
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Bayesian estimations of complex regression models with high-dimensional parameter spaces require advanced priors, capable of addressing both sparsity and multicollinearity in the data. The Dirichlet-horseshoe, a new prior distribution that combines and expands on the concepts of the regularized horseshoe and the Dirichlet-Laplace priors, is a novel approach that offers a high degree of flexibility and yields estimates with comparably high accuracy. To evaluate its performance in different frameworks, this study reports on two replicated simulation studies and a real-data example. Across all tested settings, the proposed approach outperforms or achieves similar performance to well-established regularization priors in terms of loss.
1. Introduction
Applied research in both natural and social sciences, such as genetics, psychology, and economics, often deals with intricate models using high-dimensional parameter spaces that incorporate several interactions, splines, and quadratic effects (e.g., Brandt et al., Citation2018; Engle & Rangel, Citation2008; Watt, Citation2004). In such settings, estimation techniques such as ordinary least squares tend to provide biased parameter estimates with low accuracy, because asymptotic theories do not hold when the number of predictors D is greater than the number of observations N. When the design matrix is sparse or the data feature high multicollinearity, dimensionality reduction is of particular importance.
To address problems associated with overfitting and overparametrization (Williams & Rodriguez, Citation2022), frequentist approaches apply penalized regression methods such as L1 or L2 regularization (Marquardt & Snee, Citation1975; Tibshirani, Citation1996). In Bayesian frameworks, regularization can be induced through the specification of prior distributions, which allocate substantial probability mass around 0 to shrink small coefficients toward 0. The heavy tails of these distributions create a means to accommodate large coefficients. Renowned examples of such approaches include the spike-and-slab prior (George & McCulloch, Citation1993; Ishwaran & Rao, Citation2005; Mitchell & Beauchamp, Citation1988) and the Bayesian lasso (Park & Casella, Citation2008). Although these approaches serve as good starting points, various issues emerge, related to their practical use.
Specifically, spike-and-slab priors were considered the gold standard in sparse Bayesian estimation for a long time because of their well-understood theoretical properties and good performance in a variety of settings related to sparsity. However, they become computationally intensive, particularly when used in high-dimensional spaces, because posterior sampling requires a stochastic search over a tremendous space, leading to slow mixing and convergence (Bhadra et al., Citation2017; Mitchell & Beauchamp, Citation1988). As noted by Piironen and Vehtari (Citation2017), their results also can be sensitive to prior choices (i.e., slab width and prior inclusion probability), which can be difficult to determine (Ishwaran & Rao, Citation2005). Moreover, Mitchell and Beauchamp (Citation1988) point out challenges in modeling correlated predictors and class variables with more than two levels.
The popularity of the Bayesian lasso stems largely from its simplicity and computational efficiency (Piironen & Vehtari, Citation2017). As Park and Casella (Citation2008) note, the Bayesian lasso ensures a unimodal posterior, which facilitates fast convergence and produces meaningful estimates. However, Carvalho et al. (Citation2008) and Armagan et al. (Citation2013) caution that it also insufficiently shrinks small coefficients (representing noise) while overshrinking large coefficients due to its relatively light tails, such that it is less robust to outliers–a notable drawback. Carvalho et al. (Citation2009) also identify two other factors that hamper the performance of the Bayesian lasso method: overestimation of the signal share in the parameter vector and underestimation of the presence of large coefficients. Finally, due to its reliance on a single hyperparameter in the double exponential (Laplace) prior, the Bayesian lasso suffers restricted flexibility and adaptivity to different problems (Brown & Griffin, Citation2010).
Some more recently developed priors include, for example, continuous shrinkage priors, which sometimes are expressed as one-group global-local scale mixtures of Gaussians, like the horseshoe (Carvalho et al., Citation2010). These priors achieve good performance in high-dimensional settings with regard to sparsity (Van Der Pas et al., Citation2014), exhibit adaptivity to unknown sparsity and signal-to-noise ratios (Carvalho et al., Citation2008), and offer computational efficiency, in the sense that their complexity depends on the sparsity ratio rather than the number of observations (Van Der Pas et al., Citation2014). Despite its popularity, some shortcomings of the horseshoe limit its practical use. In particular, Piironen and Vehtari (Citation2017) highlight the lack of a possibility to incorporate prior knowledge about the sparsity level in the parameter vector for the global shrinkage hyperparameter. They assert that the default choices encourage solutions in which too many parameters remain unshrunk. Van Der Pas et al. (Citation2014) also report both over- and underestimation of the sparsity ratio when applying full Bayes implementation with a Cauchy prior on the global hyperparameter. Notably, the horseshoe’s shrinkage profile keeps large coefficients unshrunk, which can be a favorable property, but it also can deteriorate performance when the parameters are only weakly identified by the data, such as when dealing with flat likelihoods emerging in logistic regressions with data separation (Piironen & Vehtari, Citation2017). In addition, it can cause the means of the posteriors to vanish, as observed for the Cauchy prior (Ghosh et al., Citation2018). Another concern stems from the multimodality of the posterior, caused by correlated predictors, which can raise sampling and convergence issues for the inference algorithms (Piironen & Vehtari, Citation2017). Noticeable convergence issues have also been reported by Piironen and Vehtari (Citation2015), even for simple regression problems.
More advanced priors include the regularized horseshoe (Piironen & Vehtari, Citation2017) and Dirichlet-Laplace priors (Bhattacharya et al., Citation2015). The former is a generalization of the horseshoe and nests the horseshoe as a special case. Accordingly, the regularized horseshoe is commonly applied to high-dimensional regression problems in which the number of predictors is much greater than the number of observations, due to its strong performance in such settings. Furthermore, it can incorporate prior knowledge about the degree of sparsity in the global hyperparameter. By adding a small degree of regularization to the large coefficients, the regularized horseshoe yields more reasonable parameter estimates, ensures that the posterior mean exists, and avoids sampling issues related to divergent transitions (Piironen & Vehtari, Citation2017). Although these improvements lead to improved performance and applicability of the horseshoe, as Piironen and Vehtari (Citation2017) emphasize, the issues related to multimodality due to correlated predictors still persist. Furthermore, as they demonstrate, a misspecification of the hyperparameters can result in overly strong regularization.
Dirichlet-Laplace priors unify Dirichlet and Laplace priors to induce sparsity in models. Whereas the Laplacian part controls the overall amount of shrinkage, concentrating the Dirichlet elements constrains the number of non-zero coefficients. Thus, Dirichlet-Laplace priors are theoretically sound; they provide a closed-form representation that is appealing theoretically and also allows for an exact representation of the posterior. According to Bhattacharya et al. (Citation2015), Dirichlet-Laplace priors yield efficient posterior computations, with an appropriate chosen concentration rate, such that they offer an optimal posterior concentration (minimax rate of convergence). Nevertheless, their practical use is limited, because the results depend powerfully on the commonly unknown, hard-to-determine concentration parameter, which can exert substantial effects on the results, as demonstrated by Bhattacharya et al. (Citation2015). In , we provide an overview of the properties of these priors.
2. Article Aims
To overcome some of these limitations, we suggest a novel prior approach, which we call Dirichlet-horseshoe that combines and expands on the principles of the regularized horseshoe and the Dirichlet-Laplace priors. We test its performance by conducting two replicated simulation studies, along with a real-data example. In the first simulation study, which reflects the normal means problem (see Bhattacharya et al., Citation2015), Gaussian white noise gets added to a high-dimensional vector of signals with varying signal strengths and different sparsity ratios. Then the second simulation study features a multiple regression setting, such that we draw predictor variables from a multivariate normal distribution with varying correlation strengths and generate a sparse vector of regression coefficients from a log-normal distribution. In the real-data example, we replicate the estimation procedure implemented by Fischer et al. (Citation2023) but apply our proposed Dirichlet-horseshoe prior. Fischer et al. (Citation2023) estimate the effects of emotional cues on minute-by-minute, aggregated alcohol consumption in a soccer stadium, on the basis of intensive longitudinal data and by employing a random intercept regime-switching model. The data set consists of 8,820 observations, with 10 predictors at the within-level and 49 predictors at the between-level.
These illustrative studies confirm that the Dirichlet-horseshoe can deal with different sparsity ratios, handle high multicollinearity, and cope well with small N, large D settings. In all setups, its performance, measured in terms of loss, is either superior or similar to that of competing regularization priors. The results suggest that our proposed prior is best suited for sparse, small sample settings (e.g., 100 observations with 5% relevant predictors) that require precise estimates and a high probability of isolating important predictors from less important ones.
3. Common Priors
To distinguish the Dirichlet-horseshoe prior from existing ones, we briefly introduce five well-established approaches, in chronological publication order. More precisely, we introduce three central concepts (“baseline priors”), which are prone to the issues we outlined previously. Then, we present two more recent (“advanced”) priors, on which we build to construct the Dirichlet-horseshoe. Throughout this article, we use N to denote the number of observations, with and D to indicate dimensionality, equal to the number of predictor variables in a regression, where
The vector of regression coefficients to be estimated is signified by
and
represents the noise variance. Vectors and matrices are highlighted in bold.
3.1. Baseline Priors
3.1.1. Spike-and-Slab
The spike-and-slab prior (George & McCulloch, Citation1993; Ishwaran & Rao, Citation2005; Mitchell & Beauchamp, Citation1988) belongs to the class of discrete mixture priors and is based on a binary decision. Either the point mass for βj is at 0 (i.e., it comes from a spike), or the coefficient is drawn from a diffuse uniform distribution (i.e., it comes from a slab). This prior is often written as a two-component mixture of Gaussian functions (Piironen & Vehtari, Citation2017) such that
in which the hyperparameter c controls the shape of the distribution (slab width), and π is the prior inclusion probability. This prior establishes an ideal theoretical benchmark, due to its notable properties. First, it fully reflects the concept of regularization, because coefficients can become exactly 0. Second, there exists a closed-form solution for the posterior distribution. By choosing
and replacing the discrete Bernoulli distribution with a continuous Beta, the prior can be expressed as
For example, would be an uninformative Jeffrey’s prior.
3.1.2. Bayesian (Adaptive) Lasso
Park and Casella (Citation2008) introduce the Bayesian lasso,
for which the shape of the coefficient’s distribution is governed by
and the fixed shrinkage parameter λ. According to Park and Casella (Citation2008), estimates have both lasso and ridge regression properties, and the posterior mode is equivalent to the frequentist lasso estimator introduced by Tibshirani (Citation1996). In an attempt to allow for different shrinkage for different coefficients, while maintaining parsimony, Leng et al. (Citation2014) propose the Bayesian adaptive lasso,
which also ensures that the posterior is unimodal, given any choice of λj (Leng et al., Citation2014; Park & Casella, Citation2008).
3.1.3. Horseshoe
Carvalho et al. (Citation2010) propose the horseshoe,
a prior distribution with a global (τ) and a local (λj) shrinkage parameter. The general degree of regularization τ (often referred to as the global regularization component) shrinks all coefficients toward 0; the local regularization component λj allows large coefficients to escape shrinkage. The horseshoe’s heavy tails, resulting from the half-Chauchy distribution, allows the prior to accommodate even the largest coefficients.
3.2. Advanced Priors
3.2.1. Dirichlet-Laplace
Dirichlet-Laplace priors (Bhattacharya et al., Citation2015) are another class of shrinkage priors that extend the global-local approach by introducing relative predictor importance according to a concentration parameter a, as in
The components of the Dirichlet distribution add up to 1 (i.e., the Dirichlet is a multivariate generalization of the Beta distribution). In these equations, DE refers to the double exponential (Laplace) distribution. The concentration parameter a guides the sparsity allocation of the probability mass, such that the larger a is, the more mass gets concentrated on one component, and the smaller a is, the sparser the resulting distribution.
3.2.2. Regularized Horseshoe
The regularized horseshoe, as proposed by Piironen and Vehtari (Citation2017), is a generalization of the horseshoe, expressed as:
(1)
(1)
If such that βj is close to 0, then
and EquationEquation (1)
(1)
(1) approaches the original horseshoe. But if
such that βj is far from 0, then
and EquationEquation (1)
(1)
(1) approaches
which is equivalent to the spike-and-slab estimator for the case in which the coefficient comes from a slab. The regularized version enhances the horseshoe in several ways. First, the global shrinkage parameter τ depends on prior information about the sparsity ratio in the design matrix, because
where p0 denotes the number of relevant predictor variables. On the basis of the dimensionality of the data set and an assumed number of relevant predictors, the global shrinkage parameter can be defined systematically. Second, sparsity information enters the reformulated local shrinkage parameter
through τ, which prevents the vanishing mean problem that arises with the horseshoe, as well as the aforementioned issues attributed to weakly identified parameters.
4. The Dirichlet-Horseshoe Prior
To enhance precision and offer more adaptivity, we combine the Dirichlet-Laplace with the regularized horseshoe, such that we integrate the notion of relative levels of predictor importance and local shrinkage, using information on the overall sparsity. The implied hierarchical structure of the Dirichlet-horseshoe then can be expressed as:
The proposed Dirichlet-horseshoe unifies global (τ), local (λj), and joint () regularization. The global and local regularization trade off in
with the objective of also shrinking large coefficients when they are weakly identified, to prevent flat posteriors. The peculiarity of the Dirichlet distribution maps all components in
between 0 and 1; it guarantees that the sum of these components is equal to 1. Rescaling the components by D allows the Dirichlet-horseshoe to nest the regularized horseshoe estimator as a special case, as long as the posterior for
In practice, this special case is unlikely; it implies equally important predictor variables. However, the Dirichlet-horseshoe might increasingly come to resemble the regularized horseshoe when the predictor variables grow more homogeneous in their explanatory power for the target variable. For
the Dirichlet-horseshoe shrinks all predictors that are less important than an average to be stronger than the regularized horseshoe does, such that for
it holds that
Analogously, any predictor of greater importance than the average is subjected to a smaller degree of shrinkage. In turn, the Dirichlet-horseshoe functions as a regularizer with greater selectivity capacity between important and unimportant signals.
The slab width can be adjusted by means of c. In line with Piironen and Vehtari (Citation2017), we suggest establishing a weakly informative prior for c. A reasonable choice is the inverse-Gamma distribution,
which has a heavy right and light left tail, so it does not concentrate excessive probability mass near 0, a feature that is desirable for coefficients that already are considered far from 0 (Piironen & Vehtari, Citation2017). Incorporating global parameters in the model, estimated from available data, also provides a high degree of adaptivity to different sparsity patterns and can control for Type I errors (Berry, Citation1987; Scott & Berger, Citation2006). The local regularization component λj, drawn from a half-Cauchy distribution, enables our prior to accommodate even the largest coefficients. The component’s impact on the estimator can be controlled by the scale parameter γ. For the optimal choice of τ0, we follow Piironen and Vehtari (Citation2017) and use:
Then we define hyperpriors for both the concentration parameter a and the number of relevant predictors p0 to reduce the dependence of the results on these parameters when little or no prior information is available. To induce sparsity through the concentration rates must lie between 0 and 1. To increase the degree of sparsity, modelers should choose smaller values. The number of relevant predictors p0 controls the scale τ0 of the half-Cauchy distribution from which the global hyperparameter τ is drawn; p0 is inversely related to the degree of global regularization. In practice, p0 is often unknown and needs to be sampled. For statistical reasons, we recommend drawing the fraction of relevant predictors η rather than the number of relevant predictors p0, according to
because η is a continuous quantity bounded between 0 and 1, which makes it more convenient to sample using numerical methods, such as Markov chain Monte Carlo or Hamiltonian Monte Carlo.
On the basis of empirical experience, Bhattacharya et al. (Citation2015) determine that choosing may induce over-shrinkage if some relatively small coefficients exist. They also emphasize that
can create numerical issues when D is large. In addition to fixing a = 0.5, they use a uniform prior for the concentration rate a, but uniform distributions can lead to slow convergence and high autocorrelation in the chain. Therefore, we recommend drawing a and η from informative Beta distributions, skewed toward 0 (relative to the presumed sparsity ratio), to allocate more prior probability near 0 than near 1. This effort can help the sampler explore the posterior distribution more efficiently. For example,
has a mean equal to 0.2, which may be appropriate if the researcher assumes around 20% of the predictors are relevant, a priori. According to our findings, and in an effort to restrain computational expense, it may be reasonable to define one joint parameter ν for both the concentration a and the fraction of relevant predictors η, such that
with
shows the marginal density of the Dirichlet-horseshoe compared with the other priors. We use the double exponential prior in place of the Bayesian adaptive lasso, because in a Bayesian lasso regression, each regression coefficient follows a conditional double exponential prior (i.e., Laplace prior) (Park & Casella, Citation2008; Tibshirani, Citation1996). We observe that the Dirichlet-horseshoe allocates substantial probability mass close to 0 and has a relatively light tail. The tails are large enough to accommodate large coefficients though, and they are more pronounced than those of the double exponential prior. These key features enable the Dirichlet-horseshoe to perform well in relation to the problems of sparse Bayesian regularization and prediction (Polson & Scott, Citation2010). The density functions provided by horseshoe, regularized horseshoe, and Dirichlet-horseshoe all lack a closed-form representation. We approximate the horseshoe density using the elementary functions, as detailed in Theorem 1 offered by Carvalho et al. (Citation2010). The density functions for the latter two priors are sampled using 10,000,000 draws. We assume N = 100, D = 100, a = 0.5, and σ = 1, and we smooth the tails of the regularized and Dirichlet horseshoes by scaling the kernel bandwidth, for illustration.
5. Simulation Studies
We illustrate the finite sample performance of the proposed Dirichlet-horseshoe prior, compared with the other priors, using the normal means problem (Bhattacharya et al., Citation2015; Van Der Pas et al., Citation2014), and then a multiple regression problem with correlated predictors under sparsity.
5.1. Simulation Study I: Normal Means Problem
In the normal means problem, we strive to estimate a D-dimensional mean based on a D-dimensional vector of observations y corrupted with Gaussian white noise,
for various sparsity ratios qD and mean sizes defined by the signal strength A. Particularly, we sample Ω = 100 replicates of a D = 400 dimensional vector y from a
distribution, where
has
nonzero entries, all set to a constant value
In turn, we conduct six simulation settings per prior candidate in each replication, for 3,600 simulations in total. Note that
is the “universal” threshold for this problem (Johnstone & Silverman, Citation2004; Van Der Pas et al., Citation2014). Below this threshold, the nonzero components in
are too small to be detected (Piironen & Vehtari, Citation2017). Therefore, we expect the most imprecise estimates to manifest for A = 4.
We also seek to illustrate the impact of the hyperparameter choice ν, which controls both the concentration rate and the fraction of relevant parameters in the Dirichlet-horseshoe prior, by presenting the results for different hyperparameter selections in the simulation study: D = 400, and A varying over
The hyperprior choices include
and
5.2. Simulation Study II: Multiple Regression Problem
In the multiple regression problem, we aim to estimate a D-dimensional parameter vector drawn from a log-normal distribution based on a N × D dimensional design matrix X, which in turn is drawn from a multivariate normal distribution, such that
The variance-covariance matrix contains unit standard deviation on its main diagonal and varying, pairwise correlations ρ on its off-diagonals. We set the number of predictors D = 100, let the sample size be
(N < D, N > D), and vary the correlations ρ over
(weak, moderate, strong). The parameter vector
has a sparsity ratio of 20%, such that we set 80 of the 100 predictors to 0. Again, we conduct Ω = 100 replications per setting and prior candidate, which yields a total of 3,600 simulations.
5.3. Estimation
For the estimation, we use the probabilistic programming package PyMC (Salvatier et al., Citation2016). In particular, we apply the No-U-Turn (NUTS) sampler (Hoffman & Gelman, Citation2014), a recursive algorithm for continuous variables based on Hamiltonian mechanics. It extends the Hamiltonian Monte Carlo by eliminating the need to set a number of steps, because an automatic stoppage occurs once the sampler starts to make a U-turn. We set a large acceptance probability of 0.99 (the default value is 0.8), which implies a small step size, so that we can achieve non-divergent trajectories for the samples. For each specification, we run three chains with 3,000 iterations and an additional 1,000 burn-in samples that we discard. We monitor convergence with the Gelman-Rubin statistic (Brooks & Gelman, Citation1998; Gelman & Rubin, Citation1992).
6. Results
This section presents the results of both simulation studies. We illustrate the performance of the Dirichlet-horseshoe compared with the alternative priors. and depict the squared error loss corresponding to the posterior median. in Appendix A present these results in tabular form, along with several additional measures, such as coverage based on the 95% highest density intervals (HDIs), standard deviation of loss, standard deviation of the median, Type I error, runtime, and number of divergences. These measures are averaged across replications, and all values converge. We present the detailed hierarchical structure of all priors, together with the parameter values used in the simulation studies, in Appendix B.
6.1. Simulation Study I: Normal Means Problem
depicts the loss for varying signal strengths based on sparsity ratios of
(left panel) and
(right panel) for the normal means problem with dimensionality
. Specifically, for a sparsity ratio of 5% and a signal strength of 4, the lowest loss occurs for the regularized horseshoe (69.3), followed closely by Dirichlet-horseshoe (69.5), Dirichlet-Laplace (70.6), and horseshoe (73.8) priors. Bayesian adaptive lasso and spike-and-slab priors reveal the most imprecise results (97.1 and 96.6), which persists at larger signal strengths too. As the signals strengthen, the losses associated with all priors except spike-and-slab decrease, as is to be expected, because the signal-to-noise ratio grows. For
and
, the Dirichlet-horseshoe achieves the lowest loss (41.8 and 34.0), followed by the horseshoe (43.9 and 34.6) and regularized horseshoe (44.8 and 35.8). The Dirichlet-Laplace prior performance deteriorates (59.9 and 55.8). At a sparsity ratio of 10%, we find similar patterns. For
, the loss for the Dirichlet-horseshoe (110.0) is slightly higher than that for the Dirichlet-Laplace (108.0) but considerably lower than those of the regularized horseshoe (114.0), horseshoe (118.0), Bayesian adaptive lasso (127.0), and spike-and-slab (137.0). For the signal strengths
and
, the loss of the Dirichlet-horseshoe (81.9 and 66.7) is lowest, and the differences with the other priors grow more pronounced. That is, the horseshoe (89.4 and 73.1) comes second, closely followed by the Dirichlet-Laplace (91.3 and 80.8) and regularized horseshoe (92.6 and 76.7). Overall, the proposed, novel prior consistently demonstrates superior or competitive accuracy on all tested specifications.
illustrates the sensitivity of the Dirichlet-horseshoe to a selection of hyperparameters that constitute the proposed hyperprior , together with fixed values of
,
, and
. We evaluate the results on the basis of the loss calculated from the normal means problem with dimensionality
, sparsity ratio
, and varying signal strengths
. For the smallest signal strength
, we observe minor differences in losses across the hyperprior choices
,
, and
, but the largest loss emerges for
. As (Bhattacharya 2015) point out, choosing overly small values for the concentration parameter can lead to overshrinkage and poor performance in the presence of relatively small signals. For
and
, we note the weak sensitivity of the Dirichlet-horseshoe to the hyperprior choice. The differences in loss are rather small, indicating that the choice of hyperparameter has only a minor impact in these settings.
6.2. Simulation Study II: Multiple Regression Problem
depicts the loss estimated from the multiple regression problem with predictors for varying correlation strengths
(weak, moderate, strong) in samples with
observations (left panel) and
observations (right panel).
For the small sample size of 80 and weak to moderate predictor correlations, the Dirichlet-horseshoe achieves the lowest loss (1.11 and 1.85), followed by the regularized horseshoe (1.35 and 2.12), horseshoe (1.37 and 2.13), and Dirichlet-Laplace (1.44 and 2.21). Similar to the normal means problem in Simulation Study I, the Bayesian adaptive lasso and spike-and-slab priors produce the most imprecise results, as is true for all the predictor correlations we examine. With strong correlations, the Dirichlet-horseshoe reveals a loss of 4.49–slightly larger than the values for the regularized horseshoe (4.41) and slightly lower than the horseshoe (4.50), and Dirichlet-Laplace (4.66). With a larger sample size (200), our proposed Dirichlet-horseshoe prior exhibits the smallest loss for all predictor correlations , with values equal to 0.21, 0.33, and 0.76, respectively. Thus, it also achieves the best outcome for strong correlations, followed by regularized horseshoe (0.28, 0.42, 0.90), horseshoe (0.29, 0.43, 0.91), and Dirichlet-Laplace (0.35, 0.51, 1.00).
Generally, the loss of all priors diminishes with the larger sample size but grows with increasing predictor correlations, which is reasonable, in that it becomes more challenging for the algorithms to disentangle predictor variables. As in the normal means problem, our proposed Dirichlet-horseshoe prior achieves superior or highly competitive accuracy for all the tested specifications.
7. Real-Data Example: Alcohol Use and Emotional Cues
In this section, we extend the performance illustration with a real-data example. Similar to Fischer et al. (Citation2023), we estimate the effect of the reference point-dependent emotional cues Surprise and Suspense (Ely et al., Citation2015), with the same data set and using their proposed hierarchical state-switching model. However, we apply the Dirichlet-horseshoe instead of the spike-and-slab prior used by those authors. The data set consists of minute-by-minute recorded beer sales in a soccer stadium, as well as data related to in-play betting odds, in-play match events, and match-day information. The design matrix contains 10 predictors at the within-level and 49 predictors at the between-level. All data are observed over six soccer seasons, from 2013/14 to 2018/19, which entail 98 matches, leading to observations in total (a match lasts 90 minutes). Away-team stands are excluded from this sample.
Fischer et al. (Citation2023) follow Buraimo et al. (Citation2020) and use betting odds to estimate outcome probabilities p for all potential outcomes of the match, namely, home win (H), draw (D), or away win (A), in each match minute t. Using these estimated probabilities, they calculate the constructs Surprise and Suspense. Fischer et al. (Citation2023) also determine (emotional) states S = 0 and S = 1 on basis of these estimates, such that Surprise, calculated as,
is high if the current outcome probabilities contradict the anterior beliefs (backward-looking). In contrast, Suspense,
is a forward-looking measure that increases when the variance related to possible outcomes in the next minute is high. Here,
is the probability that the home team scores in the next minute. The superscript “AG” instead refers to the away team’s probability of scoring. The utility function is
for both measures. The two emotional states then are given as
where S = 0 denotes the negative state, because the outcome probabilities for the home team have decreased from the last period to the current period. The positive state is indicated by S = 1. These states are well-justified, because consumption by home and away team fans is separated by stands. This model also allows for a random intercept at the between-level. The within-level is given by,
where,
at the between-level. Beer sales are collected in Y, and
contains the key regressors, Surprise and Suspense. Covariates in
capturing weather conditions and match key events, among other variables, control for potential confounds at the within-level. Covariates related to match-specific information, like the number of spectators, beer price, weekday, and so on, and gathered by
control for confounds at the between-level. We use the estimation procedure described for Simulation Studies I and II. presents the results based on Dirichlet-horseshoe. The regressors are standardized, and the dependent variable contains inverse hyperbolic sine-transformed sales. Therefore, the marginal effects can be interpreted in terms of a one standard deviation increase. Our results resonate with the main findings of Fischer et al. (Citation2023). We find predominantly positive effects for Surprise and negative effects for Suspense on the number of beer sales in both states. Moreover, the effects are stronger for the positive state S = 1 overall. We observe a greater level of decisiveness (sharpness) for the Dirichlet-horseshoe compared with the spike-and-slab prior when it comes to variable selection. Accordingly, we observe a higher density allocated around 0 for small-coefficient posteriors exposed at lags 6-8, for example, as well as slightly weaker effects for Suspense when l = 3. For some nonzero posteriors, the probability mass locally peaks close to 0 though. The resulting tendency for multimodal posteriors is typical of horseshoe priors, due to the global and local shrinkage aspects.
8. Discussion
We present the Dirichlet-horseshoe, a novel prior designed for sparse estimations in high-dimensional settings, which integrates the concept of Dirichlet-Laplace priors with the regularized horseshoe. In two simulation studies and a real-data example, we demonstrate that the proposed prior yields more accurate estimates than both well-established and recently developed methods, namely, the spike-and-slab prior, Bayesian adaptive lasso, horseshoe, Dirichlet-Laplace, and regularized horseshoe. Our approach offers a reliable default choice for addressing problems related to varied levels of sparsity (i.e., identifying needles and straws in haystacks), and it exhibits favorable convergence properties. Considering the normal means problem with sparsity ratios of 5% and 10%, our proposed prior achieves significantly better performance than the spike-and-slab and Bayesian adaptive lasso; it performs similarly to the horseshoe, Dirichlet-Laplace, and regularized horseshoe priors at a signal strength of 4. At higher signal strengths (5 or 6), the proposed Dirichlet-horseshoe exhibits a slight advantage over all these priors, showcasing its superior performance.
The Dirichlet-horseshoe also is well suited for small N, large D problems, and it can deal with correlated predictor variables. Specifically, for weak to moderate correlations (i.e., 0.25 to 0.5), the Dirichlet-horseshoe provides more accurate estimates than competing priors. Furthermore, even in the presence of strong correlations, the prior continues to be more accurate, as long as the sample sizes are sufficiently large. Our novel prior further offers a significant degree of flexibility, allowing for easy customization to accommodate specific settings, as demonstrated in the real-data example. Therefore, we consider the Dirichlet-horseshoe prior relevant for a wide range of application fields. It also can address various common challenges in modern statistics, including high-parametric, complex settings, such as network models (Epskamp et al., Citation2017) or dynamic latent variable models (Kelava & Brandt, Citation2019), as well as common regression and classification tasks, function estimation, and covariance matrix regularization.
Unless substantial knowledge about the hyperpriors of the Dirichlet-horseshoe exists, we advocate for using the parameters in EquationEquation (B1)(B1)
(B1) as a good starting point. Furthermore, we emphasize that this novel approach extends beyond this particular option; it may be possible to test alternative hyperpriors as well. We use full Bayesian inference for the hyperpriors since opting for empirical Bayes estimation of hyperparameters (as highlighted in the advantages of the empirical Bayes method by Petrone et al. (Citation2014)) or using cross-validation would pose computational difficulties and would not allow accounting for the characteristics of the posterior distributions. When using numerical methods for posterior estimation, such as Markov chain Monte Carlo, Hamiltonian Monte Carlo, or NUTS, we recommend a noncentered representation of the densities, combined with small step sizes, to achieve fewer divergences in the trajectories for the samples. Continued research might investigate reducing the computational expense required for Dirichlet-horseshoe, without sacrificing its performance. Tests of the prior in various applications also are required to confirm its robustness and further specify both its strengths and its weaknesses.
Disclosure Statement
No potential conflict of interest was reported by the authors.
Data Availability Statement
The data and code that support the findings of this study are openly available at https://zenodo.org/doi/10.5281/zenodo.10707994.
Additional information
Funding
References
- Armagan, A., Dunson, D. B., & Lee, J. (2013). Generalized double pareto shrinkage. Statistica Sinica, 23, 119. https://doi.org/10.5705/ss.2011.048
- Berry, D. A. (1987). Multiple comparisons, multiple tests, and data dredging: A Bayesian perspective (Tech. Rep. No. 486 April, 1987). University of Minnesota.
- Bhadra, A., Datta, J., Polson, N. G., & Willard, B. (2017). The Horseshoe + estimator of ultra-sparse signals. Bayesian Analysis, 12, 1105–1131. https://doi.org/10.1214/16-BA1028
- Bhattacharya, A., Pati, D., Pillai, N. S., & Dunson, D. B. (2015). Dirichlet–Laplace priors for optimal shrinkage. Journal of the American Statistical Association, 110, 1479–1490. https://doi.org/10.1080/01621459.2014.960967
- Brandt, H., Cambria, J., & Kelava, A. (2018). An adaptive Bayesian Lasso approach with spike-and-slab priors to identify multiple linear and nonlinear effects in structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 25, 946–960. https://doi.org/10.1080/10705511.2018.1474114
- Brooks, S., & Gelman, A. (1998). General methods for monitoring convergence of iterative simulations. Journal of Computational and Graphical Statistics, 7, 434–455. https://doi.org/10.2307/1390675
- Brown, P. J., & Griffin, J. E. (2010). Inference with normal-gamma prior distributions in regression problems. Bayesian Analysis, 5, 171–188. https://doi.org/10.1214/10-BA507
- Buraimo, B., Forrest, D., McHale, I. G., & Tena, J. d D. (2020). Unscripted drama: Soccer audience response to suspense, surprise, and shock. Economic Inquiry, 58, 881–896. https://doi.org/10.1111/ecin.12874
- Carvalho, C. M., Polson, N. G., & Scott, J. G. (2008). The Horseshoe estimator for sparse signals. Duke University Department of Statistical Science, Discussion Paper 2008-31.
- Carvalho, C. M., Polson, N. G., & Scott, J. G. (2009). Handling sparsity via the Horseshoe. In Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics (Vol. 5, pp. 73–80.). PMLR.
- Carvalho, C. M., Polson, N. G., & Scott, J. G. (2010). The Horseshoe estimator for sparse signals. Biometrika, 97, 465–480. https://doi.org/10.1093/biomet/asq017
- Ely, J., Frankel, A., & Kamenica, E. (2015). Suspense and surprise. Journal of Political Economy, 123, 215–260. https://doi.org/10.1086/677350
- Engle, R. F., & Rangel, J. G. (2008). The spline-GARCH model for low-frequency volatility and its global macroeconomic causes. Review of Financial Studies, 21, 1187–1222. https://doi.org/10.1093/rfs/hhn004
- Epskamp, S., Rhemtulla, M., & Borsboom, D. (2017). Generalized network psychometrics: combining network and latent variable models. Psychometrika, 82, 904–927. https://doi.org/10.1007/s11336-017-9557-x
- Fischer, L., Nagel, M., Kelava, A., & Pawlowski, T. (2023). Celebration beats frustration: Emotional cues and alcohol use during soccer matches. Available at SSRN: https://ssrn.com/abstract=4569227 or http://dx.doi.org/10.2139/ssrn.4569227
- Gelman, A., & Rubin, D. B. (1992). A single series from the gibbs sampler provides a false sense of security. In J. M. Bernardo (Ed.), Bayesian statistics. Oxford University Press.
- George, E. I., & McCulloch, R. E. (1993). Variable selection via gibbs sampling. Journal of the American Statistical Association, 88, 881–889. https://doi.org/10.1080/01621459.1993.10476353
- Ghosh, J., Li, Y., & Mitra, R. (2018). On the use of cauchy prior distributions for Bayesian logistic regression. Bayesian Analysis, 13, 359–383. https://doi.org/10.1214/17-BA1051
- Hoffman, M. D., & Gelman, A. (2014). The No-U-Turn sampler: Adaptively setting path lengthsin Hamiltonian Monte Carlo. Journal of Machine Learning Research, 15, 1593–1623.
- Ishwaran, H., & Rao, J. S. (2005). Spike and slab variable selection: Frequentist and Bayesian strategies. The Annals of Statistics, 33, 730–773. https://doi.org/10.1214/009053604000001147
- Johnstone, I. M., & Silverman, B. W. (2004). Needles and straw in haystacks: Empirical Bayes estimates of possibly sparse sequences. The Annals of Statistics, 32, 1594–1649. https://doi.org/10.1214/009053604000000030
- Kelava, A., & Brandt, H. (2019). A nonlinear dynamic latent class structural equation model. Structural Equation Modeling: A Multidisciplinary Journal, 26, 509–528. https://doi.org/10.1080/10705511.2018.1555692
- Leng, C., Tran, M.-N., & Nott, D. (2014). Bayesian adaptive Lasso. Annals of the Institute of Statistical Mathematics, 66, 221–244. https://doi.org/10.1007/s10463-013-0429-6
- Marquardt, D. W., & Snee, R. D. (1975). Ridge regression in practice. The American Statistician, 29, 3–20. https://doi.org/10.2307/2683673
- Mitchell, T. J., & Beauchamp, J. J. (1988). Bayesian variable selection in linear regression. Journal of the American Statistical Association, 83, 1023–1032. https://doi.org/10.1080/01621459.1988.10478694
- Park, T., & Casella, G. (2008). The Bayesian Lasso. Journal of the American Statistical Association, 103, 681–686. https://doi.org/10.1198/016214508000000337
- Petrone, S., Rousseau, J., & Scricciolo, C. (2014). Bayes and empirical Bayes: Do they merge? Biometrika, 101, 285–302. https://doi.org/10.1093/biomet/ast067
- Piironen, J., & Vehtari, A. (2015). Projection predictive variable selection using Stan + R. arXiv Preprint arXiv:1508.02502.
- Piironen, J., & Vehtari, A. (2017). Sparsity information and regularizationin the horseshoe and other shrinkage priors. Electronic Journal of Statistics, 11, 5018–5051. https://doi.org/10.1214/17-EJS1337SI
- Polson, N. G., & Scott, J. G. (2010). Shrink globally, act locally: Sparse Bayesian regularization and prediction. Bayesian Statistics, 9, 105.
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. (2016). Probabilistic programming in python using PyMC3. PeerJ Computer Science, 2, e55. https://doi.org/10.7717/peerj-cs.55
- Scott, J. G., & Berger, J. O. (2006). An exploration of aspects of bayesian multiple testing. Journal of Statistical Planning and Inference, 136, 2144–2162. https://doi.org/10.1016/j.jspi.2005.08.031
- Tibshirani, R. (1996). Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58, 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
- Van Der Pas, S. L., Kleijn, B. J., & Van Der Vaart, A. W. (2014). The Horseshoe estimator: Posterior concentration around nearly black vectors. Electronic Journal of Statistics, 8, 2585–2618. https://doi.org/10.1214/14-EJS962
- Watt, H. M. (2004). Development of adolescents’ self-perceptions, values, and task perceptions according to gender and domain in 7th-through 11th-grade australian students. Child Development, 75, 1556–1574. https://doi.org/10.1111/j.1467-8624.2004.00757.x
- Williams, D. R., & Rodriguez, J. E. (2022). Why overfitting is not (usually) a problem in partial correlation networks. Psychological Methods, 27, 822–840. https://doi.org/10.1037/met0000437
Appendix A.
Further results
Figure 1. Marginal density of the Dirichlet-horseshoe (DHS) in comparison with those of the double exponential (DE), horseshoe (HS), Dirichlet-Laplace (DL), and regularized horseshoe (RHS) priors.
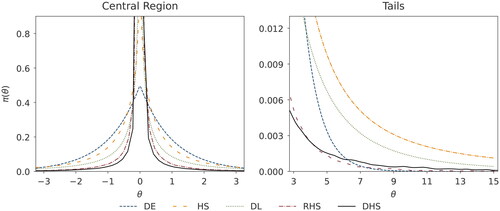
Figure 2. Squared error loss corresponding to the posterior median derived from the normal means problem (Simulation Study I), with a D = 400 dimensional parameter vector for varying signal strengths and sparsity ratios
(left panel) and
(right panel). We abbreviate the considered priors SPSL (spike-and-slab), BAL (Bayesian Adaptive lasso), HS (horseshoe), DL (Dirichlet-Laplace), RHS (regularized horseshoe), and DHS (Dirichlet-horseshoe).
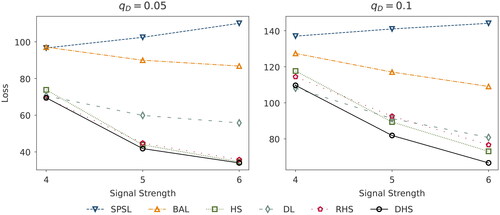
Figure 3. Squared error loss corresponding to the posterior median for different hyperparameter choices ν, derived from the normal means problem with a D = 400 dimensional parameter vector, sparsity ratio and varying signal strengths
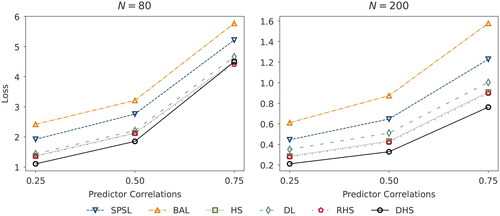
Figure 4. Squared error loss corresponding to the posterior median derived from the multiple regression setting (Simulation Study II) with a D = 100 dimensional parameter vector drawn from a log-normal distribution for varying correlations and observations N = 80 (left panel) and N = 200 (right panel). The design matrix is generated by a multivariate normal distribution with correlated predictors. The parameter vector
has a sparsity ratio of 20%, such that we set 80 of the 100 predictors to 0. We abbreviate the priors SPSL (spike-and-slab), BAL (Bayesian Adaptive lasso), HS (horseshoe), DL (Dirichlet-Laplace), RHS (regularized horseshoe), and DHS (Dirichlet-horseshoe).
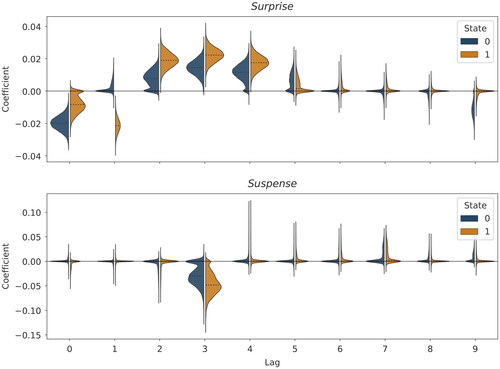
Figure 5. Posterior distributions of the effects of the emotional cues Surprise and Suspense on beer sales, derived from the real-data example. The figure shows posteriors for all lags in both states (negative S = 0 and positive S = 1). The dotted lines indicate the estimated median effect.
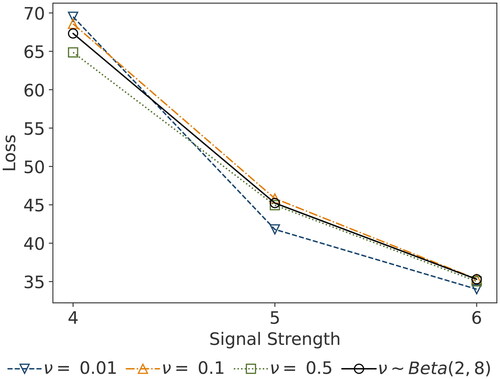
Table 1. This table provides a brief summary of the properties of prior distributions.
Table A1. This table presents performance metrics based on 95% HDIs, averaged across simulation replicates. The measures are derived from the normal means problem (Simulation Study I) with a D = 400 dimensional parameter vector. We perform Ω = 100 replications for all combinations of signals strengths and sparsity ratios
We consider the spike-and-slab (SPSL), Bayesian Adaptive lasso (BAL), horseshoe (HS), Dirichlet-Laplace (DL), regularized horseshoe (RHS), and Dirichlet-horseshoe (DHS) priors.
Table A2. See the descriptive notes to .
Table A3. This table presents performance metrics based on 95% HDIs, averaged across simulation replicates. The measures are derived from the multiple regression setting (Simulation Study II) with a D = 100 dimensional parameter vector drawn from a log-normal distribution. The design matrix is generated by a multivariate normal distribution with correlated predictors. We perform Ω = 100 replications for all combinations of observations and correlations
We consider the spike-and-slab (SPSL), Bayesian Adaptive lasso (BAL), horseshoe (HS), Dirichlet-Laplace (DL), regularized horseshoe (RHS), and Dirichlet-horseshoe (DHS) priors.
Table A4. See the descriptions for .
Appendix B. Priors simulation studies
B.1 Spike-and-slab
B.2 Bayesian Adaptive Lasso
B.3 Horseshoe
B.4 Dirichlet-Laplace
B.5 Regularized Horseshoe
B.6 Dirichlet-Horseshoe
(B1)
(B1)