
Abstract
The induction problems facing language learners have played a central role in debates about the types of learning biases that exist in the human brain. Many linguists have argued that some of the learning biases necessary to solve these language induction problems must be both innate and language-specific (i.e., the Universal Grammar (UG) hypothesis). Though there have been several recent high-profile investigations of the necessary learning bias types for different linguistic phenomena, the UG hypothesis is still the dominant assumption for a large segment of linguists due to the lack of studies addressing central phenomena in generative linguistics. To address this, we focus on how to learn constraints on long-distance dependencies, also known as syntactic island constraints. We use formal acceptability judgment data to identify the target state of learning for syntactic island constraints and conduct a corpus analysis of child-directed data to affirm that there does appear to be an induction problem when learning these constraints. We then create a computational learning model that implements a learning strategy capable of successfully learning the pattern of acceptability judgments observed in formal experiments, based on realistic input. Importantly, this model does not explicitly encode syntactic constraints. We discuss learning biases required by this model in detail as they highlight the potential problems posed by syntactic island effects for any theory of syntactic acquisition. We find that, although the proposed learning strategy requires fewer complex and domain-specific components than previous theories of syntactic island learning, it still raises difficult questions about how the specific biases required by syntactic islands arise in the learner. We discuss the consequences of these results for theories of acquisition and theories of syntax.
ACKNOWLEDGEMENTS
We would like to thank Colin Phillips, Jeff Lidz, Norbert Hornstein, Julien Musolino, Bob Berwick, Bob Frank, Virginia Valian, Alexander Clark, Misha Becker, Anne Hsu, Kamil Ud Deen, Charles Yang, Julian Pine, Terry Regier, William Sakas, Amy Perfors, Tom Roeper, two anonymous reviewers, the attendees of the Input & Syntactic Acquisition workshop held at the LSA in 2012 and at UC Irvine in 2009, and the audience at the Ecole Normale Supérieure in 2011 for numerous comments and suggestions on previous versions of this work. All errors remain our own. In addition, we are very grateful to Jessica Lee, Uma Patel, Kristen Byer, Christine Thrasher, and other members of the Computation of Language Laboratory who aided in the syntactic annotation of the child-directed speech. This work was supported in part by NSF grant BCS-0843896.
Notes
1Since the distinction between hypothesis space and learning mechanism does not impact a bias's status as UG or not, we will not discuss it further here. However, it is worth noting this distinction because many UG proposals tend to involve explicit constraints on the hypothesis space (e.g., certain hypotheses are not available to the child a priori), while many non-UG proposals tend to involve implicit constraints on the learning mechanism (e.g., use statistical learning). This is not a logical necessity, as one could easily imagine a UG bias about the learning mechanism (e.g., use a language-specific learning strategy) as well as a non-UG bias about the hypothesis space (e.g., certain hypotheses are a priori less probable in a particular hypothesis space, as is the case in Bayesian inference over a subset-superset hypothesis space).
2Notably, however, this does not address the induction problem traditionally associated with structure dependence, which concerns hypothesizing structure-dependent rules that utilize these hierarchical representations (CitationBerwick et al. 2011). Just because structured representations are available does not necessarily mean children know to use them when forming rules.
3We follow the field of syntax in assuming that well-controlled acceptability judgments can be used to infer grammaticality (see CitationChomsky 1965; CitationSchütze 1996; Schütze & Sprouse in press; Sprouse & Almeida in press).We also follow the conclusion in CitationSprouse, Wagers & Phillips (2012a, Citation2012b) that the acceptability judgment pattern observed for syntactic islands is due to grammatical constraints and likely cannot be explained as an epiphenomenon of sentence processing.
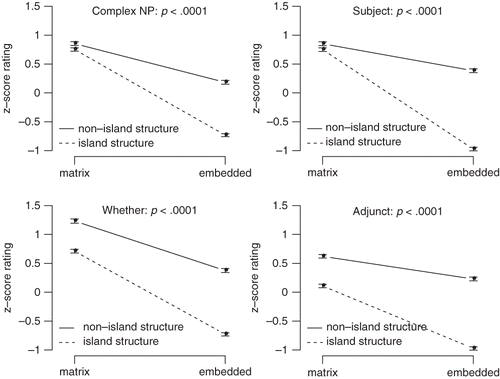
FIGURE 2 Experimentally derived acceptability judgments for the four island types from CitationSprouse, Wagers & Phillips (2012a) (N = 173).
4Available at ftp://ftp.cs.brown.edu/pub/nlparser/ (31 October, 2012.)
5This work was conducted as part of NSF grant BCS-0843896, and the parsed corpora are available at http://www.socsci.uci.edu/~lpearl/CoLaLab/TestingUG/index.html (31 October, 2012).
6Interestingly, the idea of indirect positive evidence is similar in spirit to what linguistic parameters are meant to do in generative linguistic theory—if multiple linguistic phenomena are controlled by the same parameter, data for any of these phenomena can be treated as an equivalence class, where learning about some linguistic phenomena yields information about others (CitationChomsky 1981; CitationViau & Lidz 2011; CitationPearl & Lidz in press).
7Note that this means the learner is learning from data containing dependencies besides the one of interest, treating the other dependencies as indirect positive evidence (CitationPearl & Mis 2012). For example, a learner deciding about the sequence IP-VP-CP that -IP-VP would learn from IP-VP dependencies that the trigram start-IP-VP appears. This is a learning bias that expands the relevant intake set of the learner—all dependencies are informative, not just the ones being judged as grammatical or ungrammatical.
8We note that the learner we implement in section 4.4 uses smoothed trigram probabilities (using Lidstone's Law [CitationManning & Schütze 1999] with smoothing constant α = 0.5), so unobserved trigrams have a frequency slightly above 0. Thus, the equation for a trigram t's probability is
9Here and throughout we will use the term grammaticality preference to refer to the result of the learning algorithm (a probability), and acceptability judgments to refer to the actual observed behavior of adults in an experimental setting (e.g., CitationSprouse, Wagers & Phillips 2012a). As discussed at the end of section 4, an acceptability judgment is the result of several factors, of which the grammaticality preferences generated by our learner are just one. Other factors affecting acceptability judgments include semantic plausibility, lexical properties, and parsing difficulty.
10This shows that actual process of generating acceptability judgments is likely more nuanced than the basic implementation in the current algorithm. One clear difference is that the current algorithm does not factor in the portion of the utterance beyond the gap position, whereas the actual process in humans likely does. For example, Who saw it? is not judged as equivalent to Who thought that Jack said that Lily saw it?, even though both are IP dependencies. Similarly, the current algorithm does not factor lexical or semantic properties into the judgments, whereas the actual process in humans likely does. This is why experimental studies have to balance the lexical, structural, and semantic properties of the experimental materials, as CitationSprouse, Wagers & Phillips (2012a) did.
11This measurement is similar to surprisal, which is traditionally defined as the negative log probability of occurrence (CitationTribus 1961) and has been used recently within the sentence processing literature (CitationHale 2001; Jaeger & Snider 2008; CitationLevy 2008, Citation2011). Under this view, less acceptable dependencies are more surprising.
12We are especially grateful to Colin Phillips for his thoughts and suggestions concerning this.
13We note that if a combination operation is always part of the learner's treatment of utterances containing gaps, this should not affect our current results on dependencies associated with a single gap. This is because single gap dependencies would presumably be a special case for the combination operation where no combination of dependency information would need to occur.
14Of course, our model assumes that the phrase structure has already been inferred, and learning phrase structure may require sophisticated probabilistic inference methods. However, once the phrase structure is available, no sophisticated inference is required to learn syntactic island constraints, which is the learning process explicitly modeled here.