
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The restricted mean time in favor (RMT-IF) summarizes the treatment effect on a hierarchical composite endpoint with mortality at the top. Its crude decomposition into “stage-wise effects,” i.e., the net average time gained by the treatment prior to each component event, does not reveal the patient state in which the extra time is spent. To obtain this information, we break each stage-wise effect into subcomponents according to the specific state to which the reference condition is improved. After re-expressing the subcomponents as functionals of the marginal survival functions of outcome events, we estimate them conveniently by plugging in the Kaplan -- Meier estimators. Their robust variance matrices allow us to construct joint tests on the decomposed units, which are particularly powerful against component-wise differential treatment effects. By reanalyzing a cancer trial and a cardiovascular trial, we acquire new insights into the quality and composition of the extra survival times, as well as the extra time with fewer hospitalizations, gained by the treatment in question. The proposed methods are implemented in the rmt package freely available on the Comprehensive R Archive Network (CRAN).
1. Introduction
Patients in a phase-III clinical trial often experience nonfatal events like hospitalization or relapse of disease before they die. Assessing the composite outcomes based solely on time to the first event, whichever type it is, raises concerns over the inefficient use of data as well as indiscrimination between morbidity and mortality (Anker and McMurray Citation2012; Armstrong and Westerhout Citation2017; Freemantle et al. Citation2003; Mao and Kim Citation2021). In response, investigators increasingly turn to methods that compare patients in pairs across arms, as this allows them to capture the entirety of patient data and to prioritize death over lesser events (see, e.g., Abdalla et al. Citation2016; Buyse Citation2010; Cui et al. Citation2022; Dong et al. Citation2018, Citation2022, Citation2023; Finkelstein and Schoenfeld Citation1999; Kandzari et al. Citation2021; Mao et al. Citation2022; Maurer et al. Citation2018; Pocock et al. Citation2012; Redfors et al. Citation2020; Seifu et al. Citation2022).
The restricted mean time in favor (RMT-IF) of treatment is one such method (Mao Citation2023). Defined as the net average time a treated patient fares in a more “favorable” state than an untreated one within a fixed time window, the RMT-IF has all the advantages of a pairwise comparison scheme. In addition, by pre-setting the time frame of comparison, it produces a well-defined estimand that is transferable across studies with different censoring patterns (Akacha et al. Citation2017; Dong et al. Citation2020; Oakes Citation2016). Furthermore, the estimand can be additively decomposed into a number of “stage-wise” effects according to the event type against which favorability is measured. Against relapse, for example, a patient gains favorable time by staying in remission; against death, by staying alive (in this case, the stage-wise effect coincides with the difference in restricted mean survival time, or RMST (McCaw et al. Citation2019; Royston and Parmar Citation2011; Tian et al. Citation2018; Uno et al. Citation2014)). Such decomposition reveals the contributions of different events to the overall effect.
Yet it may still hide important details. The stage-wise effect for survival (i.e., net RMST), for example, provides the average (treatment-conferred) extra lifetime without telling whether it is lived healthily or with illness. Similar ambiguity arises in any nonfatal event ranked above a less severe one, say, metastasis over non-metastatic relapse of cancer (Crowther and Lambert Citation2017). The stage-wise effect for metastasis then concerns only time spent metastasis-free, whether that means in complete remission or after relapse. Inquisition into such details requires us to further break down the stage-wise effects. While Mao (Citation2023) alluded to the possibility of doing so, a full solution has not yet been worked out.
Another problem mentioned in the original paper but still left untreated is joint testing of the decomposed units. Although it is natural to use the estimator of the overall RMT-IF for a global test, this may not always be optimal because it hides possible variations among the components. A joint test, on the other hand, is expected to be more sensitive to component-specific deviations from the null.
In this paper, we proposed methods to further decompose the stage-wise effects to answer the kind of substantive questions raised earlier. We also develop joint tests on the stage-wise components as well as their subcomponents to provide more options for testing. We begin Section 2 by reviewing the RMT-IF and its main components with the outcomes formulated as a multistate process with hierarchically ranked states. We then introduce the subcomponents and develop estimators as well as inference procedures, with technical details relegated to the Appendix. The robust variance matrices for the main and subcomponents are then used to construct chi-square tests with multiple degrees of freedom. For both the further decomposition and joint testing, a separate strategy is designed for the special case of recurrent events and death. We also describe the usage of the R-programs that implement the new analyses. Extensive simulations are conducted in Section 3 to assess the finite-sample performance of the estimation and testing procedures. The colon cancer and heart failure trials considered in Mao (Citation2023) are reanalyzed in Section 4 for deeper understanding of the treatment effects. We conclude the paper in Section 5 with a summary and some practical considerations.
2. Methods
2.1. Review of RMT-IF
As in Mao (Citation2023), we use a multistate process to denote the composite outcomes on a generic subject from group
, where
and 0 indicate the treatment and control groups, respectively. Suppose
, with a larger number representing a more adverse state. In particular, states 0 and
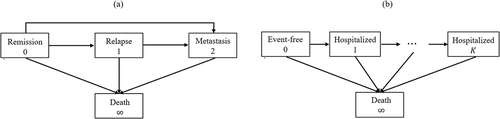
will always represent the initial event-free status and death, respectively. Those in-between depend on the application, e.g., 1 for cancer relapse and 2 for metastasis, as shown in (a); or
for the cumulative number of a recurrent event like hospitalization, as shown in (b), where
is the (data-dependent) maximum number of events per patient.
Figure 1. Composite endpoints formulated as multistate processes: (a) Relapse, metastasis, and death in cancer studies (Crowther and Lambert Citation2017); (b) Repeated hospitalizations and death in, e.g., cardiovascular trials (Vardeny et al. Citation2021).
With restricting time , the RMT-IF estimand can be expressed as
where and
are two generic outcomes independently drawn from the treatment and control groups, respectively, and
is the indicator function. Since
is the length of time
occupies a less severe state than
does in
, the right-hand side of (1) can be interpreted as the net average time gained by the treatment in a more favorable state as compared to the control in the first, say,
years. As with the RMST, the interpretation of the RMT-IF is tied to the choice of the restricting time.
In the comparison, we can split into
main components or stage-wise effects, according to the “losing” state. For example, in (a) where
, a favorable comparison can result from being (i) event-free (state 0) vs relapsed but non-metastatic and alive (state 1); (ii) non-metastatic and alive (states 0 or 1) vs metastatic and alive (state 2); and (iii) alive (states 0, 1, or 2) vs dead (state
). More generally, write
(the indicators in the sum are non-overlapping). Then, by (1), it is easy to find that
where
The th component
measures the net average time favorable with reference to state
. Hence, in (a),
is the net average relapse-free time (vs relapsed but non-metastatic and alive);
is the net average metastasis-free time (vs metastatic but alive); and
is the net average lifetime (alive vs dead), i.e., net RMST. With recurrent events and death ( (b)), Mao (Citation2023) suggested using instead the aggregate measure
to summarize treatment effects on the nonfatal events as a whole.
2.2. Further decomposition and estimation
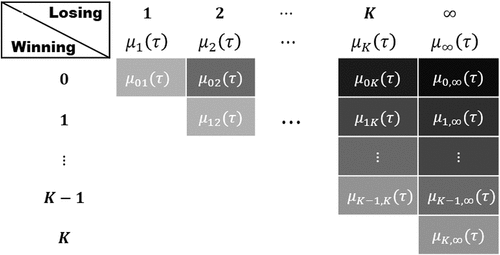
Except for , all other
can be further divided. Indeed, we can do so by differentiating on the “winning” state in each
via
. This leads to
where
The subcomponent measures the net average time improved from state
to state
specifically
. Again using (a) as an example,
and
are the average pre-metastasis time gained in remission and post-relapse, respectively. Likewise,
, and
are the average lifetime gained in remission, post-relapse (but pre-metastasis), and post-metastasis, respectively. Clearly, the farther apart
and
are, the more valuable
is per unit. In that sense,
, and
are ordered by importance, which justifies their separate analyses. shows this two-level decomposition of
diagrammatically.
Figure 2. A graphical dissection of .
The same strategy used to estimate with censored data applies to the
, only with additional derivations. As in Mao (Citation2023), suppose that
is a progressive process in the sense that
for all
(true for both examples in ). Let
. Because
is increasing,
is just the first time it goes up to state
or higher. In (a), for example,
is the time to the earliest of relapse, metastasis, and death;
is the time to the earlier of metastasis and death; and
is the time to death. Obviously,
(with equalities attainable in cases of “state skipping,” e.g., death without any nonfatal events). Because of progressivity,
is completely determined by the
transition times. In fact,
is equivalent to
for
with
and
, and
is equivalent to
. This means that
where
. Using
as an alias for
, we find that
for , where
. The first equality in (4) follows by interchanging the expectation and integration in (2), the second by the independence of
and
, and the third by (3).
In practice, the are censored. With
denoting the independent censoring time, we observe
, where
. In parallel with the latent
, we can equivalently express
using a sequence of censored transition times, namely,
, where
and
. Let
denote a random
-sample of
and write
. In the absence of competing risks other than death (see, e.g., Mao Citation2023), we can estimate the unknown
in (4) by the Kaplan--Meier estimator based on the
-sample of
.
Proposition 1
Let denote the Kaplan–Meier estimator for
with
and
. Then, for
, the subcomponent
can be consistently estimated by
which is asymptotically normal with variance that can be robustly estimated by (12) in the Appendix.
It can be easily shown that , where
is Mao (Citation2023)’s estimator for
. To derive the asymptotic normality and variance of
, we can expand it asymptotically into a linear form (Tsiatis Citation2006), i.e., a sum of i.i.d. terms, using the functional delta method on the
, whose asymptotic linear forms are known (see, e.g., Corollary 3.2.1 of Fleming and Harrington Citation1991). Appendix A.1 lays out the details. Using these results, we can easily make inferences and construct confidence intervals for each
.
2.3. Joint tests on the components
There are several ways to test the overall treatment effect on the composite endpoint. The simplest one is to test using the estimator
along with its standard error. Alternatively, one can test on the
stage-wise effects jointly, i.e.,
or even on the subcomponents, i.e.,
These two tests can be advantageous when treatment effect varies substantially across components.
Proposition 2 Write
Let and
denote the robust variance matrix estimators for
and
, respectively, given in Appendix A.2. Then,
Based on the null distributions of the quadratic forms, we can easily construct chi-square tests with and
degrees of freedom (d.f.) to test
and
, respectively.
2.4. Special case with recurrent events and death
The procedures in Sections 2.2 and 2.3 technically apply when represents recurrent events and death such as in (b). However, comparison of individual states is substantively less meaningful when those pertain to the number of occurrences of the same event. It is rarely of interest, for example, to separate out time spent having been hospitalized twice as opposed to, say, three, four, five, or more times. Coalescing the
into a smaller set would make interpretation easier.
One way of doing so is to dichotomize between event-free (state 0) versus living with one or more events (states ). This splits
(net RMST) into
, the extra lifetime gained event-free, and
, the extra lifetime gained having experienced at least one event. Likewise,
(see the end of Section 2.1) is split into
, the extra time gained event-free when alive, and
, the extra time gained with fewer, but nonzero, nonfatal events when alive. In sum, we have that
Hence no matter how large is, we will always have two main components and four subcomponents. These can be estimated by aggregating the lower-level
introduced in Proposition 1. A computationally more efficient approach is outlined in the supplementary materials. Corresponding joint tests with 2 and 4 d.f.’s can be constructed along the lines of Proposition 2.
2.5. Software
The R-programs that implement the new procedures are integrated with the original methodology in the rmt package. Recall that the main function to fit the RMT-IF is rmtfit(), with the basic syntax
obj <- rmtfit(id, time, status, trt, type=c(“multistate”,”recurrent”))
It accepts input data in the long format, with an id variable holding the unique patient identifiers. The time and status variables contain the event times and labels of event types, respectively. With type=”multistate” (default) for standard multistate data, the value of status corresponds to the label of the state triggered by the event, except that status = 0 for censoring and status = K + 1 for death. In (a), for example, status = 1, 2, and 3 indicate relapse, metastasis, and death, respectively. With type=”recurrent” for recurrent-event data, status = 1 for all nonfatal events (ordered chronologically) and status = 2 for death. In addition, the trt variable contains binary indicators for the treatment against control. At this point, we do not need to specify the restricting time
. Instead, we do so when using the summary() function on the rmtfit object to extract results on the overall and stage-wise effects for a particular
, output in a similar format to of Mao (Citation2023).
Table 1. Simulation results for the estimation and inference of the .
Table 2. Simulation results for the empirical type I error of different tests.
Table 3. Analysis of the colon cancer trial using the RMT-IF (months) of combined treatment.
Now, to carry out the further decomposition, apply the new function dissect() similarly on the rmtfit object with a user-specified , e.g., dissect(obj, tau = 3.0). To illustrate, we pick a random dataset with
and
in the first simulations in Section 3 and run
The output is largely self-explanatory. In the table below the function call, the unindented lines show results for and the
, whereas the indented ones concern the subcomponents
(check the numerical additivity of Estimate!). The entire table is available as a numeric matrix in obj_sub$tab. We also see the results of the
(same as in the Overall line of the previous table),
, and
tests, whose
-values can be extracted from the trivariate vector obj_sub$pval. When we have recurrent events instead of standard multistate data, the decomposition scheme will be different according to Section 2.4, but the output will be similarly structured.
Finally, we introduce a graphic tool called “favorability plot.” Because all components of RMT-IF (and itself) are net measures of favorable and unfavorable times, a natural way to visualize them is to put the two opposing metrics side by side, as commonly seen in opinion polls of public figures or policies. To do so, use the ggrmtif() function (powered by ggplot2) directly on the dissect object, e.g.,
ggrmtif(obj_sub, unit = “months”)
This will generate a graphic that looks like or 6 ahead. It differs from the “bouquet plot” (Mao Citation2023) in that it maps out sub- as well as main components at a fixed , rather than just the main components over a spectrum of
. We can add a state.label option to name states
in the graphic. For example, use state.label=c(“Remission”,”Relapse”) to produce the labels appearing on the left of . For detailed usage of the rmt package, see documentation and vignettes at https://cran.r-project.org/package=rmt.
3. Simulation Studies
In this section, we consider a standard multistate process with , as in (a). Simulations for recurrent events and death are described in the supplementary materials. For a generic patient in group
, use
,
, and
to denote the latent relapse, metastasis, and death times, respectively. When
, we consider the patient to have metastasized without experiencing (non-metastatic) relapse. This leads to a progressive process with transition times
,
, and
. We generated the latent event times through a trivariate Gumbel--Hougaard copula model (Oakes Citation1989)
where ,
,
,
(producing Kendall’s concordance coefficient
between components; see Oakes (Citation1989)), and
is a common hazard ratio (HR) for all events. Under (7), we can use the relationship between the transition and latent event times to show that the former follow exponential distributions:
,
, and
, where
and
. These marginal distributions allow us to derive the
as functions of
in closed form using (4) (see supplementary materials for details). For censoring, let
. Under this setup, the observed relapse, metastasis, and death rates are about 60%, 35%, and 20%, respectively.
We first focused on the estimation and inference of described in Proposition 1. With
and 0.8, we generated samples of size
with equal allocations to the treatment and control, and estimated the
and
for
and 3.0. The results are summarized in . All estimators show minimal bias, with robust standard errors closely reflecting their empirical variations. The corresponding 95% confidence intervals cover the true values at about the nominal rate. The same simulations were repeated with sample sizes
, and 2000. Similar results are shown in Tables S1–S3 in the supplementary materials.
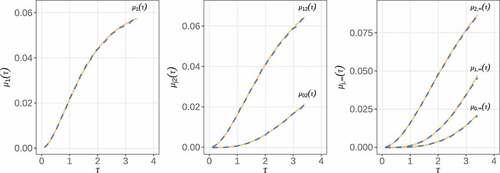
Next, we checked the accuracy of the over a spectrum of
. Under
, we plotted the average estimates across
samples generated in the previous simulations and overlaid them with the true values computed from the analytic formulas given in the supplementary materials. As seen from , the average estimates are virtually indistinguishable from the true curves. Similar accuracy is observed for samples of size
and
(see Figures S1 and S2 in the supplementary materials).
Figure 3. Estimation of as a function of
. Solid line, true values; dashed line, average estimates based on 10,000 replicates of size
.
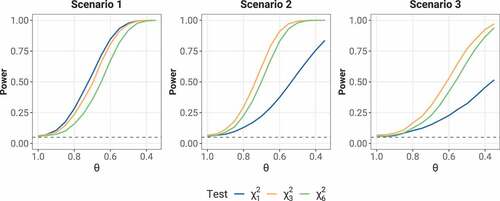
Finally, we turned to the joint tests proposed in Section 2.3. Three types of tests were considered: a test based on
, a
test based on the
, and a
test based on the
, with the latter two described in (5) of Proposition 2. Because their relative performance likely depends on the pattern of component-wise effects, we relaxed model (7) to
where ,
, and
are the component-specific HRs for relapse, metastasis, and death, respectively. We first checked the type I error rates of these tests with
, where the two groups are equivalent. All other parameters remain the same as in previous simulations. With
, we performed level-0.05 tests at
and
for
, and 2000. The empirical rejection rates are summarized across 10,000 samples in . All three tests show roughly correct type I error rate (with a slight deflation for
), confirming their validity.
We then compared the power of these tests under alternative hypotheses. We set up three scenarios—(1) identical component-wise HR: ; (2) identical HR on relapse and metastasis and no effect on death:
and
; (3) possible effect on death but no effect on relapse or metastasis:
and
. In each scenario, we ran the three types of tests at
on 10,000 replicate samples of size
as
decreases from 1.0 to 0.4. The resulting empirical rejection rates are plotted as a function of
in . When component-wise HRs are the same,
is the most powerful of the three. However, it is easily outperformed by the joint tests in the latter two scenarios with heterogeneous component-wise effects.
Figure 4. Empirical power as a function of HR at restricting time
based on 10,000 replicate samples of size
. Scenario 1:
; scenario 2:
and
; scenario 3:
and
. Dashed line, the
significance level.
4. Real examples
With the new tools, we delve deeper into the two trials analyzed in Mao (Citation2023) by the RMT-IF.
4.1. A colon cancer study
Moertel et al. (Citation1990) reported a landmark colon cancer trial that established the efficacy of levamisole and fluorouracil in reducing the mortality and relapse in patients with stage C disease. The original trial involved 929 patients randomized into three arms: control , levamisole alone
, and levamisole combined with fluorouracil
. Mao (Citation2023) analyzed the data by comparing the combined treatment to the control in terms of RMT-IF, with death prioritized over relapse
. Over a median follow-up of 5.5 years, 119 (39%) patients in the combined treatment relapsed, 18 (5.9%) died before relapse, and 105 (34.5%) died after; 177 (56%) patients in the control relapsed, 15 (4.8%) died before relapse, and 153 (48.6%) died after. It was shown that, in the first
years after resection of tumor (the point of randomization), the treatment on average gains the patient
months in a more favorable state, including an extra
months survival time and
months in remission as opposed to relapse.
Following this analysis, we further examine the composition of the survival component. We consider restricting times , and 7.5 years, and use Proposition 1 to estimate and make inferences on the subcomponents. It turns out from that the survival benefits are fully explained by net gains in remission, which means that the prolonged life is of high quality. (The negative values of the other subcomponents are statistically insignificant and may only reflect a general reduction in relapse.) In particular, in the first
years, treated patients on average survive 8.1 extra months in remission and lose 0.7 month post-relapse, accounting for a total of 7.4 months of net survival time. This pattern is shown in the favorability plot in , where the between-arm imbalance in “Death vs Life” is visibly driven by “Death vs Remission”.
Figure 5. Favorability plot for the colon cancer trial at years.
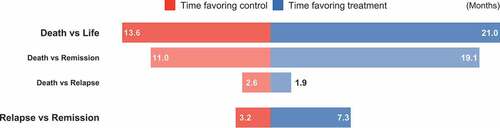
For the composite endpoint of death and relapse, we perform joint tests with 2 and 3 d.f. following Section 2.3. All -values are smaller than the corresponding single-d.f. tests in the bottom line of . This is not surprising given the consistently more significant effect on relapse than on survival, compounded by the even greater lopsidedness between the two subcomponents within survival.
4.2. A heart failure study
The Heart Failure: A Controlled Trial Investigating Outcomes of Exercise Training (HF-ACTION) study (O’Connor et al. Citation2009) evaluated the effect of adding exercise training to the usual care of over 2,000 heart failure patients. Mao (Citation2023) analyzed the data on a high-risk subgroup consisting of 426 nonischemic patients with poor performance in cardiopulmonary exercise test at baseline. In the cohort, 205 patients were randomized to receive exercise training along with usual care, and the remaining 221 received usual care alone as control. They were followed over a median length of 2.5 years. In the training group, there were 145 (71%) first hospitalizations and 306 (1.5 per patient) recurring hospitalizations; 6 (3%) and 20 (15%) patients died before and after the first hospitalization, respectively. In the control group, there were 170 (77%) first hospitalizations and 401 (1.8 per patient) recurring hospitalizations; 5 (2%) and 52 (24%) patients died before and after the first hospitalization, respectively. These crude statistics point to potential benefits of exercise training on both death and hospitalization. Indeed, it was shown that the treatment on average gains the patient months in a more favorable state in the first
years post-randomization, including extra
months survival time and
months living with fewer hospitalizations.
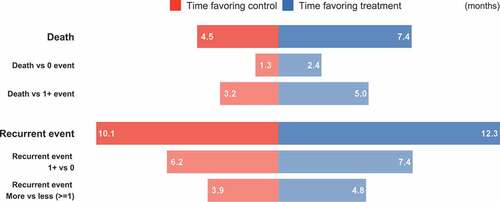
We look further into the two main components through the decompositions of (6). We find that the extra lifetime consists of 1.1 months hospitalization-free (standard error 0.52 and -value 0.032) and 1.8 months having been hospitalized at least once (standard error 0.99 and
-value 0.076), a much more balanced composition than that in the colon cancer trial of Section 4.1. Likewise, the extra time spent living with fewer hospitalizations consists of 1.3 months hospitalization-free (standard error 1.2 and
-value 0.314) and 0.9 month having been hospitalized at least once (standard error 0.8 and
-value 0.215). The favorability plot in shows the structure of the effect sizes. The
and
joint tests yield
-values 0.039 and 0.173, respectively, both less significant than the
overall test (
-value 0.018; see Mao (Citation2023)) due to the largely homogeneous effects across components.
Figure 6. Favorability plot for the HF-ACTION trial at years.
5. Concluding remarks
Our dissection of the RMT-IF helps further reveal the makeup of the overall effect size. The resulting subcomponents, a product of state-to-state comparisons, provide detailed information about the changes in the average time spent in one state over another. Their estimation and inference are facilitated by the correspondence between the state probabilities and the survival functions of transition events, which allows the use of Kaplan--Meier curves to handle censored observations. These procedures will find use in the secondary analysis of composite endpoints, with the aim of understanding how the treatment affects different aspects of patient experience.
As a byproduct of component-wise inferences, their robust variance matrices have allowed us to construct joint tests, which empirically outperform the test on the overall RMT-IF when component-wise effects differ widely. To choose an optimal test in practice, the investigator should consider historical evidence on the heterogeneity of treatment effect as well as the current trial’s sample size (relative to which the test d.f. should be small). In any case, a decision must be made before looking at the data in order to maintain the correct type I error.
The restricting time also needs to be pre-specified. Ideally, the time window should be wide enough to be of clinical interest and to at least allow the treatment effect to come through. With years in the colon cancer trial of Section 4.1, for example, we could hardly see any improvement in patient survival (first row of ), probably because the baseline mortality rate is still too low in such a short term. On the other hand, a restricting time beyond the last event in the data may cause numerical issues. Recently Tian et al. (Citation2020) explored data-dependent choice of the time window for the RMST. A similar study could be done for the RMT-IF.
We have given a separate treatment to recurrent events and death as deserved by their special features. Since the transient (i.e., nonterminal) states, potentially many, are triggered by the same type of event, a meticulous state-to-state comparison feels unnecessary and cumbersome. The merge of intermediate states proposed in Section 2.4 reduces the number of subcomponents down to four, yet still allowing us to distinguish whether the patient has had any nonfatal events or not. Compared with the standard partition based on the specific number of event (Mao Citation2023), this new approach seems to strike a better balance between the level of detail and ease of interpretation.
Supplemental Material
Download PDF (533.7 KB)Disclosure statement
No potential conflict of interest was reported by the authors.
Supplemental data
Supplemental data for this article can be accessed online at https://doi.org/10.1080/10543406.2023.2210658
Additional information
Funding
References
- Abdalla, S., M. E. Montez-Rath, P. S. Parfrey, and G. M. Chertow. 2016. The win ratio approach to analyzing composite outcomes: An application to the evolve trial. Contemporary Clinical Trials 48:119–124. doi:10.1016/j.cct.2016.04.001.
- Akacha, M., F. Bretz, D. Ohlssen, G. Rosenkranz, and H. Schmidli. 2017. Estimands and their role in clinical trials. Statistics in Biopharmaceutical Research 9 (3):268–271. doi:10.1080/19466315.2017.1302358.
- Anker, S. D., and J. V. McMurray. 2012. Time to move on from “time-to-first”: Should all events be included in the analysis of clinical trials. European Heart Journal 33 (22):2764–2765. doi:10.1093/eurheartj/ehs277.
- Armstrong, P. W., and C. M. Westerhout. 2017. Composite end points in clinical research: A time for reappraisal. Circulation 135 (23):2299–2307. doi:10.1161/CIRCULATIONAHA.117.026229.
- Buyse, M. 2010. Generalized pairwise comparisons of prioritized outcomes in the two-sample problem. Statistics in Medicine 29 (30):3245–3257. doi:10.1002/sim.3923.
- Crowther, M. J., and P. C. Lambert. 2017. Parametric multistate survival models: Flexible modelling allowing transition-specific distributions with application to estimating clinically useful measures of effect differences. Statistics in Medicine 36 (29):4719–4742. doi:10.1002/sim.7448.
- Cui, Y., G. Dong, P. F. Kuan, and B. Huang. 2022. Evidence synthesis analysis with prioritized benefit outcomes in oncology clinical trials. Journal of Biopharmaceutical Statistics 33 (3):272–288. doi:10.1080/10543406.2022.2141769.
- Dong, G., D. C. Hoaglin, B. Huang, Y. Cui, D. Wang, Y. Cheng, and M. Gamalo-Siebers. 2023. The stratified win statistics (win ratio, win odds, and net benefit). Pharmaceutical Statistics. doi:10.1002/pst.2293.
- Dong, G., B. Huang, Y. -W. Chang, Y. Seifu, J. Song, and D. C. Hoaglin. 2020. The win ratio: Impact of censoring and follow-up time and use with nonproportional hazards. Pharmaceutical Statistics 19 (3):168–177. doi:10.1002/pst.1977.
- Dong, G., B. Huang, J. Verbeeck, Y. Cui, J. Song, M. Gamalo-Siebers, D. Wang, D. C. Hoaglin, Y. Seifu, T. Mütze, et al. (2022). Win statistics (win ratio, win odds, and net benefit) can complement one another to show the strength of the treatment effect on time-to-event outcomes. Pharmaceutical Statistics 10.1002/pst.2251.
- Dong, G., J. Qiu, D. Wang, and M. Vandemeulebroecke. 2018. The stratified win ratio. Journal of Biopharmaceutical Statistics 28 (4):778–796. doi:10.1080/10543406.2017.1397007.
- Finkelstein, D. M., and D. A. Schoenfeld. 1999. Combining mortality and longitudinal measures in clinical trials. Statistics in Medicine 18 (11):1341–1354. doi:10.1002/(SICI)1097-0258(19990615)18:11<1341:AID-SIM129>3.0.CO;2-7.
- Fleming, T. R., and D. P. Harrington. 1991. Counting Processes and Survival Analysis. Hoboken, NJ: John Wiley & Sons.
- Freemantle, N., M. Calvert, J. Wood, J. Eastaugh, and C. Griffin. 2003. Composite outcomes in randomized trials: Greater precision but with greater uncertainty. Journal of the American Medical Association 289 (19):2554–2559. doi:10.1001/jama.289.19.2554.
- Kandzari, D. E., G. L. Hickey, S. J. Pocock, M. A. Weber, M. Boehm, S. A. Cohen, M. Fahy, G. Lamberti, and F. Mahfoud. 2021. Prioritised endpoints for device-based hypertension trials: The win ratio methodology. EuroIntervention: Journal of EuroPcr in Collaboration with the Working Group on Interventional Cardiology of the European Society of Cardiology 16 (18):e1496–1502. doi:10.4244/EIJ-D-20-01090.
- Mao, L. 2023. On restricted mean time in favor of treatment. Biometrics 79 (1):61–72. doi:10.1111/biom.13570.
- Mao, L., and K. Kim. 2021. Statistical models for composite endpoints of death and non-fatal events: A review. Statistics in Biopharmaceutical Research 13 (3):260–269. doi:10.1080/19466315.2021.1927824.
- Mao, L., K. Kim, and Y. Li. 2022. On recurrent-event win ratio. Statistical Methods in Medical Research 31 (6):1120–1134. doi:10.1177/09622802221084134.
- Maurer, M. S., J. H. Schwartz, B. Gundapaneni, P. M. Elliott, G. Merlini, M. Waddington-Cruz, A. V. Kristen, M. Grogan, R. Witteles, T. Damy, et al. 2018. Tafamidis treatment for patients with transthyretin amyloid cardiomyopathy. The New England Journal of Medicine. 379(11):1007–1016. doi:10.1056/NEJMoa1805689.
- McCaw, Z. R., G. Yin, and L. -J. Wei. 2019. Using the restricted mean survival time difference as an alternative to the hazard ratio for analyzing clinical cardiovascular studies. Circulation 140 (17):1366–1368. doi:10.1161/CIRCULATIONAHA.119.040680.
- Moertel, C. G., T. R. Fleming, J. S. Macdonald, D. G. Haller, J. A. Laurie, P. J. Goodman, J. S. Ungerleider, W. A. Emerson, D. C. Tormey, J. H. Glick, et al. 1990. Levamisole and fluorouracil for adjuvant therapy of resected colon carcinoma. The New England Journal of Medicine. 322(6):352–358. doi:10.1056/NEJM199002083220602.
- Oakes, D. 1989. Bivariate survival models induced by frailties. Journal of the American Statistical Association 84 (406):487–493. doi:10.1080/01621459.1989.10478795.
- Oakes, D. 2016. On the win-ratio statistic in clinical trials with multiple types of event. Biometrika 103 (3):742–745. doi:10.1093/biomet/asw026.
- O’Connor, C. M., D. J. Whellan, K. L. Lee, S. J. Keteyian, L. S. Cooper, S. J. Ellis, E. S. Leifer, W. E. Kraus, D. W. Kitzman, J. A. Blumenthal, et al. 2009. Efficacy and safety of exercise training in patients with chronic heart failure: Hf-action randomized controlled trial. Journal of the American Medical Association. 301(14):1439–1450. doi:10.1001/jama.2009.454.
- Pocock, S., C. Ariti, T. Collier, and D. Wang. 2012. The win ratio: A new approach to the analysis of composite endpoints in clinical trials based on clinical priorities. European Heart Journal 33 (2):176–182. doi:10.1093/eurheartj/ehr352.
- Redfors, B., J. Gregson, A. Crowley, T. McAndrew, O. Ben-Yehuda, G. W. Stone, and S. J. Pocock. 2020. The win ratio approach for composite endpoints: Practical guidance based on previous experience. European Heart Journal 41 (46):4391–4399. doi:10.1093/eurheartj/ehaa665.
- Royston, P., and M. K. Parmar. 2011. The use of restricted mean survival time to estimate the treatment effect in randomized clinical trials when the proportional hazards assumption is in doubt. Statistics in Medicine 30 (19):2409–2421. doi:10.1002/sim.4274.
- Seifu, Y., S. Mt-Isa, K. Duke, M. Gamalo-Siebers, W. Wang, G. Dong, and J. Kolassa. 2022. Design of paediatric trials with benefit-risk endpoints using a composite score of adverse events of interest (aei) and win-statistics. Journal of Biopharmaceutical Statistics 1–12. doi:10.1080/10543406.2022.2153202.
- Tian, L., H. Fu, S. J. Ruberg, H. Uno, and L. -J. Wei. 2018. Efficiency of two sample tests via the restricted mean survival time for analyzing event time observations. Biometrics 74 (2):694–702. doi:10.1111/biom.12770.
- Tian, L., H. Jin, H. Uno, Y. Lu, B. Huang, K. M. Anderson, and L. Wei. 2020. On the empirical choice of the time window for restricted mean survival time. Biometrics 76 (4):1157–1166. doi:10.1111/biom.13237.
- Tsiatis, A. 2006. Semiparametric Theory and Missing Data. New York: Springer.
- Uno, H., B. Claggett, L. Tian, E. Inoue, P. Gallo, T. Miyata, D. Schrag, M. Takeuchi, Y. Uyama, L. Zhao, et al. 2014. Moving beyond the hazard ratio in quantifying the between-group difference in survival analysis. Journal of Clinical Oncology. 32(22):2380. doi:10.1200/JCO.2014.55.2208.
- Vardeny, O., K. Kim, J. A. Udell, J. Joseph, A. S. Desai, M. E. Farkouh, S. M. Hegde, A. F. Hernandez, A. McGeer, H. K. Talbot, et al. 2021. Effect of high-dose trivalent vs standard-dose quadrivalent influenza vaccine on mortality or cardiopulmonary hospitalization in patients with high-risk cardiovascular disease: A randomized clinical trial. JAMA. 325(1):39–49. doi:10.1001/jama.2020.23649.
Appendix
Rearranging the terms on the far right hand side of (4), we obtain that
where
Let denote the estimator of
by substituting the Kaplan–Meier estimator
for
in (9). If we can expand
asymptotically in the linear form
where and the
are some mean-zero influence functions (Tsiatis Citation2006), then by (8) we will have that
where . Let
denote a nonparametric estimator of
(based on estimators for the
below). Then, the asymptotic variance of
can be estimated by the empirical second moment
It now remains to derive and estimate in (10). By Corollary 3.2.1 of Fleming and Harrington (Citation1991), the Kaplan–Meier estimator can be expanded by
where
and is the cumulative hazard function for
. We can estimate
by replacing
with its empirical analog and
with the standard Nelson–Aalen estimator. Denote the resulting estimator by
. Then, using the delta method on
as a functional of the
and
in (9), we find that
which can be estimated by substituting for
and
for
.
A.2 Construction of the joint tests
The robust variance matrix . can be constructed using the coordinate-wise influence functions in (11). Specifically, write
Then by a similar construction to (12), we find that
where for any vector
. The matrix
can be derived similarly using the coordinate-wise influence
functions of
given in Proposition 1 of Mao (2023).