
ABSTRACT
This study aims to investigate English as a foreign language (EFL) learners’ use of context information under various noise conditions. The participants were seven Japanese undergraduate students. A noise test adopted from the Speech-Perception-in-Noise (SPIN) test (Kalikow et al., 1977) was used. Four signal-tonoise ratio (SNR) conditions (SNR = 0, 5, 10, 15) and a condition without noise were added to the SPIN test. Data were collected using think-aloud protocol procedures. Some target words presented in the noise test were supported with contextual information, enabling learners to use top-down prediction, whereas others were not supported with contextual information, making it difficult for learners to predict the target words. The results showed that, first, learners used contextual information at all noise levels, but differently in high- and low-context sentences. Second, participants’ listening comprehension was greatly affected by background noise. The scores on the noise test and their confidence levels decreased as the level of noise increased. Third, the participants used contextual information successfully and most frequently when the SNR = 15. It was also found that the tolerance level for noise varied among participants. Implications for listening assessment and teaching are discussed.
Introduction
Listening input and background noise are inseparable in daily life. There are occasions where background noise should be kept to a minimum to prevent distractions to the audience, such as during lectures, interviews, or meetings; however, listening activities also occur in situations where background noise is present. We listen when we chat at a coffee shop, listen to announcements at train stations, or speak outdoors in the presence of traffic noise.
In language education, background noise is one factor that affects language learners’ listening comprehension (Buck, Citation2001; Richards, Citation2005; Scharenborg & Os, Citation2019). While language learners are accustomed to clear listening texts without background noise, in real-life settings they must listen to what other interlocutors are saying in circumstances filled with background noise. Listeners need to rely on context and co-text information under such adverse noise conditions because they cannot only rely on direct input due to noise interruptions (Field, Citation2008).
Doctoring and editing the listening passages to eliminate noise helps language learners concentrate on the linguistic input; however, this may lead to a decrease in the passage authenticity (e.g., Carroll, Citation1980). According to Carroll (Citation1980, p. 12), authenticity in verbal language comprehension is partly related to the fact “that the contexts of the interchanges are realistic, with the ordinary interruptions, background noises, and irrelevancies found in the airport or lecture-room.”
Similarly, the Common European Framework of Reference for Languages (CEFR) underscores the role of background noise in listening comprehension during communicative activities. At level B1, “only extreme background noise, inadequate discourse structure and/or idiomatic usage influence the ability to understand” (Council of Europe, Citation2001, p. 66). Regarding listening to announcements and instructions, a level C1 language learner “can extract specific information from poor quality, audibly distorted public announcements, e.g., in a station, sports stadium etc.” (Council of Europe, Citation2001, p. 67). These descriptions indicate that extreme background noise can negatively affect language learners’ listening comprehension. High-proficiency listeners may have the ability to extract the necessary information under such noise; however, the noise may be more distracting to low-proficiency listeners (Peng & Wang, Citation2016; Shi, Citation2009).
The use of background noise in language learning and assessment has been a contentious subject. Some researchers have suggested that language instructors should consider background noise and its effects on language learners’ listening comprehension in language teaching (e.g., Field, Citation2008; Hodoshima et al., Citation2009; Lecumberri & Cooke, Citation2006; Shi, Citation2009). Hodoshima et al. (Citation2009) argued that language learners, accustomed to “clean” listening materials without any background noise, might not be able to reach high listening comprehensibility. Lecumberri and Cooke (Citation2006) reviewed experimental studies on non-native listening in adverse conditions. Making a clear distinction between second languages (L2s) and foreign languages (FLs), they argued that an FL is learned through instruction, and FL learners lack massive and natural input. Therefore, the quantity and quality of input may be a dominant factor in speech perception for FL speakers. Lecumberri and Cooke (Citation2006) also argued that in the context of English as a Foreign Language (EFL), having the capacity to effectively process and comprehend less than optimal aural stimuli in the target language is a critical capacity. However, in most cases, there is minimal to no background noise in the listening materials developed for language learning or language testing. In some cases, language testing professionals aim to document the voice with no other noise to make the voice as clear as possible when making voice recordings (Buck, Citation2001). Though creating materials with clear sound might be important for material developers, it is still beneficial for educators to use listening materials that have adverse noise features in language instruction and language testing, especially in EFL settings. By adopting listening materials with noise, language instructors can provide EFL learners opportunities to experience the various types of aural stimuli they might encounter in real-life settings. However, there is limited research concerning the effects of noise on listening, specifically in EFL settings. The current research seeks to provide more information on the listening comprehension process of EFL learners under adverse noise conditions.
Noise test
Several studies have examined noise effects on listening comprehension from various viewpoints. In an early study, Gaies et al. (Citation1977) introduced a noise test as a listening proficiency test. They evaluated English proficiency using a noise test designed to measure whether people with reduced acoustic intelligibility can comprehend messages. Based on the results, they concluded that non-native speakers performed poorly on noise tests that contained sentences for which their comprehension depended on contextual information. In a more recent study, Buck (Citation2001) observed test takers’ reactions to noise tests. Noise tests were introduced where the test-takers listened to a passage with background noise, thus partially masking the text. He noted that listening tests containing background noise were unpopular with material developers because they require good equipment and technical expertise. He also found that test takers disliked white noise, a continuous hissing sound that covers most of the spectrum’s negative frequency range.
Effects of noise on bilingual listeners
Several studies have investigated the effects of noise on bilingual listeners and their age of acquisition. Rogers et al. (Citation2006) found that bilingual speakers who acquire a target language at an early age have more inadequate listening comprehension than native speakers in noisy settings. They also explained that bilingual speakers who have little difficulty in listening comprehension are at a disadvantage when it comes to listening comprehension under noisy conditions. In another study, Shi (Citation2009) examined whether a bilingual listener’s age of acquisition affected listening comprehension in the presence of noise. The study concluded that even early bilingual speakers used contextual information less effectively than native speakers under noisy circumstances. In a recent study, Skoe and Karayanidi (Citation2019) investigated native and bilingual listeners’ use of contextual cues when hearing English speech in noisy settings. They concluded that bilingual listeners perform similar to their monolingual counterparts under noisy conditions. In such circumstances, contextual information was not facilitative to their understanding, and they underperformed in noisy circumstances where the linguistic context was not facilitative to their understanding.
Kousaie et al. (Citation2019) examined the relationship between language acquisition age and noise effects from a neuropsychological viewpoint. They conducted a neuropsychological experiment to examine how the age of acquisition affected the bilingual speakers’ use of contextual information in noisy settings. The behavioral and neural results showed that native listeners benefited more from contextual information in noisy conditions than bilingual listeners because speech perception became more difficult for bilingual listeners. Kousaie et al. concluded from the study’s results that an individual’s ability to use contextual information to process speech in noise is likely associated with the timing of language learning. This is because individuals who learn a non-native language after the age of six do not benefit from contextual information. They also face difficulty in attaining a high level of listening comprehensibility under adverse noise conditions. Bilingual speakers can effectively use contextual information in settings without noise; however, they experience difficulties under noisy conditions.
Neurocognitive mechanisms of listening comprehension in noise
The hampering role of background noise in listening comprehension may be explained in terms of the neurocognitive mechanisms induced by non-linguistic inputs in contrast to linguistic inputs. In a recent neuroimaging study, Lee et al. (Citation2020) stated that listening test takers exhibit significant brain activation, representing cognitive load, in three regions of the brain’s left hemisphere (the inferior frontal gyrus, dorsomedial prefrontal cortex, and posterior middle temporal gyrus). They experience this while listening to lectures and the natural sounds of animal vocalizations. However, the activation level is significantly higher when listening to lectures. It can be assumed that listeners’ cognitive load increases significantly in such circumstances, even though Lee et al. did not conduct the same test with background noise. This is because the brain is simultaneously processing two types of stimuli. In another study, Rammell et al. (Citation2019) examined the neural correlates of L2 speech perception in noise. The participants listened to their first language (L1) and L2 speech in both quiet and noisy conditions. The participants’ recognition of L2 sentences was high even under noisy conditions, but they focused on decoding speech at the perceptual level using a bottom-up processing strategy. Conversely, there was significant activation in the region linked to lexical-semantic access in the L1 noise condition. This suggests that the participants more frequently used top-down processing in the L1 noise condition than in the L2 noise condition. Thus, the findings suggest that the participants used different perceptional strategies to understand L1 and L2 speech in noisy conditions.
Variables affecting listening comprehension in noise
The effects of noise on listening comprehension have been examined in relation to other factors, such as speakers’ accent and listening efforts. Rogers et al.’s (Citation2004) assessment of speakers’ foreign accents revealed that adding noise to a highly proficient Chinese-accented English speech reduced intelligibility more than that of native speech. Peng and Wang (Citation2019) investigated how various realistic acoustic factors affect listening efforts, such as adverse acoustics, speakers’ accents, and listeners’ language abilities. Native and non-native listeners with normal hearing participated in the study using questionnaires and listening comprehension tests. Non-native listeners reported that they exerted more listening effort in comprehending speech with adverse acoustics than did native listeners. Moreover, highly proficient non-native listeners performed better with background noise than low-proficiency non-native listeners. Second, while non-native listeners who shared foreign speakers’ accents did not report any changes in their listening effort, other listeners reported more frustration in understanding accented speech. These studies suggest that the adverse effects of noise on listening comprehension are exacerbated by speakers’ foreign accents. This is especially true when listeners do not share the speakers’ accents.
Listening comprehension under noise in EFL context
Research on listening comprehension under noise is scarce, especially in EFL settings. Among the few studies that have been conducted, Hodoshima et al.’s (Citation2009) research investigated the relationship between EFL learners’ proficiency levels and their listening comprehension. In their study, Japanese EFL learners with different proficiency levels took word identification listening tests under quiet, noisy, and reverberant conditions. The results showed that all participants’ listening comprehension deteriorated under noisy and reverberant conditions, irrespective of their proficiency levels.
Another study focused on Japanese EFL learners. Masuda’s (Citation2016) study examined Japanese EFL learners’ misperception patterns with American English consonants. Native and EFL listeners with different proficiency levels participated in a consonant identification experiment, and native listeners achieved higher identification rates than EFL listeners. Masuda also observed a positive correlation between English proficiency and identification rates. Additionally, it is worth noting that the misperception patterns among high-proficiency listeners began to resemble those of the low-proficiency listeners. This holds true as the amount of background disturbance increases. Similarly, Fujita (Citation2016) conducted an experiment on Japanese EFL learners, focusing on their use of contextual information under noise. Fujita investigated how the presence of background noise and sentence predictability affected Japanese EFL learners’ listening comprehension by adopting the speech-perception-in-noise (SPIN) test devised by Kalikow et al. (Citation1977). Five noise conditions in his study: no noise, signal-to-noise ratio (SNR) = 15, SNR = 10, SNR = 5, and SNR = 0. The Japanese EFL learners took the SPIN tests under these five conditions and rated their confidence levels regarding their listening comprehension. The results revealed that contextual information positively affected their listening comprehension at SNR = 15 and SNR = 5; however, such an effect was not achieved under the no-noise condition. These findings imply that the effects of contextual information on participants’ listening comprehension varies depending on noise level.
Variables in L2 listening comprehension
Listening comprehension is a complex process involving many variables. Buck (Citation2001) stated that both linguistic and non-linguistic knowledge are involved in language comprehension. Linguistic knowledge involves phonology, lexis, syntax, semantics, and discourse structures. Non-linguistic knowledge refers to knowledge about topics, contexts, and general knowledge about the world. Recent studies have claimed that L2 lexical knowledge is the most important factor in successful L2 listening processes (e.g., Vafaee & Suzuki, Citation2019; Vandergrift & Baker, Citation2015; Wallace, Citation2020). Vandergrift and Baker (Citation2015) investigated learner variables predicting success in L2 listening. They explored cognitive learner variables, including L1 listening ability, L1 vocabulary knowledge, L2 vocabulary knowledge, auditory discrimination ability, metacognitive awareness of listening, and working memory capacity, analyzing how each variable was related to learners’ L2 listening ability. The results revealed that L1 and L2 vocabulary knowledge played a robust role in L2 listening comprehension, in addition to general skills such as auditory discrimination and working memory. In a recent study, Wallace (Citation2020) examined the effects of domain-specific knowledge (e.g., vocabulary knowledge and topical knowledge) and domain-general cognitive abilities (e.g., metacognitive awareness, memory, and attentional control) on L2 listening comprehension. The results of the listening and memory tests and questionnaires showed that vocabulary knowledge and topical knowledge had the strongest effect on listening comprehension among the examined variables. Vafaee and Suzuki (Citation2019) specifically focused on the effects of syntactic and vocabulary knowledge on L2 listening comprehension. They utilized linguistic, cognitive, and affective measures and a listening test to obtain their results. The results revealed that vocabulary knowledge played a more important role than syntactic knowledge in L2 listening, even though both factors were significant predictors of L2 listening abilities. Overall, these studies indicate that vocabulary knowledge plays the most crucial role in successful L2 listening comprehension.
Dictation test and L2 listening comprehension
The relationship between dictation tests and L2 listening comprehension is noteworthy as the current study employs dictation tests in assessing learners’ listening comprehension. The dictation test is the most widely used integrative listening test, analyzing learners’ ability to recognize words (Buck, Citation2001; Field, Citation2008). Previous studies have supported the connection between partial dictation-type tests and L2 listening comprehension. Matthews and Cheng (Citation2015) used a partial dictation test to investigate the relationship between the recognition of high-frequency words from speech and L2 listening comprehension. Based on the results, they found a strong association between word recognition in speech test scores and listening comprehension test scores. The findings suggest that recognizing high-frequency words as assessed by the partial dictation test is a predictor of successful L2 listening comprehension. In a recent study by Lange and Matthews (Citation2020), which focused on Japanese EFL learners, a strong correlation was found among vocabulary, lexical segmentation abilities, and L2 listening comprehension tests. In their study, a listening vocabulary test and performed transcription tests were conducted. The scores were then compared with the results of the English proficiency tests. The results showed that aural knowledge of high-frequency vocabulary and lexical segmentation ability are strongly associated with L2 listening ability. These studies suggest that dictation style tests are a useful approach to measuring listening comprehension skills.
The current study
The current study builds upon Fujita’s (Citation2016) work, which used a quantitative experimentation approach. Although previous studies have investigated the effects of noise from various perspectives, most studies have used quantitative methods. Quantitative methods have their advantages in that the data from many participants can be generalized (Fujita & Hirai, Citation2018). Qualitative methods also have some strengths, including the ability to explore learners’ behaviors, perceptions, feelings, and understanding (Rahman, Citation2017). Therefore, the current study employs qualitative and quantitative methods on a smaller scale to analyze learners’ listening comprehension processes by investigating how they use contextual information under various noise conditions.
Examining learners’ use of contextual information under noise conditions in more detail and focusing on each learner, we throw light on other findings. This study’s research questions are as follows:
RQ1: How does contextual information affect EFL learners’ listening comprehension?
RQ2: How does background noise affect EFL learners’ listening comprehension?
RQ3: Do EFL learners change their use of contextual information according to the noise level?
Materials and Methods
Participants
Seven Japanese undergraduate students aged 18 to 20 participated in the study. Their majors varied, ranging from international studies, humanities, and physical education, to medicine. All participants had normal hearing. Their proficiency levels ranged from CEFR A1 to B1, based on the Test of English as a Foreign Language (TOEFL)- Institutional Testing Program (ITP) scores conducted as a placement test.
Materials
Listening proficiency test
The listening test was adapted from the Test of English for International Communication (TOEIC) practice test (Kokusai Business Communication Kyokai, Citation2011). The test consists of four tasks: (a) photograph recognition (four items), (b) single-sentence inquiry (four items), (c) conversation (six items), and (d) monologue (six items). There are 20 questions in total, all of which are multiple-choice. One point was allocated to each item, and the highest score was 20. All participants completed the proficiency test. Their mean score was 14.50 (SD = 2.88). The proficiency test’s reliability was low at α = 0.597; however, the relatively low α value was understandable considering the small sample size. The listening proficiency test scores indicated that the participants’ proficiency levels were high-intermediate.
Noise test
This study applied the noise test used in Fujita (Citation2016) (see the Appendix), which is conducted through several steps. First, sentences are selected. Originally, the texts used were based on the SPIN test (Kalikow et al., Citation1977), which includes a list of sentences, and the last word, a monosyllabic noun, is the target word. Some target words presented in the noise test are supported by contextual information that aids top-down prediction. However, the other words are unsupported by contextual information, such that contextual information does not aid word inference.
The vocabulary level of the target words was set to be lower than Level 3 of the Japan Association of College English Teachers (JACET) 8000 to ensure that the participants were familiar with the vocabulary used (see ). JACET 8000 is a word list designed for English learners in Japan. It comprises eight levels, determined according to the frequency and educational significance of each word (Uemura & Ishikawa, Citation2004). The 8000 words in the list are divided into eight levels, each with 1000 words. The vocabulary levels of the whole sentences used in the noise test showed that 95.5% of the tokens were lower than Level 3 of the JACET 8000. The noise test’s vocabulary levels were also analyzed using the framework of the British National Corpus and the Corpus of Contemporary American English (BNC-COCA) word list through Vocabprofile (Cobb, Citation2021). shows that words up to and including the 3000-frequency level exceed 95% coverage for the whole sentences in the noise test. Regarding the target words, words up to and including the 4000-frequency level exceed 95% coverage.
TABLE 1. Vocabulary levels of the noise test analyzed with the framework of the JACET 8000
TABLE 2. Vocabulary levels of the noise test analyzed with the framework of the BNC-COCA word list
The examples in paragraph (1), below, are sentences with high- and low-context information, and the underlined words represent the target words. The target word “sheet” is supported by the phrase “made the bed,” as shown in the high-predictability sentence. Conversely, there is no contextual information or words supporting the target word “knife” in the low-predictability sentence. Thus, the target word was difficult for listeners to guess.
(1) High-predictability sentence: She made the bed with clean sheets.
Low-predictability sentence: I am thinking about a knife.
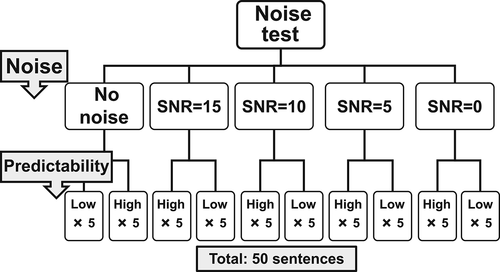
Second, the sentences were transformed into sound files using Globalvoice English version 2, a synthetic text-to-speech program. Synthetic speech is a useful tool for creating listening materials, especially for EFL teachers, and its quality is perceived to be almost as natural as human speech (Hirai & O’ki, Citation2011). The speech rate was at 2.06 words per second and 2.34 syllables per second. Sentences were articulated in a discrete citation form and not just connected words with phonological modifications. Finally, the background noise of a crowd talking (Sound Jay, Citation2014) was added to the sound files. The noise level, measured by the SNR, was set to an SNR of +15, +10, +5, and +0. Larger SNR values indicate lower noise levels. When the SNR equals 0, the noise and signal levels are the same. At each noise level, five low-predictability sentences and five high-predictability sentences were used. As shows, 10 types of sound files were created for each noise level, and a total of 50 sentences were used. For each noise level, the total score is 10, with five points each for low- and high-predictability sentences.
Figure 1. 50 sentences in the noise test (Adopted from “Effects of sentence predictability on EFL learners’ speech-in-noise recognition,” by R. Fujita, Citation2016, English Language Assessment, 11(1), p.12. Copyright 2016 by the The Korea English Language Testing Association).
After testing at each noise level, a question about participants’ confidence level was prepared by asking whether they were able to comprehend the listening text. The responses are on a 4-point Likert-type scale ranging from 1 (I could not comprehend anything at all) to 4 (I could comprehend everything).
Procedure
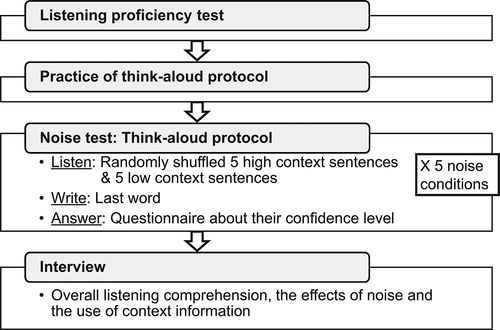
Overall, the study consisted of three phases: a listening proficiency test, a noise test with a think-aloud protocol, and an interview (see ). Participants completed the tests and were interviewed individually.
Figure 2. The procedure of the experiment.
Listening proficiency test
The experiment was conducted in a quiet room. After receiving the overall instructions, participants were provided the listening proficiency test.
Noise test with think-aloud protocol
Data were collected using think-aloud protocol procedures. The experiment was administered to participants individually in a quiet room. The think-aloud procedures included a training session and a data collection phase. The instructions were provided entirely in Japanese using English materials.
The students were pre-trained to think aloud so that they had a good understanding of how to do so and an opportunity to practice before taking the noise test. The researcher explained how the think-aloud protocol worked. We used English grammar questions as sample questions and asked the participants to answer the questions and to verbally report what thoughts occurred in their minds. They were instructed to think aloud, either in Japanese or English. For example, they spoke in English when reading English sentences aloud; however, they spoke in Japanese when thinking aloud about the process of solving the grammar questions. If the participants remained silent or did not report in detail what they were thinking, the researcher asked them to elaborate on how they solved the question and why they chose their answer.
After the training, the participants practiced thinking aloud while listening to the sample questions and were asked to verbally report what they were thinking in Japanese or English. They were asked to do so while listening to the English sentences in the noise test. The participants wore headphones and were instructed to pause after listening to each sentence in order to ensure they had time to write down their answers. The participants’ voices were recorded using an audio recorder, and they verbally reported what they were thinking or how they arrived at their answers while listening to the sentences. After listening, they wrote their answers on the answer sheet. They completed the task at their own pace, and the researcher stayed in the same room during the task in case any technical problems arose. The researcher also reminded the participants to think aloud when needed.
Interview
After the think-aloud protocol session, the researcher conducted individual interviews in Japanese with each participant. The interviews were audio recorded, and the researcher followed a semi-structured interview format. The purpose of the semi-structured interview is to allow participants to freely comment on their experiences as the order of the questions can be changed depending on participants’ responses (Fujita & Hirai, Citation2018). The following questions’ stems were prepared beforehand. They are concerned with the learners’ overall listening comprehension, effects of noise, and their use of contextual information.
Can you tell me your general comments about the listening task?
In which part did the noise start to disrupt your listening comprehension? Why?
Did you use any contextual information while listening? Why?
When needed, the researcher and the participants listened to the audio again during the interview to help the participants remember what they were thinking during the listening task.
Scoring and data analysis
Noise test
The noise test was scored based on the dictation tests’ scoring criteria. First, spelling mistakes were ignored as is the convention in marking dictation tests (Buck, Citation2001; Oller, Citation1979). Oller (Citation1979) argued that spelling mistakes that do not influence pronunciation should be counted as correct. Based on Oller’s proposed marking method, the target words were marked.
If a word had a different meaning because of the spelling mistake, the answer was considered incorrect. For example, if the participant’s answer was cost, and the right answer was “coast,” the word was counted as incorrect. Whereas, “steem” for “steam” was counted as correct because “steem” is not an actual word and can be considered a spelling mistake.
In this study, the participants’ answers were also checked using the think-aloud data, and additional criteria for marking were set based on that. When the think-aloud data showed that the participant misunderstood or did not understand the meaning of the word, the word was counted as incorrect.
Another notable point on the scoring of the noise test was the interchange of “l” and “r.” As Japanese does not distinguish between “l” and “r,” many participants used “l” and “r” interchangeably, which was also counted as a spelling error.
In each noise condition, there were ten questions, five of which contained high-context information and the other five contained low-context information. Each score was calculated based on the number of correct answers given. As the number of participants was small, the Wilcoxon test was conducted for each noise condition to examine the effects of contextual information.
Think-aloud protocol and interview
All data from the think-aloud protocol and interviews were transcribed and pseudonyms were used for all names. The think-aloud protocol data and participant answers to the noise test were analyzed qualitatively.
The think-aloud protocol data was first divided into sentences in each part. Next, the utterances were examined to determine whether the participants mentioned the use of contextual information. In addition to contextual information, any information related to their listening comprehension process was noted. For example, notes were taken when they mentioned the use of grammatical knowledge or when they stated they had misinterpreted certain words. In the next phase, the utterances using contextual information were placed under sub-categories. The criteria of the sub-categories included the types of contextual information used by the learners. For example, the use of the first word, the last two words, or only the last word as contextual information was examined. After coding the think-aloud data, the utterances, along with the coding annotations at each noise level, were divided into high-context and low-context sentences. Counting the number of occurrences for each context use is important in identifying the contextual information’s use.
A similar coding procedure was followed for the interview data. First, the idea units were identified from each participant’s utterances, and the units with similar ideas were then categorized and labeled. For example, the following is an excerpt from a student, “Makoto”:
(2) Excerpt: Makoto
When the noise level is low, I can listen to the whole sentence. Therefore, I thought that there was a lot of information in the input. For example, the clue that I needed to guess the last word was either a verb, subject, or preposition. (Translated from Japanese.)
The main idea from the excerpt of Makoto’s utterances was “when the noise level is low, contextual information is helpful.” It was then labeled as “noise and contextual information.” Other labels include noise level, testing strategy, think-aloud protocols, general listening skills, or unknown words. All utterances under the same labels were ordered together and later analyzed.
Results
Noise test
The results of the noise test are shown in and and . shows the results of the noise test scores and their confidence levels. shows the results of the same noise tests divided into low-context and high-context conditions. Overall, the noise test scores gradually decreased as the level of noise increased, especially in the SNR = 0 condition.
TABLE 3. The Results of the Noise Test
Figure 3. The results of the noise test and confidence levels.
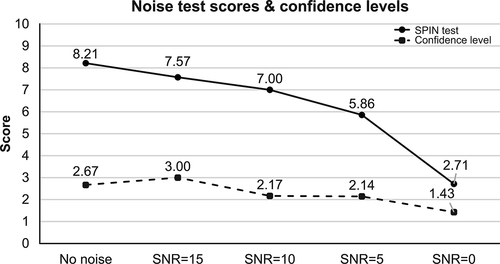
Figure 4. The results of the noise test scores in low-context and high-context conditions.
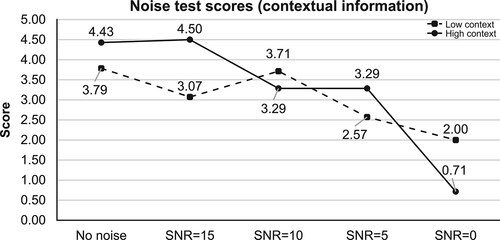
To compare the scores of low-context and high-context sentences, the Wilcoxon test was conducted for each noise condition. The results of the Wilcoxon test showed that there were statistically significant differences between the high- and low-context conditions in the SNR = 15 and SNR = 0 conditions.
For SNR = 15, the scores were significantly higher in the high-context condition (Mdn = 4.5) than in the low-context condition (Mdn = 3.5), z= 2.862, p < .01, r = 1.01 (effect size is large). For SNR = 0, the scores were significantly higher in the low-context condition (Mdn = 2.0) than in the high-context condition (Mdn = 1.0), z = 2.394, p < .05, r = .91 (effect size is large). As shown in , their confidence level also dropped in noise levels noisier than SNR = 15. In the no-noise and SNR = 15 conditions, the scores were similar.
Think-aloud protocol
The think-aloud protocol data were analyzed in terms of the use of contextual information. It was observed that the learners used contextual information differently in sentences with high and low contextual information.
In sentences with high-context information, the use of contextual information was observed. As shown in excerpts from the think-aloud data in (2) to (5) below, the participants were able to find the words or phrases related to the target word and used the information to confirm that they understood the target word correctly. For example, in (3), the participant focused on the word “TV.” She confirmed that the target word was “screen,” which was part of a TV set. Similarly, “airmail” and “stamp” in (4), as well as “football” and “kick” in (6), are word pairs that frequently co-occur. The phrase “drop a bomb” in (5) is also considered a collocation. Each sentence in the noise test was short. However, the participants were able to recognize words related to the target word in the short sentences. For example, in (6), the participant was able to pay attention to “football,” which had the highest contextual information. However, the participant did not focus on “boy,” which is the subject of the sentence. This is because the word “boy” provided no contextual information to the target word “kick.”
(3) No noise
(The participant hears: “My T.V. has a 12-inch screen.”)
“テレビ, 主語はテレビで “screen”って聞こえたので画面の意味かなって思う。”
{TV; The subject is TVand I heard “screen,” so I think it means the screen.}
(4) SNR = 15
(The participant hears: “Air mail requires a special stamp.”)
“Airmail発行というか, 切手がおされている, 一般的な話なので恐らくstamp。”
{To issue the airmail, a stamp is put. It is a common story, so maybe “stamp.”}
(5) SNR = 10
(The participant hears: “The airplane dropped a bomb.”)
“The airplaneときて, bombあとdropときたから爆弾かな?”
{It says airplane, bomb, then drop. So, maybe bomb?}
(6) SNR = 5
(The participant hears: “The boy gave the football a kick.”)
“footballってきて, kickって聞こえたから蹴るかな?”
{It says football. I then hear “kick.” So maybe kick?}
shows the number of times the participants used contextual information at each noise level. The number of times that they used contextual information was the highest at SNR = 15, though the frequency of its use varied across participants. The scores on the noise test with contextual information were significantly higher than those without contextual information.
TABLE 4. The number of times the participants used the contextual information
Another feature of the students’ use of contextual information was that in the low-context sentences, most students repeated two or three words at the end of the sentence. In other words, they attempted to obtain information from words immediately before the target word. As in excerpt (7) below, the participant just repeated and translated the phrase “thinking about.” However, it was difficult for him to make any connection between the phrase and the target word, “knife.” Excerpt (8) also shows that the student simply repeated the last three words of the sentence without being able to find any contextual information. This resulted in the student giving the wrong answer: “duck” instead of “lock.”
(7) No noise
(The participant hears: “I am thinking about a knife.”)
“thinking about何かを考えている, thinking about ナイフ。”
{thinking about, thinking about, thinking about knife}
(8) SNR = 15
(The participant hears: “We heard you call about the lock.”)
“called aboutduck, “call aboutduck”かな?”
{called about duck; was it “call aboutduck?”}
Overall, the think-aloud protocol results also revealed the learners’ variability. The data depended on each participant’s characteristics. For example, “Hayato” paid careful attention to detailed grammatical points whenever he answered the questions. As shown in excerpt (9), he paid attention to the parts of speech, evaluating whether the target word, a noun, was singular or plural. As shown in excerpt (10), “Kana” also translated the English sentences she heard into Japanese. She even translated the whole sentence into Japanese in the excerpt below and guessed the target word after translating the whole sentence.
(9) Hayato
(The participant hears: “The old train was powered by steam.”)
“the all すべては何か steam蒸気で動いているとかそういうことかな。steam, 蒸気, 加算できるとは思えないのでこのままsteam。”
{The all? What is all? Steam? Maybe it is moved by steam or something similar. Steam; I do not think it is countable, so just steam as it is.}
(10) Kana
(The participant hears: “The old man discussed the dive.”)
“全ての男性が議論する, ダイブ, 何かについて議論するから, ライブ?”
{All the men discuss the dive, or are discussing something? So live?}
The think-aloud protocol analyses showed that some participants wrongly used the contextual information. As a result, some of their answers were incorrect, as shown in excerpt (11) below. In excerpt (11), the participant was able to hear the phrase “on the beach,” providing high-context information to the target word, “sand.” However, she guessed wrongly and imagined a person on the beach, which resulted in her giving the wrong answer, “Sam.” Excerpt (12) below demonstrates the incorrect use of contextual information in sentences with low-contextual information. In excerpt (12), the participant paid attention to the word “hear,” which was not intended to provide the learner with contextual information; nonetheless, the learner made a connection between “hear” and “rock,” which is a music genre. In this case, it is also noted that the participant misheard the letter “l” as “r.” This is because the distinction between the letters “l” and “r” is known to be difficult for Japanese learners.
(11) (The participant hears: “On the beach we play in the sand.”)
“on the beachって言って, サム, といったから人の名前かな, と。”
{It says “on the beach,” and I heard “Sam.” So maybe it is a person’s name.}
(12) (The participant hears: “We hear you called about the lock.”)
“We hearで, hearと聞こえたので, 音楽のrock。”
{It says “we hear”, and I heard “hear,” so it should be rock, as in music.}
Interview
As the interview was semi-structured, the interviewer asked the participants questions about their overall listening comprehension, the effects of noise, and their use of contextual information. The interviews were transcribed and later coded. The categories identified after coding were the level of noise, noise, contextual information, testing strategy, and others, such as general listening skills or unknown words.
Most of the interview data concerned the level of noise and the participants’ tolerance level for noise. The perception of how their listening comprehension was affected by noise varied among the participants. Among the seven students, three students said that they could tolerate the noise up to SNR = 15, two students up to SNR = 10, and two students up to SNR = 5. Their comments about discomfort from the noise are shown in (13), below.
(13) “From level 4 (SNR = 5), I felt discomfort with the noise.”
“I couldn’t even hear the subject (of the sentence) in level 5 (SNR = 0).” (Translated from Japanese into English)
Two students said that they could concentrate more when there was some noise, as in (14) below. One of them stated that she preferred listening under noise, up to an SNR = 10 level.
(14) “Up to level 3 (SNR = 10), I preferred the sound with noise.”
“The noise didn’t disturb my listening comprehension up to level 3 (SNR = 10).” (Translated from Japanese.)
Regarding their general comments about noise, some students were not used to it and said that consonants were difficult to hear because of the noise. Some learner variability was observed in these comments (see (15) below):
(15) “I was surprised when I heard the noise for the first time.”
“I couldn’t hear consonant sounds well when there was noise.” (Translated from Japanese.)
Some students noted that they used contextual information. One student mentioned that information about content words (nouns and verbs) was useful; however, verbs lacking contextual information, such as “discuss,” were not useful. Another participant commented that she was able to use the contextual information well only when there was no noise.
The use of testing strategies was also mentioned. As shown in (16), they decided which words to pay attention to while listening. The fact that all the target words were nouns was useful information as well.
(16) I tried to pay attention to the words at the beginning and end of the sentence.
I realized that the target words were all nouns, which helped me guess the answer. (Translated from Japanese.)
Discussion
RQ1: how does contextual information affect EFL learners’ listening comprehension?
Overall, the participants tried to use contextual information in both high- and low-context sentences. However, the think-aloud data and the interview data revealed that the way they used contextual information differed depending on the predictability of the sentences. In high-context sentences, the participants focused on content words, such as verbs and nouns, while in low-context sentences, some participants repeated the words immediately before the target word. In this case, the use of testing strategies was observed. Because they knew that the target words were the last word in the sentence, they sought relevant information from the words immediately before it.
In addition, when comprehensibility was low, it was observed that they tried to repeat the whole sentence, suggesting that the learners actually relied on contextual information, especially when their comprehension was limited. This finding supports the argument by Field (Citation2008) that when listeners cannot rely on the input, they need to rely on context and co-text information. The interview data and think-aloud data also revealed learner variation. Some students focused on contextual information and relied on it more frequently than others.
Previous studies have suggested that non-native speakers scored poorly on sentences whose comprehension depended on contextual information (Gaies et al., Citation1977; Shi, Citation2009). The findings of the current study show that the learners were able to take advantage of contextual information in noisy conditions and tried using it, irrespective of the success of contextual information.
These findings suggest that the correct use of contextual information is important for language learners. Listening comprehension is highly reliant on the contextual information that speakers provide, especially in real-life situations. Native speakers and highly proficient learners automatically use contextual information to achieve high levels of comprehension. Therefore, the correct use of contextual information is a critical skill that learners must acquire, particularly for low proficiency learners whose listening comprehension is limited. From the perspective of language assessment, including listening comprehension questions that require learners to use contextual information is recommended. By including such questions, researchers can assess whether learners have the skills required in real-life circumstances.
RQ2: how does background noise affect EFL learners’ listening comprehension?
Most of the interview data concerned the level of noise; therefore, we can assume that the participants paid great attention to the presence of noise. Generally, developers of listening materials aim to record the voice with no other noise, and most listening materials lack noise (Buck, Citation2001). The participants, who were EFL learners, received most of their listening input from materials used in classrooms, which were developed for language learners. Therefore, they might not have been accustomed to the noise in the listening text.
The noise test results showed that the mean scores decreased as the level of noise increased, and participants’ confidence levels in listening comprehension also decreased. This indicates that listening comprehension is negatively affected by the presence of noise.
Another point to be noted is learner variation. Hodoshima et al. (Citation2009) reported that how language learners are affected by the noise varies depending on their proficiency levels. They found that lower-level learners were more susceptible to noise than higher level learners. The findings of the current study suggest that not only proficiency levels, but learner variation should be considered in terms of the effects of noise on listening comprehension.
The interview data demonstrated that the noise tolerance level varied among the participants except in the SNR = 0 condition, in which all the participants expressed discomfort. Three participants stated that they could tolerate the noise at SNR = 15, which was the lowest level, two stated that the noise level did not bother them up to SNR = 10, which was moderate, and the remaining two commented that their listening was not badly affected at the SNR = 5 level, which was a relatively high level of noise. Some students also said that they could concentrate more if there was some noise. These findings indicate that how noise affects learners is highly subjective, based on learner variation.
Under authentic conditions, the likelihood that language learners need to engage in listening comprehension in noisy settings is high. These circumstances may include announcements at stadiums or airports, or conversations with a group of people at a party or in a subway. In these types of noisy conditions, a high level of listening comprehension is required, including inference-making skills. It is important to develop listening materials that are similar to what is heard in authentic situations, especially for EFL learners who lack opportunities to listen to English in real settings. By adding noise to listening materials, language learners can notice that listening comprehension in noisy conditions is vital to real-life communication. In addition, by introducing listening test materials that include background noise, learners can practice their listening comprehension and utilize inference-making skills under noisy circumstances.
RQ3. do EFL learners change their use of contextual information according to the noise level?
The results of the listening test showed that at SNR = 15, the scores of high-context sentences were significantly higher than those of low-context sentences. Contrarily, in the SNR = 0 condition, the scores of low-context sentences were higher than those of high-context sentences.
The think-aloud protocol data also verified that the participants used contextual information the most at SNR = 15. We can assume that in the SNR = 15 condition, they used contextual information more because they heard the noise for the first time, which distracted them, causing them to rely on contextual information. The results of the noise test showed that they used contextual information less frequently in quiet and extremely noisy conditions than in moderate noise conditions.
Another point to be noted is that learners used contextual information at all noise levels. According to the think-aloud protocol data, few differences were observed regarding how they used contextual information at different levels of noise, but the frequency of their use of contextual information varied by noise level. The think-aloud protocol data showed that when listening to sentences with high-context information, they utlilized contextual information at all noise levels, although the use of contextual information was limited in the SNR = 0 condition. In SNR = 0, the noise was so loud that it did not matter whether or not there was contextual information. They also used contextual information in the no-noise condition; however, compared to noisy conditions, less use of contextual information was observed in the no-noise condition.
Field (Citation2008) stated that the use of contextual information in listening comprehension involves a balance between the confidence level in the input and how listeners use external information. In the case of this study’s participants, the results of the questions asked after testing at each noise level suggest that confidence levels were not high even in the no-noise condition and dropped as the level of noise increased. Therefore, because the participants were not confident in their listening comprehension under noisy conditions, they tried to extract as much external information as possible from the text.
Fujita (Citation2016) found that contextual information aided the participants’ listening comprehension when the noise level was moderate. However, their listening comprehensibility deteriorated as noise levels increased. The results of the current study are in accordance with Fujita’s (Citation2016) findings, but learner variation was observed. The interview data showed that one of the participants used contextual information only when there was no noise. Some said that moderate noise had positive effects. Therefore, similar to the effects of noise on listening comprehension, the use of contextual information in noise and the way its usage changes depending on the degree of noise are related to learner variation. Despite such variations, the effective use of contextual information, especially under conditions that limit comprehension, is critical for language learners and can help them identify meaning in real-life conversation.
Conclusion
The current study examined the effects of noise on EFL learners’ listening comprehension, largely using a qualitative analysis. How learners used contextual information in conditions with different degrees of noise was analyzed, yielding several findings about the use of contextual information, the effects of background noise, and learners’ use of contextual information in different degrees of noise.
First, regarding the use of contextual information, most of the participants used contextual information at all noise levels but used it differently in high- and low-context sentences. In high-context sentences, they focused on content words for meaning; whereas, in low-context sentences, they focused on the words immediately before the last word, which was the target word. As some students used contextual information more than others, learner variation was also observed.
Second, the results showed that the participants’ listening comprehensibility was greatly affected by background noise. The scores on the noise test and their confidence levels decreased as the level of noise increased. Although all the participants expressed their discomfort under extremely noisy conditions, at SNR = 0, the tolerance level of the background noise varied. Some were able to tolerate the noise up to a relatively high level, while others chose a lower level of noise, and still others mentioned that they were able to concentrate more with some background noise. These results suggest that learners’ listening comprehension generally deteriorates as noise increases, but like the use of contextual information, learner variation should be taken into consideration.
Regarding how different levels of noise affect learners’ use of contextual information, it was found that learners used contextual information more in moderate noise conditions than in no-noise and extreme noise conditions. The participants used the contextual information successfully and most frequently in the SNR = 15 condition, which had the lowest level of noise. However, in all noise conditions, they tried to use contextual information, albeit with learner variation.
Although the current study revealed some of the effects of noise on learners’ listening comprehension, it has several limitations. First, regarding the structure of the test, the participants listened to short sentences and wrote down the last word; thus, the focused information was already selected. From the perspective of authenticity, the test items used in the noise test were also different from the listening input that is heard in real-life situations. The noise might affect learners’ listening comprehensibility differently when they listen to listening texts in other sentence structures or in more authentic situations.
Second, learners’ aural vocabulary knowledge should be considered. L2 listening research has shown that even texts comprising high-frequency vocabulary can lead to comprehension difficulties for L2 listeners (Carney, Citation2020; Lange & Matthews, Citation2020). Some learners might have had a hard time recognizing the known words in listening, even though the words used in the noise test were limited to high-frequency words only.
Third, the think-aloud protocol may have affected the results. Even though the participants were pre-trained on the think-aloud protocol and given some instruction, there is a possibility that some participants failed to report verbally everything they thought during the noise test. It is possible that some elements were not reported in the think-aloud protocol data.
Fourth, the number of participants was small. The aim of the current study was to qualitatively examine the effects of noise and contextual information. The small number of participants enabled us to examine the factors from different perspectives, unlike a quantitative study that includes a large number of participants. However, it is difficult to generalize the findings as a result.
Despite the above limitations, this study has numerous pedagogical implications. First, learner variation was found in listening comprehension in noisy situations. Some participants were more susceptible to noise than others, and some were able to concentrate more in the presence of noise. Therefore, in using listening materials with background noise, instructors should be aware that noise affects learners’ listening comprehension processes differently. If some learners are negatively affected by noise during listening comprehension, instructors can teach them using contextual information and inference making. This will allow them to reach high listening comprehensibility. The second point concerns the authenticity of listening materials. For more authentic listening materials, test or material developers should consider adding background noise to the listening texts. This is especially important in EFL settings, where it may be important for learners to be habituated to listening materials with some noise to prepare them for listening comprehension in authentic contexts full of background noise.
The findings of the current study have some important implications regarding the effects of noise and learners’ use of contextual information in listening comprehension. Further studies are needed to add information regarding the current topic and improve the quality of listening tests, listening materials, and listening instructions.
Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP16K16869. I am grateful to the anonymous reviewers for their constructive comments and suggested revisions, which helped me improve this manuscript.
Additional information
Funding
References
- Buck, G. (2001). Assessing listening. Cambridge University Press. doi: https://doi.org/10.1017/CBO9780511732959.
- Carney, N. (2020). Diagnosing L2 listeners’ difficulty comprehending known lexis. TESOL Quarterly. Advance online publication. https://doi.org/https://doi.org/10.1002/tesq.3000
- Carroll, B. J. (1980). Testing communicative performance. Pergamon Press.
- Cobb, T. (2021). Web vocabprofile. [Computer software]. http://www.lextutor.ca/.
- Council of Europe. (2001). Common European framework of reference for languages: Learning, teaching, assessment. Cambridge University Press.
- Field, J. (2008). Listening in the language classroom. Cambridge University Press.
- Fujita, R. (2016). Effects of sentence predictability on EFL learners’ speech-in-noise recognition. English Language Assessment, 11, 9–23.
- Fujita, R., & Hirai, A. (2018). Shituteki kenkyuu [Qualitative Study]. In A. Hirai (Ed.), Kyoiku shinri gengokenkyuu no tameno deta bunseki [Data analyses for research in education, psychology, and linguistics] (pp. 237–257). Tokyotosho.
- Gaies, S. J., Gradman, H. L., & Spolsky, B. (1977). Toward the measurement of functional proficiency: contextualization of the noise test. TESOL Quarterly, 11(1), 51–57. https://doi.org/https://doi.org/10.2307/3585591
- Hirai, A., & O’ki, T. (2011). Comprehensibility and naturalness of text-to-speech synthetic materials for EFL listeners. JACET Journal, 53, 1–17.
- Hodoshima, N., Masuda, H., Yasu, K., & Arai, T. (2009). Development of scientific english learning materials in noise and reverberation. The Institute of Electronics, Information and Communication Engineers (IECE) technical report. Speech, 109(10), 1–6.
- Jay, S. (2014). Crowd talking 1. [Data file]. Retrieved from http://www.soundjay.com/crowd-talking-1.html
- Kalikow, D. N., Stevens, K. N., & Elliott, L. L. (1977). Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. The Journal of the Acoustical Society of America, 61(5), 1337–1351. https://doi.org/https://doi.org/10.1121/1.381436
- Kokusai Business Communication Kyokai. (2011). TOEIC Test Sin Koshiki Mondaishuu [TOEIC Test New Official Workbook] (4th ed.).
- Kousaie, S., Baum, S., Phillips, N. A., Gracco, V., Titone, D., Chen, J., Chai, X. J., Klein, D., et al (2019). Language learning experience and mastering the challenges of perceiving speech in noise. Brain and Language, 196, 104645. https://doi.org/http://dx.doi.org/10.1016/j.bandl.2019.104645
- Lange, K., & Matthews, J. (2020). Exploring the relationships between L2 vocabulary knowledge, lexical segmentation, and L2 listening comprehension. Studies in Second Language Learning and Teaching, 10(4), 723–749. https://doi.org/https://doi.org/10.14746/ssllt.2020.10.4.4
- Lecumberri, M. L. G., & Cooke, M. (2006). Effect of masker type on native and non-native consonant perception in noise. Acoustical Society of America, 119(4), 2445–2454. https://doi.org/https://doi.org/10.1121/1.2180210
- Lee, J. J. Y., Aryadoust, V., Ng, L. Y., & Foo, S. (2020). A neurocognitive comparison of listening to academic lectures and natural sounds: implications for test validity. International Journal of Listening. Advance online publication. https://doi.org/https://doi.org/10.1080/10904018.2020.1818565
- Masuda, M. (2016). Misperception patterns of American english consonants by Japanese listeners in reverberant and noisy environments. Speech Communication, 79, 74–87. https://doi.org/https://doi.org/10.1016/j.specom.2016.02.007
- Matthews, J., & Cheng, J. (2015). Recognition of high frequency words from speech as a predictor of L2 listening comprehension. System, 52, 1–13. https://doi.org/https://doi.org/10.1016/j.system.2015.04.015
- Oller, J. (1979). Language testing at school: A pragmatic approach. Longman.
- Peng, Z. E., & Wang, L. M. (2016). Effects of noise, reverberation and foreign accent on native and non-native listeners’ performance of english speech comprehension. The Journal of the Acoustical Society of America, 139(5), 2772. https://doi.org/https://doi.org/10.1121/1.4948564
- Peng, Z. E., & Wang, L. M. (2019). Listening effort by native and nonnative listeners due to noise, reverberation, and talker foreign accent during english speech perception. Journal of Speech Language and Hearing Research, 62(4), 1–14. https://doi.org/https://doi.org/10.1044/2018_JSLHR-H-17-0423
- Rahman, M. S. (2017). The advantages and disadvantages of using qualitative and quantitative approaches and methods in language “Testing and Assessment” research: A literature review. Journal of Education and Learning, 6(1), 102–112. https://search.proquest.com/scholarly-journals/advantages-disadvantages-using-qualitative/docview/1969018595/se-2?accountid=44073. https://doi.org/https://doi.org/10.5539/jel.v6n1p102
- Rammell, C. S., Cheng, H., Pisoni, D. B., & Newman, S. D. (2019). L2 speech perception in noise: an fMRI study of advanced Spanish learners. Brain Research, 1720, 146316. https://doi.org/http://dx.doi.org/10.1016/j.brainres.2019.146316
- Richards, J. C. (2005). Second Language Listening. Cambridge University Press.
- Rogers, C. L., Dalby, J., & Nishi, K. (2004). Effects of noise and proficiency on intelligibility of Chinese-accented english. Language and Speech, 47(2), 139–154. https://doi.org/https://doi.org/10.1177/00238309040470020201
- Rogers, C. L., Lister, J. J., Febo, D. M., Besing, J. M., & Abrams, H. B. (2006). Effects of bilingualism, noise, and reverberation on speech perception by listeners with normal hearing. Applied Psycholinguistics, 27(3), 465–485. https://doi.org/https://doi.org/10.1017/S014271640606036X
- Scharenborg, O., & Os, M. (2019). Why listening in background noise is harder in a non-native language than in a native language: A review. Speech Communication, 108, 53–64. https://doi.org/https://doi.org/10.1016/j.specom.2019.03.001
- Shi, L. F. (2009). Normal-hearing english-as-a-second-language listeners’ recognition of english words in competing signals. International Journal of Audiology, 48(5), 260–270. https://doi.org/https://doi.org/10.1080/14992020802607431
- Skoe, E., & Karayanidi, K. (2019). Bilingualism and speech understanding in noise: auditory and linguistic factors. Journal of the American Academy of Audiology, 30(2), 115–130. https://doi.org/http://dx.doi.org/10.3766/jaaa.17082
- Uemura, T., & Ishikawa, S. (2004). JACET 8000 and Asia TEFL vocabulary initiative. Journal of Asia TEFL, 1(1), 333–347.
- Vafaee, P., & Suzuki, Y. (2019). The relative significance of syntactic knowledge and vocabulary knowledge in second language listening ability. Studies in Second Language Acquisition, 1–28. https://doi.org/https://doi.org/10.1017/S0272263119000676
- Vandergrift, L., & Baker, S. (2015). Learner variables in second language listening comprehension: an exploratory path analysis. Language Learning, 65(2), 390–416. https://doi.org/https://doi.org/10.1111/lang.12105
- Wallace, M. P. (2020). Individual differences in second language listening: examining the role of knowledge, metacognitive awareness, memory, and attention. Language Learning. Advance online publication. https://doi.org/https://doi.org/10.1111/lang.12424
Appendix
Sentences in each part in the Noise Test (Adopted from Fujita, Citation2016)
(In the parentheses, L means Low predictability. H means high predictability)
Part 1 (No noise)
I am thinking about the knife. (L)
His boss made him work like a slave. (H)
The old man discussed the dive. (L)
The old train was powered by steam. (H)
Bob heard Paul called about the strips. (L)
I should have considered the map. (L)
Miss Brown shouldn’t discuss the sand. (L)
She made the bed with clean sheets. (H)
He caught the fish in his net. (H)
My T.V. has a twelve-inch screen. (H)
Part 2 (SNR = 15)
She’s spoken about the bomb. (L)
She couldn’t discuss the pine. (L)
Miss Black knew about the doll. (L)
She wore a feather in her cap. (H)
Football is a dangerous sport. (H)
Tom wants to know about the cake. (L)
We hear you called about the lock. (L)
Hold the baby on your lap. (H)
The boat sailed along the coast. (H)
Air mail requires a special stamp. (H)
Part 3 (SNR = 10)
We’re discussing the sheets. (L)
Miss Black thought about the lap. (L)
They did not discuss the screen. (L)
On the beach we play in the sand. (H)
They’re glad we heard about the track. (L)
Household goods are moved in a van. (H)
You heard Jane called about the van. (L)
The airplane dropped a bomb. (H)
The airplane went into a dive. (H)
We’re lost so let’s look at the map. (H)
Part 4 (SNR = 5)
This key won’t fit in the lock. (H)
The drowning man let out a yell. (H)
You’re glad they heard about the slave. (L)
I want to know about the crop. (L)
Paul should know about the net. (L)
The old man discussed the yell. (L)
Tom could have thought about the sport. (L)
I cut my finger with a knife. (H)
The furniture was made of pine. (H)
The boy gave the football a kick. (H)
Part 5 (SNR = 0)
She wants to speak about the ant. (L)
We shipped the furniture by truck. (H)
Ruth poured the water down the drain. (H)
They marched to the beat of the drum. (H)
I’ve spoken about the pile. (L)
The soup was served in a bowl. (H)
Mr. Smith thinks about the cap. (L)
They played a game of cat and mouse. (H)
Mr. Black considered the fleet. (L)
Miss Brown might consider the coast. (L)