
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper explores nonlinear cointegration between Chinese mainland stock markets and Hong Kong stock market in a multivariate framework for the period January, 1998 to December, 2014 by a nonparametric method. The local linear kernel smoothing method is developed to estimate the unknown function, and the practical problem of implementation is also addressed. Then, a simple nonparametric version of a bootstrap test is adapted for testing misspecification. Furthermore, Some Monte Carlo experiments are presented to examine the finite sample performance of the proposed procedure. Finally, the stock markets data set is discussed in detail by using proposed procedures, showing that Shanghai Stock Index (SHSI) and Shenzhen Component Index (SZCI) can affect Hang Seng Index (HSI), and the influence appears to be a strong nonlinear characteristics.
1. Introduction
China is one of the fastest-growing economies in the world. According to International Monetary Fund (IMF) and purchasing power parity (PPP), Chinese economy is the second largest in the world by nominal GDP. China’s financial sector, especially stock market has complemented the growth process significantly since the onset of financial reforms in the late nineties. Over the past two decades, the stock market has grown stupendously in terms of increase in size and volume of investment by both domestic and international investors. The relationship between stock prices and macroeconomic variables has been discussed all over the world. The growing linkages between macroeconomic variables and the movement of stock prices have well been documented in the literature over the last several years (Sadorsky, Citation2003; Chen, Citation2003; Hadi, Katircioğlu, & Adaoglu, Citation2019; Katircioğlu, Alkhazaleh, & Katircioğlu, Citation2018; Katircioğlu & Zabolotnov, Citation2019; Rezgallah, Özataç, & Katircioğlu, Citation2019; Shaeri & Katircioğlu, Citation2018). Campbell (Citation1987, Citation1991), Fama and Schwert (Citation1997) showed that short- and long-term interest rates have a modest degree of forecasting power for excess stock returns. Similarly, other studies, such as Campbell and Shiller (Citation1991) and Fama (1984), have shown that the slope of the term structure of interest rates helps to forecast excess stock returns. On the other hand, Campbell and Ammer (Citation1993) showed that short-term interest rates affect stock prices. Daily stock prices are determined by many factors, including enterprise performance, dividends, other countries stock prices, gross domestic product, exchange rates, interest rates, current account, money supply, employment, and so on. Countless factors impact stock prices. In China, the regional stock exchanges from Shanghai, Shenzhen and Hong Kong simultaneously reflect the country’s economy. For the different locations, economic development backgrounds and trading rules, the three stock markets are showing different operating characteristics. To better explore the susceptibility the movements of of stock market in relation to country’s macroeconomic indicators and fashion investment decisions and policy decisions for investors and policy makers, it is necessary to study the contact of the three stock markets.
The study of linear nonstationary time series and linear cointegration relationships has led to a huge development in macro econometrics and financial econometrics, since most of macro and financial time series exhibit nonstationary features. One of the main disadvantages of conventional linear cointegration methodologies is that it assumes that the cointegrating relationship does not change over the entire data span, which is too unrealistic to be true especially when the time series is long, such as Johansen (Citation1988, Citation1991, Citation1995), Johansen and Juselius (Citation1990), Pesaran and Shin (Citation1998), and Pesaran, Shin, and Smith (Citation2001) for more details. Recently, there is a growing interest on the nonlinear properties of nonstationary time series. In this article, we investigate the local linear estimation of a nonparametric multivariate cointegration model of the form
(1)
(1)
where Xt is d-dimensional predictor variable with each element I(1) process,
is an unknown to be estimated with the observed data
but sufficiently smooth function, and ut is an I(0) process.
When Xt is a univariate I(1) process, model (1) has been studied by many researchers. For instance, Kanas (Citation2003) used the alternating conditional expectations (ACE) algorithm to nonlinearly transform stock prices and dividends for the USA for the period 1871–1999 and found strong evidence of cointegration between the transformed variables, which could be characterized as nonlinear cointegration. Karlsen, Myklebust, and Tjøstheim (Citation2007) discussed the estimation of model (1) by the local constant kernel estimator and derive the asymptotic result under the framework of null recurrent Markov chains which include the unit root process as a special case. Based on the local constant kernel estimator, Wang and Phillips (Citation2009a) developed the asymptotic theory for local time density estimation for a general class of functionals of integrated and fractionally integrated time series. Wang and Phillips (Citation2009b) investigated model (1) with endogeneity, i.e., there is dependence between the nonstationary regressor Xt and the stationary error ut. They show that the local constant kernel estimator is consistent and the limit distribution is mixed normal. Furthermore, by using local linear method, Liang, Lin, and Hsiao (Citation2015) studied model (1), and derived the properties of the local linear estimator in the nonstationary setting. They also considered a data-driven method to select the bandwidth, and found a drastic improvement of the mean squared errors of the local linear estimator compared to the local constant estimator. Other papers include Breitung (Citation2002); Ma and Kanas (Citation2004); Bae, Kakkar, and Ogaki (Citation2006); Jawadi, Bruneau, and Sghaier (Citation2009); Cross and Worden (Citation2011); and Ghosh and Kanjilal (Citation2014) and reference therein. To our best known, however, a study on the estimation and application of multivariate nonlinear cointegration has been missing.
The development of the multivariate cointegration time series models was motivated by structural modeling of stock markets data of stock data of China. The data set consisting of 204 observations from Shanghai Stock Market, Shenzhen Stock Market and Hong Kong Stock Market, respectively, which can be obtained from http://finance.sina.com.cn/. The data is from January, 1998 to December, 2014 and the monthly closing prices of three market indexes are used. The interest of our study is to analyze the long-term relationship among SHSI (), SZCI (
) and HSI (
). Some financial time series such as quarterly earning per share of a company exhibits certain seasonality. In some applications, seasonality is of secondary importance and is removed from the data, resulting in a seasonally adjusted time series that is then used to make inference. Detailed analysis of the data set is reported in Section 4.
It is well known that in the stationary setup the local linear kernel estimator is superior to the local constant kernel estimator because it has less finite sample bias and no boundary effect, see Fan and Gijbels (Citation1996). Therefore, in this article, we extend the local linear estimator to deal with the estimation of multivariate cointegration models. Also, we consider a data-driven method to select the bandwidth matrix. Further, the proposed method is applied to investigate the relationship among three stock markets in China, which shows that the proposed method is valid and accurate.
The plan of the article is as follows. Section 2 gives the selection and pre-processing of data. Section 3 discusses the analysis of stock index and the Granger causality test. Section 4 develops the proposed estimation method and presents an empirical application to stock index data. Section 5 contains the conclusion and discussion.
2. Methodologies and practical issues in model building
This section consists of two parts. In Section 2.1, the proposed local linear estimation is described. Some practical issues in model building are discussed in Section 2.2.
2.1. Local linear estimation
We consider the nonparametric cointegration model (1), where is a smooth function without other restrictions on its specific functional form. Xt follows an I(1) process, i.e.,
with
and
being a weakly dependent stationary process. The disturbance ut is a stationary process, i.e., an I(0) process.
For nonparametric regression models with independent and weakly dependent stationary data, it is well established that the local linear estimation method enjoys some optimality properties such as boundary estimation accuracy and minimax efficiency. In this paper, we develop a class of kernel-type nonparametric regression estimators based on local least squares fitting using kernel weights. Much of our attention will be devoted to the local linear least squares kernel estimator of f and its derivative function which is
and
respectively, the solution for α and β to the following problem:
(2)
(2)
where x is a given point in a neighborhood of Xt, and H is a d × d symmetric positive definite matrix depending on n, and
is d-variate kernel such that
and
We call
the bandwidth matrix since it is the multivariate extension of the usual bandwidth parameter. Problem (2) is a straightforward weighted least squares problem, and assuming that
is nonsingular, (2) has solution
(3)
(3)
where
and
denotes the
vector of first-order partial derivatives. Then, the least squares estimator of
is given by
(4)
(4)
where e1 is the
vector having 1 in the first entry and all other entries 0.
It is well known that the bandwidth plays an essential role in the trade-off between reducing bias and variance. Similar to Cai and Tiwari (Citation2000) and Cai (2007), we suggest a nonparametric version of Akaike Information Criterion (AIC) to select the bandwidth matrices. The basic idea is described as follows. For the observed values the fitted values
can be expressed as
where SH is a smoother (or hat) matrix associated with the smoothing parameter matrix H. By recalling the AIC for linear models under the likelihood setting
we select the optimal bandwidth matrix Hopt by minimizing
where
is an estimate of
and
is the trace of SH, regarded as the nonparametric version degrees of freedom. This selection criterion counteracts the over/under-fitting tendency of the generalized cross-validation and the AIC; see Cai and Tiwari (Citation2000) and Cai (2002) for more details. Alternatively, one might use other existing methods although they may be required more computing; see Yao and Tong (Citation1994), Fan and Gijbels (Citation1996), and Tschernig and Yang (Citation2000).
In practice, it is desirable to have a quick and easy implementation to estimate the asymptotic variance of to construct a pointwise confidence interval. Specially, we first compute the residuals
using the local linear estimation, and then apply a simple moment estimation to obtain a direct and naive estimator of
that is,
It might be shown that is a consistent estimate of
Therefore,
is a consistent estimate of Σ, where
is a consistent estimator of
with
Other alternative methods might also be applicable here.
2.2. Testing misspecification
In applications, it might be important and interesting to test whether model (1) holds with a specified parametric form. Inspired by Fan, Zhang, and Zhang (Citation2001) and Juhl (2005), we consider the following testing problem
(5)
(5)
where
is a given function indexed by an unknown parameter vector θ.
For an easy implementation purpose, we adapt a misspecification test by comparing the residual sum of squares (RSS) from both parametric and nonparametric fittings. The testing procedure is described as follows. Let be an estimator of θ. Then, the RSS under
is
where
and the RSS under
is
where
Further, the test statistic is defined as
The null hypothesis (5) is rejected for a large value of Tn. For the sake of simplicity, we evaluate the p-value by using the following nonparametric bootstrap approach, which can be described as follow.
Step 1. Obtain the residuals where
is the local linear estimate of
Step 2. Obtain the bootstrap residuals by randomly resampling with replacement from the set
with
Then,
Step 3. Regress on Xt to obtain the estimator
under
and Regress
on Xt to obtain
under
Calculate the bootstrap residuals
and
respectively. The test statistic
is constructed based on
Step 4. Repeat steps 2-3 B times and denote the bootstrap statistics as The bootstrap p-value is computed by
where
is an indicator function.
We bootstrap the residuals from the nonparametric fitting instead of the parametric fitting, since the nonparametric estimation is always consistent, no matter whether the null or the alternative hypothesis is correct. Therefore, the method should provide a consistent estimator of the null distribution even when the null hypothesis does not hold. This test is similar to the generalized likelihood ratio test proposed by Fan et al. (Citation2001) except that the samples used here are not independent.
3. Monte Carlo experiments
3.1. Monte Carlo design
In order to illustrate our modeling procedure, we consider some simulated experiments. In the Monte Carlo experiments, the Epanechnikov kernel is used and the optimal bandwidth matrix Hopt is selected as follows. For a predetermined sequence of H’s from a wide square range, say both horizontal axis and vertical axis from 0.1 to 0.7 with an increment 0.025, based on the AIC bandwidth selector described in Section 2.2, we compute
for each H and choose Hopt to minimize
The performance of the proposed estimators is evaluated by the mean absolute deviation error (MADE)
which is a common criteria and also is employed in Ye, Lin, Zhao, and Hao (Citation2015).
We assess the finite sample performances of the local linear estimator and test with an example of the multivariate cointegration time series model. The generating mechanism follows (1) and has the explicit form
where
is simulated from the model
with
generated from
independently,
is generated from the model
with
generated from
independently, ut is drawn from
and
and ut are independent.
3.2. Monte Carlo results
The simulation is repeated 500 times for each of sample sizes n = 100, 200, and 500 and we compute the optimal bandwidth matrix for each replication and each sample size. The median and standard deviation (in parentheses) of the 500 MADE values of for local linear estimate are summarized in . We can observe from , that all MADE values decrease as n increases. The values of MADE and standard deviation for the case that is i.i.d. (
) are both smaller than those for the dependent cases (
), as one would have expected. The MADE values increase as ρ1 decreases when
but the standard deviation values are opposite. Furthermore, for the case that both the time series
and
are nonstationary, i.e.,
the performance of proposed estimator is also satisfactory. In addition, we can see clearly that the MADE and the standard deviations are both small, which makes the asymptotic theory more relevant. For the sample size n = 200,
and
we can easily compute the true value for Σ for this model, which is given by
and
The selected optimal bandwidth is
for this sample. In summary, we can conclude that the proposed estimation procedures perform fairly well.
Table 1. The MADE values of local linear estimation for each set and each sample.
3.3. Model misspecification checks
The aim of this set of experiments is to investigate the extent in which the proposed testing procedure is effective in dealing with misspecification.
We use the null hypothesis (a constant) versus the alternative
to demonstrate the power of the proposed misspecification test. The power function is evaluated under a family of alternative models indexed by γ,
and
where
is the true surface and η is the average height of
(indeed,
). The other type of tests can be considered in the same way. For n = 100 and 200, the misspecification test described in Section 2.2 with 500 replications is employed and for each realization, the bootstrap sampling is 1000. For each replication and each sample size, according to the AIC bandwidth selector described in Section 4.2, the optimal bandwidth is computed and for simplicity, this optimal bandwidth is used in calculating the test statistics for both original sample and bootstrap samples.
The simulated power values against γ are presented in for different sample sizes. It is clear from that the power for n = 500 is lower than that for n = 100 and 200. When γ = 0, the specified alternative hypothesis collapses into the null hypothesis. For instance, when n = 500, the empirical power is 0.048, which is close to the significance level of 5%. This demonstrates that the bootstrap estimate of the null distribution is approximately correct. The power function shows that our test is indeed powerful.
Table 2. Empirical powers for different γ and n under the significance level 5%.
4. Analysis for the closing price data of stock market in China
We apply the proposed model and its modeling procedures to analyze the long-term relationship among Shanghai Stock Index (SHSI, ), Shenzhen Component Index (SZCI,
) and Hang Seng Index (HSI,
). Let
and
represent the monthly closing value of SHSI, SZCI and HSI after logarithmic transformation.
The stock index data concerned here can be seen as time series data. In order to get a better insight, the time series plots of and
from January, 1998 to December 2011 are depicted in , respectively. Following the convention in the finance literature, we consider the simple monthly positive returns
for i = 1, 2, 3, corresponding to SHSI, SZCI and HSI. The time series plots of
and
are displayed in , respectively. In order to check the stationarity of
and
the augmented Dickey-Fuller (ADF; Dickey & Fuller, Citation1979) test is used for the unit root of the series
and
Here, other criteria introduced in Phillips and Perron (Citation1988), Kwiatkowski, Phillips, Schmidt, and Shin (Citation1992), Elliot, Rothenberg, and Stock (Citation1996) or Ng and Perron (Citation2001) could also be employed. The test results are presented in . We can observe from , that the series
are nonstationary while the series
are stationary, which implies that
are I(1), that is, they are one-order integratedness. Furthermore, the Granger causality test shows that the current SHSI (
) and SZCI (
) can affect the current HSI
Figure 1. Graphs for time series: (a) The time series plot of (b) the time series plot of
(c) the time series plot of
(d) the time series plot of
(e) the time series plot of
(f) the time series plot of
Source: The Authors.
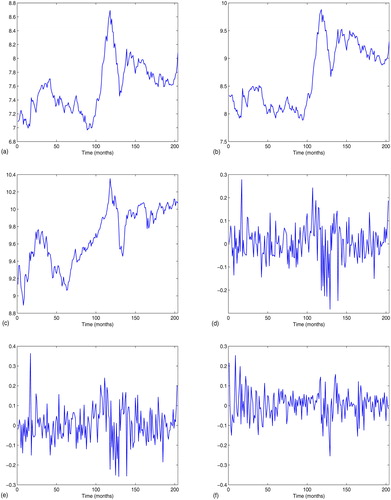
Table 3. True value and fitted value at points.
To establish the empirical relationship among the series of SHSI, SZCI and HSI, similar to Tsay (Citation2005) who considered the linear relationship between the one-year Treasury constant maturity rate and the three-year Treasury constant maturity rate, we first fit a simple linear regression model based on the above results of Granger causality test
(6)
(6)
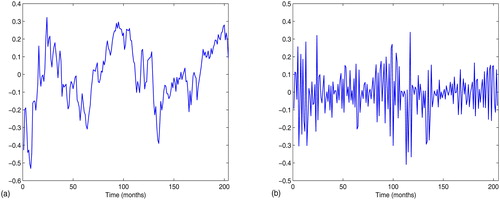
As a result, the least-square estimates of a0, a1 and a2 are 5.7663(0.2807), −0.1514(0.0905) and 0.5835(0.0590), respectively. The adjusted R-squared is 0.6290, and the values of F-statistic and Durbin-Waston statistic are 261.9054 and 0.1617. By comparing these results with those from standard linear model, we might suspect that the considered model might be nonlinear. To this end, we examine the residual series derived from (6) and find that it does depend on time; see . Therefore, we have sufficient reasons to fit the following nonparametric model:
(7)
(7)
Figure 2. Residual graphs: (a) The residual plot of model (Equation6(6)
(6) ); (b) The residual plot of model (Equation7
(7)
(7) ). Source: The Authors.
The local linear estimator is computed based on the optimal bandwidth matrix
which is selected by the AIC bandwidth matrix selector described in Section 2.2. The residual plot in shows that the errors are close to normal, thus the local linear estimates are expected to be efficient.
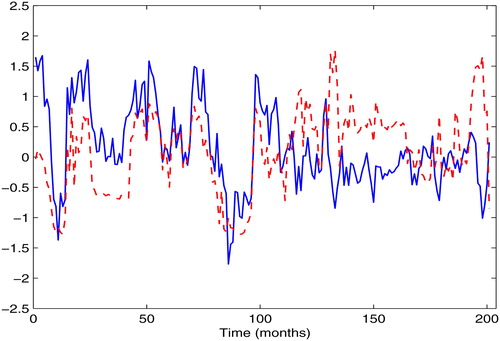
To further study the effect of SHCI and SZCI on HSI, we computer the first-order partial derivatives of HSI over SHCI and SZCI, which are depicted in (solid curve represents the derivative of with respect to
dashed curve represents the derivative of
with respect to
). We can observe from that the influence of SHCI and SZCI to HSI appears to be a strong nonlinear characteristics. Meanwhile, this effect presents a significant period, and it can be roughly divided into two periods: the first period of the trading months from 1 to 104 (The corresponding calendar months are from January, 1998–July, 2006.), the effect of SZCI
and HSI
on HSI
is synchronous. The positive and negative roles appear alternately; the second period of the trading months from 105 to 204 (The corresponding calender months are from August, 2006 to December, 2014.), the SZCI
shows a strong positive impact on HSI
while the SHCI
has a negative impact on HSI
Therefore, one might conclude that three is a nonparametric cointegration relationship among SHCI, SZCI and HSI. Finally, to support our conclusions statistically, we consider the testing null hypothesis
and the testing procedure described in Section 2.2 is used with the bootstrap sampling 1000 times. As a result, the p-value is less than 0.001. Thus, this test result further supports our finding that the relationship among SHCI, SZCI and HSI can be described by a nonparametric cointegration model.
Figure 3. The estimated first-order partial derivative: solid curve represents the derivative of with respect to
dashed curve represents the derivative of
with respect to
Source: The Authors.
5. Conclusion and discussion
In this article, we developed a multivariate cointegration time series model to model nonlinear and nonstationary time series. A nonparametric local linear kernel smoothing method was proposed for estimating the model function. Then, we adapted a testing procedure for testing misspecification, based on the comparison of the RSS and suggested using a bootstrap to estimate the p-value. Furthermore, We obtained some insights about the modeling methods via some Monte Carlo experiments and demonstrated that the local linear estimator performed well. Finally, the usefulness of the considered model was demonstrated by an empirical application.
Some further research can be conducted in several directions. Firstly, we would consider models allowing to be heteroscedastic, and it would be of interest to extend this study to models containing lagged dependent variables. Secondly, an extension of the semiparametric modeling and estimation to multivariate cointegration time series models would also be interesting. Thirdly, the predictive utility of multivariate cointegration time series models needs further investigation.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Bae, Y., Kakkar, V., & Ogaki, M. (2006). Money demand in Japan and nonlinear cointegration. Journal of Money, Credit, and Banking, 38(6), 1659–1667. doi:10.1353/mcb.2006.0076
- Breitung, J. (2002). Nonparametric tests for unit roots and cointegration. Journal of Econometrics, 108(2), 343–363. doi:10.1016/S0304-4076(01)00139-7
- Cai, Z. (2002). A two-stage approach to additive time series models. Statistica Neerlandica, 56(4), 415–433. doi:10.1111/1467-9574.00210
- Cai, Z. (2007). Trending time-varying coefficient time series models with serially correlated errors. Journal of Econometrics, 136(1), 163–188. doi:10.1016/j.jeconom.2005.08.004
- Cai, Z., & Tiwari, R. C. (2000). Application of a local linear autoregressive model to BOD time series. Environmetrics, 11(3), 341–350. doi:10.1002/(SICI)1099-095X(200005/06)11:3<341::AID-ENV421>3.0.CO;2-8
- Campbell, J. Y. (1987). Stock returns and the term structure. Journal of Financial Economics, 18(2), 373–399. doi:10.1016/0304-405X(87)90045-6
- Campbell, J. Y. (1991). A variance decomposition for stock returns. The Economic Journal, 101(405), 157–179. doi:10.2307/2233809
- Campbell, J. Y., & Ammer, J. (1993). What moves the stock and bond markets? A variance decomposition for long-term asset returns. The Journal of Finance, 48(1), 3–37. doi:10.1111/j.1540-6261.1993.tb04700.x
- Campbell, J. Y., & Shiller, R. J. (1991). Yield spreads and interest rate movements, a bird’s eye view. The Review of Economic Studies, 58(3), 495–514. doi:10.2307/2298008
- Chen, M. H. (2003). Risk and return: CAPM and CCAPM. The Quarterly Review of Economics and Finance, 43(2), 369–393. doi:10.1016/S1062-9769(02)00125-4
- Cross, E., & Worden, K. (2011). Approaches to nonlinear cointegration with a view towards applications in SHM. Journal of Physics: Conference Series, 305(1), 012069. doi:10.1088/1742-6596/305/1/012069
- Dickey, D. A., & Fuller, W. A. (1979). Distributions of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74(366), 427–481. doi:10.2307/2286348
- Elliot, G., Rothenberg, T. J., & Stock, J. H. (1996). Efficient tests for an autoregressive unit root. Econometrica, 64, 813–836. doi:10.2307/2171846
- Fama, E. F. (1984). The information in the term structure. Journal of Financial Economics, 13(4), 509–528. doi:10.1016/0304-405X(84)90013-8
- Fama, E., & Schwert, G. W. (1997). Asset returns and in ation. Journal of Financial Economics, 5, 115–146.
- Fan, J., & Gijbels, I. (1996). Local polynomial modelling and its application. London: Chapman and Hall.
- Fan, J., Zhang, C., & Zhang, J. (2001). Generalized likelihood ratio statistics and Wilks phenomenon. The Annals of Statistics, 29(1), 153–193. doi:10.1214/aos/996986505
- Ghosh, S., & Kanjilal, K. (2014). Co-movement of international crude oil price and Indian stock market: Evidences from nonlinear cointegration tests. Energy Economics, 53, 111–117. doi:10.1016/j.eneco.2014.11.002
- Hadi, M. D., Katircioğlu, S., & Adaoglu, C. (2019). The vulnerability of tourism firms’ stocks to the terrorist incidents. Current Issues in Tourism, 1–15. doi:10.1080/13683500.2019.1592124
- Jawadi, F., Bruneau, C., & Sghaier, N. (2009). Nonlinear cointegration relationships between non-life insurance premiums and financial markets. Journal of Risk and Insurance, 76(3), 753–783. doi:10.1111/j.1539-6975.2009.01314.x
- Johansen, S. (1988). Statistical analysis of cointegrating vectors. Journal of Economic Dynamics and Control, 12(2-3), 231–254. doi:10.1016/0165-1889(88)90041-3
- Johansen, S. (1991). Estimation and hypothesis testing of cointegrating vectors in Gaussian autoregressive models. Econometrica, 59(6), 1551–1580. doi:10.2307/2938278
- Johansen, S. (1995). Likelihood-based inference in cointegrated vectors autoregressive models. Oxford: Oxford University Press.
- Johansen, S., & Juselius, K. (1990). Maximum likelihood estimation and inference on cointegration-with applications to the demand for money. Oxford Bulletin of Economics and Statistics, 52(2), 169–210. doi:10.1111/j.1468-0084.1990.mp52002003.x
- Juhl, T. (2005). Functional-coefficient models under unit root behaviour. The Econometrics Journal, 8(2), 197–213. doi:10.1111/j.1368-423X.2005.00160.x
- Kanas, A. (2003). Non-linear cointegration between stock prices and dividends. Applied Economics Letters, 10(7), 401–405. doi:10.1080/1350485022000044020
- Karlsen, H. A., Myklebust, T., & Tjøstheim, D. (2007). Nonparametric estimation in a nonlinear cointegration type model. The Annals of Statistics, 35(1), 252–299. doi:10.1214/009053606000001181
- Katircioğlu, S., Alkhazaleh, M. M. H., & Katircioğlu, S. (2018). Interactions between oil prices and financial sectors’ performances: empirical evidence from Amman Stock Exchange. Environmental Science and Pollution Research, 25(33), 33702–33708. 2018, doi:10.1007/s11356-018-3311-5
- Katircioğlu, S., & Zabolotnov, A. (2019). Role of financial development in economic globalization: evidence from global panel. Applied Economics Letters, 1–7. doi:10.1080/13504851.2019.1616058
- Kwiatkowski, D., Phillips, P. C. B., Schmidt, P., & Shin, Y. (1992). Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? Journal of Econometrics, 54(1-3), 159–178. doi:10.1016/0304-4076(92)90104-Y
- Liang, Z., Lin, Z., & Hsiao, C. (2015). Local linear estimation of a nonparametric cointegration model. Econometric Reviews, 34(6-10), 882–906. doi:10.1080/07474938.2014.956610
- Ma, Y., & Kanas, A. (2004). Intrinsic bubbles revisited: Evidence from nonlinear cointegration and forecasting. Journal of Forecasting, 23(4), 237–250. doi:10.1002/for.909
- Ng, S., & Perron, P. (2001). LAG length selection and the construction of unit root tests with good size and power. Econometrica, 69(6), 1519–1554. doi:10.1111/1468-0262.00256
- Pesaran, H. H., & Shin, Y. (1998). Generalized impulse response analysis in linear multivariate models. Economics Letters, 58(1), 17–29. doi:10.1016/S0165-1765(97)00214-0
- Pesaran, M. H., Shin, Y., & Smith, R. J. (2001). Bounds testing approaches to the analysis of level relationships. Journal of Applied Econometrics, 16(3), 289–326. doi:10.1002/jae.616
- Phillips, P. C. B., & Perron, P. (1988). Testing for a unit root in time series regression. Biometrika, 75(2), 335–346. doi:10.1093/biomet/75.2.335
- Rezgallah, H., Özataç, N., & Katircioğlu, S. (2019). The impact of political instability on risk-taking in the banking sector: International evidence using a dynamic panel data model (System-GMM). Managerial and Decision Economics, 40(8), 891–906. doi:10.1002/mde.3075i
- Sadorsky, P. (2003). The macroeconomic determinants of technology stock price volatility. Review of Financial Economics, 12(2), 191–205. doi:10.1016/S1058-3300(02)00071-X
- Shaeri, K., & Katircioğlu, S. (2018). The nexus between oil prices and stock prices of oil, technology and transportation companies under multiple regime shifts. Economic Research-Ekonomska Istraživanja, 31(1), 681–702. doi:10.1080/1331677X.2018.1426472
- Tsay, R. S. (2005). Analysis of financial time series. New York: John Wiley & Sons.
- Tschernig, R., & Yang, L. (2000). Nonparametric lag selection for time series. Journal of Time Series Analysis, 21(4), 457–487. doi:10.1111/1467-9892.00193
- Wang, Q., & Phillips, P. C. B. (2009a). Asymptotic theory for local time density estimation and nonparametric cointegrating regression. Econometric Theory, 25(3), 710–738. doi:10.1017/S0266466608090269
- Wang, Q., & Phillips, P. C. B. (2009b). Structural nonparametric cointegrating regression. Econometrica, 77(6), 1901–1948.
- Yao, Q., & Tong, H. (1994). On subset selection in non-parametric stochastic regression. Statistica Sinica, 4(1), 51–70. doi:10.5705/ss.202016.0369
- Ye, X. G., Lin, J. G., Zhao, Y. Y., & Hao, H. X. (2015). Two-step estimation of the volatility functions in diffusion models with empirical applications. Journal of Empirical Finance, 33, 135–159. doi:10.1016/j.jempfin.2015.05.001