
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
There is currently a lack of methods for non-linear structural equation modeling (NSEM) for non-parametric relationships between latent variables when data are ordinal. To this end, a semiparametric approach for flexible NSEMs without parametric forms is developed for ordinal data. An indirect application of a finite mixture of structural equation models (SEMM) is employed for modeling the conditional expected mean of endogenous latent variables. In this context, the latent classes are not to be interpreted as groups of observations belonging to those classes, rather they serve as means to model flexible non-linear functions as locally linear functions which together approximate a globally non-linear function. The proposed method is based on a hybrid of direct maximization and expectation-maximization algorithms. Two simulation studies are performed which show that parameter estimates are associated with low bias and a non-linear functional form is satisfactorily estimated using the proposed approach.
Introduction
In recent decades, structural equation modeling (SEM) has become available to applied researchers, particularly in social sciences, thanks to software packages such as LISREL (Jöreskog & Sörbom, Citation1993, Citation1996) and Mplus (Muthén & Muthén, Citation2020) by modeling the covariance structure assuming normally distributed latent variables. Most SEM approaches have historically focused on linear relationships between latent variables. In this paper, we will refer the exogenous variables as the variables that are not determined by other variables in the model, whereas endogenous variables as the variables determined by other variables in the model. However, it is frequently necessary to incorporate more flexible functions in order to capture the true relationships. See Ajzen and Madden (Citation1986), Ajzen (Citation1991), and Agustin and Singh (Citation2005) for examples of such considerations. When the structural relationship is nonlinear, the latent endogenous variables are not normally distributed. Hence, the parameters cannot be determined only based on the covariance structure. Subsequently, new approaches were developed starting with Kenny and Judd (Citation1984), where products of indicators were used as indicators corresponding to product and interaction terms. This approach was further developed by Jaccard and Wan (Citation1995), Jöreskog and Yang (Citation1996), Kelava and Brandt (Citation2009), and Wall and Amemiya (Citation2001). By forming products of indicators for interaction and quadratic terms, estimation of nonlinear structural models was made possible in (at the time) existing software. The product indicator approaches have been criticized for their ad-hoc nature and arbitrariness in terms of which indicators to include (e.g.,Wall (Citation2009) and Harring et al. (Citation2012)). Since then, the methodological development for estimating nonlinear structural equation models (NSEM) has continued by maximum likelihood-based approaches, among which Klein and Moosbrugger (Citation2000) and Klein and Muthén (Citation2007) are the most established methods. Bayesian approaches of Arminger and Muthén (Citation1998) and Zhu and Lee (Citation1999), and two-stage least square approaches of Bollen (Citation1995, Citation1996) have also been considered. Most of the development for NSEM has been focused on models with continuous indicators, although there are exceptions such as Lee and Zhu (Citation2000), Lee and Song (Citation2003), Rizopoulos and Moustaki (Citation2008), and Muthén (Citation2001).
In all methods mentioned above, the functional form of the structural model is specified. However, it is sometimes desirable to relax this requirement in order to model a more general family of functions. Nonparametric approaches, such as Song et al. (Citation2014), and semiparametric approaches, e.g., Bauer (Citation2005), Pek et al. (Citation2011), Song and Lu (Citation2010), Finch (Citation2015), and Guo et al. (Citation2012) provide the opportunity to estimate models with unspecified functional forms. In the finite mixture of structural equation models (SEMMs), e.g., Bauer (Citation2005) and Pek et al. (Citation2011), latent exogenous variables are modeled as mixtures of multivariate normal distributions. The mixture-based semiparametric approaches have two directions of purposes. In the direct approach, the groups are interpreted as real subpopulations and, hence, group-specific structural parameters are interpreted as parameters associated with the corresponding subpopulation. On the other hand, in the indirect approach, the groups are not to be interpreted as subpopulations in any substantive sense. Instead, they provide means to model nonnormal latent variables as mixtures of normal distributions as in the nonlinear structural equation mixture model (NSEMM) by Kelava et al. (Citation2014). Hence, model estimation, robust to nonnormal exogenous latent variables, is possible in a parametric context. Another application of the indirect approach, as in the SEMM by Bauer (Citation2005) and Pek et al. (Citation2011), is to model a nonlinear relationship as weighted group-specific linear functions. In this approach, both nonlinearity and nonnormality in the latent variables are modeled by the normal mixture, resulting in the flexible model estimation, robust to nonnormal latent exogenous variables.
There is, at present, a lack of non- and semiparametric approaches for latent variable modeling in the presence of ordinal data, although there are a few exceptions, e.g., Song et al. (Citation2013) who extended the penalized Bayesian P-splines approach of Song and Lu (Citation2010) to incorporate mixed data types. It has been demonstrated that treating ordinal data as continuous can produce bias (Finney & DiStefano, Citation2006; Rhemtulla et al., Citation2012). In this article, a semiparametric approach, based on the work of Bauer (Citation2005) and Pek et al. (Citation2011) is developed to allow for ordinal indicators based on quasi-maximum likelihood estimation, combining the direct maximization of the approximated log-likelihood of Jin et al. (Citation2020) and the expectation-maximization (EM) algorithm of Dempster et al. (Citation1977).
The article is organized as follows. First, the model is outlined, followed by the estimation procedure. Two simulation studies are reported in the following section. The first study recognizes that accurate, group-specific parameters are obtained, whereas the second study shows that a structural model of quadratic form is satisfactorily estimated using the developed approach. The article concludes with discussion and conclusion. An appendix is provided with technical details.
The semiparametric model
In the SEMM, as proposed by Bauer (Citation2005) and Pek et al. (Citation2011), a weighted sum of linear components is used to model the conditional expected value as
where is a
-dimensional vector of latent exogenous variables,
is a
-dimensional vector of latent endogenous variables,
is the number of components in the mixture,
is a
-vector of intercepts for component
,
is a
-matrix representing linear effects of component
, and the conditional probability of component
is
where is the multivariate normal density function,
is the population proportion of component
,
is the population mean vector of dimension
corresponding to component
and
is the population covariance matrix of
corresponding to component
of dimension
.
Only continuous data are considered by Bauer (Citation2005) and Pek et al. (Citation2011). In this work, their approach is extended to work for ordinal data. Define to be the
ordinal indicator of
and
to be the
ordinal indicator of
.Footnote1 The number of indicators corresponding to
and
is denoted by
and
, respectively, such that
and
are the
and
dimensional realizations of
, for
and
for
, respectively. The measurement model relating the continuous latent variables
and
to the ordinal observed variables
and
is then
where and
are the link functions,
is the
-vector of factor loadings of indicator
,
is the
-vector of factor loadings of indicator
, and
and
are the number of categories of corresponding indicator. Here we let
and
.
Maximum likelihood estimation
The joint density function of ,
,
,
and
is referred to as
. We assume that the observed variables
and
are independent, conditioned on the latent variables
and
and component
. The distribution of
is determined by
and the distribution of
is determined by
from the measurement model (EquationEquations (3)
(3)
(3) and (Equation4
(4)
(4) )). The measurement model does not depend on the group
. The SEMM (1) indicates that the distribution of
is determined by
and component
and that the distribution of
is determined by the component
. Thus, the joint density function is equivalent to
where and
are given by the measurement model (3) and (4),
with the restriction of total probability . The conditional distribution of
given
and component
is assumed to be
In the current setting is the same for all
components for simplicity. This restriction could easily be lifted. Neither the latent variables
and
, nor the components
, are observed, where subscript
refers to observation
. Hence, under the assumption of independent observations, the objective function for maximization is the observed log-likelihood
where is the vector of unrestricted parameters,
is the number of observations and
, i.e., the vector of latent variables of the
observation. Similarly,
and
are vectors of observed indicators of the
observation, and
represents the
component.
Estimation
The aim is to maximize with respect to
. In situations with missing data (or latent variables), it is common to employ the EM algorithm (Dempster et al., Citation1977). However, the EM algorithm is known for its slow convergence. Jin et al. (Citation2020) proposed to estimate an extended NSEM by a quasi-Newton method where the exact gradient of the approximated log likelihood is calculated for finding the maximum of
without using EM, hence, referred to as direct maximization (DM). For the extended NSEM, we expect DM to be computationally more efficient than EM. Instead of purely relying on the EM algorithm, we propose to use a hybrid of EM and DM in Jin et al. (Citation2020) in order to estimate the SEMM. The developed version of the EM algorithm is expected to be reasonably computationally efficient since there are closed-form solutions to the parameter updates in one EM step. For the purpose of presentation, a sketch of the proposed algorithm is described here. A detailed description of the procedure can be found in the appendix.
Let and
be the maximum number of categories of the indicators corresponding to
and
, respectively. Then let
be a
-matrix with element
on row
and column
,
be a
-matrix with element
on row
and column
. Let
be a
-matrix with the row vector
on row
and
be a
-matrix with
on row
. For convenience, the vector of unconstrained parameters is partitioned as
, where
is a vector of unrestricted elements in
,
,
and
and
is a vector of unrestricted parameters in
,
, …,
,
,
,
, …,
,
, …,
,
, …,
. For a given
,
only consists of group invariant parameters in the measurement model. We propose to maximize
with respect to
for fixed
by DM. No closed-form updates of
are found. Hence, the quasi-Newton’s method is used to update
numerically. For a given
,
is updated using the EM algorithm. EM is used for some parameters since the logarithm of the sum over the components
in (9) generates instability in the gradient of
. Further, in the proposed version of EM, the conditional maximization has closed-form solutions.
Both the closed-form updates in EM and the to be maximized in DM involve intractable integrals and approximations are required. In DM, the log-likelihood
is approximated by the adaptive Gauss-Hermite quadrature (AGHQ, Liu & Pierce, Citation1994). The reader is directed to the appendix for the expression of an AGHQ approximation. For an unimodal function, the error rate of the AGHQ approximation is
(Jin & Andersson, Citation2020) where
takes the largest integer that is less than the enclosed value and
is the number of quadrature points per latent variable. The AGHQ approximation was accurate for the extended NSEM investigated by Jin et al. (Citation2020) for
.
The exact gradient of the approximated log-likelihood is calculated in the quasi-Newton’s method, which is similar to the method of Jin et al. (Citation2020). In EM, the integrals in the closed-form solutions are also approximated by the AGHQ and are expected to be accurate for large samples and sufficiently large . See the appendix for details. A pseudocode of the proposed approach is presented in Algorithm 1 at iteration
.
Algorithm 1 Proposed approach: Hybrid of EM and DM
while convergence criterion not met do
(a) DM Step: Conditional on , update
by maximizing the approximated
using a quasi-Newton’s method
(b) EM step: Conditional on , update
with approximated closed-form solutions
end
Restrictions
In the SEM framework, a common assumption is that . In the proposed semiparametric setting, it is more convenient to put restrictions in the measurement model as explained below. It is, however, whenever appropriate, possible to perform a change of variables such that the new variables,
, where
is a function of model parameters. The transformed variables satisfy
. The common assumption that
, corresponds to
restriction equations for proportions and means of exogenous latent variables. The corresponding maximization equations in the EM step then lack closed-form solutions. In the current work, we define
restrictions on
instead. Impose the restrictions
where
is an index corresponding to a row of
and on the same row in
there is a restricted element setting the scale of a latent variable. There is one such restriction per latent exogenous variable giving rise to
restrictions. Consider a change of variables for
, where
. In the translated variables we have
. Then, the measurement model, e.g., corresponding to the indicator
, is
where and
. Similarly,
in general. Correspondingly number of restrictions for
are also needed. For this reason, the restriction
is imposed. Then, the change of variables
gives
. Thus, it is possible and straightforward to alternate between the sets of variables
, for which the estimation procedure is designed, and
which has mean zero. For example, the population latent regression in Simulation Study 2 in the next section is
, which is based on the zero-mean parametrization, namely,
. The linear predictor for the first indicator is
, where
, when generating the ordinal values. During estimation in our parametrization, we restrict
and
. The linear predictor for the first indicator becomes
and the latent regression in the first group is
. Consequently, neither
nor
is necessarily zero. Instead, they are
and
, respectively. We can easily transform the estimates from our parametrization to the zero-mean parametrization using
and
. In particular, the
and
, for all
, remain the same. The measurement models in two parametrizations can be transformed by
For the latent regression, our parametrization yields , which indicates that
Hence, the conditional mean in the zero-mean parametrization can be obtained by
where .
Simulations
In order to investigate the performance of the proposed method, two simulation studies are performed. In the first study, data is generated using prespecified, true model parameters, and the accuracy of the parameter estimation is investigated. In the second study, the data is generated using a quadratic function. Hence, no true parameters are known (or even existing). The degree to which the procedure captures the true nonlinear function is investigated, without having access to true parameters. The code is written in R (R Core Team, Citation2018) and will be provided upon request and will be released as an R package. In the simulations, the estimation stops when the maximum absolute difference in the parameters between two consecutive iterations is less than . In each simulation study, 1000 samples are generated and estimated using 5 quadrature points. For evaluation purposes in Simulation Study 1, the relative bias
, root mean squared error
, and standard deviation
are calculated for each structural parameter
, where
is the number of replications and
is the corresponding estimate at the
replication, and
is the average estimate of the parameter
.
Simulation study 1
Simulation design
In the first simulation study, data is generated using two bivariate normally distributed components with population proportions of the two latent exogenous variables (
and
). Within each component, the variances are
and covariances
. In this setting, the component means (
and
) are not free parameters, rather functions of other parmeters, as explained in the previous section. One latent endogenous variable
is generated conditioned on
and
from a normal distribution with conditional mean given by (1) and (2), with an error term with variance
. The generated latent variables are used to generate the ordinal indicators
and
from a measurement model given by (3) and (4) with the probit link function. For setting the location of
,
. Similarly, restrict the local intercept
, for setting the location on
. Furthermore, the zero elements in
are restricted to zero, which gives a simple structure.Footnote2 In order to set the scale of the latent variables
. The model parameters of the measurement model are then given by
The remaining, free model parameters are the local, linear parameters ,
and the local intercept
. The parameters are such that the
of the structural model is approximately 0.69. Reliabilities are between 0.79 and 0.86 for
and between 0.86 and 0.91 for
. Furthermore, the marginal probabilities of the respective categories are 0.15, 0.45, 0.15, 0.15, 0.10 for all items in
, and 0.20,0.20, 0.30, 0.20, 0.10 for all items in
. The sample sizes investigated are
.
Simulation results
Two (out of 1000) replications failed to converge for and all samples converged for
. In line with the literature (Flora & Curran, Citation2004), relative biases larger than 5 are considered to be moderate to substantial. In (
) and (
) the population parameter values (
), average estimates (
), RB,
SD and
RMSE are reported for the parameters associated with the structural, semiparametric model. The proposed semiparametric method provides low biases for all parameters. The RMSE is almost exclusively constituted by the variance of the estimates.
Table 1. Parameter and corresponding average estimates using AGHQ approximation with 5 quadrature points per latent dimension and 1000 replications. RB, SD, and RMSE stand for relative bias, standard deviation, and root mean squared error, respectively. The sample size is
Table 2. Parameter and corresponding average estimates using AGHQ approximation with 5 quadrature points per latent dimension and 1000 replications. RB, SD, and RMSE stand for relative bias, standard deviation, and root mean squared error, respectively. The sample size is
Simulation study 2
Simulation design
In the second simulation study, data () were generated using the same quadratic function as Bauer (Citation2005), namely
where is generated from a standard normal distribution, the error term
is generated from a normal distribution with mean 0 and variance 0.25. The stars are used because
. Hence, after estimation, the estimated function is shifted as described before. The parameters of the measurement model are given by
where and
are imposed restrictions. This gives an
of the structural model of approximately 0.71 and reliabilities between 0.73 and 0.81 for all indicators. The marginal probabilities in respective categories are the same as in those of Simulation Study 1. The sample size is 1000.
Simulation results
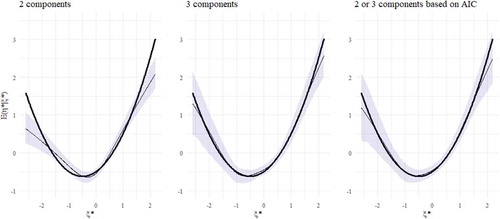
The conditional expected mean is shown as a function of
in when 2 and 3 components are used (left and middle panels), respectively. The bold line represents the population function in Equationequation (10)
(10)
(10) , whereas the thin line represents the average estimated conditional mean function. Ninety-five percent of the estimated functions are within the shaded areas. With two components the functional form is captured to some degree, although the performance is substantially better using three components. Although the average result is acceptable, in some instances, the form of the conditional expected mean is jumping peculiarly when one of the proportions is estimated to be close to zero. In practice, it is difficult to know how many components to use. One possibility is to use the Akaike information criterion (AIC) for selecting the number of components. The AIC is defined as
Figure 1. The conditional mean of the true data generating process (thick line) and the average estimated conditional mean (thin line) with empirical 95% intervals (filled blue areas) for 2 components (left), 3 components (middle) and when AIC is used for selecting the number of components (right)
where is the number of estimated parameters and
is the approximated log likelihood at the mode. In the simulations, 3 components are recommended in approximately 84% of the replications. In the right panel of , each replication has been estimated using 2 and 3 components and the model with the lowest AIC has been selected. The average estimated conditional mean function (the thin line) captures the population function well.
Discussion and conclusion
In NSEM it is common to consider terms corresponding to interaction and quadratic effects for modeling nonlinearities in the structural model. It is sometimes appropriate to consider more flexible functions with less, or no a priori assumptions about the functional form. Such models are less common in the literature, particularly models which consider ordinal data. In this article, a semiparametric structural model (Bauer, Citation2005; Pek et al., Citation2011) is proposed in the presence of ordinal data. The structural model consists of a weighted sum of locally linear functions, which together approximate a globally nonlinear function. A hybrid of a direct maximization approach (Jin et al., Citation2020) and an expectation-maximization algorithm (Dempster et al., Citation1977) is suggested and implemented for maximizing the marginal log-likelihood of the observed ordinal data. Two simulation studies are performed. The first shows that the proposed method provides parameter estimates with low relative bias, whereas the second study illustrates how the method accurately captures a nonlinear structural model in terms of the conditional mean of the latent endogenous variable. The accurate parameter estimates and performance in estimating the conditional mean suggest that the AGHQ approximations are of high quality for in models similar to those investigated in this study. Two and three components are used in the second study. Using two components yields a reasonable and stable functional form, whereas three components yield a more accurate functional form on average, with the drawback of occasionally unstable estimates. The number of components might possibly be selected using AIC. Advantages of the proposed method include the capacity of modeling flexible structural models in the presence of ordinal data when the latent exogenous variables are not necessarily normal. In this study, little attention is devoted to the latter point. A suggestion for future studies is to investigate the performance of the proposed method under moderate to severe nonnormality of latent exogenous variables. This is left as a future project.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes
1 The subscripts on and
should in principle be different, e.g.,
and
but for notational convenience, we use the same (
) for
and
.
2 A simple structure is not necessary, but in this first study, a simple structure is employed for simplicity.
References
- Agustin, C., & Singh, J. (2005). Curvilinear effects of consumer loyalty determinants in relational exchanges. Journal of Marketing Research, 42, 96–108. https://doi.org/10.1509/jmkr.42.1.96.56961
- Ajzen, I. (1991). The theory of planned behavior. Organizational Behavior and Human Decision Processes, 50, 179–211. https://doi.org/10.1016/0749-5978(91)90020-T
- Ajzen, I., & Madden, T. J. (1986). Prediction of goal-directed behavior: Attitudes, intentions, and perceived behavioral control. Journal of Experimental Social Psychology, 22, 453–474. https://doi.org/10.1016/0022-1031(86)90045-4
- Arminger, G., & Muthén, B. O. (1998). A Bayesian approach to nonlinear latent variable models using the Gibbs sampler and the Metropolis-Hastings algorithm. Psychometrika, 63, 271–300. https://doi.org/10.1007/BF02294856
- Bauer, D. J. (2005). A semiparametric approach to modeling nonlinear relations among latent variables. Structural Equation Modeling: A Multidisciplinary Journal, 12, 513–535. https://doi.org/10.1207/s15328007sem1204_1
- Bollen, K. A. (1995). Structural equation models that are nonlinear in latent variables: A least-squares estimator. In Sociological methodology (pp. 223–251). Washington, DC: American Sociological Association.
- Bollen, K. A. (1996). An alternative two stage least squares (2SLS) estimator for latent variable equations. Psychometrika, 61, 109–121. https://doi.org/10.1007/BF02296961
- R Core Team (2018). R: A language and environment for statistical computing. Vienna, AU: R Foundation for Statistical Computing.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39, 1–38. https://www.jstor.org/stable/2984875
- Finch, W. H. (2015). Modeling nonlinear structural equation models: A comparison of the two-stage generalized additive models and the finite mixture structural equation model. Structural Equation Modeling: A Multidisciplinary Journal, 22, 60–75. https://doi.org/10.1080/10705511.2014.935749
- Finney, S. J., & DiStefano, C. (2006). Structural equation modeling: A second course. Information Age Publishing.
- Flora, D. B., & Curran, P. J. (2004). An empirical evaluation of alternative methods of estimation for confirmatory factor analysis with ordinal data. Psychological Methods, 9, 446–491. https://doi.org/10.1037/1082-989X.9.4.466
- Guo, R., Zhu, H., Chow, S.-M., & Ibrahim, J. G. (2012). Bayesian lasso for semiparametric structural equation models. Biometrics, 68, 567–577. https://doi.org/10.1111/j.1541-0420.2012.01751.x
- Harring, J. R., Weiss, B. A., & Hsu, J.-C. (2012). A comparison of methods for estimating quadratic effects in nonlinear structural equation models. Psychological Methods, 17, 193. https://doi.org/10.1037/a0027539
- Jaccard, J., & Wan, C. K. (1995). Measurement error in the analysis of interaction effects between continuous predictors using multiple regression: Multiple indicator and structural equation approaches. Psychological Bulletin, 117(2), 348–357. https://doi.org/10.1037/0033-2909.117.2.348
- Jin, S., & Andersson, B. (2020). A note on the accuracy of adaptive Gauss–Hermite quadrature. Biometrika, 107, 737–744. https://doi.org/10.1093/biomet/asz080
- Jin, S., Vegelius, J., & Yang-Wallentin, F. (2020). A marginal maximum likelihood approach for extended quadratic structural equation modeling with ordinal data. Advance Online Publication in Structural Equation Modeling: A Multidisciplinary Journal, 1–10. https://doi.org/10.1080/10705511.2020.1712552
- Jöreskog, K. G., & Sörbom, D. (1993). New features in lisrel 8. Scientific Software.
- Jöreskog, K. G., & Sörbom, D. (1996). LISREL 8: User’s reference guide. Scientific Software International.
- Jöreskog, K. G., & Yang, F. (1996). Non-linear structural equation models: The kenny-judd model with interaction effects. In G. A. Marcoulides & R. E. Schumacker (Eds.), Advanced structural equation modeling: Issues and techniques (pp. 57–88). Lawrence Erlbaum Associates.
- Kelava, A., & Brandt, H. (2009). Estimation of nonlinear latent structural equation models using the extended unconstrained approach. Review of Psychology, 16, 123–132. https://hrcak.srce.hr/70644
- Kelava, A., Nagengast, B., & Brandt, H. (2014). A nonlinear structural equation mixture modeling approach for nonnormally distributed latent predictor variables. Structural Equation Modeling: A Multidisciplinary Journal, 21, 468–481. https://doi.org/10.1080/10705511.2014.915379
- Kenny, D. A., & Judd, C. M. (1984). Estimating the nonlinear and interactive effects of latent variables. Psychological Bulletin, 96, 201–210. https://doi.org/10.1037/0033-2909.96.1.201
- Klein, A., & Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika, 65, 457–474. https://doi.org/10.1007/BF02296338
- Klein, A., & Muthén, B. (2007). Quasi-maximum likelihood estimation of structural equation models with multiple interaction and quadratic effects. Multivariate Behavioral Research, 42, 647–673. https://doi.org/10.1080/00273170701710205
- Lee, S.-Y., & Song, X.-Y. (2003). Model comparison of nonlinear structural equation models with fixed covariates. Psychometrika, 68, 27–47. https://doi.org/10.1007/BF02296651
- Lee, S.-Y., & Zhu, H.-T. (2000). Statistical analysis of nonlinear structural equation models with continuous and polytomous data. British Journal of Mathematical and Statistical Psychology, 53, 209–232. https://doi.org/10.1348/000711000159303
- Liu, Q., & Pierce, D. A. (1994). A note on Gauss-Hermite quadrature. Biometrika, 81, 624–629. https://doi.org/10.2307/2337136
- Muthén, B. (2001). Second-generation structural equation modeling with a combination of categorical and continuous latent variables: New opportunities for latent class/latent growth modeling. In L. M. Collins, & A. Sayer (Eds.), New methods for the analysis of change (pp. 291–322). Washington, DC: APA.
- Muthén, L., & Muthén, B. (2020). Mplus. The comprehensive modelling program for applied researchers: user’s guide, 5. Los Angeles, CA: Muthén & Muthén.
- Naylor, J. C., & Smith, A. F. (1982). Applications of a method for the efficient computation of posterior distributions. Journal of the Royal Statistical Society. Series C, Applied Statistics, 31, 214–225. https://doi.org/10.2307/2347995
- Pek, J., Losardo, D., & Bauer, D. J. (2011). Confidence intervals for a semiparametric approach to modeling nonlinear relations among latent variables. Structural Equation Modeling: A Multidisciplinary Journal, 18, 537–553. https://doi.org/10.1080/10705511.2011.607072
- Rhemtulla, M., Brosseau-Liard, P. E., & Savalei, V. (2012). When can categorical variables be treated as continuous? A comparison of robust continuous and categorical sem estimation methods under suboptimal condition. Psychological Methods, 17, 354–373. https://doi.org/10.1037/a0029315
- Rizopoulos, D., & Moustaki, I. (2008). Generalized latent variable models with non-linear effects. British Journal of Mathematical and Statistical Psychology, 61, 415–438. https://doi.org/10.1348/000711007X213963
- Song, X.-Y., Lu, Z., & Feng, X. (2014). Latent variable models with nonparametric interaction effects of latent variables. Statistics in Medicine, 33, 1723–1737. https://doi.org/10.1002/sim.6065
- Song, X.-Y., & Lu, Z.-H. (2010). Semiparametric latent variable models with bayesian p-splines. Journal of Computational and Graphical Statistics, 19, 590–608. https://doi.org/10.1198/jcgs.2010.09094
- Song, X.-Y., Lu, Z.-H., Cai, J.-H., & Ip, E. H.-S. (2013). A bayesian modeling approach for generalized semiparametric structural equation models. Psychometrika, 78, 624–647. https://doi.org/10.1007/s11336-013-9323-7
- Wall, M. M. (2009). Maximum likelihood and bayesian estimation for nonlinear structural equation models. In R. E. Millsap & A. Maydeu-Olivares (Eds.), The SAGE handbook of quantitative methods in psychology (pp. 540–567). London: Sage Publications Ltd.
- Wall, M. M., & Amemiya, Y. (2001). Generalized appended product indicator procedure for nonlinear structural equation analysis. Journal of Educational and Behavioral Statistics, 26, 1–29. https://doi.org/10.3102/10769986026001001
- Zhu, H.-T., & Lee, S.-Y. (1999). Statistical analysis of nonlinear factor analysis models. British Journal of Mathematical and Statistical Psychology, 52, 225–242. https://doi.org/10.1348/000711099159080
Integral approximation
The integrals in Equationequation (9)(9)
(9) are intractable. In this work, such integrals are approximated using the AGHQ approximation. The Gauss-Hermite quadrature approximation of the
-dimensional integral
is a weighed sum of function values as
where
where and
are the Gauss-Hermite quadrature points and weights, respectively.
is the number of quadrature points per dimension. In adaptive Gauss-Hermite quadrature approximation, proposed by Liu and Pierce (Citation1994), the quadrature points are translated and dilated to improve the approximation of unimodel functions
.
Maximum Likelihood Estimation
Define
Then, (5) yields
EquationEquations (3)(3)
(3) , (Equation4
(4)
(4) ), (Equation6
(6)
(6) ), (Equation7
(7)
(7) ), (Equation8
(8)
(8) ) and (Equation13
(13)
(13) ) give
Measurement Model Estimation
Since the sum in (9) does not depend on the parameters in , direct maximization, as proposed by Jin et al. (Citation2020) is implemented for
given the current estimates of
. The observed likelihood is
where is the observed likelihood of the
observation. Let the mode
be the solution to
and the Hessian be
evaluated at the mode. Further, let . Applying the AGHQ approximation using Equationequations (11)
(11)
(11) and (Equation12
(12)
(12) ) to the
factor of Equationequation (14)
(14)
(14) , gives
where are the translated and dilated latent variables about the mode. And with
the corresponding observed log-likelihood is
where is the log of the
term in Equationequation (15)
(15)
(15) .
is updated by solving
with respect to , using the approximation in Equationequation (15)
(15)
(15) . Then Equationequation (16)
(16)
(16) is
Acknowledging that the mode depends on
, the gradient of
is
where is the derivative of
with respect to
, treating
as constant, whereas
is the derivative of
with respect to the latent variables, treating
as fixed. The first factor in the second term of (17) is, by the implicit function theorem
In order to find the solution to Equationequation (16)(16)
(16) the BFGS approximation to the Newton–Raphson method is implemented. The inverse of
is approximated and updated by low-rank approximation at each iteration. The updated parameter vector
is obtained by updating
with the BFGS algorithm a number of times.
Structural Model Estimation
If the quasi-Newton-Raphson method proposed in the previous section would be used, the sum in Equationequation (14)(14)
(14) introduces instability for parameters, which depend on
. All elements in
depend on
except for
.
is the same for all
in this setting only for simplicity. The reason for keeping
in
is for convenience at later stages in more general settings. The EM algorithm of Dempster et al. (Citation1977) is implemented for updating
given the current estimates of
, as follows:
Treating and
as random variables, let the conditional distribution of
and
be
at the current iteration given the parameter values obtained in the previous iteration, . The update of
is the vector that maximizes the expected value of the complete log-likelihood given the conditional distribution in Equationequation (18)
(18)
(18) . Throughout this section,
is fixed to the current estimate. Hence, for simplicity,
is dropped. Then, the objective function is
The maximum of (19) is attained at and can be expressed in terms of the following integrals:
and the current estimate of the effective number of observations per component
Then the updated parameter vector is composed of
for , and
where
The integrals in (36) are intractable. For the AGHQ approximation is applied as in the previous section. For the other integrals, the same weights and quadrature points are used. Integrals should still be asymptotically well approximated since the original integrand is multiplied by a polynomial of degree at most 2, as argued by Naylor and Smith (Citation1982). Once the updated estimates are obtained the previous estimates
are replaced by the updated
and the procedure is repeated a number of times.