
ABSTRACT
With the advent of unconventional natural gas resources, new research focuses on the efficiency and emissions of the prime movers powering these fleets. These prime movers also play important roles in emissions inventories for this sector. Industry seeks to reduce operating costs by decreasing the required fuel demands of these high horsepower engines but conducting in-field or full-scale research on new technologies is cost prohibitive. As such, this research completed extensive in-use data collection efforts for the engines powering over-the-road trucks, drilling engines, and hydraulic stimulation pump engines. These engine activity data were processed in order to make representative test cycles using a Markov Chain, Monte Carlo (MCMC) simulation method. Such cycles can be applied under controlled environments on scaled engines for future research. In addition to MCMC, genetic algorithms were used to improve the overall performance values for the test cycles and smoothing was applied to ensure regression criteria were met during implementation on a test engine and dynamometer. The variations in cycle and in-use statistics are presented along with comparisons to conventional test cycles used for emissions compliance.
Implications: Development of representative, engine dynamometer test cycles, from in-use activity data, is crucial in understanding fuel efficiency and emissions for engine operating modes that are different from cycles mandated by the Code of Federal Regulations. Representative cycles were created for the prime movers of unconventional well development—over-the-road (OTR) trucks and drilling and hydraulic fracturing engines. The representative cycles are implemented on scaled engines to reduce fuel consumption during research and development of new technologies in controlled laboratory environments.
Introduction
The United States has experienced growth in the natural gas industry over the past decade. Annual gross withdrawals of natural gas in the United States have increased 25% since 2005 from 23 million to over 31 million cubic feet (U.S. Energy Information Administration [EIA], Citation2016). The U.S. Energy Information Administration (EIA) also estimates that there are about 2.276 trillion cubic feet (Tcf) of recoverable resources of dry natural gas in the United States, which at the current rate of consumption is enough to last about 84 years (EIA, Citation2015). These advances are a product of the new technologies of horizontal drilling and hydraulic fracturing. In order to utilize these resources, strategies are being implemented to reduce costs and emissions. One strategy involves displacing diesel fuel with natural gas in the prime movers associated with well development via either dual-fuel or dedicated natural gas applications. These prime movers, or major diesel consumers, include heavy-duty over-the-road (OTR) trucks and high-horsepower drilling and fracturing engines.
The process of unconventional well development consists of four major steps: planning and preparation of the well pad site, drilling, casing and cementing, and completion and stimulation (Canadian Society for Unconventional Resources, Citation2012). The primary consumer of fuel during preparation of the site is OTR trucks. Heavy-duty OTR trucks transport gravel, dirt, and other materials to and from the site. Vertical and horizontal drilling applications use high-horsepower engines to power rigs. Heavy-duty OTR trucks also haul water, drilling fluids, and other supplies during drilling. The drilling company often performs casing and cementing that involve the same engines as drilling, with an increase in truck traffic. Hydraulic fracturing is the most energy-intensive step in the process and involves the use of high-horsepower fracturing engines and large amounts of truck traffic for the delivery of water, sand, and fracturing chemicals. It is estimated that a Marcellus Shale well pad with four wells requires 20,000–30,000 truck trips during the completion of those wells—yielding up to 4 million truck trips per year for the entire Marcellus region (Carr et al., Citation2012). Drilling engines operate continuously from rig setup until drilling, casing, and cementing are completed. The Texas Commission on Environmental Quality, in a survey of 1261 wells, found that the average drilling duration for a well was between 8 and 27 days depending on the depth of the vertical section and length of the horizontal sections. On average, the drilling rigs consisted of 2.15 engines, with an average size of 1381 horsepower (hp) each. These engines operate on average 62.6 hr per 1000 feet drilled at an average load of 48.5% (Baker and Pring, Citation2009). A report by Global Hunter Securities in collaboration with Prometheus Energy states that the average drilling rig uses between 62.5 and 83.3 gallons of diesel fuel per hour, resulting in 1500–2200 gallons of diesel per day (Kelly, Citation2012). A study by Argonne National Laboratory (ANL) assumed that a rig ran on one 2000-hp engine at 45% load and consumed 0.06 gal/hp/hr in its analysis. The study focused on four major shale plays and the fuel consumed in these plays depended mostly on the depth of the well and the amount of time required for drilling. Diesel fuel consumption by shale play ranged from 43,041 gallons for the Fayetteville Shale to 85,845 gallons for the Haynesville, with the Barnett and Marcellus within this range (Clark et al., Citation2012).
High-horsepower diesel engines also power hydraulic fracturing pumps. A typical fracturing fleet features engine capacities over 20,000 hp. An average site requires 8–12 fracturing pumps, but some require up to two dozen, each rated between 1500 and 2500 hp. Fracturing a well can consume between 2000 and 8000 gallons of diesel fuel per day. The University of Michigan performed site surveys in the Marcellus and Eagle Ford shale plays and showed average fleet sizes of 14 and 16 engines, respectively. The average fuel consumption during stimulation of a well in these shales was 20,800 and 22,100 gallons, respectively. The engines at both sites were Caterpillar 3512Cs (Peoria, IL) rated at 2250 hp.
Prime mover engines are subject to emissions compliance regulations as tested over specific engine cycles. The primary engine test cycle over which on-road heavy-duty diesel engines are certified is the transient Federal Test Procedure (FTP) engine dynamometer test cycle defined in Code of Federal Regulation (CFR) Title 40 Subchapter C Part 86 Appendix I. The new greenhouse gas (GHG) standards also use the FTP cycle for certification of vocational engines. This cycle is a series of speed and torque points normalized to a percentage for applicability to all engines (DieselNet, Citation1999). As a result of the consent decrees, engine certification also involves the Supplemental Emission Test (SET) and not-to-exceed (NTE) testing, in addition to the FTP cycle (DieselNet, Citation2015). Certification of nonroad engines is also based on the emissions standards outlined by the CFR. Engine tests occur on dynamometers based on the procedures of CFR Title 40 Chapter I Subchapter U Part 1039. Certification of Tier 1–3 engines requires operation over steady-state tests. The International Organization for Standardization ISO 8178 is the standard for nonroad engine emissions testing. This test, also known as the Non-Road Steady Cycle (NRSC), consists of five modes of steady-state operation and is applicable to both drilling and hydraulic fracturing engines (DieselNet, Citation2001).
Although these cycles are well defined, they may not be representative of in-use operation. Additionally, research and development on full-scale engines is energy intensive and cost prohibitive from a fueling standpoint. Therefore, our goal was to collect representative in-use activity data and develop a method to create representative cycles for application on scaled engines within our test cell.
Data collection
OTR trucks
Collection of data from OTR trucks servicing the unconventional well development industry was performed over a 6-month period, beginning June 6, 2014, and concluding January 9, 2015. The vehicles targeted for data collection were heavy-duty diesel vehicles that were travelling to and from unconventional natural gas wells in the Marcellus Shale region. These heavy-duty OTR trucks consisted of those hauling water, sand, and gravel. Over 100 companies in the Marcellus and other shale plays were contacted. Seven different companies located throughout Ohio, Pennsylvania, and West Virginia provided access to 25 vehicles for data collection. Vehicle instrumentation was random within each fleet, and no specifications on vehicle age, mileage, or other variables were required. Of the 25 vehicles, 18 were water haulers, 6 were sand haulers, and 1 carried gravel for site preparation. The engines populating the vehicles consisted of 18 Cummins ISX-15 (Columbus, IN) engines, 4 Caterpillar C-15 (Peoria, IL) engines, 2 Volvo D13 (Greensboro, NC) engines, and 1 Mack MP8 (Greensboro, NC). provides a summary of the vehicles instrumented. It is noted that the vehicles all operated within the greater Marcellus region and their activity may not be representative of all unconventional natural gas shale plays. The number of truck trips varies by well pad, region, infrastructure, and other logistical variables. Three studies have estimated that a majority of truck trips per well development are attributed to hauling water to and from sites (67–78% of all truck trips) (Maryland Department of the Environment [MDE], Citation2014; Felsburg Holt and Ullevig, Citation2013; Massachusetts Institute of Technology [MIT], Citation2011). Of the 25 random vehicles in this program, 68% were water-hauling trucks.
Table 1. Well service vehicle data collection information.
Data collection occurred at a rate of 1 Hz using DAWN J1939 Mini Loggers (HEM Data, Citation2015). Although dozens of engine control unit (ECU) parameters were available and ultimately collected, the only parameters relevant to the creation of engine test cycles under this work were engine speed and percent load at current speed. The resulting data set included 4,724,800 data points, or over 54 days of data. The International Society of Automotive Engineers (SAE) under J1939 protocol defines the parameters as follows:
Engine percent load at current speed—SPN 92: The ratio of actual engine percent torque (indicated) to maximum available at the current engine speed, clipped to zero torque during engine braking.
Engine speed—SPN 190: Actual engine speed calculated over a minimum crankshaft angle of 720 degrees divided by the number of cylinders (“Vehicle Application Layer”; SAE, 2015).
Drilling
Drilling activity data collection occurred during the drilling of two horizontal wells in Westover, West Virginia. The collection of data occurred over a period of 11 days from September 9, 2015, to September 21, 2015. The rig used three Caterpillar 3512C generator units, rated at 1101 kW. These engines were outfitted with dynamic gas blending (DGB) kits allowing the engines to run in either dual fuel or diesel only mode. Data collected occurred on a single engine that operated continuously during rig setup, preparation, pipe tripping (PT), and steady-state drilling (SSD).
The engine control unit broadcasted data, which were recorded using a nine-pin Deutsch connector and a VIA HDV100A1 from B&B Electronics (Ottawa, IL). An in-house software recorded SAE J1939 parameters. After conversion of data to CSV format, it was determined that only 233 of the 311 hr were valid.
Use of activity logs from the drilling company assisted in sorting data. presents a breakdown of the engine activity. This breakdown shows the amount of time spent performing each type of activity necessary for the completion of drilling. Note that data were obtained during the horizontal portions of the wells and may not be representative of the vertical or conventional drilling portion. In addition, drilling activity varies by well, depth, operator, and shale play; but in discussions with the site operators, the activities were typical for the Marcellus region.
Table 2. Drilling activity breakdown.
Hydraulic fracturing
Collection of hydraulic fracturing activity occurred during two separate campaigns with two different fracturing fleets. Collection of data was similar to drilling: with a nine-pin Deutsch connector, serial cable, VIA model HDV100A1 from B&B Electronics (Ottawa, IL), and a laptop computer. The first data collection effort occurred over 21 days between July 19, 2015, and August 8, 2015, from a well pad in central West Virginia. Data collection occurred on four different hydraulic fracturing pumps during the stimulation of six wells. Cummins QSK50 engines, rated at 1678 kW, powered these pumps.
The second data collection effort occurred at a well pad near Morgantown, West Virginia. Data collection occurred on a Caterpillar 3512B-HD engine rated at 1678 kW over a period of 7 days from November 5, 2015, to November 12, 2015. The engine included a dynamic gas blending kit allowing it to operate in either diesel only or dual fuel mode. We collected data from 12 fracturing stages. We eliminated data from three stages due to erratic values. The hydraulic fracturing engines operated at rated speed except for when the engines were idling between stages, which was limited. presents a summary of the data. Since the engines typically operated at rated speed, the most important engine parameter was percent load at current speed. Note that all OTR and drilling data were collected at 1 Hz. In some cases of hydraulic fracturing, data were collected at 10 Hz (due to hardware), but a 10-point average was used to down-sample the data for use as 1 Hz. Both data sets were collected in the Marcellus Shale region. In addition, hydraulic stimulation activity varies by well, depth, operator, and shale play; but in discussions with the site operators, the activities were typical for the Marcellus region.
Table 3. Hydraulic fracturing data collection information.
Cycle development
Numerous approaches are available to create engine or chassis dynamometer test cycles, including Markov chain Monte Carlo simulations, micro-trips, or day-in-the-life cycles (Clark et al., Citation2007; Steven, Citation2001; Ullman, Citation1999). The technique selected was a stochastic second-by-second concatenation, which utilized Markov chain theory. We applied the same method to all three types of cycle development. We selected a starting period of engine idle and from there the Markov chain technique was allowed to progress freely based on the transition probability matrix of each of the respective data sets. We imposed a time limit of 30 min (1800 sec) on each of the cycles. The FTP cycle is 20 min long (DieselNet, Citation1999); however, research suggests that longer Markov chains were more representative when attempting to match a distribution (Geyer, Citation1992; Smith, Citation2003). Previous studies on cycle development used 30 min as the time of the cycle (Steven, Citation2001). We selected 30 min to align with Steven (Citation2001) and to provide a longer than conventional engine cycle length. Longer cycles should be examined under future work, but due to fuel restrictions, we retained 30 min as the upper limit such that a single cold start and three repeated hot starts could be conducted using the same compressed natural gas cylinder bank.
Review
Wide varieties of sciences use Markov chain Monte Carlo (MCMC) simulations as a way to estimate probabilities and perform numerical integration. MCMC is “a general method for the simulation of stochastic processes having probability densities known up to a constant proportionality” (Geyer, Citation1992).
The theory behind MCMC is subdivided into Markov chain techniques and Monte Carlo simulations. A Markov chain is a stochastic process that has stationary transition probabilities. The Markov chain is a string of concatenated values from a defined “state space,” or data being sampled (Smith, Citation2003). A Markov chain is often described by saying that there exists some state, or event, and that state contains a transitional probability matrix, which gives the likelihood of the next state.
The next state in the chain depends only on the current state and its transition probability matrix. The Markov chain is “stationary” if any state in the chain has a transitional probability distribution that is independent of the location of the state. Thus, probability of reaching the next state is the same for all states in the chain and likely independent on initial distribution. If a Markov chain is not stationary, then the transition probabilities change as the chain moves further from the initial state. As the length of the chain increases, the distribution of the states becomes less dependent on the initial state and more dependent on the transition probabilities (Geyser, Citation2011).
If an overall distribution defines each states transition probability matrix and if the chain becomes “long,” the distribution of the chain itself will approach the overall distribution (Smith, Citation2003). The most effective way to reach this desired distribution is by allowing the Markov chain array to grow large. The actual size necessary to properly represent a distribution will be dependent on the size of the data set, and the problem at hand. Cycle development extensively employs Markov chains, as shown in the next section. MCMC simulations expand on the idea of Markov chains, but flip the objective of the problem. Rather than attempting to find the distribution of a specific Markov chain, MCMC starts with a defined distribution and attempts to create a Markov chain that has this same distribution (Smith, Citation2003). When this is the case, one knows the distribution of interest and the Markov chain proceeds in the same stochastic manner until it has an array length, which is long enough to adequately represent the distribution. Researchers employ MCMC techniques to genomics, variable selection in regression, spatial statistics, longitudinal studies, mathematical chemistry, statistical physics, or when more simplistic techniques cannot be used.
The work performed by Smith is the most relevant example of engine test cycle development using a MCMC method for heavy-duty on-road vehicles (Smith, Citation1978). Researchers commonly use MCMC for generation of drive cycles. Ohio State University’s Center for Automotive Research generated driving cycles of plug-in hybrid electric vehicle (PHEV) using a Markov chain technique. Researchers collected data from nine PHEV passenger cars consisting of over 70,000 miles of data that were segmented into 530 “sessions” defined from key-on to key-off (Gong et al., Citation2011). Dembski et al., also of Ohio State University, used similar techniques and calculations of sequence occurrence probabilities to analyze drive cycles for passenger cars. Kinematic sequences defined by velocity and acceleration were developed and linked together based on the probability of each type of sequence occurring, essentially utilizing a Markov chain to create drive cycles (Dembski et al., Citation2002). Researchers at University of California–Davis used Markov chains to produce drive cycles for a number of research programs from light-duty vehicles and chase vehicles (Lin and Niemeier, Citation2002; Lin and Niemeier, Citation2003; Dai et al., Citation2008).
Data processing and second-by-second concatenation
OTR trucks
We used MATLAB (MathWorks, Natick, MA) for data processing and cycle development algorithms. Normalization of engine data is necessary to compare engine operation between different sizes, makes, and models. All normalized data points contain a value from 0 to 1, representing 0–100% of the maximum possible value. The parameter percent load at current speed is an example of a normalized parameter. This parameter is based on the lug curve of the engine and is broadcasted as a percentage of the maximum possible load at a given engine speed. Previous studies considered this value similar to percent engine torque, especially at high loads (Clark et al., Citation2007). We used this parameter as an equivalent value of normalized percent torque for this methodology. Engine speed normalization was based on the equation used for denormalizing speed from the CFR Title 40 Chapter I Subchapter C Part 86 Subpart N Section 86.1333. Normalizing engine speed was performed using eq 1. It is noted that these engines were all diesel fuel engines, which typically include a factor of 112% of rated speed. Any data within ±2% of 0% speed were set to 0, and the same was done for engine percent load. Any speed between rated and 102% of rated was set to rated speed or 1. Of the over 4 million data points collected, speeds between rated and governed only represented 0.29% of activity and were excluded. It is also noted that all OTR data were collected in the Appalachian Basin and OTR activity may differ by shale play.
Elimination of some data was necessary because the engines often broadcasted false data or trended to an infinite value if the size of the file became too large. Data were deemed invalid if the broadcasted value was outside of the defined limits of a specific parameter and the cause was not known. The second source of invalid data was due to hardware and software issues where an error in recording caused subsequent data to increase in value through the duration of the recording. After filtering of invalid data, speed and load were arranged in a two-column array and concatenated, for each engine.
Data binning used 5% increments for both speed and load. The bins contained values of speed and load greater than or equal to the governing value of the current bin and less than the governing value of the next highest bin. shows the distribution of data. Note that nearly 20% of the activity data occurred in a single bin. This was bin (1, 3) and it contained nearly all of the points that occurred at idle engine speed.
Figure 1. Truck data distribution.
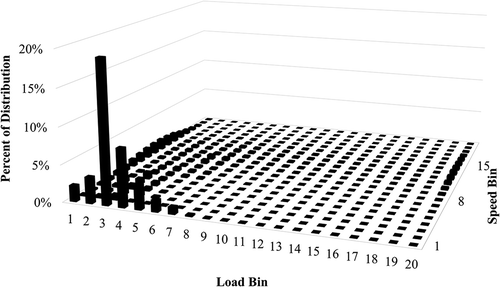
Once the algorithm binned the current point in the distribution matrix, analysis of the next point occurred. The algorithm binned this data point into the transition matrix of the bin of the previously selected point and the overall distribution matrix. The program used a multilayered structure to allow each bin of the overall distribution matrix to also contain a secondary transition matrix of the same size. This was necessary because of the stochastic logic of the Markov chain technique. Once the entire length of the array was binned, a normalized distribution was created by dividing the size of each data bin by the total length of the array. Statistics of the data set were calculated. In addition, tabulated were average speed and load, and time at idle. The idle data points were excluded from a second calculation so that the non-idle speed and load averages could be determined (see ).
Table 4. Trucking data statistics.
Drilling engines
Drilling engines operated at nearly constant rated speed and in this study operated at 1200 revolutions per minute (rpm). The binning logic used was similar to that used for OTR trucks except that it focused only on load. shows the distribution of engine load bins.
Figure 2. Drilling data distribution.
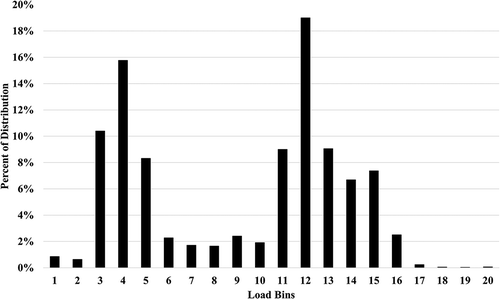
We further subdivided data into two categories of load, high load and low load, for the purpose of calculating statistics. High load was any value at or above 40% and low load below 40%. We selected 40% to ensure that all steady drilling operations were high load. Some of these events occurred at steady-state values below 50%, but none occurred below 40%. The idle time of the data was also calculated and included operation at 0% load—a small overall portion of the time. The average value and the normalized time of high- and low-load operations were calculated. shows the statistics of these data.
Table 5. Drilling data statistics.
Hydraulic fracturing engines
Hydraulic fracturing data binning used the same methodology as drilling. Data bins were in 5% increments, forming an overall distribution matrix by stepping through each point of the array. shows the distribution of these data.
Figure 3. Fracturing data distribution.
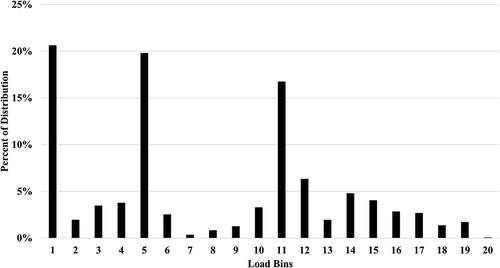
Data were sorted into idle (0% load), low load (points below 40% load), and high load (points at or above 40% load). The average overall load, high load, and low load as well as normalized idle, low-load, and high-load times were calculated. provides the tabular statistics of these data.
Table 6. Fracturing data statistics.
MCMC
The cycle began with a period of idle, and from there the Markov chain technique progressed freely based on the transition probability matrix of each of the respective data sets. Based on the nature of driving and observations made during data collection, it was determined that, at a minimum, the first 30 sec should be idle. Therefore, the algorithm sampled points between 1 and 30 from the zero-speed row of the distribution matrix and weighted on the transition probability matrix of the current bin.
Once 30 sec of idle were completed, the overall distribution matrix was open for sampling and the Marko chain proceeded. We employed a weighted sampling technique to pseudorandomly select the next bin of the cycle. Columns and rows had separate weights. The weights of each were a function of the ratio of the time in a given bin to the total time spent in the column or row. Then, the row of the next bin was selected by sampling 1–20 (the number of rows), based on the weights of the rows developed previously. Selection of the next column bin used the same manner. Once the row and column of the next bin were found, the bin was defined and the algorithm randomly selected from the bin’s population. This point represented the next point in the cycle and was added to the end of the current cycle array. The transition matrix of the selected bin then governed the weights used for selection of the next bin.
The Markov chain continued to sample using the defined method up to 1770 sec. It was determined that the vehicle should return to a state of idle 30 sec before the end of the test to simulate real-world activity and also mark the end of the cycle. If the speed bin of the cycle at this point was above 10, meaning normalized speed was above 50%, an intermediate point was required at point 1771, to create an acceptable derivative of speed. Sampling for that bin moved to the row that was five bins lower than the current bin. Once the current speed bin was below 10, the speed row was forced to 1, the idle speed row, and the process continued as it did in the first 30 sec of cycle construction, with selection of points based only on the load columns until the cycle reached a length of 1800 sec.
With the cycle completed, we imposed limitations on the cycles in two steps. The first was to search the cycle and determine if there were any single points of nonzero speed between points of zero speed. This type of activity made segmentation of cycles, discussed later, difficult and was not necessary to represent real-world engine operation. Once located, we forced these points to zero speed. As an example, in the creation of 100 cycles, each with a length of 1800 sec, only 29 of these points occurred (0.016%) and were forced to zero. The second step was that all points below 2% normal speed or load were forced to zero. The reduction of these points did not change the overall distribution of the cycle and had no effect on idle time, and we verified this by applying the change to a randomly generated sample population of 100 cycles.
We created a distribution of each cycle by stepping through the cycle and binning its points in the same manner as the overall in-use data. The same average statistics were determined from the cycles as from the data. These values included average speed, average load, average non-idle speed, average non-idle load, and normalized idle time. We compared the distribution and average statistics with those of the data and calculated values that defined the representativeness of the individual cycles. These values included the “statistical value” (SV), the “distribution value” (DV), and the “performance value” (PV). Absolute differences between the desired data set and the created cycles defined these values. The DV was defined by taking the absolute difference between the cycle and data of the time distribution of each bin. Each absolute difference was multiplied by 0.05 (equal weighting factor for each of the 20 bins, summing to unity), and the sum of those weighted absolute differences determined the value. Equation 2 gives the definition of DV.
The SV was similar except that it used the absolute differences of the statistics. Each of the five statistics previously defined were given an equal weighting of 0.2 (equal weighting factor for the five statistical categories, summing to unity), and the sum of the weighted differences was used to calculate the SV, as shown by eq 3.
The PV was calculated by combining the DV and SV with equivalent weights of 0.5 and summing them, as shown by eq 4.
We used the above approach for drilling and fracturing engines, with the only major difference being idle time at the beginning and end of each cycle. Based on in-use statistics, we determined that only 10 sec of low load were required at the beginning and end of the cycle.
The use of Markov chain logic should create cycles, which have a similar distribution to that of the overall data. Sometimes, however, a cycle can be stuck in a certain bin or “space,” or a cycle may move through the space while choosing low probability events—a side effect of the random nature of the Markov chain. MCMC simulation is the idea of creating a Markov chain that has an equivalent distribution to the one desired. This can theoretically be accomplished with the creation of one long chain or several smaller chains. Ideally, a cycle constructed under the logic of a Markov chain would exactly match the desired distribution if the cycle grew to infinite length. The other option available to best represent the desired distribution would be to create a “large” number of cycles until one matches the desired distribution. The first option could not be applied, as cycles must have a reasonable length. The second option raised a number of questions. Since an infinite number of cycles could not be created, the main issue was answering the question: “How large must the sample size be for a cycle of optimal representation to be found?” It was not practical to create hundreds of thousands of cycles to find an ideal candidate. In an initial attempt to find the optimal cycle for each of the three prime movers, we used Monte Carlo simulation to create populations of 10,000 cycles for each prime mover. The best PV from these populations of OTR truck, drilling, and hydraulic fracturing cycles were 0.0327, 0.0038, and 0.0323, respectively.
Optimization with a genetic algorithm
Review
The concept of the genetic algorithm (GA) stems from Darwin’s theory of evolution, developed in 1859. The governing principle of the theory is survival of the fittest. The key aspect that separates GAs from algorithms that are more traditional is the use of the population rather than analyzing one individual at a time (Sivanandam and Deepa, Citation2008). GAs are advantageous in solving complex problems for several reasons. These advantages include their ability to discover global optimum solutions, their ability to handle large and poorly understood search spaces, their performance with large-scale optimization, and their easy application to a large variety of problems (Sivandam and Deepa, Citation2008). These advantages make GAs a choice for difficult problems such as cycle development. Several works from West Virginia University (WVU) have used GAs for problems involving cycle development (Marlow, Citation2009; Perhinschi et al., Citation2011).
Design
The first issue encountered was determining how to define the chromosomes and genes of the GA population. The overall cycles constructed by the Markov chain technique defined the chromosomes or individuals. The individuals were composed of 1800-point arrays of speed and load pairs. These individuals all had SVs, DVs, and PVs associated with them as well as distribution matrices and average cycle statistics. We created genes from these individuals. Typically, when using GAs, individuals are converted to binary strings and bits in the strings represent the genes. It was impractical to convert the entire array to binary representation, and so another methodology defined genes. Each cycle was “segmented” into portions of different activity. We defined segments in a similar manner to “micro-trips” from previous studies (Dai et al., Citation2008; Clark et al., Citation2007; Perhinschi et al., Citation2011). Instead of using vehicle speed to define micro-trips, we selected engine speed. Periods of idle and non-idle represented different segments. An idle segment was any length of the cycle longer than 10 sec in which the speed remained at 0% of rated. A non-idle segment was any length of the cycle in which there were more than 10 consecutive seconds of non-idle operation. One hundred random cycles from the 10,000 cycles generated by the MCMC defined the initial population.
With genes defined, we then selected and implemented genetic operators. The GA applied mutation first. The cycles selected for mutation were randomly chosen based on the mutation rate. The GA applied a random number for each cycle in the population. If the number generated was less than the rate of mutation, then the cycle in question experienced mutation. Mutation was the replacement of a segment of the selected cycle by a segment randomly chosen from the pool of segments.
Once mutation occurred, the GA selected cycles for crossover. Determining cycles to experience crossover relied on random number generation for each of the cycles in the initial population of the current generation. Cycles added to the population due to mutation were not eligible for crossover, but the cycles from which they emanated were. If the random number applied to a given cycle was less than the defined crossover rate, then the cycle was selected for crossover. In order to perform crossover, we required another cycle from the population. The GA randomly selected this cycle from the remaining 99 cycles of the current generation.
The new population size was determined by adding the number of newly created cycles from mutation and crossover to the original population size of the generation, which we fixed at 100. We then calculated cycle statistics of the newly created cycles, since newly formed cycles did not contain any information other than the speed load array.
The next step in the GA was to sort the cycles based on their respective PVs in order to determine which individuals were most representative. The PV was desired to be as close to 0 as possible; however, it was not well scaled, between 0 and 1, over the entire population. Many of the cycles within a given population had PVs closer to 0 than 1. In order to more evenly distribute the population so that selection of the next population could be implemented, “evaluation” and “fitness” functions were defined. These functions were necessary to employ roulette-wheel selection to define the next generation. In order to map the PV over the range of [0, 1] to create selection probabilities, the largest and smallest PVs of the respective generation were defined as PVmax and PVmin, respectively. These values were then used to create coefficients a and b, and scale the PV into an “evaluation function” (EF), as shown in eqs 6, 7, and 8.
The use of these equations defined an evaluation function for every cycle. Since a lower PV was desirable, it was more valuable to define the opposite of the EF desired. Equation 9 shows the definition of the inverse EF.
A total fitness (TF) value (see eq 10) and a probability array were then constructed based on each individual’s evaluation function, as is shown in eq 11.
A “q” array was defined that acted as a number line with spacing equivalent to the probabilities defined from eq 12.
Equations 6–12 were all defined in Roeva et al. (Citation2013). With the “q” array defined, roulette-wheel selection could take place to define the next population. In addition to roulette-wheel selection, the GA used elitist selection to ensure the cycle with the lowest PV advanced to the next generation. Elitist selection improves exploitation and reduces variability between generations (Roeva et al., Citation2013). Roulette-wheel selection defined the remaining population. To implement the selection process, we generated a random number between 0 and 1, and placed it on the “q” number line as described above. The index of the “q” value falling directly to the right of the random number was the index of the cycle that advanced. Note that we performed this without removal of the cycle from the pool. This meant that it was possible for the same cycle to have multiple copies in the next generation and that other cycles not selected became extinct. This process continued to define the entire new population of the next generation.
One issue in defining the GA was finding genetic operation rates that most efficiently found a solution. In other words, it was necessary to select the best form of the GA to use in cycle development. We applied several iterations of the GA in an attempt to find the best performing genetic operation rates. During these iterations, the GA ran for a life span of 30 generations with the fixed population of 100. The genetic operation rates varied during these iterations, and each of the iterations was ranked based on the value of the elite PV that was produced. The final GA used the operators that produced the lowest average PV amongst the three cycles. shows the results of this analysis.
Table 7. Genetic algorithm iteration results.
Based on the analysis, the final genetic operation rates of 0.4 or 40% for crossover and 0.2 or 20% for mutation yielded the best results. For each of the three types of cycles, an initial population of 100 cycles was applied to the final GA. Each final GA had a life span of 50 generations. We extended the life span of the GA with the goal of giving better results than those seen in the initial iterations, which were shorter to save computational time.
Results
OTR trucks
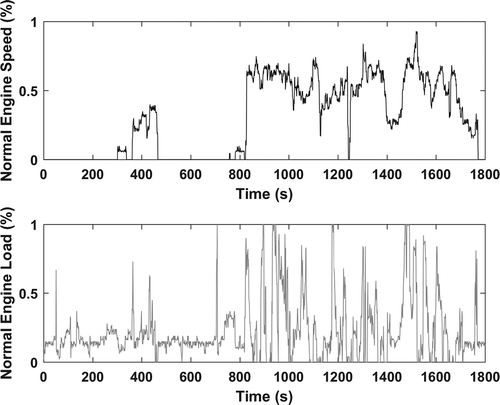
The initial population of 100 truck cycles had an average PV of 0.0910, and after 50 generations the average PV reduced by 61% to 0.0354. The elite PV of the initial population was 0.0388 and reduced by 18% to 0.0320 by the final generation. shows the improvements of the average and elite PVs as a function of the GA generation. At the 50th generation, the average PV improved by only 0.35% from the previous generation and the elite PV did not improve. shows the elite OTR truck cycle. presents the statistics of the elite OTR truck cycles as compared with the in-use data.
Table 8. OTR truck cycle and data statistics.
Figure 4. OTR truck GA improvements.
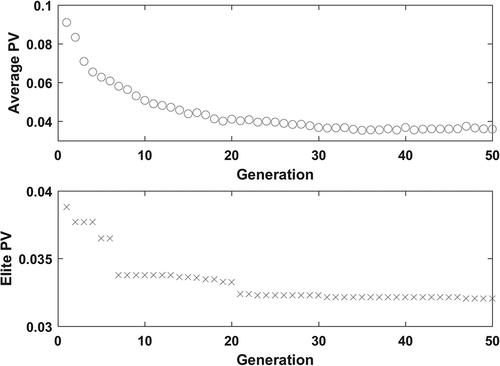
Figure 5. Elite OTR truck cycle.
Drilling
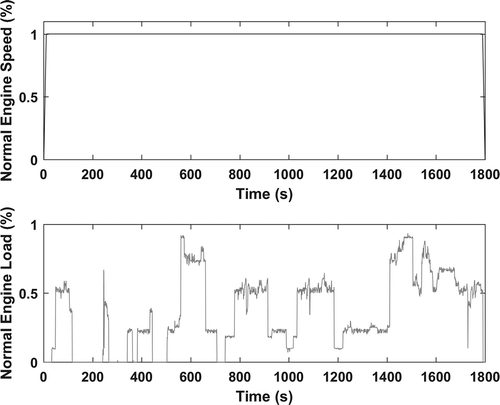
The initial population of 100 created drilling cycles had an average PV of 0.0249. After 50 generations, the average PV reduced by 82% to 0.0044. The elite PV of the initial population was 0.0075 and reduced by 65% to 0.0026 by the end of the 50th generation. The average PV at the 50th generation actually was worse than it was in the 49th generation, and the elite PV showed no improvement. shows the elite drilling cycle, and presents the statistics of the elite drilling cycle as compared with in-use data.
Table 9. Drilling cycle and data statistics.
Figure 6. Elite drilling cycle.
Hydraulic fracturing
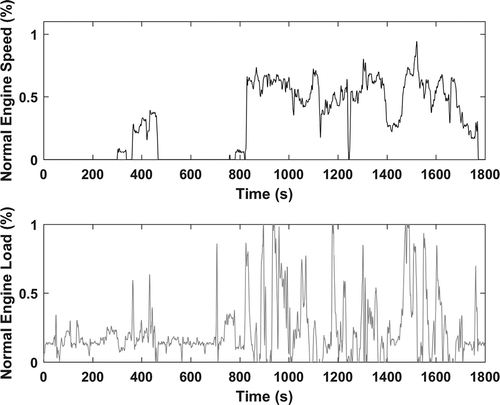
The initial population of 100 hydraulic fracturing cycles had an average PV of 0.0762. After 50 generations, the average PV reduced by 54% to 0.0347. The elite PV of the initial population was 0.0406 and reduced by 25% to 0.0305 by the end of the 50th generation. The 50th generation elite PV showed no improvement over the 49th generation, and the average PV only improved by 0.55%. shows the elite hydraulic fracturing cycle, and presents the statistics of the elite cycle and the in-use data statistics.
Table 10. Fracturing cycle and data statistics.
Figure 7. Elite fracturing cycle.
Implementing the dynamometer cycles
We exercised a test engine over the elite cycles to ensure their applicability to an engine dynamometer configuration. The engine used for the purpose of cycle verification was a 2008 Cummins 8.9-L ISL-G, rated at 280 hp. provides engine specifications. A GE 800-hp dynamometer controlled engine speed, and load was measured via side-arm torque. Note that eq 1 was directly applicable to the ISL-G, which operates over the Otto cycle. Typically, denormalization for diesel engines includes values up to 112% of rated speed, but data beyond rated speed only represented 0.29% of over 4 million data points and were excluded from this analysis. In the case of diesel-fueled engines for drilling and fracturing, operation only occurred at rated speed.
Table 11. Cummins ISL-G engine specifications.
Regression and smoothing
Before use for research or measurement of emissions, a cycle regression analysis must occur. Regression statistics must be within a certain range according to the CFR for validation of the cycle. provides the validation criteria as defined by CFR Title 40 Chapter I Subchapter U Part 1065 Subpart F Section 514.
Table 12. Cycle regression validation criteria for Cummins ISL-G.
Drilling and fracturing cycles
and provide the passing results for the drilling and hydraulic fracturing cycles, respectively.
Table 13. Drilling cycle regression results.
Application of smoothing for the OTR truck cycle
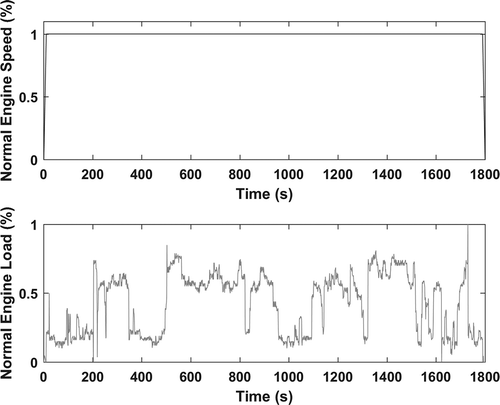
The elite OTR truck cycle did not meet regression criteria in original form. The failure of regression for this cycle was most likely the result of the second-by-second concatenation technique. This technique allowed activity points to sometimes jump by intervals of as much as 10%. This did not allow the engine to respond to the dynamometers signals in time to meet the desired set points. We decided to implement a smoothing technique to reduce the rate of change between certain points of both speed and load. Several smoothing and filtering techniques were considered for this application, including moving average, Savitsky-Golay (SG), and local regression methods (loess and lowess). These techniques smoothed the speed and load array with the defined function and parameters and calculated the new statistics of the cycle. An analysis determined how the different smoothing techniques affected the cycle with different levels of span and degree. We performed a sensitivity analysis of the various techniques to examine their effects on the cycle PV. The goal was to apply a technique, which smoothed the cycle with minimal effect on the PV. Based on the analysis, the SG13-7 was determined to be the best method. The SG13-7 smoothing technique had an effect on 1799 of 1800 cycle points. The smoothing technique changed the affected speed points by an average of 4% and the load points by an average of 15%. provides the statistics of the smoothed elite OTR truck cycle and in-use data. presents the passing results of the regression test, and displays the final normalized OTR truck cycle.
Table 14. Hydraulic fracturing cycle regression results.
Table 15. Smooth OTR truck cycle and data statistics.
Table 16. Smooth OTR truck cycle regression results.
Figure 8. Normalized OTR truck cycle with SG13-7 smoothing.
Comparison of the generated cycles with current cycles
OTR and FTP
As the 8.9-L ISL-G is a heavy-duty engine used in OTR trucks, we compared both the cycle statistics and emissions results from the OTR truck cycle and the standard FTP. presents both the statistics and emissions comparisons with the FTP values as reference. Emissions data were collected using a 40 CFR 1065–compliant dilution tunnel and constant-volume sampling system (“Code of Federal Regulations”; Wu et al., Citation2009). Carbon monoxide (CO), oxide of nitrogen (NOx), carbon dioxide (CO2), and total hydrocarbon (THC) emissions were measured with a Horiba MEXA 7200 D analytical bench. Brake-specific emissions results are only shown for hot-start tests and are the average of three repeated tests. The OTR cycle has decreased time at idle in comparison with the FTP and therefore produces slightly higher CO2 emissions (2.9% higher than FTP), which correlates to a slight increase in brake-specific fuel consumption. Of greater concern are the increases in CO, NOx, and THC emissions over those produced from the FTP. The certification levels for CO and NOx for this engine were 14.4 and 0.2 g/bhp-hr, respectively. We see that the FTP values are below or near the certification levels. However, when operated on the OTR cycle, CO, THC, and NOx emissions increased by factors of 1.69, 2.85, and 1.79, respectively. Therefore, inventories that utilize FTP emissions values to represent this particular trucking sector could be significantly underestimating these regulated pollutants. Greater than 90% of the THC emissions from this engine was methane, a potent greenhouse gas, and its relative increase should be addressed for any greenhouse gas inventories or when reporting CO2-equivalent emissions.
Table 17. Smooth OTR truck cycle regression results compared with FTP.
NRSC and drilling and fracturing cycles
Both drilling and hydraulic fracturing engines are subject to certification when operated over the NRSC. The NSRC cycle consists of five modes, with torque set points of 100, 75, 50, 25, and 10%. The weighting factors for each mode are 0.05, 0.25, 0.3, 0.3, and 0.1, respectively. The average time-weighted load of the NSRC is 47.25%. The average load of the drilling cycle was 42.95%, and the average load of the hydraulic fracturing cycle was 35.83%. We set a high-load and a low-load threshold of 40% based on operating statistics from in-field data. The NSRC yields 60% time of high-load operation and 40% low-load operation. The time of high-load operation for drilling was 58.5%, whereas low-load was 41.5%. The time of high-load operation for hydraulic fracturing was 46.1%, whereas low-load was 53.9%. The in-use engines are not subjected to transient operation but do experience transient operation in the field and within the newly developed cycles. The transient operation of the drilling cycle reflects activities such as drilling, pipe connections, operation of draw works, circulation of fluids, and other intermittent activities. The transient operation of the hydraulic fracturing cycle reflects multiple stages of stimulation, which may occur at different loads due to varied pressures and gear selection of the pumps. Transient operation of turbocharged diesel engines can produce higher combustion temperatures, which lead to increased NOx and particulate matter emissions (Rakopoulos and Giakoumis, Citation2006). Off-road spark ignited engines have also shown to increase THC plus NOx emissions by a factor of 6 and CO emissions by a factor 5 when comparing real in-use transient operation with those emissions produced from the C2 NRSC (U.S. Environmental Protection Agency [EPA], Citation2001). Future work will examine NSRC emissions from the 8.9-L ISL-G engine as compared with those from this work.
Summary
To reduce fuel costs and emissions, the unconventional well completion industry has been attempting to utilize produced natural gas to meet power demands for cost savings. Several companies are doing this by displacing diesel fuel normally used for engines. The primary consumers, or prime movers, of diesel fuel in unconventional natural gas well development are OTR trucks, and high-horsepower drilling and hydraulic fracturing engines. In order to conduct cost- and time-effective research and evaluations, we developed a method to create engine test cycles for application to scaled engines in a laboratory setting.
We collected in-use engine activity data for the three prime movers. Data collected included engine speed and load from OTR trucks traveling to and from well sites hauling water, sand, and gravel, hydraulic fracturing engines used to power pumps for several jobs on two separate pads, and drilling engines used to drill two wells on a single pad. We employed a MCMC technique to create cycles. The goal was to replicate data by creating a large number of potential cycles. A Markov chain utilized second-by-second concatenation and a transition probability matrix. We combined the Markov chain technique with Monte Carlo simulations to create a population of 10,000 cycles for each prime mover. The elite PVs of the populations of OTR truck, drilling, and hydraulic fracturing cycles were 0.0327, 0.0042, and 0.0072, respectively. We then used a GA to optimize the cycle selection process. The GA employed elitist and roulette-wheel selection to determine the members of the population allowed to advance to the next generation. The final GA used genetic operation rates of 40% for crossover and 20% for mutation. It utilized an initial population of 100 cycles and had a life span of 50 generations.
After completion of the GA, the elite OTR truck cycle, drilling cycle, and hydraulic fracturing improved PVs by 18%, 62%, and 65%, respectively. The GA reduced PVs from 0.0388 to 0.0320 for OTR trucks, 0.0079 to 0.0030 for drilling, and from 0.0155 to 0.0054 for hydraulic fracturing. We exercised the cycles on an engine and dynamometer to confirm that they met regression criteria for transient cycles defined by the CFR.
The elite drilling and hydraulic fracturing cycles passed the regression criteria needed as initially defined. The OTR cycle, however, failed regression based on the R2 of torque and power criteria. We applied a smoothing technique to the normalized cycle speed and load arrays. A sensitivity analysis determined the effect of smoothing techniques on the PV of the cycles. A SG filter with a span of 13 and polynomial degree of 7 was implemented. The smoothing resulted in a 1.25% increase in the PV from 0.0320 to 0.0324. We then exercised the smoothed OTR truck cycle on the same engine and dynamometer platform, and it passed all necessary criteria.
Based on our analyses, we feel these cycles are representative of actual engine operation in the field and will use them for research related to unconventional natural gas well development. We also provide the final cycles in tabular format for evaluation and use by other researchers. Cycle development will continue to be necessary for research as emissions standards become more stringent and different industries come under the scrutiny of regulatory institutions. For these reasons, it is important to look for new ways to apply and optimize the techniques of in-field data representation. Future research should also include catalyst temperature as a cycle metric. Older off-road engines are typically Tier 2 with no aftertreatment; however, newer engines that can be run on dual fuels have diesel oxidation catalysts (DOCs) and new Tier 4 engines may have both diesel particulate filters (DPFs) and selective catalytic reduction (SCR)—the efficiency of both are correlated with exhaust energy.
In addition, we have shown that from an emissions perspective, a dedicated natural gas engine operated over our OTR cycle produced more CO, NOx, and THC emissions compared with the conventional FTP cycle. Although we did not compare the drilling and hydraulic fracturing cycle emissions with those from the NRSC, we plan to do so in the future. The drilling cycle high-load and low-load time distribution is similar to the NRSC but includes realistic transient operation. The hydraulic fracturing cycle yielded increased low-load operation compared with the NRSC. The transient nature of the in-use engines and our cycles will likely increase emissions over those collected during NRSC certification tests. As such, current test methods and inventory methods, which utilize current emissions factors, may be underreporting regulated emissions compared with those that occur in use.
Acknowledgment
The authors thank numerous industry collaborators for allowing them to collect these valuable data.
Funding
This work was made possible under a grant from the Department of Energy’s National Energy Technology Laboratory, DE-FE0013689, under direction of Mr. William Fincham. Some data were also collected during a collaborative effort under a separate grant, DE-FE0024297.
Additional information
Funding
Notes on contributors
Derek Johnson
Derek Johnson, Ph.D., is a research assistant professor at West Virginia University (WVU) conducting research focused on methane and other emissions associated with the use of natural gas.
Robert Heltzel
Robert Heltzel, M.S.M.E., is a research assistant at WVU’s Center for Alternative Fuels, Engines, and Emissions.
Andrew Nix
Andrew Nix, Ph.D., is an assistant professor at WVU conducting research on natural gas reciprocating engines and gas turbines.
Rebekah Barrow
Rebekah Barrow is an undergraduate research assistant pursuing bachelor's degrees in mechanical and aerospace engineering.
References
- Baker, R., and M. Pring. 2009. Drilling Rig Emission Inventory for the State of Texas. Austin, TX: Eastern Research Group.
- Canadian Society for Unconventional Resources. 2012. Understanding Well Construction and Surface Footprint. http://www.csur.com/sites/default/files/Understanding_Well_Construction_final.pdf ( accessed February 1, 2016).
- Carr, R., S. Pearson, and D. Wedemeyer. 2012. On the Road Again: Managing Transportation Logistics for Unconventional Drilling. Deloitte Development LLC. https://www.deloitte.com/assets/Dcom-UnitedStates/Local Assets/Documents/Consulting MOs/CSMLs/us_consulting_Managingtransportationlogisticsforunconventional_06212012.pdf ( accessed March 14, 2014).
- Clark, C., J. Han, A. Burnham, J. Dunn, and M. Wang. 2012. Life-Cycle Analysis of Shale Gas and Natural Gas. Argonne National Laboratory, Energy Systems Division. http://www.transportation.anl.gov/pdfs/EE/813.PDF ( accessed February 1, 2016).
- Clark, N., M. Gautam, W.S. Wayne, G. Thompson, D.W. Lyons, F. Zhen, C. Bedick, R.J. Atkinson, and D.L. McKain. 2007. Creation of the “Heavy Heavy-Duty Diesel Engine Test Schedule,” for Representative Measurement of Heavy-Duty Engine Emissions. Alpharetta, GA: Coordinating Research Council, Inc.
- Code of Federal Regulations (CFR) Title 40 Part 1065—Engine Test Procedures. US Government Printing Office. http://www.ecfr.gov/cgi-bin/text-idx?SID=bbe9d63c0ee4a5186a4588726f252e0f&mc=true&node=pt40.37.1065&rgn=div5 ( accessed August 1, 2016).
- Dai, Z., D. Niemeier, and D. Eisinger. 2008. Driving Cycles: A New Cycle-Building Method that Better Represents Real-World Emissions. Sacramento, CA: U.C. Davis Caltrans Air Quality Project.
- Dembski, D., Y. Guezennec, and A. Soliman. 2002. Analysis and Experimental Refinement of Real-World Driving Cycles. SAE 2002-03-04. Warrendale, PA: SAE International.
- DieselNet. 1999. Heavy-duty FTP transient cycle. https://www.dieselnet.com/standards/cycles/ftp_trans.php. (accessed February 2, 2016).
- DieselNet. 2001 October. ISO 8178. https://www.dieselnet.com/standards/cycles/iso8178.php ( accessed February 2, 2016).
- DieselNet. 2015 October. Heavy-duty onroad engines. https://www.dieselnet.com/standards/us/hd.php ( accessed February 2, 2016).
- Felsburg Holt and Ullevig. 2013 January. Boulder County Oil and Gas Roadway Impact Study. http://www.bouldercounty.org/doc/landuse/dc120003oilgasroadwaystudy20130114.pdf (accessed August 1, 2016).
- Geyer, C.J. 1992. Practical Markov chain Monte Carlo. Stat. Sci. 7(4):473–483. doi:10.1214/ss/1177011137
- Geyer, C.J. 2011. Introduction to Markov chain Monte Carlo. In Handbook of Markov Chain Monte Carlo, ed. S. Brooks, A. Gelman, G. Jones, and X. Meng, 1–47. Boca Raton, FL: CRC Press.
- Gong, Q., S. Midlam-Mohler, V. Marano, and G. Rizzoni. 2011. An Iterative Markov Chain Approach for Generating Driving Cycles. SAE 2011-01-0880. Warrendale, PA: SAE International.
- HEM Data. 2015. J1939 Mini Logger. http://www.hemdata.com/products/dawn/j1939-mini-logger ( accessed February 15, 2016).
- International Society of Automotive Engineers. 2015 June. Vehicle application layer. http://standards.sae.org/j1939/71_201506/( accessed February 15, 2016).
- Kelly, M. 2012 April. Energy: Exploration and Production, Global Hunter Securities. http://www.prometheusenergy.com/solutions/documents/Nat_Gas_Rigs.pdf (accessed March 14, 2014).
- Lin, J., and D.A. Niemeier. 2002. An exploratory analysis comparing a stochastic driving cycle to California’s regulatory cycle. Atmos. Environ. 36:5759–5770. doi:10.1016/S1352-2310(02)00695-7
- Lin, J., and D.A. Niemeier. 2003. Estimating regional air quality vehicle emission inventories: Constructing robust driving cycles. Transport. Sci. 37(3):330–346. doi: 0.1287/trsc.37.3.330.16045
- Marlowe, C.L. 2009. Development of computational tools for modeling engine fuel economy and emissions. Master’s thesis, West Virginia University, Morgantown, WV.
- Maryland Department of the Environment. 2014. Truck Traffic Volume Increases Projected to Result from Unconventional Gas Well Development (UGWD) in Maryland. http://www.mde.state.md.us/programs/Land/mining/marcellus/Documents/Information_on_traffic.pdf ( accessed August 1, 2016).
- Massachusetts Institute of Technology. 2011. The future of natural gas. http://energy.mit.edu/research/future-natural-gas/(accessed August 1, 2016).
- Perhinschi, M.G. 2015. Genetic Algorithms (or Evolutionary Algorithms. Artificial Intelligence Course Notes. Morgantown, WV: Author.
- Perhinschi, M.G., C. Marlowe, S. Tamayo, J. Tu, and W.S. Wayne. 2011. Evolutionary algorithm for vehicle driving cycle generation. J. Air Waste Manage. Assoc. 61(9):923–931. doi:10.1080/10473289.2011.596742.
- Rakopoulus, C., and E. Giakoumis. 2006. Review of Thermodynamic Diesel Engine Simulations Under Transient Operating Conditions. SAE 2006-01-0884. Warrendale, PA: SAE International.
- Roeva, O., S. Fidanova, and M. Paprzycki. 2013. Influence of the population size on the genetic algorithm performance in case of cultivation process modelling. Proceedings of the 2013 Federated Conference on Computer Science and Information Systems, 371–376.
- Sivanandam, S., and S. Deepa. 2008. Introduction to Genetic Algorithms. Berlin: Springer.
- Smith, A. 2003. Markov Chain Monte Carlo Simulation Made Simple. New York: Department of Politics, New York University. http://www.nyu.edu/gsas/dept/politics/grad/classes/quant2/mcmc_note.pdf ( accessed August 1, 2016).
- Smith, M. 1978. Heavy-Duty Vehicle Cycle Development. EPA 460/3-78-008. Washington, DC: U.S. Environmental Protection Agency.
- Steven, H. 2001. Development of a Worldwide Harmonised Heavy-duty Engine Emissions Test Cycle. Geneva, Switzerland: Working Party on Pollution and Energy.
- Ullman, T.L., C.C. Webb, C.C. Jackson Jr., and M.H. Doorlag. 1999. Nonroad Engine Activity Analysis and Transient Cycle Generation. SAE 1999-01-2800. Warrendale, PA: SAE International.
- U.S. Energy Information Administration. 2015 November. Frequently asked questions, https://www.eia.gov/tools/faqs/faq.cfm?id=58&t=8 ( accessed February 1, 2016).
- U.S. Energy Information Administration. 2016 January. Natural gas. http://www.eia.gov/dnav/ng/hist/n9010us2A.htm ( accessed February 1, 2016).
- U.S. Environmental Protection Agency. 2001 January. Emission Data and Procedures for Large SI Engines. https://www3.epa.gov/nonroad/largesi/f00050.pdf ( accessed August 1, 2016).
- Wu, Y., D. Carder, B. Shade, R. Atkinson, N. Clark, and M. Gautam. 2009. A CFR1065-compliant transportable/on-road low emissions measurement laboratory with dual primary full-flow dilution tunnels. In Proceedings of the American Society of Mechanical Engineers Internal Combustion Engine Division Spring Technical Conference, Milwaukee, WI, 399–410. New York, NY: ASME Digital Collection. doi:10.1080/10473289.2011.596742