
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The main purpose of this article is to present a new class of bivariate mixed Poisson regression models with varying dispersion that offers sufficient flexibility for accommodating overdispersion and accounting for the positive correlation between the number of claims from third-party liability bodily injury and property damage. Maximum likelihood estimation for this family of models is achieved through an expectation-maximization algorithm that is shown to have a satisfactory performance when three members of this family, namely, the bivariate negative binomial, bivariate Poisson–inverse Gaussian, and bivariate Poisson–Lognormal distributions with regression specifications on every parameter are fitted on two-dimensional motor insurance data from a European motor insurer. The a posteriori, or bonus-malus, premium rates that are determined by these models are calculated via the expected value and variance principles and are compared to those based only on the a posteriori criteria. Finally, we present an extension of the proposed approach with varying dispersion by developing a bivariate Normal copula-based mixed Poisson regression model with varying dispersion and dependence parameters. This approach allows us to consider the influence of individual and coverage-specific risk factors on the mean, dispersion, and copula parameters when modeling different types of claims from different types of coverage. For expository purposes, the Normal copula paired with negative binomial distributions for marginals and regressors on the mean, dispersion, and copula parameters is fitted on a simulated dataset via maximum likelihood.
1. INTRODUCTION
The rapid advent of big data over the last few decades has motivated the need for constructing bivariate (and/or multivariate) regression models that can permit inferences about dependence structures that typically arise in high-dimensional count-valued data-sets based on explanatory variables. The main classes of models that have been widely applied in various fields of studies including, but not limited to, marketing, epidemiology, medical science, and finance are the bivariate (and/or multivariate) Poisson and mixed Poisson models and copula-based models. References, include, for example, Jung and Winkelmann (Citation1993), Munkin and Trivedi (Citation1999), Lee (Citation1999), Gurmu and Elder (Citation2000), Ho and Singer (Citation2001), Kocherlakota and Kocherlakota (Citation2001), Chib and Winkelmann (Citation2001), Wang (Citation2003), Alfò and Trovato (Citation2004), Cameron et al. (Citation2004), Karlis and Meligkotsidou (Citation2005), Zimmer and Trivedi (Citation2006), Park and Lord (Citation2007), Winkelmann (Citation2008), Ma, Kockelman, and Damien (Citation2008), El-Basyouny and Sayed (Citation2009), Aguero-Valverde and Jovanis (Citation2009), Famoye (Citation2010, Citation2012), Nikoloulopoulos and Karlis (Citation2010), Ghitany et al. (Citation2012), Cameron and Trivedi (Citation2013), Nikoloulopoulos (Citation2013a, Citation2013b), Zhan, Aziz, and Ukkusuri (Citation2015), and Silva et al. (Citation2017), among many others.
As far as ratemaking in non-life insurance, which is the main focus of this work, is concerned, the interested reader is referred to the articles by Bermúdez (Citation2009), Bermúdez and Karlis (Citation2011, Citation2012), and Shi and Valdez (Citation2014b), who introduced different bivariate (and/or multivariate) regression and copula-based models and also pointed out the existence of a positive correlation between claim counts of two (and/or multiple) types of claims. Also, Bermúdez and Karlis (Citation2017) were the first to take the Bayesian view for constructing two experience rating models, which integrate the a priori ratemaking based on bivariate Poisson regression models, extending the existing literature in the bivariate setting, which was confined on ratemaking models that were derived via the credibility approach. Additionally, it should be noted that recently many alternative approaches have been proposed in the literature for constructing flexible bivariate (and/or multivariate) insurance claim frequency regression models; see, for instance, Abdallah, Boucher, and Cossette (Citation2016), Bermúdez, Guillén, and Karlis (Citation2018), Pechon, Trufin, and Denuit (Citation2018); Pechon, Denuit, and Trufin (Citation2019, Citation2021), Bolancé and Vernic (Citation2019), Denuit, Guillen, and Trufin (Citation2019), Fung, Badescu, and Lin (Citation2019a, Citation2019b), and Bolancé, Guillen, and Pitarque (Citation2020).
In this study, we introduce a new class of bivariate mixed Poisson regression models with varying dispersion for modeling jointly bodily injury and property damage claim frequencies in motor third party liability (MTPL) insurance. This class is based on a mixing between two marginal Poisson distributions and a unit mean continuous prior, or mixing, distribution that belongs to a general distribution family including those that do not belong to the natural exponential family and/or are not conjugate to the Poisson. Within the adopted framework, both marginal mean parameters and the dispersion parameter are modeled jointly as parametric functions of explanatory variables.
In what follows, we provide a detailed discussion of our contributions, putting special emphasis on the suitability of the proposed family of models when dealing with MTPL claim count data in the bivariate setting, the maximum likelihood (ML) estimation procedure, and practical application aspects in the context of a posteriori ratemaking.
Firstly, as is well known, the aim of compulsory MTPL insurance is to provide coverage against the bodily injuries and property damage that may inflicted on third parties during a motor vehicle–related accident. As empirical evidence has shown, bodily injury claims are less frequent than property damage claims but have the biggest impact on the insurance company’s claim expenditure. For example, according to a recent report by Insurance Europe (Citation2019), even if in 2013 bodily injury claims only accounted for just under 14% of all MTPL claims recorded by European insurers, they represented 48.4% of all claims expenditure. Furthermore, on some occasions bodily injuries and property damage can be the result of the same accident because there are many factors in the MTPL insurance line that can simultaneously affect the joint dynamics of bodily injury and property damage claims. These are observable risk factors concerning the policyholders and their vehicles and differences among policyholders that cannot be observed by the actuary and give rise to positive correlation and overdispersion, which can be attributed to the excess of zeros and/or heavy upper tails (see Shared Citation1980) in MTPL bodily injury and property damage count data. It is natural to expect that the impact of such risks factors on the magnitude of the positive dependence between bodily injury and property damage claims could be different. For instance, this dependence might be stronger in urban regions and, in particular, in large cities than in small cities, and in the case of young drivers who are more likely to make more claims irrespective of the type. Also, as previous papers have concluded (see Bermúdez Citation2009; Bermúdez and Karlis Citation2017), even if the dependence between different claim types is not very strong, it must be taken into account in order to refine ratemaking. Additionally, in MTPL insurance the occurrence of bodily injury and property damage claims is strongly related to the unobserved heterogeneity, such as policyholders’ driving skills and habits and perception of the highway code, because both claim types are usually under the control of the driver. Therefore, in order to capture the influence of such factors to a good approximation, it is important to have all the necessary due diligence in place when constructing a bivariate claim frequency regression model for taking into account the relationship between MTPL bodily injury and property damage claims and a set of covariates when pricing the policies. Otherwise, a potential distribution misspecification can result in biased and unreliable parameter estimates, which, in turn may lead to inaccurate ratemaking that can result in nonnegligible financial implications for the company, because policyholders may switch to competing companies. The family of bivariate mixed Poisson regression models with varying dispersion we present in this article, can efficiently capture the complex features of two-dimensional MTPL data. In particular, our model class can accommodate overdispersion and account for positive dependencies between bivariate responses, which is what we expect from these data, in a very flexible manner because it permits for a variety of different distributional assumptions for the mixing density, which measures the level of unobservable risk associated with each policy and allows every parameter of the bivariate mixed Poisson model to be modeled in terms of important risk factors for both MTPL claim types, hence resulting in an improved risk evaluation. In order to emphasize the utility and generality of the proposed family of models, we focus on three of its members, namely, the bivariate negative binomial (BNB), bivariate Poisson–inverse Gaussian (BPIG), and bivariate Poisson–lognormal (BPLN) models with regression specifications on both their mean and dispersion parameters.
Secondly, it is worth noting that the development of ML estimation procedures for joint modeling of all the parameters of mixed Poisson distributions in terms of covariate information remains a largely uncharted territory even within the univariate regression analysis context in the majority of both statistical and actuarial applications. In particular, regarding the statistical setting, this approach has only been explored so far by Rigby and Stasinopoulos (Citation2005) and Barreto-Souza and Simas (Citation2016). Rigby and Stasinopoulos (Citation2005) proposed the generalized additive models for location, scale, and shape. The ML estimation of these regression-type models can be carried out using either the RS algorithm (see Rigby and Stasinopoulos Citation1996a, Citation1996b) or the CG algorithm (see Cole and Green Citation1992). Furthermore, Barreto-Souza and Simas (Citation2016) used the expectation-maximization (EM) algorithm for fitting a general family of mixed Poisson regression models with varying dispersion. In their application they focused on the estimation of the negative binomial (NB) and Poisson–inverse Gaussian (PIG) regression models with regression structures on both their mean and dispersion parameters. Regarding the actuarial setting, Tzougas and Karlis (Citation2020) implemented the EM algorithm for estimating the parameters of mixed exponential regression models with varying dispersion and Tzougas (Citation2020) employed the EM algorithm for ML estimation in the Poisson–inverse Gamma (PIGA) regression model with varying dispersion. However, using the ML estimation procedure for the case when all parameters of bivariate mixed Poisson distributions are allowed to vary through covariates has not yet been addressed in the statistical or actuarial literature. The reason for this is because the log-likelihood of the mixed Poisson model becomes more complicated in the two-dimensional setting and hence allowing for regressors on every parameter further increases the computational burden, especially for members of the mixed Poisson family that have complicated densities that either are expressed in terms of special functions or cannot be written in a tractable closed form such as, for instance, the BPIG and BPLN models. The main achievement of this article is that it demonstrates that ML estimation for our class of bivariate mixed Poisson regression models with varying dispersion can be accomplished via an efficient and easily implementable EM-type algorithm that exploits the latent structure that is implied by the mixture representation of the bivariate mixed Poisson model and thus it reduces the problem of maximizing its joint likelihood function to the problem of maximizing the likelihood function of its mixing distribution.
Thirdly, following the setup of Bermúdez and Karlis (Citation2017), the proposed class of mixed Poisson regression models with varying dispersion will be used within the Bayesian paradigm for deriving a posteriori ratemaking mechanisms, or bonus-malus systems. At this point we would like to call attention to the fact that, because the posterior claim frequency distribution is expressed in terms of both mean parameters and the dispersion parameter of the bivariate mixed Poisson model, using regressors on every parameter results in better risk-adjusted a posteriori, or bonus-malus, premiums. More important, because the motor insurance market is highly competitive, our family of models is well justified for use in practice, because it can enable the actuary to set fair and equitable premiums based on a sound risk measuring basis. These premiums tailor-made to the risk involved are calculated based on the expected value and variance principles,Footnote1 providing the company with useful alternative tariff structures.
Finally, it is important to note that when modelling different types of claims from different types of coverage, such as, for example, motor and home insurance bundled into a single policy, the mean, dispersion, and dependence components of a bivariate claim count model may be influenced by different individual and coverage-type risk characteristics. However, in the case of the bivariate mixed Poisson regression model with varying dispersion, the dispersion parameter can only be modeled using common covariates for both claim types. Moreover, in such cases, the dependence between the different claim count response variables may not necessarily be positive. Therefore, it is interesting to extend the proposed modeling framework by pairing a bivariate Normal copula with a dependence parameter that can vary through covariates with mixed Poisson regression models with varying dispersion. Under this general approach, in addition to the mean parameters, the dispersion and copula parameters of the model can vary through covariate information regarding different coverage types and the policyholders. For demonstration purposes, the bivariate Normal copula-based NB regression model with varying dispersion and dependence parameters is fitted on a simulated data set using ML estimation.
The remainder of this article proceeds as follows. In Section 2 we provide an in depth description of the proposed class of bivariate mixed Poisson regression models with varying dispersion. Also, we derive the joint probability mass function (jpmf) of the BNB, BPIG, and BPLN regression models with varying dispersion. Section 3 describes the ML estimation via the EM algorithm. Furthermore, we consider detailed EM algorithms for the BNB, BPIG, and BPLN regression models with varying dispersion. In Section 4 we calculate the a posteriori premiums using the expected value and variance principles. Section 5 presents the derivation of the bivariate Normal copula-based mixed Poisson regression model with varying dispersion and dependence parameters. In Section 6 the BNB, BPIG, and BPLN models are fitted on a real MTPL dataset. Also, the a posteriori premiums determined by these models are computed. Additionally, the bivariate Normal copula-based NB regression model with varying dispersion and dependence parameters is fitted on a simulated data set. Finally, concluding remarks are given in Section 7.
2. THE BIVARIATE MIXED POISSON REGRESSION MODEL WITH VARYING DISPERSION
The general class of bivariate mixed Poisson regression models with varying dispersion that we consider in this article can be described as follows.
Assume that the individual claim frequencies where i = 1 denotes the MTPL bodily injury claims and i = 2 denotes the MTPL property damage claims, arising from a policyholder j,
are independent per j and consider that given the random variables Zj > 0,
per claim type i = 1, 2, are distributed according to a Poisson distribution with probability mass function (pmf) given by
(1)
(1)
for
where
with mean and variance
and
Furthermore, suppose that Zj are random variables from a continuous and at least twice-differentiable mixing distribution with probability density function (pdf) where we assume that
because this ensures that the model is identifiable and where
is the dispersion parameter.
Therefore, considering the previous assumptions, we can easily see that the unconditional distribution of is a bivariate mixed Poisson distribution with joint probability mass function (jpmf) given by
(2)
(2)
To allow the two mean parameters and the dispersion parameter to be modeled in terms of explanatory variables with parametric linear functional forms we consider that
(3)
(3)
(4)
(4)
(5)
(5)
where
and
are vectors of covariates with dimensions
and
respectively, with
and
the corresponding parameter vectors and where it is assumed that the matrices
and
with rows given by
and
respectively, are of full rank.
Finally, the following properties associated with the proposed bivariate mixed Poisson regression model with varying dispersion ensure its flexibility in the context of MTPL insurance:
The marginal distribution of
for i = 1, 2, is the same mixed Poisson distribution as its bivariate counterpart. Also, the mean and the variance of
The covariance (Cov) between
The correlation (Corr) between
The generalized variance ratio (GVR) between a bivariate mixed Poisson model with varying dispersion––that is,
As it can be seen from EquationEquations (9)(9)
(9) and Equation(10)
(10)
(10) ,
and GVR > 1. Also, the GVR increases as the variance of the mixing distribution increases. Thus, as was previously mentioned, the bivariate mixed Poisson regression model allows for the positive correlation between the MTPL bodily injury and property damage claims and accommodates overdispersion.
In what follows, different bivariate mixed Poisson distributions with regression structures on every parameter are used to describe the behavior of the number of bodily injury and property damage claims as a function of the explanatory variables including the BNB, BPIG, and BPLN distributions.
2.1. BNB Regression Model with Varying Dispersion
Let Zj follow a Gamma distribution with a pdf
(11)
(11)
where
with mean and variance
(12)
(12)
and
(13)
(13)
for
Thus, based on EquationEquations (1)(1)
(1) and Equation(11)
(11)
(11) it is easy to see that the resulting distribution is the BNB distribution with jpmf
(14)
(14)
2.2. BPIG Regression Model with Varying Dispersion
Let Zj follow an Inverse Gaussian distribution with a pdf of the form
(15)
(15)
where
with mean and variance
(16)
(16)
and
(17)
(17)
for
Therefore, considering the assumptions in EquationEquations (1)(1)
(1) and Equation(15)
(15)
(15) it can be verified that the resulting distribution is the BPIG distribution with jpmf
(18)
(18)
where
and
denotes the modified Bessel function of the third kind of order ν and argument ω.
2.3. BPLN Regression Model with Varying Dispersion
Let Zj follow an Lognormal distribution with a pdf of the form
(19)
(19)
where
with mean and variance
(20)
(20)
and
(21)
(21)
for
Thus, based on EquationEquations (1)(1)
(1) and Equation(19)
(19)
(19) it is easy to see that the resulting distribution is the BPLN distribution with jpmf
(22)
(22)
which could not be written in closed form and hence numerical integration is required.
3. THE EM ALGORITHM
In this section we describe how the EM algorithm (see Dempster, Laird, and Rubin Citation1977; McLachlan and Krishnan Citation2007) can be employed for facilitating ML estimation of the parameters of the bivariate mixed Poisson regression model for marginal means and dispersion described in Section 2.
Let
be a sample of independent observations, where
and
are the response variables and
and
are the vectors of covariate information with dimensions
and
respectively. Also, suppose that the data are produced according to the bivariate mixed Poisson model. Then, the log-likelihood of the model can be written as
(23)
(23)
where
is the vector of the parameters and where
is the jpmf of the bivariate mixed Poisson model, which is given by EquationEquation (2)
(2)
(2) .
Direct maximization of EquationEquation (23)(23)
(23) with respect to the vector of parameters
is cumbersome because the log-likelihood of the bivariate mixed Poisson model is not usually tractable. Moreover, when both mean parameters and the dispersion parameter are modeled as functions of explanatory variables, this raises additional computational challenges.
Fortunately, ML estimation can be accomplished relatively easily via an EM-type algorithm that is specifically tailored to ML estimation for univariate and bivariate (and/or multivariate) mixed Poisson models (see, for instance, Karlis Citation2001, Citation2005; Ghitany et al. Citation2012; Barreto-Souza and Simas Citation2016; Tzougas Citation2020) because their stochastic mixture representation involving a nonobservable random variable, denoted by Zj herein, can be considered to produce missing data. In our case, by augmentation of the unobserved Zj one can write the complete log-likelihood as follows:
(24)
(24)
for i = 1, 2 and
where
is the pdf of the mixing distribution and where
and σj are given by EquationEquations (3)
(3)
(3) , Equation(4)
(4)
(4) and Equation(5)
(5)
(5) , respectively.
The E- and the M-steps of our EM-type algorithm procedure for the bivariate mixed Poisson regression model with varying dispersion are described below, including a few comments for each step.
E-Step:
The
M-Step:
Using the pseudo-values wj and
Firstly, differentiating the
for
Then, the iterative procedure for the Newton-Raphson algorithm for
Secondly, differentiating the
for
Then, the iterative procedure for the Newton-Raphson algorithm for
Thirdly, differentiating the
where for calculating
Then, the Newton-Raphson iterative algorithm for
Finally, iterate between the E- and the M-steps until some convergence criterion is satisfied; for example,
Note that when the regression specifications for both mean parameters and the dispersion parameter of the model are limited to the constants
In what follows, we describe in detail the E- and the M-steps of our EM-type algorithm for the BNB, BPIG, and BPLN regression models with varying dispersion.
3.1. BNB Regression Model with Varying Dispersion
In the case of the Gamma mixing distribution with pdf given by EquationEquation (11)(11)
(11) we have that the posterior distribution of
is a Gamma with parameters
and
for
Then, the EM algorithm is as follows:
E-Step:
Calculate for all
M-Step:
Update the regression parameters
Update the regression parameters
Then, we can obtain the updated estimates of
3.2. BPIG Regression Model with Varying Dispersion
In the case of the inverse Gaussian mixing distribution with pdf given by EquationEquation (15)(15)
(15) we have that the posterior distribution of
is a generalized inverse gaussian distribution with pdf
(40)
(40)
where
for
Then the EM algorithm is as follows:
E-Step:
Calculate for all
M-Step:
Update the regression parameters
Update the regression parameters
Then, we can obtain the updated estimates of
3.3. BPLN Regression Model with Varying Dispersion
The EM algorithm can also be employed to find the ML estimates of the BPLN model defined in EquationEquation (22)(22)
(22) . In this case, the complete data log-likelihood takes the form
(45)
(45)
for i = 1, 2 and
Thus, the expectations needed for the M-step are
and
Therefore, the algorithm can be written as follows:
E-Step:
Calculate for all
M-Step:
Update the regression parameters
Update the regression parameters
4. CALCULATION OF THE PREMIUMS ACCORDING TO THE EXPECTED VALUE AND VARIANCE PRINCIPLES
Consider the policyholder j, with number of bodily injury and property damage claims
and
respectively, for the year of coverage l, with
Also, assume that, for all the years that the individual j has been registered with the insurance company, their cumulative number of claims per type i = 1, 2 is given by
Then, employing Bayes’ theorem, we can easily compute the posterior distribution of
for the period t + 1 given the observations of the reported accidents in the preceding t periods and observable characteristics in the preceding t + 1 periods and the current period. In particular, the posterior distribution of
can be derived as follows:
(50)
(50)
where
is the bivariate Poisson distribution and where
is the pdf of the mixing distribution.
4.1. Expected Value Principle
The a posteriori, or bonus-malus, premiums calculated according to the expected value principle are given by
(51)
(51)
where
is a risk load and where the expectation in EquationEquation (51)
(51)
(51) is that of the posterior distribution given by EquationEquation (50)
(50)
(50) .
In the case of the BNB model, EquationEquation (50)
In the case of the BPIG model, EquationEquation (50)
In the case of the BPLN model, the posterior expectation in EquationEquation (51)
4.2. Variance Principle
The a posteriori, or bonus-malus, premiums calculated according to the variance principle are given by
(55)
(55)
where
is a risk load and where the expectation and the variance in EquationEquation (55)
(55)
(55) are those of the posterior distribution in EquationEquation (50)
(50)
(50) .
In the case of the BNB model, using the result in EquationEquation (52)
In the case of the BPIG model, using the result in EquationEquation (53)
In the case of the BPLN model, the posterior mean and the posterior variance in EquationEquation (55)
5. THE BIVARIATE NORMAL COPULA-BASED MIXED POISSON REGRESSION MODEL WITH VARYING DISPERSION AND DEPENDENCE PARAMETERS
This section describes the derivation of the bivariate Normal copula-based mixed Poisson regression model with varying dispersion and dependence parameters.
As is well known, a bivariate copula is a cumulative distribution function (cdf) with uniform marginals and θ is the copula parameter. A bivariate count distribution can be derived by pairing a continuous copula distribution with two discrete margins. The copula function can fully specify the dependence structure, which can be both positive and negative, separately from the marginals; see, for instance, Joe (Citation1997). Furthermore, a large number of different copula families have been proposed in the literature. For a detailed description of copulas, including inference procedures, one can refer to Denuit et al. (Citation2006). Additionally, regarding copula-based count regression modelsFootnote4 one can see, for instance, Lee (Citation1999), Cameron, Trivedi, and Zimmer (Citation2004), Nikoloulopoulos and Karlis (Citation2009, Citation2010), and Nikoloulopoulos (Citation2013a, Citation2013b, Citation2016).
Let and
be the vector of claim frequencies for two types of claims and its corresponding realizations, for
Also, consider that
per claim type i = 1, 2, is distributed according to a Poisson distribution with pmf given by EquationEquation (1)
(1)
(1) , where Zj is a continuous random variable with pdf
which is defined on
and has a unit mean and
Depending on the choice of
the unconditional distributions of
and
are mixed Poisson distributions with cdfs
and
Then, the bivariate distribution
is given by
Thus, using the finite differences of the copula representation of H (see, for example, Xue-Kun Song Citation2000), we obtain the jpmf
(59)
(59)
Here, the dependence among the mixed Poisson marginals is modeled by a Normal copula that, due to its mathematical tractability, has been widely used for modelling the dependence between different types of claims; see, for example, Shi and Valdez (Citation2014a). In particular, we consider that
(60)
(60)
where
is a standard Normal cdf,
is the inverse cdf of the standard Normal distribution, with
and where
for i = 1, 2 and
Under our general approach, the mean, dispersion, and dependence parameters are modeled in terms of explanatory variables as follows:
(61)
(61)
(62)
(62)
(63)
(63)
(64)
(64)
(65)
(65)
where
and
are vectors of covariates with dimensions
and
respectively, with
and
the corresponding parameter vectors. Also, the design matrices are denoted as
and
with
and
respectively, which we assume are of full rank.
6. NUMERICAL ILLUSTRATION
6.1. The MTPL Data
The study is based on a subset of claim frequency data that was randomly selected from a larger pool of MTPL insurance policies observed during the year 2017 from a major European insurance company. The MTPL insurance cover was activated when the policyholder was at fault for the cases of causing bodily injury of a person or inflicting damage on a property during the operation of the motor vehicle identified on the policy. We are interested in modeling the MTPL bodily injury and property damage claims with their associated claim counts, denoted by and
respectively, for
For each policy, the total number of claims for each type of claim were reported within this yearly period. A claim that was counted as bodily injury was not counted twice, namely, as property damage as well, and vice versa. In the sample we included only policyholders with complete records; that is, with availability of all the explanatory variables that affect both
and
Furthermore, an exploratory analysis was carried out in order to accurately select the subset of explanatory variables with the highest predictive power for both
and
There were n = 5186 observations and three explanatory variables that met our criteria.Footnote5 Additionally, in light of the heterogeneity that exists within the portfolio, we grouped the levels of each explanatory variable with respect to similar risk profiles with regard to the MTPL bodily injury and property damage claim frequencies. This is necessary because it will enable us to achieve ratemaking accuracy and balance homogeneity and sufficiency of the volume of data in each cell in order to provide credible patterns. summarizes the explanatory variables.
TABLE 1 The Explanatory Variables and Their Description
shows the effects of the explanatory variables on the claim counts and
based on all 5186 observations. The first column presents the categories for each explanatory variable and the second column shows how many of the 5186 policyholders in our sample belong to each category. In the remaining columns of the table we see, per category of each explanatory variable, the percentage of policies with claim frequencies equal to
for
and
respectively. For example, the following observations can be made from . Firstly, regarding the variable city population (v1) we see that out of the 2203 policyholders who live in a small city (C1), 92.81% have not made any bodily injury claims and 94.68% have not made any property damage claims. On the other hand, out of the 597 individuals who live in a large city (C3), only 92.34% and 93.46% are claim-free for bodily injury and property damage claims, respectively, meaning that living in a large city seems to be a risky characteristic. Secondly, as far as the variable number of years that the policyholder has been registered with the insurance company (v2) is concerned, it seems that the longer a policyholder has been with the company (C2), the riskier it gets. Finally, in the case of the variable horsepower of the car (v3), we can see that a more powerful car (C3) leads to more accidents, for both
and
TABLE 2 Summary Statistics for Claim Frequencies as Classified by the Explanatory Variables
In what follows, in order to motivate the BNB, BPIG, and BPLN regression models with varying dispersion, a marginal analysis for both response variables and
is carried out. Specifically, in we present some standard descriptive statistics for the claims
and
as well as the values of Kendall’s τ and Spearman’s ρ correlation coefficients. As expected, shows the existence of positive correlation between
and
as well as their marginal overdispersion, because the marginal variances exceed the respective means. Thus, the bivariate mixed Poisson model with varying overdispersion is a better choice than the Poisson model, because the latter is not equipped to handle overdispersion.
TABLE 3 Descriptive Statistics for the Two Responses
At this point it should be noted that, as is well known, the range of Kendall’s τ and Spearman’s ρ for discrete random variables is narrower than see Denuit and Lambert (Citation2005), Mesfioui and Tajar (Citation2005), and Mesfioui, Trufin, and Zuyderhoff (Citation2021). Also, Nikoloulopoulos and Karlis (Citation2010) and Safari-Katesari, Samadi, and Zaroudi (Citation2020) paired copulas with discrete marginal distributions to compute the population versions of Kendall’s τ and Spearman’s ρ. Here, as an example, we combined two marginal Poisson distributions with varying mean parameter μ from 1 up to 20 using the Normal copula and we assumed that the copula parameter θ can vary from -–1 to 1. We observed that for a value of μ greater than 10 the values of Kendall’s τ and Spearman’s ρ stabilize close to 1. Regarding the variability of the population versions of Kendall’s τ and Spearman’s ρ from lowest to highest attainable values when combining different marginal distributions using alternative copula functions, the interested reader can refer to all of the previous articles.
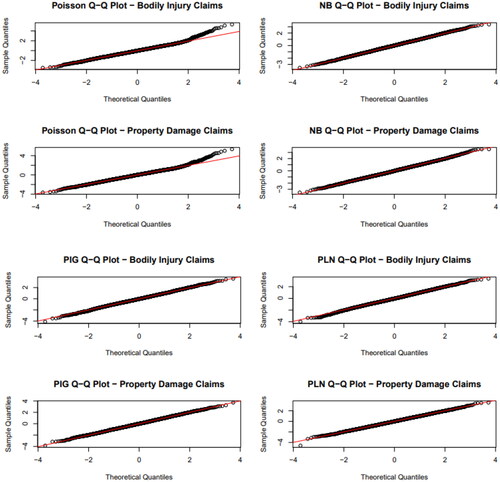
Finally, we fit the univariate NB, PIG, and PLN regression models with varying dispersion for claim frequencies using the univariate version of the EM algorithm presented in Section 2. Additionally, the simple Poisson regression model was fitted for comparison purposes. The normalized randomized quantile residuals (see Dunn and Smyth Citation1996) are used as a graphical tool to help us assess the adequacy of the fit of the competing models for both bodily injury and property damage claim counts and
For these discrete response distributions, the normalized randomized quantile residuals are defined as
where
is the inverse cdf of a standard Normal distribution and where uj is defined as a random value from the uniform distribution on the interval
where Fj is the cdf estimated for the jth individual and where
contains all estimated model parameters after the EM algorithm has reached the global maximum and χj is the corresponding observation. The normalized (random) quantiles for the Poisson, NB, PIG, and PLN models are presented in per claim type i = 1, 2. From , we observe that the NB, PIG, and PLN are better assumptions than the Poisson model, which does not capture the tails of the claim frequency distributions of
and
In particular, the residuals of the three mixed Poisson models are close to the diagonal and indicate a good fit to the distributions of both
and
whereas the sample quantiles of the Poisson model, due to the equidispersion constraint, near the tail end of the distributions of both
and
are significantly higher than the theoretical quantiles.
Figure 1. Normalized Quantiles for the Poisson, NB, PIG, and PLN Regression Models with Varying Dispersion.
6.2. Modeling Results
This subsection describes the modeling results of the BNB, BPIG, and BPLN distributions and regression models with varying dispersion.
The ML estimates of their parameters and the corresponding standard errors in parentheses are presented in for the distributionsFootnote6 and in for the regression models with varying dispersion. Note that in the latter case, for illustrative purposes we considered that the two location parameters and the dispersion parameter
of the aforementioned models are modeled using all three available explanatory variables. However, it should be noted that for larger datasets variable selection can start with the examination of the two mean parameters of the bivariate mixed Poisson regression model with varying dispersion. This can be achieved by adding all available covariates and testing whether the exclusion of each one lowers the global deviance (DEV), Akaike information criterion (AIC), and Schwartz Bayesian criterion (SBC) values. Then, after having selected the best predictors for the two mean parameters, we can continue in determining the remaining predictors by testing which rating variable between those used in the two mean parameters would lead to a further decrease of the DEV, AIC, and SBC values when inserted in the dispersion parameter of the bivariate claim frequency model with varying dispersion. Additionally, if between the same bivariate mixed Poisson distribution with different parameter specifications several models have similar DEV, AIC, and SBC values, the simpler model can be used in order to avoid overfitting. Therefore, in such cases, it should be expected that the dispersion parameters of the bivariate mixed Poisson regression model with varying dispersion may have fewer predictors than the two mean parameters.
TABLE 4 Parameters Estimates and Associated Standard Errors of the Fitted BNB, BPIG, and BPLN Distributions
TABLE 5 Parameters Estimates and Associated Standard Errors of the Fitted BNB, BPIG, and BPLN Regression Models with Varying Dispersion for Each Covariate
As we can see from , the values of the estimated regression coefficients of the variables v1, v2, and v3 are almost identical for and
across all three bivariate mixed Poisson distributions, whereas they differ hugely for the dispersion parameter σj. Additionally, we observe that the same explanatory variables always have the same effect (positive and/or negative) on the parameter σj in the case of the BNB and BPIG models but have a different effect for σj in the case of the BPLN model.
6.3. Model Comparison
In this subsection we compare the fit of the BNB, BPIG, and BPLN distributions/regression models with varying dispersion based on the classic hypothesis/specification tests DEV, AIC, and SBC. The DEV is given by
(66)
(66)
with
being the maximum of the log-likelihood and
the vector of estimated parameters of the model. Moreover, the AIC is defined as
(67)
(67)
and the SBC is given by
(68)
(68)
where df are the degrees of freedom that correspond to the number of fitted parameters in the model and n is the number of observations in the sample. The values of the DEV, AIC, and SBC for the competing bivariate mixed Poisson distributions/regression models with varying dispersion are given in . According to a very well-known rule of thumb, two models can be considered to be significantly different if the difference in the log-likelihoods exceeds 5, corresponding to a difference in their respective AIC and SBC values of greater than 10 and 5 respectively; see Anderson and Burnham (Citation2004) and Raftery (Citation1995). Therefore, in this case we see that the best fitting performances are provided by the BPIG distribution/regression model with varying dispersion.
TABLE 6 Models Comparison Based on Global Deviance, AIC, and SBC
6.4. Application to Ratemaking
In this subsection, following the current methodology, as presented in Section 4, we calculate the a posteriori, or bonus-malus, premiums resulting from the three BNB, BPIG, and BPLN distributions/regression models with varying dispersion using the expected value and the variance principles. The premium rates will be divided by the premium when ––that is, we calculate the relative premiums––because we are interested in the differences between various classes and the results are presented so that the premium for a new policyholder is 100. Thus, in what follows, when the expected value principle is used, note the disappearance of the factor
from EquationEquations (52)
(52)
(52) , Equation(53)
(53)
(53) , and Equation(54)
(54)
(54) . Also, when the variance principle is used, following, and extending to the bivariate case the framework of Lemaire (Citation1995) and Tzougas et al. (Citation2018), we consider that
in EquationEquations (56)
(56)
(56) , Equation(57)
(57)
(57) , and Equation(58)
(58)
(58) , which corresponds to a safety loading of 25% of the net premium.
Firstly, assuming that the number of individual bodily injury and property damage claims, and
respectively, with
ranges from 0 to 3 and the age of the policy is t = 1, t = 2, and t = 3 years, we computed comparable relative premiums for the three bivariate mixed Poisson distributions. and present the premium rates calculated according to the expected value and variance principles, respectively.
TABLE 7 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for Bivariate Claim Frequency Distributions under the Expected Value Principle
TABLE 8 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for Bivariate Claim Frequency Distributions under the Variance Principle
Secondly, when both the a posteriori and the a priori criteria––that is the characteristics of the policyholders and their cars––are considered, we analyze three risk class profiles that we classify as best, average, and worst according to the values of the mean claim frequencies and
which are calculated using the same set of explanatory variables per claim type i = 1, 2 in the case of the BNB, BPIG, and BPLN models, respectively. More specifically, for our data, we characterize the best, average, and worst profiles as such based on category C1 for all three explanatory variables v1, v2, and v3 in the case of the first; category C2 for v1, v2, and v3 in the case of the second; and category C3 for v1 and v3 and C2 for v2 in the case of the third. Also, the dispersion parameter
of the BNB, BPIG, and BPLN models is computed for each risk class profile. The results are shown in .
Table 9 Results of the Fitted BNB, BPIG, and BPLN Regression Models with Varying Dispersion for Each Risk Class Profile
From we observe that for all three risk profiles small differences lie in the mean values and
of the BNB, BPG, and BPLN models. On the contrary, as previously mentioned, more significant differences are noticed across the three risk profiles in the values of the dispersion parameters σj of the bivariate mixed Poisson models. Due to these discrepancies, the a posteriori, or bonus-malus, premium rates that will result from the three models by updating their posterior mean and the posterior variance will be better distinguished under different distributional assumptions. Thus, as was previously mentioned, the proposed modeling framework leads to a better tariffication than the assumption of a constant dispersion σj.
In what follows, depict the premiums computed under the expected value principle for the three risk profiles during the years t = 1, t = 2, and t = 3 respectively. Furthermore, present the premiums calculated via the variance principle for the same risk profiles and years of insurance policy.
TABLE 10 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 1 under the Expected Value Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
TABLE 11 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 2 under the Expected Value Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
TABLE 12 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 3 under the Expected Value Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
TABLE 13 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 1 under the Variance Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
TABLE 14 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 2 under the Variance Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
TABLE 15 Comparison of the A Posteriori, or Bonus–Malus, Premium Rates for t = 3 under the Variance Principle, Bivariate Claim Frequency Regression Models with Varying Dispersion
We make the following observations regarding the results presented in .
Firstly, we see that if the policyholder j has a claim-free year, the premium rates reduce, whereas if they have one or more claims, the premium rates increase, resulting in bonus or malus, respectively.
For example, for the case when the expected value principle is used, we observe from that a claim-free year for both types of claims i = 1, 2 the policyholder will receive bonuses of 27.31%, 20.20% and 18.53% in year
Similarly, for the case when the variance principle is used, we observe from that a claim-free individual for both types of claims i = 1, 2 insured will receive a bonus of 60.78%, 49.11%, and 46.06% in year t = 3 in the case of the BNB, BPIG, and BPLN distributions, respectively. Also, individuals who had
Secondly, regarding the premiums resulting from the same bivariate mixed Poisson distribution/regression model with varying dispersions, we see that
For the cases without and with covariates, the use of the variance principle results in higher bonuses for claim-free policyholders than those that are awarded to them using the expected value principle.
For the case with covariates, as we can see from , the proposed modeling framework encourages good driving behavior in two ways:
The bonuses that are awarded to claim-free policyholders with higher risk profiles are slightly higher than those that are awarded to claim-free insureds with lower risk profiles.
The maluses that should be paid by policyholders who had at least one bodily injury and/or property damage claim are slightly lower if they have a higher risk profile.
Finally, it is worth noting that provide a more complete picture to the insurance company than and of when only the a posteriori criteria were considered, because all of the important a priori and a posteriori information for the number of bodily injury and property damage claims,
6.5. The Simulated Data
In this subsection, we demonstrate the flexibility of the copula-based model discussed in Section 5 for taking into account the effect of policyholder and coverage type covariates on the mean, dispersion, and dependence components.
For illustrative purposes, the Normal copula will be paired with two NB Type I (NBI), or Poisson–Gamma, distributions.Footnote7 Then, the jpmf of the Normal copula-based NB regression model with varying dispersion and dependence can be obtained using EquationEquation (59)(59)
(59) .
A dataset of size n = 20,000 was randomly generated from the bivariate normal copula with two univariate NBI regression models with varying dispersion and we assumed that the two response variables and
represent claim frequencies for two types of claims, Type I and Type II, from different types of coverage. Furthermore, we considered that the explanatory variables v1–v5 influence the mean, dispersion, and copula parameters. In particular, we assumed that v1 is continuous and it can take integer values between 18 and 75 and v2–v5 are discrete, with v2, v4, and v5 having two categories each and v3 having three categories. Furthermore, we included v1, v2, v3, and v4 in EquationEquations (61)
(61)
(61) and Equation(63)
(63)
(63) to explain the mean and dispersion of Type I claims and v1, v2, v3, and v5 in EquationEquations (62)
(62)
(62) and Equation(64)
(64)
(64) to explain the mean and dispersion of Type II claims. Finally, we selected the common variables v1–v3 in EquationEquation (65)
(65)
(65) to explain the dependence heterogeneity between two coverages.
The bivariate Normal copula-based NB regression model with varying dispersion and dependence is fitted on these data and the resultsFootnote8 are presented in .
TABLE 16 Normal Copula-Based NB Regression Model with Varying Dispersion and Dependence
6.6. Computational Aspects
This subsection discusses the computational issues related to the implementation of the EM algorithm for the BNB, BPIG, and BPLN regression models with varying dispersion and the standard ML estimation method used for the Normal copula-based NB regression model with varying dispersion and dependence. All computing was done using the programming language R (R Core Team Citation2021).
Regarding the EM estimation procedure for the BNB, BPIG, and BPLN regression models, it should be noted that a rather strict criterion was used and it took the algorithm, for cases both with and without covariate information, a quite large number of iterations to converge. In particular, the stopping criterion was set as The standard errors of the BNB, BPIG, and BPLN regression models with varying dispersion were obtained using the standard approach of Louis (Citation1982) for the standard errors for the EM algorithm.
We also call attention to the fact that, because the M-step involves three Newton-Raphson iterations, the choice of meaningful initial values for the vectors of regression coefficients and
of all three bivariate mixed Poisson models is important, because it can influence the speed of convergence of the algorithm and its ability to locate the global maximum. Good starting values for the regression parameters
and
were obtained by fitting two simple Poisson regressions. Alternatively, the initial values can be obtained based on the data as follows: (i) calculate
with i = 1, 2 and
for the 18 different risk classes, which can be formed by dividing the portfolio into clusters defined by the combinations of the available explanatory variables in and (ii) assuming a log-link functions for
(see Equations [3] and [4]), solve EquationEquation (6)
(6)
(6) with respect to
and
in the case i = 1 and i = 2, respectively, because, under the parameterization we adopted, the marginal means are explicit parameters of the bivariate mixed Poisson models with varying dispersion. Furthermore, meaningful initial values for the regression parameters
were obtained by (i) calculating
for the 18 different risk classes based on all observations
(ii) calculating
with i = 1, 2 for the 18 different risk classes (or, alternatively, calculating
for i = 1, 2, based on the initial values for
and
and on the log-link functions given by Eqs. [3] and [4]), (iii) solving EquationEquation (9)
(9)
(9) with respect to
and subsequently (iv) solving the EquationEquations (13)
(13)
(13) , Equation(17)
(17)
(17) , and Equation(21)
(21)
(21) with respect to σj and using the log-link function for σj (see Eq. [5]) in the case of the BNB, BPIG, and BPLN models, respectively.
The computational time requirements of the BPLN distribution/regression model with varying dispersion, which has a jpmf that cannot be written in closed form, were compared to those of the BNB and BPIG distributions/regression models with varying dispersion. As anticipated, the BNB and BPIG distributions/regression models with varying dispersion compared favorably to the BPLN distribution/regression model with varying dispersion in terms of computing times required for ML estimation, because the numerical evaluation of the integrals at the E-step is chronologically demanding in the case of the BPLN distribution/regression model with varying dispersion.
As far as the ML estimation of the parameters of the Normal copula-based NB regression model with varying dispersion and dependence is concerned, the log-likelihood to be maximized is given by
(69)
(69)
where
is the vector of the parameters and where h is the jpmf of the bivariate mixed Poisson model, which is given by EquationEquation (59)
(59)
(59) .
Minimization methods, such as the Nelder-Mead algorithm, can be used for estimating the parameters of the model. These methods require the negative of the log-likelihood, which is given in EquationEquation (69)(69)
(69) , and the standard errors of the parameters are computed numerically using the Hessian matrix, which is updated in each iteration. Finally, good initial values can be provided by fitting the univariate NB regression models with varying dispersion on the number claims for each claim type via a univariate version of the EM algorithm described in Subsection 2.1 and using the method of inference functions for margins (see Joe Citation1997, Citation2005).
7. CONCLUDING REMARKS
In this article we introduced a general class of bivariate mixed Poisson regression models with varying dispersion that can efficiently capture overdispersion and accurately account for the strength of the positive correlation between MTPL bodily injury and property damage claims by offering full flexibility in the choice of marginals and by utilizing all available information from important risk factors through regression specifications for both mean parameters and the dispersion parameter of the models.
Our main contribution is that we developed an EM-type algorithm that can reduce the computational burden for ML estimation for our family models, the majority of which have cumbersome densities. In order to illustrate the versatility of the EM estimation scheme we presented, we fitted three members of this family, the BNB, BPIG, and BPLN regression models with varying dispersion, on two-dimensional MTPL data from a European insurance company. Also, reliable estimates of the standard errors of the parameters of these models were obtained through expressions that were directly produced by the EM algorithm for the observed information matrix of each model.
Furthermore, from a practical business point of view, the proposed family of models combined with the adopted modeling framework can provide insurance companies with a useful tool for pricing motor insurance contracts when the dynamics for premium determination are governed by the interactions of the different types of MTPL claims. In our real data application, the bonus-malus premiums resulting from the BNB, BPIG, and BPLN models were computed via the expected value and variance principles, providing alternative options to the insurer when deciding on their ratemaking strategies. Additionally, it is worth noting that this family of models is suitable for applications not only for bivariate MTPL insurance ratemaking purposes but also in various multivariate domains, because these models can be easily generalized to any vector size response variable, thus providing a very flexible way of modeling overdispersed high-dimensional count valued data that contain variables that exhibit complex positive dependencies. An interesting future research direction would be to tackle bonus-malus ratemaking based on generalizations of the proposed family of models, such as, for example, by adding different random effects for modeling the unobserved heterogeneity when dealing with different types of claims from different types of coverage (see Bermúdez and Karlis Citation2017) or, for instance, by including time series components to take into account both cross-dependence between different types of claims and time dependence; see Bermúdez, Guillén, and Karlis (Citation2018).
Also, we presented a generalization of the previous setup by considering a Normal copula-based mixed Poisson regression model for dispersion and dependence parameters that is ideally suited for modeling count data that contain claims from different types of coverage, because it allows us to take into account the effect of policyholder and coverage type covariates on the mean, dispersion, and copula parameters. We exemplified our approach by fitting the Normal copula-based NB regression model with varying dispersion and dependence on a simulated dataset using ML estimation. Finally, it is worth noting that an alternative approach for modeling two different types of claims from different types of coverage would be to take into account the policyholder and coverage-type effects through the dependence structure between the random effects in the mixed Poisson margins that are assumed to follow continuous mixing densities. This dependence can be introduced by means of a Normal copula proceeding along similar lines as in Pechon, Trufin, and Denuit (Citation2018). This approach will be explored in a forthcoming paper for the case when regression specifications are allowed on the mean, dispersion, and dependence parameters.
Discussions on this article can be submitted until July 1, 2022. The authors reserve the right to reply to any discussion. Please see the Instructions for Authors found online at http://www.tandfonline.com/uaaj for submission instructions.
ACKNOWLEDGMENTS
The authors thank the handling editor and the two anonymous referees for their very helpful comments and suggestions that have significantly improved this article.
Notes
1 Note that Lemaire (Citation1995), Heilmann (Citation1989), Gómez-Déniz, Vázquez Polo, and Bastida (Citation2000), and Gómez-Déniz et al. (Citation2002) used the variance principle for deriving bonus-malus systems in the univariate context based only on the a posteriori criteria, whereas Tzougas, Vrontos, and Frangos (Citation2018) proposed its use for developing such sytems based on both the a priori and the a posteriori criteria. The variance is an important risk measure and the difference in the bonus-malus premiums that it implies can act as a cushion against adverse experience. However, the use of the variance principle for computing bonus-malus premiums in a way that takes into consideration the positive correlation between MTPL bodily injury and property damage claims has not yet been proposed and thus this work expands on this setup as well.
2 Note that, as it will be demonstrated in what follows, if is a linear function, then the conditional posterior expectations can be computed in an easy and accurate way. However, for more complicated functions, for which an exact solution is not available, one can use Taylor approximations, or numerical approximations, including numerical integration, and/or simulation based approximations.
3 Note also that this procedure can be used for every continuous and at least twice-differentiable mixing distribution; that is, similar to those we consider in this work. Therefore, we provide a complete estimation tool for our class of bivariate mixed Poisson regression models with varying dispersion. However, for some other mixing distributions, a special iterative scheme or another EM algorithm inside the M-step may be more appropriate.
4 It is worth noting that regression specifications for the dispersion parameters of the discrete marginal distributions have not been used in the literature so far.
5 Note that it would be interesting to fit the same models to larger data sets with more available features that could simultaneously affect and
such as age of driver, age of the car, and driving zone, which have been traditionally used in MTPL insurance.
6 Note that the mean parameters of the BNB, BPIG, and BPLN distributions are denoted by μ1 and μ2 and the dispersion parameter is denoted by σ.
7 Note that the Gamma mixing density that is used to derive the NBI has a different parameterization than the Gamma distribution given in Equation (12). For more details about the use of the NBI distribution in an actuarial context, see, for instance, Tzougas, Vrontos, and Frangos (Citation2018).
8 Note that all the parameters of the model are statistically significant at a 5% threshold.
References
- Abdallah, A., J.-P. Boucher, and H. Cossette. 2016. Sarmanov family of multivariate distributions for bivariate dynamic claim counts model. Insurance: Mathematics and Economics 68:120–33. doi:10.1016/j.insmatheco.2016.01.003
- Aguero-Valverde, J., and P. P. Jovanis. 2009. Bayesian multivariate Poisson Lognormal models for crash severity modeling and site ranking. Transportation Research Record 2136 (1):82–91. doi:10.3141/2136-10
- Alfò, M., and G. Trovato. 2004. Semiparametric mixture models for multivariate count data, with application. The Econometrics Journal 7 (2):426–54. doi:10.1111/j.1368-423X.2004.00138.x
- Anderson, D., and K. Burnham. 2004. Model selection and multi-model inference. 2nd ed. New York: Springer.
- Barreto-Souza, W., and A. B. Simas. 2016. General mixed Poisson regression models with varying dispersion. Statistics and Computing 26 (6):1263–280. doi:10.1007/s11222-015-9601-6
- Bermúdez, L. (2009). A priori ratemaking using bivariate Poisson regression models. Insurance: Mathematics and Economics 44 (1):135–41.
- Bermúdez, L., M. Guillén, and D. Karlis. 2018. Allowing for time and cross dependence assumptions between claim counts in ratemaking models. Insurance: Mathematics and Economics 83:161–69. doi:10.1016/j.insmatheco.2018.06.003
- Bermúdez, L., and D. Karlis. 2011. Bayesian multivariate Poisson models for insurance ratemaking. Insurance: Mathematics and Economics 48 (2):226–36. doi:10.1016/j.insmatheco.2010.11.001
- Bermúdez, L., and D. Karlis. 2012. A finite mixture of bivariate Poisson regression models with an application to insurance ratemaking. Computational Statistics & Data Analysis 56 (12):3988–999. doi:10.1016/j.csda.2012.05.016
- Bermúdez, L., and D. Karlis. 2017. A posteriori ratemaking using bivariate Poisson models. Scandinavian Actuarial Journal 2017 (2):148–58. doi:10.1080/03461238.2015.1094403
- Abdallah, A., J.-P. Boucher, and H. Cossette. 2016. Sarmanov family of multivariate distributions for bivariate dynamic claim counts model. Insurance: Mathematics and Economics 68:120–33. doi:10.1016/j.insmatheco.2016.01.003
- Aguero-Valverde, J., and P. P. Jovanis. 2009. Bayesian multivariate Poisson Lognormal models for crash severity modeling and site ranking. Transportation Research Record 2136 (1):82–91. doi:10.3141/2136-10
- Alfò, M., and G. Trovato. 2004. Semiparametric mixture models for multivariate count data, with application. The Econometrics Journal 7 (2):426–54. doi:10.1111/j.1368-423X.2004.00138.x
- Anderson, D., and K. Burnham. 2004. Model selection and multi-model inference. 2nd ed. New York: Springer.
- Barreto-Souza, W., and A. B. Simas. 2016. General mixed Poisson regression models with varying dispersion. Statistics and Computing 26 (6):1263–280. doi:10.1007/s11222-015-9601-6
- Bermúdez, L. (2009). A priori ratemaking using bivariate Poisson regression models. Insurance: Mathematics and Economics 44 (1):135–41.
- Bermúdez, L., M. Guillén, and D. Karlis. 2018. Allowing for time and cross dependence assumptions between claim counts in ratemaking models. Insurance: Mathematics and Economics 83:161–69. doi:10.1016/j.insmatheco.2018.06.003
- Bermúdez, L., and D. Karlis. 2011. Bayesian multivariate Poisson models for insurance ratemaking. Insurance: Mathematics and Economics 48 (2):226–36. doi:10.1016/j.insmatheco.2010.11.001
- Bermúdez, L., and D. Karlis. 2012. A finite mixture of bivariate Poisson regression models with an application to insurance ratemaking. Computational Statistics & Data Analysis 56 (12):3988–999. doi:10.1016/j.csda.2012.05.016
- Bermúdez, L., and D. Karlis. 2017. A posteriori ratemaking using bivariate Poisson models. Scandinavian Actuarial Journal 2017 (2):148–58. doi:10.1080/03461238.2015.1094403
- Bolancé, C., M. Guillen, and A. Pitarque. 2020. A Sarmanov distribution with beta marginals: An application to motor insurance pricing. Mathematics 8 (11):49–59. doi:10.3390/math8112020
- Bolancé, C., and R. Vernic. 2019. Multivariate count data generalized linear models: Three approaches based on the Sarmanov distribution. Insurance: Mathematics and Economics 85:89–103. doi:10.1016/j.insmatheco.2019.01.001
- Booth, J. G., and J. P. Hobert. 1999. Maximizing generalized linear mixed model likelihoods with an automated Monte Carlo EM algorithm. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 61 (1):265–85. doi:10.1111/1467-9868.00176
- Booth, J. G., J. P. Hobert, and W. Jank. 2001. A survey of Monte Carlo algorithms for maximizing the likelihood of a two-stage hierarchical model. Statistical Modelling 1 (4):333–49. doi:10.1177/1471082X0100100407
- Cameron, A. C., T. Li, P. K. Trivedi, and D. M. Zimmer. 2004. Modelling the differences in counted outcomes using bivariate copula models with application to mismeasured counts. The Econometrics Journal 7 (2):566–84. doi:10.1111/j.1368-423X.2004.00144.x
- Cameron, A. C., and P. K. Trivedi. 2013. Regression analysis of count data. Vol. 53. New York, NY: Cambridge University Press.
- Chib, S., and R. Winkelmann. 2001. Markov chain Monte Carlo analysis of correlated count data. Journal of Business & Economic Statistics 19 (4):428–35. doi:10.1198/07350010152596673
- Cole, T. J., and P. J. Green. 1992. Smoothing reference centile curves: The LMS method and penalized likelihood. Statistics in Medicine 11 (10):1305–319. doi:10.1002/sim.4780111005
- Dempster, A. P., N. M. Laird, and D. B. Rubin. 1977. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological) 39 (1):1–22.
- Denuit, M., J. Dhaene, M. Goovaerts, and R. Kaas. 2006. Actuarial theory for dependent risks: Measures, orders and models. West Sussex, England: John Wiley & Sons.
- Denuit, M., M. Guillen, and J. Trufin. 2019. Multivariate credibility modelling for usage-based motor insurance pricing with behavioural data. Annals of Actuarial Science 13 (2):378–99. doi:10.1017/S1748499518000349
- Denuit, M., and P. Lambert. 2005. Constraints on concordance measures in bivariate discrete data. Journal of Multivariate Analysis 93 (1):40–57. doi:10.1016/j.jmva.2004.01.004
- Dunn, P. K., and G. K. Smyth. 1996. Randomized quantile residuals. Journal of Computational and Graphical Statistics 5 (3):236–44.
- El-Basyouny, K., and T. Sayed. 2009. Collision prediction models using multivariate Poisson–Lognormal regression. Accident Analysis & Prevention 41 (4):820–28. doi:10.1016/j.aap.2009.04.005
- Famoye, F. 2010. A new bivariate generalized Poisson distribution. Statistica Neerlandica 64 (1):112–24. doi:10.1111/j.1467-9574.2009.00446.x
- Famoye, F. 2012. Comparisons of some bivariate regression models. Journal of Statistical Computation and Simulation 82 (7):937–49. doi:10.1080/00949655.2010.543679
- Fung, T. C., A. L. Badescu, and X. S. Lin. 2019a. A class of mixture of experts models for general insurance: Application to correlated claim frequencies. ASTIN Bulletin 49 (3):647–88. doi:10.1017/asb.2019.25
- Fung, T. C., A. L. Badescu, and X. S. Lin. 2019b. A class of mixture of experts models for general insurance: Theoretical developments. Insurance: Mathematics and Economics 89:111–27. doi:10.1016/j.insmatheco.2019.09.007
- Ghitany, M., D. Karlis, D. Al-Mutairi, and F. Al-Awadhi. 2012. An EM algorithm for multivariate mixed Poisson regression models and its application. Applied Mathematical Sciences 6 (137):6843–856.
- Gómez-Déniz, E., A. Hernández, J. M. Pérez, and F. J. Vázquez-Polo. 2002. Measuring sensitivity in a bonus-malus system. Insurance: Mathematics and Economics 31 (1):105–13.
- Gómez-Déniz, E., F. J. Vázquez Polo, and A. H. Bastida. 2000. Robust Bayesian premium principles in actuarial science. Journal of the Royal Statistical Society: Series D (The Statistician) 49 (2):241–52. doi:10.1111/1467-9884.00234
- Gurmu, S., and J. Elder. 2000. Generalized bivariate count data regression models. Economics Letters 68 (1):31–36. doi:10.1016/S0165-1765(00)00225-1
- Heilmann, W.-R. 1989. Decision theoretic foundations of credibility theory. Insurance: Mathematics and Economics 8 (1):77–95. doi:10.1016/0167-6687(89)90050-4
- Ho, L. L., and J. d. M. Singer. 2001. Generalized least squares methods for bivariate Poisson regression. Communications in Statistics - Theory and Methods 30 (2):263–77. doi:10.1081/STA-100002030
- Insurance Europe. 2019. European Motor Insurance Markets 2019. Accessed February 8, 2019. https://www.insuranceeurope.eu/european-motor-insurance-markets-2019.
- Joe, H. 1997. Multivariate models and multivariate dependence concepts. New York: CRC Press.
- Joe, H. 2005. Asymptotic efficiency of the two-stage estimation method for copula-based models. Journal of Multivariate Analysis 94 (2):401–19. doi:10.1016/j.jmva.2004.06.003
- Jung, R. C., and R. Winkelmann. 1993. Two aspects of labor mobility: A bivariate Poisson regression approach. Empirical Economics 18 (3):543–56. doi:10.1007/BF01176203
- Karlis, D. 2001. A general EM approach for maximum likelihood estimation in mixed Poisson regression models. Statistical Modelling 1 (4):305–18. doi:10.1177/1471082X0100100405
- Karlis, D. 2005. EM algorithm for mixed Poisson and other discrete distributions. ASTIN Bulletin 35 (1):3–24. doi:10.1017/S0515036100014033
- Karlis, D., and L. Meligkotsidou. 2005. Multivariate Poisson regression with covariance structure. Statistics and Computing 15 (4):255–65. doi:10.1007/s11222-005-4069-4
- Kocherlakota, S., and K. Kocherlakota. 2001. Regression in the bivariate Poisson distribution. Communications in Statistics - Theory and Methods 30 (5):815–25. doi:10.1081/STA-100002259
- Lee, A. 1999. Applications: Modelling rugby league data via bivariate negative binomial regression. Australian & New Zealand Journal of Statistics 41 (2):141–52. doi:10.1111/1467-842X.00070
- Lemaire, J. 1995. Bonus-malus systems in automobile insurance. New York: Kluwer Academic.
- Louis, T. A. 1982. Finding the observed information matrix when using the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological) 44 (2):226–33.
- Ma, J., K. M. Kockelman, and P. Damien. 2008. A multivariate Poisson–Lognormal regression model for prediction of crash counts by severity, using Bayesian methods. Accident Analysis & Prevention 40 (3):964–75. doi:10.1016/j.aap.2007.11.002
- McLachlan, G. J., and T. Krishnan. 2007. The EM algorithm and extensions. Vol. 382. Hoboken, NJ: John Wiley & Sons.
- Mesfioui, M., and A. Tajar. 2005. On the properties of some nonparametric concordance measures in the discrete case. Nonparametric Statistics 17 (5):541–54. doi:10.1080/10485250500038967
- Mesfioui, M., J. Trufin, and P. Zuyderhoff. 2021. Bounds on Spearman’s rho when at least one random variable is discrete. European Actuarial Journal 12:1–28. doi:10.1007/s13385-021-00289-8
- Munkin, M. K., and P. K. Trivedi. 1999. Simulated maximum likelihood estimation of multivariate mixed-Poisson regression models, with application. The Econometrics Journal 2 (1):29–48. doi:10.1111/1368-423X.00019
- Nikoloulopoulos, A. K. 2013a. Copula-based models for multivariate discrete response data. In Copulae in mathematical and quantitative finance, 231–49. Berlin, Heidelberg: Springer.
- Nikoloulopoulos, A. K. 2013b. On the estimation of Normal copula discrete regression models using the continuous extension and simulated likelihood. Journal of Statistical Planning and Inference 143 (11):1923–937. doi:10.1016/j.jspi.2013.06.015
- Nikoloulopoulos, A. K. 2016. Efficient estimation of high-dimensional multivariate normal copula models with discrete spatial responses. Stochastic Environmental Research and Risk Assessment 30 (2):493–505. doi:10.1007/s00477-015-1060-2
- Nikoloulopoulos, A. K., and D. Karlis. 2009. Modeling multivariate count data using copulas. Communications in Statistics - Simulation and Computation 39 (1):172–87. doi:10.1080/03610910903391262
- Nikoloulopoulos, A. K., and D. Karlis. 2010. Regression in a copula model for bivariate count data. Journal of Applied Statistics 37 (9):1555–568. doi:10.1080/02664760903093591
- Park, E. S., and D. Lord. 2007. Multivariate Poisson–Lognormal models for jointly modeling crash frequency by severity. Transportation Research Record 2019 (1):1–6. doi:10.3141/2019-01
- Pechon, F., M. Denuit, and J. Trufin. 2019. Multivariate modelling of multiple guarantees in motor insurance of a household. European Actuarial Journal 9 (2):575–602. doi:10.1007/s13385-019-00201-5
- Pechon, F., M. Denuit, and J. Trufin. 2021. Home and motor insurance joined at a household level using multivariate credibility. Annals of Actuarial Science 15 (1):82–114. doi:10.1017/S1748499520000160
- Pechon, F., J. Trufin, and M. Denuit. 2018. Multivariate modelling of household claim frequencies in motor third-party liability insurance. ASTIN Bulletin 48 (3):969–93. doi:10.1017/asb.2018.21
- R Core Team. (2021). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
- Raftery, A. E. 1995. Bayesian model selection in social research. Sociological Methodology 25:111–63. doi:10.2307/271063
- Rigby, R. A., and M. D. Stasinopoulos. 1996a. Mean and dispersion additive models. In Statistical theory and computational aspects of smoothing, 215–230. Heidelberg: Physica-Verlag.
- Rigby, R. A., and D. Stasinopoulos. 1996b. A semi-parametric additive model for variance heterogeneity. Statistics and Computing 6 (1):57–65. doi:10.1007/BF00161574
- Rigby, R. A., and D. M. Stasinopoulos. 2005. Generalized additive models for location, scale and shape. Journal of the Royal Statistical Society: Series C (Applied Statistics) 54 (3):507–54.
- Safari-Katesari, H., S. Y. Samadi, and S. Zaroudi. 2020. Modelling count data via copulas. Statistics 54 (6):1329–355. doi:10.1080/02331888.2020.1867140
- Shared, M. 1980. On mixtures from exponential families. Journal of the Royal Statistical Society: Series B (Methodological) 42 (2):192–98.
- Shi, P., and E. A. Valdez. 2014a. Longitudinal modeling of insurance claim counts using jitters. Scandinavian Actuarial Journal 2014 (2):159–79. doi:10.1080/03461238.2012.670611
- Shi, P., and E. A. Valdez. 2014b. Multivariate negative binomial models for insurance claim counts. Insurance: Mathematics and Economics 55:18–29. doi:10.1016/j.insmatheco.2013.11.011
- Silva, A., S. J. Rothstein, P. D. McNicholas, and S. Subedi. 2017. A multivariate Poisson–Lognormal mixture model for clustering transcriptome sequencing data. arXiv preprint arXiv:1711.11190.
- Tzougas, G. 2020. EM estimation for the Poisson–inverse Gamma regression model with varying dispersion: An application to insurance ratemaking. Risks 8 (3):31–53. doi:10.3390/risks8030097
- Tzougas, G., and D. Karlis. 2020. An EM algorithm for fitting a new class of mixed exponential regression models with varying dispersion. ASTIN Bulletin 50:555–83. doi:10.1017/asb.2020.13
- Tzougas, G., S. Vrontos, and N. Frangos. 2018. Bonus-malus systems with two-component mixture models arising from different parametric families. North American Actuarial Journal 22 (1):55–91. doi:10.1080/10920277.2017.1368398
- Wang, P. 2003. A bivariate zero-inflated negative binomial regression model for count data with excess zeros. Economics Letters 78 (3):373–78. doi:10.1016/S0165-1765(02)00262-8
- Winkelmann, R. 2008. Econometric analysis of count data. Berlin, Heidelberg: Springer Science & Business Media.
- Xue-Kun Song, P. 2000. Multivariate dispersion models generated from Gaussian copula. Scandinavian Journal of Statistics 27 (2):305–20. doi:10.1111/1467-9469.00191
- Zhan, X., H. A. Aziz, and S. V. Ukkusuri. 2015. An efficient parallel sampling technique for multivariate Poisson–Lognormal model: Analysis with two crash count datasets. Analytic Methods in Accident Research 8:45–60. doi:10.1016/j.amar.2015.10.002
- Zimmer, D. M., and P. K. Trivedi. 2006. Using trivariate copulas to model sample selection and treatment effects: Application to family health care demand. Journal of Business & Economic Statistics 24 (1):63–76. doi:10.1198/073500105000000153