
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Given the widespread use of word processing systems today, error correction and text editing tasks are frequently performed. A novel method for error correction and text editing using voice&mouse was developed and evaluated. A within-participants counterbalanced study design was used to compare users’ performance and satisfaction with the proposed method to their performance and satisfaction with two other methods that enable natural interaction with Microsoft Word, voice-only and voice&gaze, and with conventional interaction using the keyboard&mouse method, when performing error correction and text editing tasks. Our comprehensive evaluation showed that for all of the examined tasks the proposed voice&mouse method performed comparably to the voice-only and voice&gaze methods or significantly outperformed them on all evaluation measures. The keyboard&mouse method yielded significantly higher average SUS scores and lower NASA-TLX task loads than the other methods. However, participants significantly preferred using the voice&mouse method, in general, and especially for tasks that typically require typing in addition to using a mouse, such as fix, replace, and add, and the performance times for the two methods were comparable when performing these tasks. The findings support the use of the voice&mouse method for error correction and text editing along with the keyboard&mouse method. This would allow users to choose their preferred interaction method for each scenario and task while improving their performance and satisfaction.
1. Introduction
Error correction is an integral part of the text entry process, especially when using speech recognition systems. Speech recognition systems, which aim at increasing the speed of input compared to typing on a keyboard (Sindhwani et al., Citation2019) have become popular (Hamaker, Citation2012; Sengupta et al., Citation2020). However, when using such systems, especially when talking quickly, or, alternatively, when typing at high speed using the keyboard, the number of typos that need to be corrected increases (Chu & Povey, Citation2010; Hamaker, Citation2012; Siegler & Stern, Citation1995). In these situations, validation of the entered text is necessary, as recognition and typing errors are inevitable. Although many word processors include spelling and grammar checkers, as well as automatic spelling correction features, many users turn off auto-correct features because they perceive miscorrections as overly annoying (Alharbi et al., Citation2019). Thus, error correction remains a major issue to be dealt with by the user (Madison, Citation2012; Wang & Soong, Citation2009) and involves the tasks of identifying errors, navigating to the errors, and applying corrective measures (Sengupta et al., Citation2020).
There are two classes of spelling errors: non-word errors and real-word errors. In contrast to non-word errors, which are misspelled words, real-word errors occur when the user enters a correctly spelled word by mistake when something else is implied. Peterson (Citation1986) pointed out the limitations of spell checkers, which efficiently address non-word errors but struggle to detect and correct context-sensitive errors. Mitton (Citation1996) found that real-word errors account for about a quarter to a third of all spelling errors. Finding real-word errors is a tricky task for spell checkers, as context needs to be taken into account. In another study, undetected errors accounted for about 20% of all errors and most were real-word errors (Pedler, Citation2007). In cases in which the spell checker detects a non-word error, it flags the word as an error by underlining it in red, determines the closest/most suitable correct words, sorts them from the most likely correction to the least, and recommends a list of alternatives to the user. In popular text editors, this can be done by right-clicking the mouse or touchpad to reveal the list of options and then pointing and left-clicking the mouse to select the appropriate option. It was previously found that the mouse works better than the touchpad in the task of correcting errors (Shanis & Hedge, Citation2003).
Human-computer interaction is enhanced by using interfaces with two or more input channels, known as multimodal user interfaces (Becker et al., Citation2006; Bolt, Citation1980; Bullinger et al., Citation2002; Ruiz et al., Citation2009), which employ various techniques like voice, gaze, gesture, or body motions to enable a more implicit and natural way of interacting with a system (Jacob et al., Citation1993; Nielsen, Citation1993). A direct- and indirect-writing handwriting interface for text editing was also proposed (Gu & Lee, Citation2023). Using innate means of communication such as voice and gaze as input channels can provide users with a more natural form of interaction (Kettebekov & Sharma, Citation2000; Maglio et al., Citation2000; Oviatt & Cohen, Citation2000; Ruiz et al., Citation2009). Such interfaces also avoid problematic repetitive hand switches between the keyboard and mouse, which are time-consuming, cause discomfort and fatigue (Woods et al., Citation2002), and may also lead to cumulative trauma disorders (CTDs) (Amell & Kumar, Citation2000). In addition, natural multimodal interfaces enable people with disabilities to work with text more easily (Trewin & Pain, Citation1999; Valles et al., Citation1996).
Using voice commands for text editing eliminates the need to memorize keyboard shortcuts for editing or search for the location of buttons on the toolbar and enables implementation of these commands using the user’s voice. The main challenge in using a voice input channel is indicating the word to be edited (Basri et al., Citation2012; Yeh et al., Citation2015). Two main approaches were suggested to overcome the challenge of providing spatial information: target-based and direction-based navigation. In direction-based navigation, users specify the direction and distance the cursor should move, such as “move up four lines,” or “move right three words” (Feng & Sears, Citation2007). In target-based navigation, the user specifies the destination using a word that exists in the document. For example, “Select Friday” would highlight the word Friday (Sears et al., Citation2003). If the target appears on the screen multiple times, additional commands may be required. Sengupta et al. (Citation2020) used target-based navigation similar to “Handsfree for web – voice control” (Google, n.d.) for voice-only error correction, using the command “Map” to assign a unique number to each erroneous word in a passage.
The user’s gaze has also been considered (Bullinger et al., Citation2002) as a way of positioning the cursor to navigate the text and indicating the word that the user wants to correct. To address the problem of frequent switches between the keyboard and mouse which can slow down the editing workflow considerably, ReType (Sindhwani et al., Citation2019), a gaze-assisted positioning technique combining the use of the keyboard with gaze input based on a “patching” metaphor, was proposed. ReType allows users to perform some common editing operations while keeping their hands on the keyboard. A comparative user study showed that ReType was able to match or even exceed the speed of mouse-based interaction for small text edits. The authors concluded that their gaze-augmented user interface can make common interactions more fluent, especially for professional keyboard users. In Sengupta et al. (Citation2020), gaze was combined with voice (Talk-and-Gaze: TaG) to overcome the difficulty of voice-only systems to provide spatial information. The user’s point of gaze was used to select an erroneous word either by dwelling on the word for 800 ms (D-TaG) or by using a “select” voice command (V-TaG). Once the erroneous word is selected, the system offers a list of predictions from which the user has to make a selection by uttering the number associated with the correct prediction. In cases in which no prediction fits, the system offers an additional mode of correction, the “spell” mode, where the participant performs letter-level correction for incorrect transcriptions caused by homophones, diction, or ambient noise. A user study compared D-TaG, V-TaG, and a voice-only method for selecting and correcting words, but a comparison to the conventional interaction of keyboard&mouse was not performed. Objective measures and subjective feedback for a read and correct task showed that D-TaG performed better than a voice-only approach and V-TaG.
Jacob (Citation1995) described a phenomenon termed “the Midas Touch” which is a problem involving eye movements, which are often unintentional or unconscious, so they must be interpreted carefully to avoid unwanted activations or responses to user actions. To overcome the difficulty of voice-only systems to provide spatial information and the challenge of unintended gaze-based activation resulting from the Midas Touch problem (Velichkovsky et al., Citation1997), in this paper, we propose a method of error correction and text editing using mouse and voice: FixOver. The little research investigating the combined use of voice and mouse for error correction and text editing was performed decades ago (Danis et al., Citation1994; Larson & Mowatt, Citation2003; McNair & Waibel, Citation1994). A prior study demonstrated (McNair & Waibel, Citation1994) that highlighting an errorful subsection of the voice recognition input using a mouse results in higher success rates for repair methods and greater improvement in sentence accuracy than using a voice-only auto-locate method requiring the user to respeak the erroneous part of the primary utterance.
In contrast to studies in which the erroneous word is selected by highlighting it with the mouse and then redictating it, or by inferring the selection by measuring the elapsed pointing time (Danis et al., Citation1994), in our voice&mouse system word selection is done by a combination of mouse pointing and a voice command. Our system is accessible to older adults and users with motor impairments due to the fact that there is no need to click, but rather only to point, so that while uttering a command, the system searches for the erroneous word around the cursor position, and not at the exact mouse position, (e.g., Findlater et al., Citation2010; Hwang et al., Citation2003; Trewin et al., Citation2006; Wobbrock et al., Citation2009; Wobbrock & Gajos, Citation2008; Worden et al., Citation1997). It has previously been shown (Trewin et al., Citation2006) that these populations have difficulty positioning the cursor over small targets and keeping the cursor over the target when clicking the mouse (slipping while clicking). Furthermore, in order to minimize the number of interaction steps needed for error correction or text editing and reduce the effort required and number of recognition errors, in our voice&mouse method, selection and correction/editing are performed in the same step. This eliminates the need to select the correct prediction from a list of numbered predictions, as is done in other systems (e.g., the TaG-method proposed by Sengupta et al., Citation2020). In our method, the user points the cursor at the text segment designated for correction or editing and utters the required command. For example, to correct a word that is a non-word error, the user simply points the cursor at the word they want to correct and says: "fix." The erroneous word is immediately auto-corrected to the first option provided by Microsoft (MS) Word’s spell checker for the word. It has previously been shown (e.g., Flor & Futagi, Citation2012) that the top-ranked suggestion of the MS Word spell checker is adequate in the vast majority of the cases recognized by the spell checker.
To evaluate our proposed voice&mouse method we developed three interaction systems with different interface modalities to enable natural interaction with MS Word for the purpose of error correction and text editing: FixOver - implementing our voice&mouse method, VoiceIT - using voice-only, and Teyepo - using voice&gaze. A within-participants counterbalanced study design was used to compare users’ performance and satisfaction when using the three interaction methods and conventional interaction with a keyboard and mouse for error correction (fix, fix + options, replace) and text editing (copy, paste, add, delete). The methods were evaluated both in terms of the performance measures of task performance time and task effort, as well as the subjective measures of task load (NASA-TLX), usability (SUS score), and preference. To the best of our knowledge, this is the first study evaluating the voice&mouse method for error correction and text editing not only compared to using voice-only, but also to voice&gaze and to the traditional keyboard&mouse interaction method. In addition, we examined a wide variety of editing tasks that were not evaluated in previous studies.
The context of use explored in our research is one in which someone types a manuscript using a word processor (so non-word errors and real-word errors are possible) and edits it, using one of our correction methods. When documents are produced using speech dictation, the language model cannot produce non-word errors. FixOver is integrated into MS Word, which allows speech dictation input in addition to keyboard typing. Therefore, in contrast to systems using speech recognition for text entry and voice&mouse for error correction (Larson & Mowatt, Citation2003; McNair & Waibel, Citation1994), which handle only real-word errors, the proposed FixOver system is also suitable for non-word errors.
We address the following research questions:
RQ1: How can a mouse be naturally combined with voice for error correction and text editing?
RQ2: How do the voice-only, voice&gaze and voice&mouse editing methods compare to one another and the conventional keyboard&mouse editing method?
2. Related work
2.1. Error correction
Text entry users spend an inordinate amount of time on error correction. Previous research (Commarford & Lewis, Citation2004; Karat et al., Citation1999; Larson & Mowatt, Citation2003; Lewis, Citation1999; Sears et al., Citation2001) demonstrated that in many cases users spend much more time correcting errors than they spend dictating new text. For example, Sears et al. (Citation2001) reported that users spend 66% of their time on correction activities and only 33% on actual dictation when using voice text entry systems. Azenkot and Lee (Citation2013) found that participants spent an average of 80.3% of their time editing and while they were mostly satisfied with speech input, they viewed editing recognition errors as frustrating.
To improve error correction efficiency, word processors provide spell checker tools (Rello et al., Citation2015; Singh & Singh, Citation2018). When detecting a misspelling, a spell checker will generally underline it and offer a short, ordered list of suggested corrections, with the best option presented at the top (Mitton, Citation2009). Agirre et al. (Citation1998) proposed guessers, which provide correction suggestions, that produced a single recommendation 98% of the time and demonstrated 80% precision for all non-word errors in the text. Research on various spell checkers reported that in over 90% of cases, the appropriate option is among the first three suggestions (Kukich, Citation1992). A study by Flor and Futagi (Citation2012) showed that when using only the first top-ranked suggestion, the MS Word spell checker provided adequate correction in about 73% of the cases recognized by the spell checker, while its precision was only about 67–69% due to a large number of false alarms. It placed the target correction among the top two and three candidates in more than 80% of cases. These results improved on those of Mitton (Citation2009) who found that the adequate target correction was the spell checker’s first suggestion in just 44% of the cases.
The use of a keyboard and mouse, and more specifically, pointing and clicking with the mouse and switching back and forth between the two, is potentially challenging for older users and/or users with motor skill difficulties, such as users with arthritis, partial paralysis, or neurological disorders. Particularly when the text is small, pointing and clicking on given targets can increase inaccuracy (Brownlow et al., Citation1989; Czaja, Citation1997; Czaja & Lee, Citation2002; Riviere & Thakor, Citation1996; Trewin & Pain, Citation1999), and extensive use of a keyboard and mouse can lead to repetitive stress injuries (RSIs), e.g., carpal tunnel syndrome. As a result, alternative methods for facilitating text entry, error correction, and text editing were suggested; using innate means of communication such as voice and gaze as input channels can provide users with a more natural interaction (Kettebekov & Sharma, Citation2000; Maglio et al., Citation2000; Oviatt & Cohen, Citation2000; Ruiz et al., Citation2009). Danis et al. (Citation1994) developed a speech editor to assist newspaper reporters suffering from RSIs. Beelders and Blignaut (Citation2010) developed a multimodal interface for MS Word that integrates eye tracking and speech recognition as interaction techniques for users with disabilities and mainstream users.
A variety of unimodal and multimodal approaches involving voice, gaze, and the use of a keyboard and mouse have been proposed for error correction and text editing, many of which are described in the subsections below.
2.2. Unimodal approaches for error correction and text editing
2.2.1. Gaze-only
The gaze position implicitly indicates the area of the user’s attention, and using it as a method of interaction frees the hands for other tasks (Sibert & Jacob, Citation2000). The authors compared gaze and mouse interaction methods for the task of selecting a letter from a grid of letters and found that it was significantly faster to select a letter using the gaze method.
The eye gaze modality for interaction was integrated in Word 2007 by Beelders and Blignaut (Citation2010). The user has the option to activate eye gaze, which can then be used to position the cursor in the document or over an object to be manipulated; dwell time or blinking can also be used to fixate on a position and simulate a left mouse click. Magnification of the interface was provided to improve accuracy, and multiple onscreen keyboards were offered to enable hands-free typing capabilities. However, it was shown that users may find the on-screen keyboard cumbersome (Azenkot & Lee, Citation2013).
Several studies focused on facilitating the use of the eye-gaze methodology for text entry, error correction, and text editing (Kishi & Hayashi, Citation2015; Majaranta et al., Citation2009; Portela & Rozado, Citation2014; Vertanen & MacKay, Citation2010). Kishi and Hayashi (Citation2015) introduced a system for effective gaze writing in which a gaze interface was created for copying text and pasting it to the desired position. Majaranta et al. (Citation2009) facilitated the use of gaze for text editing with a dynamic pie-like menu that appears in the area focused on by the user. In other systems, voice was used for text entry, while error correction or editing was performed using gaze. For example, using Speech Dasher (Vertanen & MacKay, Citation2010), after each spoken phrase/sentence, an editing process is required. The most probable hypotheses for words or letters are presented in visual boxes that must be selected using gaze.
2.2.2. Voice-only
Many applications have successfully incorporated speech recognition, aiming at increasing the speed of text entry and providing hands-free interaction (Ruan et al., Citation2018). The design and implementation of speech user interfaces remain challenging tasks. Misrecognition problems affect both text entry and the use of voice commands to navigate the text and correct errors. The main difficulty is navigating to the word being edited (the challenge of providing spatial information). Another challenge is enabling voice interaction with a specific device in settings with multiple smart voice devices (e.g., in smart homes, classrooms, and offices); Bu and Guo (Citation2023) incorporated voice orientation recognition technology into the speech-based human-computer interaction scenario to facilitate voice interaction with a specific device and reducing unintended responses from other devices.
Methods that use voice commands to navigate to a desired word within a document have been proposed to overcome the challenge of providing spatial information. These methods can be categorized as direction-based, target-based, and continuous. Mihara et al. (Citation2005) presented the migratory cursor, which is a speech-based, interactive interface based on a continuous speech-based cursor movement. The migratory cursor displays multiple ghost cursors that are aligned vertically or horizontally with the actual cursor. The user quickly specifies an approximate position by referring to the ghost cursor nearest the desired position and then uses non-verbal vocalizations to move the ghost cursor continuously until it reaches the desired position. De Mauro et al. (Citation1999) proposed an approach in which the current cursor motion is maintained until a new command is produced. In both of these methods, the user must wait until the cursor reaches the desired position.
Sears et al. (Citation2003) compared the efficiency of target- and direction-based navigation for error correction using voice commands. Target-based navigation allowed users to quickly move to the desired location, often with only a single command “correct word”. If the desired word appears multiple times in the text, additional commands may be required. Yet, a misrecognition of the target word may cause the cursor moved to the wrong location. Their direction-based navigation command consisting of direction, distance, and movement units (e.g., move left three characters) also faced challenges mainly stemming from the incorrect recognition and pronunciation of invalid commands by the user. This methodology was also found to slow the navigation process and requires the user to recall multiple commands.
As part of the StoryWriter project, Danis et al. (Citation1994) recommended six methods for text editing, including an all-speech procedure incorporating both target- and direction-based navigation (e.g., “cursor-up five,” “move-right three,” “delete word”). Substantial research was directed at solving the problem of speech recognition errors, by employing the target-based approach in which the incorrect word is replaced by respeaking it (Larson & Mowatt, Citation2003; Portela & Rozado, Citation2014; Suhm et al., Citation2001). Suhm et al. (Citation2001) demonstrated that despite the fact that respeaking allows the user to correct more than one word at a time, the unimodal method was inefficient compared to multimodal strategies. Larson and Mowatt (Citation2003) showed that a method in which the user selects the misrecognized word with a speech command and then redictates the word to correct it took significantly longer and received poorer satisfaction scores than multimodal correction strategies. Additionally, users have experienced difficulty learning the available commands. If there are multiple instances of a word in a document, the speech recognition program might have selected a different instance than the one intended. Portela and Rozado (Citation2014) used a similar approach of respeaking for the selection of the erroneous word, while to correct it, the user had to select the alternate word by uttering its number from a list of alternatives. None of the above methods using respeaking to correct speech recognition errors allow the user to correct non-word errors in the text.
In the voice-only modality implemented by Beelders and Blignaut (Citation2010), a command mode provides the functions of cursor control, formatting capabilities, and certain document handling capabilities. Verbal commands can be issued in sequence to perform relatively complex document manipulation. The voice-only method proposed by Sengupta et al. (Citation2020) allows the user to correct errors recognized by the spell checker. The command “map” assigns a unique number to each erroneous word. The user then utters the number to select a word. This eliminates the need to recall commands and allows the user to directly select an incorrect word. It also adresses the challenge when a word occurs twice or more in a sentence. The system then offers a numbered list of predictions along with three additional editing options: delete, spell, and case change. However, the authors did not discuss the scenario in which the system does not recognize a word that the user wants to correct as an error, such as a real-word error (Rello et al., Citation2015; Singh & Singh, Citation2018).
Text editing becomes even more challenging when the ability to view the text is limited, e.g., while walking or driving. Ghosh et al. (Citation2020b) designed a voice-based interface and implemented and evaluated two eyes-free techniques: commanding and redictation. They found that while redictation was more efficient and easier to use than commanding for tasks that require more complex editing operations, commanding performed similarly to redictation for single operations and worked better for deletions; improved usability was demonstrated when the techniques were used in combination with one another.
2.3. Multimodal approaches for error correction and text editing
Research has demonstrated that multimodal error correction methods in which two or more input channels are applied are much more effective than unimodal methods (Larson & Mowatt, Citation2003; Lewis, Citation1999; Suhm et al., Citation2001). To overcome the limitations of voice input, the integration of multimodal interfaces was explored and found to improve performance; for example, Oviatt (Citation1997) and Oviatt et al. (Citation2000) combined voice with pen-based gestures, and voice was combined with gaze for the following tasks: menu selection (Mantravadi, Citation2009), hands-free use of a Web browser (Sengupta et al., Citation2018), interaction with a real desktop environment (Castellina et al., Citation2008), and error correction and text editing for mobile devices (Zhao et al., Citation2021, Citation2022).
Sindhwani et al. (Citation2019) developed the ReType method to perform error correction and some editing operations, using the keyboard and the user’s gaze, while keeping hands on the keyboard. The gaze was only activated if (1) the user looked away from the cursor, and (2) typed a string that is an approximate match with text at (or near) the gaze position. The authors found that ReType could match or beat the speed of mouse-based interaction for small text edits, and their analysis showed that many participants, regardless of their typing skills, liked the method. Ghosh et al. (Citation2020a) proposed a method that combines voice input with a hand-controller for on-the-go text editing. The results showed that the proposed method outperformed smartphones as the path or task became more difficult, however the performance gain narrowed when both the path and the task demanded high visual attention.
2.3.1. Voice&gaze
Aiming at giving users access to more intuitive interaction techniques, Beelders and Blignaut (Citation2010) added the additional modalities of eye gaze and speech recognition in Word 2007 as interaction techniques. The added techniques are fully customizable and can be used in isolation or in combination. Magnification of the interface was also provided to improve accuracy and multiple onscreen keyboards are provided to provide hands-free typing capabilities. Portela and Rozado (Citation2014) proposed employing the user’s gaze to point at words that were misrecognized by speech recognition algorithms and select the appropriate word from a list of alternatives.
In the V-TaG version of the Talk-and-Gaze (TaG) method for selecting and correcting errors with voice and gaze proposed by Sengupta et al. (Citation2020), the erroneous word is selected by focusing on it and saying the “select” voice command. In another version of this method, D-TaG, the user had to gaze and dwell on the incorrect word for 0.8 seconds. In both versions, a list of possible words is provided by the system, and the user corrects the word by stating the number of the word selected from the list. Although D-TaG was preferred by users, the voice-only method topped the list in terms of comfort. Participants noted it was difficult to focus on an erroneous word while giving the command for selection with V-TaG. Regarding the use of D-TaG, participants raised issues with the accidental selection of non-erroneous words. Uttering just the number associated with the correct prediction instead of the entire word reduced the effort required and recognition errors. The study focused on character-level error correction and did not investigate more complex text edits.
The use of multimodal input in text editing has evolved further in the mobile context, moving from requiring precise input to allowing for more fuzzy input by using artificial intelligence (Fan et al., Citation2021; Luo et al., Citation2022). Zhao et al. (Citation2022) designed and implemented EyeSayCorrect, an eye-gaze- and voice-based multimodal error correction system for mobile devices that offers users a hands-free approach for correcting words or phrases and can accommodate ambiguous and noisy input signals, utilizing a text correction algorithm presented previously by Zhao et al. (Citation2021). Their evaluation showed that EyeSayCorrect is a feasible hands-free text correction method for mobile devices.
2.3.2. Voice&mouse
Research investigating the combined use of voice and mouse for error correction is scarce and was performed decades ago (Danis et al., Citation1994; Larson & Mowatt, Citation2003; McNair & Waibel, Citation1994). Danis et al. (Citation1994) developed the StoryWriter editor, which accepts speech and keyboard input for text creation and six types of input for application control functions (speech, keyboard, mouse, foot pedal, and two novel techniques: pointer touch and point and speak). StoryWriter editor was developed for newspaper reporters suffering from RSIs, however, the authors did not report on a quantitative evaluation of their interaction methods. In their pointer touch method, the mouse pointing function served as an action trigger. The pointer touch controls were presented on the screen as buttons that are activated by positioning the pointer on the button and pausing until the button is activated. In their point and speak method, the mouse is used for item selection and speech is used to specify an action. Point and speak functions allowed the user to indicate a text location and select, delete, copy, move, or correct a quantity of text by pointing with the mouse rather than manipulating the cursor position. This design eliminated the need to click the mouse, since selection is inferred based on the elapsed time; this could result in misselection if the mouse unintentionally hovered over the incorrect word. In contrast, in our voice&mouse system, word selection is performed by pointing the mouse and uttering a command, minimizing missselection. Their study is further limited, since the authors did not perform a quantitative evaluation of the interaction methods.
In the speech interface developed by McNair and Waibel (Citation1994), the mouse is used to highlight misrecognitions, and the voice is used to respeak or spell the misrecognized section. Based on this, the language model creates a list of the n-best hypotheses for the given utterance, and the erroneous word is replaced by the top item in the list. The authors found that highlighting the erroneous word with the mouse improved sentence accuracy compared to using just the voice to make the correction.
A similar redictation approach was used in the interface proposed by Larson and Mowatt (Citation2003), where the participant selects the misrecognized word with the mouse and then redictates the word to correct it. This method was compared with the voice-only method, as well as with an error correction method in which a list of alternative words is provided. When using the latter, the mouse is used to select the misrecognized word, access the list, and select the correct word with the mouse; the user can also switch to a soft-keyboard (a keyboard displayed at the bottom of the screen where users “type” by clicking virtual keys) to correct the error. Users had the least success and satisfaction with the voice-only method. The redictation approach is also employed in Google’s Voice Typing (Type With Your Voice - Google Docs Editors Help, n.d.) where the cursor can be used to select a word, and the user can speak the new word to replace it with. Other speech commands can be used, as well as the mouse, which can be used to choose a suggestion provided by the system. Zhao et al. (Citation2021) presented VT, a voice- and touch-based multimodal text editing and correction method for smartphones. In this case, the user glides a finger over a text fragment and dictates a command to edit text. Their evaluation showed that VT significantly improves the efficiency of text editing and correcting on smartphones over a touch-only method and the iOS’s Voice Control method.
In contrast to methods in which the erroneous word is selected by highlighting it with the mouse (Larson & Mowatt, Citation2003; McNair & Waibel, Citation1994) or a finger (Zhao et al., Citation2021) and then redictating the word, in the proposed FixOver system, the selection of the erroneous word does not require clicking or tapping but is done by pointing the mouse and stating the desired command. If there are several erroneous words within a specific predefined radius from the cursor position, the erroneous word closest to the cursor is selected. This will enable the elderly and people with disabilities to easily correct errors and edit text (Trewin & Pain, Citation1999; Valles et al., Citation1996). In addition, using re-dictation or uttering the prediction selection might increase effort and recognition errors. Therefore, in our FixOver system the selection and correction are performed at the same stage, as the erroneous word is autocorrected to the first prediction offered by the spell checker. Additionally, unlike methods that use speech recognition for text entry and voice&mouse for error correction (Larson & Mowatt, Citation2003; McNair & Waibel, Citation1994), which can only handle real-word errors, FixOver can deal with non-word errors. Finally, in our comprehensive evaluation of the proposed method, we compare its performance on a diverse array of editing tasks, including those not examined in previous studies, to that of voice-only, voice&gaze, and the conventional keyboard&mouse methods.
3. Methods
3.1. Interface design
3.1.1. FixOver design process
In developing our voice and mouse system for error correction and text editing, we employed an iterative design process, ensuring a user-centered approach to create an intuitive and effective interface. Here’s how we implemented this design methodology:
User Research - We conducted extensive user research to comprehend the specific needs and challenges users face in error correction and text editing. This included identifying common errors and understanding user expectations regarding voice and mouse interactions.
Task Analysis - Tasks associated with error correction and text editing were dissected into smaller components such as identifying errors, navigating to the error, word selection, selection of a part of sentence, and applying various correcting and editing measures. We analyzed existing user workflows to pinpoint challenges and areas for improvement.
Create Personas - We developed two main personas: (1) A student who typed a project using MS Word and is interested in editing it before submission. He is reading the document while his hand is on the mouse and is interested in a natural interaction for text editing and error correction without repetitive switching between the mouse and keyboard; (2) An older adult who typed a document that he is interested to edit before submitting it to an official authority, but has a difficulty in keeping the cursor over the target while clicking (slipping while clicking).
Design choices - Based on the task analysis and research of designs of previous multimodal methods for error correction, we focused on two main design choices: (1) Selecting a prediction - our first design choice was inspired by the V-TaG voice and gaze system (Sengupta et al., Citation2020), where focusing on the incorrect word and then saying “select” selects the erroneous word and opens a list of numbered predictions. The user then has to utter the number of the correct prediction. Uttering just the number associated with the correct prediction instead of the entire word reduced the effort and recognition errors. Similarly, in our first design choice of the voice&mouse system the word selection is done by mouse pointing combined with uttering the command “fix”. The system then offers a numbered list of predictions. The number associated with the desired option must be uttered and then an automatic change to the selected option is made and the corrected word is highlighted for two seconds. (2) Autocorrect - our second design choice was motivated by the desire to minimize the number of interaction steps needed for error correction or text editing and to further reduce the effort and recognition errors. It was also based on the finding (e.g., Flor & Futagi, Citation2012) that when using the first top-ranked suggestion, the Microsoft Word spell checker provides adequate correction in the vast majority of the cases recognized by the spell checker. In order to correct an erroneous word, the users have to place the mouse cursor on the word they want to correct and then say: "fix." The system autocorrects to the first option offered by MS Word’s Spell Checker for correcting the erroneous word selected by the user’s cursor position. The corrected word will be highlighted for two seconds. If the users are not satisfied from the automatic correction, they can apply the command fix + options to present a list of numbered predictions or use the command replace and re-speak the correction.
User Testing, Feedback Analysis, Refinement and Iteration - We conducted a pilot study to evaluate the two design choices. Using a within participants study design, all seven participants of the pilot study used two prototypes which implemented the two design choices. All participants preferred the second design choice in which the system autocorrects to the first option offered by MS Word’s Spell Checker. In case the spell-checker autocorrected to the desired prediction, the correction time was significantly shorter when the users used the automatic fix, which saved the interaction step of selecting the correct prediction. The participants commented that the autocorrect design choice would be also very efficient for applying corrective measures when noticing an error while typing. Our main concern was that when performing the fix task, the user will not notice the case that the spellchecker auto-corrected to a prediction which was not intended by the user. To investigate if this was the case, we deliberately used for some of the correction tasks errors which were autocorrected to a wrong prediction. The results showed that the users recognized all of these cases and applied further necessary corrective measures. Therefore, we decided to use the autocorrect design choice for our FixOver system.
A second pilot was conducted to test the usability with three representative users (students - one of our main personas that frequently use word processors) and representative tasks to assess the effectiveness and efficiency of the final prototype designed according to the autocorrect design choice. Qualitative and quantitative data guided design iterations. Feedback was collected on the clarity of voice commands, ease of voice and mouse interactions, and overall user satisfaction. User feedback was thoroughly analyzed to identify areas for improvement and elements that resonated well. The interface design was refined based on user feedback, with adjustments made in each iteration.
Technical Implementation - The technical implementation of the final design is described in section 3.1.2.2.
Evaluation – A controlled experiment was conducted to evaluate our voice&mouse methods compared to two other natural interaction methods of voice-only and voice&gaze and to the traditional keyboard&mouse method. The evaluation of the final implemented interface is elaborated in section 3.2. The description of our FixOver system and of the two additional system which were developed for the purpose of the evaluation is provided in the subsections below.
3.1.2. Error correction and text editing systems
Three natural interaction systems with different combinations of interface modalities were developed to enable interaction with MS Word for the purpose of error correction and text editing: VoiceIT (using voice-only), FixOver (using voice&mouse), and Teyepo (using voice&gaze). The three systems were compared to the traditional keyboard&mouse. All of the systems are event-driven and were developed in the C# programming language using the .NET Framework 4.6.1 platform for Windows applications. The Microsoft Visual Studio development environment was used.
3.1.2.1. Tasks
A description of the seven error correction and text editing tasks (fix, fix + options, replace, add before/after, copy from to, paste after, delete) examined in this study and the workflow for performing the tasks using each system is provided below and depicted in .
Figure 1. Workflow of the fix task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).
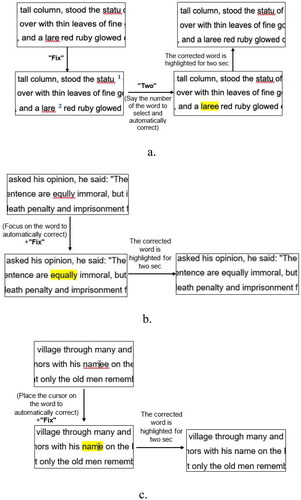
Figure 2. Workflow of the fix + options task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).
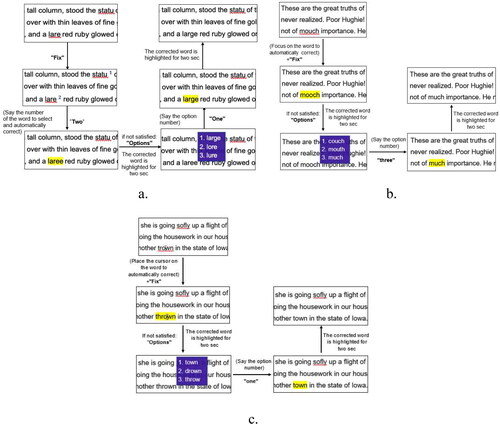
Figure 3. Workflow of the replace task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).
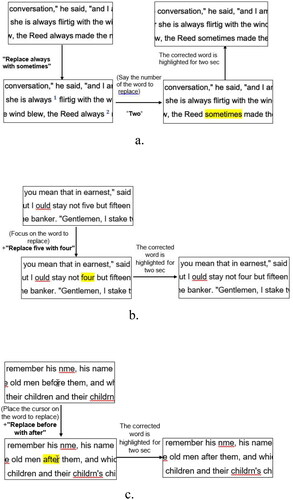
Figure 4. Workflow of the copy task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).

Figure 5. Workflow of the paste task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).

Figure 6. Workflow of the add task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).

Figure 7. Workflow of the delete task using the three systems: voice-only (a), voice&gaze (b), and voice&mouse (c).

3.1.2.1.1. Error correction tasks
Fix – The purpose of the fix task is to correct a word that is a non-word error (the spell checker identifies a non-word error and underlines it in red).
In the Teyepo system, to perform the task, the user has to focus their gaze on the word they want to correct and then say: “fix.”
In the FixOver system, to perform the task, the user has to position the cursor on the word they want to correct and then say: “fix.”
In the VoiceIT system, to perform the task, the user has to say: “fix.” Then, the system recognizes the command and maps all the erroneous words in the document (non-word errors) to unique numbers, and the user has to utter the number of the word they want to correct.
Each of the systems automatically selects the first option provided by MS Word’s spell checker, and then, depending on the system, the erroneous word indicated by the user’s gaze, cursor, or voice is replaced with the word provided by the spell checker. The corrected word is highlighted for two seconds to facilitate the review of the correction by drawing the user’s attention. It should be noted that in the Teyepo and FixOver systems, the corrections are made to the erroneous word that is closest to where the user has focused their gaze or positioned the cursor, respectively, while saying the voice command. The workflow of the fix task for all three systems is presented in .
Fix + options – This command is used when a user executes the fix task but is not satisfied with the correction made.
In each of the systems, to choose another option for correcting the word, the user has to utter the command “options”; then, a numbered list of three additional alternative words for correcting the original erroneous word is displayed. To replace the erroneous word with one of the options, the user has to state the number associated with the option; then the system makes the change, and the corrected word is highlighted for two seconds. Alternatively, if the user is unsatisfied with the options presented, they can utter the “replace” command (described below). The workflow of the fix + options task for all three systems is presented in .
Replace – The purpose of the replace task is to correct a word that is a real-word error. This task replaces one word (“word1”) with another word (“word2”).
In the Teyepo system, to perform the task, the user has to focus their gaze on the word they want to replace (“word1”) and then say: “replace+‘word1’+with+‘word2’.”
In the FixOver system, to perform the task, the user has to position the cursor on the word they want to replace (“word1”) and then say: “replace+‘word1’+with+‘word2’.”
In the VoiceIT system, to perform the task, the user has to say: “replace+‘word1’+with+‘word2’.” If there are several occurrences of “word1” in the document, the system will first map all the occurrences to unique numbers, and then the user has to utter the number of the desired occurrence.
In each of the systems, the corrected word (“word2”) is highlighted for two seconds. The workflow of the replace task for all three systems is presented in .
3.1.2.1.2. Editing tasks
Copy from to – This is an editing task whose purpose is to copy a sequence of words in the document (copy from “word1” to “word2,” including both words and the words in between).
In the Teyepo system, to perform the task, the user has to focus their gaze on the word at the beginning of the sequence that they want to copy (“word1”) and then say: “copy from+’word1’.” Then, “word1” will be highlighted. After that, the user has to focus their gaze on the last word in the sequence they would like to copy (“word2”) and then say: “to+‘word2’.” Then, the sequence of words from “word1” to “word2” will be highlighted until the user utters the paste or cancel command.
In the FixOver system, to perform the task, the user has to position the cursor on the word at the beginning of the sequence they want to copy (“word1”) and then say: “copy from+‘word1’.” Then, “word1” will be highlighted. After that, the user has to position the cursor on the last word in the sequence they would like to copy (“word2”) and then say: “to+‘word2’.” The sequence of words from “word1” to “word2” will be highlighted until the user utters the paste or cancel command.
In the VoiceIT system, to perform the task, the user has to say: “copy from+‘word1’+to+‘word2’.” If there are several sequences that start with “word1” and end with “word2,” the system will first map all occurrences to unique numbers and highlight them in yellow. Then the user has to utter the number of the desired sequence. The sequence chosen to be copied will be highlighted until the user utters the paste or cancel command.
The workflow of the copy from to task for all three systems is presented in .
Paste before/after – This is an editing task whose purpose is to paste a sequence of words before/after a word (“word1”) in the document. This task is a follow-up task to the copy task.
In the Teyepo system, to perform the task, the user has to focus their gaze on the word that appears immediately before or after the location at which they want to paste the sequence of words and then say: “paste + after/before+‘word1’.”
In the FixOver system, to perform the task, the user has to position the cursor on the word that appears immediately before or after the location at which they want to paste the sequence of words and then say: “paste + after/before+‘word1’.”
In the VoiceIT system, to perform the task, the user has to say: “paste + after/before+‘word1’.” If there are several occurrences of the target word in the document, the system will first map all the occurrences of the word to unique numbers. Then the user has to say the number of the desired occurrence.
In all systems, after pasting, the pasted sequence of words and the target word (“word1”) will be highlighted for two seconds. The workflow of the paste before/after task for all three systems is presented in .
Add before/after – The purpose of this editing task is to add “word1,” before/after “word2,” which is a real-word error.
In the Teyepo system, to perform this task, the user has to focus their gaze on the word (“word2”) before or after which they want to add another word (“word 1”) and then say: “add+‘word1’+before/after+‘word2’.”
In the FixOver system, to perform this task, the user has to position the cursor on the word (“word2”) immediately before or after which they want to add another word (“word 1”) and then say: “add+‘word1’+before/after+‘word2’.”
In the VoiceIT system, to perform this task, the user has to say: “add+‘word1’+before/after+‘word2’.” If there are several occurrences of “word2” in the document, the system will first map all the occurrences of the word to unique numbers. Then the user has to utter the number of the desired occurrence.
In all systems, after the addition, the two words (“word1”+“word2”) will be highlighted for two seconds. The workflow of the add before/after task for all three systems is presented in .
Delete – This is an editing task whose purpose is to delete a sequence of words in the document (deleting from “word1” to “word2,” including both words and the words in between).
In the Teyepo system, to perform this task, the user has to focus their gaze on “word1” and say: “delete from+‘word1’.” As a result, “word1” will be highlighted. Then the user has to focus their gaze on “word2” and say: “to+‘word2’.”
In the FixOver system, to perform this task, the user has to position the cursor on ‘word1’ and say: “delete from+‘word1’.” Then “word1” will be highlighted. After that, the user has to position the cursor on “word2” and say: “to+‘word2’.”
In the VoiceIT system, to perform this task, the user has to say: “delete from+‘word1’+to+‘word2’.” If there are several sequences that start with “word1” and end with “word2,” the system will first map all occurrences of the sequence to unique numbers. Then the user has to utter the number of the desired occurrence.
In all systems, the sequence from “word1” to “word2,” which is selected to be deleted, will be highlighted for two seconds and then deleted. The workflow of the delete from to task for all three systems is presented in .
An additional task that can be performed after each of the seven correction and editing tasks while using each of the three natural interaction systems is the cancel task.
Cancel – This is a task whose purpose is to undo the last correction or editing operation performed.
To perform this task, the user has to say: "cancel." The word or sequence of words on which the last correction or editing operation was performed before the cancel command is issued will be highlighted for two seconds, and then the document will return to its state before the correction or editing operation was performed.
3.1.2.2. Technical implementation
The systems included six main components:
Position Tracker - responsible for tracking the position of the desired word to correct, or the desired sentence to edit. This component exists only in the Teyepo and FixOver systems.
In the Teyepo system, the Position Tracker component is responsible for tracking the user’s gaze movements. This component interacts with the API of the eye tracker (Gazepoint GP3) and receives from it the gaze position data on the screen in pixels and converts them to position coordinates (x,y) in real time. In addition, this component interacts with the Text Editor component, which converts these coordinates to the word from the text on which the user focused his gaze.
In the FixOver system, the Position Tracker component is responsible for tracking the mouse movements. This component receives from an internal C# library coordinates (x,y) of the cursor position in real time. After that, the component interacts with the Text Editor component which converts these coordinates to the word in the text on which the user placed the mouse cursor.
Speech to Text - responsible for recognizing the user’s voice and converting it to text (string). This component interacts with the Command Interface and submits to it as a string all the words that were spoken and identified as valid words in the language. This component is provided by several companies which offer speech to text services. For this experiment we used the component which is provided by Microsoft Azure Cloud services.
Command Interface - receives from Speech to Text component all the words spoken as a string and recognizes whether a predefined edit/correction command was spoken. The component interacts with the Text Editor and defines for it which action should be performed in the word processor.
Spell Checker - responsible for identifying the erroneous word (non-word error) in the position closest to the focus of the user’s gaze in the Teyepo system, or alternatively to the mouse position in the VoiceIT system. In addition, the component provides correction options for erroneous words. This component is provided by the Microsoft Word API.
Text Editor - responsible for making updates and changes in the document. This component interacts with the Microsoft Word API using the data on the position of the words on which an editing operation is required. This component receives the position of the word (coordinates) to be edited/corrected from the Position Tracker using the user’s gaze in the Teyepo system, or using the position of the mouse cursor in the FixOver system, converts these coordinates to the word on which the correction/editing action is required and receives the type of the correction/editing action to be done from the Command Interface and implements this operation in the text document in the word processor.
When using the FixOver or Teyepo systems:
If the fix or fix + options tasks (these are the only tasks that are said on their own, without any other words added) are stated, the system’s Text Editor looks at the text within a specified radius (up/down/left/right) from the cursor or the user’s gaze point and uses the spell checker to identify the erroneous word within that radius. If there are several erroneous words, the erroneous word closest to the cursor or gaze point is selected. Then the spell checker offers a list of options to correct.
If any of the other main tasks, i.e., replace, copy, paste, add, delete, (the tasks in which some other words are added to the task itself) is stated, the Text Editor looks at the words within a specified radius around the mouse cursor or the user’s gaze point and compares each of the words within that radius to the word that was stated after the command (using the Levenshtein distance). The word with the minimal Levenshtein distance is selected for the current edit.
The VoiceIT system is based on voice only, so the user does not have the option of targeting the command for a specific occurrence of a word in the document. Therefore, it is quite possible that a certain word appears in the document several times, although the user may wish to correct just one of its occurrences in the text. In the same way, the sequence of words that the user wants to edit (e.g., copy or delete) may appear several times in the text, although the user wants to edit just a specific occurrence of it. Therefore, in the VoiceIT system, word/sequence occurrences are mapped to allow the user to navigate the document. After saying the required command, the system’s Text Editor displays the number of the relevant words/sequences in the document, in order to allow the user to select a certain occurrence that requires correction or editing.
Controller - The central component is responsible for coordinating the actions between the various components. It receives indications of events that occurred in the system according to the Event-Driven architecture and activates the appropriate components.
3.2. Evaluation
3.2.1. Participants
The participants in our user study were 24 university students, studying at in the Department of Software and Information Systems Engineering. All participants had an advanced level of English and used text editors on a daily basis. Their ages ranged between 19 to 28 years, with an average age of 24.21 years. All participants had normal or corrected to normal vision. The participants received a bonus of up to three extra points, which were added to their grade in one of their university courses (courses with related material).
3.2.2. Apparatus and materials
The experiment was conducted on a desktop computer with a 22-inch adjustable monitor in a computer laboratory with an environment of controlled ambient light and sound. OBS Studio software was installed on the computer to record videos of the screen and the participants’ voices during the experiment, as a means of tracking users’ interactions with the systems. A standalone height-adjustable microphone (Fifine Microphone K668) was positioned next to the monitor.
3.2.2.1. Eye tracking system
A Gazepoint GP3 eye tracker, which is a non-contact infrared camera with a sample rate of 150 Hz, was used to collect the gaze data and enable voice and gaze interaction with the word processor. The eye tracker was positioned below the monitor using a mounting stand. It is safe to use and non-invasive, and the participants had no physical contact with it during the experiment. Participants sat on a stable chair without wheels to avoid excessive movement away from the eye tracker. depicts the experimental setup, including the monitor, the eye tracker positioned on a mounting stand, the standalone microphone, and a participant performing error corrections using the Teyepo system.
Figure 8. Experimental setup for the Teyepo system.

3.2.2.2. Texts
Each participant was asked to perform error correction and editing tasks in four texts containing erroneous words, including different types of non-word errors (misspellings, incorrect letter entry, missing letters, and misordered order) and real-word errors (mistakes), using the four text editing systems (voice-only, voice&mouse, and voice&gaze, and the conventional keyboard&mouse system) examined in this study. Each participant edited a total of 16 different texts. The texts were taken from American short stories, in the category of great short stories (https://americanliterature.com/100-great-short-stories). Each text is approximately 450 words long, a length which covers over 100% of the screen space, and therefore scrolling was required.
3.2.2.3. Experiment execution and data collection
To enable the experiment’s execution and data collection, an independent, event-driven system was developed in C#. This experiment system stores paths to MS Word files that contain pre-prepared texts with erroneous words. When initializing the experiment system, the text editing system must first be selected. The text editing system provides the experiment system with the user’s name and identification number and returns the path to the MS Word file, which is opened by the text editing system selected. The user interface was developed using the .NET Framework 4.6.1 Platform for Windows applications and presents a standard Word file, supplemented with page, paragraph, and line numbering to make navigation easier for the user. During the experiment, the experiment system presents various error correction or text editing tasks on top of the Word file. Before each task, a navigation instruction is presented, instructing the user to go to the specific page, paragraph, and line where the correction/editing action should be performed.
The experiment system records all user actions and their timestamps: experiment beginning, task beginning and end, the participants’ voice commands, the status of the file before and after each command, and the end of the experiment. The experiment system checks whether the task was successfully completed (by comparing the status of the file after the user’s correction to how the file should appear after a successful correction was made). The system also calculates the task completion time (in real time) by subtracting the task beginning time from the task ending time, and the task effort by counting all voice commands issued by the user in order to complete this task (which represents the number of attempts made by the user to correct or edit, as the voice component is required to perform each task, when using the voice-only, voice&mouse, and Voice&Gaze systems system. Data were stored in .csv files for further evaluation.
3.2.3. Procedure
Before starting the experiment, participants signed an informed consent form and completed a demographic questionnaire, in which they provided information including their full name, ID number, email, gender, and age. These details remained confidential and were only used to perform statistical analyses of the results. An individual session was held with each participant, to avoid interference when using the voice commands, and the only person in the room besides the participant during the approximately two and a half hour session was the experimenter. The participants received a short explanation regarding the goals of the study, namely comparing the usability of the four systems for error correction and text editing.
The experiment comprised four parts. In each part, the participant was asked to perform error correction and text editing tasks using one of the four editing systems. The participants could take a break between the parts of the experiment if they wished. Each part consisted of the following stages:
The participant watched a training video demonstrating how to work with the text editing system to perform the seven error correction and editing tasks (fix, fix + options, replace, add before/after, copy from to, paste after, delete). The exact command for each task was specified and demonstrated. After watching the video, the participant was asked to repeat the various tasks and their execution commands. If the participant could not remember the command or made a mistake, the experimenter clarified it.
The participants performed a training block, followed by three testing blocks. In each block, they were presented with a single text which contained text errors and required to perform the seven error correction and editing tasks. Upon successful completion of the training block, the participants could proceed to the testing blocks. In order to compare the four interfaces and avoid bias, all tasks were performed on the same word processor - Microsoft Word. Therefore, non-word errors were underlined in red.
Before each task, an instruction appeared at the top of the screen, requesting the user to navigate to a specific row in a specific paragraph on a specific page of the presented text. The purpose of this was to exclude the visual search time from the interaction. Upon clicking on the “Next” button, the error correction or text editing task appeared. The participant performed the task and then clicked on the “Next” button to navigate to the next task. When interacting with the voice&gaze system, before each block, the eye tracker was calibrated for each participant, using five calibration points.
After performing the tasks in all of the training and testing blocks using the four text editing systems (the four parts of the experiment), the participants completed three questionnaires: the NASA-TLX questionnaire, the SUS questionnaire, and a system preference questionnaire in which the participants had to rank their preference for using the four systems in general and when using the systems to perform each of the error correction and text editing task.
3.2.4. Experimental design
A within-subjects design was used, in which each participant interacted with each of the four editing systems (voice-only, voice&mouse, voice&gaze, and keyboard&mouse). Interaction with each system included the completion of one training block and three testing blocks. In each block, seven error correction and text editing tasks were performed (fix, fix + options, replace, add before/after, copy from to, paste after, delete) on a single text. The texts were different for each of the four blocks performed using each editing system and among the systems (all together each participant interacted with 16 different texts). In summary, the total number of testing trials (error correction and text editing tasks) performed was: 24 (participants) x 4 (editing methods) x 3 (testing blocks) x 7 (tasks per block) = 2,016. The order of the four types of editing systems and the order of the texts to be edited using each editing system were counterbalanced across participants. The order of the tasks to be performed in each block was randomly permuted.
4. Results
4.1. Objective measures
To investigate the effects of the editing method, block, and task on the performance time and task effort two separate three-way repeated measures ANOVAs were conducted. In the first analysis, the performance time was the dependent variable, and in the second analysis, the task effort was the dependent variable. In both analyses, the editing method (voice-only, voice&mouse, voice&gaze, and keyboard&mouse (included only in the performance time analysis)), the block (block1, block2, block3), and the task (fix, fix + options, replace, paste, add, copy, delete) were within-subjects independent measures. As the task effort was defined as the number of voice commands issued to successfully complete the task and since participants could use different strategies for task execution when using the keyboard&mouse method, in the task effort analysis, the editing method variable did not include the keyboard&mouse editing method. When using the three natural interaction methods (voice-only, voice&mouse, and voice&gaze), all actions were voice-activated or were a combination of voice and another modality (mouse or gaze). The results of the two analyses, which are presented in , showed that in both analyses the effect of the block was not statistically significant as a main effect or as a component of interaction. However, the main effects of the editing method and the task were found to be significant. The interaction of the editing method task was also significant.
Table 1. The results of the separate three-way ANOVAs with repeated measures on the performance time and the task effort.
4.1.1. Performance time
The average performance time as a function of the editing method and task is presented in . It can be seen that the performance time when using the voice&mouse and voice&gaze methods was shorter than when using the voice-only method for most error correction tasks. The performance time when using the voice&mouse and voice-only methods was shorter than that of the voice&gaze method for most editing tasks. The average performance time when using the keyboard&mouse method was the shortest relative to using all other methods across all tasks. The method with the second shortest average performance time was the voice&mouse editing method, for which the average performance time was similar to that obtained when using the keyboard&mouse and performing the fix, replace, and add tasks.
Figure 9. The average performance time as a function of the editing method and task.
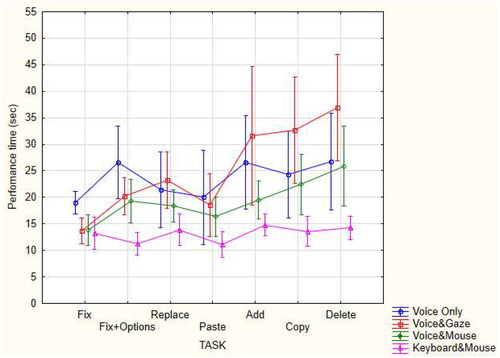
A post-hoc Duncan test was conducted to find homogenous groups on the average performance time when using each editing method to perform the different tasks. First, we compared the performance time when using the three natural interaction methods (voice&mouse, voice&gaze, and voice-only) to perform the tasks. This analysis showed that the average performance time when performing the fix and fix + options tasks was significantly shorter when using the voice&mouse (p < 0.05) and voice&gaze (p < 0.05) methods than when using the voice-only editing method. When performing the replace and paste tasks, no significant differences were found in the average performance time when using the voice&mouse, voice&gaze, and voice-only editing methods. However, the average performance time was significantly different for the three methods (p < 0.05) when performing the add task, where the shortest average performance time was obtained by the voice&mouse method and the longest was obtained by the voice&gaze method. The average performance time when using the voice&gaze method was significantly longer than when using the voice&mouse (p < 0.0001) and voice-only (p < 0.001) methods when performing the copy and delete tasks.
The average performance time when using the keyboard&mouse method was significantly shorter than when using the voice&gaze (p < 0.01) and voice-only (p < 0.01) methods for all tasks except for the fix task. When performing the fix task, no significant difference was found between the average performance time of the keyboard&mouse and voice&gaze methods, however the keyboard&mouse method was significantly faster than the voice-only method (p < 0.05). The average performance time when using the keyboard&mouse method was significantly shorter than that of the voice&mouse method when performing the fix + options (p < 0.001), paste (p < 0.05), copy (p < 0.001), and delete (p < 0.001) tasks but was not significantly different from that of the voice&mouse method when performing the fix, replace, and add tasks which typically require using the keyboard in addition to the mouse.
4.1.2. Task effort
The average task effort as a function of the editing method and task is presented in . It can be seen that the task effort when using the voice&mouse and voice&gaze methods was less than when using the voice-only method for all correction tasks. The average task effort when using the voice&mouse and voice-only methods was less than when using the voice&gaze method for most editing tasks. The lowest average task effort for the three natural interaction methods was obtained when using the voice&mouse method when performing all tasks.
Figure 10. The average task effort as a function of the editing method and task.
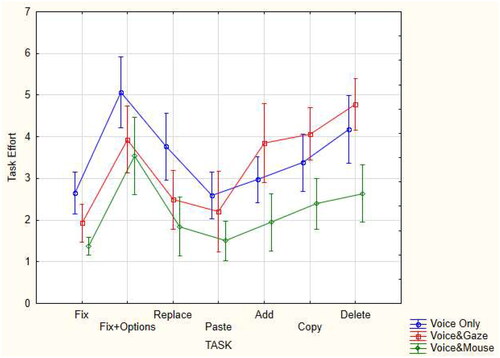
A post-hoc Duncan test was conducted to find homogenous groups on the average task effort when using each method to perform the different tasks. This analysis showed that the average task effort for all correction tasks (fix, fix + options, and replace) was significantly higher when using voice-only than when using the voice&mouse (p < 0.0001) and voice&gaze (p < 0.05) methods. The average task effort when using the voice&mouse and voice&gaze editing methods was not found to be statistically significantly different when performing the fix and fix + options tasks, but when performing the replace task, the average task effort when using the voice&mouse method was significantly lower than when using voice&gaze (p < 0.05) method. When performing the paste task, the average task effort was significantly lower when using the voice&mouse editing method than when using the voice&gaze (p < 0.05) and voice-only (p < 0.001) methods, for which the results were not found to be significantly different. The average task effort was significantly different among the three editing methods when performing the add (p < 0.01), copy (p < 0.05), and delete (p < 0.05) tasks, for which the lowest average task effort was obtained by the voice&mouse method and the highest was obtained by the voice&gaze method.
4.2. Subjective measures
4.2.1. Task load (NASA-TLX)
To investigate the effects of the editing method and task type on the NASA-TLX task load, we conducted two-way repeated measures ANOVA. The perceived NASA-TLX task load was the dependent variable. The editing method (voice-only, voice&mouse, voice&gaze, and keyboard&mouse) and task type (correction tasks and editing tasks) were within-subjects independent measures. This analysis showed that the main effects of the editing method (F(3,69) = 41.06, p < 0.0001) and task type (F(1,23) = 23.55, p < 0.0001) were significant. The interaction of the editing method X task type (F(3,69) = 7.40, p < 0.001) was also significant, as seen in .
Figure 11. The average perceived NASA-TLX task load as a function of the editing method and task type.
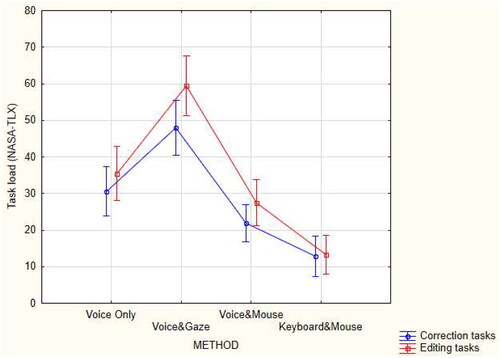
A post-hoc Duncan test was conducted to find homogenous groups on the average task load scores when using each method to perform the error correction and text editing tasks. This analysis showed that the average perceived task load scores were significantly different from each other among the four methods, both when performing the correction tasks (p < 0.0001) and when performing the editing tasks (p < 0.0001). The perceived task load of both correction and editing tasks was the highest when using the voice&gaze method, the second-highest when using the voice-only method; this was followed by the voice&mouse method, and it was the lowest when using the keyboard&mouse method. Moreover, for all methods except the keyboard&mouse, the perceived task load when performing the editing tasks was significantly higher (p < 0.005) than when performing the correction tasks. The gap (p < 0.0005) between the editing and correction task loads was the largest with the voice&gaze method.
4.2.2. Usability (SUS scores)
To investigate the effect of the editing method on the SUS scores, a one-way repeated measures ANOVA was conducted. The SUS score was the dependent variable, and the editing method (voice-only, voice&mouse, voice&gaze, and keyboard&mouse) was a within-subjects independent measure. This analysis showed that the effect of the editing method (F(3, 69) = 35.52, p < 0.0001) was significant, as seen in .
Figure 12. The average SUS score for each editing method.
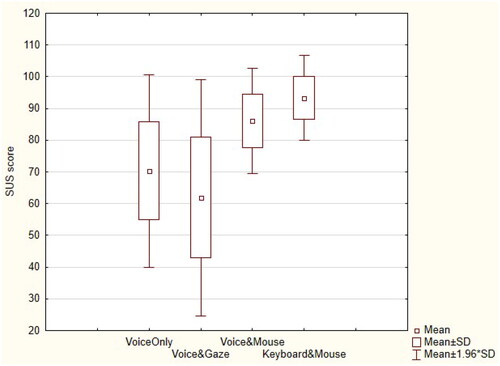
A post-hoc Duncan test was conducted to find homogenous groups on the average SUS scores when using each method to perform the error correction and text editing tasks. The analysis showed that the average SUS scores were significantly different from each other among the four methods (p < 0.05).
The average SUS score was the highest when using the keyboard&mouse method, the second-highest was when using the voice&mouse method; this was followed by the voice-only method, and it was the lowest when using the voice&gaze method.
4.2.3. Preference
To investigate the effect of the editing method (voice-only, voice&mouse, voice&gaze, keyboard&mouse) used to perform each task (general, fix, fix + options, replace, paste, add, copy, delete) on the user’s preference, we conducted a two-way Friedman non-parametric test. The preference score was the dependent variable. This analysis indicated that the differences among the editing methods used to perform each task were significant (χ2 (31) = 241.85, p < 0.0001). presents the preference score as a function of the editing method and task.
Figure 13. The preference score as a function of the editing method and task.
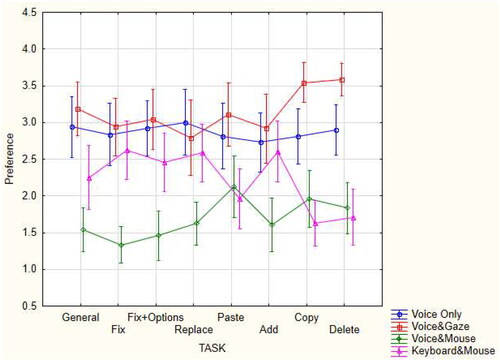
Pairwise comparisons adjusted by the Bonferroni correction for multiple tests showed that participants significantly preferred using voice&mouse over using the voice-only and voice&gaze methods for all correction (p < 0.001) and editing (p < 0.05) tasks and in general (p < 0.0001). There were no significant differences in preferences observed between the voice-only and voice&gaze methods in general and for all correction and editing tasks, except for the copy and delete (p < 0.05) tasks. Users significantly preferred using the voice-only method over using the voice&gaze method to perform the copy and delete tasks.
When asked to report their general preference across all tasks, participants significantly preferred using the voice&mouse method over the keyboard&mouse method (p < 0.05) and both were more preferred than the voice-only and voice&gaze methods (p < 0.05). In cases in which the tasks required using the keyboard with the keyboard&mouse method, i.e., fix (p < 0.001), fix + options (p < 0.01), replace (p < 0.01), and add (p < 0.005), users significantly preferred using the voice&mouse method over using the keyboard&mouse method. In these cases, there were no significant differences in preferences observed between the voice-only, voice&gaze, and keyboard&mouse methods. For the copy, paste, and delete tasks, which do not require using the keyboard with the keyboard&mouse method, there were no significant differences in preferences observed between the voice&mouse and keyboard&mouse methods, however both methods were significantly more preferred than the voice-only and voice&gaze methods (p < 0.05).
5. Discussion
In this study, we proposed a novel method that integrates voice&mouse for error correction and text editing and described its design and implementation. The results indicated that it is possible to combine voice and mouse for error correction and text editing (RQ1). Using the voice&mouse method, users demonstrated excellent objective and subjective measures. They executed all tasks with high efficiency (low task effort and short performance time), with results which were similar to those obtained with the keyboard&mouse method on some of the tasks that typically require the use of a keyboard. The average ± SD voice&mouse system usability score was 86 ± 8, which is considered excellent (Bangor et al., Citation2009), and the users’ perceived task load was low, both when performing the correction tasks and the editing tasks. Moreover, users most preferred using the voice&mouse method. It eliminated the need to use the keyboard, sparing the users from switching back and forth between the keyboard and the mouse. In addition, it overcame the difficulty of providing spatial information faced by voice-only systems and eliminated the challenge of gaze-based activation resulting from the Midas Touch problem. In our voice&mouse method, the selection of the erroneous word is done by positioning the cursor and uttering a command. The fact that there is no need to click on the mouse and the system searches for the erroneous word in the area around the cursor’s position and not at the exact position makes our system more accessible to a wide population and different kinds of users. For example, older adults and users with motor impairments, who according to previous studies (e.g., Trewin et al., Citation2006) have difficulty positioning the cursor on small targets and keeping the cursor on the target while clicking.
To evaluate our proposed voice&mouse method, we developed three systems with different interface modalities to enable natural interaction with MS Word for the purpose of error correction and text editing: FixOver - using voice&mouse, VoiceIT - using voice-only, and Teyepo - using voice&gaze. We compared the three methods of natural interaction to each other as well as to the traditional form of interaction using keyboard&mouse when performing error correction (fix, fix + options, replace) and text editing (copy, paste, add, delete) tasks (RQ2). The interfaces implemented were evaluated in terms of the objective performance measures of task performance time and task effort, as well as in terms of the subjective measures of task load (NASA-TLX), usability (SUS score), and preference.
5.1. Comparing the three natural interaction methods
The voice&mouse method outperformed at least one of the other two natural interaction methods in terms of the objective measures of performance time and task effort on all tasks. The use of the voice&mouse and voice&gaze methods resulted in significantly shorter performance times and less task effort than that of the voice-only method for most correction tasks. This is consistent with the results of a previous study (Larson & Mowatt, Citation2003), which reported that their version of the voice&mouse method (redictating) for error correction was significantly faster than the voice-only method (voice commanding). This result can be explained by the fact that in our study the voice-only method always required the additional step of uttering another command in order to select the number of the word to be corrected. This step addresses the inability of the voice-only method to naturally provide spatial orientation. A suggestion for improving the voice-only method that the participants raised during the debriefing was to number only the erroneous words that appear on the screen presented to the user when they utter the command. This would make the selection process easier for the user; decrease their cognitive load, as they would focus their attention only on the presented screen; and minimize recognition errors, as the system could be taught to expect a smaller range of numbers. In cases in which the user is interested in numbering all of the instances of the erroneous words, the word “all” could be added to the command (for example: “fix all”).
The use of the voice&mouse and voice-only methods resulted in significantly shorter performance times and less task effort than that of the voice&gaze method for most editing tasks. These differences were especially large when performing the add, copy, and delete tasks. This might stem from the fact that when using the voice&gaze method to perform the copy and delete tasks the user had to fixate on two words, changing the focus of their gaze from the word to copy/delete from to the last word to be copied or deleted. This could explain the fact that the largest gap in the perceived NASA-TLX task loads between the editing and correction tasks was obtained for the voice&gaze method. In addition, the voice&gaze method was the least preferred method for performing the copy and delete tasks. In the debriefing after the experiment, the participants noted that having to fixate on two words when using the voice&gaze method was extremely exhausting and strained their eyes. When performing the add task using the voice&gaze method participants first had to focus on the word before/after which another word or word sequence should be added according to their command. While focusing on that word, participants anticipated the uttered word/s that should be added to appear, which naturally caused their gaze to drift. Then, they had to shift their focus to the added text to verify that it was added correctly.
The voice&mouse outperformed the voice&gaze and voice-only methods in terms of the subjective measures of task load (NASA-TLX), usability (SUS score), and preference. A possible reason that the voice&mouse method was more usable and preferred than the voice&gaze method is the significantly higher task effort associated with the voice&gaze method, both in terms of the objective effort (the number of attempts made by the user to correct or edit for most tasks) and perceived effort (measured using NASA-TLX) for both the correction and editing tasks. Sengupta et al. (Citation2020) found that their gaze-based D-TaG interface was considered more comfortable than the V-TaG interface and suggested that the reason for this result might be the jitter in gaze movement when fixating on the incorrect word before saying “select.” Selection errors sometimes occurred, and this forced the participant to repeat the selection process. Our voice&mouse method avoids such wrong selection problems. During the debriefing in our study, participants commented that when using the voice&gaze method it was difficult to fixate on the word and utter the command at the same time and that they were not sure that the eye tracking system captured the target word (perhaps because of the jittering effect). Interestingly, participants reported that this caused them to use the mouse to point the cursor on the target word, even when using the voice&gaze method. Participants also suggested indicating the gaze point on the screen. This was implemented in Beelders’ study (2010), in which visual feedback was provided to the user to indicate which button would be clicked according to their eye fixation when the verbal command is issued. The user could also select which shape they wanted to use for visual feedback regarding their eye fixation on the screen. Providing visual feedback for the gaze position corresponds with Shneiderman’s golden rule for interface design, which states that for every user action, there should be informative interface feedback. The visual presentation of the objects of interest provides a convenient environment for showing changes explicitly (Shneiderman et al., Citation2016).
Participants also noted that they were not always sure whether the voice&gaze and voice-only systems correctly understood their intentions. This stemmed from the difficulty in determining the gaze point in the voice&gaze system and voice recognition errors, especially in the voice-only system, which required more voice interaction steps. As a result, users felt less in control when using these systems. This was reflected in the following examples of participants’ comments: “When performing copy/delete tasks using the voice-only system, I wasn’t sure that the system got my command, because the highlighting of copied/deleted words was not performed immediately after saying “copy from,” as was done when using the voice&mouse and voice&gaze methods but only after finishing saying the complete command: “copy from+‘word1’+to+‘word2’”; “I preferred voice&mouse method, because it was the fastest and most convenient. I could also control what I change, and it was clearer to see it. My second priority was the keyboard&mouse system, because I'm used to it and compared to the others it went easily, even though it’s the only one I had to type when using it. Then, I preferred the option of voice, only because I got along with it, and I believe it went relatively quickly. It was also easy to control when I chose which number to change. Editing operations went relatively easily with it compared to the gaze. With the gaze, it was relatively difficult for me to follow each target word with my eyes, and editing actions were difficult. It was also difficult, because I couldn’t tell where my gaze was on the text and if it worked.” The users noted that they felt more in control when using the systems with mouse modality (voice&mouse and keyboard&mouse) and therefore preferred using these methods. This also corresponds with Shneiderman’s golden rule for interface design (Shneiderman et al., Citation2016) which states that users should be kept in control, as users strongly desire the sense that they are in charge of the interface and that the interface responds to their actions.
Although the task effort when using the voice-only method was higher than when using the voice&gaze method for the correction tasks and vice versa for the editing tasks, participants rated the usability of the voice-only method significantly higher than the voice&gaze method for both task types. They also preferred using the voice-only method in general and especially for the editing tasks. This contradiction was also found by Sengupta et al. (Citation2020), and it was recommended that designers of applications for a multimodal hands-free environment primarily utilize the available modalities, but the voice-only approach can be used as a fallback method if eye strain or eye tracker drift becomes an issue. The eye strain caused by the need to fixate multiple times when performing the editing tasks in our study was reported by the participants as a problematic issue of the voice&gaze method.
5.2. Comparing the three natural interaction methods to the keyboard&mouse method
The average performance times when using the keyboard&mouse method were the shortest of the methods for most tasks. This corresponds with the user study by Portela and Rozado (Citation2014) which showed that while their proposed system was not as fast as using a keyboard and mouse for correction, their gaze-enhanced correction method significantly outperformed voice-alone correction and was preferred by users, offering a truly hands-free means of interaction. The method with the second shortest average performance time in our study was the voice&mouse editing method, for which the average performance time was similar to that of the keyboard&mouse for the fix, replace, and add tasks. Although there were no significant differences observed between the two methods in the performance time for these tasks, users significantly preferred the voice&mouse method to perform them. These tasks usually require text entry, as a part of the correction or editing task. This necessitated using the keyboard in addition to the mouse in the keyboard&mouse method or using the voice in addition to the mouse in the voice&mouse method. The reason that the keyboard&mouse method was less preferred for performing these tasks might stem from the fact that the back-and-forth switches between the keyboard and mouse are time-consuming and tiring, and therefore users preferred using the voice&mouse, which allows them to constantly keep their hand on the mouse. During the debriefing, users praised the intuitiveness of the voice&mouse method, in which a command is stated while pointing to the desired word with the mouse and noted that the addition of the voice modality eliminated the use of the keyboard and made the process of error correction more natural. When performing tasks that did not necessarily require a keyboard in addition to a mouse, such as copy, paste, and delete, performance times were significantly shorter using the keyboard&mouse method compared to the voice&mouse method.
Average performance times were not significantly different when using voice&mouse, voice&gaze, and keyboard&mouse for the fix task. This is most probably due to the fact that in the voice&mouse and voice&gaze systems, the selection and correction of erroneous words are performed in the same step. In contrast, in the keyboard&mouse method, the user positions the cursor, deletes the incorrect characters, and types the correct ones. Alternatively, they right-clicked the mouse and chose the desired option for correction. When the participants had to perform the fix + options task, the performance time was significantly shorter when using the voice&mouse and voice&gaze methods than when using the voice-only method but longer than the keyboard&mouse method. Another reason for the short performance time when using the voice&mouse and voice&gaze methods for the fix task is that “fix” is a short single command. When using the three natural interaction methods, which are all voice-based methods, the performance times and task effort were higher for longer commands (which included more words). This pertained especially to the voice&gaze method. This might be attributed to the jitter in gaze movement when fixating on the incorrect word and stating the command. The participants noted that it was difficult to gaze and speak at the same time, especially when the commands were long. In addition, the longer the command, the higher the likelihood of misrecognition, and consequently the greater the number of attempts, which in turn resulted in higher task effort and cognitive load. This might also be the reason that in all methods except the keyboard&mouse, the perceived task load when performing the editing tasks was significantly higher than when performing the correction tasks, and the largest gap was seen in the voice&gaze method.
The results on the subjective measures significantly differed for the four editing methods. The use of the keyboard&mouse method resulted in significantly higher average SUS scores and lower NASA-TLX task loads for both correction and editing tasks, compared to using the voice&mouse method, and both methods outperformed the voice-only and voice&gaze methods. The use of the voice&gaze method resulted in the poorest results in terms of the average SUS scores and NASA-TLX task load. Despite the superiority of the keyboard&mouse method in terms of the average SUS scores and NASA-TLX task loads, when asked to report their general preference across all tasks, participants significantly preferred using the voice&mouse method over the keyboard&mouse method, and both were more preferred than the voice-only and voice&gaze methods. There were also no significant differences in preferences between the voice&mouse and keyboard&mouse for most of the editing tasks, such as copy, paste, and delete, which could be performed using just the mouse when using the keyboard&mouse method. However, for the fix, fix + options, replace, and add tasks, which usually involve using the keyboard in the keyboard&mouse method, participants preferred using the voice&mouse method.
6. Study limitations and future work
This study has several limitations. After watching the training video for each method participants were asked to repeat the execution command for each task and were permitted to perform the testing blocks only upon successful completion of the training block. Nevertheless, it should be noted that the participants have years of experience in error correction and text editing using the keyboard&mouse method. This might have put the natural editing systems at a disadvantage relative to the keyboard&mouse method. Furthermore, the lack of previous use of eye tracking was noted by all participants, as well as some users’ lack of experience in using the voice modality. Future studies could consider the use of these methods, which include natural modalities, over a longer period of time, to provide greater insight into the extent to which performance can be improved. The fact that the performance time when using the three natural interaction systems also included the response times of the speech-to-text system might have also biased the results in favor of the keyboard&mouse method. However, it should be noted that if such bias occurred, it would have pertained equally to all three natural interaction systems. As speech recognition systems improve, the response times from stating the command to the command transcription and execution will become shorter.
Words that are phonetically similar were often mistranscribed, leading to incorrect recognition; this in turn increased the number of attempts to correct errors and edit text (task effort) and the performance time. This is also relevant to the incorrect recognition of voice commands. For example, "to" in the command “copy from ‘word1’ to ‘word2’” was often recognized as "two." Another example is when the user had to select the number of the word to correct, which was “three”; in that instance, the system often recognized the word “tree.” This can be dealt with by instructing the voice-integrated systems that in cases in which certain commands (such as copy) are stated, the command should be followed by the word “to.” In the scenario of selecting the number of the word to correct, the system should be instructed to expect receiving numbers as input. We also recommend incorporating a set of methods and algorithms aimed at facilitating the understanding of the users’ correction and editing intentions in the systems. This was previously done in VT (Zhao et al., Citation2021), which combines touch and voice inputs with language context, such as a language model and phrase similarity, to deduce a user’s correction and editing intention. This approach can effectively handle ambiguities and noisy input signals.
We aimed our voice&mouse method at most word processor users (specifically those using MS Word). This is a diverse population with a range of needs. However, the participants in our user study were university students, who frequently use word processors but do not represent the entire population of word processor users. Therefore, it would be worthwhile to conduct a follow-up study that comprehensively explores the proposed voice&mouse method’s applicability across different user groups. Our method offers great potential for diverse populations and specifically for older adults and users with motor impairments, who are known to have difficulty positioning the cursor on small targets and keeping the cursor on the target when clicking the mouse (Trewin et al., Citation2006). Therefore, it is reasonable to assume they are in real need of extra modality support beyond that provided by the keyboard&mouse method and could benefit greatly from our method. Further research will center on customizing the design to meet the distinct requirements of these populations, along with conducting a comparative analysis of various user groups.
7. Conclusions
The proposed voice&mouse method outperformed at least one of the other two natural interaction methods examined in terms of the objective measures of performance times and task effort for most correction and editing tasks. Moreover, the voice&mouse method significantly outperformed the voice&gaze and voice-only interaction methods in terms of all subjective measures. Based on these results, we conclude that of the three natural interaction methods investigated in this study, the voice&mouse method is the best candidate as a potential substitute for the traditional keyboard&mouse method.
The use of the keyboard&mouse method resulted in significantly higher average SUS scores and lower NASA-TLX task loads relative to the use of the voice&mouse method. However, when asked to report their general preference across all tasks, participants significantly preferred using the voice&mouse method over the keyboard&mouse method, and both were more preferred than the voice-only and voice&gaze methods. Using the keyboard&mouse method, performance times were significantly shorter than when using the voice&mouse method for tasks that did not necessarily require typing in addition to using the mouse, such as the copy, paste, and delete tasks. However, the performance times of the two methods were comparable for tasks that usually involve using the keyboard, in addition to the mouse, for text entry when using the keyboard&mouse method, such as the fix, replace, and add tasks; in those cases, participants preferred using the voice&mouse method. In other words, in cases where the tasks could be performed using one modality, such as the mouse, participants did not feel the need to utilize the voice modality. For example, for copying or deleting, users could mark the required text with the mouse, right-click the mouse, and choose the appropriate option from the drop-down menu. They could also use keyboard shortcuts and use only the keyboard to perform these tasks. In cases where two modalities were required to complete the task (for example, using the keyboard for typing after positioning the mouse to perform the add task when using the keyboard&mouse method), the users preferred using the voice modality for text entry over typing.
The findings of this study support the use of the voice&mouse method for error correction and text editing along with the keyboard&mouse method. This would allow users to choose their preferred interaction method for each scenario and task while improving their performance and satisfaction. This also corresponds well with the increasing popularity of voice-based text entry systems. As users adapt to interacting with the voice&mouse method, and speech recognition systems’ response times will improve, the voice&mouse interaction method might take the lead in error correction and text editing.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Meirav Taieb-Maimon
Meirav Taieb-Maimon is a senior faculty member in the Department of Software and Information Systems Engineering at Ben-Gurion University of the Negev, Israel. She specializes in human factors, human-computer interaction, information visualization, design and analysis of experiments, and evaluation of information systems, interfaces, and visual analytics systems.
Luiza Romanovskii-Chernik
Luiza Romanovskii-Chernik is an M.Sc. student in the Department of Software and Information Systems Engineering at Ben-Gurion University of the Negev, Israel. She earned a B.Sc. and M.Sc. in secure communication systems from Bonch-Bruevich Saint-Petersburg State University of Telecommunications.
References
- Agirre, E., Gojenola, K., & Sarasola, K. (1998). Towards a single proposal is spelling correction. arXiv preprint cmp-lg/9806010.
- Alharbi, O., Arif, A. S., Stuerzlinger, W., Dunlop, M. D., & Komninos, A. (2019). WiseType: A tablet keyboard with color-coded visualization and various editing options for error correction [Paper presentation]. Graphics Interface 2019.
- Amell, T. K., & Kumar, S. (2000). Cumulative trauma disorders and keyboarding work. International Journal of Industrial Ergonomics, 25(1), 69–78. https://doi.org/10.1016/S0169-8141(98)00099-7
- Azenkot, S., & Lee, N. B. (2013). Exploring the use of speech input by blind people on mobile devices [Paper presentation]. Proceedings of the 15th International ACM SIGACCESS Conference on Computers and Accessibility, October, (pp. 1–8). https://doi.org/10.1145/2513383.2513440
- Bangor, A., Kortum, P., & Miller, J. (2009). Determining what individual SUS scores mean: Adding an adjective rating scale. Journal of usability studies, 4(3), 114–123.
- Basri, S. B., Alfred, R., On, C. K. (2012). Automatic spell checker for Malay blog. 2012 IEEE International Conference on Control System, Computing and Engineering, November, (pp. 506–510). IEEE.
- Becker, T., Blaylock, N., Gerstenberger, C., Kruijff-Korbayová, I., Korthauer, A., Pinkal, M., … Schehl, J. (2006, May). Natural and intuitive multimodal dialogue for in-car applications: The SAMMIE system. In ECAI (Vol. 6, pp. 612–616).
- Beelders, T. R., & Blignaut, P. J. (2010) Using vision and voice to create a multimodal interface for Microsoft Word 2007 [Paper presentation]. Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications, March, (pp. 173–176). https://doi.org/10.1145/1743666.1743709
- Bolt, R. A., (1980). Put-that-there” Voice and gesture at the graphics interface [Paper presentation]. Proceedings of the 7th Annual Conference on Computer Graphics and Interactive Techniques, July, (pp. 262–270). https://doi.org/10.1145/800250.807503
- Brownlow, N., Shein, F., Thomas, D., Milner, M., & Parnes, P. (1989). Direct manipulation: Problems with pointing devices. In Resna, June (Vol. 89, pp. 246–247).
- Bu, Y., & Guo, P. (2023). Voice orientation recognition: New paradigm of speech-based human-computer interaction. International Journal of Human–Computer Interaction, 1–20. https://doi.org/10.1080/10447318.2023.2233128
- Bullinger, H. J., Ziegler, J., & Bauer, W. (2002). Intuitive human-computer interaction-toward a user-friendly information society. International Journal of Human-Computer Interaction, 14(1), 1–23. https://doi.org/10.1207/S15327590IJHC1401_1
- Castellina, E., Corno, F., & Pellegrino, P. (2008). Integrated speech and gaze control for realistic desktop environments [Paper presentation]. Proceedings of the 2008 Symposium on Eye Tracking Research & Applications, March, (pp. 79–82). https://doi.org/10.1145/1344471.1344492
- Chu, S. M., & Povey, D. (2010). Speaking rate adaptation using continuous frame rate normalization [Paper presentation]. 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March (pp. 4306–4309). IEEE. https://doi.org/10.1109/ICASSP.2010.5495656
- Commarford, P. M., & Lewis, J. R. (2004). Models of throughput rates for dictation and voice spelling for handheld devices. International Journal of Speech Technology, 7(1), 69–79. https://doi.org/10.1023/B:IJST.0000004809.33755.b7
- Czaja, S. J. (1997). Computer technology and the older adult. In M. G. Helander, T. K. Landauer, & P. V. Prabhu (Eds.), Handbook of human-computer interaction (2nd ed., pp. 797–812). North-Holland. https://doi.org/10.1016/B978-044481862-1.50100-X
- Czaja, S. J., & Lee, C. C. (2002). Designing computer systems for older adults. In The human-computer interaction handbook: Fundamentals, evolving technologies and emerging applications (pp. 413–427). L. Erlbaum Associates Inc.
- Danis, C., Comerford, L., Janke, E., Davies, K., De Vries, J., & Bertrand, A. (1994). Conference companion on Human factors in computing systems,. Storywriter: A speech oriented editor, April (pp. 277–278). https://doi.org/10.1145/259963.260490
- De Mauro, C., Gori, M., Maggini, M., Martinelli, E. (1999). A voice device with an application-adapted protocol for microsoft windows. In Proceedings IEEE International Conference on Multimedia Computing and Systems, June, (Vol. 2, pp. 1015–1016.). IEEE.
- Fan, J., Xu, C., Yu, C., & Shi, Y. (2021). Just speak it: Minimize cognitive load for eyes-free text editing with a smart voice assistant [Paper presentation]. The 34th Annual ACM Symposium on User Interface Software and Technology, October. (pp. 910–921). https://doi.org/10.1145/3472749.3474795
- Feng, J., & Sears, A. (2007). Interaction techniques for users with spinal injuries: A speech-based solution. Universal Usability: Designing Computer Interfaces for Diverse User Populations.
- Findlater, L., Jansen, A., Shinohara, K., Dixon, M., Kamb, P., Rakita, J., Wobbrock, J. O. (2010). Enhanced area cursors: Reducing fine pointing demands for people with motor impairments. In Proceedings of the 23nd Annual ACM Symposium on User Interface Software and Technology, October, (pp. 153–162).
- Flor, M., Futagi, Y. (2012). On using context for automatic correction of non-word misspellings in student essays. In Proceedings of the Seventh Workshop on Building Educational Applications Using NLP, June. (pp. 105–115).
- Ghosh, D., Foong, P. S., Zhao, S., Liu, C., Janaka, N., Erusu, V. (2020a). Eyeditor: Towards on-the-go heads-up text editing using voice and manual input. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, April, (pp. 1–13).
- Ghosh, D., Liu, C., Zhao, S., & Hara, K. (2020b). Commanding and re-dictation: Developing eyes-free voice-based interaction for editing dictated text. ACM Transactions on Computer-Human Interaction, 27(4), 1–31. https://doi.org/10.1145/3390889
- Google. (n.d). Handsfree for web - voice control. Google. Retrieved September 17, 2022, from https://chrome.google.com/webstore/detail/handsfree-for-web-voice-c/ldfboinpfdahkgnljbkohgimhimmafip?hl=en
- Gu, J., & Lee, G. (2023). Towards more direct text editing with handwriting interfaces. International Journal of Human–Computer Interaction, 39(1), 233–248. https://doi.org/10.1080/10447318.2022.2041893
- Hamaker, E. L. (2012). Why researchers should think" within-person": A paradigmatic rationale.
- Hwang, F., Keates, S., Langdon, P., & Clarkson, P. J. (2003). Multiple haptic targets for motion-impaired computer users [Paper presentation]. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, April, (pp. 41–48). https://doi.org/10.1145/642611.642620
- Jacob, R. J. K. (1995). Eye tracking in advanced interface design. In W. Barfield & T. A. Furness (Eds.), Virtual environments and advanced interface design (pp. 258–288). Oxford University Press.
- Jacob, R. J., Leggett, J. J., Myers, B. A., & Pausch, R. (1993). Interaction styles and input/output devices. Behaviour & Information Technology, 12(2), 69–79. https://doi.org/10.1080/01449299308924369
- Karat, C. M., Halverson, C., Horn, D., & Karat, J. (1999). Patterns of entry and correction in large vocabulary continuous speech recognition systems [Paper presentation]. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, May, (pp. 568–575). https://doi.org/10.1145/302979.303160
- Kettebekov, S., & Sharma, R. (2000). Understanding gestures in multimodal human computer interaction. International Journal on Artificial Intelligence Tools, 09(02), 205–223. https://doi.org/10.1142/S021821300000015X
- Kishi, R., & Hayashi, T. (2015). Effective gazewriting with support of text copy and paste [Paper presentation]. 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS), June, (pp. 125–130). IEEE. https://doi.org/10.1109/ICIS.2015.7166581
- Kukich, K. (1992). Techniques for automatically correcting words in text. ACM Computing Surveys, 24(4), 377–439. https://doi.org/10.1145/146370.146380
- Larson, K., & Mowatt, D. (2003). Speech error correction: The story of the alternates list. International Journal of Speech Technology, 6(2), 183–194. https://doi.org/10.1023/A:1022342732234
- Lewis, J. R. (1999). Effect of error correction strategy on speech dictation throughput [Paper presentation]. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, September. (Vol. 43, No. 5, pp. 457–461). SAGE Publications. https://doi.org/10.1177/154193129904300514
- Luo, Y., Lee, B., Kim, Y. H., & Choe, E. K. (2022). NoteWordy: Investigating touch and speech input on smartphones for personal data capture. Proceedings of the ACM on Human-Computer Interaction, 6(ISS), 568–591. https://doi.org/10.1145/3567734
- Madison, J. (2012). Damn you, autocorrect!. Random House.
- Maglio, P. P., Matlock, T., Campbell, C. S., Zhai, S., & Smith, B. A. (2000). Gaze and speech in attentive user interfaces. In International Conference on Multimodal Interfaces, October (pp. 1–7). Springer.
- Majaranta, P., Majaranta, N., Daunys, G., Špakov, O. (2009). May)Text editing by gaze: Static vs. dynamic menus. In Proceedings of the 5th Conference on Communication by Gaze Interaction (COGAIN) (pp. 19–24.).
- Mantravadi, C. S. (2009). Adaptive multimodal integration of speech and gaze. Rutgers the State University of New Jersey-New Brunswick.
- McNair, A. E., & Waibel, A. (1994). Improving recognizer acceptance through robust, natural speech repair [Paper presentation]. Third International Conference on Spoken Language Processing.
- Mihara, Y., Shibayama, E., & Takahashi, S. (2005, October). The migratory cursor: Accurate speech-based cursor movement by moving multiple ghost cursors using non-verbal vocalizations. In Proceedings of the 7th International ACM SIGACCESS Conference on Computers and Accessibility (pp. 76–83).
- Mitton, R. (1996). English spelling and the computer. Longman Group.
- Mitton, R. (2009). Ordering the suggestions of a spellchecker without using context. Natural Language Engineering, 15(2), 173–192. https://doi.org/10.1017/S1351324908004804
- Nielsen, J. (1993). Noncommand user interfaces. Communications of the ACM, 36(4), 83–99. https://doi.org/10.1145/255950.153582
- Oviatt, S. (1997). Mulitmodal interactive maps: Designing for human performance. Human-Computer Interaction, 12(1), 93–129. https://doi.org/10.1207/s15327051hci1201&2_4
- Oviatt, S., & Cohen, P. (2000). Perceptual user interfaces: Multimodal interfaces that process what comes naturally. Communications of the ACM, 43(3), 45–53. https://doi.org/10.1145/330534.330538
- Oviatt, S., Cohen, P., Wu, L., Duncan, L., Suhm, B., Bers, J., Holzman, T., Winograd, T., Landay, J., Larson, J., & Ferro, D. (2000). Designing the user interface for multimodal speech and pen-based gesture applications: State-of-the-art systems and future research directions. Human–Computer Interaction, 15(4), 263–322. https://doi.org/10.1207/S15327051HCI1504_1
- Pedler, J. (2007). Computer correction of real-word spelling errors in dyslexic text [Doctoral dissertation]. University of London.
- Peterson, J. L. (1986). A note on undetected typing errors. Communications of the ACM, 29(7), 633–637. https://doi.org/10.1145/6138.6146
- Portela, M. V., & Rozado, D. (2014). Gaze enhanced speech recognition for truly hands-free and efficient text input during hci [Paper presentation]. Proceedings of the 26th Australian Computer-Human Interaction Conference on Designing Futures: The Future of Design, December (pp. 426–429). https://doi.org/10.1145/2686612.2686679
- Rello, L., Ballesteros, M., & Bigham, J. P. (2015). A spellchecker for dyslexia [Paper presentation]. Proceedings of the 17th International ACM SIGACCESS Conference on Computers & Accessibility, October (pp. 39–47). https://doi.org/10.1145/2700648.2809850
- Riviere, C. N., & Thakor, N. V. (1996). Effects of age and disability on tracking tasks with a computer mouse: Accuracy and linearity. Journal of Rehabilitation Research and Development, 33(1), 6–15. http://europepmc.org/abstract/MED/8868412
- Ruan, S., Wobbrock, J. O., Liou, K., Ng, A., & Landay, J. A. (2018). Comparing speech and keyboard text entry for short messages in two languages on touchscreen phones. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 1(4), 1–23. https://doi.org/10.1145/3161187
- Ruiz, N., Chen, F., Oviatt, S., Thiran, J. P., Marques, F., & Bourlard, H. (2009). Multimodal input. Multimodal Signal Processing: Theory and applications for human-computer interaction, 231–255.
- Sears, A., Feng, J., Oseitutu, K., & Karat, C. M. (2003). Hands-free, speech-based navigation during dictation: Difficulties, consequences, and solutions. Human-Computer Interaction, 18(3), 229–257. https://doi.org/10.1207/S15327051HCI1803_2
- Sears, A., Karat, C. M., Oseitutu, K., Karimullah, A., & Feng, J. (2001). Productivity, satisfaction, and interaction strategies of individuals with spinal cord injuries and traditional users interacting with speech recognition software. Universal Access in the Information Society, 1(1), 4–15. https://doi.org/10.1007/s102090100001
- Sengupta, K., Ke, M., Menges, R., Kumar, C., Staab, S. (2018). Hands-free web browsing: Enriching the user experience with gaze and voice modality. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, June (pp. 1–3).
- Sengupta, K., Bhattarai, S., Sarcar, S., MacKenzie, I. S., & Staab, S. (2020). Leveraging error correction in voice-based text entry by Talk-and-Gaze [Paper presentation]. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, April (pp. 1–11). https://doi.org/10.1145/3313831.3376579
- Shanis, J. M., & Hedge, A. (2003). Comparison of mouse, touchpad and multitouch input technologies [Paper presentation]. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, October (Vol. 47, No. 4, pp. 746–750). SAGE Publications. https://doi.org/10.1177/154193120304700418
- Shneiderman, B., Plaisant, C., Cohen, M. S., Jacobs, S., Elmqvist, N., & Diakopoulos, N. (2016). Designing the user interface: Strategies for effective human-computer interaction (6th ed.). Pearson. http://www.cs.umd.edu/hcil/DTUI6
- Sibert, L. E., & Jacob, R. J. (2000). Evaluation of eye gaze interaction [Paper presentation]. Proceedings of the SIGCHI conference on Human Factors in Computing Systems, April) (pp. 281–288). https://doi.org/10.1145/332040.332445
- Siegler, M. A., Stern, R. M. (1995). On the effects of speech rate in large vocabulary speech recognition systems. In 1995 International Conference on Acoustics, Speech, and Signal Processing, May (Vol. 1, pp. 612–615). IEEE.
- Sindhwani, S., Lutteroth, C., Weber, G. (2019). ReType: Quick text editing with keyboard and gaze. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, May) (pp. 1–13).
- Singh, S., & Singh, S. (2018). Review of real-word error detection and correction methods in text documents [Paper presentation]. 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), March (pp. 1076–1081). IEEE. https://doi.org/10.1109/ICECA.2018.8474700
- Suhm, B., Myers, B., & Waibel, A. (2001). Multimodal error correction for speech user interfaces. ACM Transactions on Computer-Human Interaction, 8(1), 60–98. https://doi.org/10.1145/371127.371166
- Trewin, S., & Pain, H. (1999). Keyboard and mouse errors due to motor disabilities. International Journal of Human-Computer Studies, 50(2), 109–144. https://doi.org/10.1006/ijhc.1998.0238
- Trewin, S., Keates, S., & Moffatt, K. (2006). Developing steady clicks: A method of cursor assistance for people with motor impairments [Paper presentation]. Proceedings of the 8th International ACM SIGACCESS Conference on Computers and Accessibility, October (pp. 26–33).
- Type with your voice - Google Docs Editors Help. (n.d). https://support.google.com/docs/answer/4492226?hl=en#zippy=%2Cedit-your-document
- Valles, M., Manso, F., Arredondo, M. T., del Pozo, F. (1996). Multimodal environmental control system for elderly and disabled people. In Proceedings of 18th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, October (Vol. 2, pp. 516–517.). IEEE.
- Velichkovsky, B., Sprenger, A., & Unema, P. (1997). Towards gaze-mediated interaction: Collecting solutions of the “Midas touch problem. In Human-Computer Interaction INTERACT’97 (pp. 509–516). Springer.
- Vertanen, K., MacKay, D. J. (2010). Speech dasher: Fast writing using speech and gaze. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, April (pp. 595–598).
- Wang, L., & Soong, F. K. P. (2009). U.S. Patent Application No. 12/042. 344.
- Wobbrock, J. O., Fogarty, J., Liu, S. Y., Kimuro, S., Harada, S. (2009). The angle mouse: Target-agnostic dynamic gain adjustment based on angular deviation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, April (pp. 1401–1410).
- Wobbrock, J. O., & Gajos, K. Z. (2008). Goal crossing with mice and trackballs for people with motor impairments: Performance, submovements, and design directions. ACM Transactions on Accessible Computing, 1(1), 1–37. https://doi.org/10.1145/1361203.1361207
- Woods, V., Hastings, S., Buckle, P., & Haslam, R. (2002). Ergonomics of using a mouse or other non-keyboard input device. © Health and Safety Executive.
- Worden, A., Walker, N., Bharat, K., Hudson, S. (1997). Making computers easier for older adults to use: Area cursors and sticky icons. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, March (pp. 266–271).
- Yeh, J. F., Chen, W. Y., & Su, M. C. (2015). Chinese spelling checker based on an inverted index list with a rescoring mechanism. ACM Transactions on Asian and Low-Resource Language Information Processing, 14(4), 1–28. https://doi.org/10.1145/2826235
- Zhao, M., Cui, W., Ramakrishnan, I. V., Zhai, S., & Bi, X. (2021). Voice and touch based error-tolerant multimodal text editing and correction for smartphones [Paper presentation]. In the 34th Annual ACM Symposium on User Interface Software and Technology, October (pp. 162–178). https://doi.org/10.1145/3472749.3474742
- Zhao, M., Huang, H., Li, Z., Liu, R., Cui, W., Toshniwal, K., … Bi, X. (2022). EyeSayCorrect: Eye gaze and voice based hands-free text correction for mobile devices [Paper presentation]. 27th International Conference on Intelligent User Interfaces, March (pp. 470–482). https://doi.org/10.1145/3490099.3511103