
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Functional data analysis covers a wide range of data types. They all have in common that the observed objects are functions of a univariate argument (e.g., time or wavelength) or a multivariate argument (say, a spatial position). These functions take on values which can in turn be univariate (such as the absorbance level) or multivariate (such as the red/green/blue color levels of an image). In practice it is important to be able to detect outliers in such data. For this purpose we introduce a new measure of outlyingness that we compute at each gridpoint of the functions’ domain. The proposed directional outlyingness (DO) measure accounts for skewness in the data and only requires computation time per direction. We derive the influence function of the DO and compute a cutoff for outlier detection. The resulting heatmap and functional outlier map reflect local and global outlyingness of a function. To illustrate the performance of the method on real data it is applied to spectra, MRI images, and video surveillance data.
1. Introduction
Functional data analysis (Ramsay and Silverman Citation2005; Ferraty and Vieu Citation2006) is a rapidly growing research area. Often the focus is on functions with a univariate domain, such as time series or spectra. The function values may be multivariate, such as temperatures measured at 3, 9, and 12 cm below ground (Berrendero, Justel, and Svarc Citation2011) or human ECG data measured at eight different places on the body (Pigoli and Sangalli Citation2012). In this article we will also consider functions whose domain is multivariate. In particular, images and surfaces are functions on a bivariate domain. Our methods generalize to higher-dimensional domains, for example the voxels of a three-dimensional image of a human brain are defined on a trivariate domain.
Detecting outliers in functional data is an important task. Recent developments include the approaches of Febrero-Bande, Galeano, and González-Manteiga (Citation2008) and Hyndman and Shang (Citation2010). Sun and Genton (Citation2011) proposed the functional boxplot, and Arribas-Gil et al. (Citation2014) developed the outliergram. Our approach is somewhat different. To detect outlying functions or outlying parts of a function (in a dataset consisting of several functions) we will look at its (possibly multivariate) function value in every time point/pixel/voxel/... of its domain. For this purpose we need a tool that assigns a measure of outlyingness to every data point in a multivariate nonfunctional sample. A popular measure is the Stahel-Donoho outlyingness (SDO) due to Stahel (Citation1981) and Donoho (Citation1982) which works best when the distribution of the inliers is roughly elliptical. However, it is less suited for skewed data. To address this issue, Brys, Hubert, and Rousseeuw (Citation2005) proposed the (skewness-) adjusted outlyingness (AO) which takes the skewness of the underlying distribution into account. However, the AO has two drawbacks. The first is that the AO scale has a large bias as soon as the contamination fraction exceeds 10%. Furthermore, its computation time is per direction due to its rather involved construction.
To remedy these deficiencies we propose a new measure in this article, the directional outlyingness (DO). The DO also takes the skewness of the underlying distribution into account, by the intuitive idea of splitting a univariate dataset in two half samples around the median. The AO incorporates a more robust scale estimator, which requires only operations.
Section 2 defines the DO, investigates its theoretical properties, and illustrates it on univariate, bivariate, and spectral data. Section 3 derives a cutoff value for the DO and applies it to outlier detection. It also extends the functional outlier map of Hubert, Rousseeuw, and Segaert (Citation2015) to the DO, and in it constructs a curve separating outliers from inliers. Section 4 shows an application to MRI images, and Section 5 analyzes video data. Section 6 contains simulations in various settings, to study the behavior of DO and compare its performance to other methods. Section 7 concludes.
2. A Notion of Directional Outlyingness
2.1. Univariate Setting
In the univariate setting, the Stahel-Donoho outlyingness of a point y relative to a sample Y = {y1, …, yn} is defined as
(1)
(1) where the denominator is the median absolute deviation (MAD) of the sample, given by
where Φ is the standard normal cdf. The SDO is affine invariant, meaning that it remains the same when a constant is added to Y and y, and also when they are multiplied by a nonzero constant.
A limitation of the SDO is that it implicitly assumes the inliers (i.e., the nonoutliers) to be roughly symmetrically distributed. But when the inliers have a skewed distribution, using the MAD as a single measure of scale does not capture the asymmetry. For instance, when the data stem from a right-skewed distribution, the SDO may become large for inliers on the right-hand side, and not large enough for actual outliers on the left-hand side.
This observation led to the (skewness-) adjusted outlyingness (AO) proposed by Brys, Hubert, and Rousseeuw (Citation2005). This notion employs a robust measure of skewness called the medcouple (Brys, Hubert, and Struyf Citation2004), which however requires computation time. Moreover, we will see in the next subsection that it leads to a rather large explosion bias.
In this article we propose the notion of directional outlyingness (DO) which also takes the potential skewness of the underlying distribution into account, while attaining a smaller computation time and bias. The main idea is to split the sample into two half samples, and then to apply a robust scale estimator to each of them.
More precisely, let y1 ⩽ y2 ⩽ ⋅⋅⋅ ⩽ yn be a univariate sample. (The actual algorithm does not require sorting the data.) We then construct two subsamples of size as follows. For even n we take Ya = {yh + 1, …, yn} and Yb = {y1, …, yh} where the subscripts a and b stand for above and below the median. For odd n we put Ya = {yh, …, yn} and Yb = {y1, …, yh} so that Ya and Yb share one data point and have the same size.
Next, we compute a scale estimate for each subsample. Among many available robust estimators we choose a one-step M-estimator with Huber ρ-function due to its fast computation and favorable properties. We first compute initial scale estimates
where
and
and where Φ− 1(0.75) ensures consistency for Gaussian data. The one-step M-estimates are then given by
(2)
(2) where again
and where α = ∫∞0ρc(x)dΦ(x). Here ρc denotes the Huber rho function for scale
with c a tuning parameter regulating the trade-off between efficiency and bias.
Finally, the DO of a point y relative to a univariate sample Y = {y1, …, yn} is given by
(3)
(3) Note that DO is affine invariant. In particular, flipping the signs of Y and y interchanges sa and sb which results in DO( − y; −Y) = DO(y; Y).
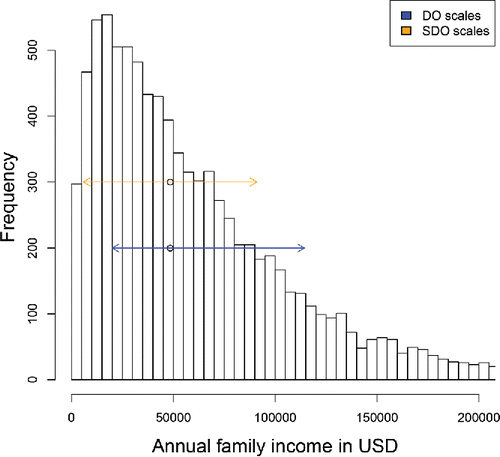
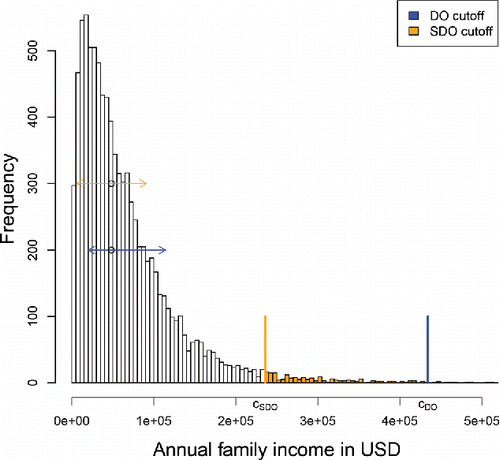
illustrates the denominators of the SDO and DO expressions on the family income dataset from https://psidonline.isr.umich.edu which contains 8962 strictly positive incomes in the tax year 2012. Their histogram is clearly right-skewed. The MAD in the denominator of SDO equals < ent {$ 42, 650 and is used both to the left and to the right of the median, as depicted by the orange arrows. For the DO the “above” scale sa = <ent {$ 58, 681 exceeds the “below” scale sb = <ent {$ 35, 737 (blue arrows). Therefore, a point to the right of the median will have a lower DO than a point to the left at the same distance to the median. This is a desirable property in view of the difference between the left and right tails.
Figure 1. Scale estimates of the family income data. The SDO scale is measured symmetrically about the median, whereas the DO scales are not and reflect skewness.
2.2. Robustness Properties
Let us now study the robustness properties of the scales sa and sb and the resulting DO. It will be convenient to write sa and sb as functionals of the data distribution F:
(4)
(4) where ρc is the Huber ρ-function.
We will first focus on the worst-case bias of sa due to a fraction ϵ of contamination, following Martin and Zamar (Citation1993). At a given distribution F, the explosion bias curve of sa is defined as
where
in which H can be any distribution. The implosion bias curve is defined similarly as
From here onward we will assume that F is symmetric about some center m and has a continuous density f(x) which is strictly decreasing in x > m. To derive the explosion and implosion bias we require the following lemma (all proofs can be found in the Appendix):
Lemma 1.
| (i) | For fixed μ it holds that | ||||
| (ii) | For fixed σ > 0 it holds that | ||||
Proposition 1.
For any 0 < ϵ < 0.25 the implosion bias of sa is given by
where
In fact, the implosion bias of sa is reached when is the distribution that puts all its mass in the point
. Note that the implosion breakdown value of sa is 25% because for ϵ → 0.25 we obtain sa → 0.
Proposition 2.
For any 0 < ϵ < 0.25 the explosion bias of sa is given by
where
The explosion bias of sa is reached at all distributions Fϵ = (1 − ϵ)F + ϵΔ(d) for which d > B+(ϵ, med, F) + cB+(ϵ, so, a, F) which ensures that d lands on the constant part of ρc. For ϵ → 0.25 we find d → ∞ and sa → ∞, so the explosion breakdown value of sa is 25%.
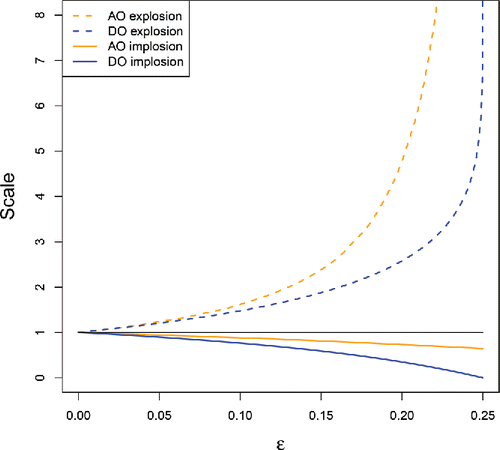
The blue curves in are the explosion and implosion bias curves of sa when F = Φ is the standard Gaussian distribution, and the tuning constant in ρc is c = 2.1 corresponding to 85% efficiency. By affine equivariance the curves for sb are exactly the same, so these are the curves of both DO scales. The orange curves correspond to explosion and implosion of the scales used in the adjusted outlyingness AO under the same contamination. We see that the AO scale explodes faster, due to using the medcouple in its definition. The fact that the DO scale is typically smaller enables the DO to attain larger values in outliers.
Figure 2. Comparison of explosion and implosion bias of the AO and DO scales.
Another tool to measure the (non-)robustness of a procedure is the influence function (IF). Let T be a statistical functional, and consider the contaminated distribution Fϵ, z = (1 − ϵ)F + ϵΔ(z). The influence function of T at F is then given by
and basically describes how T reacts to a small amount of contamination.
This concept justifies our choice for the function ρc. Indeed, the IF of a fully iterated M-estimator of scale with function ρ is proportional to ρ(z) − β with the constant β = ∫∞− ∞ρ(x)dF(x). We use ρ = ρc with c = 2.1. It was shown in Hampel et al. (Citation1986) that at F = Φ this ρc yields the M-estimator with highest asymptotic efficiency subject to an upper bound on the absolute value of its IF.
We will now derive the IF of the one-step M-estimator sa given by (Equation4(4)
(4) ).
Proposition 3.
The influence function of sa is given by
where IF(z, so, a, F) is the influence function of so, a.
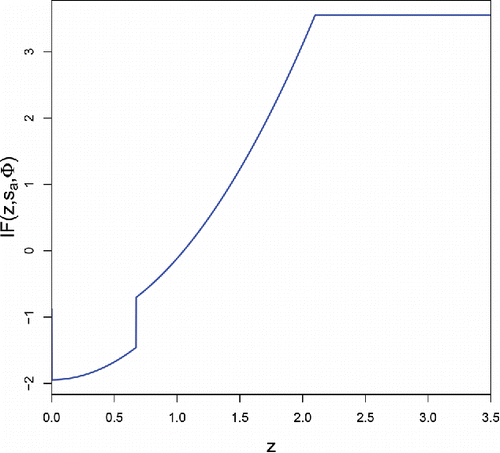
The resulting IF of sa at F = Φ is shown in . [Note that IF(z, sb, Φ) = IF( − z, sa, Φ).] It is bounded, indicating that sa is robust to a small amount of contamination even when it is far away. Note that the IF has a jump at the third quartile Q3 ≈ 0.674 due to the initial estimate so, a. If we were to iterate (Equation4(4)
(4) ) to convergence this jump would vanish, but then the explosion bias would go up a lot, similarly to the computation in Rousseeuw and Croux (Citation1994).
Figure 3. Influence function of sa at F = Φ.
Let us now compute the influence function of DO(x; F) given by (Equation3(3)
(3) ) for contamination in the point z, noting that x and z need not be the same.
Proposition 4.
When it holds that
whereas for x < med(F) we obtain
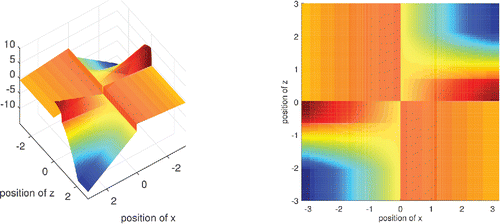
For a fixed value of x the influence function of DO(x) is bounded in z. This is a desirable robustness property. shows the influence function (which is a surface) when F is the standard Gaussian distribution.
Figure 4. Influence function of DO(x) for F = Φ. Left: 3D, right: 2D seen from above. For a fixed point x it is bounded over all possible positions z of contamination.
2.3. Multivariate Setting
In the multivariate setting we can apply the principle that a point is outlying with respect to a dataset if it stands out in at least one direction. Like the Stahel-Donoho outlyingness, the multivariate DO is defined by means of univariate projections. To be precise, the DO of a d-variate point relative to a d-variate sample
is defined as
(5)
(5) where the right-hand side uses the univariate DO of (Equation3
(3)
(3) ).
To compute the multivariate DO we have to rely on approximate algorithms, as it is impossible to project on all directions in d-dimensional space. A popular procedure to generate a direction is to randomly draw d data points, compute the hyperplane passing through them, and then to take the direction
orthogonal to it. This guarantees that the multivariate DO is affine invariant. That is, the DO does not change when we add a constant vector to the data, or multiply the data by a nonsingular d × d matrix.
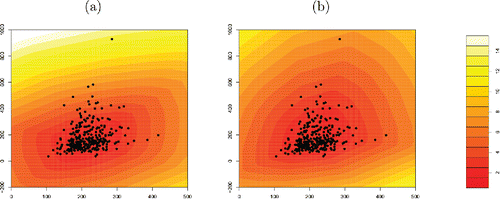
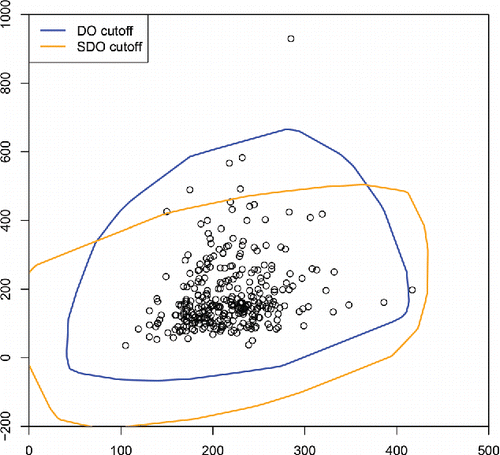
As an illustration we take the bloodfat dataset, which contains plasma cholesterol and plasma triglyceride concentrations (in mg/dl) of 320 male subjects for whom there is evidence of narrowing arteries (Hand et al. Citation1994). Here n = 320 and d = 2, and following Hubert and Van der Veeken (Citation2008) we generated 250d = 500 directions . shows the contour plots of both the DO and SDO measures. Their contours are always convex. We see that the contours of the DO capture the skewness in the dataset, whereas those of the SDO are more symmetric even though the data themselves are not.
Figure 5. Bloodfat data with (a) SDO contours, and (b) DO contours. The DO contours better reflect the skewness in the data.
2.4. Functional Directional Outlyingness
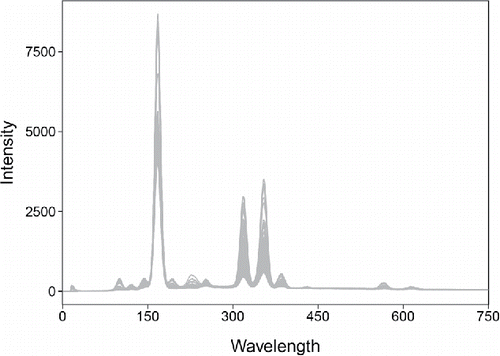
We now extend the DO to data where the objects are functions. To fix ideas we will consider an example. The glass dataset consists of spectra with d = 750 wavelengths resulting from spectroscopy on n = 180 archeological glass samples (Lemberge et al. Citation2000). shows the 180 curves.
Figure 6. Spectra of 180 archeological glass samples.
At each wavelength the response is a single number, the intensity, so this is a univariate functional dataset. However, we can incorporate the dynamic behavior of these curves by numerically computing their first derivative. This yields bivariate functions, where the response consists of both the intensity and its derivative.
In general we write a functional dataset as where each Yi is a d-dimensional function. As in this example, the Yi are typically observed on a discrete set of points in their domain. For a univariate domain this set is denoted as {t1, …, tT}.
Now we want to define the DO of a d-variate function X on the same domain, where X need not be one of the Yi. For this we look at all the domain points tj in turn, and define the functional directional outlyingness (fDO) of X with respect to the sample Y as
(6)
(6) where W(.) is a weight function for which ∑Tj = 1W(tj) = 1. Such a weight function allows us to assign a different importance to the outlyingness of a curve at different domain points. For instance, one could downweight time points near the boundaries if measurements are recorded less accurately at the beginning and the end of the process.
shows the fDO of the 180 bivariate functions in the glass data, where W(.) was set to zero for the first 13 wavelengths where the spectra had no variability, and constant at the remaining wavelengths. These fDO values allow us to rank the spectra from most to least outlying, but do not contain much information about how the outlying curves are different from the majority.
Figure 7. Functional DO (fDO) values of the 180 glass spectra. Higher fDO values correspond to curves that are more outlying on average.
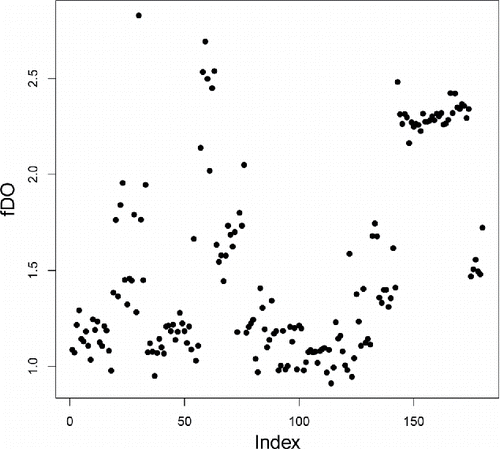
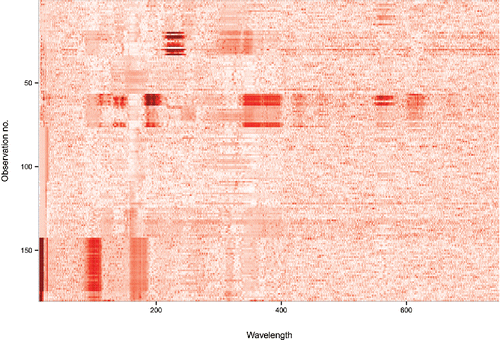
In addition to this global outlyingness measure fDO we also want to look at the local outlyingness. To this end shows the individual for each of the 180 functions Yi of the glass data at each wavelength tj. Higher values of DO are shown by darker red in this heatmap. Now we see that there are a few groups of curves with particular anomalies: one group around function 25, one around function 60, and one with functions near the bottom. Note that the global outlyingness measure fDO flags outlying rows in this heatmap, whereas the dark spots inside the heatmap can be seen as outlying cells. It is also possible to sort the rows of the heatmap according to their fDO values. Note that the wavelength at which a dark spot in the heatmap occurs allows to identify the chemical element responsible.
Figure 8. Heatmap of DO of the glass data. Darker pixels indicate outlying behavior.
As in Hubert, Rousseeuw, and Segaert (Citation2015) we can transform the DO to the multivariate depth function 1/(DO + 1), and the fDO to the functional depth function 1/(fDO + 1).
3. Outlier Detection
3.1. A Cutoff for Directional Outlyingness
When analyzing a real dataset we do not know its underlying distribution, but still we would like a rough indication of which observations should be flagged as outliers. For this purpose we need an approximate cutoff value on the DO. We first consider non-functional data, leaving the functional case for the next subsection. Let be a d-variate dataset (d ⩾ 1) with directional outlyingness values {DO1, …, DOn}. The DOi have a right-skewed distribution, so we transform them to {LDO1, …, LDOn} = {log (0.1 + DO1), …, log (0.1 + DOn)} of which the majority is closer to Gaussian. Then we center and normalize the resulting values in a robust way and compare them to a high gaussian quantile. For instance, we can flag
as outlying whenever
(7)
(7) so the cutoff for the DO values is
. (Note that we can use the same formulas for functional data by replacing DO by fDO.)
For an illustration we return to the family income data of . The blue vertical line in corresponds to the DO cutoff, whereas the orange line is the result of the same computation applied to the SDO. The DO cutoff is the more conservative one, because it takes the skewness of the income distribution into account.
Figure 9. Outlier cutoffs for the family income data. The DO-based cutoff takes the data skewness into account.
shows the DO and SDO cutoffs for the bivariate bloodfat data of . The DO captures the skewness in the data and flags only two points as outlying, whereas the SDO takes a more symmetric view and also flags five of the presumed inliers.
Figure 10. Outlier detection on bloodfat data. The DO-based cutoff adapts to the data skewness and flags fewer points as outlying.
3.2. The Functional Outlier Map
When the dataset consists of functions there can be several types of outlyingness. As an aid to distinguish between them, Hubert, Rousseeuw, and Segaert (Citation2015) introduced a graphical tool called the functional outlier map (FOM). Here we will extend the FOM to the new DO measure and add a cutoff to it, to increase its utility.
Consider a functional dataset . The fDO [see (Equation6
(6)
(6) )] of a function Yi can be interpreted as the “average outlyingness” of its (possibly multivariate) function values. We now also measure the variability of its DO values, by
(8)
(8) Note that (Equation8
(8)
(8) ) has the fDO in the denominator to measure relative instead of absolute variability. This can be understood as follows. Suppose that the functions Yi are centered around zero and that Yk(tj) = 2Yi(tj) for all j. Then
but their relative variability is the same. Because
, putting fDO in the denominator normalizes for this. In the numerator we could also compute a weighted standard deviation with the weights W(tj) from (Equation6
(6)
(6) ).
The FOM is then the scatterplot of the points
(9)
(9) for i = 1, …, n. Its goal is to reveal outliers in the data, and its interpretation is fairly straightforward. Points in the lower left part of the FOM represent regular functions which hold a central position in the dataset. Points in the lower right part are functions with a high fDO but a low variability of DO values. This happens for shift outliers, that is, functions which have a regular shape but are shifted on the whole domain. Points in the upper left part have a low fDO but a high vDO. Typical examples are local outliers, that is functions which only display outlyingness over a small part of their domain. The points in the upper right part of the FOM have both a high fDO and a high vDO. These correspond to functions which are strongly outlying on a substantial part of their domain.
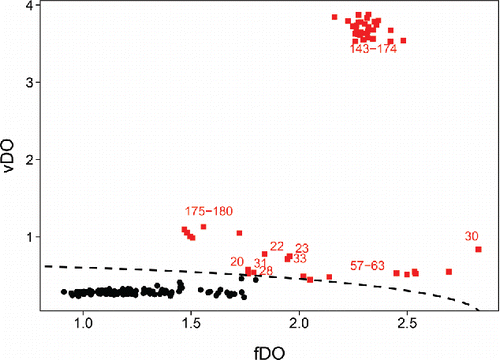
As an illustration we revisit the glass data. Their FOM in contains a lot more information than their fDO values alone in . In the heatmap () we noticed three groups of outliers, which also stand out in the FOM. The first group consists of the spectra 20, 22, 23, 28, 30, 31, and 33. Among these, number 30 lies furthest to the right in the FOM. It corresponds to row 30 in which has a dark red piece. It does not look like a shift outlier, for which the row would have a more homogeneous color (hence a lower vDO). The second group, with functions 57–63, occupies a similar position in the FOM. The group standing out the most consists of functions 143–174. They are situated in the upper part of the FOM, indicating that they are shape outliers. Indeed, they deviate strongly from the majority in three fairly small series of wavelengths. Their outlyingness is thus more local than that of functions 57–63.
Figure 11. Functional outlier map (FOM) of the glass data, with cutoff curve.
We now add a new feature to the FOM, namely a rule to flag outliers. For this we define the combined functional outlyingness (CFO) of a function Yi as
(10)
(10) where
and
, and similarly for vDO. Note that the CFO characterizes the points in the FOM through their Euclidean distance to the origin, after scaling. We expect outliers to have a large CFO. In general, the distribution of the CFO is unknown but skewed to the right. To construct a cutoff for CFO we use the same reasoning as for the cutoff (Equation7
(7)
(7) ) on fDO: First we compute
for all i = 1, …, n, and then we flag function Yi as outlying if
(11)
(11) This yields the dashed curve (which is part of an ellipse) in the FOM of .
4. Application to Image Data
Images are functions on a bivariate domain. In practice the domain is a grid of discrete points, for example the horizontal and vertical pixels of an image. It is convenient to use two indices j = 1, …, J and k = 1, …, K, one for each dimension of the grid, to characterize these points. An image (or a surface) is then a function on the J × K points of the grid. Note that the function values can be univariate, like gray intensities, but they can also be multivariate, for example the intensities of red, green, and blue (RGB). In general we will write an image dataset as a sample where each Yi is a function from {(j, k); j = 1, …, J and k = 1, …, K} to
.
The fDO (Equation6(6)
(6) ) and vDO (Equation8
(8)
(8) ) notions that we saw for functional data with a univariate domain can easily be extended to functions with a bivariate domain by computing
(12)
(12) where the weights Wjk must satisfy ∑Jj = 1∑k = 1KWjk = 1, and
(13)
(13) where the standard deviation can also be weighted by the Wjk. (The simplest weight function is the constant Wjk = 1/(JK) for all j = 1, …, J and k = 1, …, K.) Note that (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) can trivially be extended to functions with domains in more than 2 dimensions, such as three-dimensional images consisting of voxels. In each case we obtain fDOi and vDOi values that we can plot in a FOM, with cutoff value (Equation11
(11)
(11) ).
As an illustration we analyze a dataset containing MRI brain images of 416 subjects aged between 18 and 96 (Marcus et al. Citation2007), which can be freely accessed at www.oasis-brains.org. For each subject several images are provided; we will use the masked atlas-registered gain field-corrected images resampled to 1mm isotropic pixels. The masking has set all non-brain pixels to an intensity value of zero. The provided images are already normalized, meaning that the size of the head is exactly the same in each image. The images have 176 by 208 pixels, with grayscale values between 0 and 255. All together we thus have 416 observed images Yi containing univariate intensity values Yi(j, k), where j = 1, …, J = 176 and k = 1, …, K = 208.
There is more information in such an image than just the raw values. We can incorporate shape information by computing the gradient in every pixel of the image. The gradient in pixel (j, k) is defined as the two-dimensional vector in which the derivatives have to be approximated numerically. In the pixels at the boundary of the brain we compute forward and backward finite differences, and for the other pixels we employ central differences. In the horizontal direction we thus compute one of three expressions:
depending on where the pixel is located. The derivatives in the vertical direction are computed analogously.
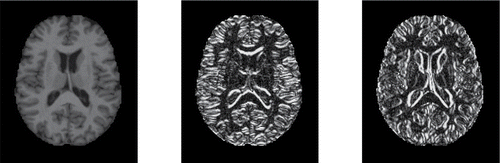
Incorporating these derivatives yields a dataset of dimensions 416 × 176 × 208 × 3, so the final Yi(j, k) are trivariate. For each subject we thus have three data matrices which represent the original MRI image and its derivatives in both directions. shows these three matrices for subject number 387.
Figure 12. Original MRI image of subject 387, and its derivatives in the horizontal and vertical direction.
The functional DO of an MRI image Yi is given by (Equation12(12)
(12) ):
where
is the DO of the trivariate point Yi(j, k) relative to the trivariate dataset {Y1(j, k), …, Y416(j, k)}. In this example, we have set the weight Wjk equal to zero at the grid points that are not part of the brain, shown as the black pixels around it. The grid points inside the brain receive full weight.
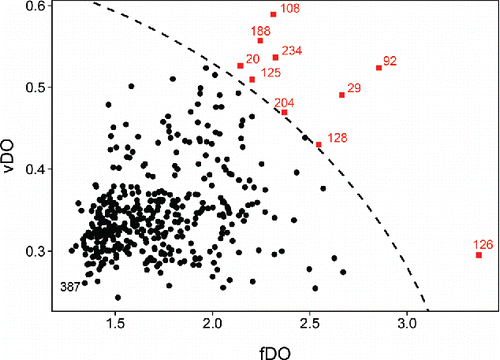
shows the resulting FOM, which indicates the presence of several outliers. Image 126 has the highest fDO combined with a relatively low vDO. This suggests a shift outlier, that is, a function whose values are all shifted relative to the majority of the data. Images 29 and 92 have a large fDO in combination with a high vDO, indicating that they have strongly outlying subdomains. Images 108, 188, and 234 have an fDO which is on the high end relative to the dataset, which by itself does not make them outlying. Only in combination with their large vDO are they flagged as outliers. These images have strongly outlying subdomains which are smaller that those of functions 29 and 92. The remaining flagged images are fairly close to the cutoff, meaning they are merely borderline cases.
Figure 13. Functional outlier map (FOM) of the MRI dataset, with cutoff curve.
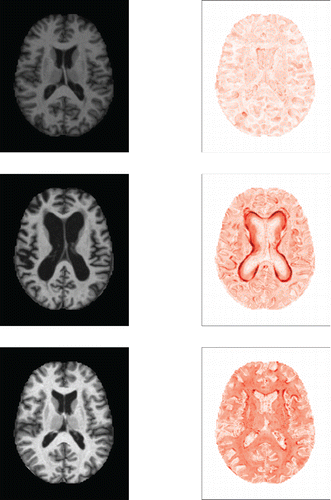
To find out why a particular image is outlying it is instructive to look at a heatmap of its DO values. In we compare the MRI images (on the left) and the DO heatmaps (on the right) of subjects 387, 92, and 126. DO values of 15 or higher received the darkest color. Image 387 has the smallest CFO value, and can be thought of as the most central image in the dataset. As expected, the DO heatmap of image 387 shows very few outlying pixels. For subject 92, the DO heatmap nicely marks the region in which the MRI image deviates most from the majority of the images. Note that the boundaries of this region have the highest outlyingness. This is due to including the derivatives in the analysis, as they emphasize the pixels at which the grayscale intensity changes. The DO heatmap of subject 126 does not show any extremely outlying region but has a rather high outlyingness over the whole domain, which explains its large fDO and regular vDO value. The actual MRI image to its left is globally lighter than the others, confirming that it is a shift outlier.
Figure 14. MRI image (left) and DO heatmap (right) of subjects 387 (top), 92 (middle), and 126 (bottom).
5. Application to Video
We analyze a surveillance video of a beach, filmed with a static camera (Li et al. Citation2004). This dataset can be found at http://perception.i2r.a-star.edu.sg/bk_model/bk_index.html and consists of 633 frames.
The first 8 seconds of the video show a beach with a tree, as in the leftmost panel of . Then a man enters the screen from the left (second panel), disappears behind the tree (third panel), and then reappears to the right of the tree and stays on screen until the end of the video. The frames have 160 × 128 pixels and are stored using the RGB (Red, Green and Blue) color model, so each frame corresponds to three matrices of size 160 × 128. Overall we have 633 frames Yi containing trivariate Yi(j, k) for j = 1, …, J = 160 and k = 1, …, K = 128.
Figure 15. Frames number 100, 487, 491, and 500 from the video dataset.

Computing the fDO (Equation12(12)
(12) ) in this dataset is time consuming since we have to execute the projection pursuit algorithm (Equation5
(5)
(5) ) in
for each pixel, so 160 × 128 = 20, 480 times. The entire computation took 25 minutes on a laptop. Therefore we switch to an alternative computation. We define the componentwise DO of a d-variate point
relative to a d-variate sample
as
(14)
(14) where DO(yh; Yh) is the univariate DO of the h-th coordinate of
relative to the h th coordinate of
. Analyzing the video data with this componentwise procedure took 15 seconds, so it is a 100 times faster than with projection pursuit, and it produced almost the same FOM. shows the FOM obtained from the CDO computation.
Figure 16. Functional outlier map of the video data.
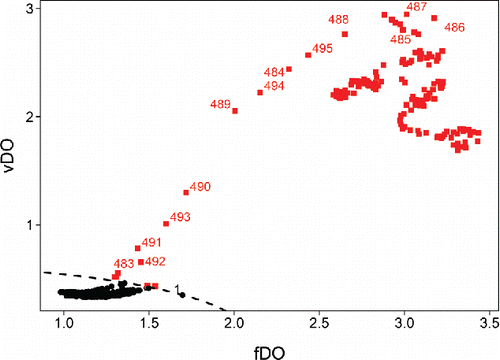
The first 480 frames, which depict the beach and the tree with only the ocean surface moving slightly, are found at the bottom left part of the FOM. They fall inside the dashed curve that separates the regular frames from the outliers. At frame 483 the man enters the picture, making the standard deviation of the DO rise slightly. The fDO increases more slowly, as the fraction of the pixels covered by the man is still low at this stage. This frame can thus be seen as locally outlying. The subsequent frames 484–487 have very high fDO and vDO. In them the man is clearly visible between the left border of the frame and the tree, so these frames have outlying pixels in a substantial part of their domain. Frames 489–492 see the man disappear behind the tree, so the fDO goes down as the fraction of outlying pixels decreases. From frame 493 onward the man reappears to the right of the tree and stays on screen until the end. These frames contain many outlying pixels, yielding points in the upper right part of the FOM.
In the FOM we also labeled frame 1, which lies close to the outlyingness border. Further inspection indicated that this frame is a bit lighter than the others, which might be due to the initialization of the camera at the start of the video.
In addition to the FOM we can draw DO heatmaps of the individual frames. For frames 100, 487, 491, and 500, shows the raw frame on the left, the DO heatmap in the middle and the FOM on the right, in which a blue circle marks the position of the frame. In this figure we can follow the man's path in the FOM, while the DO heatmaps show exactly where the man is in those frames. We have created a video in which the raw frame, the DO heatmap and the FOM evolve alongside each other. It can be downloaded from http://wis.kuleuven.be/stat/robust/papers-since-2010.
Figure 17. Left: Frames 100, 487, 491, and 500 from the video. Middle: DO heatmaps of these frames. Right: FOM with blue marker at the position of the frame.

6. Simulation Study
We would also like to study the performance of the DO when the data generating mechanism is known, and compare it with the AO measure proposed by Brys, Hubert, and Rousseeuw (Citation2005) and studied by Hubert and Van der Veeken (Citation2008) and Hubert, Rousseeuw, and Segaert (Citation2015). For this we carried out an extensive simulation study, covering univariate as well as multivariate and functional data.
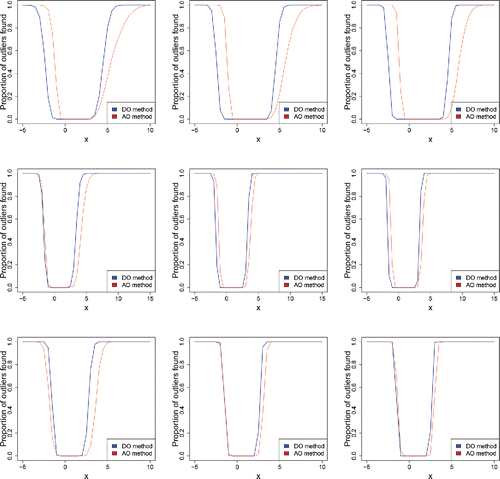
In the univariate case we generated m = 1000 standard lognormal samples of size n = {200, 500, 1000} with 10% and 15% of outliers at the position x, which may be negative. shows the effect of the contamination at x on our figure of merit, the percentage of outliers flagged (averaged over the m replications).
Figure 18. Percentage of outliers found in univariate lognormal samples of size n = 200 (left), n = 500 (middle), and n = 1000 (right), with 10% (top) and 15% (bottom) of outliers in x.
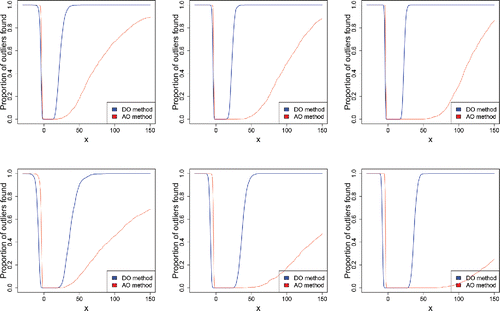
In the direction of the short left tail of the lognormal distribution we see that the adjusted outlyingness AO flags about the same percentage of outliers as the DO. But the AO is much slower in flagging outliers in the direction of the long right tail of the lognormal. This is due to the relatively high explosion bias of the scale used in the denominator of the AO for points to the right of the median. The DO flags outliers to the right of the median much faster, due to its lower explosion bias.
We have also extended the multivariate simulation of AO in Hubert and Van der Veeken (Citation2008). Our simulation consists of m = 1000 samples in dimensions d = {2, 5, 10} and with sample sizes n = {200, 500, 1000}. The clean data were generated from the multivariate skew normal distribution (Azzalini and Dalla Valle Citation1996) with density where Φ is the standard normal cdf, φp is the d-variate standard normal density, and
is a d-variate vector which regulates the shape. In our simulations
is a vector with entries equal to 10 or 4. For d = 2 we used
, for d = 5 we put
, and for d = 10 we took
. To this we added 10% of contamination with a normal distribution
around the point
, where x is on the horizontal axis of . In d = 2 dimensions we see that AO flags the outliers a bit faster in the direction of the shortest tail, but slower in the direction of the longest tail. The latter is similar to what we saw for univariate data, due to the higher explosion bias of the scale used (implicitly) in the AO. When both the dimension d and the sample size n go up, the DO and AO methods give more similar results. This is because, in most directions, the scales sa and sb of the projected data get closer to each other. This is because the projections of the good data (i.e., without the outliers) tend to become more Gaussian as the dimension d and the sample size n go up, as shown by Diaconis and Freedman (Citation1984) for random directions uniformly distributed on the unit sphere and under moment conditions on the data distribution.
Figure 19. Percentage of outliers found in multivariate skew normal samples of size n = 200 (left), n = 500 (middle), and n = 1000 (right), with 10% of outliers around , in dimensions d = 2 (top), d = 5 (middle), and d = 10 (bottom).
We also carried out a simulation with functional data. We have generated m = 1000 samples of n = {200, 500, 1000} functions of the form
(15)
(15) where ln (Li) ∼ N(0, 1) and
. That is, the base function is the sine and we add different straight lines of which the slopes are generated by a lognormal distribution. We then replace 10% of the functions by contaminated ones, which are generated from (Equation15
(15)
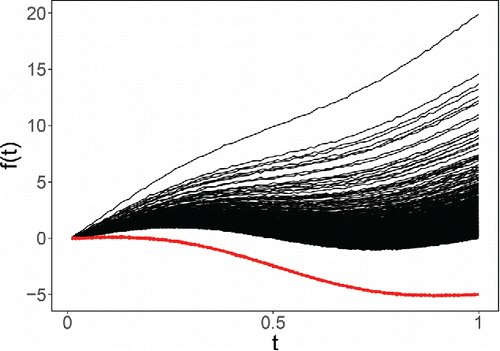
(15) ) but where Li is taken higher or lower than what one would expect under the lognormal model. shows such a generated dataset of size n = 1000, with outlying functions (with negative Li) in red.
Figure 20. n = 1000 generated functions with 10% contamination.
In the simulation we used a single slope L for the 10% of contaminated curves, and this L is shown on the horizontal axis in . When the outlying functions lie below the regular ones (i.e., for negative L), we see that the DO and AO behave similarly. On the other hand, when the outlying functions lie above the regular ones (i.e., in the direction of the long tail), the AO is much slower to flag them than DO.
Figure 21. Percentage of outliers found in functional samples of size n = 200 (left), n = 500 (middle), and n = 1000 (right), with 10% of contaminated curves with slope L.
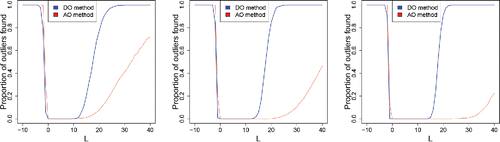
These simulations together suggest that the DO outperforms AO in directions where the uncontaminated data has a longer tail, while performing similarly in the other directions.
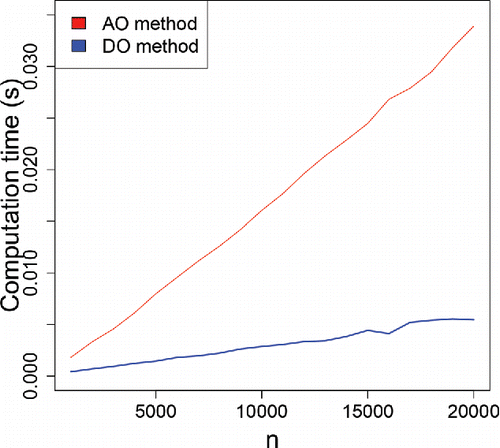
Note that the DO requires only computation time per direction, which is especially beneficial for functional data with a large domain. In particular, DO is much faster than AO which requires
operations. shows the average computation time (in seconds) of both measures as a function of the sample size n, for m = 1000 samples from the standard normal. The AO time is substantially above the DO time.
Figure 22. Average computation time of DO and AO as a function of sample size.
7. Conclusion
The notion of directional outlyingness (DO) is well-suited for skewed distributions. It has good robustness properties, and lends itself to the analysis of univariate, multivariate, and functional data, in which both the domain and the function values can be multivariate. Rough cutoffs for outlier detection are available. The DO is also a building block of several graphical tools like DO heatmaps, DO contours, and the functional outlier map (FOM). These proved useful when analyzing spectra, MRI images, and surveillance video. In the MRI images we added gradients to the data to reflect shape/spatial information. In video data we could also add the numerical derivative in the time direction. In our example this would make the frames six-dimensional, but the componentwise DO in (Equation14(14)
(14) ) would remain fast to compute.
8. Available Software
The methods described in this article are available in R (R core team 2016), in the package mrfDepth (https://CRAN.R-project.org/package=mrfDepth). An R script and the data sets for reproducing the examples in the article are available from our website http://wis.kuleuven.be/stat/robust/software.
Acknowledgments
This research has been supported by projects of Internal Funds KU Leuven. The authors are grateful for interesting discussions with Pieter Segaert.
Funding
Onderzoeksraad, KU Leuven.
References
- Arribas-Gil, A., and Romo, J. (2014), “Shape Outlier Detection and Visualization for Functional Data: The Outliergram,” Biostatistics, 15, 603–619.
- Azzalini, A., and Dalla Valle, A. (1996), “The Multivariate Skew-Normal Distribution,” Biometrika, 83, 715–726.
- Berrendero, J., Justel, A., and Svarc, M. (2011), “‘Principal Components for Multivariate Functional Data,” Computational Statistics & Data Analysis, 55, 2619–2634.
- Brys, G., Hubert, M., and Rousseeuw, P. J. (2005), “A Robustification of Independent Component Analysis,” Journal of Chemometrics, 19, 364–375.
- Brys, G., Hubert, M., and Struyf, A. (2004), “A Robust Measure of Skewness,” Journal of Computational and Graphical Statistics, 13, 996–1017.
- Diaconis, P., and Freedman, D. (1984), “Asymptotics of Graphical Projection Pursuit,” The Annals of Statistics, 12, 793–815.
- Donoho, D. (1982), Breakdown Properties of Multivariate Location Estimators, Ph.D. dissertation, Department of Statistics, Harvard University.
- Febrero-Bande, M., Galeano, P., and González-Manteiga, W. (2008), “Outlier Detection in Functional Data by Depth Measures, With Application to Identify Abnormal NOx Levels,” Environmetrics, 19, 331–345.
- Ferraty, F., and Vieu, P. (2006), Nonparametric Functional Data Analysis: Theory and Practice, New York, NY: Springer.
- Hampel, F., Ronchetti, E., Rousseeuw, P., and Stahel, W. (1986), Robust Statistics: The Approach Based on Influence Functions, New York: Wiley.
- Hand, D., Lunn, A., McConway, A., and Ostrowski, E. (1994), A Handbook of Small Data Sets, London, UK: Chapman and Hall.
- Hubert, M., Rousseeuw, P. J., and Segaert, P. (2015), “Multivariate Functional Outlier Detection” (with discussion), Statistical Methods & Applications, 24, 177–246.
- Hubert, M., and Van der Veeken, S. (2008), “Outlier Detection for Skewed Data,” Journal of Chemometrics, 22, 235–246.
- Hyndman, R., and Shang, H. (2010), “Rainbow Plots, Bagplots, and Boxplots for Functional Data,” Journal of Computational and Graphical Statistics, 19, 29–45.
- Lemberge, P., De Raedt, I., Janssens, K., Wei, F., and Van Espen, P. (2000), “Quantitative Z-Analysis of 16th–17th Century Archaeological Glass Vessels Using PLS Regression of EPXMA and μ-XRF Data,” Journal of Chemometrics, 14, 751–763.
- Li, L., Huang, W., Gu, I. Y.-H., and Tian, Q. (2004), “Statistical Modeling of Complex Backgrounds for Foreground Object Detection,” IEEE Transactions on Image Processing, 13, 1459–1472.
- Marcus, D., Wang, T., Parker, J., Csernansky, J., Morris, J., and Buckner, R. (2007), “Open Access Series of Imaging Studies (OASIS): Cross-Sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults,” Journal of Cognitive Neuroscience, 19, 1498–1507.
- Martin, R., and Zamar, R. (1993), “Bias Robust Estimation of Scale,” The Annals of Statistics, 21, 991–1017.
- Pigoli, D., and Sangalli, L. (2012), “Wavelets in Functional Data Analysis: Estimation of Multidimensional Curves and Their Derivatives,” Computational Statistics & Data Analysis, 56, 1482–1498.
- R Core Team (2016), “R: A Language and Environment for Statistical Computing,” R Foundation for Statistical Computing, Vienna, Austria. Available at: https://www.R-project.org/
- Ramsay, J., and Silverman, B. (2005), Functional Data Analysis (2nd ed.), New York: Springer.
- Rousseeuw, P., and Croux, C. (1994), “The Bias of k-Step M-Estimators,” Statistics & Probability Letters, 20, 411–420.
- Stahel, W. (1981), Robuste Schätzungen: Infinitesimale Optimalität und Schätzungen von Kovarianzmatrizen, Ph.D. dissertation. Switzerland: ETHZürich.
- Sun, Y., and Genton, M. (2011), “Functional Boxplots,” Journal of Computational and Graphical Statistics, 20, 316–334.
Appendix
Proof of Lemma 1(i).
Let be fixed. For the function ρc we have that
For all u ⩾ 0 it holds that
is nondecreasing in t, and even strictly increasing in t at large enough u. This proves (i) since f(x) > 0 in all x.
Proof of Lemma 1(ii).
Fix σ > 0. It follows from the Leibniz integral rule that
because ρc(0) = 0. Note now that
This implies that
for all t.
Proof of Proposition 1.
Let 0 < ϵ < 0.25 be fixed and let Fϵ, H be a minimizing distribution, that is,
with Fϵ, G = (1 − ϵ)F + ϵG. Inserting the contaminated distribution Fϵ, H into sa(Fϵ, H) yields the scale
(A.1)
(A.1) For simplicity, put
(A.2)
(A.2) We then have the contaminated scale
(A.3)
(A.3) Denote by Q2, ϵ = F− 1ϵ, H(0.5) and Q3, ϵ = F− 1ϵ, H(0.75) the median and the third quartile of the contaminated distribution.
For the distribution H it has to hold that H(Q3, ϵ) = 1 and . This can be seen as follows. Suppose H(∞) − H(Q3, ϵ) = p ∈ (0, 1]. Then consider
where
and denote by Q*2, ϵ and Q*3, ϵ the median and third quartile of
. Note that Q2, ϵ = Q*2, ϵ and Q3, ϵ > Q*3, ϵ. Therefore, we have
. It then follows from Lemma 1(i) that
and
. Therefore,
. It now follows that
, which is a contradiction since H minimizes sa. Therefore, H(∞) − H(Q3, ϵ) = 0. A similar argument can be made to show that
. It follows that H(Q3, ϵ) = 1 and H(x) = 0 for all x < Q2, ϵ, so all the mass of H is inside [Q2, ϵ , Q3, ϵ].
We can now argue that H must have all its mass in Q2, ϵ. Note that if H(Q3, ϵ) = 1 and we have
and
, depending on
. Given that Q2, ϵ is fixed, we can minimize W1(Fϵ, H) by minimizing Q3, ϵ. Now Q3, ϵ is minimal for
as this yields
. Note that this choice of H to minimize Q3, ϵ is not unique as any H which makes
does the job. Note finally that W2(Fϵ, H) is also minimal for
as ρc(t) is nondecreasing in |t|, and this choice of H yields W2(Fϵ, H) = 0.
We now know that minimizes sa(Fϵ, H). Furthermore, we have
and
. Therefore, the implosion bias of sa is
where
Proof of Proposition 2.
Let 0 < ϵ < 0.25 be fixed and let Fϵ, H be a maximizing distribution, that is,
with Fϵ, G = (1 − ϵ)F + ϵG. Inserting the contaminated distribution Fϵ, H into sa(Fϵ, H) yields the scale (EquationA.1
(A.1)
(A.1) ), which can be rewritten as in (EquationA.2
(A.2)
(A.2) ) and (EquationA.3
(A.3)
(A.3) ).
For the distribution H it has to hold that H(Q3, ϵ) = limx → Q−2, ϵH(x). This can be seen as follows. Suppose H(Q3, ϵ) − limx → Q−2, ϵH(x) = p ∈ (0, 1]. Now put and consider the distribution
where
and denote by Q*2, ϵ and Q*3, ϵ the median and third quartile of
. Note that Q2, ϵ = Q*2, ϵ and Q3, ϵ < Q*3, ϵ. Therefore
and thus
because of Lemma 1(i). Furthermore,
because ρc(t) is nondecreasing in |t|, thus
. It now follows that
, which is a contradiction since H maximizes sa. Therefore H(Q3, ϵ) = limx → Q−2, ϵH(x), so H has no mass inside [Q2, ϵ , Q3, ϵ].
Without loss of generality we can thus assume that H is of the form H = dΔ(e1) + (1 − d)Δ(e2) with and
where d ∈ [0, 1]. This choice of e1 and e2 is not unique but it maximizes sa(Fϵ, H) because ρc(t) is nondecreasing in |t|. Inserting the distribution Fd ≔ Fϵ, H yields
(A.4)
(A.4) where
,
, and so, a(Fd) = (Q3, d − Q2, d)/Φ− 1(0.75). Note that this expression depends on d but no longer on e1 and e2. We will show that this expression is maximized for d = 0.
First we show that so, a(Fd) is maximized for d = 0. Let
(A.5)
(A.5) for any d ∈ [0, 1]. Note that
does not depend on d. Therefore, we can write g(d) = (F− 1(v + ξ) − F− 1(v))/Φ− 1(0.75) where
is a strictly decreasing function of d. Note that we can write
. The density f is symmetric about some m, and by affine equivariance we can assume m = 0 w.l.o.g. Since f is unimodal with f(x) > 0 for all x, the function
is strictly decreasing up to its minimum (corresponding to the mode of f) and then strictly increasing. Therefore, g(d) is maximal for v as large as possible, that is, for d = 0. In that case, we have
.
Next, we maximize
(A.6)
(A.6) for any fixed σ > 0. This is equivalent to maximizing
(A.7)
(A.7) where q is such that
. Note that
, where the second term doesn’t depend on q. Maximizing (EquationA.7
(A.7)
(A.7) ) with respect to q is therefore equivalent to maximizing
. Note that this is equal to
. For all x in [0, cσ] it holds that
, hence the latter integral is maximized by minimizing f(q + x) for all x ∈ [0, cσ]. For this q must take on its highest possible value
, because we then have f(q + x) ⩽ f(q2 + x) for all x in [0, cσ] and all q2 in
. Therefore, (EquationA.6
(A.6)
(A.6) ) is maximized for d = 0.
We now know that (EquationA.5(A.5)
(A.5) ) and (EquationA.6
(A.6)
(A.6) ) satisfy max dg(d) = g(0) and max dh(σ, d) = h(σ, 0) for all σ > 0. By Lemma 1(i), h(σ, 0) is increasing in σ. Combining these results yields
so s2a(Fd) is maximized for d = 0. Therefore, s2a(Fϵ, H) is maximized for H = Δ(e2), hence
and
. The explosion bias is thus
where
Proof of Proposition 3.
Plugging the contaminated distribution Fϵ, z = (1 − ϵ)F + ϵΔz into the functional form (Equation4(4)
(4) ) of sa yields
We take the derivative with respect to ϵ and evaluate it in ϵ = 0. Note that ρc(t) is not differentiable at t = c and t = −c, but as these two points form a set of measure zero this does not affect the integral containing ρ′c(t). We also use that ρc(0) = 0 and IF(z, s2a, F) = 2sa(F)IF(z, sa, F) yielding the desired expression. For F = Φ we have
.
Proof of Proposition 4.
We show the proof for , the other case being analogous. Plugging the contaminated distribution Fϵ, z = (1 − ϵ)F + ϵΔz into
yields