
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Cohomology fractals are images naturally associated to cohomology classes in hyperbolic three-manifolds. We generate these images for cusped, incomplete, and closed hyperbolic three-manifolds in real-time by ray-tracing to a fixed visual radius. We discovered cohomology fractals while attempting to illustrate Cannon–Thurston maps without using vector graphics; we prove a correspondence between these two, when the cohomology class is dual to a fibration. This allows us to verify our implementations by comparing our images of cohomology fractals to existing pictures of Cannon–Thurston maps.
In a sequence of experiments, we explore the limiting behaviour of cohomology fractals as the visual radius increases. Motivated by these experiments, we prove that the values of the cohomology fractals are normally distributed, but with diverging standard deviations. In fact, the cohomology fractals do not converge to a function in the limit. Instead, we show that the limit is a distribution on the sphere at infinity, only depending on the manifold and cohomology class.
1. Introduction
Cannon and Thurston discovered that Peano curves arise naturally in hyperbolic geometry [Citation13]. They proved that for every closed hyperbolic three-manifold, equipped with a fibration over the circle, there is a map from the circle to the sphere that is continuous, finite to one, and surjective. Furthermore this Cannon–Thurston map is equivariant with respect to the action of the fundamental group. We review their construction in Section 3; shows an approximation.
Fig. 1 Matching up Cannon–Thurston map images with the cohomology fractal for m004, the figure-eight knot complement. Compare our with Figure 10.11 of Indra’s Pearls [32, page 335], which was produced by paint-filling a vector graphics image [Citation48].
![Fig. 1 Matching up Cannon–Thurston map images with the cohomology fractal for m004, the figure-eight knot complement. Compare our Figure 1(c) with Figure 10.11 of Indra’s Pearls [32, page 335], which was produced by paint-filling a vector graphics image [Citation48].](/cms/asset/026bc471-44dc-42f8-850b-73133f19e597/uexm_a_1994059_f0001_c.jpg)
In a previous expository paper [Citation4], we introduced cohomology fractals; these are images arising from a hyperbolic three-manifold M equipped with a cohomology class . See . In that paper we gave an overview of the construction; we also discussed some of the features of the three-manifold and cohomology class that can be seen in its cohomology fractal. We have also written an open-source [Citation5] real-time web application for exploring these fractals. This is available at https://henryseg.github.io/cohomology_fractals/.
In the present work we give rigorous definitions of cohomology fractals, we relate them to Cannon–Thurston maps (see ), we give technical details of our implementation, and we discuss their limiting behaviour.
We now outline the contents of each section of the paper. Note that we include a glossary of notation in Appendix A. We begin by reviewing the definitions of ideal and material triangulations, and their hyperbolic geometry in Section 2. In Section 3 we define Cannon–Thurston maps. In Section 4 we discuss the differences between vector and raster graphics. We also recall a vector graphics algorithm (Algorithm Citation4.Citation2) used in previous work to illustrate Cannon–Thurston maps.
In Section 5 we give several equivalent definitions of the cohomology fractal. It depends on choices beyond the manifold M and the cohomology class : there is a choice of viewpoint
and a choice of a visual radius R. The cohomology fractal is a function
. Roughly, for each vector
we build the geodesic arc γ of length R from p in the direction of v and compute
. (Note that we repeatedly generalise the definition of the cohomology fractal throughout the paper; the decorations alter to remind the reader of the desired context.)
In , we see a cohomology fractal closely matching an approximation of a Cannon–Thurston map, as produced by Algorithm Citation4.Citation2. In Section 6 we prove the following.
Proposition 6.2.
Cohomology fractals are dual to approximations of the Cannon–Thurston map.
Thus we have a new representation of Cannon–Thurston maps. We also compare cohomology fractals with the lightning curves of Dicks and various coauthors. (The name is due to Wright [32, page 324].) We experimentally observe that the lightning curve corresponds to some of the brightest points of the cohomology fractal.
In Section 7 we describe the algorithms we use to produce images of cohomology fractals. Adding the ability to move through the manifold leads us to separate the viewpoint p from a basepoint, denoted b, of the cohomology fractal. We still trace rays starting at p, but then evaluate ω on any path in from b to the endpoint of γ.
We also generalise the above material view (with vectors v in ) to the ideal and hyperideal views (with vectors v being perpendicular to a horosphere or geodesic plane, respectively). Each view is a subset
; our notation for the cohomology fractal becomes
.
In Section 8 we discuss cohomology fractals for incomplete and closed manifolds. We draw cohomology fractals in the closed case in two ways. First, we deform the cohomology fractal for a surgery parent through Thurston’s Dehn surgery space. Second, we reimplement our algorithms using material triangulations. We also discuss possible sources of numerical error in our implementations.
In Section 9 we give a sequence of experiments exploring the dependence of cohomology fractals on the visual radius R. For any fixed R, the cohomology fractal is constant on regions with sizes roughly proportional to . As R increases, these regions subdivide, and intricate patterns come into focus. This suggests that there is a limiting object. The following shows that such a limit cannot be a function.
Theorem 9.2.
Suppose that M is a finite volume, oriented hyperbolic three-manifold. Suppose that F is a transversely oriented surface. Then the limit
does not exist for almost all
.
Indeed, experimentally, increasing R leads to noisy pictures. However, this is due to undersampling. A heuristic argument (see Remark 9.7) shows that we can avoid noise if we increase the screen resolution as we increase R. We simulate this by computing supersampled images. These, and further experiments, indicate that in contrast with Theorem 9.2, the mean of the cohomology fractal, taken over a pixel, converges. Its values appear to be normally distributed with standard deviation growing like .
Motivated by this, in Section 10, we show that the cohomology fractal obeys a central limit theorem.
Theorem 10.7.
Fix a connected, orientable, finite volume, complete hyperbolic three-manifold M and a closed, non-exact, compactly supported one-form . There is
such that for all basepoints b, all views D with area measure μD, for all probability measures
, and for all
, we have
where
is the associated cohomology fractal.
That is, if we regard the cohomology fractal across a pixel as a random variable, divide it by , and take the limit, the result is a normal distribution of mean zero. The standard deviation of the normal distribution only depends on the manifold and cohomology class. The proof uses Sinai’s central limit theorem for geodesic flows.
In Section 11, we prove that treating the cohomology fractals as distributions gives a well-defined limit. In this introduction, for simplicity, we focus on the case where D is a material view. The pixel theorem (Theorem 11.4) states that the limitis well-defined for any two-form
. Theorem 11.4 also states various transformation laws relating, for example, the distributions corresponding to different views. Thus there is a view-independent distribution related to the view-dependent distributions via the conformal isomorphism iD from D to
.
Corollary 11.5.
Suppose that M is a connected, orientable, finite volume, complete hyperbolic three-manifold. Fix a closed, compactly supported one-form and a basepoint
. Then there is a distribution
on
so that, for any material view D and for any
, we have
The above discussion addresses smooth test functions. We can also prove convergence for a wider class of test functions; these include the indicator functions of regions with piecewise smooth boundary. However, we do not know whether or not the cohomology fractal converges to a measure.
We conclude with a few questions and directions for future work in Section 12.
Acknowledgements
This material is based in part upon work supported by the National Science Foundation under Grant No. DMS-1439786 and the Alfred P. Sloan Foundation award G-2019-11406 while the authors were in residence at the Institute for Computational and Experimental Research in Mathematics in Providence, RI, during the Illustrating Mathematics program. The fourth author was supported in part by National Science Foundation grant DMS-1708239.
We thank François Guéritaud for suggesting we use ray-tracing to generate cohomology fractals. We thank Curt McMullen for suggesting that Theorem 11.4 should be true and also for giving us permission to reproduce . We thank Mark Pollicott and Alex Kontorovich for guiding us through the literature on exponential mixing of the geodesic flow. We thank Ian Melbourne for enlightening conversations on central limit theorems. We thank the anonymous referee for many helpful comments and corrections.
2. Triangulations
We briefly review the notions of material and ideal triangulations of three-manifolds.
2.1. Combinatorics
Suppose that M is a compact, connected, oriented three-manifold. We will consider two cases. Either
the boundary
is empty; here we call M closed, or
the boundary is non-empty, consisting entirely of tori; here we call M cusped.
Suppose that is a triangulation: that is, a collection of oriented model tetrahedra together with a collection of orientation-reversing face pairings. We allow distinct faces of a tetrahedron to be glued, but we do not allow a face to be glued to itself. The quotient space, denoted
, is thus a CW–complex which is an oriented three-manifold away from its zero-skeleton. We say that
is a material triangulation of M if there is an orientation-preserving homeomorphism from
to M. We say that
is an ideal triangulation of M if there is an orientation-preserving homeomorphism from
, minus a small open neighbourhood of its vertices, to M. Equivalently,
minus its vertices is homeomorphic to
, the interior of M.
Example 2.2.
Suppose that M is obtained from S3 by removing a small open neighbourhood of the figure-eight knot. See . As discussed in [42, Chapter 1], the knot exterior M has an ideal triangulation with two tetrahedra. See . Here we have not truncated the model tetrahedra. Instead we draw the vertex link; in this case it is a torus in M.
Fig. 2 The figure-eight knot complement. This manifold is known as ![]()
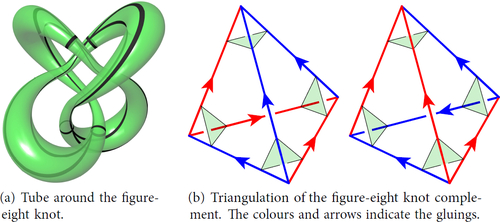
2.3. Geometry
We deal with the geometry of the two types of triangulations separately.
2.3.1 Ideal triangulations
We give each model ideal tetrahedron t a hyperbolic structure. That is, we realise t as an ideal tetrahedron in with geodesic faces. This can be constructed as the convex hull of four points on
. We require that the face pairings be orientation reversing isometries. For these hyperbolic tetrahedra to combine to give a complete hyperbolic structure on the manifold
requires certain conditions to be satisfied. Very briefly: consider a loop in the dual one-skeleton of the triangulation. This visits the tetrahedra in some order. The product of the corresponding sequence of isometries must give the identity if the loop is trivial in the fundamental group. If the loop is peripheral then the product must be a parabolic element.
These conditions reduce to a finite set of algebraic constraints. These are Thurston’s gluing equations, see [42, Section 4.2] and [35, Section 4.2]. Using the upper half-space model of we define the shape of each ideal hyperbolic tetrahedron to be the cross-ratio of its four ideal points. The gluing equations impose a finite number of polynomial conditions on these shapes.
For our implementation, we also require that the shapes have positive imaginary part. This ensures that the ideal hyperbolic tetrahedra glue together to give a complete, finite volume hyperbolic structure on . Furthermore, the model orientations of all of the tetrahedra agree with the orientation on M. In particular, when a geodesic ray crosses a face, it has a sensible continuation.
2.3.2 Material triangulations
To find a hyperbolic structure for material triangulations, we replace Thurston’s gluing equations with a construction due to Andrew Casson [Citation8] and Damian Heard [Citation20, Citation21]. To specify a hyperbolic structure on a material triangulation, it suffices to assign lengths to its edges. This is because the isometry class of an oriented material hyperbolic tetrahedron is determined by its six edge lengths.
There are two conditions that must be satisfied. First, for each model tetrahedron, there is a collection of inequalities that must be satisfied for its edges. Second, for each edge of the triangulation, the dihedral angles about it must sum to .
If these inequalities and equalities hold, then we obtain a hyperbolic structure on the three-manifold. See [19, Section 2] for further details.
3. Cannon–Thurston maps
Here we sketch Cannon and Thurston’s construction; see for an overview. We refer to [Citation13] for the details. See also [Citation31].
Fig. 3 The various spaces and maps involved in constructing the Cannon–Thurston map .
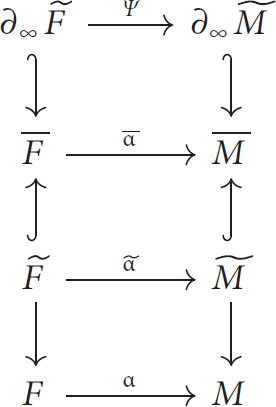
Suppose that and
are connected, compact, oriented two- and three-manifolds. Suppose that
and
admit complete hyperbolic metrics of finite area and volume respectively. In an abuse of notation, we will conflate F with
, and similarly M with
. We call a proper embedding
a fibre if there is a map
so that for all
the preimage
is a surface properly isotopic to
.
Let and
be the universal covers of F and M respectively. Since F and M are hyperbolic, their covers are identified with hyperbolic two- and three-space respectively. Let
and
be their ideal boundaries. We set
Each union is equipped with the unique topology that makes the group action continuous. Note that and
are homeomorphic to a closed two- and three-ball, respectively.
We compose the covering map from with the embedding α and then lift to obtain an equivariant map
. We call
an elevation of F. shows an elevation of the fibre of the figure-eight knot complement.
Fig. 4 Views in the universal cover of the figure-eight knot complement.
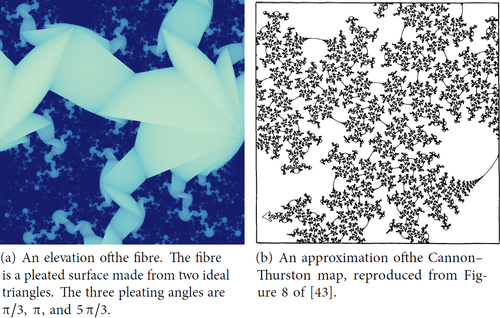
Cannon and Thurston gave the first proof of the following theorem in the closed case [13, page 1319]. The cusped case follows from work of Bowditch [3, Theorem 0.1].
Theorem 3.1.
Suppose M is a connected, oriented, finite volume hyperbolic three-manifold. Suppose that is a fibre of a surface bundle structure on M. Then there is an extension of
to a continuous and equivariant (with respect to the fundamental group of M) map
. The restriction of
to
gives a sphere-filling curve.
We will use the notation for the restriction of
to
. We call this a Cannon–Thurston map. We now turn to the task of visualising
.
4. Illustrating Cannon–Thurston maps
The standard joke (see [43, page 373] and [32, page 335]) is that it is straightforward to draw an accurate picture of a Cannon–Thurston map; it is solid black.
The first (more instructive) illustration of a Cannon–Thurston map is due to Thurston. He gives a sequence of approximations to the sphere-filling curve in [43, ]. We reproduce the last of these in . A striking version of this image by Wright also appears in Indra’s Pearls [32, Figure 10.11]. In this example both M and F are non-compact; M is the complement of the figure-eight knot and F is a Seifert surface.
4.1. Vector and raster graphics
In this section, we outline the technique used by Thurston and Wright to generate images of Cannon–Thurston maps, in order to contrast it with our algorithm.
Our algorithm generates an image by producing a colour for each pixel on a screen. In other words, its output is a map from a grid of pixels in the image plane into a space of possible colours. We call such a map a raster graphics image.
In contrast, Algorithm Citation4.Citation2 (below) produces vector graphics – that is a description of an image as a collection of various primitive objects in the (euclidean) image plane. An example of a primitive is a line segment, specified by the coordinates of its end points. Other primitives include arcs, circles, and so on. Note that we generally need to convert vector graphics to raster graphics to make a physical representation of an image. To rasterise a vector graphics image, we need to decide which pixels are coloured by which primitives. For example, a disk colours all of the pixels whose coordinates are close enough to the centre of the disk. Rasterisation is necessary for most output devices, such as screens or printers. The exceptions include plotters, laser cutters, and cathode-ray oscilloscopes. There are advantages to deferring rasterisation and saving the vector graphics to a file (in the PDF, PostScript, or SVG format, for example). For example, deferred rasterisation can take the resolution of the output device into account. Design programs such as Inkscape and Adobe Illustrator allow editing the geometric primitives in a vector graphics image. Rasterisation is usually carried out by a black-box general purpose algorithm, the details of which are hidden from the user.
Algorithm 4.2. (Approximate a Cannon–Thurston map) We are given a fibre F of the three-manifold M. We choose an elevation of F. As described in Section 3, the map
is sphere-filling.
To approximate , we first choose a large disk
. Typically, M is described with an ideal triangulation
, with F realised as a surface carried by the two-skeleton
. Therefore
is given as a surface carried by
. The disk D then consists of some finite collection of ideal hyperbolic triangles in
. The boundary of D consists of a loop of geodesics in
. We now define
to be the loop in
obtained by projecting each arc of
to an arc in
.
Note that the algorithm produces a circularly ordered collection of points in spanning geodesics in
. However, conventional vector graphics require primitives to be in the euclidean plane. Thus, we must make two choices of projections. The first projection from
to
takes the geodesics to arcs in
and the second projection takes these arcs in
to arcs in the euclidean image plane.
We draw our pictures in the “ideal view”. That is, we use the upper half space model of and project
down to
(viewed as the boundary of
). The arcs between vertices now simply become straight lines in
. This is also the choice made by Thurston in , as well as Wada in his program OPTi [Citation46]. Other depictions by McMullen [Citation28] and Calegari [7, Figure 1.14] project outward from the origin to the boundary of the Poincaré ball model of
(and then to the image plane using a perspective or orthogonal projection).
Remark 4.3.
The images in Indra’s Pearls [Citation32] have been rasterised using a customised rasteriser that illustrates further features of the Cannon–Thurston map. For example, one side of the polygonal path of line segments is filled, or the line segments are coloured using some combinatorial condition. See Figures 10.11 and 10.13 of [Citation32].
4.4 Motivating raster graphics
Our work here began when we asked if we could avoid vector graphics when illustrating Cannon–Thurston maps. This is less natural, but would allow us to take advantage of extremely fast graphics processing unit (GPU) calculation. We were inspired in part by work of Vladimir Bulatov [Citation6] and also of Roice Nelson and the fourth author [Citation33], using reflection orbihedra. (See also the work of Peter Stampfli [Citation39].) They all use raster graphics strategies to draw tilings of and
.
A number of others have also used raster graphics to explore kleinian groups, outside of the setting of reflection orbihedra. They include Peter Liepa [Citation26], Jos Leys [Citation25], and Abdelaziz Nait Merzouk [Citation30] (also see [Citation12]).
5 Cohomology fractals
We give a sequence of more-or-less equivalent definitions of cohomology fractals, beginning with the conceptually simplest (for us), and moving towards versions that are most convenient for our implementation or our proofs. Fixing notation, we take M to be a riemannian manifold and its universal cover. We also take
and
to be their unit tangent bundles. Take
to be the bundle map.
Definition 5.1.
Suppose that we are given the following data.
A connected, complete, oriented riemannian manifold Mn,
a cocycle
a point
a radius
From these, we define the cohomology fractal on the unit sphere . This is a function
defined as follows.
Suppose that is a unit tangent vector. Let γ be the unique geodesic segment starting at p with initial direction v and of length R. Let q be the endpoint of γ. Choose any shortest path
from q to p (on a set of full measure
is unique). Thus
is a one-cycle. We define
.
Our next definition moves in the direction of concrete examples:
Definition 5.2.
Here we further assume that M is a three-manifold. Let be a properly embedded, transversely oriented surface. We choose F so that
. We define γ and q as above. Now take
to be the shortest path from q to p in the complement of F. We now define
to be the algebraic intersection number between F and
.
We modify once again to obtain a definition very close to our implementation.
Definition 5.3.
We equip M with a material (or ideal) triangulation . We properly homotope the surface F to lie in the two-skeleton
. For each face f this gives us a weight
. This is the signed number of sheets of F running across f. We dispense with
; we take
to be the sum of the weighted intersections between γ and the faces of the triangulation.
To aid in comparing cohomology fractals to Cannon–Thurston maps (in Section 6), we lift to the universal cover, .
Definition 5.4.
Since cochains pull back, let be the lift of ω. Let
be a fixed lift of the point p. Since
is a coboundary, it has a primitive, say W; we choose W so that
. We form
as before and let
be its endpoint. We define
.
To analyse the behaviour of the cohomology fractal as R tends to infinity, we rephrase our definition in a dynamical setting. Here, the radius R is replaced by a time T.
Definition 5.5.
Suppose that is a closed one-form. Let
be the geodesic flow for time t. We define
In a slight abuse of notation, we also use to denote the geodesic flow on
.
In Section 7 we will discuss how to calculate in practice. Before giving those details, we show the reader what
looks like for a few values of R. See . The map
maps into
; we indicate the value of
by brightness. For each value of R, we draw the value of
for a small square subset of the unit tangent vectors,
.
Fig. 5 Cohomology fractals for m004, with various values of R.
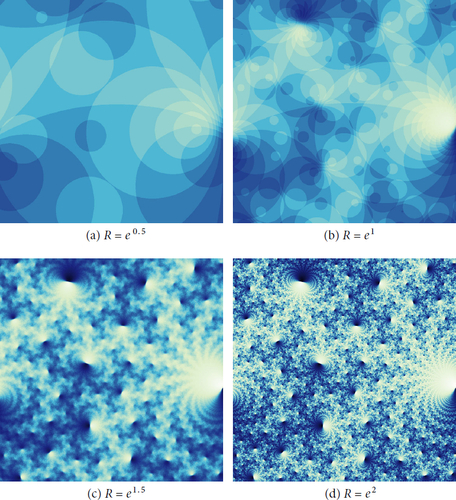
Here we are using Definition 5.3, our manifold M is the complement of the figure-eight knot, and the surface F is a fibre of M. Note that when R is small, as in , is constant on large regions of the sphere. As R increases, the value of
on nearby rays becomes less correlated, and we see a fractal structure come into focus.
Remark 5.6.
This complicated behaviour is a consequence of the hyperbolic geometry of our manifold. Consider instead the example where M is the three-torus and the surface F is an essential torus embedded in M. Again,
counts the number of elevations of F the ray γ passes through. Since the elevations are parallel planes in
, the value of
is constant on circles in
parallel to these planes. Here
is much simpler.
Remark 5.7.
Some of the geometry and topology of the manifold M can be seen from the cohomology fractal . Our recent expository paper on cohomology fractals [Citation4] gives many such examples, including the appearances of cusps, totally geodesic subsurfaces, and loxodromic elements of the fundamental group.
6. Matching figures
In this section we compare our cohomology fractals to Cannon–Thurston maps.
Example 6.1.
Suppose that M is the figure-eight knot complement. Suppose that F is a fibre of the fibration of M. Suppose that is the associated Cannon–Thurston map. shows an approximation
of
; we produced this image using Algorithm Citation4.Citation2. (Note that the vector graphics image in has been converted to a raster graphics image to save on file size and rendering time.)
shows a cohomology fractal corresponding to F and looking towards the same part of
. shows
again, but with the contrast increased and colour scheme simplified. Here the colour associated to a vector v is either white or grey, according to whether
is negative or not.
shows 1(a) overlaid on 1(c). We see that the red curve of is almost the common boundary of the white and grey regions of
. There are several small areas where
does not track the boundary. These only appear close to fairly large cusps; they exist because implementations of Algorithm Citation4.Citation2 generally have trouble approaching cusps from the side. In the cohomology fractal
we see that there are chains of “octopus heads” that reach almost all the way towards each cusp.
This behaviour is generally true for fibrations, as follows. Suppose and define
to be the inward central projection. Here we follow Definition 5.4.
Proposition 6.2.
Suppose that M is a connected, oriented, finite volume hyperbolic three-manifold. Suppose that is a fibre of a surface bundle structure on M. Fix p in F, and a lift
. Fix any R > 0 and let
be the resulting cohomology fractal for F. Let
.
Then there is a disk , containing
, so that (the image of) the Cannon–Thurston map approximation
is a component of
(with error at most
).
Proof
sketch. We assume we are in the setting of Definition 5.3. Let ω be the one-cocycle dual to F. Let W be a primitive for . Consider the two regions of
where W is negative or, respectively, non-negative. The common boundary of these is exactly an elevation
of the fibre F.
Let be the ball in
of radius R with centre
. Let
be the boundary of
. Thus the intersection
is a collection of curves; these separate the points
where W is negative from those where it is non-negative. Finally, note that
is the exponential map. Thus
.
Recall that is a union of triangles. Assume that one of these contains
. Let E be the collection of triangles of
having at least one edge meeting the ball
. Let D be the connected component of (the union over) E that contains
.
In a slight abuse of notation, let be the inward central projection. For any set
we call the diameter of
the visual diameter of K. This is measured with respect to the fixed metric on the unit two-sphere
.
Suppose that e is a bi-infinite geodesic in . If e lies outside of
then the visual diameter of e is small; in fact, for large R the visual diameter of e is less than
. Likewise, if e meets
, then for either component
of
the visual diameter of
is less than
.
Now suppose that T is a triangle of E. Using the above, we deduce that the visual diameter of each component of is small. Thus the inward central projections of
and
have Hausdorff distance bounded by a small multiple of
.
So let be the curve in
obtained by projecting
outwards. By the above, each arc of the resulting polygonal curve has small visual diameter. Also by the above, the Hausdorff distance between the curves
and
is small. □
Remark 6.3.
Suppose that F is totally geodesic or, more generally, quasi-fuchsian. In this case, the Cannon–Thurston map is a circle or quasi-circle, respectively. Note however that different elevations now give distinct Cannon–Thurston maps. It is natural to take their union and obtain a circle (or quasi-circle) packing.
Now, if F is also Thurston-norm minimising then we still obtain matches. For example in [4, ], we see how, for a totally geodesic surface in the Whitehead link complement, the cohomology fractal matches the associated circle packing. On the other hand, if is trivial in
then the cohomology fractal
is bounded and oscillates as R tends to infinity.
Fig. 6 Matching up the lightning curve, reproduced from [10, ], with the cohomology fractal for m004.
![Fig. 6 Matching up the lightning curve, reproduced from [10, Figure 7], with the cohomology fractal for m004.](/cms/asset/2d5e6685-8ad2-4bcd-8e1f-b6a8eded41ec/uexm_a_1994059_f0006_c.jpg)
6.4. Lightning curves
Suppose that M is a cusped, fibred three-manifold, with fibre F. Dicks with various co-authors defines and studies the lightning curves [Citation1, Citation9, Citation10, Citation14, Citation15, Citation17]; these are certain fractal arcs in the plane. In more detail; suppose that c and d are distinct cusps of an elevation of F. Let
be the arc of
that is between c and d and anti-clockwise of c. The Cannon–Thurston map
sends the arc
to a union of disks in
meeting only along points. The boundary of any one of these disks is a lightning curve.
Since the lightning curve is defined in terms of the Cannon–Thurston map, it is not too surprising that we can also see something of the lightning curve in the cohomology fractal. In we show a segment of the lightning curve for the figure-eight knot complement generated by Cannon and Dicks [10, ] overlaid on . The lightning curve seems to follow some of the brightest pixels in the cohomology fractal. is a black and white version of , with a relatively high threshold set for a pixel to be white – the lightning curve seems to be there, but this is nowhere near as clear as it was for the approximations to the Cannon–Thurston map. We do not fully understand the correspondence here.
Fig. 7 A toy example of developing a ray through a tiling of a euclidean torus. Note that the geodesic segments passing through a tile are parallel; this is only because the geometry is euclidean. In a hyperbolic tiling the segments are much less ordered.
We note that for clarity, shows only one segment of the lightning curve. There is another segment, symmetrical with the shown segment under a 180 degree rotation about the centre of the image. This second segment seems to follow the darkest pixels of the cohomology fractal.
7. Implementation
In this section we give an overview of an implementation of cohomology fractals. Our implementation is written in Javascript and GLSL; the code is available at [Citation5]. We have also made cohomology fractals available in SnapPy [Citation11]. Note that SnapPy cannot find hyperbolic structures on finite triangulations.
We now follow Definition 5.3. Suppose that M is a connected, oriented, finite volume hyperbolic three-manifold. Let be a material or ideal triangulation of M. We are given a weighting
for the faces of the two-skeleton.
We represent the triangulation as a collection
of model hyperbolic tetrahedra. Each tetrahedron ti has four faces
lying in four geodesic planes
in the hyperboloid model of
. Suppose that
is another model tetrahedron, with faces
. If the face
is glued to
, then we have isometries
and
realising the gluings. Note that
and
are inverses.
We are given a camera location p in M; this is realised as a point (again called p) in some tetrahedron ti.
Remark 7.1.
The reader familiar with computer graphics will note that we also require a frame at the camera location. To simplify the exposition, we will mostly suppress this detail.
We are also given a radius R as well as a maximum allowed step count S.
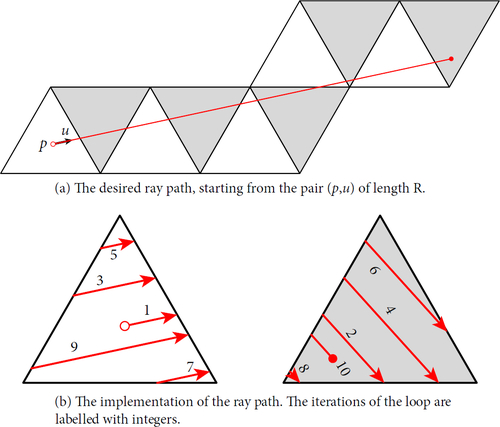
7.2. Ray-tracing
For each pixel of the screen, we generate a corresponding unit tangent vector u in the tangent space to the current tetrahedron ti. We then ray-trace through . That is, we travel along the geodesic starting at p, in the direction u, for distance R, taking at most S steps. shows a toy example, where we replace the three-dimensional hyperbolic triangulation
of M with a two-dimensional euclidean triangulation of the two-torus.
It is perhaps most natural to think of ray-tracing as occurring in , the universal cover of the manifold, as shown in . However, the naïve floating-point implementation in the hyperboloid model quickly loses precision. We instead ray-trace in the manifold, as illustrated in . Thus, all points we calculate lie within our fixed collection of ideal hyperbolic tetrahedra
.
For each pixel, we do the following.
The following initial data are given: an index i of a tetrahedron, a point p in ti, and a tangent vector u at p. Initialise the following variables.
The total distance travelled:
The number of steps taken:
The current tetrahedron index:
The current position:
The current tangent vector:
Let γ be the geodesic ray starting at p in the direction of u. Find the index n so that γ exits tj through the face
Calculate the position
If r > R or s > S then stop.
Set
Go to step (2).
This implements the ray-tracing part of the algorithm. In our toy example, this is shown in .
7.3. Integrating
To determine the colour of the pixel, we also track the total signed weight we accumulate along the ray. For this, we add the following steps to the loop above.
(1b)An initial weight w0 is given. Initialise the following.
The current weight:
(5b)Let f be the face between t and
At the end of the loop, the value of wc gives the brightness of the current pixel. (In fact, we apply a function very similar to the arctangent function to remap the possible values of wc to a bounded interval. We then apply a gradient that passes through a number of different colours. This helps the eye see finer differences between values than a direct map to brightness.)
7.4. Moving the camera
In our applications, we enable the user to fly through the manifold M. Depending on the keys pressed by the user at each time step, we apply an isometry g to p. We also track an orthonormal frame for the user; this determines how tangent vectors correspond to pixels of the screen. We also apply the isometry g to this frame. When the user flies out of a face f of the tetrahedron they are in, we apply the corresponding isometry to the position p and the user’s frame. We also add w(f) to the initial weight w0. Without this last step, the overall brightness of the image would change abruptly as the user flies through a face with non-zero weight.
Remark 7.5.
With this last modification, the cohomology fractal depends on a choice of basepoint . The point
must now also be replaced by
(abusing notation, we use the same symbol for both points). We add b to the notation, and now write the cohomology fractal as
Remark 7.6.
The dependence of the cohomology fractal on b is minor: If we change b to , then the value of
changes by the weight we pick up along any path from
to b.
7.7. Material, ideal, and hyperideal views
The above discussion describes the material view; the geodesic rays emanate radially from p. To render an image, we place a rectangle in the tangent space at p. For each pixel of the screen, we take the tangent vector u to be the corresponding point of the rectangle. See .
Fig. 8 Comparison between different views of the cohomology fractal for m004.

Definition 7.8.
The field of view of a material image is the angle between the tangent vectors pointing at the midpoints of the left and right sides of the image.
Remark 7.9.
The material view suffers from perspective distortion. This is most noticeable towards the edges of the image, and is worse when the field of view is large.
To generalise the material view to the ideal and hyperideal, we introduce the following terminology. We say that a subset is a view if it is one of the following.
In the material view, D is a fibre
In the ideal view, we take D to be the collection of outward normals to a horosphere H. That is, the vectors point away from
In the hyperideal view, we take D to be the collection of normals to a transversely oriented geodesic plane P. We draw P on the euclidean rectangle of the screen using the Klein model. The algorithm is otherwise identical to the ideal view case. See .
Remark 7.10.
The ideal view in hyperbolic geometry is the analogue of an orthogonal view in euclidean geometry. In both cases this is the limit of backing the camera away from the subject while simultaneously zooming in.
Remark 7.11.
The hyperideal view suffers from an “inverse” form of perspective distortion. Towards the edges of the image, round circles look like ellipses, with the minor axis along the radial direction.
Definition 7.12.
Let be a view, as discussed above. In the notation for the cohomology fractal, we replace p by D:
7.13. Edges
We give the user the option to see the edges of the triangulation. The user selects an edge thickness . The web application implements this in a lightweight fashion: In step (3), if the distance from the point
to one of the three edges of the face we have intersected is less than ε, then we exit the loop early. Depending on user choice, the pixel is either coloured by the weight wc or by the distance d. See . In SnapPy, we compute the intersection of the ray with a cylinder about the edge in addition to the intersection with the faces.
Fig. 9 Edges of the ideal triangulation of m004, as seen in the material view.

7.14. Elevations
We also give the user the option to see several elevations of the surface F. The user selects a weight . In step (5b), if
but
, then we have crossed the elevation at weight zero. In this case we exit the loop, and colour the pixel by the distance d. Similarly, if
but
, then we have crossed the elevation at weight
, and again we stop and colour by distance. Finally, if
, then we stop if wc has changed from w0. shows a single elevation.
7.15. Triangulations, geometry, and cocycles
We obtain our triangulations and their hyperbolic shapes from the SnapPy census. We put some effort into choosing good representative cocycles; the choice here makes very little difference to the appearance of the cohomology fractal, but it makes a large difference to the appearance of the elevations. That is, a poor choice of cocycle gives a “noisy” elevation. For example, adding the boundary of a tetrahedron to the Poincaré dual surface may perform a one-three move to its triangulation. This adds unnecessary “spikes” to the elevations.
When our manifold has Betti number one, there is only one cohomology class of interest. Here we searched for taut ideal structures dual to this class [Citation24]. When the SnapPy triangulation did not admit such a taut structure, we randomly searched for one that did. A taut structure gives a Poincaré dual surface with the minimum possible Euler characteristic.
When the Betti number is larger than one, we used tnorm [Citation47] to find initial simplicial representatives of vertices of the Thurston norm ball [Citation44] in . We then greedily performed Pachner moves to reduce the complexity of the cocycles. We often, but not always, realised the minimum possible Euler characteristic.
7.16. Discussion
Any visualisation of a hyperbolic tiling suffers from the mismatch between the hyperbolic metric of the tiling and the euclidean metric of the image. The tools for generating more of the tiling involve applying hyperbolic isometries. The tiles thus shrink exponentially in size while growing exponentially in number. This makes it difficult for the tiles to cleanly approach or
. Approaching a “parabolic” point at infinity is even more difficult.
In the vector graphics approach, one must be careful to avoid wasting time generating huge numbers of invisible objects: tiles may be too small or their aspect ratios too large.
The ray-tracing approach (and any similar raster graphics approach) deals with this mismatch directly. Here we start with the pixel that is to be coloured and then generate only the hyperbolic geometry needed to determine its colour.
A disadvantage of the ray-tracing approach is that we generate the hyperbolic geometry necessary for each pixel independently, meaning that much work is duplicated. However, the massive parallelism in modern graphics processing units mitigates, and is in fact designed to deal with, this kind of issue. It often turns out to be faster to duplicate work in many parallel processes rather than compute once then transmit the result to all processes requiring it.
8. Incomplete structures and closed manifolds
Suppose that M is a cusped hyperbolic manifold. Recall that we generate cohomology fractals for M by using an ideal triangulation . Associated to
there is the shape variety; that is we impose the gluing equations outlined in Section 2.3, omitting the peripheral ones. This gives us a space of deformations of the complete hyperbolic structure to incomplete hyperbolic structures; see [42, Section 4.4] and [35, Section 6.2]. If we deform correctly, we reach an incomplete structure whose completion has the structure of a hyperbolic manifold. The result is a hyperbolic Dehn filling of the original cusped manifold.
8.1. Incomplete structures
Suppose that is an ideally triangulated manifold. Let Zs be a path in the shape variety, where
is the complete structure and the completion of Z1 is a closed hyperbolic three-manifold obtained by Dehn filling M. Between the two endpoints, we have incomplete structures Ms on the manifold M.
In an incomplete geometry, there are geodesic segments that cannot be extended indefinitely. Suppose that, as in our algorithm, we only consider geodesic segments emanating from p of length at most R. The endpoints of the rays that do not extend to distance R form the incompleteness locus Σs in the ball . It follows from work of Thurston that Σs is a discrete collection of geodesic segments, for generic values of s [Citation43].
Suppose that is the given weight function dual to a properly embedded surface F in M. We assume that the boundary of F (if any) gives loops in the filled manifold that, there, bound disks. Thus F also gives a cohomology fractal in the filled manifold.
Remark 8.2.
Note that there is no canonical way of transferring a base point b or view D between two different geometric structures Ms and . However, we can choose b and D for each Ms in a way that gives us continuously varying pictures. We do not dwell on the details here.
shows cohomology fractals for various Ms. We see a kind of branch cut in the background to either side of the incompleteness locus Σs. As we vary s, the background appears to bend along the geodesic. Other paths in the shape variety will give shearing as well as (or instead of) bending.
Fig. 10 Cohomology fractals for m122 () as s varies.

When we reach a Dehn filling, the two sides again match, and we see the structure of the closed filled manifold. See . (The two sides can also match before we reach the Dehn filling due to symmetries of the cusped manifold lining up with the cone structure.)
Fig. 11 Cohomology fractal for the Dehn filling m122(4,-1). This gives a final image for , with .

8.3. Numerical instability near the incompleteness locus
Our algorithm, given in Section 7, does not require completeness. However, a ray from p to Σs necessarily meets infinitely many tetrahedra. This is because near Σs we are far from the thick part of any tetrahedron, and the thin parts of the tetrahedra are almost “parallel” to Σs. Thus the innermost loop of the algorithm will always halt by reaching the maximum step count; it follows that we cannot “see through” a neighbourhood of Σs. shows the cohomology fractal drawn with a small maximum step count, making such a neighbourhood visible.
Fig. 12 Cohomology fractal for the Dehn filling m122(4,-1) drawn with an incomplete structure on an ideal triangulation. Here the maximum number of steps S is 55. Compare with .

Increasing the maximum step count shrinks the opaque neighbourhood of Σs. However, as a ray approaches Σs, its segments within the model tetrahedra tend to their ideal vertices. Thus the coordinates blow up; this appears to lead to numerically unstable behaviour. See . In the next section we describe a method to eliminate these numerical defects; we use this to produce .
Fig. 13 A view of the cohomology fractal for the manifold m122(4,-1) near the incompleteness locus. On the left we have taken the maximum number of steps S sufficiently large to ensure that all rays reach distance R.

Note that numerical instability caused by rays approaching the ideal vertices also occurs for the complete structure on a cusped manifold. It is less noticeable in this case however, because these errors occur in a small part of the visual sphere for typical positions.
8.4. Material triangulations
In order to remove instability around the incompleteness locus, we remove it. That is, we abandon (spun) ideal triangulations in favour of material triangulations. There is no change to the algorithm in Section 7; we only alter the input data (the planes and face-pairing matrices
):
Given the edge lengths (see Section 2.3.2) for a material triangulation, [19, Lemma 3.4] assigns hyperbolic isometries to the edges of a doubly truncated simplex (also known as permutahedron). These can be used to switch a tetrahedron between different standard positions (as defined in [19, Definition 3.2]) where one of its faces is in the plane. We assume that every tetrahedron is in
–standard position. Given a face-pairing, we apply the respective isometries to each of the two tetrahedra such that the faces in question line up in the
plane. The face-pairing matrix
is now given by composing the inverse of the first isometry with the second isometry. For example, let face 3 of one tetrahedron be paired with face 2 of another tetrahedron via the permutation
. To line up the faces, we need to bring the second tetrahedron from the default
–standard position into
–standard position by applying γ012 from [19, Lemma 3.4] which will thus be the face-pairing matrix, see [19, ]. It is left to compute the planes
. Note that
(for each i) is the canonical copy of
. All other
can be obtained by applying the isometries from [19, Lemma 3.4] again.
8.5. Cannon–Thurston maps in the closed case
Cannon and Thurston’s original proof was in the closed case. Thurston’s original images and all subsequent renderings, with one notable exception, are in the cusped case. With some minor modifications, Proposition 6.2 applies in the closed case; thus the cohomology fractals again approximate Cannon–Thurston maps.
We are aware of only one previous example in the closed case, due to McMullen [Citation28]. In we give a rasterisation of his original vector graphics image [Citation29], and our version of the same view. The filling m004(0,2) of the figure-eight knot complement has an incomplete hyperbolic metric. The completion is a hyperbolic orbifold with angle π about the orbifold locus; the universal cover is
.
Fig. 14 Views of ![]()

Since the filling is a multiple of the longitude, the orbifold is again fibred. An elevation of this fibre to
gives a Cannon–Thurston map. Our image, is the cohomology fractal for the fibre in
, in the hyperideal view. This is implemented using a material triangulation of an eight-fold cover M. Since M with its fibre, is commensurable with
with its fibre, we obtain the same image.
McMullen’s image, reproduced in was generated using his program lim [Citation27]. Briefly, let be the infinite cyclic cover of
. McMullen produces a sequence
of quasi-fuchsian orbifolds that converge in the geometric topology to
. In each of these the convex core boundary is a pleated surface. The supporting planes of this pleated surfaces give round circles in
. His image then is obtained by taking n fairly large, passing to the universal cover of
, and drawing the boundaries of many supporting planes [Citation29].
8.6. Accumulation of floating point errors
Our implementation uses single-precision floating point numbers. As we saw in Section 8.3, this can cause problems when rays approach the vertices of ideal tetrahedra. However, floating point errors can accumulate for large values of R whether or not rays approach the vertices. This can therefore also affect material triangulations.
With these problems in mind, we cannot claim that our images are rigorously correct. However, for small values of R we can be confident that our images are accurate. For very small values the endpoints of our rays all sit within the same tetrahedron, and so all pixels are the same colour. As we increase R (as in ), we see regions of constant colour, separated by arcs of circles. This is provably correct: (horo-)spheres meet the totally geodesic faces of tetrahedra in circles.
If we zoom in whilst increasing R, eventually floating point errors become visible. shows the results of an experiment to determine when this happens, for a material triangulation. At around R = 11, the circular arcs separating regions of the same colour become stippled. At around R = 13, the regions are no longer distinct.
Fig. 15 We zoom into the cohomology fractal for m122(4,-1) while increasing R. The field of view of the image is proportional to . Noise due to rounding errors becomes visible at
and completely dominates the picture when
.

Remark 8.7.
Perhaps surprisingly, this accumulation of error does not mean that our pictures are inaccurate. Suppose that the side lengths of our pixels are on a somewhat larger scale than the precision of our floating point numbers. For each pixel, our implementation produces a piecewise geodesic, starting in the direction through the centre of the pixel, but with small angle defect at each vertex. Due to the nature of hyperbolic geometry, this piecewise geodesic cannot curve away from the true geodesic fast enough to leave the visual cone on the desired pixel. Thus, as long as the pixel size is not too small, each pixel is coloured according to some sample within that pixel.
9. Experiments
The sequence of images in suggests that some form of fractal object is coming into focus. When R is small, the function is constant on large regions of D. As R increases, these regions subdivide, producing intricate structures.
As we have defined it so far, the cohomology fractal depends on R. A natural question is whether or not there is a limiting object that does not depend on R. In this section we describe a sequence of experiments we undertook to explore this question. Inspired by these, in Sections 10 and 11 we provide mathematical explanations of our observations.
9.1. These pictures do not exist
A naïve guess might be that the cohomology fractal converges to a function as R tends to infinity. However, consider a ray following a closed geodesic γ in M that has positive algebraic intersection with the surface F. Choosing D so that it contains a tangent direction v along γ, we see that diverges to infinity as R tends to infinity. The issue is not restricted to the measure zero set of rays along closed geodesics. Suppose that v is a generic vector in a material view D. Recall that the geodesic flow is ergodic [22, Hauptsatz 7.1]. Thus the ray starting from v hits F infinitely many times. So
again diverges. Thus we have the following theorem.
Theorem 9.2.
Suppose that M is a finite volume, oriented hyperbolic three-manifold. Suppose that p is any point of M. Suppose that F is a compact, transversely oriented surface. Then the limit
does not exist for almost all
.
Remark 9.3
To generalise Theorem 9.2 from finite volume to infinite volume manifolds, we must replace Hopf’s ergodicity theorem by some other dynamical property. For example, Rees [36, Theorem 4.7] proves the ergodicity of the geodesic flow on the infinite cyclic cover of a hyperbolic surface bundle. This is generalised to the bounded geometry case by Bishop and Jones [2, Corollary 1.4]. Both of these works rely in a crucial fashion on Sullivan’s equivalent criteria for ergodicity [41, page 172].
One might hope that as R tends to infinity, nearby points diverge in similar ways. If so, we might be able to rescale and have, say, or
converge. However, increasing R in our implementation produces the sequence of images shown in . We see that, as we increase R, the images become noisy as neighbouring pixels appear to decorrelate. Eventually the fractal structure is washed away. Dividing the cohomology fractal by, say, some power of R only changes the contrast. Depending on this power, the limit is either almost always zero or does not exist.
Fig. 16 Cohomology fractals for m004, with larger values of R. Each image here and in has 1000 × 1000 pixels.

also demonstrates that Remark 8.7, while valid, is misleading; it is true that for large R, every ray ends up somewhere within its pixel, but the colour one obtains is random noise. This noise is due to undersampling. In our images each pixel U is coloured using a single ray passing (almost, as we saw in Section 8.6) through its centre. When R is small relative to the side length of U the function is generally constant; thus any sample is a good representative. As R becomes larger the function
varies more and more wildly; thus a single sample does not suffice.
9.4. Take a step back and look from afar
Let D be an ideal view in the sense of Section 7.7. We identify , isometrically, with the euclidean plane
. Using this identification, we may refer to the vectors of D as zD for
. Let E be the ideal view obtained from D by flowing outwards by a distance d. Thus,
. We similarly identify
with the euclidean plane, in such a way that for each
, we have
. We may now state the following.
Lemma 9.5.
Suppose that D is an ideal view and . Then the cohomology fractal based at b satisfies
Proof.
Consider . □
Fig. 17 Side view of “screens” (in red) for two ideal views, drawn in the upper half space model. The outward pointing normals to each horosphere point down in the figure.
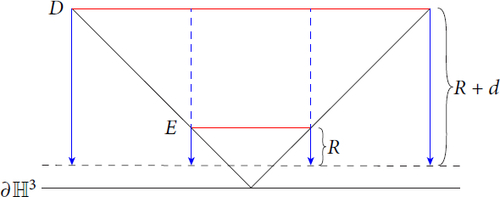
Said another way, if we fly backwards a distance d and replace R with R + d, we see the exact same image, scaled down by a factor of ed. As a consequence, in the ideal view we have the following.
Remark 9.6.
Each small part of a cohomology fractal with large R is the same as the cohomology fractal for a smaller R with a different view.
Remark 9.7.
Since we know that we can make non-noisy images for small enough values of R, we can therefore make a non-noisy image of a cohomology fractal for any value of R, as long as we are willing to use a screen with high enough resolution.
The natural question then is how the perceived image changes as we simultaneously increase the resolution and increase R. This convergence question is different from the convergence of the cohomology fractal to a function as in Theorem 9.2: when we look at a very large screen from far away, our eyes average the colours of nearby pixels. Thus, we move away from thinking of the limit as a function evaluated at points, towards thinking of it as a measure evaluated by integrating over a region. As we will see later, in fact the correct limiting object is a distribution.
9.8. Supersampling
To investigate this without requiring ever larger screens to view the results, we sample the cohomology fractal at many vectors in a grid within each pixel and average the results to give a colour for the pixel. That is, we employ supersampling. See . Here we draw cohomology fractals with R ranging from 4 to 12, and with either 1, 22, or 1282 subsamples for each pixel. Each image has resolution .
Fig. 18. m122(4,-1). Field of view: .
pixels. For each image, the visual radius R is given at the start of its row, while the number of samples per pixel is given at the top of its column.
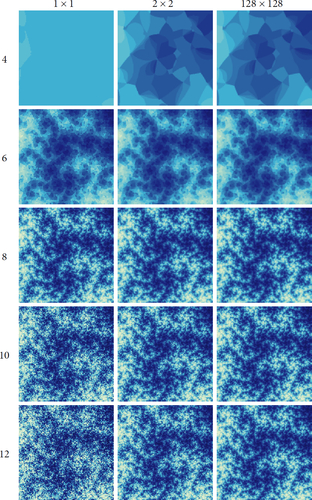
Remark.
Note that some pdf readers do not show individual pixels with sharp boundaries: they automatically blur the image when zooming in. To combat this blurring and see the pixels clearly, we have scaled each image by a factor of three, so each pixel of our result is represented by nine pixels in these images.
With one sample per pixel, as we increase R the fractal structure comes into focus but then is lost to noise. This matches our observations in and . Taking subsamples and averaging makes little difference for small R: the only advantage is an anti-aliasing effect on the boundaries between regions of constant value. However, subsamples help greatly with reducing noise for larger R. With 2 × 2 subsamples, we see much less noise at R = 10, becoming more noticeable at R = 12. Taking 128 × 128 samples seems to be very stable: there is almost no difference between the images with R = 10 and R = 12. This suggests that the perceived images converge.
9.9. Mean and variance within a pixel
To better understand how subsampling interacts with increasing R, in we graph the average value within a selection of pixel-sized regions as R increases.
Fig. 19 The graph of the average value of the cohomology fractal for m122(4,-1) for various square regions U with field of view . Thus, these are the same size as the pixels of . These are each computed by taking 1000 × 1000 samples. We also show the envelopes of 0.5, 1.0 and 1.5 standard deviations.
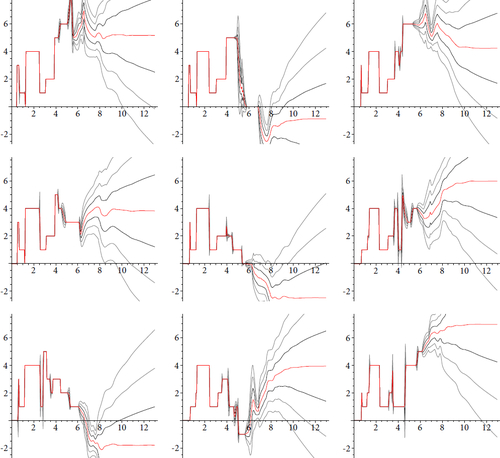
When R is small, the graphs are more-or-less step functions, as much of the time the pixel U is inside of a constant value region of the cohomology fractal. The graphs are also very similar for small R. This is because the pixels are close to each other, so all of their rays initially cross the same sequence of faces of the triangulation. Around R = 6, we reach the “last step” of the step function, then the regions of constant value become smaller than U. For , the mean seems to settle down, while the standard deviation appears to grow like
.
Again this suggests that the perceived images converge. However, if the standard deviation continues to increase with R, then eventually any number of subsamples within each pixel will succumb to noise.
9.10. Histograms
We have looked at the standard deviation of a sample of values within a pixel. Next, we analyse the distribution of these values in more detail. See .
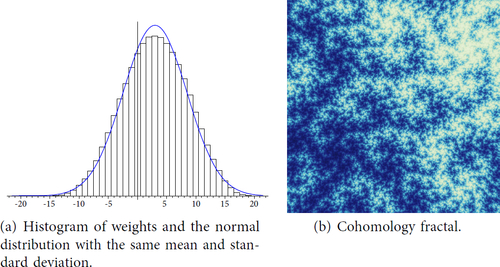
Fig. 20 Statistics for a cohomology fractal of m122(4,-1) for a square region with field of view and
.
We fix . We sample
at each point of a
grid within a square of a material view with field of view
. We chose a relatively large field of view here so that we get an “in focus” image of the cohomology fractal with a relatively small value of R. Here we are being cautious to get good data, avoiding potential problems that our implementation has with large values of R as discussed in Section 8.6.
We histogram the resulting data with appropriate choices of bucket widths. In we show the histogram and the normal distribution with the same mean and standard deviation for our closed example, m122(4,-1). In we show the sample data as a 1000 by 1000 pixel image. We also draw the normal distribution with the same mean and standard deviation; the data seems to fit this well.
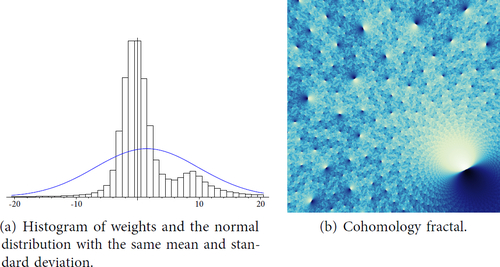
We repeat this experiment back in the cusped case with s789. See and . Here we show the cohomology fractal for two different cohomology classes . The cohomology class shown in vanishes when restricted to
, while in it does not. The distribution appears to be normal when the cohomology class vanishes on
. When
does not vanish on
, something more complicated appears to be happening. One feature here is that the tails are much too long for a normal distribution. A heuristic explanation for this is that in a neighbourhood of the cusp, a geodesic ray crosses the surface repeatedly in the same direction. This allows it to gain a linear weight in logarithmic distance.
Fig. 21 Statistics for a cohomology fractal of s789 for a class vanishing on cusp.
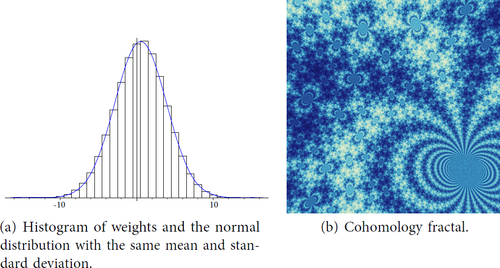
Fig. 22 Statistics for a cohomology fractal of s789 for a class not vanishing on cusp.
10. The central limit theorem
In this section, we prove a central limit theorem for the values of the cohomology fractal across a pixel. That is, the distribution of the values of the scaled cohomology fractal
converges to a normal distribution with mean zero.
10.1 Setup
We recall the framework introduced in Section 7.7 that unifies the material, ideal, and hyperideal views. Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold. As above we set and
. We call a two-dimensional subset
a view if it is of one of the following.
For a material view, fix a basepoint
For the ideal view, fix a horosphere
For the hyperideal view, fix a hyperbolic plane
Note that has a riemannian metric induced from the riemannian metric on
. This metric also endows D with an area two-form and associated measure denoted by
and
. Recall that
is the projection to the base space.
Remark 10.2.
Note that there is another riemannian metric on D for the ideal and hyperideal view coming from isometrically identifying the horosphere or hyperbolic plane with
or with, respectively,
. Up to a constant factor, this metric is the same as the above metric. The factor is trivial for the hyperideal view; it is
for the ideal view. This arises as
from the extrinsic curvature KH of H. We have KH = 1 so that adding KH to the ambient curvature –1 of
gives zero, the horosphere’s intrinsic curvature.
In this notation, the definition of the cohomology fractal, for a given closed one-form and basepoint
, becomes the following. For
, we have
(10.3)
(10.3)
For the second integral, any path from b to in
can be chosen as ω is closed. This integral is constant in v for the material view since
. Choosing
so that
and W(b) = 0, we can simply write
The central limit theorem will apply to probability measures νD that are absolutely continuous with respect to the area measure μD on D. We use the usual notation for absolute continuity. By the Radon-Nikodym theorem, this is equivalent to saying that the measure νD is given by
(10.4)
(10.4) where
is measurable with
.
Remark 10.5.
In Section 11, we will switch from measures νD to forms ηD, for the following reason. Here, in Section 10 we follow the well-established notation of [Citation37, Citation49]. However, the transformation laws in Section 11 are better stated in the language of forms. In both cases we consider probability measures or two-forms that are “products”: namely of a suitable function with the area measure μD or two-form ζD respectively. The function h should be thought of as an indicator (or a kernel) function for a pixel.
10.6. The statement of the central limit theorem
The goal of this section is to prove the following.
Theorem 10.7.
Fix a connected, orientable, finite volume, complete hyperbolic three-manifold M and a closed, non-exact, compactly supported one-form . There is
such that for all basepoints b, for all views D with area measure μD, for all probability measures
, and for all
, we have
where
is the associated cohomology fractal.
Let us recall some notions from probability to clarify what this means. Let be a probability space. For each
, let
be a measurable function. For each T, the probability measure ν on P induces a probability measure
on
telling us how the values of the random variable RT are distributed when sampling P with respect to ν. Let ψ be a probability measure on
.
Definition 10.8.
We say that the random variables RT converges in distribution to ψ if the measures converge in measure to ψ. This is denoted by
.
Here, by the Portmanteau theorem, we can use any of several equivalent definitions of weak convergence of measures. We are only interested in the case where ψ is absolutely continuous with respect to Lebesgue measure on ; that is, we can write
for any measurable
. Note that here
is the probability density function for ψ. Convergence in distribution
is then equivalent to saying that for all α we have
We define
The latter is the normal distribution with mean zero and standard deviation σ.
Example 10.9.
The process of flipping coins can be modelled as follows. Set . We define a measure νP on P as follows. Given any prefix v of length n, the set of all infinite words in P starting with v has measure
. Let
be the random variable
as wi is heads or tails respectively. Define
. The classical central limit theorem states that
We can now restate Theorem 10.7 as
10.10 Sinai’s theorem
Our proof of Theorem 10.7 starts with Sinai’s central limit theorem for geodesic flows [Citation37]. We use the following version of Sinai’s theorem which is adopted from [18, Theorem VIII.7.1 and subsequent Nota Bene]. This applies to functions that are not derivatives in the following sense. Recall that .
Definition 10.11.
Let be a smooth function. We say that f is a derivative if there is a smooth function
such that
Let be the normalised Haar measure.
Theorem 10.12
(Sinai-Le Jan’s Central Limit Theorem). Fix a connected, orientable, finite volume, complete hyperbolic three-manifold M. Let be a compactly supported, smooth function with
. Assume f is not a derivative. Let
Then there is a such that
.
In fact, the constant σ appearing in Theorem 10.12 is the square root of the variance of f which Franchi–Le Jan denote by . They give a formula for
in [18, Theorem VIII.7.1] and state that
vanishes if and only if f is a derivative.
Remark 10.13.
To relate Theorem 10.12 to [18, Theorem VIII.7.1], note that Franchi–Le Jan think of f as a function on the frame bundle of that is both Γ and
–invariant. Since f is smooth and compactly supported, it satisfies the hypotheses of their theorem. Note that they also require f to not be a derivative (denoted by
, see [18, (VIII.1)]) of a function h but allow h to be a function on the frame bundle. However, if an
–invariant f is the derivative of a function h on the frame bundle, it is also the derivative of an
–invariant function on the frame bundle.
We deduce Theorem 10.7 from Sinai’s theorem in three steps.
Theorem 10.18 generalises Sinai’s theorem to arbitrary probability measures
Theorem 10.27 restricts from X to the two-dimensional view D using a measure
Finally, we show that the term
10.14. Generalising Sinai’s Theorem
We begin with a definition.
Definition 10.15.
Let be a finite measure space. For
, let
be a measurable function. We say that Qn converges to zero in probability and write
if for all
we have
The following result is called strong distributional convergence, see [49, Proposition 3.4].
Theorem 10.16.
Let be a finite measure space and
be an ergodic, measure-preserving transformation. For all
, let
be a measurable function. Let
and suppose that
. Let ψ be a probability measure on
. If we have
for some probability measure
, then we have
for all probability measures
.
Remark 10.17.
We have specialised Zweimüller’s Proposition 3.4 in [Citation49] to finite measure spaces. To obtain Zweimüller’s result for σ–finite measure spaces , we need to replace the requirement
by the following weaker requirement denoted by
in [49, Footnote 3]: for all probability measures
we have
. To see that
is weaker, we can use the following standard result: for any
we have
The requirements and
are equivalent if μ is finite.
Using this, we now give our first variant of Sinai’s theorem.
Theorem 10.18.
With the same hypotheses as in Theorem 10.12, we have the following. There is a such that for any probability measure
we have
.
Proof.
By Theorem 10.12, there is a σ such that as
. Note that the random variables in Theorem 10.16 are indexed by
instead of
but it is easy to see that sequential convergence and convergence in distribution are equivalent. In other words, it is suffices to show that for any sequence
with
the random variables
satisfy
. In order to apply Theorem 10.16, we need the following two claims.
Claim 10.19. The time-one map for the geodesic flow is ergodic.
Proof.
By [18, Theorem V.3.1] the geodesic flow is mixing. It follows that the time-one map is also mixing, and thus ergodic.
Claim 10.20. Let . Then,
.
Proof.
We will prove a stronger statement: .
We can now finish the proof of Theorem 10.18. We apply Theorem 10.16 with Rn replaced by Sn and T replaced by .
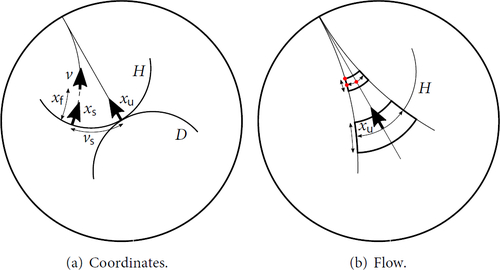
10.21. Coordinates
Given a view D, we introduce coordinates for a neighbourhood of D in as follows; it may be helpful to consult Figure 10.21(a). Fix
. If v is close enough to D in
, then there is an
such that the rays emanating from
and v converge to the same ideal point in
. Consider the set
such that
H are the “inward pointing” normals to
Let be the intersection of H with the line through v. Let
be the signed distance from
to v along this line. The triple
determines the vector
uniquely. In an abuse of notation, we will simply write
.
Suppose N is a submanifold. Let denote the length of the shortest curve in N connecting p and q. Given
, let
Let
Fig. 23 Coordinates for and flow of a box
.
Remark 10.22.
Note that the subscripts appearing in the coordinates refer to the unstable, flow, and stable foliations.
The points
If we fix
Also, if we fix
Note that each is isometric to a (pointed) copy of
. However, the coordinates above do not live in a geometric product
. They instead form a smooth fibre bundle over D. (In the material case, the view D is a copy of S2. If we factor away the flow direction from our coordinates, what remains is isomorphic to the non-trivial bundle
.) Thus we will only locally appeal to a “product structure” on these coordinates.
The following lemma is deduced from the exponential convergence inside of stable leaves. See Figure 10.21(b).
Lemma 10.23.
For all and all
, we have
Proof.
In our coordinates we have and
. We take
. Then we have
and
Applying the triangle inequality gives the result. □
10.24. Proof of the central limit theorem
We now use these coordinates to continue with the proof of Theorem 10.7.
Lemma 10.25.
Let be a probability space. Let
be a pair of one-parameter families of measurable functions. Assume that
where ψ is a probability measure on
with bounded probability density function
. Assume that there is a monotonically growing family
of measurable sets such that
and
. Then
.
Proof.
Fix α and let
We need to show that for every , there is a T0 such that for all
we have
We only deal with the second inequality since the first inequality can be derived in an analogous way using . We have the following estimate.
Fix . Let
. By hypothesis, we have for all large enough T
Because , we furthermore have for all large enough T
We return to the case of interest where f is given by a one-form ω.
Lemma 10.26.
Let be closed but not exact. Then
is not a derivative in the sense of Definition 10.11.
Proof.
We prove the contrapositive: that is, if ω is a derivative in the sense of Definition 10.11 then for a function
. Fix a basepoint
. We define
. Here γ is a path from p to q. All that is left is to show that W is well-defined.
So, suppose that is another path from p to q. Thus
is a cycle. Let
be the geodesic representative of z. Since ω is closed we have
. Since ω is a derivative we have
and we are done. □
Theorem 10.27.
With the same hypotheses as in Theorem 10.7, we have the following. There is such that for all views D with area measure μD, for all probability measures
, and for all
, we have
where
.
Proof.
The one-form ω is not a derivative by Lemma 10.26. Taking , let σ be as in Theorem 10.18.
Fix a probability measure . We define a measure
on
using the coordinates
by taking the product of, in order,
νD
the Lebesgue measure on
the Lebesgue measure on
We scale to be a probability measure. Note that the Lebesgue measure on
does not depend on the isometric identification of
with
. Thus
is well-defined.
By summing over fundamental domains, the probability measure descends to a probability measure
on X. Given that
is
–invariant, Theorem 10.18 yields
.
Note that is supported in the closure of D1 (as defined before Remark 10.22). We have a projection
where
. By construction, we have
for any measurable set
.
Claim 10.28. We have
Proof.
We take P = D and we take UT = D for all T. Applying Lemma 10.25, it is left to show that . Let
be a primitive of
. That is
. In an abuse of notation, we abbreviate
as W. Recall that
. We can now write
Since , it is sufficient to show that both of
are bounded by twice the Lipschitz constant of W. This follows from Lemma 10.23 when replacing ε by 1 and setting t to either T or 0. □
Fix α. Theorem 10.27 follows fromconverging to
by Claim 10.28. □
Proof of Theorem 10.7.
Note that Theorem 10.27 shows convergence in distribution for
However we need to show convergence in distribution for , the difference being
where
is a fixed basepoint. Thus, we need to show that Lemma 10.25 applies when taking
. Denote the constant
by C. Let
be a bound on the absolute value of
. It is convenient to let
Then, for
. Since UT exhausts D and ν is a finite measure,
. □
11. The pixel theorem
In this section, we prove that the cohomology fractal gives rise to a distribution at infinity. That is, integrating against the cohomology fractal then taking the limit as R tends to infinity, gives a continuous linear functional on smooth, compactly supported functions.
11.1. Motivation
Throughout the paper, we have drawn many images of cohomology fractals, always depending on a visual radius R. The obvious question is whether there is a limiting image as R tends to infinity.
It turns out that the answer critically hinges on the question of what a pixel is. As we showed in Theorem 9.2, thinking of a pixel as a sampled point does not work. After realising this, our next thought was that the cohomology fractal might converge to a signed measure μ. We managed to prove this for squares (as well as for regions with piecewise smooth boundary). However our proof does not generalise to arbitrary measurable sets. See Section 11.35 for a discussion.
We finally arrived at the notion of thinking of a pixel as a smooth test function; see [Citation38]. The cohomology fractal now assigns to a pixel its weighted “average value”; in other words, we obtain a well-defined distribution. This distribution satisfies various transformation laws; these describe how it changes as we alter the chosen cocycle, basepoint, or view. To prove these we rely heavily on the exponential mixing of the geodesic flow.
11.2. Background and statement
Before stating the theorem we establish our notation. We define ω, b, D, and T as in Section 10.1. However, as mentioned in Remark 10.5, we switch from using the area measure μD to the area two-form ζD and from a probability measure νD to a compactly supported two-form ηD. To obtain , we set
; here
is compactly supported and smooth. That is, h is Hodge dual to η.
The function h should be thought of as the kernel function for a pixel. The discussion below could be phrased completely in terms of h. However, using η allows us to neatly express the transformation laws between different views.
Definition 11.3.
For a compactly supported two-form , we define
As we shall see, is a distribution: a continuous linear functional on
. We recall the topology on
in the proof of Theorem 11.4. We will use
to denote the canonical distribution
.
To give a transformation law between views D and E, we will need a way to relate one to the other. Recall that is isometric to
; thus we have
. As t tends to infinity, the flow
takes a unit tangent vector
to some point
. This induces a conformal embedding iD of D into
. We define iE similarly. We take
where it is defined. This is a conformal isomorphism from (a subset of) E to (a subset of) D. We can now state the main result of this section.
Theorem 11.4
(Pixel theorem). Suppose that M is a connected, orientable, finite volume, complete hyperbolic three-manifold. Fix a closed, compactly supported one-form , a basepoint
, and a view D.
Then
Given
Given another basepoint
Given another view E and a two-form
The last property gives us a distribution at infinity as follows.
Corollary 11.5.
Suppose that M is a connected, orientable, finite volume, complete hyperbolic three-manifold. Fix a closed, compactly supported one-form and a basepoint
. Then there is a distribution
on
so that, for any view D and any
, we have
11.6 Proof of the pixel theorem
We now describe some background necessary to prove the theorem. Throughout this section, we fix a connected, orientable, finite volume, complete hyperbolic three-manifold M. Again we take and
. Let
(11.7)
(11.7)
Fubini’s theorem implies that(11.8)
(11.8) so much of the proof boils down to obtaining exponential decay of
.
In this section we will use the Haar measure for integrals over
. We will use the shorthand
throughout.
We also need to introduce the Sobolev norm for smooth functions f on homogeneous spaces. First consider functions
where G is a Lie group. Fix a basis for the Lie algebra of G; we think of the elements in this basis as left-invariant vector fields on G. The Sobolev norm
is the maximum of all
–norms of functions obtained by differentiating f up to m times using these vector fields in any order. Suppose that Γ and H are (respectively) discrete and compact subgroups of G. The Sobolev norm of
is the Sobolev norm of the lift of f to G.
As usual, we have . Likewise, we have
. For any of the three views, material, ideal, or hyperideal, we can also express D in this fashion. For example, in the material view we have
.
For , define
where h is the Hodge dual of η. Note that the Sobolev norm depends on our choice of basis; however, changing the basis changes the resulting norm by a bounded factor and thus only changes the constant C in the following lemma.
Lemma 11.9.
Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold. There is a constant such that the following is true. Fix a view D in M and a smooth, compactly supported function
with
. Fix a compact set
. There are constants C > 0 and c > 0 such that for all two-forms
supported in K and for all
, we have
To prove this, we use the exponential decay of correlation coefficients for geodesic flows. This is a much studied area. We will rely on [Citation23] because they explicitly give the dependence of the decay on the Sobolev norms of the functions involved. For hyperbolic, finite volume three-manifolds, their theorem can be simplified to the following.
Theorem 11.10.
Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold. Then there exists , C > 0 and c > 0 with the following property. For any smooth functions
with
and for all
, we have
(11.11)
(11.11)
Proof.
The more general [23, Theorem 3.1] relates to Theorem 11.10 as follows. They integrate over the frame bundle using the Bowen-Margulis-Sullivan-measure. However, we can think of a function
as an
–invariant function on the frame bundle and the BMS-measure is simply the Haar measure in the case of a hyperbolic, finite volume three-manifold
. Note that [23, Theorem 3.1] requires the functions f and g to be supported on a unit neighbourhood of the preimage of the convex core of M. However, for finite volume M, the convex core is just M. Furthermore, conventions for the Sobolev norm
differ in whether to take the sum or maximum of the
–norms of derivatives; however the resulting norms are equivalent because they differ by a constant factor. □
Let be a compactly supported, smooth function and
its lift. To prove Lemma 11.9 using Theorem 11.10, we construct test functions
that tend to the given two-form
in the sense that
(11.12)
(11.12) can be approximated by
(11.13)
(11.13)
Note that there are several incompatibilities between η and :
D is two-, not five-dimensional.
The first issue is solved by using the Hodge dual . That is,
where
is the area form on D.
For the second issue, we reformulate Theorem 11.10 as follows:
Theorem 11.14.
Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold. There is a constant such that the following is true. Fix a smooth, compactly supported function
with
and a compact set
. There exists C > 0 and c > 0 such that for all smooth functions
supported in K and all
, we have
(11.15)
(11.15)
Proof.
Note thatwhere
is the sum of all
where
is a preimage of
. Since K is covered by a finite number of copies of a fundamental domain of M, the sum
has a finite and bounded number of terms. Since f has compact support,
is finite and the result follows from Theorem 11.10. □
To address the third issue, we make the following definition.
Definition 11.16.
Define an ε–bump function byand set
.
We again use the coordinates on already introduced in Section 10.21. Recall that
. We define
. Again, see Figure A. We now define
(11.17)
(11.17)
Using Fubini’s theorem, we can now writewhere
, where
and
are using the area measures on D and
, respectively, and where JD is the smooth function such that
(11.18)
(11.18)
Note that, by construction, JD is invariant under isometries fixing D. In particular, is a positive constant. We set
.
Defining(11.19)
(11.19)
where again , we can write
Lemma 11.20.
For any smooth, compactly supported function and any view D, there is a C > 0 such that for all
, for all
, and for all
, we have
Proof.
Note that the support of is contained in the closure of
and that the second factor in (11.17) is normalised such that
for all
. Thus, it suffices to show that there is a C > 0 such that for all
, for all
, and for all
, we have
(11.21)
(11.21)
Claim 11.22. Let be a smooth, compactly supported function. Let
be a Lipschitz constant for f and let
be its lift. For all
, for all
, and for all
, we have
Proof.
The first inequality follows from Lemma 10.23. The second is by definition. □
Claim 11.23. The function JD has a finite Lipschitz constant when restricted to D1. Thus, for all
and for all
, we have
Proof.
Since JD is invariant under isometries preserving D, we can assume that is fixed. Then, the domain
has compact closure and thus JD has a finite Lipschitz constant
when restricted to it. The claim now follows from Lemma 10.23. □
Using the above two claims, the left hand side of (11.21) is bounded by . Thus setting
suffices to prove Lemma 11.20. □
Lemma 11.24.
Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold and a smooth, compactly supported function. Fix a view D and a compact set
. Let
be the area form on D. There is a C > 0 such that for all smooth
supported in K and for all
, we have
Proof.
We havewhich is bounded by
by Lemma 11.20. The result now follows since K has finite area. □
Lemma 11.25.
Let M be a connected, orientable, finite volume, complete hyperbolic three-manifold. Fix . Fix a view D and a compact set
. There is a C > 0 such that for all smooth
supported in K and all
, we have
where
is as defined in (11.17).
Proof.
We estimate by using that
is separable as defined in (11.17). In suitable coordinates, the second factor can be written as
We have so
. Using that all
are supported in a common compact set, the lemma follows from the following fact about Sobolev norms.
Recall that a Sobolev norm requires a choice of vector fields that pointwise span the tangent space of the manifold (or a bundle over the manifold when using the Sobolev norm defined earlier by lifting a function to G). However, any two such choices yield Sobolev norms that differ by a bounded factor when restricting to a small enough neighbourhood or compact set. In particular, up to a bounded factor, we can estimate the Sobolev norm
by Sobolev norms using local coordinates in which
is separable. □
Proof of Lemma 11.9.
Let m be as in Theorem 11.14. Fix a smooth, compactly supported function f, a view D, and a compact . Theorem 11.14 states that there is a C0 and c0 such that for all smooth
supported in K and all
, we may set
and have
Applying Lemma 11.24 to the left-hand side and Lemma 11.25 to the right hand-side, there are C1 and C2 such that
Since this holds for all , we can set
and obtain
Proof of Theorem 11.4.
Recall that(11.26)
(11.26)
We now discuss the topology on . Many textbooks on distributions define the topology on
. This suffices in the ideal and hyperideal cases, where the view D is diffeomorphic to
. When D is a two-sphere, we instead rely on the general theory of distributions on smooth manifolds. We point the reader to [45, Section 2.3] where such distributions are called “generalised sections”. In particular, the definition of
in [Citation45] gives the correct topology on
and thus on
.
Using [45, Corollary 2.2.1] and the definition of the topology on , it is not hard to see that statement (1) of the theorem is equivalent to the following claim.
Claim 11.27. For any compact , there is a C > 0 such that for all
, the integrals in
exist and we have
Proof.
We apply Lemma 11.9 to . The lemma implies that there is a
such that for all
, the integral
exists and is bounded by
. Let
be the area of K and C2 be the maximum of
over
. Recall that
denotes the Hodge dual to
. Then, by EquationEquation 11.26
(11.7)
(11.7) , we have the following.
Let be a primitive such that
. We again abbreviate
as W. We have
(11.28)
(11.28)
Statement (2) is equivalent to the following claim.
Claim 11.29. If , there is a C such that
Proof.
Since ω is a coboundary, its primitive descends to a map . Add a constant to W to arrange
; here we integrate with respect to the volume measure. Now taking f = W, Lemma 11.9 now applies to (11.28) and we have
. □
Statement (3) follows from from Remark 7.6.
It is left to show Statement (4). Recall that we defined maps and
. Let
. Furthermore, let us define two distributions on U by
For every , there is a compactly supported two-form δ on U such that
and
. Thus, it is enough to show that
(11.30)
(11.30)
Claim 11.31. For every and
, there is a neighbourhood
of p, a number
and
such that for all
and
, we have
Remark 11.32.
Note that the left hand side can be made arbitrary small by shrinking N. However, for fixed N increasing T might not suffice. This is why we will need to use a partition of unity argument to verify (11.30).
Proof
of Claim 11.31. It might be helpful to consult . Let L be a Lipschitz constant of .
Fig. 24 The regions and
for two material views. The distance between corresponding points in the two regions is bounded by a constant for all large enough T. The constant can be made arbitrarily small by making the neighbourhood N about p small enough.
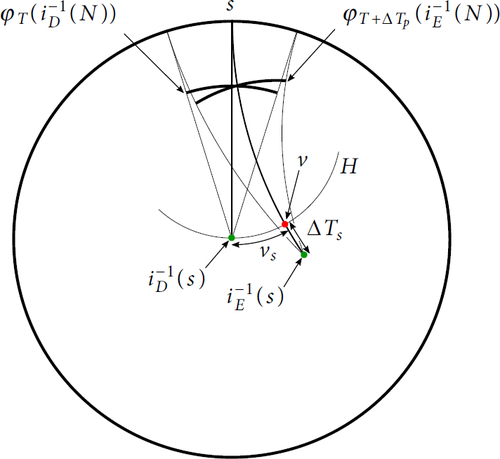
Suppose that s lies in . Let γD and γE be the oriented, pointed, geodesics through
and
respectively. Both forward converge to s. Let H be the horosphere centered at s containing
. Note that γE intersects H orthogonally, say at v. Let
be the signed distance, along γE, from
to v. Let
.
Recall that p lies in . Recall that
is the geodesic flow. Exponential convergence and the triangle inequality give the following estimate:
We refer to Remark 10.2 to explain the factor of .
There is a neighbourhood N of p such that for all , we have
. Note that vs is bounded on N so there is a T0 such that
. We deduce that
Since L is a Lipschitz constant for , the claim follows by setting
. □
We now define a norm on
. Identify
with S2. Such an identification induces an area form
on
. Given
, let d be the Hodge dual, that is
. Let
Note that does not depend on the identification of
with S2.
Claim 11.33. For every and
, there is a neighbourhood
of p such that for all
, we have
Proof.
Let N, , and T0 as in Claim 11.31. Add a constant to the primitive W of ω such that W(b) = 0. Then, the difference
can be expressed using W as follows.
Claim 11.31 implies that the integral is bounded by , for all
. Thus the limit is bounded by
. □
We now verify (11.30). Fix a smooth, compactly supported . Also fix
. For each
, pick a neighbourhood N as in Claim 11.33. The support
can be covered by finitely many of these neighbourhoods. Consider a partition of unity with respect to this finite cover. By multiplying δ by the partition functions, we obtain smooth two-forms
. Let di be the Hodge dual of δi. Since
(pointwise) we have
. Thus Claim 11.33 implies
Since ε was arbitrary, we are done. □
Remark 11.34.
McMullen [Citation29] suggests another approach to Theorem 11.4. Arrange matters so that W, the primitive of ω, is harmonic with respect to the hyperbolic metric. Prove that W has suitably bounded growth as it approaches , in terms of the euclidean metric in the Poincaré ball model. Now prove and then apply an appropriate version (of part (iii) implies part (i)) of [40, Theorem 1.1].
11.35. The cohomology fractal as a measure
We do not know whether the cohomology fractal converges to a signed measure; that is we do not know whether or notconverges for every measurable
. Instead, we have the following partial result.
Theorem 11.36
(Square pixel theorem). Suppose that M is a connected, orientable, finite volume, complete hyperbolic three-manifold. Fix a closed, compactly supported one-form , a basepoint
, and a view D. Suppose that
is bounded. Suppose further that
has finite length. Then the following limit exists
Remark 11.37.
Recall that the pictures in were generated by uniformly sampling across a pixel square. Theorem 11.36 finally proves that this technique (with enough samples) will give accurate images in some non-empty range of visual radii. Note that the earlier Theorem 11.4 is not sufficient; it required a smooth filter function.
Remark 11.38.
It seems difficult to generalise Theorem 11.36 to measurable subsets. Our proof does not apply, for example, to an open set bounded by several Osgood arcs [Citation34].
Before sketching a proof of Theorem 11.36, we discuss mollification. Suppose that is a bounded measurable function with compact support. We define
by setting
(11.39)
(11.39)
Here is a normalisation factor such that
. We call
the ε–mollification (in the unstable direction) of h.
Lemma 11.40.
Let be a bounded measurable function with compact support. Assume that there are constants c > 0 and C > 0 such that for all
, we have
Then the following limit exists
Proof
sketch. We will show that decays exponentially. Let
and
. Regarding ω as function
, we have
Since h is bounded, the Sobolev norm of the mollification of h can be estimated from the Sobolev norm of the mollification kernel. This can be done similarly to Lemma 11.25. Thus, there is a
such that for all
, we have
. Taking
and
, Lemma 11.9 states that there is a
and
such that for all
and
, we have
Thus, we have
We obtain exponential decay when setting □
Proof
sketch of Theorem 11.36. The theorem follows from Lemma 11.40 by taking h to be the indicator function χU. It is left to show that there is a C such that .
Note that is bounded by one, thus it is enough to show that the area where
is non-trivial is bounded by
. Tthe area of this neighbourhood is bounded above, up to multiplication by a universal constant, by the length of
multiplied by ε. □
12. Questions and projects
Question 12.1. Suppose that F is a surface in a hyperbolic three-manifold M. Theorem 10.7 tells us that the standard deviation σ is a topological invariant of the pair (M, F). What are the number theoretic (or other) properties of σ? Fixing M, does σ “see” the shape of the Thurston norm ball?
Question 12.2. Suppose that F is a fibre of a closed, connected hyperbolic surface bundle M. In Proposition 6.2 we showed that approximations of the Cannon–Thurston map are (components of) level sets of the cohomology fractal. Is there some more precise sense in which the Cannon–Thurston map
Question 12.3. Can the cohomology class
Question 12.4. suggests that in the example of m122(4,-1) the mean has settled down at around R = 10 for a pixel size of
Question 12.5. In Figure 18, the image with 1 × 1 samples and R = 8 is very similar to the image with
Question 12.6 (Mark Pollicott). We consider lowering the dimension of F and M by one. Let F be a non-separating curve in a closed, connected hyperbolic surface M. Fix a point
Question 12.7. The histogram in Figure 20(a) is low near the mean. Increasing R (within the range that we trust our experiments, see Section 8.6) reduces, but does not remove, this gap. Why is it there? (This does not seem to happen in Figure 20(b), where the surface is closed but the manifold is not.)
Question 12.8. Consider the experiment shown in Figure 22. Here the support of the cocycle ω is not compact. We see that the distribution of the cohomology fractal, over a pixel, appears to not be normal. Further experiments show that it depends sensitively on the choice of pixel. Can one verify rigorously that it is not normal?
We suspect that some version of “subtracting the largest excursion” (see the remarks immediately before [16, Theorem 1]) will yield a more reasonable distribution.
Question 12.9. Theorem 11.4 applies to cocycles ω with compact support. Consider a cusped manifold and a cocycle ω such that the pullback of
Question 12.10. In the fibred case, what is the relationship between the cohomology fractal and the lightning curve? See Section 6.4.
We end with some ideas for future software projects.
Project 12.11. One could use material triangulations in the closed case to draw an approximation
Project 12.12. In Section 8, we discussed cohomology fractals for incomplete structures along a line in Dehn surgery space. As discussed in Section 8.3, all of these suffer from numerical defects along the incompleteness locus Σs. These defects are visible (although small) in Figure 10. When the slope s is integral, we use material triangulations (Section 8.4) to remove these defects. For general s, material triangulations are not available. Instead, one could accelerate through tubes about Σs. That is, we modify the cellulation of the manifold by truncating each tetrahedron, replacing the lost volume with a solid torus “cell” around Σs.
Acknowledgments
This work is in the public domain except for and .
References
- Roger C. Alperin, Warren Dicks, and Joan Porti. The boundary of the Gieseking tree in hyperbolic three-space. Topology Appl., 93(3):219–259, 1999. doi:10.1016/S0166-8641(97)00270-8
- Christopher J. Bishop and Peter W. Jones. The law of the iterated logarithm for Kleinian groups. In Lipa’s legacy (New York, 1995), volume 211 of Contemp. Math., pages 17–50. Amer. Math. Soc., Providence, RI, 1997. doi:10.1090/conm/211/02813
- Brian H. Bowditch. The Cannon–Thurston map for punctured-surface groups. Math. Z., 255(1):35–76, 2007. doi:10.1007/s00209-006-0012-4
- David Bachman, Saul Schleimer, and Henry Segerman. Cohomology fractals. In Carolyn Yackel, Robert Bosch, Eve Torrence, and Kristóf Fenyvesi, editors, Proceedings of Bridges 2020: Mathematics, Art, Music, Architecture, Education, Culture, pages 175–182, Phoenix, Arizona, 2020. Tessellations Publishing. http://archive.bridgesmathart.org/2020/bridges2020-175.html, arXiv:2002.00239.
- David Bachman, Saul Schleimer, and Henry Segerman. Cohomology fractals, 2020. https://github.com/henryseg/cohomology_fractals.
- Vladimir Bulatov. 3d hyperbolic tiling and horosphere cross section, 2018. Joint AMS/MAA meeting, San Diego, January 10, 2018. http://bulatov.org/math/180110/index.html.
- Danny Calegari. Foliations and the geometry of 3–manifolds. Oxford Mathematical Monographs. Oxford University Press, 2007. http://math.uchicago.edu/dannyc/books/foliations/foliations.html.
- Andrew Casson. geo, software for geometrizing three-manifolds. https://faculty.math.illinois.edu/nmd/computop/software/casson.tar.gz.
- James W. Cannon and Warren Dicks. On hyperbolic once-punctured-torus bundles. Geom. Dedicata, 94:141–183, 2002. doi:10.1023/A:1020956906487
- James W. Cannon and Warren Dicks. On hyperbolic once-punctured-torus bundles. II. Fractal tessellations of the plane. Geom. Dedicata, 123:11–63, 2006. doi:10.1007/s10711-006-9070-3
- Marc Culler, Nathan M. Dunfield, Matthias Goerner, and Jeffrey R. Weeks. SnapPy, software for studying the geometry and topology of three-manifolds, (version 3.0). http://snappy.computop.org.
- Mikael Hvidtfeldt Christensen. Building 4d polytopes. https://syntopia.github.io/Polytopia/polytopes.html.
- James W. Cannon and William P. Thurston. Group invariant Peano curves. Geom. Topol., 11:1315–1355, 2007. doi:10.2140/gt.2007.11.1315
- Warren Dicks and Joan Porti. On the Hausdorff dimension of the Gieseking fractal. Topology Appl., 126(1-2):169–186, 2002. doi:10.1016/S0166-8641(02)00077-9
- Warren Dicks and Makoto Sakuma. On hyperbolic once-punctured-torus bundles. III. Comparing two tessellations of the complex plane. Topology Appl., 157(12):1873–1899, 2010. arXiv:0811.1678, doi:10.1016/j.topol.2010.02.010
- Harold G. Diamond and Jeffrey D. Vaaler. Estimates for partial sums of continued fraction partial quotients. Pacific J. Math., 122(1):73–82, 1986. doi:10.2140/pjm.1986.122.73
- Warren Dicks and David J. Wright. On hyperbolic once-punctured-torus bundles IV: Automata for lightning curves. Topology Appl., 159(1):98–132, 2012. doi:10.1016/j.topol.2011.08.018
- Jacques Franchi and Yves Le Jan. Hyperbolic dynamics and Brownian motion. Oxford University Press, 2012. doi:10.1093/acprof:oso/9780199654109.001.0001
- Matthias Goerner. Verified computations for closed hyperbolic 3-manifolds. Bull. Lond. Math. Soc., 53(2):596–618, 2021. arXiv:1904.12095, doi:10.1112/blms.12445
- Damian Heard. Orb, software for studying hyperbolic three-orbifolds and three-manifolds (2018-06-30). https://github.com/DamianHeard/orb.
- Damian Heard. Computation of hyperbolic structures on 3–dimensional orbifolds. PhD thesis, University of Melbourne, 2005. https://github.com/DamianHeard/orb-thesis/.
- Eberhard Hopf. Statistik der geodätischen Linien in Mannigfaltigkeiten negativer Krümmung. Ber. Verh. Sächs. Akad. Wiss. Leipzig Math.-Phys. Kl., 91:261–304, 1939.
- Dubi Kelmer and Hee Oh. Exponential mixing and shrinking targets for geodesic flow on geometrically finite hyperbolic manifolds. 2018. arXiv:1812.05251v3.
- Marc Lackenby. Taut ideal triangulations of 3–manifolds. Geom. Topol., 4:369–395, 2000. arXiv:math/0003132, doi:10.2140/gt.2000.4.369
- Jos Leys. A fast algorithm for limit sets of kleinian groups with the Maskit parametrisation, 2017. http://www.josleys.com/articles/Kleinian%20escape-time_3.pdf.
- Peter Liepa. Visualizing hyperbolic symmetries using WebGL (aka a hyperbolic doodler in your browser). https://brainjam.home.blog/2011/02/19/visualizing-hyperbolic-symmetries-using-webgl/.
- Curtis T. McMullen. lim. http://people.math.harvard.edu/ctm/programs/home/prog/lim/src/lim.tar.
- Curtis T. McMullen. Figure-eight orbifold fiber, 1995. http://people.math.harvard.edu/ctm/gallery/index.html.
- Curtis T. McMullen. 2019–2020. personal communication.
- Abdelaziz Nait Merzouk. Knighty collection. https://github.com/Syntopia/Fragmentarium/tree/master/Fragmentarium-Source/Examples/Knighty%20Collection.
- Mahan Mj. Cannon–Thurston maps. In Proceedings of the International Congress of Mathematicians—Rio de Janeiro 2018. Vol. II. Invited lectures, pages 885–917. World Sci. Publ., Hackensack, NJ, 2018. arXiv:1712.00760, doi:10.1142/11060
- David Mumford, Caroline Series, and David Wright. Indra’s pearls. Cambridge University Press, New York, 2002. The vision of Felix Klein. doi:10.1017/CBO9781107050051.024
- Roice Nelson and Henry Segerman. Visualizing hyperbolic honeycombs. Journal of Mathematics and the Arts, 11(1):4–39, 2017. arXiv:1511.02851, doi:10.1080/17513472.2016.1263789
- William F. Osgood. A Jordan curve of positive area. Trans. Amer. Math. Soc., 4(1):107–112, 1903. doi:10.2307/1986455
- Jessica S. Purcell. Hyperbolic knot theory (Graduate Studies in Mathematics). American Mathematical Society, Providence, RI, 2020. arXiv:2002.12652.
- Mary Rees. Checking ergodicity of some geodesic flows with infinite Gibbs measure. Ergodic Theory Dynam. Systems, 1(1):107–133, 1981. doi:10.1017/S0143385700001206
- Ja. G. Sinaĭ. The central limit theorem for geodesic flows on manifolds of constant negative curvature. Soviet Math. Dokl., 1:983–987, 1960.
- Alvy Smith. A pixel is not a little square, a pixel is not a little square, a pixel is not a little square, 1995. http://alvyray.com/Memos/CG/Microsoft/6_pixel.pdf.
- Peter Stampfli. Fractal images from multiple inversion in circles. In Susan Goldstine, Douglas McKenna, and Kristóf Fenyvesi, editors, Proceedings of Bridges 2019: Mathematics, Art, Music, Architecture, Education, Culture, pages 263–270, Phoenix, Arizona, 2019. Tessellations Publishing. http://archive.bridgesmathart.org/2019/bridges2019-263.pdf.
- Emil J. Straube. Harmonic and analytic functions admitting a distribution boundary value. Ann. Scuola Norm. Sup. Pisa Cl. Sci. (4), 11(4):559–591, 1984. http://www.numdam.org/item?id=ASNSP_1984_4_11_4_559_0.
- Dennis Sullivan. The density at infinity of a discrete group of hyperbolic motions. Inst. Hautes Études Sci. Publ. Math., (50):171–202, 1979. doi:10.1007/BF02684773
- William P. Thurston. Geometry and topology of 3–manifolds. 1978. https://msri.org/publications/books/gt3m/.
- William P. Thurston. Three-dimensional manifolds, kleinian groups and hyperbolic geometry. Bull. Amer. Math. Soc. (N.S.), 6(3):357–381, 1982. doi:10.1090/S0273-0979-1982-15003-0
- William P. Thurston. A norm for the homology of 3–manifolds. Mem. Amer. Math. Soc., 59(339):i–vi and 99–130, 1986.
- Erik van den Ban and Marius Crainic. Analysis on manifolds. https://webspace.science.uu.nl/crain101/AS-2013/chapters-1-2-3.pdf, https://webspace.science.uu.nl/ban00101/anman2009/lecture2.pdf.
- Masaaki Wada. OPTi, software for visualising quasi-conformal deformations of once-punctured torus groups (version 4.0.5). https://apps.apple.com/us/app/opti/id1111993523.
- William Worden. tnorm, software for computing the thurston norm unit ball of finite volume orientable hyperbolic three-manifolds, 2018–2020. (version 0.1.14). https://pypi.python.org/pypi/tnorm.
- David Wright. 2019. personal communication.
- Roland Zweimüller. Infinite measure preserving transformations with compact first regeneration. J. Anal. Math., 103:93–131, 2007. doi:10.1007/s11854-008-0003-y
Appendix A:
Notation
For the convenience of the reader, we list some of the notation used in the paper.
Table
Table