
ABSTRACT
This paper investigates how the associations between tavern proximity, tavern density and area unit socio-economic status with assault occurrence vary in a temporal sense. Using New Zealand Police data specifying the day, time and location of assaults in 2016 and Ministry of Justice data specifying the location of on-licenced taverns, we construct logistic regression models to determine how well tavern proximity, tavern density and socio-economic status predict the occurrence of assaults at peak (Fri 22:00–Sat 03:00 and Sat 22:00–Sun 03:00) and off-peak times. An equal-sized sample of traffic generators (public venues whose primary function is not the sale of alcohol) is constructed and similar procedures applied. We find that tavern proximity and tavern density are stronger predictors of assault occurrence at peak, compared to off-peak, times. Conversely, socio-economic status is a better predictor of assault occurrence at off-peak times. We also find that whilst tavern proximity and density are stronger predictors of assault occurrence relative to traffic generator proximity and density at peak times, the opposite is true at off-peak times. These results suggest that in order to minimise alcohol-related harm, there is a need for policy-makers to take into account the temporal nature of these relationships.
1. Introduction
There is a huge amount of literature, both worldwide and within New Zealand, concerning the social harms caused by the consumption of alcohol. Within the New Zealand context, where it has been estimated that approximately 31% of all recorded crime is perpetrated by an individual who has consumed alcohol prior to offending (Stevenson Citation2009), there is an extremely well developed body of literature linking alcohol outlet density and violent crime (Cameron et al. Citation2012, Citation2016). Furthermore, there is also a growing body of evidence linking alcohol outlet proximity to instances of violence. For example, Day et al. (Citation2012) found a significant association between the distance to licenced alcohol outlet and serious violent offences, with greater levels of such offences occurring in areas closer to outlets compared to those further away. Gruenewald (Citation2007) details various theoretical mechanisms by which the increased availability of alcohol and density of alcohol outlets can result in increased levels of assault. For instance, so-called flow models assert that an increase in the number of alcohol outlets within an area is usually associated with in an increase in the number of patrons frequenting them, such that if the proportion of drinkers prone to acts of violence is assumed to be constant this will be enough to increase the number of assaults observed. In one of the few studies to make use of data on actual alcohol sales, Liang and Chikritzhs (Citation2011) found the density of pubs to be positively associated with incidents of violence even when controlling for the amount of alcohol consumed. Indeed, other mechanisms described by Gruenewald (Citation2007) are able to relate increases in outlet density to increases in assaults without appealing to increased levels of alcohol consumption. Within the context of ‘niche theory’ increased outlet density results in greater market stratification and diversity of outlets as commercial enterprises attempt to carve out a market niche for themselves. Hence, the process of competition serves to concentrate drinkers predisposed to violence within certain venues thereby increasing the number of assaults observed. This is re-inforced by ‘assortative drinking models’ whereby drinkers actively seek out venues with like-minded patrons, thereby further concentrating violence-prone individuals into a smaller number of premises. That there is also a relationship between increased levels of socio-economic deprivation and increased levels of (alcohol related) violence within New Zealand, as well as elsewhere in the world, is very well known (Livingston Citation2008; Day et al. Citation2012; Mair et al. Citation2013). A possible causal mechanism for this is provided by ‘social disorganization theory’ (Banerjee et al. Citation2008). From the perspective of this theory areas with greater manifestations of neighbourhood disorder, such as high densities of alcohol outlets, will naturally be associated with a greater level of incivility and assaults (Gruenewald Citation2007).
Whilst there is undoubtedly an association between the density and proximity of alcohol outlets, socio-economic status and assault occurrence, a fundamental limitation of the existing body of research within New Zealand is that it does not take into account how these associations vary in a temporal sense. As noted by Cameron et al. (Citation2016):
… it is likely that the relationships between outlet density and alcohol related harms vary not just across space, but across time as well.
A further limitation of the existing body of research within the New Zealand context, and more generally, is that it is unclear to what extent the associations between outlet density, outlet proximity and assault occurrence are affected by the presence of other traffic generators. Here the term traffic generator is a generic term describing any venue around which people may congregate whose primary function is not the sale of alcohol. Everyday experience would suggest that areas which have a high density of (are in close proximity to) alcohol outlets also have a high density of (are in close proximity to) other traffic generators and therefore, as suggested by Burgess and Moffat (Citation2011):
It is possible that people who frequent alcohol outlets (or thereabouts) have only an average risk of assault but the sheer volume of people in those areas accounts for the high concentration of assault.
As such the aims of this paper are twofold. First, we compare the association between tavern density, tavern proximity and area unit socio-economic status with meshblock assault occurrence at peak (Friday 22:00–Saturday 03:00 and Saturday 22:00–Sunday 03:00) and off-peak times. Here the term tavern refers to on-licenced pubs or bars. Secondly, we construct a sample of traffic generators (equal in size to the number of taverns and exhibiting a similar level of geo-spatial clustering) and compare the associations between peak and off-peak assault occurrence with traffic generator density and proximity relative to the associations observed with regards to taverns.
2. Materials and methods
2.1 Construction of meshblock centroids
Meshblocks are contiguous geographical units defined by Statistics New Zealand and are the smallest geographic unit for which statistical data are publicly reported. Each meshblock borders another to form a network covering all of New Zealand’s land mass and 200-mile exclusive economic zone. Although meshblocks can vary in size considerably in rural areas, in urban areas meshblocks usually coincide with streets or city blocks. Area Units (AUs) are aggregations of meshblocks which in urban areas generally coincide with suburbs or parts thereof. At the time of the 2013 New Zealand Census, the median usually resident meshblock and AU populations were 78 people and 1985 people, respectively. The geographic regions defined by meshblocks and AUs are updated by Statistics New Zealand on the 1st of January every year. The meshblock geographies for 2016 (QGIS maps) and concordance with geographies for previous years can be found on the Statistics New Zealand website (Citation2017a, Citation2017b).
Using the aforementioned geographic boundary files, we obtained the geo-coordinates of the 46,393 inland New Zealand meshblock centroids by utilising the QGIS ‘Polygon Centroid’ geometry tool. Meshblock centroids are effectively the centre of mass for the meshblock polygon, such that if some flat substance of uniform thickness were cut into the shape of the meshblock polygon, then the shape would balance at the point of the centroid. Extracting the subsequent attribute table also enabled us to determine the land mass (km2) covered by each meshblock. A similar, technique was used to determine the land mass covered by each AU.
2.2 Meshblock and AU population estimates
The usually resident population of each 2016 meshblock was estimated in the following way. We took the medium usually resident AU population projections constructed by Statistics New Zealand ( Citation2017c) for 2013 and 2018 and linearly interpolated between the two in order to obtain AU population estimates for 2016. Using publicly available data from the 2013 New Zealand census (Statistics New Zealand Citation2013) we calculated the proportion of 2013 AU population contributed by each 2013 meshblock. The 2016 meshblock population was then inferred by assuming that each meshblock contributed the same proportion of AU population as it did in 2013. Many meshblocks had been split into smaller component meshblocks between 2013 and 2016 (Statistics New Zealand Citation2017b). In order to take this into account we assumed that if, for example, a meshblock contributed 20% of AU population in 2013 and had been split into four smaller component meshblocks by 2016, then each of these smaller meshblocks contributed 5% of AU population. In addition, by combining the 2016 AU population projections with the aforementioned AU land mass estimates we were able to estimate AU population densities (1000 population per km2).
2.3 Assault data
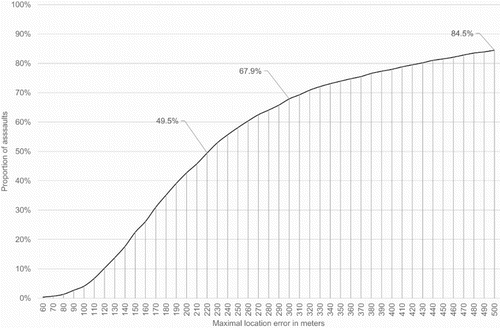
In November 2016, New Zealand Police began publishing data online specifying the year, month, day of week, hour, meshblock of occurrence and type of offence of all reported crimes within New Zealand (New Zealand Police Citation2016). In May 2017, we downloaded all data relating to crimes that occurred in 2016 whose Australian and New Zealand Standard Offence Classification (ANZSOC) group was labelled as either ‘Common Assault’, ‘Serious Assault Resulting in Injury’ or ‘Serious Assault Not Resulting in Injury’. There were total of 20,602 such crimes. After removing any data to which we could not definitively assign a day of week, hour or meshblock of occurrence to, we obtained a list of 17,374 assaults that occurred within New Zealand in 2016. These 17,374 assaults occurred within just 8542 distinct meshblocks indicating a tendency for multiple assaults to occur within the same meshblock. In the absence of more specific information, we assumed that each assault took place at the centroid of the specified meshblock of occurrence. For the purpose of our analysis, this is a reasonable assumption to make. For each meshblock where an assault took place, we calculated the maximal location error that could be incurred as a result of making this assumption by finding the greatest possible distance from the meshblock’s centroid to its boundary. This was achieved by using a variety of QGIS tools to determine the radius of the smallest possible circle, centred at the meshblock centroid, which would completely contain the meshblock. As indicated in , for approximately 50% of all assaults the maximal error in location measurement was less than 220 m and was less than 500 m in 85% of cases. Since, in reality, there is no reason to assume that each assault took place at the point within the meshblock furthest from the centroid, meshblock centroid can be considered a very good approximation of the location of assault occurrence in the vast majority of cases.
Figure 1. Proportion of assaults where the maximal error in location measurement is less than a specified amount.
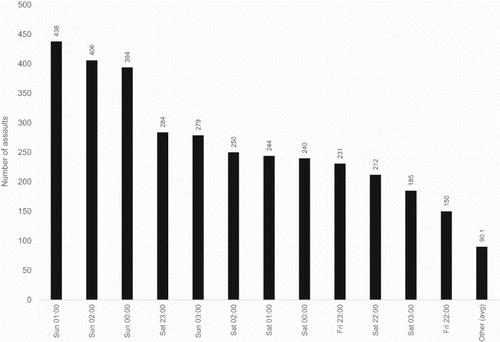
By looking at the distribution of assaults by day of week and hour (see ) we found that 3313 (19%) of all assaults occurred between the hours of Friday 22:00–Saturday 03:00 and Saturday 22:00–Sunday 03:00. Consequently, assaults occurring within these hours were defined as having occurred at ‘peak time’, whereas assaults occurring outside of these hours were defined to have occurred ‘off-peak’.
Figure 2. New Zealand assaults in 2016 by selected day of week and hour.
2.4 Location of taverns
Quarterly liquor licencing data were obtained from the Ministry of Justice (Citation2017). This data set contained the names and addresses of all venues licenced to sell alcohol within New Zealand as of March 2017. We chose to refine this data set to on-licenced taverns only for the following two reasons. First, this eliminates the possibility of diffusion bias. By definition, with off-licence venues the location of alcohol purchase differs from the location of consumption. For on-licenced venues there is no separation between the location of purchase and consumption meaning that any alcohol-related violence is more likely to occur within a small vicinity of the venue (Cameron et al. Citation2016). Secondly, by focusing upon taverns, we ensure that we consider only venues where the consumption of alcohol can be considered to be the main activity undertaken. We also removed from the data set any tavern which had received their first licence after 31st December 2016 in order to ensure that the remaining venues were active in the sale of alcohol for at least some part of 2016. In this way, we obtained a list of 1510 on-licenced taverns. Using online batch geo-coding websites we were able to obtain geo-coordinates for 1412 of these taverns. For verification purposes, the addresses of these 1412 taverns were geo-coded a second time by a separate researcher. In 97% of all cases, the distance between the reported locations of the taverns was less than 35 m and was less than 200 m in 99% of all cases.
2.5 Traffic generators
As was mentioned in the introduction, one of the aims of this paper is to compare how the associations between peak and off-peak assault occurrence with tavern density and proximity vary relative to traffic generator density and proximity. However, it is hard to make such comparisons for a number of reasons. The first problem that a researcher encounters in this regard is how to define a traffic generator. Depending upon how liberal a definition is used, one could identify a vast number of potential traffic generators. Secondly, greater levels of geo-spatial clustering exhibited by traffic generators relative to taverns, or vice versa, could potentially bias measures of the associations under investigation.
The solution adopted within this paper was to construct a sample of traffic generators equal in size to the number of taverns and which exhibited a similar level of geo-spatial clustering. To this end we constructed a sample of 1412 traffic generators, distributed throughout New Zealand, consisting of 763 fast food restaurants (164 McDonalds, 83 Burger Kings, 20 KFCs, 63 Hell Pizzas, 85 Dominos Pizzas, 84 Pizza Huts, 264 Subways), 105 shopping centres, 360 supermarkets (172 Countdowns, 51 Pak’nSaves, 137 New Worlds) and 184 BP petrol stations. The data used to construct this sample of traffic generators was obtained from downloads from Zenbu (Citation2016), an online directory providing the addresses and geo-coordinates of New Zealand based businesses. In addition to only using venues whose location had been verified by Zenbu from 2014 onwards, we also calculated the geo-coordinates of each traffic generator independently using batch geo-coding websites and then referenced this against the geo-coordinates provided by Zenbu. Whenever the distance between corresponding pairs of geo-coordinates was greater than 50 m, the geo-coordinates were recalculated manually using a combination of Google Maps and Google Street View.
Since the area covered by the union of disjoint circles is always greater than the area covered by the union of intersecting circles, there is a natural way to measure how highly spatially clustered this sample of traffic generators is relative to taverns. Using, the QGIS ‘Dissolve’ geometry tool we found that the geometric region formed by taking the union of all circles of radius 500 m centred at tavern locations covered an area of 521 km2. Performing the same procedure for the constructed sample of traffic generators yielded a geometric region covering an area of 492 km2. This marks a 5.9% difference in area covered.
2.6 Measures of AU socio-economic status
Within New Zealand, the standard measures of area level socio-economic status are the NZDEP studies constructed by Crampton et al. (Citation1998a, Citation1998b, Citation2002, Citation2007, Citation2014). Using census data from the corresponding year these studies assign a deprivation score to each populated meshblock within New Zealand. A deprivation score for each AU is then calculated as a population weighted average of the associated meshblock deprivation scores. Meshblocks and AUs are then ranked into deciles (known as deprivation indices) on the basis of their score. Conceptually, the higher the deprivation decile to which a meshblock or AU is assigned the higher the level of socio-economic deprivation endured by its inhabitants. The most recent of these studies, NZDEP13 (Crampton et al. Citation2014), is constructed using census data from March 2013.
Due to their small size there is a considerable degree of variation in meshblock deprivation score, and consequent movement of meshblocks between deprivation deciles, from one census to another such that Crampton et al. (Citation2014) warn:
Comparison of areas as small as a single meshblock across time may not be meaningful.
The NZDEP studies are extremely rigorous and are widely used in government funding formulas and by social policy researchers. However, being constructed from census data they are only able to provide a snapshot of the distribution of socio-economic deprivation across New Zealand at five-year intervals or more. A more up to date measure of the national distribution of AU socio-economic status is given by the Dynamic Deprivation Index™ (DDI) developed by DOT Loves Data. The DDI uses a combination of publicly available and commercially purchased data sets to assign a deprivation score and decile to each populated AU within New Zealand on a monthly basis. These data sets cover consumer spending patterns, area level educational attainment, gambling spends per capita, health outcomes, etc. The DDI is seeded by the NZDEP13 study in the sense that the deprivation deciles assigned to each AU in March 2013 by the DDI coincide with the deprivation deciles associated to each AU in the NZDEP13 study. As such, the DDI can be regarded as a direct continuation of the NZDEP13 study. For each subsequent month, the movement of AUs between deprivation deciles is controlled by a Markov gating procedure whereby only a certain proportion of AUs within each decile (those with the highest and lowest scores for that month) are allowed to transition to neighbouring deciles. The proportion of AUs allowed to transition between deciles each month is calculated to mimic the pro-rata movement of AUs between deprivation deciles between the NZDEP06 and NZDEP13 studies.
For ease of exposition, in the remainder of this paper, we take our measure of AU socio-economic status to be the deprivation deciles given by the NZDEP13 study unless otherwise stated. However, our conclusions are not changed to any significant extent if we use the more contemporary measure of AU socio-economic status, DDI Dec16, instead.
2.7 Proximity measures
Our measure of tavern proximity is the geodetic distance in kilometres from each meshblock centroid to the nearest tavern. This distance was computed using the QGIS ‘Distance Matrix’ analysis tool. We verified the results obtained by taking the 8542 meshblocks in which an assault occurred and calculating the distance from meshblock centroid to the nearest tavern using the ‘Geodist’ function within the SAS language. In 8476 (99%) of all instances, the absolute difference in computed nearest distance was less than 15 m.
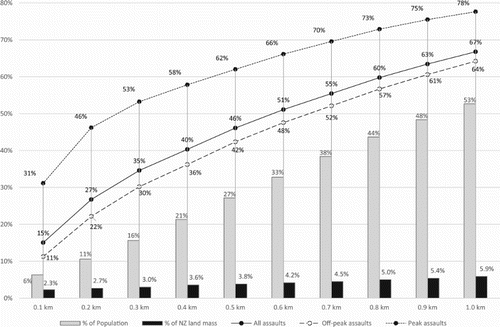
Since this process enabled us to calculate the distance from meshblock centroid to nearest tavern for all meshblocks in which an assault occurred, and since each assault is assumed to have occurred at the corresponding meshblock centroid, we were able to use these results to estimate the proportion of assaults occurring within arbitrary distances of taverns and determine how this broke down by peak and off-peak time. Furthermore, by using the QGIS ‘Intersection’ geo-processing tool we were able to determine which meshblocks lay within (intersected) this geometric region. By combining this with the meshblock population estimates described in Section 2.2, we were able to estimate the proportion of the population living within the specified distance from a tavern and the proportion of New Zealand land mass covered.
Figure 3. Proportion of population, land mass, assaults, peak time assaults and off-peak assaults occurring within a given distance of taverns.
Similarly, our measure of traffic generator proximity is the geodetic distance in kilometres from each meshblock centroid to the nearest traffic generator. Again this was computed using the QGIS ‘Distance Matrix’ tool and checked using the ‘Geodist’ function within the SAS language. The absolute difference in computed nearest distances was again less than 15 m in 99% of cases.
2.8 Density measures
Our measure of tavern density is the number of taverns lying within a 500-m radius of each meshblock centroid and was computed in the following way. First, a circle of radius 500 m was centred at each meshblock centroid using the QGIS ‘Fixed Distance Buffer’ geo-processing tool. Next, the number of taverns lying within each circle was calculated using the QGIS ‘Count Points in Polygon’ analysis tool. For verification purposes, we took the 8542 meshblocks in which an assault occurred and calculated the number of taverns within 500 m of the meshblock centroids using SAS. The resultant concordance rate was 98%. Our measure of traffic generator density (the number of traffic generators from our sample within a 500 m radius of each meshblock centroid) was calculated in the same way and verified in an analogous fashion, the resultant concordance rate being 99%.
2.9 Data analysis
For each 2016 meshblock we used the assault data described in Section 2.3 to create four binary dependent variables (Peak Assaults, Multiple Peak Assaults, Off-Peak Assaults, Multiple Off-Peak Assaults), respectively, detailing whether during the course of 2016:
At least one peak time assault;
Multiple peak time assaults;
At least one off-peak assault;
Multiple off-peak assaults;
Table 1. Results of logistic regression – Part I.
There is little consensus on how best to rank predictors within logistic regression models and many methods for doing so have been proposed. Two widely used, and computationally simple, ways of ranking the predictive capabilities of independent variables within such models are to compare standardised regression coefficients and Gini coefficients. With regards to the former, within the SAS language, the standardised coefficient for predictor is defined as
where
is the estimated unstandardised logistic regression coefficient and
is the sample standard deviation of the predictor. The standardised logistic regression coefficients can be interpreted in the same way as standardised coefficients within ordinary linear regression models so that the greater the absolute value of the standardised co-efficient the greater the association between the dependent and independent variable (Menard Citation2004). With regards to the latter, the Gini coefficient measures the ability of a model to differentiate between binary outcomes. The closer the value of the Gini coefficient is to one, the better able the model is to correctly differentiate between outcomes.
Using correlation analysis and comparison of standard errors to ensure an absence of multicollinearity, two further models were selected consisting of the following independent variables:
Model 1: AU Socio-economic Status, Tavern Proximity, Tavern Density.
Model 2: AU Socio-economic Status, Traffic Generator Proximity, Traffic Generator Density.
Table 2. Results of logistic regression - Part II.
3. Results
below details the ability of each of the aforementioned independent variables to individually predict the four dependent variables, whilst shows the results of the logistic regressions performed for Model 1 and Model 2. Although we are primarily concerned with the values of the standardised regression coefficients and Gini coefficients, odds ratios (the exponentiated unstandardised regression coefficients) are also reported as a means of easily interpreting the direction of the relationships between dependent and independent variables. For instance, the odds ratio for model A1 in is 0.883. This indicates that a one kilometre increase in the distance from meshblock centroid to the nearest tavern decreases the odds of a peak time assault occurring within the meshblock by 11.7%. Similarly, the odds ratio of 1.132 in model A2 indicates that for each additional tavern located within 500 m of a meshblock centroid the odds of a peak time assault occurring within that meshblock increase by 13.2%.
3.1 The temporal association between tavern proximity, tavern density and assault occurrence
As illustrated in , the proportion of assaults occurring within any given distance of taverns within New Zealand is disproportionate to both the usually resident population living within that geometric region and the proportion of New Zealand land mass covered. This effect is particularly prominent at peak times. For instance, it is estimated that 31% of peak time assaults occur within 100 m of a tavern whereas this geometric region constitutes only 2.3% of New Zealand’s land mass and contains only 6.3% of the population. This suggests that tavern proximity is likely to be a stronger predictor of assault occurrence at peak time compared to off-peak time. and indicate that this is indeed the case and that the same is also true for tavern density (compare the Ginis and standardised coefficients for model A1 vs. A7, A2 vs. A8 and B1 vs. B3). Furthermore, whilst tavern proximity and tavern density are both strong predictors of the occurrence of multiple peak and multiple off-peak assaults they are both stronger predictors of multiple peak time assault than of multiple off-peak assault (compare the Ginis and standardised coefficients for models A13 vs. A19, A14 vs. A20 and B5 vs. B7).
3.2 The temporal association between socio-economic status and assault occurrence
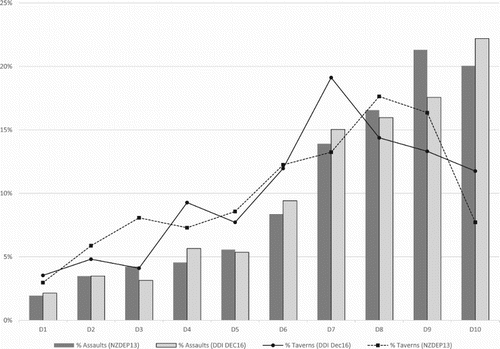
shows that the proportion of assaults occurring within AUs belonging to each deprivation decile increases almost monotonically as we progress from the least to most socio-economically deprived deciles. signifies that socio-economic status is a stronger predictor of assault occurrence and multiple assault occurrence at off-peak times compared to peak times (compare the Ginis and standardised coefficients for models A5 vs. A11 and A17 vs. A23). As evidenced in , one potential reason for this is that the number of taverns located in AUs belonging to each deprivation decile peaks around decile 8 (or decile 7 if using DDI Dec16) and declines thereafter.
Figure 4. Proportion of all assaults and taverns in 2016 by deprivation decile classification.
3.3 Comparison of the association between tavern proximity and density, traffic generator proximity and density and assault occurrence
At peak time tavern proximity is an unambiguously stronger predictor of assault and multiple assault occurrence compared to traffic generator proximity (compare the Ginis and standardised coefficients for models A1 vs. A3, A13 vs. A15, B1 vs. B2 and B5 vs. B6). Similarly, comparison of the Ginis for models A2 vs. A4, A14 vs. A16, B1 vs. B2 and B5 vs. B6 would suggest that tavern density is at least as good a predictor of peak time (multiple) assault occurrence as traffic generator density. However, in the latter case, analysis of the standardised coefficients within these models would suggest the opposite to be true.
At off-peak time traffic generator density is an unambiguously stronger predictor of assault and multiple assault occurrence compared to tavern density. This can be seen by comparing the Ginis and standardised coefficients for models A8 vs. A10, A20 vs. A22, B3 vs. B4 and B7 vs. B8. In terms of proximity measures, comparison of the Ginis for models A7 vs. A9, A19 vs. A21, B3 vs. B4 and B7 vs. B8 would suggest that traffic generator proximity is a stronger predictor of (multiple) assault occurrence at off-peak times compared to tavern proximity. However, analysis of the standardised coefficients for the aforementioned models would (except in the case of A19 vs. A21) suggest tavern proximity to be the stronger predictor.
A more succinct conclusion can be drawn by looking at the results within alone. Taken together, along with AU socio-economic status, we see that tavern proximity and tavern density are better able to predict assault occurrence and multiple assault occurrence at peak time (compare the Ginis for models B1 vs. B2 and B5 vs. B6), whereas traffic generator proximity and traffic generator density are better able to predict assault occurrence and multiple assault occurrence at off-peak times (compare the Ginis for models B3 vs. B4 and B7 vs. B8).
4. Discussion and conclusion
Several qualifications should be made with regards to this study. First, we have restricted our analysis to taverns only and have made no attempt to analyse the associations between assault occurrence and the density and proximity of other types of on-licence (e.g. restaurants) or off-licence (e.g. bottle shops) outlets. Secondly, due to the nature of the data set analysed, we have made no consideration as to the volume of alcohol sold at each tavern, nor have we taken into account their individual operating hours. In other words, we have assumed all taverns to be homogenous and have consequently treated a small countryside tavern in the same way as we would treat a multi-level bar or nightclub in a major urban area. Thirdly, due to multicollinearity, we were unable to incorporate AU population density into all of the models used to analyse the associations between dependent and independent variables (see Section 2.9). Finally, there is a degree of randomness in our comparison of the association between assault occurrence with tavern density and proximity relative to that of traffic generator density and proximity. That is to say that we have compared the density and proximity of taverns to the density and proximity of an equal sized sample of traffic generators. There is no way to determine whether this sample is in any way representative so that, potentially, a different sample of traffic generators may yield different results. Furthermore, although we selected a sample of traffic generators that exhibited a similar degree of geo-spatial clustering to that exhibited by taverns, the slight differential observed in this regard (see Section 2.5) may still have upwardly biased the ability of traffic generator density to predict assault occurrence relative to tavern density. On the other hand, this may have also biased the ability of traffic generator proximity to predict assault occurrence relative to tavern proximity in the opposite direction.
Despite these limitations, there are a number of strengths within our approach. In particular, we are the first in the New Zealand context to analyse how the associations between tavern density, tavern proximity and AU socio-economic status with assault occurrence vary in a temporal sense. Similarly, this is also the first study (that we are aware of) to assess how the associations between assault occurrence with tavern density and proximity vary in a temporal sense relative to the density and proximity of a sample of traffic generators. Broadly speaking, we feel that there are three elements of our results that require further discussion.
To begin with, our results in Section 3.1 indicate that the proportion of assaults occurring within any given distance of taverns is disproportionate to both the usually resident population living within the corresponding geographical region and to the proportion of New Zealand land mass covered. Our findings in this regard are consistent with a broad consensus of studies both within Australasia and internationally (see, for instance, Langley et al. Citation1996; Briscoe and Donnelly Citation2001; Fitzgerald et al. Citation2010). However, our estimates of the proportion of assaults occurring within a given radius of taverns are certainly lower than those reported in the most easily comparable studies. For instance, whilst Burgess and Moffat (Citation2011) reported that approximately 37% of all assaults within the Sydney LGA occurred within 20 m of a licenced premises, our results suggest that only 15% of all assaults recorded in New Zealand during 2016 occurred within 100 m of a tavern. The main reason for this marked difference is that the study by Burgess et al. includes off-licenced as well as on-licenced premises. Furthermore, our results are likely to be underestimates given that we were forced to assume that each assault occurred at the centroid of the meshblock in which it was reported and given that at least some assaults will have occurred within taverns themselves.
Next, our results in Section 3.1 and 3.2 show that whilst tavern density and tavern proximity are more strongly associated to assault occurrence at peak times compared to off-peak times, AU socio-economic status is more strongly associated to assault occurrence at off-peak times compared to peak times. Whilst we are the first to study how the associations between assault occurrence with tavern density and proximity vary in a temporal sense within New Zealand, our findings are broadly consistent with a variety of international studies which descriptively report peaks in assault occurrence around on-licenced premises during weekend evenings (Teece and Williams Citation2000; Briscoe and Donnelly Citation2001; Nelson et al. Citation2001; Budd et al. Citation2003; Brower and Carroll Citation2007). However, only a handful of previous studies have attempted to statistically analyse the temporal nature of these associations. One such Philadelphia based study conducted by Morrison et al. (Citation2017) showed that proximity to bars and restaurants was associated with decreased odds of (non-gun) assault before 1pm but with increased odds of assault after 7pm. Another Toronto based study (Cusimano et al. Citation2010) used ambulance data to map incidents of violent injury across the city by time of day. The study found that during day time hours the greatest concentration of assaults were found in areas characterised by high proportions of social housing communities, homeless shelters, high unemployment rates and very low mean household incomes, i.e. areas exhibiting high levels of socio-economic deprivation. In contrast, during the early morning hours between 00:00 and 03:59 the most prominent hotspot for ambulance dispatch for assault injuries was in the ‘entertainment district’ characterised by lower levels of socio-economic deprivation and a higher density of bars and clubs. The highest counts of injuries were reported as occurring around 02:00 (the closing time of on-licenced premises). The results provided by Morrison et al. (Citation2017) and Cusimano et al. (Citation2010) therefore strongly reflect our findings that tavern density and proximity are more strongly associated with assault occurrence at peak time compared to off-peak time whereas the reverse is true with regards to AU socio-economic status. With regards to the latter, this effect is likely to be exacerbated in the New Zealand case by the fact that the number of taverns does not increase monotonically with higher levels of socio-economic deprivation (see ).
As a final point, our results show that whilst tavern density and proximity are more strongly associated to assault occurrence at peak times compared to traffic generator density and proximity, the reverse is true at off-peak times. It is not surprising that tavern density and proximity should be more strongly associated with assault occurrence at peak times compared to traffic generators given that the majority of the traffic generators within our sample are unlikely to open throughout peak hours. The fact that traffic generator density and proximity are more strongly associated to assault occurrence at off-peak times compared to tavern density and proximity suggests that off-peak assaults are less likely to be alcohol-related and more likely to be the result of a large amount of people interacting in the immediate vicinity of the traffic generators. From a policy perspective, this leads credence to the argument that the social harm caused by taverns operating outside of peak hours is less than taverns operating during peak hours and that this should be reflected in licencing decisions.
However, our results in this regard are far from definitive. As we have already alluded to, had we chosen a different sample of traffic generators we may have arrived at different results. As such, a potential line of further research to help more fully compare the temporal associations between assault occurrence with tavern density and proximity relative to traffic generator density and proximity would be the development of an efficient algorithm which facilitates the following procedure:
Obtain a list of taverns (or other alcohol outlets) within a particular area and their respective geo-codes.
Determine the level of geo-spatial clustering exhibited by the taverns. Also calculate some metric that describes the association between tavern density, tavern proximity and (peak/off-peak) assault occurrence. For ease of reference, in what follows we will refer to the calculated quantity as the association metric. As examples one may take the number of assaults occurring with an r-metre radius of taverns as the association metric or one could perform logistic regressions and calculate the relevant Gini coefficient.
Form a comprehensive list of all potential traffic generators within the area and their respective geo-codes.
From this list randomly select a sample of traffic generators equal in size to the number of taverns. If the chosen sample of traffic generators exhibits a similar level of geo-spatial clustering as that exhibited by taverns (i.e. within a specified degree of tolerance) then continue to step 5, otherwise chose a different sample.
Calculate the association metric for this sample of traffic generators.
Repeat steps 4 and 5 a large number of times in order to obtain a sample of association metrics, each individual value corresponding to a different sample of traffic generators. Compare the association metric observed for the taverns relative to the sample association metrics. The more extreme the value of the tavern association metric relative to the sample of association metrics, the greater the evidence for or against a stronger association between (peak/off-peak) assault occurrence with taverns relative to traffic generators.
We have stressed the word efficient above as the authors acknowledge that there are many computational challenges involved in developing such an algorithm, not least the geo-coding of a comprehensive list of traffic generators as in step 3 or the repeated calculation of the chosen association metric as in step 5. Consequently, such analysis may be far more amenable at a regional, rather than national, level as the number of taverns and meshblocks to consider will be much smaller.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Adam D. Ward http://orcid.org/0000-0002-5259-2728
References
- Banerjee A, LaScala E, Gruenewald P, Freisthler B, Treno A, Remer LG. 2008. Geography and drug addiction Springer: Netherlands. Chapter 7, Social disorganization, alcohol, and drug markets and violence; p. 117–130.
- Briscoe S, Donnelly N. 2001. Temporal and regional aspects of alcohol-related violence and disorder. Alcohol Studies Bulletin (No. 1). Sydney: NSW Bureau of Crime Statistics and Research.
- Brower A, Carroll L. 2007. Spatial and temporal aspects of alcohol-related crime in a college town. J Am Coll Health. 55(5):267–275. doi: 10.3200/JACH.55.5.267-276
- Budd T, Tedstone C, Curry D. 2003. Alcohol-related assault: findings from the British Crime Survey. London: Home Office.
- Burgess M, Moffat S. 2011. The association between alcohol outlet density and assaults on and around licensed premises. Contemporary Issues in Crime and Justice No. 147. Sydney: NSW Bureau of Crime Statistics and Research.
- Cameron MP, Cochrane W, Gordon C, Livingston M. 2016. Alcohol outlet density and violence: a geographically weighted regression approach. Drug and Alcohol Review. 35:280–288. doi: 10.1111/dar.12295
- Cameron MP, Cochrane W, McNeill K, Melbourne P, Morrison SL, Robertson N. 2012. Alcohol outlet density is related to police events and motor vehicle accidents in Manukau City, New Zealand. Aust N Z J Public Health. 36(6):537–542. doi: 10.1111/j.1753-6405.2012.00935.x
- Crampton P, Salmond C, Sutton F. 1998a. NZDEP91: a New Zealand index of deprivation. Aust N Z J Public Health. 22(7):835–837. http://www.otago.ac.nz/wellington/departments/publichealth/research/hirp/otago020194.html. doi: 10.1111/j.1467-842X.1998.tb01505.x
- Crampton P, Salmond C, Sutton F. 1998b. NZDEP96: Index of deprivation. Health Services Research Centre. http://www.otago.ac.nz/wellington/departments/publichealth/research/hirp/otago020194.html.
- Crampton P, Salmond C, Sutton F. 2002. NZDEP01: Index of deprivation. Research report. http://www.otago.ac.nz/wellington/departments/publichealth/research/hirp/otago020194.html.
- Crampton P, Salmond C, Atkinson J. 2007. NZDEP06: Index of Deprivation. http://www.otago.ac.nz/wellington/departments/publichealth/research/hirp/otago020194.html.
- Crampton P, Salmond C, Atkinson J. 2014. NZDEP2013: Index of deprivation. New Zealand Ministry of Health. http://www.otago.ac.nz/wellington/departments/publichealth/research/hirp/otago020194.html.
- Cusimano M, Marshall S, Rinner C, Jiang D, Chipman M. 2010. Patterns of urban violent injury: a spatio-temporal analysis. PLoS One. 5(1):e8669. doi: 10.1371/journal.pone.0008669
- Day P, Breetzke G, Kingham S, Campbell M. 2012. Close proximity to alcohol outlets is associated with increased serious violent crime in New Zealand. Aust N Z J Public Health. 36:48–54. doi: 10.1111/j.1753-6405.2012.00827.x
- Fitzgerald J, Mason A, Borzycki C. 2010. The nature of assaults recorded on licensed premises. Bureau Brief (No. 43). Sydney: NSW Bureau of Crime Statistics and Research.
- Gruenewald P. 2007. The spatial ecology of alcohol problems: niche theory and assortative drinking. Addiction. 102:870–878. doi: 10.1111/j.1360-0443.2007.01856.x
- Langley J, Chalmers D, Fanslow J. 1996. Incidence of death and hospitalization from assault occurring in and around licensed premises: a comparative analysis. Addiction. 91(7):985–993. doi: 10.1111/j.1360-0443.1996.tb03595.x
- Liang W, Chikritzhs T. 2011. Revealing the link between licensed outlets and violence: counting venues versus measuring alcohol availability. Drug and Alcohol Review. 30:524–535. doi: 10.1111/j.1465-3362.2010.00281.x
- Livingston M. 2008. Alcohol outlet density and assault: a spatial analysis. Addiction. 103(4):619–628. doi: 10.1111/j.1360-0443.2008.02136.x
- Mair C, Gruenewald P, Ponicki WR, Remer L. 2013. Varying impacts of alcohol outlet densities on violent assaults: explaining differences across neighborhoods. J Stud Alcohol Drugs. 74(1):50–58. doi: 10.15288/jsad.2013.74.50
- Menard S. 2004. Six approaches to calculating standardized logistic regression coefficients. Am Stat. 58(3):218–223. doi: 10.1198/000313004X946
- Ministry of Justice. 2017. [accessed 2017 Aug 1]. https://www.justice.govt.nz/tribunals/licences-certificates/arla/register-of-licences-and-certificates/.
- Morrison C, Dong B, Branas C, Richmond T, Wiebe D. 2017. A momentary exposures analysis of proximity to alcohol outlets and risk for assault. Addiction. 112(2):269–278. doi: 10.1111/add.13637
- Nelson A, Bromley R, Thomas C. 2001. Identifying micro-spatial and temporal patterns of violent crime and disorder in the British city centre. Appl Geogr. 21(3):249–274. doi: 10.1016/S0143-6228(01)00008-X
- New Zealand Police. 2016. Polcedata.nz - Victim Time and place. [accessed 2017 May 14]. http://www.police.govt.nz/about-us/publications-and-statistics/statistics/policedatanz.
- Statistics New Zealand. 2013. Census data tables. [accessed 2017 Sep 9]. http://www.stats.govt.nz/Census/2013-census/data-tables.aspx.
- Statistics New Zealand. 2017a. Geographic boundary files. [accessed 2017 Sep 9]. http://m.stats.govt.nz/browse_for_stats/Maps_and_geography/Geographic-areas/digital-boundary-files.aspx.
- Statistics New Zealand. 2017b. Geographic area files. [accessed 2017 Sep 9]. http://www.stats.govt.nz/browse_for_stats/Maps_and_geography/Geographic-areas/geographic-area-files.aspx.
- Statistics New Zealand. 2017c. Population projection tables. [accessed 2017 Sep 8]. http://www.stats.govt.nz/tools_and_services/nzdotstat/tables-by-subject/population-projections-tables.aspx.
- Stevenson R. 2009. National alcohol assessment. New Zealand police. [accessed 2017 Sep 29]. http://www.police.govt.nz/sites/default/files/Police-National-Alcohol-Assessment.pdf.
- Teece M, Williams P. 2000. Alcohol-related assault: time and place. Canberra: Australian Institute of Criminology.
- Zenbu Online Directory. 2016. [accessed 2017 Aug 15]. https://www.zenbu.co.nz/.