
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Different approaches to determining two-sided interval estimators for risk measures such as Value-at-Risk (VaR) and conditional tail expectation (CTE) when modeling loss data exist in the actuarial literature. Two contrasting methods can be distinguished: a nonparametric one not relying on distributional assumptions or a fully parametric one relying on standard asymptotic theory to apply. We complement these approaches and take advantage of currently available computer power to propose the bias-corrected and accelerated (BCA) confidence intervals for VaR and CTE. The BCA confidence intervals allow the use of a parametric model but do not require standard asymptotic theory to apply. We outline the details to determine interval estimators for these three different approaches using general computational tools as well as with analytical formulas when assuming the truncated Lognormal distribution as a parametric model for insurance loss data. An extensive simulation study is performed to assess the performance of the proposed BCA method in comparison to the two alternative methods. A real dataset of left-truncated insurance losses is employed to illustrate the implementation of the BCA-VaR and BCA-CTE interval estimators in practice when using the truncated Lognormal distribution for modeling the loss data.
1. INTRODUCTION
Interval estimation, in addition to point estimation of the population parameters, represents an important foundation in statistical inference. Interval estimators are commonly referred to as “confidence intervals.” The confidence interval expresses the uncertainty that exists between the estimate and the true population parameter given a certain confidence level. Many inferential statistical methods to construct confidence intervals in actuarial science applications build on asymptotic theory.
There are two main standard approaches to determine confidence intervals: (1) a nonparametric and (2) a parametric asymptotic approach. The nonparametric approach determines the confidence interval based on the empirical cumulative distribution function (ecdf) relying on the fact that the ecdf is guaranteed to converge to the underlying cdf (refer to the Glivenko-Cantelli theorem; Gnedenko Citation1950; Tucker Citation1959). In the finite sample case, the nonparametric approach thus relies on assuming that the ecdf approximates the underlying cdf of the independent and identically distributed (i.i.d.) data well. In the parametric case, the cdf is specified by a parametric model where only a vector of parameters needs to be estimated from the data and the fitted distribution can then be used to determine the quantity of interest; for example, the risk measure. Parameter estimation can be performed using general maximum likelihood (ML) theory, and for i.i.d. data the ML estimates are asymptotically normally distributed, with the uncertainty being captured by the Fisher information matrix. Point estimates as well as interval estimates of the risk measures are then determined conditionally on the fitted model; for example, using the quantile function or the conditional expectation, given the implied parametric distribution, as well as combining the results from standard ML theory with the Delta method to obtain uncertainty estimates. This approach heavily relies on the asymptotic normal distribution of the estimators; that is, the distribution obtained for a sample containing infinitely many observations. When determining confidence intervals of risk measures such as Value-at-Risk (VaR) and conditional tail expectation (CTE), it might be particularly questionable to rely on the assumption of the asymptotic distribution being suitable to use for samples of rather limited size given the nature of insurance losses that exhibit a large departure from normality.
Determining interval estimators for the CTE has previously been discussed in the actuarial literature. Manistre and Hancock (Citation2005) focused on the nonparametric estimator of the CTE and determined a suitable variance estimate of the CTE estimator that they then plugged into a confidence interval estimate of the form point estimate ± quantile of the normal distribution times the standard error estimate. Brazauskas et al. (Citation2008) considered nonparametric and parametric approaches to estimate the CTE. In the nonparametric case, estimation of the confidence intervals was also based on estimates of the standard error, where they proposed to either use the bootstrap or base the estimate on order statistics of the sample. In addition, they considered a parametric approach where they focused on three specific parametric models. Each of these parametric models contained a single parameter only and constituted shifted versions of the Exponential, Pareto, and Lognormal distributions. The parameters were estimated using ML and the standard error of the estimates was obtained using the Delta method to then derive confidence intervals. An alternative to ML estimation was introduced by Brazauskas, Jones, and Zitikis (Citation2009) as the so-called method of trimmed moments (MTM). Using MTM, one removes a small predetermined proportion of extreme observations before parameter estimation to robustify parameter estimation. In the following we focus on ML estimation but would like to point out that in the presence of outliers, MTM could be a preferable parameter estimation method.
Focusing on one-parameter families only in the parametric approach seems overly restrictive. For example, in many actuarial applications, the two-parameter Lognormal distribution is needed to obtain a good fit for the loss data (see Blostein and Miljkovic Citation2019). When additional constraints are added to this model, such as left truncation or censoring (i.e., driven by the policy regulations), obtaining analytical solutions for the risk measures becomes extremely tedious and may not be attractive in practice. This may be one of the reasons why many studies in the area of risk measures focus on curve fitting with the point estimation of risk measures without looking at their uncertainty. Even though researchers recognize that the risk measures are subject to uncertainty, the interval estimation of risk measures seems to be a less popular research area. Thus, one of the goals of this study is to explore alternative computational solutions for obtaining parametric asymptotic confidence intervals for VaR and CTE. With the use of computer power and general computational tools in R (R Core Team Citation2021), we are able to substitute analytical work, related to the Delta method, with computational solutions to improve the efficiency of the implementation and increase awareness for practical use of these computational tools.
As a part of the computational effort, this study introduces a new approach to building the confidence intervals of risk measures based on the bias-corrected and accelerated (BCA) method previously introduced and refined in a sequence of publications by Efron (Citation1979), Tibshirani (Citation1988), Efron and Hastie (Citation2016), and Efron and Narasimhan (Citation2020a). This BCA method allows for the implementation of three corrections to the standard confidence interval. These corrections account for nonnormality, the bias and the nonconstant standard error of the bootstrap distribution, which is often not symmetric in the case of risk measures. Thus, we propose the new BCA-VaR and BCA-CTE confidence intervals that build on the BCA method for the confidence interval estimation of risk measures by taking advantage of the R package bcaboot (see Efron and Narasimhan Citation2020b). The proposed BCA confidence intervals should perform better for small to moderate sample sizes or in the case of violations of the asymptotic normality assumptions when the parametric asymptotic intervals, as well as nonparametric intervals, are not fully reliable.
Considering BCA confidence intervals complements other approaches discussed in the extensive literature available for interval estimation of the risk measures VaR and CTE. We refer the reader to the books by Serfling (Citation1980) and DasGupta (Citation2008) for general topics and additional publications by Hosking and Wallis (Citation1987), Brazauskas and Kaiser (Citation2004), Manistre and Hancock (Citation2005), Kaiser and Brazauskas (Citation2006), Kim and Hardy (Citation2007), Brazauskas et al. (Citation2008), Miljkovic, Causey, and Jovanović (Citation2022), and many others. In comparison to these other approaches, BCA confidence intervals are appealing for their generic nature, allowing for straightforward application to different insurance loss models while requiring fewer assumptions than standard asymptotic theory.
In conclusion, our study focuses on the following aims: (1) introduce the BCA method in the computation of interval estimators for risk measures and evaluate its performance relative to the nonparametric and parametric asymptotic alternatives and (2) assess the performance of the confidence intervals determined based on the analytical formulas compared to those obtained using generic computational tools. For those approaches requiring a parametric model, we assume that the data come from a left-truncated Lognormal distribution when addressing these two aims. We hope that this model will serve as a point of reference for many other parametric models to be considered in future implementations.
We proceed as follows. In Section 2, we discuss the proposed BCA method for risk measures in general and its specific implementation assuming a left-truncated Lognormal distribution for the insurance loss data. Existing methods for nonparametric and parametric asymptotic interval estimators are reviewed in Section 3. This section also provides new analytical formulas to determine the parametric asymptotic interval estimators of the left-truncated Lognormal distribution. In Section 4, we show the application of the proposed BCA confidence intervals on the left-truncated automobile claims of Secura Re losses. Section 5 assesses the performance of the three methods considered in the confidence interval estimation through several different simulation settings and two different implementation methods. Section 6 provides concluding remarks.
2. METHODOLOGY
2.1. Background
Statistical methods relying on asymptotic normality of the parameter estimate construct a standard confidence interval for the parameter of interest θ in the following way:
(2.1)
(2.1)
where
is a point estimate,
is an estimate of the standard error of the point estimate, and
is the
th quantile of the standard normal distribution. For
we expect this interval to have approximately 95% coverage. However, in many applications, this might not be the case because the accuracy of EquationEquation (2.1)
(2.1)
(2.1) can be of concern.
Efron (Citation1987) and DiCiccio and Efron (Citation1996) showed that the standard intervals are first-order accurate, having the error in their claimed coverage probability going to zero at rate where n denotes the sample size. Bootstrap confidence intervals have better performance because they are shown to be second-order accurate, having the error in their claimed coverage probability going to zero at rate
Compared to the standard confidence intervals, suitable bootstrap-based confidence intervals are able to correct (1) for nonnormality of (2) for bias of
and (3) for nonconstant standard error of
In particular, confidence intervals for risk measures might be suspected to suffer from these issues. Bootstrap confidence intervals offer an improvement from the first to the second order in accuracy, and in the estimation of the extreme quantiles, all three corrections may have a substantial effect on the results (see Kim and Hardy Citation2007; Brazauskas et al. Citation2008).
To include these three corrections in the confidence interval construction, Efron (Citation1987) proposed the BCA level-α endpoints of the confidence intervals defined as
(2.2)
(2.2)
where
represents the bootstrap distribution of
which accounts for nonnormality of
is the bias correction; and
is the acceleration that corrects for a nonconstant standard error. Here,
denotes the cdf of the standard normal distribution. When
and
are equal to zero, the lower and upper bounds of the confidence interval, based on the bootstrap distribution, coincide with the values obtained from the percentile method.
In most cases, these three quantities are obtained based on simulations. When the assumptions required for applying the parametric approach are questionable (as they often are; see Micceri Citation1989), the BCA method constitutes an alternative approach for deriving confidence intervals that––in combination with the suitability of the parametric model assumed––only relies on the assumption that the available data represent a random and representative sample from the population of interest allowing for a suitable estimation of the cdf (see Kelley Citation2005; Efron and Narasimhan Citation2020a).
2.2. The BCA Confidence Interval for Risk Measures
2.2.1. Preliminaries
Consider a set of realizations of insurance severity claims; that is, where xi are observations from i.i.d. random variables that come from an unknown probability distribution F on a space Ω,
(2.3)
(2.3)
In general, this set of realizations is not observed because the claims are subject to some policy restriction; for example, all claims below a level b for b > 0 are not observed because claims are only reported above the level b. This leads to the observed dataset consisting of the subset of subject to the restriction b, denoted as
and defined as
These observed data follow an unknown modified probability distribution
on a space Ω; that is,
with n being the sample size of
We refer to this data transformation process as truncation from below because the range of claim values is restricted on the left side of the interval; that is, the support is given by and the point of restriction b is referred to as truncation point. The modified unknown distribution Fb is referred to as the left-truncated distribution. The subscript b is introduced to indicate the left truncation and distinguish between the two distributions under discussion. The fact that Ω is a one-dimensional space with
being the cdf of a truncated random variable from a parametric family with parameter ψ makes this a one-dimensional problem of suitably modeling univariate insurance claims.
In the following, we are interested in proposing the BCA methods for automatic construction of confidence intervals for the risk measures (VaR and CTE) associated with specific upper quantiles and conditional expectations of The aim is to obtain reliable confidence intervals that will efficiently handle bias correction and perform well for skewed and heavy-tailed insurance data where the reliance on asymptotic theory assumptions might be questionable.
2.2.2. Proposed Algorithm
We are interested in determining a confidence interval for a real-valued parameter or measure θ. We have a function given that estimates θ given the observed data as follows:
Any function that obtains suitable point estimates for θ given the data
might be considered. For example, a parametric model could be assumed, with the parameters estimated using ML and then the parameter θ determined based on the fitted parametric model. In this article, we focus on a set of real-valued statistics
where πp represents VaR and ηp is equal to the CTE at a given security level p, subject to
A nonparametric bootstrap sample is composed of n random draws with replacement from the set of original observations
and is denoted by
Bootstrap replications for πp and ηp are obtained by drawing i.i.d. bootstrap samples and determining the risk measure B times, which results in
for
The bootstrap estimate of the standard error is the empirical standard deviation of
and
defined as
where
and
represent the means of the bootstrap estimates for πp and ηp, respectively.
The vectors of bootstrap replications; that is,
form the basis for estimating G (based on the ecdf) and
(the quantile of the standard normal distribution for
evaluated at
). Both of these quantities are used in EquationEquation (2.2)
(2.2)
(2.2) .
To obtain an estimate for the acceleration a, the jackknife (or leave-one-out procedure) differences are obtained. For the two risk measures, for which we are interested in developing the confidence intervals, they are given by
(2.4)
(2.4)
The jackknife estimates and
are obtained on the dataset
of size n – 1 after removing xi from
The jackknife differences computed by EquationEquation (2.4)
(2.4)
(2.4) provide an estimate of the acceleration rate a (refer to Efron and Hastie Citation2016, 194) as follows:
with di being replaced by
(VaR) and
(CTE) for the computation of their confidence intervals, denoted as BCA-VaR and BCA-CTE, respectively. Efron (Citation1987, section 10) shows that for one-parameter families, one-sixth of the skewness estimate is an excellent estimate for the acceleration a.
2.2.3. Implementation
The general algorithm to determine BCA confidence intervals as outlined in Section 2.2.2 and proposed in Efron and Narasimhan (Citation2020a) is implemented in the R (R Core Team Citation2021) package bcaboot (Efron and Narasimhan Citation2020b). The package provides function “bcajack()” which returns the endpoints of the BCA α-confidence intervals for a given vector of α values. The function requires as input the dataset the number of bootstrap replications B, as well as a function that, given the data, returns the point estimate of the risk measure; for example,
for BCA-VaR and
for BCA-CTE. An outline of the computations required for the BCA confidence intervals is given in Algorithm 1.
Algorithm 1:
Computation of BCA-VaR and BCA-CTE confidence intervals.
Data:
Input: Functions l = 1, 2, to estimate VaR and CTE given a dataset
a security level p, and a confidence level α.
for j = 1,…, B do
Sample with replacement from to obtain
Estimate the risk measure using
end
for i = 1,…, n do
Estimate the risk measure using
end
Determine: and
and apply Equation(2.2)
(2.2)
(2.2) using α to obtain the bounds.
Result: Lower and upper bound of the confidence interval for BCA-VaR and BCA-CTE.
In the following, we assume that the functions and
implement the derivations of the point estimates of the risk measures using two steps: (1) fitting a parametric model to the data using ML estimation and (2) determining the risk measures given the parametric model together with the parameter estimates. For a sample
Step 1 consists of determining the maximum likelihood estimates (MLEs)
(2.5)
(2.5)
where fb() is the probability density function for the cdf Fb().
In Step 2, the risk measures are determined given the parametric model, the MLE and the security level p:
(2.6)
(2.6)
A generic approach to implementing these functions requires as input (1) the probability density function (pdf) of the parametric model and (2) a quantile function or a conditional expectation function for the parametric model to obtain the risk measures. The MLE for the parametric model can be obtained using a general-purpose optimizer (e.g., “optim()” in R) after defining the log-likelihood function using the pdf and the dataset as well as initial parameter values as input. Alternatively, for some parametric models, closed-form analytical formulas might be available to obtain the MLE. We would like to note that Poudyal (Citation2021) also derived the MLE and Fisher information for the mean and variance of the left-truncated Lognormal distribution. However, the author did not consider estimating the risk measures.
Instead of providing a quantile function and a conditional expectation function, computational tools might also be exploited to determine the risk measures based on the parametric model and the MLE. In this case, only the pdf and cdf of the parametric model given the parameter values are required. The quantile can then be obtained using the pdf together with a root-finding algorithm; for example, using function “uniroot()” in R. “uniroot()” requires the function as input as well as an interval of finite length preferably containing the root. However, in case the specified interval does not contain the root, the limits are automatically extended internally in “uniroot().” In this way, the VaR is obtained. The CTE may then be determined using numeric integration based on the pdf and using suitable integral limits implied by the VaR; for example, using the R function “integrate().” For a sketch of this generic implementation of l = 1, 2, see Algorithm 2.
Algorithm 2:
Generic implementation of functions and
Data:
Input: pdf and cdf of the parametric model, initial parameter values the security level p, and a confidence level α.
Step 1: Determine the MLE given the data
using a general-purpose optimizer with the initial parameter values
as starting values and the log-likelihood function based on the pdf.
Step 2: Determine the risk measures and
given the security level p and the parametric model together with the MLE
using computational tools for root finding and numeric integration based on the pdf and cdf of the parametric model.
Result:
Left-truncated Lognormal distribution.
In the following, we assume for the functions and
which estimate VaR and CTE, respectively, that the data generating process is given by a left-truncated Lognormal distribution
with the parameter vector
The Lognormal distribution is known to provide a reasonable model for fitting insurance claims data. We outline the derivation of the log-likelihood function to obtain the MLE. We then also derive closed-form formulas to determine the risk measures.
The likelihood function for the left-truncated Lognormal sample, defined by EquationEquation (2.3)(2.3)
(2.3) , has the following form:
where
The corresponding log-likelihood function is defined as
Setting and considering that
and
are the pdf and cdf of the standard normal distribution yields the following system of two estimating equations:
Due to the dependence of B on the parameter values μ and σ, no closed-form solution seems possible to solve this system. Numeric tools are required to obtain the solution For example, function “optim()” in R may be used together with a definition of the log-likelihood function to obtain the parameter estimates. A general-purpose optimizer usually requires starting values inside the feasible parameter range. In case of the left-truncated Lognormal distribution, the closed-form formulas for the Lognormal distribution might be used as starting values; that is, ignoring the truncation at b:
Given the MLE, VaR and CTE can be computed in closed form as a result of the following lemmas.
Lemma 1.
Suppose that a random variable X follows a left-truncated Lognormal distribution with parameters μ and σ and the truncation point b. Then the quantile of X may be expressed as
The proof is provided in Appendix A.
Lemma 2.
Suppose that X follows a left-truncated Lognormal distribution with parameters μ and σ and the truncation point b. Then the conditional tail expectation of X for the security level p may be expressed as
The proof is provided in Appendix B. It is worth mentioning that the computation of ηp is not impacted by the truncation b once πp is fixed. The unconditional sample and the conditional sample
result in the same value for ηp once πp is given.
3. COMPARISON TO EXISTING METHODS
In this section, we discuss existing alternative approaches proposed for confidence interval estimation of the risk measures VaR and CTE. In particular, we outline the nonparametric as well as the parametric asymptotic approaches. The standard nonparametric formulas for both VaR and CTE are readily available in the literature (see Serfling Citation1980; Manistre and Hancock Citation2005; Kaiser and Brazauskas Citation2006). For the parametric asymptotic approach, we specifically investigate the derivation for the left-truncated Lognormal distribution. The general parametric asymptotic approach based on the Delta method is already outlined in the literature (see Hogg, McKean, and Craig Citation2005), and Brazauskas et al. (Citation2008) applied this approach specifically for the CTE. This article provides an additional contribution in the area of the parametric asymptotic interval estimation of the risk measures VaR and CTE by providing analytic results in Section 3.2 for the left-truncated Lognormal distribution.
3.1. Nonparametric Interval Estimators for VaR and CTE
Serfling (Citation1980) derived the nonparametric formulas for confidence intervals related to the upper quantiles and the conditional tail expectation based on the order statistics ). Kaiser and Brazauskas (Citation2006) provided the formulas for the nonparametric interval of CTE that builds on the work done by Manistre and Hancock (Citation2005). In the following we summarize all of these formulas in the context of our notation used in this article. Note that these formulas for CTE are only valid in the finite variance case. An alternative nonparametric CTE estimator with suitable interval estimators would need to be considered otherwise (see Necir, Rassoul, and Zitikis Citation2010).
The Nonparametric  Confidence Interval for VaR.
Confidence Interval for VaR.
The empirical sample quantile of VaR is defined as where
denotes the empirical distribution and
denotes “greatest integer part.” The
nonparametric confidence interval of the VaR is given by
where the sequences of integers
and
satisfy
and
The Nonparametric Confidence Interval for CTE.
The distribution-free confidence interval for CTE is given by
where
(3.1)
(3.1)
(3.2)
(3.2)
3.2. Asymptotic Parametric Interval Estimators for VaR and CTE
In the following we assume that a parametric distribution with parameter ψ is used to model the data and MLEs are obtained for ψ. Estimates for the risk measures VaR and CTE as well as their interval estimators are then based on this parametric model conditional on the MLE
Brazauskas et al. (Citation2008) developed inferential tools for estimating the 95% confidence interval for the CTE obtained based on a parametric model. More specifically, the authors considered a simplified case of a shifted Lognormal distribution with an unknown parameter μ as parametric distribution. We use their approach based on ML inference in combination with the multivariate Delta method to derive the interval estimators for VaR as well as CTE using an asymptotic parametric approach for any parametric model.
The Parametric Asymptotic Confidence Interval for VaR.
We derive an estimate of the variance function of the VaR estimator to develop the
for πp in the following form:
(3.3)
(3.3)
The lower and upper bounds of this confidence interval are derived based on the asymptotic normal distribution of with
the maximum likelihood parameter estimates of the parametric model. We combine ML estimation with the multivariate Delta method to determine the variance function:
with
the observed Fisher information matrix, which converges in probability to the expected Fisher information.
The Parametric Asymptotic Confidence Interval for CTE.
Following the same approach based on ML inference and the multivariate Delta method, we derive the variance function of the CTE estimator to develop the confidence interval for ηp in the following form:
(3.4)
(3.4)
with
3.3. Implementation
The implementation of the nonparametric approach requires sorting the dataset and then selecting the observations with indices given by
(3.5)
(3.5)
where
denotes rounding to the nearest integer. For details, see Algorithm 3.
Algorithm 3:
Computation of nonparametric (non-par) confidence intervals.
Data:
Input: The security level p and a confidence level α.
Step 1: Determine the indices of the sorted observations for the lower and upper bounds using Equation(3.5)(3.5)
(3.5) and select these observations for the confidence interval of the VaR.
Step 2: Calculate the empirical mean of the sorted observations with indices and higher to obtain the CTE estimate using Equation(3.1)
(3.1)
(3.1) .
Step 3: Calculate Vp as the sum of the empirical sample variance of the observations sorted in ascending order with the highest indices and p times the squared difference between VaR and CTE estimate. Then determine the bounds of the confidence interval for CTE with Equation(3.2)
(3.2)
(3.2) .
Result: Lower and upper bounds of the confidence intervals.
For the parametric approach, the following quantities are required: (1) MLE of the parameters of the parametric model together with the Hessian of the log-likelihood function at the MLE and (2) the gradient of the VaR or CTE risk measures as functions of the parameters of the parametric model evaluated at the MLE
Determining the MLE was outlined in Section 2.2.3 for a general implementation regardless of the parametric model as well as the left-truncated Lognormal distribution in particular. The Hessian might be obtained numerically as a by-product returned by the general-purpose optimizer (e.g., the R function “optim()” has a logical argument specifying whether a numerically differentiated Hessian matrix should be returned). Alternatively, given the log-likelihood function and the MLE, the Hessian can also be obtained using a numerical approximation in a separate step; for example, using function “hessian()” from the R package numDeriv (Gilbert and Varadhan Citation2019). Section 2.2.3 also discusses computational tools to determine the risk measures VaR and CTE based on the parametric model and the MLE requiring only the specification of the pdf and cdf of the parametric model. Using these tools, the gradients required for the variance functions might be numerically approximated using function “grad()” available in the R package numDeriv. The stepwise procedure for determining the asymptotic parametric confidence intervals for the risk measures is outlined in Algorithm 4.
Algorithm 4:
Computation of parametric asymptotic (par-comp) confidence intervals.
Data:
Input: pdf and cdf of the parametric model, initial parameter values the security level p, and a confidence level α.
Step 1: Determine the MLE given the data
using a general-purpose optimizer with the initial parameter values
as starting values and the log-likelihood function based on the pdf.
Step 2: Determine the gradients of the risk measure functions and
and the Hessian of the log-likelihood at
using numerical differentiation.
Step 3: Calculate the variance functions and
using matrix inversion and multiplication and determine the bounds of the
confidence intervals using Equation(3.3)
(3.3)
(3.3) and Equation(3.4)
(3.4)
(3.4) .
Result: Lower and upper bounds of the confidence intervals.
This implies that for any parametric model the asymptotic parametric confidence intervals for the risk measures VaR and CTE may be obtained using general computational tools for optimization, root finding, integration, and determining derivatives in addition to the provision of the pdf and cdf of the parametric model as well as starting values for the ML estimation. Starting values need to be inside the feasible region of the parameter space. Alternatively, closed-form formulas might be available for specific parametric models to determine the MLE and determine the quantile and the conditional expectation as well as the gradients of the risk measures and the observed Fisher information matrix of the MLE. In the following, we investigate this for the left-truncated Lognormal distribution.
Left-truncated Lognormal Distribution.
Section 2.2.3 indicates that numeric methods are required for the left-truncated Lognormal model to determine the MLE. However, closed-form formulas are provided for determining the quantiles and conditional expectations. In the following, we derive closed-form formulas for the observed Fisher information matrix and the gradients of the risk measures VaR and CTE as functions of the parameters μ and σ. These can be used to determine the parametric asymptotic confidence intervals instead of relying on numerical differentiation.
The observed Fisher information matrix is available in closed form as a result of the following lemma.
Lemma 3.
Let represent the observed Fisher information matrix for a sample
of size n from the left-truncated Lognormal distribution with parameters μ and σ and the truncation point b. Then
The proof is provided in Appendix C.
Lemma 4.
The gradient vector of the Value-at-Risk function for the left-truncated Lognormal distribution with parameters μ and σ and the truncation point b and the security level
can be expressed as
where
The proof is provided in Appendix D.
Lemma 5.
The gradient vector of the conditional tail expectation function for the left-truncated Lognormal distribution with parameters μ and σ and the truncation point b and the security level
can be expressed as
where
and
The proof is provided in Appendix E.
4. APPLICATION
In this section, we illustrate the calculations of the BCA-VaR and BCA-CTE on the real dataset of insurance automobile claims provided by Secura Re, a Belgian reinsurer. The raw dataset is available as part of the book published by Beirlant et al. (Citation2004). It is also included in the R package ltmix developed by Blostein and Miljkovic (Citation2021) for modeling Secura Re using left-truncated mixture models (see Blostein and Miljkovic Citation2019). Secura Re contains 371 automobile claims in the amount of at least 1.2 million euros. Claim amounts less than 1.2 million were not reported to the reinsurer. Therefore, the data are left-truncated with a truncation point at 1.2 million. The smallest automobile claim is 1.21 million and the largest automobile claim is 7.9 million.
This dataset has been used by several researchers (Verbelen et al. Citation2015; Reynkens et al. Citation2017; Blostein and Miljkovic Citation2019) to illustrate methodologies for different application areas: estimation of the excess of loss insurance premium for different retention levels and estimation of risk measures. These authors first performed model calibration considering different classes of models for density estimation and then estimated the quantities of interest after having determined the best model. For both of these application areas, the researchers focused only on point estimation without performing a variability assessment of the estimates. Blostein and Miljkovic (Citation2019) showed that not only is the left-truncated Lognormal distribution the most parsimonious model for calibrating Secura Re losses but it also achieves the lowest Bayesian information criterion and Akaike information criterion among other models under consideration. The authors also used quantile–quantile (Q–Q) plots as a model diagnostic tool to validate and assess model fit. For this reason, we will adopt the left-truncated Lognormal distribution to illustrate the computations of the BCA confidence intervals based on the methodology presented in Section 2. Further, the BCA results will be compared to those generated using the nonparametric and parametric asymptotic methods presented in Section 3. For the parametric asymptotic approach, the left-truncated Lognormal distribution is also used. The computational implementations outlined in Algorithms 2 and 4 are used for the parametric asymptotic and BCA results presented. Using the analytical formulas developed in Lemmas 1–5 would lead to essentially the same results.
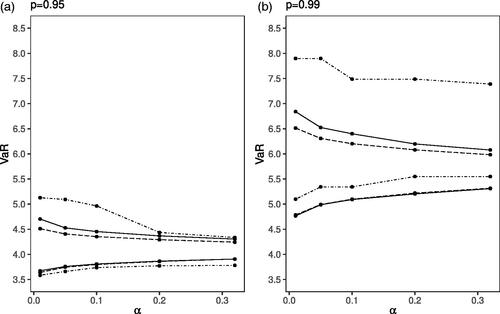
shows two-sided confidence limits of the VaR generated using the three different methods with security levels p = 0.95 (left) and p = 0.99 (right) for The three methods included are BCA-VaR (determined using the computational tools), nonparametric, and parametric (using the computational tools). The values on the x-axis represent the wide range of α values considered to determine the
-confidence intervals, and the values on the y-axis represent the bounds of the confidence intervals for the VaR. Several observations are drawn based on this data visualization. First, as expected based on results previously reported in the literature, the width of the confidence interval for VaR increases with a higher security level as well as smaller α values or higher coverage levels (see Miljkovic, Causey, and Jovanović Citation2022). Second, there are some new observations: The nonparametric confidence intervals are particularly different when the security level is 0.99: we see a strong increase in the upper bound of the confidence interval. The same phenomenon is observed for p = 0.95 when the coverage levels are above 0.8 (
). The lower bounds of the confidence intervals obtained with BCA-VaR and par-comp are visually the same for both security levels. The upper bounds of the confidence intervals for the BCA-VaR and par-comp differ slightly, with the BCA-VaR results providing higher upper bounds than those obtained with the par-comp method for both security levels and the discrepancy increasing with decreasing α values.
Figure 1. Two-Sided Confidence Limits for VaR for Security Level: (a) p = 0.95 and (b) p = 0.99. Note: Different line styles indicate the method used: BCA-VaR (solid line), par-comp (long dashed line), and non-par (dot-dashed line).
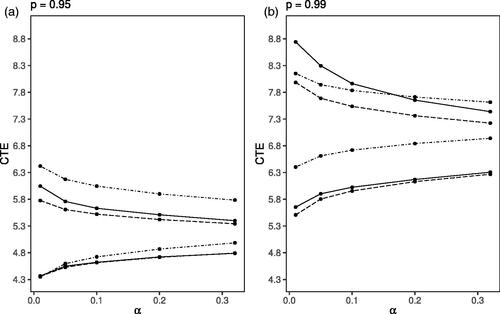
Similarly, we present the results for CTE in . For p = 0.95, both BCA-CTE and par-comp generate the same results for the lower limit of the confidence intervals regardless of the confidence level implied by α. The results for the upper limits of both methods indicate that the BCA-CTE values are slightly above the par-comp values. The nonparametric confidence intervals for p = 0.95 are quite different from those obtained with the other two methods, in particular, the upper limits are considerably larger. Also, the lower limits for the nonparametric confidence intervals are above the lower limits of the other two methods except for very small values of α. For p = 0.99 the results for BCA-CTE and par-comp again rather closely align for the lower limits whereas the nonparametric estimates are much higher. The results are different for the upper limits where BCA-CTE leads to the highest upper limits for small α values followed by the nonparametric estimates, while for higher α values again the nonparametric approach results in the highest upper limits.
Figure 2. Two-Sided Confidence Limits for CTE for Security Level: (a) p = 0.95 and (b) p = 0.99. Note: Different line styles indicate the method used: BCA-CTE (solid line), par-comp (long dashed line), and non-par (dot-dashed line).
Complementing and , provides the numerical summary of the confidence intervals for VaR and CTE for the Secura Re dataset when the left-truncated Lognormal model is fitted. Two security levels and three estimation methods are considered. The lower and upper bounds of the 95% () and 99% (
) confidence intervals are included for each estimation method.
Table 1 Summary of the Interval Estimates for VaR and CTE Based on the Secura Re Dataset
provides the summary of the computational parametric and BCA estimates associated with the computation of the confidence intervals for VaR and CTE at two different security levels (0.95 and 0.99). The standard deviation of the distribution developed for the par-comp method is provided in the column labeled by The estimates of the standard deviation of the bootstrap distribution
defined by EquationEquation (2.2)
(2.2)
(2.2) , are provided in the column labeled by
The values of the standard deviations are similar, with consistently slightly higher values for the BCA approach with the security level fixed. The skewness estimate of
is labeled as “Skew” and reported in the last column of the table. This indicates that
is slightly right-skewed. Bias correction and acceleration value estimates are reported in columns labeled as
and
respectively. These values are positive, indicating an upward correction to the standard confidence limits. According to Efron and Narasimhan Citation2020a (616), if
is right-skewed, the confidence limits should not be skewed to the left, at least for the distribution in the exponential family. The differences observed between the parametric and BCA methods in the estimation of the upper confidence limits for VaR and CTE raise doubts about the underlying statistical assumptions imposed for the par-comp approach being suitable, in particular given that the Secura Re dataset is only of moderate size with a skewness coefficient of 2.42. Rather, it is suggested that the results obtained from the BCA method provide better accuracy. In addition, we conjecture that the differences between the results of these two approaches may be even more pronounced for datasets exhibiting a stronger heavy tail such as those modeled by Miljkovic and Grün (Citation2016).
Table 2 Summary of the Computational Parametric and BCA Estimates for VaR and CTE Based on the Secura Re Dataset
5. SIMULATION
In this section, we use a simulation study with artificial data where the true data generating process and hence the true values for VaR and CTE are known. Our objective is to compare the performance of the proposed BCA confidence intervals (BCA-VaR and BCA-CTE) with confidence intervals obtained using the nonparametric (non-par) as well as parametric (par-comp) approaches discussed in Section 3. The performance of these three methods is evaluated based on their coverage probability and the width of the confidence intervals calculated for different simulation settings. Coverage probability is estimated using the proportion of the confidence intervals that contain the true value of VaR or CTE. The width of the confidence interval is computed as the difference between the upper and lower bound estimates. We draw random samples from the left-truncated Lognormal distribution assuming that this distribution represents the true data generating process. Three sample sizes with two security levels
and confidence coefficients
are considered.
The goal of the simulation study is to answer the following questions related to the BCA, nonparametric, and parametric methods used in construction of the confidence intervals:
How do the methods compare in terms of coverage probability also taking into account the width of the confidence interval?
How do the results of the BCA and the parametric approach differ for the left-truncated Lognormal model depending on the implementation; that is, if the general computational tools or the analytical solutions from Lemmas 1–5 are used for implementation?
The left-truncated Lognormal model was fitted to the Secura Re dataset used in Section 4 and parameter estimates were obtained using ML estimation. This model, together with the estimated parameters, was used as data generating processes in the simulation study. The datasets created in this way hence followed a distribution that mimics the data distribution observed for the Secura Re dataset. We generated 10,000 samples for each simulation setting. For calculation of the BCA confidence interval, each sample was bootstrapped 2000 times (i.e., resampled with B = 2000).
displays the multipanel plot of the simulation results related to the coverage probability and displays the multipanel plot of the simulation results related to the interval width. Each multipanel plot is arranged across several dimensions of the simulation study: we consider two risk measures, two security levels, and three sample sizes. For each of these 12 slices of data, we show how the coverage probability or interval width (y-axis) varies with the confidence coefficient (x-axis) across the three different estimation methods displayed with different line styles. The simulation results for the BCA method are shown with the black solid line and the non-par and par-comp methods are denoted by dotted and dashed lines, respectively.
Figure 3. Coverage Probability for the Left-Truncated Lognormal Distribution of the Three Estimation Methods: BCA (solid), non-par (dotted), par-comp (dashed). Note: Dashed gray lines denote the expected coverage probability.
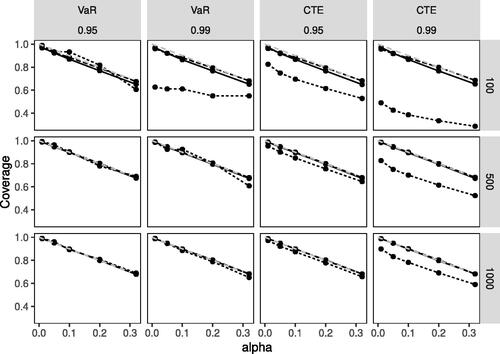
Figure 4. Average Width of the Confidence Interval for the Left-Truncated Lognormal Distribution of the Three Estimation Methods: BCA (solid), non-par (dotted), par-comp (dashed).
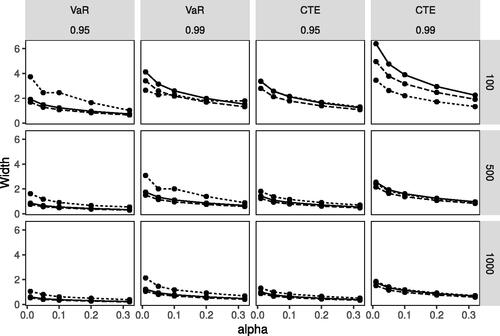
The VaR results (shown in the two left columns in and ) indicate that the par-comp as well as the BCA approach provide comparable good coverage and similar width of the confidence intervals. The results of the nonparametric approach indicate that coverage is only reasonable if either the sample size is not too small or the security level is not too high (with the coverage results being poor for p = 0.99 and n = 100 in case of the nonparametric approach) and that the interval width in general is higher than for the other two approaches, except in the case where coverage was not satisfactory.
The CTE results (shown in the two right columns in and ) indicate that coverage is again comparable good for the par-comp and the BCA approaches regardless of security level and sample size. Only considering the interval width the par-comp approach leads to considerably shorter intervals for p = 0.99 and n = 100. The non-par method proves inferior in terms of coverage and the interval width when p = 0.99 across all three sample sizes, with the coverage performance also being poor for the small sample size, n = 100 when p = 0.95.
The results of the simulation study were obtained for a setting where the true data generating process is a truncated Lognormal distribution that is also used as the parametric model in the parametric and BCA approaches for determining the confidence intervals. In this case, the results obtained with the nonparametric approach are clearly inferior for sample sizes up to 1000. In the case of the VaR, the nonparametric approach at least provides reasonable coverage in case But in all cases, the width of the confidence intervals is higher than for the other two approaches when coverage is satisfactory. The underlying assumptions of the parametric approach on the data generating process are met in this simulation study, and relying on the approximation based on the asymptotic normality seems to be reasonable. The BCA approach requires fewer assumptions and provides similar results and hence might be preferable in practice where the underlying data generating process is unknown.
To address the second question of the simulation study, we compare the results of the BCA approach as well as the parametric asymptotic approach depending on two different implementation methods: fully computational (method 1) and partially computational (method 2). Maximum likelihood estimation of the parameters given a dataset requires computational tools for both approaches regardless of the implementation. We also compare the coverage of method 1 and method 2 to their respective true coverages.
In the case of the BCA approach, the point estimates of the risk measures were found for the fully computational method using a root-finding algorithm (for VaR) and the numerical integration tools (for CTE) in R. When a partially computational method was used for the BCA approach, the point estimators of the risk measures were implemented using the analytical results obtained by Lemmas 1 and 2. The relative differences between method 1 and method 2 in percent were calculated for the width and coverage of the confidence intervals of both risk measures across all simulation settings. The ranges of these results are summarized in the top portion of . The columns labeled Δwidth and Δcov show the ranges of relative differences in percent between the two implementation methods. We observed minor differences between method 1 and method 2, indicating that these two methods are similar in terms of their performance and either one can be used in practice. The range of relative differences between coverage calculated by method 1 and the true coverage in percent is shown in the column labeled Similarly, the range of relative differences between coverage calculated by method 2 and the true coverage in percent is shown in the column labeled
Both
and
results include zero within the given range, indicating that the calculated confidence intervals lead to over- as well as undercoverage compared to the true coverage.
Table 3 Comparison of the Implementation Methods (%): BCA (Top) and Parametric Asymptotic (Bottom).
Similarly, the implementations of the parametric asymptotic confidence intervals were compared when using either the analytical solutions (method 1) provided by Lemmas 1–5 or using general computational tools (method 2) available in R for finding the Hessian of the log-likelihood function and the gradients of the variance function numerically. The results are summarized in the bottom portion of . The columns labeled Δwidth and Δcov show the ranges of the relative differences in percent between the two implementation methods. Here, the results point to some systematic differences in both width and coverage between the two methods. We again investigate which of the two methods has better coverage compared to the true coverage. Similar to the BCA implementation approach, we compute the range of relative differences between coverage calculated by method 1 and the true coverage in percent as shown in the column labeled The range of relative differences between coverage calculated by method 2 and the true coverage in percent is shown in the column labeled
Based on these results, we note that method 1 implemented based on the analytical solutions of Lemmas 1–5 consistently underestimates the true coverage probability for both risk measures as observed in
By contrast, the results for
include zero within the given range. Overall method 2, based on general computational tools, produces better coverage of the confidence intervals for both risk measures and should be adopted in practice.
Through this simulation study, we learned that the BCA approach can be used to validate the results of using the parametric asymptotic approach to determine the confidence intervals. For large sample sizes, both methods yield similar results. For small to moderate sample sizes, small differences between the two methods are observed when modeling the real dataset of Secura Re losses. In summary, the simulation study provided insightful information about the behavior of the three types of confidence intervals under consideration as well as the influence of the implementation used.
6. CONCLUSION
In this article, we advanced the study of interval estimation of risk measures in the actuarial literature. We proposed the automated bias-corrected and accelerated bootstrap confidence intervals, named BCA-VAR and BCA-CTE for VaR and CTE, respectively, using, in particular, the left-truncated Lognormal distribution. The performance of the proposed intervals was assessed in comparison to nonparametric and parametric asymptotic approaches based on the same parametric distribution. For the application of the parametric approach, we also obtained new analytical results required when using the Delta method and asymptotic theory to derive the confidence intervals, which were previously not available in the literature for the left-truncated Lognormal loss model.
Our results showed that the nonparametric approach to interval estimation is generally inferior to the other two methods. The asymptotic parametric approach relies on the asymptotic normality of the risk measure estimates as the sample size increases and the regulatory conditions are met. However, when this assumption is violated, the BCA method will provide a more realistic assessment of the uncertainty of the risk measure estimates.
When testing these three methods on the real Secura Re dataset, we found that the BCA and parametric approaches, generated similar results for the lower limit but slightly different results for the upper limit of the confidence interval. When the results of the parametric and the BCA methods agree, the results can be taken to be accurate and meaningful. But if these methods yield different results such as those observed for the upper limit, researchers should ask themselves whether the statistical assumptions of the parametric approach are likely to be violated, hence supporting the validity of the BCA method.
In future applications involving computations of the confidence intervals for risk measures, we recommend using the BCA method to validate the parametric results. If the two methods produce different results, the insurer should refer to the BCA method because its bias correction and acceleration procedures allow for a higher level of accuracy in the results.
We focused on the left-truncated Lognormal model to derive the empirical results and also provided analytical formulas for this parametric model. However, the computational tools outlined are rather generic and might easily be used for other nonparametric estimators where standard error estimates are available and any kind of parametric model regardless of the estimation method used; for example, using the method of trimmed moments instead of ML. The comparison of the empirical results obtained with the computational and analytical implementations confirms the reliability of the computational tools. Hence, our study can be easily extended to include other parametric models such as the composite models considered by Grün and Miljkovic (Citation2019) with the efficient implementation of computational tools. The BCA approach would require that the user provides the loss data as well as the input functions and
based on the considered parametric model to estimate the risk measures. For many composite models, these functions can be derived analytically. The BCA method can also be explored with the model averaging approach considered by Miljkovic and Grün (Citation2021) to account for model uncertainty in the estimation of the confidence intervals.
Acknowlegements
We thank the editors and the anonymous reviewers for their helpful comments that improved the readability and quality of this article.
References
- Beirlant, J., Y. Goegebeur, J. Segers, and J. L. Teugels. 2004. Statistics of extremes: Theory and applications. Chichester, West Sussex: John Wiley & Sons.
- Blostein, M., and T. Miljkovic. 2019. On modeling left-truncated loss data using mixtures of distributions. Insurance: Mathematics and Economics 85:35–46.
- Blostein, M., and T. Miljkovic. 2021. ltmix: Left-truncated mixtures of Gamma, Weibull, and Lognormal distributions. R package version 0.2.1. https://CRAN.R-project.org/package=ltmix
- Brazauskas, V., B. L. Jones, M. L. Puri, and R. Zitikis. 2008. Estimating conditional tail expectation with actuarial applications in view. Journal of Statistical Planning and Inference 138 (11):3590–604.
- Brazauskas, V., B. L. Jones, and R. Zitikis. 2009. Robust fitting of claim severity distributions and the method of trimmed moments. Journal of Statistical Planning and Inference 139 (6):2028–43.
- Brazauskas, V., and T. Kaiser. 2004. “Empirical estimation of risk measures and related quantities,” Bruce L. Jones and Ricărdas Zitikis, October 2003. North American Actuarial Journal 8 (3):114.
- DasGupta, A. 2008. Asymptotic theory of statistics and probability. Vol. 180. New York, NY: Springer.
- DiCiccio, T. J., and B. Efron. 1996. Bootstrap confidence intervals. Statistical Science 11 (3):189–228.
- Efron, B. 1979. Bootstrap methods: Another look at the jackknife. The Annals of Statistics 7 (1):1–26.
- Efron, B. 1987. Better bootstrap confidence intervals. Journal of the American Statistical Association 82 (397):171–85.
- Efron, B., and T. Hastie. 2016. Computer age statistical inference. Vol. 5. New York, NY: Cambridge University Press.
- Efron, B., and B. Narasimhan. 2020a. The automatic construction of bootstrap confidence intervals. Journal of Computational and Graphical Statistics 29 (3):608–19.
- Efron, B., and B. Narasimhan. 2020b. bcaboot: Bias corrected bootstrap confidence intervals. R package version 0.2-3. https://CRAN.R-project.org/package=bcaboot
- Gilbert, P., and R. Varadhan. 2019. numDeriv: Accurate numerical derivatives. R package version 2016.8-1.1. https://CRAN.R-project.org/package=numDeriv
- Gnedenko, B. V. 1950. Kurs teorii veroyatnostyey [Probability theory course]. Moscow: Gosudarstvennoye Izdatyel’stvo Technico-Teoreticheskoi Literaturi.
- Grün, B., and T. Miljkovic. 2019. Extending composite loss models using a general framework of advanced computational tools. Scandinavian Actuarial Journal 2019 (8):642–60.
- Hogg, R. V., J. McKean, and A. T. Craig. 2005. Introduction to mathematical statistics. Upper Saddle River, NJ: Pearson Education.
- Hosking, J. R., and J. R. Wallis. 1987. Parameter and quantile estimation for the generalized Pareto distribution. Technometrics 29 (3):339–49.
- Kaiser, T., and V. Brazauskas. 2006. Interval estimation of actuarial risk measures. North American Actuarial Journal 10 (4):249–68.
- Kelley, K. 2005. The effects of nonnormal distributions on confidence intervals around the standardized mean difference: Bootstrap and parametric confidence intervals. Educational and Psychological Measurement 65 (1):51–69.
- Kim, J. H. T., and M. R. Hardy. 2007. Quantifying and correcting the bias in estimated risk measures. ASTIN Bulletin 37 (2):365–86.
- Klugman, S. A., H. H. Panjer, and G. E. Willmot. 2012. Loss models: From data to decisions. 4th ed. Hoboken, NJ: John Wiley & Sons.
- Loomis, L. H., and S. Sternberg. 1968. Advanced calculus. Reading, Massachusetts: Addison-Wesley.
- Manistre, J. B., and G. H. Hancock. 2005. Variance of the CTE estimator. North American Actuarial Journal 9 (2):129–56.
- Micceri, T. 1989. The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin 105 (1):156–66.
- Miljkovic, T., R. Causey, and M. Jovanović. 2022. Assessing the performance of confidence intervals for high quantiles of Burr XII and inverse Burr mixtures. Communications in Statistics – Simulation and Computation 51 (8):4677–99.
- Miljkovic, T., and B. Grün. 2016. Modeling loss data using mixtures of distributions. Insurance: Mathematics and Economics 70:387–96.
- Miljkovic, T., and B. Grün. 2021. Using model averaging to determine suitable risk measure estimates. North American Actuarial Journal 25 (4):562–79.
- Necir, A., A. Rassoul, and R. Zitikis. 2010. Estimating the conditional tail expectation in the case of heavy-tailed losses. Journal of Probability and Statistics 2010:1–17.
- Poudyal, C. 2021. Robust estimation of loss models for lognormal insurance payment severity data. ASTIN Bulletin 51 (2):475–507.
- R Core Team. 2021. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/
- Reynkens, T., R. Verbelen, J. Beirlant, and K. Antonio. 2017. Modelling censored losses using splicing: A global fit strategy with mixed Erlang and extreme value distributions. Insurance: Mathematics and Economics 77:65–77.
- Serfling, R. 1980. Approximation theorems of mathematical statistics. New York: Wiley.
- Tibshirani, R. 1988. Variance stabilization and the bootstrap. Biometrika 75 (3):433–44.
- Tucker, H. G. 1959. A generalization of the Glivenko-Cantelli theorem. The Annals of Mathematical Statistics 30 (3):828–30.
- Verbelen, R., L. Gong, K. Antonio, A. Badescu, and S. Lin. 2015. Fitting mixtures of Erlangs to censored and truncated data using the EM algorithm. ASTIN Bulletin 45 (3):729–58.
APPENDIX A.
Proof of Lemma 1
The cdf of the observations in the truncated sample
can be expressed using the corresponding untruncated cdf
as follows:
where
is the indicator function. The inverse function
provides the 100pth percentile of the left-truncated distribution of X, which gives the result for πp.
APPENDIX B.
PROOF OF LEMMA 2
The estimator of CTE for the security level p (see Klugman, Panjer, and Willmot 2012) is defined as
(B.1)
(B.1)
where Consider the substitution
Then Equation (B.1) can be written in terms of the quantile function
for
That is,
(B.2)
(B.2)
The quantile function for the left-truncated Lognormal distribution is given by
and when this result is included directly in Equation (B.2), we obtain the following integral:
Using substitution the integral above simplifies to
where the lower limit of integration is set by and the density of the standard normal distribution is
By combining the exponents, the above integral becomes
Rewrite the exponent as and rearrange some terms. Consider the symmetry of the standard normal distribution, which implies
Then, with additional simple substitutions, we easily arrive at the final solution,
APPENDIX C.
PROOF OF LEMMA 3
Let denote the Hessian matrix of the second-order partial derivatives hij for
of the log-likelihood function under parameters μ and σ where
and
The following simple equations
and
as well as the application of the chain rule with some straightforward simplifications result in
Using the standard formulas for the elements of the observed Fisher information, it follows that
as desired.
APPENDIX D.
PROOF OF LEMMA 4
The first derivatives of πp with respect to the parameters μ and σ, respectively, are defined as and
The derivative of the inverse cdf of the standard normal distribution for
may be determined by
which can be derived using any standard calculus book (i.e., Loomis and Sternberg 1968). Using this and the chain rule, we arrive at
where
APPENDIX E.
PROOF OF LEMMA 5
The first derivatives of ηp with respect to the parameters μ and σ, respectively, are defined as and
Using the chain rule and some straightforward simplifications, we arrive at
The partial derivatives of and
are determined separately. Using again
and after applying the chain rule to a composite function and performing some simplifications, we obtain the desired solution in closed form as follows:
