelligent–intelligent,” and “unreasonable–reasonable”.
2.5.2. Satisfaction
We assessed satisfaction with the chatbot using three items by Cheng & Jiang (Citation2020). The items, i.e., “I am satisfied with the chatbot,” “The chatbot did a good job,” and “The chatbot did what I expected,” were translated to German, adapted to chatbots, and measured on 7-point Likert-type rating scales (1 = do not agree at all, 7 = completely agree).
2.5.3. Intention to use
Intention to continuously use the chatbot was measured using a validated scale by Cheng & Jiang (Citation2020), comprising three items, i.e., “I would continue to use the chatbot,” “I would use the chatbot for purposes other than my current use,” and “I would explore other services of the chatbot than the ones I currently use”. Continued use was translated to German, adapted to chatbots, and measured on a 7-point Likert-typed rating scale (1 = do not agree at all, 7 = completely agree).
2.5.4. Emotional connection with the company
Emotional connection with the company refers to “the affinity between customers and [a] brand” (Christodoulides et al., Citation2006, p. 805). We adapted Christodoulides et al. (Citation2006)’s three-item scale by leaving out the item “I feel related to the type of people who are [X]’s customers” and replacing “brand” with our company name in the other two items because we were interested in the emotional connection with the company (Araujo, Citation2018). The items “I feel like myclothes.deu actually cares about me” and “I feel that myclothes.deu really understands me” were translated to German and measured on 7-point Likert-typed rating scales (1 = do not agree at all, 7 = completely agree).
Descriptive statistics, bivariate correlations, and Cronbach’s alpha values for all study variables are displayed in .
Table 1. Descriptive statistics, correlations, and alpha values for study variables.
2.5.5. Manipulation checks
We included manipulation checks for interaction mechanism and error response to ensure the manipulations were effective. To ensure participants encountered at least one chatbot error, we asked them how many mistakes they experienced during the interaction. To assess the error response manipulation, we asked participants whether the chatbot apologized for its error and disclosed that it was still learning at some point during the interaction.
3. Results
3.1. Manipulation checks
The analysis of conversation protocols and self-reported data confirmed that all participants in the final sample experienced at least one error. Most participants indicated having encountered one or two errors (61.1%), while the others encountered three or more. Most participants in the social error response conditions noticed the chatbot’s social error response; 9 participants (2.2%) did not notice the chatbot’s apology, and 57 participants (13.7%) did not notice the chatbot’s disclosure that it was still learning.
Of all participants, the majority (n = 278) solved either four or five of five tasks, 87 solved three, 28 participants solved two, and 13 participants solved one task. The tasks that were solved most often were task 1 “gift card balance” (n = 403), and 3 “parcel tracking” (n = 364). Tasks 2 “delivery issue” and 4 “return cost” with the inbuilt error as well as the voluntary task 5 “newsletter registration” were solved less often (nTask2 = 334, nTask4 = 284, nTask5 = 222). Participants mostly needed one attempt to solve tasks 1 (95.53%), 3 (83.79%), and 5 (96.40%), and two attempts for tasks 2 (61.68%) and 4 (72.89%).
3.2. Hypothesis testing
To test H1–H3, we conducted five two-way analyses of variance (ANOVA) with interaction mechanism and error response as independent variables, including their interaction. We added warmth (a), competence (b), satisfaction (c), intention to use (d), and emotional connection with the company (e) as respective dependent variables (). shows the means and standard deviations of the outcome variables by interaction mechanism and error response.
Table 2. Results of two-way analyses of variance in study variables.
Table 3. Means and standard deviations of interaction mechanism and error response main effects on study variables.
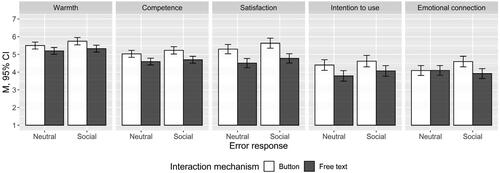
Contrary to our first hypothesis, we did not find positive main effects of interaction mechanism (free text) on perceived warmth and competence, satisfaction, and intention to use. Instead, participants indicated statistically significant lower values in the free text (vs. button) conditions on all dependent variables. Thus, H1 was not supported.
In line with our second hypothesis, we found a significant positive effect of social error response on satisfaction (F(1, 412) = 4.89, p = .028, η2partial = .01). Interacting with a socially responding chatbot led to significantly higher satisfaction (M = 5.18, SD = 1.34) than interacting with a neutrally responding chatbot (M = 4.90, SD = 1.52). The effect of social error response on perceived warmth was descriptively positive but only marginally significant (MNeutral = 5.35, SDNeutral = 1.06, MSocial = 5.52, SDSocial = 1.03; F(1, 412) = 3.34, p = .068, η2partial = .01). Although descriptively positive, error response had no significant effects on intention to use and emotional connection with the company. Only H2c was supported.
Regarding our interaction hypothesis (H3), we found one statistically significant interaction effect on emotional connection with the company (F(1, 412) = 5.66, p = .018, η2partial = .01), which was, however, not in line with our expectations (). We expected the effect of social (as opposed to neutral) error responses on the outcome variables to be stronger when the interaction mechanism is free text (as opposed to buttons). However, post hoc testing using Tukey’s HSD only yielded one significant mean difference: Participants in the social error response conditions indicated a higher emotional connection with the company when interacting with the button-based chatbot (M = 4.60, SD = 1.46) compared to the free text chatbot (M = 3.92, SD = 1.60, p = .006, d = −0.44). No difference was found in the neutral conditions (MButton = 4.09, SDButton = 1.36, MFree text = 4.10, SDFree text = 1.45, p = 1.000). H3 was thus not supported.
Figure 3. Interaction plots of error response and interaction mechanism on study variables.
Note. N = 416.
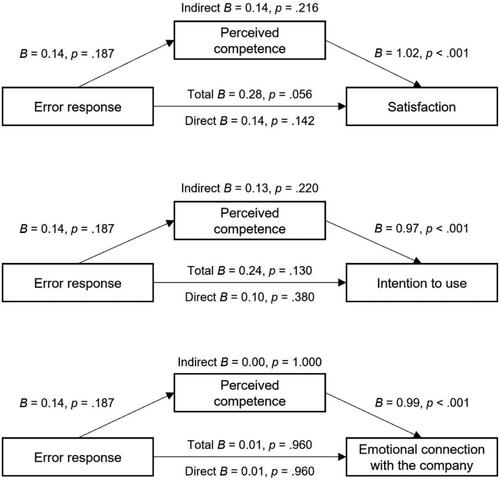
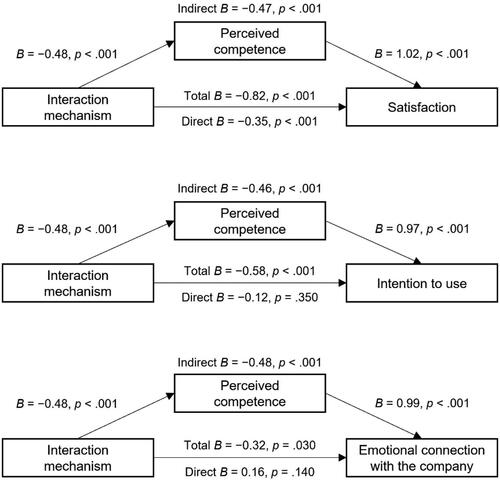
To test H4 and H5, we ran separate mediation models for each outcome variable with interaction mechanism and error responses as independent variables, using the R mediation package v4.5.0 (Tingley et al., Citation2019). The mediation analyses conducted to test H4.1, which stated that perceived warmth mediated the effects of interaction mechanism on satisfaction, intention to use, and emotional connection with the company, yielded some interesting results (). The interaction via free text was perceived as less warm, which led to less satisfaction, intention to use, and emotional connection with the company. Besides this indirect effect, there was still a direct effect indicating that warmth only partially explained the relationship. The same pattern emerged for the interaction mechanism effect on intention to use via perceived warmth, where a significant negative indirect effect emerged as well. Including the mediator in the model led to a negative direct effect that was smaller in magnitude than the total effect. Although there was no direct effect, we found an indirect effect from interaction mechanism on emotional connection with the company.
Figure 4. Mediation results of interaction mechanism on satisfaction, intention to use, and emotional connection with the company via perceived warmth.
Note. Interaction mechanism: 0 = button and 1 = free text. N = 416.
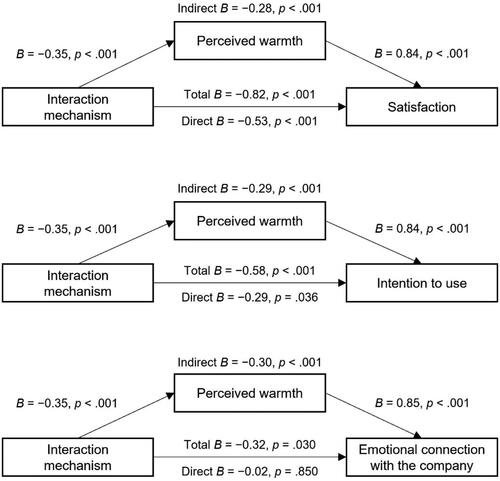
shows the results of the mediation analyses to test H4.2. Regarding perceived competence as mediator of the relationship between interaction mechanism and satisfaction, a significant negative indirect effect emerged, with the direct effect still being significant, indicating that perceived competence only partially explained the relationship between interaction mechanism and satisfaction. A full mediation was observed for intention to use and emotional connection with the company, where we found significant negative indirect effects as well as non-significant direct effects.
Figure 5. Mediation results of interaction mechanism on satisfaction, intention to use, and emotional connection with the company via perceived competence.
Note. Interaction mechanism: 0 = button and 1 = free text. N = 416.
A partial mediation with marginally significant indirect and total effects emerged when including perceived warmth as mediator of the relationship between error response and satisfaction (H5.1). We computed mediation models for the other outcomes, although no significant total effects were found when testing H2. No significant indirect effects were found for the other outcomes. Also, no significant indirect effects were found when including perceived competence as a mediator (H5.2). The full mediation models for H5.1 and H5.2 are displayed in Appendix B.
An overview of the results can be found in .
Table 4. Overview of results.
3.3. Additional analyses
As the pretest results indicated, perceived ease of use might be a potential influencing factor of users’ chatbot acceptance. Exploratory Welch two-sample t-tests yielded a higher perceived ease of use among participants who interacted via buttons compared to free text (MButton = 5.41, SDButton = 1.20, MFree text = 4.74, SDFree text = 1.49; t(406.90) = 5.03, p < .001, d = 0.49). Participants who interacted via buttons (vs. free text) also indicated fewer encountered errors (MButton = 1.89, SDButton = 0.74, MFree text = 3.31, SDFree text = 2.03; t(276.58) = −9.65, p < .001, d = −0.92). When controlling the relationship between interaction mechanism and the outcome variables for perceived ease of use, the negative effects of the free text interaction were mitigated: The effects on warmth, competence, intention to use, and emotional connection with the company became non-significant. The effect on satisfaction became less negative. Full results of the additional analyses can be found in our OSF repository.
4. Discussion
The rapid development of AI-based technologies has enabled chatbots to interact with users in a natural and human-like way. However, conversing with chatbots via free text often results in users experiencing feelings of frustration and abandoning conversations (Følstad & Taylor, Citation2020). To investigate the impact of interaction mechanism and error response, we conducted an online experiment where participants directly interacted with a chatbot in a common customer service setting. Four main findings emerged.
First, the free text chatbot was rated more negatively than the button chatbot regarding perceived warmth, competence, user satisfaction, and intention to use, which does not correspond with our expectations. This finding also contradicts previous research, which found free text interaction to positively impact service encounter satisfaction through feelings of humanness in the interaction (Diederich et al., Citation2019). Strikingly, additional analyses showed that the negative effects of interaction mechanism on the outcomes of interest were mitigated when controlled for perceived ease of use. This suggests that users are well trained through previous online experiences in interacting by mouse and hence preferred the button chatbot, which was navigable using the mouse. This is directly related to the fact that typing a request typically takes longer than simply clicking a button. Users might have preferred the button chatbot because the buttons matched the tasks very well, were easy to find, and structured the problem, whereas free text input requires the user to come up with the proper words, questions, and requests, as our exploratory analyses suggest. When users entered their request in this study, they could either do so via pre-defined buttons or via free text, i.e., only one interaction mechanism was available at the same time. Future research could investigate whether allowing users to choose between buttons and free text input would be beneficial, as this provides guidance and flexibility simultaneously (Haugeland et al., Citation2022).
Second, social error responses increased users’ satisfaction with the chatbot (H2). Our study conceptually replicated previous findings on the positive impact of social error responses on user satisfaction with social robots in the domain of text-based chatbots (Cameron et al., Citation2021). However, we did not find significant effects of social error responses on perceived warmth, competence, intention to use, and emotional connection with the company.
Surprisingly, we did not find interaction effects in line with our third hypothesis. There was, however, one significant interaction effect: The free text chatbot that responded socially to errors lead to a lower emotional connection with the company than the button chatbot that responded socially to mistakes, whereas the two chatbots did not differ when not responding socially to errors. A reason for that could be that the button (vs. free text) chatbot, which apologized for its errors and, at the same time, communicated that it is still learning, might have signaled to users that the company tries to anticipate its customers’ needs by collecting frequently asked questions and turning them into buttons. However, since we did not preregister this effect, its interpretation is exploratory and must be taken cautiously. Overall, we do not find evidence that the effects of social error responses on warmth, competence, satisfaction, and intention to use depend on how users interact with a chatbot.
Fourth, perceived warmth and perceived competence mediated the effect of interaction mechanism on the outcomes. However, mediation effects did not go in the predicted direction (H4). Instead, as suggested by our results for H1, free text interaction predicted less satisfaction, intention to use, and emotional connection with the company, presumably because participants perceived the free text chatbot to be less warm and less competent. The result of our additional analyses, namely, that perceived ease of use mitigated the negative effects of free text interaction as well as the fact that perceived ease of use was strongly correlated to both perceived warmth (r = .54) and competence (r = .59), suggest that the lower the perceived ease of use of a chatbot, the less warm and competent users perceive the chatbot. We did not find perceived warmth and competence to be significant mediators of the relationship between error response and the outcomes.
4.1. Theoretical implications
The MASA paradigm and Social Response Theory claim that the more social or human-like a chatbot is, the more positive the user responses will be (Lombard & Xu, Citation2021). However, this prediction appears to discount the relevance of usability aspects to the extent that they matter more than previously thought: Our results suggest that the benefits of using buttons, i.e., structuring the conversational flow and enhancing navigability, appear to outweigh the benefits of human-like interactions with chatbots. From a theoretical point of view, our findings thus challenge the applicability of the MASA paradigm in task-based contexts like customer service. There might be a difference between the effects of a human-like interaction mechanism and other human-like cues of the chatbot, e.g., language style or personality. Our study suggests that while human-like language cues generally positively impact user responses (Araujo, Citation2018; Adam et al., Citation2021), a human-like interaction mechanism might have different effects because it might be perceived as inefficient and impractical in particular in reasonably structured problems such as customer service (Haugeland et al., Citation2022).
The findings may also be an indication that the preference for button vs. free-text bots is contingent on the type of tasks the user has to solve. The tasks we studied could have been more suitable to be answered based on buttons (vs. free text). It would be interesting to investigate which questions users believe the button and free text bots are suitable for, i.e., buttons might be more suitable for task-related queries, and free text might be more suitable for emotional/social topics.
Although participants in this study interacted with an actual chatbot, the scenario was fictitious, i.e., the conversation was not about an actual order, reducing participant stakes. However, solving real-world tasks in the context of customer service, e.g., keeping track of a parcel, may also be associated with emotional responses, such as anger or frustration. Future research could, therefore, explore the impact of the interaction mechanism in contexts where there is more at stake for the user, i.e., where they need to explain, argue, or justify more complex matters and situations or in situations where an active exchange and social factors matter more, e.g., in mental health or financial counseling.
Our results on the effect of social error responses on satisfaction align with the main premise of social response theory, i.e., the more social cues a media agent possesses, the more positive users respond to it (Nass & Moon, Citation2000). We did not find significant effects of social error responses on the remaining outcomes. Language cues are secondary cues, i.e., “they have less power in activating user’s social perception and responses” (Lombard & Xu, Citation2021, p. 34). The apology, combined with the statement that the chatbot is still learning, may not have been salient enough to elicit feelings of similarity with the chatbot. This could be why we did not find the expected effects for perceived warmth, competence, intent to use, and emotional engagement with the company. At the same time, the wording we chose reflects what is commonly used in real chatbot applications. Hence, it appears that the social error response does not seem to be the decisive factor that governs user perceptions of chatbots. Our mediation findings indicate that perceived warmth and competence are indeed central constructs for people’s evaluations of a chatbot (Fiske et al., Citation2007).
4.2. Practical implications and outlook
Our findings have several implications for marketing practice (e.g., Huang & Rust, Citation2021). A direct corollary of the results is that firms seeking to implement chatbots may want to leverage the benefits of both interaction mechanisms, i.e., buttons can structure the conversational flow of a chatbot when the problem is well-defined, and free text input might help with new user queries or queries that occur less frequently. Hence, the findings suggest that companies should give relatively more weight to the usability aspect over the potential benefit of human-like interaction mechanisms. In contrast, firms need to be less concerned about the way they implement an error response, i.e., consumers appear to appreciate a social error response, but we do not have evidence that this is a strong driver of how they view the chatbot or the firm.
It is also of relevance for firms to understand how these findings relate to the role of the recently released LLMs like GPT-4 (OpenAI, Citation2023). LLMs have the potential to provide even more efficient and accurate automated customer service, e.g., by providing personalized, human-like responses to customer requests (Floridi & Chiriatti, Citation2020; Rivas & Zhao, Citation2023). In this light, we must ask ourselves if our results will look different in a few years when people have more experience using chatbots powered by LLMs. However, several reasons speak for the continued relevance of our results:
LLMs have to be trained on current and relevant customer data: Until timely data is available to train these models, they are not a real alternative for companies to current customer service chatbots (Rivas & Zhao, Citation2023). In our experiment, participants had to solve pre-defined tasks. However, knowledge of chatbots based on LLMs is often rather broad than deep, i.e., they lack knowledge on specific topics. ChatGPT, for example, is often used for writing poems in different styles (Haque et al., Citation2022) but not necessarily for specific tasks like booking a flight or registering for a degree program. Yet, the primary goal in customer service is to give customers controllable, complete, and correct information (Rivas & Zhao, Citation2023).
ChatGPT’s interaction mechanism is free text. However, developers of LLM-based chatbots also employ buttons; e.g., Bing’s chatbot suggests answer options and further questions via buttons (Bing, Citation2023). Therefore, researching the influence of different interaction mechanisms remains a relevant line of research. Even chatbots based on LLMs make mistakes or hallucinate, e.g., they give incorrect answers to math problems, make up references, or get tangled up in contradictions (Borji, Citation2023; Sundar & Liao, Citation2023; Van der Meulen, Citation2023). Thus, the need for an adequate response remains relevant, e.g., when a user confronts the system with an error it has made or is programmed not to answer specific questions.
Lastly, although LLMs provide many opportunities, they come with less control over the conversational flow. Our collaboration with a startup specialized in conversational AI gave us full control over our experimental stimuli, i.e., the content, timing, and type of chatbot utterances, a prerequisite for valid and reliable experimental research on human-machine communication (Greussing et al., Citation2022). At the same time, this high degree of control over the answers is also critical for firms that must ensure that the chatbot’s responses are always accurate (Rivas & Zhao, Citation2023). Hence, the lack of control over the conversational flow is not only a challenge for valid and reliable experimental studies but also for firms seeking to implement this kind of technology. This challenge is amplified by recent findings of substantial variability of LLM’s responses over time (L. Chen et al., Citation2023).
Chatbot quality is a potential moderator of the relationships between its social cues and users’ responses. Although the transcripts of our participants’ chat conversations indicate that this chatbot was already quite good, we see the need for future research comparing state-of-the-art chatbots with chatbots based on LLMs.
4.3. Limitations and future research
First, experimental online studies have higher internal but less external validity than field studies. We, therefore, suggest future research to validate our findings in a real-world environment. Compared to our study’s controlled experimental setting that included a fictitious scenario and fake customer credentials, customer stakes and potentially also emotions such as anger and frustration, are higher when interacting with a customer service chatbot about a real order, e.g., when a package has been lost on the way to the customer. Emotions like customer anger might moderate the effect between the predictors and user acceptance. Specifically, social cues might lose their benefits when customers already enter the interaction in an angry state (Crolic et al., Citation2022). In this context, qualitatively analyzing chat transcripts of interactions between customers and chatbots might provide valuable additional insights into how users talk to chatbots, how they immediately react to a chatbot apologizing for an error, and when and why users abort a conversation. Second, we investigated our research question in the customer service context, as chatbots are already commonly used here. However, there might be differences in the impact of free text interaction or social error responses regarding chatbots in domains where social and emotional factors matter more, e.g., chatbots as social companions or mental health advisors. In addition, chatbots in customer service frequently answer relatively simple and predictable questions customers might have before or after purchasing or using products or services. Future research could, therefore, address contexts in which users face more complex problems. Third, all our study participants were based in Germany. Testing our hypotheses using a sample from a different cultural context would further strengthen our results. Finally, we cannot make any statement about causality regarding the mediation analyses. A longitudinal study could provide answers to this question in future research.
5. Conclusion
This study investigated the impact of free text interaction and social error responses in human-chatbot interactions on perceived warmth and competence, satisfaction, intention to use, and emotional connection with the company through an online experiment. Interestingly, we found that chatbots using free text interaction decrease users’ warmth and competence perceptions, satisfaction, intention to use, and emotional connection with the company compared to chatbots with a structured conversation flow. Additionally, chatbots that respond to errors in a social way increase user satisfaction but not the other outcomes. Our findings suggest that designing chatbots to be more human-like is not always optimal for user perceptions of the chatbot and the employing company, particularly when the chatbot is strongly task-focused. In our study, the chatbot’s error-proneness trumped its humanness. Our insights can guide practitioners in designing efficient, accurate, and accessible chatbots.
Open science statement
Study materials, data, and corresponding R code files are available on OSF: https://osf.io/j8hde/
Acknowledgments
We thank an anonymous firm for allowing us to use and adapt their chatbot implementation. We thank Dominik Warlich for his expertise and valuable support in developing the chatbot and Natalie Kraus and Anne Bucher for their assistance in preparing the stimulus materials.
Disclosure statement
The authors report there are no competing interests to declare.
Additional information
Notes on contributors
Stefanie H. Klein
Stefanie H. Klein is a doctoral student in the Everyday Media Lab at Leibniz-Institut für Wissensmedien Tübingen, Germany. Her research focuses on human-machine communication, particularly the impact of chatbots’ conversational characteristics on user acceptance.
Dominik Papies
Dominik Papies is a Professor of Marketing at the School of Business and Economics at the University of Tübingen. His research focuses on econometric modeling of consumer and business behavior.
Sonja Utz
Sonja Utz is a Professor of Communication Via Social Media at the University of Tübingen and the head of the Everyday Media lab at Leibniz-Institut für Wissensmedien in Tübingen. Her research focuses on the effects of social and mobile media use as well as on human-machine interaction.
Notes
1 Bidirectional Encoder Representations from Transformers (BERT) is a language representation model developed by Google. BERT is used to pre-train bidirectional representations from unlabeled text. It can then be fine-tuned to create models for many language understanding tasks, e.g., question-answering and translation (Devlin et al., Citation2019).
References
- Adam, M., Wessel, M., & Benlian, A. (2021). AI-based chatbots in customer service and their effects on user compliance. Electronic Markets, 31(2), 427–445. https://doi.org/10.1007/s12525-020-00414-7
- Araujo, T. (2018). Living up to the chatbot hype: The influence of anthropomorphic design cues and communicative agency framing on conversational agent and company perceptions. Computers in Human Behavior, 85, 183–189. https://doi.org/10.1016/j.chb.2018.03.051
- Ashktorab, Z., Jain, M., Liao, Q. V., & Weisz, J. D. (2019). Resilient chatbots: Repair strategy preferences for conversational breakdowns. In S. Brewster, G. Fitzpatrick, A. Cox & V. Kostakos (Eds.), Proceedings of the 2019 CHI conference on human factors in computing systems (pp. 1–12). Association for Information Systems. https://doi.org/10.1145/3290605.3300484
- Bangor, A., Kortum, P. T., & Miller, J. T. (2008). An empirical evaluation of the system usability scale. International Journal of Human-Computer Interaction, 24(6), 574–594. https://doi.org/10.1080/10447310802205776
- Bartneck, C., Kulić, D., Croft, E., & Zoghbi, S. (2009). Measurement instruments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of Robots. International Journal of Social Robotics, 1(1), 71–81. https://doi.org/10.1007/s12369-008-0001-3
- Beattie, A., Edwards, A. P., & Edwards, C. (2020). A bot and a smile: Interpersonal impressions of chatbots and humans using emoji in computer-mediated communication. Communication Studies, 71(3), 409–427. https://doi.org/10.1080/10510974.2020.1725082
- Benner, D., Elshan, E., Schöbel, S., Janson, A. (2021). What do you mean? A review on recovery strategies to overcome conversational breakdowns of conversational agents. In International Conference on Information Systems 2021 Proceedings. 13. https://aisel.aisnet.org/icis2021/hci_robot/hci_robot/13
- Bing. (2023). The new Bing | Spark creativity. [Video]. YouTube. https://www.youtube.com/watch?v=UHMb5vSP_U8&t=11s
- Blut, M., Wang, C., Wünderlich, N. V., & Brock, C. (2021). Understanding anthropomorphism in service provision: A meta-analysis of physical robots, chatbots, and other AI. Journal of the Academy of Marketing Science, 49(4), 632–658. https://doi.org/10.1007/s11747-020-00762-y
- Borji, A. (2023). A categorical archive of ChatGPT failures. PsyArXiv. https://doi.org/10.48550/arXiv.2302.03494
- Brandtzaeg, P. B., & Følstad, A. (2017). Why people use chatbots. In I. Kompatsiaris, J. Cave, A. Satsiou, G. Carle, A. Passani, E. Kontopoulos, S. Diplaris, D. McMillan (Eds.), Internet science 2017. Lecture notes in computer science (vol. 10673, pp. 377–392). Springer. https://doi.org/10.1007/978-3-319-70284-1_30
- Cameron, D., Saille, S., Collins, E. C., Aitken, J. M., Cheung, H., Chua, A., Loh, E. J., & Law, J. (2021). The effect of social-cognitive recovery strategies on likability, capability and trust in social robots. Computers in Human Behavior, 114, 106561. https://doi.org/10.1016/j.chb.2020.106561
- Chattaraman, V., Kwon, W.-S., Gilbert, J. E., & Ross, K. (2019). Should AI-Based, conversational digital assistants employ social- or task-oriented interaction style? A task-competency and reciprocity perspective for older adults. Computers in Human Behavior, 90, 315–330. https://doi.org/10.1016/j.chb.2018.08.048
- Chen, J., Guo, F., Ren, Z., Li, M., & Ham, J. (2023). Effects of anthropomorphic design cues of chatbots on users’ perception and visual behaviors. International Journal of Human–Computer Interaction. Advance online publication. https://doi.org/10.1080/10447318.2023.2193514
- Chen, L., Zaharia, M., & Zou, J. (2023). How is ChatGPT’s behavior changing over time? arXiv. https://doi.org/10.48550/arXiv.2307.09009
- Cheng, Y., & Jiang, H. (2020). How do AI-driven chatbots impact user experience? Examining gratifications, perceived privacy risk, satisfaction, loyalty, and continued use. Journal of Broadcasting & Electronic Media, 64(4), 592–614. https://doi.org/10.1080/08838151.2020.1834296
- Christodoulides, G., Chernatony, L., Furrer, O., Shiu, E., & Abimbola, T. (2006). Conceptualising and measuring the equity of online brands. Journal of Marketing Management, 22(7-8), 799–825. https://doi.org/10.1362/026725706778612149
- Ciechanowski, L., Przegalinska, A., Magnuski, M., & Gloor, P. (2019). In the shades of the uncanny valley: An experimental study of human–chatbot interaction. Future Generation Computer Systems, 92, 539–548. https://doi.org/10.1016/j.future.2018.01.055
- Clustaar. (2019). 10 best customer support chatbots. Chatbots Life. https://chatbotslife.com/10-best-customer-support-chatbots-5be630b7b081
- Costello, K., LoDolce, M. (2022). Gartner predicts chatbots will become a primary customer service channel within five years: Chatbot investment on the rise but low ROI and other challenges persist. Gartner. https://www.gartner.com/en/newsroom/press-releases/2022-07-27-gartner-predicts-chatbots-will-become-a-primary-customer-service-channel-within-five-years
- Crolic, C., Thomaz, F., Hadi, R., & Stephen, A. T. (2022). Blame the bot: Anthropomorphism and anger in customer–chatbot interactions. Journal of Marketing, 86(1), 132–148. https://doi.org/10.1177/00222429211045687
- De Andrés-Sánchez, J., & Gené-Albesa, J. (2023). Assessing attitude and behavioral intention toward chatbots in an insurance setting: A mixed method approach. International Journal of Human–Computer Interaction, 1(2), 1–16. https://doi.org/10.1080/10447318.2023.2227833
- De Sá Siqueira, M. A., Müller, B. C. N., & Bosse, T. (2023). When do we accept mistakes from chatbots? The impact of human-like communication on user experience in chatbots that make mistakes. International Journal of Human–Computer Interaction. Advance online publication. https://doi.org/10.1080/10447318.2023.2175158
- Desai, R. (2023). Streamlining customer support with ChatGPT chatbots! Medium. https://medium.com/@rutujadesai/streamlining-customer-support-with-chatgpt-chatbots-d26913a1a826
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv. https://doi.org/10.48550/arXiv.1810.04805
- Diederich, S., Brendel, A. B., Lichtenberg, S., Kolbe, L. (2019). Design for fast request fulfillment or natural interaction? Insights from an experiment with a conversational agent. In Proceedings of the 27th European Conference on Information Systems 2019. https://aisel.aisnet.org/ecis2019_rp/20
- Epley, N., Waytz, A., & Cacioppo, J. T. (2007). On seeing human: A three-factor theory of anthropomorphism. Psychological Review, 114(4), 864–886. https://doi.org/10.1037/0033-295X.114.4.864
- Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/bf03193146
- Feine, J., Gnewuch, U., Morana, S., & Maedche, A. (2019). A taxonomy of social cues for conversational agents. International Journal of Human-Computer Studies, 132, 138–161. https://doi.org/10.1016/j.ijhcs.2019.07.009
- Fiore, S. M., Wiltshire, T. J., Lobato, E. J. C., Jentsch, F. G., Huang, W. H., & Axelrod, B. (2013). Toward understanding social cues and signals in human-robot interaction: Effects of robot gaze and proxemic behavior. Frontiers in Psychology, 4(859), 859. https://doi.org/10.3389/fpsyg.2013.00859
- Fiske, S. T. (2018). Stereotype content: Warmth and competence endure. Current Directions in Psychological Science, 27(2), 67–73. https://doi.org/10.1177/0963721417738825
- Fiske, S. T., Cuddy, A. J. C., & Glick, P. (2007). Universal dimensions of social cognition: Warmth and competence. Trends in Cognitive Sciences, 11(2), 77–83. https://doi.org/10.1016/j.tics.2006.11.005
- Floridi, L., & Chiriatti, M. (2020). GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 30(4), 681–694. https://doi.org/10.1007/s11023-020-09548-1
- Fogg, B. J. (Ed.). (2003). Persuasive technology: Using computers to change what we think and do. Morgan Kaufmann. https://doi.org/10.1145/764008.763957
- Følstad, A., & Taylor, C. (2020). Conversational repair in chatbots for customer service: The Effect of expressing uncertainty and suggesting alternatives. In A. Følstad, T. Araujo, S. Papadopoulos, E. L.-C. Law, O.-C. Granmo, E. Luger, & P. B. Brandtzaeg (Eds.), Chatbot research and design. CONVERSATIONS 2019. Lecture notes in computer science (vol. 11970, pp. 201–214). Springer. https://doi.org/10.1007/978-3-030-39540-7_14
- Følstad, A., Skjuve, M., & Brandtzaeg, P. B. (2019). Different chatbots for different purposes: Towards a typology of chatbots to understand interaction design. In S. S. Bodrunova, O. Koltsova, A. Følstad, H. Halpin, P. Kolozaridi & H. Niedermayer (Eds.), Internet science 2019. Lecture notes in computer science (vol. 11551, pp. 145–156). https://doi.org/10.1007/978-3-030-17705-8_13
- Gambino, A., Fox, J., & Ratan, R. (2020). Building a stronger CASA: Extending the computers are social actors paradigm. Human-Machine Communication, 1(1), 71–86. https://doi.org/10.30658/hmc.1.5
- Gnewuch, U., Morana, S., Adam, M. T. P., Maedche, A. (2018). Faster is not always better: Understanding the effect of dynamic response delays in human-chatbot interaction. In Proceedings of the 26th European Conference on Information Systems 2018. 113. https://aisel.aisnet.org/ecis2018_rp/113
- Go, E., & Sundar, S. S. (2019). Humanizing chatbots: The effects of visual, identity and conversational cues on humanness perceptions. Computers in Human Behavior, 97, 304–316. https://doi.org/10.1016/j.chb.2019.01.020
- Gopinath, K., & Kasilingam, D. (2023). Antecedents of intention to use chatbots in service encounters: A meta-analytic review. International Journal of Consumer Studies, 47(6), 2367–2395. https://doi.org/10.1111/ijcs.12933
- Greussing, E., Gaiser, F., Klein, S. H., Straßmann, C., Ischen, C., Eimler, S., Frehmann, K., Gieselmann, M., Knorr, C., Lermann Henestrosa, A., Räder, A., & Utz, S. (2022). Researching interactions between humans and machines: Methodological challenges. Publizistik, 67(4), 531–554. https://doi.org/10.1007/s11616-022-00759-3
- Groom, V., Chen, J., Johnson, T., Kara, F. A., & Nass, C. (2010). Critic, compatriot, or chump?: Responses to robot blame attribution [Paper presentation].2010 5th ACM/IEEE International Conference on Human-Robot Interaction, In (pp. 211–217). Institute of Electrical and Electronics Engineers. https://doi.org/10.1109/HRI.2010.5453192
- Guzman, A. L. (2018). What is human-machine communication, anyway? In A. L. Guzman (Ed.), Human-machine communication: Rethinking communication, technology and ourselves (pp. 1–28). Peter Lang.
- Haque, M. U., Dharmadasa, I., Sworna, Z. T., Rajapakse, R. N., & Ahmad, H. (2022). “I think this is the most disruptive technology”: Exploring sentiments of ChatGPT early adopters using twitter data. (arXiv:2212.05856). arXiv. https://doi.org/10.48550/arXiv.2212.05856
- Haugeland, I. K. F., Følstad, A., Taylor, C., & Bjørkli, C. A. (2022). Understanding the user experience of customer service chatbots: An experimental study of chatbot interaction design. International Journal of Human-Computer Studies, 161, 102788. https://doi.org/10.1016/j.ijhcs.2022.102788
- Holmes, S., Moorhead, A., Bond, R., Zheng, H., Coates, V., & Mctear, M. (2019). Usability testing of a healthcare chatbot: Can we use conventional methods to assess conversational user interfaces? [Paper presentation]. In ECCE ’19: Proceedings of the 31st European Conference on Cognitive Ergonomics, M. Mulvenna & R. Bond (Eds.), (pp. 207–214). Association for Computing Machinery. https://doi.org/10.1145/3335082.3335094
- Huang, M.-H., & Rust, R. T. (2021). Engaged to a robot? The role of AI in service. Journal of Service Research, 24(1), 30–41. https://doi.org/10.1177/1094670520902266
- ISO. (2018). Ergonomics of human-system interaction—Part 11: Usability: Definitions and concepts. https://www.iso.org/obp/ui/#iso:std:iso:9241:-11:ed-2:v1:en
- Jaimes, A., & Sebe, N. (2007). Multimodal human–computer interaction: A survey. Computer Vision and Image Understanding, 108(1-2), 116–134. https://doi.org/10.1016/j.cviu.2006.10.019
- Jain, M., Kumar, P., Kota, R., & Patel, S. N. (2018). Evaluating and informing the design of chatbots [Paper presentation]. DIS ’18: Proceedings of the 2018 Designing Interactive Systems Conference., In I. Koskinen & Y.-K. Lim (Eds.), Association for Computing Machinery. https://doi.org/10.1145/3196709.3196735
- Kamoen, N., McCartan, T., & Liebrecht, C. (2022). Conversational agent voting advice applications: A comparison between a structured, semi-structured, and non-structured chatbot design for communicating with voters about political issues. In A. Følstad, T. Araujo, S. Papadopoulos, E. L.-C. Law, E. Luger, M. Goodwin, & P. B. Brandtzaeg (Eds.), Chatbot research and design. CONVERSATIONS 2021. Lecture notes in computer science (vol. 13171, pp. 160–175). Springer. https://doi.org/10.1007/978-3-030-94890-0_10
- Klopfenstein, L. C., Delpriori, S., Malatini, S., & Bogliolo, A. (2017). The rise of bots: A survey of conversational interfaces, patterns, and paradigms [Paper presentation]. Proceedings of the 2017 Conference on Designing Interactive Systems, In O. Mival, M. Smyth, & PDalsgaard (Eds.), (pp. 555–565). Association for Computing Machinery. https://doi.org/10.1145/3064663.3064672
- Lee, B.-K., Lee, E. H., & Lee, T. (2023). The effect of E-Government website evaluation on user satisfaction and intention to use: The mediating role of warmth and competence judgment on government. Information, Communication & Society, 26(9), 1868–1889. https://doi.org/10.1080/1369118X.2022.2041701
- Lee, M. K., Kiesler, S., Forlizzi, J., Srinivasa, S., & Rybski, P. (2010). Gracefully mitigating breakdowns in robotic services [Paper presentation].2010 5th ACM/IEEE International Conference on Human-Robot Interaction, In (pp. 203–210). Institute of Electrical and Electronics Engineers. https://doi.org/10.1109/HRI.2010.5453195
- Lee, S., Lee, N., & Sah, Y. J. (2020). Perceiving a mind in a chatbot: Effect of mind perception and social cues on co-presence, closeness, and intention to use. International Journal of Human–Computer Interaction, 36(10), 930–940. https://doi.org/10.1080/10447318.2019.1699748
- Lombard, M., & Xu, K. (2021). Social responses to media technologies in the 21st century: The Media are Social Actors Paradigm. Human-Machine Communication, 2(1), 29–55. https://doi.org/10.30658/hmc.2.2
- Mai, V., Neef, C., & Richert, A. (2022). “Clicking vs. writing”—The impact of a chatbot’s interaction method on the working alliance in AI-based coaching. Coaching | Theorie & Praxis, 8(1), 15–31. https://doi.org/10.1365/s40896-021-00063-3
- McKnight, D. H., Choudhury, V., & Kacmar, C. (2002). Developing and validating tust measures for e-commerce: An integrative typology. Information Systems Research, 13(3), 334–359. https://doi.org/10.1287/isre.13.3.334.81
- Narducci, F., Basile, P., de Gemmis, M., Lops, P., & Semeraro, G. (2020). An investigation on the user interaction modes of conversational recommender systems for the music domain. User Modeling and User-Adapted Interaction, 30(2), 251–284. https://doi.org/10.1007/s11257-019-09250-7
- Nass, C., & Moon, Y. (2000). Machines and mindlessness: Social responses to computers. Journal of Social Issues, 56(1), 81–103. https://doi.org/10.1111/0022-4537.00153
- Nass, C., Steuer, J., & Tauber, E. R. (1994). Computers are social actors [Paper presentation]. CHI ’94: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, In B. Adelson, S. Dumais & JOlson (Eds.), (pp. 72–78). Association for Computing Machinery. https://doi.org/10.1145/191666.191703
- OpenAI. (2023). Documentation. https://platform.openai.com/docs/introduction
- Reeves, B., & Nass, C. (1996). The media equation: How people treat computers, television, and new media like real people and places. CSLI Publications.
- Rivas, P., & Zhao, L. (2023). Marketing with ChatGPT: Navigating the ethical terrain of GPT-based chatbot technology. AI, 4(2), 375–384. https://doi.org/10.3390/ai4020019
- Robinette, P., Howard, A. M., & Wagner, A. R. (2015). Timing is key for robot trust repair. In A. Tapus, E. André, J.-C. Martin, F. Ferland, & M. Ammi (Eds.), 7th international conference on social robotics proceedings (vol. 9388, pp. 574–583). Springer. https://doi.org/10.1007/978-3-319-25554-5_57
- Schrepp, M., Hinderks, A., & Thomaschewski, J. (2017). Design and evaluation of a short version of the user experience questionnaire (UEQ-S). International Journal of Interactive Multimedia and Artificial Intelligence, 4(6), 103. https://doi.org/10.9781/ijimai.2017.09.001
- Seeger, A.-M., & Heinzl, A. (2021). Chatbots often fail! Can anthropomorphic design mitigate trust loss in conversational agents for customer service? [Paper presentation]. European Conference on Information Systems 2021 Proceedings, 12. https://aisel.aisnet.org/ecis2021_rp/12
- Seeger, A.-M., Pfeiffer, J., & Heinzl, A, University of Mannheim, Germany. (2021). Texting with human-like conversational agents: Designing for anthropomorphism. Journal of the Association for Information Systems, 22(4), 931–967. https://doi.org/10.17705/1jais.00685
- Shawar, B. A., & Atwell, E. (2007). Chatbots: Are they really useful? Journal for Language Technology and Computational Linguistics, 22(1), 29–49. https://doi.org/10.21248/jlcl.22.2007.88
- Sheehan, B., Jin, H. S., & Gottlieb, U. (2020). Customer service chatbots: Anthropomorphism and adoption. Journal of Business Research, 115, 14–24. https://doi.org/10.1016/j.jbusres.2020.04.030
- Sundar, S. S., & Liao, M. (2023). Calling BS on ChatGPT: Reflections on AI as a communication source. Journalism & Communication Monographs, 25(2), 165–180. https://doi.org/10.1177/15226379231167135
- Tingley, D., Yamamoto, K., Keele, L., Imai, K., Trinh, M., Wong, W. (2019). Package ‘mediation’: Causal Mediation Analysis. https://imai.princeton.edu/projects/mechanisms.html
- Toader, D.-C., Boca, G., Toader, R., Măcelaru, M., Toader, C., Ighian, D., & Rădulescu, A. T. (2019). The effect of social presence and chatbot errors on trust. Sustainability, 12(1), 256. https://doi.org/10.3390/su12010256
- Valério, F. A. M., Guimarães, T. G., Prates, R. O., & Candello, H. (2020). Comparing users’ perception of different chatbot interaction paradigms [Paper presentation]. Proceedings of the 19th Brazilian Symposium on Human Factors in Computing Systems, In C. Q. Santos & M. L. Bento Villela (Eds.), (pp. 1–10). Association for Computing Machinery. https://doi.org/10.1145/3424953.3426501
- Van der Meulen, R. (2023). Gartner identifies six ChatGPT risks legal and compliance leaders must evaluate. Gartner. https://www.gartner.com/en/newsroom/press-releases/2023-05-18-gartner-identifies-six-chatgpt-risks-legal-and-compliance-must-evaluate
- Van Pinxteren, M., Pluymaekers, M., Lemmink, J., & Krispin, A. (2023). Effects of communication style on relational outcomes in interactions between customers and embodied conversational agents. Psychology & Marketing, 40(5), 938–953. https://doi.org/10.1002/mar.21792
- Verma, V., Sharma, D., & Sheth, J. (2016). Does relationship marketing matter in online retailing? A meta-analytic approach. Journal of the Academy of Marketing Science, 44(2), 206–217. https://doi.org/10.1007/s11747-015-0429-6
- Vial, G., Cameron, A.-F., Giannelia, T., & Jiang, J. (2023). Managing artificial intelligence projects: Key insights from an AI consulting firm. Information Systems Journal, 33(3), 669–691. https://doi.org/10.1111/isj.12420
- Weiss, A., & Bartneck, C. (2015). Meta analysis of the usage of the Godspeed Questionnaire Series [Paper presentation]. 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), 381–388. https://doi.org/10.1109/ROMAN.2015.7333568
- Wojciszke, B., Abele, A. E., & Baryla, W. (2009). Two dimensions of interpersonal attitudes: Liking depends on communion, respect depends on agency. European Journal of Social Psychology, 39(6), 973–990. https://doi.org/10.1002/ejsp.595
- Zheng, T., Duan, X., Zhang, K., Yang, X., & Jiang, Y. (2023). How chatbots’ anthropomorphism affects user satisfaction: The mediating role of perceived warmth and competence. In Y. Tu & M. Chi (Eds.), E-business. Digital empowerment for an intelligent future (pp. 96–107). Springer. https://doi.org/10.1007/978-3-031-32302-7_9
- Zierau, N., Elshan, E., Visini, C., Janson, A. (2020). A review of the empirical literature on conversational agents and future research directions. International Conference on Information Systems 2020 Proceedings. 5. https://aisel.aisnet.org/icis2020/hci_artintel/hci_artintel/5
Appendix A.
Exemplary Translated Conversational Flows in Button and Free Text Chatbot Conditions
Figure A. Exemplary translated conversational flows in button and free text chatbot conditions.
Note. Figures A and B show exemplary conversations with the button and the free text chatbot, respectively. Chatbot responses are shown in light grey, and user responses in dark grey.

Appendix B.
Mediation results
Figure B1. Mediation results of error response on satisfaction, intention to use, and emotional connection with the company via perceived warmth.
Note. Error response: 0 = neutral and 1 = social. N = 416.
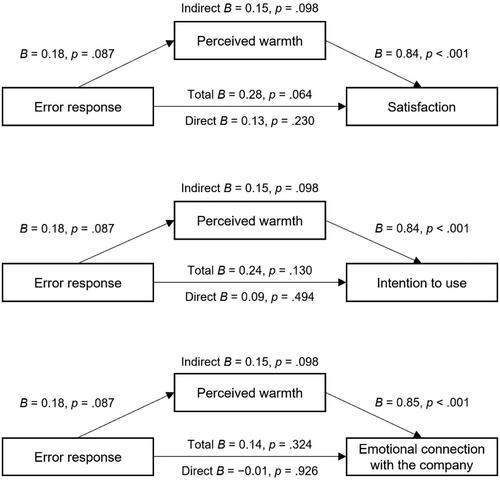
Figure B2. Mediation results of error response on satisfaction, intention to use, and emotional connection with the company via perceived competence.
Note. Error response: 0 = neutral and 1 = social. N = 416.