Abstract
A local modal estimation procedure is proposed for the regression function in a nonparametric regression model. A distinguishing characteristic of the proposed procedure is that it introduces an additional tuning parameter that is automatically selected using the observed data in order to achieve both robustness and efficiency of the resulting estimate. We demonstrate both theoretically and empirically that the resulting estimator is more efficient than the ordinary local polynomial regression (LPR) estimator in the presence of outliers or heavy-tail error distribution (such as t-distribution). Furthermore, we show that the proposed procedure is as asymptotically efficient as the LPR estimator when there are no outliers and the error distribution is a Gaussian distribution. We propose an expectation–maximisation-type algorithm for the proposed estimation procedure. A Monte Carlo simulation study is conducted to examine the finite sample performance of the proposed method. The simulation results confirm the theoretical findings. The proposed methodology is further illustrated via an analysis of a real data example.
1. Introduction
Local polynomial regression (LPR) has been popular in the literature due to its simplicity of computation and nice asymptotic properties (Fan and Gijbels Citation1996). The local M-estimator (LM) has been investigated in the presence of outliers by many authors; see Härdle and Gasser Citation(1984), Tsybakov Citation(1986), Härdle and Tsybakov Citation(1988), Hall and Jones Citation(1990), Fan, Hu, and Truong Citation(1994), Fan and Jiang Citation(2000), Jiang and Mack Citation(2001), among others. As usual, a nonparametric M-type of regression will be more efficient than least-squares-based nonparametric regression when there are outliers or the error distribution has a heavy tail. However, these methods lose some efficiency when there are no outliers or the error distribution is normal. Thus, it is desirable to develop a new local modelling procedure which can achieve both robustness and efficiency by adapting to different types of error distributions.
In this paper, we propose a local modal regression (LMR) procedure. The sampling properties of the proposed estimation procedure are systematically studied. We show that the proposed estimator is more efficient than the ordinary least-squares-based LPR estimator in the presence of outliers or heavy-tail error distribution. Furthermore, the proposed estimator achieves a full asymptotic efficiency of the ordinary LPR estimator when there are no outliers and the error distribution is a Gaussian distribution. We further develop a modal expectation–maximisation (MEM) algorithm for the LMR. Thus, the proposed modal regression can be implemented easily in practice. We conduct a Monte Carlo simulation to assess the finite sample performance of the proposed procedure. The simulation results show that the proposed procedure is robust to outliers and performs almost as well as the local likelihood regression (LLH) estimator (Tibshirani and Hastie Citation1987) constructed using the true error function. In other words, the proposed estimator is almost as efficient as an omniscient estimator.
The remainder of the paper is organised as follows. In Section 2, we propose the LMR, develop the MEM algorithm for the LMR estimator, and study the asymptotic properties of the resulting estimator. In Section 3, we describe the Monte Carlo simulation study conducted and use a real data example to illustrate the proposed methodology. Technical conditions and proofs are given in Appendix 1.
2. The LMR estimator
Suppose that are independent and identically distributed (iid) random samples from
The local parameter is estimated by minimising the following weighted least-squares function:
Our LMR estimation procedure is to maximise over
We will refer to as the LMR estimator. Specially, when p=1 and v=0, we refer to this method as local linear modal regression (LLMR). When p=0, EquationEquation (2)
reduces to
In general, it is known that the sample mode is inherently insensitive to outliers as an estimator for the population mode. The robustness of the proposed procedure can be further interpreted from the point of view of M-estimation. If we treat as a loss function, the resulting M-estimator is an LMR estimator. The bandwidth h
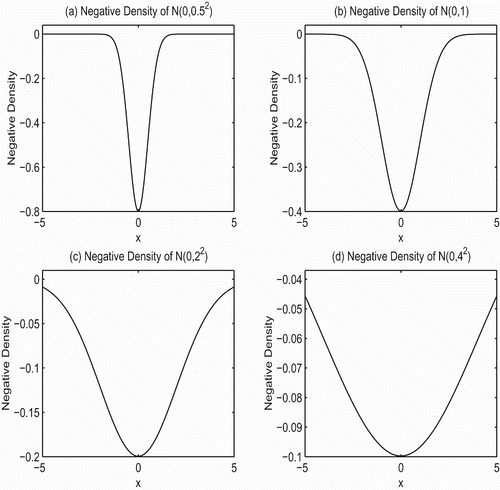
2 determines the degree of robustness of the estimator. provides insights into how the LMR estimator achieves the adaptive robustness. Note that
corresponds to the variance in the normal density. From , it can be seen that the negative normal density with small h
2, such as h
2=0.5, looks like an outlier-resistant loss function, while the shape of the negative normal density with large h
2, for example, h
2=4, is similar to that of the L
2-loss function. In practice, h
2 is selected by a data-driven method so that the resulting local estimate is adaptively robust. The issue of selection of both bandwidths h
1 and h
2 will be addressed later on.
Figure 1. Plot of negative normal densities.
2.1. The MEM algorithm
In this section, we extend the MEM algorithm, proposed by Li, Ray, and Lindsay Citation(2007), to maximise EquationEquation (2). Similar to an expectation–maximisation (EM) algorithm, the MEM algorithm also consists of two steps: E-step and M-step. Let
be the initial value and start with k=0:
E-step: In this step, we update | |||||
M-step: In this step, we update | |||||
The MEM algorithm requires one to iterate the E-step and the M-step until the algorithm converges. The ascending property of the proposed MEM algorithm can be established along the lines of the study of Li et al. Citation(2007). The closed-form solution for is one of the benefits of using the normal density function
in EquationEquation (2)
. If
, it can be seen in the E-step that
From the MEM algorithm, it can be seen that the major difference between the LPR and the LMR lies in the E-step. The contribution of observation (x
i
, y
i
) to the LPR depends on the weight , which in turn depends on how close x
i
is to x
0 only. On the other hand, the weight in the LMR depends on both how close x
i
is to x
0 and how close y
i
is to the regression curve. This weight scheme allows the LMR to downweight the observations further away from the regression curve to achieve adaptive robustness.
The iteratively reweighted least-squares (IRWLS) algorithm can be also applied to our proposed LMR. When normal kernel is used for φ(·), the reweighted least-squares algorithm is actually equivalent to the proposed EM algorithm (but they are different if φ(·) is not normal). In addition, the IRWLS algorithm has been proved to have monotone and convergence properties if −φ(x)/x is non-increasing. But the proposed EM algorithm has been proved to have monotone property for any kernel density φ(·). Note that −φ(x)/x is not non-increasing if φ(x) has normal density. Therefore, the proposed EM algorithm provides a better explanation why the IRWLS algorithm is monotone for normal kernel density.
2.2. Theoretical properties
We first establish the convergence rate of the LMR estimator in the following theorem, the proof of which is given in Appendix 1.
Theorem 2.1
Under the regularity conditions (A1)– (A7) given in Appendix 1, with probability approaching 1, there exists a consistent local maximiser
of Equation
Equation(2)
such that
To derive the asymptotic bias and variance of the LMR estimator, we need the following notation. The moments of K and K 2 are denoted, respectively, by
Let
If ε and X are independent, then F(x, h 2) and G(x, h 2) are independent of x and we will use F(h 2) and G(h 2) to denote them, respectively, in this situation. Furthermore, denote the marginal density of X, that is, the design density, by f(·).
Theorem 2.2
Under the regularity conditions (A1)– (A7) given in Appendix 1, the asymptotic variance of
given in Theorem 2.1, is given by
The proof of Theorem 2.2 is given in Appendix 1. Based on EquationEquation (7) and the asymptotic variance of the LPR estimator given in Fan and Gijbels Citation(1996), we can show that the ratio of the asymptotic variance of the LMR estimator to that of the LPR estimator is given by
Based on EquationEquations (8) and Equation(9)
and the asymptotic bias of the LPR estimator (Fan and Gijbels Citation1996), we know that the LMR estimator and the LPR estimator have the same asymptotic bias when p−v is odd. When p−v is even, they are still the same provided that ε and X are independent as a(x
0) defined in EquationEquation (10)
equals
, but they are different if ε and X are not independent. Similar to the LPR, the second term in EquationEquation (9)
often creates extra bias. Thus, it is preferable to use odd values of p−v in practice. Thus, it is consistent with the selection order of p for the LPR (Fan and Gijbels Citation1996). From now on, we will concentrate on the case when p−v is odd.
Theorem 2.3
Under the regularity conditions (A1)– (A7) given in Appendix 1, the estimate
given in Theorem 2.1, has the following asymptotic distribution:
The proof of Theorem 2.3 is given in Appendix 1.
2.3. Asymptotic bandwidth and relative efficiency
Note that the mean squared error (MSE) of the LMR estimator, , is
The asymptotic relative efficiency (ARE) between the LMR estimator with h 1, opt and h 2, opt and the LPR estimator with h LPR of m (v)(x 0) with order p is
From EquationEquation (16), we can see that R(x
0, h
2) completely determines the ARE for fixed p and v. Let us study the properties of R(x, h
2) further.
Theorem 2.4
Let
be the conditional density of ε given X=x. For R(x, h
2) defined in Equation
Equation(11)
, given any x, we have the following results.
(a)
| |||||
(b) If
| |||||
(c) Assuming
| |||||
The proof of Theorem 2.4 is given in Appendix 1. From (a) and EquationEquation (16), one can see that the supremum (over h
2) of the relative efficiency between the LMR and the LPR is greater than or equal to 1. Hence, the LMR works at least as well as the LPR for any error distribution. If there exists some h
2 such that R(x, h
2)<1, then the LMR estimator has a smaller asymptotic MSE than the LPR estimator.
As discussed in Section 2.3, when , the LMR converges to the LPR. The equation
of (a) confirms this result. It can be seen from (b) that when
, the optimal LMR (with
) is the same as the LPR. This is why the LMR will not lose efficiency under normal distribution. From (c), one can see that the optimal h
2 should not be too small, which is quite different from the needed locality effect of h
1.
lists the ARE between the LLMR estimator (LMR with p=1 and v=0) and the local linear regression (LLR) estimator for a normal error distribution and some special error distributions that are generally used to evaluate the robustness of a regression method. The normal mixture is used to mimic the outlier situation. This kind of mixture distribution is also called the contaminated normal distribution. The t-distributions with degrees of freedom ranging from 3 to 5 are often used to represent heavy-tail distributions. From , one can see that the improvement of the LLMR over the LLR is substantial when there are outliers or the error distribution has heavy tails.
Table 1. Relative efficiency between the LLMR estimator and the LLR estimator.
3. Simulation study and application
In this section, we describe the Monte Carlo simulation conducted to assess the performance of the proposed LLMR estimator and compare it with the LLR estimator and some commonly used robust estimators. We first address how to select the bandwidths h 1 and h 2 in practice.
3.1. Bandwidth selection in practice
In our simulation setting, ε and X are independent. Thus, we need to estimate F(h
2) and G(h
2) defined in EquationEquation (6) in order to find the optimal bandwidth h
2, opt based on EquationEquation (12)
. To this end, we first get an initial estimate of m(x), denoted by
, and the residual
, by fitting the data using any simple robust smoothing method, such as locally weighted scatterplot smoothing (LOWESS). Then, we estimate F(h
2) and G(h
2) by
The asymptotically optimal bandwidth h
1 is much easier to estimate after finding . Based on formula Equation(14)
given in Section 2.5, the asymptotically optimal bandwidth for h
1 of the LLMR is h
LLR multiplied by a factor
. After finding
, we can estimate
by
. We can then employ an existing bandwidth selector for the LLR, such as the plug-in method (Ruppert, Sheather, and Wand Citation1995). If the optimal bandwidth selected for the LLR is
, then h
1 is estimated by
.
When ε and X are independent, the relationship Equation(14) also holds for the global optimal bandwidth that is obtained by minimising the weighted mean integrated square error
where w≥0 is some weight function, such as 1 or design density f(x). Hence, the above proposed method of finding
also works for the global optimal bandwidth. For simplicity of computation, we use the global optimal bandwidth for
and thus
for our examples in Sections 3.2 and 3.3.
3.2. Simulation study
For comparison, in our simulation study, we included the LLH estimator (Tibshirani and Hastie Citation1987) assuming that the error distribution is known. Specifically, suppose the error distribution is g(t), the LLH estimator finds by maximising the following local likelihood:
If the error density g(t) is assumed to be known, the LLH estimator Equation(17) is the most efficient estimator. However, in reality, we seldom know the true error density. The LLH estimator is just used as a benchmark, omniscient estimator to check how well the LLMR estimator adapts to different true densities.
We generated the iid data from the model
, where X
i
∼ U(0, 1). We considered the following three cases:
Case I: | |||||
Case II: | |||||
Case III: | |||||
We compared the following five estimators:
(1) LLR. We used the plug-in bandwidth (Ruppert et al. Citation1995). | |||||
(2) Local ℓ1 regression/median regression (LMED). | |||||
(3) LM using Huber's function | |||||
(4) LLMR (LMR with p=1 and v=0). | |||||
(5) LLH using the true error density. | |||||
For comparison, in , we report the relative efficiency between different estimators and the benchmark estimator LLH, where RE(LLMR) is the relative efficiency between the LLMR estimator and the LLH estimator. That is, RE(LLMR) is the ratio of MSE(LLH) to MSE(LLMR) (based on 50 equally spaced grid points from 0.05 to 0.95 and 500 replicates). The same notation applies to other methods.
Table 2. Relative efficiency between different estimators and the LLH estimator.
From , it can be seen that for a normal error, the LLMR had a relative efficiency very close to 1 from the small sample size 50 to the large sample size 500. Note that in Case I, we need not use a robust procedure and the LLR should work the best in this case. Note that in this case, the LLR is the same as the LLH. However, the newly proposed method LLMR worked almost as well as the LLR/LLH when the error distribution was exactly the normal distribution. Hence, the LLMR adapted to normal errors very well. In addition, we can see that the LM lost about 8% efficiency for the small size 50 and lost about 5% efficiency for the large sample size 500. The LMED lost more than 30% efficiency under normal errors.
For contaminated normal errors, the LLMR still had a relative efficiency close to 1 and worked better than the LM, especially for large sample sizes. Hence, the LLMR adapted to contaminated normal error distributions quite well. In this case, the LLR lost more than 40% efficiency and the LMED lost about 30% efficiency.
For t 3 error, it can be seen from that the LLMR also worked similarly to the LLH and a little better than the LM, especially for large sample sizes. Hence, the LLMR also adapted to t-distribution errors quite well. In this case, the LLR lost more than 40% efficiency and the LMED lost about 15% efficiency.
3.3. An application
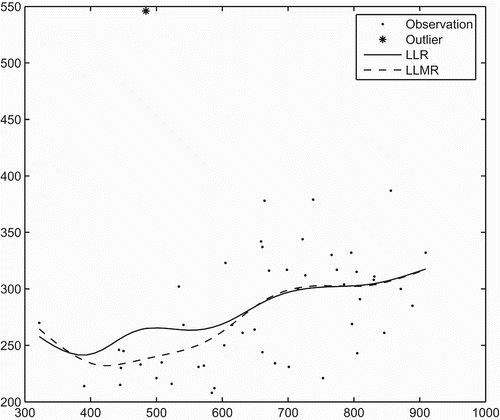
In this section, we illustrate the proposed methodology by analysis of the Education Expenditure Data (Chatterjee and Price Citation1977). This data set consists of 50 observations from 50 states, one for each state. The two variables to be considered here are X, the number of residents per thousand residing in urban areas in 1970, and Y, the per capita expenditure on public education in a state, projected for 1975. For this example, one can easily identify the outlier. We use this example to show how the obvious outlier will affect the LLR fit and the LLMR fit.
shows the scatter plot of the original observations and the fitted regression curves by the LLR and the LLMR. From , one can see that there is an extreme observation (outlier). This extreme observation is from Hawaii, which has a very high per capita expenditure on public education with x value being close to 500. This observation created the biggest difference between the two fitted curves around x=500. The observations with x around 500 appear to go down in that area compared with the observations with x around 600. Thus, the regression function should also go down when x moves from 600 to 500. The LLMR fit reflected this fact. (For this example, the robust estimators LMED and LM provided results that were similar to those of the estimator LLMR.) However, the LLR fit went up in that area due to the big impact of the extreme observation from Hawaii. In fact, this extreme observation received about a 10% weight in the LLR fit at x=500, compared with nearly 0% weight in the LLMR fit. Hence, unlike the LLR, the LLMR adapts to, and is thereby robust to, outliers.
Figure 2. Plot of fitted regression curves for the Education Expenditure Data. The star point represents the extreme observation from Hawaii. The solid curve represents the LLR fit. The dashed curve represents the LLMR fit.
4. Discussion
In this paper, we have proposed an LMR procedure. It introduces an additional tuning parameter that is automatically selected using the observed data in order to achieve both robustness and efficiency of the resulting nonparametric regression estimator. Modal regression has been briefly discussed in Scott (Citation1992, sec. 8.3.2) without any detailed asymptotic results. Scott (Citation1992, sec. 8.3.2) used a constant β0 to estimate the local mode as EquationEquation (4). Due to the advantage of the LPR over the local constant regression, we extended the local constant structure to a local polynomial structure and provided a systematic study of the asymptotic results of the LMR estimator. As a measure of centre, the modal regression uses the ‘most likely’ conditional values rather than the conditional average. When the conditional density is symmetric, these two criteria match. However, as stated by Scott (Citation1992, sec. 8.3.2), the modal regression, besides robustness, can explore a more complicated data structure when there are multiple local modes. Hence, the LMR may be applied to a mixture of regressions (Goldfeld and Quandt Citation1976; Fruhwirth-Schnatter 2001; Green and Richardson Citation2002; Rossi, Allenby, and McCulloch Citation2005) and ‘change point’ problems (Lai Citation2001; Bai and Perron Citation2003; Goldenshluger, Tsbakov, and Zeevi Citation2006). This requires further research.
Chu, Glad, Godtliebsen, and Marron Citation(1998) also used the Gaussian kernel as the outlier-resistant function in their proposed local constant M-smoother for image processing. However, they let and aimed at edge-preserving smoothing when there is a jump in the regression curves. In this paper, the goal was different; we sought to provide an adaptive robust regression estimate for the smooth regression function m(x) by adaptively choosing h
2. In addition, we proved that for a regression estimate, the optimal h
2 does not depend on n and should not be too small.
In addition, note that the LMR does not estimate the mean function in general. It requires the assumption , which holds if the error density is symmetric about zero. If the above assumption about the error density does not hold, the proposed estimate is actually estimating the function
Acknowledgements
The authors are grateful to the editors and the referees for their insightful comments on this paper. Bruce G. Lindsay's research was supported by an NSF grant CCF 0936948. Runze Li's research was supported by the National Natural Science Foundation of China grant 11028103, NSF grant DMS 0348869, and National Institute on Drug Abuse (NIDA) grant P50-DA10075. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIDA or the NIH.
References
- Bai , J. and Perron , P. 2003 . Computation and Analysis of Multiple Structural Change Models . Journal of Applied Econometrics , 18 : 1 – 22 .
- Chatterjee , S. and Price , B. 1977 . Regression Analysis by Example , New York : Wiley .
- Chu , C. K. , Glad , I. , Godtliebsen , F. and Marron , J. S. 1998 . Edge-Preserving Smoothers for Image Processing (with discussion) . Journal of the American Statistical Association , 93 : 526 – 556 .
- Fan , J. and Gijbels , I. 1996 . Local Polynomial Modelling and its Applications , London : Chapman and Hall .
- Fan , J. and Jiang , J. 2000 . Variable Bandwidth and One-Step Local M-Estimator . Science in China Series A , 43 : 65 – 81 .
- Fan , J. , Hu , T. and Truong , Y. 1994 . Robust Non-Parametric Function Estimation . Scandinavian Journal of Statistics , 21 : 433 – 446 .
- Frühwirth-Schnatter , S. 2001 . Markov Chain Monte Carlo Estimation of Classical and Dynamic Switching and Mixture Models . Journal of the American Statistical Association , 96 : 194 – 209 .
- Goldenshluger , A. , Tsbakov , A. and Zeevi , A. 2006 . Optimal Change-Point Estimation from Indirect Observations . Annals of Statistics , 34 : 350 – 372 .
- Goldfeld , S. M. and Quandt , R. E. 1976 . A Markov Model for Switching Regression . Journal of Econometrics , 1 : 3 – 16 .
- Green , P. J. and Richardson , S. 2002 . Hidden Markov Models and Disease Mapping . Journal of the American Statistical Association , 97 : 1055 – 1070 .
- Hall , P. and Jones , M. C. 1990 . Adaptive M-Estimation in Nonparametric Regression . Annals of Statistics , 18 : 1712 – 1728 .
- Härdle , W. and Gasser , T. 1984 . Robust Nonparametric Function Fitting . Journal of the Royal Statistical Society Series B Statistical Methodology , 46 : 42 – 51 .
- Härdle , W. and Tsybakov , A. B. 1988 . Robust Nonparametric Regression with Simultaneous Scale Curve Estimation . Annals of Statistics , 16 : 120 – 135 .
- Jiang , J. and Mack , Y. 2001 . Robust Local Polynomial Regression for Dependent Data . Statistica Sinica , 11 : 705 – 722 .
- Lai , T. L. 2001 . Sequential Analysis: Some Classical Problems and New Challenges . Statistica Sinica , 11 : 303 – 408 .
- Li , J. , Ray , S. and Lindsay , B. G. 2007 . A Nonparametric Statistical Approach to Clustering via Mode Identification . Journal of Machine Learning Research , 8 ( 8 ) : 1687 – 1723 .
- Rossi , P. E. , Allenby , G. M. and McCulloch , R. 2005 . Bayesian Statistics and Marketing , Chichester : Wiley .
- Ruppert , D. , Sheather , S. J. and Wand , M. P. 1995 . An Effective Bandwidth Selector for Local Least Squares Regression . Journal of the American Statistical Association , 90 : 1257 – 1270 .
- Scott , D. W. 1992 . Multivariate Density Estimation: Theory, Practice and Visualization , New York : Wiley .
- Tibshirani , R. J. and Hastie , T. J. 1987 . Local Likelihood Estimation . Journal of the American Statistical Association , 82 : 559 – 567 .
- Tsybakov , A. B. 1986 . Robust Reconstruction of Functions by the Local Approximation Method . Problems in Information Transmission , 22 : 133 – 146 .
Appendix 1: Proofs
The following technical conditions are imposed in this section:
Equation(A1) | |||||
(A2) f(x) has a continuous first derivative at the point x 0 and f(x 0)>0. | |||||
(A3) F(x, h
2) and G(x, h
2) are continuous with respect to x at the point x
0, where F(x, h
2) and G(x, h
2) are defined in EquationEquation (6) | |||||
(A4) K(·) is a symmetric (about zero) probability density with compact support [−1, 1]. | |||||
(A5) F(x 0, h 2)<0 for any h 2>0. | |||||
(A6) | |||||
(A7) The bandwidth h
1 tends to zero such that | |||||
Denote ,
,
,
, and
, where
, j=0, 1, …, p. The following lemmas are needed for our technical proofs.
Lemma A.1
Assume that conditions A1–A6 hold. We have
Proof
We shall prove Equation Equation(A1), since Equation Equation(A2)
can be shown by the same arguments. Denote
. In lines of arguments that are the same as those in Lemma 5.1 of Fan and Jiang Citation(2000), we have
Proof
[Proof of Theorem 2.1] Denote . It is sufficient to show that for any given η>0, there exists a large constant c such that
Using Taylor expansion, it follows that
By directly calculating the mean and the variance, we obtain
Define
Lemma A.2
Under conditions (A1)– (A6), it follows that
Proof
Let
Proof
[Proof of Theorem 2.2] Based on Equation Equation(A5) and condition Equation(A6)
, we can easily get
. Similar to the proof in Lemma A.1, we have
Then, it follows from Equation Equation(A7) that
Proof
[Proof of Theorem 2.3] It is sufficient to show that
Proof
[Proof of Theorem 2.4]
(a) Note that | |||||
(b) Suppose | |||||
(c) Suppose that | |||||