
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a distribution-free distance-based method for high dimensional change points that can address challenging situations when the sample size is very small compared to the dimension as in the so-called HDLSS data or when non-sparse changes may occur due to change in many variables but with small significant magnitudes. Our method can detect changes in mean or variance of high dimensional observations as well as other distributional changes. We present efficient algorithms that can detect single and multiple high dimensional change points. We use nonparametric metrics, including a new dissimilarity measure and some new distance and difference distance matrices, to develop a procedure to estimate change point locations. We also introduce a nonparametric test to determine the significance of estimated change points. We provide theoretical guaranties for our method and demonstrate its empirical performance in comparison with some of the recent methods for high dimensional change points. An R package called HDDchangepoint is developed to implement the proposed method.
Disclaimer
As a service to authors and researchers we are providing this version of an accepted manuscript (AM). Copyediting, typesetting, and review of the resulting proofs will be undertaken on this manuscript before final publication of the Version of Record (VoR). During production and pre-press, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal relate to these versions also.1 Introduction
Change point analysis is frequently used in various fields such as economics, finance, engineering, genetics and medical research. The main objective is to detect significant changes in the underlying distribution of a data sequence. The change point problem is well studied for low dimensional data in the literature, however change point analysis is challenging for high dimensional data which are growing in different domains. A change could happen in a small or large subset of the variables and with a small or large magnitude, but when the sample size is small compared to the number of variables it is difficult to distinguish a significant change point from just random variability.
In recent years there has been increasing interest in the so-called high-dimensional low-sample-size (HDLSS) data where the sample size n is very small while the dimension p can be very large. The asymptotics for HDLSS data is different than the usual high dimensional asymptotic setting (i.e., ) in the sense that
but the sample size n can remain fixed (e.g., Hall et al., 2005; Jung and Marron, 2009; Li, 2020). Detecting change points is more challenging for HDLSS data with small samples. In this paper, we will see that recent methods for high dimensional change points struggle to have a good performance with HDLSS data where sample size is very small compared to dimension.
A common strategy in the literature of high dimensional change points is to simplify the problem by reducing the dimension of data so a simpler algorithm such as a univariate change point algorithm can be applied to the transformed data. This may be done using random projection (e.g., Wang and Samworth, 2018; Hahn et al., 2020), geometric mapping (e.g., Grundy et al., 2020) or any other relevant techniques such as principal components (e.g., Xiao et al., 2019), factor analysis (e.g., Barigozzi et al., 2018) and regularisation approaches (e.g., Lee et al., 2016; Safikhani and Shojaie, 2022). This strategy relies on sparsity, often a significant amount of sparsity, to maintain its oracle performance. Such techniques may not be suitable for non-sparse change point problems. By non-sparse change points, we mean the changes that can happen in many variables and with small significant magnitudes.
Another strategy is to search for change point locations through dissimilarity distances between pairs of observations. This may be done using appropriate dissimilarity measures such as the interpoint distances (e.g., Li, 2020) or the divergence measures based on Euclidean distance (e.g., Matteson and James, 2014). Some authors including Garreau and Arlot (2018) and Chu and Chen (2019) indirectly use interpoint distances to develop methods based on counting the number of edges from a certain similarity graph constructed from interpoint distances. The performance, especially power, of such methods generally depends on distance measures and test statistics used, as also discussed in Li (2020). In this paper, we aim to develop a novel powerful method for detecting high dimensional change points based on dissimilarity measures, especially suitable for HDLSS data.
There has been a growing literature on change point analysis for high dimensional data in recent years. We review some of the recent methods focusing on offline change point detection. Chen and Zhang (2015), Garreau and Arlot (2018) and Chu and Chen (2019) developed change-point detection methods using kernels and similarity graphs. Wang and Samworth (2018) proposed a two-stage procedure called inspect for estimation of change points, which is based on random projection and sparsity. Their approach assumes the mean structure changes in a sparse subset of the variables and requires the normality assumption. Enikeeva and Harchaoui (2019) suggested a method for detecting a sparse change in mean in a sequence of high dimensional vectors. This method was studied for a single change point detection and was developed based on the normality assumption. Grundy et al. (2020) used geometric mapping to project the high dimensional data to two dimensions, namely distances and angles. Their approach requires the normality assumption. Liu et al. (2020) developed a general data-adaptive framework by extending the classical CUSUM statistic to construct a U-statistic-based CUSUM matrix. Their approach is based on the independence assumption for variables and is mainly studied for single change point detection. Li (2020) proposed an asymptotic distribution-free distance-based procedure for change point detection in high dimensional data. Using the random projection approach of Wang and Samworth (2018), Hahn et al. (2020) proposed a Bayesian algorithm to efficiently estimate the projection direction for change point detection. Yu and Chen (2021) established a bootstrap CUSUM test for finite sample change point inference in high dimensions. Follain et al. (2022) extended the random projection approach to estimate change points with heterogeneous missingness. There have also been a few other methods, some of which are reviewed in Liu et al. (2022).
Below we highlight the importance of our work and summarise our main contributions.
Change point detection for HDLSS data, when the sample size is very small, is challenging and understudied. Also, many of the existing methods focused on sparse change points (e.g., Wang and Samworth, 2018; Enikeeva and Harchaoui, 2019; Follain et al., 2022). Our method can deal with non-sparse high dimensional situations. Unlike existing methods which mainly detect changes in mean of high dimensional observations, our method can detect changes in mean or variance of observations and other distributional changes.
Unlike most of the recent methods for high dimensional change point detection which require the normality assumption as reviewed above, our approach does not require normality or any other distribution for variables. We use novel nonparametric tools to develop a method to detect change point locations.
Many of the recent methods in the literature either used a bootstrap/permutation procedure or derived asymptotic distribution to test significance of change points (e.g., Wang and Samworth, 2018; Yu and Chen, 2021). We establish both asymptotic and permutation procedures for our method to handle both small and large sample size situations.
Our strategy is to search for change point locations through an n × n matrix of distances instead of the n × p matrix of observations. Because the n × n matrix of distances has a smaller dimension which does not grow with p, it would be easier mathematically and computationally to investigate the distance matrix for a change point location.
We use the following notation throughout the paper. For a vector , we write the Lq
-norm as
. The infinity norm is defined as
. We write
as the short version of square root. For a real-value constant a, notation
denotes the absolute value of a, while for a set C,
denotes the cardinality of C. Also,
and
denote the usual big O and little o notation. We sometimes write
or
to emphasise them for
. We write
and
to denote, respectively, the big O in probability and the little o in probability. We use
and
for convergence in probability and convergence in distribution, respectively. We also define some more specific notation as we develop the paper.
2 Methodology
Let be a sequence of independent p-dimensional random vectors with unknown probability distributions
, respectively. In high dimensional settings we have
and that the p variables in each observation
are potentially correlated. We aim to develop a distribution-free approach, so we do not assume a parametric form for the distributions
.
For the sake of clarity, we first present the proposed approach for detecting a single change point in high dimensions and then extend the idea for multiple change point detection in Section 3. The problem of detecting a single change point in general can be formulated as the following hypothesis testing problem(1)
(1) where τ is a change point location, which is unknown too. When conducting this single change point problem, we first estimate the change point location τ and then test for significance of the estimated change point.
Let represent the entire data as an n × p matrix. As discussed in the introduction, the problem of change point detection in high dimensional situations is challenging, especially when n is very small compared to p. In our approach, instead of searching in the n × p space, we translate the problem into the lower dimensional space n × n without reducing the dimension of data. This is different than the dimensionality reduction techniques such as random projection (e.g., Wang and Samworth, 2018), geometric mapping (e.g., Grundy et al., 2020), principal components (e.g., Xiao et al., 2019) and factor analysis (e.g., Barigozzi et al., 2018) which reduce the dimension of data. We propose a distance-based method based on dissimilarity measures to find the change point location in the original data
through the distance matrix of
. The dimension of the observed data
is n × p while the dimension of its distance matrix is n × n, so it is easier mathematically and computationally to investigate the distance matrix for a change point location as n is small compared to p in high dimensions, especially in HDLSS data. We describe the idea in the sequel.
Let be a dissimilarity distance between observations
and
, where
is a suitable dissimilarity distance function for high dimensional vectors. Since our proposal can be implemented with any suitable dissimilarity distance, we discuss the choice of dissimilarity distance measure after illustrating the main mechanism. We use the dissimilarity measure dij
to obtain the n × n distance matrix between all pairs of the observations
as follows
in which
.
To find the location of change point τ, we propose a procedure that finds an estimate of τ by finding the maximum distance between observations in the distance matrix D. For this, we define the distance difference between each pair of the observations as
This gives the following n × n matrix of distance differences, which we call difference distance matrix,
We then suggest an estimate of the change point location τ, based on the difference distance matrix Δ, as follows(2)
(2)
The change point estimate is the location of maximum slope among the column sums of the difference distance matrix Δ (a simple illustrative example will be given later in Figure 1). If
for all
or if they all are equal, then we set
, where the empty set
means no change point is detected.
It is known that the Euclidean distance is not appropriate for high dimensional situations. A modified version of Euclidean distance can be obtained by dividing it by for convergence guarantees in high dimensions, as suggested by Hall et al. (2005). One can use the modified Euclidean distance
or other Lq
-norm distances in our approach. However, a more general dissimilarity measure that takes into account the information of distances from all the n – 2 other observations can be defined as
(3)
(3) where
can be any appropriate distance function. We here suggest two simple options for this. A natural multivariate option is to use the modified Euclidean distance function
or modified L1-norm
. A univariate option is to use a distance function based on differences between the sample mean and variance of the observations. For this, let
and
denote, respectively, the mean and standard deviation of the i-th observation
. We define
, which quantifies the differences between the sample mean and variance of each pair of observations.
The following theorem shows the dissimilarity measure in (3) is a pseudometric, that is
and
. The proof along with all other technical proofs are provided in Appendix A.
Theorem 1. The dissimilarity measure in (3) is a pseudometric on
for
.
The following theorem indicates that proximity in terms of the modified Euclidean distance implies proximity in terms of , but the converse implication does not hold.
Theorem 2. Consider the dissimilarity measure in (3) and the Euclidean distance
for each pair of observations
and
. We have
.
In Section 4, we show that if
and
have the same distribution. The computational cost of the dissimilarity measure
is of order O(np). The cost of computing
for all
is
with n not being fixed. The cost is O(p) with fixed n as in HDLSS data.
We here provide a simple illustrative example with one change point for which we generate 5 observations from a standard multivariate normal distribution with p = 500 and another 5 observations from the same distribution but with the mean being shifted by 0.5. Figures 1(a) and 1(b) visualise all elements of the distance matrix D obtained using the dissimilarity measure in (3) with both the univariate distance function based on differences of the sample mean and variance of observations and the multivariate distance function based on the modified Euclidean distance. From both plots, it can be seen that the observations from the first distribution show a larger dissimilarity with the observations from the second distribution, and vice versa, so both distance functions capture the change point trend. More interestingly, Figure 1(c) visualises all elements of the matrix Δ based on the dissimilarity measure (3), which indicates that the change point location (i.e., location 6) has the largest values
. Also, Figure 1(d) presents all the column sums of Δ, which reveals the change point location exactly as in the proposed estimate
in (2). In Section 4, we will prove that
is consistent for the true change point, denoted by τ0, under some assumptions.
We now construct a test statistic based on the change point estimate to conduct the test whether or not the change point estimate
is statistically significant. Our proposed test statistic uses the information of dij
and Δij
before and after the change point estimate
. For this, considering the hypothesis test (1), we first define two sets of indices one for observations before and one for observations after the change point estimate
as follows
The two sets and
are visualised in Figure 2, showing their connection with the change point candidate
. We then propose the following test statistic for testing the significance of change point estimate
(4)
(4) where
and
are the cardinalities of
and
, respectively.
We will investigate the theoretical properties of the statistic in Section 4. Intuitively, the test statistic
quantifies the differences between distances for the observations before change point and the observations after change point. If there is no change point then the differences will be small, and if there is a change point then
will deviate from 0. In fact, we will prove that as
where
is specified in Theorem 3 with τ0 being the true change point. We can therefore carry out the hypothesis test for a single change point and reject the null hypothesis H0 for large values of
. For large n, we conduct the test using the asymptotic distribution of
under H0, when
. In Theorem 7, we will prove that the asymptotic distribution of
, denoted by
, is a normal distribution as
under some assumptions, so that
under H0, where
and
are specified in the statement of Theorem 7.
For small n, we use a permutation procedure based on to conduct the test. Permutation testing is useful here because all the observations have the same distribution under H0 and hence are exchangeable or permutable. In each permutation step, we randomly permute the indices of observations before and after the change point estimate
, while holding the change point location, to get a random permutation sample. Based on R permutations, the approximate permutation distribution of the test statistic, denoted by
, is defined as
(5)
(5) where
is the indicator function and
is the test statistic calculated for the r-th permutation sample. The p-value of the permutation test, denoted by
, is given by
(6)
(6)
where
is the test statistic for the observed sample. Our theoretical results show that
for all
. We will show the asymptotic and permutation tests are equivalent asymptotically under H0, that is
for all t as
. Algorithm 1 summarises our proposed method for single change point detection in high dimensional data.
Algorithm 1: Single change point detection
Input: A data sequence or matrix of observations .
Output: Change point estimate , or “NA” if there is no significant change point.
Step 1: Calculate the n × n distance matrix D for the n × p data matrix .
Step 2: Calculate the n × n difference distance matrix Δ.
Step 3: Calculate the change point estimate . If
stop the algorithm and return “NA” for no detected change point. Otherwise, go to the next step.
Step 4: Calculate the test statistic .
Step 5: Apply the permutation test based on if n is small, or the asymptotic test if n is large, to test the significance of the change point estimate
.
Step 6: If it is significant, return the change point estimate . Otherwise, return “NA” for no significant change point.
In addition to estimation and hypothesis test for change point τ, we can also construct confidence interval for change point location τ using the change point estimate . Finding the exact or asymptotic distribution of the change point estimate (2) is difficult due to the absolute value functions in both the definition of Δij
and the dissimilarity measure dij
in (3). We instead obtain a permutation-based confidence interval for τ. Unlike the above permutation procedure which conducts under H0, we here obtain a permutation sample by separately permuting observations before and after the change point location τ among themselves. The reason is that observations before the change point τ have the same distribution and observations after the change point τ also have the same distribution. We calculate the change point estimate (2) for each permutation sample from R permutations and denote these permutation estimates by
. Then, a
confidence interval for change point location τ is
(7)
(7) in which
and
are, respectively, the
-th and
-th percentiles of the R ordered permutation estimates.
3 Multiple change point detection
In this section, we extend our approach to detect multiple change points in high dimensional data. The problem of detecting multiple change points in general can be formulated as(8)
(8) where
are the unknown change point locations and s is the number of change points, which is also unknown. If the above null hypothesis is rejected, the main objective will be to find the s change point estimates
.
Similar to the illustrative example in Figure 1 for single change point, Figure 3 shows how the dissimilarity measure (3) and the proposed approach based on the difference distance matrix Δ can be helpful for finding multiple change points (here the same settings as previous example but with two true change points at locations 6 and 11). To carry out the problem of multiple change points, we use a recursive binary segmentation procedure on the basis of our method for single change point detection. We also demonstrate combining with the wild binary segmentation procedure of Fryzlewicz (2014) at the end of this section. We sequentially apply the proposed single change point method to uncover all significant change points in the data according to our asymptotic or permutation test. Suppose that s change points are detected sequentially and denoted by . We use the notation
because the detected change points using binary segmentation are not necessarily in increasing order, when there are more than one change point. Note that
.
The recursive binary segmentation starts with applying the single change point algorithm to the data sequence , and if a change point is detected then the data sequence will be split to two segments (data sub-sequences) before and after the detected change point in order to continue the same process with each data sub-sequence separately for any further change points. Let bk
and ek
denote the beginning and ending indices of observations for a data sub-sequence, say
, for finding a potential change point
. We apply the single change point algorithm to this data sub-sequence and if a change point location
is detected, we split the data sequence
to two sub-sequences before and after the change point
, say
and
respectively. We apply the single change point algorithm to each of these two sub-sequences to check for further change points. We continue the process until no further change points are detected.
For multiple change point detection, we extend the formula of single change point estimate (2) and write the estimate of the change point location γk
as follows(9)
(9) where we note that
and
, implying
. When checking the significance of the change point estimate
, we need to update both
and
according to the change point estimate
. For this, the two sets of indices for observations before and after the change point estimate
are expressed as
To conduct the test for significance of , the test statistic can be defined similarly as
which simplifies to the test statistic (4) when k = 1. Algorithm 2 summarises our method for multiple change point detection.
Algorithm 2: Multiple change point detection
Input: A data sequence or matrix of observations .
Output: A list of significant change point estimates , or “NA” if there is no significant change point.
Step 1: Apply the single change point Algorithm 1 to the data sequence . If there is no significant change point, end the process and return “NA”. Otherwise, denote the detected change point by
and go to next step.
Step 2: Split the data sequence to two sub-sequences before and after the detected change point. Apply Algorithm 1 to each of the two sub-sequences separately to check for further change points.
Step 3: Repeat Step 2 until no further sub-sequences have significant change points.
Step 4: Denote all the detected change points by . Return
as a list of significant change points.
We also incorporate the wild binary segmentation procedure of Fryzlewicz (2014) in our proposal for multiple change points. For this, following the principle of wild binary segmentation, we first randomly draw a large number of pairs from the whole domain
including the pair
, and find
for each draw. The candidate change point location is the one that has the largest
among all the draws. We test the significance of the change point candidate using either the asymptotic or permutation test. If it is significant, the same procedure will be repeated to the left and to the right of it. The process is continued recursively until there is no further significant change point. The theory of wild binary segmentation shows it performs at least as good as the standard binary segmentation. Algorithm 2 then easily updates with the wild binary segmentation.
4 Asymptotic results
We study the asymptotic properties of our method for detecting single and multiple high dimensional change points. We establish the theory with both the multivariate modified Euclidean distance function and the univariate distance function based on differences between the sample mean and variance of observations, although one could see that the theory could similarly follow with other suitable distance measures including other Lq -norm distances. We study the situations when both n and p approach infinity, as well as when p approaches infinity but n remains finite as in HDLSS data.
To develop the asymptotic theory with based on the multivariate modified Euclidean distance function, according to Hall et al. (2005) we make the following three assumptions on observations
.
(A1) Assume that .
(A2) Assume and
for
.
(A3) Assume .
Alternatively, for using the univariate distance function based on differences between the sample mean and variance of observations, we make the following assumptions.
(B1) Assume that .
(B2) Let and define
. Assume
.
(B3) For all and
, define
and assume
and
as
.
(B4) Assume and
as
.
(B5) Assume as
.
Assumptions (A1)-(A3) are required for the convergence of the modified Euclidean distance used by Hall et al. (2005), Li (2020), and many others. Assumption (A3) implies weak dependence among variables and is only needed for the case of correlated variables, which is trivial if the variables are independent. Assumptions (B1) and (B2) ensure bounded second moments for convergence of the mean and standard deviation
. Assumption (B3) is the usual Lindeberg condition which is a common assumption for applying central limit theorem (a weaker condition compared to Lyapunov condition). Assumptions (B4)-(B5) imply weak dependence among variables and are only required for the case of correlated variables. Assumptions (B4) guarantees bounded covariances for the case of correlated variables
, which is a typical assumption for dependent variables to satisfy the conditions for central limit theorem and weak law of large numbers. Assumption (B5) is a similar covariance condition for
which can be simplified since
. Note that Assumptions (B1) and (B2) imply
. We also note that Assumptions (A3) and (B4)-(B5) hold for variables with the ρ-mixing property (e.g., Utev, 1990) as well as with the spatial dependence (e.g., Wang and Samworth, 2018), so we here consider a more general dependence structure. For instance, under the spatial dependence
with
, it is easy to show
.
If observations and
have the same distribution, we can write
and alsoin which
and
for
. Note that
and
. The following theorem concerns the asymptotic behaviour of the dissimilarity measure
for high dimensional observations.
Theorem 3. Consider the data sequence and dissimilarity measure
in (3). Suppose that τ is a change point so that
. We have
as
, where for the modified Euclidean distance function, under Assumptions (A1)-(A3),
while for the univariate distance function based on differences between the sample mean and variance, under Assumptions (B1)-(B4),
The next two theorems provide guaranties for consistency of the proposed single change point estimate (2) for high dimensional observations when and n is fixed, as well as when
and n diverges too.
Theorem 4. Suppose that there is a true single change point τ0, , so that
. Under the assumptions of Theorem 3, (a) we have as
, with any fixed n,
where
under Assumptions (A1)-(A2) or (B1)-(B2).
(b) it follows , hence the change point estimate
is consistent for τ0 as
.
From this theorem, the consistency of the proposed change point estimate holds when and n is fixed as in HDLSS data. In the following result, we show that the consistency also holds when
as well, as one expects.
Theorem 5. Under the conditions in Theorem 4, we have as and
The next theorem studies the asymptotic limit of the proposed test statistic (4) under the null hypothesis H0 as well as under the alternative hypothesis .
Theorem 6. Suppose that there is a true single change point τ0, , and consider the test statistic
in (4) based on the change point estimate
. Under the above assumptions, we have as
The following theorem proves that the asymptotic distribution of the test statistic (4) is a normal distribution under above conditions when both n and p go to infinity.
Theorem 7. Consider the test statistic in (4) for testing a significant change point. Under the null hypothesis H0 and the above assumptions, we have as
and
where
is defined as standardised test statistic. For the univariate distance function we have
and
where
and and
. For the multivariate modified Euclidean distance function we have
and
Remark. We use estimates of the constant quantities vij
and to calculate
and
. Following Slutsky’s theorem, the result of Theorem 7 also holds when plugging in consistent estimates of the quantities vij
and
. For the univariate distance case, we get a consistent estimate of
in vij
using (under Assumption (B4))
and . Similarly, we get a consistent estimate of
in
by first using (under Assumption (B4))
(10)
(10) and
, and then applying the delta method to obtain the required estimate as
. Note that the last equality in (10) is obtained by applying the Taylor expansion
. Also for the modified Euclidean distance case, under Assumption (A3), we use the consistent estimates of
and
as obtained in Li (2020).
We now study the optimality and detection power of the proposed method and obtain conditions for optimal detection rates and full power.
Theorem 8. Consider the conditions in Theorem 3 and Theorem 7. We have, as ,
where
is the CDF of standard normal distribution,
is the corresponding critical point of standard normal distribution,
with
given in Theorem 7, and
with
where bijkl is specified in the proof of theorem.
Under Assumptions (B4)-(B5) or (A3) the covariances are bounded asymptotically, so c and are finite. So, with
, the test is consistent and has full power as
, that is,
Also, with fixed n as in HDLSS data, the test is consistent if diverges. The following results demonstrate this for two cases when there is a change point in mean and when there is change in variance of observations considering the sparsity level and the change magnitude.
Corollary 1. Consider a change point in mean of high dimensional observations, while variance remains unchanged, with the mean shift , for all
. Let
be the set of variables having a change point with
being its cardinality or the sparsity level. Then,
and
Hence, with fixed n, the test is consistent if . In particular, when
for all
with
, the optimality is achieved if
Corollary 2. Consider a change point in variance of high dimensional observations, while mean remains unchanged, with the variance shift , for all
. Let
be the set of variables having a change point in this case with
being the sparsity level. Then,
. Hence, similar to Corollary 1, with fixed n, the test is consistent if
, where the assumption of finite variance implies
. In particular, when
for all
with
, the optimality is achieved if
We now demonstrate the consistency of multiple change point estimates from Algorithm 2 for multiple high dimensional change point detection.
Theorem 9. Suppose there are s true change points , so that
. Assume the minimum spacing between change points satisfies
for some M > 0 and
. Under the above assumptions, Algorithm 2 returns the change point estimates
that satisfy
.
Note that the condition ensures that there are not too many change points to detect, because it implies that
since
. The following result shows that the asymptotic test and the permutation test are equivalent asymptotically and that the permutation test is also unbiased when
and
.
Theorem 10. Consider the asymptotic test with the distribution obtained in Theorem 7 as well as the permutation test with the approximate permutation distribution
in (5) and with the permutation-based p-value
in (6). Assume the above assumptions hold. Under the null hypothesis H0 of no change points, we have as
and
(a) ,
(b) .
5 Numerical results
In this section, we evaluate the performance of the proposed methods under various simulation scenarios and in comparison with some of the recent methods in the literature for high dimensional change points. We compare our methods with the nonparametric method proposed by Matteson and James (2014), called E-divisive, the method based on random projection developed by Wang and Samworth (2018), called Inspect, and the nonparametric method of Li et al. (2019) for high dimensional change points, called HDcpdetect. In the simulations, we set the tuning parameter selection of these methods as the recommended defaults in their R packages. We assess the performance of all the methods for detecting a single change point as well as multiple change points under different scenarios, especially for the challenging situation when n is very small compared to p as in HDLSS data. We investigate the performance of our asymptotic and permutation tests using both the univariate and multivariate distance functions. In the simulations we find that the results of our method with the univariate and multivariate distance functions are quite similar, so for simplicity of presentation and comparisons with the other methods, we avoid presenting duplicate results unless when the results are different as in Section 5.4. Some simulation results are deferred to Appendix B due to space limitation.
5.1 Simulations for a single change in mean
We first start with the case of a single change point in mean of high dimensional observations, where we generate data with n random observations from a p-variate normal distribution, where the first
observations are generated from
and the other
observations are generated from
. We consider different high dimensional settings with
and
, as well as with
and
where
and
denote p-dimensional vectors of zeros and ones, respectively. We here set
where
and
represents the covariance structure of data. In the simulations, we consider two covariance structures: the uncorrelated structure
where
is the identity matrix of size p, and the correlated autoregressive structure
. Note that the true change point location here is
for all scenarios, except for the scenario when
as it implies there is no change point. We consider 250 replications for each simulation scenario and use R = 200 random permutations for the permutation test. We apply each of the change point methods to the generated data sets and record, in addition to the change point estimates, the frequency and average number of detected change points over 250 replications for each method. The results on frequency and average number of the change points detected are presented in Table 1. From the table, it can be seen that all the methods perform well when there is no change point, but for the cases with a true change point our proposed method based on both the asymptotic and permutation tests performs better than all the other methods E-divisive, Inspect and HDcpdetect. On average across the 250 replications, the proposed method detects the change point in a higher frequency compared to the other methods under all scenarios considered. We note that the method Inspect of Wang and Samworth (2018) is not very competitive under such non-sparse high dimensional scenarios because it requires sparsity and performs better with much larger sample sizes n when p is very large (see Wang and Samworth, 2018; Hahn et al., 2020; Follain et al., 2022). Also, Figure 4 presents the box plots of the estimated change point from each of the methods over 250 replications. The box plots show that the proposed method also produces a more accurate change point estimate compared to the other methods. The performance of our method for the correlated autoregressive structure is similar, so we skip the similar results because of space limitation.
5.2 Simulations for multiple changes in mean
We next consider the case of multiple change points in mean of high dimensional observations, where we use the same simulation settings as before but here with three true change points in the simulated data. For this, we generate data with n random observations from a p-variate normal distribution, where the first
observations are generated from
, the next
observations are generated from
, the next
observations are generated from
and the last
observations are generated from
. So the three true change point locations here are
and
. We again use 250 replications for each simulation scenario and apply the proposed method and the other methods to the generated data sets. We here set the minimum segment length to 5. For each method we calculate the frequency and average number of the correctly detected change points over 250 replications. We also calculate the total number of change points detected (correct or incorrect detection). Table 2 shows the results on frequency and average number of the correctly detected change points for each method. From the results in Table 2, we can see that all the methods tend to perform well in the cases when there is no change point. For the cases with three true change points, our method based on both the asymptotic and permutation tests outperforms all the other methods in all scenarios considered. The frequency of the correctly detected change points, reported in the table, shows that the proposed method detects the true change points more accurately compared to the other methods. The performance of our method and the E-divisive by Matteson and James (2014) improves when the dimension p increases, but this is not the case for the Inspect by Wang and Samworth (2018) as it relies on sparsity and tends to improve with the sample size n (see Wang and Samworth, 2018; Hahn et al., 2020; Follain et al., 2022). The average number of correctly detected change points over the 250 replications is much closer to the actual number of true change points for our method in the case of multiple change points too. The results on average number of the total change points detected (correct or incorrect) are reported in Figures 5(a) and 5(b), which suggest that our method does not over-detect or under-detect change points.
5.3 Simulations for a change in variance
We then investigate the performance of the methods for detecting a change in variance of observations while mean remains unchanged. We consider two scenarios for this when the variance of observations is increased by 0.1 and 0.2, that is and
, while the mean of observations is the same, that is
. The simulation results for all the methods considered are reported in Table 3. From the results, one can see that our proposed method based on both the asymptotic and permutation tests perform well in detecting such a change in variance, but the other methods do not have power for detecting the change point due to the variance of observations.
5.4 Simulations for change in distribution while mean and variance remain unchanged
It is a challenging problem for many methods in the literature to detect a change in distribution while the mean and variance of observations remain unchanged (see Zhang and Drikvandi, 2023). We consider two simulation scenarios for this with n = 45 and a change in distribution at location 28 when the variables for observations are generated from and t(5) respectively, both having the same means and variances, as well as from N(1, 1) and
. Considering the asymptotic limit of the univariate distance function and the modified Euclidean distance, they might not distinguish between distributions when their mean and variance are the same, so we here also include the modified L1 norm distance to see how it performs in this situation. Thus, we try our method with these three distance functions all using the permutation test for a fair comparison. The simulation results over 250 replications, which are reported in Table 4, show that all the methods perform quite poorly in this case, except our method with the modified L1 norm distance function which performs reasonably good in this challenging situation. This is because the asymptotic limit of the L1 norm distance does not simplify to expressions just in terms of the mean and variance of observations.
6 Real data application
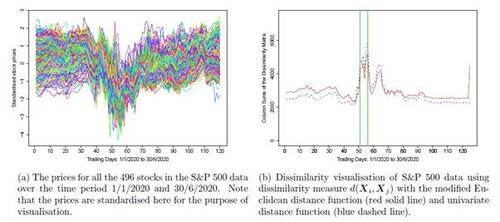
We apply the proposed method to a real data application from the US stock return data. The data set is available at https://www.finance.yahoo.com and can be obtained using the R package BatchGetSymbols for different time periods. The data we use here holds the daily closing prices of stocks from the S&P 500 index during the first year of COVID-19 pandemic between 1st January 2020 and 30th June 2020, which results in n = 125 time points and p = 496 stocks. This specific time period is chosen because based on the experts analysis reported in Statista Research Department (2022), the S&P 500 index showed much volatility and dropped by about 20% in early March 2020 entering into a bear market. While the drop was the steepest one-day fall since 1987, S&P 500 index began to recover at the start of April 2020. Stock markets fell in the wake of the COVID-19 pandemic, with investors fearing its spread could destroy economic growth. Figure 6(a) shows a rough display of the price changes for all the stocks over this time period, where all the stock prices are standardised for visualisation purpose. One can see the very steep drop around early March 2020, as explained. The drop seems to be happened for a majority of stocks with some different magnitudes, suggesting a non-sparse high dimensional change point problem here.
Figure 6(b) displays the dissimilarity visualisation of the S&P 500 data using the dissimilarity measure with both the modified Euclidean distance function and the univariate distance function, which show a similar trend. Note that the column sums of the two dissimilarity indices are drawn for those trading days in the first half of 2020. The figure suggests that the trading days 13th and 16th March 2020 show the largest total dissimilarity from all the other observations and are marked by vertical bars.
We first implement our distribution-free method, using our R package HDDchangepoint, to find significant change points in this high dimensional data set. Our method with the asymptotic test, using both distance functions, returns six change point locations, namely 51, 57, 66, 95, 106, 112. The method with the permutation test returns four change point locations, namely 51, 57, 66, 95. While the two tests produce four common change points, the permutation test is a bit conservative considering the dimension of data, which is in line with our numerical results. The asymptotic p-values for these four significant change points are and
, respectively. Also, the same four change points are obtained when we use 10 or 15 as the minimum segment length for the binary segmentation. We then apply the E-divisive method of Matteson and James (2014) with the minimum segment length being 15, which detects seven significant change points, namely 15, 37, 48, 68, 80, 95, 106. Also, the random projection method of Wang and Samworth (2018) finds nine change point locations, namely 18, 35, 44, 50, 65, 78, 99, 111, 124. The HDcpdetect method of Li et al. (2019) only finds two change point locations 48, 80. As in our numerical results, HDcpdetect tends to detect fewer change points when there are multiple change points (see Figures 5(a) and 5(b)), and the random projection method shows a lower accuracy in such high dimensional data with a small sample size (see Table 2). Considering our simulation results especially those in Table 2 for multiple change points, we believe our estimates of change point locations are more accurate, especially the detected locations 51 and 57 which coincide with the steep drop in the stock prices in early March 2020 due to the COVID-19 impact on the market. Some further results on our analysis of this data set is reported in Appendix C.
7 Concluding remarks
We have proposed a distance-based method for detecting single and multiple change points in non-sparse high dimensional data. The proposed approach is based on new dissimilarity measures and some proposed distance and difference distance matrices, which does not require normality or any other specific distribution for the observations. However, we note that our asymptotic tests require up to four finite moments of the distribution. Our method is especially useful for change point detection in HDLSS data when the sample size is very small compared to the dimension of data. This is an understudied problem in the literature of high dimensional change points. Our method can handle non-sparse high dimensional situations where changes may happen in many variables and with small significant magnitudes. We have introduced a novel test statistic to formally test the significance of estimated change points and established its asymptotic and permutation distributions to address both small and large sample size situations. We have shown that our proposed estimates of change point locations are consistent for the true unknown change points under some standard conditions and that our proposed tests are consistent asymptotically. Our simulation results showed that both asymptotic and permutation tests perform well compared to some of the recent methods for high dimensional change points. Our R package HDDchangepoint for implementation of the proposed method, including both the recursive binary segmentation and the wild binary segmentation as well as the real data application, can be obtained from “https://github.com/rezadrikvandi/HDDchangepoint“. The R package returns significant change point estimates and their corresponding p-values, and it can also be applied with any other dissimilarity measure specified by the user.
Disclosure statement
The authors report there are no competing interests to declare.
Table 1 Frequency and average number of the detected change points over 250 replications by each of the methods when there is one true change point, also including the case with no change point.
Table 2 Frequency and average number of the correctly detected change points over 250 replications by each of the methods when there are three true change points, also including the case with no change points.
Table 3 Frequency and average number of the detected change points over 250 replications by each of the methods when there is a true change in variance of observations.
Table 4 Frequency and average number of the detected change points over 250 replications by each of the methods when there is a change in distribution of observations while their mean and variance remain the same.
Figure 1 Illustrative example with one change point: plots for all elements of the distance matrix D obtained using the dissimilarity measure in (3) with both the univariate and multivariate distance functions, as well as for all column sums of the difference distance matrix Δ.
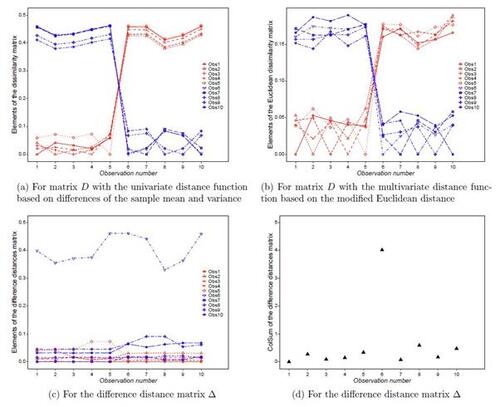
Figure 2 The sets and
with the estimated change point location
.
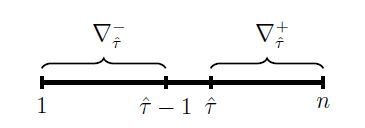
Figure 3 Illustrative example with two change points: plots for all elements of the distance matrix D obtained using the dissimilarity measure in (3) with both the univariate and multivariate distance functions, as well as for all column sums of the difference distance matrix Δ.
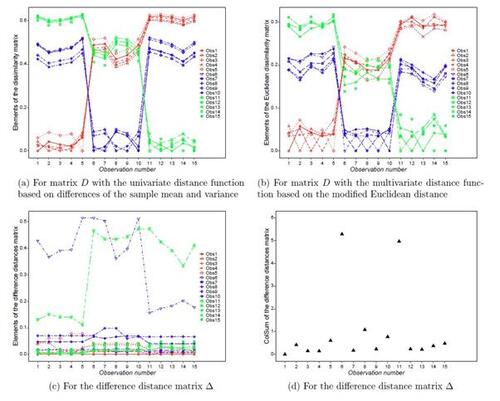
Figure 4 The estimate of change point from each of the methods over 250 replications with a true single change point at location when n = 45.
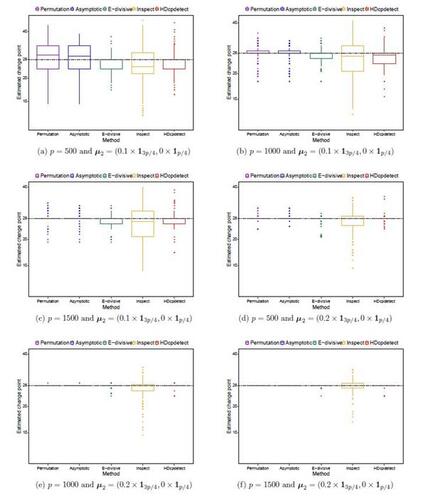
Figure 5 Average number of the total change points detected (correct or incorrect detection) over 250 replications by each of the methods for multiple change point detection.
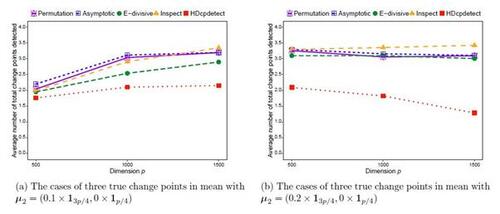
Figure 6 Change point plots for the S&P 500 data over the time period 1/1/2020 and 30/6/2020 during the COVID-19 pandemic. In plot (b) the two trading days 13th and 16th March 2020 show the largest total dissimilarity from all the other days and are marked by vertical bars (in green).
SupplementaryMaterials.pdf
Download PDF (313.4 KB)References
- Barigozzi, M., Cho, H. and Fryzlewicz, P. (2018), ‘Simultaneous multiple change-point and factor analysis for high-dimensional time series’, Journal of Econometrics 206, 187–225.
- Chen, H. and Zhang, N. (2015), ‘Graph-based change-point detection’, The Annals of Statistics 43, 139–176.
- Chu, L. and Chen, H. (2019), ‘Asymptotic distribution-free change-point detection for multivariate and non-euclidean data’, The Annals of Statistics 47, 382–414.
- Enikeeva, F. and Harchaoui, Z. (2019), ‘High-dimensional change-point detection under sparse alternatives’, The Annals of Statistics 47, 2051–2079.
- Follain, B., Wang, T. and Samworth, R. J. (2022), ‘High-dimensional changepoint estimation with heterogeneous missingness’, Journal of the Royal Statistical Society Series B 84, 1023–1055.
- Fryzlewicz, P. (2014), ‘Wild binary segmentation for multiple change-point detection’, The Annals of Statistics 42, 2243–2281.
- Garreau, D. and Arlot, S. (2018), ‘Consistent change-point detection with kernels’, Electronic Journal of Statistics 12, 4440–4486.
- Grundy, T., Killick, R. and Mihaylov, G. (2020), ‘High-dimensional changepoint detection via a geometrically inspired mapping’, Statistics and Computing 30, 1155–1166.
- Hahn, G., Fearnhead, P. and Eckley, I. A. (2020), ‘BayesProject: Fast computation of a projection direction for multivariate changepoint detection’, Statistics and Computing 30, 1691–1705.
- Hall, P., Marron, J. S. and Neeman, A. (2005), ‘Geometric representation of high dimension, low sample size data’, Journal of the Royal Statistical Society: Series B 67, 427–444.
- Jung, S. and Marron, J. (2009), ‘PCA consistency in high dimension, low sample size context’, The Annals of Statistics 37, 4104–4130.
- Lee, S., Seo, M. H. and Shin, Y. (2016), ‘The lasso for high dimensional regression with a possible change point’, Journal of the Royal Statistical Society: Series B 78, 193–210.
- Li, J. (2020), ‘Asymptotic distribution-free change-point detection based on interpoint distances for high-dimensional data’, Journal of Nonparametric Statistics 32, 157–184.
- Li, J., Xu, M., Zhong, P.-S. and Li, L. (2019), ‘Change point detection in the mean of high-dimensional time series data under dependence’. arXiv:1903.07006.
- Liu, B., Zhang, X. and Liu, Y. (2022), ‘High dimensional change point inference: Recent developments and extensions’, Journal of Multivariate Analysis 188, 1–19.
- Liu, B., Zhou, C., Zhang, X. and Liu, Y. (2020), ‘A unified data-adaptive framework for high dimensional change point detection’, Journal of the Royal Statistical Society: Series B 82, 933–963.
- Matteson, D. S. and James, N. A. (2014), ‘A nonparametric approach for multiple change point analysis of multivariate data’, Journal of the American Statistical Association 109, 334–345.
- Safikhani, A. and Shojaie, A. (2022), ‘Joint structural break detection and parameter estimation in high-dimensional nonstationary VAR models’, Journal of the American Statistical Association 117, 251–264.
- Statista Research Department (2022), ‘Weekly development of the S&P 500 index from January 2020 to September 2022’, https://www.statista.com/statistics/1104270/weekly-sandp-500-index-performance/.
- Utev, S. A. (1990), ‘Central limit theorem for dependent random variables’, Probability Theory and Mathematical Statistics 2, 519–528.
- Wang, T. and Samworth, R. J. (2018), ‘High dimensional change point estimation via sparse projection’, Journal of the Royal Statistical Society: Series B 80, 57–83.
- Xiao, W., Huang, X., He, F., Silva, J., Emrani, S. and Chaudhuri, A. (2019), ‘Online robust principal component analysis with change point detection’, IEEE Transactions on Multimedia 22, 59–68.
- Yu, M. and Chen, X. (2021), ‘Finite sample change point inference and identification for high-dimensional mean vectors’, Journal of the Royal Statistical Society: Series B 83, 247–270.
- Zhang, L. and Drikvandi, R. (2023), ‘High dimensional change points: challenges and some proposals’, Proceedings of the 5th International Conference on Statistics: Theory and Applications, Paper No. 142. DOI: 10.11159/icsta23.142.