?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Regularized structural equation models have gained considerable traction in the social sciences. They promise to reduce overfitting by focusing on out-of-sample predictions and sparsity. To this end, a set of increasingly constrained models is fitted to the data. Subsequently, one of the models is selected, usually by means of information criteria. Current implementations of regularized structural equation models differ in their optimizers: Some use general purpose optimizers whereas others use specialized optimization routines. While both approaches often perform similarly, we show that they can produce very different results. We argue that in particular, the interaction between optimizer and selection criterion (e.g., BIC) contributes to these differences. We substantiate our arguments with an empirical demonstration and a simulation study. Based on these findings, we conclude that researchers should consider specialized optimizers whenever possible. To facilitate the implementation of such optimizers, we provide the R package lessSEM.
Structural equation modeling (SEM) is a confirmatory framework, where a model is first specified and then fitted to the data set. To this end, knowledge about each and every effect, (co-)variance, and intercept included in the model is required (e.g., based on theoretical considerations and prior analyses). Often, however, little is known about the underlying mechanisms and structure of the psychological constructs under investigation. Even in well-established fields, purely confirmatory modeling can fail to adequately reflect the data due to the rigidity of the underlying framework (e.g., Marsh et al., Citation2010).
Regularized SEM has been proposed as a compromise between the confirmatory SEM and exploratory model search strategies (Huang et al., Citation2017; Jacobucci et al., Citation2016). This “semi-confirmatory approach” (Huang et al., Citation2017, p. 330) allows for more flexibility during data analysis, while still operating in a framework familiar to many social scientists. Regularized SEM has a strong focus on the predictive performance and sparsity of the model (Huang et al., Citation2017; Jacobucci et al., Citation2016). To this end, selected parameter estimates are shrunken toward zero (Tibshirani, Citation1996). This shrinkage restricts the degree to which a model is allowed to adapt to the data set and can improve its predictive performance if applied carefully (e.g., Huang et al., Citation2017; Jacobucci et al., Citation2016; Tibshirani, Citation1996). Additionally, many regularization techniques can set parameter estimates to zero, resulting in sparser models which may simplify the interpretation considerably (e.g., Fan & Li, Citation2001; Tibshirani, Citation1996; Zhang, Citation2010; Zou, Citation2006). The aforementioned properties make a compelling argument for the use of regularized SEM, which has consequently gained a foothold in the social sciences (e.g., Davis et al., Citation2019; Epskamp et al., Citation2017; Finch & Miller, Citation2021; Friemelt et al., Citation2022; Góngora et al., Citation2020; Jacobucci et al., Citation2019; Jacobucci & Grimm, Citation2018; Koncz et al., Citation2022; Scharf & Nestler, Citation2019; Ye et al., Citation2021).
The R (R Core Team, Citation2022) packages regsem (Jacobucci, Citation2017) and lslx (Huang, Citation2020a) greatly simplify fitting regularized SEMs. While regsem and lslx differ in their features,Footnote1 most “standard” SEMs can be regularized with both packages and—in theory—regsem and lslx should result in similar parameter estimates. Direct comparisons, however, suggest performance differences, for instance, in terms of the final fitting function value (Huang, Citation2020a), the number of non-convergent results (Finch & Miller, Citation2021; Friemelt et al., Citation2022; Huang, Citation2020a), and the predictive performance (Finch & Miller, Citation2021; Geminiani et al., Citation2021).
It is important to understand the roots of such differences, both theoretically (e.g., when implementing regularization methods for other models) and practically (e.g., when choosing between different implementations of the same methods). Huang (Citation2018) attributes some differences to the optimizers used by both packages. While the default setting in regsem is to rely on a general purpose optimizer that is not adapted to the specific penalty functions, Huang (Citation2020a) implemented specialized optimizers (regsem optionally provides a specialized optimizer as well). For lasso regularization, Huang (Citation2018) states that the method by Jacobucci (Citation2017) “cannot efficiently find a local maximizer, especially when the model is relatively complex” (Huang, Citation2018, p. 500). Likewise, Orzek and Voelkle (Citation2023) observed differences between general purpose optimizers and specialized optimizers in lasso regularized continuous time SEM and therefore used specialized optimizers. In contrast, Ridler (Citation2022) used the general purpose optimizer after observing differences between both types of optimizers implemented in regsem based on the recommendation provided in the package. Furthermore, Belzak and Bauer (Citation2020) used general purpose optimizers to assess differential item functioning in item response theory models and found that their implementation performed similarly to specialized optimizers (see also Belzak, Citation2021). Finally, Battauz (Citation2020) found that a general purpose optimizer resulted in a better fit than specialized optimizers in regularized nominal response models. It, therefore, remains unclear if the finding by Orzek and Voelkle (Citation2023) generalizes to the “standard” regularized SEM, where general purpose optimizers are already routinely used—a question that we set out to answer in this work.
In the following, we will first provide an introduction to regularized SEM, focusing specifically on the issue of optimization. Building on Orzek and Voelkle (Citation2023), we will demonstrate the consequences of using general purpose optimizers with an empirical example and provide new insights with a simulation study. Our results indicate that differences in the optimization procedures could partially explain the performance discrepancies observed between regsem and lslx in the literature (e.g., Finch & Miller, Citation2021; Friemelt et al., Citation2022; Geminiani et al., Citation2021; Huang, Citation2020a). We conclude that researchers using regularized SEM should prefer specialized optimizers where available. To facilitate the development of regularized SEM we provide the new R package lessSEM.
1. The Two Steps of Regularized Structural Equation Modeling
At its core, regularized SEM is a two-step procedure: In the first step, a set of increasingly sparse models is estimated. This is followed by the second step, where one of the models is selected (e.g., Huang et al., Citation2017; Jacobucci et al., Citation2016; Tibshirani, Citation1996). Building on an extensive background of research on regularization techniques in machine learning (e.g., Fan & Li, Citation2001; Tibshirani, Citation1996; Zhang, Citation2010; Zou, Citation2006), different strategies for both steps, estimating increasingly sparse models and selecting one of these models, have been proposed in the regularized SEM framework (e.g., Huang et al., Citation2017; Jacobucci et al., Citation2016; Li & Jacobucci, Citation2021).
1.1. Step One: Estimating Increasingly Sparse Models
In regularized SEM, a set of increasingly sparse models is estimated by slightly altering the fitting function. This function is minimized when estimating the parameters We will restrict the discussion to the commonly used −2 log-likelihood fitting function
Furthermore, we will assume that the likelihood itself is given by the multivariate normal density function, the default in most SEM applications. In regularized SEM,
is combined with a penalty term
(Huang et al., Citation2017; Jacobucci et al., Citation2016):
(1)
(1)
Finding the parameter estimates , which minimize
, requires balancing the two forces in the new fitting function. This can be thought of as a tug-of-war, where
ties to pull
to the maximum likelihood estimates
and
pulls selected parameters toward zero. The tuning parameter
allows for shifting the balance between these two forces: If λ is close to zero, the maximum likelihood part
will dominate the fitting function and parameters will be close to
In contrast, if λ is very large, the penalty term
will take over the fitting function and parameters will be close to zero (this is demonstrated in for different penalty functions
). We can conceive of λ as the ratio of players per team in our tug-of-war game which allows us to give one team an advantage over the other. Finally, the penalty term in EquationEquation (1)
(1)
(1) is multiplied with sample size N to stay consistent with current implementations of regularized SEM in regsem and lslx. Importantly, the parameter λ itself is not estimated alongside the other parameters in
Instead, researchers must define a set of λ values (e.g.,
) and fit a separate model for each of them (e.g., Jacobucci et al., Citation2016). Thus, the number of λ values dictates how many models are estimated (see Huang et al., Citation2017; Jacobucci et al., Citation2016, for more details).
Many different penalty functions have been proposed, such as the ridge (Hoerl & Kennard, Citation1970), lasso (Tibshirani, Citation1996), adaptive lasso (Zou, Citation2006), elastic net (Zou & Hastie, Citation2005), scad (Fan & Li, Citation2001), lsp (Candès et al., Citation2008), cappedL1 (Zhang, Citation2010), and mcp (Zhang, Citation2010). Most importantly, the different penalty functions exhibit distinct properties. For instance, ridge regularization can only shrink parameters toward zero, while the other penalties mentioned above can shrink parameters and set them to zero; that is, they perform parameter selection (e.g., Tibshirani, Citation1996, see for a visualization of different penalty functions). In SEM this can, for instance, be used to identify non-zero cross-loadings (Scharf & Nestler, Citation2019) or to simplify multiple-indicator-multiple-causes models (Jacobucci et al., Citation2019). Most of the penalty functions mentioned above are implemented in the R packages regsem (Jacobucci, Citation2017) or lslx (Huang, Citation2020a). For simplicity, we will focus on lasso regularization in the following. However, we expect the results to be similar for all other penalties which use the absolute value function (e.g., adaptive lasso, elastic net, scad, lsp, cappedL1, and mcp). The lasso is defined as
(2)
(2)
Here, J is the number of parameters in and rj is a selection operator. If rj = 1, the parameter θj is regularized and if rj = 0 the parameter θj remains unregularized. This allows for regularizing only a subset of the parameters, for instance, only the loadings. Finally,
denotes the absolute value function.
1.2. Step Two: Selecting the Best Model
Different values of λ can result in vastly different parameter estimates (e.g., see ). This property was used in step one to estimate a set of increasingly sparse models. In step two, one of these models must be selected (i.e., an appropriate value for λ must be found). Too little regularization may result in an overly complex model that still overfits the data and generalizes poorly. Too much regularization, in contrast, may result in an overly sparse model that underfits the data. Different procedures for selecting λ have been proposed (e.g., Tibshirani, Citation1996). The most prominent in regularized SEM are cross-validation and information criteria (Huang et al., Citation2017; Jacobucci et al., Citation2016; Li et al., Citation2021).
Cross-validation provides a direct way to measure how well a model generalizes to data sets that come from the same population but have not been used to estimate the model parameters (e.g., Browne, Citation2000). To this end, the models are fitted on one part of the data set, using the remaining part to evaluate the out of sample fit. In k-fold cross-validation, the data set is split in k subsets. Subsequently, each subset serves as a test set while fitting the model using the left out k − 1 subsets (a general introduction to cross-validation is, for instance, provided by James et al., Citation2013). The main drawbacks of cross-validation are that (1) refitting the model on subsets of the data may result in non-convergence and worse parameter estimates due to the smaller sample size, and (2) depending on the complexity of the model, refitting the model may take a relatively long time. Therefore, cross-validated regularized SEM is rarely used in practice.
Information criteria are an alternative to cross-validation that do not require any refitting (asymptotically, information criteria and cross-validation are closely related; Shao, Citation1997; Stone, Citation1977). The Bayesian information criterion (BIC; Schwarz, Citation1978), for example, is defined as
(3)
(3)
Smaller BIC values indicate better fit and can be achieved by either reducing or by reducing the number of model parameters t. The latter can be seen as the BIC rewarding model sparsity. In regularized SEM, the BIC and similar information criteria are typically used to select the final parameters if the penalty can set them to zero and therefore reduce t (Huang et al., Citation2017; Jacobucci et al., Citation2016). Importantly, information criteria are currently the standard model selection procedure in regsem and lslx and are used in many recent publications (e.g., Brandmaier & Jacobucci, in press; Davis et al., Citation2019; Finch & Miller, Citation2021; Góngora et al., Citation2020; Huang et al., Citation2017; Jacobucci et al., Citation2019; Koncz et al., Citation2022; Li et al., Citation2021; Scharf & Nestler, Citation2019; Ye et al., Citation2021). However, as we will discuss in detail in the next section, combining information criteria with general purpose optimizers requires two additional parameters that determine which model gets selected (see also Orzek & Voelkle, Citation2023).
2. General Purpose and Specialized Optimizers
While adding the penalty function to
seems innocuous, it can have severe consequences for parameter estimation. Uncovering these consequences requires a closer look at optimization algorithms (see also Belzak, Citation2021; Orzek & Voelkle, Citation2023).
To estimate the model parameters must be minimized. What sounds like a simple procedure is, in fact, a tedious process with numerous pitfalls. For the models under consideration here, there is (in general) no direct (i.e., closed form) solution to minimizing
Instead, an iterative procedure is used which replaces the difficult to answer question “What is the minimum of
?” with a simpler one: “Is there a parameter vector
close to the current point
that results in a smaller
?” This question is asked repeatedly until no further improvement to
can be made. Many different procedures that formalize and answer this surrogate question have been proposed, which differ in the functions they can minimize (see Nocedal & Wright, Citation2006, for an introduction). To better understand why
is a special problem, we will concentrate on so-called Newton-type optimization algorithms. Here, in each iteration k, one tries to take a step of length sk in a downward direction
The new parameter vector
is then given by:
A visual representation of this approach for a single parameter θ and fitting function
is provided in . Note that we get closer to the minimum of the fitting function with each step.
Newton-type optimizers typically use the gradients and the Hessian of the fitting function to determine the step direction (e.g., Nocedal & Wright, Citation2006).Footnote2 Therefore, they assume that both, the gradients and the Hessian, can be computed (this assumption is often stated as “
is a smooth function” or “
is continuously differentiable”; Nocedal & Wright, Citation2006, p. 10 and p. 14)
For this leaves us with a problem: Whereas gradients and the Hessian for
are typically well defined (e.g., von Oertzen & Brick, Citation2013), this is not the case for any of the penalty functions introduced above, with the exception of ridge, which does not set parameters to zero. exemplarily shows the ridge and lasso penalty values for a single parameter. Note that the ridge penalty is smooth (or differentiable) whereas the lasso is non-smooth (or non-differentiable) at θ = 0. To demonstrate the non-differentiability of the lasso mathematically, we can rewrite the absolute value as
where
is the positive square root. Differentiating with respect to θj, we get:
If follows that
if
if
and
results in division by zero if
The non-differentiability is essential for the parameter selection property of the lasso and related regularization procedures (e.g., Fan & Li, Citation2001): The steepness of the curves shown in corresponds to the force with which they push parameters to zero (Andrew & Gao, Citation2007). For the ridge penalty, the steepness decreases as θ approaches zero. As a consequence, any small force pushing θ away from zero ( in our case) will overrule the ridge penalty and parameters will stay non-zero. Contrast this with the lasso penalty, which retains its steepness. This allows the lasso to relentlessly push θ to zero, overruling any opposing force by
(Andrew & Gao, Citation2007).
As outlined above, the non-differentiability of the lasso penalty violates the assumptions underlying many common optimizers. In the following, we will present two ways of dealing with this issue: First, by using general purpose optimizers, and second by using specialized optimizers (e.g., Belzak, Citation2021; Orzek & Voelkle, Citation2023; Schmidt et al., Citation2009).
2.1. General Purpose Optimizers
One way of dealing with the non-differentiability of the lasso is to ignore it. As the lasso is differentiable almost everywhere (with being the only exception), optimizers that require differentiability will often converge to a solution close to the true minimum. Formally, this approach violates the assumptions of the optimizer, however.
Alternatively, the non-smooth penalty could be replaced with a smooth surrogate (e.g., Battauz, Citation2020; Fan & Li, Citation2001; Geminiani et al., Citation2021; Lee et al., Citation2006; Muggeo, Citation2010; Orzek & Voelkle, Citation2023; Ulbricht, Citation2010). This is shown in . Here, the absolute value is replaced with
where the smoothing parameter ϵ is a small positive value (e.g., Lee et al., Citation2006; Ulbricht, Citation2010). Mathematically, the derivative is now given by
and the division by zero is avoided. Therefore, the smoothness-assumption underlying many general purpose optimizers is met.
From an optimization perspective, the smoothed approximation has one major advantage: Many optimizers rely on the gradients to judge the convergence (if all gradients are close enough to zero, the optimization stops). The gradients of the lasso penalty, however, are either −1, 1, or invalid. The optimizer may therefore miss the minimum, which results in long run times (small ϵ can also result in an ill-conditioned Hessian; Schmidt et al., Citation2009). In the smoothed lasso, in contrast, the gradient is zero at θ = 0, allowing for the standard convergence criteria to work well (assuming ϵ is large enough).
The beauty of either ignoring the non-differentiability or smoothing the lasso penalty function lies in its simplicity. Building on existing optimizers implies that the algorithms used to find the parameter estimates are well-established and reliable. A downside, however, is that none of the parameter estimates will be zeroed (e.g., Chamroukhi & Huynh, Citation2019; Muggeo, Citation2010; Orzek & Voelkle, Citation2023): When ignoring the non-differentiability, this is just a side-product of using an optimizer which is not well suited for the optimization problem. In contrast, a smoothed lasso will no longer have the force to push parameters all the way to zero given any opposing force—this is similar to the ridge penalty. To achieve sparsity, a threshold parameter τ can be defined (e.g. ). If the absolute value of a regularized parameter falls below the threshold, this parameter is treated as zeroed (e.g., Belzak & Bauer, Citation2020; Chamroukhi & Huynh, Citation2019; Epskamp et al., Citation2017; Orzek & Voelkle, Citation2023). Because none of the parameters can be zeroed, we will refer to the parameter estimates provided by both approaches outlined above as approximate solutions.
2.2. Specialized Optimizers
Many specialized optimizers have been developed specifically for penalty functions, such as the lasso (e.g., Andrew & Gao, Citation2007; Friedman et al., Citation2010; Gong et al., Citation2013; Huang et al., Citation2017; Yuan et al., Citation2012). Thorough introductions are, for instance, provided by Goldstein et al. (Citation2016), Parikh and Boyd (Citation2013), and Yuan et al. (Citation2010). For our objectives, the most important difference between the general purpose optimizers presented in the previous section and the specialized optimizers discussed here is that specialized optimizers can account for the non-differentiability of the penalty function. As a result, they can push parameters all the way to zero; that is, they will provide what we will call exact solutions to the optimization problem.
To demonstrate how an exact solution can be found, we will make use of a simplified objective function. Assume that we want to minimize the lasso regularized function We first take the derivative with respect to θ and set it to zero:
As outlined above, the derivative
may be undefined. Therefore, we typically resort to subderivatives, a generalization of derivatives (e.g., Hastie et al., Citation2015). For our purposes, however, we can use the fact that (1) the function we try to minimize has one and only one minimum (this follows from the function being strictly convex; see also Nocedal & Wright, Citation2006) and (2) as derived above
if
and
if
With this in mind, we are ready to readdress our original problem:
Let’s assume that θ is smaller than zero. In this case, we know that
and it follows that
minimizes
Note that we can rewrite our assumption
as
Next, assume that
It follows that
and the θ minimizing
is given by
Again, we can rewrite the assumption
as
Combined, we get
The last case follows from statement (1) above: The function has one and only one minimum. If this minimum is neither in nor in
this just leaves θ = 0 as minimum. This last case is crucial because it lets us set θ to exactly zero. With this, we have developed a specialized optimizer that provides an exact solution to our simplified objective function. Optimizers for more complex models can be developed with a similar procedure.
The main disadvantage of specialized optimizers is that they have to be adapted to each and every penalty function. The solution for our simplified objective function above, for example, only works for the lasso penalty. Deriving the optimization steps for a new penalty function can be complicated (e.g., Gong et al., Citation2013), considerably increasing the effort required to get exact solutions. Thus, one may rightfully wonder if specialized optimizers are, in fact, necessary. We will return to this important question later on.
3. Information Criteria for Model Selection: Close to Zero Is Not Zero
As discussed above, the BIC (and similar information criteria) rewards model sparsity by penalizing with respect to the number of parameters t in the model. As apparent from EquationEquation (3)(3)
(3) , the only way for regularization to improve the BIC (as currently used in lasso regularized SEM) is by zeroing parameters. Importantly, a parameter value of
is seen as qualitatively different from a parameter value of 0 because only in the latter case, the number of free parameters t is reduced by one (see EquationEquation 3
(3)
(3) ). This results in the “ragged” BIC pattern shown in .
Issues arise, however, when using approximate solutions generated by general purpose optimizers, as none of the parameters is exactly zero. To address this shortcoming, the threshold parameter τ can also be applied for model selection: Any regularized parameter with an absolute value below threshold τ is counted as zeroed in the BIC (e.g., Belzak & Bauer, Citation2020; Epskamp et al., Citation2017; Muggeo, Citation2010; Orzek & Voelkle, Citation2023). Consequently, threshold parameter τ directly affects model sparsity (e.g., Chamroukhi & Huynh, Citation2019; see also Zou & Li, Citation2008), information criteria, and, therefore, also model selection (e.g., Orzek & Voelkle, Citation2023). With this in mind, we can readdress the findings of Orzek and Voelkle (Citation2023) and Belzak and Bauer (Citation2020) mentioned in the introduction: Orzek and Voelkle (Citation2023) found that regularized continuous time SEM estimated with the general purpose optimizer implemented in Rsolnp (Ghalanos & Theussl, Citation2015; Ye, Citation1987, the same optimizer is used in regsem by default) can differ from those estimated with the specialized optimizer GIST (Gong et al., Citation2013). This was due to the Akaike information criterion being highly affected by the threshold parameter τ, resulting in different models being selected when the general purpose optimizer was used (smoothing parameter ϵ was set to 0.001 for all analyses). Belzak and Bauer (Citation2020) combined a general purpose optimizer with a thresholding parameter of to investigate differential item functioning in item response theory models and report that their method performed similarly to existing procedures using specialized optimizers. This was studied in more detail by Belzak (Citation2021) who found that a general purpose and a specialized optimizer produced mostly identical results, with some differences in the number of zeroed parameters. However, to the best of our understanding, they did not vary the value of the smoothing parameter ϵ or threshold parameter τ.
Given that general purpose optimizers are already routinely used in regularized SEM, it is important to test the degree to which these models may be affected as well. To this end, we will build on and extend the findings of Orzek and Voelkle (Citation2023) to regularized SEM by (1) using an empirical example and a simulation study, (2) two very similar optimizers, and (3) different values for both, τ and ϵ.
4. lessSEM—A Flexible Regularized SEM Package
At the time of writing, the two most prominent R packages implementing regularized SEM are regsem (Jacobucci, Citation2017) and lslx (Huang, Citation2020a), with additional packages (e.g., regCtsem; Orzek & Voelkle, Citation2023 and lvnet; Epskamp et al., Citation2017) available for more specialized applications. By default, regsem relies on general purpose optimization with Rsolnp (Ghalanos & Theussl, Citation2015; Ye, Citation1987), setting smoothing parameter ϵ to zero and threshold parameter τ to Footnote3 In addition, a specialized optimizer using coordinate descent is optionally available. Other software implementations, such as lvnet (interfacing to OpenMx; Neale et al., Citation2016) and regCtsem also offer general purpose optimization. In contrast, lslx offers a specialized quasi-Newton optimizer, that takes the non-differentiability into account (Huang, Citation2020a). This optimizer was originally developed by Friedman et al. (Citation2010) and Yuan et al. (Citation2012) and a variant thereof is also implemented in the prominent glmnet package (Friedman et al., Citation2010) and the regCtsem package (Orzek & Voelkle, Citation2023) alongside a proximal operator based procedure (see Gong et al., Citation2013).
Given the many differences between the packages mentioned above, a direct comparison of general purpose optimizers and specialized optimizers is difficult. Comparing regsem and lslx, for instance, would conflate differences between optimizers and differences in the implementation of the underlying model. Using the general purpose and specialized optimizers in regsem would base the comparison on two fairly different optimization routines. To provide a fair comparison, we created a new R package, lessSEM, using two quasi-Newton procedures.Footnote4 The general purpose optimizer is based on the so-called BFGS procedure, which we describe in more detail in Appendix A (this optimizer is similar to the BFGS procedure in the optim package; R Core Team, Citation2022). As specialized optimizer, we implemented the GLMNET procedure (Friedman et al., Citation2010; Huang, Citation2020a; Yuan et al., Citation2012) based on regCtsem, which is described in more detail in Appendix B.Footnote5
Importantly, the objectives of lessSEM are not to replace the existing more mature packages regsem and lslx but to (1) provide a more level playing field for the comparison of general purpose and specialized optimizers in regularized SEM and (2) to make specialized optimizers for exact solutions more easily available. To this end, all optimizers implemented in lessSEM can be accessed both from R and C++ using Rcpp (Eddelbuettel & François, Citation2011) and RcppArmadillo (Eddelbuettel & Sanderson, Citation2014), simplifying the development of new regularized models (see Appendix C for an example).Footnote6 For instance, lessSEM could also be used by regsem which currently does not support the GLMNET procedure. In addition (3), lessSEM provides automatic cross-validation, full information maximum likelihood estimation in case of missing data, and multi-group models (see also Huang, Citation2018). Furthermore, lessSEM extends the functionality of existing packages, for example, by providing definition variables, parameter transformations inspired by OpenMx (Neale et al., Citation2016), and combinations of different penalties (e.g., for use in multi-group models; see Geminiani et al., Citation2021). Therefore, method developers can use lessSEM as a basis for creating new regularized SEM. For instance, regularized continuous time SEM can also be implemented in lessSEM despite the fairly involved transformations required to estimate such models (see Voelkle et al., Citation2012, for more details).
5. Empirical Demonstration
To demonstrate differences that can occur between general purpose optimization and specialized optimization, we used the bfi data set provided in the psychTools package (Revelle, Citation2022; Revelle et al., Citation2010). This data set consists of 2,800 subjects who answered 25 items measuring five personality factors: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism, and was also analyzed by Huang (Citation2020b). Following Huang (Citation2020b), we used only complete cases (N = 2,436) and estimated a semi-confirmatory factor analysis, where all cross-loadings were regularized (see ). We used lasso regularization with 200 evenly spaced λ values between 0 and the first λ that sets all regularized parameters to zero (this value was computed with the procedure outlined in Orzek & Voelkle, Citation2023). The convergence threshold was set to for both, the general purpose and the specialized optimizer. For the general purpose optimizer, we set ϵ to
as this value performed well in the simulation study (see next section). Finally, because regularized SEM is often proposed for situations where the model is relatively complex but N is small (e.g., Jacobucci et al., Citation2019), we repeated the analysis using randomly selected subsets of size
We standardized all data sets prior to the analysis (see Jacobucci et al., Citation2016, for more details on standardization). In the following, we will only report the results for N = 500. The remaining results are reported in the osf repository at https://osf.io/kh9tr/.
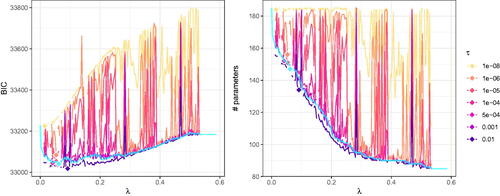
shows the BIC as well as the number of parameters remaining in the model. Note that, consistent with findings by Orzek and Voelkle (Citation2023) in continuous time SEM, the model selection is highly susceptible to the thresholding parameter τ. That is, depending on the optimization routine and threshold parameter setting used, researchers may come to different conclusions regarding the number of non-zero parameters. In Appendix D, we additionally provide parameter estimates for the loadings matrices of the specialized optimizer and three selected approximate solutions of the general purpose optimizer. Therein, we also present a comparison to the approximate solutions returned by the current version of regsem (package version 1.9.3) using the default general purpose optimizer. Similar to the results shown in , in Appendix D shows that the threshold parameter τ has a considerable influence on the parameters returned by the regsem package.
Our empirical example provided the first evidence that the threshold parameter τ can affect the final parameter estimates in regularized SEM, both when using the newly developed package lessSEM as well as when using the established package regsem. In the next section, we will systematize these findings in a simulation study.
6. Simulation Study
To systematically compare general purpose optimizers and specialized optimizers, we ran a simulation study where we used lasso regularization to identify non-zero cross-loadings in a confirmatory factor analysis (see also Huang et al., Citation2017; Scharf & Nestler, Citation2019). We used a three factor CFA as population model, defining the model and its population parameter values as follows:Footnote7
(4)
(4)
(5)
(5)
(6)
(6)
EquationEquation (4)(4)
(4) shows the measurement model, where we assumed that the core of the three latent factors (ξ1, ξ2, ξ3) is reflected by five items each. Loadings on these items are underlined in EquationEquation (4)
(4)
(4) and will be referred to as core-loadings in the following. Among these core-loadings, one was set to 1; this loading was used for scaling the latent variables in the analysis.Footnote8 All other core-loadings were drawn from the uniform distribution
Additionally, we allowed for three non-zero cross-loadings per latent factor. The location of these cross-loadings was randomly selected and their values drawn from
The variances of the three factors was set to one (see EquationEquation 5
(5)
(5) ; the diag
operator populates the diagonal of a square zero matrix with the embraced values) and the variances of the residuals was set such that the overall-variance of each manifest variable was 1.2 (see EquationEquation 6
(6)
(6) ). Because all items have the same expected variance no further standardization is required.
We simulated five hundred data sets with a sample size of N = 250 and fitted unregularized and regularized models with R (R Core Team, Citation2022) using lavaan (Rosseel, Citation2012) and lessSEM. We estimated both core- and cross-loadings freely with the exception of the first core-loading of each latent variable which we set to 1 for scaling. All cross-loadings were regularized with the lasso penalty. For the tuning parameter λ, we generated 200 evenly spaced values between 0 and the first λ that zeroed all regularized parameters. In case of the general purpose optimizer, we either ignored the non-differentiability or smoothed the lasso penalty with and estimated the parameters with the BFGS procedure outlined in Appendix A. We stopped the optimization if the GLMNET criterion outlined in Yuan et al. (Citation2012, see Equation 25) was met for both, general purpose and specialized optimization. The only exception was the combination of general purpose optimizer and ignored non-differentiability, where we treated the model as converged if the change in fit from one iteration to the next fell below the threshold
This exception was made due to the long runtimes when using the gradient-based GLMNET criterion. Average run times were between 4.4 (general purpose optimization with
) and 11.8 s (general purpose optimization when ignoring the non-differentiability). In the following, we will compare the results of the general purpose optimizer and the specialized optimizer for the two steps of estimating a regularized SEM separately. This will shed light on the roots of the differences observed in the empirical example.
6.1. Differences in Step One: Estimating Increasingly Sparse Models
We first checked if both optimization routines—the general purpose optimizer and the specialized optimizer—performed similarly in terms of minimizing To this end, we defined the relative fit (RF) for repetition
as
(7)
(7)
where
is the value of the regularized fitting function in repetition r for a given λ. The vector
holds approximate parameter estimates returned by the general purpose optimizer for a given smoothing parameter ϵ. Similarly,
is a vector with exact parameter estimates produced by the specialized optimizer. A value of 1.02, for example, indicates that the approximate solution of the general purpose optimizer resulted in a 2% larger (i.e., worse) fitting function value than the exact solution of the specialized optimizer. Values below 1, in contrast, indicate that the general purpose optimizer outperformed the specialized optimizer.
Additionally, we computed the sum of the squared differences (SSD) between the parameter estimates of the general purpose optimizer and the specialized optimizer. The SSD was defined as:
(8)
(8)
Larger values indicate larger differences between the general purpose optimizer and the specialized optimizer.
shows the relative fit of the approximate solutions with the general purpose optimizer as compared to the exact solutions of the specialized optimizer. Note that the specialized optimizer almost always resulted in a better fit than the general purpose optimizer. However, the differences were negligible in many cases. Ignoring the non-differentiability resulted in a worse fit, which may have been due to issues with the gradient computation. Furthermore, smoothing the penalty function worked better with smaller ϵ values.
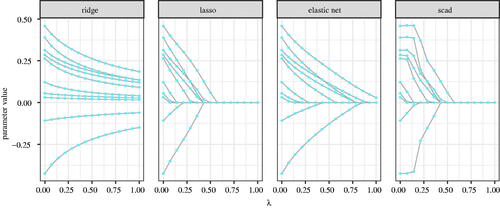
shows the SSD. Notably, the differences in the fitting function values are also reflected in differences in the parameter estimates. To provide additional insights into the roots of the differences observed in , we plotted the regularized parameter estimates returned by the general purpose optimizer and the specialized optimizer for the first of the 500 repetitions in . Note that (1) larger ϵ values result in slower shrinkage toward zero and (2) ignoring the non-differentiability results in more “ragged” paths, indicating that the optimizer may have had difficulties finding a minimum.
Overall, our results suggest that approximate solutions based on general purpose optimizers with smoothed penalty functions and exact solutions using a specialized optimizer perform similarly in terms of model fit and SSD if ϵ is set carefully. Importantly, however, model selection is not yet taken into account in these comparisons. In practice, only the parameter estimates of the final model (i.e., a specific λ value) are of relevance. For this reason, we now turn to model selection and repeat the comparison for the final model as selected by the BIC.
6.2. Differences in Step Two: Selecting the Best Model
To test the model selection with the BIC, we set the threshold parameter τ to Footnote9 Additionally, we also used 5-fold cross-validation instead of the BIC to select the final model. Because cross-validation does not require zeroed parameters to improve, no threshold parameter τ is needed (τ was introduced because the BIC only improves if some parameters are set to exactly zero).
The selected models were again compared to the exact solution provided by the specialized optimizer using the SSD defined in EquationEquation (9)(9)
(9) .
(9)
(9)
Here, and
are the final parameter estimates for the general purpose and specialized optimizer, respectively. In case of the general purpose optimizer, the final parameter estimate depends on both smoothing parameter ϵ and threshold parameter τ. Again, larger SSD indicate larger differences between the approximate optimizer and the specialized optimizer.
Because model sparsity is often a motivation for using LASSO regularization, we also investigated the differences in the number of parameters t remaining in the model ():
(10)
(10)
Here, J is the length of parameter vector is an indicator function that returns one if the embraced condition is met and zero otherwise, and
is the j-th element of vector
A
of one, for instance, indicates that the approximate solution of the general purpose optimizer has one parameter more than the exact solution of the specialized optimizer. That is, researchers may come to different conclusions depending on which of the two optimization procedures they used. The difference
was not computed in case of cross-validation as cross-validation does not use τ and therefore none of the parameters will be set to zero in case of general purpose optimization.
shows the SSD of the final parameter estimates of the approximate solutions provided by the general purpose optimizer compared to the exact solutions provided by the specialized optimizer across all 500 simulation runs when using the BIC to select the final models. As expected, τ clearly affected the model selection. If τ is very small, the selected approximate solution was often the maximum likelihood estimates This is because the regularized estimates rarely fell below τ and therefore no improvement in the BIC was observed. Moreover, τ also interacted with ϵ in the smoothed penalty functions such that, for instance,
worked well when
but not with
Smaller ϵ values typically resulted in regularized estimates which are closer to zero and thus more likely to fall below a small threshold τ (this follows from , where larger ϵ resulted in slower convergence to zero). Ignoring the non-differentiability performed worse than smoothing the penalty function with a small ϵ.
shows the SSD when using 5-fold cross-validation to select the final model. The model selection was considerably more consistent between both general purpose optimization and specialized optimization. However, none of the parameters is exactly zero in case of the general purpose optimization, which may impact the interpretation of the model (e.g., Orzek & Voelkle, Citation2023).
shows the difference in the number of parameters remaining in the model () when using the BIC to select the final model. Importantly, general purpose optimization could result in a very different number of parameters, even in the best settings tested here. As non-zeroed parameter estimates are considered to be important (e.g., Jacobucci et al., Citation2019), this may also affect the conclusions drawn from the final model.
Overall, our results show that relatively small differences in the two additional tuning parameters—ϵ and τ—can alter the results substantially. For us, the only way to tell which combination works best was to implement both, a general purpose optimizer and a specialized optimizer. For the BFGS procedure used here, the combination of and
performed fairly well.
7. Discussion
The objective of this work was to systematically test the differences between general purpose optimizers and specialized optimizers as currently used in regularized SEM in order to shed light on differences observed between regsem and lslx. To this end, we compared both, the fit and the parameter estimates of regularized SEM with two similar optimization strategies: A quasi-Newton optimizer for smooth fitting functions (BFGS) and a quasi-Newton optimizer for non-smooth fitting functions (GLMNET). Ignoring model selection, we found that (1) differences in the fit and the parameter estimates between both optimization procedures are often negligible. However, (2) when combined with information criteria, as currently used in regsem, even small differences can result in unstable model selection. Only if both tuning parameters of general purpose optimizers—the smoothing parameter ϵ and the threshold parameter τ—are well selected can we expect similar results.
Our results are consistent with Orzek and Voelkle (Citation2023), who found that the threshold parameter τ is critical in regularized continuous-time SEM. Moreover, we revealed an interaction of ϵ and τ: Specific combinations for ϵ and τ may exist for which the differences between approximate and exact solutions are small. In practice, however, these settings are unknown and, as our simulation demonstrated, may fail for any given data set. Importantly, the combination that worked best for the general purpose optimizer used in our simulations may not generalize to, for instance, regsem, where SEMs are implemented differently and other optimizers are used. Furthermore, our simulations showed that ignoring the non-differentiability can result in worse parameter estimates than a smoothly approximated penalty. Overall, this suggests that researchers using approximate solutions should be cautious when selecting models by means of information criteria.
On the other hand, our results showed that cross-validation is a viable alternative to using information criteria with approximate solutions. Importantly, no threshold parameter τ is required when using cross-validation for model selection. However, cross-validation is time consuming and may therefore be impractical for some models.
A promising alternative is to adapt the computation of the number of parameters t in the BIC (e.g., Geminiani et al., Citation2021; Muggeo, Citation2010; Ulbricht, Citation2010). The approximation strategy proposed by Geminiani et al. (Citation2021) and based on Ulbricht (Citation2010), for instance, uses the generalized information criterion (Konishi & Kitagawa, Citation1996). This approach does not require the threshold parameter τ and is implemented in the R package penfa (Geminiani et al., Citation2021) for confirmatory factor analyses. However, to the best of our knowledge, this approximation strategy has not yet been extended to SEM. Additionally, the specific approximations proposed by Geminiani et al. (Citation2021) are fairly involved, reducing the simplicity-advantage of implementing approximate solutions. On the other hand, Geminiani et al. (Citation2021) also proposed confidence intervals and an automatic tuning parameter selection for their approximation. Extending this approach to SEM, therefore, appears promising. Alternatively, procedures may be developed that allow for a more sophisticated threshold parameter τ (see e.g., Cao et al., Citation2017, for such a procedure in group bridge penalized regression). Finally, for a different smooth approximation, Muggeo (Citation2010) found that their smoothing parameter c can have a considerable effect on the model selection even if an adapted computation for the number of parameters t is used. This should be considered when implementing such approximations.
On a final note, our findings are most likely not limited to regularized SEM: Other regularized models may also be fitted with either general purpose or specialized optimizers. However, the situation in regularized SEM is special in that one of the most popular implementations of regularized SEM to date relies on the combination of a general purpose optimizer for estimation and the BIC for model selection by default. Other packages for regularized estimation use specialized optimizers instead (e.g., lslx, Huang, Citation2020a; glmnet, Friedman et al., Citation2010; ncvreg, Breheny & Huang, Citation2011, or LIBLINEAR, Fan et al., Citation2008). Thus, while our findings may generalize to other models, they are of central importance to the regularization of SEM.
Our study comes with several limitations. First, we only looked at the lasso penalty. One may therefore wonder if the results generalize to the wealth of other penalty functions proposed in the literature, such as the adaptive lasso (Zou, Citation2006), elastic net (Zou & Hastie, Citation2005), scad (Fan & Li, Citation2001), lsp (Candès et al., Citation2008), cappedL1 (Zhang, Citation2010), and mcp (Zhang, Citation2010). Importantly, all of the penalties mentioned above use the absolute value function to obtain sparse solutions. Replacing this absolute value function with an approximation, as done for the lasso penalty in this study, results in non-sparse solutions and requires the threshold parameter τ. Still, more in-depth analyses for these penalty functions may be worthwhile given that they also come with additional tuning parameters besides λ. Second, we did not compare the final parameter estimates of the general purpose optimizer and the specialized optimizer to the true parameters used in the simulation. The reason for this is that the objective of the approximation used in the general purpose optimizer is to return parameter estimates, which are as close as possible to the exact solution of the specialized optimizer. Outperforming exact solutions is not the reason for existence of the approximation. And even if approximate solutions would outperform exact solutions for some specific settings of ϵ and τ, this may just reflect that approximate solutions have more tuning parameters. Making use of these tuning parameters would require optimizing models for an entire tuning grid (combinations of all λ, ϵ, and τ values), resulting in a considerable increase in run time. This is especially true because τ cannot be selected with information criteria.Footnote10 Third, we restricted our analyses to models fitted with lessSEM using two optimizers only (BFGS and GLMNET). These optimizers were selected because of their popularity and similarity due to both employing quasi-Newton procedures. However, it remains unclear if the results generalize to other optimizers as well.
All in all, we conclude that specialized optimizers should be preferred over general purpose optimizers in regularized SEM when using the current implementations of information criteria to select the final parameter estimates. These specialized optimizers are the default in lslx and lessSEM, and optionally available in regsem. When developing new regularized SEMs (e.g., models estimated with the Kalman filter), however, our results leave researchers between a rock and a hard place. General purpose optimizers are widely available and therefore easier to implement but may result in questionable model selection if standard information criteria are used. Implementing specialized optimizers, on the other hand, is time consuming and error prone. Here, lessSEM can provide a starting point because all optimizers implemented therein can be accessed using both, R and C++ (see Appendix C for an example). In addition to the lasso penalty discussed above, researchers using lessSEM also have access to optimizers for all other penalty functions mentioned in the introduction (namely ridge, adaptive lasso, elastic net, cappedL1, lsp, scad, and mcp). Combined with the additional features of lessSEM (full information maximum likelihood estimation, multi-group models, definition variables, parameters transformations, and mixtures of penalties), this allows for the rapid development of new regularized models.
Acknowledgments
During the work on his dissertation, Jannik H. Orzek was a pre-doctoral fellow of the International Max Planck Research School on the Life Course (https://www.imprs-life.mpg.de/) of the Max Planck Institute for Human Development, Berlin, Germany. We acknowledge support by the Open Access Publication Fund of Humboldt-Universität zu Berlin. Figures in this article were created with ggplot2 (Wickham, Citation2016) and ggdist (Kay, Citation2022). The online supplement can be found at https://osf.io/kh9tr/.
Notes
1 For instance, lslx offers multi-group regularization, whereas regsem allows for equality constraints of parameters.
2 The gradient is a vector of first derivatives of the fitting function with respect to the parameters and the Hessian is a matrix with second derivatives.
3 The threshold parameter τ can be adapted with the round parameter in regsem; see regsem-function in the regsem package.
4 The lessSEM (lessSEM estimates sparse SEM) version used in this study is available from https://osf.io/kh9tr/. The most recent version can be found at https://github.com/jhorzek/lessSEM. Similar to regsem, lessSEM builds on models from lavaan (Rosseel, Citation2012).
5 We compare our implementation with lslx in the osf repository at https://osf.io/kh9tr/.
6 See fasta (Goldstein et al., Citation2016) for an alternative R package implementing general purpose optimization of non-differentiable penalty functions in pure R.
7 Files to replicate the simulations and the empirical example are provided in the osf repository at https://osf.io/kh9tr/. All analyses were performed using a single core of an Intel® Xeon® E5-2670 processor.
8 We chose this way of scaling because scaling by setting the variances to 1 would allow for multiple equivalent solutions with reversed signs of loadings.
9 In regsem is the current default, while Belzak and Bauer (Citation2020) and Epskamp et al. (Citation2017) used
10 The best BIC, for example, would always be achieved by setting and λ = 0. Then, the BIC reduces to
(the −2 log-likelihood of the maximum likelihood parameter estimates) plus
times the number of unregularized parameters.
References
- Andrew, G., & Gao, J. (2007). Scalable training of L1-regularized log-linear models. In Proceedings of the 24th International Conference on Machine Learning – ICML ’07 (pp. 33–40). ACM Press.
- Battauz, M. (2020). Regularized estimation of the nominal response model. Multivariate Behavioral Research, 55, 811–824. https://doi.org/10.1080/00273171.2019.1681252
- Belzak, W. C. M. (2021). Using regularization to evaluate differential item functioning among multiple covariates: A penalized expectation-maximization algorithm via coordinate descent and soft-thresholding [doctoral dissertation]. University of North Carolina, Chapel Hill.
- Belzak, W. C. M., & Bauer, D. J. (2020). Improving the assessment of measurement invariance: Using regularization to select anchor items and identify differential item functioning. Psychological Methods, 25, 673–690. https://doi.org/10.1037/met0000253
- Brandmaier, A. M., & Jacobucci, R. C. (in press). Machine-learning approaches to structural equation modeling. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (2nd ed.). Guilford Press.
- Breheny, P., & Huang, J. (2011). Coordinate descent algorithms for nonconvex penalized regression, with applications to biological feature selection. The Annals of Applied Statistics, 5, 232–253. https://doi.org/10.1214/10-AOAS388
- Browne, M. W. (2000). Cross-validation methods. Journal of Mathematical Psychology, 44, 108–132. https://doi.org/10.1006/jmps.1999.1279
- Candès, E. J., Wakin, M. B., & Boyd, S. P. (2008). Enhancing sparsity by reweighted l1 minimization. Journal of Fourier Analysis and Applications, 14, 877–905. https://doi.org/10.1007/s00041-008-9045-x
- Cao, Y., Huang, J., Jiao, Y., & Liu, Y. (2017). A lower bound based smoothed quasi-Newton algorithm for group bridge penalized regression. Communications in Statistics-Simulation and Computation, 46, 4694–4707. https://doi.org/10.1080/03610918.2015.1129409
- Chamroukhi, F., & Huynh, B.-T. (2019). Regularized maximum likelihood estimation and feature selection in mixtures-of-experts models. Journal de la Société Française de Statistique, 160, 57–85.
- Davis, S. W., Szymanski, A., Boms, H., Fink, T., & Cabeza, R. (2019). Cooperative contributions of structural and functional connectivity to successful memory in aging. Network Neuroscience, 3, 173–194. https://doi.org/10.1162/netn_a_00064
- Eddelbuettel, D., & François, R. (2011). Rcpp: Seamless R and C++ integration. Journal of Statistical Software, 40, 1–18. https://doi.org/10.18637/jss.v040.i08
- Eddelbuettel, D., & Sanderson, C. (2014). RcppArmadillo: Accelerating R with high-performance C++ linear algebra. Computational Statistics & Data Analysis, 71, 1054–1063. https://doi.org/10.1016/j.csda.2013.02.005
- Epskamp, S., Rhemtulla, M., & Borsboom, D. (2017). Generalized network psychometrics: Combining network and latent variable models. Psychometrika, 82, 904–927. https://doi.org/10.1007/s11336-017-9557-x
- Fan, J., & Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96, 1348–1360. https://doi.org/10.1198/016214501753382273
- Fan, R.-E., Chang, K.-W., Hsieh, C.-J., Wang, X.-R., & Lin, C.-J. (2008). LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9, 1871–1874.
- Finch, W. H., & Miller, J. E. (2021). A comparison of regularized maximum-likelihood, regularized 2-stage least squares, and maximum-likelihood estimation with misspecified models, small samples, and weak factor structure. Multivariate Behavioral Research, 56, 608–626. https://doi.org/10.1080/00273171.2020.1753005
- Friedman, J., Hastie, T., & Tibshirani, R. (2010). Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33, 1–20. https://doi.org/10.18637/jss.v033.i01
- Friemelt, B., Bloszies, C., Ernst, M. S., Peikert, A., Brandmaier, A. M., & Koch, T. (2022). On the performance of different regularization methods in bifactor-(S-1) models with explanatory variables—Caveats, recommendations, and future directions. Structural Equation Modeling: A Multidisciplinary Journal. Advance online publication. https://doi.org/10.1080/10705511.2022.2140664
- Geminiani, E., Marra, G., & Moustaki, I. (2021). Single- and multiple-group penalized factor analysis: A trust-region algorithm approach with integrated automatic multiple tuning parameter selection. Psychometrika, 86, 65–95. https://doi.org/10.1007/s11336-021-09751-8
- Ghalanos, A., & Theussl, S. (2015). Rsolnp: General non-linear optimization using augmented lagrange multiplier method.
- Goldstein, T., Studer, C., & Baraniuk, R. (2016). A field guide to forward-backward splitting with a FASTA implementation (No. arXiv:1411.3406). arXiv.
- Gong, P., Zhang, C., Lu, Z., Huang, J., Ye, J. (2013). A general iterative shrinkage and thresholding algorithm for non-convex regularized optimization problems. In Proceedings of the 30th International Conference on Machine Learning (Vol. 28, pp. 37–45). PMLR.
- Góngora, D., Vega-Hernández, M., Jahanshahi, M., Valdés-Sosa, P. A., Bringas-Vega, M. L., & C. (2020). Crystallized and fluid intelligence are predicted by microstructure of specific white-matter tracts. Human Brain Mapping, 41, 906–916. https://doi.org/10.1002/hbm.24848
- Hastie, T., Tibshirani, R., & Wainwright, M. (2015). Statistical learning with sparsity: The lasso and generalizations. CRC Press.
- Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12, 55–67. https://doi.org/10.1080/00401706.1970.10488634
- Huang, P.-H. (2018). A penalized likelihood method for multi-group structural equation modelling. British Journal of Mathematical and Statistical Psychology, 71, 499–522. https://doi.org/10.1111/bmsp.12130
- Huang, P.-H. (2020a). Lslx: Semi-confirmatory structural equation modeling via penalized likelihood. Journal of Statistical Software, 93, 1–37. https://doi.org/10.18637/jss.v093.i07
- Huang, P.-H. (2020b). Penalized least squares for structural equation modeling with ordinal responses. Multivariate Behavioral Research, 57, 279–297. https://doi.org/10.1080/00273171.2020.1820309
- Huang, P.-H., Chen, H., & Weng, L.-J. (2017). A penalized likelihood method for structural equation modeling. Psychometrika, 82, 329–354. https://doi.org/10.1007/s11336-017-9566-9
- Jacobucci, R. (2017). Regsem: Regularized structural equation modeling. arXiv:1703.08489 [stat].
- Jacobucci, R., Brandmaier, A. M., & Kievit, R. A. (2019). A practical guide to variable selection in structural equation modeling by using regularized multiple-indicators, multiple-causes models. Advances in Methods and Practices in Psychological Science, 2, 55–76. https://doi.org/10.1177/2515245919826527
- Jacobucci, R., & Grimm, K. J. (2018). Regularized estimation of multivariate latent change score models. In E. Ferrer, S. M. Boker, & K. J. Grimm (Eds.), Longitudinal multivariate psychology (1st ed., pp. 109–125). Routledge.
- Jacobucci, R., Grimm, K. J., & McArdle, J. J. (2016). Regularized structural equation modeling. Structural Equation Modeling: A Multidisciplinary Journal, 23, 555–566. https://doi.org/10.1080/10705511.2016.1154793
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning: With applications in R (No. 103). Springer.
- Kay, M. (2022). {ggdist}: Visualizations of distributions and uncertainty.
- Koncz, R., Wen, W., Makkar, S. R., Lam, B. C. P., Crawford, J. D., Rowe, C. C., & Sachdev, P. (2022). The interaction between vascular risk factors, cerebral small vessel disease, and amyloid burden in older adults. Journal of Alzheimer’s Disease, 86, 1617–1628. https://doi.org/10.3233/JAD-210358
- Konishi, S., & Kitagawa, G. (1996). Generalised information criteria in model selection. Biometrika, 83, 875–890. https://doi.org/10.1093/biomet/83.4.875
- Lee, S.-I., Lee, H., Abbeel, P., Ng, A. Y. (2006). Efficient l1 regularized logistic regression. In Proceedings of the Twenty-First National Conference on Artificial Intelligence (AAAI-06) (pp. 401–408).
- Li, X., & Jacobucci, R. (2021). Regularized structural equation modeling with stability selection. Psychological Methods, 27, 497–518. https://doi.org/10.1037/met0000389
- Li, X., Jacobucci, R., & Ammerman, B. A. (2021). Tutorial on the use of the regsem package in R. Psych, 3, 579–592. https://doi.org/10.3390/psych3040038
- Marsh, H. W., Lüdtke, O., Muthén, B., Asparouhov, T., Morin, A. J. S., Trautwein, U., et al. (2010). A new look at the big five factor structure through exploratory structural equation modeling. Psychological Assessment, 22, 471–491. https://doi.org/10.1037/a0019227
- Muggeo, V. M. R. (2010). LASSO regression via smooth L1-norm approximation. In Proceedings of the 25th International Workshop on Statistical Modelling (pp. 391–396). Glasgow.
- Neale, M. C., Hunter, M. D., Pritikin, J. N., Zahery, M., Brick, T. R., Kirkpatrick, R. M., et al. (2016). OpenMx 2.0: Extended structural equation and statistical modeling. Psychometrika, 81, 535–549. https://doi.org/10.1007/s11336-014-9435-8
- Nocedal, J., & Wright, S. J. (2006). Numerical optimization (2nd ed.). Springer.
- Orzek, J. H., & Voelkle, M. C. (2023). Regularized continuous time structural equation models: A network perspective. Psychological Methods. Advance online publication. https://doi.org/10.1037/met0000550
- Parikh, N., & Boyd, S. (2013). Proximal algorithms. Foundations and Trends in Optimization, 1, 123–231.
- Petersen, K. B., & Pedersen, M. S. (2012). Matrix cookbook. Technical University of Denmark.
- R Core Team (2022). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
- Revelle, W. (2022). psychTools: Tools to accompany the psych package for psychological research. Northwestern University.
- Revelle, W., Wilt, J., & Rosenthal, A. (2010). Individual differences in cognition: New methods for examining the personality-cognition link. In A. Gruszka, G. Matthews, & B. Szymura (Eds.), Handbook of individual differences in cognition: Attention, memory, and executive control (pp. 27–49). Springer.
- Ridler, I. (2022). Applications of regularised structural equation modelling to psychometrics and behavioural genetics [doctoral dissertation]. King’s College.
- Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36. https://doi.org/10.18637/jss.v048.i02
- Scharf, F., & Nestler, S. (2019). Should regularization replace simple structure rotation in exploratory factor analysis? Structural Equation Modeling: A Multidisciplinary Journal, 26, 576–590. https://doi.org/10.1080/10705511.2018.1558060
- Schmidt, M., Fung, G., & Rosaless, R. (2009). Optimization methods for l1 regularization. Technical Report TR-2009-19. University of British Columbia.
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6, 461–464. https://doi.org/10.1214/aos/1176344136
- Shao, J. (1997). An asymptotic theory for linear model selection. Statistica Sinica, 7, 221–242.
- Stone, M. (1977). An asymptotic equivalence of choice of model by cross-validation and Akaike’s criterion. Journal of the Royal Statistical Society: Series B (Methodological), 39, 44–47. https://doi.org/10.1111/j.2517-6161.1977.tb01603.x
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 58, 267–288.
- Ulbricht, J. (2010). Variable selection in generalized linear models [doctoral dissertation]. Ludwig-Maximilians-Universität München.
- Voelkle, M. C., Oud, J. H. L., Davidov, E., & Schmidt, P. (2012). An SEM approach to continuous time modeling of panel data: Relating authoritarianism and anomia. Psychological Methods, 17, 176–192. https://doi.org/10.1037/a0027543
- von Oertzen, T., & Brick, T. R. (2013). Efficient Hessian computation using sparse matrix derivatives in RAM notation. Behavior Research Methods, 46, 385–395. https://doi.org/10.3758/s13428-013-0384-4
- Wickham, H. (2016). Ggplot2: Elegant graphics for data analysis (2nd ed.). Springer International Publishing.
- Ye, A., Gates, K. M., Henry, T. R., & Luo, L. (2021). Path and directionality discovery in individual dynamic models: A regularized unified structural equation modeling approach for hybrid vector autoregression. Psychometrika, 86, 404–441.
- Ye, Y. (1987). Interior algorithms for linear, quadratic, and linearly constrained non-linear programming [doctoral dissertation]. Department of EES, Stanford University.
- Yuan, G.-X., Chang, K.-W., Hsieh, C.-J., & Lin, C.-J. (2010). A comparison of optimization methods and software for large-scale l1-regularized linear classification. Journal of Machine Learning Research, 11, 3183–3234.
- Yuan, G.-X., Ho, C.-H., & Lin, C.-J. (2012). An improved GLMNET for l1-regularized logistic regression. The Journal of Machine Learning Research, 13, 1999–2030. https://doi.org/10.1145/2020408.2020421
- Zhang, C.-H. (2010). Nearly unbiased variable selection under minimax concave penalty. The Annals of Statistics, 38, 894–942. https://doi.org/10.1214/09-AOS729
- Zhang, T. (2010). Analysis of multi-stage convex relaxation for sparse regularization. Journal of Machine Learning Research, 11, 1081–1107.
- Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101, 1418–1429. https://doi.org/10.1198/016214506000000735
- Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67, 301–320. https://doi.org/10.1111/j.1467-9868.2005.00503.x
- Zou, H., & Li, R. (2008). One-step sparse estimates in nonconcave penalized likelihood models. Annals of Statistics, 36, 1509–1533. https://doi.org/10.1214/009053607000000802
Appendix A
A.1 A Short Introduction to Quasi-Newton Optimization
Assume that is twice continuously differentiable and that in iteration k we are at the point
Points of
close to
are approximated using a truncated Taylor series:
(A.1)
(A.1)
Here, is the gradient of the function at point
and
is the Hessian. If the Hessian
is positive definite, EquationEquation (A.1)
(A.1)
(A.1) has the minimum
which is used as step direction
(so-called Newton direction; Nocedal & Wright, Citation2006). In this case, the step of length sk is typically set to 1. shows such Newton steps, with the blue lines depicting the approximations using EquationEquation (A.1)
(A.1)
(A.1) at the points θ1, θ2, θ3, and θ4. However, computing the true Hessian is often prohibitively expensive and one may resort to an approximation thereof. In lessSEM, we use the Broyden–Fletcher–Goldfarb–Shanno (BFGS) approximation (see e.g., Nocedal & Wright, Citation2006), resulting in a quasi-Newton procedure. When approximating the Hessian, sk = 1 may be a poor choice and the best step length is therefore found in a second optimization (e.g., Nocedal & Wright, Citation2006). To increase the similarity between the quasi-Newton optimizer outlined here and the GLMNET optimizer introduced in the next section, we used the same procedure to find the step size sk: We decreased s until the criterion shown in EquationEquation (A.2)
(A.2)
(A.2) was met, where
This criterion is a simplification of the criterion proposed by Yuan et al. (Citation2012) for GLMNET, where we take the differentiability of the approximated penalty into account. In fact, EquationEquation (A.2)
(A.2)
(A.2) is identical to the Armijo condition used by many optimizers (e.g., Nocedal & Wright, Citation2006, p. 33).
(A.2)
(A.2)
Note that EquationEquation (A.2)(A.2)
(A.2) enforces a decrease in
from one iteration to the next. This follows from
The matrix H is a positive definite (approximation of the) Hessian matrix. The inequality follows from (1) H being positive definite and therefore being positive definite and (2) the definition of a positive definite matrix as a matrix M, where
for any non-zero vector x (e.g., Petersen & Pedersen, Citation2012, pp. 50–51).
Appendix B
B.1 A Short Introduction to the GLMNET Optimizer
We will restrict the presentation of the GLMNET optimizer to a short primer. A thorough derivation is provided in the original publications (see Friedman et al., Citation2010; Yuan et al., Citation2012). We also recommend reading Appendix A before, as the quasi-Newton optimizer presented therein provides more background information on the general ideas used in the following. The GLMNET optimizer is also implemented in lslx (Huang, Citation2020a) and regCtsem (Orzek & Voelkle, Citation2023).
GLMNET is based on the assumption that the maximum likelihood fitting function in EquationEquation (1)
(1)
(1) is at least twice differentiable. Then,
can be approximated with
(B.1)
(B.1)
Note that the penalty function is not approximated in EquationEquation (B.1)
(B.1)
(B.1) . From iteration k to iteration k + 1, our objective is to make EquationEquation (B.1)
(B.1)
(B.1) smaller; or formally, we search a direction vector
which minimizes
(B.2)
(B.2)
The new problem, minimizing is then solved with a coordinate descent procedure (Yuan et al., Citation2012). To this end, a second optimization is used, where single elements of
are updated iteratively. Broadly speaking, the procedure is similar to the simplified example developed in the main text. However, the details are beyond the scope of the current article and the interested reader is referred to Friedman et al. (Citation2010) and Yuan et al. (Citation2012). In lessSEM, we additionally replace the Hessian matrix with the BFGS approximation.
After finding step direction with the coordinate descent procedure, the step length sk is found by decreasing s until the criterion in EquationEquation (B.3)
(B.3)
(B.3) is met, where
(this criterion was proposed by Yuan et al., Citation2012 and is also used by Huang, Citation2020a):
(B.3)
(B.3)
For our purpose, the most important message is that the quasi-Newton optimizer presented in Appendix A and the GLMNET optimizer discussed here are similar in that they rely on truncated second order Taylor series approximations to Both use the BFGS approximation for the Hessian matrix and rely on a similar procedure to find step size sk.
Appendix C
C.1 Optimizing Lasso Regression with lessSEM
To demonstrate the specialized optimizers implemented in the lessSEM package, we use a linear regression example.
Appendix D
D.1 Empirical Example
Figure 1. Parameter estimates for four different penalty functions (ridge, lasso, elastic net, and scad) for increasing values of λ. The dots represent the selected points of λ at which parameters were estimated.
D.1.1 Comparison to regsem
When fitting the model with regsem, we used the defaults of the cv_regsem function except for (1) setting mult.start = TRUE because we observed many non-convergent results otherwise (2) and adapting the round parameter to match the τ values used above. We removed all models for which regsem reported a non-zero convergence code, regsem returned negative variances, or the parameter estimates implied correlations between latent variables which were not in the interval shows the relative fit for each τ (the results from regsem differ between τ values because mult.start = TRUE uses random starting values). Both packages resulted in nearly identical fit values. shows the BIC and the number of non-zero parameters for regsem and lessSEM. Despite the similarity in fit, both packages select different final parameter estimates.
Figure 2. Steps taken by an optimizer. The red line is the function we want to minimize. The dots indicate the steps taken during the optimization and the blue lines are the approximations generated at these points (see Appendix A). Each point θk is found by minimizing the approximation at the previous point
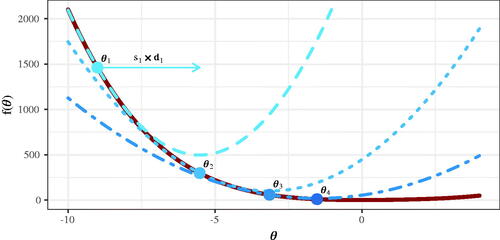
Figure 3. Penalty function values for a single parameter θ. The ridge is differentiable, whereas the lasso is not.
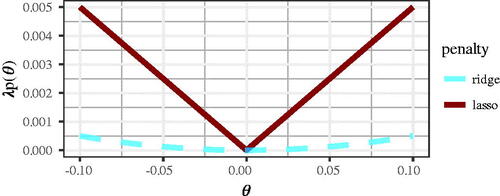
Figure 4. Penalty function values for a single parameter θ. Both, ridge and smoothed lasso are differentiable.
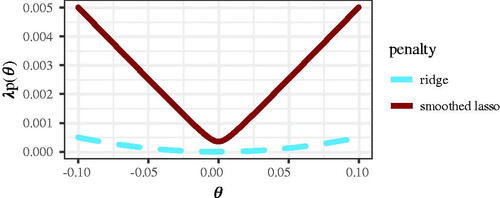
Figure 5. BIC for increasing λ values based on a single data set from the simulation study (see below). Dots indicate the discrete λ values for which models were fitted.
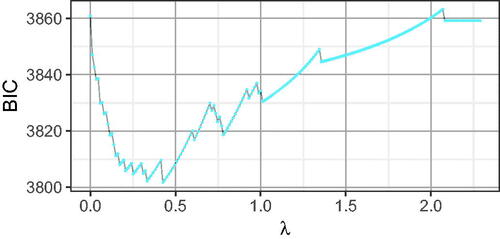
Figure 6. CFA for the bfi data set. Dashed blue paths are regularized cross-loadings.
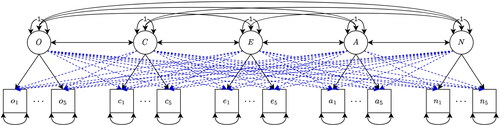
Figure 7. BIC and number of parameters for the N = 500 subset of the bfi data set when using approximate solutions (with the general purpose optimizer BFGS). The blue line is the exact solution (with the specialized optimizer GLMNET). Diamonds represent the respective selected models.
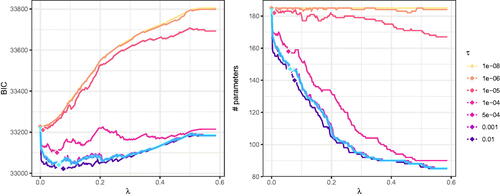
Figure 8. Quantile plots showing the relative fit. The quantiles were computed for each λ value separately. Values above 1 indicate better fit of the exact solution (using the specialized optimizer GLMNET), values below 1 indicate better fit of approximate solutions (using the general purpose optimizer BFGS). The black line shows the median. Values outside of the 95% quantile are not shown. A figure with all data points is included in the osf repository at https://osf.io/kh9tr/.
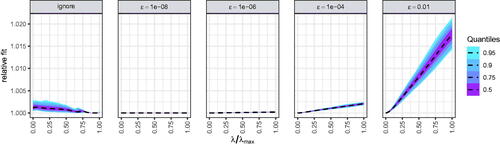
Figure 9. Quantile plots showing the sum of squared differences between exact solutions from the specialized optimizer and approximate solutions from the general purpose optimizer. Quantiles were computed for each λ separately. The black line shows the median. Values outside of the 95% quantile are not shown. A figure with all data points is included in the osf repository at https://osf.io/kh9tr/.
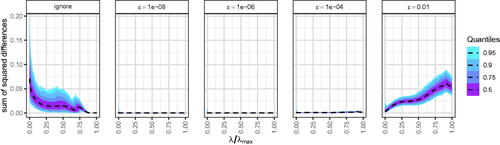
Figure 10. Regularized parameters estimates of the first repetition for exact solutions (using the specialized optimizer GLMNET) and approximate solutions (using the general purpose optimizer BFGS) for different levels of smoothing parameter ϵ.
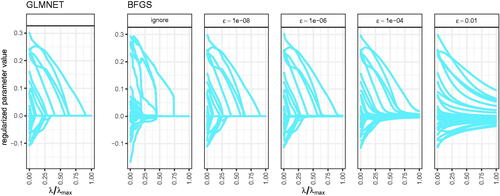
Figure 11. Sum of squared differences between exact solutions (using the specialized optimizer GLMNET) and approximate solutions (using the general purpose optimizer BFGS) in the final parameter estimates when using the BIC for model selection. Each dot represents one of the 500 simulation runs. Red dots indicate that the approximate solution selected the maximum likelihood estimates (i.e., ).
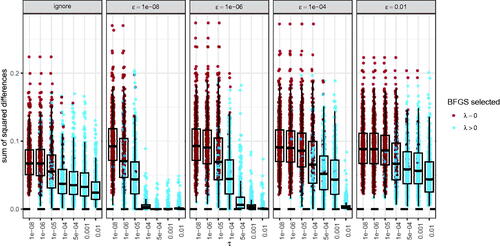
Figure 12. Sum of squared differences between exact solutions (using GLMNET) and approximate solutions (using BFGS) in the final parameter estimates when using 5-fold cross-validation for model selection.

Figure 13. Difference in the number of non-zero parameter estimates between approximate and exact solutions when using the BIC for model selection. A value of 3, for instance, indicates that the approximate solution (using BFGS) has three more parameters than the exact solution (using GLMNET). Each dot represents one of the 500 simulation runs. Red dots indicate that the approximate solution selected the maximum likelihood estimates (i.e., λ = 0).
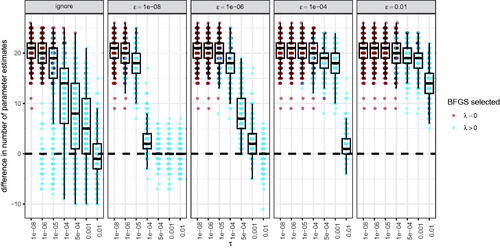
Figure D1. Final loadings estimated by exact (a) and approximate solutions (b–d) with different τ values. Results are rounded to three digits. Dots represent parameters which are either exactly zero (in case of exact solutions) or fall below the threshold τ.
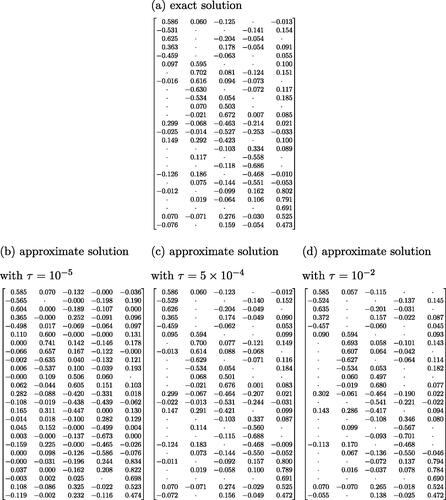
Figure D2. Relative fit of regsem as compared to lessSEM with GLMNET optimizer. A value of 1.01, for example, indicates a 1% larger fitting function value for regsem. The gaps represent non-convergent results based on (1) non-zero convergence codes, (2) negative variances, or (3) invalid correlations between latent variables in regsem.
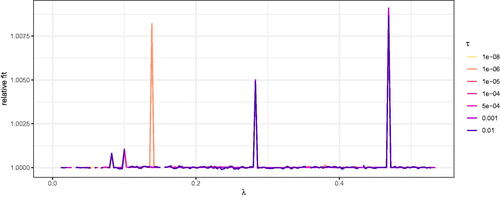
Figure D3. BIC and number of parameters for the bfi data set when using the regsem package. The blue line is the exact solution returned by lessSEM using the GLMNET optimizer. All other lines are the solutions returned by regsem using different levels of τ. Diamonds represent the respective selected models. The gaps in the BIC and the number of parameters for regsem represent non-convergent results based on (1) non-zero convergence codes, (2) negative variances, or (3) invalid correlations between latent variables.