
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article addresses the issue of selecting Financial Strategies in Multi-National companies (F.S.M.). The F.S.M. typically has to consider multiple factors involving multiple stakeholders and, hence, can be handled by applying an appropriate Multi-Criteria Group Decision-Making (M.C.G.D.M.) approach. To address this issue, we develop an M.C.G.D.M. framework to tackle the F.S.M. problem. To handle inherent uncertainty in business decisions as reflected by linguistic reasoning, we embark on constructing a Linguistic Pythagorean Fuzzy (L.P.F.) M.C.G.D.M. framework that is capable of tackling both uncertain decision information and linguistic variables. The proposed approach extends the combinative distance-based assessment (C.O.D.A.S.) method into the L.P.F. environment, and processes decision input expressed as Pythagorean fuzzy sets (P.F.S.) and pure linguistic variables (rather than converting linguistic information into fuzzy numbers). The developed L.P.F.-C.O.D.A.S. technique aggregates the L.P.F. information and is applied to the F.S.M. problem with uncertain linguistic information. A comparative analysis is carried out to compare the results obtained from the proposed L.P.F.-C.O.D.A.S. approach with those from other extensions of C.O.D.A.S. Furthermore, a sensitivity analysis is conducted to check the impact of changes in a distance threshold parameter on the ranking results.
1. Introduction
Multi-criteria group decision-making (M.C.G.D.M.) methods are important in solving managerial problems in many areas, ranging from location selection, to supply chain management and financial management (Dorokhov et al., Citation2018; Liu, He, & Xu, Citation2019; Pongpimol et al., Citation2020). These problems are often too complex to be defined in crisp values. In addition, a single estimate is often unavailable to describe the properties of the alternatives involved in an analysis. Under these circumstances, subjective expert assessments can be exploited. Within the aforementioned context, multi-faceted problems require both proper theoretical concepts and quantitative techniques. The fuzzy set theory and M.C.G.D.M. techniques can be convenient tools to solve managerial problems involving varying degrees of uncertainty. Due to increasing complexity of the real world decision problems, different M.C.D.G.M. methods have been proposed to cope with uncertainty characterised by the fuzzy information (Chen, Citation2000; Wang & Chang, Citation2005; Keshavarz Ghorabaee et al., Citation2016; Gao, Lu, & Wei, Citation2019). They have been employed to identify the most desirable solutions in many different applications (Aliakbari Nouri, Khalili Esbouei, & Antucheviciene, Citation2015; Vinodh, Sai Balagi, & Patil, Citation2016; Hosseini et al., Citation2016). More detailed surveys on theoretical and applied advancements in the area of fuzzy M.C.G.D.M. were presented by Kahraman, Onar, and Oztaysi (Citation2015).
The crisp set theory characterises either completely certain membership or non-membership to a certain set. M.C.G.D.M. models based on this input requires precise data (i.e., crisp numbers). The fuzzy set theory (Zadeh, Citation1965) relaxed those assumptions by allowing for partial membership degrees between 0 and 1. In this instance, M.C.G.D.M. models can handle vague information. Yet another improvement in accounting for uncertainty was offered by Atanassov (Citation1986) who introduced the intuitionistic fuzzy sets (I.F.S.s). In the I.F.S. setting, one can take into account of indeterminacy on top of membership and non-membership (Wu, Gao, & Wei, Citation2019). In this case, the values of the membership, non-membership and indeterminacy functions are assumed to add up to unity at each data point. In practice, this assumption may be violated. For instance, experts may fail to consider the constraints on the degrees of membership, non-membership and indeterminacy when providing information on the performance of the alternatives under consideration. Although the I.F.S. allows for more flexibility in describing fuzzy input, some situations may still require additional considerations.
An extension of I.F.S.s was furnished by Yager (Citation2013), who introduced the Pythagorean fuzzy set (P.F.S.) relaxes the restrictive assumption on the degrees of membership, non-membership and indeterminacy in I.F.S.s. The correspondence between the P.F.S. membership degrees and complex numbers was established by Yager (Citation2016). He showed that the P.F.S. membership degrees can be considered as a sub-class of the complex numbers. Garg (Citation2016) proposed correlation coefficients for P.F.S.s. Beliakov and James (Citation2014) discussed the averaging operators and their performance in the P.F.S. environment. Wei (Citation2019) proposed the extension of the Hamacher power operator. Lu et al. (Citation2019) applied the P.F.S. with the bidirectional projection approach for the M.C.G.D.M. Tang and Wei (Citation2019) applied the dual hesitant P.F.S. for the decision-making.
By capitalising on the notion of linguistic P.F.S.s proposed by Garg (Citation2018), this article extends the so-called combinative distance-based assessment (C.O.D.A.S.) method and proposes a linguistic Pythagorean fuzzy (L.P.F.) C.O.D.A.S. (L.P.F-C.O.D.A.S.) framework. This group decision model can handle pure linguistic variables and is more flexible in dealing with uncertainty inherent in decision-making processes.
The rest of the article proceeds as follows: Section 2 furnishes a literature review of related works. Section 3 introduces the basic concepts to make the article self-contained. Section 4 proposes a new decision framework, the so-called L.P.F.-C.O.D.A.S. An application of the L.P.F.-C.O.D.A.S. is illustrated by examining the selection of financial strategies in a multi-national company (F.S.M.) in Section 5. Section 6 conducts sensitivity and comparative analyses, followed by conducting remarks in Section 7.
2. Related works
As decision-making processes can be further improved by applying P.F.S.s, different scholars proposed various aggregation operators and M.C.D.G.M. techniques with this type of information. P.F.S.-based aggregation operators were put forward by Yager (Citation2014), Zhou, Su, Baležentis, and Streimikiene (Citation2018), Wang, Gao, and Wei (Citation2019), Zeng (Citation2017), Wei (Citation2019) among others. M.C.G.D.M. approaches involving P.F.S.s have also been developed (Peng & Selvachandran, Citation2019). Ren, Xu, and Gou (Citation2016) established a T.O.D.I.M. (an acronym in Portuguese for Interactive Multi-Criteria Decision-Making) technique based on P.F.S.s. Peng and Yang (Citation2016) offered an Multi-Attributive Border Approximation Area Comparison (M.A.B.A.C.) technique with P.F.S. and Choquet integral. Bolturk (Citation2018) proposed a C.O.D.A.S. method based on the P.F.S.s. Liang, Xu, and Darko (Citation2017) defined Pythagorean fuzzy numbers and developed T.O.P.S.I.S. based on P.F.S.s. Reformat and Yager (Citation2014) discussed the possibilities of applying P.F.S.s for content-based recommender systems. Garg (Citation2018) put forward the concept of linguistic P.F.S.s (L.P.F.S.s). In this case, linguistic terms are used to describe the membership degrees with cardinality of the linguistic term set being the restrictive factor. Thus, P.F.S.s have been applied for different aggregation rules and case studies. These generic M.C.G.D.M. models are applicable to decision processes in a wide range of areas including financial problems such as F.S.M. in this research. F.S.M. plays a significant role for a firm to expand its market globally. When a multinational firm plans its financial strategies, it has to accommodate different perspectives and interests. M.C.G.D.M. approaches are convenient tools for handling F.S.M. problems.
The C.O.D.A.S. method (Ghorabaee et al., Citation2016) relies on the Euclidean and Hamming distances that are calculated with respect to the negative-ideal point. The Euclidean distance is applied first and the Hamming distance is applied second if two alternatives cannot be distinguished by the former. lists studies on the theoretical development and applications of the C.O.D.A.S. method. As one can note, there have been a number of extensions of the C.O.D.A.S. method. They differ in terms of decision input and specific techniques. As shows, there is still a lack of C.O.D.A.S. based on L.P.F.S.s introduced by Garg (Citation2018), which can increase the applicability of C.O.D.A.S. as L.P.F.S.s can exploit uncertainty in the decision process with higher flexibility.
Table 1. Some fuzzy extensions and applications of C.O.D.A.S.
3. Preliminaries
The complexity of business decisions often makes it hard to use exact information to describe all possible criteria of alternatives under consideration. Therefore, multi-criteria analysis typically involves uncertain data that can be handled by fuzzy set theory. In this article, we resort to the L.P.F.S. to characterise decision input (Garg, Citation2018).
In order to exploit this type of information, one needs to apply the relevant arithmetic operations and laws of comparison. This section begins with presenting the basic notions of the P.F.S. and linguistic sets along with the L.P.F.S. that integrates the former two concepts. The theoretical preliminaries presented in this section are then used to construct the M.C.G.D.M. approach based on the L.P.F.S.-C.O.D.A.S. The following notations used in this article are listed in .
Table 2. List of notations.
3.1. Pythagorean fuzzy sets
The I.F.S. provides the core foundation of uncertain decision-making when there is not only uncertainty on the membership of a given element to a certain set, but also a kind of indeterminacy. The indeterminacy may be related to the confidence of the decision-maker (expert) in the context of group decision-making. For instance, some experts may have stronger background in economics rather than in technologies. In the latter instance, they may exert higher degree of indeterminacy when providing rating on technological criteria of alternatives under consideration. By introducing the degree of indeterminacy, Atanassov (Citation1986) proposed the following definition of the I.F.S.:
Definition 3.1.
Let X denote a universe of discourse. An I.F.S. A in X is then defined in terms of element and the corresponding degrees of membership and non-membership as:
(3.1)
(3.1)
where x is a certain element of X,
and
are the degrees of membership and non-membership with
The indeterminacy is characterised by
In the definition of the I.F.S., the values of the membership and non-membership functions are expressed in real numbers. However, decision-makers may be unable to furnish real numbers in a meaningful manner. To further improve the decision-making process, linguistic information can be introduced in the computations. We will next present the concept of linguistic sets and then show how it can be further extended into the L.P.F.S. environment following Garg (Citation2018).
A linguistic sets comprises different labels corresponding to different levels of performance. The labels are assumed to be ordered so that operations with different labels are possible. Furthermore, labels are represented by indexes that can then be mapped on a continuous line. Linguistic fuzzy sets can be further integrated into the other types of fuzzy sets to establish concepts relevant for group decision-making under linguistic uncertainty. A linguistic set is defined as follows:
Definition 3.2.
Let be a collection of linguistic terms and assume that the cardinality of S is an odd number, where sh is a feasible linguistic term in S (Herrera & Martínez, Citation2001). S is called a linguistic set if it satisfies the following relationships:
elements of the set can be ordered:
a negation operator can be applied on the elements of S:
where
max operator can be used to compare elements of S:
min operator can be used to compare elements of S:
One can consider the following set as an example of a linguistic set with seven terms:
In real-world applications, the use of discrete linguistic labels may be feasible at the stage of data collection. However, it is unlikely that the resulting calculations would also yield discrete labels. Therefore, a discrete linguistic set S can be extended to a continuous linguistic term set with its elements satisfying conditions outlined in Definition 3.2 (Xu, Citation2004).
Yager (Citation2013) proposed a generalisation of the I.F.S. by allowing for more flexibility in the membership degree. The restriction on the degrees of membership and non-membership provided in Definition 3.1 is relaxed in the case of the P.F.S., as given in Definition 3.3.
Definition 3.3.
For a universe of discourse X, a P.F.S. A is defined as a set of elements in X along with the associated degrees of membership and non-membership, i.e.:
(3.2)
(3.2)
where the values of the membership and non-membership functions at
are given by,
and
respectively, and satisfy
The degree of indeterminacy for a P.F.S. can be calculated residually based on the values of the membership and non-membership degrees, i.e., For sake of brevity, a Pythagorean fuzzy number was introduced by Yager (Citation2013) which comprises the degrees of membership and non-membership,
where
Comparison of two P.F.N.s requires special rules based on the score and accuracy functions, which are defined below:
Definition 3.4.
For a given P.F.N., its score function S takes the following form (Zhang and Xu, Citation2014):
(3.3)
(3.3)
For the same P.F.N. α, its accuracy function H is given as follows:
(3.4)
(3.4)
Definition 3.4 indicates that information on the membership and non-membership is exploited to calculate the values of the score function. This calculation is not affected by the degree of indeterminacy. As for the accuracy function, even though the calculation is based on the membership and non-membership degrees, it implicitly accounts for the degree of indeterminacy due to the constraint of the membership and non-membership degrees given in Definition 3.3.
The interaction between two P.F.S.s can be modeled by considering the intersection and union operators. These results can also be used for the case of the P.F.N.s. Thus, we discuss the notions of the intersection and generalised union of two P.F.S.s as follows:
Definition 3.5.
For two P.F.S.s, A and B, the generalised intersection and generalised union
operators are defined as follows (Deschrijver & Kerre, Citation2002):
(3.5)
(3.5)
(3.6)
(3.6)
where
and
are any t-norm and t-conorm functions, respectively. Algebraic sum
and product
can be given as the instances of t-conorm and t-norm, respectively. In the case of the P.F.S.s, they are defined in the following manner:
(3.7)
(3.7)
Note that S(a, b) given in EquationEq. (3.7)(3.7)
(3.7) is a t-conorm satisfying the following properties:
Boundedness:
Monotonicity: If
Commutativity:
Associativity:
T(a, b) given in EquationEq. (3.7)(3.7)
(3.7) is a t-norm satisfying the following properties:
Boundedness:
Monotonicity: If
Commutativity:
Associativity:
The concepts of the intersection and union of the P.F.S.s can be exploited to define interactions between P.F.N.s. These are important in decision-making as aggregation of decision information relies on arithmetical operations among the arguments to be aggregated. In the case of P.F.N.s, the following operations are defined by a scalar and exponent of a scalar:
Definition 3.6.
Denote three P.F.N.s by and
along with a real number
For operations with these variables, the following operational laws hold (Yager, Citation2014):
The complement of a fuzzy number is important as it acts as a negation operator in the decision process. Next we define the rules for P.F.N. complement, subset, equivalence, intersection and union as:
Definition 3.7.
Denote three P.F.N.s by and
along with a real number
The following operational laws hold (Yager, Citation2014):
The operational laws discussed in this sub-section can be applied to aggregate of the expert assessments expressed as P.F.N.s. They can also be adapted to the case of linguistic reasoning discussed next.
3.2. Linguistic Pythagorean fuzzy numbers
The need for the use of linguistic information in decision-making roots in both human nature and complexity of socio-economic phenomena. Accordingly, linguistic term sets can be employed by decision-makers to express their ratings. In addition, the degree of indeterminacy should be attached to linguistic ratings in order to increase the effectiveness of decision-making. The concept of I.F.S.s allows one to accommodate this along with a linguistic rating. As an extension of I.F.S.s, P.F.S.s can also handle linguistic with indeterminacy under more relaxed constraint on membership and non-membership degrees. Thus, the concepts of the linguistic term set and P.F.S. are integrated into a new notion of an L.P.F.S. (Garg, Citation2018).
The key feature of a P.F.S. is the degree of indeterminacy and the relaxed constraint on the membership and non-membership degrees (Definition 3.3). As for a linguistic set, the use of linguistic labels is the character (Definition 3.2). An L.P.F.S combines these two features and is defined as follows:
Definition 3.8.
Let be a continuous linguistic term set. For a finite universe of discourse X, L.P.F.S. A is defined for
and the associated membership and non-membership degrees expressed in linguistic terms from
(3.9)
(3.9)
where
are the linguistic membership degree and non-membership degree of element x to A, respectively. For any
the degrees of membership and non-membership are constrained by
The degree of linguistic indeterminacy
describing the hesitancy of x to A is defined as follows:
The degrees of membership and non-membership can be used to represent the underlying L.P.F.S. in a shorthand notation. Specifically, a pair describing membership and non-membership of x in A is denoted as
Then,
is called a linguistic Pythagorean fuzzy value (L.P.F.V.) or linguistic Pythagorean fuzzy number (L.P.F.N.) (Garg, Citation2018).
Linguistic reasoning requires comparison of the values. For L.P.F.N.s, the linguistic membership and non-membership degrees can be exploited to compare any two L.P.F.V.s as shown below.
Definition 3.9.
For a certain L.P.F.V. with its membership and non-membership degrees belonging to a P.F.L.S., i.e.,
its score function is defined in terms of the difference between the squared degrees of membership and non-membership as follows:
(3.10)
(3.10)
whereas the accuracy function is defined in terms of the sum of the squared degrees of membership and non-membership as follows:
(3.11)
(3.11)
It can be verified that and
which implies that
Given the functions defined in Definition 3.9, any two L.P.F.V.s, A and B, can be compared by following procedure (Garg, Citation2018):
If
If
The decision-making process requires aggregating L.P.F.N.s. In order to do so, arithmetic operations have to be carried out for these numbers. Thus, the following operations can be defined for L.P.F.N.s (Garg, Citation2018):
Definition 3.10.
For any two L.P.F.N.s denoted by and
the following rules are introduced:
A = B, if
Intersection:
Union:
A < B, if
The addition and multiplication operations are crucial for aggregating L.P.F.N.s. First, these operations can be defined for the linguistic variables by exploiting the notions of t-norm and t-conorm. Following Garg (Citation2018), we introduce the following laws of operations hold:
Definition 3.11.
For any two L.P.F.N.s The addition and the multiplication operations of two linguistic variables are defined as follows:
(3.12)
(3.12)
(3.13)
(3.13)
where
and
are t-conorm and t-norm, respectively, which lies between
and hence
Thus,
Based on Definition 3.11, we can get the operational laws for L.P.F.N.s as follows (Garg, Citation2018).
Definition 3.12.
Let and
be two L.P.F.N.s, where
with
being a real number, then
It can also be shown that the outcome of calculations based on Definitions 3.12 above is also an L.P.F.N. Formally, the following Lemma states this result:
Lemma 3.1.
Let be any two L.P.F.N.s. Then, the values resulting from applications of the fuzzy addition
, fuzzy multiplication
, multiplication by a scalar λA and exponent of a scalar
are also L.P.F.N.s with
(Garg, Citation2018).
4. L.P.F. M.C.G.D.M. model
In this section, we present a decision-making approach based on L.P.F.N.s and the L.P.F.N.-C.O.D.A.S. technique. In addition, an A.H.P.-like method based on pair-wise comparisons of criteria in terms of linguistic variables is used to derive criteria weights.
4.1. Determining criteria weights using L.P.F.N.s and pair-wise comparison
Criteria weights used in the decision-making comprise and important element of the overall process. Thus, it is critical to apply a technique that allows for an effective analysis of priorities of criteria. In this sub-section, we describe an A.H.P.-like approach that takes L.P.F.N.s and pair-wise comparisons as decision input. This setting allows D.M.s for more flexibility in assessing the importance of criteria as well as their confidence. In addition, different weights can be assigned to different experts to reflect their importance in the decision-making process. Criteria weight determination proceeds as follows (Pamučar et al., 2018):
Step 1. Given m experts in set and n criteria in set
Each expert provides pair-wise comparison for each pair of criteria under consideration. The results of the assessment are the elements of a pair-wise comparison matrix for the l-th expert. We allow for differences in the importance of the D.M.s by assigning them weights
such that
The pair-wise comparison is given as L.P.F.N.s with elements of linguistic term set
being used for membership and non-membership degrees. Thus, the resulting expert-specific assessment matrix takes the following form:
where elements
are L.P.F.N.s based on linguistic variables from
The diagonal elements of
i.e.,
are equal to the midpoint of the linguistic term set,
As the pair-wise matrix needs to be reciprocal, D.M.s need only to furnish half of the off-diagonal elements (either upper or lower part). Assume that the experts provide the upper part of the pair-wise comparison matrix as
Then, the elements in the lower diagonal part of the matrix are obtained by applying the following rule:
Note that L.P.F.N. gives the membership and non-membership degrees to which criterion i is more important than criterion j based on expert
assessment.
Step 2. Expert opinions can be aggregated into a single matrix by applying either arithmetic or geometric averaging. This can also take into account of the importance of D.M.s. The aggregated decision matrix is defined as:
with its elements
being the results of the aggregation based upon the L.P.F. weighted averaging operators which can be either arithmetic or geometric. The use of an arithmetic aggregation operator increases substitution among the expert opinions, whereas the adoption of a multiplicative aggregation operator decreases the compensatory effect. For instance, the L.P.F. weighted arithmetic averaging (LPFWAA) operator can be applied to obtain the elements of N:
(4.14)
(4.14)
Similarly, the L.P.F. weighted geometric averaging (L.P.F.W.G.A.) operator can be exploited to aggregate the expert opinions into the elements of an aggregated pair-wise comparison matrix as follows:
(4.15)
(4.15)
In EquationEqs. (4.14)(4.14)
(4.14) and (4.15),
are the elements of the expert
pair-wise comparison matrix.
Step 3. The differences among the elements of the aggregated pair-wise comparison matrix N is calculated at the element, criterion and matrix level.
At the element level, the differences are calculated for each ξij with respect to These calculations are carried out for each criterion
as follows:
(4.16)
(4.16)
where
stands for the distance between elements of the aggregated pair-wise comparison matrix,
and
At the criterion level, the differences obtained by EquationEq. (4.16)(4.16)
(4.16) are aggregated across the columns of N for each criterion
as follows:
(4.17)
(4.17)
Finally, the matrix-level difference is calculated as the sum of deviations in EquationEq. (4.17)(4.17)
(4.17) :
(4.18)
(4.18)
It is clear that, summarises the total difference in N and can be used as a normalisation.
Step 4. The criteria weights are obtained by normalising the criterion-specific values γi from EquationEq. (4.17)(4.17)
(4.17) by the overall deviation γ from EquationEq. (4.18)
(4.18)
(4.18) :
(4.19)
(4.19)
where
satisfies
4.2. An L.P.F.-C.O.D.A.S. approach
In this sub-section, we propose an approach to deal with M.C.G.D.M. problems involving uncertain linguistic assessment. The decision information is provided in terms of the L.P.F.N.s. The C.O.D.A.S. method (Keshavarz Ghorabaee et al., Citation2016) is extended to handle the L.P.F.N.s and referred to as L.P.F.-C.O.D.A.S. Note that the C.O.D.A.S. technique provides an effective approach for M.C.G.D.M. by introducing a threshold for distances among the items under consideration that activates the use of an additional distance measure. The L.P.F.-C.O.D.A.S. proceeds as follows:
Step 1. The aggregated decision matrix N is constructed to assess the performance of b alternatives denoted by set with respect to n criteria denoted by set
The assessment of the performance of the alternatives against the criteria is provided by the experts. Denote the m experts by set
These experts are associated with different weights arranged into vector
so that
First, each expert provides assessments of the alternatives under consideration in the form of L.P.F.N.s. The ratings are arranged into expert-specific decision matrices The elements of
are
corresponding to the rating of the i-th alternative against the j-th criterion. Thus, the decision matrix for expert l takes the following form:
with
belonging to the continuous linguistic term set
i.e.,
and
Note that L.P.F.N.,
is used to describe the extent to which expert l agrees or disagrees that alternative i satisfies criterion j as well as the implied indeterminacy.
Aggregation operators can be applied to derive an aggregated decision matrix N. The aggregated decision matrix N comprises b × n elements, assessing the overall performance of the alternatives under consideration based on the expert ratings:
In case of a geometric aggregation, the LPFWGA operator is applied. Thus, the following weighted geometric mean is determined for
(4.20)
(4.20)
with
being the values from the decision matrix of the l-th expert.
Step 2. The cost and benefit criteria have different directions of optimisation (cost criteria are minimised, whereas benefit criteria are maximised when identifying the best-performing alternative). Therefore, the decision matrix needs to be unified in this regard prior to further processing. The cost and benefit criteria are unified by means of the complements of the P.F.L.N.s. The normalised matrix comprises elements
defined as follows:
(4.21)
(4.21)
where B and C represent the sets of benefit and cost criteria, respectively, and the elements of N are used for determining the normalised values.
Step 3. The criteria considered in the M.C.G.D.M. problem are attributed to different importance by assigning them different weights. Thus, the normalised decision matrix, is weighted and, consequently, the weighted normalised matrix G is obtained. Matrix G comprises L.P.F.N.s., i.e.,
which obtained by exploiting the arithmetic operator for L.P.F.N.s as follows:
(4.22)
(4.22)
Step 4. The weighted normalised decision matrix is then employed to identify the theoretical (negative ideal) alternative that defines the lowest level of performance given the decision input. The negative ideal solution is defined by vector with its elements defined as the minima of the columns of the weighted normalised decision matrix:
(4.23)
(4.23)
where nsj is an LPFN denoted by
Step 5. The distance between the negative ideal solution NS and the elements of the weighted normalised decision matrix G is calculated by measuring the performance of each alternative with regard to the worst possible situation. The L.P.F. Euclidean and L.P.F. Hamming-like distances are applied as the measures of distance here; the obtained measures are denoted by EDi and HLDi respectively. Both of the distances are calculated as follows. First, the Euclidean distance is defined as the following sum:
(4.24)
(4.24)
where
is the Euclidean distance of the j-th alternative from the negative ideal solution with respect to the i-the criterion, which is defined as:
(4.25)
(4.25)
Similarly, the Hamming-like distance is given as the following sum:
(4.26)
(4.26)
where
is the Hamming-like distance of the i-th alternative from the negative ideal solution with respect to the i-the criterion, which is defined as:
(4.27)
(4.27)
Note that and the degree of indeterminacy,
and
are obtained following Definition 3.8.
Step 6. The Euclidean and Hamming-like distances are applied to assess the distances among the alternatives. The obtained distances are arranged into matrix with its elements being defined as
(4.28)
(4.28)
where
keeps tracks of the alternatives under comparison and ρ denotes the binary threshold function that may involve the Hamming-like distance in the analysis. The threshold function is defined as (Keshavarz-Ghorabaee et al., Citation2016):
(4.29)
(4.29)
where ε is a given threshold parameter. We pick
for the analysis in the case study in Section 5.
Step 7. The distances obtained in Step 6 are further aggregated to obtain the utility scores for each alternative i. The utility scores Si are obtained as:
(4.30)
(4.30)
The higher the value, the better the performance of the alternative, thus alternatives are arranged in a descending order of Si.
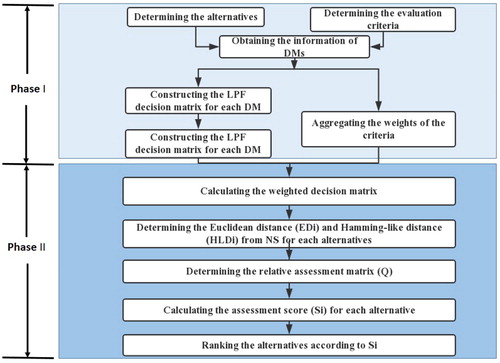
In summary, the procedure of the proposed method is given in .
Figure 1. The procedure of the proposed LPFN-CODAS method. Source: Designed by the authors.
5. A case study
The increasing complexity of business environment and emergence of new business models based on new types of information require complex approach towards performance assessment (Iqbal, Chu, & Hali, Citation2019; Rondovic et al., Citation2018; Knezevic, Citation2018; Pan et al., Citation2019). The proposed decision framework outlined in Section 4 is applied to the case of selecting financial strategies in a multinational firm that involves multiple criteria and DMs (Garg, Citation2018). The application of the P.F.L.N.s is relevant in this case as the D.M.s may not be experienced enough to respect the constraints associated with I.F.S.s. In addition, the use of linguistic information allows one to assess different alternatives (i.e., investment strategies) that can only be defined in approximate terms due to inherent uncertainties and complexity. Thus, this case study of selecting financial strategies allows the experts to exploit both quantitative and qualitative assessment information to find a best solution.
Assume that a company is about to choose a proper investment strategy at different geographical locations. Specifically, it considers expanding its operations to Asia, Africa or Northern America (these alternatives are denoted by ). In addition, simultaneous expansion to all the three regions is included in the analysis as A4. An expert group is established to identify the most promising investment strategy.
The alternatives under consideration are evaluated with respect to the four criteria representing the prospect in the short, medium and long run (denoted as ) along with the risk profile attached to the alternatives (criterion C4). Obviously, the first three criteria are benefit ones as the company seeks to enhance the prospect of the investment, whereas the fourth criterion is a cost one as the company seeks to minimise the risk associated with the alternatives. Furthermore, the differences in the importance of the benefit criteria exist as the discount rate affects the preferences of the D.M.s with respect to
Thus, the identification of the investment strategy constitutes an M.C.G.D.M. problem.
The expert group comprises three D.M.s. Due to differences in their background, the experts taking part in the M.C.G.D.M. are assigned with different importance as reflected in the weight vector The experts are denoted as
The decision-making proceeds by providing the linguistic ratings from the linguistic term set
These terms are applied to assess the performance of the alternatives with regards to the criteria.
5.1. Determination of criteria weights
We assume that the weights of criteria are unknown. Thus, the procedure given in Section 4.1 is applied to derive the weights from pair-wise comparisons between each pair of criteria. Each expert taking part in the M.C.G.D.M. procedure provides his/her assessment on the perceived importance of the criteria in a pairwise manner. The detailed procedure is given as follows:
Step 1. Each expert provides his/her preferences in regard to the importance of a certain criterion with respect to each of the other three criteria by conducting pair-wise comparisons. The comparison is based on the linguistic labels from
The results of pair-wise comparisons are given in .
Table 3. The pair-wise comparison of the importance of criteria by expert D1.
Table 4. The pair-wise comparison of the importance of criteria by expert D2.
Table 5. The pair-wise comparison of the importance of criteria by expert D3.
Step 2. The results provided by the three experts are aggregated into a single pair-wise comparison matrix N. In order to aggregate the information across the experts, the L.P.F.W.G.A. operator Eq. (4.15) is utilised. The resulting aggregated pair-wise comparison matrix is shown below:
Step 3. The weights of criteria are established on the basis of the variation of the data within matrix N. Therefore, Eqs (4.16)–(4.18) are applied in order to calculate the overall measures of differences:
Step 4. Finally, the measures obtained in Step 3 are further aggregated by means of Eq. (4.19) to derive criteria weights:
5.2. Ranking the alternatives
The criteria weights determined by pair-wise comparisons in Section 4.1 can be further used to aggregate preference data on alternatives against criteria provided by the experts. In this sub-section, we focus on the multi-criteria assessment of the alternatives following the procedure outlined in Section 4.2. As an outcome, the four investment strategies are assigned with utility scores and ranked accordingly.
The three experts provide their assessments on alternatives with regards to criteria
The linguistic ratings indicate how well a given alternative perform on a certain criterion. The degrees of satisfaction and dissatisfaction are expressed in the nine-point scale with possible hesitancy due to the nature of L.P.F.N.s (i.e., degree of indeterminacy is allowed for). Specifically, the following linguistic term set is used:
Step 1. The experts provide their ratings for each alternative according to the four criteria in linguistic terms in S. The results are arranged into individual decision matrices in . The resulting data are further processed by applying an appropriate aggregation operators (the L.P.F.W.G.A. is used here).
Table 6. Decision matrix provided by expert D1.
Table 7. Decision matrix provided by expert D2.
Table 8. Decision matrix provided by expert D3.
Step 2. The ratings provided by the three experts are aggregated into an aggregated decision matrix N. This is accomplished applying the L.P.F.W.G.A. operator Eq. (4.20). The assessment of the investment strategies depends on both benefit and cost criteria. In this case, the data need to be normalised as Eq. (4.21), resulting in the normalised aggregated decision matrix below:
Step 3. The criteria have different importance based on the expert ratings discussed in Section 5.1. Accordingly, the normalised aggregated decision matrix should be further processed to incorporate the criteria weight information. In this case study we apply arithmetic operator for the P.F.L.N.s Eq. (4.22). The resulting weighted decision matrix is given in . These values will be employed to identify the theoretical worst-performing alternative.
Table 9. The weighted normalised aggregated decision matrix G.
Step 4. The C.O.D.A.S. relies on the reference point the worst-performing (negative ideal) alternative, which is defined by the minimum elements of the columns of the weighted matrix G. For this case study, the negative ideal alternative is given by vector By Eq. (4.22), the elements of N.S. are obtained as:
Step 5. The distances between the alternatives and the negative ideal solution are measured to identify the deviations from the worst-performing case. These will be used as the relative measures of the performance of the alternatives. The C.O.D.A.S. involves both Euclidean and Hamming-like distances. Accordingly, Eqs (4.24) and (4.26) are utilised to obtain the distances from the negative ideal solution, EDi and HLDi, respectively. The data in G are used to obtain the distances given in .
Table 10. LPF Weighted Euclidean and Hamming-like distances.
Step 6. The distances obtained in Step 5 are employed to compare the alternatives against each other (with the negative ideal solution acting as a reference point) like in a pair-wise manner Eq. (4.28). The resulting matrix Q summarises the comparison result. presents the results.
Table 11. Relative assessment matrix (Q).
Step 7. The distances describing the relative performance of the alternative are aggregated to obtain the utility scores for the alternatives. The analysis proceeds by adding up the elements within each row of matrix Q as outlined in Eq. (4.30). The utility scores Si are obtained. These are reported in the second column from the right in . A higher value of Si implies a higher distance from the negative ideal alternative. Therefore, we rank the alternatives in descending order of Si. As a result, the mixed strategy (simultaneous expansions in Asia, Africa, and Northern America) is the most preferred. The overall ranking is
6. Comparative analysis
The results of M.C.G.D.M. are often sensitive to different aggregation operators. Accordingly, we conduct a comparative analysis to ascertain whether the results obtained by the L.P.F.-C.O.D.A.S. are comparable in the context of other M.C.D.M. techniques. This kind of analysis allows one to draw conclusions on the validity of the proposed approach.
We compare the results from our proposed L.P.F.-C.O.D.A.S. with those obtained F.L.N.s-A.H.P., I.F.S.-A.H.P., L.N.F.-P.W., I.V.F.-W.D.B.A. and I.V.P.F.-Entropy methods. As there have been different variations of the A.H.P. method in the literature, we follow the proposed version by Panchal et al. (Citation2017). We apply the same decision data in Section 5 for this comparative analysis. The results are given in . Obviously, the best- and worst-ranked alternatives remain the same across the comparative approaches, and the middle two alternatives are also ranked the same in our proposed approach with five of the seven other approaches, suggesting that ranking result by the L.P.F.-C.O.D.A.S. is reliable.
Table 12. Comparison of ranking results with various fuzzy extensions of C.O.D.A.S.
The C.O.D.A.S. method applies an additional distance measure, the Hamming-like distance, if two alternatives cannot be distinguished by the Euclidean distance, i.e., the Euclidean distance between these two alternatives does not exceed the threshold parameter ε; see EquationEq. (4.28)(4.28)
(4.28) . As the threshold parameter is given exogenously, it is important to carry out a sensitivity analysis to check if the ranking is affected by the changes in the threshold parameter. In order to proceed with the sensitivity analysis, we select different values of the threshold parameter and repeat the L.P.F.-C.O.D.A.S. procedure. Fifteen values of the threshold parameter in [0.01, 1] are selected for this exercise and ranking result are given in , and visually displayed in .
Figure 2. Ranking results with various values of parameter ε.
Note: Cases 1–15 correspond to the different values of as shown in . Source: Designed by the authors.
![Figure 2. Ranking results with various values of parameter ε.Note: Cases 1–15 correspond to the different values of ε∈[0.01,1.00] as shown in Table 13. Source: Designed by the authors.](/cms/asset/b52a6580-ef9b-431b-a3cb-b013de8dc86c/rero_a_1736117_f0002_c.jpg)
Table 13. Ranking results with different values of threshold ε.
The results in and indicate the ranking results by the L.P.F.-C.O.D.A.S. remain the same when the threshold parameter ε ranges from 0.01 to 0.3. For the most preferred alternative remains the same (A4), but the ranking results of the other three alternatives become different. This sensitivity analysis indicates that the L.P.F.-C.O.D.A.S. is not so sensitive to the threshold parameter, especially in terms of the most preferred alternative.
7. Conclusion
This article proposes an extension of the C.O.D.A.S. technique for M.C.G.D.M., so-called L.P.F.-C.O.D.A.S. This proposed approach takes the L.P.F. numbers as basic decision input, which allows D.M.s express their ratings more conveniently. Furthermore, the linguistic information is maintained throughout the aggregation process.
A case study of investment strategy selection is implemented to demonstrate the operationality of the C.O.D.A.S. method. A comparative analysis and sensitivity analysis are carried out to check the performance of the proposed method. Results of the comparative analysis suggest that the results obtained by the L.P.F.-C.O.D.A.S. are consistent with the other M.C.G.D.M. methods. Sensitivity analysis confirms that the ranking results of our approach remains the same for a wide range of the threshold parameter values.
Further research can be carried out to apply different distance functions and threshold rules in the decision-making process. Monte Carlo simulations can also be carried out to identify the best performing settings. The proposed method can be applied for solving problems in different domains.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aliakbari Nouri, F., Khalili Esbouei, S., & Antucheviciene, J. (2015). A hybrid MCDM approach based on fuzzy ANP and fuzzy TOPSIS for technology selection. Informatica, 26(3), 369–388. doi:10.15388/Informatica.2015.53
- Atanassov, K. T. (1986). Intuitionistic fuzzy sets. Fuzzy Sets and Systems., 20(1), 87–96. doi:10.1016/S0165-0114(86)80034-3
- Beliakov, G., & James, S. (2014). Averaging aggregation functions for preferences expressed as Pythagorean membership grades and fuzzy orthopairs. IEEE International Conference on Fuzzy Systems, 298–305.
- Bolturk, E. (2018). Pythagorean fuzzy CODAS and its application to supplier selection in a manufacturing firm. Journal of Enterprise Information Management, 31(4), 550–564. doi:10.1108/JEIM-01-2018-0020
- Bolturk, E., & Kahraman, C. (2018). Interval-valued intuitionistic fuzzy CODAS method and its application to wave energy facility location selection problem. Journal of Intelligent and Fuzzy Systems, 35(4), 4865–4877. doi:10.3233/JIFS-18979
- Chen, C. T. (2000). Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets and Systems, 114(1), 1–9. doi:10.1016/S0165-0114(97)00377-1
- Deschrijver, G., & Kerre, E. E. (2002). A generalization of operators on intuitionistic fuzzy sets using triangular norms and conorms. Notes on Intuitionistic Fuzzy Sets, 8(1), 19–27.
- Dorokhov, O., Chernov, V., Dorokhova, L., & Streimkis, J. (2018). Multi-Criteria Choice of Alternatives under Fuzzy Information. Transformations in Business & Economics, 17(2), 95–106.
- Fatma, B. Y., & Gökhan, Ö. (2018). Interval-valued Atanassov intuitionistic fuzzy CODAS method for multi-criteria group decision making problems. Group Decision and Negotiation, 28, 433–452.
- Gao, H., Lu, M., & Wei, Y. (2019). Dual hesitant bipolar fuzzy hamacher aggregation operators and their applications to multiple attribute decision making. Journal of Intelligent & Fuzzy Systems, 37(4), 5755–5766. doi:10.3233/JIFS-18266
- Garg, H. (2016). A novel correlation coefficients between Pythagorean fuzzy sets and its applications to decision-making processes. International Journal of Intelligent Systems, 31(12), 1234–1252. doi:10.1002/int.21827
- Garg, H. (2018). Linguistic Pythagorean fuzzy sets and its applications in multi-attribute decision-making process. International Journal of Intelligent Systems, 33(6), 1234–1263.. doi:10.1002/int.21979
- Ghorabaee, M. K., Amiri, M., Zavadskas, E. K., Hooshmand, R., & Antucheviciene, J. (2017). Fuzzy extension of the CODAS method for multi-criteria market segment evaluation. Journal of Business Economics and Management, 18(1), 1–19. doi:10.3846/16111699.2016.1278559
- Herrera, F., & Martínez, L. (2001). A model based on linguistic 2-tuples for dealing with multigranular hierarchical linguistic contexts in multiexpert decision-making. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 31(2), 227–234.
- Hosseini, S. T., Lale Arefi, S., Bitarafan, M., Abazarlou, S., & Zavadskas, E. K. (2016). Evaluation types of exterior walls to reconstruct Iran earthquake areas (Ahar Heris Varzeqan) by using AHP and fuzzy methods. International Journal of Strategic Property Management, 20(3), 328–340. doi:10.3846/1648715X.2016.1190794
- Iqbal, S., Chu, J. X., & Hali, S. M. (2019). Projecting impact of CPEC on Pakistan’s electric power crisis. Chinese Journal of Population Resources and Environment, 17(4), 310–321. doi:10.1080/10042857.2019.1681879
- Kahraman, C., Onar, S. C., & Oztaysi, B. (2015). Fuzzy multicriteria decision-making: a literature review. International Journal of Computational Intelligence Systems, 8(4), 637–666. doi:10.1080/18756891.2015.1046325
- Ghorabaee, M. K., Zavadskas, E. K., Turskis, Z., & Antucheviciene, J. (2016). A new combinative distance-based assessment (CODAS) method for multi-criteria decision-making. Economic Computation and Economic Cybernetics Studies and Research, 50(3), 25–44.
- Knezevic, D. (2018). Impact of Blockchain Technology Platform in Changing the Financial Sector and Other Industries. Montenegrin Journal of Economics, 14(1), 109–120. doi:10.14254/1800-5845/2018.14-1.8
- Liang, D. C., Xu, Z. S., & Darko, A. P. (2017). Projection model for fusing the information of Pythagorean fuzzy multicriteria group decision making based on geometric Bonferroni mean. International Journal of Intelligent Systems, 32(9), 966–987. doi:10.1002/int.21879
- Liu, N., He, Y., & Xu, Z. (2019). Evaluate Public-Private-Partnership’s advancement using double hierarchy hesitant fuzzy linguistic PROMETHEE with subjective and objective information from stakeholder perspective. Technological and Economic Development of Economy, 25(3), 386–420. doi:10.3846/tede.2019.7588
- Lu, J., Tang, X., Wei, G., Wei, C., & Wei, Y. (2019). Bidirectional project method for dual hesitant Pythagorean fuzzy multiple attribute decision-making and their application to performance assessment of new rural construction. International Journal of Intelligent Systems, 34(8), 1920–1934. doi:10.1002/int.22126
- Pamucar, D., Badi, I., Sanja, K., & Obradović, R. (2018). A novel approach for the selection of power-generation technology using a linguistic Neutrosophic CODAS method: a case study in Libya. Energies, 11(9), 2489–2514. doi:10.3390/en11092489
- Pan, X. F., Pan, X. Y., Song, M. L., Ai, B. W., & Ming, Y. (2019). Blockchain technology and enterprise operational capabilities: An empirical test. International Journal of Information Management, 101946. DOI:. doi:10.1016/j.ijinfomgt.2019.05.002
- Panchal, D., Chatterjee, P., Shukla, R. K., Choudhury, T., Tamosaitiene, J., et al. (2017). Integrated fuzzy AHP-CODAS framework for maintenance decision in urea fertilizer industry. Economic Computation and Economic Cybernetics Studies and Research, 51(3), 179–196.
- Peng, X. D., & Garg, H. (2018). Algorithms for interval-valued fuzzy soft sets in emergency decision making based on WDBA and CODAS with new information measure. Computers and Industrial Engineering, 119, 439–452.
- Peng, X. D., & Li, W. (2019). Algorithms for interval-valued Pythagorean fuzzy sets in emergency decision making based on multi-parametric similarity measures and WDBA. IEEE Access., 7, 7419–7441. doi:10.1109/ACCESS.2018.2890097
- Peng, X., & Selvachandran, G. (2019). Pythagorean fuzzy set: state of the art and future directions. Artificial Intelligence Review, 52(3), 1873–1927.
- Peng, X., & Yang, Y. (2016). Pythagorean fuzzy Choquet integral based MABAC method for multiple attribute group decision making. International Journal of Intelligent Systems, 31(10), 989–1020. doi:10.1002/int.21814
- Pongpimol, S., Badir, Y., Erik, B., & Sukhotu, V. (2020). A multi-criteria assessment of alternative sustainable solid waste management of flexible packaging. Management of Environmental Quality: An International Journal, 31(1), 201–222. doi:10.1108/MEQ-11-2018-0197
- Reformat, M. Z., & Yager, R. R. (2014). Suggesting recommendations using Pythagorean fuzzy sets illustrated using Netflix movie data. Information processing and management of uncertainty in knowledge-based Systems, 546–556 Berlin: Springer.
- Ren, J. Z. (2018). Sustainability prioritization of energy storage technologies for promoting the development of renewable energy: a novel intuitionistic fuzzy combinative distance-based assessment approach. Renewable Energy., 121, 666–676. doi:10.1016/j.renene.2018.01.087
- Ren, P., Xu, Z., & Gou, X. (2016). Pythagorean fuzzy TODIM approach to multi-criteria decision making. Applied Soft Computing, 42, 246–259. doi:10.1016/j.asoc.2015.12.020
- Rondovic, B., Melovic, B., Mitrovic, S., & Ocovaj, S. B. (2018). Determinants of ECRM Adoption and Diffusion-Multistage Analysis in The South-Eastern Europe. Transformations in Business & Economics, 17(3C), 328–346.
- Tang, X., & Wei, G. (2019). Multiple attribute decision-making with dual hesitant Pythagorean fuzzy information. Cognitive Computation, 11(2), 193–211. doi:10.1007/s12559-018-9610-9
- Vinodh, S., Sai Balagi, T. S., & Patil, A. (2016). A hybrid MCDM approach for agile concept selection using fuzzy DEMATEL, fuzzy ANP and fuzzy TOPSIS. The International Journal of Advanced Manufacturing Technology, 83(9-12), 1979–1987. doi:10.1007/s00170-015-7718-6
- Wang, J., Gao, H., & Wei, G. (2019). The generalized Dice similarity measures for Pythagorean fuzzy multiple attribute group decision making. International Journal of Intelligent Systems, 34(6), 1158–1183. doi:10.1002/int.22090
- Wang, T., & Chang, T. (2005). Fuzzy VIKOR as a resolution for multi-criteria group decision-making. In: 11th International Conference on Industrial Engineering and Engineering Management, Shenyang, China, 352–356.
- Wei, G. W. (2019). Pythagorean fuzzy Hamacher power aggregation operators in multiple attribute decision making. Fundamenta Informaticae, 166(1), 57–85. doi:10.3233/FI-2019-1794
- Wu, L., Gao, H., & Wei, C. (2019). VIKOR method for financing risk assessment of rural tourism projects under interval-valued intuitionistic fuzzy environment. Journal of Intelligent & Fuzzy Systems, 37(2), 2001–2008. doi:10.3233/JIFS-179262
- Xu, Z. S. (2004). A method based on linguistic aggregation operators for group decision making under linguistic preference relations. Information Sciences, 166(1-4), 19–30. doi:10.1016/j.ins.2003.10.006
- Yager, R. R. (2013). Pythagorean fuzzy subsets. In: Proceedings Joint IFSA World Congress and NAFIPS Annual Meeting, Edmonton, Canada. Piscataway, NJ, 57–61.
- Yager, R. R. (2016). Properties and applications of Pythagorean fuzzy sets. Imprecision and Uncertainty in Information Representation and Processing, 332, 119–136.
- Yager, R. R. (2014). Pythagorean membership grades in multi-criteria decision making. IEEE Transactions on Fuzzy Systems, 22(4), 958–965. doi:10.1109/TFUZZ.2013.2278989
- Zadeh, L. A. (1965). Fuzzy sets. Information and Control, 8(3), 338–353. doi:10.1016/S0019-9958(65)90241-X
- Zeng, S. Z. (2017). Pythagorean fuzzy multi-attribute group decision making with probabilistic information and OWA approach. International Journal of Intelligent Systems, 32(11), 1136–1150. doi:10.1002/int.21886
- Zhang, X. L., & Xu, Z. S. (2014). Extension of TOPSIS to multi-criteria decision making with Pythagorean fuzzy sets. International Journal of Intelligent Systems, 29(12), 1061–1078. doi:10.1002/int.21676
- Zhou, J. M., Su, W. H., Baležentis, T., & Streimikiene, D. (2018). Multiple criteria group decision-making considering symmetry with regards to the positive and negative ideal solutions via the Pythagorean normal cloud model for application to economic decisions. Symmetry, 10(5), 140–155. doi:10.3390/sym10050140