
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
As immunological and clinical studies become more complex, there is an increasing need to analyze temporal immunophenotypes alongside demographic and clinical covariates, where each subject receives matrix-valued time series observations for potentially high-dimensional longitudinal features, as well as other static characterizations. Researchers aim to find the low-dimensional embedding of subjects using matrix-valued time series observations and investigate relationships between static clinical responses and the embedding. However, constructing these embeddings can be challenging due to high dimensionality, sparsity, and irregularity in sample collection over time. In addition, the incorporation of static auxiliary covariates is frequently desired during such a construction. To address these issues, we propose a smoothed probabilistic PARAFAC model with covariates (SPACO) that uses auxiliary covariates of interest. We provide extensive simulations to test different aspects of SPACO and demonstrate its application to an immunological dataset from patients with SARS-CoV-2 infection. Supplementary materials for this article are available online.
1 Introduction
Sparsely observed multivariate time series data are now common in immunological studies. For each subject or participant
, we can collect multiple measurements on
features over time, but often at
different time stamps
. For example, for each subject, immune profiles are measured for hundreds of markers at irregular sampling times in Lucas et al. (Citation2020) and Rendeiro et al. (Citation2021). Let
be the longitudinal measurements for subject
, and
be the sparse three-way tensor collecting
for all
subjects, where
is the number of unique time points across all subjects, for example,
. A major computational task in practice is to construct low-dimensional embeddings that capture data variability in
across subjects. Tensor decomposition is a widely used technique for achieving this goal. demonstrates the PARAFAC/CP tensor decomposition and utilization of the decomposition results (Harshman and Lundy Citation1994), where we approximate a tensor by the sum of rank-one tensors. Apart from tensor reconstruction and denoising, the decomposition of the three-way tensor X provides decomposed factors
,
, and
, which aim to capture major variations along the subject, feature, and time directions, respectively. These factors can be used for further downstream analysis. For instance, factors
(also denoted as the subject scores) serve as the aforementioned subject embeddings, which can be used to investigate the relationship between immune profiles and various clinical/demographic covariates.
Fig. 1 Illustration of the PARAFAC/CP decomposition method for immunoprofiles measured longitudinally. The white color represents missing data in the time direction. The three-way tensor is approximated as the sum of rank-one tensors
. Each rank-one tensor
can be expressed using a factor along the subject direction
, a factor along the feature direction
, and a factor along the time direction
. The factors associated with the tensor decomposition can be used in downstream analysis.
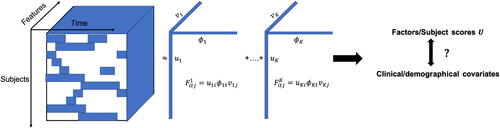
The immune profiles are usually highly sparse observed along the time dimensions, that is, the sets {} for different subjects i tend to be small in size and have low overlaps, resulting in a high missing rate along the time dimension of X (). In addition, researchers may have access to nontemporal covariates for each subject, such as medical conditions and demographic information, which may partially explain the variation in the temporal measurements of X across subjects. As an example, the IMPACT study (Lucas et al. Citation2020) analyzed immune profiles of 98 COVID-19 infected individuals. Researchers measured immune profiles for more than 30 days after symptom onset, but only an average of 1.84 measured time points per subject. Auxiliary demographic information, including sex and age, and several preexisting medical conditions, were also collected. To better estimate
in this example, a tensor decomposition tool that can properly model the longitudinal behavior of the factors and incorporate available auxiliary covariates is needed.
In this article, we propose SPACO (smooth and probabilistic PARAFAC model with auxiliary covariates) to adapt to the sparsity long the time dimension in X and use the auxiliary covariates Z. SPACO assumes that X is a noisy realization of some low-rank signal tensor whose time components are smooth and subject scores have a potential dependence on the auxiliary covariates Z:
Here, (a) zi is the ith row of Z and describes the dependence of the expected subject score for subject i on zi, (b) uik,
, vjk are the subject score, trajectory value and feature loading for factor k in the PARAFAC model and the observation indexed by (i, t, j) where
has a normal prior
. We impose smoothness on time trajectories
and sparsity on β to deal with the irregular sampling along the time dimension and potentially high dimensionality in Z.
Alongside the proposal of the model, we will delve into several issues pertinent to SPACO, including model initialization, auto-tuning of smoothness and sparsity in β, and hypothesis testing on β. Effectively addressing these concerns is crucial for applying SPACO in practice. In the remainder of the article, we summarize work closely related to our study in Section 1.1. We describe the SPACO model in Section 2 and discuss model parameter estimation with predetermined tuning parameters in Section 3. Section 4 is dedicated to the examination of the aforementioned issues that bear practical significance. A comparative analysis of SPACO with existing methods on synthetic data is presented in Section 5. Lastly, in Section 6, we employ SPACO on a highly sparse tensor containing immunological measurements from SARS-COV-2 infected patients. We also provide a Python package, SPACO, for researchers who are interested in using the proposed method.
1.1 Related Work
Matrix-valued observations have become increasingly important in modern applications, particularly in the context of dimension reduction or matrix-valued data clustering (Chang Citation1983; Vichi, Rocci, and Kiers Citation2007; Viroli Citation2011; Anderlucci and Viroli Citation2015).
Tensor decomposition is a useful technique for modeling matrix-valued observations, and has been applied in various fields (Acar and Yener Citation2008; Kolda and Bader Citation2009; Sidiropoulos et al. Citation2017). In the study of multivariate longitudinal data, researchers in economics have combined tensor decomposition with auto-cross-covariance estimation and autoregressive models (Fan, Fan, and Lv Citation2008; Lam, Yao, and Bathia Citation2011; Fan, Liao, and Mincheva Citation2011; Bai and Wang Citation2015, Citation2016; Wang, Liu, and Chen Citation2019; Wang et al. Citation2021). However, these approaches are either not compatible with highly sparse data or do not scale well with the feature dimensions, both of which are important for medical applications.
Functional PCA (Besse and Ramsay Citation1986; Yao, Müller, and Wang Citation2005) is often used for modeling sparse longitudinal data in the matrix form. It uses the smoothness of time trajectories to handle sparsity in longitudinal observations and estimates the eigenvectors and factor scores under this smoothness assumption. Yokota, Zhao, and Cichocki (Citation2016) and Imaizumi and Hayashi (Citation2017) introduced smoothness into tensor decomposition and estimated the parameters by iteratively solving penalized regression problems. However, these methods do not consider auxiliary covariates.
It has been previously discussed that including auxiliary information could potentially improve our estimation. For example, Li, Shen, and Huang (Citation2016) proposed the supervised sparse and functional principal component (SupSFPC) method and observed that auxiliary covariates improve signal estimation quality in the matrix setting for modeling multivariate longitudinal observations. In Chen, Tsay, and Chen (Citation2020), the authors observed that inclusion of auxiliary constraints improve the quality of tensor decomposition. Lock and Li (Citation2018) proposed SupCP, a supervised multiway factorization model with complete observation that employs a probabilistic tensor model (Tipping and Bishop Citation1999; Mnih and Salakhutdinov Citation2007; Hinrich and Mørup Citation2019). Although an extension to sparse tensor is straightforward, SupCP does not model smoothness and can be highly affected by severe missingness along the time dimension.
To address these limitations, we propose SPACO, an extension of functional PCA and SupSFPC to the setting of three-way tensor decomposition using the parallel factor (PARAFAC) model (Carroll, Pruzansky, and Kruskal Citation1980; Harshman and Lundy Citation1994). SPACO jointly models smooth longitudinal data with potentially high-dimensional static covariates Z using a probabilistic model. When Z is unavailable, we refer to the SPACO model as SPACO-. SPACO- itself is also an attractive alternative to existing tensor decomposition implementations with probabilistic modeling, smoothness regularization, and automatic parameter tuning. In our numerical experiments, we demonstrate the advantages of SPACO and SPACO- over several state-of-the-art tensor decomposition methods and the improvement of SPACO over SPACO- by using Z.
2 SPACO Model
2.1 Notations
We use (a) bolded uppercase letters to represent three-way tensors, (b) regular uppercase letters to represent a matrix, and (c) bolded lowercase to represent vectors. Following this convection, let be the tensor for some sparse multivariate longitudinal observations, where I is the number of subjects, J is the number of features, and T is the number of total unique time points. Let
be the matrix unfolding of X in the subject/feature/time dimension respectively. For any matrix A, we let
denote its ith row/column, and often write
as Ai for the ith column for convenience. We also define:
Tensor product :
, then,
with
.
Kronecker product ⊗: , then
is the Kronecker product of A and B:
.
Column-wise Khatri-Rao product :
, then
with
for
.
Element-wise multiplication :
, then
with
; for
; for
.
2.2 Smooth and Probabilistic PARAFAC Model with Covariates
We assume X to be a noisy realization of an underlying signal array F which is a rank K tensor with be the decomposed factor matrices, for example,
, where
are kth columns of
. We denote the rows of
by
, and their entries by
. We let xitj denote the (i, t, j)-entry of X. Then,
(1)
(1) where
is a K × K diagonal covariance matrix and
is a mean vector of length K. In practice, although the observation tensor X is almost always of high-rank, it is often assumed that F is (or approximately) low-rank with K being small.
We set in the absence of auxiliary covariates
. In the setting where we are interested in explaining the heterogeneity
across subjects using Z, we may model
as a function of
. Here, we consider a linear model
for
, where ηik is the kth entry of
and
is the coefficients matrix describing the dependence of subject scores on Z. To avoid confusion, we will always call X the “features”, and Z the “covariates” or “variables”.
Recalling that is the unfolding of X in the subject direction, we write
for the indices of observed values in the ith row of XI, and
for the vector of these observed values. Each such observed value xitj has noise variance
, and we write
to represent the diagonal covariance matrix with diagonal values
being the corresponding variances for
at indices in
. Similarly, we define
for the unfolding
, and
for the observed indices, the associated observed vector and diagonal covariance matrix for the jth row in
. We set
to denote all model parameters. Set
and
as the residual vector after removing mean signals from observations for subject i. If U is observed, the complete log-likelihood is
(2)
(2)
Set . The marginalized log-likelihood integrating out the randomness in U enjoys a closed form (Lock and Li Citation2018):
(3)
(3)
Model parameters in (3) are not identifiable due to (a) parameters rescaling from to
for any
, and (b) reordering of different component k for
. More discussions of the model identifiability can be found in Lock and Li (Citation2018). Hence, adopting similar rules from Lock and Li (Citation2018), we require
(C.1) .
(C.2)The latent components are in decreasing order based on their overall variances , and the first nonzero entries in Vk and
to be positive, for example,
and
if they are nonzero.
In the immunological application being considered, U represents subject scores, which are latent variables characterizing differences across subjects, V represents feature loadings, revealing the composition of factors using the original features and aiding downstream interpretation, and represents time trajectories interpreted as function values sampled from some underlying smooth functions
at a set of discrete-time points where the sampling in the time direction is often highly sparse.
Algorithm 1:
SPACO with fixed penalties
Data: X, Ω, λ1, λ2, K
Result: Estimated V, , β, s2,
and posterior distribution of
and the marginalized density
.
Initialization of V,
, β, s2,
while Not converged do
for
end
For
Update the posterior distribution (posterior mean and covariance) of U.
end
We address the challenge of sparse sampling utilizing the smoothness assumption in and encourage it by directly penalizing the function values via a penalty term
. This article considers a Laplacian smoothing (Sorkine et al. Citation2004) with a weighted adjacency matrix Γ. Let
be the time associated with the tth slice along the time dimension, for example, time associated with
. We define Ω and Γ as
The Laplacian smoothing discourages abrupt trajectory changes in observations from close-by time points, which is usually a reasonable assumption biologically. Practitioners may choose other forms for Ω based on their applications. For example, if practitioners want to have slowly varying derivatives, they can also use a penalty matrix that penalizes changes in gradients over time.
Further, when the number of covariates q in Z is moderately large, we may wish to impose sparsity in the β parameter. We encourage such sparsity by including a lasso penalty (Tibshirani Citation2011) in the model. In summary, our goal is then to find parameters maximizing the expected penalized log-likelihood, or minimizing the penalized expected deviance loss , under norm constraints:
(4)
(4)
The objective only incorporates the identifiability constraint (C.1). By changing the signs in V, , β and reordering them, we can always ensure (C.2) without altering the attained objective value.
EquationEquation (4)(4)
(4) characterizes a nonconvex problem. We will obtain local optimal solutions via an alternating update procedure: (a) we update β through lasso regressions while keeping other parameters fixed, (b) we update other model parameters using the EM algorithm while keeping β fixed. See Section 3 for more details.
3 Model Parameter Estimation
Given the model rank K and penalty terms , we alternately update parameters β, V, U, s2, and
with a mixed EM procedure described in Algorithm 1. We briefly explain the updating steps here:
Given other parameters, we find β to directly minimize the objective by solving a least-squares regression problem with lasso penalty.
Fixing β, we update the other parameters using an EM procedure. Denote the current parameters as
under the current posterior distribution
Algorithm 1 describes the high level ideas of our updating schemes. The posterior distribution of for each row in U is Gaussian, with posterior covariance Σi and posterior mean
given below,
(6)
(6)
(7)
(7)
In line 5 and 6, we guarantee the norm constraints on Vk and by adding an additional quadratic term and set the coefficient ν to guarantee the norm requirements. Although the problem is not convex, our proposed approaches yield optimal solutions for updating different parameter blocks in the sub-routines, and the penalized (marginalized) deviance loss is nonincreasing over the iterations.
Theorem 3.1.
In Algorithm 1, let and
are the estimated parameters at the beginning and end of the
th iteration of the outer while loop. We have
.
Proof of Theorem 3.1 is given in Appendix B.1. Derivations and explicit steps for carrying subroutines are deferred to Appendix A.1.
Algorithm 2:
Initialization of SPACO
Let
Set
Let
Let
Let
Let
For each
4 Initialization, Tuning and Testing
4.1 Initialization
One popular initialization approach for PARAFAC decomposition is through the Tucker decomposition of X using HOSVD/MLSVD (De Lathauwer, De Moor, and Vandewalle Citation2000) where
is the core tensor and
are unitary matrices multiplied with the core tensors along the subject, time and feature directions respectively (
is the smallest between K and
), and then perform PARAFAC decomposition on the small core tensor G (Bro and Andersson Citation1998; Phan, Tichavskỳ, and Cichocki Citation2013). Here, we propose to initialize SPACO with Algorithm 2, which combines the aforementioned approach with functional PCA (Yao, Müller, and Wang Citation2005) to handle sparse longitudinal data. Algorithm 2 proceeds as follows: (a) perform SVD on XJ to get
; (b) project XJ onto each column of
and perform functional PCA to estimate
; (c) a ridge-penalized regression regressing rows of XI on
, and estimate
and G from the regression coefficients.
In a noiseless model with δ = 0 and complete temporal observations, one may replace the functional PCA step of Algorithm 2 with standard PCA. Then becomes a PARAFAC decomposition of
.
Lemma 4.1.
Suppose and is completely observed. Replace
in Algorithm 2 by the top K eigenvectors of
. Then, the outputs
of Algorithm 2 satisfy that
.
By default, we set . Proof of Lemma 4.1 is given in Appendix B.2.
4.2 Auto-Selection of Tuning Parameters
Selection of regularizers λ1 and λ2: One possible approach to select the tuning parameters and
is through cross-validation. However, this can be computationally expensive even when tuning each parameter sequentially. Additionally, determining a suitable set of candidate values for the parameters before running the SPACO algorithm can be challenging. To address these issues, we adopt nested cross-validation, which has been empirically demonstrated to be useful (Huang, Shen, and Buja Citation2008; Li, Shen, and Huang Citation2016). Specifically, we tune the parameters within their corresponding subroutines as follows:
In the update for
In the update for βk, we perform K-fold cross-validation to select
Rank selection: Rank selection can be performed through cross-validation, as suggested in SupCP (Lock and Li Citation2018). To reduce computational costs, we adopt two strategies (see Appendix A.4 for more details):
1. We initialize the cross-validation parameters with estimates obtained from running a full SPACO/SPACO- analysis and only carry out a limited number of iterations to update the parameters. We find that using 5 or 10 iterations is sufficient in our experiments (the default maximum number of iterations is 10).
Algorithm 3:
Randomization test for Zj
1 for do
3 Construct responses and features as described in Lemma 4.2.
5 Define by
7 Compute the designed test statistic T using .
9 Compute randomized statistics using
, where
for
are (conditionally or marginally) independent copies of Zj.
11 Let be the empirical estimate of the CDF of T under H0 using
, and return the two-sided p-value
.
12 end
2. We start the analysis with the smallest possible rank and gradually increase it. We terminate the analysis when either the cross-validated marginal log-likelihood stops improving or when we reach the maximum rank that we are willing to consider.
4.3 Covariate Importance
In Section 5 of our synthetic experiments, we found that incorporating Z could improve the estimation of subject scores when Z strongly influenced the subject scores. This leads us to question how to determine the significance of such covariates when they are present. Here, we consider the construction of approximated p-values from partial independence/marginal independence tests between Zj and ηk:
both of which are practical interest.
Recap on randomization-based hypothesis testing: Before introducing our proposal, we will revisit concepts of hypothesis testing via randomization in the traditional setting where we investigate the relationship between a response variable y and a covariate variable z.
First, we investigate the marginal independence between y and z, with the null hypothesis . The randomization test, widely employed for independence testing, offers a valid p-value without assuming a specific dependence structure between y and z (Fisher Citation1936; Pitman Citation1937; Efron et al. Citation2001; Ernst Citation2004). Here, we outline the randomization test for marginal independence. Let
be a test statistic where
and
are the observation vectors for z and response y. For instance, one may set
. Let
and
, for
, where
is either a permutation of
or a vector of independent realizations from the marginal distribution of z. There are subtle differences between using
generated from a permutation and using one generated from the marginal distribution (Onghena Citation2017); however, we will not distinguish them in this context. Under the null hypothesis
are exchangeable. Thus, for any
, we have
, where
is the
-percentile of the empirical distribution constituted by
.
In addition to marginal independence, many statistical inquiries focus on the conditional or partial independence between y and z given additional variable(s) zo, with the null hypothesis . For illustration, one may consider a linear regression model expressed by the following equation:
where ζ is a mean-zero noise term independent of z and zo. In recent years, the conditional randomization test has emerged as a popular method for testing the partial independence between variables z and y, given zo. If the conditional distribution of
is known, the conditional randomization test generates new copies of z from the distribution
, allowing the construction of randomized test statistics that are exchangeable with the original one under
. This approach leverages the known conditional distribution to construct valid testing procedures without imposing additional constraints on the relationship between y and
(Candes et al. Citation2018; Berrett et al. Citation2020). To be specific, we define the test statistic
where zo represents the observations for variables zo. The test statistics
can take any function form, for example, we can set
. Let
and
, where
is an independent copy of the observation vector generated from the distribution of
, for
. Under the null hypothesis
, the test statistics T and
have the same conditional distribution given
and
. Hence,
, where
is the
-percentile of the conditional distribution of
(Candes et al. Citation2018).
In this article, we propose to adapt the idea of randomization tests to construct robust p-values for testing independence/conditional independence between factors and auxiliary covariates in SPACO, where the responses are not given beforehand.
Oracle randomization test in SPACO: Returning to SPACO, we first consider the ideal scenario where V, , s2, and
are given. Lemma 4.2 forms the basis of our proposal.
Lemma 4.2.
Given , and let
be the true regression coefficients on the covariates Z for
. For any
, set
Then, we have , where
is independent of auxiliary covariates.
Lemma 4.2 is proved via direct calculation in Appendix B.3. Readers may recognize that y and Z match the regression model, potentially allowing the application of the standard randomization technique. Proposition 4.3 details our construction of both observed and randomized test statistics, the validity of which is a result of Lemma 4.2 and Lemma F.1 in Candes et al. (Citation2018). A proof is provided in Appendix B.4 for completeness.
Proposition 4.3.
Set for
estimated without the jth covariate Zj,
. Replacing Zj with the properly randomized
to create
and
, where
is a permutation of Zj for
and
is independently generated from
for
, we have
(8)
(8)
(9)
(9)
Algorithm 3 outlines our proposal. The conditional randomization test involves generating from the conditional distribution
, which is estimated using an appropriate exponential family distribution. Further details on the generations of
can be found in Appendix A.5.
Approximated p-value construction with estimated model paramters: The true model parameters V, , s2, and
are unknown, so we will substitute the true parameters with their empirical estimates. However, the empirical estimates from a full SPACO fit tend to suffer from fitting toward the noise. To mitigate such influence, we use
from cross-validation described in Section 4.2. Specifically, for
, the index set for fold m, we construct
using estimates
and the prior covariance estimate
from other folds, by setting
with
is also estimated using
,
, and
. This procedure, referred to as cross-fit, employs data from other folds to estimate certain parameters, and forms the final quantity of interest with them and data from current fold. Additionally, initializing each fold at the global solution enhances the comparability of the constructed
and
across different folds. This cross-fit approach yields improved Type I error control compared to the naive incorporation of full estimates in our empirical experiments.
5 Numerical Studies with Synthetic Data
This section presents an evaluation of SPACO using synthetic Gaussian data. The noise variance is fixed at 1, and the true rank is set to K = 3. The simulated data consists of with dimensions
. The observed rate (i.e.,
the missing rate) along the time dimension is set to
, with observed time stamps chosen randomly for each subject. To generate the data, we first set
and
for
and
. Then, we set
, and
with random parameters
for
. We also set
for
for the first
, and set
otherwise. Here, c1 controls the signal-to-noise ratio (SNR) in the observed tensor X and is referred to as SNR1; c2 captures the signal-to-noise ratio in the auxiliary covariates Z and is also referred to as SNR2. Each Uk is standardized to have mean 0 and variance 1 after generation. This generates 54 different simulation setups in total.
5.1 Reconstruction Quality Evaluation
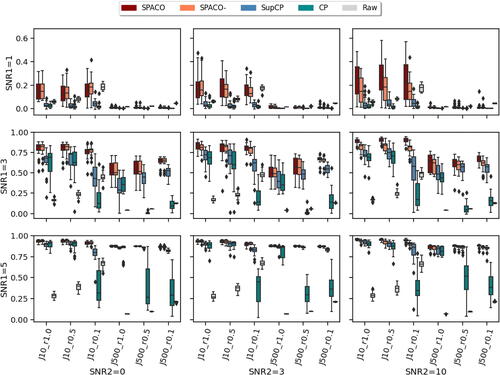
We compare SPACO, SPACO-, plain CP from python package tensorly, and a proxy to SupCP by setting in SPACO as small fixed values (additional small penalties enhance numerical stability when dealing with large q and a high missing rate). Although this is not exactly SupCP, it bears high resemblance. This special case of SPACO is referred to as SupCP, which is included to assess gains from smoothness regularization on the time trajectory. Note that SPACO, SPACO-, and SupCP all employ our proposed initialization, improving stability and performance at high missing rates. An analysis contrasting SupCP with random and proposed initialization is presented in Appendix C.1. In our experiments, we used the true rank for all methods. The accuracy the rank estimation procedure proposed in Section 4.2 is assessed in Appendix C.3. In our experiments, the rank estimation procedure closely approximates the true model rank when the signal is strong, with a tendency to underestimate in cases of weaker signal. This underestimation does not, however, lead to significant increases in reconstruction loss.
shows the achieved correlation between the reconstructed tensors and the underlying signal tensors across various setups and 20 random repetitions. The correlation between two tensors F and is defined as
, where
and
are the demeaned version the original and estimated tensors, respectively, and
is their inner product. Each subplot corresponds to different signal-to-noise ratio combinations (SNR1, SNR2), as indicated by its row and column labels. The y-axis represents the achieved correlation, while the x-axis shows different combinations of J and observation rate. For example, x-axis label
means the feature dimension is 10, and 10% of entries are observed. The “Raw” method, which correlates the true signal with the empirical observation on non-missing entries, is included to demonstrate signal level in different simulation setups, even though it is not directly comparable to other others in the presence of missing data. A comparison of reconstruction quality on missing entries is provided in Appendix C.2.
Fig. 2 Reconstruction evaluation by the correlation between the estimates and the true signal tensor. In each subplot, the x-axis label indicates different J and observing rate, the y-axis is the achieved correlation, and the box colors represent different methods. The corresponding subplot column/row name represents the signal-to-noise ratio SNR1/SNR2.
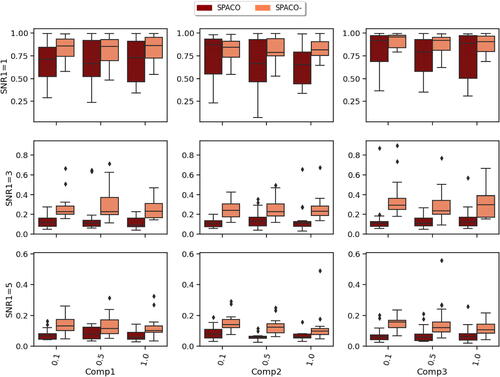
SPACO achieves better reconstruction than SPACO- when subject scores U depend strongly on Z. This is likely due to improved quality in estimating U. To confirm this, we evaluate the estimation quality of U at J = 10 and SNR2 and measure the estimation quality by R2 (regressing the true subject scores on the estimated ones). In , we show the achieved
for SPACO and SPACO- (smaller is better), where the x-axis label represents the observing rate and column names represent the component, for example, Comp1
.
Fig. 3 Comparison of SPACO and SPACO- for reconstructing U at J = 10, SNR2. In each subplot, the x-axis label indicates different component and observing rate, the y-axis is the achieved
, and the box colors represent different methods. The corresponding subplot column/row name represents the signal-to-noise ratio SNR1/component.
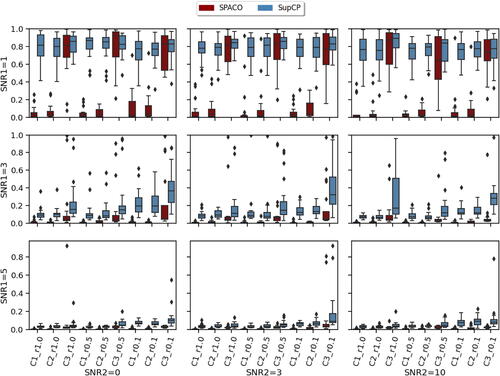
SPACO/SPACO- are both top performers for our smooth tensor decomposition problem and achieve significantly better performance than CP and SupCP when the signal is weak and when the missing rate is high by using the smoothness of the time trajectory. To see this, we compared the estimation quality of the time trajectories using SPACO and SupCP. In , we show the achieved for SPACO and SupCP at J = 10. The x-axis label represents different trajectory and observing rate, for example,
represents estimation of
at observing rate r = 1.0. When the signal is weak (SNR1 = 1), SPACO can approximate the constant trajectory component (C1) and begin to estimate other trajectories successfully as the signal increases. SPACO achieves significantly better estimation of the true underlying trajectories than SupCP for various signal-to-noise ratios.
Fig. 4 Comparison of SPACO and SupCP for reconstructing at J = 10. In each subplot, the x-axis label indicates different component and observing rate, the y-axis is the achieved
, and the box colors represent different methods. The corresponding subplot column/row name represents the signal-to-noise ratio SNR1/SNR2.
5.2 Variable Importance and Hypothesis Testing
We investigate the approximated p-values based on cross-fit for testing the partial and marginal associations of Z with U under the same simulation set-ups. Since our variables in Z are generated independently, the two null hypotheses coincide. Nevertheless, the two tests have different powers given the same p-value cutoff, as a result of different test statistics adopted. The proposed randomization tests for SPACO achieve reasonable Type I error controls. Using Cross-fit is important for maintaining good Type I error control. In Appendix C.5, we present qq-plots comparing p-values using cross-fitted V and to the naive construction. The latter exhibits noticeable deviations from the uniform distribution for the later construction when the signal-to-noise ratio is low. and show the achieved Type I error and power with p-value cutoffs at
and with an observing rate r = 0.5. The Type I errors are also well controlled for
(Appendix C.4).
Fig. 5 Achieved Type I errors at observing rate r = 0.5. In each subplot, x-axis label indicates different combination of feature dimension J and targeted level , while the y-axis represents the achieved Type I errors. Different bar colors represent different tests (partial or marginal). The two dashed horizontal lines correspond to levels 0.01 and 0.05.
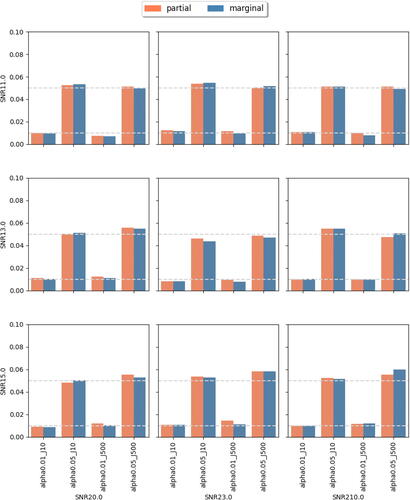
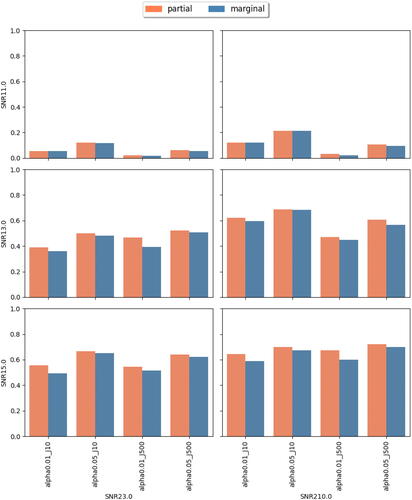
Fig. 6 Achieved power at observing rate r = 0.5. In each subplot, the x-axis label indicates different combinations of feature dimension J and targeted level , the y-axis indicates the achieved power. Different bar colors represent different tests (partial or marginal).
6 Case Study
SPACO was employed to analyze a longitudinal immunological dataset on COVID-19 obtained from the IMPACT study (Lucas et al. Citation2020). The original dataset comprised 180 samples collected from 98 COVID-19 infected participants, measuring 135 immunological features. Features with more than 20% missing observations were excluded, and the remaining missing values were imputed using MOFA (Argelaguet et al. Citation2018) (see Appendix D for more details), resulting a complete matrix of 111 features and 180 samples. This matrix was organized into a sparsely observed tensor of size , where T is the number of unique days from symptom onset (DFSO). The average observing rate along the time dimension was 1.84. Additionally, we had access to auxiliary covariates Z containing eight risk factors (COVID_risk1 - COVID_risk5, age, sex, BMI), as well as four symptom measures (ICU, Clinical score, Length of Stay, Coagulopathy). We ran SPACO with X and Z and SPACO- with X only, selecting a model rank of K = 3 based on 5-fold cross-validation. The three estimated components are denoted as C1/C2/C3. Integrating static covariates Z with the longitudinal measurements can sometimes improve the estimation quality of subject scores compared to SPACO-, as demonstrated in our synthetic data examples. While true subject scores are unobtainable in the real dataset, the clinical relevance of the estimated subject scores can still be assessed by comparing them with clinical responses.
SPACO and SPACO- yielded overall highly similar estimations and subject scores, as depicted in , with the second component exhibiting the largest discrepancy, yet maintaining a correlation above 0.98. Despite this similarity, we observed a noticeable increase in correlations between C2 from SPACO and ICU/Clinical scores/Length of Stay. The permutation p-values from tests on whether the association between these clinical responses are higher with C2 from SPACO than with C2 from SPACO- are 0.006, 0.008, and 0.002 for ICU, Clinical scores and Length of Stay, respectively, as shown in .
Fig. 7 Comparisons between subject scores estimated from SPACO and SPACO- as well as the static risk factors. Panel A displays the high concordance in the correlations between estimated subject scores from SPACO and SPACO-. Panel B shows the correlations with clinical responses (row label) using subject scores from the most distinct component, C2, estimated with SPACO and SPACO-. The associated permutation p-values, which assess the improvement in correlations with the four clinical responses using SPACO, are shown beneath the row label. Panel C shows the correlation between clinical responses and the two most significant risk factors identified through conditional independence testing, COVIDRISK_3 and BMI.
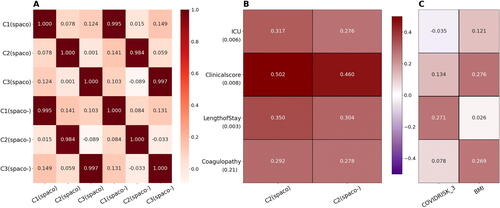
Through the use of the randomization test, we can assess the contribution of each Zj to C2. provides the p-value and adjusted p-value from the conditional independence test, with the number of randomization B = 2000. The top associated risk factor is COVIDRISK_3 (hypertension) with a p-value of 0.001 (adjusted p-value around 0.01). BMI is also weakly associated with C2, with a p-value of 0.07. Both these risk factors displayed much weaker associations with symptom measures when analyzed separately. By including these risk factors in SPACO, the method not only outperforms SPACO-, but also achieves a stronger association with the clinical responses compared to the risk factors themselve ().
Table 1 Results from randomization test for the second component (C2).
7 Discussion
We propose SPACO to model sparse multivariate longitudinal data and auxiliary covariates jointly. The smoothness regularization used in SPACO may lead to a significant improvement in estimation quality, particularly when the missing rate is high. Inclusion of informative auxiliary covariates can also enhance the estimation of subject scores. We applied our proposed pipeline to COVID-19 datasets and demonstrated its effectiveness in identifying components with subject scores that are closely associated with clinical outcomes of interest. Moreover, SPACO can identify static covariates that may contribute to severe symptoms. In the future, we plan to extend SPACO to model multi-omics data, characterized by differing data types, scales, and potentially measurement times. Such an extension will require a tailored model design that carefully integrates the different omics data, rather than a naive approach of blindly pooling them together.
Supplementary Materials
Online Appendices: (Online Appendices.pdf, pdf file) provides additional details of the algorithms, more results from numerical experiments and technical proofs.
Experiment Code: (SPACOexperiments.zip, zip file) It contains code for reproducing results in synthetic and real data experiments, and organized read dataset. A README.md document has been included to for detailed instructions on how to reproduce results represented in this article. Contents in this zip file can also be found at https://github.com/LeyingGuan/SPACOexperments.
Python package for SPACO: (SPACO.zip, zip file) It contains the Python implementation of the SPACO package. Readers can also find and install SPACO from GitHub at https://github.com/LeyingGuan/SPACO.
Acknowledgments
We express our gratitude to the editor, associate editor, and two reviewers for their insightful feedback, which has substantially enhanced the article.
Disclosure Statement
The author reports there are no competing interests to declare.
Additional information
Funding
References
- Acar, E., and Yener, B. (2008), “Unsupervised Multiway Data Analysis: A Literature Survey,” IEEE Transactions on Knowledge and Data Engineering, 21, 6–20. DOI: 10.1109/TKDE.2008.112.
- Anderlucci, L., and Viroli, C. (2015), “Covariance Pattern Mixture Models for the Analysis of Multivariate Heterogeneous Longitudinal Data,” The Annals of Applied Statistics, 9, 777–800. DOI: 10.1214/15-AOAS816.
- Argelaguet, R., Velten, B., Arnol, D., Dietrich, S., Zenz, T., Marioni, J. C., Buettner, F., Huber, W., and Stegle, O. (2018), “Multi-Omics Factor Analysis–A Framework for Unsupervised Integration of Multi-Omics Data Sets,” Molecular Systems Biology, 14, e8124. DOI: 10.15252/msb.20178124.
- Bai, J., and Wang, P. (2015), “Identification and Bayesian Estimation of Dynamic Factor Models,” Journal of Business & Economic Statistics, 33, 221–240. DOI: 10.1080/07350015.2014.941467.
- Bai, J., and Wang, P. (2016), “Econometric Analysis of Large Factor Models,” Annual Review of Economics, 8, 53–80. DOI: 10.1146/annurev-economics-080315-015356.
- Berrett, T. B., Wang, Y., Barber, R. F., and Samworth, R. J. (2020), “The Conditional Permutation Test for Independence While Controlling for Confounders,” Journal of the Royal Statistical Society, Series B, 82, 175–197. DOI: 10.1111/rssb.12340.
- Besse, P., and Ramsay, J. O. (1986), “Principal Components Analysis of Sampled Functions,” Psychometrika, 51, 285–311. DOI: 10.1007/BF02293986.
- Bro, R., and Andersson, C. A. (1998), “Improving the Speed of Multiway Algorithms: Part II: Compression,” Chemometrics and Intelligent Laboratory Systems, 42, 105–113. DOI: 10.1016/S0169-7439(98)00011-2.
- Candes, E., Fan, Y., Janson, L., and Lv, J. (2018), “Panning for Gold: ‘model-x’ Knockoffs for High Dimensional Controlled Variable Selection,” Journal of the Royal Statistical Society, Series B, 80, 551–577. DOI: 10.1111/rssb.12265.
- Carroll, J. D., Pruzansky, S., and Kruskal, J. B. (1980), “Candelinc: A General Approach to Multidimensional Analysis of Many-Way Arrays with Linear Constraints on Parameters,” Psychometrika, 45, 3–24. DOI: 10.1007/BF02293596.
- Chang, W.-C. (1983), “On Using Principal Components before Separating a Mixture of Two Multivariate Normal Distributions,” Journal of the Royal Statistical Society, Series C, 32, 267–275. DOI: 10.2307/2347949.
- Chen, E. Y., Tsay, R. S., and Chen, R. (2020), “Constrained Factor Models for High-Dimensional Matrix-Variate Time Series,” Journal of the American Statistical Association, 115, 775–793. DOI: 10.1080/01621459.2019.1584899.
- De Lathauwer, L., De Moor, B., and Vandewalle, J. (2000), “A Multilinear Singular Value Decomposition,” SIAM Journal on Matrix Analysis and Applications, 21, 1253–1278. DOI: 10.1137/S0895479896305696.
- Efron, B., Tibshirani, R., Storey, J. D., and Tusher, V. (2001), “Empirical Bayes Analysis of a Microarray Experiment,” Journal of the American Statistical Association, 96, 1151–1160. DOI: 10.1198/016214501753382129.
- Ernst, M. D. (2004), “Permutation Methods: A Basis for Exact Inference,” Statistical Science, 19, 676–685. DOI: 10.1214/088342304000000396.
- Fan, J., Fan, Y., and Lv, J. (2008), “High Dimensional Covariance Matrix Estimation Using a Factor Model,” Journal of Econometrics, 147, 186–197. DOI: 10.1016/j.jeconom.2008.09.017.
- Fan, J., Liao, Y., and Mincheva, M. (2011), “High Dimensional Covariance Matrix Estimation in Approximate Factor Models,” Annals of Statistics, 39, 3320–3356. DOI: 10.1214/11-AOS944.
- Fisher, R. A. (1936), “Design of Experiments,” British Medical Journal, 1, 554. DOI: 10.1136/bmj.1.3923.554-a.
- Harshman, R. A., and Lundy, M. E. (1994), “Parafac: Parallel Factor Analysis,” Computational Statistics & Data Analysis, 18, 39–72. DOI: 10.1016/0167-9473(94)90132-5.
- Hinrich, J. L., and Mørup, M. (2019), “Probabilistic Tensor Train Decomposition,” in 2019 27th European Signal Processing Conference (EUSIPCO), pp. 1–5, IEEE. DOI: 10.23919/EUSIPCO.2019.8903177.
- Huang, J. Z., Shen, H., and Buja, A. (2008),“Functional Principal Components Analysis via Penalized Rank One Approximation,” Electronic Journal of Statistics, 2, 678–695. DOI: 10.1214/08-EJS218.
- Imaizumi, M., and Hayashi, K. (2017), “Tensor Decomposition with Smoothness,” in International Conference on Machine Learning, pp. 1597–1606, PMLR.
- Kolda, T. G., and Bader, B. W. (2009), “Tensor Decompositions and Applications,” SIAM Review, 51, 455–500. DOI: 10.1137/07070111X.
- Lam, C., Yao, Q., and Bathia, N. (2011), “Estimation of Latent Factors for High-Dimensional Time Series,” Biometrika, 98, 901–918. DOI: 10.1093/biomet/asr048.
- Li, G., Shen, H., and Huang, J. Z. (2016), “Supervised Sparse and Functional Principal Component Analysis,” Journal of Computational and Graphical Statistics, 25, 859–878. DOI: 10.1080/10618600.2015.1064434.
- Lock, E. F., and Li, G. (2018), “Supervised Multiway Factorization,” Electronic Journal of Statistics, 12, 1150–1180. DOI: 10.1214/18-EJS1421.
- Lucas, C., Wong, P., Klein, J., Castro, T. B., Silva, J., Sundaram, M., Ellingson, M. K., Mao, T., Oh, J. E., Israelow, B., et al. (2020), “Longitudinal Analyses Reveal Immunological Misfiring in Severe Covid-19,” Nature, 584, 463–469. DOI: 10.1038/s41586-020-2588-y.
- Mnih, A., and Salakhutdinov, R. R. (2007), “Probabilistic Matrix Factorization,” in Advances in Neural Information Processing Systems (Vol. 20), pp. 1257–1264.
- Onghena, P. (2017), “Randomization Tests or Permutation Tests? A Historical and Terminological Clarification,” in Randomization, Masking, and Allocation Concealment, pp. 209–228, New York: Chapman and Hall/CRC.
- Phan, A.-H., Tichavskỳ, P., and Cichocki, A. (2013), “Candecomp/parafac Decomposition of High-Order Tensors through Tensor Reshaping,” IEEE Transactions on Signal Processing, 61, 4847–4860. DOI: 10.1109/TSP.2013.2269046.
- Pitman, E. J. G. (1937), “Significance Tests Which May be Applied to Samples from any Populations. II. The Correlation Coefficient Test,” Supplement to the Journal of the Royal Statistical Society, 4, 225–232. DOI: 10.2307/2983647.
- Rendeiro, A. F., Casano, J., Vorkas, C. K., Singh, H., Morales, A., DeSimone, R. A., Ellsworth, G. B., Soave, R., Kapadia, S. N., Saito, K., et al. (2021), “Profiling of Immune Dysfunction in Covid-19 Patients Allows Early Prediction of Disease Progression,” Life Science Alliance, 4, e202000955. DOI: 10.26508/lsa.202000955.
- Sidiropoulos, N. D., De Lathauwer, L., Fu, X., Huang, K., Papalexakis, E. E., and Faloutsos, C. (2017), “Tensor Decomposition for Signal Processing and Machine Learning,” IEEE Transactions on Signal Processing, 65, 3551–3582. DOI: 10.1109/TSP.2017.2690524.
- Sorkine, O., Cohen-Or, D., Lipman, Y., Alexa, M., Rössl, C., and Seidel, H.-P. (2004), “Laplacian Surface Editing,” in Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing, pp. 175–184.
- Tibshirani, R. (2011), “Regression Shrinkage and Selection via the Lasso: A Retrospective,” Journal of the Royal Statistical Society, Series B, 73, 273–282. DOI: 10.1111/j.1467-9868.2011.00771.x.
- Tipping, M. E., and Bishop, C. M. (1999), “Probabilistic Principal Component Analysis,” Journal of the Royal Statistical Society, Series B, 61, 611–622. DOI: 10.1111/1467-9868.00196.
- Vichi, M., Rocci, R., and Kiers, H. A. (2007), “Simultaneous Component and Clustering Models for Three-Way Data: Within and between Approaches,” Journal of Classification, 24, 71–98. DOI: 10.1007/s00357-007-0006-x.
- Viroli, C. (2011), “Finite Mixtures of Matrix Normal Distributions for Classifying Three-Way Data,” Statistics and Computing, 21, 511–522. DOI: 10.1007/s11222-010-9188-x.
- Wang, D., Liu, X., and Chen, R. (2019), “Factor Models for Matrix-Valued High-Dimensional Time Series,” Journal of Econometrics, 208, 231–248. DOI: 10.1016/j.jeconom.2018.09.013.
- Wang, D., Zheng, Y., Lian, H., and Li, G. (2021), “High-Dimensional Vector Autoregressive Time Series Modeling via Tensor Decomposition,” Journal of the American Statistical Association, 117, 1338–1356. DOI: 10.1080/01621459.2020.1855183.
- Yao, F., Müller, H.-G., and Wang, J.-L. (2005), “Functional Data Analysis for Sparse Longitudinal Data,” Journal of the American Statistical Association, 100, 577–590. DOI: 10.1198/016214504000001745.
- Yokota, T., Zhao, Q., and Cichocki, A. (2016), “Smooth Parafac Decomposition for Tensor Completion,” IEEE Transactions on Signal Processing, 64, 5423–5436. DOI: 10.1109/TSP.2016.2586759.