?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With AI’s advancing technology and chatbots becoming more intertwined in our daily lives, pedagogical challenges are occurring. While chatbots can be used in various disciplines, they play a particularly significant role in medical education. We present the development process of OSCEBot ®, a chatbot to train medical students in the clinical interview approach. The SentenceTransformers, or SBERT, framework was used to develop this chatbot. To enable semantic search for various phrases, SBERT uses siamese and triplet networks to build sentence embeddings for each sentence that can then be compared using a cosine-similarity. Three clinical cases were developed using symptoms that followed the SOCRATES approach. The optimal cutoffs were determined, and each case’s performance metrics were calculated. Each question was divided into different categories based on their content. Regarding the performance between cases, case 3 presented higher average confidence values, explained by the continuous improvement of the cases following the feedback acquired after the sessions with the students. When evaluating performance between categories, it was found that the mean confidence values were highest for previous medical history. It is anticipated that the results can be improved upon since this study was conducted early in the chatbot deployment process. More clinical scenarios must be created to broaden the options available to students.
Background
Chatbots – ‘Can Machines Think like Doctors do?’
Chatbots, also known as artificial conversation entities, interactive agents, smart bots, and digital assistants are systems that can communicate with users by using methods and algorithms from two Artificial Intelligence (AI) domains: Natural Language Processing (NLP) and Machine Learning (ML) [Citation1–3].Until recently, the most notable instance was the usage of chatbots as personal assistants, like Google Assistant and Apple’s Siri [Citation1,Citation3]. While chatbots may be employed in various fields, they are particularly relevant in the digital transformation of education since they provide both students and teachers with new resources [Citation4–6]. Considering changes in the educational technology landscape, interactions with students must now be more individualized to support their unique learning styles and meet their various needs. The challenge of meeting the requirements of this generation is one that educators are currently facing. Chatbots might be the solution to engaging younger generations naturally and natively [Citation7,Citation8]. Recent studies have shown that virtual conversational agents act as study partners or instructors, and can improve students’ academic performance Citation9, Citation10]. Higher Education (HE) learning environments have changed significantly over the past few decades due to the use of Technology-Enhanced Learning (TEL) systems, where cutting-edge technologies and artificial intelligence are used to allow for greater flexibility, personalization, engagement, and motivation of learners [Citation11]. The future of education could be transformed by educational chatbots (ECs). With the help of a virtual assistant that simulates human interactions, these chatbots are designed to offer personalized learning [Citation3]. OpenAI’s ChatGPTTM (Chat generative pre-trained transformer), which was introduced in November 2022, is one illustration of this. Since ChatGPTTMis tailored to each learner’s needs and preferences, it may support learners’ autonomy and enhance their learning experiences. This chatbot is particularly crucial for self-learning. However, numerous people have brought attention to moral concerns like plagiarism, cheating, and data security. Additionally, there have been some reports regarding ChatGPTTM not giving bibliographical references [Citation12].
Conceptual framework
Chatbots in medical education
The practice of medicine is transforming and evolving at a remarkable rate. Due to the multifaceted demands of an aging population, the variety of available treatment choices, the multidisciplinary character of care, among others, today’s healthcare systems are considerably more complex than they were 20 years ago [Citation13]. As a result, medical education has also been adjusted to train doctors capable of dealing with this and other changes. Several factors, such as the evolving healthcare landscape, the shifting nature of the physician’s position, altered societal expectations, the fast advancement of medical knowledge, and the variety of pedagogical approaches, impact how medical education is delivered [Citation14]. The use of technology in medical education serves a variety of educational purposes, including facilitating the acquisition of fundamental knowledge, communication skills, enhancing decision-making, increasing perceptual variety, improving skill coordination, practicing for uncommon or important events, learning teamwork, and enhancing psychomotor abilities [Citation14–16]. In medical education, conversational agents are mostly used as virtual patients (VPs) that simulate clinical scenarios and enable training in interviewing and communication techniques.This type of system has seen a surge in popularity over the past 10 years, largely due to the particular benefits associated with it, including its ability to provide personalized exercises in a safe, non-threatening environment and performance assessment with opportunities for reflection and feedback [Citation15]. During the pandemic, the medical education curriculum went fully digital, undermining the attainment of these important skills for students to be successful in their academic careers. One of these skills is the ability to interview the patient, obtaining the patient’s clinical information effectively while maintaining a trusting relationship with the patient – the so-called history taking.
Why are history taking skills so important?
Clinical competencies, such as clinical reasoning, history-taking skills, diagnosis, physical examinations, and communication/professionalism skills, are crucial in medical education curricula. These skills allow students to manage knowledge to solve clinical problems while enabling them to establish a trusting relationship [Citation17]. Given that conducting medical interviews is the clinical professional’s most common activity, history taking is crucial for medicine practice [Citation18]. The importance of clinical history in arriving at a good diagnosis is crucial, and the importance of reaching a correct diagnosis cannot be overstated [Citation19,Citation20]. During their career, clinicians will interview between 100,000 and 200,000 patients [Citation18]. A noteworthy example of this is that around 60 to 80% of the information that is relevant for a diagnosis is gathered in medical history and 76–90% of all diagnoses [Citation18,Citation19] are determined solely based on the information that physicians acquire from the clinical interview. Hence, any skilled physician must possess the core abilities to gather a patient’s medical history and apply that knowledge to make accurate diagnoses [Citation21]. History taking is one of the earliest fundamental skills taught in medical school. This skill requires a systematic methodology and a clearly defined structure, which is vital for the clinical interview. In addition to following this structure, the student should also pay close attention to nonverbal cues, such as eye contact, silence, posture, etc. Appendix 1 describes this methodology for a patient presenting leg pain. This set of skills is usually trained in laboratory conditions or in the wards and assessed using Objective Structured Clinical Examination (OSCE) [Citation22] type of exams. In these assessments, students interact with a simulated patient (SP), a person trained to play a patient’s role according to a script. Despite being considered a high validity and reliability form of assessment, OSCE usually demand significant financial and human resources and infrastructure availability and time for planning and logistics [Citation17]. Additionally, training SP and deploying OSCE can be expensive, as one exam costs may amount to Eur 10 000 [Citation23] and close to Eur 100 per examinee [Citation24]. Furthermore, students have fewer opportunities to train and prepare for this kind of assessment and often have brief contact with SPs prior to the actual exam. This can negatively affect the evaluation and learning process since it can be inadequate to develop critical skills for medical practice, such as communication skills and empathy, that can influence patients’ satisfaction and improve health outcomes [Citation23,Citation25]. The development and subsequent evaluation of a chatbot to aid in and assess the growth of clinical skills in medical students will be discussed in this paper.
Materials and methods
Concept- project requirements
The major goal of this project is to create a fully functional conversational agent prototype to assist medical students in improving their clinical skills, specifically the clinical interview, and, subsequently, allow to cover a training opportunity gap for OSCEs. The educational objectives of the present system were defined in accordance with those specified for the OSCEs:
Become familiar with the work environment present in everyday clinical practice;
Develop clinical problem-solving skills,
Develop and enhance clinical interviewing skills;
Develop clinical information summary skills;
Increase diagnostic interpretation skills;
Improve confidence in decision-making and self-efficacy;
Identification of appropriate therapeutic interventions.
To achieve these goals, the project’s educational strategy used a student-centered, case-based learning technique, which required the students to take ownership of building their understanding of the clinical settings. This approach is founded on the notion that learning is maintained and remembered longer when done in a context that represents realistic workplace circumstances to encourage students to apply knowledge obtained from the classroom or through additional research to solve the case [Citation26].
Regarding the development of the current educational chatbot, several guiding concepts were selected as fundamental for the successful application of this system:
The original design and development of the chatbot should be built through co-creation, bringing together instructors, developers and end-users to create a chatbot that fits the demands and needs to help student’s preparation for OSCEs.
The framework should offer on-site data storage and all the tools required for continuing model training.
The system needs to be simple for non-technical individuals to employ. It should also be possible to customize cases and patients without scripting or programming knowledge and to increase the number of cases without sacrificing user experience standards.
The chatbot must recognize user input in natural language, respond accordingly and determine the user’s intent to offer a response appropriately using, following the NLP principles, human-like language (output).
Like Kumar [Citation27], the Reliability, Interpersonal communication, Pedagogy, and Experience (RIPE) principles were used to identify the attributes considered essential for chatbot design ().
Table 1. RIPE Principles. Adapted from Kumar, 2021.
Building the virtual patients
For the sake of comparability and efficiency of the chatbot training, we focused on symptoms that followed the SOCRATES approach. For this project, several Virtual Patients (VPs) were created covering a broad range of key symptoms: chest pain, lumbar pain, leg pain and dyspnea. Scripts were developed by clinical educators experienced in developing SP clinical cases scripts for use in OSCE and reviewed by a senior clinical educator. Cases were presented randomly to students to avoid bias regarding the case’s complexity or students’ confidence in any given subject.
Chatbot architecture
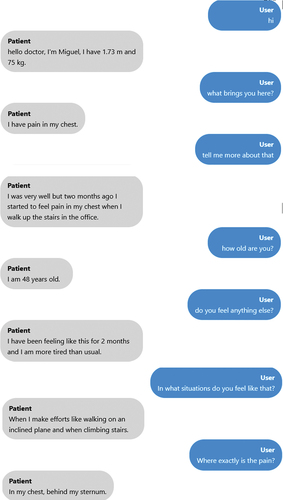
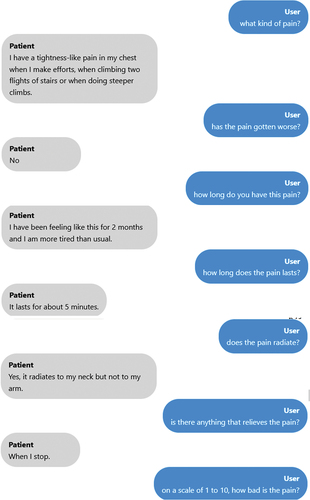
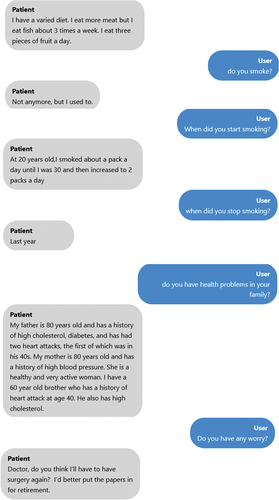
This chatbot is a web-based program that responds to queries from medical students. The chatbot answers the user by extending a friendly greeting before responding appropriately to the query posed, such as ‘what brought you here?’ In this instance, the answer would be the primary complaint (Appendix 2). The user should continue asking the chatbot questions about his symptoms, family history, personal history, and other topics, much like in a clinical interview. The chatbot will find the most appropriate trigger phrase or node and respond using a flexible pre-written script that medical specialists have approved. The prewritten script was based on the SOCRATES approach. While formulating questions to verify the exploration of the chief complaint (duration, intensity, location); clinical, social, and family history. Regardless of whether the SP suffers from leg or chest pain, the question regarding intensity, for example, will be the same. The script was built for one case, and each time a new case was introduced an experienced medical educator checked if the information was correct and if the information inserted in the script would be enough for the student to reach a diagnostic hypothesis. The chatbot will prompt the learner to reword their query if it cannot find an appropriate response or understand the question.
The system’s architecture of the chatbot system is shown in
Figure 1. Chatbot architecture.
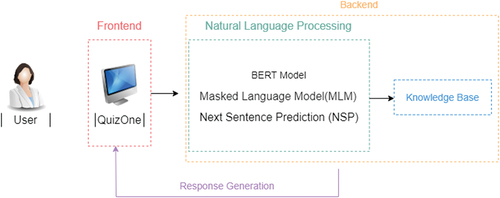
The architecture of the developed chatbot is composed of:
Frontend
Backend
Knowledge Base Module
Conversational Module
The first module, which offers a user-friendly interface, represents the presentation layer (frontend) created in this particular scenario using the Angular framework [Citation28]. Operations that are not visible to the end user are managed on the backend. The frontend communicates with the backend through an API gateway, and this gateway communicates with microservices, one of which is the Python service that uses SBERT. Due to scalability, maintenance of the analysis algorithms, speed of execution, and better match customer demand, this module operates in the background; it manages business logic and data storage while collaborating with the knowledge base. In this case, the backend was developed using.NET. The Knowledge Base Module is a unique database used for managing knowledge and information, where a server processes data. Regarding the Conversational module, based on a focused Internet search, we evaluated potential NLP tools and software solutions which could support the construction of a virtual patient. The chatbot was created with the ability to handle a diverse range of cases and randomly select one when deployed. The SentenceTransformers, or SBERT, framework was used to develop this chatbot. This is a Python framework for state-of-the-art embedding of text, phrases, and images [Citation29]. This framework can be used to create text embeddings and phrases in various languages. The pretrained BERT(short for ‘Bidirectional Encoder Representations from Transformers’) network created by [Citation30-] the basis of the SBERT model – enables bidirectional training to be applied to a word sequence using a transformer. BERT has already been investigated, outperforming other frameworks [Citation31]. It works by encoding a sequence of words (e.g., a sentence) into a fixed-length vector representation, which can then be used as input to a downstream task such as text classification or question answering. By considering the words that come before and after them and how they relate to the remainder of the sentence, it is intended to comprehend the context and meaning of the words in a particular sentence. To do this, BERT uses an attention mechanism to weigh the importance of different words in the input based on their relevance to the task. For example, in a question answering task, the model might pay more attention to the words in the question when generating an answer. These embeddings can then be compared, for instance using cosine similarity, to find sentences having a common meaning. This is helpful for semantic textual similarity searches, semantic search, and paraphrase mining. It is also open source and might be usable for real-time evaluation via an API. The preexisting models can also be modified to fit other scenarios, making this tool highly adaptable. To enable semantic search for various phrases, SBERT uses siamese and triplet networks to build sentence embeddings for each sentence that can then be compared using a cosine-similarity [Citation29]. This paradigm is especially appealing to the current study since students can ask questions in various ways, meaning different inquiries might have a semantically similar meaning. In this work, SBERT was also used as a classifier. Through the content and context similarity between the questions asked by the students and the questions present in the script, the model classifies the questions according to the pre-defined blocks (main complaint, explore the main complaint, previous clinical history, social history, family history, interview closing). By setting the level of similarity between the question asked and the question present in the script, the model applies a decision tree based on the confidence value (CV). Below a certain value, the bot will produce a response asking to rephrase the question, to avoid misplaced answers.
Sample
The study sample comprised the log file of 13 medical students from the last four years (clinical training) of the medicine program at the School of Medicine of the University of Minho, of whom 11 were females (73.3%). This sample includes log files for 13 chatbot sessions. The average self-reported English level of students was B2, according to the European framework, ranging from A1 to C2. One user was omitted from the sample due to not being comfortable with producing a discussion with the chatbot using the English language. The 813 interactions between the students and the bot were then analyzed, of which 27 interactions for the remaining 12 students were eliminated (due to using Portuguese, incomplete sentences, etc.).
Data analysis
The 813 interactions were reviewed by two independent judges, who assessed whether the bot had correctly identified the question and provided the correct answer based on its script for clinical cases. If the bot identified the correct question, it was expected to give the correct answer. Cohen’s κ was run to determine the agreement level between the two independent judges.
The confidence value (CV) for each interaction was calculated using SBERT, a machine learning model that employs siamese and triplet networks to generate sentence embeddings for each sentence [Citation29]. These embeddings can then be compared using cosine similarity to determine the similarity between the student’s questions and the questions present in the clinical case’s script. The database was created, and performance metrics were calculated using Microsoft Excel. IBM SPSS version 27 and MedCalc statistical software were used to compute the ROC curves, determine the optimal cutoff values, and compare cases and categories within cases.
ROC curves were computed to understand the optimal cutoff point for our model [Citation32]. The Youden index and the closest top-left distance were used as metrics to determine the optimal cutoff value. Once identified, the optimal cutoff point was used to compute various performance metrics, including precision, recall (sensitivity), accuracy, specificity, and F1 score. The performance metric values were determined considering the CV, as generated by the framework. The CV serves as an indication of the level of confidence in the bot’s responses. The optimal cutoff point was used to establish the CV for each case or category.
There are four possible results when a classifier, classification model, and an instance are provided: True Positives, True Negatives, False Positives, and False Negatives. True Positives were correct answers provided by the bot where the confidence value was above the cutoff value. True Negatives were determined when the bot could not answer the question and the confidence value was below the cutoff value. False Positives were defined as instances when the bot incorrectly identified the question, and the confidence value was above the cutoff value. Finally, False Negatives were situations where the bot should have provided an answer because the question was present in the script, but it did not. The confidence value was below the cutoff value.
A two-by-two confusion matrix, also known as a contingency table, can be built to express the dispositions of a set of cases given a classifier and a set of examples (the test set). Many standard performance metrics, such as precision, recall(sensitivity), accuracy, specificity, and F1 score, are built from this matrix. These metrics allow the evaluation of the model’s overall performance and understanding of how well it could identify positive cases [Citation32]. shows a confusion matrix.
Table 2. Confusion Matrix.
The performance measures were calculated with the assistance of the aforementioned table and are presented in .
Table 3. Performance Measures [Citation33,Citation34].
The differences between clinical cases and question categories were also investigated, as well as the performance metrics of the bot in the different cases and categories, this was achieved by ANOVA and ROC (receiver operating characteristic) curve computation.
Results
Dataset
Cohen’s κ was run to determine the agreement level between two independent judges on whether the bot had correctly identified the question and, consequently, given the correct answer. There was substantial to almost perfect agreement between the two judges, κ = .804 (95% CI, 0.763 to 0.845), p < .001[Citation35].
Determining the optimal cutoff value
The performance of the bot was evaluated using a ROC curve. The ROC curve plots the true positive rate (sensitivity) on the y-axis and the false positive rate (1 - specificity) on the x-axis for all possible classification thresholds [Citation36]. The area under the curve (AUC) was 0.864, indicating that the Chatbot could accurately identify the appropriate questions and provide accurate answers [Citation37].
To determine the optimal cutoff value for our model, we used two methods: the Youden index [Citation38] and the closest top-left distance. Overall, the two methods produced very similar results, with an optimal cutoff value of approximately 0.86 in both cases (0.8597 for the Youden Index and 0.8577 for the closest top-left distance). The precision, recall, and F1 score was highest at this cutoff value, with values of 0.85, 0.663, and 0.72, respectively. There were slight differences in the results of the two methods ().
Table 4. Performance measures for Youden Index and Closest top-left distance cutoff values.
The closest top-left distance produced slightly higher sensitivity and accuracy values than the Youden index. However, these differences were relatively small and are not expected to significantly affect the model’s overall performance.
Performance between cases
The performance of the bot was evaluated using three clinical cases. The case concerning chest pain was defined as case 1, lower limb pain as case 2, and dyspnea refers to case 3. The descriptive statistics for the cases are presented in .
Table 5. Descriptive Statistics for cases.
The mean CV for clinical case 1 was 0.84 (SD = 0.11). For clinical case 2, it was 0.86 (SD = 0.11), and for clinical case 3, it was 0.87 (SD = 0.97).
As expected, the mean CV value increases as the clinical cases progress because feedback from the first case was used to improve and add to the scripts of the subsequent cases. As a result, the mean CV value increases from case 1 to case 2 to case 3. A one-way ANOVA was performed to compare the effect of the clinical case in confidence value. The test revealed that there was a statistically significant difference in CV between at least two groups (F(2,810) = 3.28, p = 0.038, ηp2 = 0.008). Tukey’s HSD Test for multiple comparisons found that the mean value of CV was significantly different between clinical case 1 and 3 (p = 0.031, 95% C.I. = [-,0498,0019]). There was no statistically significant difference between clinical case 2 and case 1 (p = 0.403) and clinical case 2 and case 3 (p = 0.268). This can also be observed by the computation of ROC Curves ().
Figure 2. ROC curves for each case.
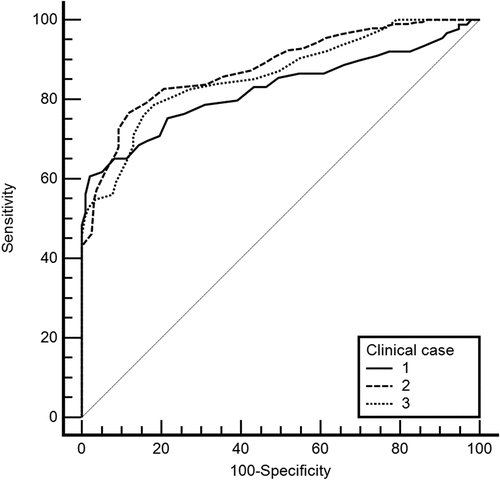
shows each case’s AUC (Area under the curve) and optimal cutoff values. The performance metrics were also computed for the optimal cutoff value.
Table 6. AUC and performance metrics per case.
The Friedman test was performed on the performance measures (precision, recall, accuracy, F1 score and specificity) across different clinical cases. The results indicate that the performance measures were not significantly different across clinical cases, χ2(2) = 0.4, p = 0.819.
Performance between categories
The interactions between the students and the bot were classified based on their type. Greeting interactions (such as ‘hello’ or ‘hi’) were placed in category 1, while interactions exploring the main concern were placed in category 2 (‘On a scale of 1 to 10, how severe is your pain?’). Questions about past medical history (‘have you ever had surgery before?’) were classified as category 3; social history (‘do you smoke?’) as category 4; family history (‘has anyone in your family ever had cancer?’) as category 5; and closing the interview (‘is there anything else you need from me?’) as category 6.
describes the frequencies of each category in all the interactions.
Table 7. Frequency distribution of categories.
Due to the low frequency of categories 1, 5, and 6, the analysis was focused on categories 2 (main complaint), 3 (Previous clinical history), and 4 (Social history) (N = 752).The mean CV for category 2 (main complaint) was 0.85 (SD = 0.10). For category 3, previous clinical history was 0.87 (SD = 0.10), and for category 4 (social history) was 0.86 (SD = 0.13).
As expected, a negative association was observed between the number of questions asked and the mean confidence value. This is likely since a larger number of questions (N = 495) was asked about the main complaint, leading to more errors and a corresponding decrease in the mean confidence value compared to other categories. There were no statistically significant differences between categories means as determined by one-way ANOVA (F(2,749) = 0.758, p = . 469, ηp2 = 0.002).
ROC curves were also computed for each category ().
Figure 3. ROC curves for each category.
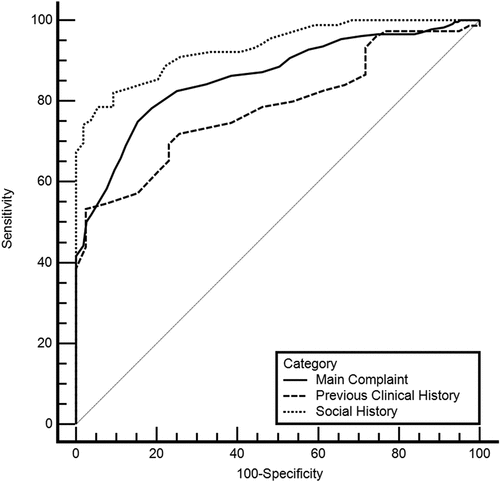
shows the AUC and optimal cutoff values for each category. The performance metrics were also computed for the optimal cutoff value.
Table 8. AUC and performance metrics per category.
As can be observed by both the ROC curves and category 4 has a higher AUC value and overall, the best performance within the categories.
The Friedman test was performed on the performance measures (precision, recall, accuracy, F1 score and specificity) across different categories. The results indicate that the performance measures were not significantly different across the different categories, χ2(2) = 0.5, p = 0.779.
Discussion
The primary objective of this study was to conduct a preliminary assessment of the OSCEBot® model for use in OSCEs training. The optimal cutoffs were determined, and the performance metrics were then calculated for each case and category. ANOVA and ROC curve computation was also used to gain a deeper understanding of the model’s performance on different clinical cases and categories and identify areas where it may be necessary to improve its accuracy.
Concerning the computation of performance measures for the overall best cutoff value, compared to the Youden index, the closest top-left distance produced somewhat higher scores for sensitivity and accuracy. The model’s performance is not anticipated to be greatly impacted by these relatively minimal changes.
Regarding the performance between cases, case 3 has a higher average CV value (0.87) than the other 2 cases. The continuous improvement of the cases could explain this following the feedback acquired after the sessions with the students. Since case 1 was the first to be developed and the one from which the following cases were developed, it is expected to have the lowest average CV. This is also corroborated by the differences in the ANOVA and the performance measures that are generally better in case 3. However, when we look only at the AUC, case 2 has a higher value, larger area, and therefore better average performance [Citation32].
When evaluating performance between categories, it was found that the mean CV was highest for category 3 (previous medical history), followed by category 4 (social history) and category 2 (main complaint). The mean CV values for these categories were 0.87, 0.86, and 0.85 respectively. While category 2 had the lowest mean CV value, it also had the highest associated sample size. This suggests that exploring the main symptom was a primary focus of the students in this study. The performance measures among the three categories were relatively similar, with categories 2 and 4 showing slightly better results than the others. Additionally, category 4 had a higher AUC value.
It is crucial, however, to emphasize that because one-dimensional performance metrics are naturally extremely variable and do not reveal the complete story, especially when they are approximated using scant data, they should only be used as fundamental suggestions [Citation39–41].
In the present study, the performance of the OSCEBot ® model was assessed, for example, by its ability to provide accurate and relevant information to users. In addition, it was possible to highlight differences in performance regarding the case and category. This study has allowed us to make a preliminary evaluation of the bot, thus enabling the continuous improvement of the model, verifying, and correcting the weak points and identifying the modules where modifications should be applied.
Additionally, some restrictions to be noted in this study were found. Initially, sample size: the study’s use of a small sample of students and cases may have prevented the findings from being applied to a larger population. Also, because the interactions with the students only focused on the clinical interview process, they were not adequately prepared for all the context and tasks necessary for an OSCE (such as a physical examination and nonverbal communication), nor were characteristics that would occur in a real situation considered (e.g., time restrictions). One potential limitation is using a language other than the students’ native language. Despite most students expressing proficiency in English, there is the possibility for grammatical and orthographic errors that could potentially compromise the results presented by the framework.
Conclusion
Although some chatbots for training OSCES already exist, the present work focused on developing it together with key players. In addition, the system is integrated into a closed-used platform already consolidated in medical education, maintaining data security and confidentiality. To the best of the author’s knowledge, no preliminary study of this kind has ever been conducted for a chatbot to acquire OSCE skills, making it an extremely important first step to put measures in place for a chatbot used in OSCE training. These measures must ensure that the chatbot is providing users with accurate and relevant information and is in line with the curriculum and program objectives for OSCE training. It is anticipated that the results can be improved since this study was conducted early in the chatbot deployment process. To ensure that the bot satisfies the requirements outlined in the paper’s first part, review, and discussion with users (students) are crucial. More clinical scenarios (with different frameworks) must be created to broaden the options available to students. The increase in sample size and understanding of differences in students’ performance regarding sex and curricular years is also a research question to be answered in the future. A module for instant feedback will also be implemented to maximise student learning and add voice communication to increase similarity to clinical settings. The integration of ChatGPT API to further improve the system is also one of the future projects.
Availability of data and materials
The datasets generated during and/or analyzed during the current study are not publicly available due confidentiality issues but are available from the corresponding author on reasonable request.
Declarations
Ethics approval and consent to participate.
Acknowledgments
All authors contributed to the final version of the manuscript and gave their final approval of the version to be published.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Adamopoulou E, Moussiades L. Chatbots: history, technology, and applications. Mach Learn Appl. 2020; 2(October):100006. doi: 10.1016/j.mlwa.2020.100006
- Caldarini G, Jaf S, McGarry K. A literature survey of recent advances in chatbots. Infor (Switzerland). 2022;13(1): Information 13 1 41. DOI: 10.3390/info13010041.
- Desale P, Mane P, Bhutawani K, et al. Virtual Personal Assistant and Improve Education System BT - ICCCE 2019. In: A. Kumar & S. Mozar, eds. Springer Singapore; 2020. pp. 15–16.
- Brown M, Mccormack M, Reeves J, et al. (2020). 2020 EDUCAUSE horizon report TM teaching and learning edition.
- Dolianiti F, Tsoupouroglou I, Antoniou P, et al. 2020. Chatbots in healthcare curricula: the case of a conversational virtual patien. In: Frasson C Goebel R, editors. Brain function assessment in learning. pp. 137–147. 10.1007/978-3-030-60735-7_15
- Zain S. Digital transformation trends in education. In: Baker D Ellis L-B-T-F-D-I-D-I, editors. Chandos digital information review. Chandos Publishing; 2021. pp. 223–234. DOI: 10.1016/B978-0-12-822144-0.00036-7.
- Gonda DE, Chu B (2019). Chatbot as a learning resource? Creating conversational bots as a supplement for teaching assistant training course. 2019 IEEE International Conference on Engineering, Technology and Education (TALE), 1–5. 10.1109/TALE48000.2019.9225974
- Ondáš S, Pleva M, Hladek D (2019). How chatbots can be involved in the education process. 10.1109/ICETA48886.2019.9040095
- Hayashi, Yugo (2013). Pedagogical Conversational Agents for Supporting Collaborative Learning: Effects of Communication Channels. CHI ’13 Extended Abstracts on Human Factors in Computing Systems, 655–660. 10.1145/2468356.2468472
- Stathakarou N, Nifakos S, Karlgren K, Konstantinidis S T, Bamidis P D, Pattichis C S, Davoody N. (2020). Students' Perceptions on Chatbots' Potential and Design Characteristics in Healthcare Education. Stud Health Technol Inform, 272 209–212. 10.3233/SHTI200531
- Ho Thao Hien, Pham-Nguyen Cuong, Le Nguyen Hoai Nam, Ho Le Thi Kim Nhung, and Le Dinh Thang. 2018. Intelligent Assistants in Higher-Education Environments: The FIT-EBot, a Chatbot for Administrative and Learning Support. In Proceedings of the 9th International Symposium on Information and Communication Technology (SoICT '18). Association for Computing Machinery, New York, NY, USA, 69–76. https://doi.org/10.1145/3287921.3287937
- Lund BD, Wang T. Chatting about ChatGPT: how may AI and GPT impact academia and libraries? Brady. Library Hi Tech News. 2023;40(3):26–29. doi: 10.1108/LHTN-01-2023-0009
- Pottle J. (2019). Virtual reality and the transformation of medical education. Future Healthc J, 6(3), 181–185. 10.7861/fhj.2019-0036
- Guze PA. Using technology to meet the challenges of medical education. Trans Am Clin Climatol Assoc. 2015;126:260–270.
- Lee J, Kim H, Kim KH, et al. Effective virtual patient simulators for medical communication training: a systematic review. Med Educ. 2020;54(9):786–795. doi: https://doi.org/10.1111/medu.14152
- Ochs M, Blache P, Ochs M, et al. (2018). Virtual reality for training doctors to break bad news to cite this version: hAL Id: hal-01462164 virtual reality for training doctors to break bad news.
- Gormley G. Summative OSCEs in undergraduate medical education. Ulster Med J. 2011;80(3):127–132.
- Keifenheim KE, Teufel M, Ip J, et al. Teaching history taking to medical students: a systematic review. BMC Med Educ. 2015;15(1). DOI: 10.1186/s12909-015-0443-x
- Fishman JM, Fishman, LM. History Taking in Medicine and Surgery. A. Grossman, ed. 2nd ed. Knutsford, Cheshire: PASTEST; 2010.
- Zipes DP. Braunwald’s heart disease: a textbook of cardiovascular medicine, 11th Ed. BMH Medical Journal - ISSN 2348–392X. 2018;5(2): April-June 2018. https://babymhospital.org/BMH_MJ/index.php/BMHMJ/article/view/163
- Maicher K. (2017). Developing a Conversational Virtual Standardized Patient to Enable Students to Practice History-Taking Skills. Simul Healthc, 12(2), 124–131. 10.1097/SIH.0000000000000195
- McLaughlin K, Gregor L, Jones A, et al. Can standardized patients replace physicians as OSCE examiners? BMC Med Educ. 2006;6(1):1–5. doi: https://doi.org/10.1186/1472-6920-6-12
- Zini JE, Rizk Y, Awad M, et al. (2019). Towards a deep learning question-answering specialized chatbot for objective structured clinical examinations. Proceedings of the International Joint Conference on Neural Networks, July, 1–9. 10.1109/IJCNN.2019.8851729
- Rau T, Fegert J, Liebhardt H. How high are the personnel costs for OSCE? A financial report on management aspects. GMS Z Med Ausbild. 2011;28(1):Doc13. doi 10.3205/zma000725
- Han ER, Yeo S, Kim MJ, et al. Medical education trends for future physicians in the era of advanced technology and artificial intelligence: an integrative review. BMC Med Educ. 2019;19(1). DOI: 10.1186/s12909-019-1891-5
- Baeten M, Struyven K, Dochy F. Student-centred teaching methods: can they optimise students’ approaches to learning in professional higher education? Stud Educ Eval. 2013; 39(1):14–22. doi: 10.1016/j.stueduc.2012.11.001
- Kumar JA. Educational chatbots for project-based learning: investigating learning outcomes for a team-based design course. Int J Educ Technol High Educ. 2021;18(1). DOI: 10.1186/s41239-021-00302-w
- Jain N, Bhansali A, Mehta D. AngularJS: a modern MVC framework in JavaScript. J Glob Res Comput Sci. 2014;5(12):17–23.
- Reimers N, Gurevych I (2019). Sentence-BERT: sentence embeddings using siamese BERT-networks. EMNLP-IJCNLP 2019 - 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, 3982–3992. 10.18653/v1/d19-1410
- Devlin J, Chang M-W, Lee K, et al. {BERT: } pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.0. 2018. Available from: http://arxiv.org/abs/1810.04805.
- Peyton K, Unnikrishnan S. Results in Engineering a comparison of chatbot platforms with the state-of-the-art sentence BERT for answering online student FAQs. Results In Eng. 2023;17(October 2022):100856. doi: 10.1016/j.rineng.2022.100856
- Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett. 2006; 27(8):861–874. doi: 10.1016/j.patrec.2005.10.010
- Das S, Kumar E (2018). Determining accuracy of chatbot by applying algorithm design and defined process. 2018 4th International Conference on Computing Communication and Automation, ICCCA 2018, 1–6. 10.1109/CCAA.2018.8777715
- Hidayatin L, Rahutomo F (2018). Query expansion evaluation for chatbot application. Proceedings of ICAITI 2018 - 1st International Conference on Applied Information Technology and Innovation: Toward A New Paradigm for the Design of Assistive Technology in Smart Home Care, 92–95. 10.1109/ICAITI.2018.8686762
- Altman DG (1990). Practical statistics for medical research.
- Voege P, Abu Sulayman IIM, Ouda A. Smart chatbot for user authentication. Electronics (Switzerland). 2022;11(23):4016. doi: 10.3390/electronics11234016
- Hosmer DW, Lemeshow S. Applied logistic regression. John Wiley and Sons: 2000. DOI: 10.1002/0471722146
- Youden WJ. Index for rating diagnostic tests. Cancer. 1950;3(1):32–35. doi: 10.1002/1097-0142(1950)3:1<32:AID-CNCR2820030106>3.0.CO;2-3
- Balfe E, Smyth B. An analysis of query similarity in collaborative web search. In: Lect notes comput sci. Vol. 3408. 2005. pp. 330–344. DOI: 10.1007/978-3-540-31865-1_24.
- Matthys J, Elwyn G, Van Nuland M, et al. Patients’ ideas, concerns, and expectations (ICE) in general practice: impact on prescribing. Br J Gen Pract. 2009;59(558):29–36. doi: 10.3399/bjgp09X394833
- Peart P. Cardiovascular history taking and clinical examination. Clinics In Integrated Care. 2022;12:100105. doi: 10.1016/j.intcar.2022.100105
Appendix
Table A1. Example of a history taking scheme focused on the symptom ‘leg pain’.
Appendix 2- Example of a conversation between the student and the chatbot.