
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose adaptive incremental mixture Markov chain Monte Carlo (AIMM), a novel approach to sample from challenging probability distributions defined on a general state-space. While adaptive MCMC methods usually update a parametric proposal kernel with a global rule, AIMM locally adapts a semiparametric kernel. AIMM is based on an independent Metropolis–Hastings proposal distribution which takes the form of a finite mixture of Gaussian distributions. Central to this approach is the idea that the proposal distribution adapts to the target by locally adding a mixture component when the discrepancy between the proposal mixture and the target is deemed to be too large. As a result, the number of components in the mixture proposal is not fixed in advance. Theoretically, we prove that there exists a stochastic process that can be made arbitrarily close to AIMM and that converges to the correct target distribution. We also illustrate that it performs well in practice in a variety of challenging situations, including high-dimensional and multimodal target distributions. Finally, the methodology is successfully applied to two real data examples, including the Bayesian inference of a semiparametric regression model for the Boston Housing dataset. Supplementary materials for this article are available online.
1 Introduction
We consider the problem of sampling from a target distribution defined on a general state space. While standard simulation methods such as the Metropolis–Hastings algorithm (Metropolis et al. Citation1953; Hastings Citation1970) and its many variants have been extensively studied, they can be inefficient in sampling from complex distributions such as those that arise in modern applications. For example, the practitioner is often faced with the issue of sampling from distributions which contain some or all of the following: multimodality, very nonelliptical high density regions, heavy tails, and high-dimensional support. In these cases, standard Markov chain Monte Carlo (MCMC) methods often face difficulties: long mixing time and large asymptotic variance leading to potentially biased and large variance MCMC estimators. Adaptive Monte Carlo methods, which can be traced back to Gilks, Roberts, and George (Citation1994), can help overcome these problems. In the specific context of MCMC algorithms, the seminal works are Gilks, Roberts, and Sahu (Citation1998) and Haario, Saksman, and Tamminen (Citation1999). The theoretical properties of these algorithms have been extensively analyzed by Andrieu and Moulines (Citation2006) and Roberts and Rosenthal (Citation2007). Adaptive MCMC methods improve the convergence of the chain by tuning its transition kernel on the fly using knowledge of the past trajectory of the process. This learning process causes a loss of the Markovian property and the resulting stochastic process is therefore no longer a Markov chain.
Most of the adaptive MCMC literature to date has focused on updating an initial parametric proposal distribution. For example, the adaptive Metropolis–Hastings algorithm (Haario, Saksman, and Tamminen Citation1999, Citation2001), hereafter referred to as AMH, adapts the covariance matrix of a Gaussian proposal kernel, used in a random walk Metropolis–Hastings algorithm. The adaptive Gaussian mixtures algorithm (Giordani and Kohn Citation2010; Luengo and Martino Citation2013), hereafter referred to as AGM, adapts a mixture of Gaussian distributions, used as the proposal in an independent Metropolis–Hastings algorithm.
When knowledge on the target distribution is limited, the assumption that a good proposal kernel can be found in a specific parametric family may lead to suboptimal performance. Indeed, a practitioner using these methods must choose, sometimes arbitrarily, (i) a parametric family and (ii) an initial set of parameters to start the sampler. However, poor choices of (i) and (ii) may hamper the adaptation and result in slow convergence.
In this article, we introduce a novel adaptive MCMC method, called adaptive incremental mixture Markov chain Monte Carlo (AIMM). This algorithm belongs to the general adaptive independent Metropolis class of methods, developed in Holden, Hauge, and Holden (Citation2009), in that AIMM adapts an independence proposal density. However, the adaptation process here is quite different from others previously explored in the literature. Although our objective remains to reduce the discrepancy between the proposal and the target distribution along the chain, AIMM proceeds without any global parameter updating scheme, as is the case with adaptive MCMC methods belonging to the framework developed in Andrieu and Moulines (Citation2006).
Our idea is instead to add a local probability mass to the current proposal kernel, when a large discrepancy between the target and the proposal is encountered. The local probability mass is added through a Gaussian kernel located in the region that is not sufficiently supported by the current proposal. The decision to increment the proposal kernel is based on the importance weight function that is implicitly computed in the Metropolis acceptance ratio. We stress that, although seemingly similar to Giordani and Kohn (Citation2010) and Luengo and Martino (Citation2013), our adaptation scheme is local and semiparametric since the number of mixture components is not specified, a subtle difference that has important theoretical and practical consequences. In particular, in contrast to AGM, the approach which we develop does not assume a fixed number of mixture components. The AIMM adaptation strategy is motivated by the quantitative bounds achieved when approximating a density using the recursive mixture density estimation algorithm proposed in Li and Barron (Citation2000). The main difference is that while in AIMM the sequence of proposals is driven by the importance weight function at locations visited by the AIMM Markov chain, it is constructed in Li and Barron (Citation2000) by successively minimizing the entropy with respect to the target distribution, an idea which was also put forward in Cappé et al. (Citation2008). In fact, the AIMM adaptation strategy shares perhaps more similarity with the adaptive rejection Metropolis sampler (ARMS) from Gilks, Best, and Tan (Citation1995) which is an MCMC extension of ARS (Gilks and Wild Citation1992). In unidimensional settings, the ARMS proposal is a piecewise exponential density which essentially interpolates the set of accepted and rejected samples of an independent MH. More recent works have developed different adaptation schemes with other nonparametric densities: piecewise triangular or trapezoidal functions (Cai, Meyer, and Perron Citation2008) and Lagrange interpolation polynomials (Meyer, Cai, and Perron Citation2008). The ARMS algorithm has been improved in Martino, Read, and Luengo (Citation2015) where the authors also use the notion of importance weight to adapt the set of points used to build the proposal density. We refer to Martino et al. (Citation2018) for a thorough review of those methods. The main drawback of those methods is that, even though Metropolis-within-Gibbs versions of those algorithms can be considered, they are essentially designed for unidimensional problems. Our work is inspired by the efficiency of those univariate nonparametric adaptation schemes which we combine with the high-dimensional flexibility offered by the mixture of Gaussian kernels.
As in most adaptive MCMC, AIMM requires the specification of some tuning parameters and in particular the threshold parameter controlling the tolerated discrepancy between the target distribution and the adaptive proposal. Although we are not able to prove any optimality result regarding those parameters, we provide a default setting that works well empirically in the examples we have considered and some heuristics that automate these choices. At a more general level, we anticipate that this work will be used by practitioners as a basis for their own inference problem. In this spirit, we also present a faster version of AIMM that guarantees that the proposal is not too costly to evaluate, a situation which occurs when the number of components in the incremental mixture gets large, especially if the state space is high dimensional.
Proving the ergodicity of adaptive MCMC methods is often made easier by expressing the adaptation as a stochastic approximation process consisting of the proposal kernel parameters (Andrieu and Moulines Citation2006). AIMM cannot be analyzed in this framework as the adaptation does not proceed with a global parameter update step. We do not study the ergodicity of the process in the framework developed by Holden, Hauge, and Holden (Citation2009), and also used in Giordani and Kohn (Citation2010), as the Doeblin condition required there is essentially equivalent to assuming that the importance function is bounded above. This condition is generally hard to meet in most practical applications, unless the state space is finite or compact. Instead, our ergodicity proof relies on the seminal work by Roberts and Rosenthal (Citation2007), which shows that (i) if the process adapts less and less (diminishing adaptation) and (ii) if any Markov kernel used by the process to transition reaches stationarity in a bounded time (containment), then the adaptive process is ergodic. We show that AIMM can be implemented in a way that guarantees diminishing adaptation, while the containment condition remains to be proven on a case by case basis, depending on the target distribution. Moreover, we show using the recent theory developed in Craiu et al. (Citation2015) and Rosenthal and Yang (Citation2017) that there exists a process, which can be made arbitrarily close to the AIMM process, which is ergodic for the target distribution at hand.
The article is organized as follows. We start in Section 2 with a pedagogical example which shows how AIMM succeeds in addressing the pitfalls of some adaptive MCMC methods. In Section 3, we formally present AIMM, and study its theoretical properties in Section 4. Section 5 illustrates the performance of AIMM on some synthetic examples, involving two high-dimensional heavy-tailed distributions and a bimodal distribution. Section 6 presents two successful applications of AIMM on Bayesian inference of real data. We conclude by discussing the connections with importance sampling methods, particularly incremental mixture of importance sampling (Raftery and Bao Citation2010), from which AIMM takes inspiration, in Section 7.
2 Introductory Example
We first illustrate some of the potential shortcomings of the adaptive methods mentioned in Section 1 and outline how AIMM addresses them. We consider the following pedagogical example where the objective is to sample efficiently from a one-dimensional target distribution.
Example 1.
Consider the target distribution
For this type of target distribution it is known that AMH (Haario, Saksman, and Tamminen Citation2001) mixes poorly since the three modes of are far apart, a problem faced by many nonindependent Metropolis algorithms. Thus, an adaptive independence sampler such as the AGM (Luengo and Martino Citation2013) is expected to be more efficient. AGM uses the history of the chain to adapt the parameters of a mixture of Gaussians on the fly to match the target distribution. For AGM, we consider here three families of proposals: the set of mixtures of two, three, and forty Gaussians, referred to as AGM-2, AGM-3, and AGM-40, respectively. The authors recommend initializing AGM proposal with a large number of components and, possibly, resampling the most important components of the proposal. By contrast, our method, AIMM offers more flexibility in terms of the specification of the proposal distributions and in particular does not set a fixed number of mixture components.
We are particularly interested in studying the tradeoff between the convergence rate of the Markov chain and the asymptotic variance of the MCMC estimators, which are known to be difficult to control simultaneously (Mira Citation2001; Rosenthal Citation2003). gives information about the asymptotic variance, through the effective sample size (ESS), and about the speed of convergence of the chain, through the mean squared error (MSE) of a tail-event probability (defined here as ). Further details of these performance indicators can be found in the supplementary materials (Section 3).
Table 1 (Example 1) Results for : effective sample size (ESS) (the larger the better), mean squared error (MSE) of
(the smaller the better).
The ability of AMH to explore the state space appears limited as it regularly fails to visit the three modes in their correct proportions after 20,000 iterations (see the MSE of in ). The efficiency of AGM depends strongly on the number of mixture components of the proposal family. In fact AGM-2 is comparable to AMH in terms of the average ESS, indicating that the adaptation failed in most runs. AIMM and AGM-3 both achieve a similar exploration of the state space and AGM-3 offers a slightly better ESS. Finally, AGM-40 outperforms the other methods in this example and it virtually samples iid draws from π. An animation corresponding to this toy example can be found at http://mathsci.ucd.ie/∼fmaire/AIMM/toy_example.html.
From this example we conclude that AGM can be extremely efficient provided some initial knowledge on the target distribution, for example, the number of modes, the location of the large density regions, and so on. If a mismatch between the family of proposal distributions and the target occurs, inference can be jeopardized. Since misspecifications are typical in real world models where one encounters high-dimensional, multimodal distributions, and other challenging situations, it leads one to question the efficiency of AGM samplers. On the other hand, AMH seems more robust to a priori lack of knowledge of the target, but the quality of the mixing of the chain remains a potential issue, especially when high density regions are disjoint.
Initiated with a naive independence proposal, AIMM adaptively builds a proposal that approximates the target iteratively by adding probability mass to locations where the proposal is not well supported relative to the target; see Section 3.6 for details. As a result, very little, if any, information regarding the target distribution is needed. Extensive experimentation in Section 5 confirms this point.
3 Adaptive Incremental Mixture MCMC
We consider target distributions defined on a measurable space
where
is an open subset of
(d > 0) and
is the Borel σ-algebra of
. Unless otherwise stated, the distributions we consider are dominated by the Lebesgue measure and we therefore denote the distribution and the density function (w.r.t the Lebesgue measure) by the same symbol. In this section, we introduce the family of adaptive algorithms referred to AIMM, the acronym for adaptive incremental mixture MCMC.
3.1 Transition Kernel
AIMM belongs to the general class of adaptive independent Metropolis algorithms originally introduced by Gåsemyr (Citation2003) and studied by Holden, Hauge, and Holden (Citation2009). AIMM generates a stochastic process that induces a collection of independence proposals
. At iteration n, the process is at Xn and attempts a move to
which is accepted with probability αn. In what follows,
denotes the sequence of proposed states that are either accepted or rejected.
More formally, AIMM produces a time inhomogeneous process whose transition kernel Kn (at iteration n) is the standard Metropolis–Hastings (MH) kernel with independence proposal Qn and target . For any
, Kn is defined by
(1)
(1)
In (1), αn denotes the usual MH acceptance probability for independence samplers, namely
(2)
(2)
where
is the importance weight function defined on
. Central to our approach is the idea that the discrepancy between
and Qn, as measured by Wn, can be exploited to adaptively improve the independence proposal. This has the advantage that Wn is computed as a matter of course in the MH acceptance probability (2).
3.2 Incremental Process
We assume that available knowledge about allows one to construct an initial proposal kernel Q0, from which it is straightforward to sample. When
is a posterior distribution, a default choice for Q0 could be the prior distribution. The initial proposal Q0 is assumed to be relatively flat, in the spirit of a defensive distribution (Hesterberg Citation1995). Initiated at Q0, a sequence of proposals
is produced by our algorithm. In particular, the proposal kernel adapts by adding probability mass where the discrepancy between Qn and
is deemed too large.
The adaptation mechanism is driven by the random sequence , which monitors the discrepancy between
and the proposals
at the proposed states
. Let
be a user-defined parameter such that the proposal kernel Qn is incremented upon the event
defined as
(3)
(3)
The event exposes subsets of
where the proposal Qn does not support π well enough. The parameter
controls the tolerated discrepancy between the proposal and the target distribution. Note that in situations where π is known up to a normalizing constant, Wn refers, with some abuse of notations, to the ratio between the unnormalized and the proposal densities. Several ways of tuning
are discussed at the beginning of Section 5.
3.3 Proposal Kernel
The proposal kernel Qn takes the form of a mixture
(4)
(4)
where
is a sequence of nonincreasing weights such that
and
(see Section 4), Mn is the number of components added to the mixture up to iteration n and
are the incremental mixture components created up to iteration n. To each incremental component
is attached a weight proportional to
(see Section 3.4).
3.4 Increment Design
Upon the occurrence of , a new component
is created. Specifically,
is a multivariate Gaussian distribution with mean
and with covariance matrix
defined by
(5)
(5)
where for a set V of vectors,
denotes the empirical covariance matrix of V and
is a subset of V defined as a neighborhood of
. In (5),
is the neighborhood of
defined as
(6)
(6)
where
is a user-defined parameter controlling the neighborhood range and ρn the number of accepted proposals up to iteration n. In (6),
denotes the quadratic form
, for some covariance matrix
. When
is a posterior distribution,
could be, for example, the prior covariance matrix. In high-dimensional settings only few samples in the vicinity of
are likely to be available, especially at the start of the algorithm, and in such a case the covariance matrix estimation is expected to be poor. We stress that the adaptation does not consist in obtaining a local Gaussian approximation of π but rather focuses on increasing the probability mass of Qn around
. Nevertheless, since a better knowledge of π’s topology and variable correlations around
yields to a more relevant approximation, it may be beneficial to run a Metropolis–Hasting sampler (or Metropolis-within-Gibbs) initialized at
in parallel to AIMM and to refine the component after more samples are available. This type of heuristic is not expected to penalize the computational performance of AIMM as long as a parallel computing environment is available. Note that in EquationEquation (6)
(6)
(6) , one can possibly plug the unnormalized probability density function instead of π. Indeed, the upper bound is proportional to τ which may be set so as to account for the normalizing constant.
Finally, a weight is attached to the new component proportional to
(7)
(7)
where
is another user-defined parameter.
We stress that unlike other works including Giordani and Kohn (Citation2010) and Luengo and Martino (Citation2013), AIMM does not adapt the parameters of a mixture of Gaussian to π: once a new component is added to the mixture, its parameters (mean, covariance, unnormalized weight) are kept unchanged throughout the algorithm. Only the weights will change because of renormalization when a new component is added.
3.5 AIMM
Algorithm 1 summarizes AIMM. Note that during an initial phase consisting of N0 iterations, no adaptation is made. This serves the purpose of gathering sample points required to produce the first increment. Also, we have denoted by N the Markov chain length which may depend on the dimension of and the computational resources available. In any case, we recommend setting
.
Algorithm 1 Adaptive incremental mixture MCMC.
1: Input:
2: Initialize: and
3: for do
4: Propose
5: Draw and set
6: if and
is true then
7: Update
8: Increment the proposal kernel with the new component
weighted by
9: Update
10: else
11: Update and
12: end if
13: end for
14: Output:
3.6 Example 1 (ctd.)
For the toy example in Section 2 we used the following parameters
shows the different states of the chain that, before the first increment takes place, are all sampled from Q0. The proposed state activates the increment process when the condition
is satisfied for the first time after the initial phase (
) is completed. At
there is a large discrepancy between the current proposal, Qn, and the target,
. The neighborhood of
is identified and defines
, the first component of the incremental mixture.
Fig. 1 (Example 1) Illustration of one AIMM increment for the target π1. Top: States of the AIMM chain, proposed new state
activating the increment process (i.e., satisfying
), and neighborhood of
,
. Bottom: Target π1, defensive kernel Q0, first increment
, and updated kernel Q1 plotted on a logarithmic scale.
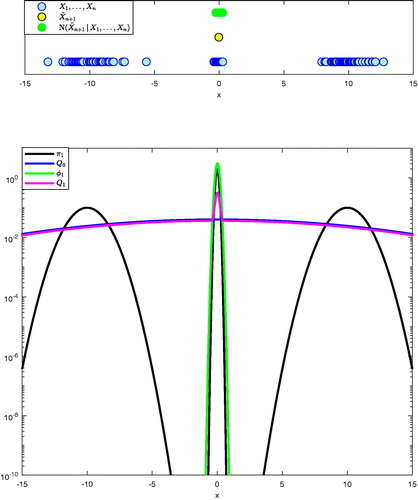
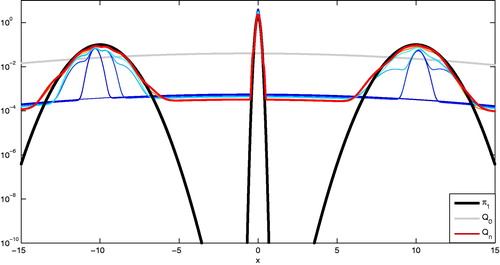
After iterations, AIMM has incremented the proposal 15 times. This sequence of proposal distributions can be seen in . The first proposals are slightly bumpy and as more samples become available, the proposal distribution gets closer to the target. Thus, even without any information about π1, AIMM is able to increment its proposal so that the discrepancy between Qn and
vanishes. This is confirmed by the fact that the acceptance rate edges toward one as the number of components in the mixture increases throughout the algorithm (see in the supplementary materials for an illustration). The AGM-3 proposal density declines to zero in π1’s low density regions (see , bottom panel in supplementary materials), which is an appealing feature in this simple example. However, AGM shrinks its proposal density in locations that have not been visited by the chain. This can be problematic if the sample space is large and it takes time to reasonably explore it (see Section 5).
Fig. 2 (Example 1) Illustration of AIMM sampling from the target π1 for iterations sequence of proposals from Q0 to Qn produced by AIMM.
4 Ergodicity of AIMM
4.1 Notation
Let be the probability space generated by AIMM. For any event
denotes the probability measure
conditionally on A. With some abuse of notations, for any
refers to the probability measure such that
. Let ν and μ be two probability measures defined on
. Recall that the Kullback–Leibler (KL) divergence between ν and μ is defined as
Moreover, the total variation distance between ν and μ can be written as
where the latter equality holds if μ and ν are both dominated by a common measure ρ. Finally, for a sequence of random variables
, the notations
stands for the convergence of
to zero in probability p (i.e., with respect to the probability measure p), and
means that
is bounded in probability p.
4.2 Ergodicity of Adaptive Markov Chains
In this section, we establish assumptions under which the AIMM process is ergodic, that is,
(8)
(8)
We use the theoretical framework developed in Roberts and Rosenthal (Citation2007). In particular, Theorem 2 in Roberts and Rosenthal (Citation2007) states that if the AIMM process satisfies the Diminishing adaptation and Containment conditions (see below) then the process is ergodic and EquationEquation (8)
(8)
(8) holds.
Condition 1. Diminishing adaptation.
For all , the stochastic process
, defined as
(9)
(9)
converges to zero in
-probability, that is,
.
Condition 2. Containment.
For all and
, the stochastic process
, defined as
(10)
(10)
is bounded in
-probability, that is,
.
Even though containment is not a necessary condition for ergodicity (see Fort, Moulines, and Priouret Citation2011) and in fact seems to hold in most practical situations (see, e.g., Rosenthal Citation2011), it remains a challenging assumption to establish rigorously for the setup considered in this article, that is, a broad class of target distributions defined on a not necessarily finite or compact state space. In the next section we show that diminishing adaptation holds for the AIMM process described at Section 3, up to minor implementation adjustments, while containment needs to be proven on a case by case basis. We also show that there exists a version of AIMM, conceptually different from the process described at Section 3 that can be made arbitrarily close to it, which is ergodic for any absolutely continuous target distribution π.
4.3 Main Ergodicity Results
We study two variants of AIMM.
4.3.1 Proposal With an Unlimited Number of Increments
The first version of AIMM is similar to the algorithm presented in Section 3. For this version of the algorithm, we prove only that the diminishing adaptation assumption holds under some minor assumptions. Indeed, proving the containment condition is challenging without further assumptions on π, for example, compact support (Craiu, Rosenthal, and Yang Citation2009) or tail properties (see Bai, Roberts, and Rosenthal (Citation2009) in the context of adaptive random walk Metropolis samplers). Moreover, most proof techniques establishing containment require the space of the adapting parameter to be compact, something which does not hold in this version of AIMM as the number of incremental components can, theoretically, grow to infinity.
Proposition 1.
Assume that there exist three positive constants such that
A1.The covariance matrix of any component of the mixture satisfies .
A2.The (unnormalized) incremental mixture weights are defined as
A3.The initial kernel Q0 is subexponential or satisfies where
, that is, Q0 has heavier tail than a Gaussian, for example, multivariate Laplace or t-distribution.
A4.There is a parameter such that the mixture increments upon the event
,
and when it increments upon , the new component is equal to Q0 and the corresponding weight is defined as in EquationEquation (7)
(7)
(7) .
Then, the AIMM process sampled using conditions A1–A4 satisfies diminishing adaptation, that is, EquationEquation (9)(9)
(9) holds.
The proof is given at Section 1 of the supplementary materials.
Remark 1.
Proposition 1 holds for parameters arbitrarily close to zero. Also, Assumption A1 can be enforced simply by expanding the neighborhood of
such that when
,
where
is a permutation of
such that
and
.
Remark 2.
The event is the counterpart of
and exposes subsets of
where the proposal puts too much probability mass at locations of low π-probability. In this case, the rationale for setting
is to reduce the probability mass of the proposal locally by increasing the weight associated to the initial proposal Q0, assumed to be vague.
4.3.2 Proposal With Adaptation on a Compact Set
The second version of AIMM that we study here represents somewhat a slight conceptual departure from the original algorithm presented in Section 3. We stress that the assumptions A1–A4 from Section 4.3.1 are not required here.
Proposition 2.
Assume that:
B1.The AIMM process has bounded jumps, that is, there exists D > 0 such that for all
B2.There is a compact set such that the weight
in the proposal (4) is replaced by
(13)
(13)
that is, if the process is such that
then the proposed state is generated from Q0 with probability one. Conversely, if the process is such that
, then the proposed state is generated as explained in Section 3, that is, from Qn (4). We denote this proposal by
.
B3.The number of incremental components in the adaptive proposal is capped, that is, there is a finite such that
and the mean μn and covariance Σn of each component are defined on a compact space.
If the AIMM process presented in Section 3 satisfies B1–B3, then it is ergodic.
This result is a consequence of Theorem 2 of Roberts and Rosenthal (Citation2007) combined with the recent developments in Craiu et al. (Citation2015) and Rosenthal and Yang (Citation2017). The proof is given at Section 2 of the supplementary materials.
We now explain how, in practice, a version of AIMM compatible with the assumptions of Proposition 2 can be constructed and made arbitrarily close to the version of AIMM presented in Section 3. First, fix an arbitratrily large constant . Assumption B1 holds by construction if
is automatically rejected when
. Assumption B2 holds by construction if
is used instead of Qn in the AIMM algorithm presented in Section 3. Finally, Assumption B3 is satisfied by slightly modifying the adaptation mechanism proposed in Section 3. Define two arbitrarily large constants L > 0 and
and increment the proposal upon the event
and in the following way
where for any vector
and any L > 0
The definition of the unnormalized weight (EquationEquation (7)
(7)
(7) ) is unchanged.
5 Simulations
In this section, we consider three target distributions:
, the banana shape distribution used in Haario, Saksman, and Tamminen (Citation2001);
Each of these distributions has a specific feature, resulting in a diverse set of challenging targets: is heavy tailed,
has a narrow, nonlinear and ridge-like support, and
has two distant modes. We consider
and
in different dimensions:
for
and
for
. We compare AIMM (Algorithm 1) with several other algorithms that are briefly described along with some performance indicators that are also outlined at Section 3 of the supplementary materials. We used the following default parameters for AIMM
The parameter requiring the most careful design is . A poor choice of
may result in a proposal that never increments or that increments too often. For each scenario, we implemented AIMM with different thresholds
valued around d to monitor the tradeoff between adaptation and computational efficiency of the algorithm. In our experience, the choice
has worked reasonably well in a wide range of examples, but there is no theoretical guarantee supporting this choice which is not optimal in any sense. Intuitively, as the dimension of the state space increases a higher threshold is required, too many kernels being created otherwise. However, a satisfactory choice of
may vary depending on the target distribution and the available computational budget. It is also possible to adapt
online during an initial phase of the algorithm as the theory remains valid as long as
is eventually set constant. Two particular situations where an automated choice of
may be particularly beneficial include setups where Q0 and π yield a significant mismatch and where π is known up to a normalizing constant. In the first case, it is necessary to initialize
at a small value and gradually increasing it until reaching the desired value. In the second one, the threshold
is adapted at the beginning of the algorithm to get the incremental process started. The threshold adaptation produces a sequence of thresholds
such that
where un is a decreasing sequence with
such as
. Since sampling from Qn (a mixture of Gaussian distributions), can be performed routinely,
is derived from a Monte Carlo estimation. As little precision is required, the Monte Carlo approximation should be rough to limit the computational burden generated by the threshold adaptation. Also, those samples used to set
can be recycled and serve as proposal states for the AIMM chain so that this automated threshold mechanism comes for free.
5.1 Banana-Shaped Target Distribution
Example 2.
Let where
is the d-dimensional Gaussian density with mean m and covariance matrix S, and let
be the mapping defined, for any
, by
We consider in dimensions d = 2, d = 10, and d = 40 and refer to the marginal of
in the ith dimension as
. The parameters
and
are held constant. The target is banana-shaped along the first two dimensions, and is challenging since the high density region has a thin and wide ridge-like shape with narrow but heavy tails. Unless otherwise stated, we use b = 0.1 which accentuates these challenging features of
. We first use the banana-shaped target
in dimension d = 2 to study the influence of AIMM’s user-defined parameters on the sampling efficiency.
5.1.1 Influence of the Defensive Distribution
With limited prior knowledge of , choosing Q0 can be challenging. Here we consider three defensive distributions Q0, represented by the black dashed contours in . The first two are Gaussian, respectively, located close to the mode and in a nearly zero probability area and the last one is the uniform distribution on the set
. and show that AIMM is robust with respect to the choice of Q0. Even when Q0 yields a significant mismatch with
(second case), the incremental mixture reaches high density areas, progressively uncovering higher density regions. The price to pay for a poorly chosen Q0 is that more components are needed in the incremental mixture to match
, as shown by . The other statistics reported in are reasonably similar for the three choices of Q0.
Fig. 3 (Example 2: π2 target, d = 2) Incremental mixture created by AIMM for three different initial proposals. Top row: Q0 is a Gaussian density (the region inside the black dashed ellipses contains 75% of the Gaussian mass) centred on a high density region (left) and a low density region (right). Bottom row: Q0 is Uniform (with support corresponding to the black dashed rectangle). The components of the incremental mixture obtained after
MCMC iterations are represented through (the region inside the ellipses contains 75% of each Gaussian mass). The color of each ellipse illustrates the corresponding component’s relative weight
(from dark blue for lower weights to red).
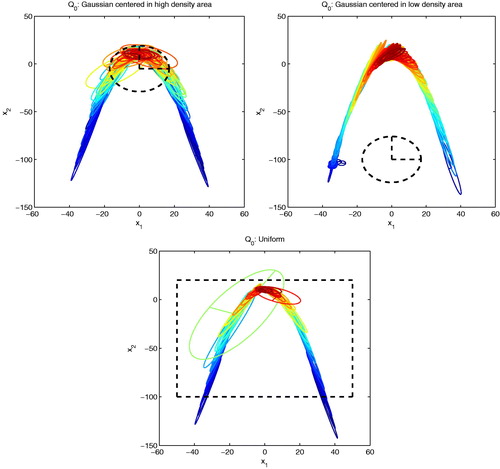
Table 2 (Example 2: π2 target, d = 2) Influence of the initial proposal Q0 on AIMM outcome after MCMC iterations (replicated 20 times).
5.1.2 Influence of the Threshold
Even though we recommend the default setting , we analyze the performances of AIMM for different values of
. We consider the same setup as in the previous subsection with the uniform defensive distribution Q0 and report the outcome of the AIMM algorithm in . As expected, the lower the threshold
, the larger the number of kernels and the better is the mixing. In all cases, the adaptive transition kernel eventually stabilizes (faster if
is large), as illustrated by , resulting from the fact that the event
occurs less often as n increases. As
decreases, the KL divergence between
and the chain reduces while the CPU cost increases since more components are created. Therefore, the sampling efficiency is best for an intermediate threshold such as
. Finally, when the threshold is too low, the distribution of the chain converges more slowly to
; see, for example, where the
indicator (defined as the KL divergence between
and the sample path of the AIMM chain; see supplementary materials) is larger for
than for
. Indeed when
, too many components are created to support high density areas and this slows down the exploration process of the lower density regions.
Fig. 4 (Example 2: π2 target, d = 2) AIMM’s incremental mixture design after MCMC iterations. (a) Evolution of the number of kernels Mn created by AIMM for different thresholds. (b) Evolution of the KL divergence between
and the incremental proposal Qn, plotted in lin-log scale.
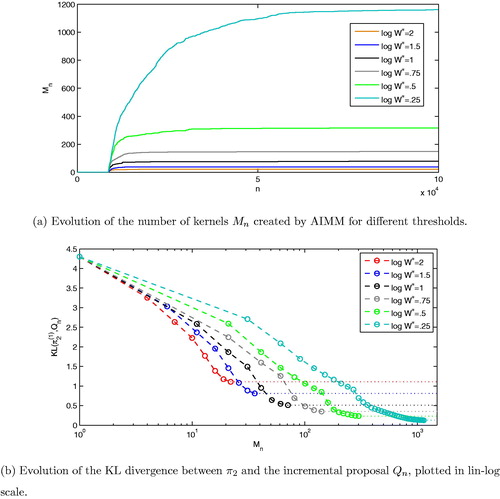
Table 3 (Example 2: π2 target, d = 2) Influence of the threshold on AIMM and f-AIMM outcomes after
MCMC iterations (replicated 20 times).
5.1.3 Speeding up AIMM
The computational efficiency of AIMM depends, to a large extent, on the number of components added in the proposal distribution, Mn. For this reason we consider a slight modification of the original AIMM algorithm to limit the number of possible components, thereby improving the computational speed of the algorithm. This variant of the algorithm is referred to as fast AIMM (denoted by f-AIMM) and proceeds as follows: let be the maximal number of components allowed in the incremental mixture proposal. If
, only the last
added components are retained, in a moving window fashion. This truncation has two main advantages, (i) approximately linearizing the computational burden once
is reached, and (ii) forgetting the first, often transient components used to jump to high density areas (see, e.g., the loose ellipses in , especially the very visible ones in the bottom panel).
shows that f-AIMM outperforms the original AIMM, with some setups being nearly twice as efficient; compare, for example, AIMM and f-AIMM with in terms of efficiency (last column). Beyond efficiency, comparing
for a given number of mixture components (Mn), shows that
is more quickly explored by f-AIMM than by AIMM. Numerical comparisons on this example of f-AIMM with other samplers (AMH, RWMH, AGM, IM) are reported in Section 5.1 of the supplementary materials. AIMM seems to yield the best tradeoff between convergence and variance in all dimensions. Inevitably, as d increases, ESS shrinks and KL increases for all algorithms but AIMM still maintains a competitive advantage over the other approaches. The other four algorithms struggle to visit the tail of the distribution. Thus, AIMM is doing better than (i) the nonindependent samplers (RWMH and AMH) that manage to explore the tail of a target distribution but need a large number of transitions to return there, and (ii) the independence samplers (IM and AGM) that can quickly explore different areas but fail to venture into the lower density regions. An animation corresponding to the exploration of π2 in dimension 2 by AIMM, AGM, and AMH can be found at http://mathsci.ucd.ie/∼fmaire/AIMM/banana.html.
5.2 Ridge Like Example
Example 3.
Let and
, where
is the d-dimensional Gaussian density with mean m and covariance matrix S. The target parameters
and
are, respectively, known means and covariance matrices and g is a nonlinear deterministic mapping
defined as
In this context, can be regarded as a prior distribution and
as a likelihood, the observations being some functional of the hidden parameter
.
Such a target distribution often arises in physics. Similar target distributions often arise in Bayesian inference for deterministic mechanistic models and in other areas of science, engineering and environmental sciences (see, e.g., Poole and Raftery Citation2000; Bates, Cullen, and Raftery Citation2003). They are hard to sample from because the probability mass is concentrated around thin curved manifolds. We compare f-AIMM with RWMH, AMH, AGM, and IM first in terms of their mixing properties; see . We also ensure that the different methods agree on the mass localization by plotting a pairwise marginal; see of the supplementary materials. In this example, f-AIMM clearly outperforms the four other methods in terms of both convergence and variance statistics. In fact, we observe in the same figure that f-AIMM is the only sampler able to discover a secondary mode in the marginal distribution of the second and fourth target components (X2, X4).
Fig. 5 (Example 5) Information regarding the acceptance rate of 100 AIMM runs are reported on the left panel and the evolution of the number of components for about 10 runs throughout the sampling is shown on the right panel.
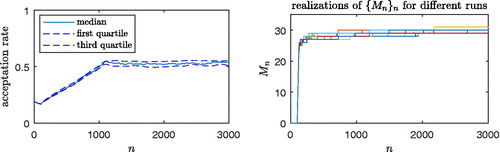
Table 4 (Example 3: π3 target, d = 6) Comparison of f-AIMM with the four other samplers after iterations (replicated 10 times).
5.3 Bimodal Distribution
Example 4.
In this example, is a posterior distribution defined on the state space
, where
. The likelihood is a mixture of two d-dimensional Gaussian distributions with weight
, mean and covariance matrix as follows
where for all is the d-dimensional first-order autoregressive matrix whose coefficients are
The prior is the uniform distribution . For f-AIMM and IM, Q0 is set as this prior distribution, while for AGM, the centers of the Gaussian components in the initial proposal kernel are drawn according to the same uniform distribution. For AMH, the initial covariance matrix
is set to be the identity matrix.
Several plots showing the outcome of this experiment are presented in Section 5.3 of the supplementary materials. On the one hand, in both setups and
, f-AIMM is more efficient at discovering and jumping from one mode to the other and allowing more kernels in the incremental mixture proposal will result in faster convergence. On the other hand, because of the distance between the two modes, RWMH visits only one while AMH visits both but in an unbalanced fashion. Increasing the dimension from d = 4 to d = 10 makes AMH unable to visit the two modes after
iterations. As for AGM, the isolated samples reflect a failure to explore the state space. These facts are confirmed in which highlights the better mixing efficiency of f-AIMM relative to the four other algorithms and in which shows that f-AIMM is the only method which, after
iterations, visits the two modes with the correct proportion.
Table 5 (Example 4: π4 target, ) Comparison of f-AIMM with RWMH, AMH, AGM, and IM after
iterations (replicated 100 times).
Table 6 (Example 4: π4 target, ) Mean square error (MSE) of the mixture parameter λ, for the different algorithms (replicated 100 times).
6 Applications
The statistical analysis of two real data problems is carried out:
the inference of a semiparametric regression model applied to the Boston Housing dataset (available at www.cs.utoronto.ca/∼delve/data/boston). This model has also been studied in Smith and Kohn (Citation1996) and more recently, using an AGM MCMC method in Giordani and Kohn (Citation2010). This model has seven parameters.
the inference of a Bayesian hierarchical model related to the James–Stein estimator (James and Stein Citation1961) applied to batting averages of 18 MLB players (first column of in Efron and Morris (Citation1975)). This model has also been used to validate the adaptation of an adaptive MCMC algorithm proposed in Roberts and Rosenthal (Citation2009). This model has twenty parameters.
6.1 Semiparametric Regression
Example 5.
We consider the following semiparametric regression model
where γ is the regression vector, Zi are the covariates for observation Yi,
are nonparametric regression functions (quadratic polynomial splines) and for all
is a critical covariate whose impact on the dependent variable is not sufficiently well described by the parametric term and thus requires an additional nonparametric regression term for further flexibility. Considering a Bayesian analysis of this model, a Gaussian prior distribution is assigned to γ and to the parameters
controlling the H splines. An inverse gamma prior is prescribed to the additive noise parameter
. It is difficult to choose the β’s priors variance and the inference is quite sensitive to this issue (see Smith and Kohn Citation1996; Giordani and Kohn Citation2010). As a consequence the variances
are included in the model and a log-normal hyperprior is assigned to those parameters. Since the regression parameters
are conjugated given the variances
sampling from the posterior of the model can be done by (i) sampling
and (ii) sampling
. The marginal posterior of θ cannot be sampled using direct methods but since its analytical expression is known up to a normalizing constant, one can be used MCMC to perform (i). In this example, the data are the logarithm of the median market value of owner-occupied home for the Boston metropolitan area reported in Harrison and Rubinfeld (Citation1978). It contains 506 observations, 13 covariates H = 6 of which beneficiate from an additional nonparametric description. The dimension of the parameter of interest θ is thus d = 7 and to avoid sampling in a constrained space, we use AIMM to sample
given
.
We follow the notations and the setup proposed in Giordani and Kohn (Citation2010) where further details can be found, with two exceptions. First, using 30 knots for each spline in the nonparametric part of the model (as recommended in Giordani and Kohn (Citation2010)) made the unnormalized posterior quite instable: the likelihood
is a normal whose covariance matrix is nearly singular for a large range of plausible parameters (a fact which was already noted in Smith and Kohn (Citation1996, sec. 6.2)). We thus used only 10 control points per spline, which is closer to what is recommended in Smith and Kohn (Citation1996) and alleviates this numerical problem. Finally, we have set the variance of the parametric regression term to
, this parameter is not specified in the analysis of Giordani and Kohn (Citation2010).
6.1.1 Results
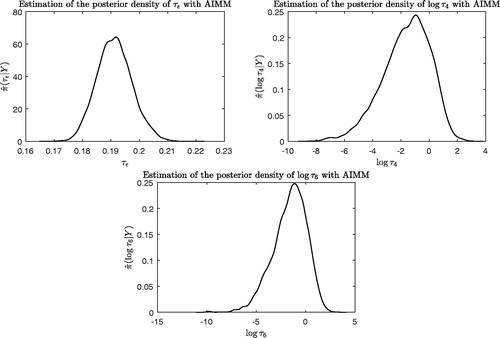
In the experimental setup considered, AIMM ended up incrementing about 30 times on average so that when Mn stabilizes AIMM acceptance rate is around 55%, as shown in . reports the estimated posterior distribution of three parameters after a long AIMM run. We note that the inference carried out is similar to what was obtained in the study of this dataset using AGM carried out in Giordani and Kohn (Citation2010). In particular, we find that most variance parameters are log-normally distributed a posteriori, except for two parameter related to the covariates X4 and X6 which matches the analysis of Giordani and Kohn (Citation2010). We note however that the additive noise SD posterior distribution is slightly shifted compared to the result of these authors, probably because the prior distribution of this parameter is different in our implementation. We observe that the acceptance rate of AIMM is “penalized” by the conservative choice of ωn. Indeed, with about kernels in the mixture, we have
which means that, approximately, at every four AIMM transition the proposed state is drawn from Q0 which is, in this example, very uninformative: this shows that the quality of the AIMM adaptation is similar to, if not better than AGM in this example. Finally, we mention that the adaptive random walk Metropolis algorithm (Haario, Saksman, and Tamminen Citation2001) was implemented in this example but the results were not relevant: after the initial nonadaptive phase, the estimated covariance matrix quickly deteriorates and the chain remains stuck for long period of times.
Fig. 6 (Example 5) Marginal posterior distribution of three parameters of the model estimated after 70,000 iterations of AIMM.
6.2 Empirical Bayes and the James–Stein Estimator
Example 6.
We consider the following hierarchical model with
(14)
(14)
The parameters of interest consist in , while the matrix V is set to the empirical Bayes estimator of the observed data
. The case
is considered so that θ is defined on a K + 2 dimensional state space. We proceed to the Bayesian inference of θ given
and thus assign an inverse gamma prior to A and a normal prior to μ. This model is of particular interest since it corresponds to the Bayesian formulation of the James–Stein estimator (James and Stein Citation1961): indeed the posterior mean of θ in the hierarchical model EquationEquation (14)
(14)
(14) defines a general class of empirical Bayes estimators which includes the James–Stein estimator, see Efron and Morris (Citation1975) and Rosenthal (1996) for more details. In this example, the data are the 1970 batting average for 18 Baseball players (see of Efron and Morris (Citation1975)) and θ is thus a 20-dimensional parameters. The hyperpriors were chosen as in Roberts and Rosenthal (Citation2009).
6.2.1 Results
reports some marginal posterior distributions estimated by AIMM and ARMS. Clearly, ARMS has not totally converged at that point as some probability mass is missing in the tails of each marginal. This may explain why ARMS seems to be slightly better in terms of acceptance rate and integrated autocorrelation time than AIMM as shown in . Indeed, an independent proposal that does not dominate the tail of a distribution correctly usually yields a misleading high acceptance rate as the risky moves are simply not attempted. We also include the results for the regional adaptive Metropolis algorithm (RAMA) reported from Roberts and Rosenthal (Citation2009). We note that comparing adaptive independent MCMC and adaptive random walk MCMC is perhaps not very informative as they are structurally different and does not probably give a fair assessment of RAMA since (i) the proposal density is adapted so that the sampler acceptance rate is 0.23 and (ii) the average squared jumping distance is always smaller of several order of magnitude (especially in high-dimensional settings) for random walks than for independent proposal algorithms.
Fig. 7 (Example 6) Marginal posterior of four parameters estimated by AIMM and ARMS after a long run of 100,000 iterations of both algorithm (full swipe update Metropolis-within-Gibbs for ARMS).
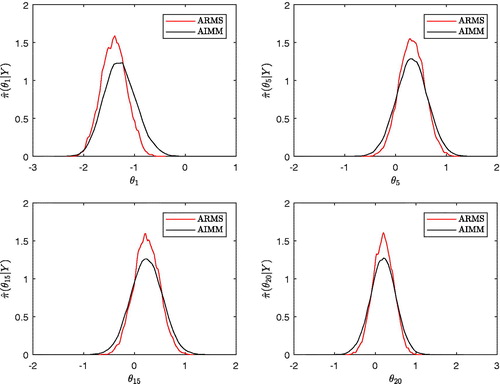
Table 7 (Example 6) Comparison of the performance of three adaptive MCMC samplers: acceptance rate, integrated autocorrelation time and average squared jumping distance.
7 Discussion
Although implicitly evaluated in an (nonadaptive) independence Metropolis–Hastings transition, the information conveyed by the ratio of importance weights is lost because of the threshold set to one in the MH acceptance probability. Indeed, while at Xn and given two realizations of the proposal Q, say and
, the two events
and
result in the same transition, that is, the proposed move is accepted with probability one, regardless of the magnitude difference between
and
. This article aims to design an adaptive MCMC algorithm that makes use of this information by incrementing the independence MH proposal distribution in the latter case and not in the former.
The general methodology, referred to as AIMM, presented and studied in this article is a novel adaptive MCMC method to sample from challenging distributions. Theoretically, we establish under very mild assumptions, that if it only adapts on a compact set and has bounded jumps, this algorithm generates an ergodic process for any distribution of interest known up to a normalizing constant. We show that these conditions can always be enforced by using a specific implementation. In simpler implementations where those conditions may not be verified, the algorithm is nevertheless shown to work well in practice. We provide an even more efficient algorithm, referred to as f-AIMM, that guarantees that the incremental proposal evaluation does not slow down the algorithm. This algorithm can be seen as a series of AIMM algorithms where Gaussian components are progressively dropped. As a consequence, f-AIMM is compatible with the theoretical framework developed at Section 4. In particular, provided that it only adapts on a compact set and has bounded jumps, this algorithm is invariant for any target distribution. We illustrate its performance in a variety of challenging sampling scenarios.
Compared to other existing adaptive MCMC methods, AIMM needs less prior knowledge of the target. Its strategy of incrementing an initial naive proposal distribution with Gaussian kernels leads to a fully adaptive exploration of the state space. Conversely, we have shown that in some examples the adaptiveness of some other MCMC samplers may be compromised when an unwise choice of parametric family for the proposal kernel is made. The performance of AIMM depends strongly on the threshold which controls the adaptation rate. This parameter should also be set according to the computational budget available. When the normalizing constant of π is unknown or when
is high-dimensional, we recommend opting for an automated adaptation of
(such as the scheme described at the beginning of Section 5) that allows to increment regularly the proposal kernel. Again, we stress that this work is pioneering the use of semiparametric adaptive kernels and does not consist in an exhaustive study of this algorithm: a reader may see our research as a basis for further optimization and may find more efficient ways to choose AIMM parameters according to their problem at hand. However, we stress that two aspects of the AIMM’s adaptation are essential: first, the defensive kernel is crucial as it safeguards the possibility to discover new parts of the support of π at a later stage of the sampling and its weight in the mixture ωn should thus not decrease too fast. Second, if an automated choice of
is used, the adaptation scheme must eventually lead to a constant threshold.
The adaptive design of AIMM was inspired by incremental mixture importance sampling (IMIS) (Raftery and Bao Citation2010). IMIS iteratively samples and weights particles according to a sequence of importance distributions that adapt over time. The adaptation strategy is similar to that in AIMM: given a population of weighted particles, the next batch of particles is simulated by a Gaussian kernel centered at the particle having the largest importance weight. However, IMIS and AIMM are structurally different since the former is an adaptive importance sampling method while the latter is an adaptive MCMC algorithm. Comparing them on a fair basis is difficult. In particular, the ESS estimators for the two methods stem from different approximations. The computational efficiency of IMIS suffers from the fact that, at each iteration, the whole population of particles must be reweighted to maintain the consistency of the importance sampling estimator. By contrast, at each transition, AIMM evaluates only the importance weight of the new proposed state. However, since IMIS calculates the importance weight of large batches of particles, it acquires a knowledge of the state space more quickly than AIMM which accepts/rejects one particle at a time.
We therefore expect AIMM to be more efficient in situations where the exploration of the state space requires a large number of increments of the proposal and IMIS to be more efficient for short run times. To substantiate this expectation, we have compared the performance of AIMM and IMIS on the last example of Section 5 in dimension 4. of the supplementary materials reports the estimation of the probability obtained through both methods for different run times. For short run times IMIS benefits from using batches of particles and gains a lot of information on π4 in a few iterations. On the other hand, AIMM provides a more accurate estimate of
after about 150 sec. (supplementary materials) illustrates the outcome of AIMM and IMIS after running them for 2000 sec. The mixture of incremental kernels obtained by AIMM is visually more appealing than the sequence of proposals derived by IMIS, reinforcing the results from (supplementary materials).
AIMM can be regarded as a transformation of IMIS, a particle-based inference method, into an adaptive Markov chain. This transformation could be applied to other adaptive importance sampling methods, thus designing Markov chains that might be more efficient than their importance sampling counterparts. In a Bayesian context, AIMM could, in addition to sampling the posterior distribution, be used to estimate intractable normalizing constants and marginal likelihoods via importance sampling. Indeed, the incremental mixture proposal produced by AIMM is an appealing importance distribution since it approximates the posterior and is straightforward to sample from.
Supplementary Materials
The supplementary materials include the proofs of the results stated in Section 4, some simulation details related to the introductory example and to the experiments presented in Section 5 and 6. Finally, two complementary illustrations for the comparison of AIMM and IMIS are reported.
Supplemental Material
Download Zip (22.2 MB)Additional information
Funding
Related Research Data
References
- Andrieu, C., and Moulines, É. (2006), “On the Ergodicity Properties of Some Adaptive MCMC Algorithms,” Annals of Applied Probability, 16, 1462–1505. DOI:10.1214/105051606000000286.
- Bai, Y., Roberts, G. O., and Rosenthal, J. S. (2009), “On the Containment Condition for Adaptive Markov Chain Monte Carlo Algorithms,” Advances and Applications in Statistics, 21, 1–54.
- Bates, S. C., Cullen, A., and Raftery, A. E. (2003), “Bayesian Uncertainty Assessment in Multicompartment Deterministic Simulation Models for Environmental Risk Assessment,” Environmetrics, 14, 355–371. DOI:10.1002/env.590.
- Cai, B., Meyer, R., and Perron, F. (2008), “Metropolis–Hastings Algorithms With Adaptive Proposals,” Statistics and Computing, 18, 421–433. DOI:10.1007/s11222-008-9051-5.
- Cappé, O., Douc, R., Guillin, A., Marin, J.-M., and Robert, C. P. (2008), “Adaptive Importance Sampling in General Mixture Classes,” Statistics and Computing, 18, 447–459. DOI:10.1007/s11222-008-9059-x.
- Craiu, R. V., Gray, L., Łatuszyński, K., Madras, N., Roberts, G. O., and Rosenthal, J. S. (2015), “Stability of Adversarial Markov Chains, With an Application to Adaptive MCMC Algorithms,” The Annals of Applied Probability, 25, 3592–3623. DOI:10.1214/14-AAP1083.
- Craiu, R. V., Rosenthal, J., and Yang, C. (2009), “Learn From the Neighbor: Parallel-Chain and Regional Adaptive MCMC,” Journal of the American Statistical Association, 104, 1454–1466. DOI:10.1198/jasa.2009.tm08393.
- Efron, B., and Morris, C. (1975), “Data Analysis Using Stein’s Estimator and Its Generalizations,” Journal of the American Statistical Association, 70, 311–319. DOI:10.1080/01621459.1975.10479864.
- Fort, G., Moulines, E., and Priouret, P. (2011), “Convergence of Adaptive and Interacting Markov Chain Monte Carlo Algorithms,” The Annals of Statistics, 39, 3262–3289. DOI:10.1214/11-AOS938.
- Gåsemyr, J. (2003), “On an Adaptive Version of the Metropolis–Hastings Algorithm With Independent Proposal Distribution,” Scandinavian Journal of Statistics, 30, 159–173.
- Gilks, W. R., Best, N., and Tan, K. (1995), “Adaptive Rejection Metropolis Sampling Within Gibbs Sampling,” Journal of the Royal Statistical Society, Series C, 44, 455–472. DOI:10.2307/2986138.
- Gilks, W. R., Roberts, G. O., and George, E. I. (1994), “Adaptive Direction Sampling,” The Statistician, 43, 179–189. DOI:10.2307/2348942.
- Gilks, W. R., Roberts, G. O., and Sahu, S. K. (1998), “Adaptive Markov Chain Monte Carlo Through Regeneration,” Journal of the American Statistical Association, 93, 1045–1054. DOI:10.1080/01621459.1998.10473766.
- Gilks, W. R., and Wild, P. (1992), “Adaptive Rejection Sampling for Gibbs Sampling,” Applied Statistics, 41, 337–348. DOI:10.2307/2347565.
- Giordani, P., and Kohn, R. (2010), “Adaptive Independent Metropolis–Hastings by Fast Estimation of Mixtures of Normals,” Journal of Computational and Graphical Statistics, 19, 243–259. DOI:10.1198/jcgs.2009.07174.
- Haario, H., Saksman, E., and Tamminen, J. (1999), “Adaptive Proposal Distribution for Random Walk Metropolis Algorithm,” Computational Statistics, 14, 375–396. DOI:10.1007/s001800050022.
- Haario, H., Saksman, E., and Tamminen, J. (2001), “An Adaptive Metropolis Algorithm,” Bernoulli, 7, 223–242. DOI:10.2307/3318737.
- Harrison, D., Jr, and Rubinfeld, D. L. (1978), “Hedonic Housing Prices and the Demand for Clean Air,” Journal of Environmental Economics and Management, 5, 81–102. DOI:10.1016/0095-0696(78)90006-2.
- Hastings, W. K. (1970), “Monte Carlo Sampling Methods Using Markov Chains and Their Applications,” Biometrika, 57, 97–109. DOI:10.1093/biomet/57.1.97.
- Hesterberg, T. (1995), “Weighted Average Importance Sampling and Defensive Mixture Distributions,” Technometrics, 37, 185–194. DOI:10.1080/00401706.1995.10484303.
- Holden, L., Hauge, R., and Holden, M. (2009), “Adaptive Independent Metropolis–Hastings,” Annals of Applied Probability, 19, 395–413. DOI:10.1214/08-AAP545.
- James, W., and Stein, C. (1961), “Estimation With Quadratic Loss,” in Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability (Vol. 1), pp. 361–379.
- Li, J. Q., and Barron, A. R. (2000), “Mixture Density Estimation,” in Advances in Neural Information Processing Systems, pp. 279–285.
- Luengo, D., and Martino, L. (2013), “Fully Adaptive Gaussian Mixture Metropolis-Hastings Algorithm,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6148–6152.
- Martino, L., Casarin, R., Leisen, F., and Luengo, D. (2018), “Adaptive Independent Sticky MCMC Algorithms,” EURASIP Journal on Advances in Signal Processing, 2018, 5.
- Martino, L., Read, J., and Luengo, D. (2015), “Independent Doubly Adaptive Rejection Metropolis Sampling Within Gibbs Sampling,” IEEE Transactions on Signal Processing, 63, 3123–3138. DOI:10.1109/TSP.2015.2420537.
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E. (1953), “Equation of State Calculations by Fast Computing Machines,” Journal of Chemical Physics, 21, 1087–1092. DOI:10.1063/1.1699114.
- Meyer, R., Cai, B., and Perron, F. (2008), “Adaptive Rejection Metropolis Sampling Using Lagrange Interpolation Polynomials of Degree 2,” Computational Statistics & Data Analysis, 52, 3408–3423. DOI:10.1016/j.csda.2008.01.005.
- Mira, A. (2001), “Ordering and Improving the Performance of Monte Carlo Markov Chains,” Statistical Science, 16, 340–350. DOI:10.1214/ss/1015346319.
- Poole, D., and Raftery, A. E. (2000), “Inference for Deterministic Simulation Models: The Bayesian Melding Approach,” Journal of the American Statistical Association, 95, 1244–1255. DOI:10.1080/01621459.2000.10474324.
- Raftery, A. E., and Bao, L. (2010), “Estimating and Projecting Trends in HIV/AIDS Generalized Epidemics Using Incremental Mixture Importance Sampling,” Biometrics, 66, 1162–1173. DOI:10.1111/j.1541-0420.2010.01399.x.
- Roberts, G. O., and Rosenthal, J. S. (2007), “Coupling and Ergodicity of Adaptive Markov Chain Monte Carlo Algorithms,” Journal of Applied Probability, 44, 458–475. DOI:10.1239/jap/1183667414.
- Roberts, G. O., and Rosenthal, J. S. (2009), “Examples of Adaptive MCMC,” Journal of Computational and Graphical Statistics, 18, 349–367. DOI:10.1198/jcgs.2009.06134.
- Rosenthal, J. S. (1996), “Analysis of the Gibbs Sampler for a Model Related to James-Stein Estimators,” Statistics and Computing, 6, 269–275. DOI:10.1007/BF00140871.
- Rosenthal, J. S. (2003), “Asymptotic Variance and Convergence Rates of Nearly-Periodic Markov Chain Monte Carlo Algorithms,” Journal of the American Statistical Association, 98, 169–177. DOI:10.1198/016214503388619193.
- Rosenthal, J. S. (2011), “Optimal Proposal Distributions and Adaptive MCMC,” in Handbook of Markov Chain Monte Carlo (Vol. 4), Boca Raton, FL: CRC Press.
- Rosenthal, J. S., and Yang, J. (2017), “Ergodicity of Combocontinuous Adaptive MCMC Algorithms,” Methodology and Computing in Applied Probability, 20, 535–551. DOI:10.1007/s11009-017-9574-3.
- Smith, M., and Kohn, R. (1996), “Nonparametric Regression Using Bayesian Variable Selection,” Journal of Econometrics, 75, 317–343. DOI:10.1016/0304-4076(95)01763-1.