
ABSTRACT
Many questions in experimental mathematics are fundamentally inductive in nature. Here we demonstrate how Bayesian inference—the logic of partial beliefs—can be used to quantify the evidence that finite data provide in favor of a general law. As a concrete example we focus on the general law which posits that certain fundamental constants (i.e., the irrational numbers π, e, , and ln 2) are normal; specifically, we consider the more restricted hypothesis that each digit in the constant’s decimal expansion occurs equally often. Our analysis indicates that for each of the four constants, the evidence in favor of the general law is overwhelming. We argue that the Bayesian paradigm is particularly apt for applications in experimental mathematics, a field in which the plausibility of a general law is in need of constant revision in light of data sets whose size is increasing continually and indefinitely.
2010 AMS SUBJECT CLASSIFICATION:
1. Introduction
Experimental mathematics focuses on data and computation in order to address and discover mathematical questions that have so far escaped formal proof [CitationBailey and Borwein 09]. In many cases, this means that mathematical conjectures are examined by studying their consequences for a large range of data; every time a consequence is confirmed this increases one’s confidence in the veracity of the conjecture. Complete confidence in the truth or falsehood of a conjecture can only be achieved with the help of a rigorous mathematical proof. Nevertheless, in between absolute truth and falsehood there exist partial beliefs, the intensity of which can be quantified using the rules of probability calculus [CitationBorel 65, CitationRamsey 26].
Thus, an important role in experimental mathematics is played by heuristic reasoning and induction. Even in pure mathematics, inductive processes facilitate novel development:
every mathematician with some experience uses readily and effectively the same method that Euler used which is basically the following: To examine a theorem T, we deduce from it some easily verifiable consequences C1, C2, C3, ⋅⋅⋅. If one of these consequences is found to be false, theorem T is refuted and the question is decided. But if all the consequences C1, C2, C3, ⋅⋅⋅ happen to be valid, we are led after a more or less lengthy sequence of verifications to an “inductive” conviction of the validity of theorem T. We attain a degree of belief so strong that it seems superfluous to make any ulterior verifications. [CitationPolya 41, pp. 455–456]
Here we illustrate how to formalize the process of induction for a venerable problem in experimental mathematics: we will quantify degree of belief in the statement that particular irrational numbers (i.e., π, e, , and ln 2) are normal, or, more specifically, that the 10 digits of their decimal expansions occur equally often. This illustration does not address the more complicated question of whether all sequences of digits occur equally often: the sequence studied here is of length 1. Nevertheless, the simplified problem highlights the favorable properties of the general method and can be extended to more complicated scenarios.
To foreshadow the conclusion, our study shows that there is overwhelming evidence in favor of the general law that all digits in the decimal expansion of π, e, , and ln 2 occur equally often. Our statistical analysis improves on standard frequentist inference in several major ways that we elaborate upon below.
2. Bayes factors to quantify evidence for general laws
In experimental mathematics, the topic of interest often concerns the possible existence of a general law. This law—sometimes termed the null hypothesis —specifies an invariance (e.g., π is normal) that imposes some sort of restriction on the data (e.g., the digits of the decimal expansion of π occur equally often). The negation of the general law—sometimes termed the alternative hypothesis
—relaxes the restriction imposed by the general law.
In order to quantify the evidence that the data provide for or against a general law, [CitationJeffreys 61] developed a formal system of statistical inference whose centerpiece is the following equation [CitationWrinch and Jeffreys 21, p. 387]:
(2--1) Jeffreys’s work focused on the Bayes factor, which is the change from prior to posterior model odds brought about by the data. The Bayes factor also quantifies the relatively predictive adequacy of the models under consideration, and the log of the Bayes factor is the weight of evidence provided by the data [CitationKass and Raftery 95]. When
this indicates that the data are 10 times more likely under
than under
; when
this indicates that the data are 5 times more likely under
than under
.
Let be specified by a series of nuisance parameters ζ and, crucially, a parameter of interest that is fixed at a specific value, θ = θ0. Then
is specified using similar nuisance parameters ζ, but in addition
releases the restriction on θ. In order to obtain the Bayes factor one needs to integrate out the model parameters as follows:
(2--2)
Equation (Equation2--2(2--2) ) reveals several properties of Bayes factor inference that distinguish it from frequentist inference using p values. First, the Bayes factor contrasts two hypotheses, the general law and its negation. Consequently, it is possible to quantify evidence in favor of the general law (i.e., whenever
). As we will see below, one of our tests for the first 100 million digits of π produces BF01 = 1.86 × 1030, which is overwhelming evidence in favor of the law that the digits of the decimal expansion of π occur equally often; in contrast, a non-significant p value can only suggest a failure to reject
(e.g., [CitationFrey 09]). Moreover, as we will demonstrate below, the evidential meaning of a p value changes with sample size [CitationLindley 57]. This is particularly problematic for the study of the behavior of decimal expansions, since there can be as many as 10 trillion digits under consideration.
Second, the Bayes factor respects the probability calculus and allows coherent updating of beliefs; specifically, consider two batches of data, y1 and y2. Then, : the Bayes factor for the joint data set can be decomposed as the product of the Bayes factor for the first batch multiplied by the Bayes factor for the second batch, conditional on the information obtained from the first data set. Consequently—and in contrast to p value inference—Bayes factors can be seamlessly updated as new data arrive, indefinitely and without a well-defined sampling plan [CitationBerger and Berry 88a, CitationBerger and Berry 88b]. This property is particularly relevant for the study of normality of fundamental constants, since new computational and mathematical developments continually increase the length of the decimal expansion [CitationWrench Jr 60].
3. The normality of irrational numbers
A real number x is normal in base b if all of the digit sequences in its base b expansion occur equally often (e.g., [CitationBorel 09]); consequently, each string of t consecutive digits has limiting frequency b− t. In our example, we consider the decimal expansion and focus on strings of length 1. Hence, normality entails that each digit occurs with limiting frequency 1/10.
The conjecture that certain fundamental constants—irrational numbers such as π, e, , and ln 2—are normal has attracted much scientific scrutiny (e.g., [CitationBailey and Borwein 09, CitationBailey and Crandall 01, CitationBorwein et al. 04]). Aside from theoretical interest and practical application, the enduring fascination with this topic may be due in part to the paradoxical result that the digits sequences are perfectly predictable yet apparently appear random:
Plenty of arrangements in which design had a hand […] would be quite indistinguishable in their results from those in which no design whatever could be traced. Perhaps the most striking case in point here is to be found in the arrangement of the digits in one of the natural arithmetical constants, such as π or e, or in a table of logarithms. If we look to the process of production of these digits, no extremer instance can be found of what we mean by the antithesis of randomness: every figure has its necessarily pre-ordained position, and a moment’s flagging of intention would defeat the whole purpose of the calculator. And yet, if we look to results only, no better instance can be found than one of these rows of digits if it were intended to illustrate what we practically understand by a chance arrangement of a number of objects. Each digit occurs approximately equally often, and this tendency developes [sic] as we advance further […] In fact, if we were to take the whole row of hitherto calculated figures, cut off the first five as familiar to us all, and contemplate the rest, no one would have the slightest reason to suppose that these had not come out as the results of a die with ten equal faces. [CitationVenn 88, p. 111]
But are constants such as π, e, , and ln 2 truly normal? Intuitive arguments suggest that normality must be the rule [CitationVenn 88, pp. 111–115] but so far the problem has eluded a rigorous mathematical proof. In lieu of such a proof, research in experimental mathematics has developed a wide range of tests to assess whether or not the hypothesis of normality can be rejected (e.g., [CitationBailey et al. 12, CitationFrey 09, CitationGanz 14, CitationJaditz 00, CitationMarsaglia 05]; [CitationTu and Fischbach 05, p. 281]), some of which involve visual methods of data presentation (e.g., [CitationAragón Artacho et al. 12]; [CitationVenn 88, p. 118]). In line with Venn’s conjecture, most tests conclude that for the constants under investigation, the hypothesis of normality cannot be rejected.
However, to the best of our knowledge only one study has tried to quantify the strength of inductive support in favor of normality (i.e., [CitationBailey et al. 12]). Below we outline a multinomial Bayes factor test of equivalence that allows one to quantify the evidence in favor of the general law that each digit occurs equally often.
4. A Bayes factor multinomial test for normality
The general law or null hypothesis states that π, e,
, and ln 2 are normal. Here we consider the more restricted law that each digit in the decimal expansion occurs equally often (i.e., we focus on series of length 1 only). Hence,
stipulates that
, where j indexes the digits.
Next we need to specify our expectations under ; that is, our beliefs about the distribution of digit occurrences under the assumption that the general law does not hold, and before having seen actual data. We explore two alternative models. The first model assigns the digit probabilities θj an uninformative Dirichlet prior D(a = 1); under this alternative hypothesis
, all combinations of digit probabilities are equally likely a priori. In other words, the predictions of
are relatively imprecise. The second model assigns the digit probabilities θj an informative Dirichlet prior D(a = 50); under this alternative hypothesis
, the predictions of
are relatively precise, and similar to those made by
. In effect, the predictions from
are the same as those made by a model that is initialized with an uninformative Dirichlet prior D(a = 1) which is then updated based on 49 hypothetical occurrences for each of the 10 digits, that is, a hypothetical sequence of a total of 490 digits that corresponds perfectly with
.
Thus, model yields predictions that are relatively imprecise, whereas model
yields predictions that are relatively precise. The Bayes factor for
versus
is an indication of relative predictive adequacy, and by constructing two very different versions of
—one predictively dissimilar to
, one predictively similar—our analysis captures a wide range of plausible outcomes (e.g., [CitationSpiegelhalter et al. 94]).
With and
specified, the Bayes factor for the multinomial test of equivalence [CitationO’Hagan and Forster 04, p. 350] is given by
(4--3) where a and n are vectors of length 10 (i.e., the number of different digits); the elements of n contain the number of occurrences for each of the 10 digits. Finally, B( · ) is a generalization of the beta distribution [CitationO’Hagan and CitationForster 04, p. 341]:
(4--4) where Γ(t) is the gamma function defined as
. For computational convenience, we use the natural logarithm of the Bayes factor:
(4--5) where N is the total number of observed digits.
4.1. Example 1: The case of π
In our first example we compute multinomial Bayes factors for the digits of π. We compute the Bayes factor sequentially, as a function of an increasing number of available digits, with an upper bound of 100 million. displays the results in steps of 1,000 digits. The Bayes factor that contrasts versus
is indicated by the black line, and it shows that the evidence increasingly supports the general law. After all 100 million digits have been taken into account, the observed data are 1.86 × 1030 times more likely to occur under
than under
. The extent of this support is overwhelming. The red line indicates the maximum Bayes factor, that is, the Bayes factor that is obtained in case the digits were to occur equally often—that is, hypothetical data perfectly consistent with
.
Figure 1. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of π. The results in the top part of the panel correspond to an uninformative D(a = 1) prior for the alternative hypothesis; the results in the lower part of the panel correspond to the use of an informative D(a = 50) prior. The red lines indicate the maximum possible evidence for , and the gray areas indicate where 95% of the Bayes factors would fall if
were true. After 100 million digits, the final Bayes factor under a D(a = 1) prior is BF01 = 1.86 × 1030 (log BF01 = 69.70); under a D(a = 50) prior, the final Bayes factor equals BF01 = 1.92 × 1022 (log BF01 = 51.31). Figure available at http://tinyurl.com/zelm4o4 under CC license https://creativecommons.org/licenses/by/2.0/.
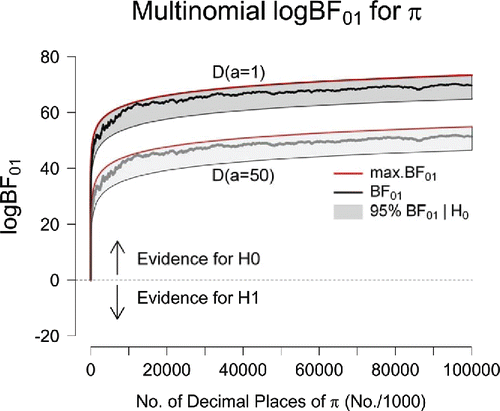
The dark gray area in indicates where a frequentist p value hypothesis test would fail to reject the null hypothesis. This area was determined in two steps. First, we considered the hypothetical distribution of counts across the 10-digit categories and constructed a threshold data set for which has a 5% chance of producing outcomes that are at least as extreme. Second, this threshold data set was used to compute a Bayes factor, and this threshold Bayes factor is plotted in as the lower bound of the dark gray area.
In order to construct the threshold data set, the number of counts in each digit category was obtained as follows. In this multinomial scenario there are 9 degrees of freedom. Without loss of generality, the number of counts in the first 8 of 10 categories may be set equal to the expected frequency of :
. Consequently, the first eight summands of the χ2-test formula are equal to 0. Furthermore, ∑9j = 0nj = N, so that if n8 is known, n9 is determined by
. We then obtain the number of counts in the ninth category n8 by solving the following quadratic equation for n8:
(4--6) where
denotes the 95th percentile of the χ2 distribution with 9 degrees of freedom.
shows that the height of the dark gray area’s lower bound increases with N. This means that it is possible to encounter a data set for which the Bayes factor indicates overwhelming evidence in favor of , whereas the fixed-α frequentist hypothesis test suggests that
ought to be rejected. In this way provides a visual illustration of the Jeffreys–Lindley paradox [CitationJeffreys 61, CitationLindley 57], a paradox that will turn out to be especially relevant for the later analysis of e,
, and ln 2.
A qualitative similar pattern of results is apparent when we consider the gray line in : the Bayes factor that contrasts versus
. Because this model makes predictions that are relatively similar to those of
, the data are less diagnostic than before. Nevertheless, the evidence increasingly supports the general law. After all 100 million digits are observed, the observed data are BF01 = 1.92 × 1022 times more likely to occur under
than under
. The extent of this support remains overwhelming.
For completeness, we also computed Bayes factors based on the first trillion decimal digits of π as reported in [CitationBailey and CitationBorwein 09, p. 11] (not shown). As expected from the upward evidential trajectories in , increasing the sequence length strengthens the support in favor of the general law: based on one trillion decimal digits, the D(a = 1) prior for yields BF01 = 3.65 × 1046 (log BF01 = 107.29)Footnote1, and the D(a = 50) prior yields BF01 = 4.07 × 1038 (log BF01 = 88.90).
Finally, consider the fact that the two evidential trajectories—one for a comparison against , one for a comparison against
—have a similar shape and appear to differ only by a constant factor. This pattern is not a coincidence, and it follows from the nature of sequential updating for Bayes factors [CitationJeffreys 61, p. 334]. Recall that there exist two mathematically equivalent ways to update the Bayes factor when new data y2 appear. The first method is to compute a single new Bayes factor using all of the available observations,
; the second method is to compute a Bayes factor only for the new data, but based on the posterior distribution which is the result of having encountered the previous data—this Bayes factor,
, is then multiplied by the Bayes factor for the old data,
, to yield the updated Bayes factor
.
Now let y1 denote a starting sequence of digits large enough so that the joint posterior distribution for the θj’s under is relatively similar to that under
(i.e., when the data are said to have overwhelmed the prior). From that point onward, the change in the Bayes factor as a result of new data y2,
, will be virtually identical for both instantiations of
. Hence, following an initial phase of posterior convergence, the subsequent evidential updates are almost completely independent of the prior distribution on the model parameters.Footnote2
Equation (Equation2--1(2--1) ) shows that the Bayes factor quantifies the change in belief brought about by the data; as a first derivative of belief (expressed on the log scale), it achieves independence of the prior model log odds. In turn, illustrates that the change in the log Bayes factor—the second derivative of belief—achieves independence of the prior distribution on the model parameters, albeit only in the limit of large samples.
The next three cases concern a study of the irrational numbers e, , and ln 2; the analysis and conclusion for these cases echo the ones for the case of π.
4.2. Example 2: The case of e
In our second example, we compute multinomial Bayes factors for the digits of the base of the natural logarithm: Euler’s number e. Proceeding in similar fashion as for the case of π, shows the evidential trajectories (in steps of 1,000 digits) for the first 100 million digits of e.Footnote3 As was the case for π, the upward trajectories signal an increasing degree of support in favor of the general law. After all 100 million digits have been taken into account, the observed data are 2.61 × 1030 times more likely to occur under than under
, and 2.69 × 1022 times more likely under
than under
. Again, the extent of this support is overwhelming.
Figure 2. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of e. The results in the top part of the panel correspond to an uninformative D(a = 1) prior for the alternative hypothesis; the results in the lower part of the panel correspond to the use of an informative D(a = 50) prior. The red lines indicate the maximum possible evidence for , and the gray areas indicate where 95% of the Bayes factors would fall if
were true. After 100 million digits, the final Bayes factor under a D(a = 1) prior is BF01 = 2.61 × 1030 (log BF01 = 70.04); under a D(a = 50) prior, the final Bayes factor equals BF01 = 2.69 × 1022 (log BF01 = 51.65). Figure available at http://tinyurl.com/h3wenqo under CC license https://creativecommons.org/licenses/by/2.0/.
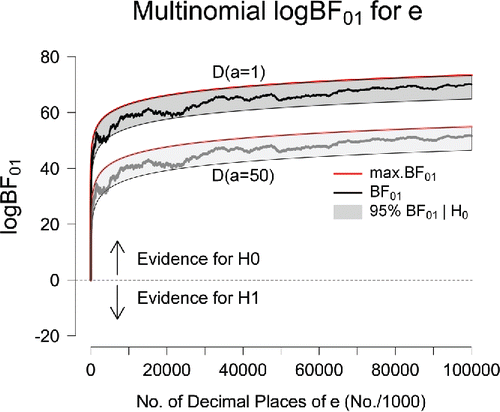
Note that, as for the case of π, the two evidential trajectories—one for a comparison against , one for a comparison against
—have a similar shape and appear to differ only by a constant factor. In contrast to the case of π, however, the Jeffreys–Lindley paradox is more than just a theoretical possibility: shows that the evidential trajectories move outside the gray area when the total digit count is between 82,100 and 254,000, meaning that for those digit counts the frequentist hypothesis test (with a fixed α-level of.05) suggests that
ought to be rejected. For the same data, both Bayes factors indicate compelling evidence in favor of
.Footnote4
4.3. Example 3: The case of 
In our third example, we compute multinomial Bayes factors for the digits of . Proceeding in similar fashion as above, shows the evidential trajectories (in steps of 1,000 digits) for the first 100 million digits of
.Footnote5 As was the case for π and e, upward evidential trajectories reveal an increasing degree of support in favor of the general law. After all 100 million digits have been taken into account, the observed data are 7.29 × 1030 times more likely to occur under
than under
, and 7.52 × 1022 times more likely under
than under
. As before, the extent of this support is overwhelming.
Figure 3. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of . The results in the top part of the panel correspond to an uninformative D(a = 1) prior for the alternative hypothesis; the results in the lower part of the panel correspond to the use of an informative D(a = 50) prior. The red lines indicate the maximum possible evidence for
, and the gray areas indicate where 95% of the Bayes factors would fall if
were true. After 100 million digits, the final Bayes factor under a D(a = 1) prior is BF01 = 7.29 × 1030 (log BF01 = 71.06); under a D(a = 50) prior, the final Bayes factor equals BF01 = 7.52 × 1022 (log BF01 = 52.67). Figure available at http://tinyurl.com/jgwu523 under CC license https://creativecommons.org/licenses/by/2.0/.
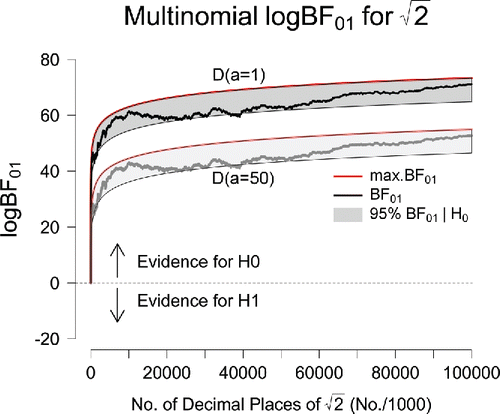
As shows, the analysis of provides yet another demonstration of the Jeffreys–Lindley paradox: when the total digit count ranges between 1 and 2 million, and between 20 and 40 million (especially close to 40 million), a frequentist analysis occasionally rejects
at an α-level of.05 (i.e., the evidential trajectories temporarily leave the gray area) whereas, for the same data, both Bayes factors indicate compelling evidence in favor of
.
4.4. Example 4: The case of ln 2
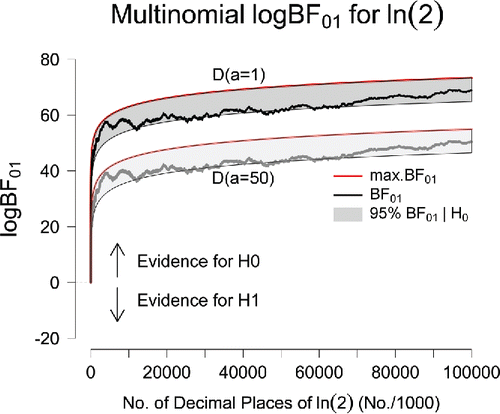
In our fourth and final example, we compute multinomial Bayes factors for the digits of ln 2. shows the evidential trajectories (in steps of 1,000 digits) for the first 100 million digits of ln 2.Footnote6 As was the case for π, e, and , upward trajectories reflect the increasing degree of support in favor of the general law. After all 100 million digits have been taken into account, the observed data are 7.58 × 1029 times more likely to occur under
than under
, and 7.81 × 1021 times more likely under
than under
. As shows, the analysis of ln 2 provides again a demonstration of the Jeffreys–Lindley paradox: the evidential trajectories leave the gray area multiple times indicating that a frequentist analysis rejects
at an α-level of.05 whereas, for the same data, both Bayes factors indicate compelling evidence in favor of
.
Figure 4. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of ln 2. The results in the top part of the panel correspond to an uninformative D(a = 1) prior for the alternative hypothesis; the results in the lower part of the panel correspond to the use of an informative D(a = 50) prior. The red lines indicate the maximum possible evidence for , and the gray areas indicate where 95% of the Bayes factors would fall if
were true. After 100 million digits, the final Bayes factor under a D(a = 1) prior is BF01 = 7.58 × 1029 (log BF01 = 68.80); under a D(a = 50) prior, the final Bayes factor equals BF01 = 7.81 × 1021 (log BF01 = 50.41). Figure available at http://tinyurl.com/jqdyd3w under CC license https://creativecommons.org/licenses/by/2.0/.
5. Alternative analysis
The analyses presented so far used two different Dirichlet distributions as a prior for the parameter vector under the alternative hypothesis . In this way, we demonstrated that the results do not change qualitatively when considering an uninformed or an informed Dirichlet prior distribution. A Dirichlet distribution is commonly used as a prior distribution for the parameter vector of a multinomial likelihood since it conveniently leads to an analytical solution for the Bayes factor.
However, one might ask whether the results are sensitive to the particular choice of the family of prior distributions used to specify the alternative hypothesis , that is the family of Dirichlet distributions. To highlight the robustness of our conclusion, we present the results of an analysis that is based on a more flexible prior distribution than the Dirichlet distribution, namely a two-component mixture of Dirichlet distributions. Mixture distributions have the property that the shape of the density is extremely flexible and can easily account for skewness, excess kurtosis, and even multi-modality [CitationFrühwirth–Schnatter 06] which makes them an ideal candidate for testing the sensitivity to a wide range of prior distributions. As [CitationDalal and CitationHall 83] showed, in fact any prior distribution may be arbitrarily closely approximated by a suitable mixture of conjugate prior distributions (i.e., prior distributions that, combined with a certain likelihood, lead to a posterior distribution that is in the same family of distributions as the prior distribution).Footnote7
As an example, we considered a two-component mixture of a D(a1 = 5) Dirichlet distribution which assigns more mass to probability vectors that have components that are similar to each other (i.e., similar digit probabilities) and a D(a2 = 1/5) Dirichlet distribution which assigns more mass to the corners of the simplex (i.e., one digit probability dominates) where the mixing weight was equal to w = 0.5.Footnote8 It is easily shown that also under this prior choice, the Bayes factor is available analytically. Recall that the Bayes factor is defined as .
is obtained by inserting
into the multinomial likelihood. In order to obtain
, we use the fact that any mixture of conjugate prior distributions is itself conjugate; that is, it leads to a posterior distribution that is again a mixture of the same family of distributions, only with updated parameters [CitationDalal and Hall 83]. Hence, since the Dirichlet distribution is conjugate to the multinomial likelihood, the posterior distribution when using a mixture of Dirichlet distributions as a prior is again a mixture of Dirichlet distributions (with updated parameters). This implies that we know the normalizing constant of the posterior distribution under the alternative hypothesis
which is equivalent to
. Hence, we can calculate the Bayes factor as follows:
(5--7)
displays the results for the 100 million digits of the four irrational numbers that are based on the two-component mixture prior described above. For π, the final Bayes factor equals 1.41 × 1027; for e, the final Bayes factor equals 1.97 × 1027; for , the final Bayes factor equals 5.52 × 1027; for ln 2 the final Bayes factor equals 5.73 × 1026.
Figure 5. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of π, e, , and ln 2. The results correspond to the use of a two-component mixture prior of a D(a1 = 5) and D(a2 = 1/5) Dirichlet distribution where the mixing weight was equal to w = 0.5. The red lines indicate the maximum possible evidence for
, and the gray areas indicate where 95% of the Bayes factors would fall if
were true. Figure available at http://tinyurl.com/hw4gmlr under CC license https://creativecommons.org/licenses/by/2.0/.
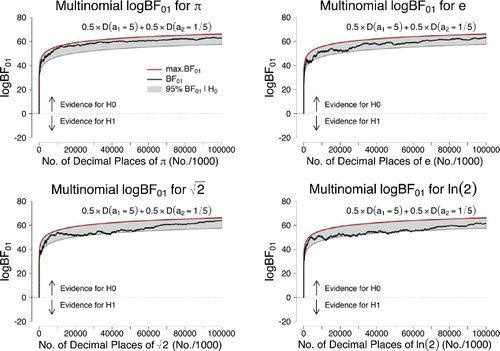
The results based on the mixture prior are very similar to the previous ones, that is, we again obtain overwhelming support in favor of the assumption that all digits occur equally often; hence, we conclude that inference appears to be relatively robust to the particular choice of prior distribution that is used.
6. Discussion and conclusion
With the help of four examples we illustrated how Bayesian inference can be used to quantify evidence in favor of a general law [CitationJeffreys 61]. Specifically, we examined the degree to which the data support the conjecture that the digits in the decimal expansion of π, e, , and ln 2 occur equally often. Our main analysis featured two prior distributions used to instantiate models as alternatives to the general law: the alternative model
resembled the general law, whereas the alternative model
did not. An infinite number of plausible alternatives and associated inferences lie in between these two extremes. Regardless of whether the comparison involved
or
, the evidence was always compelling and the sequential analysis produced evidential trajectories that reflected increasing support in favor of the general law. Future data can update the evidence and extend these trajectories indefinitely.
– clearly show the different outcomes for versus
. This dependence on the model specification is sometimes felt to be a weakness of the Bayesian approach, as the specification of the prior distribution for the model parameters is not always straightforward or objective. However, the dependence on the prior distribution is also a strength, as it allows the researcher to insert relevant information into the model to devise a test that more closely represents the underlying theory. Does it make sense to assign the model parameters a Dirichlet D(a = 50) prior? It is easy to use existing knowledge about the distribution of trillions of digits for π to argue that this Dirichlet distribution is overly wide and hence inappropriate; however, this conclusion confuses prior knowledge with posterior knowledge—as the name implies, the prior distribution should reflect our opinion before and not after the data have been observed.
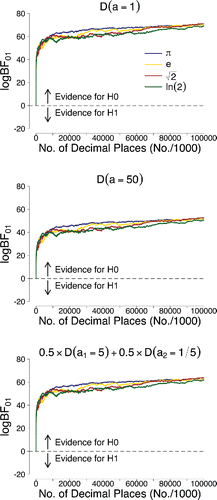
In the present work we tried to alleviate concerns about the sensitivity to the prior specification in three ways. First, for our main analysis, we used a sandwich approach in which we examined the results for two very different prior distributions, thereby capturing a wide range of outcomes for alternative specifications (e.g., [CitationSpiegelhalter et al. 94]). Second, we considered a different, very flexible family of alternative prior distributions (i.e., a two-component mixture of Dirichlet distributions) and we demonstrated that the results do not change qualitatively—the evidence in favor of the general law remains overwhelming. Third, we have shown that the second derivative of belief—the change in the Bayes factor as a result of new data—becomes insensitive to the prior specification as N grows large. Here, the evidential trajectories all suggest that the evidence for the general law increases as more digits become available. displays the results for π, e, , and ln 2 side-by-side and emphasizes that for all four irrational numbers that we investigated, we obtain similar overwhelming support for the general law which states that all digits occur equally often—this is the case for all three prior distributions that we considered.
Figure 6. Sequential Bayes factors in favor of equal occurrence probabilities based on the first 100 million digits of π, e, , and ln 2. The results in the upper panel correspond to the use of an uninformative D(a = 1) prior for the alternative hypothesis; the results in the middle panel correspond to the use of an informative D(a = 50) prior; the results in the lower panel correspond to the use of a two-component mixture prior of a D(a1 = 5) and D(a2 = 1/5) Dirichlet distribution where the mixing weight was equal to w = 0.5. Figure available at http://tinyurl.com/hhut8dp under CC license https://creativecommons.org/licenses/by/2.0/.
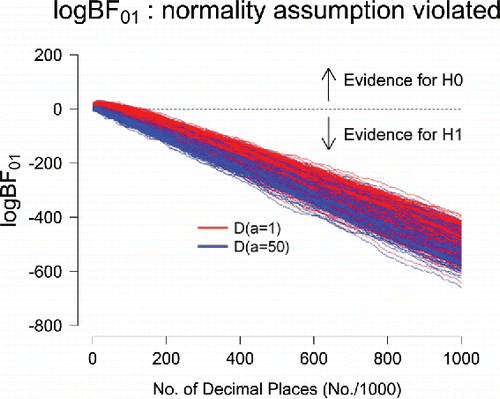
A remaining concern is that our Dirichlet prior on may be overly wide and therefore bias the test in favor of the general law. To assess the validity of this concern, we conducted a simulation study in which the normality assumption was violated: one digit was given an occurrence probability of.11, whereas each of the remaining digits were given occurrence probabilities of .89/9. shows that for all 1,000 simulated data sets, the evidential trajectories indicate increasing evidence against the general law. After 1 million digits, the average Bayes factor in favor of the alternative hypothesis is BF10 = 1.19 × 10214 (log BF10 = 492.93) under the D(a = 1) prior and BF10 = 8.88 × 10221 (log BF10 = 511.05) under the D(a = 50) prior. Thus, with our instantiations of
the Bayes factor is able to provide overwhelming evidence against the general law when it is false.
Figure 7. Sequential Bayes factors in favor of equal occurrence probabilities for 1,000 simulated data sets of 1 million digits each. In every data set, one digit was given an occurrence probability of.11 whereas each of the other digits occurred with probability .89/9. The evidential trajectories indicate increasingly strong evidence against the general law. Figure available at http://tinyurl.com/j4qk2ht under CC license https://creativecommons.org/licenses/by/2.0/.
One of the main challenges for Bayesian inference in the study of normality for fundamental constants is to extend the simple multinomial approach presented here to account for longer digit sequences. As the digit series grows large, the number of multinomial categories also grows while the number of unique sequences decreases. Ultimately, this means that even with trillions of digits, a test for normality may lack the data for a diagnostic test. Nevertheless, alternative models of randomness can be entertained and given a Bayesian implementation—once this is done, the principles outlined by Jeffreys can be used to quantify the evidence for or against the general law.
Funding
This work was supported by ERC grant 283876.
UEXM_A_1256006_supplemental_material.docx
Download MS Word (11.2 KB)Notes
1 Such an excessive degree of evidence in favor of a general law may well constitute a world record.
2 That is, after a sufficient number of observations, the trajectories of the log Bayes factors for the different priors for are equal, only shifted by a constant. In fact, regardless of the irrational number under consideration, this constant—which corresponds to the difference in
and
—approaches 18.39 (for a derivation see https://osf.io/m5jas/).
3 Data were obtained using the pifast software ( numbers.computation.free.fr/Constants/PiProgram/pifast.html).
4 A frequentist statistician may object that this is a sequential design whose proper analysis demands a correction of the α-level. However, the same data may well occur in a fixed sample size design. In addition, the frequentist correction of α-levels is undefined when the digit count increases indefinitely.
5 Data were obtained using the pifast software ( numbers.computation.free.fr/Constants/PiProgram/pifast.html).
6 Data were obtained using the pifast software ( numbers.computation.free.fr/Constants/PiProgram/pifast.html).
7 Of course, in some cases this may require a very “rich” mixture, that is, a mixture prior with many components.
8 R code that allows one to explore how the results change for a different choice of a two-component Dirichlet mixture prior is available on the Open Science Framework under https://osf.io/cmn2z/.
Related Research Data
References
- [Aragón Artacho et al. 12] F. J. A. Aragón Artacho, D. H. Bailey, J. M. Borwein, and P. B. Borwein. “Walking on Real Numbers.” Math. Intell. 35 (2012), 42–60.
- [Bailey and Borwein 09] D. H. Bailey and J. M. Borwein. “Experimental Mathematics and Computational Statistics.” Wiley Interdiscip. Rev.: Comput. Stat., 1 (2009) 12–24.
- [Bailey et al. 12] D. H. Bailey, J. M. Borwein, C. S. Calude, M. J. Dinneen, M. Dumitrescu, and A. Yee. “An Empirical Approach to the Normality of π.” Exp. Math. 21 (2012), 375–384.
- [Bailey and Crandall 01] D. H. Bailey and R. E. Crandall. “On the Random Character of Fundamental Constant Expansions.” Exp. Math. 10 (2001) 175–190.
- [Berger and Berry 88a] J. O. Berger and D. A. Berry. “The Relevance of Stopping Rules in Statistical Inference.” Statistical Decision Theory and Related Topics, vol. 4, edited by S. S. Gupta and J. O. Berger, pp. 29–72. New York: Springer Verlag, 1988a.
- [Berger and Berry 88b] J. O. Berger and D. A. Berry. “Statistical Analysis and the Illusion of Objectivity.” Am. Sci. 76 (1988b) 159–165.
- [Borel 09] E. Borel. “Les probabilités dénombrables et leurs applications arithmétiques.”, Rendiconti del Circolo Matematico di Palermo (1884--1940) 27 (1909), 247–271.
- [Borel 65] E. Borel, editor. Elements of the Theory of Probability. Englewood Cliffs, NJ: Prentice-Hall, 1965.
- [Borwein et al. 04] J. M. Borwein, D. H. Bailey, and D. Bailey. Mathematics by Experiment: Plausible Reasoning in the 21st Century. Natick, MA: AK Peters, 2004.
- [Dalal and Hall 83] S. R. Dalal and W. J. Hall. “Approximating Priors by Mixtures of Natural Conjugate Priors.” J. Royal Stat. Soc. Ser. B. (Methodol.) 45 (1983), 278–286.
- [Frey 09] J. Frey. “An Exact Multinomial Test for Equivalence.” Can. J. Stat./La Revue Canadienne de Statistique 37 (2009), 47–59.
- [Frühwirth–Schnatter 06] S. Frühwirth–Schnatter. Finite Mixture and Markov Switching Models. New York: Springer, 2006.
- [Ganz 14] R. E. Ganz. “The Decimal Expansion of π Is Not Statistically Random.” Exp. Math. 23 (2014), 99–104.
- [Jaditz 00] T. Jaditz. “Are the Digits of π an Independent and Identically Distributed Sequence?” Am. Stat. 54 (2000), 12–16.
- [Jeffreys 61] H. Jeffreys. Theory of Probability. Third edition. Oxford, UK: Oxford University Press, 1961.
- [Kass and Raftery 95] R. E. Kass and A. E. Raftery. “Bayes Factors.” J. Am. Stat. Assoc. 90 (1995), 773–795.
- [Lindley 57] D. V. Lindley. “A Statistical Paradox.” Biometrika, 44 (1957) 187–192.
- [Marsaglia 05] G. Marsaglia.,“On the Randomness of pi and Other Decimal Expansions.” Interstat 5 (2005).
- [O’Hagan and Forster 04] A. O’Hagan and J. Forster. Kendall’s Advanced Theory of Statistics, Vol. 2B: Bayesian Inference. Second edition. London: Arnold, 2004.
- [Polya 41] G. Polya. “Heuristic Reasoning and the Theory of Probability.” Am. Math. Month. 48 (1941), 450–465.
- [Ramsey 26] F. P. Ramsey. “Truth and Probability.” In: The Foundations of Mathematics and Other Logical Essays edited by R. B. Braithwaite, pp. 156–198. London: Kegan Paul, 1926.
- [Spiegelhalter et al. 94] D. J. Spiegelhalter, L. S. Freedman, and M. K. B. Parmar. “Bayesian Approaches to Randomized Trials (with discussion).” J. Royal Stat. Soc. A 157 (1994), 357–416.
- [Tu and Fischbach 05] S.-J. Tu and E. Fischbach. “A Study on the Randomness of the Digits of π.” Int. J. Mod. Phys. C. 16 (2005) 281–294.
- [Venn 88] J. Venn.The Logic of Chance. Third edition. New York: MacMillan, 1888.
- [Wrench Jr 60] J. W. Wrench Jr. “The Evolution of Extended Decimal Approximations to π.” Math. Teach. 53 (1960), 644–650.
- [Wrinch and Jeffreys 21] D. Wrinch and H. Jeffreys. “On Certain Fundamental Principles of Scientific Inquiry.” Philos. Mag. 42 (1921), 369–390.