
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We consider local polynomial estimation for varying coefficient models and derive corresponding equivalent kernels that provide insights into the role of smoothing on the data and fill a gap in the literature. We show that the asymptotic equivalent kernels have an explicit decomposition with three parts: the inverse of the conditional moment matrix of covariates given the smoothing variable, the covariate vector, and the equivalent kernels of univariable local polynomials. We discuss finite-sample reproducing property which leads to zero bias in linear models with interactions between covariates and polynomials of the smoothing variable. By expressing the model in a centered form, equivalent kernels of estimating the intercept function are asymptotically identical to those of univariable local polynomials and estimators of slope functions are local analogues of slope estimators in linear models with weights assigned by equivalent kernels. Two examples are given to illustrate the weighting schemes and reproducing property.
MATHEMATICS SUBJECT CLASSIFICATION CODE:
1. Introduction
Motivated by situations of analysing complex data, several flexible regression models have been developed during the last three decades. Among these are the varying coefficient models (Hastie and Tibshirani Citation1993). They differ from classical linear models in that the regression coefficients are no longer constants but rather functions of a smoothing variable. The model has a form:
(1)
(1) where
are continuous covariates,
, U is a continuous smoothing variable,
is the functional coefficient vector, and ε is the error term with
and
. When d = 1, model (Equation1
(1)
(1) ) is reduced to a univariable nonparametric model. If the varying coefficients are constants, i.e.
, then (Equation1
(1)
(1) ) is the multiple linear regression model. The model retains general nonparametric characteristics and allows nonlinear interactions between the smoothing variable U and covariates
. Methods of estimating
include the local polynomial approach (Fan and Zhang Citation1999), smoothing splines (Hastie and Tibshirani Citation1993; Chiang, Rice, and Wu Citation2001), and penalised splines (Ruppert, Wand, and Carroll Citation2003). An overview on methodology of varying coefficient models is given in Fan and Zhang (Citation2008) and Park, Mammen, Lee, and Lee (Citation2015).
This paper focuses on the local polynomial approach. When d = 1, with local polynomial fitting of pth order, it is well known that the estimators are linear smoothers (linear in 's) and the associated equivalent kernels are available (Fan and Gijbels Citation1996). The equivalent kernels give insights into the role of kernel smoothing on the data and the corresponding estimator of
has a remarkable ‘reproducing’ property (Tsybakov Citation2009, p:36), reproducing polynomials of degree
. However, to our knowledge, there are no results on equivalent kernels for local polynomial estimators in varying coefficient models (Equation1
(1)
(1) ) in the literature. In this paper, we fill the gap by deriving asymptotically equivalent kernels for estimating
and their derivatives, providing explicit forms of the connections between equivalent kernels of general d and those of d = 1, and studying extension of the reproducing property. The contribution of our paper includes the following: (i) under some conditions, the asymptotic equivalent kernels corresponding to estimating
in (Equation1
(1)
(1) ) have explicit decomposition forms that connect to those of d = 1 (Theorem 3.2); (ii) the finite-sample equivalent kernels corresponding to estimating
reproduce the νth derivative of polynomials of degree
in u (Proposition 3.1); (iii) with centered covariates, estimators of
are local analogues of the slope estimators in linear models (Corollary 3.2).
We start the discussion with local linear fitting p = 1 and d = 2 in Theorem 3.1, followed by extending the results to a general d in (Equation1(1)
(1) ) with pth order local polynomial fitting in Theorem 3.2. Equations (Equation16
(16)
(16) ) and (Equation26
(26)
(26) ) in Theorems 3.1 and 3.2 respectively show that there are direct connections between asymptotic equivalent kernels of (Equation1
(1)
(1) ) and those of univariable local polynomial regression ((Equation1
(1)
(1) ) with d = 1). It may be seen from the second equation in (Equation26
(26)
(26) ) that the asymptotic equivalent kernels are decomposed into three main parts, the inverse of the conditional moment matrix of
given
, the covariate vector, and the equivalent kernels of univariable local polynomials. The finite-sample reproducing property is given in Proposition 3.1, which leads to zero bias when the true regression mean is the multiple linear model with interactions between
and up to order-p polynomials of U. In Section 3.3, we present two Corollaries of Theorems 3.1 and 3.2 when
is centered. It turns out that the centered form leads to simpler and more interpretable results: equivalent kernels of estimating
) in (Equation1
(1)
(1) ) with a general d is asymptotically identical to those of d = 1; estimators of
may be asymptotically expressed in a form analogous to the slope estimators in linear models with weights assigned by equivalent kernels. This interpretation appears to be new in the literature. We conjecture that these equivalent kernel results may be useful to develop methodology when the responses are random objects, i.e. Fréchet regression. Petersen and Müller (Citation2019) propose to utilise the Euclidean local linear weights to fit Fréchet local linear regression. Thus Fréchet varying coefficient models will be an interesting topic for futureresearch.
The article is organised as follows. In Section 2, we summarise the local polynomial approach for estimating (Equation1(1)
(1) ) (Fan and Zhang Citation1999) and equivalent kernels of local polynomial regression (Fan and Gijbels Citation1996) with reproducing property in Proposition 2.1 (Tsybakov Citation2009). We present the main results in Section 3 and give two examples in Section 4 to illustrate, respectively, the weighting schemes of equivalent kernels when d = 2 and p = 1, and the reproducing property of equivalent kernels when d = 2 and p = 2. Proofs of Proposition 3.1 and Theorem 3.2 are provided in the Appendix.
2. Background
Consider a random sample from model (Equation1
(1)
(1) ) and define
. In this article, we adopt the local polynomial approach (Fan and Gijbels Citation1996) for estimating the coefficient functions
in (Equation1
(1)
(1) ). For
in a neighbourhood of a grid point
,
is approximated locally by a polynomial of order p,
based on a Taylor expansion. Then estimation is carried out by weighted least squares (Fan and Zhang Citation1999):
(2)
(2) where
,
is a symmetric probability density function, h is the bandwidth determining the size of local neighbourhood, and
. Throughout the paper, the dependence of β on
and h is suppressed if no ambiguity results. Under some conditions, (Equation2
(2)
(2) ) has a unique solution, denoted by
. It is clear that
estimates
of interest and
estimates the jth derivative
. The expression (Equation2
(2)
(2) ) and its solution can be expressed in matrix notation. Let
be an
diagonal matrix of weights
,
, and
. Then (Equation2
(2)
(2) ) can be expressed as
which yields
(3)
(3) The estimator of
is
(4)
(4) where ⊗ denotes the Kronecker product,
is a column vector of length
with 1 at the kth position and 0 elsewhere, and
is the d-dimensional identity matrix. Let
be a column vector of length
with 1 at the
th position and 0 elsewhere,
,
. Then
. In other words, if
is partitioned into d groups of length
, then
indicates the
th position in the gth group, and
. In the special case of d = 1,
.
The behaviour of differs whether
is an interior or boundary point. In this paper, we consider the case of interior points only. An informative tool to understand
is the equivalent kernel. For d = 1 in model (Equation1
(1)
(1) ), the weight function
for
, i.e.
, is given as follows (Fan and Gijbels Citation1996, p:63):
(5)
(5) where
. For an interior point
,
satisfies the following discrete moment conditions (Fan and Gijbels Citation1996, p:63 and p:103):
(6)
(6) where
is an indicator function of
. For
, the expression (Equation6
(6)
(6) ) is referred to as the ‘reproducing’ property by Tsybakov (Citation2009, p:36, Proposition 1.12) because
reproduces polynomials of degree
. Here, we extend Tsybakov's statement to a general
in the following Proposition, which shows that the local polynomial kernel approach has derivative reproducing property.
Proposition 2.1
Let be a polynomial of degree
Then (Equation6
(6)
(6) ) implies the reproducing property for
:
(7)
(7)
The proof of Proposition 2.1 is given in Tsybakov (Citation2009, pp:36-37), is straightforward based on (Equation6(6)
(6) ), and hence is omitted. For
the reproducing property (Equation7
(7)
(7) ) means that the weight function
corresponding to
reproduces the νth derivative of polynomial
with degree
. This includes shrinking polynomials of degree
to 0.
Let with
being the
th moment of
. In an asymptotic form (Fan and Gijbels Citation1996, p:64),
, where
is the density function of U and
(8)
(8) with
being the
th element of
. The
is the asymptotic equivalent kernel for
, satisfying the following property (Fan and Gijbels Citation1996, p:64):
(9)
(9) which is an asymptotic version of (Equation6
(6)
(6) ); that is,
is a kernel of order
(see Gasser, Müller, and Mammitzsch Citation1985 for definition). It has been shown in Fan and Gijbels (Citation1996) that local polynomials with
outperform those with
asymptotically.
In the next section, we derive the equivalent kernels of ,
,
, for the varying coefficient model (Equation1
(1)
(1) ), and investigate their reproducing property and connection to
in (Equation8
(8)
(8) ).
3. Results
3.1. Local linear case with d = 2
For clarity of presentation, we start with a simple case when d = 2 and p = 1, i.e.
(10)
(10) For a given interior point
, with p = 1,
defined around (Equation5
(5)
(5) ) is
with
. Under the model (Equation10
(10)
(10) ), based on (Equation3
(3)
(3) ),
, g = 1, 2 and
, is a linear smoother:
(11)
(11) where
(12)
(12) It is straightforward to show that
satisfies the following discrete moment conditions: for
, g = 1, 2,
(13)
(13) Equation (Equation13
(13)
(13) ) provides 4 moment conditions respectively for each combination of
. For g = 1,
,
, satisfies the same reproducing property as in Proposition 2.1 by the first equation in (Equation13
(13)
(13) ). In addition, by the second equation in (Equation13
(13)
(13) ),
shrinks the covariate
's and interaction term
's to 0. In other words, the equivalent kernels corresponding to estimating
of d = 2 satisfy more properties than (Equation6
(6)
(6) ) of d = 1 case. For g = 2, we list the properties of
in the following, while the general statement is given in Proposition 3.1 in Section 3.2.
For simplicity, denote . When g = 2, (Equation13
(13)
(13) ) gives the following results:
When
,
When
When
When
From 1–4 above, the finite-sample bias when estimating
Next we study the asymptotic forms for ,
and g = 1, 2, to understand the local asymptotic behaviour of
. Let
,
be the conditional density function of
given U = u, and
be the conditional expectation of
given U = u with its
th element
,
. Mimicking the derivations of (Equation8
(8)
(8) ) in Fan and Gijbels (Citation1996) and using the asymptotic forms of
in Zhang and Lee (Citation2000, equation (5.2)), we obtain
(14)
(14) where
. It can be seen from (Equation14
(14)
(14) ) that when
,
is a diagonal matrix. The following theorem gives the explicit forms for the asymptotic equivalent kernel of
for g = 1, 2 and
, and provides their moment properties.
Theorem 3.1
Consider a random sample from model (Equation10
(10)
(10) ) (d = 2 in (Equation1
(1)
(1) )) with local linear p = 1 estimators. For an interior point
, assume that
is bounded away from 0 and ∞ and has a compact support. Conditioned on
and under Conditions A in the Appendix,
, g = 1, 2,
, has the following asymptotic form:
(15)
(15) where the equivalent kernel
(16)
(16) with
and
the
th element of
and
respectively. Then for
,
(17)
(17) which are the asymptotic counterparts of (Equation13
(13)
(13) ).
The results of Theorem 3.1 is a special case (d = 2, p = 1) of Theorem 3.2 and hence the proof of Theorem 3.1 follows that of Theorem 3.2. Expression (Equation16(16)
(16) ) gives different decomposition forms of
and interpretations of Theorem 3.1 are discussed as follows.
From the first equation in (Equation16
For the second equation in (Equation16
It is clear that the
For g = 1, 2, the equivalent kernels for estimating the first derivative
(Equation17
Next we discuss the decomposition and reproducing property of equivalent kernels for model (Equation1(1)
(1) ) with general d and p.
3.2. The case with general d and p
Results in Theorem 3.1 and the reproducing property (Equation13(13)
(13) ) are extended to general d and p in this subsection. For ease of notation, let
,
(19)
(19) where
is the ith row vector of
and
without the intercept. For
and
,
is written as
(20)
(20) where the weight function
is
(21)
(21) with
defined in Section 2. Based on (Equation21
(21)
(21) ), we show in the Appendix that
(Equation21
(21)
(21) ) enjoys the following property analogous to (Equation13
(13)
(13) ): for
,
, and
,
(22)
(22) We state the reproducing property of
formally in the following Proposition.
Proposition 3.1
Let be a polynomial of degree
and
,
. Then (Equation22
(22)
(22) ) implies the reproducing property, for
:
(23)
(23) for
,
(24)
(24)
The outline of the proof of Proposition 3.1 is given in the Appendix. Proposition 3.1 shows that the equivalent kernel for estimating
reproduces the νth derivative of polynomials of
's with degree
, while shrinking
's to 0. Moreover, based on (Equation24
(24)
(24) ), the equivalent kernel
,
, for estimating
reproduces the νth derivative of
when
is a polynomial with degree
. These results imply that the finite-sample bias when estimating
is zero, and that the polynomial reproducing property in Proposition 2.1 with d = 1 is valid for the interaction terms of covariates
's and pth order polynomials of U under (Equation1
(1)
(1) ) with a general d.
Theorem 3.2 below gives the decomposition and moment property of asymptotic equivalent kernels for general d and p, which is an extension of Theorem 3.1.
Theorem 3.2
Consider a random sample from model (Equation1
(1)
(1) ) with local pth order polynomial estimators,
. For an interior point
, assume that
is bounded away from 0 and ∞ and has a compact support. Conditioned on
and under Conditions A in the Appendix,
has the following asymptotic form for
and
:
(25)
(25) where the equivalent kernel
(26)
(26) with
and
the
th element of
and
respectively. The moment property of
is given below:
(27)
(27) where
, and
. (Equation27
(27)
(27) ) is the asymptotic counterpart of (Equation22
(22)
(22) ) and contains
conditions for each combination of
.
The proof of Theorem 3.2 is given in the Appendix. From (Equation26(26)
(26) ), the equivalent kernel for
has decomposition forms analogous to the case for d = 2 and p = 1 in Theorem 3.1, while (Equation26
(26)
(26) ) involves higher orders of local polynomials and more covariates. Some interpretations about (Equation26
(26)
(26) ) is given below:
The second equation in (Equation26
The second equation in (Equation26
Based on the first equation in (Equation26
3.3. Centering covariates
For classical linear models, centering covariates is useful in interpreting the effects of covariates and the slope estimators via least squares are the same with or without centering. In this subsection, we explore an analogous centered form for (Equation1(1)
(1) ) and we show that the resulting asymptotic equivalent kernels for estimating
are identical to
in (Equation8
(8)
(8) ) of d = 1 case. Moreover, the varying coefficient model may be interpreted as locally multiple linear model with interactions.
Let be the sample mean of kth covariate
,
. Then rewrite model (Equation1
(1)
(1) ) in terms of centered covariates for the ith observation,
,
(28)
(28) It is straightforward to observe that the coefficient functions
, are the same whether the covariates are centered or not, while the intercept function
will be different. For ease of notation, define
,
,
(29)
(29) and
matrix
with
th element being
,
. When the conditional density of
given U = u is well defined,
is a function of u and
. The following Corollary for d = 2 and p = 1 is a special case of Theorem 3.1 either when
's are centered or when
.
Corollary 3.1
Under the conditions in Theorem 3.1, results (a) and (b) below hold when 's are centered.
| (a) |
| ||||
| (b) | the form of | ||||
| (c) | When | ||||
Corollary 3.1 shows that with 's, the equivalent kernels
,
corresponding to
and
respectively involve a factor
. In addition, when
and U are independent,
is a constant free of
, and further adopting standardised
in (Equation28
(28)
(28) ) by
,
, leads to
,
.
Let us further explore Corollary 3.1 by centering 's as well, denoted by
. With centered observations
, and based on (Equation30
(30)
(30) ),
(31)
(31) The denominator in (Equation31
(31)
(31) ) can be viewed as a local variance of
at
, while the numerator in (Equation31
(31)
(31) ) can be interpreted as the locally weighted sample covariance between
's and
's with weights assigned by
around
, denoted by
. Hence
may be interpreted as
. This enhances the interpretations of
for estimating
and presents a local analogue of the slope in simple linear regression. From (Equation30
(30)
(30) ),
for estimating
has an analogous interpretation as
with weights assigned by
. When d = 2 and p = 1, it is obvious that (Equation28
(28)
(28) ) could be interpreted as locally multiple linear model with interactions, since
.
We now present a Corollary of Theorem 3.2 that extends the results in Corollary 3.1 to the case with general d and p.
Corollary 3.2
Under the conditions in Theorem 3.2, with centered covariates ,
| (a) | the asymptotic equivalent kernel | ||||
| (b) | the asymptotic equivalent kernel | ||||
| (c) | Suppose that | ||||
Corollary 3.2(a) shows that with centered covariates, the asymptotic equivalent kernels corresponding to estimating of
,
,
, are identical to
in (Equation8
(8)
(8) ) of d = 1. The expression (Equation33
(33)
(33) ) in the case of
,
presents a local analogue of the slope estimators in multiple linear regression, since
is approximately the conditional variance matrix of
given
. The derivative terms
,
, could be interpreted as
asymptotically through equivalent kernels
of d = 1. We conjecture that these interpretations may be useful to develop methodology for Fréchet regression (Petersen and Müller Citation2019) when responses are random objects in a metric space. Petersen and Müller propose to adopt Euclidean local linear weights to fit Fréchet local linear regression, and in a similar approach, the equivalent kernels in Theorem 3.2 and Corollary 3.2 may be utilised to develop Fréchet varying coefficient models.
4. Examples
In Example 4.1, we demonstrate the weighting schemes of equivalent kernels (Equation13(13)
(13) ) and Corollary 3.1 when d = 2 and p = 1. Example 4.2 is for illustrating the reproducing property in Proposition 3.1 when d = 2 and p = 2. For illustration, the Epanechnikov kernel is used with a pre-specified bandwidth h = 0.1. The issues of bandwidth selection and the choice of local polynomial orders are beyond the scope of this work and the reader may explore the related discussion in Fan and Zhang (Citation2008) and Park et al. (Citation2015).
Example 4.1
,where U is Uniform
. For this example,
,
, and
and U are not independent. Since equivalent kernels (Equation8
(8)
(8) ) for estimating
are known in the literature, we illustrate equivalent kernels for estimating
,
. A random sample
with size n = 100 was drawn and at a fixed
, its neighbourhood (0.4, 0.6) contains 18 data points,
.
For
Figure (b) shows
For
Figure (d) shows
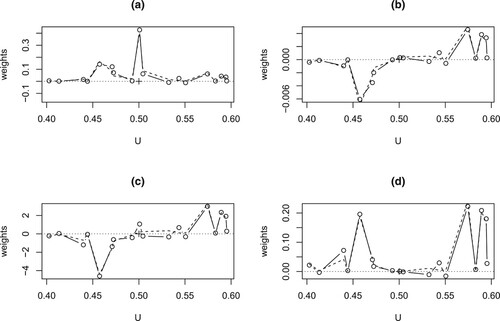
In contrast to the univariable local linear regression where the weights are typically concentrated around the target point of estimation, the weights in Figure (a,c) are influenced by the covariate
Figure 1. Example 4.1 of Section 4, comparison between the exact weight function (Equation13(13)
(13) ) (solid lines) and its normalised asymptotic form (Equation30
(30)
(30) ) (dash lines) of
with (a) q = 0 and (b) q = 1; of
with (c) q = 0 and (d) q = 1.
Example 4.2
We set 's and
's the same as those in Example 4.1, and further set
to illustrate the reproducing property in Proposition 3.1 when d = 2 and p = 2. Again, let
and h = 0.1, Figure (a) plots the points
as +'s,
, and the weights
of g = 1 and
reproducing
(a solid black-square point) are plotted as circles with lines connecting them. There are a few negative weights since the weights are not necessarily nonnegative when p = 2 and d = 2. Figures (b,c) are similar to Figure (a) except for
and 2 respectively; i.e. the + points
's and the weights
reproducing
(
and
, solid black-square points) are shown. The variation of weights increases as ν increases, as shown by the scale of the y-axis.
Figure 2. Example 4.2 of Section 4. (a)–(c) for g = 1 and 0, 1, 2, respectively: the +'s points are
,
, and the weights
reproducing
(a solid black-square point) are plotted as circles with lines. (d)-(f) for g = 2 and
0, 1, 2, respectively: The + points
's and the weights
that reproduces
(a solid black-square point) are shown.
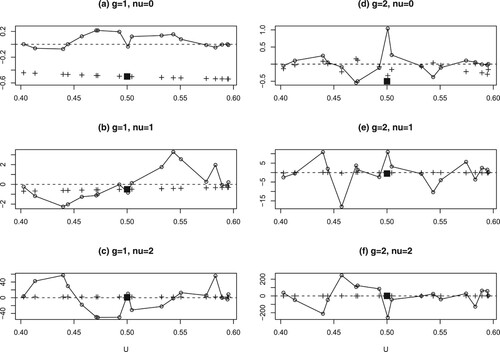
Analogous illustration is given in Figures (d–f) for g = 2 and . The + points
's and the weights
that reproduces
(a solid black-square point) are shown. Again, the variation of weights increases as ν increases, as shown by the scale of the y-axis. The difference of weights between g = 1 and 2 are visually obvious when comparing Figure (a–c,d–f).
Acknowledgments
We thank the Editor, an Associate Editor, and two referees for constructive suggestions and insightful comments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chiang, C.-T., Rice, J.A., and Wu, C.O. (2001), ‘Smoothing Spline Estimation for Varying Coefficient Models with Repeatedly Measured Dependent Variables’, Journal of the American Statistical Association, 96, 605–619.
- Fan, J., and Gijbels, I. (1996), Local Polynomial Modelling and Its Applications, London: Chapman & Hall.
- Fan, J., and Zhang, W. (1999), ‘Statistical Estimation in Varying Coefficient Models’, Annals of Statistics, 27, 1491–1518.
- Fan, J., and Zhang, W. (2008), ‘Statistical Methods with Varying Coefficient Models’, Statistics and its Interface, 1, 179–195.
- Gasser, T., Müller, H.-G., and Mammitzsch, V. (1985), ‘Kernels for Nonparametric Curve Estimation’, Journal of the Royal Statistical Society: Series B Statistical Methodology, 47, 238–252.
- Hastie, T.J., and Tibshirani, R.J. (1993), ‘Varying-Coefficient Models’, Journal of the Royal Statistical Society: Series B Statistical Methodology, 55, 757–796.
- Park, B.U., Mammen, E., Lee, Y.K., and Lee, E.R. (2015), ‘Varying Coefficient Regression Models: a Review and New Developments’, International Statistical Review, 83, 36–64.
- Petersen, A., and Müller, H.-G. (2019), ‘Fréchet Regression for Random Objects with Euclidean Predictors’, Annals of Statistics, 47, 691–719.
- Ruppert, D., Wand, M.P., and Carroll, R.J. (2003), Semiparametric Regression, London: Cambridge University Press.
- Tsybakov, A.B. (2009), Introduction to Nonparametric Estimation, New York: Springer-Verlag.
- Zhang, W., and Lee, S.Y. (2000), ‘Variable Bandwidth Selection in Varying-Coefficient Models’, Journal of Multivariate Analysis, 74, 116–134.
Appendix
Conditions A
The following assumptions are taken from Zhang and Lee (Citation2000).
| (A1) |
| ||||
| (A2) | Let | ||||
| (A3) | The functions | ||||
| (A4) | The marginal density | ||||
| (A5) | The kernel function | ||||
Proof
Proof of (Equation22(22) (22) ) and Proposition 3.1
From (Equation21(21)
(21) ), the LHS of the first equation in (Equation22
(22)
(22) ) is
Analogously, the LHS of the second equation in (Equation22
(22)
(22) ) is
Hence (Equation22
(22)
(22) ) is obtained. Then we show the results of Proposition 3.1. For (Equation23
(23)
(23) ), since
is a polynomial of degree
,
Plugging this polynomial into the LHS of (Equation23
(23)
(23) ), the RHS of (Equation23
(23)
(23) ) is obtained based on the first equation in (Equation22
(22)
(22) ). Since
, analogous arguments can be derived for (Equation24
(24)
(24) ).
Proof
Proof of Theorem 3.2
From (Equation14(14)
(14) ), the matrix
for general d and p has an asymptotic form Zhang and Lee (Citation2000, equation (5.2))
Then based on (Equation3
(3)
(3) ),
By properties of Kronecker product, the equivalent kernel corresponding to
(
is derived as follows:
To show the moment property (Equation27
(27)
(27) ), again by properties of Kronecker product, for
,