
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The literature on non-linear structural equation modeling is plentiful. Despite this fact, few studies consider interactions between exogenous and endogenous latent variables. Further, it is well known that treating ordinal data as continuous produces bias, a problem which is enhanced when non-linear relationships between latent variables are incorporated. A marginal maximum likelihood-based approach is proposed in order to fit a non-linear structural equation model including interactions between exogenous and endogenous latent variables in the presence of ordinal data. In this approach, the exact gradient of the approximated observed log-likelihood is calculated in order to attain the approximated maximum likelihood estimator. A simulation study shows that the proposed method provides estimates with low bias and accurate coverage probabilities.
Introduction
Non-linear structural equation modeling (SEM) has been of great interest in the past few decades. Fruitful theories in psychology and business studies incorporate non-linear relations among latent variables. In the Theory of Planned Behavior, Ajzen (Citation1991) emphasized the relevance of interaction between Motivation and Ability on Behavior. In a study focusing on the consumers’ loyalty, Agustin and Singh (Citation2005) proposed a quadratic relationship between the latent constructs Satisfaction, Trust, Value, and Loyalty intentions in the framework of marketing sciences. In order to fit a non-linear SEM model, various methods have been proposed, which include but are not limited to the product indicator approaches (e.g., Kelava & Brandt, Citation2009; Marsh, Wen, & Hau, Citation2004; Wall & Amemiya, Citation2001; Yang-Jonsson, Citation1997), the method of moments (e.g., Mooijaart & Bentler, Citation2010; Wall & Amemiya, Citation2000), two-stage least squares (e.g., Bollen, Citation1995, Citation1996), the distributional analytic approaches (e.g., Klein & Moosbrugger, Citation2000; Klein & Muthén, Citation2007; Lee & Zhu, Citation2002), and the Bayesian methods (e.g., Lee & Song, Citation2004a; Zhu & Lee, Citation1999). The reader is directed to Brandt, Kelava, and Klein (Citation2014) and Harring, Weiss, and Hsu (Citation2012) for reviews and simulation studies comparing the aforementioned methods. Despite that the methods of fitting a non-linear SEM model are numerous, they are not flawless and do not always meet the needs of real data analysis.
First, most studies have focused on models with continuous indicators. In such cases, distributional assumptions are violated if indicators are ordinal. This has been investigated and observed extensively in linear models (e.g., Finney & DiStefano, Citation2006; Flora & Curran, Citation2004). Rhemtulla, Brosseau-Liard, and Savalei (Citation2012) showed that ordinal data cannot be treated as continuous, unless the number of categories is large and the categories are equidistant. Due to the complexity of the non-linear model, we do not expect such methods to work well in a non-linear SEM model with ordinal data either. Lee and Zhu (Citation2000) firstly considered a non-linear SEM model with the presence of polytomous indicators and proposed a Bayesian approach to estimate the parameters. Since then, various studies that directly handle the categorical nature emerge. Lee and Song (Citation2003) extended the model in Lee and Zhu (Citation2000) by incorporating covariates in the measurement and the structural model and proposed an MCEM algorithm (Wei & Tanner, Citation1990) to estimate the parameters. A similar algorithm was used by Song and Lee (Citation2005) when the non-linear model has only dichotomous indicators. Lee and Song (Citation2008) and Song and Lee (Citation2006a) considered Bayesian estimation and comparison of non-linear models with a mixture of continuous, dichotomous, and ordinal indicators. Rizopoulos and Moustaki (Citation2008) introduced non-linear terms of the latent variables to generalized latent variable models with covariates. When the non-linear model contains missing values, Lee and Song (Citation2004a) proposed a Bayesian approach for a mixture of continuous and ordinal indicators, which is extended by Cai, Song, and Lee (Citation2008) to model non-ignorable missing. Lee and Song (Citation2007) proposed a unified maximum likelihood approach for non-linear models with different types of indicators and with or without missing values. Lee, Song, and Cai (Citation2010) exemplified the use of the Bayesian approach in the non-linear models using dichotomous indicators as examples. Studies mentioned above are devoted to single group data analysis. It is further generalized by Song and Lee (Citation2006b) to multigroup analysis and by Kelava and Brandt (Citation2014), Lee and Song (Citation2004b), Lee et al. (Citation2009), and Song and Lee (Citation2004) to multilevel analysis.
Second, in the Theory of Planned Behavior, Ajzen (Citation1991) proposed that the effect of Intention (endogenous latent variable) on Behavior is affected by Perceived Behavioral Control (exogenous latent variable). Throughout the paper, an exogenous variable is a variable that is not caused by any other variables in the model and an endogenous variable is a variable that is caused by some variables in the model. Even though some methods can incorporate ordinal data into the model, they generally lack the interaction between endogenous latent variables and exogenous latent variables. In contrast, Agustin and Singh (Citation2005) proposed an interaction effect between Consumer Trust (endogenous latent variable) and Satisfaction (exogenous latent variable). They treated ordinal data as continuous and used the two-step approach of Ping (Citation1995). To our best knowledge, there are no contemporary methods that can estimate non-linear SEM models including interactions between exogenous and endogenous latent variables in the presence of ordinal indicators.
The main purpose of the current paper is to fit the non-linear SEM model with ordinal data in the presence of interactions between latent exogenous and latent endogenous variables. We propose a marginal maximum likelihood approach to estimate the fixed unknown parameters in the model. Instead of the commonly implemented expectation-maximization (EM, Dempster, Laird, & Rubin, Citation1977) algorithm, we propose to use direct maximization. As we shall explain in later sections, the direct maximum likelihood approach is based on the true gradient of the approximated observed log-likelihood, which makes the sandwich estimator of standard errors easier to obtain. In contrast, the sandwich estimator of standard errors is not directly available in the EM algorithm. Further, when the gradients in the M-step are approximated, the EM algorithm can be less accurate than the direct maximum likelihood approach with the same approximation method (Jin & Andersson, Citation2019a).
The article is organized as follows. The model is presented in the next section, which is followed by a description of the proposed method and an outline of the suggested procedure for directly maximizing the marginal likelihood. Next, a simulation study is conducted to investigate the small-sample performance of the proposed method. An empirical example is presented to illustrate the method, followed by a discussion with conclusions.
Non-linear structural equation model
Let (exogenous) and
(endogenous) be latent random vectors with dimensions
and
, respectively. The measurement model for
, the
ordinal indicator of
, is:
where is the number of response categories for the ordinal indicator
,
is the link function,
is the category-specific intercept for observing
, and
is the factor loading vector for
. Such a setting is similar to the cumulative link model in the context of generalized linear model (Agresti, Citation2015, p. 213), but only with latent variables as explanatory variables. Likewise, the measurement model for
, the
ordinal indicator of
, is:
where is the number of response categories for the ordinal indicator
,
is the link function,
is the category-specific intercept for observing
, and
is the factor loading vector for
.
is assumed to have a
mean vector and a covariance matrix
. Further, partition
into a
vector
and a
vector
. The structural model of interest is:
where is an
identity matrix and
denotes the Kronecker product. The
matrices represent linear effects among endogenous latent variables, where
and
are
and
matrices, respectively, with zero diagonal elements, and
is a
matrix. The
matrices represent non-linear effects of exogenous latent variables on the endogenous latent variables, where
and
are
and
matrices, respectively.
is a
matrix representing interaction effects between endogenous and exogenous latent variables, and
is a
matrix, representing non-linear effects among
on
. The matrices
,
, and
are block matrices stacking upper-triangular matrices on top of one another. For example, if
,
,
, and
consist of two upper-triangular matrices each, i.e.
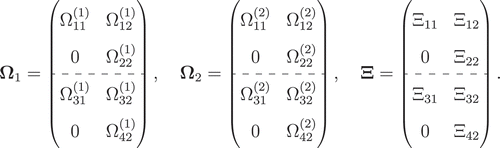
The diagonal elements of the upper-triangular matrices correspond to the quadratic effects, whereas the off-diagonal elements correspond to the interaction effects. The error terms and
are assumed to have zero mean vectors and are independent of each other with
and
covariance matrices
and
, respectively.
and
are the intercepts. The intercept
is determined such that
, that is, the
element of
is defined by:
where is the
upper-triangular matrix in
. For simplicity, we let
. Thus,
is not zero.
To our knowledge, the majority of studies on non-linear SEM overlooked Equation (3) and focused on EquationEquation (4)(4)
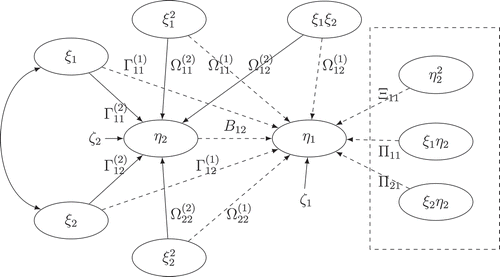
(4) . Take the path diagram of an extended quadratic structural model in as an example. If Equation (3) is ignored, the researchers are not able to model the paths in the dashed rectangle. As mentioned previously, the non-linear effects among endogenous and exogenous latent variables are commonly encountered in practice. Hence, it is of importance to include Equation (3) in the structural model.
Figure 1. The path diagram of the structural model of an extended quadratic structural equation model. The dashed paths correspond to the effects in Equation (3) and the solid paths correspond to the effects in EquationEquation (4)(4)
(4)
Marginal maximum likelihood estimation
Under the assumption of independent observations, the complete likelihood function is:
where is the number of observations, and
and
are the
observed ordinal vectors of indicators. Under the conditional independence assumption, the complete likelihood becomes:
We assume that ,
, and
. Hence,
,
, and
are multivariate normal. The expression of
under these normal assumptions can be found in the appendix.
In practice, is often a scalar that has only one binary indicator. For example,
if a behavior is conducted and 0 if not. If that is the case, further restrictions are needed for identification. One way is to let
and
. This means that
is singular and
is a one-point distribution. Equivalently,
is completely determined conditioned on
and
.
Approximated observed log-likelihood
Let be the vector of parameters that includes the unconstrained elements in the structural matrices in
,
,
,
,
,
,
,
and
, the unconstrained elements in the covariance matrices
,
, and
, and the unconstrained intercepts and factor loadings
,
,
, and
. In order to obtain the maximum likelihood estimator of
, the observed likelihood function is calculated by integrating out
with
from EquationEquation (5)
(5)
(5) , i.e.
The integral in EquationEquation (6)(6)
(6) is intractable and approximations are needed. The approximated maximum likelihood estimator is obtained by maximizing the approximated observed log-likelihood function. Commonly used numerical approximation methods include the Laplace approximation (e.g., Huber, Ronchetti, & Victoria-Feser, Citation2004) and the Gauss–Hermitequadrature-based methods (e.g., Moustaki, Citation1996; Moustaki & Knott, Citation2000; Rabe-Hesketh & Skrondal, Citation2004; Rizopoulos & Moustaki, Citation2008). Alternatively, the observed gradient can be approximated by stochastic methods (e.g., Cai, Citation2010). In the present study, the second-order Laplace approximation (Shun & McCullagh, Citation1995) and the adaptive Gauss–Hermite quadrature (AGHQ) approximation of Liu and Pierce (Citation1994) are implemented. The second-order Laplace approximation is second-order accurate and the accuracy of the AGHQ approximation depends on the number of quadrature points. A general introduction of these methods and the expressions of the approximations to EquationEquation (6)
(6)
(6) can be found in the appendix.
Maximizing the approximated observed log-likelihood
A common approach in latent variable models is to employ the EM algorithm or its variants, where the latent variables are treated as missing values and the gradient of the conditional expectation in the E-step is approximated in the M-step. For example, the EM algorithm is used by Lee and Song (Citation2004b), Lee, Song, and Lee (Citation2003), and Lee and Zhu (Citation2000) among others. The EM algorithm is known for its slow speed in many situations. When the integrals in the M-step are approximated, various studies (e.g., Bianconcini & Cagnone, Citation2012; Rizopoulos, Verbeke, & Lesaffre, Citation2009; Steele, Citation1996) argued that the fully exponential Laplace approximation (Tierney & Kadane, Citation1986; Tierney, Kass, & Kadane, Citation1989) is more accurate than the Laplace approximation. Jin and Andersson (Citation2019a) proved that the estimator based on the EM algorithm with the fully exponential Laplace approximation is the same as the estimator that maximizes the Laplace approximated observed log-likelihood function, if implemented properly. Hence, we propose to directly maximize the approximated , instead of the EM algorithm.
The gradients of the approximations can be readily obtained by the chain rule, explained in detail in the appendix. A quasi-Newton method (e.g., BFGS algorithm) can be used to find the maximizer of the approximated observed log-likelihood function. Since the approximations are subject to approximation error, the proposed approach can be interpreted as the quasi-maximum likelihood approach (Huber et al., Citation2004). If the approximated log-likelihood function is directly maximized, the gradient of the approximation is already available, which makes the standard errors easy to estimate (see EquationEquation (10)(10)
(10) in the appendix). If the EM algorithm is used, the information matrix needed for standard errors is approximated afterward by, for example, the Louis method (Louis, Citation1982).
Simulation study
In order to investigate the performance of the suggested approach, a simulation study is conducted. The setup and result are presented in the following subsections.
Simulation design
In the simulation, a four-factor model is considered with two exogenous latent variables and two endogenous latent variables
. Each latent variable is associated with three ordinal indicators with five categories each.
,
and
are generated from multivariate normal distributions. The population parameters of the measurement model (EquationEquations (1)
(1)
(1) and (Equation2
(2)
(2) )) are
where zero elements are restricted to zero. Here the element in
is
and the
row of
is
in EquationEquation (1)
(1)
(1) . Likewise, the
element in
is
and the
row of
is
in EquationEquation (2)
(2)
(2) . The factor loadings only load on one latent variable giving this setup a simple structure for simplicity.
and
are fixed to
for identification. The population covariance between the latent exogenous variables is 0.40 and the variances are fixed to 1 for identification. Ordinal observations are generated by the measurement model using the probit link function. EquationEquations (3)
(4)
(4) and (Equation4
(5)
(5) ) are set to be the same as . The population values of the structural parameters are
where the zero elements are restricted to zero. The variances of the error terms are and
. Such population values are chosen to reflect common values in practice. The
and
are chosen such that the reliabilities of the items range from 0.72 to 0.8 and the probabilities of observing each outcomes are 0.15, 0.45, 0.15, 0.15, and 0.1, respectively, for all items. The structural parameters are chosen such that the
‘s of the latent regression are approximately
and
. The
and
are chosen such that the reliabilities of the items range from 0.65 to 0.78 and the probabilities of observing each outcomes are approximately 0.10, 0.20, 0.20, 0.35, and 0.15 for all items. Four different sample sizes are considered, i.e.,
and 2000 replications are generated for each sample size. Two second-order accurate approximation methods to the observed log-likelihood are considered in the simulation, namely, the second-order Laplace approximation, denoted by Lap(2nd), and the AGHQ with 5 quadrature points per latent variable, denoted by AGHQ(5p). We expect them to perform similarly in terms of bias. The approximated maximum likelihood estimator is obtained by maximizing the approximated observed log-likelihood using the direct maximum likelihood approach by the BFGS algorithm. The algorithm is stopped when the maximum absolute change in the parameter estimates of two consecutive iterations is less than
. The code was written in R (R Core Team, Citation2018) by the aid of the package Rcpp (Eddelbuettel, Citation2013).
Simulation results
Replications which do not converge and those with nonpositive definite covariance matrices are excluded from the analysis. The percentage of excluded cases is reported in . The proportion of inadmissible cases is generally ignorable and decreases as the sample size increases.
Table 1. Percentage of inadmissible cases excluded from the analysis
In order to investigate the performance of the methods the relative bias and root mean squared error
are calculated for each structural parameter
, where
is the number of replications and
is the corresponding estimate at the
replication. shows the RB and RMSE for the structural parameters
,
,
,
,
,
,
,
and
. Following the common practice in the SEM literature (e.g., Curran, West, & Finch, Citation1996; Flora & Curran, Citation2004), relative bias lower than
is regarded as a low bias. Generally, the methods provide low biases for the sample sizes investigated. The RMSE decreases with sample size as expected. Lap(2nd) and AGHQ(5p) perform similarly in terms of RB and RMSE across parameters and sample sizes. In order to evaluate the performances of the calculated standard errors, coverage probabilities at the nominal level 95% are presented in . The coverage probabilities of covering the true values are generally close to the nominal level. Results not shown here indicate that the first-order Laplace approximation that is equivalent to the adaptive Gauss–Hermite quadrature approximation with 1 quadrature point can perform unacceptably poorly for non-linear terms.
Table 2. Relative bias and root mean squared error of the estimators of structural parameters in EquationEquations (3)(4)
(4) and (Equation4
(5)
(5) )
Table 3. Coverage probabilities (%) of the Wald confidence interval for structural parameters in EquationEquations (3)(4)
(4) and (Equation4
(5)
(5) ) at the nominal level of 95%
The Laplace approximations are expected to be computationally more efficient than AGHQ approximations for similar error rates if the number of latent variables is large. However, a higher-order Laplace approximation requires calculations of higher-order derivatives which are not straightforward, whereas the AGHQ approximation provides the possibility of decreasing error rates by increasing the number of quadrature points with the drawback of being computationally heavier. In the current simulation, the average estimation time for the sample size takes on average 90 s for AGHQ(5p) and 49 s for Lap(2nd). This relative difference is hypothesized to increase with increasing number of latent variables.
Empirical example
In order to demonstrate how the proposed method works in practice, an empirical example is considered in this section. The empirical example contains 707 complete responses of households in two Swedish municipalities Sollentuna and Saltjö-boo regarding their behavior of off-peak hour energy use (Bartusch, Juslin, Stitkvoort, Yang-Wallentin, & Öhrlund, Citation2019), in order to investigate the roles of the psychological factors, Attitude (), Belief (
), Perceived Behavioral Control (
) and Intentions (
) in relation to the Behavior (
) of shifting the energy use to off-peak hours. It is hypothesized that Behavior (
) is affected by an interaction between Perceived Behavioral Control (
) and Intentions (
).
has only one continuous indicator and it is dichotomized into a binary indicator. Other latent variables are associated with two indicators each, in the form of 7-point Likert scale items. The 7-point Likert scale items were aggregated into five categories in order to avoid categories with too few observations. For the purpose of modeling the interaction effects, we also include
and
in the model, as suggested by Kelava and Brandt (Citation2009). The structural model of interest is then:
shows the estimates and the 95% confidence intervals for the structural parameters using the AGHQ approximation with 5 quadrature points per latent variable and the second-order Laplace approximation. None of the non-linear parameters ,
and
is significant at the 5% significance level. The linear effects of Attitude and Belief on Intention (
and
) are significant at the 5% significance level, whereas the linear effects of Perceived Behavioral Control on Intention and Behavior (
and
) and of Intention on Behavior (
), are not significant at the 5% significance level. Results not presented here, show that similar results are obtained when 7 quadrature points are used, which indicates that the approximation is stabilized.
Table 4. Point estimates and 95% confidence intervals for structural parameters in the empirical example corresponding to non-linear effects for the AGHQ approximation with 5-quadrature points, denoted by AGHQ(5p), and second-order Laplace approximation, denoted by Lap(2nd)
Discussion and conclusion
In this article, a structural model with quadratic and interaction relations is considered in the presence of ordinal data. Structural models including interactions between exogenous and endogenous latent variables are rarely found in the literature. The current study provides the possibility to include such features. To this end, a marginal maximum likelihood approach is proposed, where the exact gradient of the approximated observed log-likelihood is computed and used to approximate the Hessian, providing the opportunity to obtain standard errors straightforwardly, which are not easily available using, for example, the EM algorithm.
Simulation results indicate that the second-order Laplace approximation and the AGHQ approximation with 5 quadrature points per latent variable provide accurate parameter estimators at finite sample sizes. On one hand, despite that only simply structures are considered in the current study, the proposed approach works for general loading structures, provided that the model is identified. On the other hand, more research is needed to provide a rule-of-thumb sample size requirement for non-linear models with interactions between endogenous and exogenous variables. We leave it as a future topic.
In this study, the Laplace approximation and the AGHQ approximation are used to approximate the log-likelihood function, where the quadrature nodes are chosen deterministically. Alternative approaches include the Monte Carlo-based maximum likelihood approaches (e.g., Lee & Song, Citation2003; Song & Lee, Citation2005) and the Bayesian approaches (e.g., Lee & Song, Citation2008; Lee & Zhu, Citation2000). To our knowledge, they are not yet implemented in the non-linear SEM model of our interest. This remains as a topic for future studies.
A drawback of the method is that it relies on normally distributed latent exogenous variables and error terms. It remains for future research to investigate the sensitivity against nonnormality and develop robust approaches. For example, non-normality in the latent exogenous variables could be modeled by mixtures of normals.
Acknowledgment
We thank the reviewers for useful comments that lead to an improved manuscript.
Additional information
Funding
References
- Agresti, A. (2015). Foundations of linear and generalized linear models. Hoboken, NJ: John Wiley & Sons.
- Agustin, C., & Singh, J. (2005). Curvilinear effects of consumer loyalty determinants in relational exchanges. Journal of Marketing Research, 42, 96–108. doi:10.1509/jmkr.42.1.96.56961
- Ajzen, I. (1991). The theory of planned behavior. Organizational Behavior and Human Decision Processes, 50, 179–211. doi:10.1016/0749-5978(91)90020-T
- Barndorff-Nielsen, O., & Cox, D. (1989). Asymptotic techniques for use in statistics. London, UK: Chapman and Hall.
- Bartusch, C., Juslin, P., Stitkvoort, B., Yang-Wallentin, F., & Öhrlund, I. (2019). The black box of demand response (Unpublished manuscript). Department of Engineering Sciences, Uppsala University, Uppsala, Sweden.
- Bianconcini, S. (2014). Asymptotic properties of adaptive maximum likelihood estimators in latent variable models. Bernoulli, 20, 1507–1531. doi:10.3150/13-BEJ531
- Bianconcini, S., & Cagnone, S. (2012). Estimation of generalized linear latent variable models via full exponential Laplace approximation. Journal of Multivariate Analysis, 112, 183–193. doi:10.1016/j.jmva.2012.06.005
- Bollen, K. A. (1995). Structural equation models that are nonlinear in latent variables: A least-squares estimator. Sociological Methodology, 25, 223–251. doi:10.2307/271068
- Bollen, K. A. (1996). An alternative two stage least squares (2SLS) estimator for latent variable equations. Psychometrika, 61, 109–121. doi:10.1007/BF02296961
- Brandt, H., Kelava, A., & Klein, A. (2014). A simulation study comparing recent approaches for the estimation of nonlinear effects in sem under the condition of nonnormality. Structural Equation Modeling, 21, 181–195. doi:10.1080/10705511.2014.882660
- Cai, J. H., Song, X. Y., & Lee, S. Y. (2008). Bayesian analysis of nonlinear structural equation models with mixed continuous, ordered and unordered categorical, and nonignorable missing data. Statistics and Its Interface, 1, 99–114. doi:10.4310/SII.2008.v1.n1.a9
- Cai, L. (2010). High-dimensional exploratory item factor analysis by a Metropolis-Hastings Robbins-Monro algorithm. Psychometrika, 75, 33–57. doi:10.1007/s11336-009-9136-x
- Core Team, R. (2018). R: A language and environment for statistical computing. Vienna, AU: R Foundation for Statistical Computing.
- Curran, P. J., West, S. G., & Finch, J. F. (1996). The robustness of test statistics to nonnormality and specification error in confirmatory factor analysis. Psychological Methods, 1, 16–29. doi:10.1037/1082-989X.1.1.16
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society, Series B (Methodological), 39, 1–38. doi:10.1111/rssb.1977.39.issue-1
- Eddelbuettel, D. (2013). Seamless R and C++ integration with Rcpp. New York, NY: Springer.
- Finney, S. J., & DiStefano, C. (2006). Structural equation modeling: A second course. Charlotte, NC: Information Age Publishing.
- Flora, D. B., & Curran, P. J. (2004). An empirical evaluation of alternative methods of estimation for confirmatory factor analysis with ordinal data. Psychological Methods, 9, 446–491. doi:10.1037/1082-989X.9.4.466
- Harring, J. R., Weiss, B. A., & Hsu, J.-C. (2012). A comparison of methods for estimating quadratic effects in nonlinear structural equation models. Psychological Methods, 17, 193–214. doi:10.1037/a0027539
- Huber, P., Ronchetti, E., & Victoria-Feser, M.-P. (2004). Estimation of generalized linear latent variable models. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 66, 893–908. doi:10.1111/j.1467-9868.2004.05627.x
- Jin, S., & Andersson, B. (2019a). Gains of fully exponential Laplace approximation in latent variable models (Unpublished manuscript). Department of Statistics, Uppsala University, Uppsala, Sweden.
- Jin, S., & Andersson, B. (2019b). A note on the accuracy of adaptive Gauss-Hermite quadrature. Accepted by Biometrika.
- Jin, S., Noh, M., & Lee, Y. (2018). H-likelihood approach to factor analysis for ordinal data. Structural Equation Modeling, 25, 530–540. doi:10.1080/10705511.2017.1403287
- Kelava, A., & Brandt, H. (2009). Estimation of nonlinear latent structural equation models using the extended unconstrained approach. Review of Psychology, 16, 123–132.
- Kelava, A., & Brandt, H. (2014). A general non-linear multilevel structural equation mixture model. Frontiers in Psychology, 5, 748. doi:10.3389/fpsyg.2014.00748
- Klein, A., & Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika, 65, 457–474. doi:10.1007/BF02296338
- Klein, A., & Muthén, B. (2007). Quasi-maximum likelihood estimation of structural equation models with multiple interaction and quadratic effects. Multivariate Behavioral Research, 42, 647–673. doi:10.1080/00273170701710205
- Lee, S. Y., & Song, X. Y. (2003). Maximum likelihood estimation and model comparison of nonlinear structural equation models with continuous and polytomous variables. Computational Statistics & Data Analysis, 44, 125–142. doi:10.1016/S0167-9473(02)00305-5
- Lee, S. Y., Song, X. Y., Cai, J. H., So, W. Y., Ma, C. W., & Chan, C. N. J. (2009). Non-linear structural equation models with correlated continuous and discrete data. British Journal of Mathematical and Statistical Psychology, 62, 327–347. doi:10.1348/000711008X292343
- Lee, S. Y., & Zhu, H. T. (2002). Maximum likelihood estimation of nonlinear structural equation models. Psychometrika, 67, 189–210. doi:10.1007/BF02294842
- Lee, S.-Y., & Song, X.-Y. (2004a). Bayesian model comparison of nonlinear structural equation models with missing continuous and ordinal categorical data. British Journal of Mathematical and Statistical Psychology, 57, 131–150. doi:10.1348/000711004849204
- Lee, S.-Y., & Song, X.-Y. (2004b). Maximum likelihood analysis of a general latent variable model with hierarchical mixed data. Biometrics, 60, 624–636. doi:10.1111/j.0006-341X.2004.00211.x
- Lee, S.-Y., & Song, X.-Y. (2007). A unified maximum likelihood approach for analyzing structural equation models with missing nonstandard data. Sociological Methods & Research, 35, 352–381. doi:10.1177/0049124106292357
- Lee, S.-Y., & Song, X.-Y. (2008). On Bayesian estimation and model comparison of an integrated structural equation model. Computational Statistics and Data Analysis, 52, 4814–4827. doi:10.1016/j.csda.2008.03.029
- Lee, S.-Y., Song, X.-Y., & Cai, J.-H. (2010). A bayesian approach for nonlinear structural equation models with dichotomous variables using logit and probit links. Structural Equation Modeling, 17, 280–302. doi:10.1080/10705511003659425
- Lee, S.-Y., Song, X.-Y., & Lee, J. C. (2003). Maximum likelihood estimation of nonlinear structural equation models with ignorable missing data. Journal of Educational and Behavioral Statistics, 28, 111–134. doi:10.3102/10769986028002111
- Lee, S.-Y., & Zhu, H.-T. (2000). Statistical analysis of nonlinear structural equation models with continuous and polytomous data. British Journal of Mathematical and Statistical Psychology, 53, 209–232. doi:10.1348/000711000159303
- Lee, Y., & Nelder, J. A. (2001). Hierarchical generalised linear models: A synthesis of generalised linear models, random-effect models and structured dispersions. Biometrika, 88, 987–1006. doi:10.1093/biomet/88.4.987
- Liu, Q., & Pierce, D. A. (1994). A note on Gauss-Hermite quadrature. Biometrika, 81, 624–629.
- Louis, T. A. (1982). Finding the observed information matrix when using the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 44, 226–233. doi:10.1111/rssb.1982.44.issue-2
- Marsh, H. W., Wen, Z., & Hau, K.-T. (2004). Structural equation models of latent interactions: Evaluation of alternative estimation strategies and indicator construction. Psychological Methods, 9, 275–300. doi:10.1037/1082-989X.9.3.275
- Mooijaart, A., & Bentler, P. M. (2010). An alternative approach for nonlinear latent variable models. Structural Equation Modeling, 17, 357–373. doi:10.1080/10705511.2010.488997
- Moustaki, I. (1996). A latent trait and a latent class model for mixed observed variables. British Journal of Mathematical and Statistical Psychology, 49, 313–334. doi:10.1111/j.2044-8317.1996.tb01091.x
- Moustaki, I., & Knott, M. (2000). Generalized latent trait models. Psychometrika, 65, 391–411. doi:10.1007/BF02296153
- Ping, R. A. (1995). A parsimonious estimating technique for interaction and quadratic latent variables. Journal of Marketing Research, 32, 336–347. doi:10.1177/002224379503200308
- Rabe-Hesketh, S., & Skrondal, A. (2004). Generalized multilevel structural equation modeling. Psychometrika, 69, 167–190. doi:10.1007/BF02295939
- Rhemtulla, M., Brosseau-Liard, P. E., & Savalei, V. (2012). When can categorical variables be treated as continuous? a comparison of robust continuous and categorical sem estimation methods under suboptimal condition. Psychological Methods, 17, 354–373. doi:10.1037/a0029315
- Rizopoulos, D., & Moustaki, I. (2008). Generalized latent variable models with non-linear effects. British Journal of Mathematical and Statistical Psychology, 61, 415–438. doi:10.1348/000711007X213963
- Rizopoulos, D., Verbeke, G., & Lesaffre, E. (2009). Fully exponential Laplace approximations for the joint modelling of survival and longitudinal data. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 71, 637–654. doi:10.1111/j.1467-9868.2008.00704.x
- Shun, Z., & McCullagh, P. (1995). Laplace approximation of high dimensional integrals. Journal of the Royal Statistical Society, Series B (Methodological), 57, 749–760. doi:10.1111/rssb.1995.57.issue-4
- Song, X.-Y., & Lee, S.-Y. (2004). Bayesian analysis of two-level nonlinear structural equation models with continuous and polytomous data. British Journal of Mathematical and Statistical Psychology, 57, 29–52. doi:10.1348/000711004849259
- Song, X.-Y., & Lee, S.-Y. (2005). Maximum likelihood analysis of nonlinear structural equation models with dichotomous variables. Multivariate Behavioral Research, 40, 151–177. doi:10.1207/s15327906mbr4002_1
- Song, X.-Y., & Lee, S.-Y. (2006a). Bayesian analysis of structural equation models with nonlinear covariates and latent variables. Multivariate Behavioral Research, 41, 337–365. doi:10.1207/s15327906mbr4103_4
- Song, X.-Y., & Lee, S.-Y. (2006b). A maximum likelihood approach for multisample nonlinear structural equation models with missing continuous and dichotomous data. Structural Equation Modeling, 13, 325–351. doi:10.1207/s15328007sem1303_1
- Steele, B. M. (1996). A modified EM algorithm for estimation in generalized mixed models. Biometrics, 52, 1295–1310. doi:10.2307/2532845
- Tierney, L., & Kadane, J. B. (1986). Accurate approximations for posterior moments and marginal densities. Journal of the American Statistical Association, 81, 82–86. doi:10.1080/01621459.1986.10478240
- Tierney, L., Kass, R. E., & Kadane, J. B. (1989). Fully exponential Laplace approximations to expectations and variances of nonpositive functions. Journal of the American Statistical Association, 84, 710–716. doi:10.1080/01621459.1989.10478824
- Wall, M. M., & Amemiya, Y. (2000). Estimation for polynomial structural equation models. Journal of the American Statistical Association, 95, 929–940. doi:10.1080/01621459.2000.10474283
- Wall, M. M., & Amemiya, Y. (2001). Generalized appended product indicator procedure for nonlinear structural equation analysis. Journal of Educational and Behavioral Statistics, 26, 1–29. doi:10.3102/10769986026001001
- Wei, G. C. G., & Tanner, M. A. (1990). A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithm. Journal of the American Statistician Association, 85, 699–704. doi:10.1080/01621459.1990.10474930
- Yang-Jonsson, F. (1997). Non-linear structural equation models: Simulation studies of the Kenny-Judd model (Doctoral dissertation), Department of Statistics, Uppsala University, Uppsala, Sweden.
- Zhu, H.-T., & Lee, S.-Y. (1999). Statistical analysis of nonlinear factor analysis models. British Journal of Mathematical and Statistical Psychology, 52, 225–242. doi:10.1348/000711099159080
Appendix
Approximated Maximum Likelihood Estimator
In this section, the proposed maximum likelihood estimator is described in detail. For notational convenience, let the complete log-likelihood be:
Let and
be the number of indicators associated with
and
, respectively. Under the distributional assumptions
,
and
,
where
with
and
Further, and
depend on the link function. For example, with the probit link,
where is the number of response categories for the ordinal indicator
,
is the number of response categories for the ordinal indicator
, and
is the cumulative distribution function of a standard normal random variable. Then, the observed log-likelihood to be approximated is:
If is a scalar that has only one binary indicator, we restrict
and
. The modified complete log-likelihood is then:
where
Accordingly, the vector of latent variables to be integrated out is .
Laplace Approximation
In general, the first-order Laplace approximation (Barndorff-Nielsen & Cox, Citation1989) to the integral is:
where is a
vector and
is a unimodal function with the mode
. The approximation is essentially achieved by Taylor expanding
about its mode. Shun and McCullagh (Citation1995) further derived the second-order Laplace approximation. The Laplace approximation of the observed log-likelihood is:
where or
,
is the Hessian matrix, and is evaluated at
, the solution of
with respect to for a fixed
. In the first-order approximation,
, for any
. In the second-order approximation,
where is the
element of the inverse of
and the approximation is second-order accurate (Shun & McCullagh, Citation1995). The second-order Laplace approximation has been recommended by Lee and Nelder (Citation2001) for generalized linear-mixed models and by Jin, Noh, and Lee (Citation2018) for confirmatory factor analysis models with ordinal data.
Adaptive Gauss–Hermite Quadrature Approximation
The Gauss–Hermite-Hermite quadrature rule approximates the integral by a weighted sum of function values evaluated at pre-specified quadrature points as:
where
with being the Gauss–Hermite quadrature points,
being the corresponding weights, and
being the number of quadrature points per latent variable. Liu and Pierce (Citation1994) proposed to translate and dilate the quadrature points in the weighted sum, known as the AGHQ approximation, to improve the approximation effectiveness when
is an unimodel function. The AGHQ approximated observed log-likelihood is:
where
is the latent variable vector dilated and translated around the mode with
being the Cholesky decomposition of the inverse of the negative Hessian:
and being the vector containing the
,
,…, and the
quadrature points. If only one quadrature point per latent variable is used,
is the same as the first-order approximated
. Let
be the estimator of
that maximizes (8). Following Bianconcini (Citation2014), Jin and Andersson (Citation2019b) showed that the error rate of the approximation is
and that satisfies
where is the true parameter vector and
takes the largest integer that is less than the enclosed value. Hence, using
quadrature points per latent variable yields the same error rate as the second-order Laplace approximation.
Direct Maximum Likelihood
When maximizing functions such as (7) or (8) it is important to realize that the mode depends on the parameter vector
. The gradient of the approximated observed log-likelihood (regardless of approximation method) is:
where is the derivative of the observed log-likelihood function with respect to
, treating the mode as constant. On the contrary,
is the derivative of the observed log-likelihood function with respect to
, treating
as constant. Hence, the second term acknowledges that the mode is affected by
, by applying the chain rule. By the implicit function theorem,
The sandwich estimator of standard errors can be calculated from:
where is the
term in EquationEquation (7)
(7)
(7) or (8). In the BFGS algorithm, the inverse of the Hessian matrix of
is approximated and updated by low-rank approximations at every iteration. The Hessian matrix can also be approximated from the Louis (Citation1982) method. Since the exact gradient of
is calculated by EquationEquation (9)
(9)
(9) , the sandwich estimator (10) of standard errors can be readily computed. In contrast, neither the gradient nor the Hessian matrix is the by-product in the EM algorithm and need to be computed afterward.