
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
When exposed to principal components analysis for the first time, students can sometimes miss the primary purpose of the analysis. Often the focus is solely on data reduction and what to do after the dimensions of the data have been reduced is ignored. The datasets discussed here can be used as an in-class example, a homework assignment, or a written project, with a focus in this article as an in-class example. The data give the students an opportunity to perform principal components analysis and follow-up analyses on a real dataset that is not necessarily the easiest to handle.
1 Introduction
Cooperstown, a small village in upstate New York, has been synonymous with baseball immortality ever since the founding of the National Baseball Hall of Fame and Museum there in 1939. From the stands at the ballpark, to barstools, dorm rooms, and internet chatrooms, baseball fans have long debated what players should and should not be in Major League Baseball’s Hall of Fame.
The rules for being elected to the Hall of Fame have changed quite a bit since the first class of Ty Cobb, Walter Johnson, Christy Mathewson, Babe Ruth, and Honus Wagner was elected in 1936. In its current format adopted in 2014, the Baseball Writer’s Association of America (BBWAA) consider any player for potential election to the Hall of Fame after that player has been retired for five years. Baseball writers eligible to vote can vote for up to 10 candidates on a single ballot. Any candidate receiving votes on at least 75% of the ballots is elected to the Hall of Fame. If the player fails to reach the 75% threshold, they will be on the ballot the next year assuming that they received votes on at least 5% of the ballots cast, otherwise they can no longer appear on the ballot the following year. Players can be on the ballot for up to 10 years. Players that are not elected to the Hall of Fame in this manner are then moved to an Eras Committee system where they can be evaluated and potentially elected into the Hall of Fame at any time (Baseball Hall of Fame Citation2018a). These Eras Committees are commonly referred to as the “Veterans Committee”; however, they are committees made up of former managers, umpires, executives, and retired players from the following time periods (Baseball Hall of Fame Citation2018b):
Today’s Game—1988 to present
Modern Baseball—1970 to 1987
Golden Days—1950 to 1969
Early Baseball—1871 to 1949.
Since players in this dataset have careers that span from Major League Baseball’s early days to the present, it is important to note how players were elected to the Hall of Fame prior to 2014. The election cycles have not always been consistent. From 1936 to 1939, the elections were held annually with no real set rules in place. From 1940 to 1945, the elections were held every three years, meaning they were held in 1942 and 1945 only. This may be due to baseball players serving in World War II. From 1946 to 1956, elections were once again an annual event. From 1957 to 1965, the elections were held every other year. Since 1966, elections have been an annual occurrence. Typically there are no run-off ballots; however, in 1946 the top 20 vote getters comprised a second and final ballot, if no one was elected, and no one was in 1946’s election. In 1949, there was a run-off vote, with Detroit Tigers’ second baseman Charlie Gehringer being elected to the Hall of Fame. From 1960 to 1968, there were run-off ballots where the top 30 vote getters comprised a second and final ballot, if no one was elected. In 1968, there was a limit implemented of 40 players per ballot. In 1945, voters were supposed to focus more on how the game was played on the field instead of a player’s character off the field. In terms of waiting periods for players retired to be eligible for election, from 1936 to 1945 there was no waiting period. From 1946 to 1953, a player needed to have been retired one year. In 1954, a player needed to be retired for five years prior to being eligible for election. In 1979, the “at least appearing on 5% of ballots” rule was introduced. From 1946 to 1955, a player could not be on the ballot if they have been retired for 25 years. This period was extended to 30 years in 1956. In 1962, it was reduced to 20 years. In 2014, it was reduced to its current 15-year period (Baseball Hall of Fame Citation2018c).
The data described here will focus on position players, that is, nonpitchers, who have received at least one vote for the Hall of Fame at some point in their careers. The dataset will be used as an example of principal components analysis as well as using the principal components in a logistic regression model to predict the probability of a player being enshrined into the Hall of Fame. The principal components analysis will be used to reduce the dimensions of the dataset. Logistic regression will then be performed using the retained principal components as predictors to predict the probability of a hitter being inducted into the Hall of Fame.
Specifically in this manuscript, methods and results will be presented in a way for instructors to use the dataset as an in-class example; however, instructors may wish to use this dataset for a homework assignment or as part of a data analysis project. Along the way, helpful hints, potential pitfalls, and alternative applications will be introduced to provide further guidance for any instructors. It should be noted that this type of analysis would work best for upper-level undergraduate mathematics or statistics students and first-year graduate students taking an applied statistics sequence. For the record, these data were specifically used in a master’s level applied statistics sequence at an institution where the sequence has no prerequisites and students need to have taken one linear algebra course during their academic career to be accepted into the program. This type of course might use a textbook like the one by Ramsey and Schafer (Citation2013), where the topics of principal components and logistic regression are addressed.
Helpful Hint: If using a textbook like Ramsey and Schafer’s (Citation2013) The Statistical Sleuth, an instructor will have to supplement the material involving principal components analysis with all of the necessary linear algebra needed for students to really grasp what is going on. While a very useful textbook, Ramsey and Schafer omit all of the underlying linear algebra calculations.
2 The Data and the Story
The data in the file baseballHOF.csv consist of all 602 position players that have received at least one vote for Major League Baseball’s Hall of Fame. All of the data were compiled from baseball-reference.com (Baseball Reference Citation2018). The variables are summarized in . All of these variables except for JAWSratio are found on the website. These metrics, though not a complete list of what can actually be measured on position players in the game, represent a mix of “traditional” and “modern” baseball statistics. The more traditional statistics are the career counting statistics, like batting average, hits, home runs, and runs batted in. Statistics like OPS have started to gain more traction in the baseball community in recent years, even appearing in nationally televised games and on scoreboards in baseball stadiums. Statistics like WAR are considered more “modern” baseball statistics. These attempts to measure a player’s offensive and defensive contributions to their team’s success.
Table 1 Description of variables.
Helpful Hint: Obviously not all students are baseball fans. When introducing these data to the students in class or as an assignment or project, be sure to open the dataset and walk them through the various variables. Take careful consideration when discussing the variables JAWS, Jpos, and JAWSratio. More details about these three variables are in the following Potential Pitfall.
Potential Pitfall: The variables JAWS and Jpos are meant to be compared with one another. Jpos is a variable that basically attempts to keep track of the player’s position, a categorical variable, via a quantitative variable. For example, Chipper Jones, Brooks Robinson, and Mike Schmidt are three Hall of Fame third basemen in the dataset. They all have a Jpos of 55.7. JAWSratio, JAWS divided by Jpos and multiplied by 100, is calculated so that any ratio greater than 100 means that the player had a higher value of JAWS compared to all other Hall of Fame players at that given position while a ratio less than 100 means that the player had a lower value of JAWS compared to all other Hall of fame players at that given position. When incorporating this information into the model, encourage students to use JAWSratio since it captures information from JAWS and Jpos.
3 The Analysis
All analyses were conducted using R version 3.4.3 (R Core Team Citation2018). contains summary statistics for the 17 quantitative variables of interest for position players in the Hall of Fame and those position players who received votes but failed to make the Hall of Fame. is the correlation matrix for the 17 quantitative variables of interest. If one includes all of these 17 variables as predictors in a model, severe multicollinearity occurs. The results of said model can be found in . It should be noted that the variance inflation factors for a logistic regression model using all of these variables as predictors range from 2.786 for stolen bases (SB), the only one less than 5, to 3217.564 for OPS. These variance inflation factors were calculated using the car package in R (Fox and Weinberg 2011). For more details, see the code in the online appendix. Since the variables are all on different scales, principal components based off the correlation matrix is the most appropriate method here.
Table 2 Summary statistics.
Table 3 Correlation matrix for the 17 quantitative variables of interest (lower triangle).
Table 4 Estimated coefficients for the logistic regression model: all predictors.
Using principal components analysis can help solve the problem of multicollinearity in the model. In practice, multicollinearity does not cause any issues with the model’s ability to make predictions; however, the standard errors of the regression coefficients tend to be inflated in the presence of other highly correlated predictor variables (Neter et al. Citation1996). If a researcher is using a variable selection method like forward, backward, or stepwise selection based on the t-statistic, for example, potentially important predictors will be discarded from the model since their possible larger standard errors will make the predictor seem less significant than what it might actually be.
Potential Pitfall: If not given proper guidance on an assignment or project, students may just include all of the predictors into a logistic regression model and ignore any issues pertaining to multicollinearity since it generally will not impact the model’s fit or its ability to make predictions (Neter et al. Citation1996). While performing principal components analysis does not address multicollinearity in a linear model, it can be useful in this situation since principal components are linearly uncorrelated with one another.
The goal of principal components analysis is to transform the original variables into a system of orthogonal variables and to use as few of these transformed variables as possible to describe the variation in the original dataset. Each hitter’s offensive variables are transformed viawhere
represents the principal component scores for the ith hitter, A is an orthogonal matrix, and
are the standardized variables for the ith hitter. The correlation matrix of the offensive variables, R, can be found in . The sample covariance matrix of z will be a diagonal matrix with
on the diagonal. This matrix will be equal to
. Rencher (Citation1995) employed a spectral decomposition argument to state that since A is an orthogonal matrix, the values
, will be equal to the eigenvalues of R. Also, the rows of A are the normalized eigenvectors of R. The eigenvalues for the correlation matrix can be found in . These will be investigated to determine the number of principal components that will be necessary to use in this analysis.
Table 5 Eigenvalue for the correlation matrix of the quantitative variables of interest.
Rencher (Citation1995) proposed some guidelines to assist in this process. Two of the simplest for students to understand is retaining enough components so that at least 80% of the total variance is explained and ignoring components whose eigenvalues are less than one. This latter criterion is known as the Kaiser criterion or Kaiser–Guttman rule (Guttman Citation1954; Kaiser Citation1970). Basically, if the measured variables are standardized, they have a variance equal to one. The eigenvalues represent the variance of the principal component. If the eigenvalue is less than one, it fails to account for as much variability as a single measured variable. However, Preacher and MacCallum (Citation2003) said researchers misapply this rule because they ignore the fact that it was originally supposed to be a lower bound on the number of components in principal components analysis or factors in exploratory factor analysis to retain. Since the goal of this analysis is to use principal components as predictors in a logistic regression model, the approach taken will be one similar to one taken by Milewska et al. (Citation2014). A variable selection process, specifically a backward selection procedure using p-values from the z-tests for the estimated logistic regression coefficients for this baseball analysis, will be used to determine how many principal components will be retained in the model. Using this method, potentially significant linear combinations of the hitters’ variables will not be ignored, even if the components do not necessarily explain a large proportion of variation of the original variables. The results of this variable selection procedure can be found in . The original dataset of 17 variables has now been reduced to eight principal components.
Table 6 Results of backward selection procedure: z-statistic p-values with .
shows the eigenvectors for the eight retained components of the quantitative variables of interest. These eigenvectors represent the coefficients for each of the eight retained principal components. Denoting the principal components as zi, as seen previously, the principal components are
Table 7 Eigenvectors for the correlation matrix for the retained components.
3.1 Interpreting the Principal Components
There is some debate on how to best interpret principal components. Preacher and MacCallum (Citation2003) stated because principal components analysis does not explicitly model error variance, it causes problems when attempting any interpretations of substance with respect to the principal components. They say that principal components analysis should only be used when the goal is to find linear combinations of model variables that retain as much of the variance in the model variables as possible or find components that explain as much variance as possible. If the goal is to find interpretable constructs that explain correlations among the model variables, exploratory factor analysis should be the analysis of choice.
Sharma (Citation1996) argued that because the principal components are linear combinations of variables of some interest, it is only natural to attempt to assign some meaning to the components. He stated that one should focus on the loadings of each variable to determine which variables are influential in the formation of the component. Although no additional citations were mentioned, Sharma suggested that a loading of 0.5 or above, in magnitude, is a good rule of thumb to determine which variables are influential to the component.
Rencher (Citation1995) discussed how certain patterns in the loadings and the correlation matrix can often aid in the interpretation of the principal components. If all of the loadings or elements of the first eigenvector are positive, this is sometimes referred to as a measure of size. This is analogous to the first principal component being a weighted average of the variables that make up the component. Correlations between the variables and the principal components can be computed to aid in the interpretation of the components. To calculate the correlation between the ith principal component and the jth standardized variable, take the coefficient associated with the jth standardized variable in the ith principal component and multiply that by the square root of the ith eigenvalue of the correlation matrix (see for the eigenvalues). lists the correlations between the retained principal components and the quantitative variables of interest.
Table 8 Correlation matrix for the 17 quantitative variables of interest and retained principal components.
Based on the variables’ coefficients or loadings in each of the retained principal components (Sharma’s proposed technique) as well as the corresponding correlations between each standardized variable and principal component (Rencher’s proposed technique), possible interpretations are as follows:
z1 represents a weighted average of the standardized variables since all of the loadings are positive,
z3 represents a difference in speed versus power in terms of SB and home runs, due to the large magnitudes of the loadings for those two variables,
z4 represents the batting average, or possibly the difference of hitting to get on base versus getting on base via other methods, that is, bases on balls,
z5 represents the negative of the standardized value of SB, perhaps penalizing players with poor base running skills.
Each of these previously mentioned principal components either have strong correlations with the specified standardized variables or have loadings or coefficients at least 0.5 in magnitude for each of the mentioned standardized variables. Scatterplots of the interpreted principal components versus the principal component scores can be found in .
Fig. 1 Scatterplots of the principal components scores versus their “interpretation”.
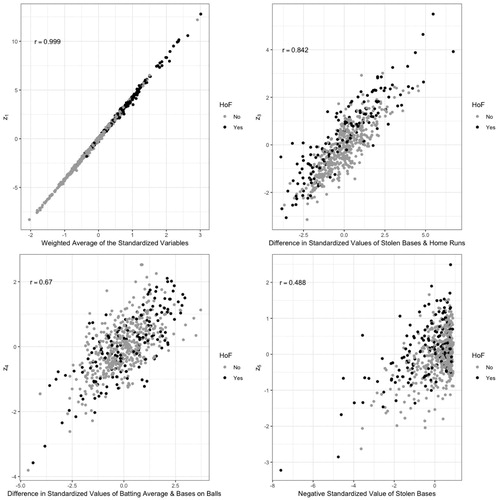
Alternative Application: For the last four retained principal components, the interpretation is not as obvious mainly due to the small magnitudes for the loadings or coefficients and the very weak correlations with the corresponding standardized variables. That makes these interpretations not as obvious. After walking through the thought process on the previous interpretations, ask students to attempt possible interpretations of the last four retained principal components.
3.2 Assessing the Model Fit
For this project (or exercise or example), students created principal components to overcome the issue of multicollinearity in a logistic regression model. A logistic regression model was fit using whether or not the player is in the Hall of Fame as a response variable, where a “success” is that the player is in the Hall of Fame, and the eight principal components as the predictor variables. contains the estimated coefficients for the logistic regression model with the eight principal components as the predictor variables. The most significant predictor is the first retained principal component, z1, given all of the other predictors in the model. Recalling that this principal component represents the weighted average of the standardized original variables, it is not surprising that the coefficient is positive, meaning that as a hitter’s metrics become more large than average, it is more likely that the hitter will be elected to the Hall of Fame, given all other predictors are held constant. The second retained principal component, z3, is the second most significant predictor, given all of the other predictors in the model. This principal component was interpreted as being a measure of speed versus power based on a difference in the standardized value of SB and the standardized value of home runs. Since this estimated regression coefficient is positive, the larger the difference in these standardized values, the more likely the hitter will be inducted into the Hall of Fame, given that all other predictors are held constant. This difference becomes more positive the more SB a hitter has than average compared to the more home runs a hitter has than average. The principal component z4 was interpreted to be the difference in the standardized value of batting average and the standardized value of bases on balls. Since this estimated regression coefficient is positive, as a hitter’s batting average becomes better than average compared to a hitter’s bases on balls compared to the average, they are more likely to be inducted into the Hall of Fame, given that all other predictors are held constant. The principal component z5 was interpreted to be basically the negative of the standardized value of SB. Since this estimated regression coefficient is positive, larger values of z5 mean the hitter is more likely to be inducted into the Hall of Fame, given that all other predictors are held constant. All things being equal, if a hitter has fewer SB than average, they are more likely to be inducted into the Hall of Fame. This may sound like it is basically the opposite conclusion of the interpretation for the regression coefficient of z3; however, z5 is looking solely at SB while z3 is measuring some combination of speed and power by measuring the difference in SB and home runs, all while holding all other principal components at fixed values.
Table 9 Estimated coefficients for the logistic regression model.
The Hosmer–Lemeshow goodness-of-fit test ( with 8 degrees of freedom, p-value = 0.9637) indicates that the model is a good fit to the data. This test was performed using the hoslem.test function in the ResourceSelection package (Lele, Keim, and Solymos Citation2017) in R. See the code in the online appendix for more details. To run this test, the estimated probability of success is calculated for all players in the dataset. These estimated probabilities are ordered into a specified number of groups, in this case 10 groups. In each group, the number of players in the Hall of Fame and not in the Hall of Fame is recorded. These observed counts are compared to the expected counts and a chi-square test statistic is computed. The test statistic is compared to a chi-square distribution with degrees of freedom equal to the number of groups minus two, in this case
.
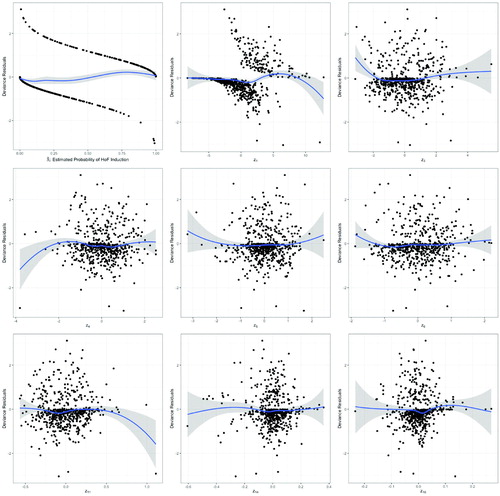
Once the model is fit, residual plots based on the deviance residuals can be plotted versus the model’s fitted values as well as each of the predictor variables. shows the deviance residual plots from the logistic regression model using the eight retained principal components as predictor variables. A loess line is also displayed on each of these plots. If the loess line is as flat as possible, that indicates that the predictor variable should not be transformed when entered into the model. If this curve appears to be quadratic, the predictor variable in question should be transformed as the square of that variable. For the most part, the loess line in all of these plots are fairly flat. This indicates that no further transformation of the predictor variables is needed in this analysis.
Fig. 2 Deviance residual plots versus fitted values and retained principal components.
shows the predicted classification of each player based on the results from the logistic regression model. Overall, the model correctly classifies 89.7% of the players (540 out of 602 players). Out of the 447 players not in the Hall of Fame, the model correctly identified 95.1% of them (425 out of 447). For the 155 players in the Hall of Fame, the model correctly identified 74.2% of them (115 out of 155).
Table 10 Player classification: logistic regression model results.
Helpful Hint: Encourage students to investigate the actual cases that are false negatives (actual Hall of Fame players identified as not worthy of selection) and false positives (players not elected to the Hall of Fame that model thinks should be in the Hall of Fame). The following discussion about and will help the students see where the models went “wrong.”
shows the “false positives” in the model, that is, the players predicted to be enshrined into the Hall of Fame but who are not actually members of the Hall of Fame. Of the twenty-three players on the list, five of them (Barry Bonds, Larry Walker, Scott Rolen, Edgar Martinez, Manny Ramirez) are all still eligible to be elected by the BBWAA; however, two of the five players mentioned (Bonds and Ramirez) might not ever be elected to the Hall of Fame due to their ties, either confirmed or alleged, to performance enhancing drugs (Fainaru-Wada and Williams Citation2006; Tayler Citation2014). Pete Rose, baseball’s all-time leader in hits, and Shoeless Joe Jackson are two players that are permanently banned from the Hall of Fame for having gambled on baseball games. Bill Dahlen was considered by many to be one of the greatest shortstops in baseball during his playing career from 1891 to 1911; however, “Bad Bill” supposedly fought with teammates, managers, and umpires and anecdotally had a bit of a drinking problem (Womack Citation2015). These “character issues” may have long turned off voters from voting for him. Many believe that voters have used a similar rationale of character issues for not inducting Dick Allen into the Hall of Fame, even though sabermetricians like Bill James once called Allen “the most gifted baseball player I have ever seen” (James Citation1987). The player in this table that might be the most curious to see for baseball fans is Nomar Garciaparra. He won the American League Rookie of the Year Award in 1997, came in second in voting for the American League Most Valuable Player Award in 1998, and was selected six times to Major League Baseball’s All Star Game; however, his career was cut short due to injuries.
Table 11 Player classification: predicted Hall of Famers not in the Hall of Fame.
shows the “false negatives” predicted by the model, that is, the players predicted not to be in the Hall of Fame but who are actually members of the Hall of Fame. Twenty-nine out of the forty players (72.5%) were elected by the veterans committees or one of the eras committees. Most of these players elected by these committees, denoted with a dagger in , played in the pre-integration era of Major League Baseball (prior to 1947, Jackie Robinson’s debut in Major League Baseball). Some of these players played in what is known as the “dead ball” era of baseball, roughly the years 1900 to 1919, prior to Babe Ruth’s emergence as a hitter rather than a pitcher. The game of baseball during this era was more strategy based. Managers would rely on SB and hit-and-run plays—which are plays in which the base runner starts running as the pitcher throws to home plate creating an opportunity to take more bases with a base hit, than on simply using home runs to score (Okrent, Lewine, and Nemec Citation2000). Players on this list from the dead ball era may have had statistics greater than their peers; however, their statistics pale in comparison to even above average players in its current iteration.
Table 12 Player classification: Hall of Famers predicted not to be in the Hall of Fame.
4 Conclusion
The previously discussed analysis is an example on how to use principal components beyond simply reducing the dimensions of a dataset. While one would hope that the logistic regression model’s ability to correctly classify players would be better than what is presented here, it gives students another example of the “joys” of working with real data. After all, the cleanest examples appear in textbooks’ examples for a reason.
The plan is to keep adding to this dataset with every annual vote for hitters’ induction into the Hall of Fame, rerunning the model, and predict which hitters would and would not be in the Hall of Fame. Perhaps with a newer generation of more statistical savvy baseball writers and Hall of Fame voters, the number of “false positives” will decrease and the number of “false negatives” will not increase, making it pretty obvious which hitters are worthy of induction. As far as the “false negatives” go, there is nothing that can be done to really reduce those numbers. Once a hitter is inducted, they cannot be retroactively removed from the Hall of Fame.
Students may wish to further explore principal components analysis, logistic regression, and baseball’s Hall of Fame. This analysis only focuses on hitters. A natural follow-up analysis or project could entail running a similar type of analysis on every pitcher that has received a vote for induction into the Hall of Fame. If baseball is not a sport of interest, and the student wanted to still apply this type of analysis in the field of sports, they could also perform this type of analysis on the National Football League, the National Basketball Association, or the National Hockey League, just to name a few professional sports leagues in North America.
Instructors wishing to use this dataset in their classrooms are not just limited to using principal components analysis or logistic regression. These data can be used in introductory statistics classes when discussing the robustness of the two-sample t-test or performing a randomization test on a variable of one’s choice to compare the difference between Hall of Fame and non-Hall of Fame players. Even though not all students follow baseball, with enough guidance, students should figure out that the Hall of Fame players should typically have greater values for the various variables than the non-Hall of Fame players.
Supplementary Materials
The R code was used to read the file baseballHOF.csv into R, fit the multiple regression model, calculate the variance inflation factors, and to generate the correlation matrix. All figures were generated using the ggplot2 package (Wickham Citation2016) in R.
Supplemental Material
Download Zip (41.8 KB)References
- Baseball Hall of Fame (2018a), “BBWAA Election Rules,” available at https://baseballhall.org/hall-of-famers/rules/bbwaa-rules-for-election.
- Baseball Hall of Fame (2018b), “Eras Committees,” available at https://baseballhall.org/hall-of-famers/rules/eras-committees.
- Baseball Hall of Fame (2018c), “Voting Rules History,” available at https://baseballhall.org/hall-of-famers/rules/voting-rules-history.
- Baseball Reference (2018), “Hall of Fame Voting,” available at https://www.baseball-reference.com/awards/hof_2018.shtml\#all_hof_BBWAA.
- Fainaru-Wada, M., and Williams, L. (2006), Game of Shadows: Barry Bonds, BALCO, and the Steroids Scandal That Rocked Professional Sports, New York, NY: Gotham Books.
- Fox, J., and Weisberg, S. (2011), An R Companion to Applied Regression (2nd ed.), Thousand Oaks, CA: SAGE.
- Guttman, L. (1954), “Some Necessary Conditions for Common-Factor Analysis,” Psychometrika, 19, 149–161. DOI: 10.1007/BF02289162.
- James, B. (1987), The Bill James Historical Baseball Abstract, New York: Villard Books.
- Kaiser, H. F. (1970), “A Second Generation Little Jiffy,” Psychometrika, 35, 401–415. DOI: 10.1007/BF02291817.
- Lele, S. R., Keim, J. L., and Solymos, P. (2017), “ResourceSelection: Resource Selection (Probability) Functions for Use-Availability Data,” R Package Version 0.3-2, available at https://CRAN.R-project.org/package=ResourceSelection.
- Milewska, A. J., Jankowska, D., Citko, D., Wiesak, T., Acacio, B., and Milewski, R. (2014), “The Use of Principal Component Analysis and Logistic Regression in Prediction of Infertility Treatment Outcome,” Studies in Logic, Grammar, and Rhetoric, 39, 7–23, DOI: 10.2478/slgr-2014-0043.
- Neter, J., Kutner, M. H., Nachtsheim, C. J., and Wasserman, W. (1996), Applied Linear Statistical Models (4th ed.), Chicago, IL: Irwin.
- Okrent, D., Lewine, H., and Nemec, D. (2000), The Ultimate Baseball Book: The Classic Illustrated History of the World’s Greatest Game, Boston, MA: Houghton Mifflin Company.
- Preacher, K. J., and MacCallum, R. C. (2003) “Repairing Tom Swift’s Electric Factor Analysis Machine,” Understanding Statistics, 2, 13–43. DOI: 10.1207/S15328031US0201_02.
- R Core Team (2018), R: A Language and Environment for Statistical Computing, Vienna, Austria: R Foundation for Statistical Computing, available at https://www.R-project.org/.
- Ramsey, F. L., and Schafer, D. W. (2013), The Statistical Sleuth: A Course in Methods of Data Analysis (3rd ed.), Boston, MA: Brooks/Cole, Cengage Learning.
- Rencher, A. C. (1995), Methods of Multivariate Analysis, New York, NY: John Wiley & Sons, Inc.
- Sharma, S. (1996), Applied Multivariate Techniques, Hoboken, NJ: Wiley.
- Tayler, J. (2014), “Manny Ramirez Opens Up on PED Suspensions, Wants to Return to Baseball,” Sports Illustrated, available at https://www.si.com/mlb/strike-zone/2014/03/13/manny-ramirez-interview-ped-suspension-mlb-return.
- Wickham, H. (2016), ggplot2: Elegant Graphics for Data Analysis, New York, Springer-Verlag.
- Womack, G. (2015), “Why Has Bill Dahlen’s Hall of Fame Induction Taken So Long?,” Sporting News, available at http://www.sportingnews.com/us/mlb/news/bill-dahlen-hall-of-fame-chances-stats-chicago-colts-orphans-brooklyn/n9j4u52dvjcm1oek5mgdt96vi.