
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose new ways of robustifying goodness-of-fit tests for structural equation modeling under non-normality. These test statistics have limit distributions characterized by eigenvalues whose estimates are highly unstable and biased in known directions. To take this into account, we design model-based trend predictions to approximate the population eigenvalues. We evaluate the new procedures in a large-scale simulation study with three confirmatory factor models of varying size (10, 20, or 40 manifest variables) and six non-normal data conditions. The eigenvalues in each simulated dataset are available in a database. Some of the new procedures markedly outperform presently available methods. We demonstrate how the new tests are calculated with a new R package and provide practical recommendations.
Goodness-of-fit testing is central when assessing whether a proposed measurement instrument can be used to understand latent psychological traits and processes. Researchers often evaluate their instruments using factor modeling where the trait is considered a latent variable that dictates the correlational structure among items. Model fit statistics and indices are then calculated, from which the researcher can assess whether the model is well specified. Only in a well-specified model can parameters such as factor loadings and correlations be properly interpreted to gain insight into the workings of a proposed instrument and the associations between latent traits.
In this article, we propose and study new classes of goodness-of-fit tests for structural equation models (SEMs) and confirmatory factor models under non-normality. As the sample size increases, commonly used test statistics have distributions that converge to distributions that are characterized by the eigenvalues of a certain matrix. Once these eigenvalues are estimated, p-values for the goodness of fit test can in principle be directly calculated. Unfortunately, as illustrated in a later section, empirical estimates of the eigenvalues are highly unstable and biased. We present an estimation theory for the eigenvalues and propose to stabilize and bias-correct the estimated eigenvalues using model-based trend predictions. This theory is based on population eigenvalues but allows for penalized estimation procedures where the penalization function can be chosen. Two classes of prediction models are investigated, where the trend for the eigenvalues may be piece-wise constant or linear. We design penalization functions for these classes that take into account the known systematic bias of eigenvalue estimates.
We start our article with a review goodness-of-fit testing in SEM, including traditional and new procedures, under both normal and non-normal data. Then we present our new tests based on penalized estimation using an illustrative example. Next, we present a large-scale Monte Carlo study to evaluate the procedures in a variety of conditions with varying sample sizes, model sizes, and data distributions. This is followed by a section that summarizes the results of the Monte Carlo simulations. Afterward, we demonstrate how to perform the tests using the new R (R Core Team, Citation2023) package semTests (Moss, Citation2024). We end with a discussion of our findings, where we also outline limitations and future research ideas.
The online supplementary material contains an analytical framework for the new tests, software snippets, mathematical deductions, and further simulation results.
1. Goodness-of-Fit Tests in Covariance Structure Analysis
Factor and structural equation models imply structural constraints on the covariance matrix Σ of the observed variables
Model parameters are contained in the q-dimensional vector θ and are estimated by minimizing a discrepancy function that measures the distance between the observed covariance matrix S from n observations and the model-implied covariance matrix
For instance, in confirmatory factor analysis, the model is specified by the equations where
is a p-dimensional vector of observed variables,
is a latent vector, and
is a p-dimensional vector of residuals, which are uncorrelated with
(Bollen, Citation1989). The elements in Λ, some of which are constrained to zero, are referred to as factor loadings. Additional constraints regarding the elements of
and
are needed for model identification, where
and
are the covariance matrices of the latent and residual variables, respectively. The model implies the following covariance structure among the observed variables:
where θ contains all the estimated parameters in
and
The most popular estimation method is normal-theory maximum likelihood (NTML), where the discrepancy function is (Bollen, Citation1989)
The corresponding estimator is the minimizer of
over θ. We remark that this estimator is consistent even under non-normal data.
1.1. Tests for Normal Data
Most tests for correct model specification in SEM are based on some model fit test statistic often referred to as a
statistic, whose sampling distribution can be approximated by a chi-square distribution when data are multivariate normally distributed and the model specification is correct. Popular model fit indices such as RMSEA (Steiger et al., Citation1985) and CFI (Bentler, Citation1990) also depend on a
that is approximately chi-square distributed under normality.
The most commonly used candidate for reported by default in most software packages, is
Under correct model specification and normal data,
converges to a chi-square distribution with
degrees of freedom, where q is the number of freely estimated model parameters (Jöreskog, Citation1969).
Another candidate for is the reweighted least squares (RLS) statistic
Here is any consistent estimator, e.g.,
Just as
is asymptotically chi-square distributed with d degrees of freedom under correct model specification and normal data (Browne, Citation1974). However, recent work by Hayakawa (Citation2019) and Zheng and Bentler (Citation2022) suggests that
converges to its limiting distribution quicker than
That is, at a given sample size with normal data,
was found to better maintain Type I error control than
1.2. Robustified Tests for Non-Normal Data
The chi-square sampling distribution of is distorted when the data fails to be normal (Micceri, Citation1989; Cain et al., Citation2017). Under correct model specification, its asymptotic distribution is a weighted sum of independent chi-square variables, each with one degree of freedom:
(1)
(1)
where the weights
are the non-zero eigenvalues of the matrix product
The matrix U depends on model characteristics. Let
where
is the half-vectorization of
i.e., the vector obtained by stacking the columns of the square matrix
one underneath the other, after eliminating all elements above the diagonal. Then
where
(Satorra and Bentler, Citation1994), and Dp is the duplication matrix (Magnus and Neudecker, Citation1999). The matrix Γ is the asymptotic covariance matrix of the sample covariances and depends solely on the data distribution.
To make use of Equationeq. (1)(1)
(1) , consistent estimates, i.e., estimates that converge in probability, of the quantities
and λ must be available. Since eigenvalues are the roots of a polynomial, they are continuous functions of the polynomial coefficients (Harris and Martin, Citation1987), and we may estimate λ consistently by
given as the eigenvalues of
provided U and Γ are consistently estimated by
and
respectively. A consistent estimator
of U can be obtained by replacing θ with an estimate
Under standard assumptions,
will be consistent (Satorra, Citation1989), implying that
is consistent as long as the mapping
is continuous, which we will assume. We will also assume that consistent estimators of Γ are available. A standard estimator of Γ is the moment-based
defined in e.g., Section 3 of Browne, Citation1984, which is consistent as long as the observations have finite eight order moments.
The most well-known robustification procedure is the Satorra–Bentler (SB) scaling (Satorra and Bentler, Citation1988) and involves scaling by a factor so that the asymptotic mean of the resulting statistic matches the expectation d of the nominal chi-square distribution:
(2)
(2)
This results in a p-value given by
where
is a chi-square distribution with d degrees of freedom.
Asparouhov and Muthén (Citation2010) proposed to scale and shift (SS) the statistic TNT,
where
and
The statistic
has the same asymptotic mean and variance as the reference chi-square distribution. Similarly to the SB-procedure, the resulting p-value is
Monte Carlo studies (e.g., Foldnes and Olsson, Citation2015) report that tend to overreject and
tend to underreject correctly specified models.
Eigenvalue block averaging (EBA) is a recent effort to improve upon and
by defining a flexible class of test statistics (Foldnes and Grønneberg, Citation2017). First, the d non-zero eigenvalues of
are sorted in increasing order,
These eigenvalues are then grouped into several equally sized bins, or blocks, and the block averages are calculated. Then, a vector of weights
is constructed by replacing the eigenvalues with their block averages. For instance, in two-block EBA, denoted EBA2, the first block has
where
denotes rounding up to the nearest integer, while the second block has
The corresponding p-value for the goodness-of-fit test is then obtained as
(3)
(3)
where
(4)
(4)
for independent standard normal variables
For a single block, each for
equals the average of all estimated eigenvalues
That is,
for
The sum of the eigenvalues of a square matrix equals its trace. Therefore,
and by Equationeq. (2)
(2)
(2) , we have
(5)
(5)
Since
Equationeq. (5)(5)
(5) shows that
That is, the p-value for a single block is identical to the Satorra–Bentler p-value.
This argument can be applied to any number of blocks, giving p-values for and so forth (Foldnes and Grønneberg, Citation2017).
All the robustified tests require an estimate of the asymptotic covariance matrix Γ. Browne (Citation1974) discussed two estimators for Γ, which we refer to as
and
The former is asymptotically consistent and is currently the default estimator used in software packages. The latter is unbiased in finite samples, and asymptotically equivalent to
It has recently attracted attention (Du and Bentler, Citation2022) as a promising alternative to
In addition, the robustified tests require a candidate for
In the present study we consider candidates
and
With two candidates for and two candidates for
there are four possible estimators for any quantity depending on them. So every robustified procedure considered in the present study has four versions, and all of these are included in our Monte Carlo design. We use the following notation: the
version is indicated as a subscript, and we indicate the use of
instead of
by employing the superscript UG. For instance, for the SB procedure we have the versions
and
1.3. Asymptotically Exact Tests
We refer to test procedures whose Type I error control under correct model specification converges to the nominal level as asymptotically exact tests. The procedures SB, SS, and EBA are not in general asymptotically exact. In other words, the Type I error rate of, e.g., SB, will not necessarily approach the nominal rate of 5% even in large samples. In contrast, the three procedures next discussed are asymptotically exact.
By imposing mild assumptions on the employed estimator and the rank of Δ and Γ, Browne (Citation1984) showed that the asymptotically distribution-free (ADF) test statistic
asymptotically follows a chi-square distribution with d degrees of freedom whenever
consistently estimates Γ. Unfortunately, many studies (e.g., Curran et al., Citation1996; Olsson et al., Citation2000) report that the ADF test requires very large sample sizes to perform satisfactorily, due to the sampling variance of the fourth-order moments involved in estimating Γ.
The second asymptotically exact test is the Bollen–Stine bootstrap (Beran and Srivastava, Citation1985; Bollen and Stine, Citation1992). The procedure starts with linearly transforming the observed data so that the model fits the transformed data perfectly. Then, a p-value for the hypothesis of correct model specification is calculated by drawing bootstrap samples from the transformed data set and fitting the model to obtain a sequence of normal theory bootstrap values. The p-value is the proportion of the
values that exceed the original
value obtained in the original data sample. The number of bootstrap samples is typically at least 1000, so the bootstrap is a computationally intensive method. This likely explains the scarcity of Monte Carlo studies that evaluate the Bollen–Stine bootstrap. Also, most of these studies focus on small models with no more than 11 observed variables (Fouladi, Citation1998; Ichikawa and Konishi, Citation2001; Nevitt and Hancock, Citation2004; Foldnes and Grønneberg, Citation2019). For larger models, to the best of our knowledge, Ferraz et al. (Citation2022) is the only available study, including up to 30 observed variables. For small models with 10 observed variables, the results of Ferraz et al. (Citation2022) were in line with previous studies in finding that the Bollen–Stine bootstrap adequately controlled Type I error rates. However, for larger models Ferraz et al. (Citation2022) concluded that the empirical rejection rates were too low. For instance, with 30 observed variables and the largest sample size included (n = 1000), the rejection rates were in the range 1.8%- 2.6% at the 5% level of significance. In our Monte Carlo study, we expand the number of observed variables to 40 and employ a larger set of non-normal data conditions than previously considered, to gain further insight into the Bollen–Stine bootstrap.
The third asymptotically exact test uses the estimated eigenvalues of directly. Since this is equivalent to block-averaging eigenvalues with blocks of size one, so that
for
we may consider this an EBA type procedure, with p-value given by
where H is defined in Equationeq. (4)
(4)
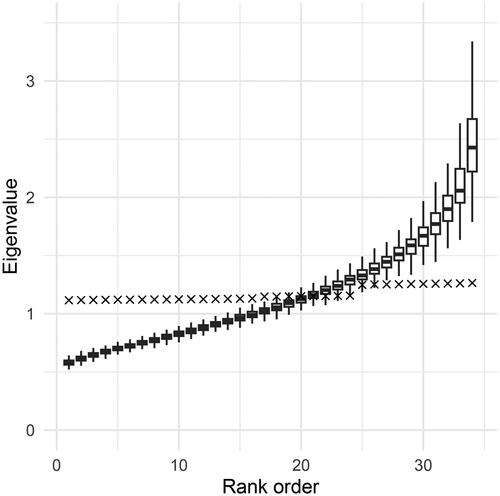
(4) . This procedure is identical to using d blocks (which are then singleton sets) in EBA, and we refer to it as EBAd. Since EBAd has not yet been studied in the literature, it is included in our Monte Carlo investigations. The estimated eigenvalues will converge toward their population counterparts as the sample size increases, so EBAd is asymptotically exact. The sampling variability of estimated eigenvalues is, however, so large that impractical sample sizes may be required to obtain acceptable Type I error control. illustrates the final sample fluctuations in the estimated eigenvalues in a ten-dimensional two-factor model with non-normal data. The model has 34 degrees of freedom, and hence 34 associated non-zero eigenvalues. In the figure, the crosses represented the population values, i.e., the eigenvalues of
in increasing order, with a range
We simulated 200 samples of size n = 1500 and extracted in each sample the sorted eigenvalues of
For each rank
the corresponding estimated eigenvalues are represented by box plots. We make the following observations: (i) The estimates have high sampling variability, especially the largest eigenvalues. (ii) The higher eigenvalues are consistently overestimated, and the lower eigenvalues are consistently underestimated. (iii) Most of the box plots do not cover their corresponding population eigenvalue. These observations suggest that directly using the estimated eigenvalues to approximate the sampling distribution of
may not work well. While both the SB and the EBA procedures attempt to handle the sampling variability of eigenvalues by averaging sets of eigenvalues, earlier literature has not addressed the problem of under- and overestimation. The new approaches proposed below take the systematic bias into account and are designed to work well when the eigenvalues are related to the true eigenvalues in the same way as in .
Figure 1. Population and estimated eigenvalues for a ten-dimensional CFA with 34 degrees of freedom. The × represent population eigenvalues, while the boxplots represent estimated eigenvalues across 200 replications at sample size n = 1500.
Before we turn to the new estimation methods, we explain why the pattern shown in is expected to occur also in conditions not covered by our Monte Carlo study.
1.4. Estimated Eigenvalues and the Empirical Spectral Function
The set of eigenvalues of a matrix are not ordered in and of themselves, although we can naturally sort the eigenvalues in increasing order. What are the statistical consequences of this ordering?
To build intuition, let us consider a highly simplified scenario where the eigenvalue estimates are independent and normal. We observe the set
where
are independent,
and
Although there is an order to the observations in our notation, we only observe the unordered set S, which plays the role of the estimated eigenvalues. This emulates a situation where
has 34 eigenvalues, each equal to either 2.5 or 3.5.
If we plot the sorted eigenvalues against their rank
and connect these points via straight lines, the resulting curve is the empirical quantile function of the data. This curve will approximate the population quantile function. To see why, recall first that the empirical quantile function is a generalized inverse of the empirical distribution function
(6)
(6)
where
is the indicator function of A, being 1 if A is true and zero otherwise. This empirical distribution function
uniformly approximate
(Shorack and Wellner, Citation2009, Chapter 25). Under the assumed distribution for
we get
The empirical quantile function will therefore approximate the inverse of
which we may denote by Q(p). Therefore, a plot of
will be close to
is based on a single realization of The quantile function Q is plotted in red, the plot of
in black, and the empirical quantile function in blue. The black curve is not visible as it is overwritten by the blue curve. displays shapes similar to the eigenvalues plotted in . There is systematic over- and underestimation of these values for i/d near zero or one, an effect that is due solely to sorting.
Figure 2. The sorted simulated data plotted against i/d for the curve in red is the theoretical quantile function. The curve in blue is the empirical quantile function. The dotted black values are the levels of the observations.
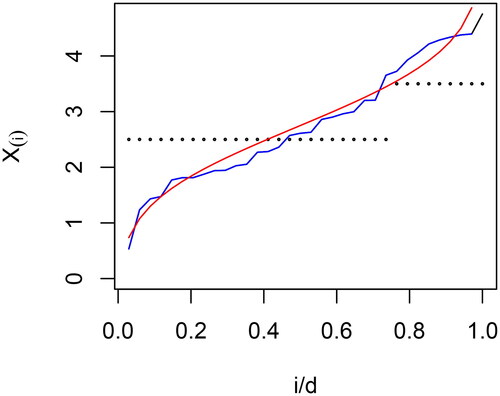
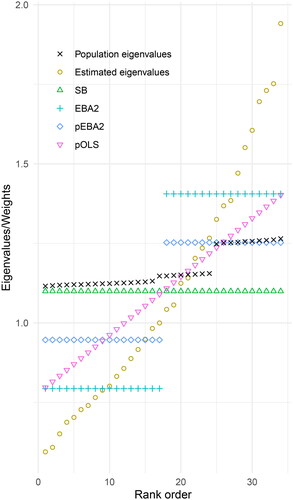
Figure 3. Estimated eigenvalues and associated weights for EBA and regression procedures. EBA2 = 2-block EBA, pEBA2 = penalized 2-block EBA, pOLS = penalized regression, SB = Satorra–Bentler.
While the estimated eigenvalues converge to λi, the variation in
will be considerable for realistic sample-sizes. A plot of
will have the shape of an empirical quantile curve defined by the same formula as
above (6), but with
in place of Xi. Such objects are known as empirical spectral functions and play an important role in random matrix theory (Pastur and Shcherbina, Citation2011; Paul and Aue, Citation2014). We conjecture that the empirical spectral function of
converges to a population function as d and n increases, so there is a limiting curve that plays a similar role as the red curve in . With insights into this limit curve, a principled estimation procedure for approximating
could be developed in future work.
1.5. New Goodness-of-Fit Tests Based on Penalized Estimation
In this section, we introduce and motivate new procedures for obtaining p-values based on penalization of the estimated eigenvalues. Technical arguments are deferred to the online supplementary material.
Similar to the EBA procedures, the new tests takes the estimated eigenvalues as input. From these values, regularized estimates
are produced as next discussed, and these are used to calculate a p-value for the goodness of fit test using H in Equationeq. (4)
(4)
(4) :
For illustration, we continue with the eigenvalues associated with the factor model discussed in Section 1.3 (), which has 34 degrees of freedom. Here, however, we consider a single random sample of size n = 1500 and the corresponding set of estimated eigenvalues, using ΓA. These estimates and their corresponding population values are plotted in . Also, the figure depicts four sets of approximated eigenvalues: First, the SB eigenvalues are plotted, all with the same value, namely the mean eigenvalue of 1.10. Second, the EBA2 approximations are depicted, with the 17 smallest eigenvalues set at the mean value 0.79 and the 17 largest eigenvalues at the mean value 1.41. The two remaining eigenvalue sets in the figure, pEBA2 and pOLS, are obtained by a process explained in the next two subsections.
1.6. Penalized EBA
The EBA procedure may be modified naturally to counteract the bias observed in and . also contains a new set of eigenvalues in the intermediate positions between SB and EBA2, which we call penalized EBA2 and denote by pEBA2. The connection to penalized estimation is explained in the online supplementary material. pEBA2 consists of a two-block set of weights equal to the average of the SB and the EBA2 weights. In , the first block of weights contains the mean value of 1.10 and 0.79, which is 0.95. Likewise, the second block has weights equal to the mean of 1.10 and 1.41, namely 1.26.
The procedure may be performed in the same manner for any number of blocks. That is, we average the EBA weights block by block with the overall average eigenvalue and thus obtain penalized versions pEBA3, pEBA4, and so forth.
The additional averaging employed in penalized EBA attempts to counteract the systematic bias observed in and . By anchoring the EBA eigenvalues closer to the global average, the overestimation for the larger eigenvalue estimates is reduced, while still not restricting the eigenvalues to be constant. Similarly, the underestimation of the smaller eigenvalue estimates is also reduced.
1.7. Penalized OLS
The penalized OLS procedure can be motivated by a simple heuristic. Let be the population eigenvalues and run a simple linear regression based on
to obtain the OLS estimates
and
The ith eigenvalue – which is positive since
is positive definite – can now be approximated by
This linear approximation inherits the systematic bias observed in and , causing the slope to be overestimated. A natural remedy to this sort of overestimation is to down-weight the regression slope using ridge regression, a well-known penalized form of OLS, which we refer to as pOLS.
The extent of down-weighting is represented by a parameter that is applied to the OLS slope parameter β1:
(7)
(7)
The corresponding ridge regression intercept is
(8)
(8)
The standard OLS estimates are recovered when γ = 1. For we obtain
and
or the Satorra–Bentler weights. Simulations show that γ = 2 works well, and we will use it in the remainder of the article. shows the predictions of pOLS.
1.8. RMSEA with Eigenvalue-Based Tests
The RMSEA is a popular measure of approximate fit originating from the work of Steiger (Citation1990). Using the Satorra–Bentler method, Li and Bentler (Citation2006) found the formula
Here λi are replaced by estimated values in practice. In the online supplementary material, it is shown the proposed penalized eigenvalue-based estimators have the same sum as the Satorra–Bentler estimate, and that the above formula for the RMSEA also holds for these procedures.
2. Monte Carlo Simulation
We considered a two-factor model where
is a p-dimensional vector of observed variables,
is a two-dimensional latent vector, and
is a p-dimensional vector of uncorrelated residuals, which is also uncorrelated with
The model had simple structure, with
loading on the first factor and
loading on the second factor. We included three model sizes with
and 40, and corresponding degrees of freedom
and 739. This study was not preregistered. The model specifications are available at https://osf.io/6trwu/, together with a database of eigenvalues for each replicated dataset in the present study. The eigenvalues are given for both the biased and the unbiased Γ estimators. The database also contains
and
and may be used for fast assessment of new variants of eigenvalue-based procedures.
2.1. Population Model
To represent a realistic scenario, we used heterogeneous factor loadings with standardized loadings uniformly drawn in the range Such loadings reflect values typically found in empirical studies (Li, Citation2016). The residual variances were then chosen to ensure that the observed variables had unit variance. The factor loadings were nested between models, e.g., for p = 20 the first five loadings for each factor were equal to the corresponding loadings in the p = 10 model. The interfactor correlations in all models were set to .5. For p = 10, the 45 correlations in the observed variables ranged from .08 to .56. For p = 20 the 190 correlations ranged from .08 to .64. The 780 correlations in the p = 40 model ranged from .045 to .64.
2.2. Data Distributions
For each population model, data were drawn from seven distributions. The distributions consisted of the normal distribution and six non-normal distributions. Three of the non-normal distributions had moderate marginal skewness and kurtosis (Curran et al., Citation1996) taking values 3 and 7, and the other three had severe marginal skewness and kurtosis (with values 3 and 21). We crossed the two marginal non-normality levels with three data distributions: The independent generator (IG) distribution (Foldnes and Olsson, Citation2016), the piece-wise linear (PL) distribution (Foldnes and Grønneberg, Citation2021), and the well-known Vale–Maurelli (VM) distribution (Vale and Maurelli, Citation1983). We use the notation VM1 and VM2 for the VM distributions with the moderate and severe levels of marginal skewness and kurtosis, and similarly for the IG and PL distributions.
Including several classes of non-normal distributions was necessary for the external validity of the study, and was also required for investigating test performance while controlling for marginal skewness and kurtosis. However, note that even with the same skewness and kurtosis, the IG, PL, and VM distributions are different.
2.3. Sample Size
We generated data at sample sizes and 3000, to reflect a range of sample sizes routinely used in empirical investigations.
2.4. Goodness-of-Fit Tests
All test statistics were calculated from normal-theory ML estimates. For the robustified tests and EBAd we considered four candidates, obtained by combining base statistic ( or
) and estimator of the asymptotic covariance matrix (
or
).
A total of 43 test statistics were evaluated, including the base statistics or
For the robustified tests we included the traditional tests
and
(a total of 8 candidates), the EBA procedures EBA2, EBA4, and EBA6 (12 candidates), the penalized EBA procedures pEBA2, pEBA4, and pEBA6 (12 candidates), and the pOLS test (4 candidates). Among the asymptotically exact tests, we included the Bollen–Stine bootstrap based on
and the EBA procedure with singleton blocks, EBAd (4 candidates).
2.5. Data Generation and Analysis
Crossing model size, distribution, and sample size resulted in 84 ( simulation conditions. We generated 3000 datasets for each condition. All tests except Bollen–Stine were evaluated in each condition based on 3000 replications. The computationally expensive Bollen–Stine test was computed only for n = 800 and n = 3000, and in the largest dimension (p = 40) the number of bootstrap replications was reduced to 1000.
All models were estimated using the maximum likelihood estimator in lavaan (Rosseel, Citation2012). The package covsim (Grønneberg et al., Citation2022) was used to simulate from the IG and PL distributions and the package lavaan was used to simulate VM distributions. The goodness-of-fit p-values were calculated using the newly developed package semTests. The package CompQuadForm (Duchesne and De Micheaux, Citation2010) computed the p-values of the type given in EquationEq. (3)(3)
(3) .
2.6. Evaluation Criteria
We employed three evaluation criteria based on the observed percentage rejection rates (RR), obtained in each of the 84 conditions as the percentage of p-values below .05. Hence, we adopted the commonly used significance value of
Our first criterion is the root-mean-square error (RMSE), which is a measure of the discrepancy between the observed rejection rate RR and the nominal 5% rejection rate: where C denotes the number of conditions we are interested in. For instance, if we look at the smallest model size, and we include all distributions and sample sizes,
Our second criterion, the mean absolute deviation (MAD), is also a measure of the difference between the empirical rejection rates and the nominal rejection rate, defined as
Our third criterion yields the percentage of acceptable rejection rates (ARR), defined as the proportion of conditions c for which (Bradley, Citation1978).
Given the large number of test candidates under evaluation, in addition to reporting these three criteria, we also sort the tests according to their RMSE performance in many of our result tables. We acknowledge that the sorting shifts the order of test statistics between tables, making it more difficult to compare the performance of a given test candidate across conditions. However, the sorting greatly facilitates the identification of the best-performing tests by inspecting the upper part of the result tables.
3. Results
3.1. ML, RLS and Robustified Tests
We evaluated two tests based on normality, either with ML and RLS, and 38 robustified tests.
3.1.1. Normal data
Type I error rates in the 12 conditions with normal data are presented in . For each model size, we have sorted the test statistics according to increasing RMSE values across the four sample sizes. At the smallest model size, p = 10, the normal-theory statistics and
performed well, as expected. All 40 test candidates had acceptable rejection rates, ARR = 1, at all sample sizes. The MAD ranged from 0.3% for ML to 0.733% for
Table 1. Type I Error rates, normal data.
With increasing model size, test performance generally deteriorated, as expected. Especially striking was the poor performance of ML in comparison to RLS. For instance, for p = 20 and p = 40 the MAD of ML was 1.18% and 5.85%, respectively. In comparison, the MAD of RLS was negligible for p = 20 and p = 40: 0.29% and 0.51%, respectively. Also, for dimensions p = 20 and p = 40 the robustified test was a top performer. Indeed, this test was the overall winner in terms of RMSE when collapsed over all 12 conditions, with RLS as the runner-up.
3.1.2. Non-Normal Data
Type I error rates for all tests in the 12 conditions (3 models, 4 sample sizes) are tabulated for each non-normal distribution in the supplementary material, see Tables B2–B7. In we report aggregated results over the six non-normal distributions. Test performance was calculated for each model size, across six distributions and four sample sizes, and test candidates were ranked according to increasing RMSE.
Table 2. Test performance across 6 non-normal distributions and 4 sample sizes, ranked in increasing RMSE order.
Under non-normality, the normal-theory statistics ML and RLS performed poorly. In fact, in none of the 72 non-normal conditions did these tests achieve an acceptable rejection rate.
Expectedly, the normal-theory tests were outperformed by the traditional robustified tests, SB and SS. Generally, SB outperformed SS, and the SB candidate with the consistently best performance was The standard SB test, which is based on ML and
performed remarkably worse than
which is based on RLS and
For instance, collapsing over all 72 non-normal conditions, the MAD of SB and
was 3.28% and 1.63%, respectively. Also, the ARR of SB was 65.3%, compared to 76.4% for
Among the SS candidates, performance was best when based on ML and
However, even for this candidate, SS, had overall poor performance, especially in the large model, where ARR was zero.
Many candidates in the family of newly developed procedures (EBA, pEBA, and pOLS) outperformed the SB and SS procedures. The RMSE rank in of the best traditional robustified test, was 17, 20, and 18 for dimensions 10, 20 and 40, respectively. To further give an overview of the best-performing tests, we aggregated also over model size, with the resulting ten best performers (in terms of RMSE) presented in . This table hence is based on collapsing 72 conditions (six distributions, four sample sizes, and 3 model sizes). The top nine performers in all belong to the new class of penalized eigenvalue modeling. Also noteworthy, eight of the ten tests are based on RLS, and only two on ML.
Table 3. Top ten robustified tests according to RMSE when aggregating 6 non-normal distributions, 4 sample sizes and 3 model sizes.
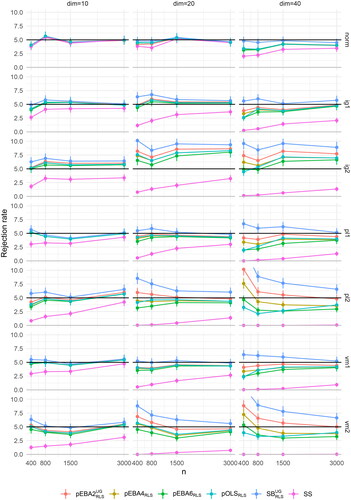
To investigate in full detail the performance of some of the best tests in , we picked the top candidate from the pEBA2, pEBA4, pEBA6, and pOLS families, namely and
The rejection rates in all 72 conditions of these four candidates are plotted in . The figure also includes the best candidate in each of the traditional families of robustified tests:
for SB, and SS for SS. A consistent pattern is that the newly developed tests were associated with rejection rates intermediate between SS, which severely under-rejected, and
which tended to over-reject. The figure demonstrates that goodness-of-fit testing was more challenging in larger models, while larger sample sizes are associated with better Type I error control. Also, the distributional type affected the test procedures. Under normality (see also ), all tests performed well, except SS in the largest model. Under non-normality, we see that performance depended on marginal kurtosis, as expected, with overall MAD (across tests, distributions, and model sizes) equal to 1.11% for the skewness = 2, kurtosis = 7 condition (IG1, PL1, VM1) and 1.88% for the skewness = 7, kurtosis = 21 condition (IG2, PL2, VM2). Also, there was some variation in overall test performance among the underlying distributional class. The overall MAD for distributions of type IG, PL, and VM was 1.56%, 1.50%, and 1.43%, respectively.
Figure 4. Rejection rates in % for six selected tests. Panel columns and rows correspond to model size and distribution, respectively.
3.2. Asymptotically Exact Tests
presents the Bollen–Stine rejection rates. The underlying distribution strongly affected test performance, with severe overrejection for PL2 and partly for VM2. In the large model, for PL2 and VM2, the rejection rate was virtually 100%, in striking contrast to the finding in Ferraz et al. (Citation2022) that the Bollen–Stine test tended to underreject in a p = 30 model. In contrast, under the normal and IG distributions, Bollen–Stine consistently underrejected, reflecting the findings in Ferraz et al. (Citation2022). Overall, echoing the findings of Ferraz et al. (Citation2022), as model size increased, Bollen–Stine performed poorly, even for n = 3000.
Table 4. Rejection rate in % for the bollen–stine bootstrap.
Next, consider the asymptotically exact test EBAd. The differences between the four EBAd candidates were small (see in the supplementary material). Therefore, in we only report results for the default version, which is based on ML and The results are aggregated over all 7 distributions. The test exhibited poor Type I error control, especially at low sample sizes, with severe underrejection. The asymptotic superiority of
was not yet detectable at sample size n = 3000. To further inspect the rate of converge to nominal 5% rejection rates, and to confirm asymptotic consistency, we simulated some very large sample size conditions (
). Even at
the tendency to underreject was still pronounced for dimensions p = 20 and p = 40. For instance, for p = 40 and
the overall rejection rate across distributions was only 2.6%.
Table 5. Rejection rate in % for the test procedure, aggregated over all seven distributions.
4. Illustration of the Package semTests
We demonstrate the use of the newly developed R package semTests (Moss, Citation2024) by conducting a small power study. Consider the model with p = 20 observed variables used in our Monte Carlo study (see supplementary online material for the complete model specification). We first simulate a n = 800 non-normal data set from this model using the VM2 distribution. Then we run the pvalues() function from semTests on the fitted model, using the default parameter values. The default p-values reported were chosen from the best-performing tests in our Monte Carlo study, in addition to the best-performing traditional test
library(semTests); library(lavaan)
set.seed(1234)
X <- simulateData(m2, sample.nobs = 800,
↪ skewness = 3, kurtosis = 21)
f <- cfa(m2, data = X)
pvals <- pvalues(f)
round(pvals,3)
#sb_ug_rls peba2_ug_rls peba4_rls peba6_rls
↪ pols2_rls
# 0.106 0.125 0.139 0.152 0.144
The reported p-values are similar, with having the smallest p-value.
Next, we conduct a small power study with 1000 replications where n = 800 and data is drawn from a VM2 distribution. Model misspecification is obtained by adding a cross-loading with standardized factor loading of 0.4.
m2_misspecified_pop <- paste(m2, “; F1=∼start
↪ (0.4)*x11”)
simres <- sapply(1:1000, \(i){
set.seed(i)
X <- simulateData(m2_misspecified_pop,
↪ sample.nobs = 800, skewness = 3, kurtosis
↪ =21)
f <- cfa(m2, data = X)
pvalues(f)})
rowMeans(simres < .05)
#sb_ug_rls peba2_ug_rls peba4_rls peba6_rls
↪ pols2_rls
# 0.705 0.666 0.624 0.598 0.631
The rejection rates are ordered in the same way as observed for the Type I errors in (see bottom middle panel at n = 800). Highest power is achieved by which also had the highest rejection rate, 7.1%, among the tests in . Hence, in terms of power,
outperformed the other test candidates. However, Type I error control is a more fundamental requirement than adequate power, and the other test candidates outperform
in terms of Type I error control.
5. Discussion
We have proposed and evaluated new goodness-of-fit methods for factor analysis and structural equation modeling with non-normal data. The new methods pEBA and pOLS apply penalization on the estimated eigenvalues of The pEBA methods were derived from the EBA approach (Foldnes and Grønneberg, Citation2017) and the pOLS methods are based on a linear approximation of the sorted eigenvalues, where the penalization is obtained by dampening the slope. We have provided a formal analysis of eigenvalue modeling that motivates pEBA and pOLS.
In the past, many tests have been proposed to handle goodness-of-fit testing under non-normality, and we conducted a large Monte Carlo study to compare the Type I error control of the new methods with well-known traditional tests such as the Satorra–Bentler scaled test, the scaled and shifted test, and the Bollen–Stine bootstrap test. Moreover, we took recent developments into account by acknowledging that the little-known normal-theory RLS test (Browne, Citation1974) might outperform the classical normal-theory ML test in multivariate normal conditions, and that replacing the traditionally used asymptotically unbiased Γ estimator by an unbiased estimator
might improve test performance. Therefore, the Monte Carlo study evaluated four versions (ML/RLS,
/
) of each test statistic.
5.1. Practical Recommendations
For the special case of normal data, our results echoed earlier findings (e.g., Hayakawa, Citation2019) in demonstrating that the RLS test is far superior to the more commonly used ML test. Therefore, we advise using instead of
when reporting goodness-of-fit in normal data conditions.
For non-normal data, our recommendations are as follows. Echoing Ferraz et al., Citation2022, we do not recommend using the Bollen–Stine bootstrap test. This test is computationally heavy and was found to adequately control Type I error only in the smallest model with 10 observed variables, and then only for five of the six non-normal conditions. In a model with 40 observed variables, we found the bootstrap test to perform poorly even with a sample size of 3000.
For the Satorra–Bentler test, we demonstrated an improved Type I error control by applying the scaling to the RLS test statistic instead of the commonly used ML statistic. Furthermore, performance is improved by replacing by
when calculating the scaling factor. As in previous studies (e.g., Foldnes and Olsson, Citation2015), the scaled-and-shifted test was found to perform poorly with severe under-rejection in most conditions, and we discourage its use unless the sample size is very large.
Overall, the nine best-performing tests in our Monte Carlo study all were of pEBA or pOLS type. Based on , we recommend basing goodness-of-fit in non-normal conditions on or
5.2. Limitations and Future Research
We have focused exclusively on continuous data. However, the methods we propose are naturally applicable to ordinal data analyzed using polychoric correlations. It is natural to ask whether pEBA and pOLS outperform the currently available methods in the testing of ordinal factor models, such as the SS test used by lavaan (Rosseel, Citation2012).
The idea of eigenvalue penalization has not been fully explored yet, and different variants could potentially result in better test performance. A more thorough analysis of eigenvalue modeling could shed more light on the subject. Using uneven block sizes in the pEBA is another possibility. Future estimation of the eigenvalues could also be based on the limiting behavior of the spectral distribution of
A natural extension of the present paper is to consider power. That is, among tests that control Type I error, which candidate best detects model misspecification? We consider this as a topic for a future Monte Carlo study. The results of such a study must involve balancing the primary concern of Type I error control with the secondary concern of power.
Our Monte Carlo design is limited in several ways. We only considered factor analysis models, not more general structural equation models. Moreover, the number of observed variables ranged from 10 to 40, but models with hundreds of observed variables are not uncommon in applied research. A study of about 50–100 variables would shed more light on such situations. We modeled three types of non-normal distributions, across two conditions of marginal non-normality as measured in terms of marginal skewness and kurtosis. But other kinds of non-normality is certainly encountered in practice, and further research could be conducted by employing more flexible non-normal distributional classes such as the flexible VITA method suggested by Grønneberg and Foldnes, Citation2017 and implemented in the R package covsim (Grønneberg et al., Citation2022). Finally, we considered model fit only for non-nested models. Nested model testing is widely conducted in measurement invariance testing, and the new test procedures can naturally be applied also in these situations.
6. Conclusion
We have proposed several new methods for evaluating model fit of structural equation models and evaluated their performance in a Monte Carlo study of factor models. The new methods outperform existing methods such as Satorra–Bentler in terms of Type I error control. The overall best-performing test, performed adequately in 69 of 72 non-normal conditions. The new methods are available in the R package semTests.
Supplemental Material
Download PDF (252.2 KB)References
- Asparouhov, T., & Muthén, B. (2010). Simple second order chi-square correction. Mplus Technical Appendix, 1–8.
- Bentler, P. M. (1990). Comparative fit indexes in structural models. Psychological Bulletin, 107, 238–246. https://doi.org/10.1037/0033-2909.107.2.238
- Beran, R., & Srivastava, M. S. (1985). Bootstrap tests and confidence regions for functions of a covariance matrix. The Annals of Statistics, 13, 95–115. https://doi.org/10.1214/aos/1176346579
- Bollen, K. A. (1989). Structural equations with latent variables. Wiley.
- Bollen, K. A., & Stine, R. A. (1992). Bootstrapping goodness-of-fit measures in structural equation models. Sociological Methods & Research, 21, 205–229. https://doi.org/10.1177/0049124192021002004
- Bradley, J. V. (1978). Robustness? British Journal of Mathematical and Statistical Psychology, 31, 144–152. https://doi.org/10.1111/j.2044-8317.1978.tb00581.x
- Browne, M. W. (1974). Generalized least squares estimators in the analysis of covariance structures. South African Statistical Journal, 8, 1–24.
- Browne, M. W. (1984). Asymptotically distribution-free methods for the analysis of covariance structures. The British Journal of Mathematical and Statistical Psychology, 37, 62–83. https://doi.org/10.1111/j.2044-8317.1984.tb00789.x
- Cain, M. K., Zhang, Z., & Yuan, K.-H. (2017). Univariate and multivariate skewness and kurtosis for measuring nonnormality: Prevalence, influence and estimation. Behavior Research Methods, 49, 1716–1735. https://doi.org/10.3758/s13428-016-0814-1
- Curran, P. J., West, S. G., & Finch, J. F. (1996). The robustness of test statistics to nonnormality and specification error in confirmatory factor analysis. Psychological Methods, 1, 16–29. https://doi.org/10.1037/1082-989X.1.1.16
- Du, H., & Bentler, P. (2022). 40-year old unbiased distribution free estimator reliably improves sem statistics for nonnormal data. Structural Equation Modeling: A Multidisciplinary Journal, 29, 872–887. https://doi.org/10.1080/10705511.2022.2063870
- Duchesne, P., & De Micheaux, P. L. (2010). Computing the distribution of quadratic forms: Further comparisons between the Liu–Tang–Zhang approximation and exact methods. Computational Statistics & Data Analysis, 54, 858–862. https://doi.org/10.1016/j.csda.2009.11.025
- Ferraz, R. C., Maydeu-Olivares, A., & Shi, D. (2022). Asymptotic is better than bollen-stine bootstrapping to assess model fit: The effect of model size on the chi-square statistic. Structural Equation Modeling: A Multidisciplinary Journal, 29, 731–743. https://doi.org/10.1080/10705511.2022.2053128
- Foldnes, N., & Grønneberg, S. (2017). Approximating test statistics using eigenvalue block averaging. Structural Equation Modeling: A Multidisciplinary Journal, 25, 101–114. https://doi.org/10.1080/10705511.2017.1373021
- Foldnes, N., & Grønneberg, S. (2019). Pernicious polychorics: The impact and detection of underlying non-normality. Structural Equation Modeling: A Multidisciplinary Journal, 27, 525–543. https://doi.org/10.1080/10705511.2019.1673168
- Foldnes, N., & Grønneberg, S. (2021). Non-normal data simulation using piecewise linear transforms. Structural Equation Modeling: A Multidisciplinary Journal, 0, 1–11.
- Foldnes, N., & Olsson, U. H. (2015). Correcting too much or too little? The performance of three chi-square corrections. Multivariate Behavioral Research, 50, 533–543. https://doi.org/10.1080/00273171.2015.1036964
- Foldnes, N., & Olsson, U. H. (2016). A simple simulation technique for nonnormal data with prespecified skewness, kurtosis, and covariance matrix. Multivariate Behavioral Research, 51, 207–219. https://doi.org/10.1080/00273171.2015.1133274
- Fouladi, R. T. (1998). Covariance structure analysis techniques under conditions of multivariate normality and nonnormality-modified and bootstrap based test statistics [Paper presentation]. Annual Meeting of the American Educational Research Association.
- Grønneberg, S., & Foldnes, N. (2017). Covariance model simulation using regular vines. Psychometrika, 82, 1035–1051. https://doi.org/10.1007/s11336-017-9569-6
- Grønneberg, S., Foldnes, N., & Marcoulides, K. M. (2022). covsim: An r package for simulating non-normal data for structural equation models using copulas. Journal of Statistical Software, 102, 1–45. https://doi.org/10.18637/jss.v102.i03
- Harris, G., & Martin, C. (1987). Shorter notes: The roots of a polynomial vary continuously as a function of the coefficients. Proceedings of the American Mathematical Society, 100, 390–392. https://doi.org/10.2307/2045978
- Hayakawa, K. (2019). Corrected goodness-of-fit test in covariance structure analysis. Psychological Methods, 24, 371–389. https://doi.org/10.1037/met0000180
- Ichikawa, M., & Konishi, S. (2001). Efficient bootstrap tests for the goodness of fit in covariance structure analysis. Behaviormetrika, 28, 103–110. https://doi.org/10.2333/bhmk.28.103
- Jöreskog, K. G. (1969). A general approach to confirmatory maximum likelihood factor analysis. Psychometrika, 34, 183–202. https://doi.org/10.1007/BF02289343
- Li, C.-H. (2016). The performance of ml, dwls, and uls estimation with robust corrections in structural equation models with ordinal variables. Psychological Methods, 21, 369–387. https://doi.org/10.1037/met0000093
- Li, & Bentler P. M. (2006). Robust statistical tests for evaluating the hypothesis of close fit of misspecified mean and covariance structural models. Technical report University of California, Los Angeles. (UCLA Statistics Preprint No. 506).
- Magnus, J. R., & Neudecker, H. (1999). Matrix Differential Calculus with Applications in Statistics and Econometrics. Wiley.
- Micceri, T. (1989). The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin, 105, 156–166. https://doi.org/10.1037/0033-2909.105.1.156
- Moss, J. (2024). semTests: Goodness-of-Fit Testing for Structural Equation Models. R Package Version 0.6.0.
- Nevitt, J., & Hancock, G. R. (2004). Evaluating small sample approaches for model test statistics in structural equation modeling. Multivariate Behavioral Research, 39, 439–478. https://doi.org/10.1207/S15327906MBR3903_3
- Olsson, U. H., Foss, T., Troye, S. V., & Howell, R. D. (2000). The performance of ml, gls, and wls estimation in structural equation modeling under conditions of misspecification and nonnormality. Structural Equation Modeling: A Multidisciplinary Journal, 7, 557–595. https://doi.org/10.1207/S15328007SEM0704_3
- Pastur, L. A., & Shcherbina, M. (2011). Eigenvalue distribution of large random matrices. Number 171. American Mathematical Soc.
- Paul, D., & Aue, A. (2014). Random matrix theory in statistics: A review. Journal of Statistical Planning and Inference, 150, 1–29. https://doi.org/10.1016/j.jspi.2013.09.005
- R Core Team. (2023). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing.
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36. https://doi.org/10.18637/jss.v048.i02
- Satorra, A. (1989). Alternative test criteria in covariance structure analysis: A unified approach. Psychometrika, 54, 131–151. https://doi.org/10.1007/BF02294453
- Satorra, A., & Bentler, P. (1988). Scaling corrections for statistics in covariance structure analysis (UCLA statistics series 2). University of California at Los Angeles, Department of Psychology.
- Satorra, A., & Bentler, P. (1994). Chapter 16, Corrections to test statistics and standard errors in covariance structure analysis. In A. Von Eye and C. Clogg (Eds.), Latent variable analysis: applications for developmental research. Sage.
- Shorack, G. R., & Wellner, J. A. (2009). Empirical processes with applications to statistics (Vol. 59). Society for Industrial and Applied Mathematics (SIAM).
- Steiger, J. H. (1990). Structural model evaluation and modification: An interval estimation approach. Multivariate Behavioral Research, 25, 173–180. https://doi.org/10.1207/s15327906mbr2502_4
- Steiger, J. H., Shapiro, A., & Browne, M. W. (1985). On the multivariate asymptotic distribution of sequential chi-square statistics. Psychometrika, 50, 253–263. https://doi.org/10.1007/BF02294104
- Vale, C. D., & Maurelli, V. A. (1983). Simulating multivariate nonnormal distributions. Psychometrika, 48, 465–471. https://doi.org/10.1007/BF02293687
- Zheng, B. Q., & Bentler, P. M. (2022). Testing mean and covariance structures with reweighted least squares. Structural Equation Modeling: A Multidisciplinary Journal, 29, 259–266. https://doi.org/10.1080/10705511.2021.1977649