
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Convolutional neural networks (CNN) have been successful in machine learning applications. Their success relies on their ability to consider space invariant local features. We consider the use of CNN to fit nuisance models in semiparametric estimation of the average causal effect of a treatment. In this setting, nuisance models are functions of pretreatment covariates that need to be controlled for. In an application where we want to estimate the effect of early retirement on a health outcome, we propose to use CNN to control for time-structured covariates. Thus, CNN is used when fitting nuisance models explaining the treatment and the outcome. These fits are then combined into an augmented inverse probability weighting estimator yielding efficient and uniformly valid inference. Theoretically, we contribute by providing rates of convergence for CNN equipped with the rectified linear unit activation function and compare it to an existing result for feedforward neural networks. We also show when those rates guarantee uniformly valid inference. A Monte Carlo study is provided where the performance of the proposed estimator is evaluated and compared with other strategies. Finally, we give results on a study of the effect of early retirement on hospitalization using data covering the whole Swedish population. Supplementary materials are available online at https://github.com/stat4reg/Causal/_CNN.
1 Introduction
Convolutional Neural Networks (CNN) have been found successful in discovering location-invariant patterns in speech, images, and time series data (LeCun and Bengio Citation1995). In particular, they have been shown to have a universal approximation property and be more efficient in terms of number of hidden layers than fully connected multi-layer networks in high-dimensional situations (Zhou Citation2020). In this article we show how CNN can be useful in controlling confounding information, including location-invariant patterns in time series, in order to perform semiparametric inference on a low dimensional causal parameter: we focus on average causal effects of a binary treatment on an outcome of interest, although our results are relevant for the semiparametric estimation of other low dimensional parameters of interest (see e.g., Chernozhukov et al. Citation2018).
Augmented Inverse Probability Weighting (AIPW) estimators (also called Double Robust (DR) estimators, Robins, Rotnitzky, and Zhao Citation1994) attain the semiparametric efficiency bound and yield uniformly valid inference as long as the nuisance functions of the confounding covariates are fitted consistenlty with fast enough convergence rates; for example, all nuisance functions are estimated with order (Belloni, Chernozhukov, and Hansen Citation2014; Farrell Citation2015; Kennedy Citation2016; Moosavi, Häggström, and de Luna Citation2021). In this article, we contribute to this theory by showing that CNN fits of nuisance functions achieve the
convergence rate required to obtain uniformly valid inference on causal parameters. To show this we use a result obtained by Farrell, Liang, and Misra (Citation2021) for Rectified Linear Unit (ReLU)-based Feed-forward Neural Networks (FNN). They show that, for large samples, the estimation error rate of FNN are bounded by the following term, with a probability at least
:
(1)
(1)
We deduce the above approximation rate for CNN architectures inspired by earlier work by Zhou (Citation2020). However, in contrast to the latter paper, we consider a larger number of free parameters by considering multi-channel convolutional neural network, so as to achieve a tradeoff between complexity penalty of the function class and approximation rate in (1), and thereby obtain the convergence rate for the CNN fit of the nuisance functions.
In the next section we formally define the causal parameters of interest using the potential outcome framework (Rubin Citation1974), and introduce the assumptions yielding identification, and locally efficient and uniformly valid inference when using AIPW estimators. We also introduce the convolutional network architectures with which we propose to fit the nuisance functions used by AIPW, followed by our main theoretical results, including conditions to obtain uniformly valid inference when using CNN based AIPW estimation. Section 3 presents numerical experiments illustrating the finite sample behavior of this estimation strategy under different data generating mechanisms. The proposed estimator is compared to AIPW, Targeted Maximum Likelihood Estimation (TMLE) (van der Laan and Rose Citation2011) and Outcome Regression (OR) estimation (Tan Citation2007; Moosavi, Häggström, and de Luna Citation2021) using fully-connected feed-forward ReLU based neural networks (Multilayer Perceptron (MLP) in Farrell, Liang, and Misra, Citation2021) and Lasso to fit the nuisance functions. In Section 4, we study the effect of early retirement (at 62 years old), compared to retiring later in life, on morbidity and mortality outcomes (Barban et al. Citation2020). We use population wide Swedish register data and follow cohorts born in 1946 and 1947 for which we have a rich reservoir of potential pretreatment confounders, including hospitalization and income histories. CNN allows us to consider that such life histories may contain location-invariant patterns that confound the causal effects of the treatment (decision to retire early).
2 Theory and Method
2.1 Causal Parameters and Uniformly Valid Inference
The Average Causal Effect (ACE) and Average Causal Effect among the Treated (ACET) of a binary treatment (T) are parameters defined using potential outcomes ((Rubin Citation1974)), respectively:
where Y(1) and Y(0) are the outcomes that would be observed if T = 1 and T = 0, respectively. For a given individual only one of these potential outcomes can be observed. This intrinsic missing data problem implies that assumptions need to be made to identify τ and τt. For this purpose, and given a vector of observed pretreatment covariates X, we assume:
Assumption 1.
No unmeasured confounders:
.
Overlap:
Consistency: The observed outcome is
Note that ACET is identified if only 1a(i), 1b(i), and 1c hold. Assumption 1a requires that the observed vector X includes all confounders. Assumption 1b requires that for any value X both treatment levels have nonzero probability to occur, and by Assumption 1c one of the potential outcomes is observed for each individual, and its value is not affected by the treatment received by other individuals in the sample.
We aim at uniformly (over the class of Data Generating Processs (DGP)s, for which Assumption 2 hold) valid inference while using semiparametric estimation (Moosavi, Häggström, and de Luna Citation2021). Therefore, the following AIPW estimators of ACE are considered (Robins, Rotnitzky, and Zhao Citation1994; Scharfstein, Rotnitzky, and Robins Citation1999):
where
is the empirical mean operator,
and
is an estimator of
.
For ACET, we use the estimator where
We use the following assumptions for the DGP’.
Assumption 2.
We have
Let
Let
The estimators of the nuisance functions have yet to be introduced for these AIPW estimation strategies. In order to get the desired results, the proposed estimators should be well behaved. More precisely, the following consistency and rate conditions are considered for the nuisance function estimators.
Assumption 3.
Let be an estimator of
which only depends on
(assumption of “no additional randomness,” Farrell Citation2015). Moreover, for a given t we have
The following proposition describes uniform validity results obtained by Farrell (Citation2018, Corollaries 2 and 3) under the above regularity conditions.
Proposition 1.
For each n, let be the set of distributions obeying Assumptions 1a(i), 1b(i), 1c, and 2a. Further, assume Assumption 2b holds for
, and let
and
fulfill Assumption 3. Then, we have:
where
and
.
Let also Assumptions 1a(ii), 1b(ii) be fulfilled and Assumption 2b hold for . Additionally, assume
fulfills Assumption 3. Then, we have:
where
Remark 1.
A multiplicative rate condition as Assumption 3(b) is weaker than separate conditions on the two nuisance model estimators. It only requires that one of the nuisance functions is estimated at faster rate if the other one is estimated at slower rate. However, in Section 2.3 the rate is obtained for each of the nuisance function estimators separately. This is to make sure Assumption 3(c) for
is also fulfilled. This latter assumption can be, however, dropped by considering sample splitting (Chernozhukov et al. Citation2018).
Assumption 3, or similar condition, has been used in the literature to obtain uniform valid inference of average causal effect estimators; see Belloni, Chernozhukov, and Hansen (Citation2014), Farrell (Citation2015), Farrell, Liang, and Misra (Citation2021), Chernozhukov et al. (Citation2018), and van der Laan and Rose (Citation2011). Machine learning algorithms estimating regression functions with rate include regression trees, lasso regressions, and neural networks (see (Kennedy Citation2016; Chernozhukov et al. Citation2018) for an overview). Concerning the neural networks,
rate of convergence was shown for shallow and deep feed-forward neural networks in Chen and White (Citation1999) and Farrell, Liang, and Misra (Citation2021), respectively. Note, finally, that because the AIPW estimators is based on the efficient influence function, its asymptotic variance is equal to the semiparametric efficiency bound (Tsiatis Citation2006).
2.2 Convolutional Neural Networks
We consider a specific CNN architecture with parallel hidden layers structured as follows. Let the input column vector be denoted by , where
. We consider L to be the number of hidden layers in which we have E number of parallel vectors. Let σ be the ReLU function defined on the space of real numbers as
for
. The vectors in each hidden layer
have size dl and are defined by
, where
is a vector called bias vector in the neural network literature,
is a weight matrix defined as
and the weight parameter
is the ith element of the filter mask
. s is considered fixed through all values of l and e. We have
, where dl is the size of vectors in the lth layer and
.
The structure of a CNN as defined above provides us with the following function space on Ω:
Similar to Zhou (Citation2020) (who, however, uses E = 1) we assume that for all values of e in and l in
the vector
has the form
with the
repeated components in the middle. Therefore, the total number of parameters (duplicate/shared weights are counted more than once), Q for the neural network fulfills the following inequality:
(2)
(2) where the notation
for two sequences of random variables xn and yn means
and
.
2.3 Main Results
In this section, we provide results that allow us to use the CNN architectures described above to fit the nuisance models needed for AIPW estimations of ACE and ACET, and obtain uniformly valid inference. In particular, we need to show that the rate conditions in Assumption 3 are fulfilled.
Assumption 4.
Assume that are iid copies of
, where U is continuously distributed. For an absolute constant M > 0 and a target
(a nuisance function), assume
and
.
Assumption 5.
Let be a loss function that, for any arbitrary functions f and g and z a realization of Z, fulfills:
where
.
Note that Assumption 5 holds for the usual mean squared error and log loss functions. Further, let be an arbitrary set of functions. We define:
(3)
(3) and
(4)
(4)
where
is the supremum norm. The following result is a special case of Theorem 2(b) given in Farrell, Liang, and Misra (Citation2021), and gives the rate of convergence for our estimate
of a target
(a nuisance function). Prior to presenting the theorem, the target space in which we seek to find the nuisance functions need to be defined. We use the notation
for the Sobolev space with smoothness
. We consider
to be the unit ball in the Sobolev space defined on
;
such as
where
is the essential supremum norm of the absolute value of a function f defined on Ω,
, and
is the weak derivative.
Theorem 1.
Let , and assume that Assumptions 4-5 hold. For an absolute constant M > 0 and
, let the approximation error
be defined as in (4). With probability at least
, and for large enough n,
(5)
(5) where the constant C > 0 is independent of n, but may depend on d, M, and other fixed constants.
Our next step is to bound the term in the above inequality on the estimation error. The following result is similar to Theorem 1 in Zhou (Citation2020). However, we allow here the number of parallel layers to grow with n, which translates into faster growing function space for our specific CNN architectures, thereby a larger decay rate for the error.
Theorem 2.
Let . If
and
,
and an integer index
, then there exist w, b and
such that
where is the space of continuous functions on the space
and c is an absolute constant and therefore
Note that this theorem holds under more general Sobolev spaces for f. For simplicity, we use the condition because it is necessary in the other theorems in this section.
Finally, our main result gives conditions for the CNN nuisance function fit to fulfill Assumption 3, and therefore conditions for AIPW estimation based on CNN fit to yield uniformly valid inference for ACE and ACET (Proposition 1).
Theorem 3.
Let the conditions in Theorem 1 hold for ui = xi, vi = yi, and with smoothness
. Let also the same conditions hold for ui = xi, vi = ti, and
with smoothness βp. Let also
, and s and d fulfill the assumptions of Theorem 2. Then, the rate conditions in Assumption 3 are fulfilled for nuisance functions estimators (3) with
and any loss function
that fulfills Assumption 5.
Remark 2.
The rate result for CNN based estimators in Theorem 3 corresponds to similar results for MLP in Farrell, Liang, and Misra (Citation2021, Theorem 3). However, the conditions on smoothness is less strict in our case. Moreover, the rate of growth for the number of parameters considered for MLP based estimators in Farrell, Liang, and Misra (Citation2021, Theorem 1) is , while we have considered the growth rate
. These rates are similar up to a log factor if d is large and β is close to d. Notice, however, that these are not necessarily minimal rates required for valid inference on ACE(T).
Remark 3.
We have assumed that both width E and depth L are growing at given rates. One interesting question is what happens if we consider one of them constant and only grew the other? It is not difficult to check that assuming constant E, and , gives us the following result:
Therefore, establishing a convergence rate of for
requires each of these terms to have a growth rate smaller than
. This implies for the first term:
, and for the third one:
. Thus, for a proper candidate for α we need:
, which contradicts the assumption d > 2. Hence, E cannot be kept fixed here.
3 Simulation Study
We perform a simulation study to evaluate the use of the CNN together with AIPW estimation strategy of average causal effects proposed above. We focus here on τt (ACET) but similar results are obtained for τ. Comparisons are made with other algorithms to fit nuisance functions, including, MLP, (Farrell, Liang, and Misra Citation2021) and post-lasso estimators (Farrell Citation2015). Moreover, we also include alternative strategies to AIPW, including OR estimation (Tan Citation2007) and targeted learning (van der Laan and Rose Citation2011).
The simulation results are based on 1000 replications. The neural networks initial weights are different for each replication, which makes the results more robust. A sequence of 10 covariates are independently generated having normal distributions with increasing means and varying variances: , and
. While these variables are independent, their ordering is going to be important in how the outcomes and treatment assignment are generated as described below in two different settings.
Setting 1 Potential outcomes and treatment assignment are generated as follows:
In this setting, polynomial functions of the difference of some neighboring variables in the sequence are used to generate the nuisance models.
Setting 2 Potential outcomes and treatment assignment are generated as follows:
where
Here, the output of l1 and l2 are nonzero only if an increase by a factor bigger than 1.15 and a decrease by a factor bigger than 1.05 is found in all consecutive pair of covariates in the input of size four, respectively. The value of l3 is nonzero if an increase by a factor bigger than 1.1 is followed by a decrease and followed by another increase by a factor of bigger than 1.1 or if the oscillation has the opposite direction.
Error terms for the outcome models, e1 and e0, are generated from the standard normal distribution as well as a heavy-tailed Gamma distribution, that is Gamma(2,0.5).
The following algorithms to estimate the nuisance functions are evaluated:
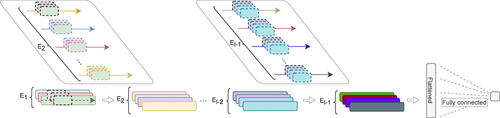
CNN A convolutional neural network using the ReLU activation function, with architecture illustrated in . Note that this architecture is slightly more flexible than the one considered in Section 2.2, hence, we expect it to perform at least as well in terms of approximation rate. Both for the potential outcome model μ0 and the propensity score p, the number of channels in the input layer is one. For the outcome models 128 channels in the first hidden layer and 16 channels in the second hidden layer have been used, while 32 channels in the first hidden layer and 8 channels in the second hidden layer have been used for fitting the propensity score. We have implemented the CNN together with AIPW estimation strategy in the package DNNcausal which is available at https://github.com/stat4reg/DNNcausal.
Fig. 1 Illustration of the convolutional neural network used in the simulations and the real data study. Each layer, contains different number of channels Ei, where E0 (not shown in the figure) is the number of time series in the set of input covariates. Each channel (feature map) in a given layer is formed by first applying
number of kernels (convolution filters) on the vectors in layer i–1 and then summing the results. There exist some covariates which are not time series. Inclusion of those vectors in the neural network is not illustrated in the figure for simplification purpose. A fully connected feed-forward structure has been used for those covariates and the results are then combined with the results from the time-series data in the flattening layer demonstrated above.
MLP A Rectified Linear Unit activation function based feedforward neural network with two hidden layers. Two different feedforward architectures are used in order to estimate μ0, and p (propensity score). The networks for fitting the outcome model consist of 128 and 80 nodes within the two layers, respectively. For the propensity score, two layers contain 32 and 8 nodes, respectively.post-lasso Nuisance models are fitted in two steps, where all higher order terms up to order three are considered. First, a lasso variable selection step is performed using the R-package hdm (Chernozhukov, Hansen, and Spindler Citation2016), and then maximum likelihood is used to fit the models with the selected covariates (those with coefficients not shrinked to zero by lasso). The lasso penalty parameter is selected as (Belloni et al. Citation2012). Variable selection is performed using two different strategies: double selection which takes the union of variables selected by regressing outcome and treatment variables and uses that to refit both models (Belloni, Chernozhukov, and Hansen Citation2014; Moosavi, Häggström, and de Luna Citation2021), and single selection, which uses two sets of variables selected by regressing outcome and treatment, and refits each of the models using their corresponding set (Farrell Citation2015).
We use the above nuisance function estimators in several different estimators of τt, as follows:
AIPW is implemented using CNN, MLP, and post-lasso with both single and double selection (denoted respectively: DRcnn, DRmlp, DRss, DRds).
OR estimator with post-lasso and double selection (denoted ORds).
TMLE using the R-package tmle and the function SL.nnet to fit all nuisance functions (denoted TMLE).
Full details with code and description of choice of architectures and hyperparameter for this simulation study are available in the Supplementary Materials.
We set sample sizes to n = 5000 and , and run 1000 replicates. Bias, standard errors (both estimated and Monte Carlo), mean squared errors (MSE, bias squared plus variance) and empirical coverages for 95% confidence intervals are reported in and .
Table 1 Setting 1 DGP: Bias, standard errors (both estimated, Est sd, and Monte Carlo, MC sd), MSEs and empirical coverages for 95% confidence intervals over 1000 replicates.
Table 2 Setting 2 DGP: Bias, standard errors (both estimated and Monte Carlo), MSEs and empirical coverages for 95% confidence intervals over 1000 replicates.
We first comment the results for the settings with normally distributed errors for the outcome models. The DGP of Setting 1 () is the least complex one and its polynomial form is favorable to the post-lasso methods which are based on higher order terms. It is therefore expected that the post-lasso methods ORds, DRss, DRds have low bias. DRcnn has larger bias, but decreasing with n. All methods have similar MSEs even though DRcnn has the lowest MSE for the largest sample size. Empirical coverages are close to the nominal 95% level for all methods.
The DGP of Setting 2 () is less smooth and we observe that the DRcnn and DRmlp methods have the lowest biases and MSEs, where DRcnn performs slightly better. TMLE and post-lasso both have such a large bias that the confidence interval coverages are far from being at the nominal level. It should be noted, however, that the TMLE uses the built-in feedforward neural network, which is not adjusted to the generated datasets, and so the comparison is not a fair one between TMLE and the DR estimators.
Results for the heavy-tailed Gamma errors are available in the supplementary materials.
The latter results are similar to those above, although Lasso approaches perform slightly worse while neural networks perform slightly better.
4 Effect of Early Retirement on Health
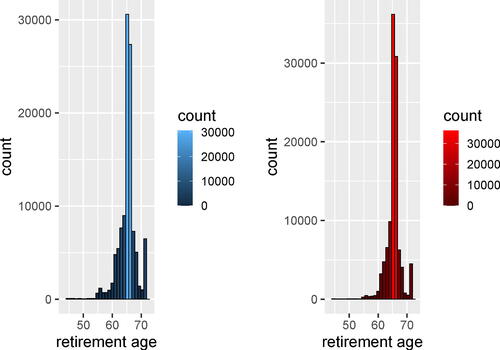
The existing theoretical and empirical evidence on the effects of early retirement on health are mixed, and both positive and negative results may be expected and have been reported in different situations; see Barban et al. (Citation2020) and the references therein. In this context, we add to the empirical evidence by studying the effect of early retirement on health using a database linking at the individual level a collection of socio-economic and health registers on the whole Swedish population (Lindgren et al. Citation2016). This allows us to follow until 2017 two complete cohorts born in 1946 and 1947 and residing in Sweden in 1990. As health outcome we observe the number of days in hospital per year after retirement. To study the effects of early retirement we consider those who were still alive at age 62, and either retire at age 62 (T = 1, treatment) or retire later (T = 0, control group). For the cohorts studied, retirement pensions are accessible from age 61, although the usual age of retirement is 65 years of age (see for descriptive statistics on age of retirement). Therefore, retiring at age of 62 is considered as early retirement since it decreases your annual pension transfers compared to later retirement; see, for example, Barban et al. (Citation2020) for details on the Swedish pension system. Barban et al. (Citation2020) also contains a study on the effects of early retirement, although based on fewer measurements for time-dependent covariates and using a matching design. This study provides new evidence by taking into account richer histories of the time-dependent covariates, and by incorporating CNN to address complex dynamics in pretreatment confounding covariates.
Fig. 2 Retirement age for men and women who belong to the cohorts born in Sweden 1946 and 1947. The last staple in each histogram displays those who retired at age 71 or later.
More precisely, the design of the study is as follows. An individual alive at age 62 is considered as taking early retirement at that age if her/his pension transfers become larger than income from work at that age for the first time (i.e., they were never so earlier). For replicability, the exact definition using income and transfer variables from the Swedish registers are available in the supplementary materials. The health outcomes of interest are the number of hospitalization days per year during the next five years following early retirement. We, however, check first whether early retirement has an effect on survival during the five first years following early retirement. There were no (or hardly significant) such effects at the 5% level (results reported in the appendix, ) and we therefore focus the analysis on the survivors when looking at effects on hospitalization. The following covariates are used as input in the CNN architures to fit treatment and outcome nuisance models. Besides the birth year we include the the following (pretreatment) covariates measured at 61 years of age: marriage status, municipality, education level, Spouse education level, and the number of biological children. Moreover, we consider the measurements of the following covariates for each of the 10 years preceding retirement: days of hospitalization and open health care, annual income from labor, annual income from pension, annual income from unemployment, annual income from early retirement and sickness benefit, annual compensation for illness, and spouse retirement status. Thus, covariates include eight time(-structured) series of 10 observations each per individual. We do separate analyses for men and women which gives two samples of approximately 100,000 individuals each.
Table 4 Effect of early retirement on survival (binary outcomes death = 1), during five years of follow up for the early retirees, and 95% confidence intervals.
The code giving details on the CNN architectures and tuning parameters can be found in the supplementary materials. We also apply the other methods evaluated in the simulation study above.
Results are presented in . Based on the naive estimation not controlling for confounders, early retirement has a clear positive effect on health (varying between 0.167 and 0.396 average number of days) and for the five years of follow up considered. These naive effects are larger for women in the beginning. These negative effects disappear when controlling for the considered covariates. This is seen most clearly with CNN which yields the effects smaller than 0.1 day (in absolute value) for all cases but one. Confidence intervals at the 95% level cover zero in most cases. Thus, while there appeared to be a positive effect on health of early retirement, this effect was probably due to confounding.
Table 3 Effect of early retirement on number of days in hospital during five years of follow up, for the early retirees, and 95% confidence intervals.
5 Discussion
We have proposed and studied a semiparametric estimation strategy for average causal effects which combine convolutional neural network with AIPW. As long as the conditions given are met, this strategy yields locally efficient and uniformly valid inference. The use of CNN has the advantage over fully-connected feed forward neural networks that they are more efficient on the number of weights (free parameters) used for approximating the nuisance functions, and are geared to take into account time invariant local features (LeCun and Bengio Citation1995) in confounding time series variables. If no time series or other structured confounding is available in the data, then other machine learning algorithms may be as appropriate to use to fit nuisance functions.
A main contribution of the article is to show under which conditions CNN fits of nuisance functions achieve convergence rate required to obtain uniformly valid inference on an ACE. Using the result in Farrell, Liang, and Misra (Citation2021) in which convergence rate of a ReLU-based feed-forward network is shown to follow (1), we show that the rate conditions in Assumption 3 are fulfilled. Specifically, we use CNN with a given complexity for which we show that approximation rate in (1) is small enough. A key component of result in Farrell, Liang, and Misra (Citation2021) is the upper bound on empirical process terms found in Bartlett, Bousquet, and Mendelson (Citation2005) based on Rademacher averages, which are measures of function space complexity. Global Rademacher averages do not provide fast rates as in (1). To derive this fast rate, localization analysis is employed which takes into consideration only intersection of the function space with a ball around the goal function; considering that in reality the algorithm only searches in a neighborhood around the true function. Moreover, the tight bound on Pseudo-dimension of deep nets found in Bartlett et al. (Citation2019) is used.
We also present numerical experiments showing the performance of the estimation strategy in finite sample and compare it to other machine learning based estimation strategies. The applicability of the method is illustrated through a population wide observational study of the effect of early retirement on hospitalization in Sweden.
Supplementary Materials
Supplementary materials are available on-line at https://github.com/stat4reg/Causal_CNN if nothing else stated.
R-package for DRcnn and DRmlp estimators:The R-package DNNcausal implements estimators of average causal effect and average causal effect on the treated, combining AIPW with deep neural networks fits of nuisance functions described in the article; available at https://github.com/stat4reg/DNNcausal. (GNU zipped tar file)
Simulation description: Code used for the simulations in Section 3. (.md file)
Simulations results: Results of simulations, and a description of how hyperparameters are tuned. (.md file)
Case study description: Supplementary material on the design of the study of the effects of early retirement on health reported in Section 4. (.md file)
Online_Materials (2).zip
Download Zip (28.7 KB)Acknowledgments
We are grateful to Xijia Liu and Jenny Häggström for helpful comments that have improved the article. We acknowledge funding from the Swedish Research Council and the Marianne and Marcus Wallenberg Foundation. The Umeå SIMSAM Lab data infrastructure used in this study was developed with support from the Swedish Research Council, the Riksbanken Jubileumsfond and by strategic funds from Umeå University.
Disclosure Statement
The authors report there are no competing interests to declare.
References
- Barban, N., de Luna, X., Lundholm, E., Svensson, I., and Billari, F. C. (2020), “Causal Effects of the Timing of Life-Course Events: Age at Retirement and Subsequent Health,” Sociological Methods & Research, 49, 216–249. DOI: 10.1177/0049124117729697.
- Bartlett, P. L., Bousquet, O., and Mendelson, S. (2005), “Local Rademacher Complexities,” The Annals of Statistics, 33, 1497–1537. DOI: 10.1214/009053605000000282.
- Bartlett, P. L., Harvey, N., Liaw, C., and Mehrabian, A. (2019), “Nearly-Tight vc-Dimension and Pseudodimension Bounds for Piecewise Linear Neural Networks,” The Journal of Machine Learning Research, 20, 2285–2301.
- Belloni, A., Chen, D., Chernozhukov, V., and Hansen, C. (2012), “Sparse Models and Methods for Optimal Instruments with an Application to Eminent Domain,” Econometrica, 80, 2369–2429.
- Belloni, A., Chernozhukov, V., and Hansen, C. (2014), “Inference on Treatment Effects After Selection Among High-Dimensional Controls,” The Review of Economic Studies, 81, 608–650. DOI: 10.1093/restud/rdt044.
- Chen, X., and White, H. (1999), “Improved Rates and Asymptotic Normality for Nonparametric Neural Network Estimators,” IEEE Transactions on Information Theory, 45, 682–691. DOI: 10.1109/18.749011.
- Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. (2018), “Double/Debiased Machine Learning for Treatment and Structural Parameters,” The Econometrics Journal, 21, C1–C68. DOI: 10.1111/ectj.12097.
- Chernozhukov, V., Hansen, C., and Spindler, M. (2016), “hdm: High-Dimensional Metrics,” R Journal, 8, 185–199. DOI: 10.32614/RJ-2016-040.
- Evans, L. C. (2010), Partial Differential Equations, Providence, RI: American Mathematical Society.
- Farrell, M. H. (2015), “Robust Inference on Average Treatment Effects with Possibly More Covariates than Observations,” Journal of Econometrics, 189, 1–23. DOI: 10.1016/j.jeconom.2015.06.017.
- Farrell, M. H. (2018), “Robust Inference on Average Treatment Effects with Possibly more Covariates than Observations,” arXiv:1309.4686v3.
- Farrell, M. H., Liang, T., and Misra, S. (2021), “Deep Neural Networks for Estimation and Inference,” Econometrica, 89, 181–213. DOI: 10.3982/ECTA16901.
- Kennedy, E. H. (2016), “Semiparametric Theory and Empirical Processes in Causal Inference,” in Statistical Causal Inferences and their Applications in Public Health Research, eds. H. He, P. Wu, D.-G. Chen, pp. 141–167, Cham: Springer.
- Klusowski, J. M., and Barron, A. R. (2018), “Approximation by Combinations of Relu and Squared Relu Ridge Functions with l1 and l0 Controls,” IEEE Transactions on Information Theory, 64, 7649–7656.
- LeCun, Y., and Bengio, Y. (1995), “Convolutional Networks for Images, Speech, and Time Series,” in The Handbook of Brain Theory and Neural Networks, 3361, ed. M. A. Arbib, pp. 255–258, Cambridge, MA: MIT Press.
- Lindgren, U., Nilsson, K., de Luna, X., and Ivarsson, A. (2016), “Data Resource Profile: Swedish Microdata Research from Childhood into Lifelong Health and Welfare (Umeå SIMSAM Lab),” International Journal of Epidemiology, 45, 1075–1075. DOI: 10.1093/ije/dyv358.
- Moosavi, N., Häggström, J., and de Luna, X. (2021), “The Costs and Benefits of Uniformly Valid Causal Inference with High-Dimensional Nuisance Parameters,” Statistical Science, to appear ArXiv preprint arXiv:2105.02071.
- Robins, J. M., Rotnitzky, A., and Zhao, L. P. (1994), “Estimation of Regression Coefficients When Some Regressors are not Always Observed,” Journal of the American statistical Association, 89, 846–866. DOI: 10.1080/01621459.1994.10476818.
- Rubin, D. B. (1974), “Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies,” Journal of Educational Psychology, 66, 688–701. DOI: 10.1037/h0037350.
- Scharfstein, D., Rotnitzky, A., and Robins, J. (1999), “Rejoinder to Comments on “Adjusting for Non-ignorable Drop-Out Using Semiparametric Non-response Models?” Journal of the American Statistical Association, 94, 1121–1146. DOI: 10.2307/2669930.
- Stein, E. M. (1970), Singular Integrals and Differentiability Properties of Functions (PMS-30), Princeton: Princeton University Press.
- Tan, Z. (2007), “Comment: Understanding OR, PS and DR,” Statistical Science, 22, 560–568. DOI: 10.1214/07-STS227A.
- Tsiatis, A. (2006), Semiparametric Theory and Missing Data, New York: Springer.
- van der Laan, M., and Rose, S. (2011), Targeted Learning: Causal Inference for Observational and Experimental Data. Springer Series in Statistics, New York: Springer.
- Zhou, D.-X. (2020), “Universality of Deep Convolutional Neural Networks,” Applied and Computational Harmonic Analysis, 48, 787–794. DOI: 10.1016/j.acha.2019.06.004.
Appendix
In this section we also consider the Sobolev space that is defined using the L2 norm instead of the
norm. Moreover, let
be the L2 norm of a function f defined on Ω.
A.1 Proof of Theorem 2
Proof.
Let . For any α that satisfies
, by Hölder’s inequality, we have:
Therefore, and
hold by
, where
. Moreover, Ω has a Lipschitz domain interior and measure zero boundary. Therefore, by Sobolev extension theorem (Stein Citation1970, Theorem 5) there is an extension
of f for which
where
is a constant that depends on β and C is a constant independent of β.
Let , where
is the Fourier transform of F.
is finite since
(see Theorem 7 chapter 5.8.4 in Evans (Citation2010); Characterization of Hk by Fourier transform), and
by Cauchy–Schwarz inequality. Consequently,
, where
is
and it is finite due to the assumption
.
Since and using Theorem 2 in Klusowski and Barron (Citation2018) we have:
where
,
,
is
(ReLU).
Let . It is shown in Zhou (Citation2020), using
and
, that
belongs to the following function space
Therefore, by the definition of , we can directly conclude that
belongs to
. Let
. Then, we have
(A.1)
(A.1)
The final result is obtained from the facts that and
(
is bounded). □
A.2 Proof of Theorem 3
Proof.
The rate conditions (a) and (b) of Assumption 3 are fulfilled if both and
are
. For this, the three terms in the upper bound (5) in Theorem 1 must be
. For the first term, based on 2, we have
The second term is also if
. For the third term, using Theorem 2 we have
To prove condition (c) of Assumption 3, we use the proof of lemma Farrell, Liang, and Misra (Citation2021, Lemma 10). In this proof it is shown that for an arbitrary class of feedforward neural networks with probability at least
Therefore, we can conclude that under the stated conditions
□
A.3 Early Retirement Effects on Survival
Additional results on the effect of early retirement on survival can be found in .