
Abstract
Occupational health and safety (OHS) represents an important field of exploration for the research community: in spite of the growth of technological innovations, the increasing complexity of systems involves critical issues in terms of degradation of the safety levels. In such a situation, new safety management approaches are now mandatory in order to face the safety implications of the current technological evolutions. Along these lines, performing risk-based analysis alone seems not to be enough anymore. The evaluation of robustness, antifragility and resilience of a socio-technical system is now indispensable in order to face unforeseen events. This article will briefly introduce the topics of Safety I and Safety II, resilience engineering and antifragility engineering, explaining correlations, overlapping aspects and synergies. Secondly, the article will discuss the applications of those paradigms to a real accident, highlighting how they can challenge, stimulate and inspire research for improving OHS conditions.
1 Introduction
Undoubtedly, socio-technical systems are becoming more complex. The interaction between the two aspects becomes tighter, no longer giving the opportunity to analyse the two parts independently. Over the last decades, as highlighted by Leverson [Citation1], the world of engineering has faced a big technological revolution, while safety approaches are not able to follow this change, and provide the expected benefits in terms of increasing safety and reducing accidents.
Moreover, complexity, as the inability to evaluate the effects of actions because too many system variables interact [Citation2], is dramatically increasing, forcing the risk experts and analysts to investigate less obvious systems [Citation3]. Nowadays, systems such as air traffic management (ATM) or railway networks are so extremely dense that a single disruptive event usually causes many domino effects, reducing performance and producing issues of different severity levels.
It appears to be clear that an approach solely based on analysing what can go wrong in the case of system perturbation cannot bring the necessary results in terms of system performance; Aven [Citation4] remarks on the importance of achieving high robustness in a system by reducing its vulnerability. To ensure this goal we must adopt a change in mindset. We need to introduce new concepts into the risk analysis. It is also considered important to start thinking not only in terms of safety and resilience, but also in terms of antifragility [Citation5].
The discussion in this article focuses on the opportunity for new researchers who look at the safety topic to take into account new ways of performing risk analysis, to study the problem from a socio-technical perspective and more robust design solutions, which are also able to adapt to the new system conditions. Introducing the topics of Safety I and Safety II, resilience engineering and antifragility engineering at the same time, and highlighting possible overlapping aspects and correlations between them, this work analyses how those approaches provide different system responses to the same perturbation, using as a case study an accident that occurred on a mobile elevating work platform (MEWP).
2 What are we talking about?
As written by several authors [Citation6,Citation7], safety is a multidisciplinary topic that involves different fields, such as economics, psychology, industrial technology, law and occupational hygiene among others. Consequently, it also requires different experts to play different roles. However, the roles that experts play and the methods they use to picture the problem need to fit the social and technological changes. Pillay [Citation8,Citation9] highlights how those approaches of investigating and preventing accidents are evolving through the decades. He identifies three safety eras characterized by five ages (i.e., technological; behavioural and human error; socio-technical; cultural; resilience), during which the way to tackle accidents, incidents and disasters moved from Heinrich's model and safety procedures to resilience, in which people have an important role in coping with uncertain situations. Recently, as already briefly introduced, the new concept of antifragility has emerged and started becoming predominant in a variety of research fields. According to the authors, antifragility could represent another step in safety evolution, representing the sixth age of the third era (Figure ).
Figure 1. Safety approach evolution through the decades.
Note: Modified from Pillay [Citation9].
![Figure 1. Safety approach evolution through the decades.Note: Modified from Pillay [Citation9].](/cms/asset/7036200d-2400-489f-a0d2-c939e853e58c/tose_a_1444724_f0001_c.jpg)
Hollnagel et al. [Citation10] stated that the most common definition of safety is the absence of calamities or, at least, low risk of incidents taking place. Safety I–II, resilience engineering and antifragility engineering tackle the same problem starting from different points. The following paragraphs will offer a definition of them, with the aim to reveal any underlining correlations and overlapping aspects.
2.1 Safety I and Safety II
As suggested by Patterson and Deutsch [Citation11], the difference between Safety I and Safety II is both philosophical and pragmatic. It is related to which side of the fence, to which part of the glass (half-full or half-empty), the analyst is referring to as the starting point.
For several decades, the techniques of risk analysis focused on root cause analysis (RCA) with the application of several hazard identification techniques in order to investigate the reasons why the system drifted from the normal working conditions. The approach is broadly used; it presents enormous advantages for learning from errors, and the knowledge gathered from the fault-cause investigation is of great importance for future situations and processes. Even though the drawn procedures can provide useful references for the execution of tasks [Citation12], most likely this results in a policy that creates only barriers, standardizes working procedures and eliminates disturbances [Citation13], develops responses to accidents and eliminates or contains identified risks. All in all, this approach is widely known as Safety I and can be considered as the mechanism of avoiding the things that go wrong (Figure ).
Figure 2. Safety I vs. Safety II philosophy.
Note: Modified from Hollnagel et al. [Citation10].
![Figure 2. Safety I vs. Safety II philosophy.Note: Modified from Hollnagel et al. [Citation10].](/cms/asset/2d69f890-de44-4b22-9145-df851eac1efa/tose_a_1444724_f0002_c.jpg)
On the contrary, the Safety II approach analyses the things that go right. It is based on the principle that, due to the complexity of the modern world, it becomes harder to predict side effects and consequences. Therefore, it becomes harder to control the work situations, especially in socio-technical situations, resulting in a varied system performance. The coupled performance variabilities determine both success and failure [Citation13]. According to that, technical systems are engineered in such a way to minimize the performance variability and operate properly, to keep the environment relatively stable, acknowledging, however, that human variability is necessary to overcome, e.g., disturbances in time and resources.
These disturbances have to be reconstructed in the case of failure to understand how these particular deviations could arise and lead to abnormal outcomes. Management of safety in this approach focuses on maximizing the ability of the system to produce a desired and acceptable outcome in the varying circumstances under which the system operates. It is therefore vital to know how and why things go right [Citation11,Citation13].
2.2 Resilience engineering and antifragility engineering
As described by Le Coze [Citation14], the story of resilience engineering is strongly attached to the evolution of cognitive engineering, and the interaction between research in engineering and psychology [Citation15,Citation16]. The topic of resilience engineering has gained attention and importance in the recent literature for its potential applications in high reliability organizations or in systems where the high level of complexity requires a high level of adaptation from the human and machine perspectives [Citation17].
Woods [Citation18] identifies four different possible definitions of the term resilience: rebound, robustness, graceful extensibility and sustained adaptability. These keywords underline the ability of a system to respond after a disruption, deal with perturbations, positively stretch near and beyond its limits [Citation11] and manage and/or regulate the parameters in a multidimensional network [Citation18]. From this spectrum, the need for prevention of unexpected events and better reliability, as well as the need for managing the environmental variety, are both embedded in the resilience engineering approach.
Thus, resilience engineering can be defined as the ability of systems to prevent or adapt to changing conditions in order to maintain (control over) a system property [Citation16] or a system performance. It can also be defined as the engineering branch of monitoring, responding and absorbing disturbances. The first involves expecting the unexpected, the second gives the opportunity to react (in relation to its boundaries) and the third ‘stretches’ the system to current perturbations. In essence, the concept of resilience engineering relies on preparing for unexpected disturbances and planning for the expected situations.
Differently, antifragility engineering considers learning and acquiring knowledge as part of the process of a system. While in resilience engineering knowledge is created based on what to expect and the prevention of the unexpected, an antifragile system should be able to learn and adapt to the real unexpected circumstances. According to this, antifragile systems are able to get benefits from disturbances in order to improve their performances in the future, enhancing in this way their adaptability to unforeseen circumstances. Thus, they will become more robust and evolve over time [Citation19,Citation20]. As shown in Figure , becoming an antifragile system requires a considerable change in the entire philosophy of designing engineering systems.
Figure 3. Resilience engineering and antifragility engineering approaches.
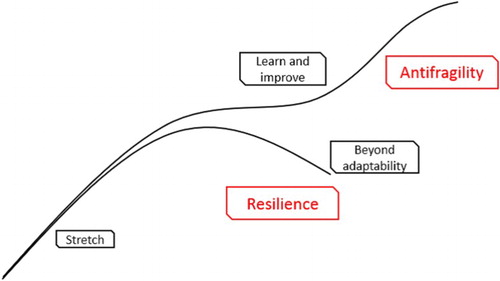
No longer should the focus be on engineering for known requirements, but a system has to be designed and developed with adaptive characteristics and requirements from scratch. This approach demands structured communication and feedback within the system itself [Citation19,Citation20].
2.3 Correlations and overlapping aspects
Sections 2.1 and 2.2 have offered a short introduction about Safety I and Safety II and about resilience and antifragility engineering. In the following, correlations and overlapping aspects will be discussed. Starting from the definitions, Table presents the keywords that identify the four approaches.
Table 1. Representative keywords of Safety I, Safety II, resilience engineering and antifragility engineering.
Among the pool of keywords found, it is possible to identify some correlations and overlapping aspects (indicated by dotted lines) between the four approaches that clarify their strength. Figure explains how the different approaches influence the reaction of the system under a general perturbation, the consequence, the system's recovery and the final configuration of the system based on its capabilities.
Figure 4. Correlations and differences.
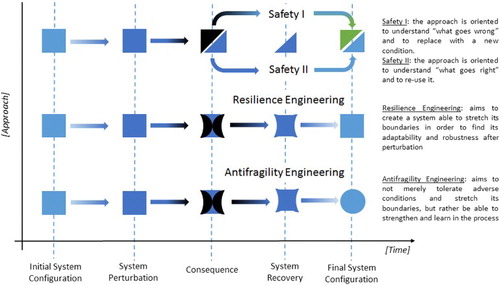
One of the conclusions drawn from Figure is that when a system fails, Safety I will investigate what went wrong and Safety II will reshape the system with the positive parts that worked during the perturbation towards a final configuration with a similar initial structure.
The resilience engineering approach, on the contrary, aims to create a system able to stretch its boundaries in order to find its adaptability and robustness after perturbations. This approach will ensure the continuity of the system offering the same performance of the initial configuration.
The essential difference between resilience engineering and antifragility engineering lies mainly in the opportunity of a system to not merely tolerate adverse conditions and stretch its boundaries, but rather be able to strengthen and learn in the process [Citation23]. The initial configuration of the system will not change at the moment that the system recovers, but will change the system according to the perturbations. The system will learn from the conditions under which it operated, offering a wider spectrum of working situations.
3 Application: a safe MEWP, a resilient MEWP and an antifragile MEWP
This section aims to discuss a possible application of Safety I and Safety II, resilience engineering and antifragility engineering to improve the design of systems and to understand how we gain positive results from a non-fatal accident.
3.1 Overview of the accident
The accident involved a self-propelled MEWP during a maintenance operation on a drainpipe at a height of about 17 m (three-storey building).
Due to incorrect operations and to an exceeding maximum lateral force (400 N), the MEWP lost stability. The MEWP chassis – positioned on a pavement made of cobblestones – skidded and fell on a side-building wall. A progressive deformation of the column on the opposite brick fence reduced the falling velocity of the platform. The operator survived by jumping from the platform and grabbing on to an orange tree branch (Figure a and b).
Figure 5. Final configuration of the MEWP after the collapse: (a) street view; (b) aerial view.
Note: MEWP = mobile elevating working platform.

MEWP overturn is a frequent cause of accidents. The potential displacement of the centre of gravity in particular stressing, loading and geometrical configurations represents one of the most critical aspects for the MEWP's stability. For MEWPs provided with stabilizers, the worst-case scenario appears in combination with the maximum horizontal outreach and maximum height. In that situation, the full machine weight loads on a single stabilizer.
It is a manufacturer's responsibility to perform proper calculations to evaluate loads and forces (such as rated loads, structural loads, wind loads, manual forces, etc.) able to produce the most unfavourable stresses for the machine's components during operation.
However, several stability problems are generated by non-conventional ways of using the MEWP that cause irregular manual forces. Standard No. EN 280:2013 [Citation24] requires values of manual forces (applied at a height of 1.1 m above the work platform floor) of 200 N for MEWPs designed to carry only one person and 400 N for MEWPs designed to carry more than one person.
Exceeding the value defined by the manufacturer will produce an oscillation of the centre of gravity resulting in an overturning torque that may jeopardize the stability of the MEWPs. Unfortunately, these exceeding forces are not easy to evaluate if no detection instruments are available.
Analysing an accident thorough an investigation protocol means understanding the chain of events, the root causes and the deviations from expected working conditions in order to discover where the system failed. During official investigations disposed by the prosecutor office, some of the authors deeply studied the accident through the computer-aided cause consequence for prevention technique proposed by Luzzi et al. [Citation25] and based on the well-known system approach [Citation26] and on bowtie analysis (a combination of fault tree analysis [FTA] and event tree analysis [ETA]). On the one hand, the selected investigation protocol deconstructs the chain of events; on the other, it links every single basic event with a possible corrective action:
Accident causes chain – from the undesired event to the direct cause (top down based on FTA). Starting from the undesired event and following a chain of intermediate events, this identifies the root causes.
Possible corrective actions – most suitable prevention measures development (bottom up based on ETA). Starting from the root causes – identified in the previous step – this highlights the most suitable prevention measures in order to break the chain of intermediate causes leading to this kind of event.
Table 2 Summary of investigation results performed with the computer-aided cause consequence for prevention technique.
Employees are rarely the sole cause of accidents (as in the case of the analysed accident). Human performance is always based on complex interactions within the socio-technical system that constitute an organization [Citation9]. Even in the presented accident, the analysis identified responsibilities related to both human errors (e.g., ‘incorrect operator behaviour, involving lateral forces exceeding the machine stability limits’) and to omissions in the risk management phase (e.g., ‘careless organization: no second operator, no supervision’).
3.2 How do Safety I and Safety II, resilience engineering and antifragility engineering tackle the accident?
As explained previously (Section 2), Safety I and Safety II, resilience engineering and antifragility engineering take different perspectives and lead to different solutions. Based on the scheme proposed previously (Figure ), Figure offers a comparison between those perspectives applied to the described accident.
Figure 6. Safety I and Safety II, resilience engineering and antifragility engineering comparison on the MEWP accident.
Note: MEWP = mobile elevating working platform.
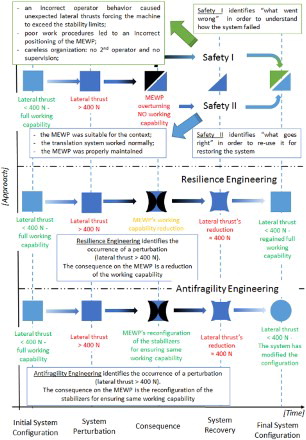
As shown in Figure , Safety I and Safety II focus attention on looking for negative and positive aspects in order to introduce coherent preventative measures tailored for specific scenarios for breaking the chain of events, avoiding the occurrence of an accident in similar conditions. Regarding ‘what went wrong’: (a) an incorrect operator's behaviour caused unexpected lateral thrusts, forcing the machine to exceed the stability limits; (b) poor work procedures led to incorrect positioning of the MEWP; (c) careless organization due to no second operator and no supervision. Regarding ‘what went right’: (a) the MEWP was suitable for the context; (b) the translation system worked normally; (c) the MEWP was properly maintained. Their combination provides valuable corrective actions to enable the system to face similar human drifts and organizational defects but not comparable physical perturbation (lateral thrust > 400 N) that stretch the technical boundaries of the MEWP.
Differently, resilience engineering operates in a system perspective, considering perturbations as unavoidable events that force the asset to deviate from the normal operative condition. From a resilience perspective, the platform should be engineered not only by evaluating loads and forces, their direction and point of application looking for the most unfavourable stresses for the components [Citation28] in coherence with Standard No. EN 280:2013 [Citation24], but also by taking into account the potential overrun of the design limits due to different load conditions and performance variabilities.
The consequence on the MEWP would be a reduction of the working capability after perturbation (lateral thrust > 400 N) operated by specific control systems (Figure ) that move the asset to adopt intermediate configuration(s) and bring the system to the initial configuration (i.e., with full working capability) once the perturbation stops. The introduction of load shift sensors on the stabilizers would allow the automatic balancing during stress conditions (i.e., exceeding the maximum force limit value) to reduce the overturning force.
Figure 7. Flow chart of a resilient solution for MEWPs.
Note: MEWP = mobile elevating working platform.
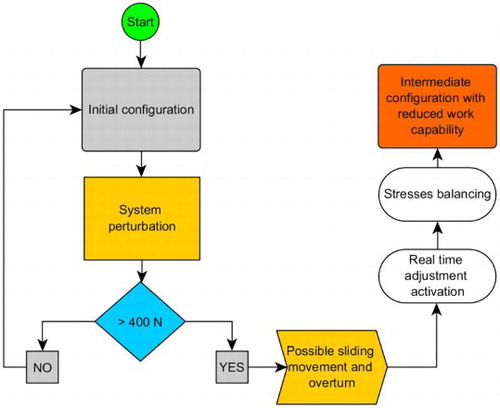
The proposed scheme for resilience engineering introduces a concept essential to make a step beyond, i.e., a monitoring function that reshapes the system if a deviation is detected. A function that can help the system to learn from a perturbation.
The application of antifragility engineering to the MEWP suggests the introduction of a smart stress control system (connected with the load shift sensors on the stabilizers) that analyses the system anomalies due to the perturbations. This smart system should recognize a situation, elaborate it and learn from it (Figure ) in order to set-up a ‘memory of the system’, being able to face this situation permitting the same system's performance. An algorithm will elaborate the new MEWP configuration to ensure same working capability. It means to offer a constant registered experience useful for unexpected status configurations of the system.
Figure 8. Flow chart of an antifragile solution for MEWPs.
Note: MEWP = mobile elevating working platform.
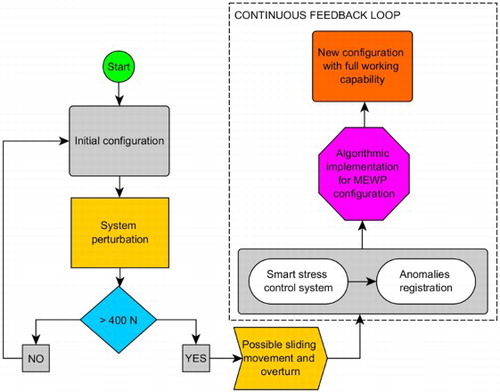
An antifragile MEWP would reconfigure spatially the stabilizers according to the external perturbation (lateral thrust > 400 N) in order to keep same working capability.
4 Discussion and limitations
Based on the results of the outlined analysis, several interesting points can be made. The fast evolution of technological innovation, the development of complex systems and transformations of the working environment require a change in thinking for safety. Systems become complicated in terms of relations between components, and thus it is difficult to predict rigorously each state of its evolution because the routine varies.
As already discussed, approaches based only on ‘find and fix’ peculiar to Safety I or based on the analysis of ‘what goes right’ of Safety II do not offer a sufficient level of resistance to new complex systems. Implementing barriers and procedures, even at an organizational level, cannot overcome the multiple perturbations that a system will experience. Proposed solutions should rely on robustness, resilience and antifragility principles. Concerning the explained opportunities, the modern system design should offer solutions, being able to:
stretch design boundaries;
not fail under unexpected events;
ensure the same working capability under stress conditions;
learn from new situations for reshaping configurations and adapting to new inputs.
Nevertheless, those innovative ways of thinking, designing and rebuilding the problem still reveal a not negligible level of complexity for being correctly deployed.
Firstly, due to technical limitations not every system can be equipped with devices able to quickly modify its structure or layout according to different situations. Only recently has this been implemented in the aeronautic industry, e.g., special purpose aircrafts have wings made of flexible materials able to adapt their shape during the flight according to the motion [Citation29]. Furthermore, in the automotive industry, high-performance vehicles use deforming components to control drag and downforce [Citation30]. Secondly, the implementations of those solutions may not be always economically feasible for every situation. The application of systems able to learn from situations is usually interesting and useful in complex network systems (i.e., smart grids, dense railway networks, ATM).
Finally, yet importantly, there is a cultural barrier to break. A not negligible mindset change has to be made in how safety is thought and applied. The challenge for new safety researchers and engineers will be using the proposed methods in order to create systems able to work in a socio-technical environment providing comparable performance, level of safety and, possibly, cost-effectiveness expected by the stakeholders.
5 Conclusion
Given the potential of unexpected events that can drift into new complex systems from designed working conditions resulting in accidents or decreased performance, there is a lack of resilience engineering and antifragility engineering applications for designing systems able to face those situations. This article, for the first time to the authors' best knowledge, offered a comparison between Safety I and Safety II approaches and the methods of resilience engineering and antifragility engineering by analysing a real accident on a MEWP and by discussing different solutions. This has resulted in the identification of future and critical research aspects to develop and investigate robust systems capable of: (a) stretching design boundaries; (b) ensuring stable working capability under stress conditions; (c) learning from new situations for reshaping configurations and adapting to new inputs.
The authors work towards the introduction of an integrated framework that will bring all four approaches together in order to deal with unexpected situations and unavoidable accidents that complex socio-technical systems may face in the future.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Alberto Martinetti http://orcid.org/0000-0002-9633-1431
References
- Leverson NG. Engineering a safer world: systems thinking applied to safety. Boston (MA): MIT Press; 2012.
- Pich MT, Loch CH, De Meyer A. On uncertainty, ambiguity, and complexity in project management. Manage Sci. 2002;48(8):1008–1023. doi: 10.1287/mnsc.48.8.1008.163
- Bristow M, Fang L, Hipe KW. System of systems engineering and risk management of extreme events: concepts and case study. Risk Anal. 2012;32(11):1935–1955. doi: 10.1111/j.1539-6924.2012.01867.x
- Aven T. The concept of antifragility and its implications for the practice of risk analysis. Risk Anal. 2015;35(3):476–483. doi: 10.1111/risa.12279
- Taleb NN. Anti-fragile: things that gain from disorder. London: Penguin; 2012.
- Bahn ST. OHS management: contemporary issues in Australia. Prahran (VIC): Tilde University Press; 2014.
- Quinlan M, Bohle P, Lamm F. Managing occupational health in safety: a multidisciplinary approach. 3rd ed. South Yarra (VIC): Victoria Palgrave Macmillan; 2010.
- Pillay M. Taking stock of hero harm: a review of theory on contemporary health and safety management in construction. In: Proceedings of the CIB W099 International Conference of Achieving Sustainable Construction Health and Safety; 2014 June 2–3; Lund, Sweden. Lund: Lund University Press, 2014. p. 75–85.
- Pillay M. Accident causation, prevention and safety management: a review of the state-of-the-art. Procedia Manu. 2015;3:1838–1845. doi: 10.1016/j.promfg.2015.07.224
- Hollnagel E, Wears RL, Braithwaite J. From Safety I to Safety II: a white paper. Odense: University of Southern Denmark; 2015.
- Patterson M, Deutsch ES. Safety-I, Safety-II and resilience engineering. Curr Probl Pediatr Adolesc Health Care. 2015;45(12):382–389. doi: 10.1016/j.cppeds.2015.10.001
- Besnard D, Hollnagel E. I Want to believe: some myths about the management of industrial safety. Cogn Technol Work. 2014;16(1):13–23. doi: 10.1007/s10111-012-0237-4
- European Organisation for the Safety of Air Navigation (Eurocontrol). From Safety-I to Safety-II: a white paper; Brussels: Eurocontrol; 2013. Available from: http://www.skybrary.aero/bookshelf/books/2437.pdf
- Le Coze JC. Vive la diversité! High reliability organisation (HRO) and resilience engineering (RE). Saf Sci. In Press. [Available online 2016 Apr 26]; [10 p]. Corrected proof available at http://doi.org/10.1016/j.ssci.2016.04.006
- Rasmussen J. The role of error in organizing behaviour. Qual Saf Health Care. 2003;12:377–383. doi: 10.1136/qhc.12.5.377
- Woods D, Cook RI. Mistaking error. In: Hatlie MJ, Youngberg BJ, editors. Patient safety handbook. Burlington (MA): Jones & Bartlett; 2004. p. 95–108.
- Pettersen KA, Schulman PR. Drift, adaptation, resilience and reliability: toward an empirical clarification. Saf Sci. In Press. [Available online 2016 Mar 26]: [9 p]. Corrected proof available at http://doi.org/10.1016/j.ssci.2016.03.004
- Woods DD. Four concepts for resilience and the implications for the future of resilience engineering. Reliab Eng Syst Safety. 2015;141:5–9. doi: 10.1016/j.ress.2015.03.018
- Verhulsta E. Applying systems and safety engineering principles for antifragility. Procedia Comput Sci. 2014;32:842–849. doi: 10.1016/j.procs.2014.05.500
- Jones KH. Engineering antifragile systems: a change in design philosophy. Procedia Comput Sci. 2014;32:870–875. doi: 10.1016/j.procs.2014.05.504
- Andersen B, Fagerhaug T. Root cause analysis: simplified tools and techniques. Milwaukee (WI): American Society for Quality, Quality Press; 2003.
- Wears R. Standardization and its discontents. Cogn Technol Work. 2015;17(1):89–94.
- De Florio V. Antifragility = elasticity + resilience + machine learning models and algorithms for open system fidelity. Procedia Comput Sci. 2014;32:834–841. doi: 10.1016/j.procs.2014.05.499
- European Committee for Standardization (CEN). Mobile elevating work platforms design calculations – stability criteria – construction – safety – examinations and tests. Brussels: CEN; 2013. Standard No. EN 280:2013.
- Luzzi R, Passannanti S, Patrucco M. Advanced technique for the in-depth analysis of occupational accidents. Chem Eng Trans. 2015;43:1219–1224.
- Reason JT. Human error: models and management. BMJ. 2000;320:768–770. doi: 10.1136/bmj.320.7237.768
- Pira E, Borchiellini R, Maida L, et al. Occupational S&H in the case of large public facilities: a specially designed and well-tested approach. Chem Eng Trans. 2015;43:2155–2160.
- Cirio C, Maida L, Patrucco M, et al. Innovative technologies and related accident scenarios: the importance of the culture of safety in activities involving mobile elevating work platforms. GEAM. 2016;16(1):21–30.
- Concilio A, Dimino I, Lecce L, et al., editors. Morphing wings technologies: large commercial aircraft and civil helicopters. Oxford: Butterworth-Heinemann; 2018.
- Ferrari S.p.A. Innovations: aerodynamics Ferrari 458 Italia. 2017 [cited 2017 Dec 6]. Available from: http://auto.ferrari.com/en_US/sports-cars-models/past-models/458-italia/#innovations-aerodynamics-3