
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A general many quantiles + noise model is studied in the robust formulation (allowing non-normal, non-independent observations), where the identifiability requirement for the noise is formulated in terms of quantiles rather than the traditional zero expectation assumption. We propose a penalisation method based on the quantile loss function with appropriately chosen penalty function making inference on possibly sparse high-dimensional quantile vector. We apply a local approach to address the optimality by comparing procedures to the oracle sparsity structure. We establish that the proposed procedure mimics the oracle in the problems of estimation and uncertainty quantification (under the so-called EBR condition). Adaptive minimax results over sparsity scale follow from our local results.
1. Introduction
Since the emergence of statistical science, the classical ‘signal+noise’ paradigm for observed data is the main testbed in theoretical statistics for a vast number of methods and techniques for various inference problems and in various optimality frameworks. Many other practically important situations can be reduced to or approximated by the ‘signal+noise’ setting, capturing the statistical essence of the original (typically, more complex) model and preserving its main features in a pure form. There is a huge literature on ‘signal+noise’ setting with big variety of combinations of the main ingredients in the study. We mention the following ingredients: assumptions on the observation model (moment conditions, independence, normality, etc.); applied methodology (LSE, penalisation, shrinkage, thresholding, (empirical) Bayesian approach, projection, FDR method); studied inference problem (estimation, detection, model selection, testing, posterior contraction, uncertainty quantification, structure recovery); structural assumptions (smoothness, sparsity, clustering, shape constraints, such as monotonicity, unimodality and convexity, loss functions (expectations of powers of -norm,
-norm; Hamming loss, etc.); optimality framework and pursued criteria (minimax rate, oracle rate, control of FDR, FNR, expectation of the loss function, exponential bounds for the large deviations of the loss functions, etc.). A small sample of relevant literature includes (Donoho, Johnstone, Hoch, and Stern Citation1992; Donoho and Johnstone Citation1994; Benjamini and Hochberg Citation1995; Birgé and Massart Citation2001; Johnstone and Silverman Citation2004; Baraud Citation2004; Abramovich, Benjamini, Donoho, and Johnstone Citation2006; Efron Citation2008; Babenko and Belitser Citation2010; Belloni, Chernozhukov, and Wang Citation2011; Castillo and van der Vaart Citation2012; Martin and Walker Citation2014; Johnstone Citation2017; Belitser Citation2017; Bellec Citation2018; Butucea, Ndaoud, Stepanova, and Tsybakov Citation2018; Belitser and Nurushev Citation2020).
Suppose we observe , where
is the parameter of interest. We shall suppress n from the notation to simply write
for
. A natural example is given by
,
, but this specific distributional assumption on the data generating process will not be imposed. The main modelling assumption in this note is that, for some fixed level
,
In other words, we deal with the setting many quantiles + noise, as
's are the τ-quantiles of the observed
's and the goal is to make an inference on the high-dimensional parameter θ. One can study and make inference on several quantiles simultaneously across different levels
. While the mean is a commonly used measure of centrality, it is heavily influenced by outliers or extreme values in the dataset. In contrast, quantiles are robust to outliers and provide information about the spread of the data as well as the location of the central values, cf., Zou and Yuan (Citation2008), Jiang, Wang, and Bondell (Citation2013) and Jiang, Bondell, and Wang (Citation2014). The setting ‘many quantiles + noise’ with sparse quantile vectors arises in statistical and machine learning applications where the goal is to estimate a large number of quantiles for a high-dimensional dataset. The number of quantiles to be estimated can be very large, while the data may be sparse, meaning that only a small fraction of the entries in the data are non-zero. In such applications, quantiles may be a more sensible object of study, especially when the distribution is skewed or contains outliers. In this setting, the interest of study focuses on the effect of the parameter values on the tails of a distribution of observations, in addition to, or instead of, the centre. For example, in finance, quantiles such as the value at risk (the value at risk in finance has the meaning of quantile) or expected shortfall are commonly used to estimate the potential losses of a portfolio of investments, rather than relying solely on the mean return. Estimating a large number of quantiles is important for risk management and portfolio optimisation, as it provides a more complete picture of the potential losses or gains of a portfolio. In genomics, estimating many quantiles can help identify genes or markers that are associated with disease. In image processing, estimating quantiles can help identify regions of interest or anomalies in images. Quantiles as objects of interest occur in diverse areas, including economics, biology, meteorology; cf. Santosa and Symes (Citation1986), Abrevaya (Citation2002), Koenker (Citation2005), Belloni and Chernozhukov (Citation2011), Hulmán et al. (Citation2015), Gabriela Ciuperca (Citation2018) and Belloni, Chernozhukov, and Kato (Citation2019).
Besides quantile formulation, the next distinctive feature of our study is the robust formulation in the sense that we do not assume any particular form of the distribution of the observed data. Only a mild condition (Condition C1) is imposed. The observations do not need to be normal and, in fact no specific distribution is assumed, the distribution of the ‘noise’ terms ,
, may depend on θ and do not even have to be independent. This makes the applicability scope of our results rather broad.
The third aspect of our study is the local approach. It is in general impossible to make sensible inference on a high-dimensional parameter without any additional structure, either in terms of assumptions on parameter, or on the observation model, or both. In this paper, we are concerned with sparsity structure, various version of which have been predominantly studied in the literature recently. Sparsity structure means that a relative majority of the parameter entries are all equal to some fixed value (typically zero). In the local approach, we address optimality by comparing procedures to the oracle sparsity structure (think of an ‘oracle observer’ that knows the best sparsity pattern of the actual θ). When applying the local approach, the idea is not to rely on sparsity as such, but rather extract all the sparsity structure present in the data, and utilise it in the aimed inference problems. The claim that a procedure performs optimally in the local sense means that it attains the oracle quality, i.e. mimics the best sparsity structure pertinent to the true parameter, whichever it is. The local result imply minimax optimality over all scales (including the traditional sparsity class ) that satisfy a certain condition.
The final feature of our study concerns the problem of uncertainty quantification. In recent years, focus in nonparametric statistics has shifted from point estimation to uncertainty quantification, a more challenging problem, much less results on this topic are available in the literature; cf. Szabó, van der Vaart, and van Zanten (Citation2015), Belitser (Citation2017), van der Pas, Szabó, and van der Vaart (Citation2017) and Belitser and Nurushev (Citation2020). Certain negative results (cf. Li Citation1989; Baraud Citation2004; Belitser and Nurushev Citation2019 and the references therein) show that in general a confidence set cannot simultaneously have coverage and the optimal size uniformly over all parameter values. This makes the construction of the so-called ‘honest’ confidence sets impossible, and a strategy recently pursued in the literature is to discard a set of ‘deceptive parameters’ to ensure coverage at the remaining parameter values, while maintaining the optimal size uniformly over the whole set. In an increasing order of generality, removing deceptive parameters is expressed by imposing the conditions of self-similarity, polished tail and excessive bias restriction (EBR), see Szabó et al. (Citation2015), Belitser (Citation2017), van der Pas et al. (Citation2017) and Belitser and Nurushev (Citation2020). All the above papers deal with -loss framework for Gaussian observations in ‘many means + noise’ setting (a more general case is considered in Belitser and Nurushev Citation2020).
In this paper, we work with a new setting ‘many quantiles + general noise’, and use the quantile loss rather than the traditional -loss. The quantile loss function has certain properties of usual loss functions, but it is not symmetric, the peculiarity essentially characterising the notion of quantile. We propose and exploit a new version of EBR condition expressed in terms of quantile loss. To the best of our knowledge, there are no results on uncertainty quantification neither for the quantile loss function, nor for the
-loss, also neither in local, nor global (minimax) formulation in this general robust setting. In this respect, our study presents the first step in this direction.
We finally summarise the main contributions of this paper.
For our new (robust) setting ‘many quantiles + general noise’ we propose a penalisation procedure for selecting the sparsity pattern, based on the quantile loss (as counterpart of the
-loss) and the corresponding penalty term.
The estimated sparsity pattern is next used for the construction of an estimator of θ and a confidence set for θ, again in terms of the quantile loss function.
Two theorems establish the local (oracle) optimality of the estimator and confidence set (under the EBR condition), respectively.
We provide an elegant and relatively short proofs of the main results; compare with the relatively laborious proofs of related results in Szabó et al. (Citation2015), Belitser (Citation2017), van der Pas et al. (Citation2017) and Belitser and Nurushev (Citation2020).
The obtained results are robust and local in the sense explained above.
The obtained local results imply adaptive minimax optimality for scales of classes that satisfy certain relation (in particular, for the traditional sparsity scale).
Organisation of the rest of the paper is as follows. In Section 2, we give a robust formulation of the observation model in the ‘many quantiles + general noise’ setting, and introduce some notations and preliminaries. In Section 3, we present the main results of the paper and discuss their consequences for the optimality in the minimax sense for the traditional sparsity scale. Section 4 contains a small simulation study. The proofs of the theorems are provided in Section 5.
2. Robust model formulation and preliminaries
We can formally rewrite the model stated in the introduction in the familiar ‘signal+noise’ form:
(1)
(1) where
can be thought of as ‘noise’. Note that all the quantities depend of course on τ. Precisely, for
, in the model (Equation1
(1)
(1) ) we have
,
with
,
. Not to overload the notation, we suppress the dependence on τ in the sequel. As we mentioned in the Introduction, we study robust setting in the sense that we do not assume any particular distribution of
. In fact, the
's do not have to be identically distributed, their distribution may depend on θ and they do not even have to be independent.
Introduce the following asymmetric absolute deviation function:
which we will also call quantile loss function,
denotes the indicator of event E.
Slightly abusing notation, we use the same notation for any
, for example, most of the time it will be either m = n or m = 1, depending on the dimensionality of the argument of the function. This will always be clear from the context. Often, we will suppress the dependence of ρ on a fixed
, unless emphasising this dependence where it is relevant.
Remark 2.1
The origin of the quantile loss function ,
, is well explained in the book (Koenker Citation2005). The function
characterises the τ-quantile of a random variable Z in the sense that the τ-quantile
of Z is known to minimise the criterion function
with respect to ϑ, i.e.
. Basically, this function plays the same role for characterising the quantiles as the quadratic function in characterising the expectation of a random variable.
The quantile loss function ρ can be related to the -criterion
,
: for any
,
(2)
(2) In particular, it follows that
. Another useful property of the quantile loss function ρ to be used later on is that, for any
,
(3)
(3)
Remark 2.2
The above quantile loss function evaluated at the difference ,
, possesses all the properties of a metric
except for the symmetry. In particular,
(zero at zero); if
,
(positivity); and finally the triangle inequality holds
(4)
(4)
Since we have as many parameters as observations, it is typically impossible to make inference on θ even in a weak sense unless the data possesses some structure. Here, we work with the structural assumption that θ is (possibly) a sparse vector. Specifically, we assume that , where
and
, where
. The structure studied here is the unknown ‘true’ sparsity pattern
, that is,
and
is the ‘minimal’ sparsity structure in the sense that
.
Introduce some further notation: let denote the family of all subsets of
; for
, denote its
-norm by
;
denote the cardinality of a set S. Further let us introduce the so-called ‘quantile projection’
onto
(called just projection in what follows), with respect to the quantile loss function
. For
, define
as follows:
In view of the properties of the quantile loss function ρ given by Remark 2.2, the projection
is readily found as the following linear operator:
We will use later a certain monotonicity property of the quantile projection operator.
(5)
(5) For
and
, denote (with the convention
for a>0)
We have that
for
, and besides, since
is increasing in
,
for all
. The function
has a meaning of complexity of structure I.
The following relation will be used later: for any ,
(6)
(6) with
.
The following conditions on is assumed throughout.
Condition C1. For some and some positive function
monotonically increasing to infinity as
, and all
,
, all
,
(7)
(7) Notice that Condition C1 is trivially fulfilled for
with zero right-hand side. Let
stand for the family of distributions
satisfying Condition C1.
As for all
, the right-hand side of (Equation7
(7)
(7) ) is further bounded by
, which we will use in the proof.
Remark 2.3
Condition C1 is mild, for instance, it holds for independent sub-gaussian 's. Recall one of the equivalent definitions of sub-gaussianity (see Vershynin Citation2018): a random variable W is called σ- sub-gaussian for
if for some
. In our case,
. For example, for
,
(see Section 4). Recall that
denotes the usual squared
-norm of
. Now, since
has at most
non-zero entries, by (Equation2
(2)
(2) ) and the Cauchy–Schwartz inequality we have
(this also follows from the following inequality between two different
-norms: for
and
,
). Recall also that
,
. Using these and the Markov inequality, we obtain that, for
,
and
,
One can extend the results to the case of the so-called sub-exponential errors, with adjusted complexity function
; see Remark 3.3.
Remark 2.4
Condition C1 is clearly satisfied for bounded, arbitrarily dependent, 's. This condition allows some interesting cases of dependent
's. By arguing in the same way as in Belitser and Nurushev (Citation2020), we can establish that Condition C1 holds also for
's which follow an autoregressive model AR(1) with sub-gaussian white noise
's (for appropriately chosen model parameters):
In Belitser and Nurushev (Citation2020), the normal white noise was used in the above model AR(1), but this can easily be extended to the sub-gaussian case by adjusting the constants involved.
Remark 2.5
We can extend our setting by including also a parameter by considering
instead of just
(and
instead of
) in (Equation1
(1)
(1) ) and in Condition C1. In that case, the parameter
is assumed to be known and fixed throughout. Together with n, it reflects the information amount in the model in the sense that
means the flux of information.
We propose a penalised projection estimator. For , define
to be a minimiser of the criterion
:
(8)
(8)
Remark 2.6
Since the proposed procedure for selecting sparsity pattern is based on the non-symmetric quantile loss function ρ, the deviations from below and from above are treated differently. But the computation of the estimator
of the sparsity pattern is not difficult. Indeed, it can be reduced to the search over n options: with
,
,
where
is the ordered sequence of
's and
.
Now, using the estimated sparsity structure , define the estimator
(9)
(9) From the triangle inequality (Equation4
(4)
(4) ), it follows that
. Using this, (Equation3
(3)
(3) ) and the definition (Equation8
(8)
(8) ), we derive that, for any
,
(10)
(10) For
,
and
, introduce the quantity
which we call the quantile rate of the sparsity structure I. The oracle sparsity structure
is the one minimising
:
(11)
(11) where its minimal value
is called the oracle quantile rate, or just oracle rate.
3. Main results
In this section, we give the main results. All the constants in the below assertions depend on the fixed constants and function ψ appearing in Condition C1, the constant κ appearing in the oracle structure definition (Equation8
(8)
(8) ), and the quantile level τ.
The next result concerns the estimation problem.
Theorem 3.1
Estimation
Let Condition C1 be fulfilled. Then for any and sufficiently large κ, there exist positive
such that
(12)
(12) where
is defined by (Equation9
(9)
(9) ).
Next we address the new problem of uncertainty quantification (UQ) for the parameter θ. A confidence set is defined in terms of quantile loss function ρ as follows:
(13)
(13) where the ‘ centre’
and ‘radius’
are measurable functions of the data X. The goal is to construct such a confidence set
that for any
and some function
,
, there exist C, c>0 such that
(14)
(14) for some
. The function
, called radial rate, is a benchmark for the effective radius of the confidence set
. The first expression in (Equation14
(14)
(14) ) is called coverage relation and the second size relation. It is desirable to find the smallest
, the biggest
and
such that (Equation14
(14)
(14) ) holds and
, where
is the optimal rate in estimation problem for θ. In our local approach, we pursue even more ambitious goal
, where
is the oracle rate from the (local) estimation problem.
Typically, the so-called deceptiveness issue arises for the UQ problem in that the confidence set of the optimal size and high coverage can only be constructed for non-deceptive parameters (in particular, cannot be the whole set
). That is, coverage with an optimal sized radius is only possible if certain deceptive set of parameters is excluded from consideration, which is expressed by imposing some condition on the parameter. For example, the EBR (excessive bias restriction) condition in case of
-norm is proposed in Belitser and Nurushev (Citation2019), Belitser (Citation2017) and Belitser and Ghosal (Citation2020). Here we need an EBR-like condition (we keep the same term EBR), but now in terms of the quantile loss function ρ.
Condition EBR. We say that parameter satisfies the excessive bias restriction (EBR) condition with structural parameter
if
where
(15)
(15) the oracle structure
is defined by (Equation11
(11)
(11) ) (with the convention
).
The extent of the restriction varies over different choices of constant t, becoming more lenient as t increases, eventually covering the entire parameter space. In general, for any t, a sequence of θ's can be found such that
, when n varies. On the other hand, the set
is not empty and consists of such θ's for which the oracle
coincides with the true sparsity structure
. For a general discussion on EBR, we refer the reader to Belitser and Nurushev (Citation2019). For sparsity structure in
-sense, the EBR condition is satisfied if the minimal absolute value of the non-zero coordinates of θ is larger than a certain lower bound, but this bound depends also on the number of the non-zero coordinates of θ. For example, for some sufficiently large C>0,
Theorem 3.2
Confidence ball
Let the confidence set be defined by (Equation13
(13)
(13) ),
,
and
be given by (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ) respectively. Then for sufficiently large
there exist constants
such that for any
,
(16)
(16)
(17)
(17)
Constants ,
,
, i = 1, 2, 3, are all evaluated in the proofs of Theorems 3.1 and 3.2 in the form of several bounds, which depend on function ψ, constants
from Condition C1, the quantile level τ and ϰ. There is no ‘optimal’ choice, in fact, many choices are possible, an improvement of one constant typically lead to worsening another one. It should also be noted that the constants (any choice satisfying the bounds in the proofs) are uniform over the whole family
of distributions satisfying Condition C1, and can therefore be significantly improved for specific error distributions.
So far, all results are formulated in terms of the oracle. For estimation and the construction of a confidence set, this local approach delivers the most general results, as the convergence rate of the proposed estimator is directly linked with the oracle sparsity rather than the true structure, which may not be sparse (but very close to a sparse structure). However, if the parameter has a true sparse structure, the method will attain the quality pertinent to that true sparsity as well.
To illustrate this, consider any . The true structure
and the oracle structure
in general do not coincide, but they are related by
(18)
(18) The first two relations hold by the definition of the oracle and the third because
for the true structure. Since
, (Equation18
(18)
(18) ) implies that
and hence
. Further, as
for
, (Equation18
(18)
(18) ) also yields
Besides, all the constants in Theorems 3.1 and 3.2 are uniform over
and
. The next result follows from these facts and Theorems 3.1 and 3.2.
Corollary 3.1
Under the conditions of Theorems 3.1 and 3.2, with the same choice of the constants,
and (Equation16
(16)
(16) ) holds.
We claim that the obtained convergence rate in terms of quantile loss function is optimal over the class
in the minimax sense. More precisely, the results of Johnstone and Silverman (Citation2004) (in Johnstone and Silverman Citation2004, relations (17) and (18) with p = 0 and q = 1) and (Equation2
(2)
(2) ) imply that for the normal model
, there exist absolute
such that
This lower bound is not quite what we need to match with our upper bound because it is formulated in terms of expectation and the
-loss. However, it is not difficult to establish the probability version of the lower bound: there exist absolute
such that
The relation (Equation2
(2)
(2) ) connects the
-loss with the quantile loss, so that the above relation implies that
In this form, the lower bound matches our upper bound given by Corollary 3.1, basically showing that our procedure attains the optimal rate
for the sparsity class
. This also means that the size of the constructed confidence ball
is also optimal over the sparsity class
in the minimax sense. However, the unavoidable price for the optimality in the size relation is that the coverage relation holds uniformly over
, not over
.
Remark 3.1
Interestingly, although there are some ‘deceptive’ θ in that are not covered by
, there are also some θ's in
which do not belong to the sparsity class
, but for which the coverage relation holds.
Remark 3.2
We derived the adaptive (sparsity s is also unknown) minimax results over the traditional sparsity scale as consequence of our local oracle results. The scope of our local result is even broader, the minimax results can be derived over any scale of classes
with the corresponding minimax rates
as longs as, for some c>0,
Indeed, if the above relation is fulfilled, we immediately obtain all the claims of Corollary 3.1 with instead of
, as consequences of Theorems 3.1 and 3.2. For example, it seems possible to derive the minimax results also for the scale of the
-balls:
,
, with
as
.
Remark 3.3
Interestingly, in relation to Remark 2.3, Condition C1 also holds for independent sub-exponential 's, but with the adjusted function
. Recall one of the equivalent definitions of sub-exponentiality (see Vershynin Citation2018): a random variable W is called σ-sub-exponential if
for some
. For example, for the Laplace distribution
,
,
, we take
. In particular, if
,
.
Now, since has at most
non-zero entries, by (Equation2
(2)
(2) ) we have
. Recall also that
,
. Using these and the Markov inequality, we obtain that
for
and
. Similarly to the setting discussed in Remark 2.4, it is possible to generalise the case of independent sub-exponential errors
's to the case of errors driven by an AR(1) model with sub-exponential white noise.
Thus, for sub-exponential 's, Theorems 3.1 and 3.2 hold with the oracle rate
. Notice a slight deterioration of the oracle rate
as compared to the sub-gaussian case, as we now have the complexity
instead of
. This will also lead to the corresponding slightly deteriorated global rate
(instead of
) in Corollary 3.1. Intuitively, a worse rate for the sub-exponential case is not surprising and should be considered as price for the ‘heavy tailedness’ of the erros
's.
The question remains whether the resulting rate in this case is minimax over the sparsity scale
for the
-norm and sub-exponential errors. We did not find relevant results in the literature on this, but we conjecture that the minimax rate over sparsity scale for the
-norm with errors with density
,
, is expected to be
.
4. A simulation study
In this section, we present a small simulation study. The main goal is to demonstrate the deceptiveness phenomenon for the UQ problem, which concerns the coverage relation of Theorem 3.2. Theorem 3.1 and the size relation of Theorem 3.2 will also be demonstrated in passing. Recall that the coverage relation in Theorem 3.2 holds only for the so-called non-deceptive parameters which are described by the EBR condition: . Below we provide an example illustrating the failure of the coverage relation for a deceptive parameter θ. Exactly, we construct a sequence of ‘deceptive’
,
, such that, for any
,
as
.
Consider the simplest setting in the model (Equation1(1)
(1) ):
,
, and
. In this case, according to Remark 3, Condition C1 is satisfied with
,
and
where
and such
that
for
, leading to a choice
. Consider a parameter
with any
, so that the oracle sparsity structure
for all
and hence the ratio in the definition (Equation15
(15)
(15) ) of the EBR condition is
,
. Since
as
, this means that the sequence
can be seen as ‘deceptive’ in that for any
there exists
such that
for all
. In the below simulations, we took
,
and
which ensures the condition
for all considered n's.
Introduce the quantities ,
and
. Now we perform the following simulations: for a chosen
and the above-described
, generate B = 1000 data samples, then compute B values of
,
, and the corresponding
,
and
,
. Since
,
and
, we can approximate the probabilities of the events from Theorems 3.1 and 3.2 as follows:
In Figure , the boxplots of
's,
's and
's are plotted for several increasing n = 50, 100, 200, 400, 800, 1600, 3200. We see that the boxplots of
(the plot on the left) stabilises around 1, this is because of the special choice of
for which
is asymptotically equivalent to the oracle rate
. Thus, the first probability in the above display will go to zero for any
, which shows that the claim of Theorem 3.1 holds also for this deceptive
as it should because the result of Theorem 3.1 is uniform over
. The size relation of Theorem 3.2 holds as well (as it also should): the boxplots of
's (the plot on the right) even move to zero, showing that the third probability in the above display will converge to zero for any
.
Figure 1. Sub-gaussian case: boxplots of 's,
's and
's for increasing n and deceptive
.
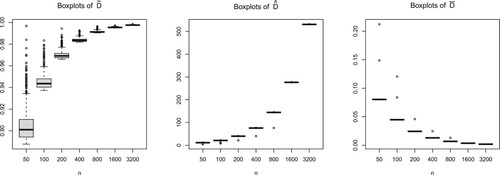
The most interesting plot is in the middle of Figure , it shows that the boxplots of 's move up as n increases, ensuring that the fraction of data points such that
goes to 1 as
for any constant
. Hence,
as
, for the chosen deceptive parameter sequence
, which demonstrates the deceptiveness phenomenon.
Finally, we perform simulations for the sub-exponential case discussed in Remark 3.3 and a non-deceptive parameter . Precisely, we consider the Laplace errors
,
(i.e. with density
), we set the first 20 entries of parameter
equal to
and the remaining coordinates to zero. This means also that we used complexity
instead of
. All the other parameters of this simulation experiment remain the same as before.
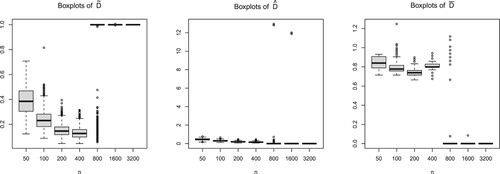
Figure shows that the claims of Theorems 3.1 and 3.2 hold for non-deceptive . We now see a downward trend in the boxplots of
's as n increases illustrating the good behaviour of the confidence set for non-deceptive
also in the sub-exponential case.
Figure 2. Sub-exponential case: boxplots of 's,
's,
's for increasing n and non-deceptive
.
5. Proofs
In this section, we present the proofs of the theorems.
Proof of Theorem 3.1.
First we introduce some notation. Define the events
where the constants
are to be chosen later. We evaluate the probability of interest
as follows:
(19)
(19) We bound these three probabilities separately.
First we bound . Using the properties (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ) of the quantile loss function ρ, we derive that the event
implies that
Hence, if
, then
(20)
(20) To bound
, write
If
is such that
, then using Condition C1 (Equation7
(7)
(7) ), we obtain that
where we set
. Recall that
is increasing for
. This, (Equation6
(6)
(6) ) and the two previous displays entail that, since
(so that
),
(21)
(21) Finally, we bound
. Using (Equation10
(10)
(10) ) with
and
, we obtain that under
,
as long as
. We conclude that the event
implies the event
, so that, by Condition C1 (Equation7
(7)
(7) ),
(22)
(22) where
if
is chosen so large that
.
To summarise the choices of the constants, we need to take such (in the claim of the theorem) and such constants
(in the proof of the theorem) that
,
,
(for example, we can fix
) and
, which is always possible since function
monotonically as
. Combining (Equation19
(19)
(19) ) –(Equation22
(22)
(22) ), we obtain the claim of the theorem with the chosen κ,
,
and
.
Proof of Theorem 3.2.
For some fixed (for example, take
), introduce the event
, where
is defined by (Equation11
(11)
(11) ).
First we evaluate . We have
By using the above relation, we obtain that, under the event
,
. Hence, we have that, under
,
The last relation, (Equation5
(5)
(5) ) with
and the definition (Equation11
(11)
(11) ) of the oracle
imply that, under
,
Recall the event
from the proof of the previous theorem and let κ be sufficiently large to satisfy
. Further, choose ϰ sufficiently large to satisfy
with such
that
. Then, under
, from (Equation10
(10)
(10) ) with
, it follows that,
(23)
(23) Using the last display, (Equation21
(21)
(21) ), Condition C1 (Equation7
(7)
(7) ) and
, we bound
(24)
(24) Now we establish the coverage property. The constants
,
and
are defined in Theorem 3.1. Take
, where fixed
is from the definition of the event
. If
, then, in view of (Equation11
(11)
(11) ),
. So,
for all
. Combining this with Theorem 3.1 and (Equation24
(24)
(24) ) yields that, uniformly in
,
The coverage relation follows.
Let us show the size property. Recall again the event from the proof of the previous theorem. By using (Equation23
(23)
(23) ) with
, we derive that the event
implies the event
with
, where
is defined in the proof of Theorem 3.1. We thus have that, for any
,
where the last inequality in the above display is obtained by (Equation21
(21)
(21) ) and Condition C1 (Equation7
(7)
(7) ), and
is chosen to be so large that
. The size relation follows.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Abramovich, F., Benjamini, Y., Donoho, D.L., and Johnstone, I.M. (2006), ‘Adapting to Unknown Sparsity by Controlling the False Discovery Rate’, The Annals of Statistics, 34, 584–653.
- Abrevaya, J. (2002), ‘The Effects of Demographics and Maternal Behavior on the Distribution of Birth Outcomes’, in Economic Applications of Quantile Regression, eds. B. Fitzenberger, R. Koenker, and J. A. F. Machado, Berlin Heidelberg: Springer-Verlag, pp. 247–257.
- Babenko, A., and Belitser, E. (2010), ‘Oracle Convergence Rate of Posterior Under Projection Prior and Bayesian Model Selection’, Mathematical Methods of Statistics, 19, 219–245.
- Baraud, Y. (2004), ‘Confidence Balls in Gaussian Regression’, The Annals of Statistics, 32, 528–551.
- Belitser, E. (2017), ‘On Coverage and Local Radial Rates of Credible Sets’, The Annals of Statistics, 45, 1124–1151.
- Belitser, E., and Ghosal, S. (2020), ‘Empirical Bayes Oracle Uncertainty Quantification for Regression’, The Annals of Statistics, 31, 536–559.
- Belitser, E., and Nurushev, N. (2019), General Framework for Projection Structures. ArXiv: 1904.01003.
- Belitser, E., and Nurushev, N. (2020), ‘Needles and Straw in a Haystack: Robust Empirical Bayes Confidence for Possibly Sparse Sequences’, Bernoulli, 26, 191–225.
- Bellec, P.C. (2018), ‘Sharp Oracle Inequalities for Least Squares Estimators in Shape Restricted Regression’, The Annals of Statistics, 46, 745–780.
- Belloni, A., and Chernozhukov, V. (2011), ‘L1-Penalized Quantile Regression in High-Dimensional Sparse Models’, The Annals of Statistics, 39, 82–130.
- Belloni, A., Chernozhukov, V., and Kato, K. (2019), ‘Valid Post-Selection Inference in High-Dimensional Approximately Sparse Quantile Regression Models’, Journal of the American Statistical Association, 114, 749–758.
- Belloni, A., Chernozhukov, V., and Wang, L. (2011), ‘Square-root Lasso: Pivotal Recovery of Sparse Signals via Conic Programming’, Biometrika, 98, 791–806.
- Benjamini, Y., and Hochberg, Y. (1995), ‘Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing’, Journal of the Royal Statistical Society: Series B, 57, 289–300.
- Birgé, L., and Massart, P. (2001), ‘Gaussian Model Selection’, Journal of the European Mathematical Society, 3, 203–268.
- Butucea, C., Ndaoud, M., Stepanova, N., and Tsybakov, A. (2018), ‘Variable Selection with Hamming Loss’, The Annals of Statistics, 46, 1837–1875.
- Castillo, I., and van der Vaart, A. (2012), ‘Needles and Straw in a Haystack: Posterior Concentration for Possibly Sparse Sequences’, The Annals of Statistics, 40, 2069–2101.
- Donoho, D.L., and Johnstone, I.M. (1994), ‘Minimax Risk Over ℓp-Balls for ℓq-Error’, Probability Theory and Related Fields, 99, 277–303.
- Donoho, D.L., Johnstone, I.M., Hoch, J.C., and Stern, A.S. (1992), ‘Maximum Entropy and the Nearly Black Object (with Discussion)’, Journal of the Royal Statistical Society: Series B, 54, 41–81.
- Efron, B. (2008), ‘Microarrays, Empirical Bayes and the Two-Groups Model’, Statistical Science, 23, 1–22.
- Gabriela Ciuperca, G. (2018), ‘Test by Adaptive Lasso Quantile Method for Real-Time Detection of a Change-Point’, Metrika, 81, 689–720.
- Hulmán, A., Witte, D.R., Kerényi, Z, Madarász, E., Tánczer, T., Bosnyák, Z, Szabó, E., Ferencz, V., Péterfalvi, A., Tabák, A.G, and Nyári, T.A. (2015), ‘Heterogeneous Effect of Gestational Weight Gain on Birth Weight: Quantile Regression Analysis From a Population-Based Screening’, Annals of Epidemiology, 25, 133–137.
- Jiang, L., Bondell, H.D., and Wang, H.J. (2014), ‘Interquantile Shrinkage and Variable Selection in Quantile Regression’, Computational Statistics & Data Analysis, 69, 208–219.
- Jiang, L., Wang, H.J., and Bondell, H.D. (2013), ‘Interquantile Shrinkage in Regression Models’, Journal of Computational and Graphical Statistics, 22, 970–986.
- Johnstone, I.M. (2017), Gaussian Estimation: Sequence and Wavelet Models, Book Draft.
- Johnstone, I.M., and Silverman, B.W. (2004), ‘Needles and Straw in Haystacks: Empirical Bayes Estimates of Possibly Sparse Sequences’, The Annals of Statistics, 32, 1594–1649.
- Koenker, R. (2005), Quantile Regression, Cambridge: Cambridge University Press.
- Li, K.-C. (1989), ‘Honest Confidence Regions for Nonparametric Regression’, The Annals of Statistics, 17, 1001–1008.
- Martin, R., and Walker, S.G. (2014), ‘Asymptotically Minimax Empirical Bayes Estimation of a Sparse Normal Mean Vector’, Electronic Journal of Statistics, 8, 2188–2206.
- Santosa, F., and Symes, W.W. (1986), ‘Linear Inversion of Band-Limited Reflection Seismograms’, SIAM Journal on Scientific and Statistical Computing, 7, 1307–1330.
- Szabó, B.T., van der Vaart, A.W., and van Zanten, J.H. (2015), ‘Frequentist Coverage of Adaptive Nonparametric Bayesian Credible Sets’, The Annals of Statistics, 43, 1391–1428.
- van der Pas, S.L., Szabó, B.T., and van der Vaart, A.W. (2017), ‘Uncertainty Quantification for the Horseshoe (with Discussion)’, Bayesian Analysis, 12, 1221–1274.
- Vershynin, R. (2018), High-Dimensional Probability. An Introduction with Applications in Data Science, Cambridge: Cambridge University Press.
- Zou, H., and Yuan, M. (2008), ‘Composite Quantile Regression and the Oracle Model Selection Theory’, The Annals of Statistics, 36, 1108–1126.