
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The uniform minimum variance unbiased estimator (UMVUE) is, by definition, a solution to removing bias in estimation following a multi-stage single-arm trial with a primary dichotomous outcome. However, the UMVUE is known to have large residual mean squared error (RMSE). Therefore, we develop an optimisation approach to finding estimators with reduced RMSE for many response rates, which attain low bias. We demonstrate that careful choice of the optimisation parameters can lead to an estimator with often substantially reduced RMSE, without the introduction of appreciable bias.
1. Introduction
Phase II oncology trials are typically designed assuming a primary dichotomous outcome variable and using a multi-stage single-arm trial design (Grayling et al. Citation2019). Among these designs, Simon’s two-stage design (Simon Citation1989) is the most commonly employed. Whilst many authors have extended Simon’s original proposal to allow for more flexible designs (see, e.g., Chen (Citation1997); Jung et al. (Citation2004); Mander and Thompson (Citation2010); Mander et al. (Citation2012); Law et al. (Citation2022)), there is also a large literature on how to analyse data on completion of such a trial. This literature exists because it has long been known that the naive maximum likelihood estimator of the response rate is biased. Biased assessment of treatment benefit is of grave concern in any clinical setting, but it may be particularly problematic in phase II oncology where critical decisions need to be made on whether to continue a treatment’s development. The estimated effect may be central to any such decision, particularly when several treatments must be selected between, and an incorrect choice can have major implications. Incorrectly terminating development of an efficacious therapy could deprive future patients of a valuable treatment option, while incorrectly continuing development of an inefficacious therapy could incur substantial costs (both financially and to the future patients given this treatment). Furthermore, the estimated treatment effect may be central to the estimate of the required sample size of any subsequent study. As such, biased estimation may enhance the possibility of conducting an under/over-powered trial, both of which lead to a waste of resources. This motivates the need for authors to propose methodology for computing alternative estimators with arguably improved performance (Chang et al. Citation1989; Guo and Liu Citation2005; Jung and Kim Citation2004; Koyama and Chen Citation2008; Li Citation2011; Pepe et al. Citation2009; Tsai et al. Citation2008). These have been effectively compared in the two-stage setting in work by Porcher and Desseaux (Citation2012).
Among the various proposed estimators, of particular note is the uniform minimum variance unbiased estimator (UMVUE) (Girshick et al. Citation1946; Jung and Kim Citation2004). That is, the estimator with uniformly minimum variance among all unbiased estimators. In the case of a multi-stage single-arm trial, however, there is in fact only a single unbiased estimator (Girshick et al. Citation1946). One may look to conclude that the UMVUE should be considered the best estimator of the response rate following a multi-stage single-arm trial. However, it is known that it can have large residual mean squared error (RMSE). As noted, attaining zero bias is usually a critical consideration for an estimator, but having low RMSE can also be of great importance, as it implies the estimated effect should usually be close to the true value. Therefore, trialists are faced with a decision of whether the UMVUE’s large RMSE is a worthy price to pay for its unbiasedness. Alternative established estimators arguably offer little in the way of a solution to this issue, as their bias can be large. Of potential utility would be an estimator that maintains low bias for most values of the response rate, preferably in some sense the ‘likely’ response rates, which has lower RMSE compared to the UMVUE across such likely response rates. That is, an estimator that trades off bias for certain response rates, to the effect of reduced RMSE for others.
In this work, we focus on the development of methodology to determine such estimators. We make no restriction on the number of study stages, meaning that our approach is applicable to more commonly utilised two-stage designs, as well as to more complex designs such as those with three stages (see, e.g., Chen (Citation1997)) or involving curtailment (see, e.g., Law et al. (Citation2022)). We propose an objective function, for subsequent optimisation, which allows the flexible specification of response rates for which bias and RMSE is of greater concern. We demonstrate a selection of constraints that can be placed on the optimised estimators to ensure their resultant estimates are not unreasonable. Using design parameters motivated by a number of recent oncology trials (see, e.g., Schoffski et al. (Citation2017); Jain et al. (Citation2014); Collen et al. (Citation2014); Lendvai et al. (Citation2014); Shim et al. (Citation2016)), we then demonstrate that our proposal can identify estimators that have substantially lower RMSE compared to the UMVUE across a wide range of response rates, whilst simultaneously achieving very low bias across these response rates. In some sense, our work can be considered similar to that of Kunzmann and Kieser (Citation2018), who recently developed procedures for optimising confidence intervals on completion of an adaptive two-stage single-arm trial, but with our focus on point rather than interval estimation.
2. Methods
2.1. Multi-stage single-arm designs for dichotomous outcomes
We briefly describe the multi-stage single-arm designs for which estimators are constructed. It is assumed that outcome from patient
is distributed as
, where
is the response rate to treatment. The end goal is to test
. Here,
is a pre-specified null response rate, typically nominated as the anticipated response rate for the current standard of care. The type-I error-rate is controlled to at most
when
, and the type-II error-rate to at most
when
, where
is the clinically relevant response rate. Inference on
is based on
. Specifically, we let
indicate the maximum number of stages in the trial (so there are potentially
analyses conducted) and suppose that
,
, and
are the number of patients in stage
, the interim efficacy bound utilised at analysis
, and the interim futility bound utilised at analysis
, respectively for
. For brevity we set
,
,
, and
. Thus, the range of index
after stage
is
. The study’s decision rules are then as follows
• For
- If , terminate the trial for futility, not rejecting
.
- Else if , terminate the trial for efficacy, rejecting
.
- Else continue to stage .
• For
- If , do not reject
.
- Else if , reject
.
To ensure that a decision is made about whether to reject , it is common to specify that
. Note that interim termination for futility or efficacy can be prevented by setting
or
respectively. Design of such a trial requires methodology for choosing
,
, and
for specified
,
,
, and
. As discussed, many papers have focused on such methodology and we refer the reader there for further information (Chen Citation1997; Jung et al. Citation2004; Law et al. Citation2022; Mander and Thompson Citation2010; Mander et al. Citation2012; Simon Citation1989).
2.2. Point estimator performance
A point estimation procedure for a multi-stage single-arm design of the above type must nominate estimates for for all possible numbers of responses and sample sizes that could be seen on trial termination. That is, for all possible values of the variable
. Given the specified decision rules, it is possible to compute the set
such that
. For example, when
with
and
(i.e., a Simon two-stage type design), we have
We will denote the point estimate for by
.
Having nominated an estimator, key factors to evaluate in assessing its performance are its bias and RMSE. These can be computed as
Here, is the probability of the trial terminating with
, conditional on
. This can be computed as (Schultz et al. Citation1973)
where is the probability mass function of a
random variable.
2.3. Optimised estimators
As discussed earlier, a desirable estimator typically has both low bias and low RMSE. If the only concern is minimisation of bias, i.e., the preference is for an unbiased estimator such that for
, the UMVUE is the optimal estimator. It sets (Jung and Kim Citation2004)
where . However, the UMVUE’s well-known, large RMSE may mean there is a sizeable price to pay in practice if one wishes to attain unbiasedness. This may lead trialists to consider whether an alternative estimator, that trades off some bias for reduced RMSE, is possible.
In this section, we describe how an optimised estimator of this kind could be determined. Firstly, an objective function to optimise is required. In the Results, we assume that the objective function that evaluates estimator is of the following form
Here, is a weight parameter that can altered to impact the relative desire to minimise the two factors that make up the objective function. The two factors are weighted averages of the absolute bias and the RMSE over
. We choose these factors as they exist on the same scale/dimension. Similarly, the squared-bias and the MSE could have been used; in the Supplementary Materials we consider what happens if the optimality criteria was formed in this way instead. Our preference for the absolute bias and RMSE is because their gradients are smaller in magnitude as a function of
relative to the squared-bias and MSE, which our investigations reveal may lead to a smoother transition in performance as
is altered.
In the above, the weighting is performed by the function . Thus,
can have a significant effect on the optimal estimator. Here, we assume that the functional form for the weighting function is given by the density of the truncated normal distribution
,
,
. We choose a truncated normal distribution as it can be readily made to be defined on
, like
, and provides through
and
a flexible way of specifying which values of
to give more weight to when evaluating the objective function. Furthermore, in comparison to the Beta distribution, which could have been an alternative choice, it has finite density on
for any values of the shape parameters (which may make numerical integration more stable), and is based on the normal distribution, which is more widely known. This last consideration may make elicitation of the weighting function (i.e., elicitation of
and
) in practice a simpler process. Nonetheless, we do contrast in the Supplementary Materials results given here to those for certain weights formed from Beta distributions.
As an example, the choice for small
would mean that the values of the absolute bias and RMSE in the region around
contribute more to the value of the objective function, and thus to the optimal estimator. In this way, we hope to trade off bias for certain values of
to reduce the RMSE at others.
Our optimisation problem, for a design with parameters ,
, and
, is thus in its most general form
For brevity, we will denote the solution to this problem by , leaving the dependence on
and
implied and making their values clear when important. Before we proceed to determine such optimised estimators, we discuss some additional constraints that could be placed on the optimisation problem
• Ordering compatible estimates: In a sequential design, there are numerous possible ‘orderings’ of the sample space (which are used, e.g., to construct p-values and confidence intervals). Each ordering states which values of are considered more extreme to
. One may choose to ensure that the returned optimal estimates are compatible with this ordering. That is, that
if
is more extreme than
. This compatibility requirement amounts to linear inequality constraints on the estimates. For example, in the case where
with
and
, compatibility with the stage-wise ordering (Armitage Citation1957; Fairbanks and Madsen Citation1982; Siegmund Citation1978; Tsiatis et al. Citation1984) would require
In our results below, we however do not consider restricting the estimates in this way as our preliminary investigations suggested they may severely impact the ability to identify viable alternative estimators to the UMVUE. Intuition for why this is the case can be seen by considering the fact that for consistency with the stage-wise ordering. Suppose that then, e.g.,
,
, and
. This requirement would mean that
. Given the MLEs in these two scenarios would be
and
, it is clear that consistency with the stage-wise ordering could place arguably unreasonable restrictions on the values of the estimates. A relaxed requirement, termed partial ordering, which we do require in our results, is that
That is, no restriction is placed on the relationship between the estimates and
if
.
• Test compatible estimates: It may be reasonable to ensure that, for ,
when
. That is, that when
is rejected, the estimate for
is greater than the boundary of the null hypothesis
. In our results, we require that the optimal estimator conforms to this requirement.
• Confidence interval constrained estimates: In the optimisation problem above, we require only that . In general, it may be desirable to constrain
further. This may assist not only with determining the optimal estimator in the search procedure (see below), but ensure that the optimal estimates do not become what may be considered practically unreasonably small/large based on
. In our results below, we constrain
for
such that
where and
are, respectively, the lower and upper limits of the ‘exact’
confidence interval based on the stage-wise ordering proposed by Jennison and Turnbull (Citation1983).
Thus, in our results below, we identify solutions to the following revised optimisation problem
Observe that this is a constrained non-linear optimisation problem, for which many algorithms are available for identifying solutions. For our results, we use a genetic algorithm via the package GA in R (Scrucca Citation2017). GA implements functions for optimisation using genetic algorithms. A genetic algorithm is a stochastic search method inspired by the principles of natural selection and how it results in genetically superior individuals over many generations of a population. Specifically, a population is constructed (i.e., a set of candidate estimators). Then, the fittest (i.e., best scoring in terms of the objective function) individuals (i.e., estimators) are evolved (i.e., modified/combined in terms of their ) over generations (i.e., iterations of the algorithm) to result in genetically superior individuals (i.e., estimators with lower objective function scores). At the end, the most genetically superior individual (i.e., the estimator with the lowest objective function score) is the one selected (i.e., taken as the solution of the optimisation problem). We favour this approach because this package provides native support for parallelisation of the search procedure, which helps reduce run time. In addition, it allows candidate
to be suggested at the beginning of the search; we utilise this here to suggest previously proposed estimators (i.e., those discussed in Porcher and Desseaux (Citation2012)). Intuitively, this can be expected to focus the search from the outset on more ‘reasonable’ estimators. Furthermore, the nature of genetic algorithms means that they are well suited to performing a search over a complex search space with potentially many local minima. Simultaneously, though, this means that the downside of using GA is that it is not guaranteed to return the global optimal solution. However, evaluation of the objective function for candidate
can be achieved in fractions of a second and consequently it is not computationally expensive to (a) repeat the search procedure for several random starting points to assess convergence or (b) place strict tolerances on the termination of a given search.
2.4. Examples
In the Supplementary Materials, we present findings for the case where ,
,
,
, and
, motivated by, e.g., the trial presented in Shim et al. (Citation2016). We base the results given here on the scenario in which
,
, and
(i.e., a desired type-I error-rate of 10% for a response rate of 10% and a desired power of 90% for a response rate of 30%). We choose these parameters as a recent review determined these to be often assumed in practice (Grayling and Mander Citation2021). For example, among a number of other studies
• Schoffski et al. (Citation2017) assumed these parameters when assessing the activity of crizotinib, via RECIST (Eisenhauer et al. Citation2009), in patients with advanced clear-cell sarcoma with MET alterations.
• Jain et al. (Citation2014) assumed these parameters when conducting an evaluation of the oral MEK inhibitor selumetinib in advanced acute myelogenous leukemia, as above choosing response as their primary outcome.
• Collen et al. (Citation2014) assumed these parameters in a study of stereotactic body radiotherapy to primary tumor and metastatic locations in oligometastatic non-small cell lung cancer patients, selecting complete metabolic response as their primary outcome.
• Lendvai et al. (Citation2014) assumed these parameters in a single-centre study of carfilzomib with in relapsed multiple myeloma patients, assessing efficacy via the response rate.
We then present results for two types of design. The first is the design for with
that minimises the expected sample size when
(i.e., what is often referred to as Simon’s optimal design); this has
,
, and
. The second is the version of this design that incorporates non-stochastic curtailment for either efficacy or futility. This has
with
where is a
vector.
Below, we present results on the optimal estimators for . Note that the optimal estimator when
is always the UMVUE, as this is the unique estimator such that
, regardless of the choice of
and
. Additional findings for
are given in the Supplementary Materials; we omit them here to increase clarity in the figures and as it is clear they often lead to very large bias (e.g.,
) that may render them unsuitable in practice.
For , we focus on results when
. We make this choice as it is logical, in our opinion, to give largest consideration to estimator performance in the case that
is in the region around the effects specified in the design calculation,
and
. As, in this case, effectively attaining a reliable estimate of the response rate may be particularly critical to decision-making on the intervention under investigation; for small
, poor estimation is less likely to impact subsequent development as the treatment will not have shown sufficient promise even if
is over-estimated. Similarly, for large
, the treatment is likely to be developed further even if, e.g., the true value of
was under-estimated. These statements can only possibly hold true though if the bias and/or RMSE does not become exceedingly large for extreme
. In addition, effective estimation across
may retain importance for several other reasons, including ascertaining whether to consider the intervention as part of a combination therapy, inclusion of the study’s results in a meta-analysis, or powering subsequent trials. Estimator bias and RMSE for more extreme
can, intuitively, be controlled by the choice of
, which determines the degree of weight given to values of
away from
. Here, based on preliminary investigations of how estimator performance varies in
, we give results for
.
3. Results
3.1. Two-stage design
We begin with results for the case where ,
, and
. presents the difference between the optimised estimates,
, and the UMVUE estimates,
, for the considered combinations of
and
, when
. It colours points corresponding to particular
by the value of
. Through this, it is clear that the difference in the optimised estimates and that of the UMVUE does not clearly depend on the value of
. The range of differences between the optimised and UMVUE estimates is seen to be highly dependent on
and
. For example, in the case of
and
, the differences are large, which has implications for the bias and RMSE of these estimators (see below). For sent the corresponding results to the differences are by comparison very small; typically the optimised estimates modify the UMVUE by less than
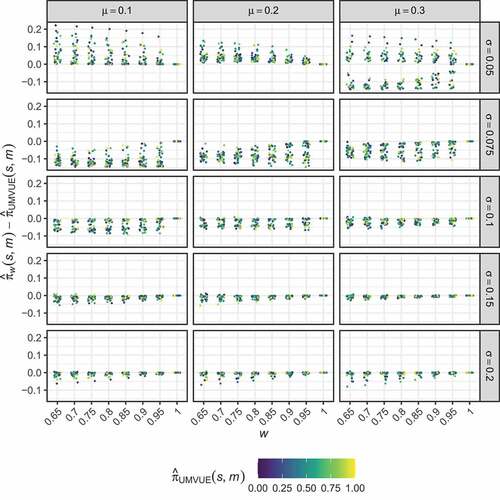
.
Figure 1. Two-stage design. The distribution of the differences between the optimised estimates, , and the UMVUE estimates,
, are shown for several combinations of
and
, as a function of
. Points corresponding to particular
are coloured by the value of
.
present the performance of the optimised estimators in terms of their bias and RMSE respectively. It is clear that careful choice of and
is required to determine an optimised estimator that has performance that may be considered preferable to the UMVUE. Particularly for
, several of the estimators exhibit large bias for values of
only a small distance from
. Whilst for
, the performance of the optimised estimators is very similar to the UMVUE, indicating they provide little benefit. The same is true when
; only for
is performance substantially different from the UMVUE observed.
Figure 2. Two-stage design. The bias of the optimal estimators, , is shown for several combinations of
,
, and
, as a function of
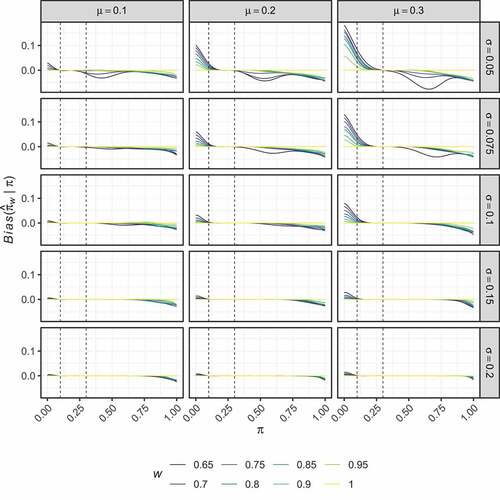
Figure 3. Two-stage design. The RMSE of the optimal estimators, , is shown for several combinations of
,
, and
, as a function of
.
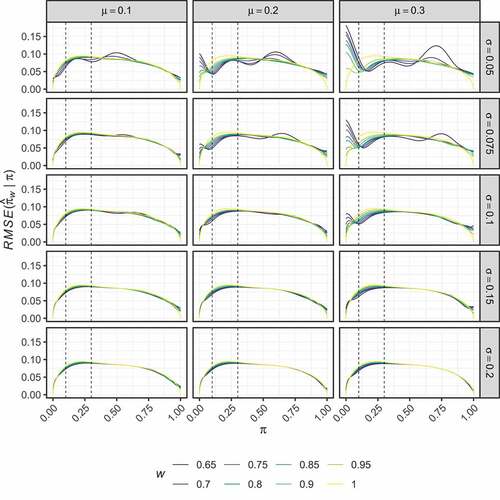
Particularly positive results are seen for when
. We focus on the sub-case where
. The optimised estimator in this case maintains an absolute bias below
when
. For the cost of the larger bias introduced outside of this region, it has a lower RMSE than the UMVUE when
. In particular, when
and
, it reduces the RMSE compared to the UMVUE by 19.7% and 9.4% respectively. presents the values of
and
in this case. From this, it is clear that it achieves the efficiency gains whilst only making minor modifications to the UMVUE estimates for most values of
. Largest differences between
and
are seen for smaller
; when the effect of the interim analysis on the final sample size is most pronounced. When the trial terminates in stage one (i.e.,
) the optimised estimator adjusts the estimates upward compared to the UMVUE; effectively treating the interim termination as a ‘random low’. When the trial terminates in stage two with a low number of responses (i.e.,
) the optimised estimator adjusts the estimates downward in a pronounced manner compared to the UMVUE; effectively treating the continuation past the interim analysis as a ‘random high’.
Table 1. The UMVUE and example optimised estimates are given for the two-stage design with ,
, and
, and it’s non-stochastically curtailed extension. For the two-stage design, the optimised estimates correspond to
,
, and
. For the non-stochastically curtailed design, the optimised estimates correspond to
,
, and
. All values are given to 3 decimal places.
3.2. Non-stochastically curtailed design
present the corresponding results to , but for the non-stochastically curtailed design. As before, displays no clear trend in the way the optimised estimators modify the UMVUE estimates. In this case, high bias is observed for larger values of than for the two-stage design setting (compare ). Here, the results for each considered
are similar across the various values of
and
. However,
typically results in slightly larger regions in which the bias remains small, and thus we now focus on this setting again.
Figure 4. Non-stochastically curtailed design. The distribution of the differences between the optimised estimates, , and the UMVUE estimates,
, are shown for several combinations of
and
, as a function of
. Points corresponding to particular
are coloured by the value of
.
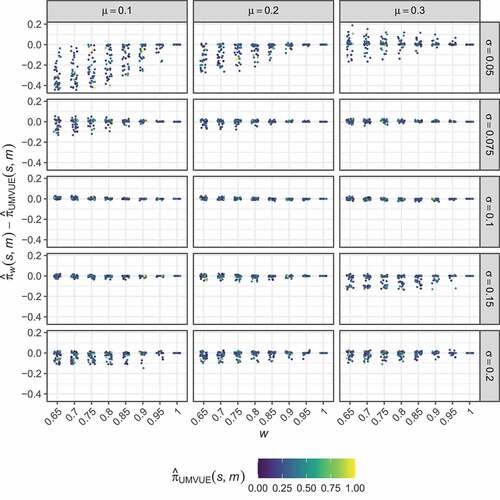
Figure 5. Non-stochastically curtailed design. The bias of the optimal estimators, , is shown for several combinations of
,
, and
, as a function of
.
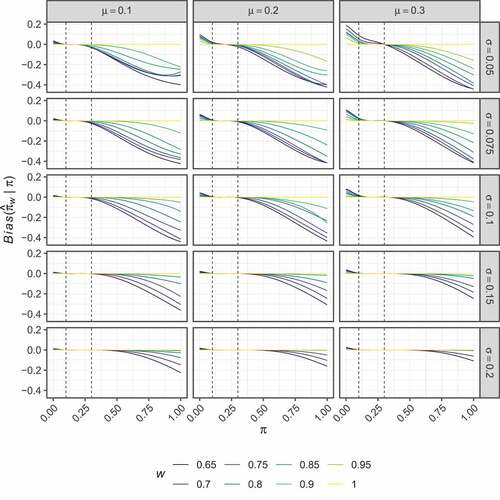
Figure 6. Non-stochastically curtailed design. The RMSE of the optimal estimators, , is shown for several combinations of
,
, and
, as a function of
.
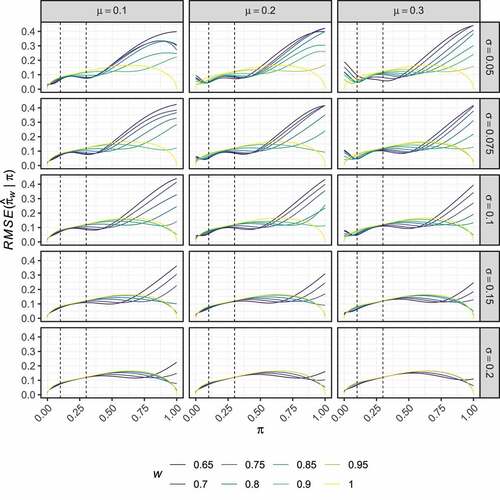
Consider the optimal estimator for and
. This estimator has an absolute bias of less than 0.01 for
. It attains an RMSE lower than the UMVUE when
; in particular when
and
, it reduces the RMSE compared to the UMVUE by 8.6% and 2.4% respectively.
4. Discussion
Point estimation following a multi-stage single-arm trial is important to subsequent decision-making on a treatments development, to the inclusion of study results in to meta-analyses, and to the design of future trials. Whilst the UMVUE for such designs is well-established, it unfortunately can suffer from large RMSE compared to alternative estimators. However, these alternative estimators often have unsuitably large bias. Therefore, in this work we proposed methodology for finding estimators that are optimal for a particular objective function. Careful choice of the parameters that influence the value of the objective function was demonstrated for examples motivated by recent oncology trials (Collen et al. Citation2014; Jain et al. Citation2014; Lendvai et al. Citation2014; Schoffski et al. Citation2017; Shim et al. Citation2016) to result in an estimator that may be considered preferable to the UMVUE. The highlighted estimators retained low bias across a wide range of response rates, specifically those that should be more realistic based on the specified and
, and reduced the RMSE for certain response rates by a large amount compared to the UMVUE. Especially strong performance was seen in the two-stage setting, where the RMSE of the optimal estimator with
,
, and
reduced the RMSE by as much as 35.2% (
).
We note some limitations to our work. Firstly, we consider only three possible sets of design parameters ,
, and
. Whilst there is no reason to assume optimised estimators that can rival the UMVUE in terms of their properties cannot be determined for other possible parameter combinations, there is also no reason to assume that they can. In addition, we focused on an objective function composed of the the marginal absolute bias and RMSE. Conditional bias and RMSE may also be of concern in general (Fan et al. Citation2004; Liu et al. Citation2004; Shimura et al. Citation2018; Troendle and Yu Citation1999). Our objective function, of course, could be readily modified to take conditional bias and RMSE in to consideration if desired, though. Furthermore, in the Supplementary Materials, we also consider the use of squared-bias and MSE. Finally, our determinations assume that the planned design will be realised in practice. Of course, this may not always be the case, and while effective procedures are now available to control the type-I error-rate in this case (Englert and Kieser Citation2015), our work does not assist in determining the best estimator when the design is likely to under/over-run.
Arguably the biggest barrier to the use of our approach in practice is how to specify the values of ,
, and
, such that the estimator is well justified. As noted, a possible solution is to elicit values of
and
based on available expertise on the anticipated response rate of the treatment under investigation (or the parameters of an appropriate Beta distribution; see the Supplementary Materials). A potentially preferential approach is to simply treat
,
, and
as nuisance parameters. By specifying, e.g., a range of values for
over which it is desired for the absolute bias to be constrained to some maximal amount, and similarly particular target reductions in the RMSE over the UMVUE for given values of
, one could simply perform a further optimisation over
,
, and
to determine the estimator with the best performance.
Given our work is motivated by a desire to see the increased utilisation of adjusted estimators, we end with a brief discourse on communicating why this is an important problem and how it may be handled to non-statistical stakeholders. Fundamentally, as discussed, the inclusion of an interim analysis will bias the results of trial inference if appropriate adjustments are not made. The estimated treatment effect is not only critical to deciding the development plan for the current treatment under investigation, but also potentially to other treatments investigated downstream. Thus, some adjustment should be made. Unfortunately, Grayling and Mander (Citation2021) recently demonstrated that very few phase II oncology trials currently make such adjustments, meaning many reported effects may be subject to appreciable bias. On specifically how to adjust, we would argue it is not important for non-statistical stakeholders to understand exactly how adjusted estimators ‘work’. They can, and arguably should, however, feed in to the decision on which adjusted estimator to use; simple explanations of bias and RMSE can let them help guide that factor is of larger concern. Then, whatever method is used, a table like that given here () can always be produced for any trial before its completion. Thus, even for more complex estimators the actual estimation remains as simple as reading from a pre-prepared table.
In conclusion, the proposed methodology for determining optimised estimators may allow the determination of an estimator that has low bias for many possible, arguably more likely, values of the response rates whilst providing reduced RMSE compared to the UMVUE across these response rates. For certain values of the response rate, this reduction in the RMSE may be sizeable.
Supplemental Material
Download PDF (10.7 MB)Data availability statement
Code to reproduce all results given in this manuscript is available from https://github.com/mjg211/article_code.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplementary material
Supplemental data for this article can be accessed on the publisher’s website
Additional information
Funding
References
- Armitage, P. 1957. Restricted sequential procedures. Biometrika 44:9–56. doi:10.1093/biomet/44.1-2.9.
- Chang, M., H. Wieand, and V. Chang. 1989. The bias of the sample proportion following a group sequential phase II clinical trial. Statistics in Medicine 8:563–570. doi:10.1002/sim.4780080505.
- Chen, T. 1997. Optimal three-stage designs for phase II cancer clinical trials. Statistics in Medicine 16:2701–2711. doi:10.1002/(SICI)1097-0258(19971215)16:23<2701::AID-SIM704>3.0.CO;2-1.
- Collen, C., N. Christian, D. Schallier, M. Meysman, M. Duchateau, G. Storme, and M. De Ridder. 2014. Phase II study of stereotactic body radiotherapy to primary tumor and metastatic locations in oligometastatic nonsmall-cell lung cancer patients. Annals of Oncology 25:1954–1959. doi:10.1093/annonc/mdu370.
- Eisenhauer, E., P. Therasse, J. Bogaerts, L. Schwartz, D. Sargent, R. Ford, J. Dancey, S. Arbuck, S. Gwyther, and M. Mooney, et al. 2009. New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1). European Journal of Cancer 45:228–247. doi:10.1016/j.ejca.2008.10.026.
- Englert, S., and M. Kieser. 2015. Methods for proper handling of overrunning and underrunning in phase II designs for oncology trials. Statistics in Medicine 34:2128–2137. doi:10.1002/sim.6479.
- Fairbanks, K., and R. Madsen. 1982. P values for tests using a repeated significance test design. Biometrika 69:69–74.
- Fan, X., D. DeMets, and K. Lan. 2004. Conditional bias of point estimates following a group sequential test. Journal of Biopharmaceutical Statistics 14:505–530. doi:10.1081/BIP-120037195.
- Girshick, M., F. Mosteller, and L. Savage. 1946. Unbiased estimates for certain binomial sampling problems with applications. The Annals of Mathematical Statistics 17:13–23. doi:10.1214/aoms/1177731018.
- Grayling, M., M. Dimairo, A. Mander, and T. Jaki. 2019. A review of perspectives on the use of randomization in phase II oncology trials. Journal of the National Cancer Institute 111:1255–1262. doi:10.1093/jnci/djz126.
- Grayling, M., and A. Mander. 2021. Two-stage single-arm trials are rarely analyzed effectively or reported adequately JCO Precision Oncology 5 1813–1820. doi:10.1200/PO.21.00276 .
- Guo, H., and A. Liu. 2005. A simple and efficient bias-reduced estimator of response probability following a group sequential phase II trial. Journal of Biopharmaceutical Statistics 15:773–781. doi:10.1081/BIP-200067771.
- Jain, N., E. Curran, N. Iyengar, E. Diaz-Flores, R. Kunnavakkam, L. Popplewell, M. Kirschbaum, T. Karrison, H. Erba, and M. Green, et al. 2014. Phase II study of the oral MEK inhibitor selumetinib in advanced acute myelogenous leukemia: A University of Chicago phase II consortium trial. Clinical Cancer Research 20:490–498. doi:10.1158/1078-0432.CCR-13-1311.
- Jennison, C., and B. Turnbull. 1983. Confidence intervals for a binomial parameter following a multistage test with application to MIL-STD 105D and medical trials. Technometrics 25:49–58. doi:10.1080/00401706.1983.10487819.
- Jung, S., and K. Kim. 2004. On the estimation of the binomial probability in multistage clinical trials. Statistics in Medicine 23 (6):881–896. doi:10.1002/sim.1653.
- Jung, S., T. Lee, K. Kim, and S. George. 2004. Admissible two-stage designs for phase II cancer clinical trials. Statistics in Medicine 23 (4):561–569. doi:10.1002/sim.1600.
- Koyama, T., and H. Chen. 2008. Proper inference from Simon’s two-stage designs. Statistics in Medicine 27 (16):3145–3154. doi:10.1002/sim.3123.
- Kunzmann, K., and M. Kieser. 2018. Test-compatible confidence intervals for adaptive two-stage single-arm designs with binary endpoint. Biometrical Journal 60 (1):196–206. doi:10.1002/bimj.201700018.
- Law, M., M. Grayling, and A. Mander. 2022. A stochastically curtailed single‐arm phase II trial design for binary outcomes Journal of Biopharmaceutical Statistics doi:10.1080/10543406.2021.2009498 . .
- Lendvai, N., P. Hilden, S. Devlin, H. Landau, H. Hassoun, A. Lesokhin, I. Tsakos, K. Redling, G. Koehne, D. Chung, et al. 2014. A phase 2 single-center study of carfilzomib 56 mg/m2 with or without low-dose dexamethasone in relapsed multiple myeloma. Blood 124 (6):899–906. doi:10.1182/blood-2014-02-556308.
- Li, Q. 2011. An MSE-reduced estimator for the response proportion in a two-stage clinical trial. Pharmaceutical Statistics 10 (3):277–279. doi:10.1002/pst.414.
- Liu, A., J. Troendle, K. Yu, and V. Yuan. 2004. Conditional maximum likelihood estimation following a group sequential test. Biometrical Journal 46 (6):760–768. doi:10.1002/bimj.200410076.
- Mander, A., and S. Thompson. 2010. Two-stage designs optimal under the alternative hypothesis for phase II cancer clinical trials. Contemporary Clinical Trials 31 (6):572–578. doi:10.1016/j.cct.2010.07.008.
- Mander, A., J. Wason, M. Sweeting, and S. Thompson. 2012. Admissible two-stage designs for phase II cancer clinical trials that incorporate the expected sample size under the alternative hypothesis. Pharmaceutical Statistics 11 (2):91–96. doi:10.1002/pst.501.
- Pepe, M., Z. Feng, G. Longton, and J. Koopmeiners. 2009. Conditional estimation of sensitivity and specificity from a phase 2 biomarker study allowing early termination for futility. Statistics in Medicine 28 (5):762–779. doi:10.1002/sim.3506.
- Porcher, R., and K. Desseaux. 2012. What inference for two-stage phase II trials? BMC Medical Research Methodology 12:117 doi:10.1186/1471-2288-12-117.
- Schoffski, P., A. Wozniak, S. Stacchiotti, P. Rutkowski, J. Blay, L. Lindner, S. Strauss, A. Anthoney, F. Duffaud, and S. Richter, et al. 2017. Activity and safety of crizotinib in patients with advanced clear-cell sarcoma with met alterations: European organization for research and treatment of cancer phase II trial 90101 ‘CREATE’. Annals of Oncology 28 (12):3000–3008. doi:10.1093/annonc/mdx527.
- Schultz, J., F. Nichol, G. Elfring, and S. Weed. 1973. Multiple-stage procedures for drug screening. Biometrics 29 (2):293–300. doi:10.2307/2529393.
- Scrucca, L. 2017. On some extensions to GA package: Hybrid optimisation, parallelisation and islands evolution. The R Journal 9 (1):187–206. doi:10.32614/RJ-2017-008.
- Shim, H., K. Kim, J. Hwang, W. Bae, S. Ryu, Y. Park, T. Nam, I. Chung, and S. Cho. 2016. A phase II study of adjuvant S-1/cisplatin chemotherapy followed by S-1-based chemoradiotherapy for D2-resected gastric cancer. Cancer Chemotherapy and Pharmacology 77 (3):605–612. doi:10.1007/s00280-016-2973-2.
- Shimura, M., K. Maruo, and M. Gosho. 2018. Conditional estimation using prior information in 2-stage group sequential designs assuming asymptotic normality when the trial terminated early. Pharmaceutical Statistics 17 (5):400–413. doi:10.1002/pst.1859.
- Siegmund, D. 1978. Estimation following sequential tests. Biometrika 65 (2):341–349. doi:10.2307/2335213.
- Simon, R. 1989. Optimal two-stage designs for phase II clinical trials. Controlled Clinical Trials 10 (1):1–10. doi:10.1016/0197-2456(89)90015-9.
- Troendle, J., and K. Yu. 1999. Conditional estimation following a group sequential clinical trial. Communications in Statistics - Theory and Methods 28 (7):1617–1634. doi:10.1080/03610929908832376.
- Tsai, W., Y. Chi, and C. Chen. 2008. Interval estimation of binomial proportion in clinical trials with a two-stage design. Statistics in Medicine 27 (1):15–35. doi:10.1002/sim.2930.
- Tsiatis, A., G. Rosner, and C. Mehta. 1984. Exact confidence intervals following a group sequential test. Biometrics 40 (3):797–803. doi:10.2307/2530924.