
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The log-rank test can be viewed as nonparametric from the standpoint of a series of tables, as semi-parametric from the standpoint of the proportional hazards model and as parametric from the viewpoint of a constructed empirical process. Under non-proportional hazards the optimality afforded by this test is lost. Some of this lost power can be recovered by more carefully structured tests. We focus on the integrated log-rank test. Under certain alternatives, we show this test to be unbiased, and consistent. It will also be seen to correlate well with the uniformly most powerful test, a test that, in practice, is not available. The integrated log-rank test is a useful addition to the clinical researcher's toolbox. For the purposes of illustration we revisit 3 recently published large scale clinical trials.
1. Introduction
In randomised clinical trials, interest will typically focus on the comparison of two survival curves, estimated using the Kaplan-Meier or Nelson-Aalen methods. In most cases the comparison concerns two parallel treatment arms although extensions to more than two groups are relatively straightforward. Our attention here is restricted to the case of two groups. In the light of its simplicity and optimality in proportional hazards situations, the log-rank test is by far the most commonly used test for comparing such estimated curves (Mantel Citation1966). Typically it will form the basis for sample size calculations when designing and analysing a large scale clinical trial. In the absence of any parametric assumptions on the conditional survival distributions, the log-rank test is known to yield maximum power under proportional hazards (PH) alternatives, that is, alternatives in which the hazard rates of the two groups is constant over time (Peto and Peto Citation1972). We describe this as a persistent treatment effect. Under non-proportional hazard situations this optimality is lost and indeed it is possible for the power of the log-rank test to be seriously compromised. Many observers have pointed this out and suggestions for alternatives when non-proportional hazards are anticipated have been made (Sposto and Stablein Citation1997; Klein et al. Citation2007; Logan et al. Citation2008; Lin and Leon Citation2017; O'Quigley Citation2022) and are well studied. While proportional hazards can be expressed in a relatively simple way, non-proportional hazards can manifest itself in a number of different ways.
Among these different ways, three of the most commonly encountered and the most easily understood are: (1) effects that diminish as time progresses, a commonly observed phenomenon in vaccine studies as well as studies where the reliability of a measured prognostic factor diminished through time, (2) effects that only manifest themselves after some initial period during which they appear to be absent, a commonly observed phenomenon in immunotherapy trials and (3) the so-called crossing survival curves problem in which effects initially appear to go in one direction but later in the study reverse and go in the opposite direction. This last situation is the least common but has been observed in studies involving surgery or studies on graft versus host disease where an initial disadvantage, if overcome, can show itself to be a long term advantage.
Fleming and Harrington (Citation1991) have considered the family of test statistics providing a set of weighted log-rank statistics. While all choices will correctly control for type 1 error, different choices can result in greater or in reduced power. The choice
specifies equal weights and corresponds to the log-rank test,
places more weight on earlier time points whereas
places more weight on the later time points. Then,
is more sensitive to early difference, a situation that corresponds to diminishing treatment effect, while
is more sensitive to late divergence of survival curves. Careful specification of the ρ and γ parameters can result in tests with very good power properties. Likewise, any misspecification can imply a loss of power. With this in mind, Lee (Citation1996) investigates a versatile test including some particular cases of
while other closely related flexible tests have also been studied (Wu and Gilbert Citation2002; Lee Citation2007).
More recent work has pushed these ideas further, investigating in particular performance of the so-called max-combo test in various situations (Lin et al. Citation2020; Wang et al. Citation2021). When treatment effects diminish through time or only manifest themselves after a significant delay, perhaps in a staggered fashion, then the log-rank test can potentially be seriously handicapped. The test may be unable to reproduce the hoped for power that would have been a part of our initial design calculations. This would naturally be the case when those initial power calculations make an appeal to an alternative characterised by a persistent treatment effect that remains steadily at its maximum. These calculations will roughly hold, albeit with some loss in power, when the treatment effect corresponds to some kind of average over the study period. The further this average from the steady anticipated maximum the greater the loss in power. Recently, a family of tests was developed for situations such as this and presents the potential for significant power gains in many circumstances (Chauvel and O'Quigley Citation2014; O'Quigley Citation2021). Our interest focuses on one particular member of this family, a test we refer to as the integrated log-rank test. One notable advantage of this particular test is that, while obtaining an important power advantage over the log-rank test in the presence of non-proportional hazards, the test loses relatively little when, indeed, the hazards are strictly proportional. Combining this test with the log-rank test is easily done and allows the possibility of getting the best of both worlds. The investigators can decide in advance how likely and by how much the real situation may stray from a proportional hazards one, enabling us to minimise potential power losses. An accurate evaluation of the real, unknown, situation is rewarded with very high, near optimal power. The trial designer can be comforted by such knowledge but might gain even greater comfort from knowing that an inaccurate evaluation, while losing optimality properties, may not be greatly penalised.
Our purpose here is to carry out further exploration of the tests based on the regression effect process with a particular focus on the integrated log-rank test, a test that relates closely to the AUC test but with a sequential standardisation that mirrors that of the log-rank construction. The test shows itself to perform especially well in particular settings, notably those where the treatment effect declines or increases monotonically through time. Under a null hypothesis of no effect, seen as a function of time, the integrated log-rank test will look like the area under a Brownian motion which, on average, will be zero. Note that area below the axis is counted as negative area. Brownian motion will look like the sum of a large number of zero mean random effects. Under a proportional hazards alternative, this regression effect process will look like Brownian motion with linear drift, the slope of this drift depending both on the sample size and the true strength of effect as measured by the regression coefficient. In a large sample sense, the log-rank test corresponds to Brownian motion whereas the integrated log-rank test corresponds to integrated Brownian motion.
The integrated log-rank test will correlate strongly with the distance travelled from the origin of the regression effect process when the hazards are proportional, this distance equating to the log-rank test. Of greater interest is the fact that the integrated log-rank test will continue to maintain good power in the presence of non-proportional hazards effects when the regression effect process has a monotonic albeit non-linear trend. We organise the article as follows. In Section 2, notation, model structure and the regression effect process in transformed time are described. Section 3 describes informally how the regression effect process opens the door to many families of tests including the log-rank and integrated log-rank tests. Section 4 pursues these ideas in a more formal statistical setting. Asymptotic theory is briefly considered in Section 5 while Section 6 presents results allowing us to gain insight on the relative efficiency of the integrated log-rank test alongside the log-rank test.
2. Basic methodology
The two subsections here outline the methods that we use. The first subsection summarises the notation and provides the essential definitions, following which we present the model structure and model parametrisation. The second subsection describes the regression effect process which is the basis for the tests that follow.
2.1. Notation and definitions
We make use of the indicator function taking the value 1 when A holds and 0 otherwise. We use an alternate notation,
when A is too long or too crowded for easy reading. Thus,
We denote the cardinality of the set A by
and, aside from some technical value in the context of large sample theory, this will simply be the number of elements in the set A. The random variables of interest are the failure time,
, the censoring time,
and the treatment indicator covariate,
,
Under weak assumptions (bounded, predictable process) we can allow
to change with time, t. In most of the applications considered here the treatment indicator covariate,
will remain constant in time. We can view these variables as a random sample from the distribution of T, C and Z. For each subject i we observe
, and
. The ‘at risk’ indicator
is defined as,
The counting process
is defined as,
and we also define
. An important quantity, the ‘effective sample size’, is
where,
which will only differ from zero when, at time t, there are in the risk set at least two subjects with distinct covariate values. For continuous covariates, and no ties,
corresponds to the number of observed failures. For a discrete covariate, for example a binary group indicator,
counts the number of failures that are informative regarding regression effects, i.e. failures
for which
. Once one group has been exhausted and the remaining failures occur in a single group, then no information can be provided regarding the regression effect and
While this is no doubt obvious it is nonetheless a little awkward notationally but is required in the semi-parametric context of proportional hazards regression. Fully parametric models are a different story. Semi-parametric inference remains invariant under monotonic increasing transformation of the
. Chauvel and O'Quigley (Citation2014) chose to work with a very specific transformation given by the following definition.
Definition 2.1
Consider the following transformation of the observed times
:
and set
We define the inverse
of
on
by
The transformation defines an isomorphism from the set of the observed times
to the set of equally spaced new ‘failure’ times,
together with the censorings that are placed uniformly between the corresponding transformed failure times. To the new set we add
Recall that the counting process
has a jump of size 1 at each time of death. Thus, on the new time scale representing the image of the observed times
under
, the values in the set
precisely correspond to times of death, and the ith time of death
is such that
The set is included in but is not necessarily equal to the transformed set of times of death. Working with the first
of these, we restrict ourselves to values less than or equal to 1. As the importance of the transformation applied to the observed times is to preserve order, various transformations – treating censoring times differently – could be used. We choose to uniformly distribute censoring times between adjacent times of failure. The time
on this new scale corresponds to the
th percentile for informative (
) deaths in the sample. For example, at time
half of these deaths have been observed. At time
, we can say that
of these deaths have occurred. The inverse of
can be obtained easily and with it we can interpret the results on the initial time scale. All of our workings will be on the transformed time scale in
and, to make this clear, we express the analogous quantities to those presented above but with respect to the new time scale. Specifically, for
, we define the individual at risk and counting processes,
and
for individuals
as well as the cumulative process by,
Finally, denote
the distribution function of the normed and centred normal distribution. If there are ties in the data our suggestion is to split them randomly although there are a number of other suggested ways of dealing with ties. All of the techniques described here require only superficial modification in order to accommodate any of these other approaches for dealing with ties.
2.2. Regression effect process in transformed time
Our main building blocks are the conditional means and variances of the covariate over the risk set at time t. Many works show how to derive these on the basis of the non-proportional hazards model, or we could, instead, simply define them directly. This can be a little sharper and so we consider the following three definitions.
Definition 2.2
We denote a process such that
(1)
(1)
In words, assumes the value of the covariate (group assignment) associated with the failure, when there is one, at time t, otherwise it assumes the value zero.
Definition 2.3
For and
the probability that individual i dies at time t under the non-proportional hazards model with parameter
, conditional on the set of individuals at risk at time of death t, is defined by
Remark
The only values at which these quantities will be calculated are the times of death . We nevertheless define
and
for all
in order to be able to write their respective sums as integrals with respect to the counting process
. The values 0 taken by them at times other than that of death are chosen arbitrarily although bounded by adjacent failures, i.e. the initial ordering is respected.
Expectations and variances with respect to the family of probabilities can now be defined.
Definition 2.4
Let . The time dependent expectations and variances of Z with respect to the family of probabilities
are obtained from the moments expressed on the transformed scale as:
(2)
(2) giving the expected values as
and the variances,
Note that at any fixed
can be viewed as an argument to
and that
, for
.
Proposition 2.1
Let . Under the non-proportional hazards model with parameter
, the expectation
and variance
of the random variable
given the σ-algebra
are
The proof of the proposition is given in Section 5. In conclusion, for and time of death
, by conditioning on the set of at-risk individuals, the expectation of
is
and its variance-covariance matrix is
. Knowledge of these moments allows us to deduce the large sample behaviour of the tests described in the following section.
Definition 2.5
The regression effect process, on
is obtained by linearly interpolating the
random variables
one of which is degenerate, taking on the value zero with probability one when
Given
for
and for
, we have;
(3)
(3) in which, for
we write,
(4)
(4)
This process forms the basis for many statistical tests which are also accompanied by a simple visual representation of regression effects. Examples are seen in Figure . By virtue of Donsker-Prokhorov's invariance principle, will look like Brownian motion when
and Brownian motion with linear drift when
The magnitude and sign of the drift will depend on the magnitude and sign of
as well as
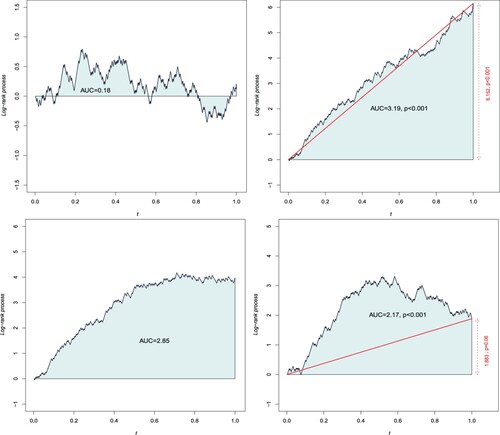
Figure 1. AUC for 4 situations with (a) no treatment effect ; (b)
; (c)
for t<0.5 and
for t>0.5; (d)
for t<0.5 and
for
Note that twice the area of the red triangle for the two right hand figures corresponds to the log-rank statistic.
3. Tests based on the regression effect process: general
A large number of tests can be based on the regression effect process. These include several well known families of tests such as the log-rank and weighted log-ranks tests. Our focus is on proportional hazards alternatives, alongside non-proportional hazards alternatives of a particular kind, specifically alternatives where the regression effect changes monotonically with time. For this purpose, we consider 5 classes of tests;
Distance from the origin test.
Log-rank test
Area under the curve test
Integrated log-rank test/conjugate integrated log-rank test
Combined tests: log-rank/integrated log-rank tests and log-rank/conjugate integrated log-rank
The first 3 of these tests have been studied to a greater or lesser extent. The properties of the log-rank test are well known. Under proportional hazards alternatives, the distance from origin test is a uniformly most powerful test, a property inherited by the log-rank test under local alternatives. This follows from convergence in distribution results stemming from applications of the Donsker-Prokhorov invariance principle (Chauvel and O'Quigley Citation2014) and direct applications of the Neyman-Pearson lemma to the Brownian motion with linear drift law (Flandre and O'Quigley Citation2019). The area-under-the-curve test was introduced in O'Quigley (Citation2008) and further studied by Chauvel and O'Quigley (Citation2014). Here we focus on the test groupings based on the integrated log-rank test. We can deduce attractive properties for these tests by appealing to a convergence in distribution result showing, under certain conditions, the large sample equivalence of the area-under-the-curve test and the integrated log-rank test. Established Brownian motion theory also provides the large sample distribution for any linear combination of the log-rank and integrated log-rank test. The large sample correlation structure of the log-rank and the integrated log-rank test is a simple one so that tests that combine the log-rank with the integrated log-rank test are readily constructed. The test described in Section 3.3 is one such example and is of particular interest in that it mirrors the integrated log-rank test but with the weightings reversed, thereby providing improved power over the log-rank itself when regression effects increase, rather than decrease, with time. This test might be viewed as being based on the area over the curve and, in view of its particular relation to the integrated log-rank test, we call it the conjugate integrated log-rank test.
3.1. Distance-from-origin and log-rank tests
We briefly recall the idea behind the distance from origin test and how it relates to the log-rank test. The relationship between the area under the curve test and integrated log-rank test is then more easily understood. Figure illustrates the connection between these tests and the regression effect process.
The ‘distance-from-origin at time t = 1 test’ – the – test is the distance between the x-axis and the arrival point of the process when t = 1. Under proportional hazards the
test, i.e.
turns out to be the best available test (Chauvel and O'Quigley Citation2014), in the sense that it is the uniformly most powerful unbiased test over the domain of β. Consider though, when testing for the presence of an effect (
against
), and suppose that, instead of standardising by
at each
we take a simple average of such quantities, over the observed failures. To see this, note that
is consistent for
when
, where
is a consistent estimate of the distribution function of T, typically the Kaplan-Meier estimator. Rather than integrate with respect to
it is more common, in the counting process context, to integrate with respect to
, the two coinciding in the absence of censoring. Either way, the approach amounts to averaging with respect to some empirical distribution. Now if, in the regression effect process, we replace
by
then the statistic at
, denoted by
, coincides with the log-rank test. Noting that the distance from origin test is the uniformly most powerful unbiased test we might conclude that the log-rank test, as it stands, is generally a less powerful test. Such a conclusion is not incorrect but we need to be mindful of the fact that, for local alternatives, the two tests can be taken to be equivalent by virtue of a convergence in distribution result (Proposition 4.3).
We can say more. For non-local alternatives, the expected value (with respect to any distribution) of the distance from origin test is greater than or equal to that of the log-rank test. This follows by an application of Jensen's inequality showing that, for random variables A, where expectations exist, then In theory then, we might hope the distance from the origin test to show some advantage over the log-rank test. In practice any advantage appears too small to make a difference and Proposition 4.3 indicates this difference to be zero for local alternatives. Inference for both tests as well as for the AUC test and integrated log-rank test lean on Theorem 1 below.
Figure shows the results of a simulation of the process describing situations with a sample size of 400 divided into two balanced treatment group (Z = 0 or 1). The first is absence of effect, i.e. under the null hypothesis
, and this corresponds to Brownian motion (Figure (a)). The second situation describes a proportional hazards model with
(Figure (b)). This plot shows a linear trend from t = 0 to t = 1 corresponding to the value of β. The third situation corresponds to a simulated process under the non-proportional hazards model, with
taken to be piece-wise constant. Before t<0.5 there is a linear trend while for t>0.5 β equals zero and the process
is constant in expectation over time. The last situation corresponds also to a non-proportional hazards model with
when t<0.5 and
when t>0.5 (Figure (d)). In this case, for t>0.5 the linear trend correspond to
and the survival curves crossed at the very end of the follow-up. The latter two situations correspond to the diminishing treatment effect issue.
3.2. Area-under-the-curve and integrated log-rank tests
A test of particular interest is that based on the area under the curve, The area under the curve test is the area, positive and negative, between the process and the horizontal axis. Again, under the null hypothesis this has expectation equal to zero. Using standard results we have that
converges in distribution to integrated Brownian motion, i.e. a Gaussian process with mean zero and covariance process
(5)
(5) It is interesting to note that, unlike Brownian motion itself, integrated Brownian motion is not a martingale. At time t = 1, rather than base a test upon the distance covered by the process
we can base a test upon the area under the curve. The two are correlated of course and if a large distance is covered we also know that there will be a large area under the curve. A two sided p-value corresponding to the null hypothesis is then obtained from
Under departures from the null which can be exactly described as proportional hazards alternatives the distance from origin test has slightly greater power than the area under the curve test (Chauvel and O'Quigley Citation2014). This is no longer true when effects decline with time and in many, possibly the majority of practical situations the area under the curve test has greater power than the distance from origin test. The following theorem makes these observations more precise.
Theorem 3.1
Take to be some set of continuous functions of t on
Let
be a constant function. Under the non-proportional hazards model with parameter
, consider
(6)
(6) where
is in the ball with centre β and radius
. Then, there exist two constants
and
such that
and
(7)
(7) where
is a standard Brownian motion. Furthermore,
(8)
(8)
Corollary 3.1
Under the non-proportional hazards model with parameter ,
Figure gives a finite sample illustration of the implications of the theorem. A proof of the theorem is given in Chauvel and O'Quigley (Citation2014). The implication of the theorem is that the regression effect process will trace out a path that closely parallels that of Simulations back this up and it is straightforward to obtain curves such as those illustrated in the figure. On the original time scale however things will not look so clear cut so that, even in the case of proportional hazards, the process can appear to be non-linear.
3.3. Conjugate integrated log-rank test
The integrated log-rank test, in close agreement with the area under the curve test, will be sensitive to departures from the null in which treatment effects steadily wane with time. This is also the case for the class of tests. In a way not very dissimilar to the flipping of the
test on its head to become the
test, sensitive to treatment effects that increase rather than decrease in time, we can readily construct a test based on the integrated log-rank test that is also sensitive to treatment effects that increase with time. This construction is intimately related to the integrated log-rank test. So much so that we refer to it as the conjugate integrated log-rank test. Denoting the integrated log-rank test as
then we refer to the conjugate integrated log-rank test as
and we have:
(9)
(9) so that, viewing
as the area under the curve up until time point t, we can view
as the area over the curve from the origin until time t. Figure provides an illustration of where
can be used to advantage. We consider some of the details of large sample theory below but, already, we can see that working results are easily obtained since, under the hypothesis,
and
will be approximated by Gaussian processes with known means and known variance-covariance structure. In particular, to build a test based on the maximum of the log-rank and the conjugate integrated log-rank test, we can use the result;
(10)
(10) and this can be written down explicitly in terms of t.
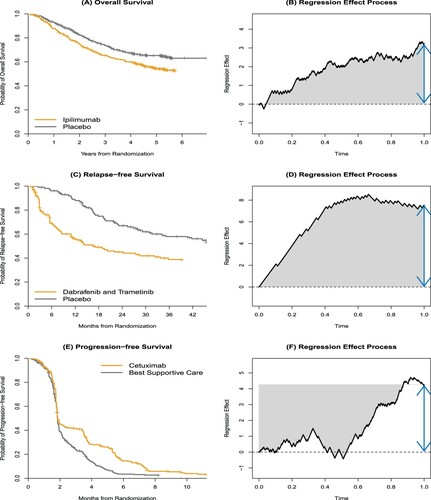
Figure 2. Figures (A) and (B) show effects that are approximately persistent. Here, twice the area under the curve and the log-rank statistic will be close and so we do not anticipate the integrated log-rank test to significantly outperform the log-rank test. Figures (C) and (D) show the strong erosion of effects that is not obvious from the K-M curves alone. The erosion is clear from the process (Figure D). Figures (E) and (F) indicate a delay in effects that is very sharp.
4. Tests based on the regression effect process: theory
The asymptotic behaviour of the regression effect process allows us to construct hypothesis tests on the value of the regression parameter
. The null hypothesis
and alternative hypothesis
that we wish to test are
where
is a fixed constant and
The reason for the slightly involved expression for
is to overcome situations in which the test could be inconsistent. The expression allows us to cater for cases where, for example,
differs from
only on a finite set of points or, to be more precise, on a set of time points of measure zero. Under
, the drift of the regression effect process
at
is zero, and the process converges to standard Brownian motion. We can therefore base tests on the properties of Brownian motion. When
, this amounts to testing for the absence of an effect between the various values of the covariate Z. In particular, if the covariate is categorical and represents different treatment groups, this means testing the presence of a treatment effect on survival. The
case corresponds to the null hypothesis of the log-rank test.
There are several possible tests based on the process, including the distance from the origin at time t, the maximal distance covered in a given time interval, the integral over some interval of the process, the supremum of a Brownian bridge, reflected Brownian motion and the arcsine law. We will take a closer look at how these relate to one another. We state a simple yet important proposition following which we look at the univariate case with one covariate and one effect to test (p = 1). Extensions to higher dimension are notationally but not theoretically demanding. For higher dimensions the number of processes of interest grows exponentially, for p = 2 for instance, we would have two conditional processes, two stratified processes, as well as processes arising as linear combinations. This is a potentially rich field for exploration and we do not take it any further here.
The following, almost trivial, result turns out to be of great help in our theoretical investigations. It is that every non-proportional hazard model, , is equivalent to a proportional hazards model.
Lemma 4.1
For given and covariate
there exists a constant
and time dependent covariate
so that
There is no loss of generality if we take The result is immediate upon introducing
and defining a time-dependent covariate
The important thing to note is that we have the same
either side of the equation and that, whatever the value of
, for all values of t, these values are exactly reproduced by either expression, i.e. we have equivalence. Simple though the lemma is, it has strong and important ramifications. It allows us to identify tests that are unbiased, consistent and, indeed, most powerful in given situations. A non-proportional hazards effect can thus be made equivalent to a proportional hazards one simply by multiplying the covariate Z by
The value of this may appear somewhat limited in that we do not know the form or magnitude of
However in terms of theoretical study, this simple observation is very useful. It will allow us to identify the uniformly most powerful test, generally unavailable to us in practice, and to gauge how close in performance comes any of those tests that are available. We first recall a useful result of Cox (Citation1975). Under the non-proportional hazards model with
, the increments of the process
are centred with variance 1. From Proposition 4.1 we also have that these increments are uncorrelated, a key property in the derivation of the log-rank statistic.
Proposition 4.1
Cox Citation1975
Under the non-proportional hazards model with parameter , the increments between the random variables
and
for
are uncorrelated.
Based on the regression effect process, two clear candidate statistics stand out for testing the null hypothesis of no effect. The first is the ‘distance-travelled’ at time t test and the second is the area under the curve test. Under proportional hazards the correlation between these two test statistics approaches one as we move away from the null. Even under the null this correlation is high and we consider this below. Under non-proportional hazards the two tests behave very differently. A combination of the two turns out to be particularly valuable for testing the null against various non-proportional hazards alternatives, including declining effects, delayed effects and effects that change direction during the study.
4.1. Distance travelled from the origin at time t
The distance travelled from the origin at time t, and in particular when appears as a logical, and intuitive, candidate for a test. Much more can be said as we see in this section. Under the null, this distance,
has expectation equal to zero. The area under the curve test is the area, positive and negative, between the process and the time-axis. Again, under the null hypothesis this has expectation equal to zero. Under proportional hazards, the test based on
turns out to be the best available test for the following reasons.
Lemma 4.2
For 0<s<1 and under the null hypothesis, converges in distribution to
where
is the standard normal distribution.
Corollary 4.1
Set such that
. The distance travelled at time t test rejects
with a type I error α if
The p-value for this test is given by
.
Corollary 4.2
The distance travelled test is unbiased against proportional hazards alternatives on the interval .
Corollary 4.3
Under the null hypothesis, the distance travelled test is consistent against proportional hazards alternatives.
The lemma is an immediate consequence of the Donsker-Prokhorov invariance principle. The corollaries follow from the Neyman-Pearson lemma as applied to the standard normal distribution and one with the same variance but a translated mean.
Corollary 4.4
Under , assuming the Breslow-Crowley conditions, i.e.
as
then, for t>s
where
behaves as a linear function of
for fixed β and a linear function of β for fixed
Note that this function is not bounded with respect to increases in β and
Corollary 4.5
Under , suppose that
is the p-value for
then, assuming that
, then, for
By applying the Neyman-Pearson lemma to the normal distribution, the above two corollaries tell us that the distance travelled test is the uniformly most powerful test of the null hypothesis, against the alternative,
The log-rank test,
shares this property and this is formalised in Proposition 4.3. Lemma 4.1 allows us to make a stronger conclusion. Assume the non-proportional hazards model and consider the null hypothesis,
for all t. Then,
Lemma 4.3
The uniformly most powerful test of for all t, is the distance travelled test applied to the proportional hazards model
in which
and where we take 0/0 to be equal to 1.
Since, under the alternative, we may have no information on the size or shape of this result is not of any immediate practical value. It can though act as a bound, not unlike the Cramer-Rao bound for unbiased estimators and let us judge how well any test is performing when compared with the optimal test in that situation.
The following proposition states that the distance test statistic is consistent; that is, the larger the sample, the better we will be able to detect the alternative hypothesis of a proportional hazards nature. The result continues to hold for tests of the null versus non-proportional hazards alternatives but restrictions are needed, the most common one being that any non-null effect is monotonic through time.
Proposition 4.2
Under the alternative hypothesis , that is, under the non-proportional hazards model with parameter
, we have
Remark
The test can be applied at any time point t, making it flexible. For example, if we have prior knowledge that the effect disappears beyond some time point τ, we can apply the test over the time interval . When such information is not available, we take t = 1, which, under proportional hazards, will maximise the power.
4.2. Relation between log-rank test and distance travelled test
Instead of standardising by at each
we might, instead, use a simple average of such quantities over the observed failures. Note that
is consistent for
under the proportional hazards model with
. Rather than integrate with respect to
it is more common, in the counting process context, to integrate with respect to
, the two coinciding in the absence of censoring. If, we replace
by
then the distance travelled test coincides exactly with the log-rank test. The following proposition gives an asymptotic equivalence under the null between the log-rank and the distance travelled tests:
Proposition 4.3
Chauvel and O'Quigley Citation2014
Let denote the log-rank statistic and let
be the distance statistic
evaluated at
. We have that
In order to obtain the result, we consider an asymptotic decomposition of the statistic in a Brownian motion with an added drift. The decomposition parallels that of the regression effect process at time t = 1. The conclusion is then immediate. A convergence in probability result implies a convergence in distribution result so that, under the conditions, the log-rank test and the distance from the origin test can be considered to be equivalent, this equivalence holding under the null and under local alternatives.
Under the conditions we have stated, the distance test statistic converges in distribution to that of the log-rank, guaranteeing maximum power under alternative hypotheses of the proportional hazards type. This result is not surprising since the expressions for the log-rank statistic and the distance test differ only in the standardisation used. For the former, standardisation takes place globally for all times at the end of the experiment, while for the latter, standardisation happens at each time of death. However, under a condition that holds precisely under the null and approximately under the alternatives, a condition analogous to that of homoscedasticity for the linear model (Chauvel and O'Quigley Citation2014), the standardisation does not change in expectation over time. Recall that this condition has been used by other authors (Grambsch and Therneau Citation1994). The result given in Proposition 4.3 also implies that the distance test is not optimal under alternative hypotheses of a non-proportional hazards nature since the power properties of the log-rank test also hold here. However, many other tests can be based on the regression effect process
the Donsker-Prokhorov invariance principle, and known properties of Brownian motion.
4.3. Combined log-rank and integrated log-rank tests
In the regression effect process, we might replace at each time point
by an average,
While
is not a martingale, it is consistent for
under the proportional hazards model with
so that, conditioning on the observed empirical variance allows us to treat this term as a constant. A similar argument has been used to justify the form of the log-rank test. Under the null, the conditional expectation does not depend on time, allowing us to work with
instead of
In this way we can obtain a convergence in distribution result for
and the area under the curve statistic, analogous to that of Proposition 4.3 above. More details are given in Section 5. The combined test, at
where,
allows us to carry out a certain degree of fine tuning of the log-rank and integrated log-rank tests. When
corresponds to the log-rank statistic whereas when
it equates to the integrated log-rank statistic. We see that
converges in distribution to a Gaussian process with mean zero and variance process equal to:
(11)
(11) which simplifies to
when
More generally we have;
Lemma 4.4
For time points s and t where we can write;
noting that, as t approaches s from above, the expressions for the covariance and variance coincide. Mostly our interest will be on a single time point, often so we will have little use for the covariance process. However, we can conceive of applications, such as clinical trials with interim analyses, where we may focus our interest on more than one time point. Although calculations may be fastidious there are no conceptual difficulties. With several time points, by virtue of having a Gaussian process, we can obtain all the needed terms of the required variance-covariance matrix.
Of equal interest, is a study on the pair and
where
This could open the way to a further degree of combination or as a means to contrast different tests based on different weightings. Choosing
allows for a study of the log-rank and integrated log-rank and these results we already have. But, of course, the comparison of other weightings can also be of interest. A calculation of the variances and co-variances allows us to obtain, for example, the Pitman efficiency of competing combinations. We have:
Lemma 4.5
At time t, for different values of the weighting parameter θ:
Lemma 4.4 provides the needed tool to study the process in time while Lemma 4.5 allows us to study the impact of different weightings. It would be relatively straightforward to complete the picture by calculating the covariance process in time for different weightings but it is not easy to see any immediate applications for that. Combinations other than the simple linear one may also suggest themselves, one obvious candidate being the maximum of the two test statistics.
4.4. Kolmogorov type tests
Since we are viewing the process as though it were a realisation of a Brownian motion, we can consider some other well-known functions of Brownian motion. Consider then the bridged process
;
Definition 4.1
The bridged process is defined by the transformation
(12)
(12)
Lemma 4.6
The process converges in distribution to the Brownian bridge, in particular
and
,
Note that a straightforward application of Slutsky's theorem enables us to claim that these large sample properties continue to hold whenever we use a consistent estimate in place of In practice this would require us to limit
to a constant or a piecewise constant function of t.
The Brownian bridge is also called tied-down Brownian motion for the obvious reason that at t = 0 and t = 1 the process takes the value 0. Carrying out a test at t = 1 will not then be particularly useful and it is more useful to consider, as a test statistic, the greatest distance of the bridged process from the time axis. We can then appeal to:
Lemma 4.7
(13)
(13)
which follows as a large sample result since
This is an alternating sign series and therefore, if we stop the series at k = 2 then the error is bounded by
which for most values of a that we will be interested in will be small enough to ignore. For alternatives to the null hypothesis (
) belonging to the proportional hazards class, the Brownian bridge test is not generally a consistent test. The reason for this is that the transformation to the Brownian bridge will have the effect of cancelling the linear drift term. The large sample distribution under both the null and the alternative will be the same. Nonetheless, the test has value under alternatives of a non-proportional hazards nature, in particular an alternative in which
is close to zero, a situation we might anticipate when the hazard functions cross over. If the transformation to a Brownian bridge results in a process that would arise with small probability under the assumption of a Brownian bridge then this is indicative of effects of a non-proportional hazards nature.
5. Large sample approximations
Each time of death is a
-stopping time where, for
, the σ-algebra
is defined by
where
is the floor function and
. Notice that if
.
Remark
Denote for
. If the covariates are time-dependent, for
, the σ-algebra
is defined by
since, as we recall, the covariate
is not observed after time
,
. To simplify notation in the following, we will write
in the place of
,
In other words, has jumps at times
for
. We make use of this in the following two lemmas.
Lemma 5.1
Let and let
be a process with values in
. Suppose that
where a is a function defined and bounded on
. Then,
Suppose that . Note that
(14)
(14) Suppose also that
For the first term we have,
Therefore,
and
As a result,
For the second term on the right hand side of Equation (Equation14
(14)
(14) ) we have,
Note that
is piecewise constant on the interval
such that
for
,
. We then have,
As a result we have,
Note that
by the uniform continuity of the function a. This implies uniform convergence
Furthermore, a is bounded so that
which shows the result since:
(15)
(15) Each time of death
is a
-stopping time where, for
, the σ-algebra
is defined by
where
is the floor function and
. Notice that if
.
Remark
Denote for
. If the covariates are time-dependent, for
, the σ-algebra
is defined by
since, as we recall, the covariate
is not observed after time
,
. To simplify notation in the following, we will write
in the place of
,
Proposition 2.1 indicates that,
under the non-proportional hazards model with parameter , the expectation
and variance
of the random variable
given the σ-algebra
are
To see this, note that for
the expectation of
(defined in (Equation1
(1)
(1) )) conditional on the σ-algebra
is
Indeed, Z and
are left-continuous, so
is
measurable. By definition, the probability that individual i has time of death t under the model with parameter
, conditional on the set of at-risk individuals at time t, is
. Thus,
The same reasoning for the second-order moment gives the variance result.
In conclusion, for and time of death
, by conditioning on the set of at-risk individuals, the expectation of
is
and its variance-covariance matrix is
. Knowledge of these moments allows us to define the regression effect process which, depending on the standardisation approach, leads to different results and tests. The large sample results here allow us to anticipate the behaviour of the integrated log-rank test as well as the joint behaviour of the log-rank and integrated log-rank tests both under the null hypothesis and under proportional hazards alternatives to the null.
6. Relative efficiency of rival tests
In order to gain greater theoretical insight we exploit the established relationships between Brownian motion and other known and studied functions of Brownian motion such as integrated Brownian motion. These provide a large sample analogy for the relationships between the log-rank and the integrated log-rank tests. For this purpose we recall and complete results given in Chauvel and O'Quigley (Citation2014, Citation2017) and Flandre and O'Quigley (Citation2019).
We now know that, under proportional hazards alternatives, the distance from the origin test is not only unbiased and consistent but is the uniformly most powerful unbiased test (UMPU). What happens though when these optimality conditions are not met, specifically when the non-proportionality shown by the regression effect takes a particular form. We might first consider different codings for in the model:
and, in view of Lemma 4.3, if
for any strictly positive
then this results in the most powerful test of
We can make use of results from Lagakos and Schoenfeld (Citation1984) in order to obtain a direct assessment of efficiency that translates as the number of extra failures that we would need observe in order to nullify the handicap resulting from not using the most powerful local test. Proposition 6.1 provides the results we need and its validity only requires the application of Lemma 4.3.
Exploiting the formal equivalence between time dependent effects and time dependency of the covariable, we can make use of a result of O'Quigley and Prentice (Citation1991) which extends a basic result of Lagakos and Schoenfeld (Citation1984). This allows us to assess the impact of using the coding in the model in place of the optimal coding
Proposition 6.1
An expression for asymptotic relative efficiency is given by;
where
The integrals are over the interval (0,1) and the expectations are taken with respect to the distribution of the transformed history prior to t, again on the interval (0,1). We can use this expression to evaluate how much we lose by using the log-rank statistic when, say, regression effects do not kick in for the first 25% of the study (on the
timescale). It can also inform us on how well we do when using, say, working with a linear combination of the log-rank and integrated log-rank tests, as opposed to the optimal (unknown in practice) test. In the absence of censoring this expression simplifies to that of the correlation between the different processes. In some cases, an example being the log-rank process, and the integrated log-rank process, the known properties of the limiting processes are readily available and provide an accurate guide.
7. Numerical evaluation of rival tests
Extensive simulations failed to tease out any clear conclusions concerning the comparative power of related different tests such as as opposed to the integrated log-rank test. These two tests are, directly and indirectly, built around the regression effect process, down-weighting contributions progressively through time. In consequence, both tests will be relatively more sensitive to situations of declining effect than would the log-rank test itself, thereby delivering greater power. However, when contrasted one against the other, there appears be no clear winner. Agreement between the two is strong and no situations were observed in which there is any important distinction between them. In certain situations
pips the integrated log-rank test at the post, in others the converse occurs. Indeed, we can always construct any particular time dependent effect that will favour one approach over the other. Lemma 4.3 provides an explanation for this. In any given situation, of the two potential constructs, one will correspond to an effect process that is closer on average to that associated with the given situation. Simulations under that situation will then favour that particular construct. The same is true when we contrast the
structure with the conjugate integrated log-rank test. Either test will generally outperform the standard log-rank when regression effects increase with time. However, unless we have some prior knowledge of the shape of regression effects, there is no good reason to choose one over the other or, indeed, any other simple structure that represents delayed effects. That is, as far as power considerations go. The graphical representation associated with the conjugate integrated log-rank test provides valuable additional information about the true form of regression effects.
Note that the comments of the previous paragraph apply equally well to tests based on the maximum of two sub-tests, assuming again that they are related in the same way. For example, there is no good reason to prefer the increasingly popular maxCombo combining, say, and the log-rank, in opposition to the maximum of the log-rank and integrated log-rank. As long as all calculations, correlations in particular, are correctly carried out, then, once again, we are highlighting the same broad regression phenomena and whichever more closely mirrors the unknown ‘truth’ will do best. But, in the absence of any such knowledge, there is no good reason to suppose that either formulation would accomplish this any better than the other.
Finally, consideration might be given to the large class of tests based on restricted mean survival time (RMST). Such tests have also gained in popularity in recent times. Reliable comparisons here are yet more difficult than those just described. There are several reasons for this. The RMST tests are not rank invariant and so account needs to be made of different possible time scales. If we were to work with the logarithm of the survival times rather than the time themselves, the results, and associated significance levels would be impacted. This is not the case for any of the other tests described in this paper. Account also needs to be made of the time duration over which the test is calculated, in addition to which the amount and structure of any censoring, the rate of change of regression effect and how it relates to the observation period, as well as the covariate (treatment) distribution all require scrutiny. Careful, well designed, simulations can help throw some light on these issues. We feel that they are beyond the scope of this current work. Instead, in the following section, we provide 3 illustrations, taken from recently published trials in the New England Journal of Medicine. The statistical results and the related graphical representations further help our intuition in seeing how things can play out in practice.
8. Illustrations from recent oncology trials
We revisit 3 recently published clinical trials. Our purpose is not to make any contrasts between tests in the hope of gaining pointers regarding relative power but simply to get some feeling as to what we might anticipate occurring under 3 broad headings: a situation where treatment effects remain persistent with time, one where effects diminish with time and one where effects are delayed following an initial period where there appears to be little or no treatment effect. This last situation is not unfamiliar in immunotherapy trials.
Long and colleagues (Long et al. Citation2017) carried out a phase III randomised trial to compare combination therapy with dabrafenib and trametinib compared to placebo in melanoma patients with a BRAF mutation. The trial enrolled 870 patients who were randomised 1:1 to the two treatment arms. The primary endpoint of the study was relapse-free survival. At the time of trial reporting, a total of 414 patients had died or relapsed. The estimated Kaplan-Meier relapse-free survival curves are shown in the second row of Figure . The estimated hazard ratio was 0.47 (95% CI: 0.38–0.57). From Figure we obtain a clear impression of effects that diminish through time. We might glean this from the Kaplan-Meier curves but it requires an experienced eye. A quick glance might otherwise suggest that the PH assumption was not unreasonable and, indeed, in the paper there was no suggestion of a possible lack of model adequacy in that assumption. The log-rank test was used in the paper of Long and colleagues and resulted in the test statistic of 7.66. In contrast the distance from origin test resulted in the statistic 7.53 showing, as expected, close agreement. However, given the clear decline observed in treatment effect we might anticipate greater values based on the area under the curve test and the integrated log-rank test. Indeed, this turns out to be the case and the statistic corresponding to the integrated log-rank test comes out be 10.69, a value close to that of the test which is 9.10.
Our second study also taken from the New England Journal of Medicine concerns a Phase III randomised study comparing cetuximab to a treatment arm of best supportive care. The study group are patients with advanced colorectal cancer expressing EGFR (Jonker et al. Citation2007). A total of 287 patients received cetuximab, while 285 received best supportive care. The investigators found that cetuximab significantly improved both overall survival and progression-free survival. The progression-free survival curves for the two treatment arms are shown in the 3rd row of Figure . The Kaplan-Meier curves themselves suggest a significant delay in the treatment effect that occurs around 2 months following randomisation. The estimated hazard ratio for the treatment effect was 0.69 (95% CI: 0.58–0.82). The log-rank test resulted in the value 4.30. We can contrast that finding to the values 4.71 and 4.90 respectively, obtained from the conjugate integrated log-rank test and the test. These latter two tests, while agreeing strongly among themselves, tend to show an increase in power and this we would expect given the evidence that effects are delayed and increase over time. At the same time the increase in power is not that great and perhaps less than we may have guessed from a perusal of the Kaplan-Meier curves.
The third study was carried out by Eggermont and colleagues (Eggermont et al. Citation2016). This was a phase III randomised trial of ipilimumab compared to placebo in patients with stage III melanoma. A total of 951 were randomised 1:1 to the two arms. Over a median follow up of 5.3 years, the authors found that ipilimumab significantly improved both overall survival and recurrence-free survival. The overall survival curves are seen in Figure . The estimated hazard ratio for the treatment effect was 0.71 (95% CI: 0.58–0.88). A proportional hazards model was seen to be a good working approximation for these data, in which case, given that the log-rank test is known to be the optimal test, we anticipate losing some power via any of the integrated log-rank test, the conjugate integrated log-rank test and their related tests based on the areas under and over the treatment effect process. The log-rank test resulted in the value 3.24. This can be compared to the values 3.21 and 2.39, based on the integrated and the conjugate integrated log-rank tests.
9. Discussion
We would like for any statistical test to provide accurate control of Type 1 error while, under the alternative, giving as much power as possible. Tests need to be unbiased and consistent so that this power will tend to one hundred percent as sample size increases under any alternative hypothesis. This is however a very minimal requirement and the power properties of tests are intimately tied up with the kind of alternative we have in mind. We can obtain very good power for one alternative and poor power for another alternative. The alternative can then guide us and, in cases where we can anticipate certain kinds of behaviour, for example waning effects if present, then this knowledge can be used to advantage by employing a test with good power properties in such situations.
In many cases we only have imprecise knowledge of the nature of the alternative we might encounter so that the most desirable test, while being optimal in certain situations will nonetheless maintain good performance, albeit a suboptimal one, in others. Such a property can be observed with the integrated log-rank test but less so with the log-rank test. The integrated log-rank test has an advantage in that it will strongly outperform the log-rank test in situations of waning effects but will not lose much to the log-rank test when a proportional hazards assumption holds. A similar argument can be made regarding the conjugate integrated log-rank test when effects are either constant or are delayed.
Lemma 4.3 indicates that the most powerful test becomes available to us if we know the form of the regression coefficient function, When this is constant, say
then the regression effect process will exhibit a linear drift proportional to
and
If we were to progressively approximate
we might appeal to a Taylor series, beginning with a constant term, then a linear term, then a quadratic term and so on. A formal approach would require the tools of analysis, intervals of convergence (in the real analysis and not the probabilistic sense) but we might feel reasonably confident in advancing a common idea that the higher the degree of the polynomial approximation, the more accurate we will be. As far as our tests are concerned, the log-rank test corresponds to making use of a linear term while the integrated log-rank test corresponds to adding in a quadratic term. We could, in principle, continue this process, adding in an ‘integrated-integrated’ log-rank test. As is often the case a quadratic approximation will show itself to be ‘good enough’ allowing us to conclude that an approach to the testing problem where the form of
is not known, based on a combination of the log-rank and the integrated log-rank statistics will effectively cover a broad range of realistic situations.
Acknowledgments
Thanks are due to Philippe Flandre for helping with simulations relating to this work. I am indebted to Sean Devlin for the calculations of the examples and the preparation of the figures. Thanks are also due to the editors and reviewers for a detailed scrutiny together with some challenging questions on an earlier version of this work. The editors also suggested we prepare a shiny version of the code behind the figures and test calculations. I thank them for that idea and, again, appreciation is due to Sean Devlin for creation of the application. It can be obtained at: www.novametrics.co.uk/data-analysis
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Chauvel, C., and O'Quigley, J. (2014), ‘Tests for Comparing Estimated Survival Functions’, Biometrika, 101(3), 535–552.
- Chauvel, C., and O'Quigley, J. (2017), ‘Survival Model Construction Guided by Fit and Predictive Strength’, Biometrics, 73(2), 483–494.
- Cox, D.R. (1975), ‘Partial Likelihood’, Biometrika, 62(2), 269–276.
- Eggermont, A.M., Chiarion-Sileni, V., Grob, J.J., Dummer, R., Wolchok, J.D., Schmidt, H., Hamid, O., Robert, C., Ascierto, P.A., Richards, J.M., Lebbé, C., Ferraresi, V., Smylie, M., Weber, J.S., Maio, M., Bastholt, L., Mortier, L., Thomas, L., Tahir, S., Hauschild, A., Hassel, J.C., Hodi, F.S., Taitt, C., V. de Pril, de Schaetzen, G., Suciu, S., and Testori, A. (2016), ‘Prolonged Survival in Stage III Melanoma with Ipilimumab Adjuvant Therapy’, New England Journal of Medicine, 375(19), 1845–1855.
- Flandre, P., and O'Quigley, J. (2019), ‘Comparing Kaplan-Meier Curves with Delayed Treatment Effects: Applications in Immunotherapy Trials’, Journal of the Royal Statistical Society Series C: Applied Statistics, 68(4), 915–939.
- Fleming, T.R., and Harrington, D.P. (1991), Counting Processes and Survival Analysis, New York: Wiley.
- Grambsch, P., and Therneau, T. (1994), ‘Proportional Hazards Tests and Diagnostics Based on Weighted Residuals’, Biometrika, 81(3), 515–526.
- Jonker, D.J., O'Callaghan, C.J., Karapetis, C.S., Zalcberg, J.R., Tu, D., Au, H.J., Berry, S.R., Krahn, M., Price, T, Simes, R.J., Tebbutt, N.C., van Hazel, G., Wierzbicki, R., Langer, C., and Moore, M.J. (2007), ‘Cetuximab for Treatment of Colorectal Cancer’, New England Journal of Medicine, 357(20), 2040–2048.
- Klein, J.P., Logan, B., Harhoff, M., and Andersen, P.K. (2007), ‘Analyzing Survival Curves At a Fixed Point in Time’, Statistics in Medicine, 26(24), 4505–4519.
- Lagakos, S.A., and Schoenfeld, D.A. (1984), ‘Properties of Proportional-Hazards Score Tests Under Misspecified Regression Models’, Biometrics, 40(4), 1037–1048.
- Lee, J.W. (1996), ‘Some Versatile Tests Based on the Simultaneous Use of Weighted Log-Rank Statistics’, Biometrics, 52(2), 721–725.
- Lee, J.W. (2007), ‘On the Versatility of the Combination of the Weighted Log-rank Statistics’, Computational Statistics and Data Analysis, 51(12), 6557–6564.
- Lin, R.S., and Leon, L.F. (2017), ‘Estimation of Treatment Effects in Weighted Log-rank Tests’, Contemporary Clinical Trials Communications, 8, 147–155.
- Lin, R. S., Lin, J., Roychoudhury, S., Anderson, K.M., Hu, T., Huang, B., Leon, L.F, Liao, J.J.Z., Liu, R., Luo, X., Mukhopadhyay, P., Qin, R., Tatsuoka, K., Wang, X., Wang, Y., Zhu, J., Chen, T.-T., and Iacona, R. (2020), ‘Alternative Analysis Methods for Time to Event Endpoints Under Nonproportional Hazards: A Comparative Analysis’, Statistics in Biopharmaceutical Research, 12(2), 187–198.
- Logan, B.R., Klein, J.P., and Zhang, M.J. (2008), ‘Comparing Treatments in the Presence of Crossing Survival Curves: An Application to Bone Marrow Transplantation’, Biometrics, 64(3), 733–740.
- Long, G.V., Hauschild, A., Santinami, M., Atkinson, V., Mandalà, M., Chiarion-Sileni, V., Larkin, J., Nyakas, M., Dutriaux, C., Haydon, A., Robert, C., Mortier, L., Schachter, J., Schadendorf, D., Lesimple, T., Plummer, R., Ji, R., Zhang, P., Mookerjee, B., Legos, J., Kefford, R., Dummer, R., and Kirkwood, J.M. (2017), ‘Adjuvant Dabrafenib Plus Trametinib in Stage III BRAF-Mutated Melanoma’, New England Journal of Medicine, 377(19), 1813–1823.
- Mantel, N. (1966), ‘Evaluation of Survival Data and Two New Rank Order Statistics Arising in Its Consideration’, Cancer Chemotherapy Reports, 50, 163–170.
- O'Quigley, J. (2003), ‘Khmaladze-type Graphical Evaluation of the Proportional Hazards Assumption’, Biometrika, 90(3), 577–584.
- O'Quigley, J. (2008), Proportional Hazards Regression, New York: Springer.
- O'Quigley, J. (2021), Survival Analysis, New York: Springer.
- O'Quigley, J. (2022), ‘Testing for Differences in Survival when Treatment Effects Are Persistent, Decaying, Or Delayed’, Journal of Clinical Oncology, 40(30), 3537–3545.
- O'Quigley, J., and Prentice, R.L. (1991), ‘Nonparametric Tests of Association Between Survival Time and Continuously Measured Covariates: The Logit-rank and Associated Procedures’, Biometrics, 47(1), 117–127.
- Peto, R., and Peto, J. (1972), ‘Asymptotically Efficient Rank Invariant Test Procedures’, Journal of the Royal Statistical Society. Series A (General), 135(2), 185–207.
- Philip, S.S and Gastrointestinal Tumor Study Group (1982), ‘A Comparison of Combination Chemotherapy and Combined Modality Therapy for Locally Advanced Gastric Carcinoma’, Cancer, 49, 1771–1777.
- Sposto, R., and Stablein, D. (1997), ‘Carter-Campbell S A Partially Grouped Logrank Test’, Statistics in Medicine, 16, 695–704.
- Stablein, D.M., Carter WH, P., and Novak, J.W. (1981), ‘Analysis of Survival Data with Non-proportional Hazard Functions’, Controlled Clinical Trials, 2(2), 149–159.
- Wang, L., Luo, X., and Zheng, C. (2021), ‘A Simulation-free Group Sequential Design with Max-combo Tests in the Presence of Non-proportional Hazards’, Pharmaceutical Statistics, 20, 879–97.
- Wu, L., and Gilbert, P.G. (2002), ‘Flexible Weighted Log-Rank Tests Optimal for Detecting Early and/or Late Survival Differences’, Biometrics, 58(4), 997–1004.
