
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Many methods have been developed to infer reciprocal relations between longitudinally observed variables. Among them, the general cross-lagged panel model (GCLM) is the most recent development as a variant of the cross-lagged panel model (CLPM), while the random-intercept CLPM (RI-CLPM) has rapidly become a popular approach. In this article, we describe how common factors and cross-lagged parameters included in these models can be interpreted, using a unified framework that was recently developed. Because common factors are modeled with lagged effects in the GCLM, they have both direct and indirect influences on observed scores, unlike stable trait factors included in the RI-CLPM. This indicates that the GCLM does not control for stable traits as the RI-CLPM does, and that there are interpretative differences in cross-lagged parameters between these models. We also explain that including such common factors as well as moving-average terms in the GCLM makes this interpretation very complicated.
Many researchers aim to uncover reciprocal (or, mutual or prospective) relations between longitudinally observed variables, and we have seen an increased number of such studies in the behavioral sciences. For example, during the past year more than 1,000 published psychology papers have dealt with this type of relation.Footnote1 For this analytic purpose, the use of the cross-lagged panel model (CLPM) and estimation via structural equation modeling (SEM) have been a standard approach for decades in the behavioral sciences. In this model, a cross-lagged coefficient, which indicates a path from one variable measured at a time point to another measured at time point
, is a key parameter. Many alternatives to the CLPM have been proposed in various disciplines using SEM approaches (see Orth et al., Citationin press; Usami, Murayama et al., Citation2019). Notably, in the last few years the random-intercept CLPM (RI-CLPM; Hamaker et al., Citation2015) has rapidly become a popular approach among psychologists, reaching more than 600 citations on Google Scholar as of August 2020. A major strength of this model is that it can account for stable trait factors that control for stable individual differences, allowing researchers to infer within-person relations between variables.
Usami, Murayama et al. (Citation2019) proposed a unified framework to clarify the mathematical and conceptual similarities and differences among various longitudinal models. This framework revealed that existing SEM-based longitudinal models can be classified according to whether the model posits unique factors and/or (dynamic) residuals, and what types of common factors are used to model changes. They argued that the latter is essential to understanding how cross-lagged parameters can be interpreted in each model, and showed from the viewpoint of a potential outcome (or counterfactual) approach (the Rubin causal model; Rubin, Citation1974) that including stable trait factors as in the RI-CLPM is mathematically equivalent to controlling for latent (unobserved) time-invariant confounders.
Although longitudinal designs have numerous advantages over cross-sectional designs (e.g., McArdle & Nesselroade, Citation2014), the issue of causal inference becomes complicated and challenging in general for longitudinal studies, because researchers must effectively account for time-varying and time-invariant confounders. For this reason, efforts by researchers to devise a better methodology are continuing (e.g., Asparouhov et al., Citation2018; Hamaker et al., Citation2015; Imai & Ratkovic, Citation2015; Robins, Citation1999; Robins & Hernán, Citation2009; Zyphur et al., Citation2020a).
Among such methodologies, the general cross-lagged panel model (GCLM; Zyphur et al., Citation2020a, Citation2020b) is a recent variant of the CLPM. This model was not covered in the discussion of Usami, Murayama et al. (Citation2019). The GCLM as a SEM-based approach assumes (time-varying) unit effects as well as moving average (MA) and cross-lagged moving average (CLMA) terms, aiming to increase the range of dynamic processes that can be modeled. Zyphur et al. (Citation2020b) discuss the relation between the GCLM and other longitudinal models such as the latent growth model (LGM; Meredith & Tisak, Citation1984, Citation1990) and the autoregressive latent trajectory (ALT) model (Bollen & Curran, Citation2004, Citation2006; Curran & Bollen, Citation2001). Many researchers have shown interest in applying the GCLM, including more than 10 citations on Google Scholar as of August 2020 (e.g., Bollmann, Rouzinov, Berchtold, & Rossier, Citation2019; Oswald, Citation2019; Zhang et al., Citation2019).
This article aims to elucidate how common factors and cross-lagged parameters included in the GCLM can be interpreted using the unified framework, and to highlight conceptual and mathematical differences among the GCLM, the RI-CLPM, and other longitudinal models. Despite interpretative differences existing in cross-lagged parameters among models, it has long been common practice for researchers to run a single model (typically, the CLPM) and evaluate its cross-lagged relations without considering potential alternative models (Usami, Todo et al., Citation2019). This article should better reveal the strengths and potential weakness of the GCLM over other alternatives, helping researchers to seek better methodologies while minimizing risk of wrong conclusions regarding reciprocal effects.
Importantly, we show that the mathematical relation between the RI-CLPM and the GCLM as described in Zyphur et al. (Citation2020b, p. 13) requires correction, and that there are interpretative differences in cross-lagged parameters and common factors in these models. Specifically, because common factors are modeled with lagged effects in the GCLM, they have both direct and indirect influences on observed scores, meaning that the GCLM does not control for stable traits as does the RI-CLPM. We will also show that including unit effects as well as moving average terms in the GCLM greatly complicates the interpretation of cross-lagged parameters.
In the next section, we provide a brief introduction for the GCLM after a brief overview of some existing models: the RI-CLPM, the LGM, and the ALT model. In the third section, we introduce the unified framework (Usami, Murayama et al., Citation2019). Readers who are already familiar with these models and the framework may skip these two sections. In the fourth section, we discuss how the GCLM can be characterized using the unified framework, showing interpretative differences in common factors and cross-lagged parameters from the RI-CLPM and other models. A conceptual diagram as well as path diagrams of models are also provided to further clarify relations between the models. The fifth section presents an empirical example to demonstrate how choice of the analysis model might lead to different conclusions about reciprocal relations. The sixth section briefly contrasts these SEM-based approaches with potential alternatives to effectively account for the influences of time-varying confounders. The final section presents our conclusions and some areas for future research.
Existing models
We first give an overview of the RI-CLPM, the LGM, and the ALT model, and then introduce the GCLM.
Random intercept cross-lagged panel model (RI-CLPM)
Throughout this article we assume that researchers are interested in reciprocal relations between two variables and
. Let
and
be the measurements at time point
(
) for person
(
). In the RI-CLPM,
and
are first modeled as
Here, and
are the temporal group means at time point
(i.e.,
,
). The terms
and
are (time-invariant) stable trait factors (alternatively, random intercepts) that represent a person’s trait-like deviations from the temporal group means. Trait factors
and
have means of 0 and a variance–covariance matrix. By accounting for stable trait factors for each person,
and
represent temporal deviations from the means of that person because they are subtracted from the expected scores of person
(i.e.,
and
). Accordingly, in the RI-CLPM, the time series
and
can be considered as within-person fluctuation. Due to this statistical property in temporal deviations, at
the initial deviation terms (
and
) are assumed to be uncorrelated with stable trait factors. Using these within-person deviation terms, in the RI-CLPM the reciprocal relations are modeled for
as
where and
are autoregressive parameters.
and
are cross-lagged parameters, which are key for inferring reciprocal relations between the variables.Footnote2 In
, the initial states
and
are modeled as exogenous variables (i.e., their variances and covariance are assumed). The residuals
and
are typically assumed to be normally distributed and correlated. If stable trait factors are omitted (i.e., if
), this version of the RI-CLPM is mathematically equivalent to the CLPM. The RI-CLPM is identified if two or more variables have been measured at three or more time points, whereas the CLPM requires only two time points (in which case it is saturated).
Because the RI-CLPM separates within-person fluctuations (temporal deviations) from stable between-person differences (stable trait factors) over time, cross-lagged relations in EquationEquation 2(2)
(2) can be considered as those pertaining to a process that takes place at the within-person level. Therefore, in the RI-CLPM,
and
can be interpreted as quantities that express the extent to which the two variables influence each other within persons. Hamaker et al. (Citation2015) argued that parameter estimates in the CLPM conflate between-person and within-person processes, and that this model provides inaccurate estimates for within-person reciprocal effects as a consequence.
EquationEquations (1(1)
(1) ) and (Equation2
(2)
(2) ) are the formulation that were used in Hamaker et al. (Citation2015). However, there is another formulation of the (RI-)CLPM if intercepts (
) are included in the lagged regressions (EquationEquation 2
(2)
(2) ) instead of excluding temporal group means (
) in EquationEquation (1)
(1)
(1) :
and
are not mathematically identical unless
, because the former is modeled jointly with lagged effects and thus the influences of effects feed forward through the lagged relations. For example, expected values for
and
at
can be calculated by substituting the relations
and
into the equations
and
. From this procedure, mathematical relations between
(in EquationEquation (3))
(3)
(3) and
(in EquationEquation (1))
(1)
(1) can be expressed as
By the same procedure, for , we can derive the relations between
and
as
Note that numbers of parameters are independent of the choice of or
, and this choice does not influence the estimation results of other parameters, such as
and
.
Latent growth model (LGM)
A bivariate version of the (linear) LGM can be expressed as
Here, and
are intercept factors and
and
are (linear) slope factors. The values
and
are unique factors (or measurement errors). In the LGM literature,
and
are often called growth factors, and nonzero factor means (as well as variances and covariances) are assumed.
The main difference between the LGM and the RI-CLPM is that while the LGM explicitly models mean growth trajectories via the intercept and slope factor means, this model instead assumes there are no lagged effects. In other words, in the RI-CLPM temporal group means () play a role in capturing mean growth trajectories without making an explicit modeling assumption (e.g., that growth trajectories are linear); instead, (within-person) reciprocal relations are modeled using lagged effects as well as stable trait factors.
Autoregressive latent trajectory (ALT) model
The ALT model was proposed by Curran and Bollen (Citation2001), aiming to synthesize the traditions of the CLPM and the LGM. The bivariate (linear) ALT model can be expressed as
As in the LGM, temporal group means () are not included. Instead, common factors
and
play a role in describing growth trajectories (i.e.,
and
have nonzero factor means). As before,
and
are autoregressive parameters,
and
are cross-lagged parameters, and
and
are residuals. The ALT is identified if two or more variables have been measured at four or more time-points when stationarity of parameters is assumed, while five or more time points are required under a non-stationarity assumption.
Obviously, the main difference between the ALT model and the LGM is that the former assumes lagged effects, as in the RI-CLPM. However, as we will see later, the presence of lagged effects causes the interpretations of common factors and
in the ALT model to differ from those of growth factors
and
in the LGM.
General cross-lagged panel model (GCLM)
The GCLM was proposed as a generalization of the CLPM by including two aspects: (1) stable trait factors (i.e., unit effects), and (2) MA and CLMA terms (Zyphur et al., Citation2020a).Footnote3 The latter idea was motivated by vector autoregressive moving average (VARMA) models (Box et al., Citation2008; Browne & Nesselroade, Citation2005; as cited in Zyphur et al., Citation2020a), which helps to expand the range of dynamic processes that can be modeled.
For the former idea, Zyphur et al. (Citation2020a) cited the work of Hamaker et al. (Citation2015) and noted the necessity of accounting for stable trait factors from the view of causal inference: “[b]y failing to model stable factors, they will be confounded with the system dynamics that should be reflected by AR and CL terms” (p. 8). Specifically, Hamaker et al. (Citation2015) argued that parameter estimates in the CLPM conflate between-person and within-person processes, while the RI-CLPM is an alternative model that can separate within-person processes from stable between-person differences. Therefore, inference of within-person reciprocal (as well as causal) effects by including stable trait factors, as in the RI-CLPM, was one of the central aims for Zyphur and colleagues in developing the GCLM.
Without loss of generality, here we can focus on a GCLM that assumes first-order lags for autoregressive and cross-lagged terms as well as for MA and CLMA terms. Zyphur et al. (Citation2020a) called this version of the GCLM the AR(1)MA(1)CL(1)CLMA(1) model (the numbers in parentheses indicate lag orders), which can be expressed asFootnote4
for . The terms
and
are occasion-specific intercepts or occasion effects. As before,
and
are (first-order) autoregressive parameters, and
and
are (first-order) cross-lagged parameters. The terms
and
are (unit-specific) common factors, which Zyphur et al. (Citation2020a, Citation2020b) called unit effects or stable (trait) factors. The means of these factors are set to zero. In addition, although not explicitly stated in Zyphur et al. (Citation2020a, Citation2020b), these factors are assumed to be uncorrelated with the initial states (
and
), though this assumption can be relaxed.
and
are weights or occasion-specific factors loadings, expressing changes in the effects of common factors over time. We will later discuss the meanings of the common factors (as well as cross-lagged parameters) in the GCLM.
The terms and
indicate MA effects, and
and
are CLMA effects. They are included to make observations a direct function of past impulses (i.e., residuals
). In this version of GCLM, the short-run persistence for a variable becomes AR+MA, and the short-run effect of one variable on another becomes CL+CLMA. Zyphur et al. (Citation2020a, p. 12) argued that past impulses
and
impact
and
via both CL and CLMA paths, respectively, because
and
are the components of
and
. Therefore, this is akin to estimating an effect of
and
on
and
as the short-run effect by
and
, again, respectively (Zyphur et al., Citation2020a, p. 12).
This version of the GCLM (the AR(1)MA(1)CL(1)CLMA(1) model) can be extended straightforwardly by including second- or higher-order terms. For example, we can include the additional terms and
for explaining
, and
and
for explaining
. This version of the GCLM can be notated as AR(2)MA(2)CL(1)CLMA(1). The AR(1)MA(1)CL(1)CLMA(1) model fixing occasion-specific factor loadings as
, which is applied in an empirical example below, is identified if two or more variables have been measured at three or more time-points when stationarity of parameters is assumed, while four or more time points are required under a non-stationarity assumption.
We can find mathematical relations between the GCLM and some of the longitudinal models we previously introduced. For example, if we set the weights of as
and exclude the intercepts (i.e.,
) as well as MA and CLMA terms (i.e.,
), and then include an additional common factor (
) whose weight is fixed to one, this version of the GCLM is mathematically equivalent to the ALT model. Likewise, by setting the weights of
as
and excluding intercepts and all lagged effects (set the AR, CL, MA, and CLMA terms to zero), and then instead including one additional common factor whose weight is fixed to one, this version of the GCLM is mathematically equivalent to the LGM. In the latter comparison, because no lagged effects are assumed to be present, the common factor (
) in the GCLM plays a similar role as the growth factor (
). In the former comparison, because AR and CL effects are still present in the GCLM (or the ALT model), the common factor (
) does not play the role as the growth factor (
) in the LGM. This is why we use the notation
(rather than
) to express common factors in the GCLM. This point is closely related to how we should interpret the common factors and cross-lagged parameters in each model. We revisit this issue later in more detail.
The relation between the CLPM and the GCLM is more obvious: excluding MA and CLMA terms as well as common factors (i.e., unit effects) from the GCLM reduces it to the CLPM. Therefore, the CLPM is a special case of the GCLM. This point might make us wonder whether the relation between the RI-CLPM and the GCLM is also simple. In fact, Zyphur et al. (Citation2020b, p. 13) explain that a variant of the RI-CLPM (a special case of the RI-CLPM that assumes specific weights (time-varying effects) for stable trait factors ) is equivalent to the GCLM with MA and CLMA terms eliminated. However, because lagged effects (i.e., the AR and CL terms) are present and they are jointly modeled with common factors
in the GCLM, even if we exclude MA and CLMA terms and fix the factor loadings to one, this version of the GCLM is not mathematically equivalent to the RI-CLPM, in which common factors (stable trait factors
) are separately (rather than jointly) modeled with lagged effects (i.e., EquationEquations (1
(1)
(1) ) and (Equation2))
(2)
(2) . Therefore, common factors (
) included in the GCLM cannot be interpreted as the stable trait factors (
) in the RI-CLPM. We discuss this point in detail using the unified framework (Usami, Murayama et al., Citation2019) described in the next section.
Unified framework and specifications of existing longitudinal models
Unified framework
Usami, Murayama et al. (Citation2019) provides a unified statistical framework that clarifies mathematical and conceptual relations among diverse SEM-based longitudinal models to examine reciprocal effects, which can be specified through this framework as particular cases. Formulation of the unified framework consists of three sets of equations, which Usami, Murayama et al. (Citation2019) called measurement equations, decomposition equations, and dynamic equations.
Measurement equations. The first set of equations can be used to separate the latent true scores from unique factors (or measurement errors) as
These unique factors are typically assumed to be normally distributed and possibly correlated. Among the models we have introduced, the LGM assumes unique factors. The GCLM as well as the (RI-)CLPM and the ALT model assume residuals in the lagged regressions, but they do not account for the presence of unique factors (or measurement errors) in their formulations. Some of the longitudinal models that include cross-lagged parameters (e.g., the stable trait autoregressive trait and state (STARTS) model; Kenny and Zautra (Citation1995, Citation2001); and latent change score (LCS) model; Hamagami and McArdle (Citation2001); McArdle and Hamagami (Citation2001) assume unique factors.
Though the inclusion of unique factors is desirable on conceptual grounds, it can easily lead to estimation problems due to the strong dependency among the estimated parameters (Usami, Murayama et al., Citation2019). Notably, the STARTS model, in which both stable trait factors and unique factors are assumed, often suffers from improper solutions (e.g., Hamaker et al., Citation2015; Usami, Todo et al., Citation2019), and a potential solution using Bayesian estimation has been recently investigated (Lüdtke et al., Citation2018). Usami, Todo et al. (Citation2019) provide a deeper discussion about improper solutions when applying the STARTS model through a simulation study that considers the presence of model misspecifications. Orth et al. (Citationin press) also compared the behavior of several longitudinal models in ten datasets, empirically showing that CLPM and the RI-CLPM converged in every sample, whereas the other (ALT, LCS, and STARTS) models frequently failed to converge or did not converge properly.
Decomposition equations. The second set of equations allow for decomposition into an individual deterministic trend and a temporal deviation from this individual trend, denoted as and
. The individual deterministic trend can depend on the temporal group means
and
and/or on the random intercepts and (linear) slopes (i.e.,
,
,
, and
). Thus, we have
Importantly, as we will show later, the common factors included in the decomposition equations (i.e., and
) have only direct effects on
, indicating these influences do not feed forward to later time points. Thus, these common factors can be characterized as stable trait (if
is omitted as in the RI-CLPM) or growth factors (i.e., random intercepts and (linear) slope factors as in the LGM).
Dynamic equations. Finally, the dynamics of the processes are modeled with the dynamic equations, which include the lagged terms as autoregressive parameters and
and cross-lagged parameters
and
along with the (dynamic) residuals
and
. In addition, they also include the common factors
and
, which are called accumulating factors in Usami, Murayama et al. (Citation2019). This gives
Although these equations may look very similar to the ALT model (EquationEquation (7)(7)
(7) ), dynamic equations are defined to explain temporal deviations
rather than observed scores. Because all terms in the dynamic equations contribute to the lagged predictors, their influences feed forward through the lagged relations and accumulate at later time points. This implies that the accumulating factors
and
as well as (dynamic) residuals
have direct and indirect effects on
, and thus on the observed scores. In contrast, the effects of stable trait or growth factors (
and
) are temporal and they have only direct effects on scores: their influences do not feed forward through the lagged relations and do not accumulate at later time points (Usami, Murayama et al., Citation2019). As we will discuss later, the choice to include accumulating factors (
and/or
) or trait/growth factors (
and/or
) in the model makes a difference in how we control (unobserved) confounders, resulting in different interpretations of the cross-lagged parameters in each model.
Note that we cannot apply this unified model to longitudinal data because it would be unidentified due to overparameterization. The aim of introducing this framework is to provide a general structure that helps to relate the many diverse modeling approaches (Usami, Murayama et al., Citation2019). Another important point is that in this framework MA and CLMA terms were not originally included, though extending the framework to include them is not difficult.
Specification of longitudinal models based on the unified framework
Using the unified framework presented above we can easily see that there are components that may or may not be included in the model. Here we explain how the longitudinal models we have introduced so far can be expressed using the unified framework.
First, the RI-CLPM can be expressed within the unified framework as
by excluding unique factors , slope factors
, and accumulating factors
and
in the unified framework. As we have explained, because in the RI-CLPM the common factors (i.e., stable trait factors) are modeled separately (rather than jointly) from lagged effects (i.e., EquationEquations (1
(1)
(1) ) and (Equation2
(2)
(2) )), they have only direct effects on observed scores.
The (linear) LGM can be expressed as
by excluding temporal group means , accumulating factors
and
, lagged effects (i.e., setting
) and (dynamic) residuals
from the unified framework.
One feature of the LGM is that it does not include lagged effects, implying that the distinction between the dynamic equations and other equations becomes meaningless in this special case. Therefore, if we temporarily disregard the original definition that terms included in the dynamic equations are to be modeled by lagged effects, we can find another expression of the (linear) LGM using different symbols:
Conceptually, the common factors ( and
) and
included in this expression are to be interpreted as growth factors and unique factors, rather than as accumulating factors and (dynamic) residuals, respectively.
The ALT model can be expressed within the unified framework as
by excluding ,
, and the growth factors
and
. We provide path diagrams of the existing models (expressed using the unified framework) as well as the unified framework itself in . This should better clarify the properties of trait/growth factors and accumulating factors: the former has only direct effects on observed scores and its influences are temporal, while the latter has both direct and indirect effects and influences feed forward through the lagged relations and accumulate at later time points.
Figure 1. Path diagrams of cross-lagged models. Notes. Residual covariances and covariances between common factors are omitted for clarity of presentation. In the LGM and the unified framework, unique factors (or measurement errors) are indicated by arrows only. Note that the means of common factors in the RI-CLPM and the GCLM are set to zero. In the GCLM, covariances between initial states and accumulating factors are not assumed
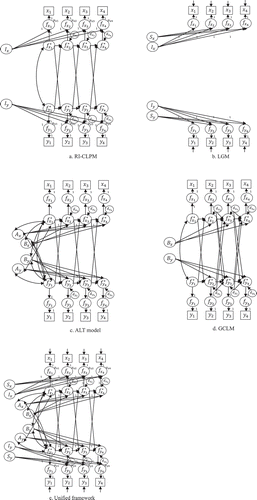
Contrasting the GCLM and the RI-CLPM
Specification of the GCLM from the unified framework
As we have observed, one important key to understanding the differences among the models is whether common factors included in the model are modeled with lagged effects, that is, whether common factors are included in either the decomposition equations (e.g., the RI-CLPM) or the dynamic equations (e.g., the ALT model).
With this point in mind, in this section we first show how the GCLM (i.e., EquationEquation 8)(8)
(8) can be expressed within the unified framework. Then we discuss the interpretative differences of cross-lagged parameters between the GCLM and the RI-CLPM, which was overlooked in Zyphur et al. (Citation2020a, Citation2020b). We also warn of the potential difficulty of its interpretation in the GCLM.
Like the (RI-)CLPM and the ALT model, the GCLM does not assume unique factors (or measurement errors), meaning . Therefore, the expression in the measurement equations for the GCLM becomes
In the GCLM, the common factors () are modeled jointly with lagged effects to explain observed scores (see EquationEquation (8)
(8)
(8) ), indicating that common factors included in this model can be considered as accumulating factors rather than stable trait or growth factors. Therefore, growth factors (
and
) in the decomposition equation can be excluded for the specification of the GCLM. Note that the original specification of the GCLM (EquationEquation (8))
(8)
(8) includes occasion-specific intercepts
. Recall that the mean structure in the model can be expressed by modeling the temporal group means
(rather than
) as a function of
and lagged effects (EquationEquations (4
(4)
(4) ) and (Equation5))
(5)
(5) . Therefore, we can express the decomposition equations for the GCLM using
as
As we have observed, the GCLM includes MA and CLMA terms to explain observed scores. However, these terms were not originally included in the unified framework. For concision, suppose we slightly extend the unified framework to include these terms in the dynamic equations and assume the weights (i.e., factor loadings) of accumulating factors are fixed to
in the GCLM. Then, the dynamic equations for the GCLM can be expressed as
by excluding accumulating factors . Note that the occasion-specific intercepts
, which are included in the original specifications of the GCLM (EquationEquation (8)
(8)
(8) ), are not modeled here because temporal group means
in the decomposition equations already account for the mean structure. A path diagram of the GCLM within the unified framework is provided in .
To better clarify the relations among models including the GCLM, a conceptual diagram is provided in , which is an extension of the figure provided in Usami, Murayama et al. (Citation2019). Note that we assumed time-invariant autoregressive and cross-lagged parameters in all the models here, though this assumption can be relaxed.
Figure 2. Conceptual diagram clarifying relations among cross-lagged models as an extension of Usami, Murayama et al. (Citation2019). Notes. Single-headed arrows indicate nested relations, with dotted lines indicating relations that can be conditionally satisfied. Double-headed dotted lines indicate that models are statistically equivalent under particular circumstances. Note that we suppose time-invariant autoregressive and cross-lagged parameters in all models. Hamaker (2005) compared the ALT model and the LCM-SR, and McArdle (2009) explained that the LGM (or, latent curve model: LCM) is a special version of the LCS model. Usami, Hayes & McArdle (2015) showed that the factor CLPM (i.e., CLPM that includes measurement errors) is a special version of the TCS model (i.e., LCS model that assumes time-varying factor loadings for accumulating factors). GCLM: general cross-lagged panel model; CLPM: cross-lagged panel model; RI-CLPM: random-intercepts CLPM; STARTS: stable trait autoregressive trait and state; LCM-SR: latent curve model with structured residuals; ALT: autoregressive latent trajectory; LCS: latent change score; TCS: triple change score
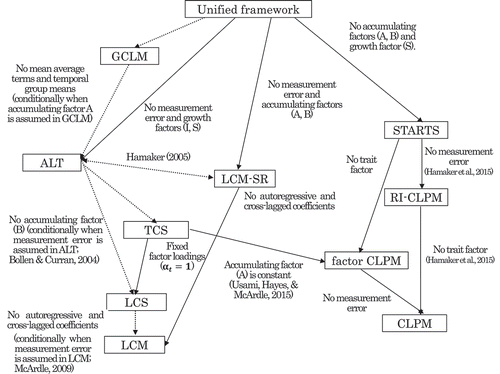
As we have observed, the GCLM and the ALT model commonly include accumulating factors, and a special case of the GCLM (in which weights are set to , intercepts as well as MA and CLMA terms are excluded as zero, and one additional common factor
is included instead) is mathematically equivalent to the ALT model. Thus, we express the (conditionally) nested relations between these two models in the diagram.
In sum, the GCLM can be viewed as a model in which all terms (excepts for temporal group means ) are posited in the dynamic equations, as in the ALT model. Thus, it is again obvious that the common factors included in the GCLM can be viewed as accumulating factors rather than as stable trait or growth factors. Therefore, one important conclusion of this article is that the common factors (unit effects) included in the GCLM cannot be interpreted as the stable trait factors used in the RI-CLPM, and that the GCLM does not control for the stable traits as in the RI-CLPM. In addition, the description that compares the RI-CLPM and the GCLM in Zyphur et al. (Citation2020b, p. 13) is incorrect, because a variant of the RI-CLPM (i.e., a special case of the RI-CLPM that assumes specific weights for stable trait factors
) is not mathematically equivalent to the GCLM with MA and CLMA terms eliminated.
Mathematical definition of stable traits and illustration of what the GCLM and the RI-CLPM control for
Psychometricians have used the terms “(stable) traits” and “within-person relations” in ambiguous ways when describing SEM-based longitudinal models, despite mathematical and interpretative differences existing between them. Common factors that play a role as accumulating factors have been called by different names. The unified framework helps to resolve this problem and facilitate comparison of different models. In this subsection we provide a mathematical definition of stable traits, and mathematically sketch what the GCLM and the RI-CLPM control for through common factors.
Inspired by the formulation of the RI-CLPM and the unified framework, Usami (Citation2020) defined a stable trait factor (say, for variable ) for person
as the difference between expected value for an observation (the true score) of this person at time
(expressed as
) and the temporal group mean at time
(
) that are invariant over time as
where and
. Note that
. Then, the within-person variability score
is also defined as the temporal deviation of person
at time
(i.e., the difference between an observation and its expected value) as
assuming that =0 and
(i.e., expected values of observations and within-person variability scores are uncorrelated). Then, Usami (Citation2020) proposed a general procedure for estimating causal effects of time-varying treatments or predictors on outcomes using within-person variability scores that are estimated by a factor analysis model.
As we have argued, the role of common factors critically depends on whether they are separated from lagged relations in the model. Because accumulating factors included in dynamic equations are not separated from the lagged relations in the model, they do not satisfy the relation in EquationEquation (19)(19)
(19) (i.e., the difference between the expected value of observation (true score) for person
and the temporal group mean is not invariant over time). To illustrate this point, we dig into the observed score of variable
at time
(
) in the RI-CLPM and the GCLM. In the RI-CLPM,
can be re-expressed using EquationEquations (1
(1)
(1) ) and (Equation2
(2)
(2) ) as
This expression shows that stable trait factor has a direct effect on
, since it does not show up in the lagged terms in EquationEquation (21)
(21)
(21) . As a result, the expected score for person
at
is
. Thus,
, indicating that the stable trait factor in the RI-CLPM satisfies the definition in EquationEquation (19)
(19)
(19) .
In contrast, in the GCLM, it can be shown that accumulating factor has both direct and indirect effects on
. Using EquationEquation (8)
(8)
(8) , we can re-express
in the GCLM as
This shows that the effect of the common factor is different at each time point, and its function becomes increasingly more complex at later time points. In the first line, where
and
are contrasted, the effect of the accumulating factor appears as
. However, in the third line, where
and
are contrasted, the effect becomes
, which reflects both a direct effect and an indirect effect of
.
also impacts
(
). Furthermore, the third line also suggests that the expected score for person
on variable
at
is a function of a) occasion-specific intercepts
, b) occasion-specific factor loadings
, c) the common factors
, d) the lagged parameters
and
, and e) the initial states
and
. These suggest that the difference between the expected value of observation (true score) for person
and the temporal group mean is not equal to
and not invariant over time. Namely, the accumulating factor in the GCLM (or the ALT model) does not satisfy the definition in EquationEquation (19)
(19)
(19) . Zyphur et al. (Citation2020a, p. 9) gave reasons for allowing the effect of accumulating factor
to vary over time (
), and the definition of stable trait factors EquationEquation (19)
(19)
(19) might be expanded to allow such time-varying effects. Regardless of how we define stable traits, however, this observation reveals that mathematical roles differ between stable trait factors in the RI-CLPM and the accumulating factors in the GCLM (or the ALT model), and that the GCLM (or the ALT model) does not control for stable traits as in the RI-CLPM.
Interpretation of cross-lagged parameters in the GCLM
Given the above, how can the cross-lagged parameters in the GCLM be interpreted, and how is this different from other models, such as the RI-CLPM? Zyphur et al. (Citation2020a) explained how the range of dynamic processes that can be modeled increases by including MA and CLMA terms, and also discussed two threats to causal inference (trends and regime changes). However, they did not provide a clear explanation of how to interpret cross-lagged parameters in the GCLM. Below we discuss the potential difficulty of interpreting cross-lagged parameters in the GCLM from two aspects: including the accumulating factors, and the MA and CLMA terms. Here we partly refer to Usami, Murayama et al. (Citation2019) for the former point.
Accumulating factors. As we have argued, the accumulating factors have both a direct effect and an indirect effect on outcomes EquationEquation (22)(22)
(22) , and the same is true even if occasion-specific factor loadings are fixed to 1 (
). Therefore, the GCLM (or the ALT model) does not control for stable traits as in the RI-CLPM. Because accumulating factor
correlates with observations and its effect differs at each time point, one could say that the GCLM (or the ALT model) implicitly controls for unobserved time-varying confounders, and that those influences feed forward through lagged relations. However, one potential risk of the GCLM is that estimates of cross-lagged parameters are biased and cannot be interpreted as causal estimates unless influences of time-varying confounders are precisely expressed by the complex function of
and
, as well as
and
EquationEquation (22)
(22)
(22) . Correct specification of a highly structured model such as the GCLM might be a strong assumption in general, and even minor model misspecifications can cause severely biased estimates of cross-lagged parameters.
Even if no model misspecification occurs, the assumption that the GCLM (or the ALT model) controls for unobserved time-varying confounders may be inappropriate for some instances, potentially leading to erroneous conclusions. Specifically, if individual differences in growth captured by accumulating factors in one of the observed variables is actually (in part) the result of growth in another observed variable, then using this model, which might cause unnecessary adjustment (i.e., overadjustmentFootnote5) of growth, is likely to result in biased estimates of reciprocal (as well as causal) effects (Usami, Murayama et al., Citation2019). Namely, there is a great risk that accumulating factors wrongly account for individual differences in growth, resulting in biased estimates of reciprocal effects if such individual differences are considered to be constituent components of these effects.Footnote6 More importantly, it is very difficult in general for researchers to precisely know what the accumulating factor as a time-varying latent variable actually represents, causing interpretative difficulty of the cross-lagged parameters if this is included in the model.
In contrast, the RI-CLPM allows for a group-level trajectory (expressed as ) that can take on any shape, and each person deviates from this trajectory by a constant distance (i.e.,
). The reciprocal effects are then modeled between the residuals, that is, the deviations from the expected scores, without controlling for persons’ growths by slope (
) or accumulating factors (
and
). Hence, in this approach, stable trait factors can be clearly interpreted, and (time-varying) individual differences in growth remain in the reciprocal parts of the model, unlike in the GCLM (or the ALT model). However, if individual differences in growth are actually caused by unobserved time-varying confounders, failing to include them in the model may also cause biased estimates of cross-lagged parameters (Usami, Murayama et al., Citation2019).
In other words, the critical point of model selection and interpretation of cross-lagged parameters lies in what aspects are considered critical components of reciprocal or causal effects. If (time-varying) individual differences in growth trajectories are considered a critical component of these effects, then the RI-CLPM might be an appropriate choice (Usami, Murayama et al., Citation2019). On the other hand, if researchers assume that the influences of unobserved time-varying confounders can be perfectly captured by accumulating factors, then the GCLM (or the ALT model) might be a better choice. However, in many cases one can see that growth aspects are considered to be a critical component of reciprocal or causal effects rather than mere unobserved time-varying confounders, so choosing the GCLM (or the ALT model) might not be appropriate. This point implies that two primary analytic purposes of applying longitudinal models that include reciprocal relations-namely, inferring reciprocal effects between variables and modeling individual differences in growth trajectories by common factors-are intertwined (Usami, Murayama et al., Citation2019).
MA and CLMA terms. We have discussed the potential limitation of interpreting cross-lagged coefficients if accumulating factors are modeled as in the GCLM. However, this problem becomes more complicated in the GCLM because it assumes MA and CLMA terms in addition to accumulating factors.
(CL)MA terms are composed by (dynamic) residuals. The residuals mean that the components of the observed scores that cannot be explained by lagged effects (i.e., deviations of observed scores from temporal group means in the previous time point) as well as accumulating factors (i.e., unit effects). Considering also that the role of the residuals in general is to account for all sources of variation unexplained by the fitted model (e.g., possible model misspecification, unobserved confounders and (dynamic) errors), it is not surprepsilong that the exact meanings of (CL)MA terms (or residuals) are obscure and their interpretations are very difficult in general. This point makes interpretation of cross-lagged parameters much more difficult in the GCLM, and can also cause biased estimates because of overadjustment.
A critical point is that (dynamic) residuals in the CLMA terms are already accounted for as one component of temporal deviations in the CL term. Specifically, say , which is a component of
in the CL term to explain
, is also accounted for by the CLMA term. This implies that in the GCLM, the same residual
is accounted for twice. Likewise, in the unified framework expression for the GCLM (),
is expressed by (i) the direct effect of
(a path
) and (ii) an indirect effect of
(a path trace
). This redundancy can cause high correlation between the CL term (
) and the CLMA term (
). As a result, not only biases in cross-lagged parameter estimates but also multicollinearity (inflated standard errors) might arise.
In sum, accumulating factors and (CL)MA terms included in the GCLM increase the risks of bias, multicollinearity (inflated standard errors), and interpretative difficulty in cross-lagged parameters to estimate reciprocal or causal effects, even if no model misspecification occurs. Although the RI-CLPM is not a perfect procedure for every situation, if the model can be correctly specified and if time-varying confounders can be appropriately controlled for, this choice better infers reciprocal or causal effects occurring at the within-person level. We revisit the issue of time-varying confounders from the view of causal inference later in this article.
Our goal in this article is not to suggest that researchers completely avoid using the model. The GCLM might be a good choice for researchers interested in building a useful linear model to predict observed scores, because this model can increase the range of dynamic processes that can be modeled. However, if the interpretation of cross-lagged parameters (inferring reciprocal effects) or controlling for stable traits (like in the RI-CLPM) is key in the application, applying the GCLM cannot be recommended.
An example using empirical data
This section presents an example using empirical data to show how estimates of reciprocal effects differ depending on model choice. Specifically, we focus on the GCLM and the RI-CLPM to illustrate (i) how differences in common factors included in the models, and (ii) how inclusion of (CL)MA terms in the GCLM influence estimates of reciprocal effects. In this example we investigate the reciprocal relation between adolescents’ exposure to smoking in movies () and their smoking intensity (
), using data from the Minnesota Adolescent Community Cohort (MACC) Study 2000–2013. The MACC Study is a prospective cohort study designed to expand understanding of the transitional process from nonsmoking to smoking during adolescence and to examine the effect of state- and local-level tobacco prevention and control programs for youth in Minnesota (Choi, Forster, Erickson, Lazovich, & Southwell, Citation2012). For illustrative purposes we used a sample of 4,671 adolescents aged 15 to 20 years who were surveyed from every six months in most years of the survey. When participants responded to two surveys in a year, only response data from the first survey were used to construct the dataset of
. More detailed information about the study design and population in the MACC study is available in Choi et al. (2012) and from the website of the Inter-university Consortium for Political and Social Research.Footnote7 Usami, Murayama et al. (Citation2019) used the same dataset to compare estimates of reciprocal effects among various models, though they did not include the GCLM in this comparison. In this example we newly fit the GCLM to the dataset for illustrative purposes.
Exposure to smoking in movies and smoking intensity were assessed during each round of data collection. Participants were asked to report how often they saw actors and actresses smoking when they watched movies, with four response options: most of the time (4), some of the time (3), hardly ever (2) and never (1). The data also included an index for six levels of smoking intensity, which was created by five measures (see Choi et al., 2012, for details). There were two sources of missing data, those missing by design and those by attrition. We used all available data when estimating parameters of the models, but we removed data for one participant with missing data for all variables at all time points. All analyses were conducted using the lavaan package (Rosseel, Citation2012) in R with the full information maximum likelihood estimation method. The lavaan source code used in this example is available in the Online Supplemental Materials.
To clarify the comparison between the models, in this example occasion-specific factor loadings are all fixed to 1 ( and
), and covariances between the first states (
and
) and accumulating factors
were not assumed in the GCLM. We then fit two kinds of first-order GCLMs to the dataset: AR(1)MA(1)CL(1)CLMA(1) and AR(1)CL(1). Comparison between these two GCLMs illustrates how inclusion of the (CL)MA terms affects estimates of cross-lagged parameters in the GCLM. Because the number of parameters is the same and the kind of common factor included is the only difference between AR(1)CL(1) and the RI-CLPM, comparing estimates from these two models illustrates how choice of common factors included in the model affects estimates of cross-lagged parameters. In both the GCLMs and the RI-CLPM, we assume stationarity of parameters (e.g., equality of AR, CL, and CL(MA) effects and residual (co)variances over time). However, because the AR(1)MA(1)CL(1)CLMA(1) model resulted in an improper solution, we assumed non-stationarity of parameters for residual variances of
and residual covariances in this model.
shows parameter estimates and fit indices from the RI-CLPM and the two GCLMs. The RI-CLPM showed nonsignificant estimates for both cross-lagged parameters (exposure to smoking in movies did not predict later smoking intensity
, and vice versa), while the two GCLMs showed significant estimates. The AR(1)MA(1)CL(1)CLMA(1) fit better than did the other models, and resulted in significant estimates for both cross-lagged parameters. Note that this model also showed relatively larger standard errors, implying the influence of multicollinearity caused by correlations among accumulating factors (
), (lagged) observations (
and
), and (lagged) residuals (
and
).
Table 1. Parameter estimates and model fit indices from different longitudinal models (N = 4,670)
This example clearly demonstrates the risk of drawing different conclusions based on the cross-lagged parameters from different models. Focusing on model fit, the AR(1)MA(1)CL(1)CLMA(1) model would be the most appropriate for these data. Moreover, since model fits of the two GCLMs were much better than that of the RI-CLPM, it seems safe to conclude that there are omitted time-varying confounders affecting both observed variables.
As we have argued, however, cross-lagged parameters in the AR(1)MA(1)CL(1)CLMA(1) model are very difficult to interpret and also pose greater risks of bias in its estimates due to inclusion of (CL)MA terms and accumulating factors. If researchers are interested in estimating reciprocal or causal effects and can reasonably expect that influences of unobserved time-varying confounders can be perfectly expressed as accumulating factor , choosing the estimation results from the AR(1)CL(1) model should be more reasonable than use of the AR(1)MA(1)CL(1)CLMA(1) model. In most cases, however, researchers are uncertain regarding how the impacts of unobserved time-varying confounders shift over time. If longitudinal changes in smoking intensity and exposure to smoking in movies are considered critical components of reciprocal effects, AR(1)CL(1) is an inappropriate option, and the RI-CLPM could be an option. In this case, it would be reasonable to conclude that there are no significant reciprocal effects between these variables. However, from the view of causal inference, we need to consider that their estimates of reciprocal effects in the RI-CLPM might be biased due to omitted time-varying confounders. To mitigate this risk, including observed time-varying confounders in this model should be a useful strategy, and this is discussed further in the next section.
Estimating causal effects by the RI-CLPM and recent potential outcome approaches
As we have argued, including accumulating factors and (CL)MA terms as in the GCLM should increase risk of bias in reciprocal or causal effect estimates. The RI-CLPM, which does not include these components, separates within-person fluctuations (temporal deviations) from stable between-person differences (stable trait factors) over time, and cross-lagged relations in EquationEquation (2)(2)
(2) can be considered as those pertaining to a process that takes place at the within-person level. From the view of the potential outcome approach, which is currently the standard framework for defining causal effects, within-person reciprocal effects estimated in the RI-CLPM can represent causal effects under assumption of no model errors and no unobserved confounders (see Usami, Murayama et al., Citation2019; Usami, Citation2020 for more details). If measurement errors (violation of the consistency assumption) are expected to be present, using the STARTS model, which is a simple extension of the RI-CLPM to allow measurement errors, might be an option. However, see Usami, Todo et al. (Citation2019) and Orth et al. (Citationin press) for further discussion about improper solutions frequently appearing in the STARTS model.
Regardless of which model we take, estimates of cross-lagged parameters are biased if there are omitted unobserved confounders. When time-varying observed confounders are available, a typical approach is to directly include them into the model like an analysis of covariance (ANCOVA). This approach requires assumptions of linearity and additivity of relations between outcomes and confounders. Namely, even if observed confounders are included when applying the RI-CLPM (or the STARTS model), it requires correctly specified linear regressions to connect variables at the within-person level. However, the linearity that is typically assumed in path modeling and SEM has often been criticized in the causal inference literature (e.g., Hong, Citation2015).
To mitigate this problem, non-SEM approaches such as marginal structural models (MSMs; Robins, Citation1998, Citation1999; Robins et al., Citation2000) or structural nested mean models (SNMMs; e.g., Robins, Citation1994, Citation1999) with -estimators are useful. They have been applied in epidemiology to estimate the causal effects of sequences of time-varying treatments or predictors
on outcomes
. Although these methods originally considered the situation where one is interested in evaluating a unidirectional relation (the effect of a treatment on an outcome) rather than reciprocal relations, they can be extended in a straightforward manner.
In MSMs, researchers specify a treatment assignment model at time point
(and previous time points) to express the probability that one receives a certain level of treatment or predictors
using the history of observed confounders
. Next, the inverse probability weights (IPW) required for estimating an outcome model
are calculated using information of inverse probability
at time point
(and previous time points) under the assumption of no unobserved confounders or sequential ignorability. Causal effects are then estimated by fitting a weighted outcome model with an IPW estimator. Unlike ANCOVA, MSMs do not demand that researchers model the relation between outcomes and observed confounders. In general, MSMs can be easily understood and fit with standard, off-the-shelf software that allows for weights (Vansteelandt & Joffe, Citation2014). However, it is also well-known that MSMs can be highly sensitive to misspecification of the treatment assignment model, even when there is a moderate number of time points (e.g., Hong, Citation2015; Lefebvre et al., Citation2008). Imai and Ratkovic (Citation2015) proposed a covariate balancing propensity score methodology for robust IPW estimation.
Although actual applications have been relatively infrequent, mainly due to a lack of the off-the-shelf software (however, see Wallace et al., Citation2017 as an exception), SNMMs with -estimators are a better approach for handling violation of assumption of no unobserved confounders or sequential ignorability (Vansteelandt & Joffe, Citation2014). Specifically, by solving estimating equations constructed based on this assumption, consistent estimates of causal parameters can be obtained when either a treatment assignment model or a model for outcome that would be observed if the treatment were stopped from a specific time can be correctly specified (the doubly robust property; see Vansteelandt & Joffe, Citation2014; Usami, Citation2020 for details). In addition, SNMMs can allow direct modeling of the interactions and moderation effects of treatments or predictors with observed confounders. Another advantage of SNMMs is that the variance of locally efficient IPW estimators in MSMs exceeds that of
-estimators in SNMMs, unless treatments or predictors and observed confounders are independent.
Note that observed confounders are typically included in applications of MSMs and SNMMs. That is, they do not often explicitly include latent variables or common factors like the stable trait factors. This implies that stable individual differences might not be adequately controlled for in usual applications of MSMs and SNMMs. Usami (Citation2020) proposes a two-step analysis method for within-person variability scores-based causal inference to estimate joint effects of time-varying treatments or predictors by controlling for stable traits as time-invariant unobserved confounders. In this method, within-person variability scores for each person EquationEquation (20)(20)
(20) , which are disaggregated from stable traits of that person, are first calculated through a factor analysis model. Causal parameters are then estimated via a potential outcome approach, either MSMs or SNMMs, using calculated within-person variability scores. Through simulation and empirical application, it was shown that the proposed method can recover causal parameters well and that causal estimates might be severely biased if one does not properly account for stable traits. It should be beneficial for researchers to take such non-SEM-based approaches as possible alternatives in future research, especially if they aim to effectively and flexibly control for time-varying confounders.
Conclusion
We discussed how common factors and cross-lagged parameters included in the GCLM can be interpreted using a unified framework, highlighting the conceptual and mathematical differences among the GCLM, the RI-CLPM, and other longitudinal models. Our conclusions can be summarized as follows: (1) Common factors included in the GCLM are not stable trait factors (as included in the RI-CLPM), but are accumulating ones (as included in the ALT model), which have both direct and indirect influences on observed scores, meaning that the GCLM does not control for stable traits of persons as does the RI-CLPM. (2) Including accumulating factors as well as (CL)MA terms, which are main features of the GCLM, makes the interpretation of cross-lagged parameters very complicated in general. (3) Even if no model misspecification occurs, seriously biased estimates of cross-lagged parameters (and inflated standard errors) might be obtained in the GCLM when (time-varying) individual differences in the growth trajectories accounted for by accumulating factors are critical components of reciprocal or causal effects. (4) Although the GCLM might be an option if one is especially interested in predicting outcomes, applying this approach entails great risk if uncovering reciprocal or causal effects is the primary focus. (5) Although the RI-CLPM (and the STARTS model) is not a perfect procedure for every situation, if the model can be correctly specified and if time-varying confounders can be appropriately controlled for, this choice is better to infer reciprocal or causal effects that occur at a within-person level. Finally, (6) If one aims to effectively and flexibly control for time-varying confounders, the RI-CLPM (or the STARTS model) with ANCOVA approach is not the only option, and it is beneficial to take non SEM-based approaches such as MSMs and SNMMs as possible alternatives. summarizes our discussion of each model.
Table 2. Summary of methods
Notably, regarding the last point, SNMMs with -estimators are a better approach for handling violation of assumption of no unobserved confounders or sequential ignorability, because of their doubly robust property. However, MSMs and SNMMs originate from epidemiology and thus have not been broadly used in the behavioral sciences. In future studies, we plan to contrast these methods with various longitudinal models from both conceptual and mathematical viewpoints, and to introduce the within-person variability scores-based causal inference approach (Usami, Citation2020). Because estimation performance of these methods has not been exhaustively compared with the RI-CLPM (with an ANCOVA approach), this point should be investigated in future studies. We hope this corner and related future studies will help researchers choose better methodologies when aiming to uncover reciprocal or causal effects with minimal risk of obtaining wrong conclusions.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes
1 Based on a literature search using the UTokyo REsource Explorer (TREE; http://tokyo.summon.serialssolutions.com/) search engine on Oct 28, 2019. TREE aggregates information from many major databases, including Web of Science, PubMed, PsycINFO, Engineering Village, ERIC, and JSTOR, as well as electronic journals under contract with the University of Tokyo. We used the keyword “cross-lagged,” searching papers published in English from Oct 2018 to Oct 2019. We limited our search to only peer-reviewed papers, resulting in 1,065 papers found. Most were applied research, though some were research reviews or theoretical/methodological studies.
2 Note that the original introduction in Hamaker et al. (Citation2015) assumed time-varying autoregressive and cross-lagged parameters, but we assume here, without loss of generality, time-invariant parameters to keep the discussion concise.
3 Zyphur et al. (Citation2020a) used the term “stable factors” rather than “stable trait factors.”
4 For consistency between expressions of the introduced models, and to clarify the meanings of parameters and common factors, here we use symbols different from those in Zyphur et al. (Citation2020ab). Specifically, in this article we use symbols ,
,
,
, and
, instead of using
,
,
,
, and
, respectively.
5 We use the terms unnecessary adjustment or overadjustment to describe a variable that increases net bias and/or decreases precision, while some researchers use these to indicate only the latter meaning. See Schisterman et al. (Citation2009) regarding this point.
6 As a variant of the ALT model, we have seen the recent development of a latent variable-autoregressive latent trajectory (LV-ALT) model (Bianconcini & Bollen, Citation2018), which aims to provide a framework for comparing different longitudinal models and allows researchers to explore alternative structures to best model their longitudinal data. One may wish to apply the bivariate version of this model to evaluate reciprocal effects between variables. However, the risk that accumulating factors wrongly account for (time-varying) individual differences in growth remains in this model.
References
- Asparouhov, T., Hamaker, E. L., & Muthen, B. (2018). Dynamic structural equation models. Structural Equation Modeling, 25(3), 359–388. https://doi.org/10.1080/10705511.2017.1406803
- Bianconcini, S., & Bollen, K. A. (2018). The latent variable autoregressive latent trajectory (LV-ALT) Model: A general framework for longitudinal data analysis. Structural Equation Modeling, 25(5), 791–808. https://doi.org/10.1080/10705511.2018.1426467
- Bollen, K. A., & Curran, P. J. (2004). Autoregressive latent trajectory (ALT) models a synthesis of two traditions. Sociological Methods and Research, 32(3), 336–383. https://doi.org/10.1177/0049124103260222
- Bollen, K. A., & Curran, P. J. (2006). Latent curve models: A structural equation approach. Hoboken, NJ: Wiley.
- Bollmann, G., Rouzinov, S., Berchtold, A., & Rossier, J. (2019). Illustrating instrumental variable regressions using the career adaptability – Job satisfaction relationship. Frontiers in Psychology, 10, 1481. https://doi.org/10.3389/fpsyg.2019.01481
- Box, G. E. P., Jenkins, G. M., & Reinsel, G. C. (2008). Time series analysis: Forecasting and control (4th ed.). Wiley.
- Browne, M., & Nesselroade, J. R. (2005). Representing psychological processes with dynamic factor models: Some promepsilong uses and extensions of autoregressive moving average time series models. In A. Madeau & J. J. McArdle (Eds.), Advances in psychometrics: A festschrift for R. P. McDonald (pp. 415–452). Erlbaum.
- Choi, K., Forster, J., Erickson, D., Lazovich, D., & Southwell, B. G. (2012). The reciprocal relationships between changes in adolescent perceived prevalence of smoking in movies and progression of smoking status. Tobacco Control, 21, 492– 496. https://doi.org/10.1136/tc.2011.044099
- Curran, P. J., & Bollen, K. A. (2001). The best of both worlds: Combining autoregressive and latent curve models. In L. M. Collins & A. G. Sayer (Eds.), New methods for the analysis of change (pp. 105–136). American Psychological Association.
- Hamagami, F., & McArdle, J. J. (2001). Advanced studies of individual differences: Linear dynamic models for longitudinal data analysis. In G. A. Marcoulides & R. E. Schumacker (Eds.), New developments and techniques in structural equation modeling (pp. 203–246). Erlbaum Associations.
- Hamaker, E. L. (2005). Conditions for the equivalence of the autoregressive latent trajectory model and a latent growth curve model with autoregressive disturbances. Sociological Methods and Research, 33(3), 404–416. https://doi.org/10.1177/0049124104270220
- Hamaker, E. L., Kuiper, R. M., & Grasman, R. P. P. P. (2015). A critique of the cross-laggedpanel model. Psychological Methods, 20(1), 102–116. https://doi.org/10.1037/a0038889
- Hong, G. (2015). Causality in a social world: Moderation, mediation and spill-over. Wiley.
- Imai, K., & Ratkovic, M. (2015). Robust estimation of inverse probability weights for marginal structural models. Journal of the American Statistical Association, 110(511), 1013–1023. https://doi.org/10.1080/01621459.2014.956872
- Kenny, D. A., & Zautra, A. (2001). Trait-state models for longitudinal data. In L. Collins & A. Sayer (Eds.), New methods for the analysis of change (pp. 243–263)). American Psychological Association.
- Kenny, D. A., & Zautra, A. (1995). The trait-state-error model for multiwave data. Journal of Consulting and Clinical Psychology, 63(1), 52–59. https://doi.org/10.1037/0022-006X.63.1.52
- Lefebvre, G., Delaney, J. A. C., & Platt, R. W. (2008). Impact of mis-specification of the treatment model on estimates from a marginal structural model. Statistics in Medicine, 27(18), 3629–3642. https://doi.org/10.1002/sim.3200
- Lüdtke, O., Robitzsch, A., & Wagner, J. (2018). More stable estimation of the STARTS model: A bayesian approach using Markov Chain Monte Carlo techniques. Psychological Methods, 23(3), 570–593. https://doi.org/http://dx.doi.10.1037/met0000155
- McArdle, J. J., & Hamagami, F. (2001). Latent difference score structural models for linear dynamic analyses with incomplete longitudinal data. In L. Collins & A. Sayer (Eds.), New methods for the analysis of change (pp. 137–175). American Psychological Association.
- McArdle, J. J. (2009). Latent variable modeling of differences and changes with longitudinal data. Annual Review of Psychology, 60(1), 577–605. https://doi.org/10.1146/annurev.psych.60.110707.163612
- McArdle, J. J., & Nesselroade, J. R. (2014). Longitudinal data analysis using structural equation models. American Psychological Association.
- Meredith, W., & Tisak, J. (1984). On “Tuckerizing” curves. Presented at the annual meeting of the psychometric society.
- Meredith, W., & Tisak, J. (1990). Latent curve analysis. Psychometrika, 55(1), 107–122. https://doi.org/10.1007/BF02294746
- Orth, U. D., Clark, A. M., Donnellan, B., & Robins, R. W. (in press). Testing prospective effects in longitudinal research: Comparing seven competing cross-lagged models. Journal of Personality and Social Psychology. http://dx.doi.org/10.1037/pspp0000358
- Oswald, F. L. (2019). Measuring and modeling cognitive ability: Some comments on process overlap theory. Journal of Applied Research in Memory and Cognition, 8(3), 296–300. https://doi.org/10.1016/j.jarmac.2019.06.009
- Robins, J. (1999). Marginal structural models versus structural nested models as tools for causal inference. In M. E. Halloran & D. Berry (Eds.), Statistical models in epidemiology: The environment and clinical trials (pp. 95–134). Springer.
- Robins, J. M. (1994). Correcting for non-compliance in randomized trials using structural nested mean models. Communications in Statistics, 23(8), 2379–2412. https://doi.org/10.1080/03610929408831393
- Robins, J. M. (1998). Marginal structural models. In 1997 proceedings of the section on bayesian statistical science, Alexandria, VA: American Statistical Association, 1–10.
- Robins, J. M., & Hernán, M. A. (2009). Estimation of the causal effect of time-varying exposures. In G. Fitzmaurice, M. Davidian, G. Verbeke, & G. Molenberghs (Eds.), Longitudinal data analysis, (pp. 553–599). CRC Press.
- Robins, J. M., Hernán, M. A., & Brumback, B. (2000). Marginal structural models and causal inference in epidemiology. Epidemiology, 11(5), 550–560. https://doi.org/10.1097/00001648-200009000-00011
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. https://doi.org/10.18637/jss.v048.i02
- Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5), 688–701. https://doi.org/10.1037/h0037350
- Schisterman, E. F., Cole, S. R., & Platt, R. W. (2009). Overadjustment bias and unnecessary adjustment in epidemiologic studies. Epidemiology, 20(4), 488–495. https://doi.org/10.1097/EDE.0b013e3181a819a1
- Usami, S. (2020). Within-person variability score-based causal inference: A two-step semiparametric estimation for joint effects of time-varying treatments. arXiv:2007.03973 [stat.ME].
- Usami, S., Hayes, T., & McArdle, J. J. (2015). On the mathematical relationship between latent change score model and autoregressive cross-lagged factor approaches: Cautions for inferring causal relationship between variables. Multivariate Behavioral Research, 50(6), 676–687. https://doi.org/10.1080/00273171.2015.1079696
- Usami, S., Murayama, K., & Hamaker, E. L. (2019). A unified framework of longitudinal models to examine reciprocal relations. Psychological Methods, 24(5), 637–657. https://doi.org/10.1037/met0000210
- Usami, S., Todo, N., & Murayama, K. (2019). Modeling reciprocal effects in medical research: Critical discussion on the current practices and potential alternative models. Plos One, 14(9), e0209133. https://doi.org/10.1371/journal.pone.0209133
- Vansteelandt, S., & Joffe, M. (2014). Structural nested models and g-estimation: The partially realized promise. Statistical Science, 29(4), 707–731. https://doi.org/10.1214/14-STS493
- Wallace, M. P., Moodie, E. E., & Stephens, D. A. (2017). An R package for G-estimation of structural nested mean models. Epidemiology, 28(2), e18–e20. https://doi.org/10.1097/EDE.0000000000000586
- Zhang, Y., Liu, X., & Chen, W. (2019). Fight and flight: A contingency model of third parties’ approach-avoidance reactions to peer abusive supervision. Journal of Business and Psychology. https://doi.org/10.1007/s10869-019-09650-x
- Zyphur, M. J., Allison, P. D., Tay, L., Voelkle, M. C., Preacher, K. J., Zhang, Z., Hamaker, E. L., Shamsollahi, A., Pierides, D. C., Koval, P., & Diener, E. (2020a). From data to causes I: Building a general cross-lagged panel model (GCLM). Organizational Research Methods, 23(4), 651–687. https://doi.org/10.1177/1094428119847278
- Zyphur, M. J., Voelkle, M. C., Tay, L., Allison, P. D., Preacher, K. J., Zhang, Z., Hamaker, E. L., Shamsollahi, A., Pierides, D. C., Koval, P., & Diener, E. (2020b). From data to causes II: Comparing approaches to panel data analysis. Organizational Research Methods, 23(4), 688–716. https://doi.org/10.1177/1094428119847280