
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper explores the homogeneity of coefficient functions in nonlinear models with functional coefficients and identifies the underlying semiparametric modelling structure. With initial kernel estimates, we combine the classic hierarchical clustering method with a generalised version of the information criterion to estimate the number of clusters, each of which has a common functional coefficient, and determine the membership of each cluster. To identify a possible semi-varying coefficient modelling framework, we further introduce a penalised local least squares method to determine zero coefficients, non-zero constant coefficients and functional coefficients which vary with an index variable. Through the nonparametric kernel-based cluster analysis and the penalised approach, we can substantially reduce the number of unknown parametric and nonparametric components in the models, thereby achieving the aim of dimension reduction. Under some regularity conditions, we establish the asymptotic properties for the proposed methods including the consistency of the homogeneity pursuit. Numerical studies, including Monte-Carlo experiments and two empirical applications, are given to demonstrate the finite-sample performance of our methods.
1. Introduction
We consider the functional-coefficient model defined by
(1)
(1)
where
is a response variable,
is a p-dimensional vector of random covariates,
is a p-dimensional vector of functional coefficients,
is a univariate index variable, and
is an independent and identically distributed (i.i.d.) error term. The functional-coefficient model is a natural extension of the classic linear regression model by allowing the regression coefficients to vary with a certain index variable and thus captures a flexible dynamic relationship between the response and covariates. In recent years, there have been extensive studies on estimation and model selection for model (Equation1
(1)
(1) ) and its various generalised versions (see, e.g. Fan and Zhang Citation1999; Cai, Fan, and Yao Citation2000; Xia, Zhang, and Tong Citation2004; Fan and Zhang Citation2008; Wang and Xia Citation2009; Kai, Li, and Zou Citation2011; Park, Mammen, Lee, and Lee Citation2015).
However, when the number of functional coefficients is large or moderately large, it is well known that a direct nonparametric estimation of the potentially p different coefficient functions in model (Equation1(1)
(1) ) would be unstable. To address this issue, there have been some extensive studies in the literature on selecting significant variables in functional-coefficient models (Fan, Ma, and Dai Citation2014; Liu, Li, and Wu Citation2014) or exploring certain rank-reduced structures in functional coefficients (Jiang, Wang, Xia, and Jiang Citation2013; Chen, Li, and Xia Citation2019), both of which aim to reduce the dimension of unknown functional coefficients and improve estimation efficiency. In this paper, we consider a different approach, i.e. we assume that there is a homogeneity structure on model (Equation1
(1)
(1) ) so that individual functional coefficients can be grouped into a number of clusters and coefficients within each cluster have the same functional pattern. Throughout the paper, we assume that the dimension p may depend on the sample size n and can be divergent with n, but the number of unknown clusters is fixed and much smaller than p. It is easy to see that the dimension reduction through homogeneity pursuit is more general than the commonly used sparsity assumption in high-dimensional functional-coefficient models (cf. Fan et al. Citation2014; Liu et al. Citation2014; Li, Ke, and Zhang Citation2015 Lee and Mammen Citation2016) as the latter can be seen as a special case of the former with a very large group of zero coefficients. Specifically, we assume the following homogeneity structure on model (Equation1
(1)
(1) ): there exists a partition of
denoted by
such that
(2)
(2)
where the Lebesgue measure of
is positive and bounded away from zero for any
, and
is a compact support of the index variable
. Furthermore, some of the functional coefficients
are allowed to have constant values, in which case model (Equation1
(1)
(1) ) is semiparametric with a combination of constant and functional coefficients. Our aim is to (i) explore homogeneity structure (Equation2
(2)
(2) ) by estimating the unknown number of clusters
and identifying members of the clusters
; and (ii) identify the clusters of constant coefficients and those of coefficients varying with
and estimate their unknown values.
The topic investigated in our paper has two close relatives in the existing literature. On the one hand, the functional-coefficient regression with the homogeneity structure is a natural extension of linear regression with homogeneity structure, which has received increasing attention in recent years. For example, Tibshirani, Saunders, Rosset, Zhu, and Knight (Citation2005) introduce the so-called fused LASSO method to study slope homogeneity; Bondell and Reich (Citation2008) propose the OSCAR penalised method for grouping pursuit; Shen and Huang (Citation2010) use a truncated penalised method to extract the latent grouping structure; and Ke, Fan, and Wu (Citation2015) propose the CARDS method to identify the homogeneity structure and estimate the parameters simultaneously. On the other hand, this paper is also relevant to some recent literature on longitudinal/panel data model classification. For example, Ke, Li, and Zhang (Citation2016) and Su, Shi, and Phillips (Citation2016) consider identifying the latent group structure for linear longitudinal data models by using the binary segmentation and shrinkage method, respectively; Vogt and Linton (Citation2017) introduce a kernel-based classification of univariate nonparametric regression functions in longitudinal data; and Su, Wang, and Jin (Citation2019) propose a penalised sieve estimation method to identify latent grouping structure for time-varying coefficient longitudinal data models. The methodology of nonparametric homogeneity pursuit developed in this paper will be substantially different from those in the aforementioned literature.
In this paper, we first estimate each functional coefficient in model (Equation1(1)
(1) ) by using the kernel smoothing method and ignoring homogeneity structure (Equation2
(2)
(2) ), and calculate the
-distance between the estimated functional coefficients. Then, we combine the classic hierarchical clustering method and a generalised version of the information criterion to explore homogeneity structure (Equation2
(2)
(2) ), i.e. estimate
and the members of
,
. Under some mild conditions, we show that the developed estimators for the number
and the index sets
,
, are consistent. After estimating structure (Equation2
(2)
(2) ), we further estimate a semi-varying coefficient modelling framework by determining the zero coefficients, non-zero constant coefficients and functional coefficients varying with the index variable. This is done by using a penalised local least squares method, where the penalty function is the weighted LASSO with the weights defined as derivatives of the well-known SCAD penalty introduced by Fan and Li (Citation2001). With the nonparametric cluster analysis and the penalised approach, we can reduce the number of unknown components in model (Equation1
(1)
(1) ) from p to
(if the zero constant coefficients exist in the model). Furthermore, the choice of the tuning parameters in the proposed estimation approach and the computational algorithm is also discussed. The simulation studies show that the proposed methods have reliable finite-sample numerical performance. We finally apply the model and methodology to analyse the Boston house price data and the plasma beta-carotene level data, and find that the original nonparametric functional-coefficient models can be simplified and the number of unknown components involved can be reduced. In particular, the out-of-sample mean absolute prediction errors of our approach are usually much smaller than those using the naive kernel method which ignores the latent homogeneity structure.
The rest of the paper is organised as follows. Section 2 introduces the clustering method, information criterion and penalised method to determine the unknown clusters and estimate the unknown components. Section 3 establishes the asymptotic theory for the proposed clustering and estimation methods. Section 4 discusses the choice of the tuning parameters and introduces an algorithm for computing the penalised estimates. Section 5 reports Monte-Carlo simulation studies. Section 6 gives the empirical applications to the Boston house price data and the plasma beta-carotene level data. Section 7 concludes the paper. The proofs of the main asymptotic theorems are given in a supplemental document.
2. Methodology
In this section, we first introduce a clustering method for kernel estimated functional coefficients in Section 2.1, followed by a generalised information criterion for determining the number of clusters in Section 2.2, and finally, propose a penalised local linear estimation approach to identify the semi-varying coefficient modelling structure in Section 2.3.
2.1. Kernel-based clustering method
Assuming that the coefficient functions have continuous second-order derivatives, we can use the kernel smoothing method (cf. Wand and Jones Citation1995) to obtain preliminary estimates of ,
, which are denoted by
,
. Let
,
and
with
, where
is a kernel function and h is a bandwidth which tends to zero as the sample size n diverges to infinity. Then the kernel estimation
can be expressed as follows:
(3)
(3)
where
is on the support of the index variable. Note that other commonly used nonparametric estimation methods such as the local polynomial method (Fan and Gijbels Citation1996) and B-spline method (Green and Silverman Citation1994) are also applicable to obtain the preliminary estimates.
Without loss of generality, we let be the compact support of the index variable
. Define
(4)
(4)
where
is defined in (Equation3
(3)
(3) ),
is the indicator function and
. The aim of truncating the observations outside
is to overcome the so-called boundary effect in the kernel estimation. Noting that
, the set
can be sufficiently close to
, and thus, the information loss is negligible. In fact,
can be viewed as a natural estimate of
(5)
(5)
where
is the density function of
. Under some smoothness conditions on
and
, we may show that
From (Equation2
(2)
(2) ) and (Equation5
(5)
(5) ), we have
for
, and
for
and
with
. Then, we define a distance matrix among the functional coefficients, denoted by
, whose
-entry is
. The corresponding estimated distance matrix, denoted by
, has entries
defined in (Equation4
(4)
(4) ). It is obvious that both
and
are
symmetric matrices with the main diagonal elements being zeros.
We next use the well-known agglomerative hierarchical clustering method to explore the homogeneity among the functional coefficients. This clustering method starts with p singleton clusters, corresponding to the p functional coefficients. In each stage, the two clusters with the smallest distance are merged into a new cluster. This continues until we end with only one full cluster. Such a clustering approach has been widely studied in the literature on cluster analysis (cf. Everitt, Landau, Leese, and Stahl Citation2011; Rencher and Christensen Citation2012). However, to the best of our knowledge, there is virtually no work combining the agglomerative hierarchical clustering method with the kernel smoothing of functional coefficients in nonparametric homogeneity pursuit. This paper fills in this gap. Specifically, the algorithm is described as follows, where the number of clusters is assumed to be known. Section 2.2 will introduce an information criterion to determine the number
.
Start with p clusters each of which contains one functional coefficient and search for the smallest distance among the off-diagonal elements of
.
Merge the two clusters with the smallest distance, and then re-calculate the distance between clusters and update the distance matrix. Here the distance between two clusters
Repeat steps 1 and 2 until the number of clusters reaches
Let be the estimated clusters obtained via the above algorithm when the true number of clusters is known a priori. More generally, if the number of clusters is assumed to be K with
, we stop the above algorithm when the number of clusters reaches K, and let
be the estimated clusters.
2.2. Estimation of the cluster number
In practice, the true number of clusters is usually unknown and needs to be estimated. When the number of clusters is assumed to be K, we define the post-clustering kernel estimation for the functional coefficients:
(6)
(6)
where
is defined as in Section 2.1. When the number K is larger than
,
is still a uniformly consistent kernel estimate of the functional coefficients (cf. the proof of Theorem 3.2 in the appendix); but when K is smaller than
, the clustering approach in Section 2.1 results in a misspecified functional-coefficient model and
constructed in (Equation6
(6)
(6) ) can be viewed as the kernel estimate of the ‘quasi’ functional coefficients which will be defined in (Equation14
(14)
(14) ).
We define the following objective function:
(7)
(7)
with
,
and determine the number of clusters through
(8)
(8)
where
is a pre-specified finite positive integer which is larger than
. In practical application,
can be chosen the same as the dimension of covariates p if the latter is either fixed or moderately large. If we choose ρ close to 1 and treat nh as the ‘effective’ sample size, the above criterion would be similar to the classic Bayesian information criterion introduced by Schwarz (Citation1978). Su et al. (Citation2016) use a similar information criterion to determine the group number in linear longitudinal data models. The Bayesian information criterion has been extended to the nonparametric framework in recent years (cf. Wang and Xia Citation2009).
2.3. Penalised local linear estimation
We next introduce a penalised approach to further identify the clusters with non-zero constant coefficients and the cluster with zero coefficient. For notational simplicity, we let and
be defined similarly to
in (Equation6
(6)
(6) ) with
. Throughout the paper, we call
the post-clustering kernel estimator. It is obvious that identifying the constant coefficients is equivalent to identifying the functional coefficients such that either their derivatives are zero or the deviation of the functional coefficients,
, is zero (cf. Li et al. Citation2015), where
In practice, we may estimate the deviation of the functional coefficients by
for
. Let
As in Li et al. (Citation2015), we define the penalised objective function as follows:
(9)
(9)
where
in which
,
denotes the Euclidean norm,
and
are two tuning parameters, and
is the derivative of the SCAD penalty function (Fan and Li Citation2001):
Following Fan and Li's (Citation2001) recommendation, we choose
in this paper. Let
(10)
(10)
be the minimiser of the objective function
defined in (Equation9
(9)
(9) ). Through the penalisation, we would expect
when
is the estimated cluster with zero coefficient, and
when
is the estimated cluster with a non-zero constant coefficient (see (Equation20
(20)
(20) ) in Theorem 3.3). Hence, if
, the corresponding covariates are not significant and should be removed from functional-coefficient model (Equation1
(1)
(1) ); and if
, the functional coefficient has a constant value and can be consistently estimated by
(11)
(11)
Implementation of the proposed methods in Sections 2.1–2.3 is summarised in the following flowchart.
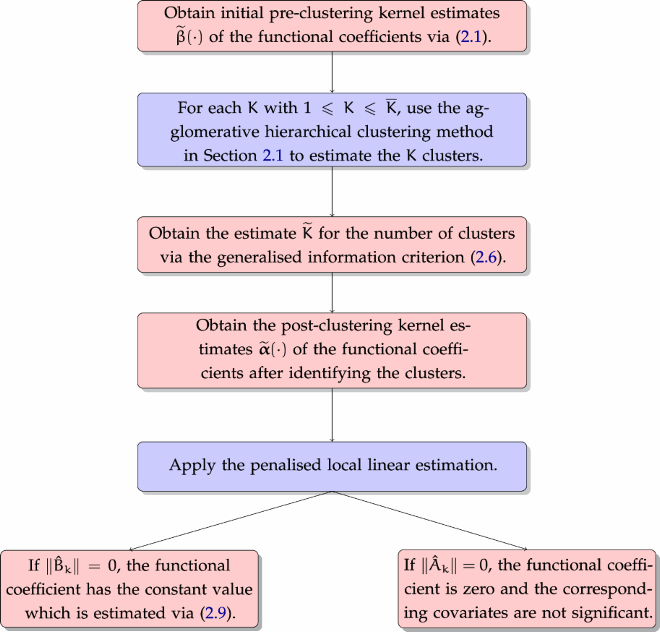
3. Asymptotic theorems
In this section, we give the asymptotic theorems for the proposed clustering and semiparametric penalised methods. We start with some regularity conditions, some of which might be weakened at the expense of more lengthy proofs.
Assumption 3.1
The kernel function is a Lipschitz continuous and symmetric probability density function with a compact support
.
Assumption 3.2
| (i) | The density function of the index variable | ||||
| (ii) | The functional coefficients | ||||
Assumption 3.3
| (i) | The | ||||
| (ii) | Let | ||||
Assumption 3.4
| (i) | Let the bandwidth h and the dimension p satisfy
| ||||
| (ii) | Let
| ||||
Remark 3.1
Assumptions 3.1–3.3 are some commonly used conditions on the kernel estimation of the functional-coefficient models. The strong moment condition on and
in Assumption 3.3(ii) is required when applying the uniform asymptotics of some kernel-based quantities. The independence condition between
and
seems restrictive, but may be replaced by the following heteroscedastic error structure:
, where
is independent of
and
is a conditional volatility function. By slightly modifying our proofs, the asymptotic properties continue to hold under this relaxed error condition. Assumption 3.4(i) restricts the divergence rate of the regressor dimension and the convergence rate of the bandwidth. In particular, if
is sufficiently large (i.e. the moment conditions in Assumption 3.3(ii) becomes stronger), the condition
could be close to the conventional condition
. Assumption 3.4(ii) indicates that the difference between two functional coefficients (in different clusters) can be convergent to zero with a certain polynomial rate. In particular, when p is fixed,
with
, and
with
, Assumption 3.4(ii) would be automatically satisfied. On the other hand, letting
and
, it follows from Assumption 3.4(i)(ii) that
indicating that the dimension p may be divergent to infinity at a polynomial rate of n.
Theorem 3.1
Suppose that Assumptions 3.1–3.4 are satisfied and is known a priori. Then, we have
(12)
(12)
when the sample size n is sufficiently large, where
is defined in Section 2.1 and
is defined in (Equation2
(2)
(2) ).
Remark 3.2
The above theorem shows the consistency of the agglomerative hierarchical clustering method proposed in Section 2.1 when the number of clusters is known a priori, i.e. with probability approaching one, the clusters can be correctly specified. It is similar to Theorem 3.1 in Vogt and Linton (Citation2017) which gives the consistency of the classification of univariate nonparametric function in the longitudinal data setting by using the nonparametric segmentation method.
We next derive the consistency for the information criterion on estimating the number of clusters which is usually unknown in practice. Some further notation and assumptions are needed. Define
and
Similarly, we can define
when
and there are further splits on at least one of
,
. Define the event:
(13)
(13)
From (Equation12
(12)
(12) ) in Theorem 3.1, we have
as
. Conditional on the event
, when the number of clusters K is smaller than
, two or more clusters of
,
, are falsely merged, which results in K clusters denoted by
, respectively,
. With such a clustering result, the group-specific functional coefficients cannot be consistently estimated by the kernel smoothing method, as the model is misspecified. However, we may define the ‘quasi’ functional coefficients by
(14)
(14)
where
,
(15)
(15)
and
given
. When
, it is easy to find that the quasi-functional coefficients become the ‘genuine’ functional coefficients conditional on the event
. Define
and
. By (Equation14
(14)
(14) ), it is easy to show that
(16)
(16)
where
is a null vector whose dimension might change from line to line. A natural nonparametric estimate of
would be
defined in (Equation6
(6)
(6) ) of Section 2.2, where the order of elements may have to be re-arranged if necessary. Result (Equation16
(16)
(16) ) and some smoothness condition on
would ensure the uniform consistency of the quasi-kernel estimation (see the proof of Theorem 3.2 in the supplemental document).
Let be the set of
-dimensional twice continuously differentiable functions
such that at least two elements of
are identical functions over
. The following additional assumptions are needed for proving the consistency of the information criterion proposed in Section 2.2.
Assumption 3.5
There exists a positive constant such that
(17)
(17)
Assumption 3.6
| (i) | For any | ||||
| (ii) | For any | ||||
Assumption 3.7
The bandwidth h and the dimension p satisfy ,
and
, where ρ is defined in (Equation7
(7)
(7) ).
Remark 3.3
Assumptions 3.5 and 3.6 are mainly used when deriving the asymptotic lower bound of which is involved in the definition of
when K is smaller than
. Restriction (Equation17
(17)
(17) ) in Assumption 3.5 indicates that the
functional elements in
needs to be ‘sufficiently’ distinct. We may show that (Equation17
(17)
(17) ) is satisfied if
and the Lebesgue measure of
is positive for any
. Assumption 3.6 is required to prove the uniform consistency of the kernel estimation for the quasi-functional coefficients. Assumption 3.7 gives some further restriction on h and p, and indicates that the dimension of the covariates can diverge to infinity at a slow polynomial rate of the sample size n. For example, letting
(i.e. under-smoothing in the kernel estimation),
and
with
, we may verify the conditions in Assumption 3.7.
Theorem 3.2 shows that the estimated number of clusters which minimises the IC objective function defined in (Equation7(7)
(7) ) is consistent.
Theorem 3.2
Suppose that Assumptions 3.1–3.7 are satisfied. Then, we have
(18)
(18)
as
, where
is defined in (Equation8
(8)
(8) ).
A combination of (Equation12(12)
(12) ) and (Equation18
(18)
(18) ) shows that the latent homogeneity structure can be consistently estimated. Define
Without loss of generality, conditional on
and
, we assume that
, otherwise we only need to re-arrange the order of the elements in
. For notational simplicity, we also assume that
and
for
with
, where
are non-zero constant coefficients (non-zero constant coefficients do not exist when
and all of the functional coefficients are constant when
). For simplicity, we next assume that all the observations of the index variable,
,
, are in the set
, to avoid the boundary effect of the kernel estimation, but this assumption can be removed if an appropriate truncation technique, such as those discussed in Sections 2.1 and 2.2, is applied to the penalised local linear estimation. Some additional conditions are needed for deriving the sparsity property for the penalised estimation proposed in Section 2.3.
Assumption 3.8
For any , there exists a positive constant
such that
with probability approaching one. When
(with
), there exists a positive constant
such that
with probability approaching one.
Assumption 3.9
Let , and the tuning parameter
satisfy
(19)
(19)
Condition (Equation19
(19)
(19) ) is also satisfied when
is replaced by
.
Remark 3.4
Assumption 3.8 is a key condition to prove that and
are bounded away from zero with probability approaching one, which together with the definition of the SCAD derivative and
in Assumption 3.9, indicates that when the functional coefficients or their deviations are significant, the influence of the penalty term in (Equation9
(9)
(9) ) can be asymptotically ignored. For the case when p is fixed and
as discussed in Remark 3.1, if we choose
with
, (Equation19
(19)
(19) ) in Assumption 3.9 would be satisfied. On the other hand, as discussed in Remarks 3.1 and 3.3, the dimension p is allowed to be divergent to infinity.
Theorem 3.3
Suppose that Assumptions 3.1–3.9 are satisfied. Then, we have
(20)
(20)
as
, where
and
are defined in (Equation10
(10)
(10) ).
The above sparsity result for the penalised local linear estimation shows that the zero coefficient and non-zero constant coefficients in the model can be identified asymptotically.
4. Practical issues in the estimation procedure
In this section, we first discuss how to choose the bandwidth in the kernel estimation and the tuning parameters in the penalised local least-squares estimation; and then introduce an easy-to-implement computational algorithm for the penalised approach in Section 2.3.
4.1. Choice of tuning parameters
The nonparametric kernel-based estimation may be sensitive to the value of bandwidth h. Therefore, choosing an appropriate bandwidth is an important issue when applying our kernel-based clustering and estimation methods. A commonly used bandwidth selection method is the so-called cross-validation criterion. Specifically, for the preliminary (or pre-clustering) kernel estimation, the objective function for the leave-one-out cross-validation is defined by
where
is the preliminary kernel estimator of
in model (Equation1
(1)
(1) ) using the bandwidth h and all observations except the tth observation. Then we determine the optimal bandwidth
by minimising
with respect to h. The cross-validation criterion for bandwidth selection in the post-clustering kernel estimation
can be defined in exactly the same way.
For the choice of the tuning parameters and
in the penalised local least-squares method, we use the generalised information criterion (GIC) proposed by Fan and Tang (Citation2013), which is briefly described as follows. Let
and denote
and
the index sets of nonparametric functional coefficients and non-zero constant coefficients, respectively (after implementing the kernel-based clustering analysis and penalised estimation with the tuning parameter vector
). As Cheng, Zhang, and Chen (Citation2009) suggest that an unknown functional parameter (varying with the index variable) would amount to
unknown constant parameters with
when the Epanechnikov kernel is used, we construct the following GIC objective function:
where
and
are defined as the penalised estimation in Section 2.3 using the tuning parameter vector
,
denotes the cardinality of the set
, and the bandwidth h can be determined by the leave-one-out cross-validation. The optimal value of
can be found by minimising the objective function
with respect to
.
4.2. Computational algorithm for penalised estimation
Let
and define
with
We next introduce an iterative procedure to compute the penalised local least-squares estimates of the functional coefficients proposed in Section 2.3 (cf. Li et al. Citation2015). It can be viewed as a nonparametric extension of the coordinate descent algorithm, which is a commonly used optimisation algorithm that finds the minimum of a function by successively minimising along the coordinate directions.
Find initial estimates of
Let
Update the derivative of the lth functional coefficient starting from l = 1. Let
Repeat Steps 2 and 3 until convergence of the estimates is achieved.
Our numerical studies in Sections 5 and 6 show that the above iterative procedure has reasonably good finite-sample performance.
5. Monte-Carlo simulation
In this section, we conduct Monte-Carlo simulation studies to evaluate the finite-sample performance of the proposed methods.
Example 5.1
Consider the following functional-coefficient model:
(21)
(21)
where the random covariate vector,
with p = 20 or 60, is independently generated from a multiple normal distribution with zero mean, unit variance and correlation coefficient ϱ being either 0 or 0.25, the univariate index variable
is independently generated from a uniform distribution
, the random error
is independently generated from the standard normal distribution and
. The homogeneity structure on model (Equation21
(21)
(21) ) is defined as follows:
where
. The above means that there are five clusters for the coefficients: some are varying with
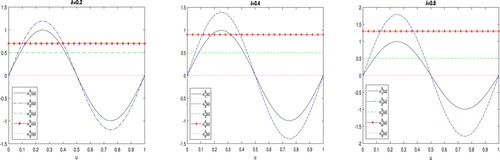
and others are constant. The size of each cluster in this example is the same (i.e. four). Figure plots the five cluster-specific coefficient functions for each value of δ. The larger the value of δ, the further the distance is between these functions, and hence, the easier it is to identify the clusters.
Figure 1. Plots of the cluster-specific coefficient functions. Left panel: ; right panel:
.
The sample size n is set to be 200, 400 or 600, and the number of replications is N = 500. We first use the kernel method to obtain preliminary nonparametric estimates of the functional coefficients , with the Epanechnikov kernel
and the optimal bandwidth selected from the cross-validation method in Section 4.1. The homogeneity and semi-varying coefficient structure in model (Equation21
(21)
(21) ) is ignored in this preliminary estimation. A combination of the kernel-based clustering method in Section 2.1 and the generalised information criterion in Section 2.2 is then used to estimate the homogeneity structure. In order to evaluate the clustering performance, we consider two commonly used measures: Normalised Mutual Information (NMI) and Purity, both of which can be used to examine how close the estimated set of clusters is to the true set of clusters. Letting
and
be two sets of disjoint clusters of
, the NMI between
and
is defined as
where
and
are the entropies of
and
, respectively, and
is the mutual information between
and
defined as
The NMI measure takes a value between 0 and 1 with a larger value indicating that the two sets of clusters are closer. The Purity measure is defined by
(22)
(22)
It is easy to find that the Purity measure also takes values between 0 and 1, and if
and
are equal, then
. However, the purity measure does not trade off the quality of clustering against the number of clusters. For example, a purity value of 1 is achieved if one set contains singleton clusters. The NMI, by contrast, allows for this trade-off.
We finally identify the clusters with zero coefficients and non-zero constant coefficients using the penalised method introduced in Section 2.3. The tuning parameters in the penalty terms are chosen by the GIC detailed in Section 4.1. In order to measure the accuracy of estimates of the coefficients ,
, we compute the Mean Absolute Estimation Error (MAEE), which, for the preliminary (pre-clustering) kernel estimates,
,
, is defined as
and for the post-clustering kernel estimates,
where
if
,
, and
,
, are the post-clustering kernel estimates of cluster-specific functional coefficients defined in (Equation6
(6)
(6) ). Let
if
,
, where
,
, are the penalised estimates of the cluster-specific functional coefficients obtained by minimising (Equation9
(9)
(9) ). The MAEE of the penalised estimates is defined as
The main purpose for considering the MAEE of the post-clustering kernel and penalised estimates for
,
, rather than for
,
, is to avoid having to order the estimated clusters and match each of them to one of the true clusters (as there is no natural way to do this).
Tables – give the simulation results for the case where the dimension of is 20. Table presents the frequency (over 500 replications) at which a number between 1 and 10 is selected as the number of clusters by the information criterion detailed in Section 2.2. Table gives the average values and standard deviations (in parentheses) of the NMI and Purity measurements over 500 replications. Table reports the average MAEEs and standard deviations (in parentheses) over 500 replications for the pre-clustering kernel estimation, post-clustering kernel estimation and the semiparametric penalised estimation. From Table , we can see that when
and the covariates are uncorrelated, the number of clusters can be correctly estimated in about 80% of the replications even when n = 200, and when δ increases to 0.8, this percentage increases to almost 98%. As the sample size increases to 400, the information criterion selects the correct number of clusters in almost all replications. When the correlation coefficient between the covariates is 0.25, the number of clusters is correctly estimated in only 34% of replications when n = 200 and
and in over 70% of replications when
. As the sample size increases to 400, this percentage rises to over 98%. However, when
, the distances between different coefficient functions become smaller and the number of clusters is often underestimated as 3 or 4, even when the covariates are uncorrelated. When the covariates are correlated, this underestimation becomes worse. In all of the specifications, the estimated number of clusters rarely goes below 3 or above 7. Table shows that when there is no correlation among the covariates and the different coefficient functions are moderately distanced (i.e.
or 0.8), the NMI and Purity values are close to 1 even when the sample size is as small as 200. The increase of the covariates correlation coefficients to 0.25 or the decrease of δ to 0.2 causes the clustering to become less accurate. Finally, the results in Table show that, after identifying the homogeneity and semi-varying coefficient structure, the average MAEE values of the semiparametric penalised estimation are smaller than those of the post-clustering kernel estimation, which in turn are much smaller than those of the pre-clustering kernel estimation. In addition, all three estimation methods improve (with decreasing average MAEE values) as the sample size increases, and their performance becomes slightly worse when the correlation between the covariates increases to 0.25.
Table 1. Results on estimation of cluster number for Example 5.1 with p = 20.
Table 2. Average NMI and Purity for Example 5.1 with p = 20.
Table 3. Average MAEE for Example 5.1 with p = 20.
Tables give the results for p = 60. Comparing these results with those for p = 20, we can see that as the dimension of the covariates increases, the estimation becomes poorer. However, the overall pattern as δ, or ϱ, or n changes is similar: as δ increases, the estimation becomes more accurate due to the clusters becoming further distanced from each other; as ϱ increases, the results become poorer; and as n increases, the results improve.
Table 4. Results on estimation of cluster number for Example 5.1 with p = 60.
Table 5. Average NMI and Purity for Example 5.1 with p = 60.
Table 6. Average MAEE for Example 5.1 with p = 60.
Example 5.2
We consider model (Equation21(21)
(21) ) with p = 20 but with the following homogeneity structure instead:
The data generating processes for the random covariates
, the index variable
and the error term
are the same as those in Example 5.1. The definitions of
and
are also the same as those in the previous example. However, the sizes of the clusters are now unequal, which are 1, 2, 4, 6, 7, respectively. To save space, we don't provide results for p = 60 for this example.
Tables and report the results for the estimation of the homogeneity structure and Table reports the average MAEEs and standard deviations (in parentheses) for the pre-clustering kernel estimation, the post-clustering kernel estimation and the penalised estimation over 500 replications. Comparing the results in Table with those in Table , we find that when , the number of clusters are more likely to be underestimated in Example 5.2 where cluster sizes are unequal. However, as δ increases, the results for the two examples become more and more comparable. The NMI and purity values in Table are similar to those in Table , while the MAEE values in Table are smaller than those in Table . The latter is mainly due to the fact that more coefficient functions (i.e. 17 out of 20) are constant in Example 5.2.
Table 7. Results on estimation of cluster number for Example 5.2 with p = 20.
Table 8. Average NMI and Purity for Example 5.2 with p = 20.
Table 9. Average MAEE for Example 5.2 with p = 20.
6. Empirical applications
In this section, we apply the developed model and methodology to two real data sets: the Boston house price data and the plasma beta-carotene level data. These two data sets have been extensively analysed in existing studies where functional-coefficient models are usually recommended. However, it is not clear whether certain homogeneity structure among the functional coefficients exists. This motivates us to further examine the modelling structure for these two data sets via the kernel-based clustering method and penalised approach introduced in Section 2.
Example 6.1
We first apply the developed model and methodology to the well-known Boston house price data. This data set has been previously analysed in many studies (cf. Fan and Huang Citation2005; Cai and Xu Citation2008; Wang and Xia Citation2009; Leng Citation2010). To investigate what factors influencing the house prices, we choose MEDV (the median value of owner-occupied homes in US$1000) as the response variable and the following 13 variables as the explanatory variables: INT (the intercept), CHAS (Charles River dummy variable; if tract bounds river, 0 otherwise), RAD (index of accessibility to radial highways), CRIM (crime rate per capita by town), ZN (proportion of residential land zoned for lots over 25,000 sq. ft.), INDUS (proportion of non-retail business acres per town), NOX (nitric oxides concentration in parts per 10 million), RM (average number of rooms per dwelling), AGE (proportion of owner-occupied units built prior to 1940), DIS (weighted distances to five Boston employment centres), TAX (full-value property-tax rate per US$ 10,000), PTRATIO (pupil–teacher ratio by town), and B (1000(Bk−0.63)
where Bk is the proportion of blacks by town). The variable LSTAT (percentage of lower status population) is chosen as the index variable in the varying-coefficient model, which enables us to investigate the interaction of LSTAT with the explanatory variables. The sample size is n = 506. The response variable and all explanatory variables (except the intercept, INT) undergo the Z-score transformation before being fitted: i.e. for any variable,
, to be transformed, its Z-score is
(23)
(23)
where
and
are the sample mean and sample standard deviation of
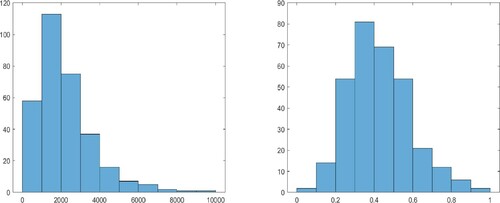
. Furthermore, as shown in the left panel of Figure , the index variable, LSTAT, exhibits strong skewness. Hence, we first take the square-root transformation of this variable to alleviate skewness and then the min–max normalisation:
(24)
(24)
where
and
denote the minimum and maximum of the observations of U, respectively. After the min–max normalisation, the support of
becomes
, consistent with the assumption made on the index variable in the asymptotic theory. A histogram of this transformed variable is shown in the right panel of Figure .
Figure 2. Histograms for the original and transformed index variable in Example 6.1. Left panel: original data for LSTAT; right panel: LSTAT after the square-root and min-max transformations.
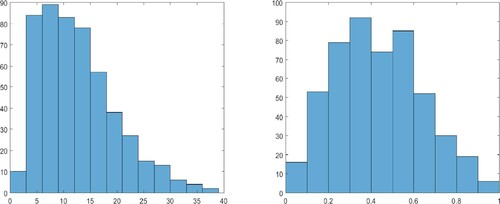
Figure plots the pre-clustering kernel estimated functional coefficients with the optimal bandwidth selected via the leave-one-out cross-validation method. The kernel-based clustering method and the generalised information criterion identify six clusters. The membership of these clusters and the characteristics of their functional coefficients are summarised in Table . DIS and TAX are found, by the penalised method, to have constant and similar negative effects on the response, while the variables CHAS, ZN, and B are found to be insignificant. All the other explanatory variables have varying effects on the response as the value of LSTAT changes. Plots of the post-clustering kernel estimates of the functional coefficients and their penalised local linear estimates are shown in Figures and , where for each ,
denotes the functional coefficient corresponding to the kth cluster listed in Table . The optimal tuning parameters in the penalised method are chosen, by the GIC, as
and
.
Figure 3. Pre-clustering estimates of the functional coefficients in Example 6.1.
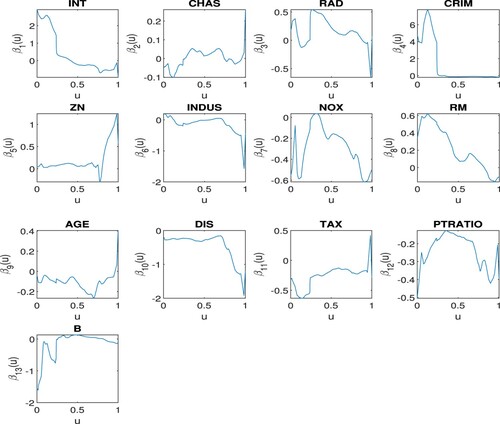
Figure 4. Post-clustering estimates of the functional coefficients in Example 6.1 with , for each
, being the estimated functional coefficient corresponding to the kth cluster listed in Table .
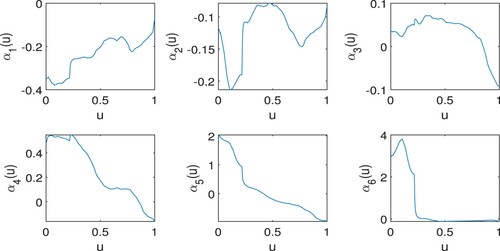
Figure 5. Penalised estimates of the functional coefficients in Example 6.1 with , for each
, being the estimated functional coefficient corresponding to the kth cluster listed in Table .
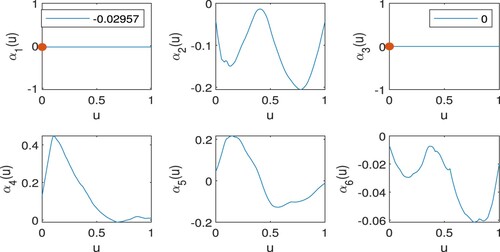
Table 10. The estimated homogeneity structure in Example 6.1.
We next compare the out-of-sample predictive performance between the pre-clustering (preliminary) kernel method, the post-clustering kernel method and the proposed penalised method. We randomly split the full sample into a training set of size 400 and a testing set of size 106 and repeat 200 times to reduce randomness in the results obtained. When calculating out-of-sample predictions for the post-clustering and penalised methods, we use the homogeneity structure (i.e. the clusters and their membership) estimated from the full sample but estimate the values of the functional coefficients (evaluated at the LSTAT values belonging to the testing set) or the constant coefficients from the training sets. The predictive performance is measured by Mean Absolute Prediction Error (MAPE), which is defined by
(25)
(25)
where
is the size of the testing set (106 in this example),
is a true value of the response variable in the testing sample, and
is the predicted value of
using the model estimated from the training sample. Table reports the average MAPE values over 200 replications of random sample splitting. We consider bandwidth values in the range
(with equal increment 0.02), which covers the optimal bandwidth of 0.168 for the preliminary kernel estimation and post-clustering kernel estimation. From Table , we can see that predicted values calculated from the model estimated by the penalised method have the smallest MAPEs over the range of bandwidth considered. Predictions made from the model estimated by the post-clustering kernel method have slightly larger MAPE values, while predictions from the pre-clustering kernel method have the largest MAPE values. This comparison result shows that the simplified functional-coefficient models from the developed kernel-based clustering and penalised methods provide a more accurate out-of-sample prediction.
Table 11. Average MAPE over 200 times of random sample splitting in Example 6.1.
Example 6.2
In this example, we use the proposed methods to analyse the plasma beta-carotene level data, which have been previously studied by Nierenberg, Stukel, Baron, Dain, and Greenberg (Citation1989), Wang and Li (Citation2009) and Kai et al. (Citation2011). The data were collected from 315 patients and are downloadable from the StatLib database http://lib.stat.cmu.edu/datasets/Plasma_Retinol. The primary interest is to investigate the relationship between personal characteristics and dietary factors, and plasma concentrations of beta-carotene. The response variable is chosen as BETAPLASMA (plasma beta-carotene level, ng/ml) and the candidate explanatory variables include INT (the intercept), AGE (years), QUETELET (Quetelet index, weight/height), CALORIES (number of calories consumed per day), FAT (grams of fat consumed per day), FIBRE (grams of fibre consumed per day), ALCOHOL (number of alcoholic drinks consumed per week), CHOLESTEROL (cholesterol consumed per day). The data set also contains categorical variables: SEX (1 = male, 2 = female), SMOKSTAT (smoking status, 1 = never, 2 = former, 3 = current smoker), VITUSE (vitamin use, 1 = yes, fairly often, 2 = yes, not often, 3 = no). We convert these into dummy variables: FEMALE ( = 1 if SEX = 2, 0 otherwise), NONSMOKER ( = 1 if SMOKSTAT = 1, 0 otherwise), FORMERSMOKER (= 1 if SMOKSTAT = 2, 0 otherwise), FREQVITUSE ( = 1 if VITUSE = 1, 0 otherwise), OCCAVITUSE ( = 1 if VITUSE = 2, 0 otherwise), and also include them as explanatory variables. As in Kai et al. (Citation2011), the index variable is chosen as BETADIET (dietary beta-carotene consumed, mcg per day). We again transform the response and explanatory variables (except the intercept, INT) by the Z-score method defined in (Equation23
(23)
(23) ). As can be seen from the left panel of Figure , the index variable BETADIET also exhibits high skewness, so we first transform it by the square-root operator and then the min–max operator in (Equation24
(24)
(24) ). Histograms for the original data for BETADIET as well as the transformed data are given in Figure .
Figure 6. Histograms for the original and transformed index variable in Example 6.2. Left panel: original data for BETADIET, right panel: BETADIET after the square-root and min-max transformations.
We again consider using a functional-coefficient model. In the preliminary kernel estimation, the Epanechnikov kernel is used and the optimal bandwidth is determined via the cross-validation method in Section 4.1. We combine the kernel-based clustering method and penalised local linear estimation (with the tuning parameters
and
chosen by the GIC method) to explore the homogeneity structure among the functional coefficients. Three distinct clusters are identified. The membership of each cluster and the characteristic of the corresponding coefficient function are summarised in Table . The pre-clustering estimates of all functional coefficients and the post-clustering and penalised estimates of the cluster-specific functional coefficients are plotted in Figures –.
Figure 7. Pre-clustering estimates of the functional coefficients in Example 6.2.
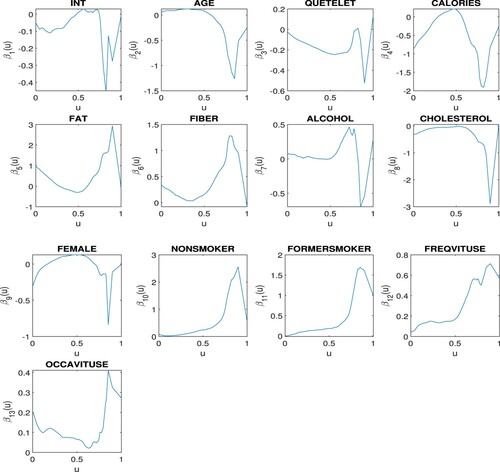
Figure 8. Post-clustering estimates of the functional coefficients in Example 6.2 with , for each k = 1, 2, 3, being the estimated functional coefficient corresponding to the kth cluster listed in Table .
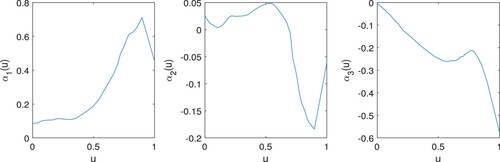
Figure 9. Penalised estimates of the functional coefficients in Example 6.2 with , for each k = 1, 2, 3, being the estimated functional coefficient corresponding to the kth cluster listed in Table .
Table 12. The estimated homogeneity structure in Example 6.2.
The kernel clustering and shrinkage estimation results show that FIBRE, NONSMOKER, FORMERSMOKER, FREQVITUSE form a cluster and their effects on the response variable, the beta-carotene level, are positive, which implies that higher fibre intake, no smoking and frequent vitamin use are helpful for increasing beta-carotene levels. The variables INT (intercept), AGE, CALORIES, ALCOHOL, CHOLESTEROL, FEMALE, and OCCAVITUSE are found to be insignificant, while QUETELET and FAT are found to have negative effects on beta-carotene levels.
As in Example 6.1, we further compare the out-of-sample predictive performance between the preliminary kernel, post-clustering kernel and penalised methods. We randomly divide the full sample (315 observations) into a training set of size 250 and a testing set of size 65, and repeat the random sample splitting 200 times and compute the average MAPE values. The predictions are calculated in the same way as in Example 6.1. The range of bandwidth values considered is between 0.20 and 0.32 with an increment of 0.02. The results are reported in Table . From the table, we find that the penalised and post-clustering kernel methods provide more accurate out-of-sample prediction in terms of MAPE defined in (Equation25(25)
(25) ) than the preliminary kernel method, with the penalised method slightly outperforming the post-clustering kernel method when the bandwidth is smaller.
Table 13. Average MAPE over 200 times of random sample splitting in Example 6.2.
7. Conclusion
In this paper, we have developed the kernel-based hierarchical clustering method and a generalised version of information criterion to uncover the latent homogeneity structure in the functional-coefficient models. Furthermore, the penalised local linear estimation approach is used to separate out the zero-constant cluster, the non-zero constant-coefficient clusters and the functional-coefficient clusters. The asymptotic theory in Section 3 shows that the estimation for the true number of clusters and the true set of clusters is consistent in the large-sample case. In the simulation study, we find that the proposed estimation methodology outperforms the direct nonparametric kernel estimation which ignores the latent structure in the model. In the empirical application to the Boston house price data and plasma beta-carotene level data, we show that the nonparametric functional-coefficient model can be substantially simplified with reduced numbers of unknown parametric and nonparametric components. As a result, the out-sample mean absolute prediction errors using the developed approach are significantly smaller than those using the naive kernel method which ignores the latent homogeneity structure among the functional coefficients.
CLWZ-Supp-27-April-2021.pdf
Download PDF (190.7 KB)Acknowledgments
The authors thank the Editor-in-Chief, an Associate Editor and two reviewers for their valuable comments, which improve the former version of the paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Bondell, H.D., and Reich, B.J. (2008), ‘Simultaneous Regression Shrinkage, Variable Selection and Supervised Clustering of Predictors with OSCAR’, Biometrics, 64(1), 115–123.
- Cai, Z., Fan, J., and Yao, Q. (2000), ‘Functional-Coefficient Regression Models for Nonlinear Time Series’, Journal of the American Statistical Association, 95(451), 941–956.
- Cai, Z., and Xu, X. (2008), ‘Nonparametric Quantile Estimations for Dynamic Smooth Coefficient Models’, Journal of the American Statistical Association, 103(484), 1595–1608.
- Chen, J., Li, D., and Xia, Y. (2019), ‘Estimation of a Rank-Reduced Functional-Coefficient Panel Data Model in Presence of Serial Correlation’, Journal of Multivariate Analysis, 173, 456–479.
- Cheng, M., Zhang, W., and Chen, L. (2009), ‘Statistical Estimation in Generalized Multiparameter Likelihood Models’, Journal of the American Statistical Association, 104(487), 1179–1191.
- Everitt, B.S., Landau, S., Leese, M., and Stahl, D. (2011), Cluster Analysis (5th ed.), Wiley Series in Probability and Statistics. Wiley.
- Fan, J., and Gijbels, I. (1996), Local Polynomial Modelling and Its Applications, London: Chapman and Hall.
- Fan, J., and Huang, T. (2005), ‘Profile Likelihood Inferences on Semiparametric Varying-Coefficient Partially Linear Models’, Bernoulli, 11(6), 1031–1057.
- Fan, J., and Li, R. (2001), ‘Variable Selection Via Nonconcave Penalized Likelihood and Its Oracle Properties’, Journal of the American Statistical Association, 96(456), 1348–1360.
- Fan, J., Ma, Y., and Dai, W. (2014), ‘Nonparametric Independence Screening in Sparse Ultra-High Dimensional Varying Coefficient Models’, Journal of the American Statistical Association, 109(507), 1270–1284.
- Fan, Y., and Tang, C.Y. (2013), ‘Tuning Parameter Selection in High Dimensional Penalized Likelihood’, Journal of the Royal Statistical Society, Series B (Statistical Methodology), 75(3), 531–552.
- Fan, J., and Zhang, W. (1999), ‘Statistical Estimation in Varying Coefficient Models’, The Annals of Statistics, 27(5), 1491–1518.
- Fan, J., and Zhang, W. (2008), ‘Statistical Methods with Varying Coefficient Models’, Statistics and Its Interface, 1(1), 179–195.
- Green, P., and Silverman, B. (1994), Nonparametric Regression and Generalized Linear Models: A Roughness Penalty Approach, London: Chapman and Hall/CRC.
- Jiang, Q., Wang, H., Xia, Y., and Jiang, G. (2013), ‘On a Principal Varying Coefficient Model’, Journal of the American Statistical Association, 108(501), 228–236.
- Kai, B., Li, R., and Zou, H. (2011), ‘New Efficient Estimation and Variable Selection Methods for Semiparametric Varying-Coefficient Partially Linear Models’, The Annals of Statistics, 39(1), 305–332.
- Ke, Z., Fan, J., and Wu, Y. (2015), ‘Homogeneity Pursuit’, Journal of the American Statistical Association, 110(509), 175–194.
- Ke, Y., Li, J., and Zhang, W. (2016), ‘Structure Identification in Panel Data Analysis’, The Annals of Statistics, 44(3), 1193–1233.
- Lee, E.R., and Mammen, E. (2016), ‘Local Linear Smoothing for Sparse High Dimensional Varying Coefficient Models’, Electronic Journal of Statistics, 10(1), 855–894.
- Leng, C. (2010), ‘Variable Selection and Coefficient Estimation Via Regularized Rank Regression’, Statistica Sinica, 20, 167–181.
- Li, D., Ke, Y., and Zhang, W. (2015), ‘Model Selection and Structure Specification in Ultra-High Dimensional Generalised Semi-Varying Coefficient Models’, The Annals of Statistics, 43(6), 2676–2705.
- Liu, J., Li, R., and Wu, R. (2014), ‘Feature Selection for Varying Coefficient Models with Ultrahigh Dimensional Covariates’, Journal of the American Statistical Association, 109(505), 266–274.
- Nierenberg, D., Stukel, T., Baron, J., Dain, B., and Greenberg, E. (1989), ‘Determinants of Plasma Levels of Beta-Carotene and Retinol’, American Journal of Epidemiology, 130(3), 511–521.
- Park, B.U., Mammen, E., Lee, Y.K., and Lee, E.R. (2015), ‘Varying Coefficient Regression Models: A Review and New Developments’, International Statistical Review, 83(1), 36–64.
- Rencher, A.C., and Christensen, W.F. (2012), Methods of Multivariate Analysis (3rd ed.), Wiley Series in Probability and Statistics. Wiley.
- Schwarz, G. (1978), ‘Estimating the Dimension of a Model’, The Annals of Statistics, 6(2), 461–464.
- Shen, X., and Huang, H.C. (2010), ‘Group Pursuit Through a Regularization Solution Surface’, Journal of the American Statistical Association, 105(490), 727–739.
- Su, L., Shi, Z., and Phillips, P.C.B. (2016), ‘Identifying Latent Structures in Panel Data’, Econometrica, 84(6), 2215–2264.
- Su, L., Wang, X., and Jin, S. (2019), ‘Sieve Estimation of Time-Varying Panel Data Models with Latent Structures’, Journal of Business and Economic Statistics, 37(2), 334–349.
- Tibshirani, R., Saunders, M., Rosset, S., Zhu, J., and Knight, K. (2005), ‘Sparsity and Smoothness Via the Fused Lasso’, Journal of the Royal Statistical Society, Series B (Statistical Methodology), 67(1), 91–108.
- Vogt, M., and Linton, O. (2017), ‘Classification of Nonparametric Regression Functions in Longitudinal Data Models’, Journal of the Royal Statistical Society, Series B (Statistical Methodology), 79(1), 5–27.
- Wand, M.P., and Jones, M.C. (1995), Kernel Smoothing, London: Chapman and Hall.
- Wang, L., and Li, R. (2009), ‘Weighted Wilcoxon-Type Smoothly Clipped Absolute Deviation Method’, Biometrics, 65(2), 564–571.
- Wang, H., and Xia, Y. (2009), ‘Shrinkage Estimation of the Varying-Coefficient Model’, Journal of the American Statistical Association, 104(486), 747–757.
- Xia, Y., Zhang, W., and Tong, H. (2004), ‘Efficient Estimation for Semivarying-Coefficient Models’, Biometrika, 91(3), 661–681.