
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The United States Pharmacopoeia (USP) presents two approaches for showing non-inferiority of an alternate qualitative microbiological method versus a compendial method. One approach compares the positive rates for the alternate and compendial methods at one spike level, while the other one compares multiple most probable number (MPN) estimates from a multi-spike design using a t-test. In this paper, we discuss these approaches under certain assumptions and propose a third approach that can be used for both single and multiple dilutions, which we call the generalized MPN (gMPN) approach. Simulations, using Poisson distributed numbers of microorganisms in test samples, confirm that the USP approach based on rates is not suitable, that the USP approach based on MPNs is appropriate for non-inferiority, but the gMPN approach outperforms the MPN-based approach and is therefore recommended.
1. Introduction
To show that a new or alternative qualitative microbiological method is acceptable to replace a current or compendial method, the USP <1223> (Citation2015) guideline states that the laboratory must demonstrate that the new procedure is as good as or better than the current procedure in terms of the ability to detect microorganisms. The USP recommends non-inferiority testing, for which it proposes two different approaches.
The first approach is based on the ratio of the proportions and
of positive samples for the alternative and the compendial method at a single spike level, respectively, similar to non-inferiority of clinical events in clinical trials. A pre-defined non-inferiority margin quantifies what difference is allowed. The second approach is based on a comparison of the most probable numbers (MPN) using a design with multiple dilutions (Cochran Citation1950). Absence/presence results obtained from multiple dilutions are used to estimate one bacterial density of organisms in the original solution. This is done multiple times with the alternative and the compendial method to create repeated estimates of the bacterial density. Then non-inferiority is tested on two sets of MPNs using a t-test.
The USP does not provide guidance when to use which of the two non-inferiority approaches, neither discusses how to interpret the results from these approaches. Based on a statistical model for the detection of microorganisms (IJzerman-Boon and Van den Heuvel Citation2015), we will assess and improve the non-inferiority approaches.
Section 2 describes the two USP approaches, on positive rates and on MPNs, as well as their implicit assumptions. Section 3 describes the statistical detection model and proposes a third approach (the generalized MPN approach). Section 4 presents different experimental designs to determine MPN estimates and explains that under the described distributional assumptions, results for testing non-inferiority with the MPN are not expected to differ. Subsequently, Sections 5 and 6 describe our simulation study and present the results, respectively. Section 7 presents (a discussion on) our conclusions.
2. Non-inferiority testing according to USP <1223>
2.1. Approach 1: non-inferiority on positive rates
In order to show non-inferiority, it is required that both methods test similar sets of samples (see Section 2.3 for details). The null hypothesis is then formulated as against the alternative hypothesis
, with
the non-inferiority margin. By proposing a non-inferiority margin of −0.2 for the difference
, the USP indirectly suggests a non-inferiority margin of
for the ratio. Following Farrington and Manning (Citation1990), the null hypothesis can be rewritten as
, and is rejected when
with the
percentile of the standard normal distribution,
and
the standard estimates of the probabilities
and
to detect positive test samples, and
the estimated variance of
under the null hypothesis. Thus, when
and
are the numbers of positive samples among
and
test samples tested with the alternative and compendial method, respectively, we have
,
, and
is
with and
the maximum likelihood estimators (MLE) under the null hypothesis, i.e.
,
,
,
,
, and
. A 5% significance level is used, i.e.
.
Note that this approach is applicable to test samples from a single dilution, since a clear extension to multiple dilutions (with different probabilities for testing positives) is not known. The USP recommends a spike level of microorganisms for this dilution at which 50–75% of the samples would be expected to be positive when tested with the compendial method.
If, instead of testing independent samples from a single dilution with the alternative and compendial method, the same samples are tested by both methods, then the results can be displayed in a 2 × 2 table (), and a paired test can be applied. In formula (1), we then use (Lachenbruch and Lynch Citation1998)
,
, resulting in
, and we replace the variance estimate (2) by
Table 1. Lay-out of results for a paired test – Numbers of positive and negative samples (associated probabilities).
where . Note that USP <1223> incorrectly suggests a variance of
, which is an estimate of the variance of
instead of
.
2.2. Approach 2: non-inferiority on MPNs
For the MPN-based approach, the null hypothesis needs to be rejected in favor of
, where
and
are the theoretical bacterial densities for the alternative and compendial method, respectively. Following Cochran (Citation1950), the probability that a sample is tested positively equals
, when λ is the mean number of organisms in the test samples and the microbiological method detects organisms perfectly. Given an estimate
for the proportion
, based on test samples with volume
taken from a single solution with volume
, the bacterial density and corresponding number of organisms in the solution are estimated by
The MPN can also be estimated from a multiple dilution experiment, but then a closed-form expression does not exist.
Based on and
MPN estimates or replicates for the two methods, respectively, a t-test for non-inferiority can be applied to the log-transformed estimates. Note that there are different ways of generating these MPN estimates (further discussed in Section 4), but when all MPNs are trying to estimate the same bacterial density and are estimated based on independent samples from the same stock solution (), then a two-sample t-test can be used. If
and
denote the average and standard deviation of the
estimates for
(or equivalently, for
) for the alternative method, and
,
, and
for the compendial method, then non-inferiority can be concluded if
Figure 1. Visualization of conditional and marginal probabilities (7) and (8)
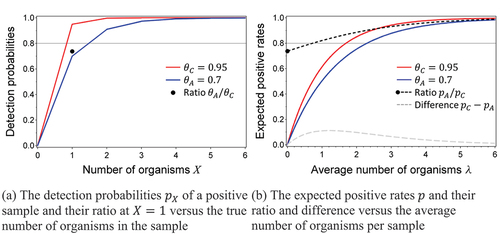
Figure 2. Experiments to generate multiple MPN estimates in a 3 × 3 design for 2 methods.
where denotes the
percentile of the t-distribution with the Satterthwaite degrees of freedom
In case the MPNs for the two methods are estimated based on samples from the same dilutions (), even though in this case the two methods do not test the exact same samples, a paired t-test may be more appropriate. When and
denote the sample mean and sample variance of the
paired differences
of the log-transformed MPN estimates for the alternative method minus the compendial method, then non-inferiority can be concluded if
2.3. Implicit assumptions in USP
In the first approach, the non-inferiority claim would only hold for the tested spike that resulted in the positive rates for which non-inferiority could be concluded. At that spike level, and under the assumption that both methods indeed received samples with similar spike levels, the two methods are likely to come to the same pass or fail conclusion. In the USP, this is referred to as decision equivalence. However, decision equivalence does not at all imply that the two microbiological methods have approximately the same sensitivity. To illustrate this, think of two microbiological methods, one detecting only molds, and one detecting only bacteria. When samples with mixtures of bacteria and molds are offered to both methods, the positive rates may be equivalent for the two methods. Nevertheless, it is obvious that the methods do not have the same sensitivity for both types of microorganisms and as a microbiologist you would never rely on just one method. Another situation where two methods might appear to be similar, is if you offer samples with a high spike. Then, even a poor test method will return only positive results. In these examples, it is clear that the number of positive samples does not only depend on the microbiological method, but also on the numbers of organisms in the test samples, and non-inferiority for one spike level (e.g. the level at which 50–75% of the samples would be positive with the compendial method) does not necessarily imply non-inferiority at other spike levels.
Another implicit assumption is that all samples have the same fixed probability ( or
depending on the test method), of becoming positive. This would be reasonable only when all samples contain the same number of organisms, but creating samples with a fixed number of organisms is currently impossible in microbiology. Even when all samples are taken from the same solution, numbers of organisms will vary from sample to sample because of sampling variability, and therefore some samples have lower probabilities of being detected positively than other samples.
In the second approach, the MPN method implicitly assumes that organisms are distributed randomly and unaggregated throughout the solution, such that the number of organisms in a small amount or test sample taken from it follows a Poisson distribution (Cochran Citation1950; Garthright and Blodgett Citation1996). Samples are assumed independent of each other (Garthright and Blodgett Citation1996), which means that the probability of a sample to be positive is not affected by other samples being positive or negative. This is practically true when the total volume of all samples constitutes a small volume of the total solution, say less than 10%.
Additionally, as Cochran (Citation1950) phrased it for growth-based methods: “each sample, when incubated in the culture medium, is certain to exhibit growth when it contains one or more microorganisms”. This would imply that every organism is detected by the method. But, if perfect detection is already part of our assumptions, what are we demonstrating when we show non-inferiority on MPNs?
3. Non-inferiority testing based on a statistical model for the detection of microorganisms
Since the number of positive test samples is not only determined by the method, but also by the unknown spike, we need an appropriate model that describes how a positive result is achieved and that can separate the spike level from the sensitivity of the method. To do this, we introduce two concepts the first concept describes the detection probability to detect one sample as positive as a function of the true number of organisms in the sample, the second concept considers a distribution for this unknown true number of organisms when we sample from a solution. Full knowledge of the first concept of the model would provide full insight into the sensitivity of the method for each possible number of organisms in the test sample. The detection probability, which should be an increasing function of the number of microorganisms in the sample, may have parameters that would characterize the performance of the method.
3.1. The binomial-Poisson model
Denote the outcome of the test sample by , which would be 0 for a negative result, and 1 for a positive result. A simple model (IJzerman-Boon and Van den Heuvel Citation2015; Van den Heuvel and IJzerman-Boon Citation2013) assumes that each microorganism has a fixed probability
(between 0 and 1) to be detected by the microbiological test method. This parameter has been called the detection proportion and represents the probability to detect one organism. The detection probability
that the microbiological test would return a positive test result for a sample, i.e. detect at least one organism, can be expressed as a conditional probability given the number of organisms
in the sample,
This model has been referred to as the binomial detection model, since it is based on the binomial distribution when the method detects organisms independently from each other. Note that for , the detection probability
reduces to the detection proportion
.
Unfortunately, it is impossible to spike test samples with a fixed number of microorganisms. The spike exhibits variability, and therefore we cannot observe the function (7) directly. If the spikes follow a Poisson distribution with a mean of
, which is a common and often a reasonable distributional model for count data (Cochran Citation1950), then the marginal probability to detect a sample as positive equals the expected positive rate
and can be written as
A graphical representation of (7) and (8) is provided in .
Based on an experiment, we can estimate the expected positive rate from (8) as described earlier. However, the sensitivity of the method is reflected by the parameter
, which cannot be separated from the average spike per test sample
. We can only estimate the product
. For a single dilution, it is estimated by
and its corresponding variance would be estimated by (IJzerman-Boon and Van den Heuvel Citation2015). Note that for
, this estimator is just the MPN estimator for the bacterial density
(Cochran Citation1950), presented in (4). Hence, our binomial detection model with
can be viewed as a generalization of the MPN and will be referred to as the generalized MPN.
3.2. Approach 3: non-inferiority on generalized MPNs
Observing that what we estimate is generally not the bacterial density itself, but its product with the detection proportion, it becomes clear that comparing the two test methods should be done by considering the ratio , which equals the accuracy or recovery
, provided both methods tested samples from the same solution with an average spike of
per test sample. Taking the ratio eliminates the spike level
from the test statistic. Testing from the same solution is important, since otherwise the average spike
does not cancel out when taking the ratio. This recovery or accuracy quantifies the relative performance of two qualitative methods and can be used to test non-inferiority of the alternative method compared to the compendial method (EP 5.1.6 Citation2017).
Approximate confidence limits for this ratio or its logarithm
have been derived in IJzerman-Boon and Van den Heuvel (Citation2015). Since in the log-scale a coverage is obtained that is closer to the nominal level, non-inferiority would be concluded if
where is the
percentile of the standard normal distribution.
Expressions (9) and (10) hold for a single dilution. Like with the MPN method, also multiple dilution experiments can be used to estimate the (ratio of) detection proportions and corresponding confidence limits using maximum likelihood, but closed-form expressions do not exist anymore (IJzerman-Boon and Van den Heuvel Citation2015). Then, a statistical package like SAS® can be used to perform the calculations.
3.3. Comparing the gMPN with the USP non-inferiority methods
(solid lines) displays functions (7) and (8) for different values of the detection proportion , where
might reflect the compendial method and
the alternative method. shows the detection probabilities that we are interested in, since it provides the performance of the alternative and compendial method when they would test samples with a fixed number of microorganisms. When using a non-inferiority margin of
0.8 in this example, the alternative method is obviously inferior compared to the compendial method, since the ratio
(black dot) of the two detection proportions for detecting samples with exactly one microorganism (
) is smaller than the non-inferiority margin
(reference line). Note that it is irrelevant that the ratio of the detection probabilities for samples with higher numbers of microorganisms (
) is larger than 0.8, since the methods are inferior for detecting one microorganism and thus inferior in detecting microorganisms. reflects the expected positive rates (
for the compendial and
for the alternative method) that we would observe in experimental data as a function of the average spike level. Since test samples will vary in their number of microorganisms in practice, they average out the detection probabilities in into the positive rates. also shows the ratio (dark dashed line) of these expected positive rates that is used to test non-inferiority in the first USP approach and the difference in positive rates (light dashed line). For
, the ratio starts at
and then increases to 1 for higher spike levels. Thus, theoretically we would be able to demonstrate inferiority of the alternative method with respect to the compendial method using the ratio of positive rates when we would be able to create a dilution with an average number of microorganisms below, say, 0.7, since then the ratio of positive rates is less than 0.8 as well. However, there are a few practical concerns. First of all, spiking dilutions is (very) imprecise, and we may easily end up with an average spike (far) above 0.7, in which case we may declare the alternative method non-inferior (since the ratio of positive rates is then above the non-inferiority margin of 0.8). Secondly, the USP suggests spike levels for experimentation for which the positive rate of the compendial method is between 50% and 75%, i.e., spike levels that would result in non-inferiority since they provide ratios of the positive rates above the non-inferiority margin. Performing the experiment in this range would suggest the use of a difference in positive rates, since it does provide the largest absolute difference between the two methods, but the difference in positive rates (
) would never be larger than 0.2 (an equivalent non-inferiority margin for differences when the ratio is 0.8 and the compendial method is close to perfect) for any of the spike levels (see the difference curve at the bottom of ). Thirdly, even if we would be able to create low spike levels, the ratio of the positive rates still provides a somewhat better result than the ratio of detection proportions
since it is larger than this ratio, unless we would spike very close to the level of blank samples, but then this would blow up the standard error of the estimated ratio and it would require very large numbers of samples. Finally, even if one would be willing to be less stringent and, instead of requiring non-inferiority on detecting a single organism, only require non-inferiority on the positive rates from a certain spike level onwards (probably at a more stringent non-inferiority margin), the uncertainty of the spike remains a problem, since it is impossible to estimate at which spike level the non-inferiority conclusion was drawn, nor does it tell anything about detection at lower spike levels or of just one organism.
Comparing formula (10) on generalized MPNs with formulas (5) and (6) on MPNs shows that both approaches actually evaluate the same thing, since the logarithm of a ratio equals the difference of the logarithms. Although the MPN approach implicitly assumes that the method is perfect, the similarity between (4) and (9) explains why a difference between MPNs, which would be an internal conflict with the assumption that two perfect methods are used to estimate the bacterial density of the same solution, may be attributed to or interpreted as a difference in detection between the two methods. The difference between the MPN approach and the generalized MPN approach is that in the latter approach all data are used to come up with one combined generalized MPN estimate for the ratio and its standard error, while in the MPN approach, first multiple MPN estimates are generated and those are used as the data in the calculations.
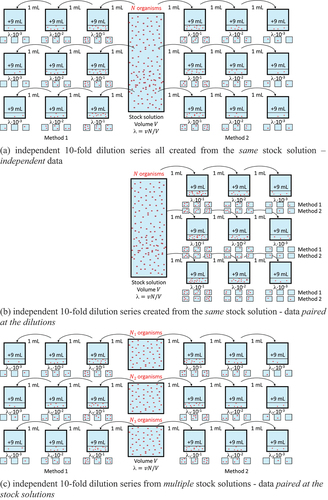
4. Independent and paired experimental designs for the MPN approach
MPN experiments with multiple dilutions can be executed in different ways. One way is to generate all MPN estimates for both methods based on independent dilution series from the same stock solution (). This implies that the MPNs can be considered independent estimates for the same bacterial density and that the two-sample t-test for independent samples can be used. Instead of creating different dilution series per method, one could take samples for both methods from the same dilutions simultaneously (). This would prevent that potential pipetting errors in creating the dilutions would lead to different results between the methods. This experiment provides paired data at the level of the dilutions. There is no formal approach mentioned in the USP to properly address this pairing, but the paired MPN t-test, in the USP only suggested for the rare case where the exact same samples are tested with both methods, is applicable to this design as well.
An alternative for both cases, which may be more practical if testing cannot be performed on one day, would be that multiple stock solutions are used, from each of which one dilution series is created for the alternative method and one for the compendial method (). In this case, data are paired at the level of the stock solutions. The disadvantage of this paired design is that the bacterial densities will vary with stock solution due to variation in spiking. Nevertheless, the paired MPN t-test can be applied in this case.
Finally, one could use different stock solutions for the two methods, but this should be avoided, because differences observed between the two methods might then be caused by differences in the spikes for the two methods, rather than differences in detection by the methods.
In general, these different designs and ways of pairing samples may lead to different correlation structures between the samples. This might require different statistical analysis methods or, when analyzed using the same statistical methods ignoring correlations, could lead to different results. If, however, the number of organisms in the stock solution follows a Poisson distribution and samples are generated from that solution using binomial or multinomial sampling, then the numbers of organisms in the individual samples also follow a Poisson distribution. In addition, independence between the samples can be proven in this case, even though the experimental design suggests dependent samples (Appendix 1). Under this assumption, it therefore does not matter whether the different samples are collected in an independent or dependent way. This simplifies simulations, since the different ways of pairing in MPN experiments () can be ignored, and the independent Poisson data generated to evaluate the independent two-sample t-test on MPNs, can also be used to evaluate the paired MPN t-test, after pairing MPN estimates randomly. Thus, under our Poisson assumptions, the MPN estimates are independent, and the paired t-test cannot be expected to gain power. To the contrary, due to a lower number of degrees of freedom used in the paired t-value, confidence intervals will get wider, leading to lower power for non-inferiority. Simulations will not be shown but are available on request.
5. Simulations
To compare the performance of the two USP approaches, based on the positive rate (referred to as USP1) and the (independent two sample) t-test on MPNs (referred to as USP2), with the generalized MPN approach (referred to as gMPN), simulations were performed for different parameter settings and designs. USP1 and gMPN were compared using designs with a single dilution with various spike levels ( to
), from which 200 samples per method were taken (
. Multiple dilution designs were used to compare USP2 and gMPN. Typical MPN designs include 3 two-fold or ten-fold dilutions with 3 or 5 samples tested per dilution (USP <1223> Citation2015; De Man Citation1983; Garthright and Blodgett Citation2003). These designs are denoted by 3 × 3 or 3 × 5, and we repeated them 22 or 13 times to get a total sample size of almost 200. In order to see whether changing the number of samples per dilution would make a difference, we also evaluated designs with other numbers of test samples per dilution (3 × 4, 3 × 6, … , 3 × 33). The 3 two-fold or ten-fold dilutions were chosen at
and λ
, i.e. such that the middle dilution would have a spike level of
.
We assumed a detection proportion of for the compendial method and evaluated the Type I error rate of (incorrectly) concluding non-inferiority at the non-inferiority margin of
(
) proposed in the guideline and at a lower ratio of
(
). For the evaluation of the power to (correctly) conclude non-inferiority, we assumed equal detection proportions
, a non-inferior and lower detection proportion (
), and a superior detection proportion
) for both non-inferiority margins
and
. For all parameter settings, 10,000 simulations were performed.
Assuming independence between the samples, simulation results were generated by drawing the true number of organisms in each sample from a Poisson distribution with mean for a single dilution, and
divided by the appropriate dilution factor for samples from a dilution series. The detection probability for each sample was then calculated using formula (7), and the outcome of the sample was positive if this probability was larger than a random number between 0 and 1, and negative otherwise. The simulated data were analyzed using the different approaches USP1, USP2, and gMPN. SAS and R codes for such analyses are presented in Appendix 2. For the USP2 approach, MPN replicates sometimes failed. In those cases, the MPN for the alternative and/or the compendial method could not be estimated because all samples in all dilutions were positive or negative for that method. In simulations where this occurred, the t-test was calculated based on the remaining MPN replicates, as one would usually do in practice. For all three methods, the Type I error and power were estimated by the percentage of simulations for which non-inferiority was concluded. Failure rates were estimated by the percentage of MPN replicates for which all samples were positive (all samples negative did not occur) out of the total number of MPN replicates across all simulations. Note that the expected failure percentages can also be calculated theoretically based on formula (8). For example, for a 3 ×
design with spike levels
,
, and
, this would be
.
6. Results
First, we compared USP1 and gMPN on their Type I error rates. shows the expected Type I error rates of around 5% for the gMPN approach, but unacceptably high Type I errors for USP1. These Type I errors increase rapidly with the spike level up to almost 100% when λ, which means that the USP1 approach based on the positive rates almost always concludes non-inferiority, while in fact the alternative method detects one organism with a probability of only 80% of that of the compendial method, which is exactly equal to the selected non-inferiority margin. Also when the ratio of detection proportions is chosen below the non-inferiority margin of 0.8 (
), USP1 still shows rapidly increasing probabilities beyond 5% when the spike level increases from 1.5 to above (Appendix 3, ), while the gMPN shows probabilities below nominal (as expected). The last two columns in show that when the ratio of positive rates equals the non-inferiority margin (which can only occur at one specific spike level), the Type I error of USP1 is around 5%. The ratio of detection proportions is then already far below the non-inferiority margin of 0.8 and the gMPN shows Type I errors below nominal.
Table 2. Type I error rate (%) to conclude non-inferiority with approaches USP1 and gMPN for a single dilution design using a non-inferiority margin of , detection proportion
,
chosen such that
or
, and
samples.
shows for the same single dilution design the power for non-inferiority when the detection proportions of the alternate and compendial method are equal (). With 200 samples per method, the powers for USP1 are very high (over 95% for spike levels of λ
or higher), but we know that this is at the cost of highly inflated Type I errors. For the gMPN method, the power using a non-inferiority margin of
attains a maximum value of about 57% for λ
. To increase the power, one should either test even more samples than
per method or relax the non-inferiority margin. When a margin of
instead of
would be applied, then the power for the gMPN approach would be sufficient, with a maximum value of 89% for the optimal spike level, and still values above 80% when the average spike level is between 1 and 3. Please note that other values than 0.8 for the equal detection proportions would have led to similar results at slightly different spike levels, since results are driven by the product
in formula (8). Appendix 3, and C3 show results for the power when detection proportions differ, i.e. for
or
Apart from the powers being lower or higher, respectively, than for
, the pattern is the same.
Table 3. Power (%) to conclude non-inferiority with approaches USP1 and gMPN for a single dilution design using a non-inferiority margin of or
, detection proportions
and
samples.
To evaluate the second USP approach, which uses a t-test on a set of estimated MPNs, we simulated multiple dilution designs and compared the Type I error and the power of USP2 with that of the gMPN approach. shows that the Type I error rates for a detection proportion ratio at the non-inferiority margin of 0.8 () are all close to the nominal 5% level for the gMPN approach, while for the USP2 approach they are in most cases smaller and below 4.5%. Only for dilution factor 2 in the 3 × 3, 3 × 4 and 3 × 5 designs, the Type I error for the USP2 approach is somewhat inflated, probably because of the higher number of failed MPN replicates in the compendial than in the alternative group, leading to elimination of the MPN replicates for which the compendial method had all samples positive. All failure rates were in line with the theoretical expected value. For a ratio of detection proportions below the non-inferiority margin (
), probabilities for both USP2 and gMPN are below the nominal 5% level, but the pattern is the same (Appendix 3, ).
Table 4. Type I error rate (%) to conclude non-inferiority with approaches USP2 and gMPN for multiple dilution designs using a non-inferiority margin of , detection proportions
and n~200 samples.
Results in show that the power for gMPN is stable across the different designs. For USP2 with dilution factor 2, the power seems to decrease with a decreasing number of replicates, while it is stable for dilution factor 10, until the number of replicates drops below 5. This may be due to a low number of degrees of freedom that is then used in the t-test. Note that for dilution factor 2, more failures occurred than for dilution factor 10, since the different dilutions are more likely to have only positives if they are closer together. The failure rate also decreases when the number of samples per dilution increases, since it becomes more difficult for a replicate to fail, i.e. to have all samples in all dilutions positive. Except for the 3 × 3 × 22 design with dilution factor 2, the power for USP2 is always smaller than for gMPN. A reason for USP2 having lower power than gMPN is most likely that USP2 compares multiple (depending on the number of replicates 22, 16, etc.) MPN estimates between the two methods but does not use the precision of the MPN estimates themselves, while the gMPN approach uses all data together without discarding or losing information.
Table 5. Power (%) to conclude non-inferiority with approaches USP2 and gMPN for multiple dilution designs using a non-inferiority margin of or
, detection proportions
and n~200 samples.
Comparing the gMPN results of with shows that the power for a single dilution experiment with a close to optimal spike level is higher than for a multiple dilution experiment, which includes only part of the data at the optimal spike level. Diluting further away from the optimal spike level decreases the power for both methods, which is also clear when comparing dilution factor 10 with dilution factor 2. Also, designs with five dilutions (not shown) would have lower power than designs with three dilutions.
Using a non-inferiority margin of instead of
would, with a dilution factor of 2, be sufficient to increase the power to values above 80% for gMPN and USP2 with the 3 × 3 × 22 design, but not for USP2 with the other designs with less replicates.
Appendix 3, and C6 show results for the power when detection proportions differ, i.e. for or
Apart from the powers being lower or higher, respectively, than for
, the pattern is the same.
7. Conclusions
This paper presented the two USP <1223> non-inferiority approaches (USP1 on positive rates, USP2 on MPNs) and a statistical model that helped to interpret these approaches and that led to a third approach (generalized MPNs). Simulations illustrated the performance of the three approaches. It can be concluded that USP1 on positive rates is not suitable, since it concludes non-inferiority too often when the alternate method is inferior in detecting a single organism. This becomes even more severe for higher spike levels (already at 2–3 CFU/sample, which is still far below the spike level of 10–50 CFU that USP suggests), for which the expected positive rates become closer to 100% and closer to each other. Obviously, for sufficiently high spike levels, also a poor method has no difficulty detecting positive samples. Hence, the positive rate is not a good measure to evaluate the method performance, since it is influenced not only by the method but also by the spike level, and the conclusion of non-inferiority would only hold for the spike level tested, which cannot be estimated. Even if one would consider non-inferiority on the positive rates from a certain spike level onwards sufficient, then the spiking uncertainty in microbiology and the fact that the power changes rapidly with the spike level, make it very difficult to set up an experiment that guarantees this. Due to this dependence on the spike level, there is also no easy way to choose a lower significance level to get the Type I error under control, in an attempt to still benefit from the increase in power.
On the other hand, USP2 is a suitable approach to evaluate the sensitivity of the alternative method in comparison with the compendial method and is not driven by the spike level. However, the proposed set-up for MPN can be improved. Instead of using multiple dilutions, it would be better to use the optimal single spike level that maximizes the power of the test. Under realistic scenarios with detection proportions above 0.7, the optimal spike level would be approximately 2 CFU/sample (for more details, see IJzerman-Boon and Van den Heuvel Citation2015; Strijbosch et al. Citation1990). If multiple dilutions are used, for example, to mitigate the risk of spiking uncertainty, then a much smaller dilution factor should be used in order to stay as close as possible to the optimal spike level. Moreover, it is recommended to use as many MPN replicates as possible, but 3 × 3 or 3 × 4 experiments are not recommended due to the high probability of failed MPN replicates, which could lead to a bias in the evaluation.
An even better alternative is to replace the t-test by the generalized MPN analysis, i.e. to use gMPN instead of USP2. The MPN approach ignores the variability of the individual MPN estimates, which is overcome in an analysis of all data simultaneously by the gMPN. Use of all data together generally increases the power and reduces the risk of failed MPN replicates in the MPN experiment. Furthermore, the sample size of 75–100 that USP <1223> suggests for 80–90% power should be increased to about 200, since lower sample sizes do not provide this power level, not even when the non-inferiority margin is 0.7. To mitigate this increase in sample size, one may consider analyzing the data of multiple organisms together, provided their ratios of detection proportions are homogeneous (Emampour et al. Citation2021).
In the simulations, we assumed that the true counts in the samples were independent Poisson. This is a theoretical assumption for the estimation of MPNs in USP2 as well as for the ratio of detection proportions in gMPN. It is not a serious drawback, since in practice it may always be approximately achieved by making sure that the volumes taken for the dilutions are small compared to the stock solution, and that the test samples are small compared to the dilutions. However, if samples are not independent Poisson, then the different ways of executing MPN experiments () may play a role, and taking into account some pairing in the analysis, using the USP2 paired MPN t-test, may become better than the gMPN approach, which currently ignores any dependence between the samples. This requires further investigation. For a single dilution design, the gMPN approach may still be used, but it may be best to completely divide the stock solution over the test samples, because in that case, the estimator based on Poisson is robust against under- or overdispersion (Manju et al. Citation2019).
One of the limitations of the gMPN approach, which also applies to the USP methods, is that we did not consider false positives in our model. If false positives are ignored, then they may compensate for false negatives, and non-inferiority may be concluded while in fact the alternate method has a lower sensitivity than the compendial in combination with false positives. This may be easily resolved, since IJzerman-Boon and Van den Heuvel (Citation2015) presented a zero-deflated binomial detection model, which extends the binomial model (7) with a parameter for the false positive rate. Use of this extended model slightly changes formulas (8), (9), and (10), but would allow a clean comparison of the sensitivity of two methods without interference by false positives.
In conclusion, the generalized MPN approach clearly outperforms the two USP approaches with a clear interpretation under the binomial-Poisson model that we presented. Non-inferiority on the positive rates is strongly discouraged. Furthermore, the robustness of the MPN and gMPN approach against other detection probability models must still be investigated.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Cochran, W. G. 1950. Estimation of bacterial density by means of the “most probable number”. Biometrics 6 (2):105–116. doi:10.2307/3001491.
- De Man, J. C. 1983. MPN tables, corrected. European Journal of Applied Microbiology and Biotechnology 17 (5):301–305. doi:10.1007/BF00508025.
- Emampour, M., P. C. IJzerman-Boon, M. A. Manju, and E. R. van den Heuvel. 2021. Optimal spiking experiment for non-inferiority of qualitative microbiological methods on accuracy with multiple microorganisms. Statistics in Biopharmaceutical Research. doi:10.1080/19466315.2021.2011397.
- EP. 2017. 5.1.6. Alternative methods for control of microbiological quality. In European Pharmacopeia, Vol. 9.2, 4339–4348. Strasbourg: EDQM.
- Farrington, C. P., and G. Manning. 1990. Test statistics and sample size formulae for comparative binomial trials with null hypothesis of non-zero risk difference or non-unity relative risk. Statistics in Medicine 9 (12):1447–1454. doi:10.1002/sim.4780091208.
- Garthright, W. E., and R. J. Blodgett. 1996. Confidence intervals for microbiological density using serial dilutions with MPN estimates. Biometrical Journal 38 (4):489–505. doi:10.1002/bimj.4710380415.
- Garthright, W. E., and R. J. Blodgett. 2003. FDA’s preferred MPN methods for standard, large or unusual tests, with a spreadsheet. Food Microbiology 20 (4):439–445. doi:10.1016/S0740-0020(02)00144-2.
- IJzerman-Boon, P. C., and E. R. van den Heuvel. 2015. Validation of qualitative microbiological test methods. Pharmaceutical Statistics 14 (2):120–128. doi:10.1002/pst.1663.
- Lachenbruch, P. A., and C. J. Lynch. 1998. Assessing screening tests: Extensions of McNemar’s test. Statistics in Medicine 17 (19):2207–2217. doi:10.1002/(SICI)1097-0258(19981015)17:19<2207::AID-SIM920>3.0.CO;2-Y.
- Manju, M. A., E. R. van den Heuvel, and P. C. IJzerman-Boon. 2019. A comparison of spiking experiments to estimate the detection proportion of qualitative microbiological methods. Journal of Biopharmaceutical Statistics 29 (1):30–55. doi:10.1080/10543406.2018.1452027.
- Patil, G. P., and S. Bildikar. 1966. Identifiability of countable mixtures of discrete probability distributions using methods of infinite matrices. Proceedings of the Cambridge Philosophical Society 62 (3):485–494. doi:10.1017/S030500410004010X.
- Strijbosch, L. W. G., R. J. M. M. Does, and W. Albers. 1990. Multiple-dose design and bias-reducing methods for limiting dilution assays. Statistica Neerlandica 44 (4):241–261. doi:10.1111/j.1467-9574.1990.tb01284.x.
- USP. 2015. <1223> Validation of alternative microbiological methods. In United States Pharmacopoeia, Vol. USP40-NF35, 1756–1770. Rockville, MD: U.S. Pharmacopoeial Convention.
- Van den Heuvel, E. R., and P. C. IJzerman-Boon. 2013. A comparison of test statistics for the recovery of rapid growth-based enumeration tests. Pharmaceutical Statistics 12 (5):291–299. doi:10.1002/pst.1581.
Appendix 1:
Proof that all samples are independent
Theorem
Suppose the number of organisms in the stock solution follows a Poisson distribution:
~
. Assume that this stock solution is split into
equal samples with numbers of organisms
. Conditional on the total number of organisms
in the stock solution, the numbers in the samples follow a multinomial distribution, with probabilities
for each organism to end up in one of the samples:
~
.
Let denote the test outcome for each sample (
negative,
positive). Assume that each sample is tested with a test method that detects organisms according to binomial detection model (7) with detection proportion
, which may differ for each sample
:
.
Then:
the true numbers of organisms
in the test samples follow an independent Poisson distribution, with marginal distribution:
the positive/negative test results
Proof
(a) This follows from Theorem 1 and its Corollary 4 in Section 4 (about mixtures on the total number () of the multinomial distribution) of Patil and Bildikar (Citation1966).
it is sufficient to prove that:
since the occurrence of 0 and 1 are complementary events, and for events , independence of the events themselves also implies independence when one or more of the events is replaced by its complementary event, i.e.
implies
,
since we can write
On the left-hand side of (A1), we have
( are conditionally independent therefore this is just the product)
(if we know , then the other
’s do not matter, whether they are independent or not)
(multinomial theorem )
(Poisson distribution adds up to 1 over all
)
On the right-hand side of (A1), we have for and similarly for
( only depends on
)
(multinomial distribution adds up to 1)
(Newton’s binomium )
(Poisson distribution adds up to 1 over all
)
Hence, the left-hand side equals the right-hand side
, thereby completing the proof.
Appendix 2
Program codes for analysis






Appendix 3
Additional simulation results
Simulations supplementing those in (Type I error USP1 vs gMPN)
Simulations supplementing those in (Power USP1 vs gMPN)
Simulations supplementing those in (Type I error USP2 vs gMPN)
Simulations supplementing those in (Power USP2 vs gMPN)
Table C1. Type I error rate (%) to conclude non-inferiority with approaches USP1 and gMPN for a single dilution design using a non-inferiority margin of , detection proportion
,
chosen such that
, and
samples.
Table C2. Power (%) to conclude non-inferiority with approaches USP1 and gMPN for a single dilution design using a non-inferiority margin of or
,
with detection proportions
and
samples.
Table C3. Power (%) to conclude non-inferiority with approaches USP1 and gMPN for a single dilution design using a non-inferiority margin of or
,
with detection proportions
and
samples.
Table C4. Type I error rate (%) to conclude non-inferiority with approaches USP2 and gMPN for multiple dilution designs using a non-inferiority margin of , detection proportions
and
samples.
Table C5. Power (%) to conclude non-inferiority with approaches USP2 and gMPN for multiple dilution designs using a non-inferiority margin of or
,
with detection proportions
and
samples.
Table C6. Power (%) to conclude non-inferiority with approaches USP2 and gMPN for multiple dilution designs using a non-inferiority margin of or
,
with detection proportions
and
samples.