
Abstract
Background
Buprenorphine for opioid use disorder (B-MOUD) is essential to improving patient outcomes; however, retention is essential.
Objective
To develop and validate machine-learning algorithms predicting retention, overdoses, and all-cause mortality among US military veterans initiating B-MOUD.
Methods
Veterans initiating B-MOUD from fiscal years 2006-2020 were identified. Veterans’ B-MOUD episodes were randomly divided into training (80%;n = 45,238) and testing samples (20%;n = 11,309). Candidate algorithms [multiple logistic regression, least absolute shrinkage and selection operator regression, random forest (RF), gradient boosting machine (GBM), and deep neural network (DNN)] were used to build and validate classification models to predict six binary outcomes: 1) B-MOUD retention, 2) any overdose, 3) opioid-related overdose, 4) overdose death, 5) opioid overdose death, and 6) all-cause mortality. Model performance was assessed using standard classification statistics [e.g., area under the receiver operating characteristic curve (AUC-ROC)].
Results
Episodes in the training sample were 93.0% male, 78.0% White, 72.3% unemployed, and 48.3% had a concurrent drug use disorder. The GBM model slightly outperformed others in predicting B-MOUD retention (AUC-ROC = 0.72). RF models outperformed others in predicting any overdose (AUC-ROC = 0.77) and opioid overdose (AUC-ROC = 0.77). RF and GBM outperformed other models for overdose death (AUC-ROC = 0.74 for both), and RF and DNN outperformed other models for opioid overdose death (RF AUC-ROC = 0.79; DNN AUC-ROC = 0.78). RF and GBM also outperformed other models for all-cause mortality (AUC-ROC = 0.76 for both). No single predictor accounted for >3% of the model’s variance.
Conclusions
Machine-learning algorithms can accurately predict OUD-related outcomes with moderate predictive performance; however, prediction of these outcomes is driven by many characteristics.
Introduction
In the US, the opioid crisis is one of the most costly public health emergencies, both in terms of lives lost and health expenditures.Citation1–3 Since 2010, deaths involving opioids have risen by over 300%, increasing from 21,089 in 2010 to 80,411 overdose deaths in 2021.Citation4 The opioid crisis has also significantly affected the U.S. economy; a new federal report estimated healthcare costs related to the opioid epidemic were $1.5 trillion in 2020 alone, a 52% increase from 2019.Citation5 Following the national trend, the number of US military veterans diagnosed with OUD has nearly tripled over the last 15 years.Citation6,Citation7
Medication treatment for opioid use disorder (MOUD; formulations of buprenorphine, methadone, and naltrexone) is the standard of care for treatment of OUD because it prevents overdoses and reduces drug use.Citation8–10 However, retention on MOUD is essential to attaining these outcomes.Citation11,Citation12 In recent years, the Veterans Health Administration (VHA) has improved veterans’ access to MOUD, particularly for buprenorphine, since it can easily be attained from pharmacies and health care clinics including primary care.Citation13 Due to VHA efforts,Citation7,Citation14 the proportion of Veterans receiving any MOUD increased from 34.6% to 48.9% from 2015 to 2020, and buprenorphine accounts for over 80% of MOUD in VHA.Citation15 Despite these gains in initiating treatment with buprenorphine, positive reductions in overdose are only achieved with adequate MOUD retention.Citation11,Citation12 Historically, the median duration of treatment with buprenorphine is 157 days.Citation16 Negative treatment experiences and not obtaining additional needed care services (e.g., counseling to address mental health comorbidities) are important risk factors for early (i.e.,<180 days) MOUD discontinuation, a minimum standard set by the National Quality Forum.Citation17,Citation18 Consequently, providers’ ability to identify veterans in need of additional support while on MOUD holds promise for increasing MOUD retention.
Predictive modeling is a real-time method to estimate a person’s probability of experiencing an outcome of interest at some point in the future. VHA currently uses clinical decision support tools based on predictive models to identify veterans at high risk for opioid overdose and suicide and to provide those veterans with additional care to improve their outcomes.Citation19,Citation20 Specifically, VHA developed Recovery Engagement and Coordination for Health-Veterans Enhanced Treatment (REACH VET) and the Stratification Tool for Opioid Risk Mitigation (STORM) dashboards, which are based on predictive models. These dashboards are used daily in VHA clinical care. Theoretically, similar clinical decision support tools could be used to reduce MOUD attrition and fatal and non-fatal overdoses among veterans with OUD. This tool could identify veterans at risk for MOUD discontinuation or overdose who may benefit from additional support including peer support, outpatient counseling, and pharmacotherapy. This tool could also identify potentially modifiable risk factors, including buprenorphine dose, polysubstance use, mental health comorbidities that could be treatment targets to improve veterans’ treatment retention and decrease their risk for overdose. The primary goal of this study was to develop and validate machine-learning algorithms to predict retention of buprenorphine treatment for veterans with OUD (B-MOUD), their fatal and non-fatal overdoses, and all-cause mortality in the year following a B-MOUD treatment episode.
Methods
Data sources
We used inpatient, outpatient, demographic, and outpatient pharmacy files from the VHA Corporate Data Warehouse (CDW) from fiscal years 2006 through 2020 (October 1, 2005 – September 30, 2020). Data are stored in the CDW relationally based on the original contributing source [e.g., electronic health record (EHR), eligibility file, vital signs data]; study personnel linked data from the extracts of the inpatient, outpatient, demographic, pharmacy, to construct an analytic file. Linking of datasets within the CDW (e.g., inpatient, outpatient, eligibility files) were done using scrambled social security numbers. EHR data were also linked with the U.S. Centers for Disease Control and Prevention/Agency for Toxic Substances and Disease Registry Social Vulnerability Index (CDC/ATSDR SVI) themes using the veteran’s zip code of residence. Specifically, we used the SASHELP.zipcode file to link the veteran’s zip code to the veteran’s county and then linked to the county version of the CDC/ATSDR SVI. The constructs of the SVI are continuous variables of four geographically defined vulnerability domains: (1) socioeconomic status (Theme 1), (2) household composition and disability (Theme 2), (3) minority status and language (Theme 3), (4) housing and transportation (Theme 4).Citation21
Study design and subjects
This study was approved by the Central Arkansas Veterans Healthcare System Institutional Review Board (Little Rock, AR; Date of Approval: 10/5/2020; Approval Number: 1578556). This study followed reporting guidelines from the Standards for Reporting of Diagnostic Accuracy (STARD) and the Transparent Reporting of Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD).Citation22,Citation23
We identified veterans who received at least one OUD diagnosis, were at least 18 years of age, and had initiated B-MOUD after receiving an OUD diagnosis between fiscal years 2006-2020. OUD diagnoses were operationalized to include the specific diagnoses below as used by Lagisetty et al., 2021.Citation24 The study period crosses over the US implementation of the International Classification of Diseases, 10th Revision, Clinical Modification (ICD-10-CM) on Oct 1, 2015; therefore, we used ICD-9-CM and ICD-10-CM codes to operationalize OUD. Eligible codes for defining OUD in the primary analysis are shown in eTable 1. Initiation of B-MOUD was defined as a prescription fill from the VHA outpatient pharmacy or from barcode administration (e.g., inpatient administration) as defined similarly to a previous MOUD algorithm.Citation25 B-MOUD episodes started on the date of a B-MOUD prescription fill. B-MOUD retention was defined as having at least 180 days of B-MOUD coverage after the start of the B-MOUD episode without a gap of 30 days or more in coverage.Citation26 Veterans could have multiple B-MOUD episodes throughout the study timeframe, and all unique episodes were considered in the analysis.Citation16 An illustration of multiple episodes can be found in eFigure 1.
Exclusion criteria
We implemented 4 exclusion criteria based on the CDW records: (1) receipt of B-MOUD from a non-VA source or as a part of a clinical trial, (2) receipt of B-MOUD before an OUD diagnosis was recorded in CDW, (3) enrollment date after B-MOUD initiation, and (4) missing key data elements for VHA priority status, race/ethnicity, CDC/ATSDR SVI themes, marital or employment status, facility type of B-MOUD initiation, VA disability or pension status, smoking status, and Rural-Urban Commuting Area (RUCA) codes.
Study outcomes
We built and validated prediction models for one primary outcome (retention on B-MOUD) and five secondary outcomes (binary measures for fatal and non-fatal overdose, fatal and non-fatal opioid overdose, overdose death, opioid overdose death, and all-cause mortality). Our primary outcome, retention on B-MOUD, was defined as a binary measure of continuous coverage with B-MOUD for at least 180 days after treatment initiation without a 30-day gap in treatment.Citation27 Our secondary outcomes were measured over the 365 days after the start of the B-MOUD episode. Fatal overdoses and all-cause mortality were defined using the VHA/DoD Mortality Data Repository.Citation28 A death was counted as an opioid overdose death or overdose death if it was recorded on the death certificate as resulting from an opioid overdose or overdose as represented by ICD-9-CM and ICD-10-CM codes.Citation29 Similarly, non-fatal overdoses were derived from VHA inpatient or outpatient visits and healthcare visits to non-VHA facilities yet paid for by VHA as represented by ICD-9-CM and ICD-10-CM codes.Citation29 Of note, fatal and non-fatal overdoses is inclusive of overdose death, and fatal and non-fatal opioid overdoses is inclusive of opioid overdose death.
Candidate predictors
We identified 114 candidate predictors based on prior evidence for their association with either MOUD retention or opioid overdose.Citation3,Citation30–39 Patient-, provider-, and facility-level candidate predictors were measured over the 365 days prior to start of the B-MOUD episode. Patient-level candidate predictors included: (1) sociodemographic factors, (2) MOUD profile characteristics, (3) health care service utilization, (4) disease comorbidity factors, (5) opioid-specific historical factors, (6) non-opioid prescription medication utilization factors, (7) social risk factors, (8) provider-level factors, and (9) facility-level factors. Sociodemographic factors included age, sex, ethnicity, race, employment status, marital status, and VHA priority status (a proxy for a veteran’s overall health need).Citation40 B-MOUD profile characteristics included dose of B-MOUD at treatment initiation, treatment setting in which the veteran initiated B-MOUD, days’ supply of B-MOUD received on the first day of the B-MOUD episode, and characteristics about prior B-MOUD episodes. Health care service utilization included the number of emergency room visits, receipt of psychotherapy, or having a general inpatient or psychiatric inpatient admission. Disease comorbidity factors included the Elixhauser comorbidity countCitation41 and concurrent diagnoses of tobacco use disorder, alcohol use disorder, other drug use disorder, major depression, psychotic disorder, post-traumatic stress disorder, anxiety disorders, bipolar disorder, hepatitis C, and chronic pain. The Elixhauser Comorbidity Index, of which we just use the count of comorbidities in the Index, is a method of categorizing comorbidities using ICD codes to measure overall severity of comorbidities. The Index has been used to predict mortality.Citation42,Citation43 Opioid-specific historical factors included opioid overdose in the 365 days prior to the start of the B-MOUD episode and receipt of prescription opioids in the 30 days prior to the start of the B-MOUD episode. Non-opioid prescription medication utilization factors included receipt of sedatives, benzodiazepines, or antidepressants in the 30 days prior to the B-MOUD episode initiation date. Social risk factors included rural residence,Citation44 justice-involvement, unhoused status,Citation45 and SVI themes.Citation21 Provider-level candidate predictors included the provider’s specialty (e.g., Addiction Medicine, Emergency Medicine), provider’s credential (e.g., MD, PA, PharmD), number of MOUD prescriptions the provider wrote in the year prior to the episode initiation date, and the percent of patients the provider retained on MOUD in the prior year. Facility-level candidate predictors included at which VHA facility the veteran initiated the B-MOUD episode, the percentage of patients at the given facility being treated with MOUD in the year prior, and whether the facility has an inpatient detoxification or opioid treatment program. eTables 2 and 3 contain the full lists all candidate predictors.
Machine learning Methods and evaluation of predictive performance
To build and validate models to predict (classification) our primary and secondary outcomes, we divided B-MOUD episodes randomly into training (80%) and testing (20%) datasets. We used the training dataset to develop the models (e.g., hyperparameter tuning and model selection) and the hold-out testing dataset to determine the performance of our selected models. We used five candidate machine-learning algorithms: (1) Multiple Logistic Regression (MLR), (2) Least Absolute Shrinkage and Selection Operator-Type Regression (LASSO) (3) Random Forest (RF), (4) Gradient Boosting Machine (GBM), and (5) Deep Neural Network (DNN). These five techniques were chosen because prior research has repeatedly demonstrated that these algorithms produce accurate prediction outcomes in a variety of applications.Citation46–48 Details on each of the models can be found in the Appendix.
We used, with each of the model types, the grid search (GridSearchCV package in Python) technique for hyperparameter turning.Citation49 Grid search methodically assesses various hyperparameters, measuring model performance via cross-validation, to identify the optimal configuration. Additional details on the hyperparameter tuning process can be found in the Appendix.
We also employed a comprehensive approach to address the imbalance in the datasets, primarily with the secondary outcomes, leveraging three distinct dataset balancing techniques to ensure robustness and reliability of the findings. These techniques are (1) Synthetic Minority Over-Sampling Technique (SMOTE), (2) Under sampling, and (3) Random Over-Sampling Examples (ROSE). Addtional details of these techniques can be found in the Appendix.
A strong evaluative framework using different evaluation metrics was developed to meticulously evaluate model performance among the testing dataset. Since we are focused on classification, we used the area under the receiver operating characteristic curve (AUC-ROC), area under the precision-recall curve (AUC-PR) sensitivity (also known as recall), specificity, positive predictive value (PPV; also known as precision), negative predictive value (NPV), and F1 score to assess the predictive performance of the models. These classification statistics were chosen because they are commonly used in determining clinical utility.Citation50,Citation51 The AUC-ROC is a graphical plot of sensitivity and 1-specificity on a continuous scale. An AUC-ROC of 0.5 means prediction is no better than chance since, for a binary outcome, chance provides an accurate prediction 50% of the time. Therefore, an AUC-ROC of 1 is considered perfect prediction. While the AUC-ROC summarizes the trade offs between the true positive and false positive rates, the precision-recall curve summarizes the trade offs between the true positive rate and the PPV. For calculation of other static measures (i.e., sensitivity, specificity, PPV, NPV, and F1 score), we selected a classification threshold to maximize the Youden index.Citation52 The Youden Index is a summary measure of accuracy of a test or model which maximizes sensitivity and specificity giving equal weight to each and ranges from 0 to 1.Citation53 We also highlight the top predictors with a cumulative importance greater than 80%, a common threshold in machine-learning.Citation54 A cumulative importance greater than 80% means the top features up to that point account for 80% of the predictive power or variation explained by the model. We used a combination of one-hot encoding and label encoding to transform the candidate predictors for modeling.Citation55 One-hot encoding was used for categorical variables with no ordinal relationship creating a new binary column (0 or 1) for each category level. Label encoding was used for categorical variables with an ordinal relationship between levels; each level was assigned an integer value.
Statistical analysis
We determined the mean and standard deviation for all continuous candidate predictors and proportions for categorical candidate predictors. We used SAS v8.3 and SQL for data manipulation and Python 3.11.5 for analyses.
Sensitivity analyses
We conducted two sensitivity analyses. First, we used principal component analysis to condense the candidate predictors down to a given number of components (n = 15, 30, and 50).Citation56 Second, we limited the predictors to only those with a cumulative importance greater than 80%, following previous methodologies, to test the impact this limitation may have on the predictive performance metrics as a more parsimonious number of predictors can be helpful in clinical implementation.Citation54
Results
Sample characteristics
A total of 56,547 B-MOUD episodes (from 34,032 Veterans) met study eligibility (eFigure 2). B-MOUD episodes in the training cohort (45,237; 80.0%) and in the testing cohort (11,310; 20.0%) were similar in candidate predictor characteristics and outcomes. Of all episodes in the training cohort, 93.0% were male, 78.0% were White, 19.4% were employed, 72.3% were unemployed, 8.4% were retired and 48.3% had a concurrent drug use disorder (). For outcomes, 37.6% of episodes were retained on B-MOUD for 180 days, 9.9% experienced a fatal or non-fatal overdose, 4.9% experienced a fatal or non-fatal opioid overdose, 1.3% died of an overdose, 1.1% died of an opioid overdose, and 3.2% died from any cause in the 365 days after B-MOUD initiation for the given episode. The testing cohort had similar characteristics. The counts of each outcome (primary and secondary outcomes) before balancing are shown in eFigure 3.
Table 1. Outcome and sociodemographic characteristics among B-moud1 episodes divided into training and testing cohorts.
Predictive performance: primary outcome of B-MOUD retention
The AUC-ROC and precision-recall curves for our 5 models for B-MOUD retention in the testing sample are displayed in . Panels A and B provide the curves for the models with all candidate predictors without a balancing technique. Panels C and D, E and F, and G and H provide the results using the ROSE, SMOTE, and under-sampling balancing techniques respectively. Across techniques, GBM and RF provided the best results. The unbalanced and under-sampling samples had the same performance (GBM AUC-ROC: 0.72, RF AUC-ROC: 0.71). ROSE balancing only slightly improved predictive performance (GBM AUC-ROC: 0.72, RF AUC-ROC: 0.72) while SMOTE balancing had similar performance as the unbalanced and under-sampling (GBM AUC-ROC: 0.71, RF AUC-ROC: 0.71).
Figure 1. Area under the receiver operating curve and precision-recall curve for B-moud retention among the unbalanced and balanced with smote, rose, and under sampling techniques.
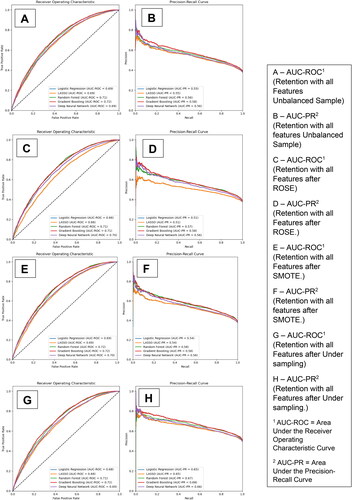
eTable 3 provides the optimized sensitivity and specificity based on the Youden index. GBM, among the unbalanced sample, had a sensitivity of 78%, specificity of 54%, PPV of 53%, and NPV of 69%. RF had a sensitivity of 75%, specificity of 55%, PPV of 52%, and NPV of 68% and both LR and LASSO had a sensitivity of 72%, specificity of 55%, PPV of 49%, and NPV of 72%.
shows the most important predictors (n = 55; cut point for cumulative performance of >80%–see Methods) for B-MOUD retention. Noteably, no single predictor contributed more than 4% to the model’s prediction for retention. The five most influential predictors were number of days between B-MOUD initiation and study start (October 1, 2005), length of VA enrollment prior to initiation of B-MOUD episode, number of days between OUD diagnosis and B-MOUD initiation, SVI Theme 3 score (minority status and language), and number of mental health visits prior to B-MOUD initiation.
Figure 2. Predictors of most importance for B-moud retention from the random forest model among the unbalanced sample (N = 55).
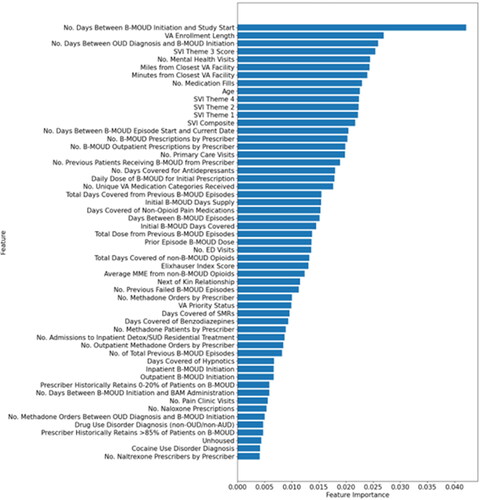
eFigures 4-6 show the most important predictors (n = 61; n = 55; n = 52 cut point for cumulative performance of >80%) for B-MOUD discontinuation after applying SMOTE, ROSE and under-sampling respectively. The most influential predictors were largely the same as in the original model based on unbalance data.
Predictive performance: Secondary outcomes
displays the AUC-ROC and precision-recall curves for our 5 models for the secondary outcomes of fatal and non-fatal overdoses, fatal and non-fatal opioid overdoses, overdose death, opioid overdose death, and all-cause mortality respectively. Panels A and B provide the curves for the models with all candidate predictors without a balancing technique for fatal and non-fatal overdoses. Panels C and D, E and F, G and H, and I and J provide the results for fatal and non-fatal opioid overdoses, overdose death, opioid overdose death, and all-cause mortality respectively. As with B-MOUD retention, GBM, RF, and DNN generally provided the highest levels of discrimination with the balancing techniques yielding slight to significant improvements in predictive performance (Fatal and Non-Fatal Opioid Overdoses—under-sampling: RF AUC-ROC: 0.77, GBM AUC-ROC: 0.76; Opioid Overdose Death—under-sampling: RF AUC-ROC: 0.79, DNN AUC-ROC: 0.78).
Figure 3. Area under the receiver operating curve and precision-recall curve for secondary outcomes among the unbalanced sample.
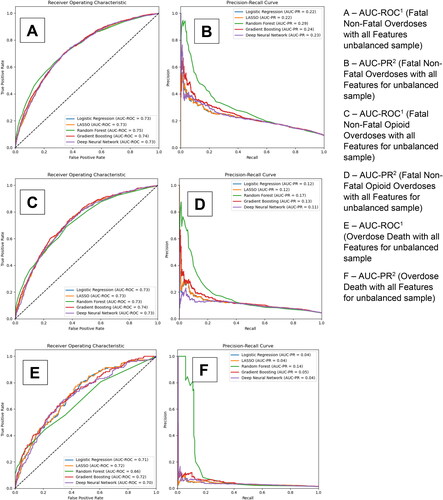
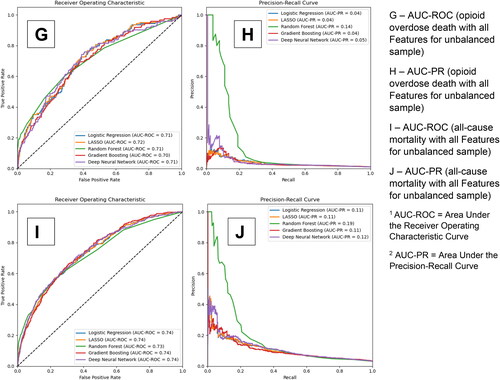
eTable 4 also provides the optimized sensitivity and specificity, based on the Youden index, for each of the secondary outcomes. For fatal and non-fatal overdoses among the unbalanced sample, GBM had an AUC-ROC of 0.74, a sensitivity of 71% and specificity of 65%, and RF had an AUC-ROC of 0.75, a sensitivity of 74% and specificity of 62%. For fatal and non-fatal opioid overdoses among the unbalanced sample, GBM had an AUC-ROC of 0.74, a sensitivity of 68% and specificity of 69%, and RF had an AUC-ROC of 0.74, a sensitivity of 65%, and specificity of 70%. For overdose death, opioid overdose death, and all-cause mortality among the unbalanced sample, GBM had an AUC-ROC of 0.71, 0.74 and 0.74 respectively and a sensitivity of 53%, 44%, and 64% and specificity of 76%, 85%, and 74% respectively.
eFigures 7-11 provide the most important predictors (n = 59 for fatal and non-fatal overdoses, n = 60 for fatal and non-fatal opioid overdoses, n = 61 for overdose death, n = 61 for opioid overdose death, and n = 60 for all-cause mortality; cut point for cumulative performance of >80%) for the unbalanced sample using the RF models. While the most influential predictors stay relatively constant, the order of these most important predictors change depending on the secondary outcome. No single predictor accounted for more than 3% of the model’s prediction of the secondary outcomes.
Sensitivity analyses
Predictive performance metrics for the models using principal components were lower than those among the full candidate predictors (AUC-ROC ranged from 0.57 to 0.63). However, limiting the number of predictors to those with cumulative importance of >80% resulted in models with similar predictive performance metrics as the full models; accuracy decreased by approximately 1% (results available upon request).
Discussion
Using national-level data from the VHA CDW, we developed and validated a suite of machine-learning models with moderate predictive performance for predicting B-MOUD retention, fatal and non-fatal overdoses, fatal and non-fatal opioid overdoses, overdose death, opioid overdose death, and all-cause mortality. For our primary outcome of B-MOUD retention, the GBM model performed similarly across the unbalanced and ROSE and under-sampling balancing techniques (0.72), likely because B-MOUD retention was not significantly unbalanced. The predictive performance for the secondary outcomes was similar across models in the unbalanced sample, also achieving moderate AUC-ROC (i.e., 0.7-0.8). Surprisingly, the DNN models either performed as well as or underperformed for all outcomes as compared to other machine-learning models, likely due to the limited number of B-MOUD episodes. DNN models generally require more data, compared to classical machine-learning models, given their complex nature. Application of SMOTE, ROSE, and under-sampling, which work best for weak classifers,Citation57 improved the predictive performance of the models among the secondary outcomes where the prevalence was low (1%-9%); under-sampling, for example, improved the predictive performance of the RF model by 0.1 for opioid overdose death (increasing from 0.69 among the unbalanced sample to 0.79). Currently there are no formal methods in clinical practice to identify patients at elevated risk of B-MOUD discontinuation. These models have important potential for real-time use within the electronic health record by clinicians to identify patients newly initiated on B-MOUD that are at high risk of B-MOUD discontinuation and experiencing fatal and non-fatal overdose that may lead to clinician interventions that could mitigate harms in this vulnerable group of patients. Specifically, a decision support tool, based on this predictive model, could be created that could update nightly to identify patients at high risk of B-MOUD discontinuation. A clinician could use this tool to talk with the patient about their risk and implement strategies to help minimize that risk (e.g., more frequent follow-up, contingency management).
While many previous studies have identified predictors of treatment retention,Citation58–63 we found only two models that have been previously published predicting treatment retention using Massachusetts All-Payer Claims DatabaseCitation52 and Treatment Episode Data Set—Discharges.Citation64 Like our study, these models did not achieve an AUC-ROC > 0.8, a common minimal target if wanting to influence clinical decisions.Citation65,Citation66 Another prediction modeling study that used electronic health record data from 23 different substance use or mental health care programs predicted B-MOUD discontinuation in the 3 months post-initiation achieved recall of 75% and precision of 90%, but the number of patients in the cohort was limited (∼5,000).Citation63 To our knowledge, no other studies have developed prediction models of the secondary outcomes used in this study (i.e., fatal and non-fatal overdoses, fatal and non-fatal opioid overdoses, overdose death, opioid overdose death, and all-cause mortality) among patients initiating MOUD for OUD. To the best of our knowledge, no studies have developed predictive models of our primary and secondary outcomes among U.S. military veterans.
Two important clinical implications can be drawn from this predictive modeling study. First, no predictor contributed more than 4% to the model’s prediction for any of the outcomes in this study. As many clinicians already know, retaining persons with OUD on MOUD is a complex issue; given that no one predictor alone contributes a substantial portion of the model’s prediction indicates that B-MOUD retention and overdose among this patient population is complex and simple heuristics that may be used by clinicians to identify likely discontinuation or overdose are unlikely to be adequate. Secondly, B-MOUD retention is a multi-faceted problem that will likely require a constelation of interventions targeting multiple predictive factors. For example, it may be that a suite of actions are needed to address the multiple predictors such as raising the B-MOUD dose, incorporating psychotherapy, or arranging transportation. In addition, these findings point to a real need for machine-learning approaches to help clinicians identify those at risk since no one predictor contributed significantly to the prediction. Our sensitivity analysis of limiting to only those predictors with a cumulative importance greater than 80% (roughly 55-60 predictors) decreased the accuracy of the models only by approximately 1%; therefore, the tradeoff between using all predictors and the limited number of predictors, when implementing in a real-time clinical decision support tool, is minimal in regard to accuracy loss but may cut down substantially the amount of computing time to derive the predictors. This would not affect the end-user clinician or patient but could help lower the information technology barriers to implementation.
Limitations
This study should be interpreted in light of several important limitations. First, B-MOUD retention was measured using B-MOUD inpatient orders or outpatient pharmacy prescriptions/administrations that were dispensed from VHA or paid for by VHA. Therefore, receipt of B-MOUD from a non-VHA pharmacy that is not paid for by VHA will not be captured and may result in misclassification of B-MOUD retention. B-MOUD receipt can also be missed if a veteran is admitted to a non-VHA hospital and uses non-VHA insurance. Second, non-fatal overdoses, as used in our secondary outcomes, are likely under-represented in the CDW as non-fatal overdoses that occur at non-VHA facilities and are not paid for by VHA are not captured in the data. Relatedly, non-fatal overdoses that do not result in a healthcare visit are not captured in any data source. Third, deaths due to overdose can also be under-represented due to undercounting of drug involvement on death certificates. Recent estimates show that opioid overdose deaths are 20-35% higher each year than reported.Citation67 Fourth, initiations of B-MOUD, despite using many years of data, are still relatively low. Therefore, more B-MOUD episodes among more veterans could be helpful for improving the predictive performance of our models, particularly for DNN. Future work will continue to refine the models as more data become available and explore the incorporation of data from other sources (e.g., unstructured data from clinical notes). Fifth, we did not require a minimum number of days of B-MOUD to constitute a B-MOUD episode which means some episodes may be from detoxification instead of true initiation of treatment. Sixth, this study evaluated B-MOUD episodes which are nested within individuals. Therefore, the validation statistics may be different if studying only the first B-MOUD episode per veteran. Seventh, Lagisetty et al. 2021,Citation24 from which the ICD-10-CM definition for OUD was derived, noted the limitations of using ICD-9-CM/ICD-10-CM codes for identifying individuals with true OUD. Specifically, the authors note only 57.7% of veterans identified as having OUD per ICD-9-CM/ICD-10-CM codes were categorized as high likelihood of truly having OUD. Therefore, the use of any ICD-based definition of OUD may overestimate the number of veterans with OUD. Eighth, traditional machine learning approaches, such as those used in this study (e.g., random forest), do not provide information on the directional effects of predictor variables. Therefore, we cannot provide coefficients for the magnitude and direction of effect of a particular predictor on the outcome of interest.
Conclusions
Through this study, we demonstrate the feasibility of developing and validating a suite of machine-learning algorithms to predict B-MOUD retention, fatal and non-fatal overdoses, and death among veterans initiating B-MOUD for OUD treatment. All of our models have moderate predictive performance. Future research should assess how these models can be improved with additional data sources (e.g., clinical notes). Future research should also evaluate how these models can be incorporated into an electronic health record-based clinical decision support tool identifying veterans at elevated risk of B-MOUD discontinuation and other important MOUD-related outcomes.
Disclaimer
The content is solely the responsibility of the authors and does not necessarily represent the official views of the U.S. Department of Veterans Affairs or the U.S. Government.
wjad_a_2363035_sm2692.docx
Download MS Word (2.7 MB)Disclosure statement
None to declare.
Additional information
Funding
References
- Hedegaard H, Miniño AM, Spencer MR, Warner M. Drug overdose deaths in the United States, 1999–2020 (NCHS Data Brief. no 428). Hyattsville, MD: National Center for Health Statistics; 2021.
- Jones CM, Einstein EB, Compton WM. Changes in synthetic opioid involvement in drug overdose deaths in the United States, 2010-2016. JAMA. 2018;319(17):1819–21. Doi:https://dx.doi.org/10.15620/cdc:112340.
- O'Donnell J, Gladden RM, Mattson CL, Hunter CT, Davis NL. Vital signs: characteristics of drug overdose deaths involving opioids and stimulants—24 states and the District of Columbia, January–June 2019. MMWR Morb Mortal Wkly Rep. 2020;69(35):1189–97. doi:10.15585/MMWR.MM6935A1.
- Drug Overdose Deaths | Drug Overdose | CDC Injury Center [Accessed 2023 Sep 7]. https://www.cdc.gov/drugoverdose/deaths/index.html.
- JEC Analysis Finds Opioid Epidemic Cost U.S. Nearly $1.5 Trillion in 2020 - JEC Analysis Finds Opioid Epidemic Cost U.S. Nearly $1.5 Trillion in 2020 - United States Joint Economic Committee [Accessed 2023 Sep 7]. https://www.jec.senate.gov/public/index.cfm/democrats/2022/9/jec-analysis-finds-opioid-epidemic-cost-u-s-nearly-1-5-trillion-in-2020.
- Gordon AJ, Trafton JA, Saxon AJ, Gifford AL, Goodman F, Calabrese VS, McNicholas L, Liberto J, Buprenorphine Work Group of the Substance Use Disorders Quality Enhancement Research Initiative. Implementation of buprenorphine in the Veterans Health Administration: results of the first 3 years. Drug Alcohol Depend. 2007;90(2-3):292–6. doi:10.1016/j.drugalcdep.2007.03.010.
- Wyse JJ, Gordon AJ, Dobscha SK, Morasco BJ, Tiffany E, Drexler K, Sandbrink F, Lovejoy TI. Medications for opioid use disorder in the Department of Veterans Affairs (VA) health care system: historical perspective, lessons learned, and next steps. Subst Abus. 2018;39(2):139–44. doi:10.1080/08897077.2018.1452327.
- Mattick RP, Breen C, Kimber J, Davoli M. Buprenorphine maintenance versus placebo or methadone maintenance for opioid dependence. Cochrane Database Syst Rev. 2014; 2014(2):CD002207. doi:10.1002/14651858.CD002207.pub4.
- Schwartz RP, Gryczynski J, O'Grady KE, Sharfstein JM, Warren G, Olsen Y, Mitchell SG, Jaffe JH. Opioid agonist treatments and heroin overdose deaths in Baltimore, Maryland, 1995–2009. Am J Public Health. 2013;103(5):917–22. doi:10.2105/AJPH.2012.301049.
- National Academies of Sciences, Engineering, and Medicine. Medications for opioid use disorder save lives. Washington, DC: The National Academies Press; 2019.
- Timko C, Schultz NR, Cucciare MA, Vittorio L, Garrison-Diehn C. Retention in medication-assisted treatment for opiate dependence: a systematic review. J Addict Dis. 2016;35(1):22–35. doi:10.1080/10550887.2016.1100960.
- Bart G. Maintenance medication for opiate addiction: the foundation of recovery. J Addict Dis. 2012;31(3):207–25. doi:10.1080/10550887.2012.694598.
- Gordon AJ, Drexler K, Hawkins EJ, Burden J, Codell NK, Mhatre-Owens A, Dungan MT, Hagedorn H. Stepped Care for Opioid Use Disorder Train the Trainer (SCOUTT) initiative: expanding access to medication treatment for opioid use disorder within Veterans Health Administration facilities. Subst Abus. 2020;41(3):275–82. doi:10.1080/08897077.2020.1787299.
- Hagedorn H, Kenny M, Gordon AJ, Ackland PE, Noorbaloochi S, Yu W, Harris AHS. Advancing pharmacological treatments for opioid use disorder (ADaPT-OUD): protocol for testing a novel strategy to improve implementation of medication-assisted treatment for veterans with opioid use disorders in low-performing facilities. Addict Sci Clin Pract. 2018;13(1):25. doi:10.1186/s13722-018-0127-z.
- Wyse JJ, Shull S, Lindner S, Morasco BJ, Gordon AJ, Carlson KF, Korthuis PT, Ono SS, Liberto JG, Lovejoy TI. Access to medications for opioid use disorder in rural versus urban Veterans Health Administration facilities. J Gen Intern Med. 2023;38(8):1871–1876. doi:10.1007/s11606-023-08027-4.
- Gordon AJ, Saxon AJ, Kertesz S, Wyse JJ, Manhapra A, Lin LA, Chen W, Hansen J, Pinnell D, Huynh T, et al. Buprenorphine use and courses of care for opioid use disorder treatment within the Veterans Health Administration. Drug Alcohol Depend. 2023;248:109902. doi:10.1016/J.DRUGALCDEP.2023.109902.
- Teruya C, Schwartz RP, Mitchell SG, Hasson AL, Thomas C, Buoncristiani SH, Hser Y-I, Wiest K, Cohen AJ, Glick N, et al. Patient perspectives on buprenorphine/naloxone: a qualitative study of retention during the starting treatment with agonist replacement therapies (START) study. J Psychoactive Drugs. 2014;46(5):412–26. doi:10.1080/02791072.2014.921743.
- National Quality Forum. NQF: Behavioral Health 2016-2017 Final Report; 2017 [Accessed 2019 Oct 8]. https://www.qualityforum.org/Publications/2017/08/Behavioral_Health_2016-2017_Final_Report.aspx
- Oliva EM, Bowe T, Tavakoli S, Martins S, Lewis ET, Paik M, Wiechers I, Henderson P, Harvey M, Avoundjian T, et al. Development and applications of the Veterans Health Administration’s Stratification Tool for Opioid Risk Mitigation (STORM) to improve opioid safety and prevent overdose and suicide. Psychol Serv. 2017;14(1):34–49. doi:10.1037/ser0000099.
- REACH VET recovery engagement and coordination for health-veterans enhanced treatment predictive analytics for suicide prevention program overview; 2018 [Accessed 2019 Sep 5]. https://www.hsrd.research.va.gov/for_researchers/cyber_seminars/archives/3527-notes.pdf.
- Lehnert EA, Wilt G, Flanagan B, Hallisey E. Spatial exploration of the CDC’s Social Vulnerability Index and heat-related health outcomes in Georgia. Int J Disaster Risk Reduct. 2020;46:101517. doi:10.1016/J.IJDRR.2020.101517.
- Bossuyt PM, Reitsma JB, Bruns DE, Gatsonis CA, Glasziou PP, Irwig L, Lijmer JG, Moher D, Rennie D, de Vet HCW, et al. STARD 2015: an updated list of essential items for reporting diagnostic accuracy studies. BMJ. 2015;351:h5527. doi:10.1136/BMJ.H5527.
- Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med. 2015;162(1):55–63. doi:10.7326/M14-0697.
- Lagisetty P, Garpestad C, Larkin A, Macleod C, Antoku D, Slat S, Thomas J, Powell V, Bohnert ASB, Lin LA, et al. Identifying individuals with opioid use disorder: validity of International Classification of Diseases diagnostic codes for opioid use, dependence and abuse. Drug Alcohol Depend. 2021;221:108583. doi:10.1016/J.DRUGALCDEP.2021.108583.
- Fairley M, Humphreys K, Joyce VR, Bounthavong M, Trafton J, Combs A, Oliva EM, Goldhaber-Fiebert JD, Asch SM, Brandeau ML, et al. Cost-effectiveness of treatments for opioid use disorder. JAMA Psychiatry. 2021;78(7):767–77. doi:10.1001/JAMAPSYCHIATRY.2021.0247.
- Olfson M, Zhang Shu V, Schoenbaum M, King M. Trends in buprenorphine treatment in the United States, 2009-2018. JAMA. 2020;323(3):276–7. doi:10.1001/JAMA.2019.18913.
- Samples H, Williams AR, Olfson M, Crystal S. Risk factors for discontinuation of buprenorphine treatment for opioid use disorders in a multi-state sample of Medicaid enrollees. J Subst Abuse Treat. 2018;95:9–17. doi:10.1016/J.JSAT.2018.09.001.
- USING DATA TO PREVENT VETERAN MORTALITY. A guide to accessing & understanding mortality data in the VA mortality data repository [Accessed 2023 Oct 2]. www.mentalhealth.va.gov/.
- Williams AR, Samples H, Crystal S, Olfson M. Acute care, prescription opioid use, and overdose following discontinuation of long-term buprenorphine treatment for opioid use disorder. Am J Psychiatry. 2020;177(2):117–24. doi:10.1176/appi.ajp.2019.19060612.
- Charlson ME, Charlson RE, Peterson JC, Marinopoulos SS, Briggs WM, Hollenberg JP. The Charlson comorbidity index is adapted to predict costs of chronic disease in primary care patients. J Clin Epidemiol. 2008;61(12):1234–40. doi:10.1016/j.jclinepi.2008.01.006.
- Cacciola JS, Alterman AI, Dephilippis D, Drapkin ML, Valadez C, Fala NC, Oslin D, McKay JR. Development and initial evaluation of the Brief Addiction Monitor (BAM). J Subst Abuse Treat. 2013;44(3):256–63. doi:10.1016/j.jsat.2012.07.013.
- Weiner SG, El Ibrahimi S, Hendricks MA, Hallvik SE, Hildebran C, Fischer MA, Weiss RD, Boyer EW, Kreiner PW, Wright DA, et al. Factors associated with opioid overdose after an initial opioid prescription. JAMA Netw Open. 2022;5(1):e2145691-e2145691. doi:10.1001/JAMANETWORKOPEN.2021.45691.
- Lyons RM, Yule AM, Schiff D, Bagley SM, Wilens TE. Risk factors for drug overdose in young people: a systematic review of the literature. J Child Adolesc Psychopharmacol. 2019;29(7):487–97. doi:10.1089/CAP.2019.0013.
- Duca JV, Rosenthal SS. Borrowing constraints and access to owner-occupied housing. Reg Sci Urban Econ. 1994;24(3):301–22. doi:10.1016/0166-0462(93)02041-Z.
- Kaplan D, Venezky RL. Literacy and voting behavior: a bivariate probit model with sample selection. Soc Sci Res. 1994;23(4):350–67. doi:10.1006/ssre.1994.1014.
- Alford DP, LaBelle CT, Kretsch N, Bergeron A, Winter M, Botticelli M, Samet JH. Collaborative care of opioid-addicted patients in primary care using buprenorphine. Arch Intern Med. 2011;171(5):425–31. doi:10.1001/archinternmed.2010.541.
- Hui D, Weinstein ZM, Cheng DM, Quinn E, Kim H, Labelle C, Samet JH. Very early disengagement and subsequent re-engagement in primary care Office Based Opioid Treatment (OBOT) with buprenorphine. J Subst Abuse Treat. 2017;79:12–9. doi:10.1016/j.jsat.2017.05.010.
- Cousins SJ, Radfar SR, Crèvecoeur-MacPhail D, Ang A, Darfler K, Rawson RA. Predictors of continued use of extended-released naltrexone (XR-NTX) for opioid-dependence: an analysis of heroin and non-heroin opioid users in Los Angeles County. J Subst Abuse Treat. 2016;63:66–71. doi:10.1016/J.JSAT.2015.12.004.
- Sullivan MA, Rothenberg JL, Vosburg SK, Church SH, Feldman SJ, Epstein EM, Kleber HD, Nunes EV. Predictors of retention in naltrexone maintenance for opioid dependence: analysis of a Stage I trial. Am J Addict. 2006;15(2):150–9. doi:10.1080/10550490500528464.
- VA Priority Groups [Accessed 2023 Nov 27]. https://veteran.com/va-priority-groups/.
- Quan H, Sundararajan V, Halfon P, Fong A, Burnand B, Luthi J-C, Saunders LD, Beck CA, Feasby TE, Ghali WA, et al. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Med Care. 2005;43(11):1130–9. doi:10.1097/01.mlr.0000182534.19832.83.
- Sharma N, Schwendimann R, Endrich O, Ausserhofer D, Simon M. Comparing Charlson and Elixhauser comorbidity indices with different weightings to predict in-hospital mortality: an analysis of national inpatient data. BMC Health Serv Res. 2021;21(1):13. doi:10.1186/S12913-020-05999-5/TABLES/3.
- Mehta HB, Li S, An H, Goodwin JS, Alexander GC, Segal JB. Development and Validation of the Summary Elixhauser Comorbidity Score for Use With ICD-10-CM–Coded Data Among Older Adults. Ann Intern Med. 2022;175(10):1423–30. doi:10.7326/M21-4204.
- USDA ERS - rural-urban commuting area codes [Accessed 2023 Oct 2]. https://www.ers.usda.gov/data-products/rural-urban-commuting-area-codes/
- Finlay AK, Harris AHS, Timko C, Yu M, Smelson D, Stimmel M, Binswanger IA. Disparities in access to medications for opioid use disorder in the veterans health administration. J Addict Med. 2021;15(2):143–9. doi:10.1097/ADM.0000000000000719.
- Chu A, Ahn H, Halwan B, Kalmin B, Artifon ELA, Barkun A, Lagoudakis MG, Kumar A. A decision support system to facilitate management of patients with acute gastrointestinal bleeding. Artif Intell Med. 2008;42(3):247–59. doi:10.1016/J.ARTMED.2007.10.003.
- Hastie T, Tibshirani R, Friedman J. The elements of statistical learning. Published online 2009; doi:10.1007/978-0-387-84858-7.
- Lo-Ciganic W-H, Huang JL, Zhang HH, Weiss JC, Wu Y, Kwoh CK, Donohue JM, Cochran G, Gordon AJ, Malone DC, et al. Evaluation of machine-learning algorithms for predicting opioid overdose risk among medicare beneficiaries with opioid prescriptions. JAMA Netw Open. 2019;2(3):e190968. doi:10.1001/jamanetworkopen.2019.0968.
- Radzi SFM, Karim MKA, Saripan MI, Rahman MAA, Isa INC, Ibahim MJ. Hyperparameter tuning and pipeline optimization via grid search method and tree-based autoML in breast cancer prediction. J Pers Med. 2021;11(10):978. doi:10.3390/JPM11100978.
- Zhu W, Zeng NF, Wang N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS. Published online 2010.
- Parikh R, Mathai A, Parikh S, Sekhar GC, Thomas R. Understanding and using sensitivity, specificity and predictive values. Indian J Ophthalmol. 2008;56(1):45–50. doi:10.4103/0301-4738.37595.
- Hasan MM, Young GJ, Shi J, Mohite P, Young LD, Weiner SG, Noor-E-Alam M. A machine learning based two-stage clinical decision support system for predicting patients’ discontinuation from opioid use disorder treatment: retrospective observational study. BMC Med Inform Decis Mak. 2021;21(1):331. doi:10.1186/S12911-021-01692-7.
- Schisterman EF, Faraggi D, Reiser B, Hu J. Youden Index and the optimal threshold for markers with mass at zero. Stat Med. 2008;27(2):297–315. doi:10.1002/SIM.2993.
- Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A. Feature selection and classification in multiple class datasets: an application to KDD Cup 99 dataset. Expert Syst Appl. 2011;38(5):5947–57. doi:10.1016/j.eswa.2010.11.028.
- Ashenden SK, Bartosik A, Agapow PM, Semenova E. Introduction to artificial intelligence and machine learning. The era of artificial intelligence, machine learning, and data science in the pharmaceutical industry. Published online January 1, 2021. p. 15–26. doi:10.1016/B978-0-12-820045-2.00003-9.
- Lever J, Krzywinski M, Altman N. Principal component analysis. Nat Methods. 2017;14(7):641–2. https://www.nature.com/articles/nmeth.4346 doi:10.1038/nmeth.4346.
- Elor Y, Averbuch-Elor H. To SMOTE, or not to SMOTE? Published online January 21, 2022 [Accessed 2024 Jan 17]. https://arxiv.org/abs/2201.08528v3
- Manhapra A, Petrakis I, Rosenheck R. Three-year retention in buprenorphine treatment for opioid use disorder nationally in the Veterans Health Administration. Am J Addict. 2017;26(6):572–80. doi:10.1111/AJAD.12553.
- Mintz CM, Presnall NJ, Xu KY, Hartz SM, Sahrmann JM, Bierut LJ, Grucza RA. An examination between treatment type and treatment retention in persons with opioid and co-occurring alcohol use disorders. Drug Alcohol Depend. 2021;226:108886. doi:10.1016/J.DRUGALCDEP.2021.108886.
- Ware OD, Manuel JI, Huhn AS. Adults with opioid and methamphetamine co-use have lower odds of completing short-term residential treatment than other opioid co-use groups: a retrospective health services study. Front Psychiatry. 2021;12:784229. doi:10.3389/FPSYT.2021.784229/BIBTEX.
- Manhapra A, Agbese E, Leslie DL, Rosenheck RA. Three-year retention in buprenorphine treatment for opioid use disorder among privately insured adults. Psychiatr Serv. 2018;69(7):768–76. doi:10.1176/APPI.PS.201700363/SUPPL_FILE/APPI.PS.201700363.DS001.PDF.
- Mintz CM, Presnall NJ, Sahrmann JM, Borodovsky JT, Glaser PEA, Bierut LJ, Grucza RA. Age disparities in six-month treatment retention for opioid use disorder. Drug Alcohol Depend. 2020;216:108312. doi:10.1016/J.DRUGALCDEP.2020.108130.
- Ker S, Hsu J, Balani A, Mukherjee SS, Rush AJ, Khan M, Elchehabi S, Huffhines S, DeMoss D, Rentería ME, et al. Factors that affect patient attrition in buprenorphine treatment for opioid use disorder: a retrospective real-world study using electronic health records. Neuropsychiatr Dis Treat. 2021;17:3229–44. doi:10.2147/NDT.S331442.
- Stafford C, Marrero WJ, Naumann RB, Lich KH, Wakeman S, Jalali MS. Identifying key risk factors for premature discontinuation of opioid use disorder treatment in the United States: a predictive modeling study. Drug Alcohol Depend. 2022;237:109507. doi:10.1016/J.DRUGALCDEP.2022.109507.
- Hosmer DW, Jr., Lemeshow S. Applied logistic regression. 2nd Edition. New York: John Wiley & Sons, Inc.; 2000.
- Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, Pencina MJ, Kattan MW. Assessing the performance of prediction models: A framework for traditional and novel measures. Epidemiology. 2010;21(1):128–38. doi:10.1097/EDE.0b013e3181c30fb2.
- Ruhm CJ. Corrected US opioid-involved drug poisoning deaths and mortality rates, 1999–2015. Addiction. 2018;113(7):1339–44. doi:10.1111/ADD.14144.
- Freijeiro-González L, Febrero-Bande M, González-Manteiga W. A critical review of LASSO and its derivatives for variable selection under dependence among covariates. Int Statistical Rev. 2022;90(1):118–45. doi:10.1111/insr.12469.
- Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. doi:10.1023/A:1010933404324.
- Svetnik V, Liaw A, Tong C, Christopher Culberson J, Sheridan RP, and Feuston BP. Random forest: a classification and regression tool for compound classification and QSAR modeling. J Chem Inf Comput Sci. 2003;43(6):1947–58. Published online doi:10.1021/CI034160G.
- Natekin A, Knoll A. Gradient boosting machines, a tutorial. Front Neurorobot. 2013;7(DEC):63623. doi:10.3389/FNBOT.2013.00021/BIBTEX.
- Montavon G, Samek W, Müller KR. Methods for interpreting and understanding deep neural networks. Digit Signal Process. 2018;73:1–15. doi:10.1016/j.dsp.2017.10.011.
- Cao XH, Stojkovic I, Obradovic Z. A robust data scaling algorithm to improve classification accuracies in biomedical data. BMC Bioinform. 2016;17(1):359. doi:10.1186/S12859-016-1236-X.
- Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. jair. 2002;16:321–57. doi:10.1613/jair.953.
- Liu XY, Wu J, Zhou ZH. Exploratory undersampling for class-imbalance learning. IEEE Trans Syst Man Cybern B Cybern. 2009;39(2):539–50. doi:10.1109/TSMCB.2008.2007853.
- Lunardon N, Menardi G, Torelli N. ROSE: A package for binary imbalanced learning. R Journal. 2014;6(1):79–89. doi:10.32614/RJ-2014-008.
- Wadekar AS. Understanding Opioid Use Disorder (OUD) using tree-based classifiers. Drug Alcohol Depend. 2020;208:107839. doi:10.1016/J.DRUGALCDEP.2020.107839.
- Sharma B, Dligach D, Swope K, Salisbury-Afshar E, Karnik NS, Joyce C, Afshar M. Publicly available machine learning models for identifying opioid misuse from the clinical notes of hospitalized patients. BMC Med Inform Decis Mak. 2020;20(1):79. doi:10.1186/S12911-020-1099-Y.
- Ellis RJ, Wang Z, Genes N, Ma’ayan A. Predicting opioid dependence from electronic health records with machine learning. BioData Min. 2019;12(1):3. doi:10.1186/S13040-019-0193-0.
- Vunikili R, Glicksberg BS, Johnson KW, Dudley JT, Subramanian L, Shameer K. Predictive modelling of susceptibility to substance abuse, mortality and drug-drug interactions in opioid patients. Front Artif Intell. 2021;4:742723. doi:10.3389/FRAI.2021.742723.
- Hasan MM, Young GJ, Patel MR, Modestino AS, Sanchez LD, Noor-E-Alam M. A machine learning framework to predict the risk of opioid use disorder. Mach Learn Appl. 2021;6:100144. doi:10.1016/j.mlwa.2021.100144.
Appendix
Machine learning methods
For this study, we used five candidate machine-learning algorithms: (1) Multiple Logistic Regression (MLR), (2) Least Absolute Shrinkage and Selection Operator-Type Regression (LASSO) (3) Gradient Boosting Machine (GBM), (4) Random Forest (RF), and (5) Deep Neural Network (DNN). MLR, widely used in studies with binary outcomes, models the log odds of the outcome as a specified function of the predictor variables.Citation65 MLR can have poor performance classifying the binary outcome when there are many predictors or multicollinearity. To address this limitation, we used a variant of MLR, LASSO regression that performs variable selection, thus allowing for a more parsimonious model and addressing multicollinearity. LASSO models use L1 regularization that results in some coefficient estimates being “shrunk” to exactly zero, thus de-selecting these variables from the model.Citation68 Both MLR and LASSO regression require the analyst to specify a parametric form for the model, which can lead to poor model performance if the model form is incorrect. To address this limitation to parametric regression, we used two alternative algorithms, RF and GBM, that combine non-parametric decision tree classifiers to optimize outcome classification and a deep learning algorithm (DNN). RF is an ensemble decision tree-based algorithm that builds numerous decision trees in parallel to classify the outcomes and outputs the mode of the classes (classification) of the individual trees for a given input. RF is a flexible algorithm that can handle many predictor variables without making strong parametric assumptions about model form and prevents overfitting by building many decision trees and combining their outputs.Citation69,Citation70 GBM is an ensemble learning technique that sequentially combines multiple decision trees.Citation71 While both RF and GBM are ensemble decision tree methods, RF independently constructs large numbers of shallow trees while GBM is trained sequentially, building trees one at a time, correcting errors of the prior tree. For this study, we used the ‘GradientBoostingClassifer’ from the scikit-learn library in Python. DNN is a “deep learning” alternative to the algorithms described above. “Deep learning” refers to the use of multiple layers that extract higher-level features from the candidate predictors. DNN models form an interconnected network from the layers, which allows for interpretation of complex patterns in the data. DNNs adaptively learn from data by iteratively refining their parameters to minimize predicted error through procedures like backpropagation and utilizing various optimization approaches.Citation72
Hyperparameter tuning
We used the GridSearchCV technique for hyperparameter tuning.Citation49 GridSearchCV provides each model hyperparameter with a range of possible values. The method uses cross-validation to fit the model, assess how well it works, and repeats the steps for each combination of these hyperparameter values. Cross-validation is a technique for assessing how the results of a model will generalize to an independent dataset. The dataset is split into two groups, a single of which is used for training the model and the other for testing it. This process is carried out multiple times using different data chunks. With this approach, the model’s optimum performance is determined by systematically finding the predefined hyperparameters. Below are the chosen hyperparameters for each model type.
Multiple logistic Regression (MLR)
StandardScaler was used to normalize the candidate predictors before implementing MLR.Citation73 For robustness in high-dimensional data settings, the MLR model was set up to iterate 10,000 times (max_iter = 10000) to ensure convergence.
Random Forest (RF)
RF is well-known for its effectiveness in managing intricate relationships and non-linear interactions. For hyperparameter tuning, the number of trees in the forest (n_estimator), maximum depth of each tree (max_depth), the minimum number of samples required to split an internal node (min_sample_split), minimum number of samples required to be at a leaf node (min_samples_leaf) were considered. We selected hyperparamaters based on the values that maximized the AUC-ROC. Specifically, we set the maximum depth of the trees at 30 (max_depth = 30) as this allowed for a balance between overfitting risk and model complexity. Two (min_samples_split = 2) and four samples (min_samples_leaf = 4) were the minimal numbers used to split an internal node and reach a leaf node, respectively. This arrangement enhances the model’s accuracy and helps improve the decision rules. A reliable aggregated prediction could be made with 300 trees in the ensemble (i.e., n_estimators = 300).
Gradient boosting machine (GBM)
For GBM, the hyperparameters considered were number of boosting stages to be run (n_estimators), shrinks the contribution of each tree (learning_rate), maximum depth of the individual regression estimators (max_depth), the minimum number of samples required to split an internal node (min_sample_split), and the minimum number of samples required to be at a leaf node (min_samples_leaf). Like with RF, the hyperparamaters were selected based on the values that maximized the AUC-ROC. Specifically, we set the learning rate to 0.2 (learning_rate = 0.2), which balances learning accuracy and speed. To avoid overfitting, the maximum depth of each regression estimator was restricted to 3 (max_depth = 3). The model was set up with the least number of samples needed at a leaf node (min_samples_leaf = 1) and the minimum number of samples required to split a node (min_samples_split = 2), respectively. This architecture ensures a fine-grained approach to learning from the data. Two hundred trees (n_estimators = 200) made up the ensemble, which balanced computational effectiveness and model complexity.
Deep neural network (DNN)
We tuned the DNN’s architecture and training procedure to maximize performance while reducing the possibility of overfitting. The number of features in the training dataset represents the dimensionality of the input that the first layer, a dense layer with 64 neurons, receives. This layer’s neurons use the Rectified Linear Unit (ReLU) activation function, which adds non-linearity to the model and helps it recognize more intricate patterns in the input. A dropout layer, which has a dropout rate of 0.5, is added after the first dense layer. By lessening the model’s sensitivity to certain weights, this layer helps avoid overfitting by arbitrarily setting a percentage of input units to 0 at each training update. The following layer is also dense and uses the ReLU activation function; it has 32 neurons. The modified inputs from the preceding levels are further processed in this layer. This dropout layer gives the model an extra degree of regularization by having a dropout rate of 0.5, much like the second layer. The final layer uses the sigmoid function and is dense, consisting of a single neuron. This setup works especially well for binary classification problems, such as those we were trying to model, since the output of the sigmoid function is a value between 0 and 1, which indicates the likelihood that the input belongs to one of the two classes.
Methods for addressing imbalanced data
We used three techniques for reducing inherent imbalances in the datasets and assist model-building with improved prediction accuracy and generalization capacities. All three were used to be able to compare how each model performs with each technique. These techniques are (1) Synthetic Minority Over-Sampling Technique (SMOTE), (2) under-sampling, and (3) Random Over-Sampling Examples (ROSE). SMOTE aims to balance the class distribution by generating synthetic instances of the minority class, thereby enhancing the model’s ability to generalize well to unseen data.Citation74 Under-sampling is a technique designed to adjust the class distribution by randomly eliminating some of the instances from the majority class. This helps in mitigating the dominance of the majority class and allows the model to perform better on minority instances.Citation75 ROSE is an advanced over-sampling technique that generates synthetic instances of the minority class by considering the feature space’s distribution. This method not only increases the minority class instances but also introduces variability, aiding the model in better understanding and classifying the minority class.Citation76 Several studies have shown these techniques improve prediction results.Citation77–81