
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The objective of this research was to forecast the tax revenue of Pakistan for the fiscal year 2016–17 using three different time series techniques and also to analyse the impact of indirect taxes on the working class. The study further analysed the efficiency of three different time series models such as the Autoregressive model (A.R. with seasonal dummies), Autoregressive Integrated Moving Average model (A.R.I.M.A.), and the Vector Autoregression (V.A.R.) model. In any economy, tax analysis and forecasting of revenues is of paramount importance to ensure the economic and fiscal policies. This study is important to identify significant variables affecting tax revenue specifically in Pakistan. The data used for this paper was from July 1985 to December 2016 (monthly) and focused on forecasting for 2017. For the forecasting of total tax revenue, we used components of tax revenues such as direct tax, sales tax, federal excise duty and customs duties. The results of this study revealed that among these models the A.R.I.M.A. model gives better-forecasted values for the total tax revenues of Pakistan. The results further demonstrated that major tax revenue is generated by indirect taxes, which cause more inflation that directly hits the working class of Pakistan.
1. Introduction
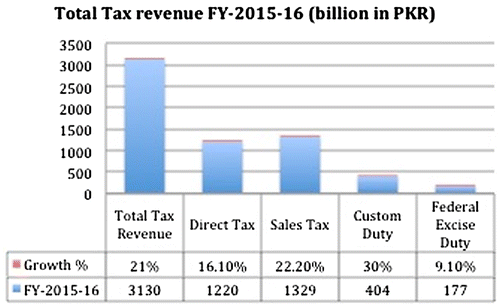
Taxation is not a popular terminology for individuals and business organisations, but it is a vital instrument for collecting revenues for government expenditure. As the collection of taxation increases, it allows the government to conceive maximum developmental projects for the public interest, and to improve the basic infrastructure of health, education, and the quality of life of common people. However, increase in taxation also increases the inflation level for goods and services, which make life more difficult to survive (Palacios & Harischandra, Citation2008; Poulson & Kaplan, Citation2008). Similarly, in business activities, local and foreign investors are reluctant to pour in any further investment in the country because of profit shrinkage. This situation triggers low output and decrease in overall G.D.P. of the country, which consequently also reduces the employment rate. The collection of taxation is now, a burning issue in Pakistan; therefore, the government is trying to document the whole economy, especially bringing services and agricultural sectors, and individual people into the tax net. The direct, and indirect taxation is an imperative question in the context of Pakistan because more than 60% of tax revenue is being collected through indirect taxes (Aamir et al., Citation2001). According to the Federal Board of Revenue (F.B.R.), the total tax revenue collection for the fiscal year (F.Y.) Citation2015–16 was Pakistani Rupee (P.K.R.) 3130 billion. a registered growth of 21% as compared to the previous fiscal year. The breakdown of total tax revenue and corresponding growth can be seen in Figure (F.B.R., Citation2015–16).
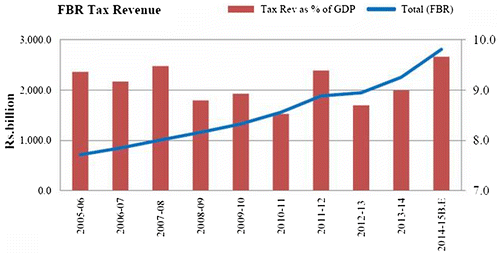
According to the Federal Board of Revenue (F.B.R.) tax to G.D.P. ratio is a burning question in the Pakistani context because it is very low, between 8.5%–9.7% for last ten years as displayed in Figure (F.B.R., Citation2015–16). It is even very low as compared to the other South Asian countries, however, the government set a target of 12.2% tax to G.D.P. ratio for the F.Y.-2016–17 (Federal Board of revenue, Citation2015–16).
This research is carried out in the context of future forecasting of these tax revenues for the fiscal year 2016–17. It is evident from Figure ; the substantial amount of tax revenue is generated by indirect taxes. According to Myles (Citation2000), the tax to G.D.P. ratio had significantly increased in developed economies, but in developing economies this ratio remained low. Chaudhry (Citation2001) has proposed an optimal tax theory, and suggested an effective agricultural policy to increase tax net, and recommended, if local bodies were made to be responsible then tax revenue can be increased significantly.
1.1. Background of the study
According to the purchasing power, Pakistan is the 25th largest economy, and in regard to G.D.P., its rank is 38th. Pakistan has a population of more than 190 million making it the 6th largest country in the world. Besides the documented economy, there is a black economy estimated at 37% of its overall economy, which is not documented and not included in the tax net (Economic Survey of Pakistan, Citation2015–16). Pakistan is still a developing economy but it has tremendous potential to evolve as one of the largest economies in the world. However, political instability, and a vulnerable law and order situation for last 35 years have worsened the social life of the common man, this situation has had adverse affects on total tax revenue generation.
The Pakistani Rupee (P.K.R.) faces terrible pressure, and has been depreciating in relation to the U.S. dollar for the last several years; therefore, the current account deficit touches the surplus. However, the central bank of Pakistan tried to keep balance by lowering the discount rate, and buying U.S. dollars from the open market to safeguard exports in order to compete with the rival economies. According to the Economic survey of Pakistan (Citation2015–16), the government has given sales tax exemptions of P.K.R.665 billion, in the current fiscal year, the government has already given sales exemption of P.K.R.478 billion in the first half.
The government has faced losses of P.K.R.65 billion taxes from the decrease in exports, and a further loss of P.K.R.18 billion is expected due to relief in tax under the fifth schedule of the sales tax act. The Federal Board of revenue also gave relief of P.K.R.83.6 billion in income tax, P.K.R.9.5 billion tax exemptions have been given to some specific industries, and P.K.R.2.5 billion losses because of inferior tax on capital gains in the stock market. Similarly, in the case of customs duty, the state provided the relief of P.K.R.103.1 billion, and P.K.R.27 billion losses incurred because of Pak-China free trade agreement. P.K.R.18.4 billion losses are expected in automobile imports’ customs duty (Federal Board of revenue, Citation2015–16). Thus, in this way the government is going to incur significant tax revenue losses for the fiscal year 2016–17.
1.2. Objective of the research
The objective of this research is to forecast the total tax revenue for the fiscal year 2016–17, and analyse the impact of indirect taxes on the working class of Pakistan. We have selected three different time series models, namely the autoregressive (A.R.) model with seasonal dummies, the autoregressive integrated moving average (A.R.I.M.A.) model, and the vector Auto regression (V.A.R.) model for forecasting purposes. For the evaluation of the efficiency of these models, we used root mean squared error (R.M.S.E.) test. We have taken monthly data for the time period from July 1985 to December 2016. For the forecasting of total tax revenue, we use components of tax revenues such as direct tax, sales tax, federal excise duty, and customs duties. For the multivariate model, we used the series such as large-scale manufacturing index (L.S.M.) – proxy for G.D.P. growth, consumer price index (C.P.I.), and international oil prices.
1.3. Significance of this research
The significance of this research is many fold, for example, we employed several econometric techniques to forecast the taken macroeconomic variables, this will be a significant addition to the literature, which will be helpful for the future research studies. We have incorporated the seasonal factors while we forecasted the total revenue of the country, this is an appropriate and suitable method in forecasting. We have examined the total revenue forecasting, the impact of direct tax, sales tax, customs duty, federal excise duty, large scale manufacturing (L.S.M.), consumer price index (C.P.I.), and international crude oil prices on total tax revenues in Pakistan. The results of this research provide the basis to formulate, and aligned the policies to the public, private institutions, and policy makers. Another important aspect of this research is the duration of the data, we have used quite substantial time period (31 years) from July 1985 to December 2016.
2. Literature review
The literature regarding determinants of tax revenue has gained considerable attention from financial experts, economist, and researchers worldwide. The findings of previous studies demonstrated the different effects in developed and developing economies. The developed economies have strong tax networks, which are well documented electronically. However, the developing countries are still in a transition phase to establish a strong and documented taxation system. Therefore, we have discussed the following previous literature specifically for the developing economies:
Himani (Citation2016) studied the elements of tax collection in the case of India; he took tax revenue collection from direct and indirect means. He concluded that the tax collected through indirect means has generated more revenue as compared to direct taxes. Aamir et al. (Citation2001) carried out a comparative study between India and Pakistan; they compared direct and indirect taxes for both countries. They concluded that Pakistan collected more revenuethrough indirect taxes, however, India generated more revenue through direct taxes. This study further indicated that indirect taxes extended the gaps between rich and poor, and further exploits the vulnerability of working class. Javid, Arif, and Arif (Citation2011) examined the fiscal performance of distinctive developing economies of Asia. They concluded that trade openness, agriculture value addition, per capita G.D.P., and debt and population growth are significant elements of total revenue to G.D.P. ratio across developing economies. These studies have limited scope and did not incorporate the individual determinants of direct and indirect tax collection; thus, this gap is bridged in our research study, and we examined the impact of indirect taxes on the working class of Pakistan.
Eugene and Chineze (Citation2016) studied the impact of taxation policies on the overall economic growth of Nigeria. The results of the study confirmed the positive impact of a tax on economic growth. The results of the study further demonstrated that there is a linear association between tax base and total tax revenue. They also concluded a positive and significant association between tax base, tax policies, and further concluded that there is no significant association between economic growth and total tax revenue. Sunday (Citation2015) also examined the tax policies of Nigeria, and its impact on inflation. He concluded that the taxation policies have a long-term association with the inflation rate, and consumption and property taxes also have a long-term positive association with inflation. The forecasting of tax revenue and other economic indicators were diagnosed through different forecasting models, and several studies proved the efficiency and superiority of these models (Lutkepohl, Citation1991, Citation1999; Sims, Citation1980; Waggoner & Zha, Citation1999; Watson, Citation1994)
Karagöz (Citation2013) has examined the fiscal deficit of Turkey, he assessed cointegration through O.L.S., and concluded that the industrial and agricultural shares in G.D.P. affect the total tax revenue; he further concluded that foreign trade openness does not have any impact on the total tax revenue. Nanthakumar, Kogid, Sakami, and Muhamad (Citation2011) examined the association between total tax revenue and the government spending in the case of Malaysia. The results of the study revealed that the total tax revenue is directly proportional to spending. Husain and Qasim (Citation2007) examined the causal relationship between the government spending and the total tax revenue in Pakistan. The results of the study exhibited the unidirectional causality from spending to the total tax revenue. On similar topics some important research studies have been carried out that established the superiority of the forecasting models (Box & Jenkins, Citation1976; Nau, Citation2014; Tiao & Box, Citation1981; Zhang, Citation2013)
Daba (Citation2015) investigated the elements of total tax revenues of Ethiopia, it is concluded from the study that F.D.I.s and per capita have a strong and significant impact on total tax collection. He further concluded that inflation and interest rates have an insignificant impact on total tax generation. According to Hassan and Tahmina (Citation2012), the government of Bangladesh is borrowing significantly from government sources, which negatively affected the overall economy of the country. They finally concluded that internal borrowing hurts the economy and G.D.P. rate more as compared to foreign debts. These studies did not consider the individual tax revenue determinants, thus in our study we have examine the impact by employing direct and indirect factors for total tax revenue. Moreover, we predict the forecasting of next year’s tax revenue by using three different methods; hence, our research is a further extension of these studies.
Patoli, Zarif, and Syed (Citation2012) investigated the association between the inflation rate and tax revenue in the case of Pakistan. They concluded that total tax revenue and inflation have a positive correlation; they further concluded that any change in the inflation rate causes further increase in the taxation rate. According to Tanko (Citation2015), personal income tax is the major source of total revenue for the Nigerian government. He concluded that the insufficiency of the internally collected tax hampers the overall economy of Nigeria. He further concluded that the greater dependency on the federal accounts and total expenses disrupt the economy, therefore, the government should craft the strategies to increase revenue creation. Rasheed (Citation2006) has studied the relationship between the total tax revenue, and G.D.P., total tax collection and money supply, total tax and broad and narrow money supply, and total tax collection and C.P.I. etc. He used the cointegration technique and concluded that there is no strong relationship between the tax revenue growth and the public debt, tax revenue growth, and C.P.I., tax revenue growth, and investment and credit. Thus, we incorporate additional factors besides the considered variables of previous research; moreover, we forecast the tax revenue for the next year, hence, our study is an extension of these studies.
Mehrara, Pahlavani, and Elyasi (Citation2011) investigated the association between the spending and the government revenue of 40 Asian economies. They recommended that the governments of these countries should enhance their total revenue, and reduce their expenditure in order to control their budgetary deficits. Chaudhry and Munir (Citation2010) examined the causes of low tax revenue in the case of Pakistan. The results of the study demonstrated that the trade openness, external aids, broad money, and political stability are the major causes of the tax collection. In the light of the results of these two studies, we have identified the gap in crucial variables, and incorporated these factors in our study to bridge this gap. Samuel (Citation2014) has conducted a study for Nigerian tax revenue collection and took federally generated tax as the dependent variable. He has taken petroleum profit tax, value added tax, custom and excise duty, and company income tax as independent variables. The result of the study indicates that V.A.T. is significantly profitable to the Nigerian economy; using the same approach we have incorporated more variables to bridge the gap of this research. Das-Gupta (Citation2011) examined the resilience of sales tax and revenue to G.D.P., and also investigated the impact of direct and indirect taxes on G.D.P. with and without V.A.T. He concluded that two thirds of the sample did not have any indirect effect on V.A.T. Kenny and Winer (Citation2006) carried out a very important study in which they studied the tax structure of 100 countries. They concluded that the structure of tax generation changes with the change of political regimes. They further concluded that progress governments do not concentrate on the collection of revenues from individual income tax. In the same manner, the study also examines determinants of indirect taxes, and their impact on the economy and the wellbeing of individuals.
An important aspect of tax collection and tax evasion is based on the morality of individuals; several research studies have been carried out on this issue. These research studies have emphasised the role of religion, culture, and economic aspects on tax compliance (Dowling, Citation2014; Strielkowski & Čábelková, Citation2015). People are ready to pay taxes but governments have failed to fulfil the social contract with their inhabitants. The vulnerability of this situation has been reflected in developing countries, particularly where the governments have shown the deficiencies in order to provide social security. Thus, the morality does not depend on the individuals only but the governments are equally responsible for this fiasco (Čábelková & Strielkowski, Citation2013; Torgler & Schneider, Citation2007).
3. Data and methodology
3.1. Data collection
In our study, for forecasting purposes, we have used univariate examination to analyse a single variable (tax revenue) at a time for univariate variables such as the total tax revenue (T.R.), and considered its four important components, direct tax (D.T.), sales tax (S.T.), federal excise duty (F.E.D.), and customs duty (C.T.), but these are the determinants of tax revenue, thus we have employed univariate analysis (Bagshaw, Citation1987). On the other hand, we have selected three isolated variables to analyse together with tax revenue for potential interfaces, thus, we have used the multivariate model, and we have taken three variables such as large-scale manufacturing (L.S.M.), international oil prices (I.O.P.), and consumer price index (C.P.I.) (Bagshaw, Citation1987). The secondary data for the whole series are collected from the different issues of the Pakistan Bureau of Statistics (P.B.S.) monthly bulletin, however, the I.O.P. data is collected from the International Monetary Fund (I.M.F.) website shown in Table . We have considered a reasonable period of time for the forecasting purposes, we took around 31 years’ data for the time period from July 1985 to December 2016. The tax exemptions have already been incorporated in the final tax revenues, which were published by the Pakistan Bureau of statistics, thus, the impact of tax exemptions does not have any distortion while we carry out the undertaken research study.
Table 1. Data collection sources.
3.2. Estimation and data analysis tools
As explained earlier, we have used time series data for the period from July 1985 to December 2016, and forecast the total tax revenue (T.R.) for Pakistan by taking its four components L.D.T., L.S.T., L.F.E.D., and L.C.D. The proposed methods used for the forecasting of total revenue are Autoregressive A.R. (1) with seasonal dummies and the A.R.I.M.A. model. For the multivariate analysis, we used the V.A.R. model for the forecasting of L.T.R. with L.L.S.M., L.C.P.I., L.I.O.P., and seasonal dummies as exogenous variables. These three forecasting methods are considered for the short run forecasting models as suggested by the cointegration analysis in last part of this section; moreover, the variables’ causal relationship was tested through the Granger causality test.
The analysis of the undertaken study began with checking the unit root test in the series, for this purpose we employed the Augmented Dickey–Fuller (Dickey & Fuller, Citation1979, Citation1981) test. The tax revenues’ four components were estimated through the autoregressive (A.R.) model with seasonal dummies (Doan, Litterman, & Sims, Citation1984; Litterman, Citation1986; Zhang, Citation2013). Similarly, we estimated the autoregressive integrated moving average (A.R.I.M.A.) model for all four components (Box & Jenkins, Citation1976; Nau, Citation2014; Tiao & Box, Citation1981; Zhang, Citation2013). Finally forecasting through the vector autoregressive (V.A.R.) model in a difference form with order L.T.R., L.L.S.M., L.C.P.I., and L.I.O.P. with seasonal dummies (Thomas, Litterman, & Sims, Citation1984; Tiao & Box, Citation1981; Zhang, Citation2013). For the causation and directionality we applied the Granger causality test to check the causality between the variables. Lastly, we employed forecasting by using models and finally compared the robustness of these models through root mean squared error (R.M.S.E.) test (Nau, Citation2014; Zhang, Citation2013).
3.3. Unit root test
The first objective of our estimation to check the stationarity of the data series because it is an essential way forward for any higher and sophisticated econometric modelling. For this purpose, we have different unit root tests, but the Augmented Dickey–Fuller (Citation1979, Citation1981) is the most popular and widely used unit root test worldwide. The generalised equation form of the test is as given follows:(1)
(1)
where: in Equation (Equation1(1)
(1) ), ‘t’ is the time period, ‘y’ denotes the time series, ‘n’ is the optimum number of lags, αo is a constant and ‘e’ is an error term.
3.4. Autoregressive model (A.R. model)
The random walk is one of the most important models in econometric time series modelling, this random walk model is also known as the autoregressive model or simply the A.R. (1) process. The following equation is the simplest form of the model:(2)
(2)
Equation (Equation2(2)
(2) ) is called the non-drift random walk; if we just add the constant value in above model then it will be converted into a random walk model with drift.
As we know, if the A.R. (p) procedure is stationary, in which it comprises to examine the roots of its characteristic modelling equation. If the φ(L)−1touches or converges to zero, then the A.R. (p) model is said to be a stationary model with lag operator notation and can be expressed as follows:(3)
(3)
If we increase the lag length, then the autocorrelations decay to zero. If the A.R. (p) procedure is said to be stationary, the following are the roots of the characteristics equation:(4)
(4)
In Equation (Equation4(4)
(4) ) all roots placed on the outer side of the circle, it is also > 1. It is important to know that if the roots of the random walk model lie on the unit circle then it is known as the non-stationary process of a random walk, and can be computed as follows:
(5)
(5)
In the above expression, ‘1−z’ is known as the characteristic equation, and the root (z) lies on the unit circle. The other characteristics of the A.R. (p) model are the variance and the mean of A.R. (1) process, and can be expressed as follows:(6)
(6)
3.5. Autoregressive integrated moving average (A.R.I.M.A.) model
The autoregressive integrated moving average (A.R.I.M.A.) is a generalised form of the autoregressive moving average (A.R.M.A.) model in econometric time series modelling. These two models are known to be the best in forecasting for future values. The equation of the stationary A.R.M.A. (p, q) process can be described as a sequence of random variables (Xt). The equation can be written as follows:(7)
(7)
In Equation (Equation7(7)
(7) ), ‘Zt’ is denoted for the sequences of uncorrelated random variables, which have zero mean and constant variance, and can be shown as follows:
(8)
(8)
In Equation (9), the ‘X’ process is known as the A.R.I.M.A. (p, d, q) procedure, if ‘d’ has a property of non-negative integers, such as, (1−B)d, then ‘X’ will be known as a causal A.R.M.A. (p, q) method. Hence, the A.R.I.M.A. (p, d, q) processes satisfy the following form of a diferential equation:(9)
(9)
where: ϕ(z) and θ(z) are known as the polynomials of p and q degrees correspondingly, moreover, ϕ(z) ≠ 0 for | z |≤1. Since the ϕ∗ (z) having a ‘0’ of order ‘d’ with z = 1.
As the procedure ‘Xt’ known as stationary if d = 0, and in this case the expression reduces to an A.R.M.A. (p, q) method. A fractionally integrated or a long memory process A.R.M.A., and autoregressive fractionally integrated moving average – A.R.F.I.M.A. (p, d, q) methods with 0 < |d| < 0.5 is called a stationary process, in which autocorrelation function ρ (k) decreasing slowly at lag k, as k→∞ that also fulfils the property of ρ(k) ~ Ck2d−1. Thus, the A.R.F.I.M.A. method also gratifies the differential expression:(10)
(10)
where:
(11)
(11)
(12)
(12)
For all the z values such as | z |≤1, here ‘B’ is known as the backward shift operator, and (1−B)d operator is described by the binomial extension as follows:(13)
(13)
Suppose ‘Yt’ is denoted for the time series, and ‘yt’ is known as the observed time series, further we also know that there is a steady decrease in the level of ‘yt’. Thus, we can obtain a new series by differencing time series at lags 1, which is almost constant in its level, and we called it ‘Xt’. For this ‘Xt’ we can tailor the A.R.M.A. (p, q) model.
3.6. Forecasting error
Since there is always error in forecasting, thus, in order to measure that error, and to ensure the utmost accuracy in forecasting we have used three techniques, namely root mean squared error (R.M.S.E.), which is known as the most reliable as compared to other two, i.e., mean absolute percentage error (M.A.P.E.), and mean absolute error (M.A.E.). The mathematical expressions for the three techniques are given as follows:(14)
(14)
(15)
(15)
(16)
(16)
where: in Equation (Equation16(16)
(16) ), ‘n’ is signified for the number of predicted values, and ‘xi’ is known as the actual observed values, whereas,
is denoted for the predicted values.
3.7. Granger causality test
It is imperative to establish that whether one variable could forecast another factor or variable in time series analysis (Granger, Citation1969). Multiple linear regressions are behind the methodology of Granger causality technique. According to Goebel, Roebroeck, Kim, and Formisano (Citation2003) by using the F-statistics on the basis of residuals factor several research studies have already been carried out. As pointed out by the Chen et al. (Citation2009) the ratified trace coefficients could be applied to perform t-test at the level of group statistics. According to McFarlin, Kerr, Green, and Nitschke (Citation2009), the negative trace coefficients are the restrained aftereffects. The pairwise Granger causality expression could be expressed as follows:(17)
(17)
(18)
(18)
In Equation (Equation18(18)
(18) ), ‘X’ and ‘Y’ known as the two time series at distinctive time period ‘t’, and ‘Xt−p’ and ‘Yt−p’ are called two data time series at period ‘t−p’. Here ‘p’ used as a number of lagged orders of the time period. Similarly, in the above expression (An) and (An’) are ratified trace coefficients then (Bn) and (Bn’) are known as the autoregression model. In the above expressions, we considered ‘Zt’ as co-variables at the time period of ‘t’. The value of F-statistics could be calculated for the normal Wald-test as follows:
(19)
(19)
Equation (Equation19(19)
(19) ) follows the Fm,n−k distribution, in which k=m+n+1. If the estimated value of ‘F’ greater than the critical value of ‘F’, then we reject the null hypothesis and concluded that Xt causes Yt.
3.8. Vector autoregression model (V.A.R. model)
For the analysis of the multivariate time series, the vector autoregression (V.A.R.) is the obvious choice because this model is very flexible and user-friendly. The vector autoregression (V.A.R.) model is the logical annex of univariate A.R. model for the dynamic multivariate data time series. This model is specifically useful for the description of the dynamic behaviour of time series and their forecasting. Sims (Citation1980) was a famous econometrician, who made this model useful and used this effectively in his research. Moreover, Lutkepohl (Citation1991, Citation1999), Watson (Citation1994), Nau (Citation2014), Zhang (Citation2013), Tiao and Box (Citation1981), and Waggoner and Zha (Citation1999) are examples of the distinctive and technical use of this model.
We can derive the following form of the V.A.R. model, let Yt = (y1t, y2t,…., ynt) signify for (n x 1) vectors of the time series variables, and fundamental ‘p’ lags for the vector autoregressive then the V.A.R. (p) model could be expressed as follows:(20)
(20)
where: t = 1, ....., T
In the above expression, Πi are the(n x n) matrices of coefficients, and ‘εt’ is as the (n x 1) non-observable mean white noise vector procedure, which is consecutively uncorrelated or independent with the time-invariant covariance matrix Σ. Thus, we can express the bivariate V.A.R. (2) model as follows:(21)
(21)
Or, it can also be written as follows:(22)
(22)
(23)
(23)
In the above expressions cov (ε1t, ε2s) = σ12 for t = s, 0 otherwise, and it is important to note that each expression has the same regressors – lagged estimations of y1t and y2t. Thus, it is observed that the V.A.R. (p) technique is just an apparently dissimilar regression (S.U.R.) model with lagged factors or variables, and in defined terms, it is same as regressors. The V.A.R. (p) can be written as follows for lag operator notation:(24)
(24)
In the above equation Π (L) = In − Π1L − ... − ΠpLp. The model V.A.R. (p) is considered to be a firm or stable if the roots placed the outer side of the multifaceted unit circle, which have modulus > 1, or evenly (equivalently). The eigenvalues of the companion matrix can be written as follows:(25)
(25)
The above expression F-matrix has modulus < 1. Suppose that procedure has been rearranged in the unlimited historical values, thus the firm V.A.R. (p) procedure is considered to be a stationary, and therefore with the time variant variance, means, and autocovariance. Let the series ‘Yt’ is reflected as covariance stationary then the unrestricted means can be expressed as follows:(26)
(26)
Thus, the mean-adjusted shape of the model V.A.R. (p) is written as:(27)
(27)
Since the fundamental V.A.R. (p) technique is so obstructive to show adequately the major characteristics of the data time series. Specifically, additional deterministic expressions, such as seasonal dummies or linear time trends may require showing the time series correctly; moreover, there is a requirement of stochastic exogenous variables. Hence, the generalised form of A.R. (p) model can be expressed with deterministic terminologies and exogenous factors as follows:(28)
(28)
In the above expression ‘Dt’ indicates (1 x 1) deterministic module matrices and ‘Xt’ signifies (m x 1) the exogenous factors matrix, whereas, Φ and Ψ are parameter matrices.
4. Estimations and results
4.1. Augmented Dickey–Fuller (A.D.F.)
The stationarity of the data is an essential condition to proceed further and employ any time series model. The augmented Dickey–Fuller (Citation1979, Citation1981) is the most widely used technique to test the stationarity of the data series. A.D.F. test outcomes (Table ) showed that L.T.R., L.D.T., L.F.E.D., L.S.T., L.C.U.S., L.L.S.M., L.I.O.P., and L.C.P.I. series have level unit root so the series are transformed and checked at first difference where they become significant and become stationary, consequently these data time series are integrated of order 1 or I(1).
Table 2. Stationarity of data series (A.D.F. test).
4.2. Graphical representation of stationarity
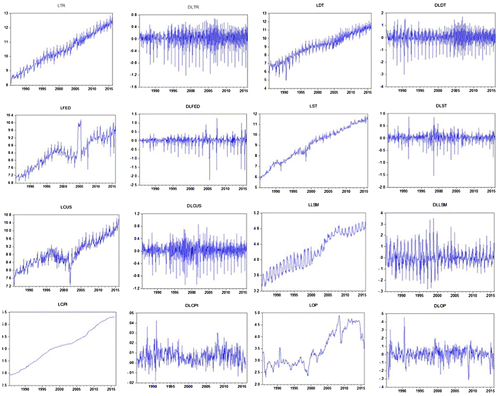
As exhibited by Figure , all the data series are non-stationary at the level, but at the first difference time series of all the eight variables became stationary. Hence, this is also confirmation of the A.D.F. test result that series are integrated of order one or I(1).
Figure 3. Stationary and non-stationary graphs of series.
4.3. Revenue forecasting: A.R. model with seasonal dummies
Autoregressive of order two with seasonal dummies are estimated to four components of total revenue (T.R.), such as: Direct Tax (D.T.), Sales Tax (S.T.), Federal Excise Duty (F.E.D.), and Customs Duty (C.U.D.). By using this model, variables are forecast for a total of 6 months, that is from January 2017 to June 2017; the Root Mean Square Error (R.M.S.E.) is calculated as 0.3215 (for the detail calculation see Annexure 1). The total of all these forecast values (January–June 2017) for total revenues (T.R.) is presented in Table . The total forecast and actual value for FY-2016–17 is P.K.R.3382.95 billion (U.S.$32.22 billion). The actual revenue of P.K.R.1468.32 billion (U.S.$13.98 billion) for the first half of F.Y.-2016–17 (July–Decemeber 2016) has been taken from the Federal Board of Revenue Department of Pakistan. The total forecast revenue of P.K.R.1914.63 billion (U.S.$18.23 billion) for the last six months of FY-2016–17 (January–June 2017) have been forecastthrough the autoregressive seasonal dummies model. The results of the forecast numbers of last six-month are presented in Table .
Table 3. Forecasted values of total revenue using A.R. model.
4.4. Revenue forecasting: the A.R.I.M.A. model
The autoregressive integrated moving average (A.R.I.M.A.) model is used for forecasting purposes by taking four components of total revenue (T.R.), such as: Direct Tax (D.T.), Sales Tax (S.T.), Federal Excise Duty (F.E.D.), and Customs Duty (CU.D.). Using this model the variables forecast total revenue of P.K.R.1807.54 billion (U.S.$17.21 billion for the last 6 months of F.Y.-2016–17 that is from January 2017 to June 2017; the Root Mean Square Error (R.M.S.E.) is calculated as 0.2235 (for the detailed calculation see Annexure 2). The second half (January–Junue 2017) forecast values of total revenues (T.R.) are presented in Table . The total forecast value for FY-2016–17 are P.K.R.3279.88 billion (US$30.93 billion) which is less than the Federal Board of Revenue (F.B.R.) target set by the government of Pakistan is P.K.R.3521 billion (revised) (U.S.$33.20 billion). Therefore, results of our study forecast the shortfall of P.K.R.241.12 billion (US$2.27 billion) as estimated by using the A.R.I.M.A. model.
Table 4. Forecasted values of total revenue using A.R.I.M.A. model.
4.5. Granger causality test
Before applying the Vector Autoregression (V.A.R.) model, it is better to find out if the direction of the variables, which are used in the V.A.R. model, have any causal relationship or not. The Granger Causality test applied between the pairs of L.T.R. with L.L.S.M. L.C.P.I., and L.I.O.P. in difference form with using lag 1 and lag 2. The results are given in Table , shows that at lag 2, L.L.S.M. and L.C.P.I. have the two-way causal relation, whereas L.I.O.P. has a one-way causal relationship to L.T.R. (bold figures). Which means that we can apply V.A.R. and the results obtained through V.A.R. may be the better than other models, which are used in this study.
Table 5. Pairwise Granger causality test.
4.6. Revenue forecasting: vector autoregression model (V.A.R.)
V.A.R. of the order D.(L.T.R.) D.(L.L.S.M.) D.(L.C.P.I.) D.(L.I.O.P.) is estimated using the lags 1 to 7 and 9 to14 with seasonal dummies as exogenous variables. Lags are selected by applying the V.A.R. lag exclusion Wald test (for detailed results see Annexure 3 and 4). Then forecast values are obtained from January 2017 to June 2017 that is P.K.R.1840.60 billion (U.S.$17.53 billion) as showed in Table , with R.M.S.E. 0.2354. Thus, the total revenues forecasted for F.Y.-2016–17 are P.K.R.3312.92 billion (U.S.$31.24 billion). According to the Federal Board of Revenue (F.B.R.) department, the actual total revenue collected in a first half of the fiscal year (July–December 2016) was P.K.R.1468.32 billion (U.S.$13.98 billion). Therefore, the results of our study forecast the shortfall of P.K.R.208.08 billion (U.S.$1.96 billion) as estimated by using the V.A.R. model against the budgeted total revenue for F.Y.-2016–17.
Table 6. Forecast values of total tax revenue using V.A.R. model.
4.7. Total revenue forecasting error
Since the R.M.S.E., M.A.E., and M.A.P.E. of the A.R.I.M.A. model is minimal for the A.R.I.M.A. model as shown by Table among the other two time series models, which are used to forecast the total revenues for Pakistan, Now, we can say that the forecast value of total revenues for Pakistan for F.Y.-2016–17 is P.K.R.3279.88 billion (U.S.$31.20 billion), which is less than the Federal Board of Revenue (F.B.R.) target set by the government of Pakistan of P.K.R.3521 billion (revised) (U.S.$33.20 billion). Therefore, results of our study forecast a shortfall of P.K.R.241.12 billion (U.S.$2.27 billion) as estimated by using the A.R.I.M.A. model.
Table 7. Total Revenue Forecasting Error.
4.8. Johansen cointegration technique
We employed a test for cointegration, and for this purpose we employed the Johansen cointegration approach. Outcomes of Table and Table exhibited that there is no evidence of long run relationship amongst the variables because both Max-eigenvalues and Trace statistic values are less than the critical values, thus, it is established that there is only short run association exisiting amongst the variables. Therefore, the short run association has already been estimated in the three forecasting models discussed earlier.
Table 8. Unrestricted cointegration rank test (trace).
Table 9. Unrestricted cointegration rank test (maximum eigenvalue).
4.9. Actual and forecast tax revenue (January 2017–June 2017)
Outcomes of Table exhibited the actual and forecast tax revenue (January 2017–June 2017) values of the A.R. model with seasonal dummies, A.R.I.M.A. model and V.A.R. model. The individual components of the actual total tax revenue, and total tax revenue values are depicted in Table . The results show that the A.R. model with seasonal dummies are closer to the forecast values as far as the total revenue is concerned, however, the actual values of direct tax revenue are the best forecast values as compared to other models. The wide variation is observed in the sales tax and customs duty, most probably the reason behind the unexpected increase of sales tax and custom duty in Q4 2017. The government has increased G.S.T. on more than 40 items, similarly, increased customs duty on luxury goods, and other important items in Q4 2017 as well. Thus, the gap between the actual and forecast values of sales tax and customs duty is more noticeable. Moreover, the government has revised the total tax revenue target and re-adjusted from P.K.R.3621 billion to P.K.R.3521 billion in Q4 2017 (F.B.R., 2016–17). Hence, this deviation has occurred due to these two components, otherwise, the A.R.I.M.A. model has best forecast the values of the direct tax and federal excise duty.
Table 10. Actual and forecast values of tax revenue (January 2017–June 2017).
5. Discussions and conclusions
5.1. Discussions
According to the results, the A.R.I.M.A. model shows the best forecasting values of total tax revenue because the value of the R.M.S.E. is minimum as compared to the A.R. model with seasonal dummies and the V.A.R. model. The results of the study further showed that the major portion of tax revenue is generated by indirect taxes. The results are consistent with previous research (Aamir et al., Citation2001; Chaudhry & Munir, Citation2010; Himani, Citation2016), which studied the elements of tax collection in the case of India and Pakistan and concluded that in Pakistan, the ratio of tax collection is significant through indirect taxes. They concluded that the indirect taxes have widened the gap between the rich and poor, and further exploits the vulnerability of the working class. In our research, we used the total tax revenue as a dependent variable, and direct and indirect taxes as independent variables, previous studies also used the same variables (Aamir et al., Citation2001; Himani, Citation2016; Husain & Qasim, Citation2007; Patoli et al., Citation2012; Samuel, Citation2014). They concluded the same results that indirect taxes are more prominent compared with direct taxes except for the findings of Himani (Citation2016) in which he concluded that the total tax revenue is more prominent and dominant than the direct taxes in the case of India. The results also showed unidirectional causalities and concluded that there is Granger causality from the total tax revenue to large-scale manufacturing, and the total tax revenue to consumer price index in lag 1. However, lag 2 revealed a bidirectional causality between the total tax revenue and large-scale manufacturing, and consumer price index, whereas, the crude oil prices Granger causes to the total tax revenue. Thus, these results concluded that excessive tax collection causes inflation, and because of inflation the government is imposing further taxes on the working class of Pakistan in the form of indirect taxes. Similarly, the government of Pakistan collects more taxes from the large-scale manufacturing sector or in other words the growth of L.S.M. increases the tax net, which further increases tax collections. These results are also consistent with previous research studies (Chaudhry & Munir, Citation2010; Daba, Citation2015; Daba & Mishra, Citation2014; Rasheed, Citation2006; Samuel, Citation2014; Sunday, Citation2015). The study further showed that there is a Granger cause from crude oil prices to the total tax revenue. Since Pakistan is an oil importing country, and taxes are 40% on petroleum products, thus, these results are very much aligned with the true picture or ground realities, and also consistent with the previous research studies such as Chen et al. (Citation2009), Eugene and Chineze (Citation2015), Hassan and Tahmina (Citation2012), and Karagöz (Citation2013).
5.2. Conclusions
The results of the study demonstrated the effectiveness of three different time series models, moreover, the precise results of forecasting, total tax revenue for the F.Y.-2016–17, which lay down the foundations for proper policy-making by the government of Pakistan. The results of this study revealed that among these models A.R.I.M.A. model gives better-forecast values for the total tax revenues of Pakistan, Now, we can say that the forecast value of total revenues for Pakistan for F.Y.-2016–17 is P.K.R.3279.88 billion (U.S.$30.92 billion). Hence, the forecast tax revenue is less than the Federal Board of Revenue (F.B.R.) target set by the government of Pakistan that is P.K.R.3521 billion (U.S.$33.20 billion). Moreover, we have equated the actual and forecast tax revenues; the comparison revealed that the A.R. model with seasonal dummies have forecast the results closer to the actual results of total tax revenue. However, the actual values of direct tax revenue are the best-forecast values as compared to the other models. Wide variation is observed in the sales tax and custom duty, most probably the reason behind the unexpected increase of sales tax and custom duty in Q4 2017. The government has increased G.S.T. on more than 40 items, similarly, increased customs duty on luxury goods, and other important items in Q4 2017. Thus, the gap between the actual and forecast values of sales tax and customs duty is more noticeable. Hence, this deviation has occurred due to these two components, otherwise, the A.R.I.M.A. model has best forecast the values of the direct tax and federal excise duty. Therefore, the results of our study forecast the shortfall of P.K.R.341.12 billion (U.S.$2.27 billion) as estimated by using the A.R.I.M.A. model. Therefore, the government should take appropriate and immediate measures in order to fix this anticipated problem. A very important finding of our research is that the government is collecting three times more taxes from indirect means compared to direct taxes. This is quite unusual if we compare the developing and developed economies, where the major chunk of taxes is being generated from the direct taxes. This shows the weak tax collection system in Pakistan because the government has failed to broaden the tax net of income tax from the individuals, merchants, individual services, real estate, stock market, and the agriculture sector. Therefore, the government achieves its tax revenue budget by imposing indirect taxes in the form of G.S.T.; gain tax, levies tax, withholding tax, customs duty, federal excise duty etc. The tax to G.D.P. ratio is also very alarming, and was between 8.5% to 9.7% for the last ten years, it is not comparable to the developed economies, even very low compared to the other South Asian developing countries such as India, Bangladesh, Sri Lanka, and China etc. Therefore, there is a strong need to improve the tax collection system and the government should bring new tax reforms, and broaden the tax net.
5.3. Limitations of the study
The undertaken study has certain limitations, for instance, we did not incorporate exogenous factors like political instability, local and international economic turmoil, terrorism, and government policies, thus, future research studies may incorporate these exogenous factors. Moreover, these exogenous variables may cause structural breaks in the considered time series. Thus, this research study has not incorporated these structural breaks; this is another limitation of the study. Future studies may incorporate these structural breaks. Finally, other macroeconomic indicators such as inflation rate, exchange rate, and unemployment have not been incorporated in undertaken study; thus, it might be another potential area for future studies. In Pakistan the segregated data for total revenues is not available in monthly frequency that is why we use the total revenues such as direct tax, sales tax, custom duty and excise tax, this is another limitation of undertaken research. For the case of Pakistan the model established after trying all possible macroeconomic variables in relation with total revenues and the best model is estimated in this study (since G.D.P. in monthly or quarterly is published by the statistical agency of Pakistan which is also one of the limitation of this study that is why we use L.S.M. as best proxy of G.D.P.).
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Aamir, M., Qayuum, A., Nasir, A., Hassain, S., Khan, K. I., & Butt (2001). Determinants of tax revenue: Comparative study of direct taxes and indirect taxes of Pakistan and India. International Journal of Business and Social Sciences, 2, 171–178.
- Bagshaw, M. L. (1987). Univariate and multivariate ARIMA versus vector ( Working Paper 8706). The Federal Reserve Bank of Cleve1and. Retrieved March 16, 2017, from https://fraser.stlouisfed.org/files/docs/historical/frbclev/wp/frbclv_wp1987-06.pdf
- Box, G. E. P., & Jenkins, G. M. (1976). Time series analysis: Forecasting and control. San Francisco, CA: Holden-Day.
- Čábelková, I., & Strielkowski, W. (2013). Is the level of taxation a product of culture? A cultural economics approach. Society and Economy, 35, 513–529.
- Chaudhry, M. G. (2001). Theory of optimal taxation and current tax policy in Pakistan’s agriculture. Pakistan Development Review, 40, 489–502.
- Chaudhry, I. S., & Munir, F. (2010). Determinants of low tax revenue in Pakistan. Pakistan Journal of Social Sciences, 30, 439–452.
- Chen, G., Hamilton, J. P., Thomason, M. E., Gotlib, I. H., Saad, Z. S., & Cox, R. W. (2009). Granger causality via vector auto-regression tuned for fMRI data analysis. Proceedings of the International Society for Magnetic Resonance in Medicine, 17, 1718.
- Daba, T. A. (2015). Determinants of tax revenue in Ethiopia (Master’s thesis). Addis Ababa University, Ethiopia. Retrieved March 6, 2017, from http://etd.aau.edu.et/bitstream/123456789/6819/1/Tesfaye%20Alemayehu.PDF
- Daba, D., & Mishra, D. K. (2014). Tax reforms and tax revenues performance in Ethiopia. Journal of Economics and Sustainable Development, 5, 11–19.
- Das-Gupta, A. (2011). An assessment of the revenue impact of the state level VAT in India (Working Paper). Goa Institute of Management, India. doi:10.2139/ssrn.1953165
- Dickey, D. A., & Fuller, W. A. (1979). Distribution of estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427–431. doi:10.1080/01621459.1979.10482531
- Dickey, D. A., & Fuller, W. A. (1981). Likelihood ratio statistics for autoregressive time series with a unit root. Econometrica, 49, 1057–1072. doi:10.2307/1912517
- Doan, T., Litterman, R., & Sims, C. (1984). Forecasting and conditional projection using realistic prior distributions. Econometric Reviews, 3, 1–100. doi:10.1080/07474938408800053
- Dowling, G. R. (2014). The curious case of corporate tax avoidance: Is it socially irresponsible? Journal of Business Ethics, 124, 173–184.
- Economic Survey of Pakistan. (2015–16). Overview of the Economy (Various issues). Retrieved March 9, 2017, from www.finance.gov.pk/survey/chapters_16/Overview_of_the_Economy.pdf
- Eugene, N., & Chineze, E. A. (2015). Productivity of the Nigerian tax system (1994–2013). International Journal of Business Administration, 6, 30–40. doi:10.5430/ijba.v6n4p30
- Eugene, N., & Chineze, E. A. (2016). Effect of tax policy on economic growth in Nigeria (1994–2013). International Journal of Business Administration, 7, 50–58. doi:10.5430/ijba.v7n1p50
- Federal Board of Revenue. (2015–16). Finance and economic survey. Retrieved March 15, 2017, from http://www.pkrevenue.com/finance/economic-survey-20152016-fbrs-tax-to-gdp-remained-narrow-despite-significant-revenue-growth/
- Goebel, R., Roebroeck, A., Kim, D. S., & Formisano, E. (2003). Investigating directed cortical interactions in time–resolved fMRI data using vector autoregressive modeling and Granger causality mapping. Magnetic Resonance Imaging, 21, 1251–1261. doi:10.1016/j.mri.2003.08.026
- Granger, C. W. J. (1969). Investigating causal relations by econometric models and cross-spectral methods. Econometrica, 37, 424–438. doi:10.2307/1912791
- Hassan, H. M., & Tahmina, A. (2012). Impact of public debt burden of economic growth: Evidence from Bangladesh: A VAR apprach. Journal of Finance and Banking, 10, doi:10.2139/ssrn.2152592
- Himani. (2016). Determinants of tax revenue in India. International Journal of Research in Economics and Social Sciences, 6, 161–170.
- Husain, F., & Qasim, M. A. (2007). The relationship between federal government revenue and expenditure in Pakistan ( Working Paper). Pakistan Institute of Development Economics.
- Javid, A. Y., Arif, U., & Arif, A. (2011). Economic, political and institutional determinants of budget deficits volatility in selected Asian countries. The Pakistan Development Review, 50, 649–662.
- Karagöz, K. (2013). Determinants of tax revenue: Does sectorial composition matter? Journal of Finance, Accounting and Management, 4, 50–63.
- Kenny, L. W., & Winer, S. L. (2006). Tax systems in the world: An empirical investigation into the importance of tax bases, administration costs, scale and political regime. International Tax and Public Finance, 13, 181–215. doi:10.1007/s10797-006-3564-7
- Litterman, R. B. (1986). Forecasting with Bayesian vector autoregression – Five years of experience. Journal of Business & Economic Statistics, 4, 25–38.
- Lutkepohl, H. (1991). Introduction to multiple time series analysis. Springer-Verlag, Berlin. doi:10.1007/978-3-662-02691-5
- Lutkepohl, H. (1999). Vector autoregressions (Unpublished manuscript). Institut fur Statistik und Okonometrie, Humboldt-Universitat zu Berlin.
- MacKinnon, J. G. (1996). Numerical distribution functions for unit root and cointegration tests. Journal of Applied Econometrics, 11, 601–618. doi:10.1002/(sici)1099-1255(199611)11:6<601::aid-jae417>3.0.co;2-t
- MacKinnon, J. G., Haug, A. A., & Michelis, L. (1999). Numerical distribution functions of likelihood ratio tests for cointegration. Journal of Applied Econometrics, 14, 563–577.
- McFarlin, D. R., Kerr, D. L., Green, D. E., & Nitschke J. B. (2009). The effect of controllability on context dependent granger causality in snake phobia fMRI data at 400-ms resolution. Society for Neuroscience, 289,15, Chicago, IL.
- Mehrara, M., Pahlavani, M., & Elyasi, Y. (2011). Government revenue and government expenditure nexus in Asian countries: Panel cointegration and causality. International Journal of Business and Social Science, 2, 199–207.
- Myles, G. (2000). Taxation and economic growth. fiscal studies. The Journal of Institute for Fiscal Studies, 21, 141–168.
- Nanthakumar, L., Kogid, M., Sakami, M. N., & Muhamad, S. (2011). Tax revenue and government spending constraints: Empirical evidence from Malaysia. China-USA Business Review, 10, 779–784.
- Nau, R. (2014). Forecasting with moving averages (Working Paper). Fuqua School of Business, Duke University. Retrieved April 16, 2017, from https://people.duke.edu/~rnau/Notes_on_forecasting_with_moving_averages–Robert_Nau.pdf
- Palacios, M., & Harischandra, K. (2008). The impact of taxes on economic behavior. In J. Clemens (Ed.), The impact and cost of taxation in Canada: The case for flat tax reform (pp. 3–31). The Fraser Institute. Retrieved March 12, 2017, from http://www.fraserinstitute.org/researchnews/display.aspx?id=13518
- Patoli, A. Q., Zarif, T., & Syed, N. A. (2012). Impact of inflation on taxes in Pakistan: An emperical study of 2000–2010 period. Journal of Management and Social Sciences, 8, 31–41.
- Poulson, B. W., & Kaplan, J. G. (2008). State income taxes and economic growth. Cato Journal, 28, 53–71.
- Rasheed, F. (2006). An analysis of the tax buoyancy rates in Pakistan. Market Forces-Journal of Management, Business & Economics, 2. Retrieved March 10, 2017, from http://www.pafkiet.edu.pk/marketforces/index.php/marketforces/article/view/107/109
- Samuel, O. L. (2014). The impact of value added tax on revenue generation in Nigeria ( Working Paper). Olabisi Onabanjo University, Nigeria. https://doi.org/10.2139/ssrn.2513207
- Sims, C. A. (1980). Macroeconomics and reality. Econometrica, 48, 1–48. doi:10.2307/1912017
- Strielkowski, W., & Čábelková, I. (2015). Religion, culture, and tax evasion: Evidence from the Czech Republic. Religions, 6, 657–669.
- Sunday, C. N. (2015). The implications of tax revenue on the economic development of Nigeria. Issues in Business Management and Economics, 3, 74–80 doi:10.15739/IBME.2014.017
- Tanko, M. (2015). The impact of personal income tax on state governments revenue profile in Nigeria (Working Paper). Kaduna State University, Nigeria. doi:10.2139/ssrn.2690402
- Thomas, D., Litterman, R., & Sims, C. (1984). Forecasting and conditional projection using realistic prior distributions. Econometric Reviews, 3, 1–100.
- Tiao, G. C., & Box, G. E. P. (1981). Modeling multiple time series with applications. Journal of the American Statistical Association, 76, 802–816.
- Torgler, B., & Schneider, F. (2007). What shapes attitudes toward paying taxes? Evidence from multicultural European countries. Social Science Quarterly, 88, 443–470.
- Waggoner, D. F., & Zha, T. (1999). Conditional forecasts in dynamic multivariate models. Review of Economics and Statistics, 81, 639–651. doi:10.1162/003465399558508
- Watson, M. W. (1994). Vector autoregressions and cointegration. In R. F. Engle & D. McFadden (Eds.), Handbook of econometrics (Volume IV). Amsterdam: Elsevier Science. doi:10.1016/s1573-4412(05)80016-9
- Zhang, H. (2013). Modeling and forecasting regional G.D.P. in Sweden using autoregressive models (Master’s thesis in Micro Data Analysis). School for Technology and Business Studies, Dalarna University.
Annexure 1
Source: Authors’ calculations
Annexure 2
Source: Authors’ calculations
Annexure 3
Source: Authors’ calculations
Annexure 4
Note: P-values < 0.05 for joint are selected as V.A.R. lags.
Source: Authors’ calculations.