Abstract
In 2012, the U.S. Department of Housing and Urban Development (HUD) released the Location Affordability Index (LAI) as an online portal and downloadable data set. The LAI has elevated the U.S. conversation on affordability to include transportation and access to opportunities, and has been used in state and federal programming, by researchers, and by private households. However, although some researchers have noted concerns with and potential limitations of the data, none has provided practitioners and researchers with an under-the-hood view of the data, analysis of its reliability or validity, or its conceptual limitations. This article recommends methodological improvements dealing with issues of variable construction, aggregation, and modeling. A recreation of the LAI at the census-tract level suggests the LAI overestimates both costs and cost burden, but especially among renters, and especially in metropolitan areas. On the transportation side, model recreation requires partnership and resourcing to both gain access to restricted data and to develop a reliable database on transit supply and use.
In 2012, the U.S. Department of Housing and Urban Development (HUD) released the Location Affordability Index (LAI) as an online portal and downloadable data set. HUD adopted and revised the LAI from its origin as the Center for Neighborhood Technology’s Housing and Transportation (H+T) Affordability Index. This database seeks to inform households and public agencies of the costs of living in various places, changing the discussion about affordability from one focused solely on housing to one inclusive of transportation costs. Numerous scholars have analyzed the LAI estimates, resulting in a special issue of Housing Policy Debate as well as other publications. These publications have addressed housing subsidies, mortgage risk, and racial disparities in costs, among other things. However, these publications have not provided practitioners and researchers with an under-the-hood view of the data, analysis of its reliability or validity, or its conceptual limitations. As this article shows, some elements of the LAI introduce either considerable error or the potential for considerable error. Many of those issues, based in variable construction, aggregation, and modeling decisions, can be fixed. Others—notably, data on transit use—are more problematic. If left unchecked, such error could misinform decisions regarding household location or public policy issues in housing or transportation—potentially costing private households or public agencies considerably. This article uses data from across the state of Ohio, intending it as an illustrative case study of the national implications of the conceptual and technical bounds of the LAI.
Following a brief background section, Section 1 provides conceptual and technical overviews of the LAI. The following, more detailed Section 2 evaluates technical issues regarding data reliability, variable construction, aggregation, and the LAI’s structural equation model (SEM). The final subsection of Section 2 presents the methods and results of reestimating the SEM. Finally, the article concludes with recommendations for LAI revision, either by HUD or for researchers seeking to replicate the index for later years, for specific geographies, or to mitigate a selection of the issues raised.
Background and Review
In the 1990s President Bill Clinton focused national economic development policy on integrating social and economic systems, using policies such as Empowerment Zones (created through the Omnibus Budget Reconciliation Act of 1993). Under the George W. Bush White House, policy changed but retained a focus on reducing housing discrimination and addressing some place-based development issues. One example is brownfield redevelopment, addressed via the Small Business Liability Relief and Brownfields Revitalization Act. President Obama continued in the direction of focusing national economic development policy on place-based change, by emphasizing strong cities as building blocks for regional development, through efforts such as the Smart Cities Initiative. Over Obama’s two terms the national discussion about place-based development evolved to consider more broad-based evaluations of affordability, and the interplay of transportation systems, economic opportunity, and housing development that influences neighborhood vitality. The Obama administration’s Partnership for Sustainable Communities represents one effort toward advancing this conversation. The LAI is an initiative of that partnership (U.S. Department of Housing and Urban Development, Citationn.d.a).
The LAI represents more than a shift in the conversation about affordability; it has direct bearing on federal policy through HUD’s Affirmatively Furthering Fair Housing (AFFH) program. The effort, an executive order of President Obama, requires some HUD grantees to complete Assessments of Fair Housing. The Assessment Tool includes (among other data points) eight indices “to help inform communities about segregation in their jurisdiction and region, as well as about disparities in access to opportunity” (Abt Associates & Mast, Citation2015, p. 10). Two of those indices use as their basis variables produced in the LAI—the Low Transportation Cost Index and the Transit Trips Index. Thus, the recommendations drawn from this article’s findings could affect not only the LAI, which is a tool for practitioners and researchers, but also policy in the form of AFFH. States such as Minnesota and Illinois have also adopted policies relying on location affordability databases (National Conference of State Legislatures, Citation2011).
The LAI also indirectly influences federal policy related to public housing programs and mortgage lending through peer-reviewed research. Several scholars have investigated the merit of adjusting subsidy levels or duration for public housing programs in scale with the presence of local amenities (Bieri & Dawkins, Citation2016) and location efficiency (Lens & Reina, Citation2016; Tremoulet, Dann, & Adkins, Citation2016). Kaza, Riley, Quercia, and Tian (Citation2016) analyze mortgage performance and location efficiency, arguing that mortgage concessions for low-income families in high-efficiency locations may not be warranted.
The LAI’s potential to influence local and regional policy provides the primary motivation for this article. In many metropolitan regions, transit authorities increasingly acknowledge issues of racial and socioeconomic segregation and opportunity, and promote goals of providing transit services where they will most benefit neighborhoods. This is the case, for instance, for the Cleveland Regional Transit Authority (henceforth RTA), which also faces a long-declining budget. With a high marginal utility of public dollars, and a high opportunity cost of investing, the RTA views location affordability as a potentially valuable tool in developing programming options. The RTA thereby joined this research effort as a match partner, enabling the work to use Cleveland, Ohio, as its case study setting for the evaluation of the LAI’s reliability, validity, and applicability, as well as other research questions that lie beyond the scope of this article. To avoid the bias that the Metropolitan Statistical Area’s (MSA) distinct economic patternsFootnote1 might exert, this article evaluates data across the state of Ohio.
Both HUD and scholars have previously identified some concerns regarding data reliability and validity in the LAI, but exploration of those concerns has almost universally ended at identification. HUD identifies two big-picture concerns regarding the LAI. First, the models assume that all households within a block group match the household type for which estimates have been produced. This is neither realistic nor desirable. The effects of housing and household diversity are many, from encouraging aging in place to decreasing time on market (for the latter, see McMillan & Chakraborty, Citation2016). Second, and echoed by Renne, Tolford, Hamidi, and Ewing (Citation2016), the housing costs included in the LAI have both temporal and spatial resolution issues and do not reflect the cost of entry for homeowners (HUD employee, personal communication, September 27, 2016).
To this, scholars have added concern regarding racial disparities. Acevedo-Garcia et al. (Citation2016) find that when other factors are held constant, racial disparities in opportunity still emerge in data covering education, health and environment, and social and economic opportunity. Transportation costs carry racial differences. Renne et al. (Citation2016) find higher transportation costs in majority African American neighborhoods—perhaps, they speculate, because of characteristics of the vehicle fleet owned. African American neighborhoods also display lower walkability (Koschinsky & Talen, Citation2016), which could decrease access to opportunities or require higher cost transportation alternatives. Relatedly, numerous scholars mention difficulties in use or interpretation stemming from the household types used in the LAI research design, as results are difficult or impossible to modify to reflect actual populations (Nguyen, Webb, Rohe, & Noria, Citation2016; Tighe & Ganning, Citation2016).
Finally, several scholars who have used the LAI in research note concern regarding the margin of error (MOE) in American Community Survey (ACS) data, especially at the block group level (Acevedo-Garcia et al., Citation2016; Haas, Newmark, & Morrison, Citation2016; Tighe & Ganning, Citation2016; Walter & Wang, Citation2016). With the exception of Haas et al. (Citation2016), external review of the LAI on the grounds of statistical reliability or validity has gone no further than this. As this article shows, although MOE does present a considerable challenge for the LAI as a whole, other considerations warrant discussion as well.
1. A Conceptual Overview
HUD’s LAI aims to provide “the public with reliable, user-friendly data and resources on combined housing and transportation costs to help consumers, policymakers, and developers make more informed decisions about where to live, work, and invest” (U.S. Department of Housing and Urban Development, Citationn.d.b). At the time of this writing, the portal uses data primarily from the 2008–2012 5-year ACS and the 2010 Census Longitudinal Employer-Household Dynamics (LEHD) Origin-Destination Employment Statistics (LODES) database. The portal provides two tools: one giving housing and transportation costs households might expect to pay in a given location, and one that guides a user through prompts to calculate their costs. This section provides a conceptual overview of each tool, although briefly, as the LAI website provides this information publicly.
The Index
The index gives the estimated percentage of income and dollar amount spent on housing and transportation costs for eight household types. The online version presents these data at the block group geography. The tabular data available for download provide estimates at various geographic levels.Footnote2. In addition to the housing and transportation cost estimates, the online tool provides an estimate of annual vehicle miles traveled, the number of annual transit trips taken, and the number of vehicles owned. The online user must select from eight household types as they are given and cannot change any of the selected type’s defining characteristics, which are various combinations of income level, household size, and number of commuters. The user can pan and zoom on a built-in map to their target neighborhood. The LAI technical documentation claims the types “are not intended to match the characteristics of any particular family. Rather, they were selected to meet the needs of a variety of users, including consumers, planning agencies, real estate professionals, and housing counselors” (U.S. Department of Housing and Urban Development, Citationn.d.c, p. 26).
Directly because users cannot adjust the estimates to reflect a higher or lower income, or more or fewer commuters, the index should be used to gauge relative, not absolute, affordability. From a technical perspective, this challenge arises from the index’s use of SEM. In an SEM, the variables, both exogenous (similar to independent variables in traditional regression) and endogenous (similar to dependent variables in traditional regression), are interrelated in multiple and complex ways. The multiple and interrelated nature of the variables renders impossible any efforts to guess how much changes in any one variable might influence total costs or affordability. For example, in the LAI’s SEM, automobile ownership for renters precipitates from a function of 12 exogenous variables and two endogenous variables, which are themselves the products of 11 and 13 other variables, respectively. How could a potential new resident gauge how much neighborhood automobile ownership stems from built-environment influences versus socioeconomic ones (the SEM includes both)?
Both practitioners and individual users must then emphasize that LAI affordability estimates are intended to reflect typical costs for household types within block groups. This suggested terminology— typical costs —reflects that the LAI does not actually provide average costs. This issue is taken up in the technical considerations section.
Stylistically, the online index does not break down transportation costs into those incurred via automobile and those incurred via public transit. Thus, users cannot reasonably estimate a difference between the modeled values and their own actual costs by manually adjusting transit costs, for instance, based on their own known behavior. Similarly, the index does not make allowances for unusual mortgage or home financing situations. The LAI’s second tool, the online calculator, better serves users who desire such a level of accuracy.
As the index does not permit manipulation of estimated costs to reflect edits to the household types, it bears noting that in virtually all cases the index will not represent actual household situations. Even if a household is reasonably well represented by a household type, the index estimates automobile ownership as a continuous (e.g., 1.7 cars owned) rather than discrete variable (e.g., two cars owned), with no information regarding the additional cost incurred by owning another 0.3 cars. Finally, the eight household types do not attempt to cover all situations. For example, no household type accommodates a four-person household with two commuters who together earn less than the regional median income. Nor are telecommuters well represented.
To summarize, the LAI represents typical housing and transportation costs at the block group level (or other geographies using the tabular, downloadable data) for prototypical but unobservable households. Users should not modify the LAI estimates in an effort to tailor the household types to individual circumstances. Implicitly, then, the index finds its highest use as either of two tools: (a) an estimate of relative locational costs for households considering relocation; or (b) a resource for analyzing regions for researchers with questions specific to different socioeconomically defined household groups, such as single-parent households, the elderly, or young professionals. The LAI’s usefulness for practitioners is less clear, because the index does not reflect the situation of actual neighborhood residents, nor can its output be easily modified to understand the influence of various characteristics.
The Calculator
The second tool caters to households who have reasonable estimates of their average monthly expenditures and desire tailored estimates of housing and transportation costs they might incur in a given location. The calculator appears to be a series of straightforward calculations based solely on user input. If a user lacks an estimate for a given expense—say, monthly public transportation costs—the calculator suggests the estimate produced by the LAI. Here, however, the LAI technical documentation provides little information, saying only that the calculator “takes advantage of the SEM using the progression of choices made by the user” (U.S. Department of Housing and Urban Development, Citationn.d.c, p. 27).
The technical documentation implies that the calculator’s suggested values come from the SEM, with no information on how this is accomplished. In a test of various fictional households in cities, the calculator’s suggested values do not match the costs estimated by the index for any of the eight household types. Nor is it clear whether or how the SEM might instantaneously run and produce estimates for user-inputted household characteristics. Nor has HUD provided coefficients that researchers could use to estimate costs for households not conforming to the eight defined household types. The suggested housing costs also mismatch with published figures from the Census Bureau’s ACS.
On one hand, if reliable, the calculator’s estimates vastly enhance the tool’s usefulness for households by providing estimates more tailored than those the index can provide. At the same time, for practitioners and researchers, this tool brings limited utility absent more information regarding the production of its estimated values for user-generated household profiles.
To conclude this conceptual overview, one aspect of the LAI evinced more questions than any other at a recent Location Affordability Round Table session held during the Association of Collegiate Schools of Planning conference in November 2016: For whom does the index exist? The questions asked mirror the narrative presented here. The eight preset household types impose unrealistic assumptions on neighborhoods—assumptions that, if held, would drastically and swiftly change the location of opportunities and costs. If, for instance, all of East Cleveland were suddenly inhabited by dual-professional households, a growth in the number of commercial establishments would quickly follow. Moreover, most index users have difficulty finding their household circumstance in the eight preset types. Language introducing the calculator might clarify its intended uses and audience.
2. Technical Considerations
The index presents affordability information for housing and transportation. The housing estimates emerge from an SEM built from Census ACS and LODES data, and the household-level characteristics of the eight prototypical types (size, number of commuters, and income level). For transportation costs, part of the LAI estimates comes from the SEM, whereas part stems from an Ordinary Least Squares (OLS) regression using the SEM outputs as inputs, along with census data inputs. This technical overview begins with concerns relating to data reliability, variable construction, and aggregation for data used in both the SEM and OLS portions of LAI estimation. Following, technical considerations relating to the SEM are addressed and a reestimation presented.
Data Reliability
HUD constructs the majority of its variables from ACS 2008–2012 5-year data at the block group level, using many transformations both to create new variables and to aggregate to larger levels of geography. ACS critics have long pointed to MOE issues. These issues stem from sample sizes and tend to be more problematic for small geographic levels such as the block group and census tract levels. An evaluation of the reliability in the underlying data thus sheds light on the reliability of LAI variables.
The Bureau of the Census publishes ACS estimates alongside each variable’s MOE. The coefficient of variation (CV; Equation 1, using a 90% confidence interval) quantifies the reliability of an estimate based on both the estimate and the MOE. After converting CV values to ordinal groups researchers can classify observations within data sets as having high (CV ≤ 12.0), medium (12.0 < CV ≤ 40.0), or low (CV > 40.0) reliability (Esri, Citation2014). Table summarizes the analysis of reliability for the LAI variables.(1)
Table 1. Reliability of Location Affordability Index (LAI) Structural Equation Model (SEM) inputs at the block group level.
Medium to Poor Reliability Variables and Tenure
Across the board, a greater proportion of observations have high reliability among owner-occupied households than among renter-occupied households (see Tables and ). This is more pronounced at the block group level (see Table ). At this level, medium reliability is the modal category for renter households for most variables. For some variables, few block groups have high reliability. Esri labels medium-reliability data as “use with caution” (Citation2014, p. 6). However, exercising caution requires an understanding of the LAI’s underlying structure.
Table 2. Reliability of Location Affordability Index (LAI) Structural Equation Model (SEM) Inputs at Census Tract Level.
For example, the LAI models four of its six endogenous variables using fraction rental units as an input. At the block group level, 46% of block groups have medium reliability for total households, and 62% for number of renter households. Ohio block groups are modally moderately reliable for estimates of the percentage of single-family detached dwelling units, as well as for the number of vehicles available. These variables collectively enter the SEM seven times.
Table shows improved data reliability across all variables when measured at the census-tract level. This finding contributes directly to one recommendation of this article: The LAI should be recreated and presented at the tract level rather than the block group level. In an ideal case, a block group-level LAI would be more useful since between-block group variation could be captured. Unfortunately, the available data’s reliability metrics support a move to the larger census tract geography, which is still considered a small geography for most policy-oriented data sets. Additionally, Table includes several variables that exist only at the tract level, although they are used in the block group-level LAI models—a practice widely discouraged in quantitative methodologies. This further bolsters the recommendation to shift to a census tract-level presentation of the LAI, eschewing the block group-level database.
Data Too Unreliable for Ethical Use
Reliability metrics for the Journey to Work (JTW) data on transit use warrant jettisoning these data altogether (see Table ). Similarly, in very few cases statewide can the number of commuters be reliably distinguished from the number of workers. Realistically, removing the transit use data brings far-reaching consequences. At a high level, it requires a replacement estimation methodology be designed and implemented for estimating annual transit trips—an important data point for consumers. Absent this, auto-based costs would replace transportation costs in the LAI. For the Cleveland RTA system area, this would overlook approximately $48,614,000 in consumer expenditures in 2010 (Rogoff, Citation2011). Relatedly, HUD undertook a significant effort to estimate MSA-based total transit expenditures in cases where multiple transit authorities serve a region, but unfortunately this information is not provided in the LAI database, making the transit-based costs very difficult to replicate anyway. Beyond the LAI, transit-use data used in the LAI are leveraged for the Affirmatively Furthering Fair Housing Assessment Tool, an important tool for fair housing policy implementation.
Given the importance of transit data for place-based housing and community development practice and policy, priority should be given to making the data reliable. The LAI could be improved by incorporating transit supply data, which require considerable inputs and processing demands. The temptation should be avoided to convert regional fare receipts to household expenditure simply by weighting tracts by number of households. In low-income neighborhoods of Cleveland and East Cleveland, for instance, the LAI auto cost model’s estimated costs of owning a vehicle are cost prohibitive for many households. Access to employment and other opportunities for these populations thus disproportionately requires access to and use of public transportation, which would be underestimated in a household-weighted distribution of transit expenditures. The situation of using the LAI for shrinking cities like Cleveland, or the AFFH for virtually any setting, would not be markedly improved by such a household-weighted approach.
Variable Construction
As is common, several variables necessary to produce both the SEM and the automobile cost estimates are constructed from other variables or represent calculations done on spatial data sets. This section presents reliability and validity considerations relating to variable construction and aggregation.
Representative Reliability in Employment Densities
The variables for job density and retail job density purport to measure the density of nearby jobs. However, the LAI uses one of three distinct rules for drawing the polygons in which proximate jobs are counted, depending, effectively, on the size and shape of the block group. If the block group rests entirely inside the half-mile buffer extending from its population-weighted centroid, the buffer area is used. If the buffer area and the block group boundary are “about the same” (U.S. Department of Housing and Urban Development, Citationn.d.c, p. 16), their union area is used. If the buffer falls entirely within the block group, the block group polygon is used. The employment density variables (total employment and retail employment) therefore face two challenges: representative reliability and reproducibility.
Representative reliability asks whether a measure produces consistent results across social groups—in this case, residents of (sometimes) more and less dense block groups. In this example, residents of high-density block groups only access jobs within a half-mile buffer, whereas residents of lower density block groups access jobs within a potentially larger area. Residents of medium-density block groups, or, possibly, block groups of any density drawn in irregular geometry such as elongated rectangles, access jobs within less than a half-mile buffer. There is no evidence that this approach provides representative reliability. The given technical documentation also provides insufficient information to enable a researcher to replicate the variable, although some information could be gleaned from the code base. HUD is aware of this issue and is addressing it through program updates (HUD employee, personal communication, September 27, 2016).
Beyond this representative reliability issue, this variable also introduces a measurement reliability concern. The LODES data used to construct these density variables (as well as median commute distance, discussed below) represent 2010—the target year of the whole LAI. However, as has been widely documented by the Census Bureau, it is methodologically indefensible to interpret 2008–2012 5-year data as representing roughly 2010.
Aggregation
The LAI Data Dictionary (U.S. Department of Housing & Urban Development, Citationn.d.d) instructs users interested in geographies larger than block groups to aggregate by weighting block groups according to the number of households. Leading the way, HUD provides most of the input variables needed to estimate the LAI aggregated to the tract level using the household-weighting scheme. HUD also provides the LAI itself at the tract level, apparently also by weighting the block group-level estimates, although this is not clear. For some input variables this approach yields results matching the census tract-level data published by the Bureau of the Census. However, for other variables this aggregation method poses one of two challenges: (a) using households as a weight might be appropriate, but weighting data representing medians introduces unnecessary error; or (b) households represent an inappropriate variable for weighting.
Creating a Weighted Average From Data Representing Medians
The LAI uses LODES data to find the median distance commuted. This is accomplished by creating a table with block of origin, block of work location, straight-line distance between the two,Footnote3 and commuter flow, then sorting block–block pairs by block group of origin and distance traveled, and identifying the median commuter at the block group level. Mathematically speaking, taking the household-weighted mean of a group of block group medians will not yield the median at the census tract level. At the mean, estimating the median commute distance via the household-weighting strategy (as recommended by the LAI) yields a value of 9.245 miles for Ohio census tracts. Recalculating the median by replicating the LAI’s process with LODES data yields an average median of 8.480 miles. Thus, at the mean, the LAI underestimates the median by 1.11 miles—an added 13.1% error.
As is the case for the variables assessed in the next subsection, added error introduces two problems. First, it leaves opportunity for heteroscedasticity to enter the estimates, which the architects of the LAI either did not encounter at the block group level or did not mention in their technical documentation. Whereas heteroscedasticity may appear for other variables upon aggregation, a Breusch–Pagan test on a bivariate OLS regression (household-weighted and recalculated median commute distance) is negative, meaning that the error does not significantly vary across values of the variable. Moreover, the correlation between the household-weighted median and the newly calculated median is linear and high (0.96), suggesting that household-weighted commute distance might serve as a reasonable proxy for median commute distance.
The second issue is that without more information than is currently available, it is unclear whether the LAI’s underlying models can or should be recreated at the tract level. Although this logic applies to multiple parts of the LAI construction, the most straightforward illustration rests in the estimation of VMT. Transportation costs consist of automobile costs and transit costs. Automobile costs consist of number owned and miles traveled, both of which are calculated based on a range of input variables. The LAI documentation describes the regression-based estimation method for Vehicle Miles Traveled (VMT) and provides the coefficients. Those coefficients, calibrated for the block group model, will not adequately accommodate the downward bias inserted into the median commute data via household weighting to the tract level. In other words, the household-weighted estimates would provide a reasonable instrumental or proxy variable for actual commuting distance, if the model’s partial coefficients were not already fixed based on noninstrumented values. Also, the model cannot be reestimated because it was calibrated using odometer data from Illinois that are not publicly available. Finally, regardless of the biased commute distance variable, the modifiable areal unit problem may invalidate the block group model’s coefficients for application to tract-level data.
Using a Weighting Scheme Misaligned With Variable Definition
In a few cases, weighting by number of households to aggregate uses the wrong variable, because the variables use land area as their denominator. This weighting issue appears in calculating household density, block density, retail density, local jobs density, and employment access. Prior to reestimation, one would hypothesize that weighting by households rather than basing density calculations on area would logically lead to overestimates of employment density for retail jobs and for all jobs. Consider the hypothetical case presented in Table .
Table 3. Hypothetical case used to illustrate inappropriate aggregation method.
Table shows, for Ohio census tracts, the difference in estimates produced using the household-weighting scheme versus a recalculation based on land area. Notably, jobs density and retail jobs density recalculations also introduce uniform buffer areas, as discussed previously. Differences in those variables’ estimates thus stem from both the weighting scheme and the research design. As hypothesized, the household-weighted figures overestimate all but the employment access variable, the calculation of which is more complicated than simple density. The household-weighting scheme introduces additional error ranging from 4.5% in the employment access index to 114% in retail density. As a slight aside, HUD provides the block group level data necessary to calculate the household-weighted census tract variables. HUD does not, however, provide the data necessary to reconstruct LODES-based variables (retail jobs/acre, jobs/acre, and employment access), although they are publicly available elsewhere.
Table 4. Aggregating area-based variables according to household weighting introduces unnecessary error.
The LAI SEM
An SEM sits at the heart of the LAI methodology. The method is well paired with the reality that socioeconomic characteristics, features of the built environment, and resulting costs have complex interactions. However, an effort to reproduce and improve the SEM reveals methodological concerns pertaining to model logic, diagnostics, and reproducibility.
SEM accommodates interrelated variables, and as such requires the researcher to identify and define those relationships. In the LAI documentation (U.S. Department of Housing and Urban Development, Citationn.d.c, p. 6), its architects provide a table elucidating the hypothesized relationships between variables. Only some of those hypothesized relationships find backing in existing theory or empirical research. Whether this constitutes a flaw in research design may be in the eye of the beholder. On one hand, as Haas et al. note, “the model was designed to maximize predictive accuracy—not to best explain the underlying phenomenon—and therefore includes some highly collinear variables that complicate interpretation” (2016, p. 576). On the other hand, the users’ manual for the Amos SEM program (SPSS’s program) states, “Do not make changes based on [modification index] and [expected predicted change] unless they make theoretical sense” (Munger, Citation2002; see also Garson, Citation2015).
The model’s technical documentation defends model fit based on three diagnostic tests: root mean square error of approximation (RMSEA), comparative fit index (CFI), and standardized root mean square residual (SRMR). Although the LAI’s SEM does fare well on these metrics, its architects omit the chi-square, a standard diagnostic for SEM. As a rule of thumb, an SEM’s chi-square should be less than 10. The chi-square for the LAI is not reported. As elaborated below, efforts to recreate the LAI for Ohio yielded chi-square values ranging from 300 into the thousands.
Putting it All Together: The Impact of Revisions on LAI Estimate Outcomes
To summarize, the recommendations for modification to the LAI include: shift from the block group level to the census tract level to improve reliability; recalculate the area-based and median-based variables rather than weighting by number of households; and make minor modifications to enhance the SEM fit. To estimate the effect of these issues on the LAI’s estimates, the SEM was rerun for Household Type 1, producing new estimates of location affordability for the median household type.
Methods
Table summarizes the variables used in the SEM, including data sources and methodological notes on any deviations from the original HUD methods. In some cases the variables resemble those immediately downloadable from the U.S. Bureau of the Census. For others, such as the median commute distance, R-based programming (the scripts for which are available from the author upon request) was used to calculate the variables.
Table 5. Summary of methods.
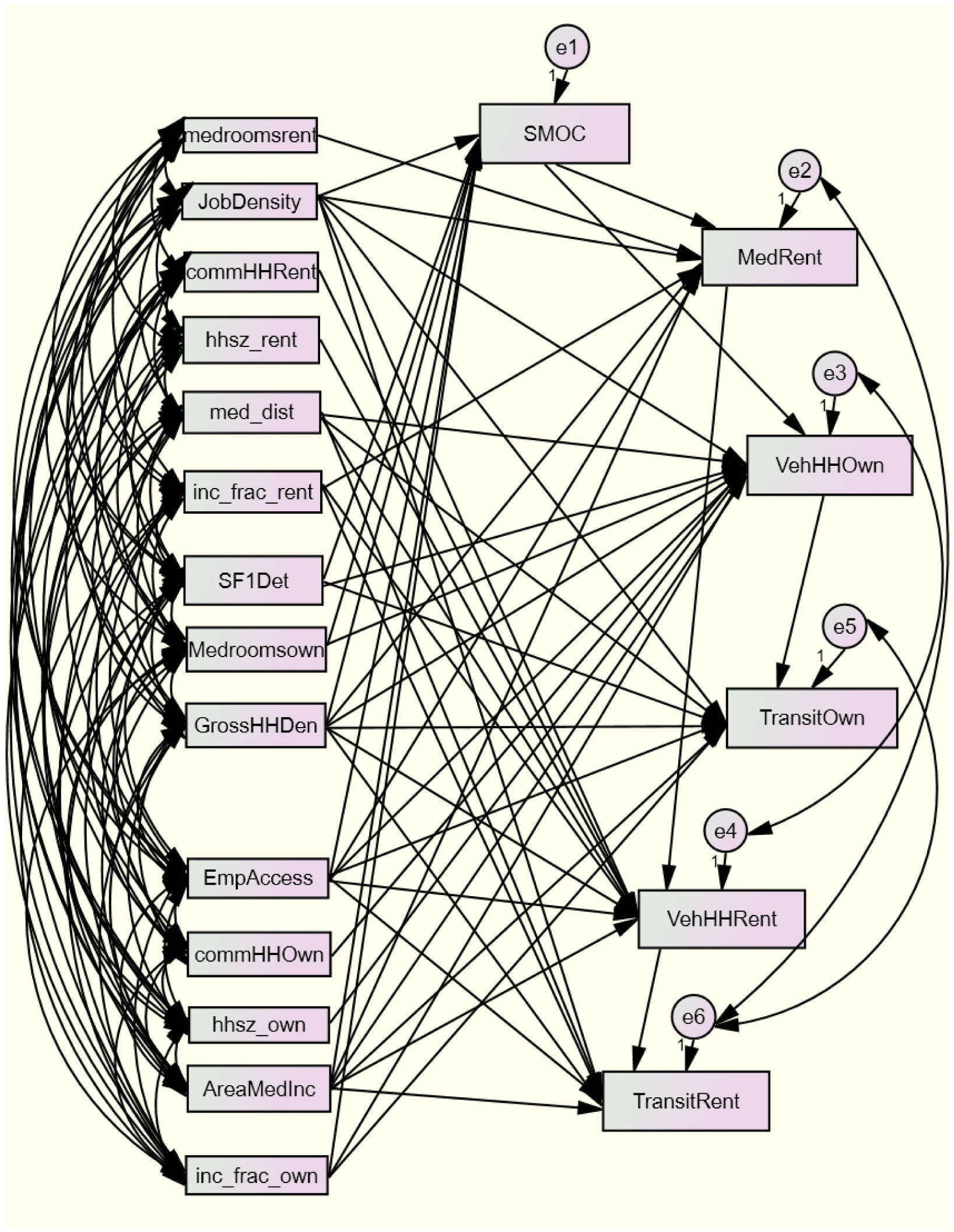
Having assembled the LAI database at the tract level, the Amos package of SPSS was used to recreate the LAI’s SEM using the causal pathways prescribed in the HUD documentation and given in the Appendix Figure A1, with variables constructed as in Table . The SEM outputs were then input into equations (R script available upon request) estimating housing costs for Household Type 1, the regional median household. As in the LAI methodology document, precautions were taken to temper extreme estimates.
The results of this estimation—abbreviated R1 below—were then compared with the tract-level estimates published in the LAI. A second comparison is also presented: one in which Household Type 1 is redefined. Household Type 1 purports to represent the regional median household, but of the three defining characteristics (income, number of commuters, and household size), only income reflects the regional median. Thus, in the estimation abbreviated R2 below, Household Type 1 was altered to use the regional (or county, in nonmetropolitan areas) average household size and number of commuters, in addition to using the regional (or county) median income.
Results
The SEM as designed by HUD fares poorly on all three evaluation metrics when run using the revised data, at the tract level. The CFI, which the LAI data and methodology document notes should surpass 0.90, instead measures 0.360. The RMSEA, which the same document suggests should fall below 0.10, is estimated instead at 0.232. The chi-square measures at 25,317.778, where values of less than 10 are preferred. That the model diagnostics differ from HUD’s published results fails to surprise; HUD executed their model at the block group level with several variables calculated differently.
The model was modified first based on a causal path diagram designed to reflect theoretically grounded relationships between variables. The path diagram was then edited by adding additional covariances and causal arrows to the model based on the Modification Index values. Figure A2 presents the resulting path diagram. With these revisions, model diagnostics easily pass the standards given above. The chi-square is 2.640, the CFI equals 1.000, and the RMSEA equals 0.000. Notably, however, this model has only 10 degrees of freedom. The outputs from this SEM were entered into equations, per the LAI methodology, to produce the R1 estimates. The same SEM model design was used, with the updated household types, to produce the R2 estimates.
The results show notable departures from the LAI published cost and affordability estimates. HUD LAI estimates for selected monthly owner costs exceed those of R1 by, on average, 5.6%, or $70, which corresponds to an additional 1.6% of household income. The variation between the LAI and R2 estimates is less than 1%. The difference in the estimate of median rent, however, exceeds 20% when comparing the HUD estimates with either R1 or R2 estimates (see Figure ). These differences correspond to 5.0% and 5.8% differences, respectively, in cost burden as a percentage of household income. In other words, the HUD LAI estimates appear not to be robust, especially in the estimation of median rent; this will impact the conclusions of all analyses drawn from research and policy decisions based on those estimates.
Figure 1. Average estimated selected monthly owner costs and median rents for Household Type 1 across Ohio census tracts: A comparison of methods. Note. U.S. Department of Housing and Urban Development (HUD).
Moran’s I tests for spatial patterning in the estimate differentials (HUD–R1, HUD–R2, and R1–R2, for owners and renters) reveal statistically significant (pseudo p value < .001, using queen-based first-order weights) positive spatial autocorrelation for all six differentials. This means that high differentials are often found adjacent to other tracts with high differentials, and the inverse is also true. Although all six differentials showed significant, positive global spatial autocorrelation, tests for local spatial autocorrelation (clusters) show variation. Table describes the patterns observed.
Table 6. Results of univariate local Moran’s tests.
As Table shows, the HUD methodology is most likely to overestimate costs in metropolitan areas and either underestimate costs or have low differentials in more rural areas, such as southeast OhioFootnote4. The estimate differentials between methods R1 and R2, which reflect differences in household size and number of commuters, also show urban–rural patterns, but inconsistently.
Transportation costs were not reestimated because of the data limitations noted in this article. Briefly, the OLS coefficients are published for the block group models, but not the census tract models. The odometer readings from Illinois, which might allow reconstruction of the regression model, are not publicly available, making the first concern obsolete. Regardless, this would provide only a partial view of transportation costs, as the census data on transit use among commuters bear margins of error prohibiting use; data on transit supply should be curated for future model implementation.
Conclusion
The effort on the part of the federal government to illuminate issues of segregation and opportunity and to shift the conversation about affordability to be inclusive of these issues is both commendable and just. There is nothing to be gained in going backward, away from a location-efficiency view of household affordability.
The LAI attempts to provide such a view of affordability by estimating housing and transportation costs for eight prototypical households at the block group level across the United States. As shown in this article, using data from the diverse state of Ohio, the LAI appears more robust in estimating housing costs for homeowners than for renters. The published LAI likely significantly overestimates median rents for Household Type 1, and for both owners and renters likely overestimates costs in metropolitan areas and underestimates them or has relatively lower error in rural areas.
For renters and for all transportation cost estimates, some measures need to be taken to shore up reliability and validity in the underlying data and metrics, and thus to protect the LAI and its related programs nationally. Some of the issues raised in this article could be resolved relatively easily. HUD could, for instance, publish tract-level data based on the ACS and stop advising users to create the data from household-weighting the block group data, introducing unnecessary error. However, that effort would repair only part of the problem.
Of greater assistance would be a wholesale recalculation at the census tract level of the LAI and its subparts, including the vehicle cost model. Three reasons recommend the switch to a tract-level LAI. First, some of the input variables already represent census tracts, yet are used to support estimates at smaller geographies, which is not methodologically ideal. Second, block group-level data suffer from unacceptable MOE for both owners and renters in some variables, and present modally medium- or low-reliability data for most variables among renter-occupied households. Using census tract-level data ameliorates much of this concern, as shown. Third, calculating the index at the tract level would prevent users from introducing error via inappropriate methods of aggregation, or by using regression coefficients intended for use in block group models.
In addition to changing the underlying data as suggested above, users may benefit from an ancillary database presenting place-based affordability for people currently residing in neighborhoods. Part of such a database can be readily developed from existing ACS data on housing affordability. Estimates of automobile-based affordability could be produced using the regressions and techniques developed for the LAI, but coefficients appropriate for use at the census tract level need to be produced and provided.
Finally, users deserve a clearer articulation of what questions the existing LAI can address—pending improvements to data reliability as noted above—and those it should not try to address. The conversation about location affordability advances national policy in the United States. The LAI constitutes an important tool in advancing that conversation and, hopefully, in advancing more equitable and sustainable place-based planning outcomes. Someday those outcomes will be measured, and the location efficiency effort as a whole evaluated. Taking steps proactively to ensure the reliability, validity, and usefulness of the LAI today will ensure that the evaluation of tomorrow focuses on social issues—not technical ones—and productive next steps.
Notes on Contributor
Joanna Ganning is an assistant professor of planning in the Levin College of Urban Affairs at Cleveland State University. She earned her PhD in regional planning from the University of Illinois Urbana–Champaign. Her research focuses on urban and regional economic development, often at the intersection of community development issues.
Disclosure Statement
No potential conflict of interest was reported by the author.
Funding
This research was funded by a grant (Grant 872) from the National Institute for Transportation and Communities, a research consortium funded by the U.S. Department of Transportation, with match funding from the University of Utah, Cleveland State University, and the Cleveland Regional Transit Authority (RTA).
Acknowledgments
I would like to acknowledge Dr. Rosie Tighe for her collaboration on related work, and Keunhyun Park, Matt Miller, and Lydia Benish for their assistance with this project.
Notes
1. That the Cleveland Regional Transit Authority (RTA) service area is not representative of places across the United States hardly warrants mention. The City of Cleveland has been losing population for decades. Population decline at that scale brings other particular conditions, like a low median household income, a high vacancy rate, and high unemployment. Additionally, the service area is entirely urban, and as a result could conceal data reliability issues more characteristic of nonmetropolitan settings. To accommodate these concerns, this article evaluates data across the state of Ohio.
2. In the hierarchy of U.S. Bureau of the Census geographies, census blocks make up block groups, block groups make up census tracts, and census tracts make up counties. Census tracts are delineated to capture, ideally, about 4,000 people, although they range in size from about 1,200 to about 8,000 people.
3. To improve the data for this article, a network-based distance calculation was attempted. The computational requirements necessary for the state of Ohio alone were insurmountable. As such, the straight-line approach is necessary, if flawed.
4. Relative population density across the state can be seen via this U.S. Census Bureau thematic map: http://www2.census.gov/geo/pdfs/maps-data/maps/thematic/us_popdensity_2010map.pdf
References
- Abt Associates & Mast, B. (2015). Affirmatively Furthering Fair Housing (AFFH) data documentation. Retrieved from https://www.huduser.gov/portal/sites/default/files/docs/AFFH_Data_Documentation_12_31_2015.docx
- Acevedo-Garcia, D., McArdle, N., Hardy, E., Dillman, K., Reece, J., Crisan, U. I., … Osypuk, T. L. (2016). Neighborhood opportunity and location affordability for low-income renter families. Housing Policy Debate, 26, 607–645.10.1080/10511482.2016.1198410
- Bieri, D. S., & Dawkins, C. J. (2016). Quality of life, transportation costs, and federal housing assistance: Leveling the playing field. Housing Policy Debate, 26, 646–669.10.1080/10511482.2016.1188844
- Department of Housing and Urban Development (HUD). (n.d.a). About the portal: Background. Retrieved from http://www.locationaffordability.info/About_Background.aspx
- Department of Housing and Urban Development (HUD). (n.d.b). About the portal: General. Retrieved from http://www.locationaffordability.info/About.aspx
- Department of Housing and Urban Development (HUD). (n.d.c). Data and methodology: Location affordability index version 2.0. Retrieved from http://www.locationaffordability.info/LAPMethodsV2.pdf
- Department of Housing and Urban Development (HUD). (n.d.d). Location affordability index data dictionary. Retrieved from http://lai.locationaffordability.info//lai_data_dictionary.pdf
- Esri. (2014). The American Community Survey. Retrieved from https://www.esri.com/library/whitepapers/pdfs/the-american-community-survey.pdf
- Garson, G. D. (2015). Structural equation modeling. Asheboro, NC: Statistical Associates Publishers.
- Haas, P. M., Newmark, G. L., & Morrison, T. R. (2016). Untangling housing cost and transportion interactions: The Location Affordability Index Model—Version 2 (LAIM2). Housing Policy Debate, 26, 568–582.10.1080/10511482.2016.1158199
- Kaza, N., Riley, S. F., Quercia, R. G., & Tian, C. Y. (2016). Location efficiency and mortgage risks for low-income households. Housing Policy Debate, 26, 750–765.10.1080/10511482.2016.1159972
- Koschinsky, J., & Talen, E. (2016). Location efficiency and affordability: A national analysis of walkable access and HUD-assisted housing. Housing Policy Debate, 26, 835–863.10.1080/10511482.2015.1137965
- Lens, M. C., & Reina, V. (2016). Preserving neighborhood opportunity: Where federal housing subsidies expire. Housing Policy Debate, 26, 714–732.10.1080/10511482.2016.1195422
- McMillan, A., & Chakraborty, A. (2016). Who buys foreclosed homes? How neighborhood characteristics influence real estate-owned home sales to investors and households. Housing Policy Debate, 26, 766–784.10.1080/10511482.2016.1163277
- Munger, K. (2002). Manual: Running SEM in Amos. Retrieved from https://krmunger.files.wordpress.com/2007/09/amos_sem-manual2.pdf
- National Conference of State Legislatures. (2011, October). Recent livability initiatives in Minnesota: An analysis. Retrieved from http://www.ncsl.org/research/transportation/recent-state-livability-initiatives-in-minnesota.aspx
- Nguyen, M. T., Webb, M., Rohe, W., & Noria, E. (2016). Beyond neighborhood quality: The role of residential instability, employment access, and location affordability in shaping work outcomes for HOPE VI participants. Housing Policy Debate, 26, 733–749.10.1080/10511482.2016.1195423
- Renne, J. L., Tolford, T., Hamidi, S., & Ewing, R. (2016). The cost and affordability paradox of transit-oriented development: A comparison of housing and transportation costs across transit-oriented development, hybrid and transit-adjacent development station typologies. Housing Policy Debate, 26, 819–834.10.1080/10511482.2016.1193038
- Rogoff, P. (2011). National transit summaries and trends national transit database 2010 report year. Federal Transit Administration, U.S. Department of Transportation. Retrieved from https://www.transit.dot.gov/sites/fta.dot.gov/files/docs/NTST%20for%20RY%202010.pdf
- Tighe, J. R., & Ganning, J. P. (2016). Do shrinking cities allow redevelopment without displacement? An analysis of affordability based on housing and transportation costs for redeveloping, declining, and stable neighborhoods. Housing Policy Debate, 26, 785–800.10.1080/10511482.2015.1085426
- Tremoulet, A., Dann, R. J., & Adkins, A. (2016). Moving to location affordability? Housing Choice Vouchers and residential relocation in the Portland, Oregon, region. Housing Policy Debate, 26, 692–713.10.1080/10511482.2016.1150314
- Walter, R. J., & Wang, R. (2016). Searching for affordability and opportunity: A framework for the Housing Choice Voucher program. Housing Policy Debate, 26, 670–691.10.1080/10511482.2016.1163276
Appendix
Figure A1. Path diagram replicating the U.S. Department of Housing and Urban Development (HUD) approach.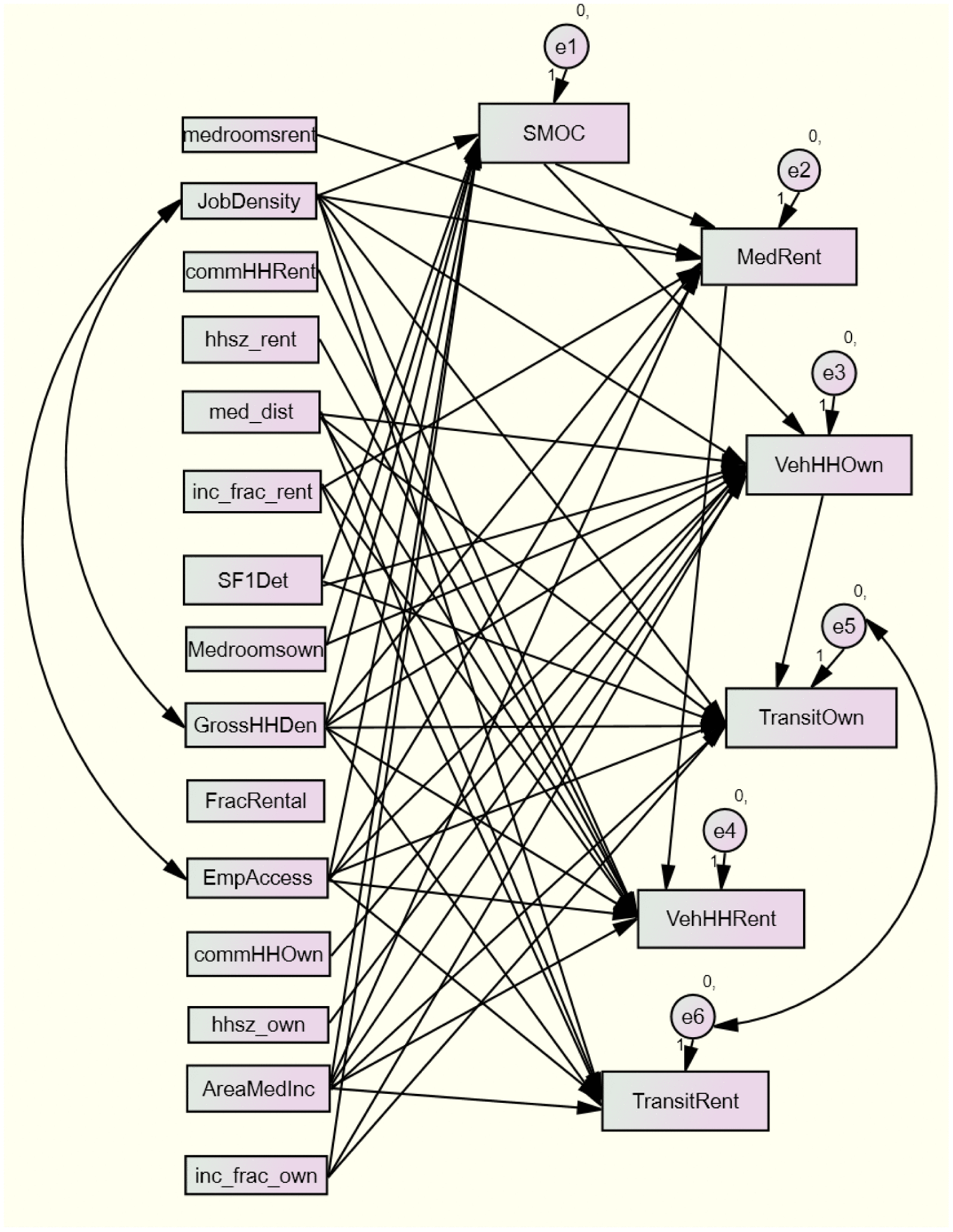
Figure A2. Revised path diagram.