Abstract
The present study developed a novel approach to modeling indoor air quality (IAQ) of a public transportation bus by the development of hybrid genetic-algorithm-based neural networks (also known as evolutionary neural networks) with input variables optimized from using the regression trees, referred as the GART approach. This study validated the applicability of the GART modeling approach in solving complex nonlinear systems by accurately predicting the monitored contaminants of carbon dioxide (CO2), carbon monoxide (CO), nitric oxide (NO), sulfur dioxide (SO2), 0.3–0.4 µm sized particle numbers, 0.4–0.5 µm sized particle numbers, particulate matter (PM) concentrations less than 1.0 µm (PM1.0), and PM concentrations less than 2.5 µm (PM2.5) inside a public transportation bus operating on 20% grade biodiesel in Toledo, OH.
First, the important variables affecting each monitored in-bus contaminant were determined using regression trees. Second, the analysis of variance was used as a complimentary sensitivity analysis to the regression tree results to determine a subset of statistically significant variables affecting each monitored in-bus contaminant. Finally, the identified subsets of statistically significant variables were used as inputs to develop three artificial neural network (ANN) models. The models developed were regression tree-based back-propagation network (BPN-RT), regression tree-based radial basis function network (RBFN-RT), and GART models. Performance measures were used to validate the predictive capacity of the developed IAQ models. The results from this approach were compared with the results obtained from using a theoretical approach and a generalized practicable approach to modeling IAQ that included the consideration of additional independent variables when developing the aforementioned ANN models. The hybrid GART models were able to capture majority of the variance in the monitored in-bus contaminants. The genetic-algorithm-based neural network IAQ models outperformed the traditional ANN methods of the back-propagation and the radial basis function networks.
Implications: The novelty of this research is the development of a novel approach to modeling vehicular indoor air quality by integration of the advanced methods of genetic algorithms, regression trees, and the analysis of variance for the monitored in-vehicle gaseous and particulate matter contaminants, and comparing the results obtained from using the developed approach with conventional artificial intelligence techniques of back propagation networks and radial basis function networks. This study validated the newly developed approach using holdout and threefold cross-validation methods. These results are of great interest to scientists, researchers, and the public in understanding the various aspects of modeling an indoor microenvironment. This methodology can easily be extended to other fields of study also.
Supplemental Materials: Supplemental materials are available for this paper. Go to the publisher's online edition of the Journal of the Air & Waste Management Association.
Introduction
Study of indoor air quality (IAQ) in a transportation microenvironment is important in understanding the occupant's exposure levels to in-vehicle contaminants, considering that people spend 5–6% of their daily time commuting, mostly between their workplace and residence (CitationKlepeis et al., 2001). One of the general methods of studying IAQ in any microenvironment is to use the mass balance models. These models are generic in nature and are derived based on the mass balance for contaminant flow into and out of the indoor volume considered. However, such models aim to resolve the underlying physical and chemical equations controlling contaminant concentrations and therefore require detailed data on indoor and/or outdoor air contaminant concentrations, meteorological conditions, and components of the indoor space (like obstructions and ventilation openings) and their respective dimensions in the microenvironment considered. Only one study modeled in-vehicle air quality using the mass balance method (CitationEsber and El-Fadel, 2008).
Another method of studying IAQ in any microenvironment is to use statistical techniques (such as the regression methods, the regression tree methods, etc.). Several studies used the regression method to study in-vehicle air quality, and a comprehensive review of these studies was provided by CitationKadiyala and Kumar (2012a). As the factors affecting in-vehicle contaminants keep changing randomly, linear regression models tend to underperform in such cases when used to model nonlinear systems. This drawback was overcome by using the regression tree method, which classified and quantified the in-bus contaminants based on a set of if–else logical split conditions (CitationKadiyala and Kumar, 2008, Citation2011a, Citation2012a, Citation2012b, Citation2012c).
Alternatively, air quality inside a microenvironment can also be modeled with the use of artificial neural networks (ANNs). ANNs' ability to solve complex systems resulted in their popularity and application in a number of areas (CitationMaier and Dandy, 2001). Several studies observed ANNs to perform much better than the conventional statistical methods (CitationGardner and Dorling, 1998,1999; CitationPerez et al., 2000; CitationKolehmainen et al., 2001; CitationKukkonen et al., 2003; CitationPapanastasiou et al., 2007). The role of ANNs in the field of air pollution was limited to modeling vehicular exhaust emissions (CitationBrunelli et al., 2007; CitationKhare and Nagendra, 2006) and atmospheric contaminants; CitationMoustris et al. (2010) provided a comprehensive review of the atmospheric studies that used ANN methods.
Considering the complex nature of predicting the air contaminants in an indoor environment using complex rules and mathematical calculations, regression trees and ANNs are easy and better to work with for predicting indoor contaminants where significant key information patterns are recognized within a multidimensional information domain. The authors make an effort to fill the knowledge gap of using these two advanced modeling techniques together by developing a new modeling approach, referred as the GART modeling approach, in reference to the development of hybrid genetic-algorithm-based neural networks with regression tree results. First, the statistically significant variables affecting the monitored in-bus contaminants of carbon dioxide (CO2), carbon monoxide (CO), nitric oxide (NO), sulfur dioxide (SO2), 0.3–0.4 µm sized particle numbers, 0.4–0.5 µm sized particle numbers, particulate matter (PM) concentration less than 1.0 µm (PM1.0), and PM concentration less than 2.5 µm (PM2.5) were determined using the analysis of variance (ANOVA) as a complimentary sensitivity analysis to the regression tree methods. More information on the use of regression trees and ANOVA to characterize in-bus air quality were provided elsewhere (CitationKadiyala and Kumar, 2012b, Citation2011a, Citation2012c; CitationKadiyala, 2012). Next, the statistically significant variables affecting each monitored in-bus contaminant identified from the use of regression trees and the ANOVA were used as the input variables to develop the corresponding GART models (also known as evolutionary neural network models). In addition to the development of GART models, the identified statistically significant variables affecting each monitored in-bus contaminant were also used to develop ANN models based on the methods of back-propagation (BPN-RT) and radial basis function (RBFN-RT). The term RT was designated as a suffix to the developed ANN models with statistically significant variables identified from using the regression trees and the ANOVA. Results from the aforementioned practicable RT modeling approach wherein the input variables were identified from using the regression trees and the ANOVA were compared with two other approaches: a theoretical approach (models represented with a suffix -TD) and a generalized practicable approach (models represented with a suffix -PDG). These two approaches were different in the sense that additional independent variables that can possibly influence the in-bus air quality were considered as input variables in the development of the ANN models.
The GART modeling approach provides environmental professionals and the scientific community with a new methodology to solve complex nonlinear multivariate environmental data systems, and the proposed approach can easily be extended to other fields of study. Considering the practical applicability and the validity of GART models in assessing the in-bus air quality, it is hoped that the proposed methodology encourages the development of more efficient environmental monitoring systems (with limited independent input variables), thereby reducing operational and maintenance costs.
Methodology
Database development
A 20% grade biodiesel fueled Thermo King air-conditioned bus (ID: 506) was selected from the 500 series fleet of Thomas-built buses (acquired by Detroit Diesel) of the Toledo Area Regional Transit Authority (TARTA) lineup, with a Mercedes Benz MBE 900 engine; the bus had all the cameras located inside the bus in working condition and ran on a single preassigned route daily. The route selected for the study was Route 20, which runs between the TARTA garage and Meijer on the Central Avenue strip (CitationTARTA Routes, 2011). The locations of the bus, in transit were identified by the global positioning system (GPS) unit located inside the bus. Continuous monitoring of the in-bus gaseous contaminants of CO2, CO, NO, and SO2, simultaneously with indoor temperature (temp.) and indoor relative humidity (RH), were done using the Yes Plus instrument. In-bus 0.3–0.4 µm sized particle numbers, 0.4–0.5 µm sized particle numbers, PM1.0, and PM2.5 were monitored using the Grimm 1.108 instrument. Both the instruments drew power continuously from adapters connected to the bus and a wired mesh box safeguarded the instruments. The instruments were held in position within the wired mesh box using Velcro attachments. On-road variables were monitored using the hard drive in the bus that recorded the video during its run. More details on the instrumentation, experimental setup, test protocol, instrument maintenance procedures, and monitoring of on-road variables were discussed elsewhere (CitationKadiyala et al., 2010; CitationKadiyala and Kumar, 2011b). Meteorological data were downloaded for the Toledo Express Airport station from the CitationNational Climatic Data Center (NCDC, 2011). The route selected for the study was within a radius of 25 miles of the meteorological station selected. Ambient PM2.5 concentrations were obtained from the U.S. Environmental Protection Agency (EPA) on request. Additionally, time-related variables and background in-bus contaminant concentrations were considered in the database development.
Thus, a comprehensive database hereon referred as the “complete database” was developed that included the monitored in-bus contaminants, time-related variables (time of the day, day of the week, month of the year, season of the year), monitored indoor comfort variables (indoor temperature, indoor RH), meteorological variables (sky condition, visibility, ambient temperature, ambient RH, wind speed, weather type, precipitation), on-road variables (passenger density, light vehicles (cars/SUVs) ahead, heavy vehicles (buses/trucks) ahead, ventilation settings representative of the bus status indicated by the bus position/door position (idle/open, idle/close, run/close), background contaminant concentrations inside the bus (previous 1-hr, 2-hr, 3-hr in-bus concentrations), and ambient PM2.5 concentrations. Note that the ambient PM2.5 concentrations were considered only for modeling PM contaminants. Data collected between April 2007 and March 2008 resulted in the development of a complete database having 1453 hourly gaseous data points, 189 hourly PM concentration data points, and 367 hourly submicrometer-sized particle data points with no missing values for any of the variables considered.
From a practical perspective, it is not always feasible to obtain background concentrations inside a transportation microenvironment. Consequently, the complete database was subdivided into three data sets, conditional on the set of independent variables chosen as the inputs to model ANNs, and were defined as:
| 1. | A real-world scenario data set developed from using the ANOVA and regression trees (RT): this included only the statistically significant variables determined using the ANOVA as a complimentary sensitivity analysis to the regression tree results (CitationKadiyala and Kumar, 2012b, Citation2011a; CitationKadiyala, 2012). provides a summary of the statistically significant variables affecting each monitored contaminant determined using the ANOVA and regression tree methods. Table 1. Summary of the statistically significant variables determined using the ANOVA and regression trees | ||||
| 2. | A generalized real-world practical data set (PDG): this included all the independent variables considered in this study, with the exception being background (previous 1-hr, 2-hr, 3-hr) in-bus contaminant concentrations. | ||||
| 3. | A theoretical data set (TD): this was the same as the complete database, and included all the considered independent variables. | ||||
Normalization of the data sets
As the dependent and the independent variables showed a wide range of numerical values, the three data sets (RT, PDG, TD) were normalized within a range of (0,1) using Equationeq 1 to avoid the overflow of network due to large or small weights produced for the data set considered and to eliminate the influence of dimensions of data on the network (CitationGardner and Dorling, 1999). Categorical variables were coded into numerical values before normalization of the data sets.
Artificial neural networks
ANNs are computational models that perform based on the operation of biological neural networks and gain knowledge through the “learning process.” Any ANN will have a number of highly interconnected processing elements (neurons) organized into three layers, namely, the input layer, the hidden layer, and the output layer. Each layer consists of a number of neurons that receive one or more inputs and produce an output with the knowledge being stored in the interneuron connected synaptic weights (CitationHaykin, 1994). The independent variables affecting the in-bus air quality are fed into the network through the input layer. There can be one or more hidden layers that can process the information from the input layer with knowledge stored in the interneuron connected synaptic weights. The final output, that is, the in-bus contaminant concentration, is attained from the output layer. There are different types of ANNs, among which the back-propagation, the radial basis function, and the hybrid genetic-algorithm-based neural networks were investigated in this study.
Back-Propagation network
Back-propagation (BP) was first introduced by CitationBryson and Ho (1969) and is now one of the most widely used learning algorithms. A BP network (BPN) is a “supervised” learning method that computes the error gradient for a feed-forward network. illustrates the BPN structure for CO2 using the RT data set with the input, hidden, and output layers indicated from left to right. The BPN has two phases: forward computation of the input data (independent variables) through the network to obtain an output pattern (predicted in-bus contaminant concentration) and back-propagation of the error signals when there is a difference between the actual monitored and the predicted in-bus contaminant concentration outputs. During this process, the synaptic weights of neurons are adjusted in accordance with the error signals. These two phases are repeated iteratively, and the error decreases at the end of each iteration until the selected error criterion (0.001) is reached. A BPN with a single hidden layer having sufficient number of neurons can approximate any smooth, measurable function between inputs and outputs by selecting a suitable set of connecting synaptic weights and a transfer function (CitationHornik et al., 1989). Hence, this study adopted the use of a single hidden layer BPN, with the widely used sigmoid transfer function that introduces the nonlinearity feature. The mathematical equations associated with the development of BPN models were documented elsewhere (CitationNegnevitsky, 2005).
Figure 1. Architecture of the BPN-CO2-RT.
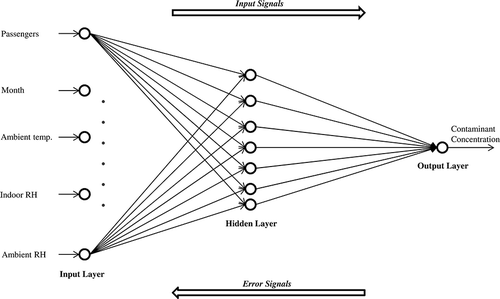
The number of neurons in the input, hidden, and output layers for any network depends on the problem considered. Accordingly, the number of neurons in the input layer and the output layer will be equivalent to the number of variables considered in the corresponding layer. If there are fewer neurons in the hidden layer, then the required accuracy may not be reached. Considering more neurons in the hidden layer may cause “overfitting” or “overtraining” that reduces the generalization capacity of the network. Thus, the selection of optimal number of neurons in the hidden layer is based on the mean absolute error (MAE) and the root mean square error (RMSE) statistics obtained from running the BPN with the associated data sets. presents the MAE and RMSE statistics obtained from running the BPN for CO2 with RT data set. From , one can observe that the BPN-CO2-RT with seven neurons in the single hidden layer produced the best results. The MAE and the RMSE in were within 8% of the maximum CO2 reading. Similar trends were observed on considering the other monitored in-bus contaminants. BPN models developed with RT, PDG, and TD data sets were referred as the BPN-RT, BPN-PDG, and BPN-TD, respectively.
Table 2. Prediction results to determine the optimal number of neurons in the single hidden layer of BPN-CO2-RT
Radial basis function network
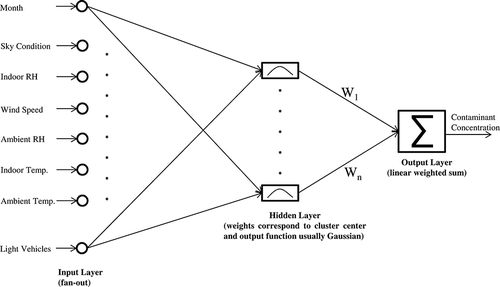
Radial basis functions (RBFs) were first introduced by CitationPowell (1977) to solve the real multivariate interpolation problem. In the field of ANNs, radial basis functions were first used by CitationBroomhead and Lowe (1988) in developing feed-forward networks. An RBF network (RBFN) is also a “supervised” learning method having three layers: an input layer, a hidden layer with nonlinear radial basis activation function, and a linear output layer. illustrates the structure of the RBFN for CO using the RT data set with the input, hidden, and output layers indicated from left to right. The independent variables affecting in-bus air quality are fed into the input layer that simply acts as a fan-out layer to feed the values to each of the neurons in the hidden layer and does not perform any processing. The hidden layer performs a nonlinear mapping from input space into a usually higher dimensional space in which patterns get linearly separable—that is, the transformation from the input layer to the hidden layer is nonlinear (CitationHaykin, 1994). The hidden layer has a variable number of neurons with each neuron having a radial basis function (generally Gaussian function) centered on a point with as many dimensions as there are predictor variables. The spread (radius) of the radial basis function may vary for each dimension. At the input of each neuron in the hidden layer, the distance between neuron center and the input vector (Euclidean distance) is computed. The output of the neuron in the hidden layer is then computed by applying the basis function to this distance. The output layer (with the predicted in-bus contaminants) performs a simple weighted sum of the linear neuron output from the hidden layer and unity bias; that is, the transformation from the hidden layer to the output layer is linear (CitationHaykin, 1994). In an RBFN, the neurons in the hidden layer are added up until the desired accuracy (0.001) is reached for a given spread. RBFN models developed with RT, PDG, and TD data sets were referred as the RBFN-RT, RBFN-PDG, and RBFN-TD, respectively.
Figure 2. Architecture of the RBFN-CO-RT.
Hybrid genetic-algorithm-based neural network
Genetic algorithms (GAs) are the optimization algorithms based on the mechanics of genetics, that is, the idea of the survival of the fittest (CitationKarr et al., 1995). GAs generate a competitive set of solutions and then the solution evolves through the process of natural selection, where poor solutions die out and better solutions survive to reproduce. This process is repeated until the optimal solution is reached by the GA. The concept of GA was first introduced by CitationHolland (1975) and further developed by CitationGoldberg (1989) and CitationMichalewicz (1996). GAs provide robust and reliable solutions for highly complex, nonlinear search and optimization problems, which previously could not be solved (CitationHolland, 1995; CitationSchwefel, 1995). The use of GAs has been increasing rapidly and they are mainly used in combination with other neural network models for extracting decision rules (CitationBlackmore and Bossamaier, 2003) and for selecting the input parameters and defining the model structure for predicting atmospheric contaminants (CitationNiska et al., 2004).
The use of GAs together with BPNs was initially explored by Dong et al. (2010) and CitationKadiyala et al. (2011). The current study extended the work by CitationKadiyala et al. (2011) to develop hybrid GA based neural networks using the BP mechanism. A hybrid GA-based neural network is fundamentally a BPN, with the only exception being that the weight matrix was attained from performing the genetic operations under optimal convergence conditions. Different options (population, fitness scaling, selection, reproduction, mutation, crossover, migration, algorithm settings, hybrid functions, and stopping criteria) need to be specified before running a GA. A comprehensive step-by-step procedure to determining the optimal GA parameters (based on the “fitness”) and extraction of the ideal weight matrix under optimal GA conditions were discussed in detail elsewhere (CitationKadiyala et al., 2011).
The methodology associated with the development of hybrid GA based neural network models can be divided into two phases: training/validation and testing. In the training/validation phase, a seven (ideal number) neuron single hidden layer BPN with random initial weights was coded in MATLAB to run with the GA option, that is, “Optimization Tool–ga solver.” The best chromosome, that is, the ideal weight matrix, which represented the optimal or near-optimal solution to the in-bus air quality prediction problem, was obtained when the GA converged under optimal conditions as tabulated in . The testing phase involved coding of the seven-neuron single hidden layer BPN with incorporation of the ideal weight matrix extracted from optimal GA conditions (in the training/validation phase) to predict the monitored in-bus contaminants. Hybrid GA-based neural network models developed with RT, PDG, and TD data sets were referred as the GART, GAPDG, and GATD, respectively.
Table 3. Summary of the optimal conditions used for running GA
Model validation
A good air quality model developed needs to provide adequate and reasonable estimates of the monitored observations. It is necessary to use statistical metrics to validate the developed air quality models. Air quality modelers have traditionally adopted the use of “holdout” validation methodology and determined the performance of model predictions using a set of operational performance measures. The holdout validation methodology was performed by further dividing the data sets (RT, PDG, TD) into three subsets, namely, the training set (60%), the validation set (20%), and the test set (20%). The training set was used for learning and the validation set was used for adjusting the neural network parameters. The test set (that sufficiently represented the corresponding complete data set comprised of 20% of the data points extracted from each month during the monitoring period between April 2007 and March 2008), independent of the training and validation sets, was used to assess the performance of ANN-based IAQ models using a set of operational performance measures as discussed in the following.
Based on a comprehensive review of the literature on air quality model evaluation, Kadiyala and Kumar (2012d) enumerated a complete list of performance metric criteria to validate indoor and atmospheric air quality models with emphasis on the modeling attributes of the extreme-end (i.e., peak-end/low-end) concentrations and the mid-range concentrations. The statistical performance measures, namely, correlation (CORR), slope of the regression line (m), ratio of the intercept of regression line to the average observed concentrations (b/C0), normalized mean square error (NMSE), fractional bias (FB), fractional variance (FV), fraction of predictions within a factor of two of the observations (FA2), model comparison measure (MCM2), geometric mean bias (MG), geometric mean variance (VG), revised index of agreement (IOAr), scatter plots, quantile–quantile (Q-Q) plots, and bootstrap 95% confidence interval estimates over NMSE, FB, CORR, VG, and MG were recommended to be used for mid-range IAQ model validation. The study also recommended a set of primary performance measures (Spearman rank correlation coefficient [ρ], m, b/C0, FV, FA2, robust highest concentration ratio [RHCratio], MCM2, MG, VG, scatter plots, Q-Q plots, bootstrap 95% confidence interval estimates over MG and VG) and a set of secondary performance measures (IOAr, accuracy of paired peaks [Ap]) for IAQ model validation, when the emphasis was on the peak-end concentrations. With the exception of RHCratio and Ap, all other performance measures recommended for the peak-end IAQ model validation were recommended to be used for the low-end IAQ model validation. Refer to Kadiyala and Kumar (2012d) for additional details on the criteria used for selection and ranking of the operational model performance measures, based on the attributes of extreme-end and mid-range IAQ modeling.
An IAQ model is considered to be ideal and perfect when b/C0, NMSE, FB, FV, and MCM2 statistics are equal to zero; CORR, ρ, m, FA2, RHCratio, MG, VG, IOAr, and Ap statistics are equal to one; and the scatter plots and the Q-Q graphical representations have the points plotted along the identity line (i.e., 1:1 line or a 45˚ line). However, models are rarely perfect in real life. Based on the recommendations made by Kadiyala and Kumar (2012d), an IAQ model is deemed acceptable from both extreme-end and mid-range modeling perspectives if it meets the criteria of (i) 0.9 ≤ CORR ≤ 1.0, (ii) 0.75 ≤ m ≤ 1.25, (iii) –25 ≤ b/C0 (%) ≤ 25, (iv) 0 ≤ NMSE ≤ 0.25, (v) –0.25 ≤ FB ≤ 0.25, (vi) –0.5 ≤ FV ≤ 0.5, (vii) 0.8 ≤ FA2 ≤ 1.2, (viii) 0 ≤ MCM2 ≤ 1.2, (ix) 0.8 ≤ MG ≤ 1.2, (x) 0.8 ≤ VG ≤ 1.2, (xi) 0.8 ≤ IOAr ≤ 1.0, (xii) 0.9 ≤ ρ ≤ 1.0, (xiii) 0.8 ≤ RHCratio ≤ 1.2, and (xiv) –15 ≤ Ap ≤ 15. In addition to the already-mentioned criteria, the degree of closeness of plotted points in the scatter and Q-Q graphical representations to the identity line can help determine the superiority of one model over the other. In this study, the performance measures of m, b/C0, FV, ρ, RHCratio, MCM2, IOAr, and Ap were computed using Microsoft Excel, while CORR, NMSE, FB, FA2, MG, VG, and bootstrap 95% confidence interval estimates over NMSE, r, FB, MG, and VG were computed using the BOOT v2.0. Graphical representations of the scatter plots and the Q-Q plots were obtained from using the MINITAB 16 and MathWorks MATLAB 2011b software, respectively.
On the contrary to general air quality model evaluation procedure, ANN modelers have preferred the use of “cross-validation” methodology and determined the performance of model predictions using the averaged cross-validation errors. In addition to validating the developed ANN-based IAQ models with the “holdout” predictions using a set of operational performance measures recommended by Kadiyala and Kumar (2012d), this study computed the threefold cross-validated root mean square error. To perform the threefold cross validation (3-fold CV), the data sets (RT, PDG, TD) were randomly divided into three independent equivalent subsets. ANN-based IAQ models were trained and validated using two subsets and the predictive error (RMSE) over the third subset (test set) was determined. The process is repeated thrice such that each of the three subsets is used as a test set for once and the RMSEs from the three runs were averaged. The holdout RMSE and the averaged 3-fold CV RMSE were divided with the mean observed values and multiplied by 100 to obtain a nondimensional prediction error term referred as RMSE (%).
Results and Discussion
Table 4 presents the statistical performance measures computed for the BP-, RBF-, and GA-based neural network models with RT, PDG, and TD data sets for the monitored in-bus contaminant of CO2 obtained from the holdout validation. From , one can note that the BPN models did not meet the stringent IAQ model acceptance criteria of 0.9 ≤ CORR ≤ 1.0, 0.75 ≤ m ≤ 1.25, −25 ≤ b/C0 (%) ≤ 25, −0.5 ≤ FV ≤ 0.5, 0.8 ≤ IOAr ≤ 1.0, and 0.9 ≤ ρ ≤ 1.0, while the RBFN models did not meet the criteria for CORR, IOAr, and ρ. Only the GA-based neural network models (GATD, GAPDG, GART) satisfied all the 14 IAQ model acceptance criteria considered in this study. There was not much difference between the computed performance measures of GATD and GART models for the in-bus CO2 contaminant concentration.
Table 4. CO2 statistical performance measures
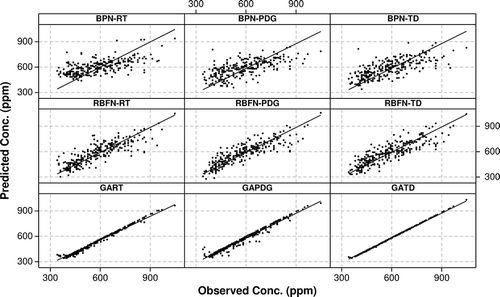
presents the bootstrap 95% confidence limits computed for the BP-, RBF-, and GA-based neural network models with the RT, PDG, and TD data sets for CO2 obtained from the holdout validation. From , one can notice that irrespective of the data set considered, all three neural network techniques (BP-, RBF-, GA-based neural networks) were significantly different from zero for NMSE, CORR, MG, and VG statistics. The BPN-RT and the three GA-based neural network models exhibited the significant difference to zero property with FB, which was not the case with the remaining BPN and RBFN models. presents the scatter plots obtained for the in-bus CO2 contaminant using the BP-, RBF-, and GA-based neural networks with RT, PDG, and TD data sets. In summary of the discussion on the performance of the developed in-bus CO2 concentration models using the holdout validation, one can conclude that the GA-based neural networks outperformed the BPN and the RBFN models, and the GART model accounted for majority of the variance observed in the in-bus CO2 contaminant concentrations.
Table 5. CO2 bootstrap 95% confidence limits
Figure 3. Scatter plots for CO2 observed and predicted values.
presents the statistical performance measures computed for the GA-based neural network models with RT, PDG, and TD data sets for the monitored in-bus contaminants of CO, NO, SO2, 0.3–0.4 particle numbers, 0.4–0.5 particle numbers, PM1.0, and PM2.5 obtained from the holdout validation. The three GA-based neural network models developed for the in-bus contaminant concentrations of CO, SO2, 0.3–0.4 particle numbers, PM1.0, and PM2.5 met all the IAQ model acceptance criteria. Of the three GA-based neural network models developed for NO concentrations inside the bus, only the GART models satisfied all the IAQ model acceptance criteria; GATD and GAPDG models did not meet the stringent guidelines for ρ. The GART models developed for in-bus 0.4–0.5 particle numbers entirely satisfied the IAQ performance measures criteria, while the GATD and GAPDG models failed to meet the stringent guidelines of MG and VG. Figures illustrate the scatter plots obtained for the in-bus contaminants of CO, NO, SO2, 0.3–0.4 particle numbers, 0.4–0.5 particle numbers, PM1.0, and PM2.5, respectively, using the BP-, RBF-, and GA-based neural networks with RT, PDG, and TD data sets. In view of the discussion on comparing the performance of the three GA-based neural network models with holdout validation, one can conclude that only the GART models satisfied all the stringent IAQ model acceptance criteria and the GART modeling approach proved to be an effective/optimal method of modeling in-bus air quality, considering the development of valid IAQ models with elimination of the insignificant independent input variables that cause noise.
Table 6. Statistical performance measures for GA-based neural networks for CO, NO, SO2, 0.3–0.4 particle numbers, 0.4–0.5 particle numbers, PM1.0, and PM2.5
Figure 4. Scatter plots for CO observed and predicted values.
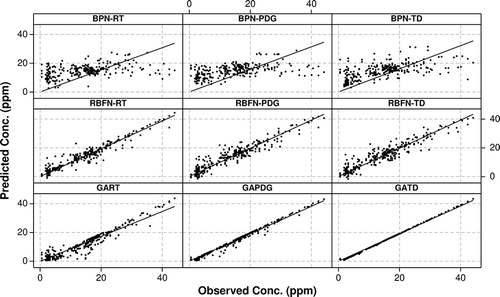
Figure 5. Scatter plots for NO observed and predicted values.
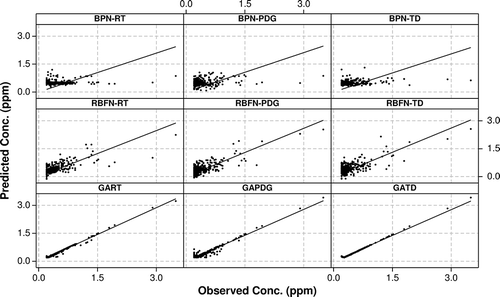
Figure 6. Scatter plots for SO2 observed and predicted values.
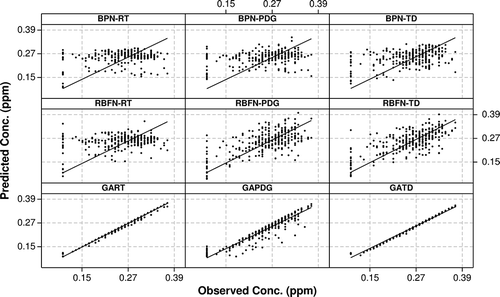
Figure 7. Scatter plots for 0.3–0.4 µm sized particle numbers observed and predicted values.
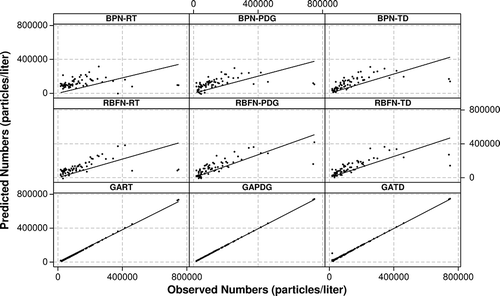
Figure 8. Scatter plots for 0.4–0.5 µm sized particle numbers observed and predicted values.
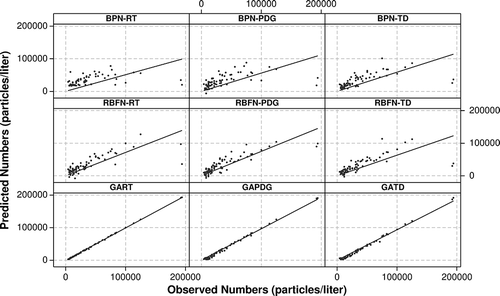
Figure 9. Scatter plots for PM1.0 observed and predicted values.
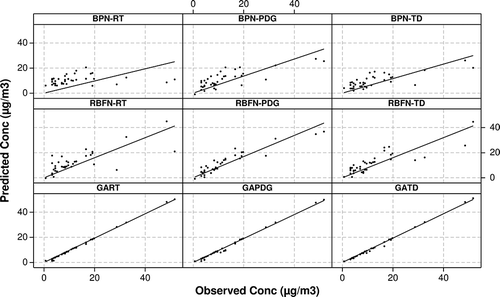
Figure 10. Scatter plots for PM2.5 observed and predicted values.
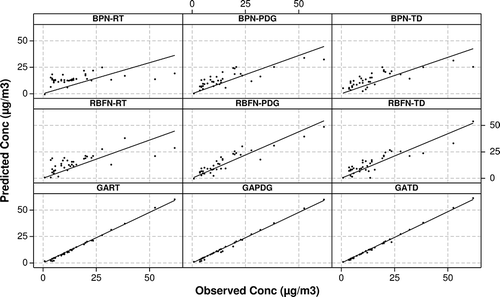
Irrespective of the in-bus contaminant considered, none of the BPN and RBFN models met all the stringent IAQ guideline criteria; the only exception was the RBFN-RT model developed for CO concentration, as can be observed from the supplemental document Tables S1 through S7 (CitationKadiyala et al., 2013). The bootstrap 95% confidence limits for the in-bus contaminants of CO, NO, SO2, 0.3–0.4 particle numbers, 0.4–0.5 particle numbers, PM1.0, and PM2.5, for the BP-, RBF-, and GA-based neural network models with RT, PDG, and TD datasets were summarized in the supplemental document Tables S8 through S14 (CitationKadiyala et al., 2013). Q-Q plots for the in-bus contaminants of CO2, CO, NO, SO2, 0.3–0.4 particle numbers, 0.4–0.5 particle numbers, PM1.0, and PM2.5, obtained from the development of BP-, RBF-, and GA-based neural networks with RT, PDG, and TD data sets were also documented as Figures S1 through S8 in the supplemental document (CitationKadiyala et al., 2013). In summary of the discussion on comparing the performance of BPN and RBFN models with holdout validation, none of the developed in-bus air quality models were valid; the only exception was the RBFN-RT model developed for CO concentrations.
presents a summary of the holdout validation and the 3-fold CV prediction errors, that is, RMSE (%), for the developed in-bus air quality models. The prediction errors with the holdout validation and the 3-fold CV varied in the ranges 0.98–17.57% and 0.91–10.16% for the BPN models, 0.74–13.13% and 0.62–6.36% for the RBFN models, and 0.13–2.09% and 0.08–3.94% for the GA-based neural network models, respectively. On considering the GART models, one can note that the 3-fold CV RMSE (%) was relatively less than the corresponding holdout validation RMSE (%), with the exception of CO and PM1.0 in-bus contaminants.
Table 7. Summary of the holdout validation and the 3-fold CV prediction errors for the developed in-bus air quality models
The development of valid in-bus air quality prediction models is useful for managing air quality and for the development of practical exposure models by computing the time-weighted average (TWA) concentration. The results from the exposure models could then be used to compare against the current IAQ guidelines as discussed by CitationKadiyala et al. (2010) and health standards. As an example, if the TWA in-bus contaminant concentrations or the peak concentrations exceed the recommended guidelines for a bus, the public transit authorities could increase the air changes per hour, which can prevent the accumulation of in-bus contaminants beyond the permissible limits.
Conclusion
A novel methodology to accurately predict the in-bus contaminant concentrations was developed and successfully applied to an experimental field program. The statistically significant variables affecting each monitored contaminant were determined from performing the ANOVA as a complimentary sensitivity analysis to the regression tree results. The identified statistically significant variables from aforementioned step were then used as input parameters to develop GA-based neural network models, referred as the GART models, which made valid predictions of the in-bus contaminant levels. Performance of the three ANNs—BP-, RBF-, and GA-based neural networks—were evaluated with the model performance measures using three data sets, namely, RT, PDG, and TD. Irrespective of the data set considered, GA-based neural network models performed much better than the BPN and RBFN models. The GART modeling approach captured majority of the variation observed in the in-bus contaminants and it is hoped that the use of GART models will be examined extensively in other fields of study also. It should be noted that this study is based on the data collected inside a single transit bus and that, while it illustrates a new methodology to modeling in-bus air quality, the results may not be generalizable.
Supplementary Material
Download MS Word (1.9 MB)Acknowledgment
The authors thank the U.S. Department of Transportation and Toledo Area Regional Transit Authority (TARTA) for the alternate fuel grant awarded to the Intermodal Transportation Institute of the University of Toledo. The authors also express their sincere gratitude to the TARTA management and the employees for their interest and involvement in this work during data collection throughout the grant period. The authors do not have any financial relationships/gains in relation to using the Grimm 1.108 instrument, Yes Plus instrument, and commercial software package used in this study such as MATLAB. The views expressed in this paper are those of the authors alone and do not represent the views of the funding organizations.
References
- Blackmore , K. and Bossomaier , T. 2003 . Using a Neural Network and Genetic Algorithm to Extract Decision Rules . Proceedings of the 8th Australian and New Zealand Conference on Intelligent Information Systems , 12 December 10 : 187 – 191 . Sydney, Australia
- Broomhead , D.S. and Lowe , D. 1988 . Multivariable Functional Interpolation and Adaptive Networks . Complex Syst. , 2 : 321 – 355 . doi: 10.1234/12345678
- Brunelli , U. , Piazza , V. , Pignato , L. , Sorbello , F. and Vitabile , S. 2007 . Two-Days Ahead Prediction of Daily Maximum Concentrations of SO2, O3, PM10, NO2, CO in the Urban Area of Palermo, Italy . Atmos. Environ. , 41 : 2967 – 2995 . doi: 10.1016/j.atmosenv.2006.12.013
- Bryson , A.E. and Ho , Y.C. 1969 . Applied Optimal Control: Optimization, Estimation and Control , New York , NY : Blaisdell Publications .
- Dong , X. , Wang , S. , Sun , R. and Zhao , S. Design of Artificial Neural Networks Using a Genetic Algorithm to Predict Saturates of Vacuum Gas Oil . Petrol. Sci. , 7 118 – 122 . doi: 10.1007/s12182-010-0015-y
- Esber , L.A. and El-Fadel , M. 2008 . In-Vehicle CO Ingression: Validation Through Field Measurements and Mass Balance Simulations . Sci. Total Environ. , 394 : 75 – 89 . doi: 10.1016/j.scitotenv.2008.01.034
- Gardner , M.W. and Dorling , S.R. 1998 . Artificial Neural Networks (the Multilayer Perceptron)—A Review of Applications in the Atmospheric Sciences . Atmos. Environ. , 32 : 2627 – 2636 . doi: 10.1016/S1352-2310(97)00447-0
- Gardner , M.W. and Dorling , S.R. 1999 . Neural Network Modelling and Prediction of Hourly NOx and NO2 Concentrations in Urban Air in London . Atmos. Environ. , 33 : 709 – 719 . doi: 10.1016/S1352-2310(98)00230-1
- Goldberg , D.E. 1989 . Genetic Algorithms in Search, Optimization and Machine Learning , Boston , MA : Addison-Wesley Longman .
- Haykin , S. 1994 . Neural Networks: A Comprehensive Foundation , 2nd , New York , NY : Macmillan Publications .
- Holland , J.H. 1975 . Adaptation in Natural and Artificial Systems , Arbor : Ann University of Michigan Press .
- Holland , J.H. 1995 . Hidden Order: How Adaptation Builds Complexity , Reading , MA : Addison-Wesley .
- Hornik , K. , Stinchcoombe , M. and White , H. 1989 . Multi Layer Feed Forward Networks Are Universal Approximators . Neural Networks , 2 : 359 – 366 . doi: 10.1016/0893-6080(89)90020-8
- Kadiyala , A. 2012 . Development and Evaluation of an Integrated Approach to Study In-Bus Exposure Using Data Mining and Artificial Intelligence Methods. PhD dissertation , Toledo , OH : University of Toledo .
- Kadiyala , A. , Kaur , D. and Kumar , A. 2011 . Application of MATLAB to Select an Optimum Performing Genetic Algorithm for Predicting In-Vehicle Pollutant Concentrations . Environ. Prog. Sustainable Energy. , 29 : 398 – 405 . doi: 10.1002/ep.10527
- Kadiyala , A. , Kaur , D. and Kumar , A. 2013 . Development of Hybrid Genetic Algorithm Based Neural Networks Using Regression Trees for Modeling . Air Quality Inside a Public Transportation Bus (Supplementary Document). ,
- Kadiyala , A. and Kumar , A. 2008 . Application of CART and Minitab Software to Identify Variables Affecting Indoor Concentration Levels . Environ. Prog. , 27 : 160 – 168 . doi: 10.1002/ep.10292
- Kadiyala , A. and Kumar , A. 2011a . Quantification of In-Vehicle Gaseous Contaminants of Carbon Dioxide and Carbon Monoxide Under Varying Climatic Conditions . Air Qual. Atmos. Health. , doi: 10.1007/s11869-011-0163-2
- Kadiyala , A. and Kumar , A. 2011b . Study of In-Vehicle Pollutant Variation in Public Transport Buses Operating on Alternative Fuels in the City of Toledo, Ohio . Open Environ. Biol. Monit. J. , 4 : 1 – 20 . doi: 10.2174/1875040001104010001
- Kadiyala , A. and Kumar , A. 2012a . “ Examination of Two Different Mathematical Techniques for Determining the Important Factors Affecting Indoor Air Quality ” . In Handbook of Genetic Algorithms: New Research , Edited by: Muñoz , A.R. and Rodriguez , I.G. p. 93–112. New York: Nova Science Publishers .
- Kadiyala , A. and Kumar , A. 2012b . Development and Application of a Methodology to Identify and Rank the Important Factors Affecting In-Vehicle Particulate Matter . J.Hazard. Mater. , 213–214 : 140 – 146 . doi: 10.1016/j.jhazmat.2012.01.072
- Kadiyala , A. and Kumar , A. 2012c . An Examination of the Sensitivity of Sulfur Dioxide, Nitric Oxide, and Nitrogen Dioxide Concentrations to the Important Factors Affecting Air Quality Inside a Public Transportation Bus . Atmosphere , 3 : 266 – 287 . doi: 10.3390/atmos3020266
- Kadiyala , A. and Kumar , A. 2012d . Guidelines for Operational Evaluation of Air Quality Models , Saarbrücken : LAP LAMBERT Academic .
- Kadiyala , A. , Kumar , A. and Vijayan , A. 2010 . Study of Occupant Exposure of Drivers and Commuters With Temporal Variation of In-Vehicle Pollutant Concentrations in Public Transport Buses Operating on Alternative Diesel Fuels . Open Environ. Eng. J. , 3 : 55 – 70 . doi: 10.2174/1874829501003010055
- Karr , C.L. , Weck , B. , Massart , D.L. and Vankeerberghen , P. 1995 . Least Median Squares Curve Fitting Using Genetic Algorithm . Eng. Appl. Artif. Intell. , 8 : 177 – 189 . doi: 10.1016/0952-1976(94)00064-T
- Khare , M. and Nagendra , S.M.S. 2006 . Artificial Neural Networks in Vehicular Pollution Modeling , New York , NY : Springer-Verlag .
- Klepeis , N.E. , Nelson , W.C. , Ott , W.R. , Robinson , J.P. , Tsang , A.M. , Switzer , P. , Behar , J.V. , Hern , S.C. and Engelmann , W.H. 2001 . The National Human Activity Pattern Survey (NHAPS): A Resource for Assessing Exposure to Environmental Pollutants . J.Expos. Anal. Environ. Epidemiol. , 11 : 231 – 252 . doi: 10.1038/sj.jea.7500165
- Kolehmainen , M. , Martikainen , H. and Ruuskanen , J. 2001 . Neural Networks and Periodic Components Used in Air Quality Forecasting . Atmos. Environ. , 35 : 815 – 825 . doi: 10.1016/S1352-2310(00)00385-X
- Kukkonen , J. , Partanen , L. , Karppinen , A. , Ruuskanen , J. , Junninen , H. , Kolehmainen , M. and Gwynne , M. 2003 . Extensive Evaluation of Neural Network Models for the Prediction of NO2 and PM10 Concentrations, Compared With a Deterministic Modelling System and Measurements in Central Helsinki . Atmos. Environ. , 37 : 4539 – 4550 . doi: 10.1016/S1352-2310(03)00583-1
- Maier , H.R. and Dandy , G.C. 2001 . Neural Network Based Modeling of Environmental Variables: A Systematic Approach . Math. Comput. Model. , 33 : 669 – 682 . doi: 10.1016/S0895-7177(00)00271-5
- Michalewicz , Z. 1996 . Genetic Algorithms + Data Structures = Evolution Programs , 3rd , New York , NY : Springer-Verlag .
- Moustris , K.P. , Ziomass , I.C. and Paliatsos , A.G. 2010 . 3-Day-Ahead Forecasting of Regional Pollution Index for the Pollutants NO2, CO, SO2, and O3 Using Artificial Neural Networks in Athens, Greece . Water Air Soil Pollut. , 209 : 29 – 43 . doi: 10.1007/s11270-009-0179-5
- National Climatic Data Center. 2011. NCDC http://cdo.ncdc.noaa.gov/ulcd/ULCD (http://cdo.ncdc.noaa.gov/ulcd/ULCD)
- Negnevitsky , M. 2005 . Artificial Intelligence: A Guide to Intelligent Systems , 2nd , Harlow : Pearson Education Limited .
- Niska , H. , Hiltunen , T. , Karppinen , A. , Ruuskanen , J. and Kolehmainen , M. 2004 . Evolving the Neural Network Model for Forecasting Air Pollution Time Series . Eng. Appl. Artif. Intell. , 17 : 159 – 167 . doi: 10.1016/j.engappai.2004.02.002
- Papanastasiou , D.K. , Melas , D. and Kioutsioukis , I. 2007 . Development and Assessment of Neural Network and Multiple Regression Models in Order to Predict PM10 Levels in a Medium-Sized Mediterranean City . Water Air Soil Pollut. , 182 : 325 – 334 . doi: 10.1007/s11270-007-9341-0
- Perez , P. , Trier , A. and Reyes , J. 2000 . Prediction of PM2.5Concentrations Several Hours in Advance Using Neural Networks in Santiago, Chile . Atmos. Environ. , 34 : 1189 – 1196 . doi: 10.1016/S1352-2310(99)00316-7
- Powell , M.J.D. 1977 . Restart Procedures for the Conjugate Gradient Method . Math. Prog. , 12 : 241 – 254 . doi: 10.1007/BF01593790
- Schwefel , H.P. 1995 . Evolution and Optimum Seeking , New York , NY : John Wiley .
- TARTA Routes, 2011. Route #20 http://www.tarta.com/wp-content/uploads/routes/20.pdf (http://www.tarta.com/wp-content/uploads/routes/20.pdf)