
Abstract
Although of high relevance to political science, the interaction between technological change and political change in the era of Big Data remains somewhat of a neglected topic. Most studies focus on the concept of e-government and e-governance, and on how already existing government activities performed through the bureaucratic body of public administration could be improved by technology. This article attempts to build a bridge between the field of e-governance and theories of public administration that goes beyond the service delivery approach that dominates a large part of e-government research. Using the policy cycle as a generic model for policy processes and policy development, a new look on how policy decision making could be conducted on the basis of ICT and Big Data is presented in this article.
1. Introduction
E-government as well as e-governance are still seen primarily as changes in policy delivery but not in policy formation. This omission is becoming increasingly difficult to justify, because the technological revolution in the realms of communication and data analyses has moved e-government beyond the concept of mere delivery systems for public services (Dunleavy et al. Citation2006a; Dunleavy and Margetts Citation2010; Dunleavy et al. Citation2006b).
As Orlikowski and Iacono pointed out, “IT matters in everyday social and economic practice,” yet we do not have a sufficiently developed research approach that allows us to look at the different aspects in which the “IT artifact” influences areas like policymaking in governments (Orlikowski and Iacono Citation2001, 133). In most studies, technology is viewed as complementary to existing organizational and administrative practices but is hardly viewed as capable of triggering changes in the actual structure of decision-making processes. When talking about a transformation; however, the change has to go beyond a mere improvement of existing services and procedures (Bannister and Connolly Citation2014). That ICT can improve bureaucratic procedures—so-called e-bureaucracy—is not a new observation (Cordella and Tempini Citation2015, 2), but the most recent developments in ICT innovation have the potential to influence the internal logic and structure of bureaucratic organizations, thereby changing the process of governance through government.
Government and governance, while similar terms, are characterized by a distinctive set of features. According to Banister and Connolly the key distinction between government and governance is that “government is about the ‘doing’ […] and governance is about the abstract structure of what is happening and changing” (Bannister and Connolly Citation2009, 9). The perception of government as the executive part is undermined by Fasenfest’s definition of government as the office, authority, or function of governing in the editorial to the sixth issue of the Critical Sociology Journal 2010. Accordingly, governance is a set of decisions and processes made to reflect social expectations through the management or leadership of the government (Fasenfest Citation2010, 771). Governments act through their public administrations, which are embedded within a governance structure. The public administration is, so to speak, the acting arm of the government, which is guided in its movements by the existing governance structure, that is, inter alia by how decisions are made, which problems are given priority, and the degree of civil society participation. The nature of this structure and its possible transformation through ICT and BDA are among the major challenges faced by states today. Bannister and Connolly continue to explain that, for example, the improved provision of services is a case of e-government, while the processes and structures as well as the intended outcomes are part of e-governance. Yet despite the improvements that ICT can deliver in terms of “doing” and “structure” there is no one-size-fits-all approach to implementation—which is demonstrated by numerous failed e-government projects (Bannister and Connolly Citation2012)
The goal should therefore not be limited to the improvement of already existing services and structures but we should aim at the transformation of the policymaking structure itself. The nature of this structure and the suggested possible reforms are based on the idea of the policy cycle. Consequently, there should be an additional focus on e-policy as a concept that goes beyond the idea of incorporating technology into the policymaking process as a mere vehicle that increases productivity thanks to improved information-processing capabilities. Although the process of policy formation is essentially still a political one, technological advances reduce the time frame and increase the evidence base for policy decisions. Whether it is the estimation of public opinion by analyzing social media, the production of daily census data, or the use of algorithms to estimate the effects of and connections between different policies, all these possibilities change the way how policymaking is perceived and executed. Just like e-governance and e-government are the continuation and evolution of traditional governance and government, e-policy is the evolution of traditional policymaking, and we use this term throughout this article to refer to the act of policymaking in e-government using e-governance processes, with the distinctive feature that evaluation happens as an integral part all along the policy cycle rather than as a separate step at the end of the policymaking process. Thus, e-policymaking shares many features of “policy informatics,” such as analysis, administration, and governance (Johnston Citation2015), and “policymaking 2.0,” which takes account of the inclusive nature of social media in government, software platforms, and innovation theory (Ferro et al. Citation2013; Misuraca, Mureddu, and Osimo Citation2014). Epistemologically, we position our contribution in the emerging field of policy analytics, which seeks to identify and describe new analytic methods that can be used to support public policy problem-solving and decision processes by delivering convincing analyses taking into account the need for satisfying legitimate public expectations about transparency and opportunities for participation (Daniell, Morton, and Insua Citation2015, 1).
This article attempts to contribute to the field of policy informatics in that it discusses applications of Big Data Analytics in the policymaking process. It contributes to the field of policymaking 2.0 in that it highlights the applicability of a Big Data-enabled procedure model for the large-scale incorporation and interpretation of public opinion, and the incorporation of dispersed knowledge and innovative power into policymaking. It contributes to the field of policy analysis by discussing the process of policymaking according to the policy cycle, yet in the light of technology: We first use the tried and proven theoretical bases of the policy cycle to denote applications of BDA in the process of public and participatory governance to finally argue that the traditional policy cycle can be shortened by incorporating the concept of continuous evaluation, instead of introducing evaluation as a separate step at the end of the policymaking process.
Methodologically, this article is based on theoretical considerations derived from an interdisciplinary approach combining political science, public governance, organizational theory, and data science. The goal of furthering the integration of aspects of technology into policymaking needs to be strengthened in its theory underpinnings in order to end the isolation between social sciences in general and the fields of e-government and e-governance. The structure of the article reflects this motivation. It starts with some fundamentals about the general issue of governance, goes on to narrow in on the question of the integration of technology into policymaking, and continues with the role of Big Data Analytics (BDA) in the policy cycle. The final part of the article will present a BDA-enabled policy cycle before we turn to the conclusions and limitations of our approach.
2. Governance in the digital age
2.1. The role of ICT in the development of political systems
Although there is general agreement that ICT will fundamentally challenge the conduct of governance, there is still a research gap as to how the process of policy formation and implementation will be affected. The lack of attention for technology in the policy sciences is a paradox as modern actual policymaking often refers to technology as the main impetus for policy change. Literature emphasizes the study of institutional structures, interaction patterns, socioeconomic developments, and ideas to understand policy choices with technology being conceptualized as an instrument. The environment of policy systems usually plays a role in the form of socioeconomic conditions, the diffusion or transfer of ideas, but not in the form of technological dynamics (Meijer and Löfgren Citation2015).
There is a growing risk that the increasing ability of people to formulate their collective demands via ICT and the inadequacy of political institutions to address them can lead to systemic crises in states. To a certain extent current developments imply a reversal of the traditional roles of state and society. What used to be a strictly top-down implementation of policy decisions, from the state down to society, is increasingly developing into a relationship in which governments have to use their capabilities and administrative power to react to organized elements of civil society.
There are a number of ways in which policymaking and the changes caused by technological progress can be transformed into new ways of governance. The implementation of Big Data Analytics supports early-warning systems, and sentiment analysis of social media or real-time decision support systems have a potential influence on the elements, steps, and consecutive nature of the policy cycle. The crucial change created by Big Data methodologies is the increased speed of (re-)action allowing policymakers, public servants, and citizens to take informed and organized collective action based on collective information, which may be distributed outside official channels (King, Pan, and Roberts Citation2013; Lorentzen Citation2014). Government reform and modernization is once again a major topic (e.g., Micklethwait and Wooldridge Citation2014), and the role of ICT is frequently at the heart of the debate. This debate is on the one hand characterized by a strong optimism about shrinking government while maintaining equal efficiency due to technological progress, while at the same time there is valid criticism that the growth in technological possibilities has not kept pace with the increasing demands of the public.
Our contribution addresses known theories of policymaking but redesigns them in order to take the changing technological environment into account. The potential of technological progress must be carefully assessed in relation to the different stages of policymaking. This article operates under the assumption that the fields of ICT research and the more theoretical disciplines of political science and organizational theory can and should inform each other.
2.2. The policymaking process
The concept of governance has been featured in many fields. Kjaer (Citation2004), for example, distinguished between governance in public administration and public policy, governance in international relations, European Union governance, governance in comparative politics, and good governance as extolled by the World Bank (Rhodes Citation2007).
For the purposes of this article, we focus on governance in the realm of public administration and public policy, using a general definition as provided by Rhodes:
Interdependence between organizations. Governance is broader than government, covering non-state actors. Changing the boundaries of the state means the boundaries between public, private, and voluntary sectors become shifting and opaque.
Continuing interactions between network members, caused by the need to exchange resources and negotiate shared purposes.
Game-like interactions, rooted in trust and regulated by rules of the game negotiated and agreed by network participants.
A significant degree of autonomy from the state. Networks are not accountable to the state; they are self-organizing. Although the state does not occupy a privileged, sovereign position, it can indirectly and imperfectly steer network.
In a wider sense, governance deals with “how the informal authority of networks supplements and supplants the formal authority of government. It explores the limits to the state and seeks to develop a more diverse view of state authority and its exercise” (Rhodes Citation2007, 1247). This forces governments to change the traditional top-down command structure into a structure that includes negotiations with civil society, and to include the public in the decision-making process. The boundaries between state and civil society are changing and becoming more porous, a development that has been accelerated by new modes of interaction and participation by means of ICT. Claus Offe described this collaboration between state and civil society as a cooperative network of “practitioners of governance, whoever they may be, [who] logically and politically can do without opposition, for all relevant actors are included” (Offe Citation2009, 551).
ICT is a key enabler of network formation and should be central to any contemporary analysis of governance. The actual possibilities of implementation will vary from state to state due to different traditions and organizational cultures (Andersen and Eliassen Citation1993; Brans Citation1997), yet while there is no one-size-fits-all approach there are some generic models that can produce a framework of recommendations, which would be adaptable to state-specific circumstances. As we will show in the following parts of the article, it is especially the tried and proven model of the policy cycle, which we believe can be efficiently adapted to describe policymaking in the digital age. There is a growing consensus in the literature that the use of ICT is a necessity for countries that aim to improve their overall performance (Gupta and Jana Citation2003; Layne and Lee Citation2001). The UK Office for National Statistics reported that private sector productivity increased by 14% between 1999 and 2013—compared to a decline by 1% in the public sector between 1999 and 2010 (Micklethwait and Wooldridge Citation2014, 19). Other advanced economies are in a similar crisis, with public administrations growing in terms of size and cost but not in terms of efficiency.
A possible remedy could be that public policymaking is increasingly influenced by research and data-based intelligence gathering (Heinrich Citation2007; Warren Citation2002) of government agencies. Despite the growing role of private sector data collectors like Google, governments have not fallen behind in this respect. As Alon Peled pointed out, “the public sector’s digital data troves are even bigger and growing at a faster rate than those in the private sector” (Peled Citation2014, Kindle Location 562). Yet the abundance of this data has not led to the improvement of the public sector that one would have expected. The reason for this is the dilemma with which public administrations undergoing technological modernization are confronted: There is ample empirical evidence that the main driving force when it comes to innovation in the government sector is bureaucratic autonomy (Carpenter Citation2001; Evans Citation1995; Fukuyama Citation2013). Autonomy describes the discretion of public agencies in their decision-making processes. While such autonomous decision-making power is often viewed as a positive characteristic, in the realm of Big Data it can pose a problem. Autonomous agencies also collect data individually and have an inclination not to share their information in order to stay independent. The failure of ICT projects in governments referred to earlier is caused in 80%–90% of cases by the unwillingness and inability of different government departments to share data-based information (Fawcett et al. Citation2009; Kamal Citation2006; Peled Citation2014). Peled demonstrates that it is not the data or the technology that is at the heart of the problem, but their application in a bureaucratic environment (Peled Citation2014, chapters 1 and 2).
At the same time, however, autonomy will also become more important: As this article will demonstrate in the following parts, one of the possible advantages of Big Data is the possibility of fast policy evaluation, allowing the responsible departments of public administrations to find out within a short time whether their policies have the desired effect or not. Given this opportunity of fast evaluation, public administrations would also need the necessary autonomy to quickly change the modes of policy implementation if the outcome is considered to be unsatisfactory and should be improved. The goal is not a smoother operation of already existing services but a reformation of the policymaking structure itself. The nature of this structure and the suggested possible reforms are based on the idea of the policy cycle.
3. Drivers of change toward a data-driven society
Our society is predominantly influenced by three driving forces: (1) Digitization has massively increased the quantity of management information available, the resolution and frequency at which it is captured, and the speed at which it can be processed. Data on inputs, outputs, productivity and processes can all be captured and recalled in more comprehensive detail than ever before. (2) Connectivity has led to network effects, which enable the integration and sharing of data. Data can quickly be integrated into systems which, if they are open for resharing and reuse, might be a source for other systems. In theory this might lead to exponential data growth, confirmed by Hilbert and colleagues in 1986 (Hilbert and López Citation2011, 61–62). (3) The application of intelligence on top of data and networks. Intelligence in this regard must not be limited to the human capacity to understand and derive meaningful results from complex nexus but also encompasses the application of sophisticated algorithms and methodologies like machine learning or artificial intelligence on top of network-connected datasets.
3.1. Assessing the characteristic features of big data
It is widely accepted that Big Data refers to data whose size forces us to look beyond the tried-and-true methods of storing, retrieving, analyzing, processing, and inspecting which are prevalent at the time (Jacobs Citation2009). While no single agreed definition of Big Data exists, the concept is attributed to Doug Laney (Laney Citation2001), who describes the main characteristics of Big Data as its size (volume), the speed at which data accrues (velocity), and its varying shape (variety), without actually naming it Big Data. M. Chen, Mao, and Liu (Citation2014) revisited the initial definition of Laney. According to them, Big Data can be defined on the basis of the following four criteria:
Speed (Velocity). Depending on the nature of the data (textual, audio, video), the typical processing requirements range from kilobytes/second to terabytes/second. Traditional algorithms, despite the processing capabilities of modern hardware, might not be able to cope with the speed at which data arrives.
Volume. A consequence of the speed at which data arrives and the fact that we are moving from data at a macro-level to personalized data is the volume which accumulates over time. This data volume gets noticed when analyzing data over time, which requires random access to large amounts of data giving its eponym. Declining storage prices combined with modern storage algorithms enable organization and access methods which can handle the typical volume of Big Data processing requirements.
Diversity (Variety). Another property of Big Data is its heterogeneity. Different origins (internal legacy systems, external data sources) and different kinds of data (audio, video, textual) result in data of different shapes and formats. This requires algorithms stemming from AI or the semantic realm, which are capable of comparing heterogeneous datasets, sometimes at the cost of losing exactitude.
Quality (Veracity). Important Big Data sources live outside of department boundaries, like information shared on social networks. The inclusion of external data sources raises questions of origin, applicability, accuracy and completeness. Even if data is incomplete it still contains a value. Algorithms incorporating incomplete datasets, however, must take into account data holes and interpolate missing data points.
Consulting companies have introduced new “V” characterizations of Big Data; however, these subsequent attempts to define Big Data also contribute to diluting Big Data’s core characterizations. Eileen McNulty of Dataconomy proposes seven Vs, extending the already presented V’s by visualizations.Footnote1 For data, and especially Big Data, visualizations are certainly appropriate to convey complex relationships, to serve as an information filter, or to identify insights yet untapped by algorithms. While (meaningful, correct, and carefully crafted) visualizations are certainly a powerful mechanism to present a complex situation, they are nonetheless a form of communicating data, hence a way to convey meaning to a human in an easily to understand manner. We argue that visualization is a transformation of data and thus does not qualify as a core property of Big Data.
Restricting the discussion on Big Data to its size, as the name would suggest, misses the point. “Big Data” is much more than data too big or too complex to process with traditional ICT infrastructure like databases or analytical instruments. The real strength of Big Data lies in the methodological toolbox and the assumptions made. According to Viktor-Mayer Schönberger (VMS), Big Data implies, among other things, firstly the end of samples: With today’s processing capabilities, all data can be processed in real time, as opposed to the taking of samples and snapshots for the purpose of interpolating the population. Second, Big Data means the end of exactitude: While we might have the capabilities to process all of the data considered relevant to solve a certain problem, we might not be able to do that in an exact manner. However, what might get lost in accuracy at the micro-level can easily be gained in insight at the macro-level (Mayer-Schönberger and Cukier Citation2013). These assumptions do not come without criticism. For example, the alleged assumption of “more data beats better data” can easily be countered with the argument “garbage in—garbage out.”
The demand for quicker and high-quality decisions based on an ever-growing sea of unstructured data requires
new forms of participation to obtain data, which has not been available for inspection before because of separated datasets;
new ways to process data, including algorithms which are capable of dealing with the vast amount of data;
redesigned processes to include more people in the interpretation of results as more data and information available for decision making will inevitably increase the information overload.
In the next sections we will follow the approach taken by Géczy (Citation2014) and observe Big Data from the data/technological perspective, the process angle, the purpose angle, and the economic angle for a holistic and contextualized view. This will help to generate the necessary insights to argumentatively underpin our proposed revised model of the policy cycle.
3.2. The data domain
The more quality and accurate information is available, the better the decisions will be. However, as Evgeniou and colleagues pointed out in HBR 2013, we should not be talking about Big Data making decisions better but about diverse data and using new technologies, processes, and skills to prevent the risk of drowning in Big Data. Declining storage costs and increasing storage capacities following Moore’s law (Schaller Citation1997) have led to an attitude of “no data lost” and subsequently to unlimited growth of data.
Internal data is either data collected or produced to fulfill a task (in the case of the public administration: to carry out its legal obligations) or trail data obtained as a result from ICT processes such as interaction patterns with websites, workflow traces, authentication data, system survey data, etc. Data which is produced and subsequently stored as a byproduct of the execution of business processes has recently been identified as a valuable source for identifying (mining) or improving (reengineering) processes in an automated manner (Van der Aalst Citation2011).
Instead of relying on self-produced or self-collected data, external data, either openly available or bought from data brokers, can improve the quality of business processes. One prominent example of improving decisions by including external data is the first Netflix challenge of 2008, where the winning team “cheated” by incorporating external data into the system recommending movies to Netflix subscribers (Buskirk Citation2009).
The greater part of the data available today is unstructured data. Unstructured data is data for which no scheme exists or where the underlying scheme is unknown. In practical terms this means that for a computer system the effort to automatically derive meaningful insights is much higher than in the case of structured data. It seems natural that a vast amount of data is unstructured as unstructured data is much better suited to store knowledge than structured data. Therefore a considerable amount of time is spent on the reshaping of unstructured data into structured data in order to facilitate the automated processing through ICT systems. The problem of structured vs. unstructured data is aggravated by the fact that much data produced today originates from sensors built, for example, into smart phones and is contained in videos, images, or textual information exchanged in social networks.
According to estimations presented at Oracles Open World conference in 2014, 88% of the data available today consists of unstructured, unannotated, nonlinked data. This fact led Davenport to the assessment that more than the amount of data itself, the unstructured data from the Web and sensors is a much more salient feature of what is being called Big Data (Davenport and Harris Citation2007). No amount of human effort would suffice to classify these huge volumes of data. This puts data mining combined with machine learning into the spotlight of CS research, which experiences a renaissance reminiscent of its heyday back in the 1980s and 1990s.
3.3. The process domain
The process domain with respect to Big Data actually has two facets: One is the technical facet, thus the ability to derive meaningful insights from data by algorithmically applying transformations in order to process the data. The second facet is business processes, which need to be adapted in order to maximize the friction-free flow and throughput of data throughout an organization. This involves the sharing of information between and collaboration of traditionally separated subentities. In this section we will predominantly concentrate on the technical processes.
Data per se has little value, unless it gets organized, processed, and interpreted in order to derive meaning. The organizing of data is performed by data management processes, whereas the processing of data is an analytical task. Typical tasks associated with data management encompass the storage, conversion, mapping, and filtering of data. In terms of analysis we differentiate between data mining (DM) and actual data analysis (DA) for the purpose of drawing conclusions about that data with the goal of identifying undiscovered patterns and hidden relationships (Coronel, Morris, and Rob Citation2012, 690). Unlike traditional DA and DM tasks, however, in the domain of Big Data these algorithms have to meet special features:
Scalability. With data being divers (rich in variety) and arriving at varying and at high speed, algorithms have to be scalable. Scalability is the ability of a system, network or process to handle a growing amount of work in a capable manner, or its ability to be enlarged to accommodate that growth (Bondi Citation2000). Linear scalability means, for example, if the amount of data doubles, the time required to process that data doubles, too. However, with network effects of Big Data becoming effective, linear scalability cannot be sustained as, for example, the number of comparisons of similarities between datasets grows exponentially. The HyperLogLog-Algorithm is one fascinating example of a Big Data-inspired approach to the seemingly easy problem of counting distinct things, as it generates very good results to the cardinality estimation problem yet only requires minimal time and space (Heule, Nunkesser, and Hall Citation2013). Scalability of a BDA system goes hand in hand with timeliness.
Timeliness. One characteristic of BDA is the ability to process large amounts of data in real time. Instead of loading data, organizing it, processing it, and presenting results, insights become available almost instantaneously the moment the data changes. Data are no longer imported into a central data repository but is instead made available to BDA as a virtual data source, an approach chosen, for example, by the Hadoop Big Data processing ecosystem via the Hadoop Dispersed File System =(Malar, Ragupathi, and Prabhu Citation2014). In the section on Continuous Evaluation in the E-Policy Cycle we will discuss timeliness and the effects on the policy cycle.
Organization. In order to use data effectively, organization is required. The early days of data organization were characterized by locked-in datasets behind walled gardens. Increasing economic pressure has put the customer/citizen at the heart of considerations: first by sharing data, later interfaces were crafted to exchange information. Encapsulating data as a service has the advantage that only the required amount of information the authorized party is allowed to obtain gets transferred, and enables the data-providing agency to track and trace data demand at a fine grained level.
3.4. The purpose domain
In public administration data can be considered as input to processes aimed at gaining new insights to enable better regulations. A comprehensive coverage on BDA in public administration is provided by a study of the TechAmerica Foundation (Citation2015, 12), which identifies these fields of application:
Efficiency and administrative reform: optimization of administrative procedures through information preparation and automation of tasks.
Security and fight against crime: mission planning of fire brigades, ambulance and police units, fight against terrorism, fraud prevention.
Public infrastructure: healthcare system support such as detection of epidemics, diagnostics, therapy and medication; control of public and private transport, smart metering, energy, education.
Economy and labor: optimized management of the labor market, performance measurement of research funding, supervision of the financial market, food control and pandemic disease control.
Modernization of legislation: analysis of scenarios in legislation, trend analysis, complex impact assessment in real time, new forms of e-participation.
Citizen and business services: usage of new technologies to enhance the quality and number of services provided by the public administration, new and enhanced services through interconnection of data and automation of processes.
Chen, Mao, and Liu (Citation2014) presented three main fields of BDA application in public administration, namely scientific exploration, regulatory enforcement and data as the basis of public information services. Asquer (Citation2013) further added improvements in societal insight into individual and society behavior for more fact-based decisions in politics and the economy.
3.5. The economic domain
Assessing the financial benefit associated with Big Data, a May 2011 report of the McKinsey Global Institute predicts $300 billion annual value to the US health care system and €250 billion annual value to Europe’s public sector administration. The report also concludes that governments will be amongst those for which realizing benefits will be hardest, as technological barriers have to be overcome, personnel requires considerable additional training and organizational changes are overdue (Manyika et al. Citation2011, 5, 10). Relevant experience in the private sector has shown undisputable, tangible benefits generated by the application of Big Data methods and technology. Companies in the top third of their industry employing Big Data mechanisms were on average 5% more productive than their competitors (McAfee and Brynjolfsson Citation2012).
While these figures are tempting and may well serve as a door opener when it comes to convincing policymakers to invest in Big Data or to adjust funding schemes, a thorough and scientifically rigorous model which would account for the vast indirect revenue cycle associated with Big Data benefits is still missing. This is backed by Harvard fellow David Weinberger, who carefully argues that (1) models which are capable of capturing the nature of Big Data and would allow us to give a clear answer in terms of anticipated outcomes fail because the world is more complex than models can capture; and (2) computer simulations show how things work even when people may not completely understand why they work (Weinberger Citation2011, 127).
4. Big data applied in policymaking: Opportunities and challenges
Before we address the stages of the policy cycle to highlight application areas of BDA, we would first like to summarize the opportunities and challenges associated with Big Data Analytics in government. Big Data is still an intensely and controversially discussed topics with consulting companies claiming benefits with lacking evidence. In the next subsections will derive opportunities and challenges from research disciplines like decision support (DS), business intelligence (BI), business analytics (BA), and BDA, which, according to Davenport and Chen and associates, are legitimate precursors of BDA (Chen, Chiang, and Storey Citation2012, 1166; Davenport Citation2014, 10).
In the government domain, Big Data has gained traction as a topic of active discussion. As such, many of the claims with respect to goals, benefits, and perils must be adopted from a business-related domain and imposed on government action and policy making, which is justified, as good governance means putting the citizen into the focus of consideration. The following subsections on opportunities and challenges associated with the application of BDA in government have been generated from desk research covering recent papers on BDA for digital government (McAfee and Brynjolfsson Citation2012; Executive Office of the President Citation2014; Chen and Hsieh Citation2014; Joseph and Johnson Citation2013; Misuraca, Mureddu, and Osimo Citation2014; Bertot et al. Citation2014)
4.1. Opportunities
Big Data technology can enable fragments of related yet heterogeneous information to be matched and linked together quickly and nonpersistently to identify yet undiscovered information flows. Hidden patterns and correlations will be identified to support common-sense experience or received wisdom. Predictive analytics applied on top will increase the quality of scenario planning and result in true evidence-based policymaking. Because of organizational changes required to leverage the promised benefits of BDA, organizations will learn about how they work and how their customers/citizens use them, and will design services accordingly. BDA will help to identify areas of underperformance, support the reallocation of resources to their most productive use, and thus increase overall performance. This is facilitated by the possibility of analyzing multiple data sources and deducting patterns. As a consequence, the time required to produce reports will be reduced and may be devoted to performing more skilled kinds of analytics.
For the citizens, BDA-improved processes will cut down paperwork as processes reorganized internally to better integrate data for analytics will facilitate cooperation among ICT systems, which reduces the need for citizens to repeatedly provide the same information. As a result, citizens will get questions answered, and receive benefits they are entitled to, more quickly. Furthermore, services may be proactively proposed as a result of large-scale predictive analytics, based on services used by comparable citizens.
4.2. Challenges
Bringing data together do not come without a caveat. Existing regulations concerning privacy and data protection have to be respected. The balance between socially beneficial uses of Big Data and the potential harm to privacy and other values is fragile. This raises intricate questions about how to ensure that discriminatory effects resulting from, for example, automated decision processes can be detected, measured, and redressed. Detailed knowledge about citizens makes it possible to forecast public behavior with high precision. This power requires responsible leadership and a system of checks and balances. The risk of a massive loss of informational privacy with respect to benefits has become much larger that there is no longer any excuse to negate tradeoff issues. The government is required to pursue this agenda with strong ethics: Big Data holds much potential but it can put civil liberty under pressure.
In order to leverage BDA effects, the organizational set-up has to be prepared for speed: Big Data is, inter alia, about volume and velocity, however, generally accepted attributes of government seldom include speed. Internally within the government, an attitude of openness is required to enable the aggregation of data beyond department borders, a challenge as great as that of making evidence-based, data-driven decisions the standard and preparing for an attitude of “good enough and failure.”
For the government CIO, Big Data and related technology causes new challenges. Big Data and veracity go hand in hand with questions concerning data quality and bias. While the requested attitude of “good enough and failure” relativizes exactitude, data origin and trust are still matters of concern. The multitude of possible external datasets as input to BDA also redefines the threshold between interoperability, standards, and heterogeneity. In future, Big Data-enabled ICT architecture will require even more integration adapters to connect legacy systems with BDA systems and cloud storage providers.
5. The policy cycle
The concept of the policy cycle is a generic model that tries to illustrate the lifecycle of policy decisions and their implementation. The idea behind this model is to identify stages of the policy process that can then be opened up for investigation (Anderson Citation1972). Additionally, the policy cycle is a dynamic model that depicts stages that mutually influence each other. As has been pointed out by previous authors, the “characterization of distinct functional activities in the policy cycle is somewhat arbitrary” (Nachmias and Felbinger Citation1982, 303). Not surprisingly, there has been some serious criticism that the policy cycle is not particularly helpful in respect of the formulation of actual policies and that it overemphasizes the process rather than quality or performance (see, e.g., Everett Citation2003). Yet others contend that there is quite some room to derive good policies from the process-based policy cycle (Bridgman and Davis Citation2003; Edwards, Howard, and Miller Citation2001). Edwards and colleagues, for example, referred to “the benefit of breaking up the policy process into clear steps in order to manage the complexities of developing policy in a systematic and rigorous manner” (Edwards, Howard, and Miller Citation2001, 4).
The policy cycle should be understood as a means to theoretically depict the emergence and implementation of policies. Rein and Schön (Citation1995) described it as an act of framing in which “the analyst imposes an order on the array of phenomena involved in the process of governing” (Colebatch Citation2005, 14). This is the very imposition of order on phenomena on which this article is based. The distinction between the individual stages is a hermeneutic device we use to give meaning to the complex process of policymaking. The realization that there is no single monolithic decision maker that deals with problems of public policy is well recognized by the model of the policy cycle, allowing for a differentiated approach when it comes to the use of ICT and Big Data in the policy process.
This brings us to the concept of evidence-based policies and their role in the policy cycle. Despite the promise of evidence- instead of estimate-based forms of policymaking, scientific results are not automatically translated into better policies (Sanderson Citation2002; Hertin et al. Citation2009; Bulmer Citation1987). As several authors have pointed out, evidence provided by research is “not always influential” and can be “supplanted by the powerful political forces of inertia, expediency, ideology, and finance.” Sanderson and Kogan wrote that governments welcome the concept of evidence-based decision making as a source of legitimacy but will often only use the evidence if it supports prior constructed goals and politically driven priorities (Kogan Citation1999). Similarly, Cook asserted that the primary goal of the politician is to be reelected and not to adhere to recommendations based on scientific and technological evidence (Sanderson Citation2002, 5). Most of the literature on evidence-based policy and decision making “fits well with a rational decision-making model of the policy process” (Sanderson Citation2002, 5). Rationality here means that the evidence is the basis of the decision, which is not necessarily the case if the evidence contradicts the political goals of the government. For this reason there has been a substantial wave of criticism regarding evidence-based policymaking (Crotty Citation1998; Guba and Lincoln Citation1989).
Nonetheless, the injection of expert knowledge and objective data can serve the goal of improved decision making. This becomes apparent in particular if we consider the possibility of feedback and evaluation loops within the policy cycle itself. Nachmias and Felbinger (Citation1982, 305) developed precisely such a policy cycle, which is why we adopt their model for our article ().
Figure 1. The policy cycle.
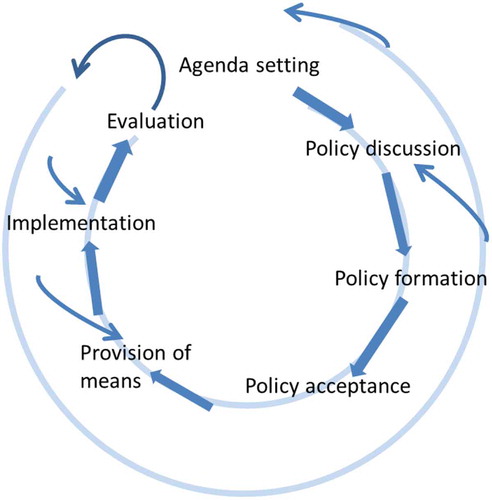
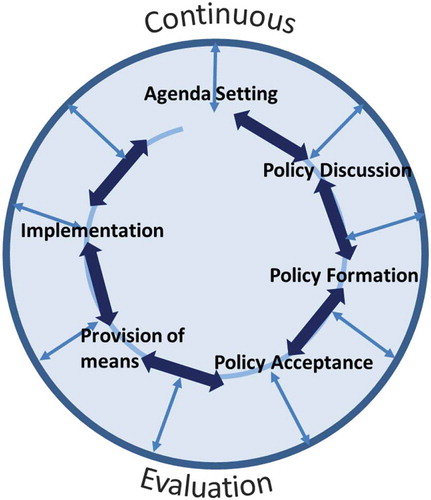
Figure 2. The big data-revised policy cycle.
This policy cycle consists of the seven stages of the original policy cycle as well as an additional feedback cycle. The first step is the agenda setting, where problems are identified and the need for action is formulated. This leads to a policy discussion aimed at identifying the right way to meet the problem defined at the agenda setting stage. The policy discussion will lead to increased public awareness and will therefore address not only the policy options but also the “conceptual foundations of the policy” and the motivations that led to the agenda setting in the first place. As a result of the policy discussion the actual policies will be formulated and translated into legislative and executive language, followed by the actual adoption of the policy and the provision of the necessary (budgetary) means.
These initial steps are followed by the actual implementation of the policy. Assuming that there is a performance expectation, the act of implementation will lead to an evaluation of the provision of means—are the means sufficient to actually implement the policy. Once the implementation has been accomplished, first an outcome evaluation will be performed to establish whether the implementation was successful, followed by a long-term evaluation that looks at the entire process from stage one, the point of agenda setting. The evaluation stage is the point at which the most profound behavior changes can be initiated, since the knowledge derived from evaluations will affect future behavior. It is important to mention that decision and transaction costs are different at each stage, and that the later stages are less responsive to public opinion or outside expertise than the earlier ones (Tresch, Sciarini, and Varone Citation2011, 5).
In the following chapter we will present areas of BDA application in the aforementioned policy cycle phases in the light of an ICT and data framework aimed at overcoming some of the shortcomings of the individual steps. This generic model should serve as a theoretical roadmap illustrating how the process of policymaking can be improved at each stage, from the agenda setting to the evaluation process, before we introduce and discuss our reinterpreted e-policy cycle.
5.1. Big data in the policy cycle
In the preceding section we discussed government identity problems and the principles of governance with respect to the usage of ICT, and introduced the concept of evidence-based policymaking as a core principle of governance, which is increasingly shifting from process orientation toward performance orientation. We contextualized the role of data and information in policymaking and introduced Big Data in policymaking. In this section we will introduce specific fields of application of BDA in the policy cycle.
Data and information are required as a basis for evidence, and the more high-quality information is available in a decision process the higher the quality of decisions will be. However, fixing the quality of total information while merely increasing attribute information will result in the decrease of decision quality (Keller and Staelin Citation1987). This relationship is a result of the information overflow, a failure of filters intended to separate noise from relevant information, given that the more data and information become available in a decision process, the more complex the decision model will get and the longer the decision making itself will take. Given that hardly any information is ever deleted we witness an increasing reluctance to apply filters for the purpose of reducing a problem’s complexity. According to Big Data claims, potentially meaningful information lies within data declared as noise, yet advanced methodologies and algorithms for extracting this valuable information from noise are not in widespread use.
As set out in the preceding section, Big Data, and specifically BDA, promises faster and better insights, given that correlations can be automatically deduced by the application of machine learning algorithms, data can be observed in its entirety, and analytical results theoretically become available instantaneously. The ability to early react to adverse effects of a decision is a comparative advantage of applied BDA, which we will describe in relation to the policy cycle process steps.
5.2. Agenda setting
The key issue in respect of agenda setting is identifying the issues that will grasp the attention of policymakers. Despite the strong record of research on this question the results remain mixed (Dearing and Rogers Citation1996; Rogers, Dearing, and Bregman Citation1993).
A central role is most definitely played by the media, which have the ability to frame issues and spread relevant information. Especially in democratic systems this has a strong impact on actual agenda setting (McCombs and Shaw Citation1972; Scheufele Citation1999). There is a worrying aspect to this, for there is some evidence indicating that high-risk issues in the realm of environmental policy, for example, receive little attention and therefore only limited funding (Barkenbus Citation1998, 3). Scientific expertise, on the other hand, seems to be only of minor importance, and “scientific research results do not play an important role in the agenda-setting process” (Dearing and Rogers Citation1996, 91). Nevertheless scientific evidence does play a part in the process—although the media might push an issue, most likely they will base their reporting on some form of scientific expertise to legitimize their choice of issues (Barkenbus Citation1998). Additionally, the interest formulated by the media forces politicians to act in order not to be seen as indifferent to a topic that is gathering widespread public attention.
In a world of evolving digital media and online publics, the dynamics of issue agendas are becoming more complex. The emergence of social media has generated renewed attention for the reverse agenda-setting idea. With a few keystrokes and mouse clicks any audience member may initiate a new discussion or respond to an existing one with text, audio, video, or images. One way for governments to early identify emergent topics and generate relevant agenda points would be to collect data from social networks with high degrees of participation and try to identify citizens’ policy preferences, which can then be taken into account by the government in setting the agenda. Yet such possibilities would have to be used with extreme caution, in the light of the knowledge that social media activity can influence policy decisions and change the behavior of citizens—thereby possibly distorting the actual salience of an issue for the general public and overemphasizing the concerns of a vocal minority (Lazer et al. Citation2014).
Online news sources which represent the online face of traditional broadcast and print media dominate public attention to news online. A large-scale survey carried out by Neuman and colleagues using BDA (Boolean search in Big Data to determine patterns of issue framing and parallel time-series analysis) showed that the public agenda as reflected in the social media is not locked in a slavish or mechanical connection to the news agenda provided by the traditional news media. The social media spend a lot more time discussing social issues such as birth control, abortion, and same-sex marriage, while they are less likely to address issues of economics and government functioning. However, the survey also critically noted the problematic practice of simply equating online tweets, blogs, and comments with “public opinion” in general, given that social media users are not demographically representative and diverse social media platforms undoubtedly develop local cultures of expressive style, which influence the character of what people choose to say (Russell Neuman et al. Citation2014, 196 and 210). While using automated and large-scale analysis of news outlets has made it possible to predict events connected to the Arab Spring and events in Eastern Europe, sometimes surpassing the predictive power of traditional models of foreign policy (Leetaru and Schrodt Citation2013; Leetaru Citation2011), the broad spectrum of issues to be dealt with cannot be covered by solely relying on public agenda setting .
BDA technologies are not only capable of predicting events in the realm of foreign policy but also in the domestic realm. This is demonstrated by countries like China or Singapore, which, rather than simply banning political discussions, observe and quantify them in order to gain information about the policy preferences of their citizens and use them as early warning systems for potential political unrest (King, Pan, and Roberts Citation2013).
5.3. Policy discussion
Policy discussions fall into a similar field as agenda setting, with the difference that while agreement on the issues that have to be dealt with has been reached, at this stage of the policy cycle the main focus is on debating the different options. Big Data can play a significant role here as well, especially when it comes to the details of pressing policy problems. The agenda-setting stage can set the priorities as to which policy should be favored, for example, whether infrastructure, security, education, and so on should be treated as a policy priority. The discussion about the actual policy to be implemented, however, can benefit from data in a different way. The collection of infrastructure-related data via citizen participation through Boston’s Street Bump Application, for example, measures the smoothness of car rides based on movements of an individual’s cell phone. Thereby it is possible to identify the areas that should go to the top of the list when it comes to infrastructure improvements (Simon Citation2014). Such information can then be used in open policy discussions, aiding the search for the most efficient starting point of implementation.
Another issue arising in public policy discussions is how to deal with the wealth of unstructured information available in public blogs or tweets or obtained through online public consultations. Public organizations and institutions can retrieve substantial feedback from the analysis of publicly available data, in the form of posts and comments received via social media channels, weblogs, or wikis; however, it becomes effectually unaffordable to manually monitor these information resources, with new blogs and channels appearing every day. It becomes essential for these entities to apply automated methods, tools and techniques from text analytics in order to incorporate this feedback into the policymaking process. Clustering techniques and machine learning algorithms help to structure this wealth of information, and ICT-supported sentiment mining/sentiment analysis will help to inform policymakers about the current trend of the political discussion as well as the changes in public opinion in the light of discussed and proposed changes (Alfaro et al. Citation2013, 2).
Online public consultations will operate on a delicate tradeoff between collecting structured vs. unstructured information: The more structured information is collected, the easier analysis can be performed, yet at the cost of reduced participation. BDA can help to overcome this challenge by applying natural language processing (NLP) on top of machine learning algorithms like cluster analysis to easier identify the needle in the haystack (Kamateri et al. Citation2015, 129). Large-scale unstructured input is often delegated to an experts committee, which will aggregate the public opinions, potentially diluting the public sentiment.
5.4. Policy formation and policy acceptance
The formation of a policy is the description of steps that are supposed to be undertaken in the implementation phase. The two stages of policy formation and policy acceptance have a different relation to (Big) Data as they are strongly anchored in the legal framework of government conduct. Big Data, however, can play a role in the realm of evaluation. Once the policy has moved from the discussion phase to the policy formation phase, policy documents can be scrutinized and governments can adopt or shape actual policies according to public demands. Especially in democracies the credibility and legitimacy of new policies is important, so it will be a useful undertaking to use means of data collection to investigate the acceptance of specific polices among different groups of society. The term acceptance in the digital age can be expanded beyond the political act of voting by political representatives to also refer to the general acceptance within the population.
In the policy formation and acceptance cycle stages, BDA can contribute to evidence-based policy making by advanced predictive analytics methodologies and scenario techniques. One example of this would be the use of BDA to analyze and prevent the spread of disease (Harris Citation2015).
Government and administration decision making is often characterized by a very high number of independent variables and conflicting target functions. Better regression algorithms are needed to handle these high-dimensional modeling challenges. Thankfully, regression analysis as a cornerstone of predictive analytics does not rely exclusively on ordinary least squares (OLS). Advances in statistic modeling have resulted in algorithms, which are much better suited to describe “the real world” instead of resorting to artificial assumptions. The predictive modeling problem can be described by imagining N entries that are associated with N outcome measurements, as well as a set of K potential predictors. In many cases the information about each entry is rich and unstructured, so there are many possible predictors that could be generated. Indeed, the number of potential predictors K may be larger than the number of observations N. An obvious concern is overfitting: with K > N it will typically be possible to perfectly explain the observed outcomes, but the out-of-sample performance may be poor. The Ridge Regression is, for once, a modeling technique that works to solve the multicollinearity problem found in OLS. Multicollinearity occurs where two or more predictor variables in statistic modeling exhibit high correlation. Traditional regression approaches as input to predictive models would involve high error values and render predictions highly volatile. The application of Ridge Regression to overcome this phenomenon, however, comes at a price as it is computation heavy (Zou, Hastie, and Tibshirani Citation2006).
Another novel algorithm used in Big Data predictive analytics is Elastic Net. As a learning algorithm it will help to set up a well-defined, parameterized model as an input to simulation data on a large dataset without overfitting.
Ridge Regression and Elastic Net are interesting in a BDA scenario as they can operate on very large datasets and computations can be parallelized, taking advantage of vector machines and cloud infrastructure. However, despite all algorithmic advances towards achieving more accurate simulation models, explanation and prediction is more difficult for policy interventions than for the selling and pricing of books. This holds especially true for national and international policymaking, for example, climate change rather than potholes (data4policy.eu Citation2015).
5.5. Provision of means
Similarly to the previous two stages, decisions on how to most efficiently provide the required personnel and financial means for the implementation of new policies can be improved if previous experiences can be analyzed in detail. Budgetary processes provide amounts of data that can enable the detection of patterns, which can then be used to design more efficient and effective ways to build a budget for a policy. A more transparent and more performance-oriented provision of means could once again be a source of legitimacy for political systems and governments. Additionally, Big Data will also potentially enable the testing of new ways of revenue-neutral financing for policies. The ability to geographically pinpoint problem areas and the possible calculation of savings and new revenues resulting from the potential resolution of the problem could make it easier to gather support for certain policies, while making the rejection of others more likely. There is already some empirical evidence that the use of big Data in budgeting can increase efficiency and effectiveness while reducing costs (Manyika et al. Citation2011). The availability of more data facilitates a shift toward outcome-oriented budgeting and the creation of evaluation frameworks that could funnel resources to where they are most needed, and not only to the areas to which they used to be allocated in previous periods due to the emergence of a “budgeting tradition” according to which some areas are granted higher budget resources because they spent more in the past and now occupy the pole position when it comes to the allocation of funds.
Funding decisions could ideally be increasingly based on the estimated impact of area-specific spending, thus reducing the allocation of funds based on the political influence of powerful government agencies. Funding needs would be determined dependent on the estimated impact on the basis of available data and evaluations of previous policies, creating a feedback loop that could help identify and discontinue unsuccessful policies and distribute more resources to successful ones.
Big Data can also play a productive role in the procurement process: Thanks to improved ways of checking the records of possible partners from the private sector public agencies are enabled to identify the best possible cooperations, while data analytics can already enable improvements in tax compliance and the avoidance of, for example, welfare benefits fraud. All these measures will improve the financial situation of public agencies and will allow funds to be used increasingly for problem solution rather than for maintaining the administrative apparatus.
5.6. Implementation
The implementation of policies could be influenced by Big Data in two ways: First, the ability to pinpoint problem zones could be a way to implement different levels of policy intensity. For example, an increase in policing can be focused more precisely on problem areas, thereby reducing the occurrence of crime at the point of its origin. Second, the very execution of new policies will almost immediately produce new data, which can then be used to evaluate the effectiveness of these policies and enhance future implementation processes by identifying problems with previous ones. As will be demonstrated in connection with the evaluation stage, it is especially the new dimension of evaluation that will probably have the most significant effect on the different stages of the policy cycle. The production of data about the implementation of policies not after but during the implementation can create an unprecedented flexibility when it comes to the transformation of policy ideas into actually executable policies. For example, a new redistributive tax code could be tested almost in real time as to whether it has the desired effect or modification will be necessary. As has been mentioned earlier in this article, this would also mean increased autonomy for public administrations to enable them to react as quickly as possible to incoming evaluation results.
Additionally, some of the fundamental sources of information for the implementation of policies can be increased in accuracy by Big Data. Census data, for example, often runs the risk of being out of date at the time it is used for the process of formulating and implementing new policies. Through the combination of several databases, however, census data could be produced on an almost daily, rolling basis instead of being updated only once or twice a decade. Demographic data, unemployment numbers or migration patterns could be observed in real time, enabling a much faster assessment of whether the implementation of a certain policy was a success or not. The inclusion of external data would be a promising further step either to enhance existing authoritative government data or to improve the data cross-check process in view of increased validity.
6. Continuous evaluation in the e-policy cycle
The attentive reader will have noticed that the section on applications of BDA in the policy cycle misses the evaluation part—for good reason. The various analytic capabilities of Big Data all apply to evaluation. But instead of enumerating and discussing BDA in policy evaluation we suggest a more radical and novel approach: A redesigned policy cycle, which takes account of advances in ICT and, specifically, the analytical capabilities provided by Big Data.
Textbooks differentiate between formative and summative evaluation, with the main difference being qualitative vs. quantitative, as well as the policy cycle stage at which evaluation is performed. Hudson und Lowe (Citation2004) claim that the rational view of evaluation is retrospective, summative judgments dominate and experimental research is regarded as the gold standard. As a response to this rational model a bottom-up approach to evaluation has emerged, which is formative, based on qualitative evidence and includes the active participation of stakeholders, with feedback appearing as the policy is being rolled out instead of after policy implementation (Parsons Citation1995).
The traditional policy cycle is characterized by evaluation happening at the very end of policymaking yet with early exits to preceding process steps the very moment failure becomes apparent. However, in this scenario adjusting the set agenda is risky as in the pre-Big Data era, the speed at which evaluations were delivered by traditional BI systems was generally not fast enough to justify early breakouts from the policy cycle.
A distinctive feature of the Big Data toolbox is the possibility of real-time processing. One advantage of instantaneous or near-instantaneous data processing is that evaluation results become available the very moment data arrives. This enables a new view on the policy cycle, namely that of continuous evaluation (). BDA enables evaluation, instead of being a well-defined process step at the very end of the policy cycle, to happen at any stage and to happen opaque to the affected stakeholders. Thus we propose a newly shaped policy cycle in which evaluation does not happen at the end of the process but continuously, opening permanent possibilities of reiteration, reassessment, and consideration. This will remove evaluation from its place at the end of the policymaking process and instead make it an integral part of every other policymaking step. This is a new feature enabled by Big Data Analytics, and we name it the e-policy cycle.
Our approach of continuous evaluation harmonizes the views of summative and formative evaluation: Continuous evaluation in the e-policy cycle is formative as it is performed throughout the policy process, and summative as it is based on rational models.
With advances in Big Data, use cases of continuous evaluation in public administration/the government become available. The US Army, for example, is testing a program called Automated Continuous Evaluation System. Utilizing BDA solutions and context aware security, the system analyzes government, commercial, and social media data to uncover patterns relating to US army applicants. In 21.7% of cases the program revealed important information the applicant had not disclosed, like serious financial problems, domestic abuse, or drug abuse. This use case presents only a very limited view of the possibilities generated by continuous evaluation (Executive Office of the President Citation2014, 36). Another example of continuous evaluation is the UK Government Program on Performance Data.Footnote2 Instead of merely providing open government data from policy programs at various stages of the policy cycle, visualizations provide a more accessible experience with respect to the evaluation of government policy making. The program is still in beta, changes are likely to happen, and many of the visualizations lack the capability to further drill down into the data the visualization has been based on. However, the UK performance program serves as another example of applied continuous evaluation.
7. Conclusions and limitations
According to our observations, the underlying concepts behind Big Data are not disruptively new; instead we witness a repackaging of terms like data mining, business intelligence, and decision support, which then become part of the Big Data arena. What is new, however, is the possibility to take decisions in real time, which holds the potential to revise the traditional model of successive execution of the individual stages of the policy cycle and supplant it by a model of continuous evaluation. This has the potential to significantly shorten the decision-making process and lead to better decisions as more valuable information can be derived from data otherwise declared as noise. BDA methodologies will also open the door for a more widespread inclusion of the public at the various stages of the cycle, as it will become easier to better deal with the wealth of collected unstructured information in order to be able to take account of the wisdom of the crowd.
As we have shown, there are multiple ways in which BDA can support the policy cycle, but, specifically taking into account methodologically Big Data-enabled, near-instantaneous evaluation results, the biggest gains can be achieved by questioning the policy cycle as an iterative concept. According to the traditional policy cycle an opportunity for making adjustments basically arises only after the evaluation of results. However, in the age of BDA it makes little sense to delegate evaluation to an isolated step at the very end of the cycle. Instead, continuous evaluation of measures at every stage of the policy cycle will reduce inefficiencies in policymaking by enabling the pursuit of alternatives identified by BDA scenario making, or even early exits from planned polices. Postulating continuous evaluation enabled by technological advances which allow access to and the processing, analysis and storage of large amounts of heterogeneous data, as opposed to ex-ante evaluation, represents our contribution to the domain of policy analysis.
At the same time, however, one must not get carried away by the technological possibilities. These innovations still take place in a bureaucratic environment with its idiosyncrasies and organizational cultures, with each participant most likely bent on turning the introduction of new technologies to their own advantage, possibly at a cost for everyone else. To define the right degree of realizing technical capabilities, openness and autonomy for government in the digital era will continue to be a challenging task for which we still lack a comprehensive answer, not least because different traditions and cultures in governments will interact differently with the introduction of technologies. Another, even more mundane challenge posed by the introduction of BDA-enabled evidence-based policymaking is the role of politicians, with evidence being accepted when it fits into a political argument and rejected when it does not. An effective countermeasure would be to prepare information in a way to enable every interested party to drill down into evidence, giving the public the ability to draw conclusions based on facts and accessible figures. The undeniable truth of facts cannot be neglected even by the most stubborn politicians.
Our article does not come without limitations, however. While we draw our conclusions from carefully selected and recognized scholarly articles, we lack empirical data. The concept of continuous evaluation is tempting, but it has not yet passed a reality test. Preliminary attempts to introduce continuous evaluation are under way (cf. US Army Automated Continuous Evaluation System, UK Government Program on Performance Data), but we do not provide a thorough evaluation framework suited to determine whether any heralded benefits are attributable to continuous evaluation or to other, as yet unidentified side effects.
Meijer and Löfgren (Citation2015) identified a gap between policy science and technological advancement which results from addressing the research domain with respect to the influence of technology on institutional structures, preferences, interaction patterns, and socioeconomic development instead of treating technology as an artifact in itself, as already demanded by Orlikowski and Iacono (Citation2001). In this regard our contribution to the research field remains limited, as our approach to Big Data is based on the application domain and the effects on institutional structures and interaction patterns, instead of giving more room to the technological artifact itself.
8. Outlook and further research
In 2013 the EU Directorate-General for Internal Policies released a study on performance-based policymaking. In section 4.2, “Key elements of performance-based policy cycle,” the authors lay emphasis on ex-ante policy formulation and ex-post assessment of the performance of a policy initiative relative to expected benefits (Muller et al. Citation2013). Even up-to-date scholarly contributions which deal with the possibilities enabled by BDA in respect of policy making and claim that these activities are relevant to all stages of the policy cycle, do not revisit the iterative cycle model or its explicit evaluation step (Kamateri et al. Citation2015, 150).
Establishing Big Data-enabled continuous evaluation in the revised policy cycle will shift the pace at which future policy making will happen, reduce the relevant costs and increase effectiveness. As the administration will expand the use of continuous evaluation across all federal levels and sectors, the privacy of employees and contractors will have to be carefully considered. The ability to refute or correct errant information that triggers evaluation results must be built into the data clearance process. BDA applied as continuous evaluation must be used as a toolset for the benefit of many. If a decision maker is not willing to accept BDA-based scrutiny, the relevant initiative should not be adopted as a government policy.
The actual transformation of the process of policymaking and the move from estimate-based policies to evidence-based policies still depends to a large extent on the commitment of the relevant political actors. In numerous countries attempts are already under way to create independent auditing institutions for monitoring the effectiveness of policies, and literature on how to design evaluation schemes for government policies is published in increasing numbers (Stockmann Citation2007). In order for such developments to be successful it is important to take the current state-of-the-art in ICT and BDA into account. New ways of governance and policymaking must not remain stuck in traditional decision-making structures if the public sector is meant to keep up with the pace of change in the private sector and the growing demands of the citizenry. In order to succeed in this endeavor, we agree with Orlikowski and Iacono (Citation2001, 131), who argue to consider ICT as an artifact and to shift attention from taking IT artifacts for granted toward explicit theorizing about specific technologies with distinctive cultural and computational capabilities. Given the context-specificity of IT artifacts, there is no single, one-size-fits-all conceptualization of technology that will work for all studies. As a result, IS research needs to develop the theoretical apparatus that is appropriate for the particular types of investigations, focus, methodology, and units of analysis. This becomes increasingly important as Big Data and BDA leave behind inflated expectations, paving the way for thorough and rigorous research.
The EU policy on performance-based policymaking does not yet take into account the distinctive new features of BDA and continuous evaluation, and we suggest revisiting this policy in the light of our proposed e-policy cycle. This requires the identification and drafting of test cases suitable for continuous evaluation in public administration to demonstrate the benefits we described, and an evaluation framework to obtain much needed quantitative, empirical evidence, which is generally lacking in this field of research. Further, a more detailed and integrated field of research that investigates the interplay of politics and technology will be needed to find new approaches and ways to take the changes brought about by the digital era into account. This article was designed to make a modest contribution to this undertaking and highlight the importance of further interdisciplinary research in this field.
What remains is the question whether everything that can be done should be done. Data collection and data analytics can support policy making in all kinds of political systems, but is the switch from solving problems via the establishment of causality to solving them via the measurement of strong correlations really as unproblematic as its proponents claim? And there is always the risk of a political backlash and the aversion of people to political decisions based on Big Data—especially if this were to mean that those who are more willing to provide data about themselves will get to benefit more from the political outcome. Governments might even come up with the idea of “bribing” citizens into giving up information about themselves as a basis for better governance, but this would equally lead to problems in the field of data security and privacy laws.
Additional information
Notes on contributors
Johann Höchtl
Johann Höchtl graduated from University of Vienna and Vienna University of Technology in Business Informatics. His current research focus is in the domain of Open Data, the effects of ICT application in a connected society and semantic technologies. Johann Höchtl is member of OKFN Austria and member of Cooperation Open Government Data Austria, where he is heading data quality sub working group. Apart from his professional work he was advisor to the E-Georgia strategy for the public administration and currently advisor to Macedonia (FYROM) to raise interoperability capabilities among federal ministries.
Peter Parycek
Peter Parycek is a full professor in E-Governance and head of the Department for E-Governance and Administration at the Danube University Krems and Chairman of the ministerial working groups “E-Democracy & E-participation” at the Austrian Federal Chancellery. He is responsible for the CeDEM conference and the open access journal JeDEM.
Ralph Schöllhammer
Ralph Schöllhammer is a faculty member at the Business and Management Department at Webster Vienna Private University. He is also an affiliated researcher with the Danube University Krems. Additionally, Ralph works as a consultant for the Austrian Federal Chancellery’s Division III: Civil Service and Administrative Innovation that deals with the reforming and modernizing the Austrian public service. Related to this research Ralph also serves as vice president for the Austrian Society for New Institutional Economics (ASNIE).
Notes
References
- Alfaro, C., J. Cano-Montero, J. Gómez, J. M. Moguerza, and F. Ortega. 2013, September. A multi-stage method for content classification and opinion mining on weblog comments. Annals of Operations Research 1–17. doi:10.1007/s10479-013-1449-6.
- Andersen, S. S., and K. A. Eliassen. 1993. Making policy in Europe: The Europeification of national policy-making. London, UK: Sage Publications Limited.
- Anderson, J. E. 1972. Public policymaking. New York: Praeger Publishing.
- Asquer, A. 2013. The Governance of big data: Perspectives and issues. SSRN Scholarly Paper ID 2272608, Social Science Research Network, Rochester, NY. http://papers.ssrn.com/abstract=2272608.
- Bannister, F., and R. Connolly. 2009. New problems for old? An exploration of e-governance. European Group of Public Administration 2:137–152.
- Bannister, F., and R. Connolly. 2012. Forward to the past: Lessons for the future of e-government from the story so far. Information Polity 17(3):211–226.
- Bannister, F., and R. Connolly. 2014. ICT, Public values and transformative government: A framework and programme for research. Government Information Quarterly 31(1):119–128. doi:10.1016/j.giq.2013.06.002.
- Barkenbus, J. 1998, September. Expertise and the policy cycle. Energy, Environment, and Resources Center, University of Tennessee, Knoxville, Tennesse.
- Bertot, J. C., U. Gorham, P. T. Jaeger, L. C. Sarin, and H. Choi. 2014. Big data, open government and E-government: Issues, policies and recommendations. Information Polity 19(1):5–16.
- Bondi, A. B. 2000. Characteristics of scalability and their impact on performance. In Proceedings of the 2nd International Workshop on Software and Performance, 195–203. WOSP ’00, New York, NY, USA, ACM. doi:10.1145/350391.350432.
- Brans, M. 1997. Challenges to the practice and theory of public administration in Europe. Journal of Theoretical Politics 9(3):389–415. doi:10.1177/0951692897009003007.
- Bridgman, P., and G. Davis. 2003. What use is a policy cycle? Plenty, if the aim is clear. Australian Journal of Public Administration 62(3):98–102. doi:10.1046/j.1467-8500.2003.00342.x.
- Bulmer, M. 1987. Social science research and government: Comparative essays on Britain and the United States. Cambridge, UK: Cambridge University Press.
- Buskirk, E. V. 2009. How the Netflix prize was won. Blog of WIRED Magazine. http://www.wired.com/2009/09/how-the-netflix-prize-was-won/ ( accessed September 22).
- Carpenter, D. P. 2001. The forging of bureaucratic autonomy: Reputations, networks, and policy innovation in executive agencies, 1862–1928. Princeton, NJ: Princeton University Press.
- Chen, H., R. H. L. Chiang, and V. C. Storey. 2012. Business intelligence and analytics: From big data to big impact. MIS Quarterly 36(4):1165–1188.
- Chen, M., S. Mao, and Y. Liu. 2014. Big data: A survey. Mobile Networks and Applications 19(2):171–209. doi:10.1007/s11036-013-0489-0.
- Chen, Y.-C., and T.-C. Hsieh. 2014. Big data for digital government: Opportunities, challenges, and strategies. International Journal of Public Administration in the Digital Age 1(1):1–14. doi:10.4018/ijpada.2014010101.
- Colebatch, H. K. 2005. Policy analysis, policy practice and political science. Australian Journal of Public Administration 64(3):14–23. doi:10.1111/ajpa.2005.64.issue-3.
- Cordella, A., and N. Tempini. 2015. E-government and organizational change: Reappraising the role of ICT and bureaucracy in public service delivery. Government Information Quarterly 32:279–286. doi:10.1016/j.giq.2015.03.005.
- Coronel, C., S. Morris, and P. Rob. 2012. Database systems: Design, implementation, and management. Stamford, Connecticut: Cengage Learning.
- Crotty, M. 1998. The foundations of social research: Meaning and perspective in the research process. London, UK: Sage Publications.
- Daniell, K. A., A. Morton, and D. R. Insua. 2015, June. Policy analysis and policy analytics. Annals of Operations Research. doi:10.1007/s10479-015-1902-9.
- data4policy.eu. 2015. Data for policy: Big data and other innovative data-driven approaches for evidence-informed policy making. Presented at Policy-making in the Big Data Era: Opportunities and Challenges, Cambridge. http://media.wix.com/ugd/c04ef4_5ae7cee4ad3c46f39668de4f3a62d2df.pdf ( accessed June 16).
- Davenport, T. H. 2014. Big data at work: Dispelling the myths, uncovering the opportunities. Boston: Harvard Business Press.
- Davenport, T. H., and J. G. Harris. 2007. Competing on analytics: The new science of winning, 1st ed. Boston: Harvard Business Review Press.
- Dearing, J. W., and E. M. Rogers. 1996. Agenda-Setting. Thousand Oaks, CA: Sage Publications.
- Dunleavy, P., and H. Margetts. 2010. The second wave of digital Era Governance. Washington, DC: Oxford University Press.
- Dunleavy, P., H. Margetts, S. Bastow, and J. Tinkler. 2006a. New public management is dead—Long live digital-Era Governance. Journal of Public Administration Research and Theory 16(3):467–494. doi:10.1093/jopart/mui057.
- Dunleavy, P., H. Margetts, S. Bastow, and J. Tinkler. 2006b. Digital era governance: IT corporations, the state, and E-Government. Oxford, UK: Oxford University Press.
- Edwards, M., C. Howard, and R. Miller. 2001. Social policy, public policy: From problems to practice. Sydney, Canberra, Australia: Allen & Unwin.
- Evans, P. B. 1995. Embedded autonomy: States and industrial transformation. Princeton paperbacks. Princeton, NJ: Princeton University Press.
- Everett, S. 2003. The policy cycle: Democratic process or rational paradigm revisited? Australian Journal of Public Administration 62(2):65–70. doi:10.1111/ajpa.2003.62.issue-2.
- Executive Office of the President. 2014. Big data: Seizing opportunities, preserving values. Washington, DC: The White House. http://www.whitehouse.gov/sites/default/files/docs/big_data_privacy_report_may_1_2014.pdf.
- Fasenfest, D. 2010. Government, governing, and governance. Critical Sociology 36(6):771–774. doi:10.1177/0896920510378192.
- Fawcett, S. E., C. Wallin, C. Allred, and G. Magnan. 2009. Supply chain information-sharing: Benchmarking a proven path. Benchmarking: An International Journal 16(2):222–246. doi:10.1108/14635770910948231.
- Ferro, E., E. N. Loukis, Y. Charalabidis, and M. Osella. 2013. Policy making 2.0: From theory to practice. Government Information Quarterly 30(4):359–368. doi:10.1016/j.giq.2013.05.018.
- Fukuyama, F. 2013. What is governance? Governance 26(3):347–368. doi:10.1111/gove.2013.26.issue-3.
- Géczy, P. 2014. Big data characteristics. The Macrotheme Review 3(6). http://macrotheme.com/yahoo_site_admin/assets/docs/8MR36Pe.97110828.pdf.
- Guba, E. G., and Y. S. Lincoln. 1989. Fourth generation evaluation. Thousand Oaks, CA: Sage Publications.
- Gupta, M. P., and D. Jana. 2003. E-Government evaluation: A framework and case study. Government Information Quarterly 20(4):365–387. doi:10.1016/j.giq.2003.08.002.
- Harris, S. 2015. The social laboratory. Foreign Policy. https://foreignpolicy.com/2014/07/29/the-social-laboratory/ ( accessed July 22).
- Heinrich, C. J. 2007. Evidence-based policy and performance management: Challenges and prospects in two parallel movements. The American Review of Public Administration 37(3):255–277. doi:10.1177/0275074007301957.
- Hertin, J., A. Jordan, J. Turnpenny, M. Nilsson, D. Russel, and N. Björn. 2009. Rationalising the policy mess? Ex ante policy assessment and the utilisation of knowledge in the policy process. Environment and Planning 41:1185–1200. doi:10.1068/a40266.
- Heule, S., M. Nunkesser, and A. Hall. 2013. HyperLogLog in practice: Algorithmic engineering of a state of the art cardinality estimation algorithm. Proceedings of the EDBT 2013 Conference, Genoa, Italy, March.
- Hilbert, M., and P. López. 2011. The world’s technological capacity to store, communicate, and compute information. Science 332(6025):60–65. doi:10.1126/science.1200970.
- Hudson, J., and S. Lowe. 2004. Understanding the policy process: Analysing welfare policy and practice. Bristol, UK: Policy Press.
- Jacobs, A. 2009. The pathologies of big data. Commun. ACM 52(8):36–44. doi:10.1145/1536616.1536632.
- Johnston, E. W. 2015. Governance in the information Era: Theory and practice of policy informatics. London, UK: Routledge.
- Joseph, R. C., and N. A. Johnson. 2013. Big data and transformational government. IT Professional 15:43–48. doi:10.1109/MITP.2013.61.
- Kamal, M. M. 2006. IT innovation adoption in the government sector: Identifying the critical success factors. Journal of Enterprise Information Management 19(2):192–222. doi:10.1108/17410390610645085.
- Kamateri, E., E. Panopoulou, E. Tambouris, K. Tarabanis, O. Adegboyega, D. Lee, and D. Price. 2015. A comparative analysis of tools and technologies for policy making. In Policy practice and digital science, ed. M. Janssen, M. A. Wimmer, and D. Ameneh, Cham: Springer International Publishing. http://link.springer.com/10.1007/978-3-319-12784-2.
- Keller, K. L., and R. Staelin. 1987. Effects of quality and quantity of information on decision effectiveness. Journal of Consumer Research 14:200–213. doi:10.1086/jcr.1987.14.issue-2.
- King, G., J. Pan, and M. E. Roberts. 2013. How censorship in China allows government criticism but silences collective expression. American Political Science Review 107(2):326–343. doi:10.1017/S0003055413000014.
- Kjaer, A. M. 2004. Governance. Cambridge, UK: Polity.
- Kogan, M. 1999. The impact of research on policy. In Speaking truth to power: Research and policy on lifelong learning, ed. F. Coffield, 11–18. Bristol, UK: Policy Press.
- Laney, D. 2001. 3D data management: Controlling data volume, velocity, and variety. 949, META Group, Stamford, Connecticut. http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf.
- Layne, K., and J. Lee. 2001. Developing fully functional E-government: A four stage model. Government Information Quarterly 18(2):122–136. doi:10.1016/S0740-624X(01)00066-1.
- Lazer, D. M., R. Kennedy, G. King, and A. Vespignani. 2014. The parable of google flu: Traps in big data analysis. Science 343(6176):1203–1205. doi:10.1126/science.1248506.
- Leetaru, K. 2011. Culturomics 2.0: Forecasting large-scale human behavior using global news media tone in time and space. First Monday 16(9). doi:10.5210/fm.v16i9.3663.
- Leetaru, K., and P. A. Schrodt. 2013. GDELT: Global data on events, location, and tone, 1979–2012. Paper Presented at the ISA Annual Convention 2:4.
- Lorentzen, P. 2014. China’s strategic censorship. American Journal of Political Science 58(2):402–414. doi:10.1111/ajps.2014.58.issue-2.
- Malar, K. U., D. Ragupathi, and G. M. Prabhu. 2014. The hadoop dispersed file system: Balancing movability and performance. New York: International Journal of Computer Sciences and Engineering, Foundation of Computer Science.
- Manyika, J., M. Chui, B. Brown, J. Bughin, R. Dobbs, C. Roxburgh, and H.-B. Angela. 2011. Big data: The next frontier for innovation, competition, and productivity. Washington, DC: McKinsey Global Institute. http://www.mckinsey.com/insights/mgi/research/technology_and_innovation/big_data_the_next_frontier_for_innovation.
- Mayer-Schönberger, V., and K. Cukier. 2013. Big data: A Revolution that will transform how we live, work, and think, 1st ed. Boston: Eamon Dolan/Houghton Mifflin Harcourt.
- McAfee, A., and E. Brynjolfsson. 2012, October. Big data: The management revolution. Harvard Business Review https://hbr.org/2012/10/big-data-the-management-revolution.
- McCombs, M. E., and D. L. Shaw. 1972. The agenda-setting function of mass media. Public Opinion Quarterly 36(2):176–87. doi:10.1086/267990.
- Meijer, A., and K. Löfgren. 2015. The neglect of technology in theories of policy change. International Journal of Public Administration in the Digital Age 2(1):75–88. doi:10.4018/ijpada.2015010105.
- Micklethwait, J., and A. Wooldridge. 2014. The fourth revolution: The global race to reinvent the State. New York: The Penguin Press.
- Misuraca, G., F. Mureddu, and D. Osimo. 2014. Policy-making 2.0: Unleashing the power of big data for public Governance. In Open Government, ed. M. Gascó-Hernández, 171–188. Public Administration and Information Technology 4. Springer New York. http://link.springer.com/chapter/10.1007/978-1-4614-9563-5_11.
- Muller, P., G. Conlon, S. Devnani, and C. Bénard. 2013. Performance based policy. IP/A/IMCO/ ST /20 13 - 04 PE 507.457, European Parliament, Brussels. http://www.europarl.europa.eu/RegData/etudes/etudes/join/2013/507457/IPOL-IMCO_ET%282013%29507457_EN.pdf.
- Nachmias, D., and C. Felbinger. 1982. Utilization in the policy cycle: Directions for research. Review of Policy Research 2(2):300–308. doi:10.1111/ropr.1982.2.issue-2.
- Offe, C. 2009. Governance: An ‘empty signifier’? Constellations 16(4):550–562. doi:10.1111/j.1467-8675.2009.00570.x.
- Orlikowski, W. J., and C. S. Iacono. 2001. Research commentary: Desperately seeking the ‘IT’ in IT research—A call to theorizing the IT Artifact. Information Systems Research 12(2):121–134. doi:10.1287/isre.12.2.121.9700.
- Parsons, D. W. 1995. Public policy: An introduction to the theory and practice of policy analysis. Aldershot, UK: Edward Elgar Publishing.
- Peled, A. 2014. Traversing digital babel: Information, E-government, and exchange. Boston: MIT Press.
- Rhodes, R. A. W. 2007. Understanding governance: Ten years on. Organization Studies 28(8):1243–1264. doi:10.1177/0170840607076586.
- Rogers, E. M., J. W. Dearing, and D. Bregman. 1993. The anatomy of Agenda‐setting research. Journal of Communication 43(2):68–84. doi:10.1111/jcom.1993.43.issue-2.
- Russell Neuman, W., L. Guggenheim, S. Mo Jang, and S. Y. Bae. 2014. The dynamics of public attention: Agenda-setting theory meets big data: Dynamics of public attention. Journal of Communication 64(2):193–214. doi:10.1111/jcom.12088.
- Sanderson, I. 2002. Evaluation, policy learning and evidence‐based policy making. Public Administration 80(1):1–22. doi:10.1111/padm.2002.80.issue-1.
- Schaller, R. R. 1997. Moore’s Law: Past, present and future. IEEE Spectrum 34(6):52–59. doi:10.1109/6.591665.
- Scheufele, D. A. 1999. Framing as a theory of media effects. Journal of Communication 49:103–122. doi:10.1111/jcom.1999.49.issue-1.
- Schön, D. A., and M. Rein. 1995. Frame reflection: Toward the resolution of intractable policy controversies. New York: Basic Books.
- Simon, P. 2014. Potholes and big data: Crowdsourcing our way to better government. WIRED. http://www.wired.com/2014/03/potholes-big-data-crowdsourcing-way-better-government/ ( accessed March 25).
- Stockmann, R. 2007. Handbuch Zur evaluation. Münster, Deutschland: Waxmann Verlag.
- TechAmerica Foundation. 2015. Demystifying big data—A practical guide to transforming the business of government, TechAmerica Foundation, Washington, DC. http://beautifuldata.net/2012/10/techamerica-publishes-big-data-a-practical-guide-to-transforming-the-business-of-government/ ( accessed June 22).
- Tresch, A., P. Sciarini, and F. Varone. 2011. A policy cycle perspective on the media’s political Agenda-setting power. Reykjavik, Island.
- Van der Aalst, W. M. P. 2011. Process mining: Discovery, conformance and enhancement of business processes, 1st ed. New York: Springer.
- Warren, E. 2002. Market for data: The changing role of social sciences in shaping the law. Wisconsin Law Review 1:1–43.
- Weinberger, D. 2011. Too big to know: Rethinking knowledge now that the facts aren’t the facts, Experts are everywhere, and the smartest person in the room is the room. New York: Basic Books.
- Zou, H., T. Hastie, and R. Tibshirani. 2006. Sparse principal component analysis. Journal of Computational and Graphical Statistics 15(2):265–286. doi:10.1198/106186006X113430.