
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A doubly latent residual approach (DLRA) is presented to explain latent specific factors in multilevel bifactor-(S-1) models. The new approach overcomes some important limitations of the multiple indicators multiple causes (MIMIC) approach and allows researchers to predict latent specific factors at different levels. The DLRA is illustrated using real data from a large-scale assessment study. Furthermore, the statistical performance and power of the DLRA is examined in a Monte Carlo simulation study. The results show that the new DLRA performs well if more than 50 clusters and more than 10 observations per cluster are sampled. The power to test structural parameters at level 2 was lower than at level 1. To test a medium effect at level 2, we recommend to sample at least 100 clusters with a minimum cluster size of 10. The advantages and limitations of the new approach are discussed and guidelines for applied researchers are provided.
Bifactor models are gaining increasing attention in psychology (Eid, Geiser, Koch, & Heene, Citation2017; Koch, Holtmann, Bohn, & Eid, Citation2017a; Reise, Citation2012; Wang & Kim, Citation2017). Originally, Holzinger and Swineford (Citation1937) proposed the bifactor model to separate general and specific components from unsystematic error variance using confirmatory factor analysis. The great flexibility and intuitive appeal of the bifactor model has led many researchers to apply bifactor models to different research designs including longitudinal designs (e.g., latent state-trait modeling, Schermelleh-Engel, Keith, Moosbrugger, & Hodapp, Citation2004; Steyer, Ferring, & Schmitt, Citation1992; Steyer, Mayer, Geiser, & Cole, Citation2015; Steyer, Schmitt, & Eid, Citation1999), multitrait-multimethod measurement designs (Eid, Lischetzke, & Nussbeck, Citation2006; Jeon & Rijmen, Citation2014; Koch, Eid, & Lochner, Citation2018; Koch, Holtmann, Bohn, & Eid, Citation2017b) as well as multilevel measurement designs (Gkolia, Koustelios, & Belias, Citation2018; Koch, Schultze, Burrus, Roberts, & Eid, Citation2015; Scherer & Gustafsson, Citation2015; Wang & Kim, Citation2017). Today, the bifactor model has become an attractive and widely applied method for modeling multidimensional data in psychology (Eid et al., Citation2017; Reise, Citation2012).
In the classical bifactor model proposed by Holzinger and Swineford (Citation1937), it is assumed that a general latent factor loads on all indicators measuring the same underlying construct, whereas a latent specific factor just loads on particular indicators that belong to the same facet or domain. Furthermore, it is assumed that the specific factors are mutually uncorrelated as well as uncorrelated with the general factor. The latent specific factors are often referred to as residual factors, representing the reliable part of the observed variables that has been corrected for the influences of the general factor. Due to the orthogonality of general and specific factors, it is possible to decompose the total variance of each observed variable into a general, a specific, and an error component.
A growing body of research is devoted to the analysis of general and specific factors by the inclusion of manifest or latent explanatory variables into the bifactor model (Koch et al., Citation2017a). Multilevel bifactor models seem to be especially attractive, as they allow researchers to relate explanatory variables to the general and the specific factors at each measurement level. In educational research, researchers often seek to identify key predictor variables for the specific factors (e.g., teacher, wording, or facet-specific effects) using a multilevel bifactor modeling approach (Koch et al., Citation2015; Scherer & Gustafsson, Citation2015; Wang, Kim, Dedrick, Ferron, & Tan, Citation2017). Similarly, psychologists have included external variables into single- and multi-level bifactor models to explain general as well as specific components of self-esteem (DiStefano & Motl, Citation2006; Tomás, Oliver, Galiana, Sancho, & Lila, Citation2013), risk-taking (Nicholson, Soane, Fenton-O’Creevy, & Willman, Citation2005), optimism (Alessandri, Vecchione, Tisak, & Barbaranelli, Citation2011), leadership performance (Gkolia et al., Citation2018), teaching quality (Scherer & Gustafsson, Citation2015), teaching quality (Hindman, Pendergast, & Gooze, Citation2016), cognitive abilities (Dickinson, Ragland, Gold, & Gur, Citation2008; Reynolds, Keith, Ridley, & Patel, Citation2008), psychopathy (Patrick, Hicks, Nichol, & Krueger, Citation2007), burn-out (Shirom, Nirel, & Vinokur, Citation2010) and depression (Yang, Tommet, & Jones, Citation2009).
According to Koch et al. (Citation2017a), explanatory variables cannot be directly linked to the latent factors in the bifactor model if the external variables correlate with both the general and the specific factors. Bifactor models assume orthogonality of general and specific factors. This assumption is, however, violated if a classical multiple indicator multiple cause (MIMIC) approach is used to link explanatory variables to the latent factors in the model. Specifically, the classical MIMIC approach leads to a suppression structure because (explanatory variable) shares variance with both
(general factor) and
(specific factors), whereas
and
are assumed to be uncorrelated in the bifactor model. The orthogonality of
and
does no longer hold if a common cause (e.g.,
) is added into the model. As a consequence, the bifactor model is misspecified because it does not represent the original bifactor model with uncorrelated general and specific factors. If the above suppression structure is not properly modeled, researchers must expect parameter bias of the structural coefficients Koch et al. (Citation2017a). Note that the suppression structure will also arise if an explanatory variable is linked to the specific factors and solely correlates with the general factor in the bifactor model. To properly handle the suppression structure and avoid parameter bias, Koch et al. (Citation2017a) proposed two modeling strategies: the multiconstruct bi-factor approach and the residual approach.
The basic idea of the two modeling strategies is to correct the original explanatory variables from unwanted influences of the general factor, when explaining the latent specific effects in the bifactor model. The multiconstruct bi-factor approach is limited to explanatory variables that can be decomposed into two orthogonal components (Koch et al., Citation2017a). For example, the multiconstruct bifactor approach has been successfully implemented in the context of latent state-trait modeling (Courvoisier, Eid, & Nussbeck, Citation2007; Hamaker, Kuiper, & Grasman, Citation2015; Luhmann, Schimmack, & Eid, Citation2011). In this context, it is common to decompose time-varying covariates into a general (i.e., time-invariant) and a specific (i.e., time-variable) component. In a second modeling step, the general and specific components of the time-varying covariate are linked to the corresponding trait and state factors in the latent state-trait model.
The residual approach is more general than the multiconstruct bifactor approach and can also be used if the explanatory variables cannot be decomposed into two orthogonal components. The residual approach is based on a latent linear regression analysis and requires two modeling steps. First, the general factor is partialled out from the covariate (e.g.,
) using a latent regression analysis. If the assumption of multivariate normality holds, the residual variable of the latent regression analysis represents the part of the original covariate that is free of (first-order) influences of the general factor and thus may be termed residualized covariate (
). In a second step, the residualized covariate
is used as an independent variable to explain the latent specific factors
in the bifactor model. The regression coefficient of a latent specific factor on the residualized covariate can be interpreted as latent partial regression coefficient, representing the link between the specific factor and the covariate while controlling for the general factor. The residual approach circumvents the suppression structure by correcting the covariates from confounding (first-order) influences of the general factor. Following a similar logic, the residual approach can be used to explain the general factor in a bifactor model while controlling for the specific factors.
In this study, we introduce a combination of the doubly latent approach proposed by Marsh et al. (Citation2009) and the residual approach proposed by Koch et al. (Citation2017a). The new approach is termed doubly latent residual approach (DLRA), as it combines the advantages of both approaches. Specifically, the DLRA allows researchers to (a) properly model the previously described suppression structure, (b) simultaneously include multiple explanatory variables at both levels, and (c) account for measurement error as well as sampling error when aggregating level-1 explanatory variables (i.e., doubly latent approach). To examine the statistical performance and power of the DLRA, we present the results of a Monte Carlo simulation study. To the best of our knowledge, no study has yet proposed an adequate transformation method to properly relate explanatory variables to the latent specific factors in multilevel bifactor models. Furthermore, it is not fully clear what sample size is required to explain latent specific effects of different effect sizes in multilevel bifactor models. With this study we aim to fill this gap in current research.
The remainder of the article is organized as follows. First, two versions of multilevel bifactor models are discussed. Second, the DLRA is presented. Third, the DLRA is illustrated using real data from a large-scale educational study to examine the key determinants of teacher effects at the student and the class level. Fourth, the statistical performance and power of the DLRA is examined under a variety of different data constellations in a Monte Carlo simulation study. Finally, the advantages and limitations of the DLRA are discussed and detailed guidelines for applying researchers are provided.
MULTILEVEL BIFACTOR MODELS
According to Eid et al. (Citation2017), two versions of bifactor models can be distinguished: (a) the classical bifactor model that assumes as many specific factors as there are facets in the design and (b) the restricted bifactor model that encompasses a reduced number of specific factors, which will be termed bifactor-(S-1) model in the remainder of the article. In this study, we focus on multilevel bifactor-(S-1) models, as such measurement designs are increasingly applied in practice. In the discussion, we consider ways to properly treat covariates in classical multilevel bifactor models with specific factors.
A typical example of a bifactor-(S-1) model is a multirater measurement designs, where different types of raters (e.g., teacher report versus student self-report) serve as facets. In educational research, it is quite common that a class teacher is asked to rate all students in a class. As a consequence, teacher and student ratings are nested within higher clusters (e.g., classes). However, student as well as teacher reports are fixed for each particular student in a class and resemble different perspectives on the target-student. Therefore, student and teacher reports cannot easily be replaced by one another. To properly model multilevel research designs with fixed raters that are nested within classes, Koch et al. (Citation2015) proposed a multilevel bifactor-(S-1) model. Originally, the model was developed for the analysis of multilevel-multitrait-multimethod designs with nested structurally different methods (Koch et al. Citation2015). In this study, we treat raters as facets and consider a minimal multilevel design including two indicators, one construct, and two raters. Later in the article, we extend our measurement design to multiple facets (i.e., 2, 3, or 4 raters).
The basic idea of the multilevel bifactor-(S-1) model proposed by Koch et al. (Citation2015) is to select a reference facet (e.g., student self-report) and contrast the remaining facets (e.g., teacher report) against this reference facet at each measurement level. We recommend researchers to select the most outstanding facet (i.e., the closed approximation to a gold standard) as the reference facet based on previous findings or substantive theory (Geiser, Eid, & Nussbeck, Citation2008). In the multilevel bifactor-(S-1) model, a reference facet is chosen by modeling –1 (instead of
) specific factors at each measurement level. If, for example, researchers want to select the first facet as the reference facet (e.g., self-report), then the specific factor of the first facet is dropped at each level. The specific factors belonging to the non-reference methods (e.g., teacher report) are defined as latent residual variables of a latent regression analysis, in which the true-score variable of the non-reference methods is regressed on the true-score variable of the reference method. Hence, the latent specific factors in the multilevel bifactor-(S-1) model reflect the reliable part of a non-reference method (e.g., teacher perspective) that is not shared with the reference method (e.g., student perspective) at a particular measurement level. This way, the multilevel bifactor-(S-1) model allows to contrast different facets (e.g., teacher and student perspective) by means of a latent linear regression analysis at each level (cf. Eid, Citation2000; Eid, Lischetzke, Nussbeck, & Trierweiler, Citation2003; Koch et al., Citation2015).
The multilevel bifactor-(S-1) model bears three advantages. First, it enables researchers to contrast different facets (or methods) that do not share a common metric (e.g., self-reports versus objective tests). Second, it allows to define the specific factors as residual factors at each level, which represent the reliable part of a particular facet that is not shared with the general factor at that level. Third, it allows researchers to decompose the true variance of each indicator belonging to a non-reference facet into a level-specific part that is shared with the reference facet (i.e., consistency coefficient) and a level-specific part that is not shared with the reference facet (i.e., specificity coefficient). shows a multilevel bifactor-(S-1) model with common latent factors.
FIGURE 1 Path diagram of a multilevel bifactor-(S-1) model with (a) common latent factors and (b) with additional indicator-specific method factors for a minimal design with two indicators and two facets (here: raters). = within observed variable (
= person,
= cluster,
= indicator, and
= facet or rater).
= between latent trait factor.
= within latent trait factor.
= between latent specific factor.
= within latent specific factor,
= between indicator-specific factor.
= within indicator-specific factor.
= within error variable. The mean structure is not shown to avoid clutter.
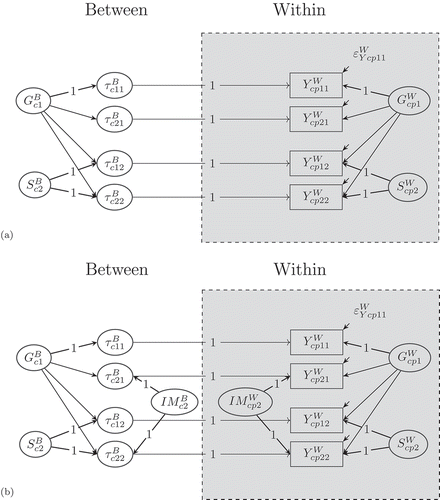
As can be seen from , the first facet (e.g., students’ self-reports) serves as the reference facet, as no latent specific factor is modeled for the first facet (). The corresponding measurement equation for the self-report of a target-student
nested in cluster
can be written as follows:
where denotes indicator and
represents the facet (here: self-reports;
= 1). The superscripts (
= within and
= between) denote the measurement level. According to the Equation (1), each observed variable
belonging to indicator
of the first facet
is decomposed into an additive constant
, a weighted between general factor
, a weighted within general factor
, and an error variable
. The values of the between general factor
represent the true scores of the first facet measured at level 2 (e.g., the overall self-reported intrinsic motivation of a particular class). The values of the within general factor reflect the true scores of the first facet measured at the student level (e.g., true self-reported intrinsic motivation of a student corrected for the true average intrinsic motivation of the class). The error variables capture unsystematic error variance at the within level. The observed variables
belonging to indicator
measured by the remaining facets (
, e.g., teacher reports) are decomposed as follows:
The specific factors and
in Equation (2) represent the reliable (between or within) part of a specific facet
(here: teacher reports) that is not shared with the reference facet (here: students’ self-reports). More specifically, the between specific factor
can be interpreted as teacher effect measured at level 2, that is, the true teacher perspective that is not shared with the student perspective at the class level, whereas
denotes the teacher effect measured at level 1, that is, the true teacher perspective that is not shared with the student perspective at the student level. Again, the error variables
capture unsystematic error variance at the within level.
The above multilevel bifactor-(S-1) model with common latent factors may be too restrictive, especially if additional indicator-specific method effects exist (e.g., wording effects due to positive and negative worded items). To account for additional indicator-specific method effects, the measurement Equations (1) and (2) can be extended in the following way (see also ):
For the remaining facets (i.e., ), the measurement equation of the observed variables is given by
In Equations (3) and (4), latent indicator-specific factors were specified at both levels. To account for the heterogeneity among the indicators, it is sufficient to specify latent indicator-specific factors. Again, researchers have to select a reference indicator (e.g.,
, positively worded items or parcels) and contrast the remaining indicators (e.g.,
, negatively worded items or parcels) against this refe4rence indicator. The indicator-specific factor
captures the reliable part of the negatively worded items that is neither shared with the positively worded items nor with the general or the specific factors at level 1. Similarly, the indicator-specific factors
capture the heterogeneity among the indicators that is not shared with the general or the specific factors at level 2.
The above multilevel bifactor-(S-1) models allow researchers to decompose the total variance of each observed variable into general, facet-specific, indicator-specific, and error components. summarizes the different variance coefficients that can be computed in the multilevel bifactor-(S-1) model with indicator-specific factors. Below we briefly explain the meaning of the most relevant variance coefficients in the model. A detailed discussion of these coefficients can be found in the study by Koch et al. (Citation2015). The consistency coefficients (,
) are indicators of the convergent validity between teacher and student reports at each level. The between consistency coefficient
can be interpreted as a measure of rater congruence between student and teacher reports at the between level, whereas
is a measure of the rater congruence at the within level. The total consistency coefficient is the sum of
and
and ranges between 0 and 2. The specificity coefficients (
,
) are the complements of the previously described consistency coefficients and reflect the degree of rater disagreement at each level. In this study, the within and between specificity coefficients will be interpreted as measures of teacher effects at both levels. The total specificity coefficient is the sum of
and
. The indicator-specificity coefficients (
and
) are measures of the heterogeneity among the indicators at each level. The true intra-class correlation (
) is defined as ratio of the true between variance to the total true variance of an indicator. Finally, the reliability (
) of an indicator is defined as ratio of the overall variance to the observed variance.
TABLE 1 Variance Components in the Multilevel Bifactor-(S-1) Model with Indicator-Specific Factors
DOUBLY LATENT RESIDUAL APPROACH
The DLRA is a combination of the classical doubly latent modeling approach proposed by Marsh et al. (Citation2009) and the residual approach proposed by Koch et al. (Citation2017a). The DLRA requires three modeling steps and is illustrated for one covariate included into a multilevel bifactor-(S-1) model with common latent factors (see ) and with indicator-specific latent factors (see ).
FIGURE 2 Path diagram of the doubly latent residual approach for a multilevel bifactor-(S-1) model with (a) common latent factors and (b) additional indicator-specific method factors for a minimal design with two indicators and two facets (here: raters). = within observed variable (
= person,
= cluster,
= indicator, and
= facet or rater).
= covariate measured by indicator
.
= between latent trait factor.
= within latent trait factor.
= between latent specific factor.
= within latent specific factor,
= between indicator-specific factor.
= within indicator-specific factor.
and
= within error variable. The mean structure is not shown to avoid clutter.
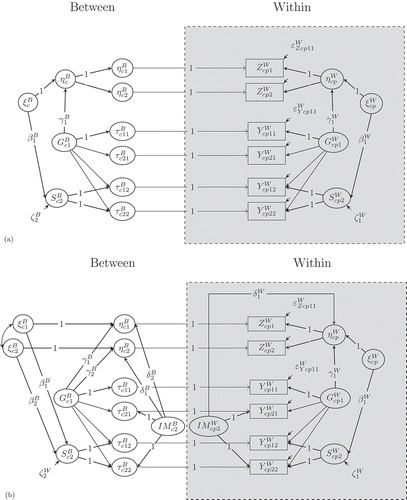
In the first modeling step, the doubly latent approach by Marsh et al. (Citation2009) is performed by specifying adequate measurement models for the explanatory variables at both levels. illustrates the decomposition of the explanatory variables into a common latent factor
measured at level 1 and a common latent factor
measured at level 2, where
= person,
= cluster, and
= indicator:
In Equation (5), reflects the reliable part of the covariate at level 2 (i.e., true average mean of the covariate), whereas
denotes the reliable part of the covariate measured at level 1 (i.e., the deviation of the individual true score from the true average mean of the covariate). For example,
may represent the true average level of parental support in a class, whereas
may represent the deviation of the true student’s level of parental support from the true average of the class. In practice, the model with common latent factors (see Equation 5) may be too restrictive. A less restrictive model with additional indicator-specific factors at level 2
is depicted in . The measurement equation of this model can be expressed as follows:
The indicator-specific latent factors account for the heterogeneity among the indicators at level 2. To avoid problems of multicollinearity, we generally recommend specifying common (instead of indicator-specific) factors if possible (see Equation 5).
In a second modeling step, the and
(see Equation 5) components of the covariate are residualized using the residual approach proposed by Koch et al. (Citation2017a). In case of a multilevel bifactor-(S-1) model with common factors (see ), the level-specific components of the covariates are regressed on the corresponding latent general factors measured at each level. The corresponding latent regression equation can be expressed as follows:
Note that the intercept parameter has been dropped in Equation (8), as the covariate at the within level is defined as zero-mean latent residual variable. The residuals in the above regression equations (see Equations 7 and 8) represent the residualized covariates (
and
).
Following a similar logic, researchers can correct the covariates of indicator-specific and general effects if the covariates share variance with both of these factors. The latent regression equations can be expressed as follows (see ):
Again, the intercept parameter has been dropped in Equation (11). The residuals of these latent regression analyses (Equations 9–11) are defined as residualized explanatory variables (,
, and
).
In a third modeling step, the residualized covariates ,
and
are used as independent variables in a latent regression analysis to predict the latent specific effects at each level. The latent regression equations can be written as follows (see and ):
In Equation (12), is a vector containing
and
. The corresponding latent regression coefficients
and
are included in the vector
. Equation (13) states a linear latent regression of the latent specific factor
on the residualized covariate
at level 1. The latent regression coefficients in Equations (12) and (13) (i.e.,
,
, and
) can be interpreted similary to the partial regression coefficients in ordinary multiple regression analysis. This means that the regression coefficients represent the associations between the specific factors (dependent variables) and the explanatory variables (independent variables) when controlling for general as well as indicator-specific effects at each level. In contrast, the explanatory variables are not residualized in the MIMIC approach, but directly related to the latent factors in the bifactor model. This means that the latent regression coefficients under the MIMIC approach are not corrected for confounding influences of the general and the indicator-specific factors and, thus, may be biased if the covariate also correlates with the general and indicator-specific factors (Koch et al., Citation2017a).
EMPIRICAL ILLUSTRATION
The DLRA is illustrated using data from the BiKS-8–14 study.Footnote1 The BiKS-8–14 study is a German large-scale assessment study investigating students’ educational development from age 8 to 14 using multiple methods (i.e., objective competence tests, self-reports, teacher reports, as well as parent reports). For a detailed description of the BiKS-8–14 study see Artelt, Blossfeld, Faust, Roßbach, and Weinert (Citation2013). Here, we re-analyzed data from the first measurement wave of the BiKS study and focused exclusively on students’ intrinsic motivation assessed via self-reports and teacher reports. In the BiKS study, each student was rated by his or her class teacher. In total, the data comprised the ratings of 2,365 students (52.33% males; average age = 9.49) from 155 classes (or class teachers) and 82 schools. The data were analyzed using a twolevel bifactor-(S-1) model (Koch et al., Citation2015). The third for (school) level was not explicitly modeled, but controlled in the analysis using the Mplus option “type = twolevel complex” (Muthén & Muthén, Citation1998–2017). As a result, the standard errors and fit statistic were adjusted for the clustering in the data (Muthen & Satorra, Citation1995). In this study, we chose students’ self-reports as the reference facet. The teacher reports served as the non-reference facet. In line with Koch et al. (Citation2015), the non-reference facet was contrasted against the reference method at both levels. The within specific factor represents the unique perspective of the class teacher on a particular student’s intrinsic motivation that is not shared with the student’s self-report (i.e., individual teacher effect). The between specific factor captures the perspective of the class teacher on the class-specific intrinsic motivation corrected for the students’ self-reported intrinsic motivation (i.e., class-specific teacher effect). The general factors in the model represent the students’ self-reported intrinsic motivation measured at level 1 and level 2. In addition, we modeled latent indicator-specific factors to account for the heterogeneity among the indicators at each level (see ). The goal of the present study was to (1) examine the congruence between teachers’ and students’ self-reports within and across classes and (2) explain the teacher-specific perspective on students’ intrinsic motivation by relating a residualized explanatory variable (i.e., parental support perceived by the class teacher) to the latent specific factors at each level. The research questions of the present study can be summarized as follows:
To what extent do teacher and student ratings overlap within and between classes?
To what extent do teachers have a different perspective on students’ intrinsic motivation that is not shared with the students’ self-reports (i.e., amount of teacher effects at each level)?
Does parental support perceived by the class teacher explain teacher effects at each level?
The first research question refers to teachers’ judgment accuracy, which can be defined as the congruence between students’ self-reports and teacher reports (Praetorius, Koch, Scheunpflug, Zeinz, & Dresel, Citation2017). Teachers’ judgment accuracy was examined with regard to the consistency coefficients at both levels (see ). The second research question refers to the amount of teacher effects at each level, which were examined with regard to the specificity coefficients. To answer the third research question, we related the explanatory variable (i.e., parental support perceived by the teacher) to the latent specific factors at each level using the DLRA.
RESULTS
First, we fitted a multilevel bifactor-(S-1) model with common latent factors (see ) to the data. This model did not fit the data well, (6,
= 2365) = 527.70,
< .001,
= .82,
= .19,
= .01,
= .13. Second, we fitted the less restrictive multilevel bifactor-(S-1) model with indicator-specific method factors (see ). This model fitted the data acceptably well,
(5,
= 2365) = 48.43,
< .001,
= .99,
= .06,
= .00,
= .12, and was therefore chosen for the subsequent analyses. In a third step, we related a residualized covariate (i.e., parental support) to the latent specific factors at both levels using the DLRA. An example Mplus code for this final model is provided in Appendix C. Note that we specified common latent factors with regard to the residualized covariate at both levels to avoid problems of multicollinearity. The fit of this explanatory multilevel bifactor-(S-1) model was acceptable,
(15,
= 2365) = 267.72,
< .001,
= .96,
= .08,
= .03,
= .12. The averaged intra-class correlations ranged between .11 for students’ self-reports and .25 for teacher reports. The averaged intra-class correlation for the explanatory variable (parental support) was .17. summarizes the results of the multilevel bifactor-(S-1) model.
TABLE 2 Consistency, Specificity and Latent Regression Coefficients
Research question 1 and 2 can be answered by means of the consistency and specificity coefficients that were computed at each level (see ). The consistency coefficients of the teacher reports varied between .084 and .090 at level 1 and between .034 and .037 at level 2. This suggests that the congruence (or convergent validity) between student and teacher reported intrinsic motivation was higher at the individual student level than at the class level. Overall, the consistency coefficients were relatively low and corresponded to a latent correlation between student and teacher reports of = .30 at level 1 and of
= .19 at level 2. These results indicate a relatively low level of convergent validity (or teacher accuracy) at the within and the between level. The specificity coefficients ranged between .851 and .910 at level 1 and between .905 and .963 at level 2 (see ). This shows that a large proportion of true variance of the teacher ratings was due to the unique perspective of the class teacher that was not shared with the students’ self-reports (i.e., teacher effects). Including the residualized covariate (here: parental support), 36% of the interindividual differences in the teacher effects could be explained at level 1 and about 20% of the interindividual differences in the teacher effects could be explained at level 2. The unstandardized regression coefficients of the residualized covariate were positive. This indicates that teachers who perceived the level of parental support as high also tended to overrate students’ intrinsic motivation at each level (i.e., the individual and the class level), when controlling for students’ self-reported intrinsic motivation at each level. The standardized regression coefficient at level 2 was non-significant. This result may be partly explained by a lack of statistical power at level 2. To evaluate the statistical performance and power of the DLRA in greater detail, we conducted a Monte Carlo study.
SIMULATION STUDY
Many applications of multilevel bifactor models involve a relatively low number of level-1 and level-2 observations. Moreover, researchers typically apply multilevel bifactor models that include multiple specific factors at each level. We conducted a simulation study to examine the statistical performance and power of the DLRA under different data constellations.
Results of previous simulation studies suggest that multilevel bifactor-(S-1) models without covariates perform well if at least 50 clusters and more than 10 observations per cluster are sampled (Koch et al., Citation2015). Other studies indicate that a larger number of clusters (100 or more) may be required to obtain proper parameter and standard error estimates in multilevel structural equation models (MSEMs, Hox, Citation2010; Julian, Citation2001). Results of recent simulation studies suggest that the number of level-1 observations per cluster (i.e., cluster size) can reduce standard error bias in longitudinal MSEMs (Koch, Schultze, Eid, & Geiser, Citation2014). Moreover, studies have shown that the performance of the doubly latent approach is positively related to the amount of information (i.e., number of clusters and the intra-class correlation) that is available with regard to the level-2 construct (Lüdtke, Marsh, Robitzsch, & Trautwein, Citation2011). Based on these results, we varied the following factors in our simulation study:
existence of indicator-specific effects: a) yes b) no
number of latent specific factors: 1, 2, or 3
effect size in terms of
at each level: small effect (
number of clusters (nL2): 50, 100, 150, 200, 300, and 500
cluster size (nL1): 10, 15, 20, and 30
The true intra-class correlation was varied across indicators belonging to different facets (raters) in the present study:
.10 for self-reports,
.30 for teacher reports, and
.20 for the explanatory variable. At each level, we related one explanatory variable to the latent specific factors (1, 2, or 3) using the DLRA. The effect sizes at each level were varied in terms of
, ranging from .05 (small), .15 (medium), .35 (large), and .50 (huge). The above
values correspond to the following standardized regression coefficients of the residualized covariate:
.224 (small),
.387 (medium),
.592 (large), and
0.707 (huge). The above regression coefficients were invariant for the within and between model part as well as for both types of bifactor models (i.e., with or without indicator-specific factors). Due to the greater model complexity (i.e. number of freely estimated parameters) of the bifactor model with indicator-specific factors, we expected a less stable performance of the DLRA in case of low sample sizes. The unstandardized regression coefficients of the explanatory variables on the general factors were set to
= 0.935 at level 1 and to
= 1.000 at level 2 in case of bifactor models with common factors (see ). In case of indicator-specific factors (see ), we chose the following values for the unstandardized regression coefficients:
=
= 0.962 and
=
= 0.924. The variance of the general factor was set to
= 8.0 at level 1 and to
= 1.0 at level 2. The variance of the indicator-specific factors was set to
= .20 at level 1 and to
= .08 at level 2. As a consequence of these settings, the variances and the effect sizes of the residualized covariates (
and
) were identical in the simulated models with and without indicator-specific factors. A complete list of the parameter settings in the simulation study is provided in Appendix A together with an example Mplus code in Appendix C.
In total, 576 conditions with 500 replications per condition were simulated (i.e., 288,000 data sets). The data were generated using Mplus 8.1 (Muthén & Muthén, 1998–2017) and MplusAutomation (Hallquist & Wiley, Citation2017) assuming complete data (i.e., no missing values). All models were fitted to the simulated data using robust maximum likelihood (MLR) estimation.
EVALUATION CRITERIA
The statistical performance of the DLRA was examined with regard to the following criteria: (a) rate of convergence, (b) the number of warning messages referring to potential improper solutions, (c) estimation bias and efficiency, and (d) statistical power.
Convergence Rate
In the simulation, we computed the percentage of the simulated models that converged properly after a maximum number of 500 iterations for the Expectation Maximum (EM) algorithm (i.e., Mplus default setting). We expected a larger number of non-converged models in cases of small sample sizes (e.g., nL2 = 50 and nL1 = 10) and in case of bifactor models including additional indicator-specific factors.
Warning Messages and Improper Solutions
Various warning messages were recorded during the simulation study: warning messages referring to (a) -problems, (b)
-problems, (c) computation problems with regard to the standard errors, (d) an ill-conditioned fisher matrix, (e) a saddle point during the estimation. Again, we expected a larger number of warning messages in extreme conditions with low sample size and high model complexity (i.e., including multiple specific factors as well as indicator-specific effects).
Estimation Bias and Efficiency
In the simulation study, we computed the relative parameter estimation bias (peb), the relative standard error estimation bias (seb), the 95% coverage rate (cover), and the mean square error (MSE) as an indicator of efficiency. The relative peb was calculated for each parameter and then averaged over parameters of the same parameter type
:
Similarly, the relative seb is calculated as follows:
In accordance with previous studies, the values of peb and seb < .10 (10%) were regarded as acceptable (e.g., Koch et al., Citation2014; Muthén & Muthén, Citation2002). The 95% coverage is the proportion of replications for which the 95% confidence interval contains the true (or population) parameter value. The MSE is defined as variance of the parameter estimates across all replications plus the square of the bias for that parameter estimates. Again, the 95% coverage rate and the MSE were averaged across parameters of the same parameter type. The coverage and the MSE indicate how well a parameter and its standard error are estimated and were interpreted as a measure of estimation efficiency. Less bias and greater efficiency were expected with increasing sample size at each level.
Power
Finally, we examined the statistical power for explaining latent specific factors under various sample size conditions as well as different model complexity (i.e., number of latent specific factors included in the model). The goal was to provide recommendations to applied researchers for designing future studies with regard to the analysis of specific effects using the DLRA.
RESULTS
Convergence Rate
Model non-convergence was encountered in 52 out of 576 conditions (9.03%). However, none of the simulated conditions showed severe convergence problems (i.e., convergence rate below 50%). Overall, there were only 14 conditions that showed a convergence rate below 90%. Convergence problems were primarily encountered in conditions with high model complexity (e.g., indicator-specific factors) and a low sample size (e.g., nL2 = 50 and nL1 = 10).
Warning Messages and Improper Solutions
From 576 conditions, 12.5% showed warning messages referring to -problems, 7.81% referring to estimation problems of the standard errors, 7.81% referring to an ill-conditioned fisher matrix, and 10.76% referring to problems of reaching a saddle point during the estimation. As expected, the majority of these warning messages were encountered in extreme conditions, in which a relatively complex multilevel bifactor-(S-1) model including multiple latent specific factors and indicator-specific factors was fit to small samples (nL2 = 50 and nL1 = 10). Based on these results, we decided to remove the condition with 50 clusters and 10 observations per cluster from further analyses. We did not encounter any warning messages referring to
-problems in our simulation study. Overall, the results are promising and show that even complex multilevel bifactor-(S-1) models with covariates at each measurement level can be successfully fitted to relatively small samples.
Estimation Bias and Efficiency
shows the averaged relative peb in the simulated multilevel bifactor-(S-1) models with respect to the sample size at both levels.
FIGURE 3 Averaged peb in the simulated multilevel bifactor-(S-1) models. The y-axis shows the averaged peb across all model parameters. The x-axis refers to the number of specific factors in the model. The upper panel denotes the number of cluster (level-2 observations) and the right panel denotes the cluster size (level-1 observations). Bars colored in light gray refer to models with common factors. Bars colored in dark gray refer to model including indicator-specific factors.
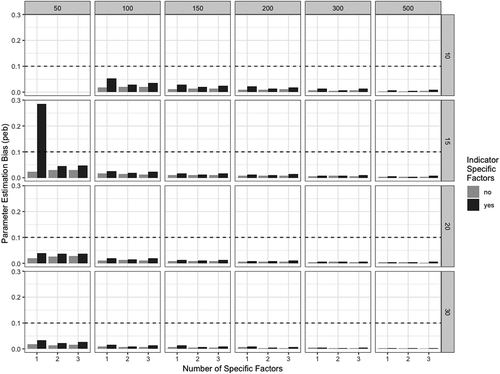
As can be seen from , the averaged peb values decreased substantially with increasing sample size at level 1 and level 2. The peb values did not exceed the cutoff value of 10%, except for one condition including 50 clusters and 15 observations per cluster. It is worth noting that the averaged peb values fell below the cutoff value when the model included multiple specific factors. A closer inspection revealed that the variance of the indicator-specific factor at level 1 was poorly estimated in the condition with one specific factor, which in turn may have led to the increased bias in the parameter estimates when explaining the latent specific factor at level 1. Notwithstanding, the number of specific factors in the simulated bifactor models had only a negligible effect on the peb values (see ). In general, the averaged peb values were consistently larger in conditions including indicator-specific factors.
shows the averaged seb values in the simulated multilevel bifactor-(S-1) models with respect to the sample size on level 1 and level 2.
FIGURE 4 Averaged seb in the simulated multilevel bifactor-(S-1) models. The y-axis shows the averaged seb across all model parameters. The x-axis refers to the number of specific factors in the model. The upper panel denotes the number of cluster (level-2 observations) and the right panel denotes the cluster size (level-1 observations). Bars colored in light gray refer to models with common factors. Bars colored in dark gray refer to model including indicator-specific factors.
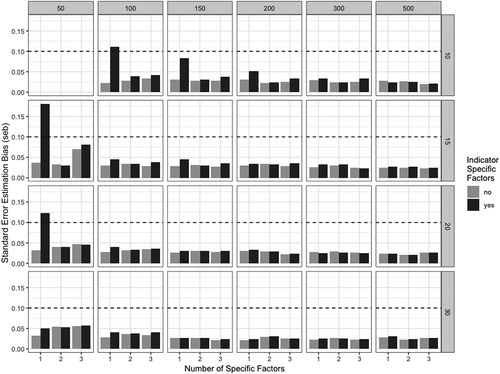
TABLE 3 Summary of Estimation Bias and Estimation Efficiency for Different Sample Sizes and Models with or without Indicator-Specific Factors
Statistical Power
The statistical power of DLRA is illustrated in for the standardized regression coefficients at level 1 and in for the standardized regression coefficients at level 2. The statistical power depended on the number of clusters (nL2), the cluster size (nL1), as well as the effect size. However, the number of specific factors in the bifactor model had only little impact on the statistical power of the DLRA approach. A detailed summary of the power analysis is provided in in Appendix B.
FIGURE 5 Power of the standardized latent regression coefficients of different effect sizes at the within level. The dotted line denotes a power of .80. The y-axis shows the statistical power of the standardized latent regression coefficients at the within level. The x-axis refers to the number of specific factors in the model. The upper panel denotes the number of cluster (level-2 observations) and the right panel denotes the cluster size (level-1 observations). Small effect = red line. Medium effect = green line. Large effect = blue line. Huge effect = purple line.
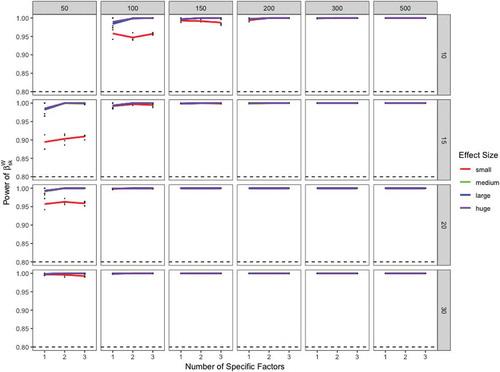
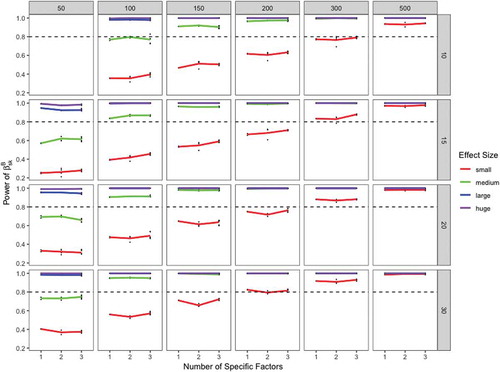
As can be seen from , the power at the within level was always greater than 80%. We did not observe a loss in statistical power if multiple specific factors were added in the multilevel bifactor-(S-1) model. This shows the DLRA approach performs well at the within level if at least 50 clusters and more than 10 observations per cluster are sampled. However, the power at the between level fell below 80% in some conditions (see ). To test a small effect () at the between level with a probability of 80%, researchers must at least sample 300 cluster with 10 observations per cluster. However, the power at the between level was often close to 80% if more than 200 clusters and more than 15 observations per cluster were sampled. To detect larger effects at the between level (i.e., medium, large, or huge effects), a minimal sample size of 100 clusters and 10 observations per cluster should be sampled. Our findings suggest that the number of clusters is a more relevant factor for a sufficient level of statistical power at the between level than the cluster size.
FIGURE 6 Power of the standardized latent regression coefficients of different effect sizes at the between level. The dotted line denotes a power of .80. The y-axis shows the statistical power of the standardized latent regression coefficients at the between level. The x-axis refers to the number of specific factors in the model. The upper panel denotes the number of cluster (level-2 observations) and the right panel denotes the cluster size (level-1 observations). Small effect = red line. Medium effect = green line. Large effect = blue line. Huge effect = purple line.
DISCUSSION
In the present study, we introduced a DLRA to properly explain latent specific factors in multilevel bifactor-(S-1) models. The DLRA combines the advantages of the residual approach by Koch et al. (Citation2017a) and the classical doubly latent approach by Marsh et al. (Citation2009) and overcomes some important limitations of the classical MIMIC approach when explaining latent factors in multilevel bifactor models. Specifically, the DLRA avoids the methodological problems that arise when directly relating explanatory variables to the specific factors in bifactor models (Koch et al., Citation2017a).
In the DLRA, level-1 explanatory variables are first decomposed into a within and a between component. In a second step, the components are corrected for confounding influences of the latent general factors on each measurement level. The residualized explanatory variables represent the part of the explanatory variables that is not determined by the general factors and thus can be safely related to the specific factors at each level. Researchers must also remove indicator-specific influences from the explanatory variables, if the indicator-specific factors in the model correlate with the explanatory variables.
Another advantage of the DLRA is that it allows researchers to relate explanatory variables to the latent specific factors on multiple measurement levels, while accounting for measurement and sampling error. The DLRA also enables a clearer interpretation of the latent regression coefficients. In the classical MIMIC approach, explanatory variables are not residualized, but directly related to the latent factors in the bifactor model. Similar to multiple regression analysis, the DLRA approach allows researchers to control for the potentially confounding factors in the bifactor model (e.g., influence of the general and/or the indicator-specific factors) when relating the explanatory variables to the latent specific factors in the model. Thus, the DLRA allows researchers to study the relationship between explanatory variables and the latent specific factors at each level when controlling for general and/or indicator-specific effects. Moreover, the residualized explanatory variables in the DLRA are already centered as recommended by many researchers in the context of multilevel modeling (Enders & Tofighi, Citation2007; Kreft, De Leeuw, & Aiken, Citation1995). In this article, the DLRA was presented using a latent linear regression analysis. Therefore, the DLRA approach only corrects for linear or first-order dependencies between the general factor and the explanatory variables. To correct for higher-order dependencies, the DLRA needs to be extended to higher-order or nonlinear effects.
The DLRA was illustrated using data from a German large-scale assessment study investigating teacher effects with regard to students’ intrinsic motivation. Our findings suggest that teachers tend to overestimate students’ intrinsic motivation at the within level if teachers also believe that their students receive a high level of parental support, controlling for students’ self-reported level of intrinsic motivation and indicator-specific effects. Similar results were found at the between level, which indicate that teachers tend to overestimate the intrinsic motivation of the entire class if they believe that students in the class receive a high level of parental support (controlling for the students’ self-reported level of intrinsic motivation and indicator-specific effects).
We examined the statistical performance and power of the DLRA in a Monte Carlo simulation study. The results showed that the DLRA performs well in a variety of different data constellations. Overall, the biases in parameter and standard error estimates were negligible and exceeded the cutoff value of 10% only in extreme conditions. The standard errors were slightly biased if a multilevel bifactor-(S-1) model with additional indicator-specific factors was fitted to small samples (i.e., 50 clusters and 15 observations per cluster). To obtain proper parameter and standard errors, we recommend sampling more than 100 clusters and more than 10 observations per cluster. These findings are in line with previous simulation studies in the context of multilevel structural equation modeling (MSEM Hox & Maas, Citation2001; Julian, Citation2001; Koch et al., Citation2014), suggesting that a sufficient number of clusters is required for proper parameter and standard error estimates in MSEM. In terms of statistical power, we recommend researchers to sample a larger number of clusters (e.g., 200–300 clusters) in order to detect small effects at the between level. To detect medium effects at the between level, a sample size of 100 clusters and 10 observations per cluster seems to be sufficient.
In this study, we introduced the DLRA in the context of multilevel bifactor modeling that included a reduced number of specific factors (i.e., -1 specific factors). It is worth noting that the DLRA can be extended straightforward to traditional multilevel bifactor models that include as many specific factors as there are facets in the design (i.e.,
specific factors). In some situations, it may be however more practical to apply the multiconstruct bifactor approach proposed by Koch et al. (Citation2017a) at both levels. For example, a multiconstruct bifactor approach would be beneficial if researchers aim to relate time-varying covariates to the latent factors in a multilevel latent state-trait model in order to explain time-variable and time-invariant interindividual differences at the within (student) and the between (class) level. A multilevel multiconstruct bifactor approach requires that the time-varying covariates are first decomposed into two orthogonal components at each level using the doubly latent approach proposed (Marsh et al., Citation2009). In a second step, a traditional bifactor structure is used to model the dependent and independent (explanatory) variables at both levels. Finally, the general factors belonging to the explanatory variables can be linked to the general factors belonging to the dependent variables at each level. Similarly, the specific factors belonging to the explanatory variables can be related to the specific factors belonging to the dependent variables at each level. It is important to note that the results of our simulation study cannot be generalized beyond the specific conditions implemented. However, the following recommendations can be derived from our results.
Tip 1: Inspect the First-Order Correlations between the Explanatory Variables and the Latent Factors in the Multilevel Bifactor Model
We recommend researchers to evaluate the first-order correlations between the explanatory variables and the latent factors in the multilevel bifactor model. This way, researchers are able to investigate whether or not a suppression structure is present in the data. The DLRA is recommended whenever the explanatory variables correlate with both the general and the specific factors at a particular level. However, the DLRA is not necessary if the explanatory variables solely correlate with the latent specific factors, but not with the remaining factors in the bifactor model. In these situations, researchers can simply relate the explanatory variables to the latent specific factors in the model and fix the remaining (non-significant) correlations to zero. However, we recommend to center the explanatory variables before the analysis.
Tip 2: Use Multiple Homogeneous Indicators
In the context of the DLRA, we recommend specifying common factors (instead of indicator-specific factors) if possible. Results of our simulation study suggest that the DLRA becomes unstable in case of indicator-specific factors (i.e., larger amount of improper solutions as well as larger bias under the same conditions). Indicator-specific factors pose a problem of multicollinearity, as the latent indicator-specific factors account for the heterogeneity among the indicators. To avoid this problem, we suggest using homogeneous indicators (three indicators per factor). If indicator-specific factors are needed for theoretical or statistical reasons, we suggest to evaluate the first-order correlations as discussed above.
Tip 3: Specify Parsimonious Multilevel Bifactor Models
Our findings suggest that the number of specific factors in the multilevel bifactor-(S-1) model had only little impact on the trustworthiness of the parameter and standard error estimates. In some cases, modeling multiple specific factors was associated with less parameter and standard error bias. Notwithstanding, we recommend specifying parsimonious multilevel bifactor-(S-1) models. Previous simulation studies have suggested that the ratio of observations to the number of freely estimated parameters should exceed 5:1 (Bentler & Chou, Citation1987) or 10:1 (Bollen, Citation1989) with regard to classical structural equation models. We recommend a minimal sample size of 50 clusters with 15 observations per cluster. This corresponds to a ratio of 12:1, that is, 750 observations and 62 freely estimated parameters in case of the most complex model. In this simulation study, we have not varied the number of explanatory variables in the model. It can be expected that the statistical power decreases if multiple explanatory variables are added simultaneously into the model.
CONCLUSION
The present study investigated the statistical performance and power of a DLRA when explaining specific factors in multilevel bifactor-(S-1) models. The proposed DLRA overcomes important limitations of the classical MIMIC approach and performs well under a variety of data constellations.
Additional information
Funding
Notes
1 The acronym BiKS stands for educational processes, competence development and selection decisions in preschool and school age.
References
- Alessandri, G., Vecchione, M., Tisak, J., & Barbaranelli, C. (2011). Investigating the nature of method factors through multiple informants: Evidence for a specific factor? Multivariate Behavioral Research, 46(4), 625–642. doi:10.1080/00273171.2011.589272
- Artelt, C., Blossfeld, H.-P., Faust, G., Roßbach, H.-G., & Weinert, S. (2013). Bildungsprozesse, Kompetenzentwicklung und Selektionsentscheidungen im vorschulund schulalter [Educational processes, competence development and selection decisions in preschool and school age] (BiKS-8-14). Version: 2 (Tech. Rep.). IQB – Institut zur Qualitätsentwicklung im Bildungswesen. Retrieved from http://doi.org/10.5159/IQB_BIKS_8_14_v2
- Bentler, P. M., & Chou, C.-P. (1987). Practical issues in structural modeling. Sociological Methods & Research, 16, 78–117. doi:10.1177/0049124187016001004
- Bollen, K. A. (1989). Structural equations with latent variables. New York, NY: John Wiley & Sons.
- Courvoisier, D. S., Eid, M., & Nussbeck, F. W. (2007). Mixture distribution latent state-trait analysis: Basic ideas and applications. Psychological Methods, 12, 80–104. doi:http://dx.doi.org/10.1037/1082-989X.12.1.80
- Dickinson, D., Ragland, J. D., Gold, J. M., & Gur, R. C. (2008). General and specific cognitive deficits in schizophrenia: Goliath defeats david? Biological Psychiatry, 64(9), 823–827. doi:10.1016/j.biopsych.2008.04.005
- DiStefano, C., & Motl, R. W. (2006). Further investigating method effects associated with negatively worded items on self-report surveys. Structural Equation Modeling: A Multidisciplinary Journal, 13(3), 440–464. doi:10.1207/s15328007sem1303_6
- Eid, M. (2000). A multitrait-multimethod model with minimal assumptions. Psychometrika, 65(2), 241–261. doi:10.1007/BF02294377
- Eid, M., Lischetzke, T., & Nussbeck, F. (2006). Structural equation models for multitrait-multimethod data. In M. Eid & E. Diener (Eds.), Handbook of multimethod measurement in psychology (pp. 289–299). Washington, DC: American Psychological Association.
- Eid, M., Geiser, C., Koch, T., & Heene, M. (2017). Anomalous results in g-factor models: Explanations and alternatives. Psychological Methods, 22(3), 541–562. doi:http://dx.doi.org/10.1037/met0000083
- Eid, M., Lischetzke, T., Nussbeck, F. W., & Trierweiler, L. I. (2003). Separating trait effects from trait-specific method effects in multitrait-multimethod models: A multiple-indicator CT-C(M-1) model. Psychological Methods, 8(1), 38–60. doi:10.1037/1082-989X.8.1.38
- Enders, C. K., & Tofighi, D. (2007). Centering predictor variables in cross-sectional multilevel models: A new look at an old issue. Psychological Methods, 12, 121–138. doi:http://dx.doi.org/10.1037/1082-989X.12.2.121
- Geiser, C., Eid, M., & Nussbeck, F. W. (2008). On the meaning of the latent variables in the CT-C(M-1) model: A comment on maydeu-olivares and coffman (2006). Psychological Methods, 13(1), 49–57. doi:10.1037/1082-989X.13.1.49
- Gkolia, A., Koustelios, A., & Belias, D. (2018). Exploring the association between transformational leadership and teacher’s self-efficacy in Greek education system: A multilevel sem model. International Journal of Leadership in Education, 21(2), 176–196. doi:10.1080/13603124.2015.1094143
- Hallquist, M., & Wiley, J. (2017). Mplusautomation: Automating mplus model estimation and interpretation [Computer software manual]. Retrieved from https://CRAN.R-project.org/package=MplusAutomation (R package version 0.7)
- Hamaker, E. L., Kuiper, R. M., & Grasman, R. P. (2015). A critique of the cross-lagged panel model. Psychological Methods, 20, 102–116. doi:http://dx.doi.org/10.1037/a0038889
- Hindman, A. H., Pendergast, L. L., & Gooze, R. A. (2016). Using bifactor models to measure teacher–Child interaction quality in early childhood: Evidence from the caregiver interaction scale. Early Childhood Research Quarterly, 36, 366–378. doi:10.1016/j.ecresq.2016.01.012
- Holzinger, K. J., & Swineford, F. (1937). The bi-factor method. Psychometrika, 2(1), 41–54. doi:10.1007/BF02287965
- Hox, J. J. (2010). Multilevel analysis techniques and applications (2nd ed.). New York, NY: Routledge.
- Hox, J. J., & Maas, C. J. (2001). The accuracy of multilevel structural equation modeling with pseudobalanced groups and small samples. Structural Equation Modeling: A Multidisciplinary Journal, 8(2), 157–174. doi:10.1207/S15328007SEM0802_1
- Jeon, M., & Rijmen, F. (2014). Recent developments in maximum likelihood estimation of mtmm models for categorical data. Frontiers in Psychology, 5, 269. doi:10.3389/fpsyg.2014.00269
- Julian, M. W. (2001). The consequences of ignoring multilevel data structures in nonhierarchical covariance modeling. Structural Equation Modeling: A Multidisciplinary Journal, 8(3), 325–352. doi:10.1207/S15328007SEM0803_1
- Koch, T., Holtmann, J., Bohn, J., & Eid, M. (2017b). Multitrait-multimethod-analysis. In V. Zeigler-Hill & T. Shakelford (Eds.), Encyclopedia of personality and individual differences. Berlin, Germany: Springer.
- Koch, T., Eid, M., & Lochner, K. (2018). Multitrait-multimethod-analysis: The psychometric foundation of CFA-MTMM models. In P. Irwing, T. Booth, & D. Hughes (Eds.), The wiley handbook of psychometric testing: A multidisciplinary reference on survey, scale and test development. London, UK: Wiley-Blackwell.
- Koch, T., Holtmann, J., Bohn, J., & Eid, M. (2017). Explaining general and specific factors in longitudinal, multimethod, and bifactor models: Some caveats and recommendations. Psychological Methods. Advance online publication. doi:10.1037/met0000146
- Koch, T., Schultze, M., Burrus, J., Roberts, R. D., & Eid, M. (2015). A multilevel CFA-MTMM model for nested structurally different methods. Journal of Educational and Behavioral Statistics, 40(5), 477–510. doi:10.3102/1076998615606109
- Koch, T., Schultze, M., Eid, M., & Geiser, C. (2014). A longitudinal multilevel CFA-MTMM model for interchangeable and structurally different methods. Frontiers in Quantative Psychology and Measurement, 5:311. doi:10.3389/fpsyg.2014.00311
- Kreft, I. G., De Leeuw, J., & Aiken, L. S. (1995). The effect of different forms of centering in hierarchical linear models. Multivariate Behavioral Research, 30, 1–21. doi:10.1207/s15327906mbr3001_1
- Lüdtke, O., Marsh, H. W., Robitzsch, A., & Trautwein, U. (2011). A 2 × 2 taxonomy of multilevel latent contextual models: Accuracy–Bias trade-offs in full and partial error correction models. Psychological Methods, 16(4), 444–467. doi:10.1037/a0024376
- Luhmann, M., Schimmack, U., & Eid, M. (2011). Stability and variability in the relationship between subjective well-being and income. Journal of Research in Personality, 45, 186–197. doi:10.1016/j.jrp.2011.01.004
- Marsh, H. W., Lüdtke, O., Robitzsch, A., Trautwein, U., Asparouhov, T., Muthén, B., & Nagengast, B. (2009). Doubly-latent models of school contextual effects: Integrating multilevel and structural equation approaches to control measurement and sampling error. Multivariate Behavioral Research, 44(6), 764–802. doi:10.1080/00273170903333665
- Muthen, B. O., & Satorra, A. (1995). Complex sample data in structural equation modeling. Sociological methodology, 267–316.
- Muthén, L. K., & Muthén, B. O. (1998- 2017). Mplus user‘s guide (8th ed.). Los Angeles, CA: Muthén & Muthén.
- Muthén, L. K., & Muthén, B. O. (2002). How to use a monte carlo study to decide on sample size and determine power. Structural Equation Modeling: A Multidisciplinary Journal, 9(4), 599–620. doi:10.1207/S15328007SEM0904_8
- Nicholson, N., Soane, E., Fenton-O’Creevy, M., & Willman, P. (2005). Personality and domain-specific risk taking. Journal of Risk Research, 8(2), 157–176. doi:10.1080/1366987032000123856
- Patrick, C. J., Hicks, B. M., Nichol, P. E., & Krueger, R. F. (2007). A bifactor approach to modeling the structure of the psychopathy checklist-revised. Journal of Personality Disorders, 21(2), 118–141. doi:10.1521/pedi.2007.21.2.118
- Praetorius, A.-K., Koch, T., Scheunpflug, A., Zeinz, H., & Dresel, M. (2017). Identifying determinants of teachers’ judgment (in) accuracy regarding students’ school-related motivations using a bayesian cross-classified multi-level model. Learning and Instruction, 52, 148–160. doi:10.1016/j.learninstruc.2017.06.003
- Reise, S. P. (2012). The rediscovery of bifactor measurement models. Multivariate Behavioral Research, 47(5), 667–696. doi:10.1080/00273171.2012.715555
- Reynolds, M. R., Keith, T. Z., Ridley, K. P., & Patel, P. G. (2008). Sex differences in latent general and broad cognitive abilities for children and youth: Evidence from higher-order mg-macs and mimic models. Intelligence, 36(3), 236–260. doi:10.1016/j.intell.2007.06.003
- Scherer, R., & Gustafsson, J.-E. (2015). Student assessment of teaching as a source of information about aspects of teaching quality in multiple subject domains: An application of multilevel bifactor structural equation modeling. Frontiers in Psychology, 6 1550 Retrieved from https://www.frontiersin.org/article/10.3389/fpsyg.2015.01550 doi:10.3389/fpsyg.2015.01550
- Schermelleh-Engel, K., Keith, N., Moosbrugger, H., & Hodapp, V. (2004). Decomposing person and occasion-specific effects: An extension of latent state-trait (LST) theory to hierarchical LST models. Psychological Methods, 9(2), 198–219. doi:10.1007/s10802-011-9547-x
- Shirom, A., Nirel, N., & Vinokur, A. D. (2010). Work hours and caseload as predictors of physician burnout: The mediating effects by perceived workload and by autonomy. Applied Psychology, 59(4), 539–565. doi:10.1111/j.1464-0597.2009.00411.x
- Steyer, R., Ferring, D., & Schmitt, M. J. (1992). States and traits in psychological assessment. European Journal of Psychological Assessment, 8(2), 79–98.
- Steyer, R., Mayer, A., Geiser, C., & Cole, D. A. (2015). A theory of states and traits—Revised. Annual Review of Clinical Psychology, 11(1), PMID: 25062476, 71–98. doi:10.1146/annurev-clinpsy-032813-153719
- Steyer, R., Schmitt, M., & Eid, M. (1999). Latent state-trait theory and research in personality and individual differences. European Journal of Personality, 13(5), 389–408. doi:10.1002/(SICI)1099-0984(199909/10)13:53.0.CO;2-A
- Tomás, J. M., Oliver, A., Galiana, L., Sancho, P., & Lila, M. (2013). Explaining method effects associated with negatively worded items in trait and state global and domain-specific self-esteem scales. Structural Equation Modeling: A Multidisciplinary Journal, 20(2), 299–313. doi:10.1080/10705511.2013.769394
- Wang, Y., & Kim, E. S. (2017). Evaluating model fit and structural coefficient bias: A Bayesian approach to multilevel bifactor model misspecification. Structural Equation Modeling: A Multidisciplinary Journal, 24(5), 699–713. doi:10.1080/10705511.2017.1333910
- Wang, Y., Kim, E. S., Dedrick, R. F., Ferron, J. M., & Tan, T. (2017). A multilevel bifactor approach to construct validation of mixed-format scales. Educational and Psychological Measurement, 78, 253–271. doi:10.1177/0013164417690858
- Yang, F. M., Tommet, D., & Jones, R. N. (2009). Disparities in self-reported geriatric depressive symptoms due to sociodemographic differences: An extension of the bi-factor item response theory model for use in differential item functioning. Journal of Psychiatric Research, 43(12), 1025–1035. doi:10.1016/j.jpsychires.2008.12.007
Appendix A Parameter Settings Used in the Simulation Study
TABLE A1 Population Values of the Structural Parameters Used in the Simulation
Appendix B Power Analysis
TABLE B1 Power of Statistical Tests of the Standardized Regression Coefficients