
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we consider the problem of finding ε-approximate stationary points of convex functions that are p-times differentiable with ν-Hölder continuous pth derivatives. We present tensor methods with and without acceleration. Specifically, we show that the non-accelerated schemes take at most iterations to reduce the norm of the gradient of the objective below given
. For accelerated tensor schemes, we establish improved complexity bounds of
and
, when the Hölder parameter
is known. For the case in which ν is unknown, we obtain a bound of
for a universal accelerated scheme. Finally, we also obtain a lower complexity bound of
for finding ε-approximate stationary points using p-order tensor methods.
1. Introduction
1.1. Motivation
In this paper, we study tensor methods for unconstrained optimization, i.e. methods in which the iterates are obtained by the (approximate) minimization of models defined from high-order Taylor approximations of the objective function. This type of method is not new in the optimization literature (see, e.g. [Citation1,Citation4,Citation33]). Recently, the interest for tensor methods has been renewed by the work in [Citation2], where p-order tensor methods were proposed for unconstrained minimization of nonconvex functions with Lipschitz continuous pth derivatives. It was shown that these methods take at most iterations to find an ε-approximate first-order stationary point of the objective, generalizing the bound of
, originally established in [Citation31] for the Cubic Regularization of Newton's Method (p = 2). After [Citation2], several high-order methods have been proposed and analysed for nonconvex optimization (see, e.g. [Citation9–11,Citation23]), resulting even in worst-case complexity bounds for the number of iterations that p-order methods need to generate approximate qth order stationary points [Citation7,Citation8].
More recently, in [Citation27], p-order tensor methods with and without acceleration were proposed for unconstrained minimization of convex functions with Lipschitz continuous pth derivatives. As it is usual in Convex Optimization, these methods aim the generation of a point such that
, where f is the objective function,
is its optimal value and
is a given precision. Specifically, it was shown that the non-accelerated scheme takes at most
iterations to reduce the functional residual below a given
, while the accelerated scheme takes at most
iterations to accomplish the same task. Auxiliary problems in these methods consist in the minimization of a
-regularization of the pth order Taylor approximation of the objective, which is a multivariate polynomial. A remarkable result shown in [Citation27] (which distinguishes this work from [Citation1]) is that, in the convex case, the auxiliary problems in tensor methods become convex when the corresponding regularization parameter is sufficiently large. Since [Citation27], several high-order methods have been proposed for convex optimization (see, e.g. [Citation13,Citation14,Citation18,Citation20]), including near-optimal methods [Citation5,Citation15,Citation21,Citation28,Citation29] motivated by the second-order method in [Citation24]. In particular, in [Citation18], we have adapted and generalized the methods in [Citation16,Citation17,Citation27] to handle convex functions with ν-Hölder continuous pth derivatives. It was shown that the non-accelerated schemes take at most
iterations to generate a point with functional residual smaller than a given
, while the accelerated variants take only
iterations when the parameter ν is explicitly used in the scheme. For the case in which ν is not known, we also proposed a universal accelerated scheme for which we established an iteration complexity bound of
.
As a natural development, in this paper, we present variants of the p-order methods () proposed in [Citation18] that aim the generation of a point
such that
, for a given threshold
. In the context of nonconvex optimization, finding approximate stationary points is usually the best one can expect from local optimization methods. In the context of convex optimization, one motivation to search for approximate stationary points is the fact that the norm of the gradient may serve as a measure of feasibility and optimality when one applies the dual approach for solving constrained convex problems (see, e.g. [Citation26]). Another motivation comes from the inexact high-order proximal-point methods, recently proposed in [Citation28,Citation29], in which the iterates are computed as approximate stationary points of uniformly convex models.
Specifically, our contributions are the following:
We show that the non-accelerated schemes in [Citation18] take at most
iterations to reduce the norm of the gradient of the objective below a given
For accelerated tensor schemes, we establish improved complexity bounds of
For the case in which ν and the corresponding Hölder constant are known, we propose tensor schemes for the composite minimization problem. In particular, we prove a bound of
Considering the same class of difficult functions described in [Citation18], we derive a lower complexity bound of
The paper is organized as follows. In Section 2, we define our problem. In Section 3, we present complexity results for tensor schemes without acceleration. In Section 4, we present complexity results for accelerated schemes. In Section 5, we analyse tensor schemes for the composite minimization problem. Finally, in Section 6, we establish lower complexity bounds for tensor methods find ε-approximate stationary points of convex functions under the Hölder condition. Some auxiliary results are left in the Appendix.
1.2. Notations and generalities
Let be a finite-dimensional real vector space, and
be its dual space. We denote by
the value of the linear functional
at point
. Spaces
and
are equipped with conjugate Euclidean norms:
(1)
(1) where
is a self-adjoint positive definite operator (
). For a smooth function
, denote by
its gradient, and by
its Hessian evaluated at point
. Then
and
for
.
For any integer , denote by
the directional derivative of function f at x along directions
,
. For any
and
we have
If
, we denote
by
. Using this notation, the pth order Taylor approximation of function f at
can be written as follows:
(2)
(2) where
(3)
(3) Since
is a symmetric p-linear form, its norm is defined as:
It can be shown that (see, e.g. Appendix 1 in [Citation30])
Similarly, since
is also a symmetric p-linear form for fixed
, it follows that
2. Problem statement
In this paper, we consider methods for solving the following minimization problem
(4)
(4) where
is a convex function p-times differentiable. We assume that (Equation4
(4)
(4) ) has at least one optimal solution
. As in [Citation18], the level of smoothness of the objective f will be characterized by the family of Hölder constants
(5)
(5) From (Equation5
(5)
(5) ), it can be shown that, for all
,
(6)
(6)
(7)
(7)
and
(8)
(8) Given
, if
and
, by (Equation6
(6)
(6) ) we have
(9)
(9) This property motivates the use of the following class of models of f around
:
(10)
(10) Note that, by (Equation9
(9)
(9) ), if
then
for all
.
3. Tensor schemes without acceleration
Let us consider the following assumption:
| H1 |
| ||||

Remark 3.1
If ν is unknown, by (Equation11(11)
(11) ) we set
in Algorithm 1. The resulting algorithm is a universal scheme that can be viewed as a generalization of the universal second-order method (6.10) in [Citation16]. Moreover, it is worth mentioning that for p = 3 and
, one can use Gradient Methods with Bregman distance [Citation19] to approximately solve (12) in the sense of (13).
For both cases (ν known or unknown), Algorithm 1 is a particular instance of Algorithm 1 in [Citation18] in which for all
. Let us define the following function of ε:
(15)
(15) The next lemma provides upper bounds on
and on the number of calls of the oracle in Algorithm 1.
Lemma 3.1
Suppose that H1 holds. Given , assume that
is a sequence generated by Algorithm 1 such that
(16)
(16) Then,
(17)
(17) and, consequently,
(18)
(18) Moreover, the number
of calls of the oracle after T iterations is bounded as follows:
(19)
(19)
Proof.
Let us prove (Equation17(17)
(17) ) by induction. Clearly, it holds for t = 0. Assume that (Equation17
(17)
(17) ) is true for some t,
. If ν is known, then by (Equation11
(11)
(11) ) we have
. Thus, it follows from H1 and Lemma A.2 in [Citation18] that the final value of
cannot be bigger than
, since otherwise we should stop the line search earlier. Therefore,
that is, (Equation17
(17)
(17) ) holds for t = t + 1. On the other hand, if ν is unknown, we have
. In view of (Equation16
(16)
(16) ), Corollary A.5 [Citation18] and
, we must have
Consequently, it follows that
that is, (Equation17
(17)
(17) ) holds for t + 1. This completes the induction argument. Using (Equation17
(17)
(17) ), for
we get
. Finally, note that at the tth iteration of Algorithm 1, the oracle is called
times. Since
, it follows that
. Thus, by (Equation17
(17)
(17) ) we get
and the proof is complete.
Let us consider the additional assumption:
| H2 | The level sets of f are bounded, that is, | ||||
The next theorem gives global convergence rates for Algorithm 1 in terms of the functional residual.
Theorem 3.2
Suppose that H1 and H2 are true and let be a sequence generated by Algorithm 1 such that, for
we have
Let m be the first iteration number such that
and assume that m<T. Then
(20)
(20) and, for all k,
we have
(21)
(21)
Proof.
By Lemma 3.1, this result follows from Theorem 3.2 in [Citation18] with .
Now, we can derive global convergence rates for Algorithm 1 in terms of the norm of the gradient.
Theorem 3.3
Under the same assumptions of Theorem 3.2, if T = m + 3s for some then
(22)
(22) Consequently,
(23)
(23) with
Proof.
By Theorem 3.2, we have
(24)
(24) for all k,
. In particular, it follows from (14) and (Equation24
(24)
(24) ) that
Therefore,
and so (Equation22
(22)
(22) ) holds. By assumption, we have
. Thus, by (Equation22
(22)
(22) ) we get
(25)
(25)
Finally, by analysing separately the cases in which ν is known and unknown, it follows from (Equation25
(25)
(25) ) and (Equation15
(15)
(15) ) that (Equation23
(23)
(23) ) is true.
Remark 3.2
Suppose that the objective f in (Equation4(4)
(4) ) is nonconvex and bounded from below by
. Then, it follows from (14) and (Equation18
(18)
(18) ) that
Summing up these inequalities, we get
and so, by (Equation15
(15)
(15) ), we obtain
. This bound generalizes the bound of
proved in [Citation16] for p = 2. It agrees in order with the complexity bounds proved in [Citation23] and [Citation9] for different universal tensor methods.
4. Accelerated tensor schemes
The schemes presented here generalize the procedures described in [Citation26] for p = 1 and p = 2. Specifically, our general scheme is obtained by adding Step 2 of Algorithm 1 at the end of Algorithm 4 in [Citation18], in order to relate the functional decrease with the norm of the gradient of f in suitable points:
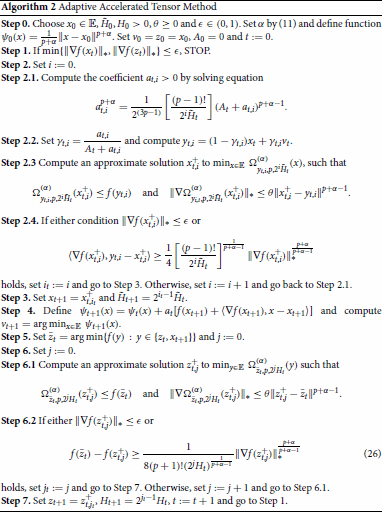
Let us define the following function of ε:
(27)
(27) In Algorithm 2, note that
is independent of
. The next theorem establishes global convergence rates for the functional residual with respect to
.
Theorem 4.1
Assume that H1 holds and let the sequence be generated by Algorithm 2 such that, for
we have
(28)
(28) Then,
(29)
(29) for
.
Proof.
As in the proof of Lemma 3.1, it follows from (Equation28(28)
(28) ), (Equation27
(27)
(27) ) and Lemmas A.6 and A.7 in [Citation18] that
which gives
Then, (Equation29
(29)
(29) ) follows directly from Theorem 4.3 in [Citation18] with
.
Now we can obtain global convergence rates for Algorithm 2 in terms of the norm of the gradient.
Theorem 4.2
Suppose that H1 holds and let sequences and
be generated by Algorithm 2. Assume that, for
we have
(30)
(30) If T = 2s for some
then
(31)
(31) where
with and
defined in (Equation15
(15)
(15) ) and (Equation27
(27)
(27) ), respectively. Consequently,
(32)
(32) if ν is known (i.e.
), and
(33)
(33)
if ν is unknown (i.e. ).
Proof.
By Theorem 4.1, we have
(34)
(34) for
. On the other hand, as in Lemma 3.1, by (Equation30
(30)
(30) ) we get
where
is defined in (Equation15
(15)
(15) ). Then, in view of (26), it follows that
(35)
(35) for
. In particular,
for
. Moreover, by the definition of
, we get
and
. Therefore
(36)
(36) and
(37)
(37) Now, since T = 2s, summing up (Equation37
(37)
(37) ), we get
Thus,
and so (Equation31
(31)
(31) ) holds. By assumption, we have
. Thus, it follows from (Equation31
(31)
(31) ) that
(38)
(38)
If ν is known, by (Equation15
(15)
(15) ) and (Equation27
(27)
(27) ) we have
. Then,
and so
(39)
(39) Combining (Equation38
(38)
(38) ), (Equation39
(39)
(39) ) and
, we obtain (Equation32
(32)
(32) ). If ν is unknown, it follows from (Equation15
(15)
(15) ) and (Equation27
(27)
(27) ) that
Then,
and so
(40)
(40) Combining (Equation38
(38)
(38) ), (Equation40
(40)
(40) ) and
, we obtain (Equation33
(33)
(33) ).
Remark 4.1
When , bounds (Equation32
(32)
(32) ) and (Equation33
(33)
(33) ) have the same dependence on ε. However, when
, the bound of
obtained for the universal scheme (i.e.
) is worse than the bound of
obtained for the non-universal scheme (i.e.
). In both cases, these complexity bounds are better than the bound of
proved for Algorithm 1.
5. Composite minimization
From now on, we will assume that ν and are known. In this setting, we can consider the composite minimization problem:
(41)
(41) where
is a convex function satisfying H1 (see page 5), and
is a simple closed convex function whose effective domain has nonempty relative interior, that is,
. We assume that there exists at least one optimal solution
for (Equation41
(41)
(41) ). By (Equation6
(6)
(6) ), if
we have
This motivates the following class of models of
around a fixed point
:
(42)
(42) where
is defined in (Equation10
(10)
(10) ). The next lemma gives a sufficient condition for function
to be convex. Its proof is an adaptation of the proof of Theorem 1 in [Citation27].
Lemma 5.1
Suppose that H1 holds for some . Then, for any
we have
(43)
(43) Moreover, if
then function
is convex for any
.
Proof.
For any , it follows from (Equation8
(8)
(8) ) that
Since
is arbitrary, we get (Equation43
(43)
(43) ).
Now, suppose that . Then, by (Equation43
(43)
(43) ) we have
Therefore,
is convex.
From Lemma 5.1, if , it follows that
is also convex. In this case, since
, any solution
of
(44)
(44) satisfies the first-order optimality condition:
(45)
(45) Therefore, there exists
such that
(46)
(46) Instead of solving (Equation44
(44)
(44) ) exactly, in our algorithms we consider inexact solutions
such thatFootnote1
(47)
(47) for some
and
. For such points
, we define
(48)
(48) with
satisfying (Equation47
(47)
(47) ). Clearly, we have
.
Lemma 5.2
Suppose that H1 holds and let be an approximate solution of (Equation44
(44)
(44) ) such that (Equation47
(47)
(47) ) holds for some
. If
(49)
(49) then
(50)
(50)
Proof.
By (Equation48(48)
(48) ), (Equation7
(7)
(7) ), (Equation10
(10)
(10) ), (Equation47
(47)
(47) ) and (Equation49
(49)
(49) ) we have
(51)
(51)
where the last inequality is due to
. On the other hand, by (Equation6
(6)
(6) ), (Equation42
(42)
(42) ), (Equation49
(49)
(49) ), we have
Note that
. Thus,
(52)
(52)
Finally, combining (Equation51
(51)
(51) ) and (Equation52
(52)
(52) ), we get (Equation50
(50)
(50) ).
In this composite context, let us consider the following scheme:
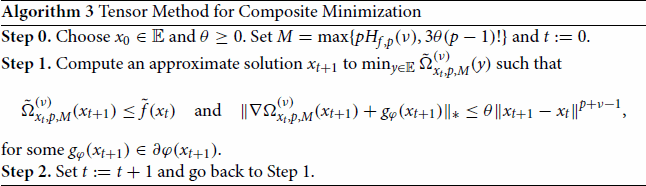
For p = 3, point at Step 1 can be computed by Algorithm 2 in [Citation19], which is linearly convergent. As far as we know, the development of efficient algorithms to approximately solve (Equation44
(44)
(44) )–(Equation42
(42)
(42) ) with p>3 is still an open problem.
Theorem 5.3
Suppose that H1 holds and that is bounded from below by
. Given
assume that
is a sequence generated by Algorithm 3 such that
for
. Then,
(53)
(53)
Proof.
By Lemma 5.2, bound (Equation53(53)
(53) ) follows as in Remark 3.2.
5.1. Extended accelerated scheme
Let us consider the following variant of Algorithm 2 for composite minimization:

The next theorem gives the global convergence rate for Algorithm 4 in terms of the norm of the gradient. Its proof is a direct adaptation of the proof of Theorem 4.2.
Theorem 5.4
Suppose that H1 holds. Assume that is a sequence generated by Algorithm 4 such that
(56)
(56) If T = 2s for some
then
(57)
(57) Consequently,
(58)
(58)
Proof.
In view of Theorem A.2, we have
(59)
(59) for
. On the other hand, by (55) and Lemma 5.2, we have
(60)
(60) for
. Thus,
and, consequently,
(61)
(61) and
(62)
(62) Since T = 2s, combining (Equation59
(59)
(59) ), (Equation61
(61)
(61) ) and (Equation62
(62)
(62) ), we obtain
where
. Therefore,
which gives (Equation57
(57)
(57) ). Finally, by (Equation56
(56)
(56) ) we have
. Thus, (Equation58
(58)
(58) ) follows directly from (Equation57
(57)
(57) ).
5.2. Regularization approach
Now, let us consider the ideal situation in which ν, and
are known. In this case, a complexity bound with a better dependence on ε can be obtained by repeatedly applying an accelerated algorithm to a suitable regularization of
. Specifically, given
, consider the regularized problem
(63)
(63) for
(64)
(64)
Lemma 5.5
Given and
let
be defined by
, where
is the Euclidean norm defined in (Equation1
(1)
(1) ). Then,
where
.
Proof.
See [Citation32].
As a consequence of the lemma above, we have the following property.
Lemma 5.6
If H1 holds, then the pth derivative of in (Equation64
(64)
(64) ) is ν-Hölder continuous with constant
.
In view of Lemma 5.6, to solve (Equation63(63)
(63) ) we can use the following instance of Algorithm A1 (see Appendix):

Let us consider the following restart procedure based on Algorithm 5.

Theorem 5.7
Suppose that H1 holds and let be a sequence generated by Algorithm 6 such that
(68)
(68) Then,
(69)
(69)
Proof.
Let . By Theorem A.2 and (66), we have
(70)
(70)
On the other hand, by Lemma 5 in [Citation12] and Lemma 1 in [Citation25], function
is uniformly convex of degree
with parameter
. Thus,
(71)
(71) Combining (Equation70
(70)
(70) ) and (Equation71
(71)
(71) ), we obtain
, and so
(72)
(72) Thus, it follows from (Equation70
(70)
(70) ) and (Equation72
(72)
(72) ) that
(73)
(73) In view of Lemma 5.2, by (67) and (65), we get
(74)
(74) Then, combining (Equation73
(73)
(73) ) and (Equation74
(74)
(74) ), it follows that
In particular, for k = T−1, it follows from (Equation68
(68)
(68) ) that
(75)
(75) Since
, it follows that
. Thus, combining this with (Equation75
(75)
(75) ), we get (Equation69
(69)
(69) ).
Corollary 5.8
Suppose that H1 holds and that . Then, Algorithm 6 with
(76)
(76) perform at most
(77)
(77) iterations of Algorithm 5 in order to generate
such that
.
Proof.
By Theorem 5.7, we can obtain with
(78)
(78) Moreover, it follows from (65), (Equation76
(76)
(76) ), the definition of
in Lemma 5.6,
and
that
(79)
(79)
Combining (Equation78
(78)
(78) ), (Equation79
(79)
(79) ) and (Equation76
(76)
(76) ), we have
(80)
(80) At this point
, we have
(81)
(81) Since
is uniformly convex of degree
with parameter
, it follows from (Equation74
(74)
(74) ) and (Equation73
(73)
(73) ) that
Therefore,
, and so
(82)
(82)
(83)
(83)
Now, combining (Equation81
(81)
(81) ), (Equation83
(83)
(83) ) and (Equation76
(76)
(76) ), we obtain
(84)
(84) The conclusion is obtained by noticing that, for δ given in (Equation76
(76)
(76) ) we have
(85)
(85)
Thus, (Equation77
(77)
(77) ) follows from multiplying (Equation80
(80)
(80) ) and (Equation85
(85)
(85) ).
Suppose now that is known. In this case, we have the following variant of Theorem 5.7.
Theorem 5.9
Suppose that H1 holds and let be a sequence generated by Algorithm 6 such that
(86)
(86) Then,
(87)
(87)
Proof.
By (Equation75(75)
(75) ), we have
(88)
(88) Since
is uniformly convex of degree
with parameter
we have
(89)
(89)
Combining (Equation88
(88)
(88) ) and (Equation89
(89)
(89) ) we get (Equation87
(87)
(87) ).
Corollary 5.10
Suppose that H1 holds and that . Then, Algorithm 6 with
(90)
(90) performs at most
(91)
(91) iterations of Algorithm 5 in order to generate
such that
.
Proof.
By Theorem 5.9, we can obtain with
(92)
(92)
In view of (Equation90
(90)
(90) ),
and
, we also have
(93)
(93) Thus, from (Equation92
(92)
(92) ) and (Equation93
(93)
(93) ), it follows that
(94)
(94) At this point
we have
By (Equation82
(82)
(82) ) and (Equation89
(89)
(89) ),
(95)
(95)
Thus, it follows from (Equation95
(95)
(95) ), (Equation95
(95)
(95) ) and (Equation90
(90)
(90) ) that
Finally, by (66) and (Equation90
(90)
(90) ) we have
Thus, (Equation91
(91)
(91) ) follows by multiplying (Equation94
(94)
(94) ) by the upper bound on m given above.
6. Lower complexity bounds under Hölder condition
In this section, we derive lower complexity bounds for p-order tensor methods applied to the problem (Equation4(4)
(4) ) in terms of the norm of the gradient of f, where the objective f is convex and
for some
.
For simplicity, assume that and
. Given an approximation
for the solution of (Equation4
(4)
(4) ), we consider p-order methods that compute trial points of the form
, where the search direction
is the solution of an auxiliary problem of the form
(96)
(96) with
,
and q>1. Denote by
the set of all stationary points of function
and define the linear subspace
(97)
(97) More specifically, we consider the class of p-order tensor methods characterized by the following assumption.
Assumption 6.1
Given , the method generates a sequence of test points
such that
(98)
(98) Given
, we consider the same family of difficult problems discussed in [Citation18], namely:
(99)
(99) The next lemma establishes that for each
we have
.
Lemma 6.1
Given an integer the pth derivative of
is ν-Hölder continuous with
(100)
(100)
Proof.
See Lemma 5.1 in [Citation18].
The next lemma provides additional properties of .
Lemma 6.2
Given an integer , let function
be defined by (Equation99
(99)
(99) ). Then,
has a unique global minimizer
. Moreover,
(101)
(101)
Proof.
See Lemma 5.2 in [Citation18].
Our goal is to understand the behaviour of the tensor methods specified by Assumption 1 when applied to the minimization of with a suitable k. For that, let us consider the following subspaces:
Lemma 6.3
For any and
.
Proof.
It follows directly from (Equation99(99)
(99) ).
Lemma 6.4
Let be a p-order tensor method satisfying Assumption 1. If
is applied to the minimization of
starting from
then the sequence
of test points generated by
satisfies
Proof.
See Lemma 2 in [Citation27].
The next lemma gives a lower bound for the norm of the gradient of on suitable points.
Lemma 6.5
Let k be an integer in the interval with
. If
then
.
Proof.
In view of (Equation99(99)
(99) ) we have
(102)
(102) where
(103)
(103) and
(104)
(104) By (Equation104
(104)
(104) ) and (Equation103
(103)
(103) ), we have
Since
, it follows that
for i>k. Therefore,
which means that
. Then, from (Equation102
(102)
(102) ), we obtain
(105)
(105)
By (Equation104
(104)
(104) ), we have
(106)
(106) Consequently,
(107)
(107) and
(108)
(108) From (Equation108
(108)
(108) ), it can be checked that
(109)
(109) with
(110)
(110) Now, combining (Equation107
(107)
(107) ) and (Equation108
(108)
(108) )–(Equation109
(109)
(109) ), we get
(111)
(111) Then, it follows from (Equation106
(106)
(106) ) and (Equation111
(111)
(111) ) that
(112)
(112)
Finally, by (Equation105
(105)
(105) ) and (Equation112
(112)
(112) ) we have
and the proof is complete.
The next theorem establishes a lower bound for the rate of convergence of p-order tensor methods with respect to the initial functional residual .
Theorem 6.6
Let be a p-order tensor method satisfying Assumption 6.1. Assume that for any function f with
this method ensures the rate of convergence:
(113)
(113) where
is the sequence generated by method
and
is the optimal value of f. Then, for all
such that
we have
(114)
(114)
Proof.
Suppose that method is applied to minimize function
with initial point
. By Lemma 6.4, we have
for all k,
. Thus, from Lemma 6.5, it follows that
(115)
(115) Then, combining (Equation113
(113)
(113) ), (Equation115
(115)
(115) ), Lemma 6.1 and Lemma 6.2, we get
where constant
is given in (Equation114
(114)
(114) ).
Remark 6.1
Theorem 6.6 gives a lower bound of for the rate of convergence of tensor methods with respect to the initial functional residual. For first-order methods in the Lipschitz case (i.e.
), we have
. This gives a lower complexity bound of
iterations for finding ε-stationary points of convex functions using first-order methods, which coincides with the lower bound (8a) in [Citation6]. Moreover, in view of Corollary 5.8, Algorithm 6 is suboptimal in terms of the initial residual, with the complexity a complexity gap that increases as p grows.
Now, we obtain a lower bound for the rate of convergence of p-order tensor methods with respect to the distance .
Theorem 6.7
Let be a p-order tensor method satisfying Assumption 1. Assume that for any function f with
this method ensures the rate of convergence:
(116)
(116) where
is the sequence generated by method
and
is a global minimizer of f. Then, for all
such that
we have
(117)
(117)
Proof.
Let us apply method for minimizing function
starting from point
. By Lemma 6.4, we have
for all k,
. Thus, from Lemma 6.5, it follows that
(118)
(118) Then, combining (Equation116
(116)
(116) ), (Equation118
(118)
(118) ), Lemma 6.1 and Lemma 6.2 we get
where constant
is given in (Equation117
(117)
(117) ).
Remark 6.2
Theorem 6.7 establishes that the lower bound for the rate of convergence of tensor methods in terms of the norm of the gradient is also of . For first-order methods in the Lipschitz case (i.e.
), we have
. This gives a lower complexity bound of
for finding ε-stationary points of convex functions using first-order methods, which coincides with the lower bound (8b) in [Citation6].
Remark 6.3
The rate of corresponds to a worst-case complexity bound of
iterations necessary to ensure
. Note that, for
, we have
Thus, by increasing the power of the oracle (i.e. the order p), our non-universal schemes become nearly optimal. For example, if
and
, we have
.
7. Conclusion
In this paper, we presented p-order methods that can find ε-approximate stationary points of convex functions that are p-times differentiable with ν-Hölder continuous pth derivatives. For the universal and the non-universal schemes without acceleration, we established iteration complexity bounds of for finding
such that
. For the case in which ν is known, we obtain improved complexity bounds of
and
for the corresponding accelerated schemes. For the case in which ν is unknown, we obtained a bound of
for a universal accelerated scheme. Similar bounds were also obtained for tensor schemes adapted to the minimization of composite convex functions. A lower complexity bound of
was obtained for the referred problem class. Therefore, in practice, our non-universal schemes become nearly optimal as we increase the order p.
As an additional result, we showed that Algorithm 6 takes at most iterations to find ε-stationary points of uniformly convex functions of degree
in the form (Equation64
(64)
(64) ). Notice that strongly convex functions are uniformly convex of degree 2. Thus, our result generalizes the known bound of
obtained for first-order schemes (p = 1) applied to strongly convex functions with Lipschitz continuous gradients (
). At this point, it is not clear to us how p-order methods (with
) behave when the objective functions are strongly convex with ν-Hölder continuous pth derivatives. Nevertheless, from the remarks done in [Citation12, p. 6] for p = 2, it appears that in our case the class of uniformly convex functions of degree
is the most suitable for p-order methods from a physical point of view.
Acknowledgements
The authors are very grateful to an anonymous referee, whose comments helped to improve the first version of this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
G. N. Grapiglia
G. N. Grapiglia obtained his doctoral degree in Mathematics in 2014 at Universidade Federal do Paraná (UFPR), Brazil. Currently, he is an Assistant Professor at UFPR. His research cover the development, analysis and application of optimization methods.
Yurii Nesterov
Yurii Nesterov is a professor at the Center for Operations Research and Econometrics (CORE) in Catholic University of Louvain (UCL), Belgium. He received his Ph.D. degree (Applied Mathematics) in 1984 at the Institute of Control Sciences, Moscow. His research interests are related to complexity issues and efficient methods for solving various optimization problems. He has received several international prizes, among which are the Dantzig Prize from SIAM and Mathematical Programming society (2000), the John von Neumann Theory Prize from INFORMS (2009), the SIAM Outstanding Paper Award (2014), and the Euro Gold Medal from the Association of European Operations Research Societies (2016). In 2018, he also won an Advanced Grant from the European Research Council.
Notes
1 Conditions (Equation47(47)
(47) ) have already been used in [Citation20] and are the composite analogue of the conditions proposed in [Citation2]. It is worth to mention that, for p = 3 and
, the tensor model
has very nice relative smoothness properties (see [Citation27]) which allow the approximate solution of (Equation44
(44)
(44) ) by Bregman Proximal Gradient Algorithms [Citation3,Citation22].
Related Research Data
References
- M. Baes, Estimate sequence methods: Extensions and approximations (2009). Available at http://www.optimization-online.org/DB_FILE/2009/08/2372.pdf.
- E.G. Birgin, J.L. Gardenghi, J.M. Martínez, S.A. Santos, and Ph.L. Toint, Worst-case evaluation complexity for unconstrained nonlinear optimization using high-order regularized models, Math. Program. 163 (2017), pp. 359–368. doi: 10.1007/s10107-016-1065-8
- J. Bolte, S. Sabach, M. Teboulle, and Y. Vaesburg, First order methods beyond convexity and Lipschitz gradient continuity with applications to quadratic inverse problems, SIAM. J. Optim. 28 (2018), pp. 2131–2151. doi: 10.1137/17M1138558
- A. Bouaricha, Tensor methods for large, sparse unconstrained optimization, SIAM. J. Optim. 7 (1997), pp. 732–756. doi: 10.1137/S1052623494267723
- S. Bubeck, Q. Jiang, Y.T. Lee, Y. Li, and A. Sidford, Near-optimal method for highly smooth convex optimization (2019). Available at arXiv, math. OC/1812.08026v2.
- Y. Carmon, J.C. Duchi, O. Hinder, and A. Sidford, Lower bounds for finding stationary points II: first-order methods (2017). Available at arXiv, math. OC/1711.00841.
- C. Cartis, N.I.M. Gould, and Ph.L. Toint, Second-order optimality and beyond: characterization and evaluation complexity in convexly constrained nonlinear optimization, Found. Comput. Math. 18 (2018), pp. 1073–1107. doi: 10.1007/s10208-017-9363-y
- C. Cartis, N.I.M. Gould, and Ph.L. Toint, Strong evaluation complexity bounds for arbitrary-order optimization of nonconvex nonsmooth composite functions (2020). Available at arXiv, math. OC/2001.10802.
- C. Cartis, N.I.M. Gould, and Ph.L. Toint, Universal regularized methods – varying the power, the smoothness, and the accuracy, SIAM. J. Optim. 29 (2019), pp. 595–615. doi: 10.1137/16M1106316
- X. Chen, Ph.L. Toint, and H. Wang, Complexity of partially separable convexly constrained optimization with non-lipschitz singularities, SIAM. J. Optim. 29 (2019), pp. 874–903. doi: 10.1137/18M1166511
- X. Chen and Ph.L. Toint, High-order evaluation complexity for convexly-constrained optimization with non-Lipschitzian group sparsity terms, Math. Program. (2020). doi:10.1007/s10107-020-01470-9.
- N. Doikov and Yu. Nesterov, Minimizing uniformly convex functions by cubic regularization of newton method (2019). Available at arXiv, math. OC/1905.02671.
- N. Doikov and Yu. Nesterov, Contracting proximal methods for smooth convex optimization. CORE Discussion Paper 2019/27.
- N. Doikov and Yu. Nesterov, Inexact tensor methods with dynamic accuracies (2020). Available at arXiv, math. OC/2002.09403.
- A. Gasnikov, P. Dvurechensky, E. Gorbunov, E. Vorontsova, D. Selikhanovych, and C.A. Uribe, The global rate of convergence for optimal tensor methods in smooth convex optimization (2019). Available at arXiv, math. OC/1809.00389v11.
- G.N. Grapiglia and Yu. Nesterov, Regularized Newton methods for minimizing functions with Hölder continuous hessians, SIAM. J. Optim. 27 (2017), pp. 478–506. doi: 10.1137/16M1087801
- G.N. Grapiglia and Yu. Nesterov, Accelerated regularized Newton methods for minimizing composite convex functions, SIAM. J. Optim. 29 (2019), pp. 77–99. doi: 10.1137/17M1142077
- G.N Grapiglia and Yu. Nesterov, Tensor methods for minimizing convex functions with Hölder continuous higher-order derivatives. To appear in SIAM Journal on Optimization.
- G.N. Grapiglia and Yu. Nesterov, On inexact solution of auxiliary problems in tensor methods for convex optimization, Optim. Methods Softw. (2020). doi:10.1080/10556788.2020.1731749.
- B. Jiang, T. Lin, and S. Zhang, A unified adaptive tensor approximation scheme to accelerated composite convex optimization (2020). Available at arXiv, math. OC/1811.02427v2.
- B. Jiang, H. Wang, and S. Zhang, An optimal high-order tensor method for convex optimization (2020). Available at arXiv, math OC/1812.06557v3.
- H. Lu, R.M. Freund, and Yu. Nesterov, Relatively smooth convex optimization by first-order methods, and applications, SIAM. J. Optim. 28 (2018), pp. 333–354. doi: 10.1137/16M1099546
- J.M. Martínez, On high-order model regularization for constrained optimization, SIAM. J. Optim. 27 (2017), pp. 2447–2458. doi: 10.1137/17M1115472
- R.D.C. Monteiro and B.F. Svaiter, An accelerated hybrid proximal extragradient method for convex optimization and its implications to second-order methods, SIAM. J. Optim. 23 (2013), pp. 1092–1125. doi: 10.1137/110833786
- Yu. Nesterov, Accelerating the cubic regularization of Newton's method on convex problems, Math. Program. 112 (2008), pp. 159–181. doi: 10.1007/s10107-006-0089-x
- Yu. Nesterov, How to make gradients small, Optima 88 (2012), pp. 10–11.
- Yu. Nesterov, Implementable tensor methods in unconstrained convex optimization, Math. Program. (2019). doi:10.1007/s10107-019-01449-1.
- Yu. Nesterov, Inexact accelerated high-order proximal-point methods. CORE Discussion Paper 2020/08.
- Yu. Nesterov, Inexact high-order proximal-point methods with auxiliary search procedure. CORE Discussion Paper 2020/10.
- Yu. Nesterov and A. Nemirovskii, Interior Point Polynomial Methods in Convex Programming: Theory and Applications, SIAM, Philadelphia, 1994.
- Yu. Nesterov and B.T. Polyak, Cubic regularization of Newton method and its global performance, Math. Program. 108 (2006), pp. 177–205. doi: 10.1007/s10107-006-0706-8
- A. Rodomanov and Yu. Nesterov, Smoothness parameter of power of Euclidean norm, J. Optim. Theory. Appl. 185 (2020), pp. 303–326. doi: 10.1007/s10957-020-01653-6
- R.B. Schnabel and T. Chow, Tensor methods for unconstrained optimization using second derivatives, SIAM. J. Optim. 1 (1991), pp. 293–315. doi: 10.1137/0801020
Appendix. Accelerated scheme for composite minimization
To solve problem (Equation41(41)
(41) ), we can apply the following modification of Algorithm 3 in [Citation18]:

In order to establish a convergence rate for Algorithm A1, we will need the following result.
Lemma A.1
Suppose that H1 holds and let be an approximate solution to
such that
(A3)
(A3) for some
. If
then
(A4)
(A4)
Proof.
Denote . Then,
which gives
(A5)
(A5)
From (EquationA5
(A5)
(A5) ), the rest of the proof follows exactly as in the proof of Lemma A.6 in [Citation18].
Theorem A.2
Suppose that H1 holds and let the sequence be generated by Algorithm A1. Then, for
(A6)
(A6)
Proof.
For all , we have
(A7)
(A7) Indeed, (EquationA7
(A7)
(A7) ) is true for t = 0 because
and
. Suppose that (EquationA7
(A7)
(A7) ) is true for some
. Then,
Thus, (EquationA7
(A7)
(A7) ) follows by induction. Now, let us prove that
(A8)
(A8) Again, using
, we see that (EquationA8
(A8)
(A8) ) is true for t = 0. Assume that (EquationA8
(A8)
(A8) ) is true for some
. Note that
is uniformly convex of degree
with parameter
. Thus, by the induction assumption
Consequently,
(A9)
(A9)
Since f is convex and differentiable and
, we have
(A10)
(A10) and
(A11)
(A11) Using (EquationA10
(A10)
(A10) ) and (EquationA11
(A11)
(A11) ) in (EquationA9
(A9)
(A9) ), it follows that
(A12)
(A12)
Note that
and
. Thus, combining (EquationA12
(A12)
(A12) ) and Lemma A.1, we obtain
where the last inequality follows from (A1) exactly as in the proof of Theorem 4.3 in [Citation18]. Thus, (EquationA8
(A8)
(A8) ) also holds for t + 1, which completes the induction argument.
Now, combining (EquationA7(A7)
(A7) ) and (EquationA8
(A8)
(A8) ), we have
(A13)
(A13) Once again, as in the proof of Theorem 4.3 in [Citation18], it follows from (A1) that
(A14)
(A14) Finally, (EquationA6
(A6)
(A6) ) follows directly from (EquationA13
(A13)
(A13) ) and (EquationA14
(A14)
(A14) ).