
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In many studies on disease progression, biomarkers are restricted by detection limits, hence informatively missing. Current approaches ignore the problem by just filling in the value of the detection limit for the missing observations for the estimation of the mean and covariance function, which yield inaccurate estimation. Inspired by our recent work [Liu and Houwing-Duistermaat (2022), ‘Fast Estimators for the Mean Function for Functional Data with Detection Limits’, Stat, e467.] in which novel estimators for mean function for data subject to detection limit are proposed, in this paper, we will propose a novel estimator for the covariance function for sparse and dense data subject to a detection limit. We will derive the asymptotic properties of the estimator. We will compare our method to the standard method, which ignores the detection limit, via simulations. We will illustrate the new approach by analysing biomarker data subject to a detection limit. In contrast to the standard method, our method appeared to provide more accurate estimates of the covariance. Moreover its computation time is small.
1. Introduction
Technological advances resulted in a growing number of datasets containing temporal observations, either dense or sparse. For analysis of these data, functional data analysis (FDA) methods have been developed, see, for example Ramsay and Silverman (Citation2005), Ferraty and Vieu (Citation2006), Horváth and Kokoszka (Citation2012) and Kokoszka and Reimherr (Citation2017) for dense data and Yao, Müller, and Wang (Citation2005), Peng and Paul (Citation2009), Li and Hsing (Citation2010), Wang, Chiou, and Müller (Citation2016) and Zhang and Wang (Citation2016) for sparse data. These methods assume that there is no missing data. However, in practice, we may have data subject to detection limits. Recently, several methods for the estimation of the mean function have been proposed and investigated when the data are subject to detection limits, namely the global method by Shi, Dong, Wang, and Cao (Citation2021) and several local methods by Liu and Houwing-Duistermaat (Citation2022). However, an estimator for the covariance has not yet been developed, which is the topic of this paper.
When levels of a specific marker in a sample have to be determined in a laboratory, we often deal with detection limits. The amount of the marker might be too low to be detected. This results in too many zeros in the dataset and an observed ‘zero’ might be a true zero or just very small. Also on the other extreme of the distribution, detection limits might occur, since measurement techniques are often optimised for a certain range of values and values above and below a certain threshold cannot be accurately measured. Detection limits are not restricted to laboratory measurements. Devices which measure certain characteristics (number of steps for example) might be out of charge yielding an underestimation of the characteristic per day (e.g. the true number of steps for a day is higher than the measured number of steps if the device was out of charge). For simplicity in this paper, we only consider detection limits on the lower extreme of the distribution, i.e. we do not observe values lower than a specific value, instead we observe this specific value which is also called detection limit (DL).
For observations subject to DL, Shi et al. (Citation2021) proposed a global method. However, since observations close to the target point t contain more information about the mean function at t than observations far away from t, local methods as proposed by Liu and Houwing-Duistermaat (Citation2022) might be more appropriate. The estimator of Liu and Houwing-Duistermaat (Citation2022) is based on approximations of the likelihood function. For data subject to DL, the likelihood function is a product of probability density functions for the observed values and of probability distribution functions for the observations subject to DL, since for the latter observations we know that the unobserved value is below a known threshold. To estimate the mean function around observed time points, the authors proposed to use the local polynomial kernel method (Fan and Gijbels Citation1995, Citation2018; Beran and Liu Citation2014, Citation2016). Further two weighting schemes for subjects have been considered (Zhang and Wang Citation2016; Liu and Houwing-Duistermaat Citation2022), namely the SUBJ scheme which assigns the same weight to each subject and the OBS scheme which assigns the same weight to each observation. The latter scheme will assign more weight to subjects with more observations. To reduce the computation time, Liu and Houwing-Duistermaat (Citation2022) proposed linear and constant approximations for the probability distribution functions in the likelihood function. The constant approximation is computationally fast especially for dense data while it only performs slightly less than the exact and linear approximation method. Note that the global method of Shi et al. (Citation2021) is even more computational inefficient than the linear approximation for dense data. Therefore, in this paper we will use constant approximations to obtain an estimator for the covariance function.
We propose a local constant estimator with approximation and derive their asymptotic behaviour. Via simulations we evaluate their performance in a sparse and a dense setting under both SUBJ and OBS weighting schemes and compare their performance with the standard method where the detection limit is used for the missing values. We also investigate the asymptotic behaviour of the estimators via simulations. To illustrate the proposed method, we apply it to temporal data from a biomarker study. We finish with a conclusion.
2. Methodology
2.1. Functional principal component analysis (FPCA)
We first define the model for functional data subject to a detection limit. Let be an
stochastic process on interval I. Let
and
be the mean and covariance function of
, respectively. Then
can be decomposed into
where
is the stochastic part of
which has mean zero, i.e.
for
, and covariance
for all
. By Karhunen–Loeve expansion and Mercer's Theorem, we have
and
where
are eigenfunctions of the covariance operator corresponding to
, positive real numbers
are the eigenvalues of the covariance operator corresponding to
, and
. Note that the functional principal components
(FPCs) are an orthonormal basis for
.
Let be n iid copies of
with
. We have observations of
at discrete time points
perturbed by an independent random error. Here,
is the number of measurements for subject i Specifically, let
denote the random variable for the jth time point for subject i with
and
. We can model
as follows:
(1)
(1) where
is an independent random measurement error term following a distribution in the exponential family with mean zero and variance
that is,
are independent for any i and j. We assume further that
is independent of
(or equivalently
). Often a Gaussian distribution is assumed, i.e. we have
and
.
Now, not all are observed due to the presence of a DL. Let
be the missingness indicator, i.e.
if
is observed, and
if
is unobserved. If
, we assume that the unobserved
has a value smaller than (or equal to) a specific threshold
. For the sake of simplicity of notation, we assume the threshold is fixed, i.e.
for all i, j. Therefore, the observations are
where
is missing for
.
The consequence of the presence of a DL is that in the likelihood function the contributions of the observations subject to the DL are represented by the probability distribution function instead of the density function. As a consequence the likelihood function is hard to maximise. Liu and Houwing-Duistermaat (Citation2022) proposed to locally approximate the probability distributions by a linear function or by a constant resulting in time efficient estimators for the mean function. They showed via simulations that the local-linear estimator performed only slightly better than the local-constant estimator, but was less time efficient. Therefore, in this paper we will only consider the local-constant estimator.
2.2. Locally Kernel weighted log-likelihood estimator for the mean function
In this section, we briefly summarise the estimation procedure of the mean function which was developed by Liu and Houwing-Duistermaat (Citation2022). For this section, without loss of generalisability, we assume that in formula (Equation1
(1)
(1) ), i.e. we ignore the covariance between
at various time points. The loglikelihood function approximated locally by a constant is as follows (see Liu and Houwing-Duistermaat Citation2022):
(2)
(2) where
and
is a kernel function see details in Assumption (A1) and
are weights. Two types of weights
are considered, namely
and
Using loglikelihood function (Equation2
(2)
(2) ), Liu and Houwing-Duistermaat (Citation2022) obtained the following local constant estimator of the mean function:
(3)
(3) where
and
Note that Liu and Houwing-Duistermaat (Citation2022) only derived the asymptotic distribution of the local linear estimator (see Theorem 2.1 of their paper). The asymptotic distribution of
given in (Equation3
(3)
(3) ) can be obtained in a similar way. In this paper, we derive estimators for the covariance function
using similar ideas.
2.3. Local Kernel weighted estimation of covariance function
In this section, we assume and
(for simplicity of notations). We propose the following fast local constant kernel weighted estimator of
:
(4)
(4) where
and
with
and
and
Remark 2.1
Note that, without DL, the local constant smoother (or NW) for the mean function is
with
for all i and j in
and
(in formula (Equation3
(3)
(3) )), and the local constant smoother for covariance is
with
for all i and j in
and
(in formula (Equation4
(4)
(4) )).
Remark 2.2
If is unknown, it can be estimated by formula (Equation3
(3)
(3) ). Then we can just replace
by
in formula (Equation4
(4)
(4) ) to obtain the estimate of
.
For the observations , we have that they are observed values of a perturbed underlying continuous function
. Now, for
, we define indicator functions
on interval I with range
and
. For the covariance estimator defined in Equation (Equation4
(4)
(4) ), Theorem 2.1 holds.
Theorem 2.1
Under Assumptions B.1–B.3 given in the Appendix, for a fixed interior point ,
where
,
,
, and
are coefficient functions which are defined in Appendix,
,
,
,
and
are covariance functions which are also defined in Appendix, and notations
and
are also defined in Appendix.
Proof.
The proof comprises showing that the asymptotic bias and the asymptotic variance of are equal to
and
respectively. Here, Assumptions on the kernel (A1), the local polynomial smoothing (B1), (B2) and (B3). Details are given in Appendix. The additional assumption (C1) assures that the asymptotic bias is bounded, and assumption (C2) guarantees that the variance of the estimator goes to zero. The final step is to prove asymptotic normality of
. Note that this follows from the asymptotic normality of
by the application of the delta method see Theorem 1.12 in Shao (Citation2003). Now, asymptotic normality of
follows from the Lyapunov condition and Cramer–Wold device. Specifically, Lyapunov CLT of
and
can be achieved by the Lyapunov condition given in Assumption (C3), where the power is 3 (i.e.
and δ is 1) using the notation in Theorem 27.3 in Billingsley (Citation2008). Then the asymptotic joint normality of
can be derived via the Cramer–Wold device for the two-dimension case, see Theorem 29.4 in Billingsley (Citation2008).
This completes the proof.
Remark 2.3
If there are no observations subject to DL, i.e. , for all i, j, then
. Moreover,
which corresponds to the results of classic local constant covariance estimator (see Zhang and Wang Citation2016).
3. Simulation study
We evaluate the performance of our proposed estimator of via simulations. We compare its performance with a standard method where the missing observations are replaced with the DL value (Yao et al. Citation2005). We compare the methods in terms of bias, efficiency, asymptotic behaviour and computation time.
We assume that for simplicity and define the true zero mean random function
as follows:
where
, ξ is a normal random variable with mean zero and variance 2, i.e.
and
. Therefore the covariance function is
The observed time points
are iid sampled from the continuous uniform distribution in the interval
. Additive errors are sampled from
. Then the response is generated by
Finally, the missing data are created with the observations less than DL are replaced by DL, with DL
.
We consider two settings, namely a sparse and a dense grid for the observations for each subject i. We, specifically, sample the number of time points for each trajectory i as follows:
Sparse setting:
i.e.
Dense setting:
For each setting, we simulate Q = 100 replicates. Each replicate contains information of n = 100 subjects.
To estimate the covariance functions in the replicates, we consider the following methods:
Our estimator based on local constant approximations using either the OBS or the SUBJ weighting schemes.
PACE which does not adjust for the detection limit (Yao et al. Citation2005).
For each replicate, the covariance functions are estimated on 20 equal-distant time points in . The variance of
is estimated as the mean squared error based on the least-squared fit using all the data (including the values subject to DL). We use the Gaussian kernel for the estimation procedure. To select the bandwidth h, the integrated squared error (ISE) is computed for a dense grid of values, namely
. The ISE is defined as follows:
where
is the estimation of C with bandwidth h. The bandwidth which minimises
is selected as the optimal bandwidth and the corresponding ISE is denoted with
(see Fan and Gijbels Citation2018).
We then calculate the mean integrated squared error (MISE) and the standard deviation of ISE over replicates:
(5)
(5)
(6)
(6) where
is the covariance estimation based on the ith replicate.
For the sparse setting, Figure depicts the first 20 of the 100 trajectories in the first replicate without a DL and subject to a DL. The proportion of observations subject to DL is 26.67% and 48.73%, respectively. The corresponding estimates of the covariance function by the local constant approximation method proposed in this paper under the OBS and SUBJ weighting schemes and by the PACE method are given in Figure .
Figure 1. The first 20 of the 100 trajectories in the first replicate of the sparse setting. Left: Data without a detection limit, middle with a detection limit of 0, right with detection limit of .
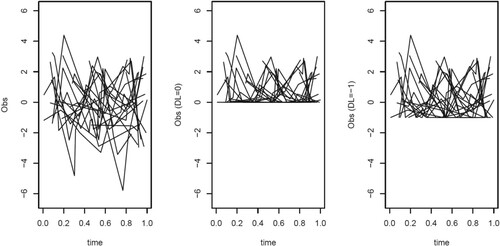
Figure 2. For replicate 1 of the sparse setting, contour plots with lines of the true and estimated covariance function for a DL of 0 (top layer) and of (bottom layer) using the constant approximation methods with the OBS and SUBJ weighting schemes (second and third columns) and using PACE (fourth column). The covariance is estimated at 20 equal-distant points in
. The bandwidth for the constant approximation method is 0.015.
![Figure 2. For replicate 1 of the sparse setting, contour plots with lines of the true and estimated covariance function for a DL of 0 (top layer) and of −1 (bottom layer) using the constant approximation methods with the OBS and SUBJ weighting schemes (second and third columns) and using PACE (fourth column). The covariance is estimated at 20 equal-distant points in [0,1]×[0,1]. The bandwidth for the constant approximation method is 0.015.](/cms/asset/31331ef2-88e7-4460-a5c3-2aba4b8cc433/gnst_a_2258999_f0002_ob.jpg)
For these two replicates, the proposed local constant approximation method performs much better than PACE. For , PACE estimates the covariance of all considered time points larger than zero while the two local constant estimates also have negative values representing the true situation. For both values of DL, the OBS scheme seems to capture the true covariance function slightly better in this replicate. Further because of less missing values, the results for
(bottom layers of Figure ) are better than that for
(top layers of these figures). The time needed for calculating the estimate of the covariance function appeared to be 4.8 seconds for
and 5.1 seconds for
for the proposed estimators while the computation time for the PACE method was 7.6 seconds for
and 7.9 seconds for
. Thus our proposed local approximation method is more time efficient than the PACE method.
For the dense setting, Figure depicts the first 20 of the 100 trajectories in the first replicate without a DL and subject to a DL of and of
. The proportions of observations subject to DL are 50.21% in the replicate with for
and 25.61% for
. The estimates of the covariance functions by the various methods using the data from these replicates are given in Figure .
Figure 3. The first 20 of the 100 trajectories in the first replicate of the dense setting. Left: Data without a detection limit, middle with a detection limit of 0, right with detection limit of .
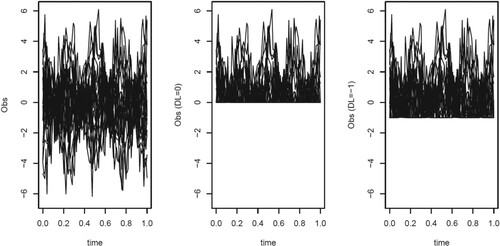
Figure 4. For replicate 1 of the dense setting, contour plots with lines of the true and estimated covariance function for a DL of 0 (top layer) and of (bottom layer) using the constant approximation methods with the OBS and SUBJ weighting schemes (second and third columns) and using PACE (fourth column). The covariance is estimated at 20 equal-distant points in
. The bandwidth for the constant approximation method is 0.03 for a DL of 0 and 0.035 for a DL of
.
![Figure 4. For replicate 1 of the dense setting, contour plots with lines of the true and estimated covariance function for a DL of 0 (top layer) and of −1 (bottom layer) using the constant approximation methods with the OBS and SUBJ weighting schemes (second and third columns) and using PACE (fourth column). The covariance is estimated at 20 equal-distant points in [0,1]×[0,1]. The bandwidth for the constant approximation method is 0.03 for a DL of 0 and 0.035 for a DL of −1.](/cms/asset/7ce1f2fb-4c4b-4557-9cf8-c82c922022d4/gnst_a_2258999_f0004_ob.jpg)
As in the sparse setting, the proposed local constant approximation method performs better than the existing PACE method for these two replicates. The two weighting schemes in the local constant approximation methods give similar estimates. The time needed for calculating the estimated covariance function is 0.03 seconds for and 0.057 seconds for
by using the local constant approximation, while for PACE it is 758 seconds for
and 773 seconds for
. Thus our proposed local approximation method is considerably more time efficient than the PACE method for the dense setting.
Table shows the results of the simulation study based on all replicates. It provides the MISE and the corresponding standard deviation (SD) for local constant approximation for the two weighting schemes (SUBJ or OBS) for increasing sample size n. Also the mode of optimal bandwidth in local constant estimation selected for each replicate is provided. We did not show the results of the PACE method, as this method appeared to give biased and inaccurate estimates, see Figures and .
Table 1. Results of the simulation study for the scenarios and
and for the sparse and dense setting.
Clearly as n increases from 100 to 1000, the MISE and corresponding SD decreases. The dense case has smaller MISE compared to the sparse case. Comparing with
, MISE is smaller for
. This can be explained by the fact that there is more information for
and in the dense setting. The optimal bandwidth is very stable across all settings for both weighting schemes. For the sparse setting, the OBS scheme performs better than the SUBJ scheme. For the dense setting, the two weighting schemes perform similar.
4. Data application
We illustrate our method using data from a longitudinal biomarker study of scleroderma patients. Scleroderma is a heterogeneous disease where the course of the severity varies among patients. The study comprises 217 patients with hospital visits from 2010 to 2015. Typically, scleroderma patients visit the hospital every 6 months to check whether the disease has progressed. However, patients missed their appointments or their data were not recorded resulting in a sparse unbalanced dataset. The data were collected according to the ethically approved protocol for observational study HRA number 15/NE/0211.
In Liu and Houwing-Duistermaat (Citation2022), the mean functions of two biomarkers subject to detection limits were estimated, namely aldose reductase (AR) and alpha fetoprotein (AF). The percentage of missing data for the AF marker is high, namely 75%, which led to uncertainty in the estimation of the mean function. The percentage of missing data due to the DL for AR is much lower namely 7.8% observations resulting in a more stable mean function. For the estimation of the covariance function we use the data on AR.
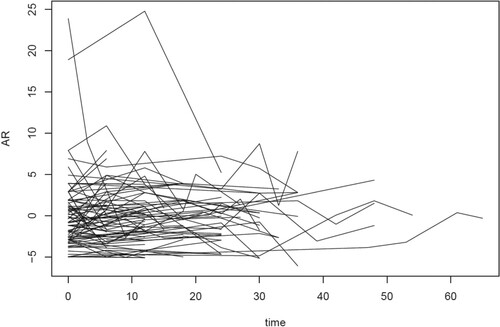
For data cleaning, we remove observations at time points with no outcomes or no biomarker values, and some outliers (AR has a value larger than 3 times the standard deviation). Finally, patients with only one observation are dropped. The final dataset comprises 90 patients within total 268 observations. The mean function of AR is estimated using the local constant approximation method under the OBS scheme. The bandwidth was selected using CV over a fine grid. The observed profiles minus the estimated mean function are shown in Figure .
Figure 5. The AR observations with estimated mean being subtracted.
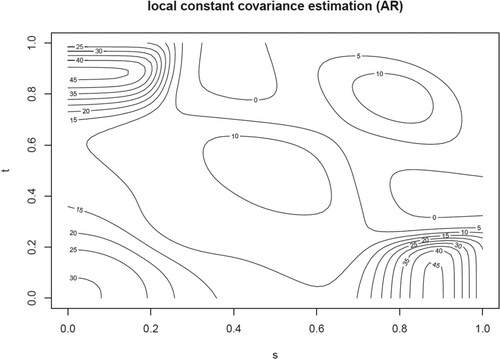
The estimate of the covariance function using the local constant method is shown in Figure . Note that the number of patients observed over a large time period is small, hence the covariance estimations for s or t larger than 0.6 have large uncertainty. For the region we observe that at larger distance the covariance decreases. Along the line s = t for the region
, the estimated covariance functions appear to decrease. This is probably due to a smaller variance (see Figure ). Finally for the regions
and
, we observe that the covariance increases when s and t respectively increase to 1. This may reflect the fact that patients observed over a longer time range are a specific subset of the patients, namely they are more stable hence show a large correlation and a large covariance over time.
Figure 6. The covariance estimation for AR by using local constant estimation method.
5. Discussion
We have proposed a novel estimator for the covariance function for sparse and dense temporal data subject to a DL. Our method is based on local smoothing of the covariance function using kernel functions. We derived the asymptotic properties of the estimator and evaluated these properties via simulations. We compared our method to the method which ignores the presence of a DL in the data sample. We showed that our methods performed better in terms of bias and computation time. We also considered two weighting schemes for the observations, one based on single observations and one based on subjects. For sparse data, weighting per observation appeared to perform better.
We illustrated the method using data from a biomarker study. The estimated covariance for the biomarker first decreased over time and then started increasing again. The latter might be explained by an increase in variance and/or in correlation. If the biomarker represents disease severity, the patients who have a longer follow up are likely to be patients with a less severe disease course. Thus these results might be explained by non-random drop out of patients. The development of estimators for the mean and covariance function for drop out will be future research.
Liu and Houwing-Duistermaat (Citation2022) also proposed a linear approximation instead of a constant approximation. We did not consider this approach here since for dense data there is no difference in performance and the linear approximation requires more computation time. For sparse data, a linear approximation might perform slightly better. Another approach is to impute the missing observations and then use PACE for the estimation of the covariance function. For cross-sectional data, Uh, Hartgers, Yazdanbakhsh, and Houwing-Duistermaat (Citation2008) studied the performance of imputation methods. They concluded that these methods may give biased estimators or underestimated variances. Given the results of Uh et al. (Citation2008) and the facts that multiple imputations would increase the computation time and that the computation time of PACE is higher than of our methods, we did not consider this approach for the estimation of covariance function.
For the selection of the bandwidth, we used cross validation in the data application while in the simulation we used ISE where we plug in the true value of the covariance function . We could have used cross validation in the simulation study as well, however, this would have increased the computation time while we expect that cross validation would only slightly change individual results and our overall conclusions with regard to the effect of DL on the estimation of the covariance and the difference between using OBS and SUBJ weighting would not change.
With the availability of estimators of the mean and the covariance function, models for temporal data subject to DL can be built. Functional principal component analysis (FPCA) can be used to reduce the infinite dimension into finite dimension. For sparse datasets, FPCA can be used to obtain smooth individual curves. Finally functional regression models can be developed to investigate the influence of covariates with DL on the outcomes which might be also subject to DL.
Acknowledgments
We would like to thank a referee for very useful constructive remarks.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Beran, J., and Liu, H. (2014), ‘On Estimation of Mean and Covariance Functions in Repeated Time Series with Long-memory Errors’, Lithuanian Mathematical Journal, 54(1), 8–34.
- Beran, J., and Liu, H. (2016), ‘Estimation of Eigenvalues, Eigenvectors and Scores in FDA Models with Strongly Dependent Errors’, Journal of Multivariate Analysis, 147, 218–233.
- Billingsley, P. (2008), Probability and Measure, Hoboken, New Jersey: John Wiley & Sons.
- Fan, J., and Gijbels, I. (1995), ‘Datadriven Bandwidth Selection in Local Polynomial Fitting: Variable Bandwidth and Spatial Adaptation’, Journal of the Royal Statistical Society: Series B (Methodological), 57(2), 371–394.
- Fan, J., and Gijbels, I. (2018), Local Polynomial Modelling and Its Applications: Monographs on Statistics and Applied Probability 66, London: Routledge.
- Ferraty, F., and Vieu, P. (2006), Nonparametric Functional Data Analysis: Theory and Practice, New York: Springer.
- Horváth, L., and Kokoszka, P. (2012), Inference for Functional Data with Applications, New York: Springer.
- Kokoszka, P., and Reimherr, M. (2017), Introduction to Functional Data Analysis, London: Chapman and Hall/CRC.
- Li, Y., and Hsing, T. (2010), ‘Uniform Convergence Rates for Nonparametric Regression and Principal Component Analysis in Functional/longitudinal Data’, The Annals of Statistics, 38(6), 3321–3351.
- Liu, H., and Houwing-Duistermaat, J. (2022), ‘Fast Estimators for the Mean Function for Functional Data with Detection Limits’, Stat, 11(1), e467.
- Peng, J., and Paul, D. (2009), ‘A Geometric Approach to Maximum Likelihood Estimation of the Functional Principal Components From Sparse Longitudinal Data’, Journal of Computational and Graphical Statistics, 18(4), 995–1015.
- Ramsay, J.O., and Silverman, B.W. (2005), Functional Data Analysis (2nd ed.), New York: Springer.
- Shao, J. (2003), Mathematical Statistics, New York: Springer Science & Business Media.
- Shi, H., Dong, J., Wang, L., and Cao, J. (2021), ‘Functional Principal Component Analysis for Longitudinal Data with Informative Dropout’, Statistics in Medicine, 40(3), 712–724.
- Uh, H.W., Hartgers, F.C., Yazdanbakhsh, M., and Houwing-Duistermaat, J.J. (2008), ‘Evaluation of Regression Methods When Immunological Measurements are Constrained by Detection Limits’, BMC Immunology, 9(1), 1–10.
- Wang, J.L., Chiou, J.M., and Müller, H.G. (2016), ‘Functional Data Analysis’, Annual Review of Statistics and Its Application, 3, 257–295.
- Yao, F., Müller, H.G., and Wang, J.L. (2005), ‘Functional Data Analysis for Sparse Longitudinal Data’, Journal of the American Statistical Association, 100(470), 577–590.
- Zhang, X., and Wang, J.L. (2016), ‘From Sparse to Dense Functional Data and Beyond’, The Annals of Statistics, 44(5), 2281–2321.
Appendix
Notations
Notation B.1
Define the following notations:
Coefficient functions
Conditional expectations
Covariance functions
Assumptions
Assumption B.1
Assumptions for the Kernel function:
| (A1) | Kernel function | ||||
Assumption B.2
Assumptions for time points and the true functions:
| (B1) | Time points | ||||
| (B2) |
| ||||
| (B3) |
| ||||
Assumption B.3
Assumptions for deriving the asymptotic distribution of the estimated covariance function:
| (C1) | For | ||||
| (C2) | For | ||||
| (C3) | For | ||||
Proof of Theorem 2.1
Proof.
The calculation of the asymptotic bias of ,
where
and
Therefore, by using the delta method, the asymptotic bias is
For the asymptotic variance, we need to calculate
. This involves the calculation of
which is equal to
if s = t and 0 if
as
, because the support of
is
. Thus
Therefore, by using the delta method, the asymptotic variance is