
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Despite the practicality of quantile regression (QR), simultaneous estimation of multiple QR curves continues to be challenging. We address this problem by proposing a Bayesian nonparametric framework that generalises the quantile pyramid by replacing each scalar variate in the quantile pyramid with a stochastic process on a covariate space. We propose a novel approach to show the existence of a quantile pyramid for all quantiles. The process of dependent quantile pyramids allows for nonlinear QR and automatically ensures non-crossing of QR curves on the covariate space. Simulation studies document the performance and robustness of our approach. An application to cyclone intensity data is presented.
1. Introduction
1.1. Quantile regression
Quantile regression (QR) has drawn increased attention as an alternative to mean regression. QR was motivated by the realisation that extreme quantiles often have a different relationship with covariates than do the centres of the response distributions. QR can target quantiles in the tail of the distribution and is more robust to outliers than is mean regression. The advantages of QR can be substantial and have led to its use in many areas, including econometrics, finance, medicine, and climatology.
The seminal work of Koenker and Bassett (Citation1978) extended median regression, which dates back at least as far as Edgeworth (Citation1888), to QR by allowing asymmetry in the objective function defining the regression. That is, when one is interested in the quantile (
) for the response
and the covariate
,
, and assuming independent responses, the estimated QR surface is
, where
and
is the (asymmetric) check loss function. This method is implemented in the R package ‘quantreg’ (Koenker Citation2005) and has led to a wide range of developments. A recent overview of the area is provided in Koenker (Citation2017).
The Bayesian counterpart of quantile regression was introduced by Yu and Moyeed (Citation2001) who used the asymmetric Laplace distribution (ALD) for the sampling density of as a device to focus on the QR for the
quantile. The ALD has density
which can be seen as a scaled and exponentiated check loss function. This substitution of a loss function for the log-density is an early example of the generalised Bayes technology developed in Bissiri et al. (Citation2016). Kozumi and Kobayashi (Citation2011) made use of the reparametrization of the ALD illustrated in Kotz et al. (Citation2001) and Tsionas (Citation2003) to create an efficient Gibbs sampling algorithm. The method is implemented in the R package ‘bayesQR’ (Benoit and Van den Poel Citation2017). Many authors have followed the approach of Yu and Moyeed (Citation2001), describing properties of the method. See, for example, Geraci and Bottai (Citation2007), Reich et al. (Citation2010), Lum and Gelfand (Citation2012), and Waldmann et al. (Citation2013). Some have appealed to a semi- or nonparametric approach. Kottas and Krnjajić (Citation2009), for instance, proposed two approaches to model the error distribution nonparametrically in QR, using a Dirichlet process (DP) mixture of uniform densities and a dependent DP mixture of normal densities. Chen and Yu (Citation2009) developed a QR function in a nonparametric fashion using piecewise polynomials.
1.2. Crossing quantiles
When more than one quantile level is considered, however, fitting a QR curve for each level by itself does not correspond to an encompassing model, may not respect the monotonicity of the quantile function, and can result in crossing quantiles. Researchers have suggested various approaches to handle this issue. Rodrigues and Fan (Citation2017) constructed a likelihood inspired by the approach of Yu and Moyeed (Citation2001), while ensuring monotonocity of quantiles with an additional adjustment step. Semi- or nonparametric Bayesian approaches to simultaneous QR include Taddy and Kottas (Citation2010) who suggested an approach to estimate the entire joint density of and then extract the QR from this density. This ensures monotonicity of quantiles since the inference of quantiles is based on a single density. Reich et al. (Citation2011) and Reich (Citation2012) model the entire quantile process using Bernstein polynomial basis functions in spatial and spatiotemporal settings. In both papers, the prior is specified to satisfy the monotonicity constraint on the quantile function. Kadane and Tokdar (Citation2012) developed a characterisation of the quantile function that induces monotonicity in the joint estimation of linear QR models for a univariate covariate. Yang and Tokdar (Citation2017) extended this to any bounded covariate space in
via reparameterization. Chen and Tokdar (Citation2021) generalised this to incorporate spatial dependence.
Hjort and Walker (Citation2009) proposed the quantile pyramid (QP) for nonparametric inference for a single distribution and briefly mentioned a possible extension to QR. Most similar to our approach, Rodrigues et al. (Citation2019a) used the QP for QR. In their work, independent QPs are used to specify the prior distribution for quantiles at pivotal locations in a bounded p dimensional covariate space. For each quantile, a linear QR is then constructed as the hyperplane passing through the specified quantile at each of the pivotal locations. Rodrigues et al. (Citation2019b) adapted this idea to a spline regression setting.
1.3. Our contribution
We generalise the construction of Hjort and Walker (Citation2009) by incorporating dependence in the QPs across the covariate space and by allowing for non-binary splits in the pyramids. Our approach allows direct and flexible modelling of the quantiles over covariate spaces and, by construction, naturally respects the monotonicity of QR curves.
Our contribution is twofold: (1) a novel approach to show the existence of a single QP, and (2) extension of the QP from a model for a single distribution to a model for a collection of distributions that vary with the covariate. The first point is a stepping stone to generalise the idea of QP. With an eye to the second point, it also involves expansion of the mathematical framework to move from a single QP to a process of QPs, with greater attention to mappings between the interval [0,1] and the real line.
The rest of this article is organised as follows. In Section 2, we introduce the idea of a process of dependent quantile pyramids (DQPs) and a canonical construction of the model. Section 3 provides theoretical results. Section 4 describes prior specification and posterior inference. Simulation studies appear in Section 5 and application to real data appears in Section 6. Section 7 presents discussion and directions for future work.
2. A process of dependent quantile pyramids
In this section, we briefly recap the QP of Hjort and Walker (Citation2009) and introduce a DQP. The following remark comes from Parzen (Citation2004).
Remark 2.1
For a random variable Y whose distribution function is , its quantile function is defined as a left-continuous function
that satisfies
if and only if
for
.
In other words, if we define the quantile function, there exists a random variable with the corresponding distribution function. This fact is useful to understand how constructing quantile functions can lead to a distribution over distribution functions.
2.1. Binary quantile pyramid
Hjort and Walker (Citation2009) created the QP, a Bayesian nonparametric model that focuses on the quantiles of a distribution. The QP provides a distribution over distribution functions, and so it is suited to be used as a prior distribution for an unknown distribution function. The quantile function, , on the unit interval
, is at the heart of the QP.
and
.
The pyramid is built in levels for dyadic quantile levels, as a binary tree. The level is the unit interval
. At the first level, the median of the unit interval is drawn from some density, which divides the interval into two subintervals. Intervals are recursively split into smaller subintervals, doubling the number of subintervals with each new level. Thus, at level m, we have specified the
quantiles,
,
. The quantiles
,
, are inherited from level m−1. The new quantiles at the
level can be expressed, for
, as
(1)
(1) where
,
, are a set of mutually independent random variables with support
. Figure (a) contains a visualisation of this idea with three quantiles. For
, less the specified quantile levels,
is filled in by linear interpolation.
Figure 1. (a) A binary QP following Hjort and Walker (Citation2009) with three quartiles; (b) An oblique QP with four quantiles following Rodrigues et al. (Citation2019a); (c) A general QP with four quantiles; (d) A process of DQPs, where there is a QP at each value of x. Each node in a tree structure corresponds to a subinterval. The first node is the unit interval. The rhombi represent quantiles pinned down in each subinterval.
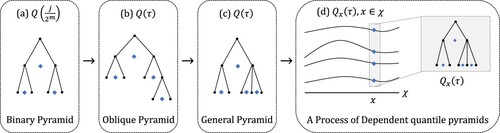
There is scope for a wide variety of choices for the distribution of the conditional medians of the subintervals (the ). If the
are assumed to have mean 1/2, for example, then
forms a martingale sequence and has a limit almost surely by Doob's martingale convergence theorem. Moreover, if
are chosen so that
, Hjort and Walker (Citation2009) showed that there exists a continuous limiting quantile process to which
converges.
While Hjort and Walker (Citation2009) primarily focussed on quantiles at the dyadic levels, we take inspiration from the oblique pyramid construction method introduced by Rodrigues et al. (Citation2019a). In the oblique pyramid, quantile levels in a binary pyramid are not limited to dyadics.
2.2. General quantile pyramid
Rodrigues et al. (Citation2019a) focus on finite quantile pyramids, where a pyramid has only M levels. They begin with scenarios where quantiles are generated at the
level of a pyramid, ensuring that each subinterval contains one specified quantile. This constraint leads to exactly
quantiles in an M-level pyramid. They then proceed to the oblique pyramid, a pyramid in which some subintervals contain a quantile but others do not. An M level pyramid may be unbalanced, specifying fewer than
quantiles.
Rodrigues et al. (Citation2019a) specify a rule for how the pyramid is constructed. We provide a brief example and refer the reader to their paper for full details. Consider the case of four quantiles, denoted as . Since there are an even number of quantiles, there are two quantiles positioned in the middle. Following the rule of Rodrigues et al. (Citation2019a), the smaller quantile serves as the middle quantile level. Thus,
is specified at the first level of the pyramid. Moving on to the second level, we have two subintervals. In the left subinterval, we specify
, while the right subinterval contains two quantiles. The smaller quantile,
, is specified at this level of the pyramid. In the third level, there are four subintervals:
,
,
,
. In this level, we specify the remaining quantile,
, in the last subinterval, while the other three subintervals remain empty. This example is illustrated in Figure (b).
We introduce additional flexibility by permitting non-binary splits. This yields the general quantile pyramid, and it empowers the user to fully customise the pyramid according to their preference. For instance, in the case of four quantiles, one can create a pyramid with at the first level and the remaining three quantiles at the second level, distributing one quantile to the left subinterval and two to the right subinterval. This concept is visually represented in Figure (c). The move from a binary pyramid to a general pyramid requires novel notation which is introduced in the next section.
2.3. Dependent quantile pyramids
In the sequel, we extend the QP from a single distribution to a collection of distributions, creating a process of dependent quantile pyramids (DQPs). To do so, we construct a QP at each value of x in some index set, . We replace each scalar
in Equation (Equation1
(1)
(1) ) with an appropriate stochastic process, say
,
. This leads to a collection of QPs that may exhibit dependence across
. Formally, we construct a distribution-valued stochastic process. For modelling purposes, the index set of the process is identified with the covariate space, as in QR. Alternatively, the index set may be described as containing values of predictors, spatial locations, constructed features, or time, to name a few possibilities. The important part is that, conditional on x, we have a model for a QP. We construct QPs on the unit interval
following Hjort and Walker (Citation2009) and use a general quantile pyramid scheme of Section 2.2. Figure (d) contains the visualisation of an example of a process of DQPs.
2.3.1. Notation
We write for the τ-quantile at x. For any x,
forms a complete quantile pyramid. For any τ,
provides the τ-quantile surface over the covariate space. We refer to this as a QR curve. The DQP is constructed sequentially. To provide intuition behind the DQP and to facilitate proofs of its existence, we establish two distinct sets of notation.
The first set of notation matches the recursive construction of the DQP. We begin with a DQP with m−1 levels, where the quantile surfaces have been specified for . That is, for
and
, the function
has already been determined in the sequential construction. The ordered quantile levels are
, with
. At the next level, these quantile levels remain. The corresponding quantiles define a set of bands within which the quantiles newly specified at level m of the pyramid must lie (at a given x, the band is merely an interval). For example, the QR curve for a quantile
that is newly specifed at level m must lie in the band with lower boundary
and upper boundary
. At level m, the specified quantiles are renumbered to form
and preserve the ordering of the
.
The second set of notation is preferred when describing the probability space that underlies the DQP. For this, we need to have each variable (with subscripts) refer to a single random element in the construction of the DQP. These variables appear in different positions in the pyramid. We introduce the ‘ϵ-notation’ to capture the position in the pyramid and to handle the potentially non-binary splits in the general quantile pyramid. Consider a pyramid with m levels. The sequential construction of the pyramid will place the quantile at level 1,
at level 2, and so on. The length of the sequence indicates the level at which the quantile was specfied. The notation also conveys the structural relationship between quantiles. The parent quantiles of
are
and
. If there are K quantiles specified in the interval between the parent quantiles,
takes a value in the set
. The left and right parent quantiles have
and
, respectively. The quantiles are increasing in
. This results in two distinct sequences
for a quantile that serves as both the left endpoint and the right endpoint of adjacent subintervals. As the construction proceeds, we use the left-endpoint sequence for which
. For convenience, a short form
will be used for the
length sequence throughout the paper. Figure illustrates both notations for a three-level DQP with a given value of x.
Figure 2. An example of a DQP with covariate x with three levels and 13 quantiles. Both and ϵ-notation is shown. At level 0, the interval at each x is
. At level 1, K = 2 quantiles are specified, creating three subintervals. At level 2, four quantiles are newly specified, leading to a total of 7 subintervals. Notation for the newly specified quantiles is shown. At level 3, one quantile is specified within each subinterval. Both notations are shown for all quantiles in
. Collecting the quantiles across x gives the QR curves. The corresponding tree structure is the same across all values of x. It is shown in the right panel. Dots and rhombi represent subintervals and quantiles, respectively.
![Figure 2. An example of a DQP with covariate x with three levels and 13 quantiles. Both τ∗ and ϵ-notation is shown. At level 0, the interval at each x is [0,1]. At level 1, K = 2 quantiles are specified, creating three subintervals. At level 2, four quantiles are newly specified, leading to a total of 7 subintervals. Notation for the newly specified quantiles is shown. At level 3, one quantile is specified within each subinterval. Both notations are shown for all quantiles in (0,1). Collecting the quantiles across x gives the QR curves. The corresponding tree structure is the same across all values of x. It is shown in the right panel. Dots and rhombi represent subintervals and quantiles, respectively.](/cms/asset/6ae27108-761b-449b-8811-327a2fbf7d9e/gnst_a_2305811_f0002_oc.jpg)
The oblique DQP is a special case in which all subintervals are split in two. In this case, K = 0 or 1 for all subintervals. For a dyadic, binary DQP, K = 1 for all subintervals and the quantile at level m is the
quantile of the distribution at x.
2.3.2. Definition
DQPs come in two main varieties. The first is the process of finite dependent quantile pyramids (FDQP) while the second, arrived at from a countable sequence of FDQPs, is termed the limit process of dependent quantile pyramids (LDQP).
We begin with the FDQP. The FDQP focuses on a finite number of quantiles. As with the QP, the FDQP is defined sequentially. We focus on the quantiles in a single interval (e.g. the centre interval at level 2 in Figure ). The description applies to all such intervals.
Definition 2.1
We call a process of Finite Dependent Quantile Pyramids (FDQP) with M levels if there exists an M-level QP valued stochastic process whose distribution
follows. That is, for each
,
is an M-level QP on
, and, for each n and distinct
, Kolmogorov's permutation and marginalization conditions are satisfied.
Definition 2.2
We call a set of conditional distribution functions induced by a process of FDQP with M levels, if for every
,
is a distribution function and
for all
.
The FDQP with M levels is given by its quantile functions, . It is defined sequentially, beginning with level 1 of the pyramid. Assume that K quantiles are to be drawn at level m, for
, in a subinterval that comes from level m−1. The subinterval is
for
and
. The endpoints
and
are quantiles inherited from level m−1 of the pyramid. When m = 1,
and
. Let
be a multivariate stochastic process with index set
. For each
and
a random vector
follows a distribution with the following conditions: (1)
; and (2)
. That is, the vector lies in the interior of the K-dimensional simplex. The quantiles for the K specified quantile levels in the subinterval are
(2)
(2) A finite number of quantiles,
, is specified in the M-level pyramid. Quantiles that are not specified directly in the pyramid are given by linear interpolation. For all
, we linearly interpolate
, i.e.
The sequential construction and interpolation together define the conditional quantiles given x for all quantile levels
.
In practice, when determining the number of quantiles, T, of an FDQP, we recognise that there is a tradeoff between the number of quantiles considered and computational efficiency. Our primary recommendation is to focus on the key quantiles of interest. A secondary, generic recommendation is to prioritise symmetric quantiles such as the three quartiles or the nine deciles.
The construction of the FDQP leads to its existence, which is formally proven in Lemma 3 in Section 3.2. At each value x, the distribution is defined by a finite collection of real valued random variates. The use of stochastic processes that are well-defined ensures that the QP construction for a single x extends to . We restrict attention to cases defined on a single probability space where the FDQP with M levels is the marginal distribution for each of the FDQPs with more than M levels, with appropriate renumbering of the quantiles in
, where
is the set of quantile levels specified at level m.
With some sufficient conditions, the limit may exist, in which case we have an infinite pyramid, leading to the LDQP. Our concern is with cases where a set of quantiles that is dense in is determined in the limit, and so we have no need for interpolation. The existence of the LDQP is established in Section 3.2. When the limit of a sequence of FDQPs exists as
, the limit process of dependent quantile pyramids (LDQP) is defined.
Definition 2.3
We call a limit process of Dependent Quantile Pyramids (LDQP) if there exists a QP valued stochastic process whose distribution Q follows. That is, for each
,
is a QP on
, and, for each n and distinct
, Kolmogorov's permutation and marginalisation conditions are satisfied.
Definition 2.4
We call a set of conditional distribution functions induced by a process of LDQP, if for every
,
is a distribution function and
for all
.
2.4. Canonical construction
In this section, we provide a canonical construction of the quantiles in an arbitrary subinterval at level m of a process of DQPs. To do so, we construct U-processes and V-processes and then make use of Equation (Equation2(2)
(2) ) in Section 2.3. We begin under the assumption that the choice of quantiles has been made and that this choice is consistent, matching the correct ordering of the quantiles. By repeatedly sampling U-processes and V-processes, we can proceed to sequential construction of the entire process of pyramids.
2.4.1. U-processes induced from Gaussian processes
Suppose that we are interested in obtaining K quantiles at level m for a subinterval ,
. For each sequence
for
, we consider a Gaussian process (GP)
with zero mean, unit variance, and some correlation function
, so that
The correlation function governs the interdependence of quantiles across the covariate space. We note that the correlation function can differ for different
.
We then construct the U-processes, for the subinterval, using the normal cumulative distribution function (cdf) transformation element-wise, i.e. for each
,
where
denotes the cdf of the standard normal distribution.
2.4.2. V-processes induced from U-processes via gamma variates
We construct the V-processes, , from the U-processes. Let
be the gamma distribution function with shape
and scale 1, for
. For each
and combination
, define
Define
. Then, for each
and ϵ, we set
which forms a Dirichlet
random vector. Lastly, collecting
together across
, we have constructed a vector-valued process
with component processes
,
When
and
do not depend on x, we omit the subscript x to simpify notation.
2.4.3. V-processes induced from U-processes via beta variates
The Dirichlet distribution can be derived from the product of independent beta random variates. This fact leads to a second construction of the V-processes. Define as before. Let
be the distribution function of a beta variate with parameters
and
. Define
for each x and
. Set
with the conventions that an empty product is 1 and that
. The vector
follows a Dirichlet
distribution.
Once V-processes are generated, we can proceed to the quantiles in the subinterval, using Equation (Equation2
(2)
(2) ). Given the left and right endpoints of the subinterval, the conditional quantiles at the same quantile level can be expressed as a simple linear transformation of the V-processes. This observation also implies the preservation of the dependence structure. In other words,
for any
and ϵ, and for all
. When K = 1 and the construction in this section is used, the random variable
follows a beta distribution. It is a continuous, monotonic transformation of
. For measures of dependence that are invariant under such a transformation, the (conditional) dependence of
and
matches that of
and
.
2.4.4. Martingale construction
One construction of the dyadic QP in Hjort and Walker (Citation2009) relies on a martingale. At each level of the QP, each interval is split in half. In this canonical construction, K = 1 and the martingale property requires that for a beta distribution. Allowing for splits that do not bisect the interval, this becomes, at level m of the pyramid,
and
for some
.
For a non-binary split of an interval, the values of need to be mapped to the relevant subintervals. Assume that a subinterval at the
level contains quantiles associated with K specified quantile levels
. Let
for
denote the scaled quantile levels in the subinterval. The quantile levels of left and right endpoints of the subinterval are denoted by
and
, respectively. Then
From this, we can derive the values of
satisfying the martingale condition. That is,
for
and some
. We note that the chosen quantile levels
do not depend on x.
2.5. Quantile mapping for transitioning to the response space
Assume that the DQP has been constructed on and denote the QP at x by
. As briefly mentioned in Hjort and Walker (Citation2009), we can transform the scale as for a proper response space, say, a real line using the inverse normal cdf transformation. Defining trend parameters
and scale parameters
, we have the canonical DQP regression model, centred on a normal theory regression:
(3)
(3) The trend parameter
is shared across the quantiles and controls the overall trend of quantiles throughout the covariate space. The scale parameter controls the dispersion of the distributions while the realised QPs determine the departures from normality. Together, the scale and QP determine the departure (or local fluctuation) from a set of constant variance normal models with centres given by
.
Various choices can be made for the trend and scale. If one believes that there is no significant global trend, can be set to a constant. Alternatively, a linear regression model,
, may provide an effective choice. The model is compatible with more complicated models for the trend. Similarly, models for
can range from a simple constant scale to more complex forms. The trend and scale parameters can be incorporated into Markov chain Monte Carlo (MCMC) procedures used to fit the model. Alternatively, to save computational effort, estimates can be plugged in and the parameters treated as fixed.
3. Theoretical results
The novel notation used in this section is formally defined in Appendix 1 while proofs of the results appear in Appendix 2.
3.1. A novel approach to existence of quantile pyramid
Hjort and Walker (Citation2009) provide two different proofs for the existence of the QP. The following results establish the existence of the QP under slightly weaker conditions than those of Hjort and Walker (Citation2009). They also apply to the oblique pyramid of Rodrigues et al. (Citation2019a).
The QP is a probability measure for a distribution-valued random element. To show its existence, we wish to show that the sequence of probability measures that define the finite quantile pyramids (FQPs) converges to a limiting probability measure. Our argument relies on two key facts. First, the space of probability measures over distribution functions with support contained in , when equipped with the Prokhorov metric, is compact (Parthasarathy Citation1967). Second, and yet to be established, the sequence of probability measures forms a Cauchy sequence. Together, these facts lead to the conclusion that the sequence of FQPs converges to a limit and that the limit is a probability measure on distribution-valued elements.
A first lemma bounds the Lévy distance, , between two distribution functions that share a set of quantiles. Let
be ordered quantile levels. The largest gap between consecutive quantile levels appears in the bound below.
Lemma 3.1
Define . Assume that F and G are two distribution functions such that there exist
for which
for
. Then,
.
The construction of the QP proceeds through a sequence of FQPs, indexed by m, the number of levels in the pyramid. These FQPs are defined on a single probability space . Each
defines a sequence of FQPs with
levels. The distributions in the sequence all have support contained in
and share values of the quantile function at certain specified quantile levels, as described in Section 2.2. In particular, the
quantiles in
and
are identical for all ω and for any positive integer k.
is the Borel σ-field generated by the open sets under the Lévy metric.
The next lemma shows that the sequence of probability measures arising from the FQPs is Cauchy. The measure provides the probability distribution on
. The distance between
and
is measured by the Prokhorov metric,
.
Lemma 3.2
Suppose that is dense in
. Then, under the Prokhorov metric
, the sequence
is a Cauchy sequence.
A Cauchy sequence on a compact set converges to a limit in the set. In this case, the sequence of measures converges to a limit measure μ. The limit measure is a probability measure on distribution-valued elements where the distributions have support contained in the interval
. This reasoning leads to the existence of the QP, stated formally in the next theorem. We note that the dyadic construction of the QP satisfies the denseness condition in Lemma 3.2.
Theorem 3.1
Suppose that is dense in
. Then, the QP constructed as in Section 2.1 or 2.2 is a random element whose distribution is determined by
.
3.2. Existence of a process of dependent quantile pyramids
The existence of a process of DQPs follows from consideration of the joint distributions of the QPs at finite sets of indices in the index set. The construction of the FDQP in Section 2.3 ensures the existence of the joint distribution of the corresponding sequence of FQPs. From here, the argument parallels that of the previous section, with the Lévy metric and Prokhorov metric replaced with their suprema over the finite set of indices. This ensures the existence of a probability space on which the limiting DQPs satisfy the requisite permutation and marginalisation conditions.
The DQP relies on a countable collection of real-valued stochastic processes, , all of which have index set
. Each of these processes satisfies Komogorov's consistency axioms. The processes are defined on a single probability space. Selecting a finite set of distinct indices, say,
, the sequence of FDQPs at these indices is generated by a countable collection of real-valued random variables. The permutation and marginalisation conditions follow immediately. This establishes the following lemma.
Lemma 3.3
Existence of FDQP
Under the conditions in the previous paragraph, for each , there exists a distribution-valued stochastic process,
, with the specified finite dimensional distributions.
Define the suprema of the Lévy metric and Prokhorov metric over a set S to be and
, respectively. Lemma A.1 appearing in Appendix 2 shows that
and
are metrics. We first reprise Lemma 3.1.
Lemma 3.4
Define . Assume that
and
,
, are two sets of distribution functions such that, for each
, there exist
for which
for
. Then,
.
The construction of the FDQPs ensures that, for all ω, for each the
quantiles in
and
are identical for every positive integer k. This lets us apply the lemma. With a suitable choice of quantile levels, the sequence of probability measures for the set of n FQPs is Cauchy.
Lemma 3.5
Suppose that is dense in
. Then, with
, under the supremum Prokhorov metric
, the sequence
is a Cauchy sequence.
Finally, noting that the set of distributions with support contained in is compact under
, by Tychonoff's Theorem, we know that
converges to some probability measure μ. This ensures the existence of the limiting DQP.
Theorem 3.2
Suppose that is dense in
. Then, for any
, the DQP for
constructed as in Section 2.3 is a random element whose distribution is determined by
. Furthermore, there exists a stochastic process defined for all
whose finite dimensional joint distributions on the QPs are exactly these.
4. Posterior inference
In this section, we discuss how to specify the DQP prior and the likelihood under the canonical construction. Suppose we have T quantiles of interest, , to be specified on the DQP. For simplicity, we work with the binary pyramid. A similar formulation can be laid out in the general case. Recall that with the canonical construction of the DQP in Section 2.4 and the canonical transformation in Section 2.5, quantiles are generated in the uniform scale and are transformed to the real line. For notational simplicity, we omit the superscript
from the quantile in (Equation3
(3)
(3) ) and let
denote the quantiles in the real line scale in this section.
4.1. Prior specification
A DQP is defined for all
as a stochastic process. Then, the finite-dimensional distributions of the DQP
can be defined for each n-tuple
of distinct elements of
(Billingsley Citation1968). While the n-tuple can be arbitrary, in practice, we choose the coordinates to be covariate values for the data points.
Let the quantiles of interest be denoted by . For convenience, we view
as a
matrix. The
row of
(denoted by
) is the vector of the
quantiles at
for
. The
quantile at
is denoted by
for
. The parent quantiles that defines the left and right endpoints of the interval on which
is generated are denoted by
and
. The vectors
and
have
and
as their elements, respectively.
Write for the vector of trend transformation parameters and
for the vector of scale transformation parameters, where
and
denote the element of
and
, respectively, corresponding to the value of
.
For a GP with zero mean given the input points , denoted by
, let
be the correlation matrix, where
is the correlation between
and
and
. Let
denote the cdf of the
distribution and
and
denote the cdfs of the
and the
distribution, respectively.
Given the parameters , the joint conditional density of the finite dimensional distribution of the specified quantile levels of the DQP at
is
where
denotes the probability distribution function (pdf) of the n-variate Normal,
, the back-transformed quantiles to the Z-scale
and the determinant of the Jacobian matrix is of the form
where
and
denote the pdfs of the
and the
distribution, respectively. The beta distribution parameters
and
can be established using the canonical choice outlined in Section 2.4. Given that we are working with the binary pyramid in this section where one quantile is estimated per subinterval, we can denote
as
using the ϵ-notation with an appropriate ϵ value. For
, we set
and
.
4.2. Updating
Since we use the normal distribution for the transformation from to
, the conditional density of the response variable is piecewise-normal. Given the values of the covariate
and the parameters
, and
, the pdf of
is
where
is an indicator function whose value is one when
and zero otherwise.
Utilizing the information present in the data through the likelihood, we can update the prior in Section 4.1 via a MCMC procedure with a Metropolis-Hastings step. More details can be found in Appendix 3. If desired, variations on the basic algorithm can be used to improve the mixing of the Markov chain.
4.3. Inference for the DQP
Posterior inference can be made based on the DQP prior and likelihood using the MCMC procedure in Appendix 3. An estimate of a set of QR curves under squared error loss is obtained by taking the posterior mean of the sample of quantiles at each x.
The dependence across the covariate space is fundamental to the DQP framework. The conditional quantiles are intrinsically dependent on one another through both the GP correlation structure, , and the pyramid structure. Typically, increasing the level of dependence results in smoother QR curves, while reducing dependence leads to more flexible and bumpier QR curves.
4.3.1. Linearized inference under the DQP
Bayesian methods allow one to distinguish between beliefs about a quantity, say a QR curve, and inference about the quantity. One strategy that has proven successful is to perform modelling in a large space and to impose parsimony through a restriction on the inference (e.g. MacEachern Citation2001; Hahn and Carvalho Citation2015). In contrast, practitioners of classical statistics generally impose parsimony by working in a smaller model space or through model selection.
Much of the literature on QR, both classical and Bayesian, focuses on linear QR. The DQP model naturally produces a posterior distribution that assigns probability one to nonlinear QR curves. To linearise inference, one needs a distribution over the covariate and a set of draws from the posterior distribution of the QR curve.
As a criterion, we minimise the integrated squared difference between the nonlinear QR curves and a linear QR curve. That is, with x following a distribution G and a quantile level of interest τ, and presuming the following integrals are finite, (4)
(4) where
denotes a posterior distribution function of
and
denotes the expectation of the quantity at each x.
In practice, if lacking a distribution G, we use the empirical cdf of x for G and the posterior mean of the conditional quantiles to estimate . With this particular choice, this minimisation is obtained as a least squares fit on the posterior mean of the conditional quantiles. The same
can be obtained in a second fashion. First, map the nonlinear QR curve at each MCMC iterate to the best fitting linear QR curve with a least squares fit. Then map this collection of linear QR curves values to the overall best linear QR curve via a second least squares regression of the least squares fits on x. More details are contained in Appendix 3.
4.3.2. Quantile prediction for a new x value
We can obtain a posterior predictive distribution of quantiles for a new x value, denoted as . This is achieved by following a two-step algorithm. First, we run an MCMC algorithm to sample mapping parameters and DQPs from their joint posterior distribution at the covariate locations where data points exist, namely
. Next, for a given MCMC iterate, we sample the DQP at the new value
from its conditional posterior distribution.
We empasize one important point. In the event that there is no existing data point at , the conditional posterior distribution is just the conditional prior distribution. By collecting the sampled quantiles at the new value
, we are able to construct the marginal posterior predictive distribution of quantiles for that specific location. For details on how to perform the posterior sampling of quantiles and mapping parameters from their respective posterior distributions, please refer to Section 4.2.
5. Simulation study
We conducted simulation studies to evaluate how the DQP performs. We considered two sets of quantiles: and
. The covariate is
and the response is
for
and
. Let
denote the standard normal distribution and
a t-distribution with df degrees of freedom. We considered the following three scenarios for the simulation study.
Scenario 1. (Homogeneous Error) Scenario 2. (Heterogeneous Error)
Scenario 3. (Nonlinear association between the covariate and the response)
For Scenarios 1 and 2, (1) ; (2)
; (3)
. Scenario 1 examines the case where the error variance is homogeneous and the normality assumption used in the mapping from
to
is satisfied (1-1), slightly violated (1-2), and more severely violated (1-3). In Scenario 2, the error variance is not constant, with a larger variance for certain covariate values, and the mapping is correctly specified (2-1), slightly misspecified (2-2), or more severely misspecified (2-3). Finally, Scenario 3 showcases settings where the error is normally distributed with homogeneous variance, but the covariate and response variables have a nonlinear association.
For each setting, we used r = 10 and r = 30 replicates at each value of x, corresponding to overall sample sizes of n = 100 and n = 300, respectively. In each of our 32 scenario-T-sample size combinations, we generated S = 100 data sets, fit QRs, and calculated the empirical mean-squared error (MSE) for each quantile τ at :
where
is an estimated quantile for τ level with
simulated data set at x. We further computed the MSE for the quantile, averaged over the distribution of x as
, which again is averaged over τ as
.
We fit a binary FDQP with two levels for the T = 3 case and with three levels for the T = 7 case based on the normal inverse cdf transformation from (Equation3(3)
(3) ), centreing the FDQP on a linear regression model with
. Regarding the dependence of the pyramids between locations x and
in the covariate space, we used the canonical construction for the Gaussian processes with zero mean vector and Gaussian correlation function
with
. For the beta distribution at level m in the construction of the binary pyramid prior, we used
and
with
. The prior distribution for
is bivariate normal with mean
and variance matrix
. For the scale transformation parameter
, we used the sample standard deviation at x as a plug-in estimator.
We compare our method to four alternatives: a classical QR approach by Koenker and Bassett (Citation1978) (‘quantreg’), a Bayesian QR approach by Yu and Moyeed (Citation2001) implemented by Benoit and Van den Poel (Citation2017) (‘bayesQR’), a simultaneous linear QR by Yang and Tokdar (Citation2017) (‘qrjoint’), and its generalised variant incorporating spatial dependence using a Gaussian process by Chen and Tokdar (Citation2021) (‘JSQR-GP’). The estimators are evaluated by AMSE. For the MCMC runs of bayesQR, qrjoint, JSQR-GP, and DQP, we used a warmup of 1, 000 iterates followed by 100, 000 draws for estimation, thinned at a rate of 1 in 100.
The AMSE values are summarised in Figure , while the corresponding values and standard errors can be found in Tables A1 and A2 in Appendix 4. Examining Figure , the linearised DQP (‘DQP-lm’) demonstrated competitive performance relative to the alternative approaches in Scenario 1. It either had the lowest AMSE or had an AMSE within a two standard error range of the lowest value for all of the cases of Scenarios 1-1 and 1-2 except for the T = 7 and n = 100 case. This suggests that when the underlying relationship between the response and covariates is believed to be linear, the DQP can be effectively used for linear inference, yielding reasonable results. In Scenario 1, qrjoint had the lowest AMSE in most cases, primarily because its linearity assumption in the model closely aligns with the underlying truth and it simultaneously estimates multiple conditional quantiles. We note that DQP struggled when the normal assumption in scale transformation of DQP is severely violated (Scenario 1-3).
Figure 3. AMSE values for each combination of scenario-T-sample size.
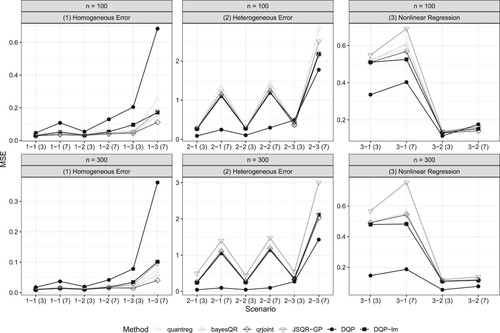
Under Scenarios 2-1 and 2-2, the DQP ourperformed all other methods. This is because the DQP is not only robust to mild misspecification of the mapping from to the response variable scale but can also account for the local nonlinearity arising from a larger variance at specific locations of the covariate. Among the linear methods, DQP-lm performed the best. This observation may be attributed to the fact that DQP-lm identifies linear QR curves by leveraging the QR curves estimated within the nonlinear model space. Even under Scenario 2-3, where the normal assumption in the DQP transformation is violated, the DQP still outperformed other methods in most of the cases except when n = 100 and T = 7.
Regarding the nonlinear association between the covariate and the response, represented by Scenarios 3-1 and 3-2, the DQP has lower AMSE than the other alternatives for most combinations of n and the number of quantiles, except for the case of n = 100 and T = 7 under Scenario 3-2. This is because the DQP can capture the local nonlinearity of quantiles, such as the cyclic movement in Scenario 3-1 and the sudden drop for small covariate values in Scenario 3-2. The advantage of the DQP becomes more evident as n increases.
6. Application
Elsner et al. (Citation2008) observed that the trend in tropical cyclone intensity in the North Atlantic Ocean from 1981 to 2006 is different for different quantiles. They fit separate linear QRs for multiple quantiles using the R package ‘quantreg’ (Koenker Citation2005) and found that the higher quantiles showed an upward trend, with statistically significant slopes above the 0.7 quantile. Lower quantiles had slopes closer to zero.
Kadane and Tokdar (Citation2012) analysed the same data set and came to a different conclusion. They developed a Bayesian approach to simultaneously fit a collection of linear QRs. They found that the increasing trend in the cyclone intensity was significant for almost all quantiles, not just the upper quantiles.
We analysed the data set (https://myweb.fsu.edu/jelsner/temp/Data.html) from Elsner et al. (Citation2008). The data consist of the lifetime maximum wind speeds of 291 North Atlantic tropical cyclones derived from satellite imagery. The wind speeds are the response (Y) and range from 29.8 to . The year is the covariate (x).
We fit a binary FDQP with four levels and 15 quantiles at τ = 0.05, 0.10, 0.20, 0.25, 0.30, 0.35, 0.40, 0.50, 0.60, 0.65, 0.70, 0.75, 0.80, 0.90, and 0.95. We used the binary canonical construction with Gaussian processes with zero mean vector and the exponential correlation function with
. For the beta distribution at level m in the construction of V processes, we used
and
with
. We again used the canonical transformation with linear regression model for the trend parameter, i.e.
. The prior distribution for
is bivariate normal with mean
and variance matrix
. For the scale transformation parameter
, we fitted an ordinary least squares model with the sample standard deviation regressed on each year and then used the resulting fitted values. We ran 10, 000 warm up iterates of MCMC followed by 200, 000 iterates, thinned to 2, 000 iterates for estimation. For the purpose of comparison, we also applied the alternative simultaneous QR methods discussed in Section 5 to the same dataset.
Figure displays the analysis results from the simultaneous QR methods, including our approach. In panel (a), the grey lines provide the posterior means at each year and the black lines the linearised fit. The lines are overlaid on the data points. The 95% credible intervals for the slopes of the linearised fit are shown in the right panel of (a). The slopes tend to be greater for greater quantiles, implying that stronger cyclones have been getting stronger more quickly. Indeed, the 95% credible interval for the slope of the 0.95 quantile is observed to be well above that of the 0.50 quantile. This means that the most intense cyclones are increasing in strength at a significantly faster rate than the moderately strong cyclones. The 95% credible intervals for the slope of the quantiles below 0.50 include zero. The slopes do not significantly differ from zero for lower quantiles. Overall, our method applied to these data shows the intensity of the upper half of the cyclones to be increasing, with more powerful cyclones intensifying at a more rapid rate.
Figure 4. Left column: 15 estimated quantiles of cyclone intensity with grey data points. Right column: Estimated slopes of the quantile lines with 95% empirical credible intervals. In (a), grey lines are the posterior means of the quantiles and black lines are the linearised fit of the posterior mean.
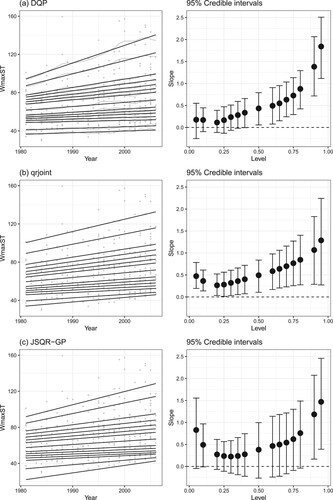
On the other hand, the outcome obtained from qrjoint in panel (b) reveals that all the 95% credible intervals lie above zero while overlapping with one another. This suggests that cyclone intensities are increasing across all levels, although the rate of increase may not significantly differ among cyclones with varying power. Meanwhile, the findings from JSQR-GP in panel (c) indicate that only the slopes for the strongest cyclones have values greater than zero, with their respective intervals also overlapping. While we lack knowledge of the absolute ground truth, it becomes evident that all three models concur on one point: the intensity of the strongest cyclones is increasing.
7. Discussion
We propose a nonparametric Bayesian approach to quantile regression, based on a process of DQPs. The DQP generalises the QP of Hjort and Walker (Citation2009) to allow dependence across a predictor space. The flexibility of the model allows us to depart from linearity and to handle regressions for multiple quantiles in unbounded predictor spaces without quantile crossing.
The canonical construction can be adapted to account for a various features of the data. As examples, the standard normal distribution used in the inverse cdf transformation can be replaced with a distribution with different tails to handle thick or thin tailed data; skewness in the quantiles can be handled by replacing the symmetric normal distribution with an asymmetric distribution; and positively valued responses can be handled by basing the transformation on a distribution supported on the half line. The linear regression model for the mean can be replaced with a nonlinear form, resulting in large-scale nonlinearity of the QRs. Simple choices for this include the use of a deterministic form such as a fixed-knot spline or a stochastic form such as a Gaussian process. Replacement of the linear form for the scale factor (say, ) with a form that ensures positivity, for example,
, relieves concerns about the implications of unbounded
.
In the simulation examples, we employed the sample standard deviation at the location x as a plug-in estimator for the scale transformation parameter . An alternative is to use a pooled sample standard deviation in situations where heterogeneity is not suspected, such as Scenario 1. The results of this alternative will be included in our future work. The simulations we report above rely on a single predictor. The stochastic processes used for the FDQP are Gaussian processes that are then passed through transformations to arrive at the FDQP. Extension to the case of multiple predictors is straightforward through the use of Gaussian processes with a multivariate index. The Gaussian processes can be replaced with other processes.
Acknowledgments
The authors wish to thank the reviewers for comments that improved the paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Benoit, D.F., and Van den Poel, D. (2017), ‘bayesQR: A Bayesian Approach to Quantile Regression’, Journal of Statistical Software, 76, 1–32.
- Billingsley, P. (1968), Convergence of Probability Measures, New York: John Wiley & Sons.
- Bissiri, P.G., Holmes, C.C., and Walker, S.G. (2016), ‘A General Framework for Updating Belief Distributions’, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78(5), 1103–1130.
- Chen, X., and Tokdar, S.T. (2021), ‘Joint Quantile Regression for Spatial Data’, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 83(4), 826–852.
- Chen, C., and Yu, K. (2009), ‘Automatic Bayesian Quantile Regression Curve Fitting’, Statistics and Computing, 19, 271–281.
- Edgeworth, F.Y. (1888), ‘The Mathematical Theory of Banking’, Journal of the Royal Statistical Society, 51(1), 113–127.
- Elsner, J.B., Kossin, J.P., and Jagger, T.H. (2008), ‘The Increasing Intensity of the Strongest Tropical Cyclones’, Nature, 455, 92–95.
- Geraci, M., and Bottai, M. (2007), ‘Quantile Regression for Longitudinal Data Using the Asymmetric Laplace Distribution’, Biostatistics, 8(1), 140–154.
- Hahn, P.R., and Carvalho, C.M. (2015), ‘Decoupling Shrinkage and Selection in Bayesian Linear Models: a Posterior Summary Perspective’, Journal of the American Statistical Association, 110(509), 435–448.
- Hjort, N.L., and Walker, S.G. (2009), ‘Quantile Pyramids for Bayesian Nonparametrics’, The Annals of Statistics, 78(1), 105–131.
- Kadane, J.B., and Tokdar, S.T. (2012), ‘Simultaneous Linear Quantile Regression: a Semiparametric Bayesian Approach’, Bayesian Analysis, 7(1), 51–72.
- Koenker, R. (2005), Quantile Regression, Econometric Society Monographs, Cambridge: Cambridge University Press.
- Koenker, R. (2017), ‘Quantile Regression: 40 Years on’, Annual Review of Economics, 9, 155–176.
- Koenker, R., and Bassett, G. (1978), ‘Regression Quantiles’, Econometrica: Journal of the Econometric Society, 46(1), 33–50.
- Kottas, A., and Krnjajić, M. (2009), ‘Bayesian Semiparametric Modelling in Quantile Regression’, Scandinavian Journal of Statistics, 36(2), 297–319.
- Kotz, S., Kozubowski, T., and Podgórski, K (2001), The Laplace Distribution and Generalizations: a Revisit with Applications to Communications, Economics, Engineering, and Finance, Boston: Springer Science & Business Media.
- Kozumi, H., and Kobayashi, G. (2011), ‘Gibbs Sampling Methods for Bayesian Quantile Regression’, Journal of Statistical Computation and Simulation, 81(11), 1565–1578.
- Lum, K., and Gelfand, A.E. (2012), ‘Spatial Quantile Multiple Regression Using the Asymmetric Laplace Process’, Bayesian Analysis, 7(2), 235–258.
- MacEachern, S.N. (2001), ‘Decision Theoretic Aspects of Dependent Nonparametric Processes’, in Bayesian Methods with Applications to Science, Policy and Official Statistics, pp. 551–560. Crete: International Society for Bayesian Analysis.
- Parthasarathy, K.R (1967), Probability Measures on Metric Spaces, New York: Academic Press Inc.
- Parzen, E. (2004), ‘Quantile Probability and Statistical Data Modeling’, Statistical Science, 19, 652–662.
- Reich, B.J. (2012), ‘Spatiotemporal Quantile Regression for Detecting Distributional Changes in Environmental Processes’, Journal of the Royal Statistical Society: Series C (Applied Statistics), 61(4), 535–553.
- Reich, B.J., Bondell, H.D., and Wang, H.J. (2010), ‘Flexible Bayesian Quantile Regression for Independent and Clustered Data’, Biostatistics, 11(2), 337–352.
- Reich, B.J., Fuentes, M., and Dunson, D.B. (2011), ‘Bayesian Spatial Quantile Regression’, Journal of the American Statistical Association, 106(493), 6–20.
- Rodrigues, T., Dortet-Bernadet, J.-L., and Fan, Y. (2019a), ‘Pyramid Quantile Regression’, Journal of Computational and Graphical Statistics, 28(3), 732–746.
- Rodrigues, T., Dortet-Bernadet, J.-L., and Fan, Y. (2019b), ‘Simultaneous Fitting of Bayesian Penalised Quantile Splines’, Computational Statistics & Data Analysis, 134, 93–109.
- Rodrigues, T., and Fan, Y. (2017), ‘Regression Adjustment for Noncrossing Bayesian Quantile Regression’, Journal of Computational and Graphical Statistics, 26(2), 275–284.
- Taddy, M.A., and Kottas, A. (2010), ‘A Bayesian Nonparametric Approach to Inference for Quantile Regression’, Journal of Business & Economic Statistics, 28(3), 357–369.
- Tsionas, E.G. (2003), ‘Bayesian Quantile Inference’, Journal of Statistical Computation and Simulation, 73(9), 659–674.
- Waldmann, E., Kneib, T., Yue, Y.R., Lang, S., and Flexeder, C. (2013), ‘Bayesian Semiparametric Additive Quantile Regression’, Statistical Modelling, 13(3), 223–252.
- Yang, Y., and Tokdar, S.T. (2017), ‘Joint Estimation of Quantile Planes Over Arbitrary Predictor Spaces’, Journal of the American Statistical Association, 112(519), 1107–1120.
- Yu, K., and Moyeed, R.A. (2001), ‘Bayesian Quantile Regression’, Statistics & Probability Letters, 54(4), 437–447.
Appendices
Appendix 1
:= a triple that defines a probability space
D = the space of all distributions with the support on
Appendix 2
Proof
Proof of Lemma 3.1
Consider . Then
. Thus
and so
. Similarly,
and so
. Thus
. Repeating the argument above for
establishes that
.
Proof
Proof of Lemma 3.2
Fix . Choose M such that
. Applying Lemma 3.1, we have
for all
and for all
. That is,
is in the ϵ-ball about
. Such an M always exists provided that
is dense in
and each
has the same pyramid structure.
Consider an arbitrary Borel set . Define the sets
and
. For every
,
is in the ϵ-ball about
. Hence
and so
.
Turning to the probability measures on the FQPs with m and n levels, we note that and
. Since
,
. A similar argument shows that
. This holds for all Borel A, and so
. Thus, for each
, there is an M such that, for all
,
. The sequence
is Cauchy.
Proof
Proof of Theorem 3.1
By Lemma 3.2, the sequence is Cauchy. Moreover, the space
equipped with the Prokhorov metric is compact, and thus complete, since the space D equipped with Lévy metric is compact (see Theorem 2.6.4 in Parthasarathy Citation1967). Therefore, the sequence
is convergent. That is, there exists μ to which
converges and that μ provides a probability distribution on
. Thus, a limit of QP exists.
Lemma A.1
as defined in Section 3.2 is a metric on the space of distributions.
is a metric on the space of probability measures over distributions. The set
need not have finite cardinality.
Proof.
Symmetry, non-negativity, the triangle inequality, and the zero property follow from straightforward calculation. With a nod to the St. Petersburg paradox, we must show that . Since
for all
, we have that
. The argument for
is established in the same way.
Proof
Proof of Lemma 3.4
From Lemma 3.1, we have for all
. Thus
.
Proof
Proof of Lemma 3.5
Replace with
,
with
, and
with
in the proof of Lemma 3.2.
Proof
Proof of Theorem 3.2
The proof of the first part of the theorem follows that of Theorem 3.1. Kolmogorov's permutation condition is satisfied at each step in the sequence of FDQPs since each of the processes satisfies the condition. His marginalisation condition is also satisfied. Since
was arbitrary, this ensures the existence of a stochastic process with the specified limiting distributions (e.g. Billingsley Citation1968, chapter 7).
Appendix 3
A.1. MCMC algorithms
Sample
Choose
Sample
Accept the new proposal
Repeat (i)–(iii) until the bottom of the pyramid.
Sample
Partition
Sample
Repeat step (ii) for
Sample
Note that the sampling of can be further broken down to sampling of smaller blocks as in step 2. Doing so impacts the acceptance rate of the proposals and the mixing of the Markov chain.
A.2. Linearized inference
Throughout this derivation, we assume that the integrals are finite. This ensures the non-trivial existence of a minimizing .
where
denotes the posterior distribution function of
,
denotes the distribution function of x, and
denotes the expectation of the quantity at each x. Moreover, if
is the empirical cdf of x, then the problem above becomes
which is equivalent to the least squares linear regression problem.
Appendix 4
Table E1. AMSE values over 100 simulated datasets with standard errors in parentheses when n = 100.
Table E2. AMSE values over 100 simulated datasets with standard errors in parentheses when n = 300.