
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Fitting hierarchical Bayesian models to spatially correlated datasets using Markov chain Monte Carlo (MCMC) techniques is computationally expensive. Complicated covariance structures of the underlying spatial processes, together with high-dimensional parameter space, mean that the number of calculations required grows cubically with the number of spatial locations at each MCMC iteration. This necessitates the need for efficient model parameterizations that hasten the convergence and improve the mixing of the associated algorithms. We consider partially centred parameterizations (PCPs) which lie on a continuum between what are known as the centered (CP) and noncentered parameterizations (NCP). By introducing a weight matrix we remove the conditional posterior correlation between the fixed and the random effects, and hence construct a PCP which achieves immediate convergence for a three-stage model, based on multiple Gaussian processes with known covariance parameters. When the covariance parameters are unknown we dynamically update the parameterization within the sampler. The PCP outperforms both the CP and the NCP and leads to a fully automated algorithm which has been demonstrated in two simulation examples. The effectiveness of the spatially varying PCP is illustrated with a practical dataset of nitrogen dioxide concentration levels. Supplemental materials consisting of appendices, datasets, and computer code to reproduce the results are available online.
1. Introduction
There is a growing interest among researchers in spatially varying coefficient (SVC) models (Hamm et al. Citation2015; Wheeler et al. Citation2014; Finley, Banerjee, and MacFarlane Citation2011; Berrocal, Gelfand, and Holland Citation2010; Gelfand et al. Citation2003). Conditional independencies determined by the hierarchical structure of the model facilitate the construction of Gibbs sampling type algorithms for model fitting (Gelfand and Smith Citation1990). A requirement of these algorithms is the repeated inversion of dense n × n covariance matrices, an operation of order O(n3) in computational complexity, for n spatial locations (Cressie and Johannesson Citation2008). This, coupled with high posterior correlation between model parameters and weakly identified covariance parameters, means that fitting these models is challenging and computationally expensive. To mitigate the computational expense practitioners require efficient model fitting strategies that produce Markov chains which converge quickly to the posterior distribution and exhibit low autocorrelation between successive iterates.
Parameterization of a hierarchical model is known to affect the performance of the Markov chain Monte Carlo (MCMC) method used for inference. For normal linear hierarchical models (NLHMs) the centred parameterization (CP) yields an efficient Gibbs sampler when the variance of the data model is low relative to that of the random effects, and the noncentered parameterization (NCP) yields an efficient Gibbs sampler when the variance of the data model is relatively high (Papaspiliopoulos, Roberts, and Sköld Citation2003, Gelfand, Sahu, and Carlin Citation1995). Where the latent variables are realizations of a spatial process with an exponential correlation function, Bass and Sahu (Citation2017) showed that increasing the strength of correlation improves the efficiency of the CP but degrades that of the NCP. Hence the sampling efficiency of the CP and the NCP is dependent upon the typically unknown variance and spatial correlation parameters and will therefore differ across different datasets. Consequently, deciding which parameterization to employ can be problematic.
With the aim of developing a robust parameterization for NLHMs, Papaspiliopoulos, Roberts, and Sköld (Citation2003) considered the CP and the NCP as extremes of a family of partially centred parameterizations (PCPs). They find the optimal PCP which results in a Gibbs sampler that produces independent samples from the posterior distributions of the mean parameters, but again this is conditioned on the covariance parameters. The question we look to answer in this article is can we create a parameterization for spatial models that is robust to the data and does not require a priori knowledge of the model parameters, and hence can be routinely implemented?
To address this question, we write a general SVC model as a three-stage NLHM. The PCP is constructed by introducing a weight matrix that allows us to eliminate the conditional posterior correlation between the global and random effects. This in turn implies immediate convergence of the associated Gibbs sampler for known variance and correlation parameters, which collectively we will call the covariance parameters. When these parameters are unknown we propose dynamically updating the weight matrix, which leads to a parameterization that is both spatially varying and dynamically updated within the Gibbs sampler. As it is necessary to invert an n × n matrix to compute the weight matrix, implementing the PCP results in an algorithm with longer run times than those associated with the CP and NCP. Consequently, we recommend this method for modest sized spatial datasets of hundreds, but not thousands, of observations.
For an exponential correlation function, we demonstrate how the weights of partial centering depend on the covariance parameters and the sampling locations, and hence vary over the spatial domain. We show that weights are higher when the data variance is relatively low and when the spatial correlation is high. Also, higher weights are given to more densely clustered sampling locations and where the covariate values are higher. To judge sampling efficiency of the PCP we use well known convergence diagnostics. The performance of the PCP is shown to be robust to changes in the covariance parameters of the data generating mechanism. Moreover, the PCP converges more quickly and produces posterior samples with lower autocorrelation than either the CP or the NCP. Note that Bass and Sahu (Citation2017) did not consider the PCP at all.
A related approach is the interweaving algorithm proposed by Yu and Meng (Citation2011). The algorithm results in a Gibbs sampler that is more efficient than the worst of the CP and NCP. However, the interweaving algorithm does not guarantee immediate convergence for known covariance parameters, whereas the PCP does, see Section A.3. Another approach is to marginalize over the random effects, thus reducing the dimension of the posterior distribution. This method can be employed when the error structures of the data and the random effects are both assumed to be Gaussian. Marginalized likelihoods are used by Gelfand et al. (Citation2003) for fitting SVC regression models. However, marginalization results in a loss of conditional conjugacy of the variance parameters and means that they have to be updated by using Metropolis-type steps, which require difficult and time consuming tuning. The scheme proposed here is fully automated.
The rest of this article is laid out as follows. Section 2 gives details of the general spatial model and the construction and properties of its PCP. Section 3 illustrates how the weights of partial centering are influenced by the model parameters and the sampling locations. Section 4 demonstrates the sampling efficiency of the PCP by applying it to simulated spatial datasets and compares its performance to the CP and the NCP. Section 5 applies the different model parameterizations to a real air pollution dataset on annual mean concentration levels of NO2 observed in Greater London in 2011. Section 6 contains some concluding remarks.
MCMC samplers are coded in the C programming language and the output is analyzed in R (R Core Team Citation2016).
2. Partial Centering of Space-Varying Coefficient Models
2.1. Model Specification
For data observed at a set of locations we consider the normal linear model with spatially varying regression coefficients (Gelfand et al. Citation2003):
(1)
(1) We model errors
as independent and normally distributed with mean zero and variance σ2ε. Spatially indexed observations
are conditionally independent and normally distributed as
where
is a vector containing covariate information for site
and
is a vector of global regression coefficients. The kth element of
is locally perturbed by a realization of a zero mean Gaussian process, denoted
, which are collected into a vector
. The n realizations of the Gaussian process associated with the kth covariate are given by
where
The form of the model given in (Equation1
(1)
(1) ) is the NCP. The CP is found by introducing the variables
. Therefore,
Global effects are assumed to be multivariate normal a priori and so we write model (Equation1
(1)
(1) ) in its hierarchically centered form as
(2)
(2) where
and
is the n × np design matrix for the first stage where
is a diagonal matrix with entries
. We denote by
the np × 1 vector of centred, spatially correlated random effects.
The design matrix for the second stage, , is a np × p block diagonal matrix, the blocks made of vectors of ones of length n. The p processes are assumed independent a priori and so
is block diagonal where the kth block is
for k = 0, 1, …, p − 1.
The global effects are assumed to be independent a priori with the kth element assigned a Gaussian prior distribution with mean mk and variance σ2kvk, hence we write θk ∼ N(mk, σ2kvk). Therefore,
and
is a diagonal matrix with diagonal entries σ2kvk for k = 0, …, p − 1.
We complete the model specification by assigning prior distributions to the covariance parameters. The realizations of the kth zero mean Gaussian process, have a prior covariance matrix given by
. This prior covariance matrix is shared by the kth centered Gaussian process,
The prior distributions for the variance parameters are given by
where we write
if X has a density proportional to x− (a + 1)e− b/x.
In this article, we consider only the exponential correlation function, which is a member of the Matérn family (Handcock and Stein Citation1993; Matérn Citation1986) and is widely applied to spatial processes (Sahu, Gelfand, and Holland Citation2010; Berrocal, Gelfand, and Holland Citation2010; Sahu, Gelfand, and Holland Citation2007; Huerta, Sansó, and Stroud Citation2004). Therefore, entries of the are
where
denotes the distance between
and
and φk controls the rate of decay of the correlation. Here the strength of correlation is characterised by the effective range, dk, which is the distance such that
. For an exponential correlation function, we have that dk = −log (0.05)/φk ≈ 3/φk.
It is not possible to consistently estimate all of the variance and decay parameters under vague prior distributions (Zhang Citation2004), and so we do not sample from the posterior distributions of the decay parameters. For the simulation studies in Section 4, the decay parameters are fixed, thus helping us to examine their impact upon the sampling efficiency of the PCP. For the real-data example in Section 5 we perform a grid search over a range of values, selecting those that offer the best out-of-sample predictions. A grid search is equivalent to placing a discrete uniform prior distribution upon the decay parameters and is a commonly adopted approach (Berrocal, Gelfand, and Holland Citation2010; Sahu, Gelfand, and Holland Citation2007).
2.2. Construction of the PCP
In Section 2.1, we consider two parameterizations, non-centered and centered, that differ by the prior mean of the spatial processes. We have for the NCP and
for the CP where a linear shift relates the two processes such that
. The PCP is formed by a partial shift, which is defined by
(3)
(3) and therefore the partially centered model is written as
(4)
(4) where
, and
.
Defining the PCP this way gives us tremendous flexibility in terms of parameterization. If is the identity matrix we recover the CP and where
is the zero matrix we have the NCP. If we let
then we have the PCP investigated by Papaspiliopoulos, Roberts, and Sköld (Citation2003, Section 4) and see also Papaspiliopoulos (Citation2003) for an independent random effect Poisson count model.
The question is how do we choose the entries of such that optimal performance of the Gibbs sampler is achieved? We answer this question by analyzing the posterior correlation between global and random effects. Returning to the CP, if we apply the calculations given in Gelfand, Sahu, and Carlin (Citation1995, Section 2) to our model set up it can be shown that
(5)
(5) where
and
(6)
(6) Therefore by substituting Equation (Equation3
(3)
(3) ) into Equation (Equation5
(5)
(5) ) we have that the posterior covariance of
and
is
(7)
(7) We can see from (Equation7
(7)
(7) ) that
when
. Therefore we define the optimal
to be
(8)
(8) For all that follows we drop the superscript from
and any time we refer to
it will be the matrix defined in (Equation8
(8)
(8) ). By the Sherman–Woodbury–Morrison identity (Harville Citation1997, Chapter 18) we can write
as
(9)
(9) which requires the inversion of matrix of order n and not of order np.
Equation (Equation8(8)
(8) ) implies that to minimise the posterior correlation between the random effects and global effects we cannot, in general, restrict
to be a diagonal matrix with entries wi, for i = 0, …, p − 1. It then follows that as
a priori, the prior mean of
will be a linear combination of all elements of
and not just a proportion of θk. For example, suppose we have p = 2 processes,
and
, and we partition
into four n × n blocks. Then, we have
and the ith row of
is the weight assigned to θ0 for
. More generally the ith row of
(k, j = 0, …, p − 1), is the weight assigned to θj for
. This is illustrated in Section 5, . Equation (Equation8
(8)
(8) ) also implies that when
contains the values of spatially referenced covariates or when
is the covariance of a spatial process, then the weights,
, will vary over space, as demonstrated in Section 3.
2.3. Exploring Block Updating for the PCP
Suppose now that we have constructed the PCP as before but we partition the partially centred random effects, , into two disjoint sets:
and
, and update them separately in a Gibbs sampler. Partitioned accordingly, the covariance matrix,
, of the joint posterior distribution of
is a 3 × 3 block matrix and
; see, for example, Harville (Citation1997, chap. 8), is also 3 × 3 block matrix. These are given by
where
Using the intermediate calculations given in Appendix A.4 in supplementary materials it can be shown that the convergence rate corresponding to the above precision matrix
is the maximum modulus eigenvalue of
which will be zero if the posterior correlation between
and
is zero.
Alternatively, suppose that we update as one block but partition
into
and
, updating them accordingly. The posterior covariance and precision matrices have the form
where
and the convergence rate is the maximum modulus eigenvalue of
which will be a null matrix if the two blocks of
are uncorrelated a posteriori.
It is the relationship between convergence rate and inter-block correlation that we take advantage of when constructing the PCP. For our construction, immediate convergence is only guaranteed if the random effects and global effects are each updated as one complete block. If a greater number of blocks are used we cannot, in general, find a matrix that will remove all cross covariances and return a convergence rate of zero. To see this first note that the posterior covariance matrix
, given in (Equation6
(6)
(6) ), is unaffected by hierarchical centering. Therefore, partial centering cannot remove any posterior correlation between subsets of
and so all of its elements must be updated together. Then, suppose that we partition the partially centered random effects into l blocks so that
. We find the posterior covariance between the ijth block to be
where
is the ijth block of
. We let
denote the rows of
associated with the ith block and let
denote the columns of
associated with the jth block, with
and
having similar interpretations. We see that if
then
, which is generally a nonzero matrix. Therefore, we must update
as one component and
as another.
2.4. PCP for Unknown Variance Parameters
The PCP relies on the matrix which, by construction, removes the posterior correlation between
and
. However, the derivation of
is conditional on the covariance matrices,
,
and
. Therefore, when the variance parameters are unknown how do we compute
? We propose a dynamically updated parameterization that uses the most recent values to recompute
at each MCMC iteration.
Let be the current state of the Markov chain, where
. Also let
be the partially updated vector without σ2k. We write
to highlight the dependency of
on the variance parameters. Recall that in Section 2.3 we show that
and
should each be updated as one block. We obtain a new sample,
as follows:
| 1. | Sample | ||||
| 2. | Sample | ||||
| 3. | For k = 0, …, p − 1, Sample | ||||
| 4. | Sample | ||||
The distributions of σ2k and σ2ε are conditioned on their respective current values through , that is, σ2(t + 1)0 is conditioned on σ2(t)0. There is no stochastic relationship between the parameters and
; given the parameters
is completely determined. However, we must ensure that by dynamically updating
we do not disturb thestationary distribution of the Markov chains generated from the Gibbs sampler. We need to show that
(10)
(10) where P{ · | · } is the transition kernel of the chain. The definition of P{ · | · } and the proof of that (Equation10
(10)
(10) ) holds is provided in Appendix A.5 in supplementary materials.
3. Spatially Varying Weights of Partial Centering
3.1. A Spatially Varying Intercept Model
In this section, we show that the weights of the PCP may vary over space and how these weights are influenced by the spatial distribution of the sampling locations. We also illustrate how the weights of partial centering depend upon the variance parameters but also the correlation structure of the latent processes. In particular, we will see how the weights vary across the spatial region and the impact of a spatially varying covariate. To focus on these relationships we will consider simplified versions of model (Equation4(4)
(4) ) that have one global parameter and one latent process. We do not need to simulate data as given a set of sampling locations we can investigate the weights through the variance and decay parameters.
We begin by looking at the following model,
(11)
(11) which has one global parameter
and one latent spatial process
, and hence can be found from (Equation4
(4)
(4) ) by letting
,
,
,
,
and
. Therefore, using the representation of
given in Equation (Equation9
(9)
(9) ) we have
(12)
(12) and so the entries of
depend on variance parameters σ20, σ2ε and, through correlation matrix
, the spatial decay parameter and the set of sampling locations,
.
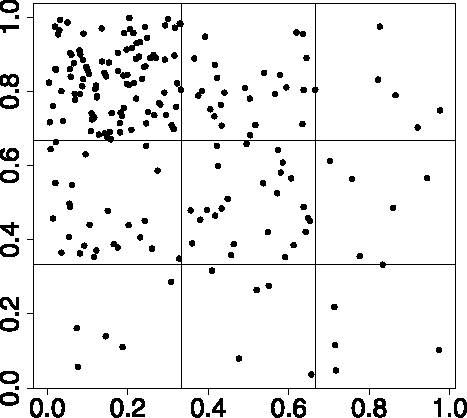
Here, we select sampling locations according to a pattern, such that the locations are more densely clustered in some regions of the domain than others. We consider 200 locations in the unit square which we split into nine subsquares of equal area, see . We randomly select 100 points in the top left square and 25 points in the three areas to which it is adjacent. The remaining five subsquares have five points randomly chosen within.
Figure 1. Patterned sampling locations. 100 top left; 25 in top middle, middle left, and middle middle; five top right, middle right, and bottom third. We use the points shown here to analyze the effect of the sampling locations on the spatially varying weights, see .
We considerfive variance ratios: δ0 = σ20/σ2ε = 0.01, 0.1, 1, 10, 100, and three effective ranges: , which are chosen with respect to the maximum separation of two points in the unit square,
. An effective range of zero, implying independent random effects, returns weights that are the same at each location. For each of the 15 variance ratio-effective range combinations we compute
, whose ith value is the weight assigned to θ0 at each
i = 1, …, 200.
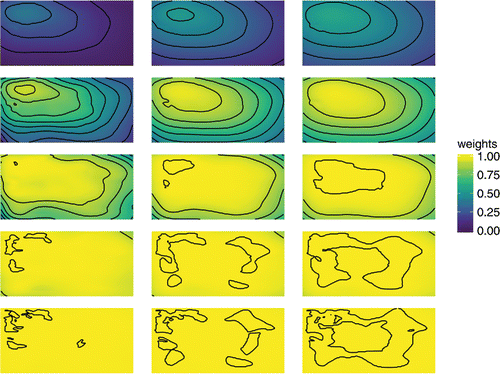
We use the interp() function in the R package akima (Akima and Gebhardt Citation2016) to interpolate the weights over the unit square. These interpolated plots of spatially varying weights are given in and are created in ggplot2 (Wickham Citation2009), making use of the ‘gather()’ function in tidyr (Wickham Citation2017) to set up the data frame. Each row corresponds to a value of δ0, from 0.01 in top row to 100 in the bottom. For each row going left to right, we have increasing effective ranges, . We can see that as the variance ratio increases the weights are higher, as they are when the effective range increases. Within each panel, the areas of higher weights are concentrated around the areas of more densely positioned sampling locations. The stronger the correlation, the farther reaching is the influence of these clusters.
Figure 2. Interpolated surfaces of weights for the PCP for 15 combinations of variance ratio δ0 and effective range d0. Rows correspond to five values of δ0 = 0.01, 0.1, 1, 10, 100, increasing top to bottom. Columns correspond to three values of , increasing left to right. The plot shows that the optimal parameterization gives greater weight to the CP where sampling locations are more densely clustered.
3.2. A Spatially Varying Slope Model
We now investigate the effect of a covariate upon the spatially varying weights. To do this we look at the following model:
(13)
(13) θ1 ∼ N(m1, σ21v1), where
and
contains the values of a known spatially referenced covariate. We have a global slope, hence
and a partially centered spatial process
. Model (Equation13
(13)
(13) ) can be retrieved from model (Equation4
(4)
(4) ) by letting
,
,
,
,
and
.
For model (Equation13(13)
(13) ) the
matrix is
To investigate how these weights vary across the domain we randomly select 200 points uniformly over the unit square. We generate the values of
by selecting a point
, which we may imagine to be the site of a source of pollution. We assume that the value for the observed covariate at site
decays exponentially at rate φx with increasing separation from
, so that
for i = 1, …, n. The spatial decay parameter φx is chosen such that there is an effective spatial range of
, that is, if
then
. The values of
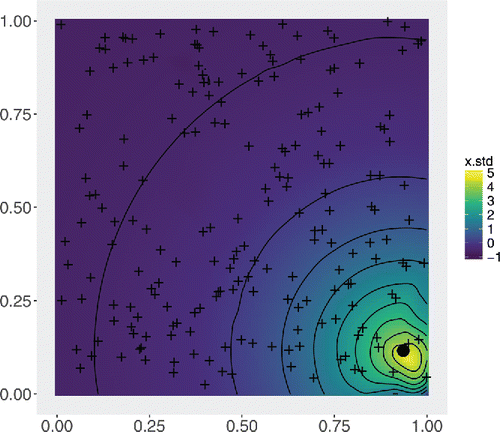
are standardized by subtracting their sample mean and dividing by their sample standard deviation. gives the interpolated covariate surface where
. We can see how the values decay with increased separation from
.
Figure 3. Interpolated surface of from the 200 uniformly sampled data locations, given by ’+’. The values of
decay with distance from the source, represented by a black dot. We use
to analyze the effect of covariates on the spatially varying weights for the PCP, see .
The optimal weights are computed for 15 combinations of variance ratio δ1 and effective range d1, where δ1 = σ21/σ2ε = 0.01, 0.1, 1, 10, 100 and ,
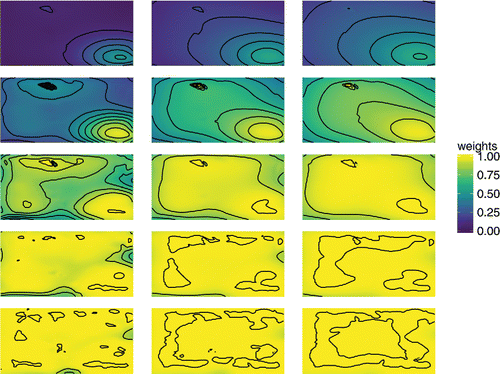
. The weights are interpolated and illustrated in . The weights increase with increasing δ1 or d1. It is also evident that for locations near
, where the values of the covariate are greatest, the weights are higher.
Figure 4. Interpolated weights for the PCP for 15 combinations of δ1 and d1. Rows correspond to five values of δ0 = 0.01, 0.1, 1, 10, 100, increasing top to bottom. Columns correspond to three values of , increasing left to right. Weights are greatest where the value of
is at its greatest, see .
4. Simulation Studies
4.1. Simulation Example 1
In this section, we use simulated data to investigate the performance of the Gibbs sampler associated with the PCP. All of the relevant posterior distributions can be found in Appendix A.6 in supplementary materials. We simulate data from model (Equation11(11)
(11) ) for n = 40 randomly chosen locations across the unit square. We let hyperparameters m0 = 0 and v0 = 104.
We set θ0 = 0 and generate data with five variance parameter ratios such that δ0 = σ20/σ2ε = 0.01, 0.1, 1, 10, 100. This is done by letting σ20 = 1 and varying σ2ε accordingly. For each of the five levels of δ0 we have four values of the decay parameter φ0, chosen such that there is an effective range, d0, of 0, ,
and
, where
is the maximum possible separation of two points in the unit square. Hence, there are 20 combinations of σ20, σ2ε and φ0 in all. Each of these combinations is used to simulate 20 datasets, and so there are 400 datasets in total.
To begin the variance parameters, σ20 and σ2ε, and the decay parameter φ0 = −log (0.05)/d0 are held fixed at their true values and so for each iteration of the Gibbs sampler we generate samples from the full conditional distributions of and θ0.
The efficiency of the sampler is judged by two measures, both of which are calculated using functions within the R package coda Plummer et al. (Citation2006). The first statistic we use is based on the potential scale reduction factor (PSRF) (Gelman and Rubin Citation1992). We define the PSRFM(1.1) to be the number of iterations required for the upper limit of the 95 % confidence interval of the PSRF to fall below 1.1 for the first time.
To compute the PSRFM(1.1), we simulate multiple chains from widely dispersed starting values. In particular, we take values that are outside of the intervals described by pilot chains. At every fifth iteration, the PSRF is calculated and the number of iterations for its value to drop below 1.1 is the value that we record. The second statistic we use is the effective sample size (ESS) of θ0, (Robert and Casella Citation2004, chap. 12).
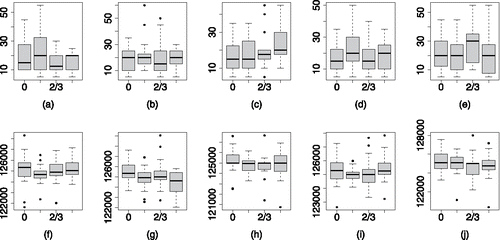
For each dataset, we generate five chains of length 25,000 and compute the PSRFM(1.1) and the ESS of θ0 out of a total of 125,000 samples. The results are plotted in . On the top row, we have the PSRFM(1.1) and on the bottom the ESS. The five panels in each row correspond to values of δ0 = 0.01, 0.1, 1, 10, 100 from left to right and within each panel we have four boxplots, one for each level of the effective range 0, ,
and
. Each boxplot consists of 20 values, for the 20 repetitions of that variance ratio-effective range combination. The figure shows that for the PCP with known variance parameters we achieve near immediate convergence and independent samples for θ0 in all cases, and that it is robust to changes in both variance ratio and strength of correlation. In some instances, we observe an ESS greater than the total number of samples. This occurs when the estimate of the integrated autocorrelation time is less than zero, which is theoretically possible; see, for example, Besag and Green (Citation1993).
Figure 5. PSRFM(1.1), panels (a)–(e), and the ESS, panels (f)–(j), of θ0 for the PCP with known variance parameters. The plots show that the performance of the PCP is insensitive to values of the variance and spatial decay parameters.
4.2. Simulation Example 2
The second simulation study drops the assumption of known variance parameters, fixing only the decay parameter. In this case, we judge performance by the MPSRFM(1.1) which we define to be the number of iterations needed for the multivariate PSRF (Brooks and Gelman Citation1998) to fall below 1.1 for the first time. Note that the MPSRF is approximate upper bound to the maximum of the univariate PRSF’s over all monitored variables, see (Brooks and Gelman Citation1998), Lemma 3. In addition, we record the ESS of θ0, σ20 and σ2ε.
Recall that variance parameters are given inverse gamma prior distributions with π(σ20) = IG(a0, b0) and π(σ2ε) = IG(aε, bε). We let a0 = aε = 2 and bε = bε = 1, implying a prior mean of one and infinite prior variance for σ20 and σ2ε. These are common hyperparameters for inverse gamma prior distributions, see Sahu, Gelfand, and Holland (Citation2010, Citation2007), Gelfand et al. (Citation2003).
shows the MPSRFM(1.1) on the top row and the ESS of θ0 on the bottom row for the 20 combinations of δ0 and d0 as in the case of . There is more variability in the results seen here for the MPSRFM(1.1) than we saw for the PSRFM(1.1) when the variance parameters were fixed, . When the random effects are independent, weak identifiability of the variance parameters can effect the performance of the sampler as marginally . However, the robustness to changes in δ0 remains and we still see rapid convergence in most cases. The ESS for θ0 remains high, with a median value above 120,000 for all of the 20 combinations of δ0 and d0.
Figure 6. MPSRFM(1.1), panels (a)–(e), and the ESS panels (f)–(j), of θ0 for the PCP with unknown variance parameters. Now, we are updating the parameterization within the sampler, but performance is still good and insensitive to the values of the variance and spatial decay parameters.
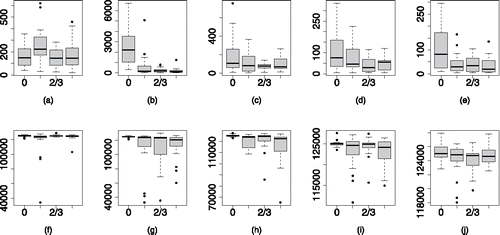
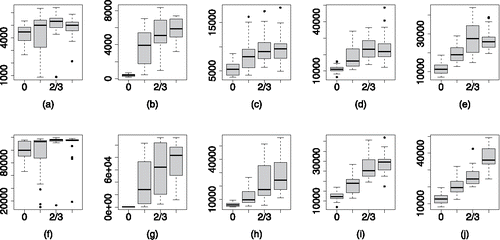
Boxplots of the ESS of the variance parameters are given in , with the resultsfor σ20 on the top row and σ2ε on the bottom row. There is a suggestion that increasing δ0 increases the ESS of σ20 and decreases the ESS of σ2ε. For a fixed value of δ0, we can see that the ESS of both variance parameters increases as the effective range increases. The stronger correlation across the random effects means that the variability seen in the data can be more easily separated between the two components.
Figure 7. ESS of σ20, panels (a)–(e), and σ2ε, panels (f)–(j) for the PCP with unknown variance parameters. The ESS of the variance parameters is not strongly effected by their ratio but does improve with stronger spatial correlation.
We compare the results for the PCP with those obtained for the CP and the NCP by calculating the mean responses of each measure of performance for each of the 20 variance ratio-effective range combinations. shows the mean MPSRFM(1.1) and mean ESS for θ0. The sampling efficiency of the CP and the NCP is dependent on the covariance parameters. The CP performs best for higher values of δ0 and longer effective ranges, and the NCP performs best for lower values of δ0 and shorter effective ranges. In contrast, the PCP is robust to changes in δ0 and d0. Moreover, we see that the PCP has a lower average MPSRFM(1.1) for most cases, and when it does not, the difference is less than 3%. It is clear that, in terms of the ESS of θ0, the PCP is superior to the CP and the NCP in all cases.
Table 1. Means of the MPSRFM(1.1) and the ESS of θ0 for 20 variance ratio-effective range combinations for the CP, the NCP and the PCP.
The ESS of the variance parameters is not strongly effected by the fitting methods we consider here as a reparameterization only acts upon the mean structure of the model. However, in cases where a particular parameterization is very inefficient, for example, for the NCP when δ0 > 1, poor mixing can occur for the variance parameters.
5. London Air Pollution Modeling Example
In this section, we compare the efficiency of the CP, the NCP and the PCP when fitting model (Equation1(1)
(1) ) to a dataset of NO2 concentration levels, downloaded from www.londonair.org.uk, for the city of Greater London. It is a spatial dataset with values, in microgram per cubic metre (
), of the annual mean concentration for the year 2011. Data have been collected at 63 irregularly spaced locations across London. We fit the model using data from 47 sites, leaving out 16 sites for validation (see ). The mean and standard deviation for the 47 data sites is 81.8
and 38.7
respectively. This annual mean value is quite high compared to the annual limit value of 40
, which has been stated in the national air quality objectives.Footnote1 This objective has been in place since 2005 and so was in effect prior to the collection of these data. Also, note that there is considerable variability in the data as is evident by the high value of the standard deviation.
Figure 8. Sampling locations for NO2 concentration data.

The spatially varying covariate we use is output from the Air Quality Unified Model (AQUM), a numerical model giving air pollution predictions at 1-km grid cell resolution (Savage et al. Citation2013). The AQUM is used as a covariate in the model, where is the AQUM output for the grid cell containing s. Therefore, we use a downscaler model as employed by Berrocal, Gelfand, and Holland (Citation2010).
As we have a spatially varying coefficient we fit the different parameterizations of model (Equation1(1)
(1) ) with p = 2. Therefore, we have two spatial processes, an intercept and a slope process and so
for the CP,
for the NCP and
for the PCP. Each process has a corresponding global parameter and a variance parameter and so
and
. We use an exponential correlation function for both processes and so
. In addition, we have the data variance, σ2ε, and so we have 2(n + 3) + 1 parameters to estimate for each parameterization.
For the prior distribution of we let
and v0 = v1 = 104. We let a0 = a1 = aε = 2 and b0 = b1 = bε = 1, so that each variance parameter is assigned an IG(2, 1) prior distribution. To stabilise the variance and avoid negative predictions, we model the data on the square root scale, as done by Sahu, Gelfand, and Holland (Citation2007) and Berrocal, Gelfand, and Holland (Citation2010) when modeling ozone concentrations for the US.
As mentioned in Section 2.1, we estimate the spatial decay parameters by performing a grid search over a range of values for φ0 and φ1. The estimates are taken to be the pair of values that minimize the prediction error with respect to the validation data. The criteria used to compute the prediction error are the mean absolute prediction error (MAPE), the root mean square prediction error (RMSPE), and the continuous ranked probability score (CRPS), see Gneiting, Balabdaoui, and Raftery (Citation2007) for example.
We select values of φ0 and φ1 corresponding to effective ranges of 5, 10, 25, 50, 100 and 250 km. For each of the 36 pairs of spatial decay parameters, we generate a single chain of 25,000 iterations and discard the first 5,000. In this way, the estimates for the spatial decay parameters are .
For each parameterization, we generate five Markov chains of length 25,000 from the same set widely dispersed starting values. The MPSRFM(1.1) and the ESS for ,
and σ2ε arecomputed and given in .
Table 2. MPSRFM(1.1) and the ESS of the model parameters.
In this example, and also previously in the simulation examples, we evaluate the efficiency of the sampling algorithms for the fixed effects and global variance parameters which are of interests for inferential purposes. However, we have also monitored the convergence for a random sample of the spatially varying random effects, . We did not encounter any problem in their convergence behavior.
We see that the CP requires far fewer iterations for the MPSRF to drop below 1.1 than the NCP, 460 versus 1230. The short effective range for the intercept process means that the ESS for θ0 is only slightly greater for the CP than the NCP, but due to the stronger spatial association in the regression process the ESS for θ1 is nearly 13 times greater for the CP than the NCP. However, the PCP, whose performance insensitive to the values of the model parameters, demonstrates extremely low autocorrelation between successive samples with an ESS greater than 120,000 for both θ0 and θ1.
The run times for the CP and the NCP are almost the same, but updating within the sampler means that the PCP is more computationally demanding. gives the same measures as but adjusted for computation time. We let
denote the computation time (in seconds) for the MPSRF to fall below 1.1, and let ESS/s denote the ESS per second.
Table 3. MPSRFt(1.1) and ESS/s of the model parameters.
Even accounting for the shorter run times of the CP, the PCP is comparable in terms of MPSRFt(1.1) and ESS/s of the variance components, but most importantly it is superior in terms of ESS/s for the mean parameters.
shows the spatially varying parameterization that results from the PCP. Contained are interpolated maps of the average weight of partial centering given by each process to each global parameter for all 63 sampling locations. The top row displays the weights given by to θ0 on the left, and the weights given by
to θ1 on the right. To restrict the interpolated weight values within the unit interval (0, 1), we first logit-transform the weights and then use the inverse logit transformation on the interpolated values.
Figure 9. Spatially varying weights for London NO2 concentration data. On the top row are the weights assigned to the global parameter corresponding to each process. On the left, the weight of θ0 in the mean of , and on the right the weight of θ1 in the mean of
. The bottom row gives the weights for the alternate global parameter. On the left, the weight of θ1 in the mean of
, and on the right the weight of θ0 in the mean of
.
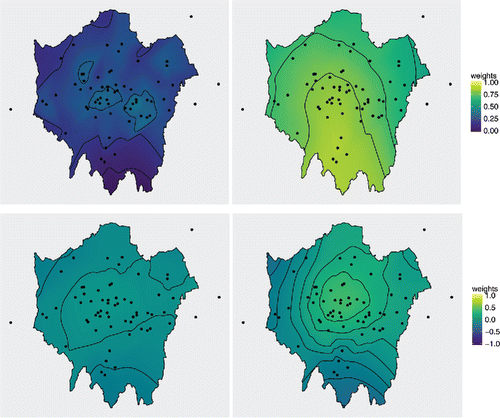
The weights for θ0 are low; the estimated weights at the data locations (not the interpolated weights) are between 0.11 and 0.38. This reflects the short effective range of the intercept process, which is 5 kilometres (km). The weights for θ1 are much higher, between 0.50 and 0.88, and this is due to the longer effective range of the slope process, 100 km. The weights vary over the spatial locations and are neither exactly zero or one, which would correspond to the NCP and CP respectively. They are higher where there are clusters of monitoring sites. We see this behavior in . It is more clearly demonstrated when there is a shorter effective range as the influence of the clustering of data points is not so far reaching, thus the pattern can be discerned from the plot.
The bottom row displays the weights given by to θ1 on the left, and the weight given by
to θ0 on the right. These take values in (–1, 1) and so we transform them to the unit interval before taking the logit transformation, then the interpolated weights are back-transformed.
When producing the plots, to have Greater London fully contained within the convex hull of the sampling locations, we move the most northerly observation site further north by adding 0.05 to its latitude. In addition to the packages needed to produce , we use functions within maptools (Bivand and Lewin-Koh Citation2016) to handle the shape files and the pointsInPoly function in spBayes to remove those points on the interpolated grid that lie outside of the polygon described by the Greater London Boundary.
6. Discussion
We have investigated the performance of a PCP for the spatially varying coefficients model. We are able to parameterize the model in such a way that we remove the posterior covariance between the random and global effects and produce a Gibbs sampler which converges immediately. The construction is conditioned on the covariance matrices in the model. We have shown that the parameterization can be updated dynamically within the Gibbs sampler for the case when these matrices are known only up to a set of covariance parameters which must be estimated.
The optimal weights of partial centering are shown to vary over the spatial domain, with higher weights given to locations where the data are more informative about the latent surface. Therefore, higher weights are found when the data precision is relatively high, or there is some clustering of locations. We also saw higher weights for locations where the value of the covariate was higher.
We make it clear that although the interpolated plots given in Sections 3 and 5 are informative they do not represent a true surface in the sense that the interpolated values are not estimates of a true value of the weights at an unsampled location. Indeed, if we were to obtain a further measurement at a new location then the values of the weights at the existing locations would change.
Our investigations show that the unlike the CP and the NCP, the performance of the PCP is robust to changes in the variance and correlation parameters. Swift convergence and independent, or near independent samples from the posterior distributions of the mean parameters are achieved for all of the datasets we considered, whether it was simulated or real data.
The PCP requires us to update all of the random effects in one block and all of the global effects in another. It is a computationally intensive strategy which we recommend for modest sized spatial datasets. However, for larger datasets many practitioners turn to Gaussian predictive process approximations, as implemented in R software packages spBayes (Finley, Banerjee, and Gelfand Citation2015) and spTimer (Bakar and Sahu Citation2015). As the method proposed in this article, can be applied to any model that can be written as a three stage NLHM, we believe that the PCP could be used in conjunction with GPP models thus broadening its applicability. We also note that PCP can be used for the Generalized linear models incorporating spatially varying random effects.
Acknowledgments
This research was supported in part by the EPSRC research grant EP/J017485/1 awarded to the correspinding author. Much of this work was completed when the first author was a PhD student in the University of Southampton. The authors thank the referees for helpful comments.
Supplementary Materials
Appendices: A.1 to A.6 containing proofs and further details as referenced in the main article. | |||||
C code: All of the C code used to generate the MCMC output which is analyzed to produce the results given in this article are contained within the folder called c_files. Full details are provided within the README.txt file contained within the folder. | |||||
Data: All data files can be found in the folder labeled data_files. A full description is given in the README.txt file contained therein. | |||||
R code: The R code used to analyze the MCMC output produced by the C code can be found in the folder labeled R_scripts. A full description of the files is given in README.txt. | |||||
Figures: The figures produced by the R code included in this article are given in the folder labeled figures. | |||||
Supplement_Bass_Sahu.zip
Download Zip (4.7 MB)Supplement.pdf
Download PDF (183.6 KB)Notes
1 https://uk-air.defra.gov.uk/air-pollution/uk-eu-limits, last modified March 3, 2017
Related Research Data
References
- Akima, H., and Gebhardt, A. (2016), “akima: Interpolation of Irregularly and Regularly Spaced Data,” R package version 0.6-2.
- Bakar, K. S., and Sahu, S. K. (2015), “spTimer: Spatio-Temporal Bayesian Modeling Using R,” Journal of Statistical Software, 63, 1–32.
- Bass, M. R., and Sahu, S. K. (2017), “A Comparison of Centring Parameterisations of Gaussian Process-Based Models for Bayesian Computation using MCMC,” Statistics and Computing, 27, 1491–1512.
- Berrocal, V. J., Gelfand, A. E., and Holland, D. M. (2010), “A Spatio-Temporal Downscaler for Output from Numerical Models,” Journal of Agricultural, Biological, and Environmental statistics, 15, 176–197.
- Besag, J., and Green, P. J. (1993), “Spatial Statistics and Bayesian Computation” (with discussion), Journal of the Royal Statistical Society, Series B, 55, 25–37.
- Bivand, R., and Lewin-Koh, N. (2016), “maptools: Tools for Reading and Handling Spatial Objects,” R package version 0.8-39.
- Brooks, S. P., and Gelman, A. (1998), “General Methods for Monitoring Convergence of Iterative Simulations,” Journal of Computational and Graphical Statistics, 7, 434–455.
- Cressie, N., and Johannesson, G. (2008), “Fixed Rank Kriging for very Large Spatial Data Sets,” Journal of the Royal Statistical Society, Series B, 70, 209–226.
- Finley, A. O., Banerjee, S., and Gelfand, A. E. (2015), “spBayes for Large Univariate and Multivariate Point-Referenced Spatio-Temporal Data Models,” Journal of Statistical Software, 63, 1–28.
- Finley, A. O., Banerjee, S., and MacFarlane, D. W. (2011), “A Hierarchical Model for Quantifying Forest Variables over Large Heterogeneous Landscapes with Uncertain Forest Areas,” Journal of the American Statistical Association, 106, 31–48.
- Gelfand, A. E., Kim, H.-J., Sirmans, C., and Banerjee, S. (2003), “Spatial Modeling with Spatially Varying Coefficient Processes,” Journal of the American Statistical Association, 98, 387–396.
- Gelfand, A. E., Sahu, S. K., and Carlin, B. P. (1995), “Efficient Parameterisations for Normal Linear Mixed Models,” Biometrika, 82, 479–488.
- Gelfand, A. E., and Smith, A. F. (1990), “Sampling-Based Approaches to Calculating Marginal Densities,” Journal of the American Statistical Association, 85, 398–409.
- Gelman, A., and Rubin, D. B. (1992), “Inference from Iterative Simulation using Multiple Sequences,” Statistical Science, 7, 457–472.
- Gneiting, T., Balabdaoui, F., and Raftery, A. E. (2007), “Probabilistic Forecasts, Calibration and Sharpness,” Journal of the Royal Statistical Society, Series B, 69, 243–268.
- Hamm, N., Finley, A., Schaap, M., and Stein, A. (2015), “A Spatially Varying Coefficient Model for Mapping PM10 Air Quality at the European Scale,” Atmospheric Environment, 102, 393–405.
- Handcock, M. S., and Stein, M. L. (1993), “A Bayesian Analysis of Kriging,” Technometrics, 35, 403–410.
- Harville, D. A. (1997), Matrix Algebra from a Statistician’s Perspective, New York: Springer-Verlag.
- Huerta, G., Sansó, B., and Stroud, J. R. (2004), “A Spatio-temporal Model for Mexico City ozone Levels,” Journal of the Royal Statistical Society, Series C, 53, 231–248.
- Matérn, B. (1986), Spatial Variation (2nd ed.), Berlin: Springer Verlag.
- Papaspiliopoulos, O. (2003), “Non-Centered Parameterisations for Data Augmentation and Hierarchical Models with Applications to Inference for Lévy-Based Stochastic Volatility Models,” Ph.D. thesis, University of Lancaster.
- Papaspiliopoulos, O., Roberts, G. O., and Sköld, M. (2003), “Non-centered parameterisations for hierarchical models and data augmentation (with discussion),” in Bayesian Statistics 7 (Bernardo, JM and Bayarri, MJ and Berger, JO and Dawid, AP and Heckerman, D and Smith, AFM and West, M): Proceedings of the Seventh Valencia International Meeting, Oxford University Press, USA, pp. 307–326.
- Plummer, M., Best, N., Cowles, K., and Vines, K. (2006), “CODA: Convergence Diagnosis and Output Analysis for MCMC,” R News, 6, 7–11.
- R Core Team (2016), R: A Language and Environment for Statistical Computing, Vienna, Austria: R Foundation for Statistical Computing.
- Robert, C. O., and Casella, G. (2004), Monte Carlo Statistical Methods” (2nd ed.), New York: Springer-Verlag.
- Sahu, S. K., Gelfand, A. E., and Holland, D. M. (2007), “High-Resolution Space–Time Ozone Modeling for Assessing Trends,” Journal of the American Statistical Association, 102, 1221–1234.
- ——— (2010), “Fusing Point and Areal Level Space–Time Data with Application to Wet Deposition,” Journal of the Royal Statistical Society, Series C, 59, 77–103.
- Savage, N., Agnew, P., Davis, L., Ordóñez, C., Thorpe, R., Johnson, C., O’Connor, F., and Dalvi, M. (2013), “Air Quality Modelling using the Met Office Unified Model (AQUM OS24-26): Model Description and Initial Evaluation,” Geoscientific Model Development, 6, 353–372.
- Wheeler, D. C., Páez, A., Spinney, J., and Waller, L. A. (2014), “A Bayesian Approach to Hedonic Price Analysis,” Papers in Regional Science, 93, 663–683.
- Wickham, H. (2009), ggplot2: Elegant Graphics for Data Analysis, New York: Springer-Verlag.
- ——— (2017), “tidyr: Easily Tidy Data with ‘spread()’ and ‘gather()’ Functions,” R package version 0.6.1.
- Yu, Y., and Meng, X.-L. (2011), “To Center or Not to Center: That is Not the Question: An Ancillarity–Sufficiency Interweaving Strategy (ASIS) for Boosting MCMC Efficiency,” Journal of Computational and Graphical Statistics, 20, 531–570.
- Zhang, H. (2004), “Inconsistent Estimation and Asymptotically Equal Interpolations in Model-Based Geostatistics,” Journal of the American Statistical Association, 99, 250–261.