
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We present an active-learning strategy for undergraduates that applies Bayesian analysis to candy-covered chocolate m&m’s®. The exercise is best suited for small class sizes and tutorial settings, after students have been introduced to the concepts of Bayesian statistics. The exercise takes advantage of the nonuniform distribution of m&m’s® colors, and the difference in distributions made at two different factories. In this paper, we provide the intended learning outcomes, lesson plan and step-by-step guide for instruction, and open-source teaching materials. We also suggest an extension to the exercise for the graduate level, which incorporates hierarchical Bayesian analysis.
1 Introduction
We have developed an active-learning exercise for upper-year undergraduates that applies Bayesian analysis to m&m’s® candy. It is a fun activity that can be completed in a tutorial or small classroom setting within a 50–80 min class. Part of the exercise relies on the fact that m&m’s® are made at two different factories, and that the color distributions produced at these factories are different. The exercise may also be extended to the graduate level as a way to introduce and practically apply hierarchical Bayesian analysis (Section 8 and Appendix A).
In short, the activity involves giving each student a bag of m&m’s® (their data), and guiding them through an exercise to perform Bayesian analysis in order to:
Infer the probability of drawing a blue m&m’s® from a new bag of m&m’s®, given a likelihood, prior, and their data.
Predict the factory from which the m&m’s® were produced, based on the posterior distribution for the entire class’ data.
The exercise is primarily meant for undergraduates who have been introduced to Bayesian statistics, but who have not yet applied Bayesian inference to a real problem. The exercise is also relevant to anyone new to Bayesian inference who has a quantitative background. The mathematics in the exercise involves probability density functions that are both analytic and readily available in many open-source software packages. Thus, it is straightforward for students to simplify the likelihood times prior on the fly, and also write computer code to plot their results immediately in class. In the Github repository associated with this paper, we also provide R and Python scripts for the instructor and/or student to complete the exercise. If class time allows, then it might be beneficial for students to write their own scripts.
In the next section of this article, Section 2, we describe the pedagogical motivation and development of the Bayesian m&m’s® exercise. In Section 3, we describe the true color distribution of m&m’s® as produced by the MARS company, and how this relates to the exercise. The lesson plan is presented in Section 4, which includes an overview (4.1), a list of intended-learning outcomes (4.2), and a detailed step-by-step outline (4.3) with suggested discussion questions and strategies for implementation of the exercise in classrooms. Next, we present the actual posterior distributions found by an undergraduate class and by a seminar for graduate students, postdocs, and faculty. Following this, we briefly describe and provide links to the publicly available software instructors might like to use while running our active-learning exercise (Section 7). Finally, we present two extensions to the m&m’s® exercise that are intended for more advanced (e.g., graduate level) students (Section 8 and Appendix A).
2 Motivation and Development
By the time students are introduced to Bayesian analysis, they have usually had several classes on the frequentist perspective. Therefore, it is important to provide students with a concrete way to conceptualize the Bayesian framework, and this can be achieved through active-learning. The m&m’s® exercise presented in this paper provides such an activity.
Author GE, in collaboration with AS, originally created the Bayesian m&m’s® lesson and activity for a guest lecture in a third-year undergraduate astronomy class focused on statistics. The students had already been exposed to the Bayesian perspective but needed an interactive example to solidify the basic concepts. The class enrollment was approximately 10 students, and classtime was 80 minutes. Thus, the learning environment was well-suited for an active-learning exercise that would engage students and allow them to apply what they had learned about Bayesian statistics to a tangible example.
While searching for an interactive learning tool for introductory Bayesian inference, GE found blog posts describing how the color distribution of m&m’s® can be used as a teaching tool for frequentist statistics.1 There is an m&m’s® exercise using Bayes’ theorem in Downey (Citation2013), but the content is quite brief and the intended-learning outcome (ILO) is somewhat unclear. The goal for the latter is to predict whether an m&m’s® came from a bag produced in 1994 or 1996 (the color distributions changed in 1995, when blue m&m’s® were introduced). Thus, it seems the ILO for the latter exercise was not to introduce Bayesian inference, but possibly to practice calculating probabilities.
A handful of publications describing learning activities with m&m’s® also exist (e.g., Alexander and SherriJoyce Citation1994a,Citationb; SherriJoyce and Alexander Citation1994; Fricker Citation1996; Dyck and Gee Citation1998; Lin and Sanders Citation2006; Froelich and Stephenson Citation2013; Schwartz Citation2013). As a group, these articles cover a variety of topics in statistics, such as regression and correlation, analysis of variance, sampling distribution of the mean, design of experiments, and chi-squared goodness-of-fit tests. Other activities have also been suggested for more general mathematics education, from population modeling (e.g., Winkel Citation2009) to memoryless processes and hypergeometric functions (e.g., Badinski et al. Citation2017).
Albert and Rossman (Citation2009)—a workbook intended for an entire introductory course on statistics through the Bayesian perspective—includes a Bayesian exercise using m&m’s®, entitled, “What proportion of m&m’s® are brown?”. This exercise resides in the Chapter “Learning about models using Bayes’ rule,” and is not meant to be a comprehensive, stand-alone activity about Bayesian inference. The activity first states that a bag of m&m’s® has 3 brown candies out of 10 (this is the “real” data). Next, a table is presented that shows mock m&m’s® data that were simulated from four different factory models. The students are tasked with comparing the “real” m&m’s® data to the simulations, along with their prior assumptions, in order to determine the best factory model given their data. Thus, the exercise is not a thorough introduction to Bayesian inference, and instead plays a small part in a workbook that has “[…] its emphasis on active learning and its use of the Bayesian viewpoint to introduce the basic notions of statistical inference” (Preface, Albert and Rossman Citation2009).
In summary, a comprehensive Bayesian example using m&m’s® candies does not seem to exist in the education literature nor is one publicly available online, even though m&m’s® have been used as a teaching tool for statistics since the 1990s. Thus, we designed this comprehensive active-learning exercise with m&m’s® to help students learn and practice the concepts of Bayesian analysis.
GE first implemented our Bayesian m&m’s® activity in a third-year undergraduate class and received very positive feedback from students. The exercise has also been presented and informally relayed at conferences in both astronomy and statistics, with consistently enthusiastic responses. We have since formalized the lesson plan, learning outcomes, and teaching materials, and made them available through this article. We have also developed and included an extension to the m&m’s® exercise for more advanced classes that can be used to introduce concepts in hierarchical Bayesian analysis (Section 8 and Appendix A).
Our goal is that the m&m’s® exercise may be widely used and improved upon by the greater statistics community and other quantitative disciplines that teach and use Bayesian analysis.
3 The Intriguing Color Distributions of m&m’s®
The active-learning exercise we present here takes advantage of an important fact about the production of m&m’s®: two factories of the MARS Company (one in Hackettstown, New Jersey, the other in Cleveland, Tennesee) make m&m’s®, but these factories produce different distributions of m&m’s® colors! As shown in , the New Jersey and Tennessee factories make significantly different percentages of blue, orange, and green m&m’s®. The New Jersey and Tennessee factories make 25% and 20.7% blue m&m’s®, respectively, and this is the color we use throughout the exercise. Of course, orange or green could instead be used and should give similar results.
Fig. 1 The m&m’s® color distributions produced at the New Jersey and Tenessee factories, respectively. The percentage of blue, orange, and green m&m’s® differ the most between the two factories. This chart originally appears in Purtill (Citation2017), and was created by Purtill (Citation2017), using data from Wicklin (Citation2017).
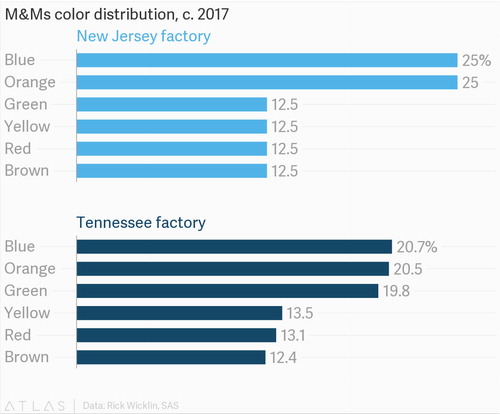
Due to the design of our activity, it is imperative to keep the true color distribution a secret from students until the end of the exercise. The exercise assumes most students have prior knowledge about m&m’s® (e.g., they have eaten them), but that they are unaware of the nonuniform color distribution. In our experience, students are surprised to find out at that the m&m’s® color distributions are actually nonuniform, and that they also differ between the two factories. We have conducted this exercise with New Jersey and Tennessee m&m’s®, and the posterior distributions predicted the correct factory in both cases. We used peanut m&m’s®, but the exercise should work with traditional m&m’s® too (and would also be more allergy-friendly). Admittedly, the exercise also relies on the factories not changing their production lines for the foreseeable future.
4 Lesson Plan
The entire lesson consists of interactive lecturing, discussion, and active-learning. We recommend not handing out the m&m’s® candy too early in the lesson, lest students become distracted, or worse, eat the evidence before it is recorded! In Sections 4.1–4.3, we provide an overview for the exercise, ILOs, and detailed steps and discussion questions.
4.1 Overview
The lesson begins with a “hook” to engage students. A bag of m&m’s® is shown to the class, and they are asked to think about the distribution of colors inside. Next, they are asked how they would predict the percentage of blue m&m’s® produced at the factory, using only a single bag of m&m’s®. The instructor leads a discussion and points out the benefits of using Bayesian inference, because it can incorporate the students’ prior knowledge about m&m’s®. Finally, the students are presented with the exercise: Use Bayes’ theorem and a single bag of m&m’s® as data to predict the percentage of blue m&m’s® produced at the factory.
To help the students start the problem, Bayes theorem is reviewed and the instructor helps students decide what likelihood will be appropriate for their study. The instructor also elicits prior information from the class, and helps students quantify the prior distribution based on this information. (Of course, this could instead be presented in reverse order, with first eliciting prior information and then introducing a likelihood.) The instructor can either select a method of prior elicitation in advance, or can present different options to the class for consideration and discussion if wanted.
Next, students work out the product of the likelihood and prior to obtain an analytic form of the posterior distribution. If there is time and computer resources available, they may also write and prepare a short computer script to plot this distribution. Alternatively, they may use the Jupyter Notebook provided as supplementary material to this article. Next, each student is given a bag of m&m’s® to open and inspect. They record the total number of m&m’s® and the number of each color, and then eat the evidence if they so wish.
Students now plot the posterior distribution given their data using either their computer script or the one provided, and then discuss the results with a partner. Following this, the instructor pools the m&m’s® data from the entire class and creates a posterior distribution for all of the m&m’s®. A discussion and question period is then led about the effect of more data on the posterior distribution.
Next, the surprise twist is revealed (), and students are asked to infer which factory produced their bag of m&m’s®, using their posterior distribution. They can also compare their inference to what they would infer given the entire class’ m&m’s®. After the students have arrived at an answer, the instructor provides the factory codes for the two factories. Students can check the lot number on the back of their m&m’s® packages for verification. In our experience, a class size of 10 or more students seems to provide enough data for the mode of the posterior to accurately predict the percentage of blue m&m’s® and the factory from which the candy originated.
It should be noted that our exercise may also provide an opportunity to compare the Bayesian formalism to the frequentist approach. Exactly how to make these connections will depend on the students’ level and depth of exposure to both topics, so we leave this to the discretion of the instructor. However, we strongly suggest that any such comparisons be done in a follow-up lesson or in a homework assignment, as adding this material to our exercise would be too much to fit into one class.
4.2 Intended Learning Outcomes
This lesson assumes that students have been exposed to the idea of probability distributions and have seen Bayes’ theorem, at least in passing. They should also have an understanding of parameters and their role in defining the shape of a probability distribution. As mentioned previously, we also assume that students do not have prior knowledge about the surprise twist mentioned in Section 3.
The intended learning outcomes (ILOs) are as follows. By the end of this lesson, students should be able to:
Recall Bayes’ theorem and identify the likelihood, prior, and posterior.
Recognize and quantify prior information.
State the conjugate prior to the binomial distribution, and list the hyperparameters.
Understand the term hyperparameters.
Calculate the posterior distribution for the probability of drawing a blue m&m’s® from a new candy bag, given the m&m’s® data and the prior distribution.
Write a working computer script to plot and compare the prior distribution to the posterior distribution obtained with their data (if computing resources are available).
Perform inference based on the Bayesian posterior distribution.
Know the appropriate terminology for reporting results from Bayesian analysis.
Connect this simple example to similar real-world practical applications from the students’ domain of study.
4.3 Detailed Steps and Discussion Questions
In many of the steps listed below, we include suggested discussion questions as bullets.
As a “hook,” show a bag of m&m’s® to the class and explain that they are going to infer the probability of getting a blue m&m’s® using Bayes’ theorem. Each person will get a bag of m&m’s® as their data, and they will use this data with a probability model to infer the percentage of blue m&m’s® produced in the factory.
Ask students prompting questions to help them formulate a quantitative picture of the problem.
What kind of data will we have when we open the m&m’s® bags? Is it numerical? Categorical? Continuous?
What’s one way to estimate the percentage of blue m&m’s® in the bag? Are there any pitfalls to the approach?
If you observe zero blue m&m’s® in your bag, then what is your estimate of the fraction of blue m&m’s® in the population? Is this realistic?
How will we record the data from the m&m’s® bags?
Review Bayes’ theorem and its constituent parts.
Lead a discussion about what likelihood might best describe the probability of drawing a blue m&m’s® from the bag, given their answers to the questions in Item 2 above. Ask for student input and guide the class to use a binomial distribution.
What assumptions are made by the likelihood?
Are we sampling with replacement or without?
After recording the data, can we eat it or should we wait until the analysis is complete?
Return to their answers in Item 2 to talk about prior information and to develop an approximate distribution for their prior belief in the percentage of blue m&m’s®.2 Some questions for eliciting prior information could include:
How do you think m&m’s® are made in the factory?
Do you think the manufacturing process affects the proportion of blue m&m’s® in a typical bag?
Do you think m&m’s® are well mixed before they are put into bags?
What do you think the percentage of blue m&m’s® is, at the factory? Do you think every bag will have this exact percentage?
Help the students quantify their prior information.
Where do you think most of the prior probability should be?
What parts of parameter space would you like to apply a very low probability?
Sketch out a distribution that encompasses your belief about the percentage of blue m&m’s® in the bag.
If conjugate priors are not a new concept to students, then briefly discuss why they are useful. If conjugate priors are new, introduce the beta distribution and its parameters, and explain its conjugacy to the binomial distribution.
Explore the properties of the beta distribution given its hyperparameters. If computer resources are available, students can interactively plot the prior distribution until they achieve a prior distribution that quantifies their prior belief about the proportion of blue m&m’s®.
What happens to the beta distribution as both hyperparameters go to one? Do you recognize this distribution?
What happens when the hyperparameters are equal?
What values of the hyperparameters best approximate the prior distribution sketched in Item 6?
Choose the hyperparameters, thus defining the prior distribution.
Why is it important that we define the prior distribution before looking at the data (i.e., before opening the bag of m&m’s®)?
How many m&m’s® worth of information does your prior contain?
As a class, decide on the hyperparameter values for the instructor’s prior distribution (which will be used with all the class’ data). One way to do achieve class agreement is for the instructor to interactively plot the prior distribution for hyperparameter values suggested by the students until a consensus is reached.
What is the mean of the prior distribution that was chosen?
How does the prior distribution compare to a uniform distribution? How does the prior distribution compare to a simple assumption that the probability of drawing a blue m&m’s® is
?
Students work out the product of likelihood and prior, and identify the kernel of this distribution. If computer resources are available, they write a short script to take in their data and plot the posterior distribution. Test their script with some toy data.
Open the bags of m&m’s® and look at the data. Make sure students record not only the number of blue m&m’s®, y, but also the total number of all m&m’s®, n.
How do the number of blue m&m’s® in your bag compare to your neighbor’s bag?
Do you think there are enough m&m’s® in one bag to correctly infer the percentage of blue m&m’s® produced at the factory?
(If computer resources are not available, then skip to the next step.) Students plot the posterior distribution given their data and prior information, and compare it to the prior distribution.
Where is most of the probability for the percentage of blue m&m’s®?
How has the posterior changed from the prior distribution?
Is this the result you expected, given that there are six different colors of m&m’s®?
How does your posterior distribution compare to your neighbor’s?
Instructor compiles the class’ data for y and n.
What assumptions have we made when combining data from different bags?
Do you have any predictions about how the posterior distribution might change in light of more data?
Instructor produces a plot comparing the class posterior distribution to the class’ prior distribution.
Where is most of the probability for the percentage of blue m&m’s®?
How does the posterior distribution for the data from the whole class compare to your own?
How does the prior compare to the posterior, now that there is more data?
Has the shape of the posterior changed with more data? Did it change in the way you expected?
What is the expected value (mean) and variance of the new posterior distribution for the percentage of blue m&m’s®?
Is this the result you expected for the percentage of blue m&m’s®, given that there are six different colors of m&m’s®? What might you infer about the color distribution of m&m’s® from these results?
Discuss the best way to report and display these results.
(Optional) Repeat the analysis for each of the other colors (red, orange, green, and yellow) for each color of m&m’s®. Repeating the analysis may help students master the practical components of the exercise which are generally useful, such as identifying the variable of interest, checking their computer code, and presenting results through graphics.
Reveal the surprise twist: Show the color distributions presented in , and ask students to discuss with one another and infer from the posterior distribution which factory their m&m’s® came from.
Once they have performed inference, then they can look at the back of the m&m’s® bag to see if their inference is correct. The lot number will show either CLV (Cleveland, Tennessee factory) or HKP (Hackettstown, New Jersey).
5 Mathematics for the m&m’s® Exercise
Bayes’ theorem states that the probability of θ given y is
(1)
(1)
where
is the likelihood. For the probability of drawing a blue m&m’s® from the bag, we use a binomial distribution for the likelihood
(2)
(2)
where y is the number of successes (blue m&m’s®), n is the total number of m&m’s® drawn from the bag, and θ is the percentage of blue m&m’s® produced at the factory.
More details about eliciting prior information from the students is presented in Section 4.3. After eliciting prior information and sketching an approximate prior distribution, we set out to quantify this information. We use the conjugate prior to EquationEquation (2)(2)
(2) , the beta distribution, for the prior on θ:
(3)
(3)
with hyperparameters α and β. EquationEquation (3)
(3)
(3) not only simplifies the m&m’s® example for a time-constrained class, but also provides the opportunity to review the concept of a conjugate prior.
Now that the prior has been defined, the posterior distribution is proportional to
(4)
(4)
We find it useful for students to simplify the likelihood and prior on their own, and then use think-pair-share to identify the form of the posterior distribution. Once students have recognized that the posterior is also a beta distribution, they may use software to plot the posterior distribution given their data (i.e., their m&m’s®).
6 Implementation and Posterior Distributions
We implemented the exercise presented in this article in a third-year undergraduate astronomy class, and in a seminar for graduate students, postdocs, and faculty at the Institute for Data Intensive Research in Astrophysics & Cosmology (DIRAC). In this section, we show the posterior distribution that resulted from both instances.
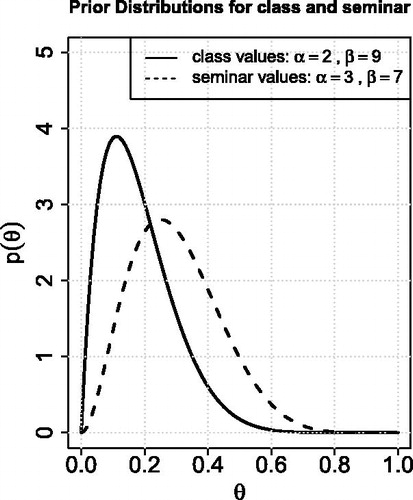
In our class of approximately 10 students, it was agreed that a beta distribution with hyperparameters α = 2 and β = 9 best described their prior information about the probability of drawing a blue m&m’s® from a bag. We reached this agreement through open discussion and the questions suggested in Items 6–10 of Section 4.3. In the seminar, the graduate students, postdocs, and faculty, used hyperparameters α = 3 and β = 7. Both prior distributions are shown in .
Fig. 2 The prior distribution for the probability of drawing a blue m&m’s® from a bag of m&m’s®, as determined by the class of undergraduates (solid curve) and by the seminar of graduate students, postdocs, and faculty (dashed curve). In general, students believed it was less likely to draw a blue m&m’s® than did the seminar members.
The posterior distribution for the first author’s data (i.e., one bag of m&m’s®), and the posterior distribution for the class’ data from all bags, are shown with the prior distribution in . The first author’s data are included in the supplementary material. The ensemble data consisted of 100 m&m’s®, 25 of which were blue. The class inferred from the total posterior distribution and its mean that the m&m’s® must have originated from the New Jersey factory. We checked the back of the packages, and indeed they showed the code HKP, indicating they came from Hackettstown, NJ ().
Fig. 3 Posterior distributions for instructor’s data (dashed curve), and for the combined data from the entire class (solid curve). The prior distribution (dotted curve) and posterior mean for the class’ posterior distribution (red vertical dashed-dotted line) are also shown for reference. The m&m’s® used were produced in the Hackettstown, New Jersey factory (HKP).
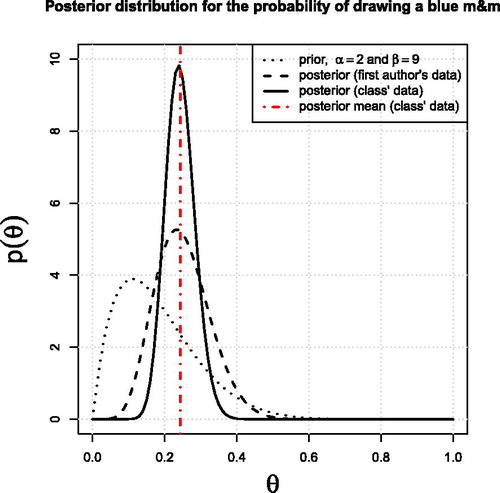
Fig. 4 A picture of the lot number from a package in the third-year undergraduate class. The code HKP indicates the package came from the Hackettstown, New Jersey factory.

For the class, we had purchased individual packages of peanut m&m’s® from a local store in Seattle, WA. For the seminar, however, we expected more than twenty people—so instead we bought a large box of peanut m&m’s® packages from Costco®.
The results from the DIRAC seminar are presented in . In this case, the first author was very surprised to see a different result than the undergraduate class, as they had expected the packages to also come from New Jersey. As it turned out, the m&m’s® packages in the large box were produced in Cleveland, Tennessee ()! The data are included in a supplementary csv file entitled DIRAC_mmsTallyCLVTennessee. Interestingly, Seattle, WA has packages from both factories, and perhaps other North American cities do too. This bodes well for instructors looking to purchase m&m’s® from a specific factory (e.g., when they wish to implement the advanced version of this exercise in Section 8).
Fig. 5 Posterior distributions for the DIRAC Institute seminar and the first author’s bag of m&m’s®. The m&m’s® used for this seminar were produced in the Cleveland, Tennessee factory (code CLV), and the data used to generate this figure are included as supplemental material.
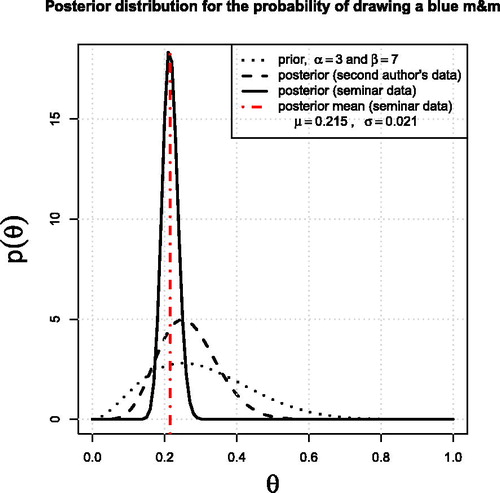
Fig. 6 A picture of the lot number from a package from the seminar. The code CLV indicates the package came from the Cleveland, Tennessee factory.

7 Open Source Scripts
Ideally, the students should be given a chance to write computer scripts to plot the prior and posterior distributions in this exercise, in their chosen software (e.g., R, Python, SAS, etc.). If classtime is short, then it might expedite the exercise to use the preauthored scripts we provide on the Github repository accompanying this article.3
8 Extensions for Advanced Classes
For higher-level (e.g., graduate-level) classes, there are several ways to extend this exercise to introduce and encompass more advanced concepts. We explored extensions that use the masses of the m&m’s®, that incorporate quality control levels at the factory, that consider multiple colors, or that include the color distributions of m&m’s® produced at different factories. The latter two most naturally follow from the original exercise, and so we describe these two ideas in more detail below.
A straightforward extension generalizes the case of two possible outcomes of the data (blue versus not-blue m&m’s®) to the case of six possible outcomes (i.e., blue, orange, green, yellow, red, or brown). By including a parameter for the probability of each color, a multi-dimensional posterior distribution is naturally introduced. More specifically, modeling all six colors of m&m’s® simultaneously involves the multinomial distribution and its conjugate prior, the Dirichlet distribution—both of which have a vast range of applications in domains with categorical data (e.g., topic modeling; see, e.g., Blei Citation2012 for an introduction).
An even more advanced extension not only incorporates multiple colors within a bag, but also the fact that m&m’s® bags may come from one of two factories, and that the two factories (Tennessee and New Jersey) produce different color distributions. Incorporating the individual bags, class collection of bags, and the two factories into the exercise provides a natural basis for introducing and applying Bayesian hierarchical modeling and mixture models.
Instead of creating a joint dataset from all bags in the class and obtaining a posterior distribution (which assumes all bags of m&m’s® originated in the same factory), the students are asked to write down a joint model for all bags, with latent variables to be inferred along with the overall distributions. Students must jointly infer the color distributions produced at each factory, the latent assignment of each bag to a factory, and the mixture proportions of factories within the set of bags in the class. The hierarchical nature of this model is in the joint inference of the latent mixture assignments with the mixture proportions. In addition, the color distributions are inferred as global population parameters, while the joint information from all bags will shrink the posteriors on the latent mixture assignment variables. The specifics of the hierarchical model for the m&m’s® exercise are shown in Appendix A.
The hierarchical version of the m&m’s® exercise is appealing because the variables’ true values can be known by the instructor; the color proportions from each factory are relatively well known (, as long as the MARS company does not change their practices), and the instructor can deliberately set the mixture proportions of the bags (depending on the availability of m&m’s® from both factories). In the context of a longer course on Bayesian analysis, this exercise can also be used to introduce related advanced concepts such as probabilistic graphical models as well as Markov chain Monte Carlo methods and Gibbs sampling.
9 Conclusion and Future Work
Many successful active-learning activities that use m&m’s® exist for topics in frequentist statistics and mathematics education. The literature, however, was lacking a Bayesian m&m’s® example. We hope that this exercise fills the gap.
Introducing Bayesian analysis to undergraduate students, regardless of their field of study, requires a discussion of Bayes’ theorem, probability distributions, and prior distributions. Examples that are meant to illuminate these concepts often rely on objects or systems such as playing cards, dice, or urns. Although these examples can be useful and familiar, we feel they are overused and have become repetitive for both students and instructors. Most undergraduates have already seen examples using playing cards, dice, and urns in high school-level mathematics classes, so it would be nice to have an entirely different type of example to entice student engagement. Students must also have the opportunity to apply what they are learning and, in Bayesian analysis in particular, develop practical skills. We hope that this m&m’s® example provides an enticing (and tasty!) alternative to traditional examples.
It would be beneficial and probably more cost-effective if instructors could source m&m’s® from the two MARS factories directly. We have not contacted the MARS Company about direct purchasing, but should they read this manuscript, we are happy to discuss setting up a program for m&m’s® discounted offers in the name of statistical education.
Supplemental Material
Download Zip (131 KB)Acknowledgments
The authors thank the editors and the anonymous referees whose comments and suggestions helped improve article. The authors would like to thank the DIRAC Institute members for their useful discussions relating to this exercise, and for their willingness to eat m&m’s® on behalf of pedagogical development. The authors would also like to thank C. Morrison for identifying the location of the lot code on the candy packages during the DIRAC seminar.
Additional information
Funding
Notes
1 https://blogs.sas.com/content/iml/2017/02/20/proportion-of-colors-mandms.html,https://joshmadison.com/2007/12/02/mms-color-distribution-analysis/,https://katedegner.wordpress.com/tag/mm-color-distribution/
2 A well-defined method of prior elicitation from the literature could be used to guide this part. A couple of entry points to the literature are Garthwaite, Kadane, and O'Hagan (2005) and Kadane and Wolfson (Citation1998) Prior elicitation is a broad topic, but one worth introducing to the students if possible; in our experience, prior elicitation is rarely covered in coursework, but can be vitally important to statistical practice.
References
- Albert, J., and Rossman, A. (2009), Workshop Statistics: Discovery with Data, A Bayesian Approach, New York: Springer-Verlag.
- Alexander, M., and SherriJoyce, K. (1994a), “Colored Candies and PROC MACONTROL: A Sweet Way to Produce Chi-Square Control Charts Part 2: Statistical Presentation,” in SUGI 19: Proceedings of the Nineteenth Annual SAS Users Group International Conference, pp. 1145–1150.
- Alexander, M., and SherriJoyce, K. (1994b), “Colored Candles and SAS/QC: A Sweet Way to Produce Chi-Square Control Charts,” SAS Conference Proceedings: SouthEast SAS Users Group 1994, South Carolina: Charleston, pp. 249–253.
- Badinski, I., Huffaker, C., McCue, N., Miller, C. N., Miller, K. S., Miller, S. J., and Stone, M. (2017), “The m&m Game: From Morsels to Modern Mathematics,” Mathematics Magazine, 90, 197–207.
- Blei, D. M. (2012), “Probabilistic Topic Models,” Communications of the ACM, 55, 77–84. DOI: 10.1145/2133806.2133826.
- Downey, A. (2013), Think Bayes, Beijing: O’Reilly.
- Dyck, J. L., and Gee, N. R. (1998), “A Sweet Way to Teach Students About the Sampling Distribution of the Mean,” Teaching of Psychology, 25, 192–195. DOI: 10.1207/s15328023top2503_6.
- Fricker, R. D. (1996), “The Mysterious Case of Blue m&m’s,” Chance, 9, 19–22.
- Froelich, A. G., and Stephenson, W. R. (2013), “How Much Do m&m’s Weigh?” Teaching Statistics, 35, 14–20.
- Garthwaite, P. H., Kadane, J. B., and O’Hagan, A. (2005), “Statistical Methods for Eliciting Probability Distributions,” Journal of the American Statistical Association, 100, 680–701. DOI: 10.1198/016214505000000105.
- Kadane, J., and Wolfson, L. J. (1998), “Experiences in Elicitation,” Journal of the Royal Statistical Society, Series D, 47, 3–19. DOI: 10.1111/1467-9884.00113.
- Lin, T., and Sanders, M. S. (2006), “A Sweet Way to Learn Doe,” Quality Progress, February, 2006, 88. http://asq.org/quality-progress/2006/02/one-good-idea/a-sweet-way-to-learn-doe.html
- Purtill, C. (2017), “A Statistician Got Curious About M&M Colors and Went on an Endearingly Geeky Quest for Answers,” Quartz, March 15, 2017, https://qz.com/918008/the-color-distribution-of-mms-as-determined-by-a-phd-in-statistics/.
- Purtill, C. (2017), “M&M’s Color Distribution, c.2017,” available at https://www.theatlas.com/charts/Hk53hJB5e.
- Schwartz, T. A. (2013), “Teaching Principles of One-way Analysis of Variance Using m&m’s Candy,” Journal of Statistics Education, 21, 1–14.
- SherriJoyce, K., and Alexander, M. (1994), “Colored Candies and Base SAS: A Sweet Way to Produce Chi-Square Control Charts Part 1: Tutorial,” SUGI 19: Proceedings of the Nineteenth Annual SAS Users Group International Conference, pp. 1470–1475.
- Wicklin, R. (2017), “The Distribution of Colors for Plain M&M Candies,” available at https://blogs.sas.com/content/iml/2017/02/20/proportion-of-colors-mandms.html.
- Winkel, B. (2009), “Population Modelling With m&m’s[textregistered],” International Journal of Mathematical Education in Science and Technology, 40, 554–558.
A Appendix: Details of the Hierarchical Bayesian Model
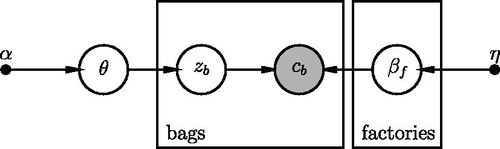
In the hierarchical version of the exercise, there are two sets of parameters β1 and β2 (one for each factory, f), and each set represents the fraction of m&m’s® per color that are produced in Factories 1 and 2. A Dirichlet prior is placed on each set of parameters, with hyperparameters η. In addition, each bag b out of the total sample of B bags is given a latent categorical variable zb that assigns the bag to Factory 1 or Factory 2. This variable is drawn from a categorical distribution describing the probability of drawing a bag from either factory. The parameters for the mixture proportions are denoted as θ. The latter, too, has a Dirichlet prior, with hyperparameters α. A graphical version of this model is shown in .
Fig. A.1 A probabilistic graphical model describing the hierarchical approach to modeling b bags of m&m’s® from different factories . The vector cb denotes the number of m&m’s® of each of the six colors in a single bag b. zb are the latent assignments of each bag to a factory, θ indicates the mixture proportions for the two factories, and βf are the colour distributions for each factory. Finally, α and η denote the hyperparameters for the Dirichlet priors on θ and βf. Figure generated using DAFT, https://daft-pgm.org/.
The full posterior distribution for the categorical mixture model described in Figure A.1 can be written as
(A.1)
(A.1)
where
(A.2)
(A.2)
Funding
ORCID
Gwendolyn Eadiehttps://orcid.org/0000-0003-3734-8177
Daniela Huppenkothenhttps://orcid.org/0000-0002-1169-7486
Aaron Springfordhttps://orcid.org/0000-0001-7179-9049
Tyler McCormickhttps://orcid.org/0000-0002-6490-1129